topic categorization of biomedical abstracts
TRANSCRIPT

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
International Journal on Artificial Intelligence Toolsc© World Scientific Publishing Company
Topic Categorization of Biomedical Abstracts
Andreas Kanavos
Computer Engineering and Informatics DepartmentUniversity of Patras
Rio, Patras, Greece, 26504
Christos Makris
Computer Engineering and Informatics Department
University of PatrasRio, Patras, Greece, 26504
Evangelos Theodoridis
Computer Engineering and Informatics DepartmentUniversity of Patras
Rio, Patras, Greece, 26504
Computer Technology InstituteRio, Patras, Greece, 26504
Received (Day Month Year)
Revised (Day Month Year)Accepted (Day Month Year)
Nowadays, people frequently use search engines in order to find the information they need
on the Web. Especially, Web search constitutes of a basic tool used by million researchers
in their everyday work. A very popular indexing engine, concerning life sciences andbiomedical research, is PubMed. PubMed is a free database accessing primarily the
MEDLINE database of references and abstracts on life sciences and biomedical topics.
The present search engines usually return search results in a global ranking, making itdifficult for the users to browse in different topics or subtopics.
In this work we propose a novel system to address the issues of clustering biomedicalsearch engine results according to their topic. A methodology that exploits semantic text
clustering techniques in order to group biomedical document collections in homogeneoustopics, is presented and evaluated. In order to provide more accurate clustering results,we utilize various biomedical ontologies, like MeSH and GeneOntology. Finally, we embed
the proposed methodology in an online system that post-processes the PubMed online
database so as to provide users the retrieved results according to well formed topics. Soas to expose our method as an online real-time service with reasonable response times,
we performed a wide range of engineering optimizations along with experimentation onpreprocessing time to precision of results trade off.
Keywords: MeSH Ontology, PubMed Search, Semantic Topic Clustering
1

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
2 A.Kanavos, C.Makris and E.Theodoridis
1. Introduction
In our days, people frequently use the Web so as to find the information they need3. Specifically, Web search as well as online indexing databases are very popular
tools, used by millions of researchers in their everyday work. Search engines are an
inestimable tool for retrieving Web information. Users place queries by inserting
appropriate keywords and then, the search engines return a list of results ranked in
order of relevance to these queries. However, an inherent weakness of this informa-
tion seeking activity is the lack in satisfying ambiguous queries. Current techniques
are generally not able to distinguish between different meanings or sub-meanings
of a query. Thus the results characterizing the different meanings will be mixed to-
gether in the finally returned list. As a consequence, the user has to access initially
a large number of Web pages in order to come across with those that interest him.
An effective solution to this Web information retrieval problem is the appropriate
clustering of the returned results, which consists of grouping the results returned
by a search engine into topic categories.
There are several online systems that try to post-process the query results of a
web search engine. The reason is that they aim to achieve a more end-user friendly
presentation of results. Such systems usually utilize advanced text mining tech-
niques(a) aiming to extract the topic structure that the results in the document set
capture. In recent years, the field of text mining has received great attention due to
the abundance of textual data, especially coming from Web. Furthermore, as a re-
search field, it became even more interesting and demanding after the development
of the World Wide Web 17. Document clustering has proven to be a challenging
computer science problem having a large number of application domains.
Text mining techniques are usually based on fragment analysis (word or phrase
granularity) of the text. The statistical analysis of a term (word or phrase) frequency
captures the importance of the specific term within a document. Nevertheless, in the
aim of achieving a more accurate analysis, the underlying mining method should
indicate terms that capture the actual semantics and meanings of the text from
which, the importance of a term in a sentence and in the document can be derived12,27. There are research works that incorporate semantic features from lexical or
entity databases like the WordNet lexical database 31. Consequently, it is possible
to improve the accuracy of many text clustering techniques with all these identified
and disambiguated semantic terms. In these works, the proposed models analyze
terms and their corresponding synonyms and/or hypernyms on the sentence and
document levels. In particular, if two documents contain different words and these
words are semantically related, then the proposed model based on this similarity, can
measure the semantic-based similarity between the two documents. The similarity
between documents relies on appropriate semantic-based similarity measures, which
aText mining refers to the discovery of previously unknown knowledge that can be found in textcollections 10.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 3
are applied to the matching concepts between documents.
The vast amount of documents available in the biomedical literature, makes the
manual handling, analysis and interpretation of textual information a quite demand-
ing task. Automated methods that help users to search through this unstructured set
of documents archives, are becoming increasingly important in scientific research.
There is a large amount of knowledge recorded in the biomedical literature, as a
significant number of articles published each year increases dramatically, following
the advances in computational methods and high-throughput experimentation. The
PubMed database 23 is a very popular indexing engine, concerning life sciences and
biomedical research and was created at 1996. PubMed is a free database access-
ing primarily the MEDLINE database of references and abstracts on life sciences
and biomedical topics, which is considered one of the most complete repositories of
biomedical articles. PubMed contains more than 12.5 million abstracts and receives
more than 70 million queries each month 25.
Systems usually rely on predefined vocabularies, ontologies and metadata so
as to extract knowledge from online biomedical document repositories. Most of
the methods in the scientific literature, exploit MeSH 19. MeSH is a controlled
vocabulary thesaurus defined by the National Library of Medicine, which includes
a set of description terms organized in a hierarchical structure, where, as usual,
more general concepts appear at the top, and more specific concepts appear at
the bottom. MeSH’s release in 2007 has totally 24.357 main headings, more than
164,000 supplementary concepts and over 90.000 entry terms.
In this work, a novel system that extends previous works by exploiting seman-
tic text clustering techniques with the aim of presenting PubMed’s query results
clustered into topics, is proposed. In order to provide more accurate clustering re-
sults, various biomedical ontologies, like MeSH in conjunction with WordNet and
common term clustering methods, are employed. We have embedded the proposed
methodology in an online system that post-processes the PubMed online database
so as to provide users the retrieved results according to formed topics. Moreover,
for exposing our method as an online real-time service with reasonable response
times, we have performed a wide range of engineering optimizations along with
experimentation on preprocessing time to precision of results trade off.
The structure of the paper is as follows: first, in section 2, previous works in this
line of research are presented. Next, in section 3, the proposed method along with
various enhancements are presented. Also, in section 4, the implementation details
and the experimental evaluation results are displayed, while finally, in section 5, we
conclude this paper by presenting key findings and future directions of this work.
2. Previous Work
Recently, there are significant efforts in the line of research in biomedical document
clustering, either by proposing novel clustering methods or by presenting new Web
applications on top of document repositories, like PubMed. Most of the research

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
4 A.Kanavos, C.Makris and E.Theodoridis
works utilize natural language processing techniques and show that information
contained in terminologies and ontologies, is very helpful as background knowledge
so as to improve the performance of document clustering.
In 33, it is initially investigated whether the biomedical ontology MeSH improves
the clustering quality for MEDLINE articles. In this work, a comparison study of
various document clustering approaches such as hierarchical clustering methods,
Bisecting K-Means 16, K-Means and suffix tree clustering, in terms of efficiency,
effectiveness and scalability is performed. According to their results, the employ-
ment of MeSH vocabulary significantly enhances clustering quality on biomedical
documents.
Furthermore, in 34, a method that represents a set of documents as bipartite
graphs using domain knowledge from the MeSH ontology is proposed. In this repre-
sentation, the concepts of the documents are classified according to their relation-
ships with documents that are reflected on the bipartite graph. Using the concept
groups, documents are clustered based on the concepts’ contribution to each docu-
ment. Their experimental results on MEDLINE articles showed that this approach
can compete some well known approached like Bisecting K-Means and CLUTO 9
(e.g. a Software for Clustering High-Dimensional Datasets).
Following a similar approach, in 28, PuReD-MCL (PubMed Related Documents-
MCL) is presented, which is based on the graph clustering algorithm MCL and rele-
vant resources from PubMed. This method avoids using natural language processing
(NLP) techniques directly; instead, it takes advantage of existing resources, which
are available from PubMed. PuReD-MCL then clusters documents using the MCL
graph clustering algorithm 11, which is based on graph flow simulation. They ap-
plied their methodology to different datasets that were associated with Escherichia
coli and yeast, as well as Drosophila respectively.
In 1, a method for Biomedical word sense disambiguation with ontologies and
meta-data is presented. Word sense disambiguation is the process of identifying
which sense of a word (meaning) is used in a sentence, when the word has multiple
meanings. For many clustering algorithms, word sense disambiguation is a funda-
mental step for mapping documents to different topics. Usually, ontology term labels
can be ambiguous and have multiple senses. There are employed three different ap-
proaches to word sense disambiguation, which use ontologies and meta-data. The
first one assumes that the ontology defines multiple senses of the term. It computes
the shortest path of co-occurring terms in the document to one of these senses.
The other method defines a log-odds ratio(b) for co-occurring terms including co-
occurrences inferred from the ontology structure. Finally, the last method trains a
classifier on meta-data. The authors have made experiments on ambiguous terms
from the Gene Ontology and MeSH and have found out that over all conditions,
their technique achieves approximatly an 80% success rate on average.
bThe odds ratio is the ratio of the odds of an event occurring in one group to the odds of occurringin another group. The term is also used to refer to sample-based estimates of this ratio.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 5
In 5, authors investigated the accuracy of different similarity approaches for clus-
tering over a large number of biomedical documents. Moreover, in 35, it is stated
that current approaches of using MeSH thesaurus have two serious limitations: Pri-
marily, important semantic information may be lost when generating MeSH concept
vectors, and in following, the content information of the original text has been dis-
carded. A method for measuring the semantic similarity between two documents
over the MeSH thesaurus, is proposed. Secondly, the combination of both seman-
tic and content similarities to generate the integrated similarity matrix between
documents is presented.
Similarly in 13, there is an approach to facilitate MeSH indexing, assigning MeSH
terms to MEDLINE citations for archiving and retrieval purposes. For each and
every document, K neighbor documents are retrieved, then a list of MeSH main
headings from neighbors is obtained, and finally the MeSH main headings are ranked
using a learning-to-rank algorithm. Experimental results show that the approach
makes fairly accurate MeSH predictions.
In this line of research in 6, the authors move beyond online resources, usually
processing titles along with abstracts and tackle the problems that appear when
dealing with full documents. In their work, they present two interesting findings;
dealing with full documents has increased demands in processing time and memory
and so there is higher risk for false positives. As an example, in a full paper there
is content (e.g. references, tables, previous work, future work etc.) not belonging
to the core topic of the document. They propose a method that trades-off between
using only parts of the full text identified as useful and using the abstract. Also,
they focus on the design of summarization strategies using MeSH terms.
Very recently in 26, a FNeTD (Frequent Nearer Terms of the Domain) method
for PubMed abstracts clustering, is proposed. Their method consists of a two-step
process: In the first step, they identify frequent words or phrases in the abstracts
through a frequent multi-word extraction algorithm and in the second step, they
identify nearer terms of the domain from the extracted frequent phrases, using the
nearest neighbors search.
Very related to our line of research are research methods presented in 2,4,20. In4, authors present U-Compare, an integrated text mining/NLP system based on the
UIMA Framework 30 (e.g. Unstructured Information Management). Moreover in 20,
they focus on event-level information represent an important resource for domain-
specific information extraction (IE) systems. They propose a system for automatic
causality recognition which suggests possible causal connections and aiding in the
curation of pathway models. Finally, in 2, they focus on Event-based search systems.
The survey recent advances in event-based text mining in the context of biomedicine
and they describe an annotation scheme used to capture this information at the
event level.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
6 A.Kanavos, C.Makris and E.Theodoridis
Our work presented herec is along this line of research, combining well known
term-based clustering techniques with exploitation of semantic knowledge bases, like
MeSH. The goal of our work is to design a system that will cluster and annotate
biomedical documents originated from the Web, having a reasonable trade-off be-
tween response time and cluster quality. The novel approach in the proposed system,
is the exploitation of MeSH in conjunction with WordNet and common terms clus-
tering methods. Finally, we embed the proposed methodology in an online system
that post-process PubMed online database so as to provide users with the retrieved
results grouped in topics.
3. Proposed Method
In this section, we present the processing steps of the method along with various
optimizations and fine tunings. The overall workflow of the method, regarding the
execution of a query, is depicted in Figure 1. The proposed method is modulated in
the following steps:
Fig. 1. Overall Workflow of the Query Processing
cInitially presented in 15.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 7
• Step1: Initially, the online Web document repository (PubMed) is queried,
in order to process the returned set of Web documents S = {d1, d2, . . . dk}.• Step2: In the following step, each one of the documents di in S is pro-
cessed so as to create the document representations. The system enriches
the document representation by annotating texts using information from
utilized vocabularies and ontologies. Briefly during this step, each docu-
ment is processed, removing stop words and then stemming the remaining
terms. Consequently, each document is represented as a term frequency -
inverse document frequency (Tf/Idf) vector 3, and some terms of the doc-
ument are annotated and mapped on senses identified from WordNet and
MeSH.
• Step3: The clustering of the documents takes place by employing K-Means.
• Step4: In the final step, the system assigns labels to the extracted clusters
in order to facilitate users to select the desired one. In the simplest possible
way, the label is recovered from the cluster’s feature vector and consists of a
few unordered terms, based on their Tf/Idf measure. On the other hand,
the system uses during clustering, the identified MeSH terms and hence
these identified terms can also serve as potential candidates for cluster
labeling as shown in 8.
In the following paragraphs, each of the aforementioned steps is presented ex-
tensively.
3.1. Retrieving PubMed Results
For retrieving search results from the PubMed, we have used its standard API 24
for document retrieval. The results are retrieved in a XML formatted file, which
later on, is parsed and author names, titles, abstracts, conference/journal name, as
well as publication date, are identified.
3.2. Document Representation
After the results S = d1, d2, . . . dk are retrieved in the initial step, each result item
di consists of six different items: title, author names, abstract content, keywords,
conference/journal name and publication date, di = {ti, ani, ai, ki, cji, pdi}. Each
item is processed by removing html tags and stop words and then stemming each
remaining term with the Porter stemmer 22. The aim of this phase is to prune from
the input, all terms that can possibly affect the quality of group descriptions. For
the time being in the clustering procedure, the title, the keywords as well as the
abstract are utilized.
However, conference/journal name and publication dates could also be used since
they capture rich knowledge (e.g. research works in the same topic usually published
in same or similar journals etc., or exploit cross-references, or common references
among the result document set S).

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
8 A.Kanavos, C.Makris and E.Theodoridis
Thereafter, each search result is converted into a vector of terms (Tf/Idfdi)
using the Tf/Idf weighting scheme, for each one of them3. As an alternative repre-
sentation, we use terms annotated to senses identified from WordNet, as proposed
in 27. So, a vector Wdi for each document, is produced. Consequently, each one
of the documents is mapped onto a set of WordNet senses, and from these set of
senses, we keep the top-k (usually K is between 5 to 10 senses) most expressive
senses by using the Wu-Palmer sense similarity metric 32 on the WordNet graph.
This means that for each pair of the selected senses, their distance in the ontology
hierarchy is measured. Ultimatelly, the k senses with less total distance to all the
other, are selected.
On the side, in similar way to WordNet senses, we identify MeSH terms from the
text information. For each document and Tf/Idfdi , we query the MeSH dictionary
and retrieve a number of entities. From the extracted MeSH terms, we select again
the most representative terms. Thereupon, for each pair of terms we count their
distance in the MeSH hierarchy and then we select the top-k (usually k is between
5 to 10 terms) with the minimum average distance to the other terms. Thus, a new
vector Mdi is produced.
Finally, we produce a document representation vector by extracting MeSH terms
from the extracted WordNet senses. Once more, from the extracted MeSH terms,
we select the more representative terms. For each pair of terms, we count their
distance in the MeSH hierarchy and then we select the top-k (usually k is between
5 to 10 terms) with the minimum average distance to the other terms. So, a new
vector WMdiis produced.
For the extracted MeSH and Wordnet term vectors, a similar vector space
Tf/Idf weighting scheme is again employed. These three alternative document
representations are used in the following by the clustering algorithm, which is re-
sponsible for building the clusters and then assign proper labels to them.
3.3. Clustering and Cluster Labeling
3.3.1. Clustering
For grouping the result document set, we apply K-Means as a common clustering
technique 17, utilizing the different document vector representations of each docu-
ment and adapting the clustering method at each case properly. For all cases, the
Cosine Similarity as well as the Euclidian Distance upon vectors, are employed.
Moreover, in this step, document vectors are constructed using document’s title
and keywords.
The four different clustering methods evaluated, are:
(1) Method using Tf/Idf Weighting Scheme: In this case, we only use the
Tf/Idf document vectors (Tf/Idfdi) and both similarity metrics in the clus-
tering method. Also, this setting has been used as a point of reference to the
performance of the other clustering method variations (see Algorithm 1).

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 9
(2) Method using WordNet and MeSH terms: Under the circumstances, the
vectors of extracted WordNet senses (Wdi) as well as Cosine Similarity and
Euclidian Distance metric in the K-Means method are used. This case con-
sists of two different steps; in the first one, we enrich documents with WordNet
information while in second step, MeSH Ontology is utilized. In the case of fail-
ure in extracting any WordNet sense vector, its corresponding Tf/Idf vector
is used and the clustering method calculates its distance to the other docu-
ments. Furthermore, in a second step, the initially produced clusters are used
as bootstrapping for a K-Means algorithm, which in this phase uses the MeSH
document vectors (WMdi) that were extracted from the WordNet senses (see
Algorithm 2).
(3) Method using MeSH terms: In this third case, we use directly the vectors
of extracted MeSH terms (Mdi), as they were extracted by the most significant
terms (using Tf/Idf). In the case of failure in extracting any MeSH term vector
once, again its corresponding Tf/Idf vector is used and the clustering method
calculates its distance to the other documents (see Algorithm 3).
(4) Method using Tf/Idf Weighting Scheme and MeSH terms (Hybrid):
In this last case, clustering methods are modified so as to use a complex dis-
tance based at the same time on the Tf/Idf and the MeSH vectors in the
spirit of 7. In this work, a combination of different levels of term as well as se-
mantic representations, is proposed. For example, clustering method calculates
document distances using the Cosine Distance of term vectors as well as of the
MeSH vectors, normalized at 50% respectively; same way using the Euclidian
Distance. So, term distance and semantic distance have the same weight in the
final distance metric. Further experimentation on this weighting is possible (see
Algorithm 4).
Preprocessing step: For each one of the aforementioned methods, it is possible
to perform a preprocessing step leading clustering method (e.g. K-Means) probably
to less iterations. At this optional step, we execute the above methods, making use
for each document, only of the title and keywords. After a few iterations of the
clustering method, the system proceeds to the next phase.
The second phase takes as input, the produced clusters of the first phase. After
that, method calculates the cluster centroids using at this time, document represen-
tations produced by including the abstract of the documents to the representation.
The intuition behind that approach, is that usually title and keywords express ex-
plicitly the content of a paper leading to initial clusters with less iterations. The
incorporation of the abstract can also be used in order to perform some refinements
and sub-cluster determination.
With this preprocessing step, we aim at more meaningful and more accurate
clusters since all available information from corresponding ducument results is used.
In figures of section 4, the novel methods that take into consideration the abstract
of the documents, are presented with the keyword ”Enriched”.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
10 A.Kanavos, C.Makris and E.Theodoridis
3.3.2. Cluster Labeling
In each cluster that our system produces, a label with various term/senses, which
define each topic, is assigned. In the simpler approach, we assume that the label is
recovered from the cluster’s feature vector and consists of a few unordered terms.
The selection is based on the set of most frequently occurring keywords in the
cluster’s documents and we can measure this frequency from the Tf/Idf scheme,
which we have already mentioned in the document representation. In particular,
we have employed the intersection of the most frequently occurring keywords of all
the documents that occur in a specific cluster. An alternative is to calculate the
centroid and then employ the most expressive dimensions of this vector.
The second approach takes advantage of the semantic MeSH terms. From these
ones, the most weighted ones are used by ranking them with the probability to be
selected as annotations in a new document. This probability is calculated by count-
ing the number of documents where the term was already selected as a keyword,
divided by the total number of documents where the term appeared.
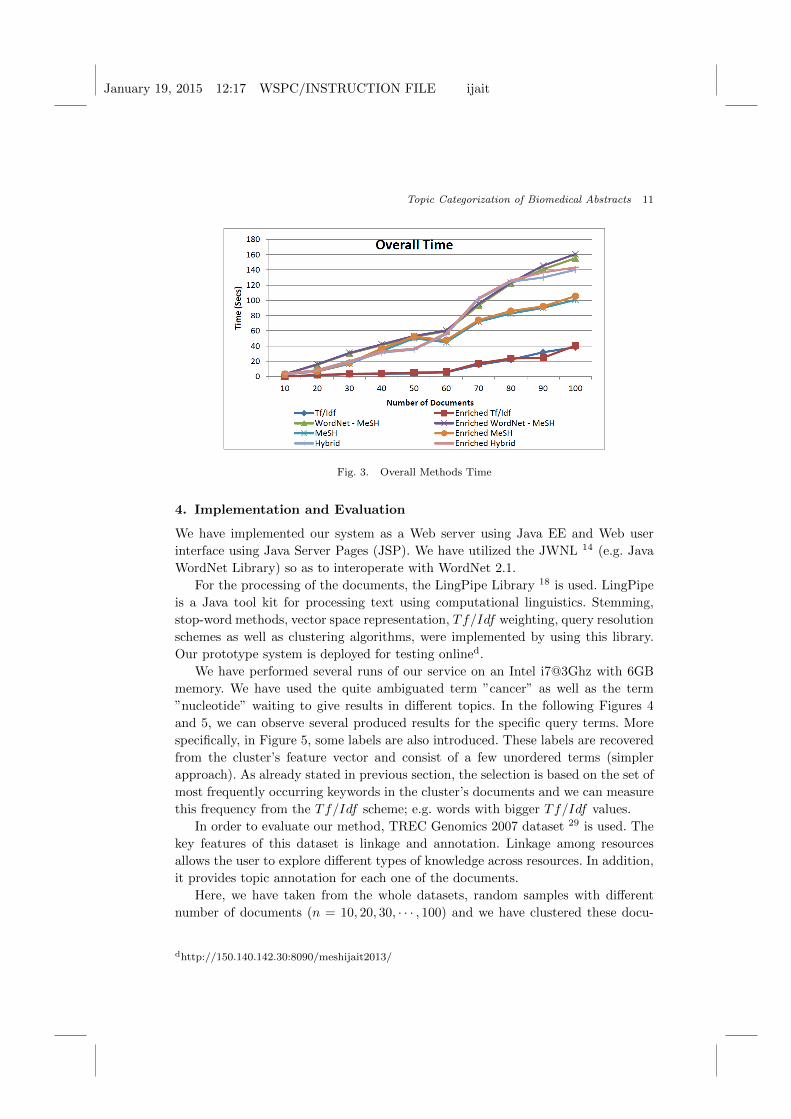
In Figure 2, the overall time performance consisting of the aforementioned steps,
is presented. In addition, in Figure 3, the overall time that our 8 methods require, is
introduced (4 single methods initially presented in 15 plus 4 ”Enriched” methods).
There, we can observe that each one of the 4 methods (Tf/Idf , WordNet and MeSH,
MeSH or Hybrid) require the same time regardless they are simple or Enriched.
Fig. 2. Time Performance
January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 11
Fig. 3. Overall Methods Time
4. Implementation and Evaluation
We have implemented our system as a Web server using Java EE and Web user
interface using Java Server Pages (JSP). We have utilized the JWNL 14 (e.g. Java
WordNet Library) so as to interoperate with WordNet 2.1.
For the processing of the documents, the LingPipe Library 18 is used. LingPipe
is a Java tool kit for processing text using computational linguistics. Stemming,
stop-word methods, vector space representation, Tf/Idf weighting, query resolution
schemes as well as clustering algorithms, were implemented by using this library.
Our prototype system is deployed for testing onlined.
We have performed several runs of our service on an Intel i7@3Ghz with 6GB
memory. We have used the quite ambiguated term ”cancer” as well as the term
”nucleotide” waiting to give results in different topics. In the following Figures 4
and 5, we can observe several produced results for the specific query terms. More
specifically, in Figure 5, some labels are also introduced. These labels are recovered
from the cluster’s feature vector and consist of a few unordered terms (simpler
approach). As already stated in previous section, the selection is based on the set of
most frequently occurring keywords in the cluster’s documents and we can measure
this frequency from the Tf/Idf scheme; e.g. words with bigger Tf/Idf values.
In order to evaluate our method, TREC Genomics 2007 dataset 29 is used. The
key features of this dataset is linkage and annotation. Linkage among resources
allows the user to explore different types of knowledge across resources. In addition,
it provides topic annotation for each one of the documents.
Here, we have taken from the whole datasets, random samples with different
number of documents (n = 10, 20, 30, · · · , 100) and we have clustered these docu-
dhttp://150.140.142.30:8090/meshijait2013/

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
12 A.Kanavos, C.Makris and E.Theodoridis
Algorithm 1 Algorithm based on Tf/Idf weighting scheme
1: input Query q
2: output Clusters produced from Tf/Idf weighting scheme,
Clusters produced from Preprocessing step, Cluster Labels
{step 1 - Retrieving PubMed Results}3: identify set of documents D = {d1, d2, . . . dn}
{step 2 - Document Representation}4: ∀ result item di = {ti, ani, ai, ki, cji, pdi} in D
5: for each di in D do
6: remove html tags and stop words from ti, ki and ai7: stem ti, ki and ai with Porter stemmer
8: end for
9: calculation of set of vectors Tf/Idf = {Tf/Idfd1 , T f/Idfd2 , . . . Tf/Idfdn}
{step 3 - Clustering}10: use as input, titles and keywords: di = {ti, ki}11: for each Tf/Idfdi
in Tf/Idf do
12: Tf/Idf Clusters ← K-Means(Tf/Idf)
{where both Cosine Similarity and Euclidian Distance metrics are applied to
K-Means}13: end for
14: production of Tf/Idf Clusters
15: if clustering technique = normal then
16: Final Clusters = Tf/Idf Clusters
17: else if clustering technique uses Preprocessing step then
18: use as input, abstracts as well: di = {ai}19: for each Tf/Idf Cluster do
20: calculate new cluster centroids
21: Preprocessing Clusters ← K-Means(Tf/Idf , Tf/Idf Cluster)
22: end for
23: production of Preprocessing Clusters
24: Final Clusters = Preprocessing Clusters
25: end if
{step 4 - Cluster Labeling}26: for all Final Clusters do
27: assign Cluster Labels from most frequently keywords
28: end for

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 13
Algorithm 2 Algorithm based on WordNet and MeSH terms
1: input Query q
2: output Clusters produced from WM vectors,
Clusters produced from Preprocessing step, Cluster Labels
{step 1 - Retrieving PubMed Results}3: identify set of documents D = {d1, d2, . . . dn}
{step 2 - Document Representation}4: ∀ result item di = {ti, ani, ai, ki, cji, pdi} in D
5: for each di in D do
6: remove html tags and stop words from ti, ki and ai7: stem ti, ki and ai with Porter stemmer
8: end for
9: calculation of set of vectors Tf/Idf = {Tf/Idfd1, Tf/Idfd2
, . . . Tf/Idfdn}
10: for each Tf/Idfdi in Tf/Idf do
11: query WordNet thesaurus and retrieve a number of senses from Tf/Idfdi
12: end for
13: calculation of set of vectors W = {Wd1,Wd2
, . . .Wdn}
14: if Wdiexists then
15: for each Wdiin W do
16: query MeSH dictionary and retrieve a number of senses from Wdi
17: end for
18: else
19: for each Tf/Idfdiin Tf/Idf do
20: query MeSH dictionary and retrieve a number of senses from Tf/Idfdi
21: end for
22: end if
23: calculation of set of vectors WM = {WMd1,WMd2
, . . .WMdn}
24: if WMdi exists then
25: proceed to step 3
26: else
27: WM = Tf/Idf
28: end if
{step 3 - Clustering}{same as Algorithm 1 except for using WMdi instead of Tf/Idfdi}
{step 4 - Cluster Labeling}{same as Algorithm 1}

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
14 A.Kanavos, C.Makris and E.Theodoridis
Algorithm 3 Algorithm based on MeSH terms
1: input Query q
2: output Clusters produced from M vectors,
Clusters produced from Preprocessing step, Cluster Labels
{step 1 - Retrieving PubMed Results}3: identify set of documents D = {d1, d2, . . . dn}
{step 2 - Document Representation}4: ∀ result item di = {ti, ani, ai, ki, cji, pdi} in D
5: for each di in D do
6: remove html tags and stop words from ti, ki and ai7: stem ti, ki and ai with Porter stemmer
8: end for
9: calculation of set of vectors Tf/Idf = {Tf/Idfd1, T f/Idfd2
, . . . Tf/Idfdn}
10: for each Tf/Idfdi in Tf/Idf do
11: query MeSH dictionary and retrieve a number of senses from Tf/Idfdi
12: end for
13: calculation of set of vectors M = {Md1,Md2
, . . .Mdn}
14: if Mdiexists then
15: proceed to step 3
16: else
17: M = Tf/Idf
18: end if
{step 3 - Clustering}{same as Algorithm 1 except for using Mdi
instead of Tf/Idfdi}
{step 4 - Cluster Labeling}{same as Algorithm 1}
ments with the evaluated methods.
Furthermore, we evaluated the produced clusters by using Precision, Recall and
F-Measure scores. Precision is calculated as the number of items correctly put into a
cluster divided by total number of items put into the cluster; Recall is defined as the
number of items correctly put into a cluster divided by all items that should have
been in the cluster; and finally F-Measure is the harmonic mean of the Precision and
Recall. The total F-Measure for the entire clustering is the sum for each objective
category; the F-Measure of the best cluster (matching this category) is normalized
to the size of the cluster.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 15
Algorithm 4 Hybrid algorithm based on Tf/Idf weighting scheme and MeSH
terms1: input Query q
2: output Clusters produced from M vectors,
Clusters produced from Preprocessing step, Cluster Labels
{step 1 - Retrieving PubMed Results}3: identify set of documents D = {d1, d2, . . . dn}
{step 2 - Document Representation}{same as Algorithm 3}
4: calculation of set of vectors Tf/Idf = {Tf/Idfd1, Tf/Idfd2
, . . . Tf/Idfdn}
5: calculation of set of vectors M = {Md1,Md2
, . . .Mdn}
{step 3 - Clustering}{same as Algorithm 3 except for using both Tf/Idfdi and Mdi}
{step 4 - Cluster Labeling}{same as Algorithm 3}
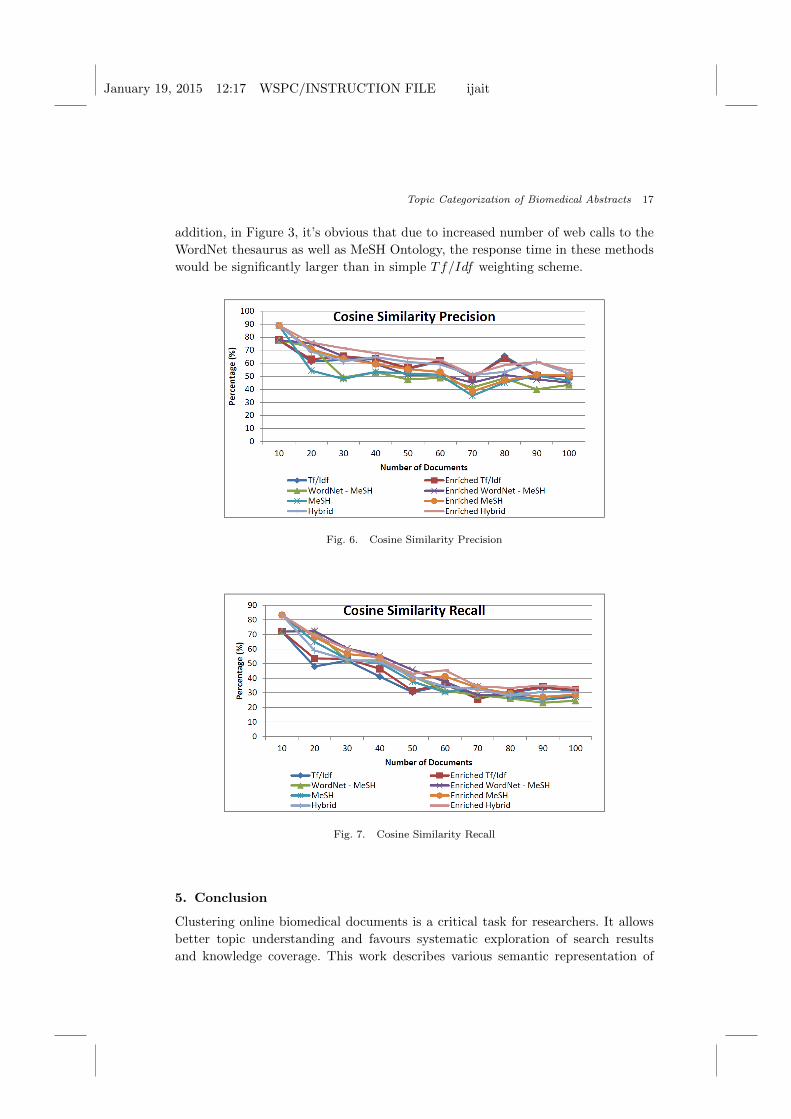
As we can see in Figures 6 to 11, the proposed representations and clustering
strategies achieve notable Precision and Recall for small and average number of
processed documents. As the number of processed documents increases, the perfor-
mance of the methods seems to decrease. The Hybrid method seems in most of the
cases to achieve better performance concerning all the metrics, especially F-Measure.
Concerning the Precision metric, Hybrid outperforms the other methods in almost
all the cases. On the other hand, method using WordNet and MeSH terms, seems
to achieve mediocre Recall in most of the cases. Observing the F-Measure, Hybrid
and common Tf/Idf weighting scheme seems to perform better for large number
of processed documents. For small number of documents, Hybrid and method using
WordNet and MeSH terms seem to have better F-Measure scores. One of our find-
ings is that postprocessing clustering with MeSH and/or WordNet features seems
to produce almost better clustering results. If we assume that we have preprocessed
feature vectors of documents, then the convergence time of the K-Means is signifi-
cantly smaller. Concluding, Enriched methods perform better than simple methods
in almost all the cases for all 4 weighting schemes, as expected, since all available
information from corresponding ducument results is used (abstract as well except
from title and keywords).
Another finding we come across is that the Euclidian Distance metric seems to
achieve better performance than Cosine Similarity, as we can observe in Figures
12, 13 and 14. There, we compare the last method (Hybrid for both simple and
Enriched version) as we observe that Hybrid outperforms the other 3 methods. In

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
16 A.Kanavos, C.Makris and E.Theodoridis
Fig. 4. Cancer Query
Fig. 5. Nucleotide Query
January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 17
addition, in Figure 3, it’s obvious that due to increased number of web calls to the
WordNet thesaurus as well as MeSH Ontology, the response time in these methods
would be significantly larger than in simple Tf/Idf weighting scheme.
Fig. 6. Cosine Similarity Precision
Fig. 7. Cosine Similarity Recall
5. Conclusion
Clustering online biomedical documents is a critical task for researchers. It allows
better topic understanding and favours systematic exploration of search results
and knowledge coverage. This work describes various semantic representation of

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
18 A.Kanavos, C.Makris and E.Theodoridis
Fig. 8. Cosine Similarity F-Measure
Fig. 9. Euclidian Distance Precision
PubMed documents in order for them to be categorized into topics. Here, various
representation methods and clustering alternatives, which show quite promising
have been covered.
Directions for further investigation in this line of research would be the achieve-
ment of a better trade-off between response time and clustering of online document
results. Small response times are critical for user adoption of an online Web doc-
ument repository, not sacrificing quality of the results. Offline storing of MeSH or
other Ontologies may be possible for local access. Noise reduction, by utilizing SVD
or PCA methods, could be very useful. Nevertheless, they are quite time/memory
consuming for integrate them in a real-time system. There is need to offline pre-
process the most frequent queries and the retrieved documents in order the overall

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 19
Fig. 10. Euclidian Distance Recall
Fig. 11. Euclidian Distance F-Measure
system to be responsive.
It would be interesting to explore techniques on how to distribute computational
effort in order to effectively preprocess offline frequent patterns of queries. Another
interesting topic of research would be how it would be possible to transfer a portion
of the computation that is performed in the client side at the user’s Web browser
taking in mind the user’s preferences and previous browsing history. We would also
like to use Hierarchical clustering algorithms 10 so as to identify the suitable number
of formed clusters with the aim of avoiding the intrinsic weakness of K-Means, and
then run the K-Means clustering for result refinement. Furthermore, we intend
to embed better domain knowledge in the clustering procedure and apply better
disambiguation strategies tailored for the MeSH ontology, using techniques similar

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
20 A.Kanavos, C.Makris and E.Theodoridis
Fig. 12. Cosine Similarity vs. Euclidian Distance Precision
Fig. 13. Cosine Similarity vs. Euclidian Distance Recall
to 1.
References
1. D. Alexopoulou, B. Andreopoulos, H. Dietzel, A. Doms, F. Gandon, J. Hakenberg,K. Khelif, M. Schroeder and T. Wachter. (2009). Biomedical word sense disambigua-tion with ontologies and metadata: automation meets accuracy. BMC Bioinformatics(BMCBI) 10.
2. S. Ananiadou, P. Thompson and R. Nawaz. (2013). Enhancing Search: Events andTheir Discourse Context. CICLing, pp. 318-334.
3. R. A. Baeza-Yates and B. A. Ribeiro-Neto. (2011). Modern Information Retrieval: theconcepts and technology behind search. Addison Wesley, Essex.
4. R. T. B. Batista-Navarro, G. Kontonatsios, C. Mihaila, P. Thompson, R. Rak, R.

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
Topic Categorization of Biomedical Abstracts 21
Fig. 14. Cosine Similarity vs. Euclidian Distance F-Measure
Nawaz, I. Korkontzelos and S. Ananiadou. (2013). Facilitating the Analysis of DiscoursePhenomena in an Interoperable NLP Platform. CICLing, pp. 559-571.
5. K. W. Boyack, D. Newman, R. J. Duhon, R. Klavans, M. Patek, J. R. Biberstine, B.Schijvenaars, A. Skupin, N. Ma and K. Borner. (2011). Clustering More than Two Mil-lion Biomedical Publications: Comparing the Accuracies of Nine Text-Based SimilarityApproaches. PLoS ONE 6(3).
6. S. Bhattacharya, V. Ha-Thuc and P. Srinivasan. (2011). MeSH: a window into full textfor document summarization. Bioinformatics 27(13), pp. 120-128.
7. A. Caputo, P. Basile and G. Semeraro. (2008). SENSE: SEmantic N-levels Search En-gine at CLEF2008 Ad Hoc Robust-WSD Track. CLEF, pp. 126-133.
8. D. Carmel, H. Roitman and N. Zwerdling. (2009). Enhancing cluster labeling usingwikipedia. SIGIR, pp. 139-146.
9. CLUTO: http://glaros.dtc.umn.edu/gkhome/cluto/cluto/overview10. M. H. Dunham. (2002). Data Mining: Introductory and Advanced Topics. Prentice
Hall.11. A. J. Enright, S. Van Dongen and C. A. Ouzounis. (2002). An efficient algorithm for
large-scale detection of protein families. Nucleic Acids Research 30(7), pp. 1575-1584.12. R. T. Hemayati, W. Meng and C. T. Yu. (2007). Semantic-Based Grouping of Search
Engine Results Using WordNet. APWeb/WAIM, pp. 678-686.13. M. Huang, A. Nvol and Z. Lu. (2011). Recommending MeSH terms for annotating
biomedical articles. JAMIA 18(5), pp. 660-667.14. JWNL (Java WordNet Library): http://sourceforge.net/projects/jwordnet/15. A. Kanavos, C. Makris and E. Theodoridis. (2012). On Topic Categorization of
PubMed Query Results. AIAI, pp. 556-565.16. R. Kashef and M. S. Kamel. (2009). Enhanced bisecting k-means clustering using
intermediate cooperation. Pattern Recognition (PR) 42(11), pp. 2557-2569.17. J. Kogan. (2007). Introduction to Clustering Large and High Dimensional Data, Cam-
bridge University Press.18. LingPipe: http://alias-i.com/lingpipe/19. MeSH: http://www.nlm.nih.gov/mesh/20. C. Mihaila, T. Ohta, S. Pyysalo and S. Ananiadou. (2013). BioCause: Annotating and

January 19, 2015 12:17 WSPC/INSTRUCTION FILE ijait
22 A.Kanavos, C.Makris and E.Theodoridis
Analysing Causality in the Biomedical Domain. BMC Bioinformatics, Volume 14, 2.21. R. Mihalcea and A. Csomai. (2007). Wikify!: linking documents to encyclopedic knowl-
edge. CIKM, pp. 233-242.22. M. F. Porter. (1980). An Algorithm for Suffix Stripping. In Program, 14, 3, pp. 130-
137.23. Pubmed: http://www.ncbi.nlm.nih.gov/pubmed24. Pubmed API: http://www.ncbi.nlm.nih.gov/books/NBK25500/25. Pubmed Statistics of 2013:
http://www.nlm.nih.gov/bsd/licensee/2013 stats/2013 LO.html26. M. D. Rajathei and S. Samuel. (2012). Clustering of PubMed abstracts using nearer
terms of the domain. Bioinformation, Volume 8, 1, pp. 20-25.27. S. Shehata. (2009). A WordNet-Based Semantic Model for Enhancing Text Clustering.
ICDM Workshops, pp. 477-482.28. T. Theodosiou, N. Darzentas, L. Angelis and C. A. Ouzounis. (2008). PuReD-MCL:
a graph-based PubMed document clustering methodology. Bioinformatics, Volume 24,17, pp. 1935-1941.
29. TREC Genomics Track: http://ir.ohsu.edu/genomics/30. UIMA: http://uima.apache.org/31. WordNet: http://wordnet.princeton.edu/32. Z. Wu and M. S. Palmer. (1994). Verb Semantics and Lexical Selection. ACL, pp.
133-138.33. I. Yoo and X. Hu. (2006). Biomedical Ontology MeSH Improves Document Clustering
Qualify on MEDLINE Articles: A Comparison Study. CBMS, pp. 577-582.34. l. Yoo and X. Hu. (2006). Clustering Large Collection of Biomedical Literature Based
on Ontology-Enriched Bipartite Graph Representation and Mutual Refinement Strat-egy. PAKDD, pp. 303-312.
35. S. Zhu, J. Zeng and H. Mamitsuka.(2009). Enhancing MEDLINE document clusteringby incorporating MeSH semantic similarity. Bioinformatics, Volume 25, 15, pp. 1944-1951.