the modular assessment pack (map): a new approach to translation quality assessment at the dgt1
TRANSCRIPT

Full Terms & Conditions of access and use can be found athttp://www.tandfonline.com/action/journalInformation?journalCode=rmps20
Download by: [Tampere University] Date: 02 August 2016, At: 03:55
PerspectivesStudies in Translatology
ISSN: 0907-676X (Print) 1747-6623 (Online) Journal homepage: http://www.tandfonline.com/loi/rmps20
The Modular Assessment Pack: a new approach totranslation quality assessment at the DirectorateGeneral for Translation
Roberto Martínez Mateo, Silvia Montero Martínez & Arsenio Jesús MoyaGuijarro
To cite this article: Roberto Martínez Mateo, Silvia Montero Martínez & Arsenio JesúsMoya Guijarro (2016): The Modular Assessment Pack: a new approach to translationquality assessment at the Directorate General for Translation, Perspectives, DOI:10.1080/0907676X.2016.1167923
To link to this article: http://dx.doi.org/10.1080/0907676X.2016.1167923
Published online: 02 May 2016.
Submit your article to this journal
Article views: 28
View related articles
View Crossmark data

The Modular Assessment Pack: a new approach to translationquality assessment at the Directorate General for TranslationRoberto Martínez Mateoa , Silvia Montero Martínezb and Arsenio Jesús MoyaGuijarroa
aDepartment of Modern Philology, University of Castilla La Mancha, Cuenca, Spain; bDepartment ofTranslation and Interpreting, University of Granada, Granada, Spain
ABSTRACTThis paper presents a conceptual proposal for Translation QualityAssessment (TQA) and its practical tool as a remedy to thedeficiencies detected in a quantitative quality assessment tooldeveloped at the Directorate General for Translation (DGT) of theEuropean Commission: the Quality Assessment Tool (QAT). Thenew theoretical model, the Functional-Componential Approach(FCA) takes on a functionalist and holistic quality definition tosolve the theoretical shortcomings of the QAT. Thus, itincorporates the complementary top-down view of a qualitativemodule to build up a quality measurement tool, the aim of whichis to increase inter- and intra-rater reliability. Its practical tool, theModular Assessment Pack (MAP), is tested using a pretest-posttestmethodology based on an ad hoc corpus of real assignmentstranslated by professional freelance translators. The results of thisexperimental pilot study, carried out with the English-Spanishlanguage pair at the Spanish Language Department of the DGT,are described and discussed. This analysis sheds some light on thebenefits of adopting a mixed bottom-up top-down approach toquality assessment and reveals some weaknesses of the FCAwhich suggest the methods of further research. Although small-scale, the findings of this pilot study indicate that improvementscan be achieved by remedying its limitations in broaderexperimental conditions and adjusting the tool for use in otherlanguage combinations.
ARTICLE HISTORYReceived 4 March 2015Accepted 29 February 2016
KEYWORDSTranslation QualityAssessment (TQA);quantitative models;qualitative models;Functional ComponentialApproach (FCA); ModularAssessment Pack (MAP)
1. Introduction
This article reviews two methodologies for Translation Quality Assessment (TQA) inorder to improve the weaknesses detected in the Quality Assessment Tool (QAT), a pro-totype quantitative tool developed by the Directorate General for Translation (DGT). Dis-cussions on how to determine the quality of a translation tend to be linked to relativity andsubjectivity. This is partly because of the blurred borders of the concept of quality itself(Bowker, 2001, p. 347) and partly because of the necessary participation of a rater (‘thehuman factor’) in the assessment (House, 1997, p. 47). That is why, currently, in TQA,
© 2016 Informa UK Limited, trading as Taylor & Francis Group
CONTACT Roberto Martínez Mateo [email protected]
PERSPECTIVES, 2016http://dx.doi.org/10.1080/0907676X.2016.1167923
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

the aim is to limit subjectivity and raise interobjectivity (Gerzymisch-Arbogast, 2001,p. 238).
There is no commonly accepted single model or methodology in TQA (Colina, 2009).On the one hand, the definitions of quality and the model of assessment have not beenempirically verified (Martínez & Hurtado, 2001, p. 274) and, on the other, no model ormethodology takes into account the combined textual, contextual and functionalaspects of a translation. These product-centered methods are divided into two mainstreamapproaches: qualitative (Williams, 1989), holistic (Waddington, 2000) or theoretical(Colina, 2009) models that offer a global assessment from a macrotextual viewpoint(top-down); and quantitative (Williams, 1989), analytic (Waddington, 2000) or practical(Colina, 2009) models that offer a microtextual approach (bottom-up). The latter are morewidely used in professional settings.
With a view to building a new theoretical approach to TQA with a practical tool, wecarried out a critical examination of the most representative quantitative and qualitativemodels.1 Quantitative tools (also known as metrics) include: the SICAL (Système Cana-dien d’appréciation de la Qualité Linguistique) (Williams, 1989, p. 14); the LISA QualityAssurance Model (LISA, 2007, p. 43); the SAE J2450 (SAE J2450, 2001, pp. 1–3); theTAUS Dynamic Quality Evaluation (QE) Model, one of the latest and most significantcontributions to TQA, developed by O’Brien (2012) in collaboration with the TranslationAutomation User Society (TAUS);2 and the QAT (EC, 2009, pp. 11–12), a prototype tooldeveloped by the DGT of the European Commission to assess quality quantification ofexternal translations.
All these stand-alone tools apply quality control procedures (Parra, 2005) (SAE J2450also allows for quality assurance). However, these TQA metrics present some commonweaknesses: they rely on rating scales that lack an explicit theoretical base (Colina,2008, 2009; Jiménez-Crespo, 2011); they rely on the central concept of error as the definingelement of their assessment model and, subsequently, on related issues such as error type,severity and error weightings, which sometimes present an unclear definition (Parra,2005); they shape their definition of a ‘quality translation’ as an error-free text or a textwith a number of errors (their allocated points) that does not surpass a predefined limit(acceptability threshold); they consider the notion of ‘error’ as absolute, disregarding itsfunctional value (Martínez & Hurtado, 2001), and they identify and tag errors in isolationrather than in relation to their context and function within the text (Nord, 1997). The linethat separates the error categories is sometimes so thin or blurred that different reviewersmight classify the same error into different categories, and the search for errors is limitedto the word and sentence level without taking into account the larger unit of the text or thecommunicative context (Colina, 2008, 2009; Nord, 1997; Williams, 2001). The revisercarries out a partial revision (Parra, 2007) of the selected sample, so the representativenessof the limited, variable-length sample could be questioned (Gouadec, 1981; Larose, 1998);these metrics do not specify what type of revision has to be made (i.e. unilingual, compara-tive, etc.; Parra, 2005).
Despite these drawbacks, these quantifying systems fill a gap in the professional TQAarena (Jiménez-Crespo, 2011), in which translation becomes a business with constraintsof time (De Rooze, 2006) and budget (O’Brien, 2012). Nevertheless, metrics have thefollowing advantages: shared repetitive macro-error categories; a clear quality categor-ization, with an acceptability threshold and different quality ranges; and the fact that
2 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

assessment relies on a predetermined error classification and transparent error weight-ings, known a priori by all parties involved (Schäffner, 1998). In addition, thesemetrics raise expectations of a high inter-rater reliability (Colina, 2008, 2009), offeringresults that are valid, justified and defendable. Metrics also bestow systematicityand reproducibility on a process that necessarily requires human intervention(Hönig, 1998).
As for the qualitative theoretical models in TQA, the most useful for this study areColina’s framework (Colina 2008, 2009), and the American Translators Association(ATA) rubric for grading (v. 2011).3 Both Colina’s framework and the American Trans-lation Association rubric adopt a textual and a functional approach to TQA as they analyzethe product of the translation (a text) taking the intended purpose of the translation as thekey criterion to determine its linguistic quality. They rely on a double-entry table thatrelates dimensions (assessment criteria that correspond to smaller units of the quality con-struct in translation), command levels and, at the intersection, level descriptors (Barberá &De Martín, 2009, p. 99). The success of this tool lies in the right choice and definition ofthese three items.
The advantages of rubrics are: they provide a reference framework for the rater thatfacilitates his decision-making based on limited, known and transparent criteria whichlimits the subjective burden inherent to any assessment process with human intervention;it is only necessary to allot positive or negative values to the descriptors to offer a summa-tive valuation; they assess translation as a product in a given instance from a top-downapproach, which offers a general valuation of the text; and, as they are based on descriptivepropositions (descriptors), dimensions simplify the rater’s task and allow the rater to con-centrate on the inadequacies from the medium range of the quality continuum (Jiménez-Crespo, 2009, p. 76).
On the other hand, the following deficiencies have been noticed: they have to ade-quately describe the object they define and descriptors have to convey the essence ofthe feature they aim to assess; currently, there is no experimental verification of the exist-ing models of translation competence, so the identification of the dimensions andcommand levels has been based on those models which enjoy a long tradition and disse-mination; and when the translator only receives the final score, its capacity to offer mean-ingful information about the overall quality may be diminished (Simon, 2001). To sum up,while practical models have an extensive application, they also have limited transferability,as they lack theoretical foundation and empirical validation (Colina, 2009, p. 237; Jiménez-Crespo, 2011, p. 316). Also, these models rely on error quantification, a central issue in thedebate about academic and professional assessment (Jiménez-Crespo, 2011; Kussmaul,1995). Meanwhile, theoretical models offer a global view, but they lack the required appli-cability that professional translation demands. In this context, this paper introduces a newtool for TQA, based on the Functional-Componential Approach (FCA) (Martínez-Mateo,2014a). This proposal aims to remedy the deficiencies found in the freelance translationquality assessment tool devised at the Spanish Department of the DGT, by combiningboth mainstream methodologies and embedding the theoretical underpinnings of theSkopos theory. It also describes and discusses the preliminary results of a small-scale,exploratory pilot study, carried out with the Modular Assessment Pack tool (MAP) (aquantitative- and qualitative-based application). Finally, some observations on theMAP’s potential adjustments to other professional contexts are made.
PERSPECTIVES 3
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

2. Outsourced translations and quality assessment at the DGT
The DGT, the European Commission translation body, handles a huge translation work-load, which forces it to outsource part of it to freelance translators. The legal framework ofthe DGT requires an assurance of the quality of their translations (EC, 2012, p. 17); thus,in-house translator reviewers, with the aid of linguistic guidelines and an error typology,assess every translated text.4
2.1. The traditional approach and QAT
The quality that the DGT seeks for its translations is summarized by the functional motto ‘fit-for-purpose’ (EC, 2009, p. 11); although, in fact, the DGT does not implement a functionalquality notion or a functional assessment methodology (Martínez-Mateo, 2014b, p. 85).
The traditional procedure consists of an in-house reviewer carrying out quality control on arandomly extracted sample text of about 10%of the target text (TT) (2–10 pages) tofind errorsand correct them.5 The reviewer relies on an eight-category error typology (sense (SENS),omission (OM), terminology (TERM), reference documents (RD), grammar (GR), spelling(SP) and punctuation (PT)), which classifies errors according to their severity (high and low).
After an internal audit in 2008, the DGT launched the ‘Program for Quality Manage-ment in Translation – 22 Quality Actions’ to tackle some deficiencies. Action 4 deals withthe shortcomings found in the freelance translation assessment system and proposesadopting a professional approach using quantitative criteria as much as possible. So, in2009, the QAT was developed. This quantitative tool is based on the DGT’s error typologyand on three textual profiles (general, technical and political). It aims to quantify qualityby error identification. Error weights depend on their text type, category and severity. Thefinal weight aggregate is subtracted from an initial bonus, taking into account the numberof pages reviewed (100 points per five pages). The final mark places the translation withina section of the DGT’s quality categorization scheme (EC, 2012, p. 16; Table 1).
When the QAT was put to the test in 2009 it produced unsatisfactory results, basicallydue to the following reasons (Martínez-Mateo, 2014b, pp. 85–86): the QAT lacks a theor-etical foundation, as do other similar quantitative tools; it relies on analysis of error typeand severity but disregards an error’s nature, a key feature in determining the error’simpact on the target text; it views errors as absolute (Martínez & Hurtado, 2001,p. 281), disregarding the error’s relative value; and analysis is only carried out at sentencelevel, ignoring supratextual, pragmatic, communicative and functional issues.
2.2. The FCA and the MAP
In line with previous empirical studies (Colina, 2008, 2009; Jiménez-Crespo, 2009; Wad-dington, 2000), the FCA embeds the ‘fit-for-purpose’ motto as a ruling principle in TQA,thus taking on a functional approach to error and a componential view of quality.
Table 1. DGT’s quality assessment scheme.Grade Unacceptable Below average Acceptable Good Very Good
Points 0–39 40–59 60–69 70–85 86–100
4 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Since Skopos theory (Reiss & Vermeer, 1996) establishes a link between a trans-lation’s quality and its adequacy for purpose, it can be asserted that a quality translationhas to be functionally, pragmatically and textually adequate (Colina, 2009; Nord, 1997,p. 137). Likewise, error definition and error typology in the FCA have to take intoaccount the relative and functional value of error within the situational context(Nord, 1997, p. 73). Consequently, this approach integrates the traditional, quantitativebottom-up approach with a new, qualitative top-down approach that allows for the con-sideration of suprasegmental issues (Waddington, 2000, p. 394). While these twoelements start from opposite ends of textual analysis, by providing them with functionalquality criteria, they each become part of a qualitative-quantitative methodological con-tinuum (Orozco, 2001, p. 102).
This functional and componential approach to TQA materializes in the MAP, a toolcomprised of two modules. The qualitative module is a four-dimensional assessmentrubric (see Section 3.3.1), in which the dimensions constitute the construct used bythe FCA to describe a good translation, relating it to the functional notion of adequacy.Every dimension has several descriptors with associated points (see Appendix 1). Themetric module, with a calculator interface, includes an error typology with allottedpoints. Therefore the MAP offers two quality indicators of the text, which provide acomprehensive approach to translation from a macrotextual and microtextualviewpoint.
3. Methods and materials
Any research on translation quality quantification must adopt an empirical approach(Rothe-Neves, 2002, p. 114). Hence, a preliminary pilot study based on a corpus(Orozco, 2001, p. 107) and all the materials needed to implement it in the DGT weredesigned.
3.1. Pretest-posttest experimental design
The pretest-posttest (Sans, 2004, p. 185) or repeated measurement (Neunzig, 2002, p. 85;Wimmer, 2011, p. 170) is the study type that best fits the experimental conditions. Here,the pretest is the QAT test that was done by the Spanish Department of the DGT in realworking conditions in 2009. Its aim was to determine the reliability and applicability of theQAT for reviewing freelance translations in the Spanish Department. The posttest is theprincipal contribution to this study, as it attempts to empirically validate the conceptual(FCA) and the methodological (MAP) improvements made to the QAT. It was conductedin 2013 and its aim was to analyze and assess the changes that occurred between thepretest and the posttest, in order to check whether the modified tool had reached theexpected results. Specifically, two hypotheses were posed to validate the use of the MAPin the DGT:
(1) Using a TQA tool that combines a qualitative and quantitative approach allows for theprovision of a more comprehensive view of a quality translation.
(2) Using the MAP for the TQA of the DGT’s outsourced translations improves inter-and/or intra-rater reliability.
PERSPECTIVES 5
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

3.2. Corpus and respondents
For the pretest and the posttest, a corpus of text samples was compiled (Bowker, 2001;Corpas, 2001): a primary corpus (pretest) and a secondary corpus (posttest). Furthermore,a group of respondents participated in processing each corpus according to specificinstructions.
3.2.1. Primary corpus and respondentsTo check the QAT’s reliability, the Spanish Department compiled 30 translations(English–Spanish) from 15 different subjects commonly dealt with by the EC (EuropeanCommission).6 These texts were chosen from those that required evaluation at that time,making up a parallel, specialized, multilingual and ad hoc corpus (Corpas, 2001, pp. 158–165).
The respondents were freelance translators (who provided the translations) and in-house translators (the reviewers). Access to confidential data, such as the identity andcharacteristics of freelancers, was not granted. The reviewers, all European civil servants,were 18 in-house translators. The test consisted of the same translator evaluating onetranslation with both the traditional method (assessment template, Appendix 2) andwith the QAT. Ten reviewers evaluated one text, four evaluated two texts and the fourremaining reviewers evaluated three texts each.7
3.2.2. Secondary corpus and respondentsIn order to experiment with the MAP, a subcorpus was compiled from the primary corpus.The 30 original items were reduced to six due to reasons beyond the researcher’s control.The workload of the translator-reviewers who participated in the pretest prevented themfrom taking part in the posttest. Instead, the Spanish Department management kindlyoffered the cooperation of two members from the Quality and Coordination Group(QCG). This unexpected event compelled us to validate these two new experts to makesure they were on the same level as the respondents of the QAT test in 2009 (seeSection 3.5.2). For this purpose, the primary corpus underwent a non-random filteringprocess following a triple representativeness criterion. The texts selected for the posttest(secondary corpus) either belonged to different subjects, had obtained coinciding marksin the pretest or had obtained differing marks in the pretest. In addition, as marks obtainedwith the traditional method and with the QAT in the pretest coincided in roughly one-third of the cases, a similar proportion was maintained in the secondary corpus. This fil-tering process allowed for the selection of six translations characterized by their authen-ticity, representativity and specificity (Sinclair, 1991), which are features required byevery corpus.
The value of these texts is their authenticity, since they were not deliberately made forthis purpose (Bowker & Pearson, 2002, p. 9). They are real translations, produced by pro-fessional freelance translators and evaluated according to set criteria, which highlightstheir great ecological validity (Orozco, 2001, p. 100). They are representative texts asthis concept is now related to the fitness for purpose notion (Varantola, 2002, p. 174).The secondary corpus is appropriate for a study on TQA at the DGT because it containstexts that are genuinely assessed in that context. Therefore, the specificity of the secondarycorpus lies in its professional profile, its purpose and its homogeneity (Corpas, 2001,
6 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

p. 157). As it is an ad hoc corpus, designed in advance to fulfill some specific purposes(Bowker, 2001, p. 349), it is justifiably unbalanced and of limited size, although extremelyhomogeneous (Corpas, 2001, p. 164) (see Appendix 3). It is therefore an adequate corpusfor carrying out this preliminary pilot study with the MAP.
As for the group of respondents, it includes freelance translators from the pretest andtwo translator-reviewers from the Spanish Department, members of the Coordinationand Quality Group (CQG). The latter are highly experienced translators who are respon-sible for dealing with terminology requests, maintaining the IATE8 database and the Guíadel Departamento de Lengua Española (the Spanish Department’s Guide), organizing in-house training and coordinating all quality-related issues (including analyzing the linguis-tic quality of translations, both internally and externally). The extensive experience of thesetwo members, in addition to their wide range of functions and their valuable experiencewith TQA, allow them to be considered as internal experts. These respondents took partin an assessment at the end of 2013, in which they evaluated the secondary corpus withthe help of the new MAP tool. Moreover, they completed a questionnaire aimed at gather-ing information on three topics: the respondent’s profile, the corpus and the MAP tool.
3.3. Tools
The posttest aims to empirically validate the MAP and its two modules. However, withinthe framework of this study, the MAP also serves a second function: that of a collectiontool that gathers information via the questionnaire.
The principal contribution of the MAP to TQA is its functional-componential rubric. Itis based on the analysis and improvement of two textual and functional approaches:Colina’s (2008, 2009) model and the ATA rubric (v. 2011). The Funtional ComponentialApproach embeds Nord’s functional view of translation quality into the four dimensionsin which the quality contruct is broken down and thus it is also integral part of the MAP.
3.3.1. The MAP qualitative moduleThe qualitative module separates the quality construct into four smaller parts: the dimen-sions. The first dimension, ‘Functional, pragmatic and textual adequacy’, measures the TTadequacy in relation to its aim, defined by the assignment specifications and the needs ofthe target audience. The FCA regards the functional issues as those textual features thathelp the TT to fulfill its intended function within the context of its reception. Pragmaticissues refer to all extralinguistic elements that characterize any communicative setting, anddetermine the sender’s (author/translator) message and the target audience’s (reader)interpretation (Escandell, 1996, p. 14). Hence, these features will not be evaluated in theformal terms of correct and incorrect, but instead in the pragmatic terms of adequateor inadequate (Escandell, 1996, p. 29), according to the intended function of the textand the target reader (Nord, 1997, p. 35).
The second dimension, ‘Specialized lexical units and content adequacy’, refers to theTT’s conveyance of specialized lexical units and content in an adequate and coherentmanner. From a cognitive and pragmatic viewpoint (León, Faber, & Montero-Martínez,2011), it is understood that expert knowledge conceptualizes reality through categoriz-ation structures typical of specialized domains. Consequently, the distinction betweengeneral and specialized language (in varying degrees of specificity) is subject to cognitive
PERSPECTIVES 7
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

and pragmatic criteria. In fact, there is no clear division between them; rather, they areadjoining and overlapping realities (Montero-Martínez, Faber, & Buendía, 2011, p. 93).
The third dimension, ‘Non-specialized lexical units and content adequacy’, describesthe TT’s conveyance of non-specialized lexical units and content in an adequate andcoherent manner. Therefore, the transferred knowledge corresponds to a basic categoriz-ation of the world, and is verbalized through lexical units with non-specialized semanticfeatures (Montero-Martínez et al., 2011, p. 22). This adequate use of language includescompliance with the language usage norms of the TT speaker community.
The last dimension, ‘Normative and stylistic adequacy’, focuses on the observance ofgrammar, spelling and punctuation rules in the TT and the use of an adequate style,bearing in mind the aim and the target audience. As Malinowski (1923) states, textshave to be understood in relation to their context of culture (genre), but also in relationto their context of situation (register). Thus texts, in relation to the extratextual(Gómez, 2006, p. 422) and intratextual situations, have to be clear, precise and concise.Three factors are considered when studying the relationship between language and thespecific communicative situation in which it is used: field, tone and mode (Martin,1992). Field refers to the subject dealt with by the Directorates-General of the EC; tonerefers to the protagonists of communication, who, in this text type, are a writer expertin the field and a general reader, with varying degrees of knowledge; and mode refers tothe communication channel, which in this case is written.
The assessment rubric is a table in which the dimensions (columns) and the levels ofmastery (rows) intersect with the descriptors (cells) (Table 2). The descriptors define theconcept alluded to by each dimension, drawing a quality continuum from the highest tothe lowest level of adequacy of the described feature. In addition, points are allotted to thegrades obtained in order for them to be operative (Mossop, 2007, p. 184). The thickerhorizontal line in Table 2 shows the acceptability threshold between the pass and fail cat-egories. In the MAP, each descriptor is associated with a number of allotted points thatwill be added up to arrive at the final count. These points vary depending on the rank ofeach dimension in the order of preference (Table 2).
3.3.2. The MAP quantitative moduleThe quantitative module is a new version of the QAT, redesigned and adjusted to correctits detected weaknesses and provide it with a functional conceptual foundation. First, theerror typology is based on that used in the QAT, due to its long tradition within the DGTand to an analysis of the most renowned quantitative evaluation systems, which revealed astrong accord with this typology (Martínez-Mateo, 2014b, p. 84). All these justified furtherexperimentation. As for error seriousness, the distinction between high and low errors ispreserved. The former cause the reader to interpret the text in a different way from thatwhich is intended, or prevent the reader from clearly understanding the message.However, the MAP includes a new error type (Addition (AD)) to complement errorsrelated to accuracy and clarity.
Second, the FCA establishes a correspondence between the qualitative module dimen-sions and the quantitative module error typology. The functionalist fit-for-purpose view,which is embodied in Nord’s (2009) error typology, acts as a hinge between the top-downand bottom-up approaches of the FCA, creating a methodological continuum in whichpragmatic, cultural and linguistic errors9 (Nord, 2009, p. 238) serve as a reference to
8 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Table 2. Qualitative module: assessment rubric.Functional, pragmaticand textual adequacy
textualSpecialized lexical unitsand content adequacy
Non-specialized lexicalunits and content
adequacyNormative and stylistic
adequacy
Very good The TT is adequate fromthe functional,pragmatic and textualviewpoint and inrelation with its usage,conditioned by theassignmentspecifications and theneeds of targetaudience.
The TT conveysspecialized lexicalunits and context in acorrect, coherent andadequate manner.
The TT conveys non-specialized lexicalunits and content ina correct, coherentand adequatemanner.
The TT abides by thegrammar, spelling andpunctuation rules ofthe target languageand employs anadequate style,bearing in mind thepurpose and thetarget audience.
Good The TT is close to thepurpose, usage,assignmentspecifications andneeds of the targetaudience, although itmay require someminor changes.
The TT may containsome minorinadequacy(ies)regarding theconveyance ofspecialized lexicalunits and/or content,bearing in mind thecontext and thepurpose of the TT.
The TT may containsome minorinadequacy(ies)regarding theconveyance of non-specialized lexicalunits and/or content,bearing in mind thecontext and thepurpose of the TT.
The TT contains (or maycontain) somegrammar, spelling orpunctuation error(s)and/or contains someminor styleinadequacy(ies) in TTfor the purpose andthe target audience.
Acceptable The TT sufficientlycomplies with thepurpose, purportedusage, assignmentspecifications andneeds of targetaudience, although itrequires some changes.
The TT contains someinadequaciesregarding theconveyance ofspecialized lexicalunits and/or content,bearing in mind thecontext of the TT,although itsufficiently complieswith its purpose.
The TT contains someinadequaciesregarding theconveyance of non-specialized lexicalunits and/or content,bearing in mind thecontext of the TT,although itsufficiently complieswith its purpose.
The TT contains somegrammar, spellingand/or punctuationerror(s) and/orcontains some styleinadequacy(ies) thatdo not compromise itspurpose for the targetaudience.
Belowaverage
The TT observes thepurpose, usage,assignmentspecifications andneeds of the targetaudience, although itcontains several minorinadequacies or onemajor inadequacy thatrequire(s) importantamendments.
The TT contains someminor inadequaciesor one majorinadequacyregarding theconveyance ofspecialized lexicalunits and/or content,bearing in mind thecontext and thepurpose of the TT,which impairs itsutility as atranslation.
The TT contains someminor inadequaciesor one majorinadequacyregarding theconveyance of non-specialized lexicalunits and/or content,bearing in mind thecontext and thepurpose of the TT,which impairs itsutility as atranslation.
The TT contains somegrammar, spellingand/or punctuationerror(s) and/orcontains some minorinadequacies or onemajor styleinadequacy thatimpair the correctconveyance of themessage for thepurpose and thetarget audience.
Unacceptable The TT does not observethe purpose, usage,assignmentspecifications andneeds of the targetaudience. It containsmajor inadequacies.
The TT contains someminor inadequaciesor one majorinadequacyregarding theconveyance ofspecialized lexicalunits and/or content,bearing in mind thecontext and thepurpose of the TT.
The TT contains someminor inadequaciesor one majorinadequacyregarding theconveyance of non-specialized lexicalunits and/or content,bearing in mind thecontext and thepurpose of the TT.
The TT containsgrammar, spellingand/or punctuationerror(s) and/orcontains styleinadequacy(ies)unacceptable for thepurpose and thetarget audience.
PERSPECTIVES 9
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

integrate quantitative and qualitative aspects. Figure 1, from the left, links, one by one,each dimension of the FCA to the two macroerror types (pragmatic and linguistic).From the right, analogous links between the QAT’s eight error types and Nord’s functionalerrors10 are established.
Third, the reviewers identified errors by comparing the source and the target textsaccording to the requirements of the assignment, usage conditions and target-culture con-ventions (Nord, 2009, p. 237). Thus, the reviewer will determine whether an error is lin-guistic or pragmatic (functional); that is to say, he/she will assess the error according to itsimpact on the function of the text, bearing in mind the communicative effect on the reader(Kussmaul, 1995, p. 132).
Fourth, the QAT’s textual profiles have been replaced with the DGT’s textual binaryclassification, which categorizes texts into two types (Quality Control 1 (QC1), QualityControl 2 (QC2)) according to the quality control level they undergo. These controllevels depend on the aim and quality requirements of the TT. The reviewer simply hasto look up the text type in the lists found in the Spanish Department of the DGT’s RevisionManual.11
Fifth, as one of the greatest deficiencies of quantitative models has to do with the varia-bility in error tagging once detected, the meta-rules12 of the SAE J2450 model are incor-porated in order to standardize error tagging. Furthermore, a preference order of errors(Martínez-Mateo, 2014a, p. 256) is set up according to textual profile. This follows atop-down hierarchy. Figures 2 and 3 show the order of preference that, when in doubt,the reviewer will follow to tag errors. Errors are ordered from the highest to the lowestwith decreasing penalty values.
Figure 1. Qualitative and quantitative continuum in the FCA.
10 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Thus, when in doubt about how to tag an error using the MAP qualitative module, thereviewer will choose: pragmatic over linguistic; the error type (SENS, TERM, etc.) accord-ing to the order of preference; and high over low.
3.3.3. QuestionnaireThe questionnaire was designed to take into account the objectives and the empirical vari-ables of this study, and is therefore structured into three content blocks.13 The first block(Sections I–III) focuses on the academic and professional profile of the respondents. Thesecond block (Section IV) looks into the theoretical underpinnings of the corpus regardingits adequacy, representativeness and sample extraction. The third block (Sections V–VI)deals with the MAP. Specifically, it poses questions regarding the qualitative module,the relevance of the dimensions, the clarity of the descriptors and the suitability of thescores. As for the quantitative module, the new text classification is assessed, as is theappropriateness of the error typology and the associated weights. The last three questionsask the respondent for an overall assessment of the MAP.
As far as the design is concerned, the funnel technique was used, i.e. the questionnairegoes from the general to the particular. In order to allow for a wide range of answers,open, dichotomous and polychotomous choice questions were employed. The languageused is clear and simple, in an attempt to create exclusive, unambiguous questions. The suit-ability of the questionnairewas subsequently validated by an expert onMethods of Research
Figure 2. Error type order of QC1 profile.
Figure 3. Error type order of QC2 profile.
PERSPECTIVES 11
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

and Diagnostics in Education from the University of Castilla La Mancha (Spain) and bythree experts on Translation and Interpreting Quality Assessment from the University ofGranada (Spain) with the help of a validation guide (Martínez-Mateo, 2014a, pp. 392–399).
3.4. The pilot study
In order to carry out the pilot study (posttest), the test of the MAP tool on the secondarycorpus, the respondents received all the necessary materials in an electronic folder calledDossier. The folder contained instructions to guide the reviewer in the process, the corpus,the MAP tool and the questionnaire.
3.4.1. ProcedureEfficiency and efficacy governed all the decisions regarding the empirical development ofthe test. Thus, the initial plan of holding an on-site training session with the two partici-pants was discarded due to their time limitations. Instead, they were contacted via email.Before commencing the study, they knew nothing about the test. Since these two membersof the QCG had not participated in the pretest, first of all they had to be validated as suit-able candidates for the posttest (see Section 3.4.2). Then came the actual test. It wasintended as an empirical validation of the conceptual and methodological improvementsof the QAT, which aimed to improve the MAP. To carry out the process, a two-week dead-line was agreed with the participants. In a second round of emails, we sent the participantsa dossier that contained two Word files and three folders. One Word file described thegeneral framework of the study and included all the necessary information to completethe test. The first folder included the secondary corpus texts. The second folder comprisedthe MAP tool, with its two modules, and instructions on how to use them. Here the theor-etical approach, the functions available and the customization capacity of MAP were sum-marized. As for the new qualitative module, a read through the assessment rubric and itsbrief instructions was sufficient for them to learn to use it. The third folder was composedof two subfolders: one for storing the assessment reports of the qualitative module andanother for the quantitative module reports. The last Word file was the questionnairethat was to be completed as a conclusion.
The most important information contained in the dossier was the implementation ofthe MAP, although the participants’ extensive knowledge of the QAT facilitated thistask. Nonetheless, a more detailed step-by-step practical explanation of the procedurethey were provided with follows.
Using the Track Changes feature in Word, reviewers had to mark the errors in theselected sample. First, they evaluated the texts with the help of the MAP qualitativemodule. For that purpose, they followed the order of preference of the dimensions inthe assessment rubric, from left to right. Next, they registered the mark obtained ineach dimension in the file Assessment summaries (see Appendix 1), the final count ofwhich appears in the Final mark column. Then they evaluated the texts according tothe MAP quantitative module (Figure 4). First, they had to choose the text Profile(QC1 or QC2) and select the page number (Pages). Next, they compared the originaltext (OT) and TT to pinpoint errors and tag them according to their nature, type andseverity. To calculate the Final grade, the values of both modules are added togetherand then divided by two (MAP Assessment summary in Appendix 1). That result is
12 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

recorded in the Recommendation (Appendix 1) table, and corresponds to the tool’s rec-ommendation for that particular translation.
3.4.2. Experimental restrictionsFirstly, as stated in Section 2, the participants of this exploratory study work for the DGTof the European Commission, a high-pressure work environment. Owing to that, anddespite their willingness to collaborate, their availability was limited. The workload ofthe professional translator-reviewers who participated in the pretest prevented themfrom taking part in the posttest. Instead, the Spanish Department management kindlyoffered cooperation from the QCG, made up of two members. This unexpected eventcompelled us to shorten the primary corpus used in the pretest (see Section 3.2.2) andto validate these two new experts so as to make sure that they were as equally qualifiedas the respondents of the QAT test in 2009.
Therefore, and for the sake of effectiveness, the respondents (hereinafter reviewer A andreviewer B) were asked to assess the six texts of the secondary corpus (extracted from theprimary corpus) with the QAT. The following premise was considered: if reviewers A andB got similar marks (that is to say, within the same mark range according to QAT’s qualityassessment scheme, Table 1) to those obtained by the pretest respondents in the assessedtexts, they would be validated to perform in the posttest in the same conditions as if theyhad taken part in the pretest. The comparison of the results showed total coincidence,which allowed for their validation as suitable respondents for the posttest (Martínez-Mateo, 2014a, pp. 298–299). The respondents completed the evaluation of the secondarycorpus and completed the questionnaire. Unfortunately, in such demanding circum-stances, there was no time for a face-to-face training session of the tool, which wouldhave solved many of the inquiries subsequently posed by the respondents. Thus, the a
Figure 4. MAP interface. © European Union 2015.
PERSPECTIVES 13
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

priori and experimental restrictions of this research conditioned its development and therespondents’ perception.
4. Results and discussion
The results gathered in the first two measurements of the pretest-posttest (2009 and 2013)allow some conclusions to be drawn regarding the concurrence or divergence of marksobtained with the DGT traditional methodology and the QAT, and then with the MAP.
4.1. Pretest results
The pretest results correspond to the TQA of the primary corpus texts (30 translations)applying the Traditional method and the QAT. With the Traditional method, 27 trans-lations passed the acceptability threshold and three failed. With the QAT, only 20 trans-lations passed, which denotes that assessment with the QAT produced lower marks thanwith the Traditional method (Martínez-Mateo, 2014a, p. 312).
The marks given by the same reviewer using the two methods mentioned above (intra-rater assessment) were gathered in order to calculate the degree of agreement or disagree-ment of the QAT (intra-rater reliability). The marks agreed in 13 and disagreed in 17 texts;that is, the intra-rater general agreement percentage was 39.81%.14
As can be seen in Table 3, while some raters assessed only one text (10 raters), othersassessed two or three texts (eight raters). From this, no regular pattern can be identified, assome raters who assessed only one text got 100% agreement, while others 100% disagree-ment and, simultaneously, raters who assessed two or three texts also obtained varyingdegrees of coincidence (from 0 to 100%).
If we look at the distribution of similar marks per section, Figure 5 shows that thelargest accumulation (11/13) was in the two higher marks (‘Very good’, ‘Good’), whilethe three other mark sections (‘Acceptable’, ‘Below average’, ‘Unacceptable’) obtainedfewer occurrences (2/13). The heterogeneity of these data is evidenced by the uneven dis-tribution of scores, particularly in the mid-range values.
Table 3. Intra-rater assessment results (pretest).Rater (R) N. of texts with coinciding grades N. of texts with differing grades % coincidence per R
R1 3 3/3 (100)R2 3 0/3 (0)R3 1 2 1/3 (33.3)R4 1 0/1 (0)R5 1 1/1 (100)R6 1 1/1 (100)R7 1 0/1 (0)R8 1 1 1/2 (50)R9 1 0/1 (0)R10 1 1/1 (100)R11 1 2 1/3 (33.3)R12 1 0/1 (0)R13 1 0/1 (0)R14 1 1 1/2 (50)R15 1 0/1 (0)R16 2 2/2 (100)R17 1 1 1/2 (50)R18 1 0/1 (0)Totals 13 coincidences 17 differences 39.81% coincidence
14 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

From a gender viewpoint, the data collected show that, on average, female intra-raterreliabilitywas ‘Acceptable’ (66.6%) andmale intra-rater reliabilitywas ‘Belowaverage’ (27.3%).
According to these data, overall intra-rater reliability can be regarded as being low, withan agreement of 43% and a slightly higher divergence of 57%. Nonetheless, reliability isinconclusive as these are mid-range values.
It is also worth noting that in the case of the Spanish Department, the QAT wasimplemented following the standard guidelines because, due to the nature of their in-house staff, it is one of the Linguistic Departments of the DGT that outsources the leastamount of translations. Hence, they used all the preset values and did not make any adjust-ments. This fact flaws the QAT’s value, for, as the developers of QAT stated, its greatestvirtue lies in its customization capacity.
4.2. Posttest results
The results of the posttest are the grades obtained by reviewers A and B in the TQA of thesecondary corpus by means of the MAP, together with the results of the questionnaire. Inaddition, these results were compared with the grades obtained by the same reviewersusing the QAT and the Traditional method in the validation phase (see Section 3.4.2)in order to draw conclusions about intra-rater reliability and inter-rater reliability.
4.2.1. Quantitative and qualitative module resultsTable 4 shows the results obtained by reviewers A and B concerning the texts of the sec-ondary corpus. The columns show the quantitative and qualitative modules, as well as thefinal MAP grade.
As for the quantitative module, the marks obtained by reviewers A and B on the sametext concur in four texts (3, 4, 5 and 6) and differ in two texts (1 and 2). This highlights theneed to complement the microtextual approach.
Regarding the errors labeled during the test (Appendix 4), reviewers A and B used thenewMAP function to tag mistakes according to their nature. For example, error 23 (Omis-sion, Pragmatic, High; Table 5) clearly shows how this inadequacy is not the result ofbreaking linguistic rules but of the peculiarities of the situational context. It should benoted that the space reserved for comments is limited.15
Likewise, to identify error 28 (Omission, Pragmatic, Low; Table 6), it is necessary toknow the purpose of the mentioned component. This information cannot merely bederived from the linguistic content but requires additional contextual information.
Figure 5. Distribution of coinciding marks (pretest).
PERSPECTIVES 15
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Regrettably, there were no instances of the new error type, AD, so no conclusions can bereached.
Regarding the results obtained with the qualitative module, reviewers agreed in allcases. An example of this can be found in Table 7, which shows that, in texts 1 and 3,reviewers have ticked the same descriptors for each dimension.
Table 4. Grades obtained with MAP (posttest).MAP results
Qualitative module Quantitative module Final grade
Text 1, Rater A 90 86 88Very good
Text 1, Rater B 90 79 84.5Good
Text 2, Rater A 75 50 62.5Acceptable
Text 2, Rater B 75 60 67.5Acceptable
Text 3, Rater A 50 45 47.5Below average
Text 3, Rater B 50 52.5 51.25Below average
Text 4, Rater A 90 94 92Very good
Text 4, Rater B 90 94 92Very good
Text 5, Rater A 50 50 50Below average
Text 5, Rater B 50 42.5 46.25Below average
Text 6, Rater A 75 61.6 68.3Acceptable
Text 6, Rater B 75 61.6 68.3Acceptable
Table 5. Error 23.Text andrater Original text
Freelancetranslation Rater translation
Error type, nature andseriousness
Text 5 – A Invalidcomment(max. 255chars)
Comentario noválido.[Invalidcomment]
Comentario demasiado extenso: no seaceptan más de 255 caracteres.[Comment too long: not more than 255chars. will be accepted]
OM P high
Table 6. Error 28.Textandrater Original text Freelance translation Rater translation
Error type,nature andseriousness
Text 6– A
The EGNOS componentslocated in the EOIGhosting sites shall beoperated by the relevantEOIG Members on acommercial basis
Los miembros del EOIG, o lasentidades que éstosdesignen, explotarán loscomponentes de EGNOS…
[The EGNOS members, or theentities designated by them,will operate the EGNOScomponents… ]
Los miembros del EOIG, o lasentidades que éstosdesignen, explotaráncomercialmente loscomponentes de EGNOS…
[The EGNOS members, or theentities designated by them,will perform commercialoperations on the EGNOScomponents… ]
OM P low
16 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

4.2.1.1. Intra-rater reliability. The intra-rater reliability of the posttest is analyzed by com-paring the results obtained by each reviewer (A and B), using comparable tools (intra-raterassessment): theQAT in the validation phase and theMAPquantitativemodule in the posttest.
In the validation phase, as Table 8 shows, scores obtained by reviewers A and B with thehelp of the QAT and the MAP qualitative module agree in three texts and differ in theother three (Martínez-Mateo, 2014a, p. 312).
These data show a low intra-rater reliability of both reviewers using the QAT and theMAP quantitative module, as 50% is considered to be ‘Below average’.
4.2.1.2. Inter-rater reliability. The inter-rater reliability of reviewers A and B was analyzedin four cases.
First, we compare the marks obtained by both reviewers when assessing the same textwith comparable tools. More precisely, these scores were obtained with the MAP quanti-tative module and the results gathered with the QAT in the expert validation phase.Table 9 shows that texts 1, 2, 4 and 5 (66.6%) had similar marks and texts 3 and 6 haddiffering marks (Martínez-Mateo, 2014a, p. 324). All these data confirm that the quanti-tative-based tools tested produce an acceptable inter-rater reliability (66.6%).
Table 7. Descriptors ticked in texts 1 and 3.Qualitative module
Text 1 Text 3
Rater A Rater B Rater A Rater B
Dimension 1 30 30 15 15Dimension 2 20 20 15 15Dimension 3 25 25 15 15Dimension 4 15 15 5 5Grade 90 90 50 50
Table 8. Intra-rater evaluation with QAT and MAP (quantitative module).RATER A RATER B
QAT in validation MAP quantitative module QAT in validation MAP quantitative module
Text 1 79 86 70 79Text 2 40 50 40 60Text 3 30 45 37.5 52.5Text 4 88 94 94 94Text 5 40 50 40 42.5Text 6 73.3 61.6 73.3 61.6
Table 9. Grades obtained with QAT and MAP quantitative modules (Inter-rater).Experts validation QAT Posttest MAP quantitative module
Rater A Rater B Rater A Rater B
Text 1 79 70 86 79Text 2 40 40 50 60Text 3 30 37.5 45 52.5Text 4 94 94 94 94Text 5 40 40 50 42.5Text 6 73.3 73.3 61.6 61.6
PERSPECTIVES 17
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

However, the distribution of marks in a bar graph (Figure 6) does not show any regularpattern. It is only worth mentioning that the lowest marks (text 3) present a greater graphdispersion and that the highest marks (text 4) appear closer.
Second, when comparing the marks obtained by reviewers A and B using the MAPqualitative module (Table 7), they agreed in all cases. Additionally, the reviewers tickedthe same descriptors for each dimension (Martínez-Mateo, 2014a, p. 325).
Third, the marks obtained using the MAP quantitative module agree in four of six texts(66.6%; Table 9), which points to an acceptable inter-rater reliability.
Fourth, the final marks given by reviewers A and B using the MAP agreed in five out ofsix texts (83.3%; Table 4). In other words, inter-rater reliability is between good and verygood; besides, in the remaining text, the difference is a mere 0.5 points (Martínez-Mateo,2014a, pp. 325–326).
4.2.2. Questionnaire resultsIn the last step of the posttest, the respondents completed a questionnaire made up of threesections. The first section consisted of questions about the respondents’ training and qua-lifications. The second dealt with the corpus: both respondents agreed that it was repre-sentative and that the selection method of the evaluation sample was adequate.Regarding the third section, centered on the MAPmodules, respondent A raised questionsabout the utility of the qualitative module and respondent B raised doubts about theweight of the descriptors. This reflects indifference to the use of the tool (position 3 ina 5-point Likert scale). When questioned about the two new text types (QC1 and QC2),both respondents agreed that it had been a wise choice. As for the correspondence estab-lished between the qualitative module dimensions and the error groups of the quantitativemodule, respondents agreed on the suitability of two of the alignments and disagreed onthe suitability of the other two (Dimension 1 with all error types and Dimension 3 withGR, SP and PT errors). Overall, their assessment of the tool in the pilot study was ‘Some-what dissatisfied’ (position 2 in a 5-point Likert scale).
4.3. Discussion
In the pretest, overall intra-rater reliability is low (39.81%), as evidenced by the two indi-cators stemming from the evaluations with the Traditional methodology and the QAT.The agreement rate is low (43%, ‘Unacceptable’) and the divergence rate is acceptable
Figure 6. Distribution of grades obtained with quantitative-based tools.
18 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

(57%). Also, the QAT produced lower marks than the Traditional methodology. Thesepoor values are due to the fact that the QAT used default settings that penalize lowerrors with three points and high errors with ten, disregarding any other variables. Inaddition, the analysis of errors tagged with the qualitative tools demonstrates that thereviewers identified different errors in the same translation and, even when they diddetect the same error, they sometimes tagged it differently, which brought about differentscores.
In response to the aforementioned deficiencies, two of the material amendmentsinserted in the MAP quantitative module were: the distinction between pragmatic and lin-guistic errors and the setting of an order of errors per text type (applicable if in doubt), andthe application of a point-deduction scheme according to text type, nature and seriousnessof error.
Another conclusion that can be drawn is that, out of the 13 translations with similarmarks (Figure 5), 11 received ‘Good’ and ‘Very good’ marks, and only two receivedmid-range marks bordering the acceptability threshold. This fact corroborates the initialassumption that the marks in the mid-range of the quality continuum gave way tovaried opinions, whereas the ‘Good’ and ‘Very good’marks generated higher levels of con-sensus amongst raters (Martínez-Mateo, 2014a, p. 314).
Finally, and from a gender perspective, results show higher female intra-rater reliability(66.6%); it would therefore have been desirable to have a larger number of female respon-dents in order to explore the reasons for those discrepancies.
In the posttest, when comparing the results obtained by the reviewers with the QAT inthe validation phase and those obtained with the MAP quantitative module, they revealthe low intra-rater reliability of the quantitative-based tools (which only reach a 50%agreement per reviewer; Table 8). This poor percentage of agreement highlights the quan-titative-based tools’ deficiencies in TQA, since they only provide a partial, microtextualview of quality, based only on the penalization of linguistic errors. In consequence, thisbiased view should be complemented with a top-down approach.
The evaluation of intra-rater reliability has also been based on the results obtained withthe MAP as a whole, and with the qualitative and quantitative modules separately. Thetotal coincidence of the results obtained by raters A and B with the MAP qualitativemodule, not only in the final score but also in every one of the descriptors ticked perdimension (Table 4), underlines the potential value of the TQA model presented in thisstudy. This module provides the reviewer with a reference framework that facilitatesdecision making according to a limited, practical, known, transparent and customizableset of criteria, restricting the subjectivity of those decisions and enhancing interobjectivity.
Marks obtained by raters A and B with the quantitative module coincide in four out ofsix texts (Table 9), and disagreeing marks only vary by one point, which causes a change ofquality range. The rise in intra-rater reliability with the MAP quantitative module, in com-parison to the QAT, indicates the positive effect of the improvements.
The comprehensive results of the reviewers of the posttest with the MAP offer highintra-rater reliability (Table 4). This seems to prove that the inclusion of the qualitativemodule in the MAP contributes to the provision of a more holistic view of the analyzedtext.
Finally, the opinions expressed by the reviewers in the questionnaire provided positiveand negative feedback, depending on the issue. Based on the analysis of the respondents’
PERSPECTIVES 19
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

questionnaires, the training procedure used in this study seems to have some flaws regard-ing the full understanding of the MAP’s functionality. This stresses the need for an in-person training session to present in full the theoretical underpinnings and capacity ofthe tool. This session could take between one and two hours for reviewers with previousknowledge of TQA aid tools.
In addition, the usefulness of the new error type (AD), as well as the possibility ofinserting another error type in reference to internal coherence, will be evaluated, followingthe recommendations provided by the respondents. The specification of an error typologyhas long been a controversial issue, although there are several proposals, from the earlyproposals of Kupsch-Losereit (1985), Gouadec (1989), Nord (1997) and Mossop (2007)to recent ones by Jiménez-Crespo (2009, 2011) and O’Brien (2012). Nevertheless, farfrom being a settled issue, it still generates heated debate, which calls for more empiricaltesting on the previous proposals.
4.4. The MAP tool in other professional contexts
As pointed out above, the adaptation potential of the MAP is one of its greatest strengths.The underlying conceptual framework provided by the FCA bestows upon it a flexiblecomponential interrelation of the items that comprise the two modules (the macrotextualand microtextual approaches). The internal features of each module may be adjusted to aconcrete situation. The qualitative module splits the quality construct into four dimen-sions and associates positive points to each dimension, while the quantitative modulehas negative points allotted to the error types according to three criteria: error nature,type and severity. Nonetheless, every parameter is customizable. The number, type andnature of error may be subject to amendments, while the point allocation of eachmodule is liable to be fine-tuned according to the quality criteria demanded by a pro-fessional institution. Besides, both modules have a preset internal order of preference ofits components (dimensions or error typology) that conditions the value of the bonuspoints (qualitative) and the severity of the penalizing points (quantitative). These canalso be adjusted to specific needs.
5. Conclusions
Although we are aware of the shortcomings of this exploratory analysis, these do notundermine the relevance of the findings. Despite the limitations, the results obtainedallow for the corroboration of the first hypothesis. The use of an assessment tool that com-bines a qualitative with a quantitative approach, and is based on common quality criteria,allows the reviewer to assess the translated text with a unified reference framework thatimproves the interobjectivity and offers a more balanced view of the assessed text, as itapproaches the text from two necessary and complementary perspectives.
With regard to the second hypothesis – that is, whether the MAP tool can be validatedas a reliable tool for the TQA of the Spanish Department of the DGT’s outsourced trans-lations – the results of this pilot study are inconclusive. This has raised conceptual andmethodological considerations with regard to future improvements. The respondents’comments challenged some issues that need re-examination: the need to count on two sep-arate dimensions to assess general and specialized language; the correspondence between
20 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

the qualitative module dimensions and the quantitative module errors; and the adjustmentof the weight of both modules.
Once improvements to the conceptual model and the MAP have been implemented, alarger-scale study (with a larger corpus and a greater number of reviewers) should providestronger evidence of the conceptual and methodological validity of the tool. Only thencould the tool be adjusted to other linguistic combinations within the institutionalcontext of the DGT, or to other professional settings, given its excellent benefit–cost ratio.
Notes
1. For an extensive review of the characteristics, weaknesses and strengths of these TQA modelsand tools, see Martínez-Mateo (2014a, 2014b).
2. It provides a customizable modular TQA system for the selected content types and qualitycriteria, which allows for adaptability to client preferences.
3. For more information, visit the website: http://www.atanet.org/certification/aboutexams_rubic.pdf
4. The Guide for External Translators aims to provide external contractors with informationabout the procedure and the technical and quality requirements that externalized translationsmust fulfill.
5. This simple revision (Parra, 2005, p. 362) is based on known criteria and fulfills summative(issues an assessment), formative (teaches freelance translator from its errors) and corrective(makes amendments) functions (Martínez & Hurtado, 2001, p. 277).
6. There are 36 subjects dealt with by the EC. For further information, visit http://europa.eu/pol/index_en.htm
7. Due to space restrictions and to ease the subsequent comparison of results, only the datarelated to the corpus, the respondents and the pretest are presented here. A complete descrip-tion of all the test elements can be found in Martínez-Mateo (2014a, pp. 284–292).
8. Inter-Active Terminology for Europe (IATE) is the EU’s inter-institutional terminologydatabase. It is publicly available at http://iate.europa.eu/SearchByQueryLoad.do;jsessionid=DTGPV9jX0sdhVVGvN2X8bVPNlyHVGLT1GsDKDzPjHZCmyLVn0MxN!1492297265?method=load
9. For the purposes of this study, cultural errors are included in pragmatic ones, since theformer are inadequacies related to world knowledge, and are not inferred from linguisticsigns or rules alone (linguistics errors) in a straightforward manner (Martínez-Mateo,2014a, p. 248).
10. An in-depth description of the correspondences established can be found in Martínez-Mateo(2014a, pp. 202–223).
11. Available on the website: http://ec.europa.eu/translation/spanish/guidelines/documents/revision_manual_es.pdf
12. ‘(1) when in doubt, always choose the earliest primary category; and (2) when in doubt,always choose “serious” over “minor”’.
13. The questionnaire itself is available upon request to the authors via email.14. General coincidence percentage = total records/total participants.15. The freelance and rater translations in the tables and in Appendix 4 have been glossed in
English.
Acknowledgments
We would like to thank the willingness and cooperation of the members of the Spanish Departmentof the Directorate-General for Translation of the European Commission. We would like to thankthe Editor and the anonymous referees for their useful comments on an earlier version of thisarticle. We also thank Maria Baldarelli for the language editing of the text.
PERSPECTIVES 21
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Disclosure statement
No potential conflict of interest was reported by the authors.
Funding
This research is part of the project Cognitive and Neurological Bases for Terminology-enhancedTranslation (CONTENT) (FFI2014–52740-P), funded by the Spanish Ministry of Economy andCompetitivity.
Notes on contributors
Roberto Martínez Mateo holds a degrees in English Philology from the University of Val-ladolid and another degree in Translation and Interpreting from the University of theBasque Country. He gained his PhD in Translation and teaches English as a foreignlanguage, didactics and translation at the University of Castile La Mancha. His researchinterests deal with translation quality assessment, communicative language skills andtranslation as a teaching tool for Foreign Language Teaching (FLT). He has publicationsin Journal of Language Teaching and research,Miscelanea: A Journal of English and Amer-ican Studies and Ocnos.
Silvia Montero Martínez holds a degree in English Language and Literature and a M.A. inSpecialized Translation from the University of Valladolid. She has a PhD in Spanish Lin-guistics. She lectures on Translation, Terminology and Translation Technologies at theUniversity of Granada. Her main research interests are terminology, specialized trans-lation and knowledge engineering. She is the author of various books and chapters onlexical semantics, translation and terminology. Her work has been published in severalinternational peer-reviewed journals, such as Terminology, Perspectives, META, Babel,and Journal of Pragmatics.
A. Jesús Moya Guijarro does research in Systemic Functional Linguistics and has pub-lished several articles on information, thematicity and picture books in international jour-nals such as Word, Text, Functions of Language, Journal of Pragmatics, Text and Talk,Review of Cognitive Linguistics and Atlantis. He is co-editor of The World Told and TheWorld Shown: Multisemiotic Issues (2009, Palgrave Macmillan). He is also author of thebook, A Multimodal Analysis of Picture Books for Children. A Systemic FunctionalApproach (2014, Equinox).
ORCID
Roberto Martínez Mateo http://orcid.org/0000-0001-7110-8789
References
Barberá, E., & Martín, E. (2009). Portfolio electrónico: aprender a evaluar el aprendizaje. Barcelona:Editorial UOC.
Bowker, L. (2001). Towards amethodology for exploiting specialized target Language corpora as trans-lation resources. International Journal of Corpus Linguistics, 5(1), 17–52. doi:10.1075/ijcl.5.1.03bow
22 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Bowker, L., & Pearson, J. (2002). Working with specialized language. A practical guide to usingcorpora. London: Routledge.
Colina, S. (2008). Translation quality evaluation: Empirical evidence for a functionalist approach.The Translator, 14(1), 97–134. doi:10.1080/13556509.2008.10799251
Colina, S. (2009). Further evidence for a functionalist approach to translation quality evaluation.Target, 21(2), 235–264. doi:10.1075/target.21.2.02col
Corpas, G. (2001). Compilación de un corpus ad hoc para la enseñanza de la traducción inversaespecializada. TRANS. Revista de traductología, 5, 155–184. Retrieved from http://www.trans.uma.es/Trans_5/t5_155–184_GCorpas.pdf
De Rooze, B. (2006). La traducción, contra reloj. Consecuencias de la presión por falta de tiempo en elproceso de traducción. (Unpublished Doctoral Dissertation). University of Granada, Spain.Retrieved from: http://isg.urv.es/library/papers/DeRooze-DissDraft03.pdf
EC. (2009). Programme for Quality Management in Translation. 22 Actions. Retrieved from http://ec.europa.eu/dgs/translation/publications/studies/quality_management_translation_en.pdf
EC. (2012). Quantifying quality costs and the cost of poor quality in translation: Studies on trans-lation and multilingualism. Retrieved from http://ec.europa.eu/dgs/translation/publications/studies/index_en.htm
Escandell, M. V. (1996). Introducción a la pragmática. Barcelona: Ariel Lingüística.Gerzymisch-Arbogast, H. (2001). Equivalence parameters and evaluation.Meta: Journal des traduc-
teurs, 46(2), 227–242. doi:10.7202/002886arGómez González-Jover, A. (2006). Terminografía, lenguajes profesionales e intermediación
interlingüística. Aplicación metodológica al léxico especializado del sector industrial delcalzado y de las industrias afines. (Doctoral Dissertation) University of Alicante, Spain.Retrieved from: http://rua.ua.es/dspace/bitstream/10045/760/1/tesis_doltoral_adelina_gomez.pdf
Gouadec, D. (1981). Paramètres de l’evaluation des traductions. Meta: Journal des traducteurs, 26(2), 99–116. doi:10.7202/002949ar
Gouadec, D. (1989). Aspects méthodologiques de l’évaluation de la qualité du travail eninterprétation simultaée. Meta, 28(3), 236–243.
Hönig, H. G. (1998). Positions, power and practice: Functionalist approaches and translationquality assessment. In C. Schäffner (Ed.), Translation and quality (pp. 6–34). Clevedon:Multilingual Matters.
House, J. (1997). Translation quality assessment: A model revisited. Tübinguen, Germany: GunterNarr.
Jiménez-Crespo, M. A. (2009). The evaluation of pragmatic and functionalist aspects in localization:Towards a holistic approach to Quality Assurance. The Journal of Internationalization andLocalization, 1, 60–93. doi:10.1075/jial.1.03jim
Jiménez-Crespo, M. A. (2011). A corpus-based error typology: Towards a more objective approachto measuring quality in localization. Perspectives, Studies in Translatology, 19(4), 315–338. doi:10.1080/0907676X.2011.615409
Kupsch-Losereit, S. (1985). The Problem of translation error evaluation. In C. Titford & A. E. Hieke(Eds.), Translation in foreign language teaching and testing (pp. 169–179). Gunter Narr:Tübingen.
Kussmaul, P. (1995). Training the translator. Amsterdam: John Benjamins.Larose, R. (1998). Méthodologie de l’évaluation des traductions. [A method for assessing translation
quality]. Meta: Journal des traducteurs, 43(2), 163–86. doi:10.7202/003410arLeón, P., Faber, P., & Montero-Martínez, S. (2011). Special language semantics. In P. Faber (Ed.), A
cognitive linguistics view of terminology and specialized language (pp. 95–176). Berlin: De GruyterMouton.
LISA. (2007). Localisation industry standards association. Retrieved from http://www.lisa.org/LISA-QA-Model-3-1.124.0.html
Malinowsky, B. (1923). The problem of meaning in Primitive Languages. Supplement I to C.K.Ogden and I.A. Richards (Ed.), The meaning of meanings (pp. 296–336). New York: HarcourtBrace and World.
PERSPECTIVES 23
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Martin, J. R. (1992). English text. System and structure. Amsterdam: John Benjamins.Martínez, N., & Hurtado, A. (2001). Assessment in translation studies: Research needs. Meta:
Journal des traducteurs, 46(2), 272–287. doi:10.7202/003624arMartínez-Mateo, R. (2014a). Propuesta de evaluación de la calidad en la DGT de la Comisión
Europea: el modelo Funcional-Componencial y las traducciones externas inglés-español.(Doctoral Dissertation) University of Castilla La Mancha, Spain. Retrieved from https://ruidera.uclm.es/xmlui/handle/10578/4120
Martínez-Mateo, R. (2014b). A deeper look into metrics for Translation Quality Assessment(TQA): A case study. Miscelanea: A Journal of English and American Studies, 49, 73–93.
Montero-Martínez, S., Faber, P., & Buendía, M. (2011). Terminología para traductores e intérpretes:Una perspectiva integradora. Granada: Ediciones Tragacanto.
Mossop, B. (2007). Revising and editing for translators. Manchester, UK: St. Jerome.Neunzig, W. (2002). Estudios empíricos en traducción: apuntes metodológicos. Cuadernos de
Tradução 10: 75–96. Retrieved from http://www.cadernos.ufsc.br/Nord, C. (1997). Translation as a purposeful activity. Manchester, UK: St. Jerome.Nord, C. (2009). El funcionalismo en la enseñanza de la traducción.Mutatis Mutandis, 2, 209–243.O’Brien, S. (2012). Towards a dynamic quality evaluation model for translation. Jostrans: The
Journal of Specialized Translation, 17. Retrieved from http://www.jostrans.org/issue17/art_obrien.php
Orozco, M. (2001). Métodos de investigación en traducción escrita: ¿qué nos ofrece el métodocientífico? Sendebar, 12, 95–115.
Parra, S. (2005). La revisión de traducciones en la Traductología: Aproximación a la práctica de larevisión en el ámbito profesional mediante el estudio de casos y propuestas de investigación.(Doctoral Dissertation) University of Granada, Spain. Retrieved from http://digibug.ugr.es/handle/10481/660
Parra Galiano, S. (2007). Propuesta metodológica para la revisión de traducciones: principios gen-erales y parámetros. TRANS (Revista De Traductología), 11, 197–214.
Reiss, K., & Vermeer, H. (1996). Fundamentos para una teoría funcional de la traducción. Madrid:Akal.
Rothe-Neves, R. (2002). Translation quality assessment for research purposes: An empiricalapproach. Cuadernos de Tradução, 10, 113–131.
SAE J2450. (2001). Surface vehicle recommended practice. SAE. The engineering society for advan-cing mobility land sea air and space. USA.
Sans, A. (2004). Métodos de investigación de enfoque experimental. En R. Bisquerra (Ed.),Metodología de la investigación educativa (pp. 167–194). Madrid: Editorial la Muralla.
Schäffner, C. (1998). From ‘good’ to ‘functionally appropriate’: Assessing translation quality. InTranslation and quality (pp. 1–5). Clevedon: Multilingual Matters.
Simon, M. & Forgette-Giroux, R. (2001). A rubric for scoring postsecondary academic skills.Practical Assessment, Research y Evaluation, 7, (18). Retrieved from: http://pareonline.net/getvn.asp?v=7yn=18
Sinclair, J. (1991). Corpus, concordance, collocation. Oxford: Oxford University Press.Varantola, K. (2002). Disposable corpora as intelligent tools in translation. Cuadernos de Tradução,
9, 171–189.Waddington, C. (2000). Estudio comparativo de diferentes métodos de evaluación de traducción
general (inglés – español). Madrid: Universidad Pontificia de Comillas.Williams, M. (1989). The assessment of professional translation quality: Creating credibility out of
chaos. TTR: Traduction, Terminologie, Redaction, 2(2), 13–33. doi:10.7202/037044arWilliams, M. (2001). The application of argumentation theory to translation quality assessment.
Meta: Journal des traducteurs, 46(2), 327–344. doi:10.7202/004605arWimmer, S. (2011). El proceso de la traducción especializada inversa: modelo, validación empírica y
aplicación didáctica. (Doctoral Dissertation) University of Autónoma, Barcelona (Spain).Retrieved from http://ddd.uab.cat/pub/tesis/2011/hdl_10803_42307/sw1de1.pdf
24 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Appendix 1
PERSPECTIVES 25
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Appendix 2
26 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Appendix 3Table 1. Secondary corpus.Subject EAC (DG
EducationandCulture)
EMPL (DGEmployment,Social Affairsand Inclusion)
ENV (DGEnvironment)
JLS (DGJustice,Liberty andSecurity)
ENTR (DGEnterprise andIndustry)
TREN (DGTransportand Energy)
Gradesobtained inpretest andposttest
Text 1(pretest:Very good;posttest:Good)
Text 2 (pretest:Good; posttest:Below average)
Text 3, (pretest:Below average;posttest:Unacceptable)
Text 4(pretest:Very good;posttest:Very good)
Text 5 (pretest:Acceptable;posttest:Belowaverage)
Text 6(pretest:Very good;posttest:Very good)
Collectiondate
Thirdtrimester of2009
Third trimester of2009
Third trimester of2009
Thirdtrimester of2009
Third trimesterof 2009
Thirdtrimester of2009
Text size c. 500–600words
c. 500–600 words c. 500–600 words c. 500–600words
c. 500–600words
c. 500–600words
PERSPECTIVES 27
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016
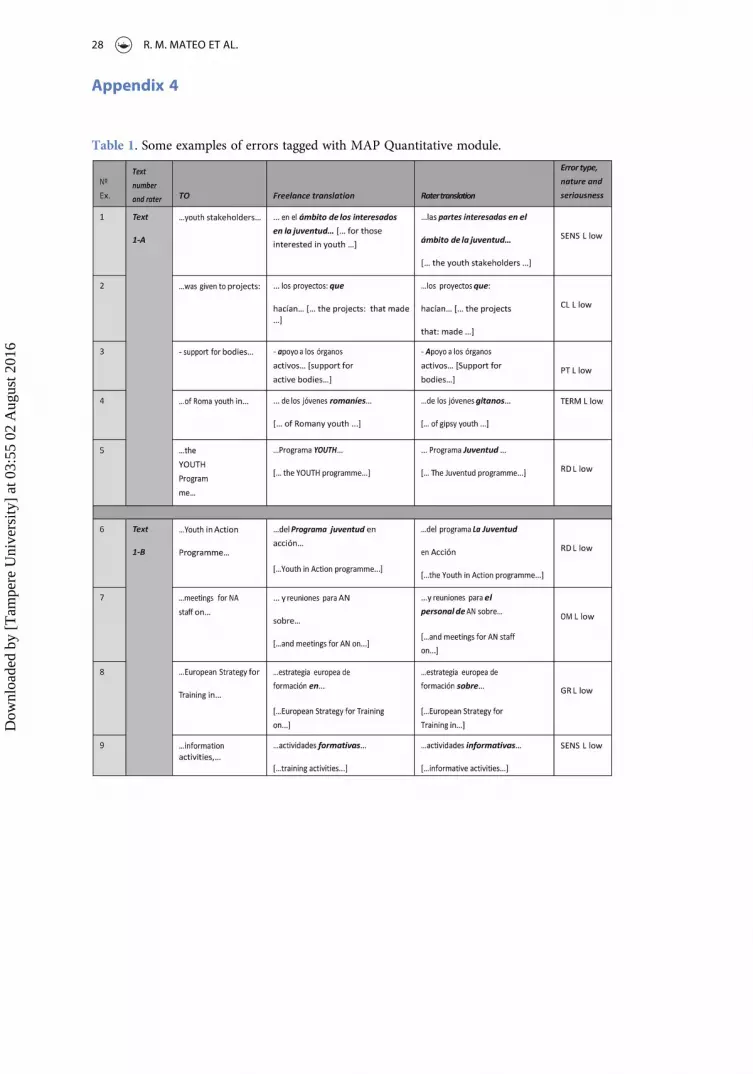
Appendix 4
Table 1. Some examples of errors tagged with MAP Quantitative module.
28 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Appendix 4
PERSPECTIVES 29
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Appendix 4
30 R. M. MATEO ET AL.
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016

Appendix 4
Notes: Errors are marked in bold type.
PERSPECTIVES 31
Dow
nloa
ded
by [
Tam
pere
Uni
vers
ity]
at 0
3:55
02
Aug
ust 2
016