succinct role based access control policies for xml documents
TRANSCRIPT

Succinct Role Based Access Control Policies for XML Documents
Tomasz Muldner1, Scott Durno1, Jan Krzysztof Miziołek2, and Tyler Corbin1
1Acadia University, Wolfville, B4P 2A9 NS, Canada; [email protected], {scottdurno, tylercorbin}@gmail.com2Faculty of Artes Liberales, University of Warsaw, Warsaw, Poland; [email protected]
Abstract—The popularity of role-based access control(RBAC) policies within industry has generated consid-erable interest in the research community. Since XMLhas become a de facto standard for data representation,most RBAC policies are expressed in XML. AlthoughXML documents can be very large, no succinct imple-mentations for these policies exist. This paper describesa novel implementation (not previously proposed) forschema-less and streamed XML documents to provideauthorized users with the results of queries on com-pressed documents. The designer of the policy does notneed to be aware of any implementation details. Resultsof this research will be essential for industry, whichcould take advantage of efficient implementations ofRBAC policies.
Keywords: XML; XML Compression; Encryp-tion; Role Based Access Control.
I. INTRODUCTION
Access control lists (ACL) define users whohave rights to access various resources; in par-ticular ACL for documents specify permissionsto read, write or modify a specific document orparts thereof. One of the most popular schemesfor defining ACL is known as role-based accesscontrol (RBAC) policy, see [1], [2], and [3] thatassociate access rights with roles.
The eXtensible Markup Language, XML [4], isa World Wide Web Consortium (W3C) endorsedstandard where textual markups are used to de-scribe the structure of the data. The adoption ofXML has allowed organizations to more easilyshare data, and some government departmentshave made portions of their databases accessibleto the public in XML format. In recent yearsthere has been significant growth in the use ofRBAC policies for managing resources in the
form of XML documents or parts thereof. Therehas been a lot of research on RBAC policiesfor XML, see [5], and [6], for which parts ofXML documents, called views, are defined us-ing XPath expressions, see [7], using one ofthe following two implementing techniques. Inan original, centralized server-based approach,the client uses secure channels to (1) provide acredential and a role name to the server; and (2)upon receiving the proper authorization, receivethe materialized view (generated by the server)associated with this role. Since this approachcannot scale up to handle applications involvinga large number of users and/or complex accesscontrol policies, a newer, decentralized client-based approach, see [8], [9], [10], [11], [12], and[13] provides the clients with a secure access topublished documents using encryption. The sys-tem generates keyrings associated with roles, andit encrypts views using the public keys, therebycreating a single version of the document, calleda multi-encrypted document, which is publishedand can be downloaded through possibly insecurechannels. Visibility only to authorized parties isenforced by the server, and these parties areprovided with keyrings consisting of private keys,to partially decrypt the encrypted document andaccess the view associated with the role. Since theserver only has to send keyrings, scalability issuesare greatly lessened. Instead of public/private keypair, a single private key (encrypted using publickey) can also be used.
However, due to XML verbosity, an encrypteddocument may be very large, e.g., using a blockcipher (such as AES [14]) the input document andthe output document are always approximately the
ISBN:978-0-9891305-8-5 ©2014 SDIWC 11

same size. Note that with the latter approach eachpublished document is static, and access controlpolicies only provide read permissions associatedwith views of documents.
There has been considerable research on com-pressing XML documents, using XML-consciouscompressors, e.g., XMill [15], XGrind [16] andXQueC [17], aware of specific syntactical featuresof XML, to increase the compression ratio incomparison to standard compression techniques(e.g., GZIP, BZIP, etc.). However, to our knowl-edge, there has been no research on combiningcompression with encryption and using this tech-nique for RBAC. Such an approach would providethe benefit of reducing data sizes complementedby enlarged informational entropy that increasessecurity against known plaintext attacks, see [18].This paper investigates succinct, client-based im-plementation of RBAC policies for schema-lessXML documents. The policy for the XML doc-ument D can specify occurrences of individualnodes of D, entire subtrees of D or specifictext elements in D. The compression process isbased on an XML compressor, called XSAQCT,see [19] and [20], (for details, see Section II).However, the designer of policies does not needto be aware of inner-workings of this compressor,or the encryption tools.
The most important rule behind our approachis that encryption should not harm the compres-sion ratio/speed, what needs to be encrypted, andhow can multiple users decrypt and decompressthe same data. In general, the biggest issue isprocessing XML text data, because such datamust be first be compressed and then encrypted(otherwise, since the distribution of encryptedcharacter data is more uniform, which typicallyharms the compression ratio). Since very largeXML files are often streamed rather than storedon the network node, incoming text data of theXML document must be split into individual units(called segments) before they are compressed.
Using the XSAQCT compressor (or most otherXML compressors), for an XML document D,its text data are divided into disjoint datasets,each of which is associated with all paths that
Figure 1: Example of an RBAC policy
are identical. This approach supports the efficientexecution of queries, since for most queries onlya single dataset needs to be accessed.
Example 1: For example, for D of the form:<a>t1<b>t4</b>t2<b>t5</b>t3</a>there are two datasets T1 = {t1, t2, t3} andT2 = {t4, t5}. In each of these two datasets, textvalues are stored in a DFS-order (correspondingto the order imposed by the SAX parser of D)and each text is \0-terminated. Every dataset iscompressed using a text compressor, such as [21].Now, assume that there is an RBAC policy withtwo roles R1 and R2 such that texts t1, t2, t4, t5are visible in the role R1 and texts t3, t4, t5 arevisible in the role R2, see Figure 1. Here, theentire T1 cannot be compressed, because, textst1, t2 are accessible in role R1 and t3 is accessiblein role R2, and so t1, t2 have to be encryptedwith a different key than t3 (and it is impossibleto find in the compressed T1 the separation of t2and t3). Therefore, T1 needs to be split into twosegments, storing respectively t1, t2 and t3, andthen each of these segments can be compressedand encrypted. On the other hand, T2 does notneed to be split into segments, because both textst4, t5 are visible in both roles R1, R2.Splitting datasets belonging to the identical paths(as described above) can also be useful for otherreasons, outside of secure publishing, for ex-ample, to improve efficiency of compression ofschema-less XML documents.
Contributions: There are several contributionsin this paper: (1) Design of a space-efficientand secure, client-based implementation of RBACpolicies for schema-less XML documents; (2)Providing space-efficiency by using a modifiedversion of the XML compressor XSAQCT; (3)Providing security by generating a minimum
ISBN:978-0-9891305-8-5 ©2014 SDIWC 12

number of public/private keys necessary, andusing public keys to encrypt the compressor’soutput; (4) Evaluating queries such that onlyauthorized users can access these views of theXML document that have been made availableby the policy; and (5) Applications of the idea ofsplitting datasets into segments to other areas.
Note that while encryption is expensive, com-paratively speaking, validation is not that expen-sive and we can not know if a document is validuntil it has been completely traversed, so we mayperform several costly and wasteful encryptionsbefore discovering that the document is invalid. Insuch a case, combining validation and encryptiononly serves to slow down the validation, whileperforming two separate passes likely would nottake much longer and would avoid wasted encryp-tions. Therefore, we first validate the documentand then encrypt it.
This paper is organized as follows: Section IIrecalls basic concepts of XSAQCT, and Sec-tion III describes document-based RBAC policies.Section IV overviews the implementation, detailsof which are provided in Section V. Finally,Section VI describes conclusions and future work,and Section VII provides description of variousfunctions used in the algorithms.
II. XSAQCTThis section defines paths, similar paths, andonly briefly describes XML compressor, calledXSAQCT, used in the implementation, for moredetails see [19].
Definition 1: A path in the XML documenttree is of the form /x1/x2[i2]/ . . . /xn[ik], wheren, k > 0, for 1 ≤ i ≤ k, ik > 0, x1 is the root ofD, and xi is tag name (the node x1 has an implicitindex 1). A path may also end at text expressionof the form text(i) or text(). Two paths in thetree D ending at element nodes are called similarif they have the same length, and the tag namesat equal positions are identical. Paths ending attexts are similar if after disregarding the textexpression(s) they are similar.If the last element of a path is a tag name x, thenthis path represents a single node x. For q = p/∗,the path q represents a subtree rooted at the node
specified by p. For q = p/text(), the path qrepresents a concatenation of text children of thenode x specified by p, and for q = p/text(i), qrepresents the i-th text child of x.
The similarity relation is an equivalence re-lation and the equivalence class of a path p iscalled an s-path for p, see [22]. For example,for the document D from Figure 2, an s-path qfor the path p=/a/b[3]/e[1]/ consists of p and/a/b[3]/e[2]/, or using a simplified notation, ans-path is denoted by the label (in upper case) ofthe last element of this path, i.e., using E for thes-path q defined above.
The underlying philosophy of XSAQCT isbased on the following observation. An XML doc-ument D can be represented as a tree, often com-posed of many similarly named and structuredsubtrees. Thus, it can be transformed to a morecompressible form, namely an annotated tree,in which all similar paths are merged into s-paths.Figure 3 shows the annotated tree TA,D for D.
Figure 2: XML document D, t1 − t19 are textdata.
Figure 3: The annotated tree TA,D.
ISBN:978-0-9891305-8-5 ©2014 SDIWC 13

Each node of TA,D is labeled with a sequenceof integers, called an annotation list, representingthe number of occurrences of this node’s chil-dren, and is needed to restore the original XMLdocument. For example, the annotation [0, 1, 0]for the node D indicates that the first and thirdoccurrence of b, b1 and b3, have no childrenlabeled d, and that the second occurrence, b2,of b has one child labeled d. In this paper, weassume the so-called full mixed-content property:non-leaf elements have N text elements, oftencorresponding to the whitespace/structure data (ora null-byte if the XML is unstructured), whereN is equal to the number of children each XMLelement has, plus one. We also assume that thereare no cycles, such as consecutive siblings of theform x→y→x, or contradicting subtree orderingssuch as x→y, y→x for different parents of thesame similar path, for more details see [20].
The idea behind using an annotated tree torepresent a document is that non-zero annotationsof the node X represent consecutive occurrencesof X . For the node X[2, 0, 4, 0, 3] and its childY [1, 2, 0, 1, 0, 2, 0, 0, 1] there are nine such occur-rences of Xs. For a child Y of X , annotationsin items represent occurrences of Y s as childrenof respective Xs. Specifically, for the first twooccurrences of X , i.e., the annotation 2, the firsttwo annotations in Y represent occurrences of Y sas children of these two Xs, here the second Xhas two children Y , while the first X has onlyone such child. Similarly, the third, fourth, fifthand sixth occurrences of X are represented by theannotation 4, and they have four occurrences ofY s as children of these Xs, i.e., the fourth Xhas one child Y , the third and fifth X have nochildren Y , and the sixth X has two children Y .
The XML compression process involves cre-ating for each s-path of an XML document textcontainers, which store a delimited list of char-acter data for all paths in the s-path. Characterdata is a general term for all the charactersnot defined in the syntax of XML, mainly textelements and structure (whitespace) data. Thisphilosophy has shown to reduce compressionratios because similar paths often have similar
data, thus improve compression efficiency. Forexample, in Figure 3 the text container T4 forC[1, 1, 1] stores three text elements t14, t15, andt19, because the three following paths are similar:/a/b[1]/c[1]/, /a/b[2]/c[1]/, /a/b[3]/c[1]/. Eachtext container is compressed using a back-endcompressor; a general-purpose compressor (suchas GZIP). Query evaluation is lazy because typ-ically only a single container has to be decom-pressed.
III. ROLE-BASED ACCESS CONTROLPOLICIES
The RBAC policy can provide separate per-missions for the following elements of an XMLdocument: a single node n, a subtree rooted at n,or some/all text values for n.
Definition 2: An atomic path is a path as de-fined in the Definition 1. A valid path is of theform p1 +p2 + . . .+pk, where k ≥ 1 representinga union of all values specified by the atomic pathsp1, p2, . . . , pn.A role is specified by an identifier, e.g., Admin.Let PD denote the set of all valid non-empty pathsin an XML document D.
Definition 3: For a finite set Ψ of roles andan XML document D, the document-level RBAC(DRBAC) policy is a mapping πD : Ψ → PD,typically shown as a tuple [(R1 : p1), (R2 :p2), . . . (Rn : pn)], where each pi ∈ PD.The designer of the DRBAC policy may decideto leave some parts of documents accessible (orinaccessible) to all users, i.e., not to encrypt themor to encrypt them, but not provide the keysneeded for decryption of these nodes to any user.In this paper, we assume that all parts of the XMLdocument not covered by πD(Ψ) are accessibleto all users. The set πD(R) combined with allelements of D that are accessible to all users, iscalled a view for the role R.
A policy can also be defined by abstractingaway the XML document and specifying paths,which are checked for validity once the policy isinstantiated to an XML document. Let P denotethe set of non-empty paths, and π be a policydefined as π : Ψ → P , where Ψ is defined as inDefinition 3. Such a policy π can be instantiated
ISBN:978-0-9891305-8-5 ©2014 SDIWC 14

to πD for various XML documents D, as long aspaths used in π are valid in D. Several examplesof DRBAC policies are provided below.
Example 2: The policy π1 is defined as fol-lows: [(R1 : /a/ + /a/b[2]/c[1]/), (R2 :/a/b[1]/∗)]
The policy π2 is defined as follows: [(R1 :/a/b[1]/text(1)), (R2 : /a/b[1]/text(1) +a/b[2]/text(2)),(R3 : a/b[1]/text(2) + a/b[2]/text(1))]
The policy π3 is defined as follows:[(R1 : /a/text(2) + /a/b[2]/text() +/a/b[3]/text(4)),
(R2 : /a/b[2]/text(1)+/a/b[2]/text(2)+/a/b[3]/text())]
A. QueryingIn this version of the paper, the authorized user
U can only execute the so-called basic queriesbased on paths from the RBAC policy. Such aquery evaluates to a compressed and encryptedresult, which has to be first decrypted using keysavailable to U , and then decompressed.
For Example 2, for the policy π1[(R1 : /a/+ /a/b[2]/c[1]/), (R2 : /a/b[1]/∗)]the only allowable queries are:
1) for the user in role R1 and query Q1:/a/+ /a/b[2]/c[1]/, /a, /a/b[2]/c[1]/
2) for the user in role R2 and query Q2:/a/b[1]/∗
Future work will support for any type of a query.
IV. OVERVIEW OF IMPLEMENTATIONThis section provides an overview of the imple-
mentation, more details are provided in Section V.Below, π is a DRBAC policy, D is an XMLdocument and πD is the instantiated policy.
A. System architectureThe system architecture is shown in Figure 4.
There are two kinds of servers, Secure Server andUn-secure Server. The secure server stores twomodules:
1) PPM , a pre-processing module, whichbased on the RBAC policy π creates ansymbolic annotated tree SA(π). The infor-mation in this tree serves as a prototype
Figure 4: System Architecture
of the structure of an annotated tree. Inparticular, while the SA(π) stores annotatednodes, these nodes may be different whenthe XML document is known. In addition,SA(π) does not include any specific textdata, as such data are not available at thisstage; instead it saves the information thatwill be used to split incoming text data intosegments (when the document is streamed),which will be individually compressed. Inaddition, SA(π) stores the information asto which nodes and text segments are to bevisible in specific roles, and this informa-tion is later used to encrypt these nodes andsegments; or not encrypt segments leavingthe nodes visible to everybody.
2) PM , a processing module, that will be acti-vated after PPM completes its actions andwhen D is being streamed and processedby the SAX parser. PM does not consultthe policy π; instead it uses the informationfrom SA(π) to create a multi-encrypted treeMA(D, π).
The un-secure server stores the tree MA(D, π)that may be downloaded by any user, e.g., usingan HTTP server.
ISBN:978-0-9891305-8-5 ©2014 SDIWC 15

B. Policy AssumptionsSince π is created with no knowledge of an
XML document tree and the annotated tree willbe multi-encrypted, i.e., various parts of the an-notated tree will be compressed (using XSAQCT)and encrypted, we make the following assump-tions:• The role granularity is the node’s label, rather
than occurrences of this label, i.e., for a givennode n that is not a root of any document Dused to instantiate π, giving access in role R(in π) to n by specifying a path p leading ton implies that for any other path q similar top, the role R has access to the last elementof q;
• π using a path p/∗ provides access to allsubtrees rooted at the last element of anypath similar to p;
It should be noted that the above assumptions donot limit the usefulness of a typical DRBAC pol-icy, because the text granularity is more importantthan node granularity (typically, the informationprovided in the XML document appears in the textvalues). For the XML document D in Figure 2,instantiated policies from Example 2 give accessrespectively to the following nodes of D:
1) For π1,D and users in role R1: a andc1, c2, c3; for users in role R2: all subtreesrooted at all nodes with the tag b, i.e.,b1, b2, b3, c1, c2, c3, d, e1, e2;
2) For π2,D, users have access to the followingtext values: (a) in role R1: t5, in role R2:t5 and t8, and in role R3: t6.
3) For π3,D, users have access to the followingtext values: (a) in role R1: t2, t7−t9 andt13, in role R2: t7−t8 and t10−t13.
C. Implementation Design RulesSince each unit of data that will be first com-
pressed and then encrypted with a single key,incoming text data from the XML document thatis being streamed need to be analyzed to createunits (called segments), each of which will becompressed but will require no more than onekey for encryption. For example, for the documentD from Figure 2, text data for any node such
as b may have to be split into segments. On theother hand, segments should be large enough sothat their compression will result in the decreaseof their sizes. Therefore, the implementation isguided by the following rules:
1) When the input document is streamed foreach role R in π two keyrings are created;a keyring KP (R) consisting of private keysand a keyring KU(R) consisting of publickeys;
2) Each keyring stores a minimal number ofkeys necessary to enforce the RBAC policy;
3) A user in a role R in π can access preciselythe view for R;
4) A multi-encrypted tree stores text in seg-ments, which are compressed. In creatingsegments, every effort is made to createas large segments as possible so that it isreasonable to expect that the compressionrate will be high;
5) Each node and each segment is en-crypted with a single public key to createMA(D, π), however nodes and segments,which are accessible to all users are notencrypted;
6) The user U who wishes to play role Rhas to provide an authorization request toPM and, if approved, she receives theprivate keyring KP (R). U downloads themulti-encrypted tree MA(D, π) from theun-secure server, and then can proceed toprocess queries. The result of a query is re-turned in a compressed and encrypted form,and it is decrypted with the private key inU ′s possession and finally decompressed.
V. DETAILS OF IMPLEMENTATIONThis section provides a detailed description of
the creation of the symbolic annotated tree andmulti-encrypted annotated tree.
A. Symbolic Annotated TreeThis section uses the following two standard
definitions: A subsequence of a sequence s =s1, . . . , sm consists of arbitrary elements of s, andfor i, j, 1 ≤ i ≤ j ≤ n, a substring <i, j> of sis a subsequence of s consisting of consecutive
ISBN:978-0-9891305-8-5 ©2014 SDIWC 16

elements of s starting at position i and endingat position j. By |s| we denote a length of thesequence s.
A symbolic annotated tree SA(π) is an un-ordered tree resembling an XSAQCT’s annotatedtree, whose nodes are annotated and additionallylabeled by zero, one or more roles. There maybe a special node ∗ indicating a subtree rooted atthis node. The reason that SA(π) is unordered isthat neither a single atomic path in π nor the +operator determine the order of children.
A pessimistic approach is used by PPM tocreate a symbolic annotated tree SA(π) becauseit has access only to the policy π and has noknowledge of any XML document D that willarrive later. For example, for the atomic path/a/b[3] in a policy, PPM will assume that therewill be three occurrences of b and will createan annotated node B[3] (we use the upper-caseletters for the annotated tree). The module PMwill use the information from the incoming XMLdocument D to create an annotated tree A(D, π),using properties of annotated trees, as describedbelow.
Consider a node X[α1, . . .,αn] and its childY [β1, . . .,βm]. For j, 1 ≤ j ≤ n, let SX(j) =∑j
i=1 αi be the sum of the first j annotations ofthe node X[α1, . . .,αn], SX(0) = 0, and SX bethe sum of all annotations of the node X . Forαj 6= 0 let I(j) be a substring of the sequence1, . . . m, called an item and defined as follows:I(j) = <SX(j − 1) + 1, SX(j)>. Thus, if α1 6= 0then I(1) = <1, α1>.
Every node in the tree SA(π) has to satisfy thefollowing conditions:
1) The root of SA(π) must have an annotation[1]
2) For any node X[α1, . . .,αn] there existsj, 1 ≤ j ≤ n s.t. αj 6= 0
3) If αi1 , . . .,αir is a subsequence consistingof all non-zero annotations in the nodeX[α1, . . .,αn] and the node Y [β1, . . .,βm] isa child of X then items I(i1), . . . , I(ir)form a disjoint partition of the sequence1, . . .,m, consisting of |I(i1)| integers, fol-lowed by |I(i2)| integers,..., followed by
|I(ir)| integers, see Figure 5.Thus, the sequence β1, . . .,βm, which an-notates the child of the node X is splitinto a sequence of substrings <1, I(i1)>,<I(i2)+1, I(i3)> . . . <I(ir−1)+1, I(ir)>,which is the same as the sequence of sub-strings <1, SX(i1)>, <SX(i2)+1, SX(i3)>. . . <SX(ir−1) + 1, SX(ir)>.
Figure 5: Items for non-zero annotations.
Example 3: For the node X[2, 0, 4, 0, 3] and itschild Y [1, 2, 0, 1, 0, 2, 0, 0, 1] (with items under-lined), we have: I(1) = <1, 2>, I(3) = <3, 6>and I(5) = <7, 9>, see Figure 6.
Figure 6: Example of items.
Corollary.1) For αj 6= 0, |I(j)| = SX(j)− (SX(j− 1) +
1) + 1 = αj , i.e., each item I(j) has αjelements.
2) For the node X[α1, . . .,αn] andits child Y [β1, . . .,βm] we have:m =
∑nj=1,αj 6=0 |I(j)| =
∑nj=1,αj 6=0 αj
=∑n
j=1 αj = SX(n), i.e., the sum of allannotations of X is equal to the number ofannotations of Y .
B. Text ProcessingSA(π) stores the information about the seg-
ments that will be allocated for texts in the treeMA(π,D), using symbolic text containers. Asymbolic text container stores a list of symbolicsegments; each symbolic segment has three asso-ciated data: sub-container number N , text numberM , and a list R of 0,1 or more roles. Here, M is of
ISBN:978-0-9891305-8-5 ©2014 SDIWC 17

one of the following forms: (1) integer value i; (2)range i..j; (3) values greater or equal than an in-teger value i∗; or (4) any positive integer value ∗.In our examples, the complete information aboutall symbolic segments will be represented by thetable, with columns representing sub-containernumbers, rows representing text numbers (withconventions described above, e.g., using 3∗), andstoring 0, 1 or more roles. However, the actualimplementation may use a more efficient solution,e.g., multilist structures.
The reason for introducing text sub-containersis that when the XML document D will bestreamed, first its text data will be arriving forthe first sub-container, then for the second sub-container, and so on. Therefore, segments willbe created during the creation of the annotatedtree, based on symbolic segments for the symbolicannotated tree and the streamed document.
Example 4: Figures 7, 8 and 9 shows all stepsin the process of creating the symbolic tree,respectively for the policy π1, π2 and π3 fromExample 2. In each part of these figures, fromthe top to bottom, the left-hand side shows anatomic path under consideration, and the right-hand side shows the resulting symbolic annotatedtree. Role names appearing in circles next to the
Figure 7: Process of creating a Symbolic Anno-tated Tree SA(π1) for the policy π1
Figure 8: Process of creating a Symbolic Anno-tated Tree SA(π2) for the policy π2
annotated node N indicate that N is accessible tothese roles. Lack of roles indicates that N will beaccessible to everybody. In Figure 7, the ∗ nodesin the resulting tree (bottom right) indicate thatany possible children of the node B[2] other thanC[0, 1] will be accessible in roles R1 and R2,and any possible children of the node C[0, 1] willbe accessible in role R2. The tables representingsymbolic segments in Figures 8 and 9 indicatewhen the current segment (in the annotated tree)that stores incoming text data should be sentfor compression and the next segment should becreated. For example, in Figure 9 there will bethree separate segments for b[2], respectively forthe first and the second text data, accessible to
ISBN:978-0-9891305-8-5 ©2014 SDIWC 18
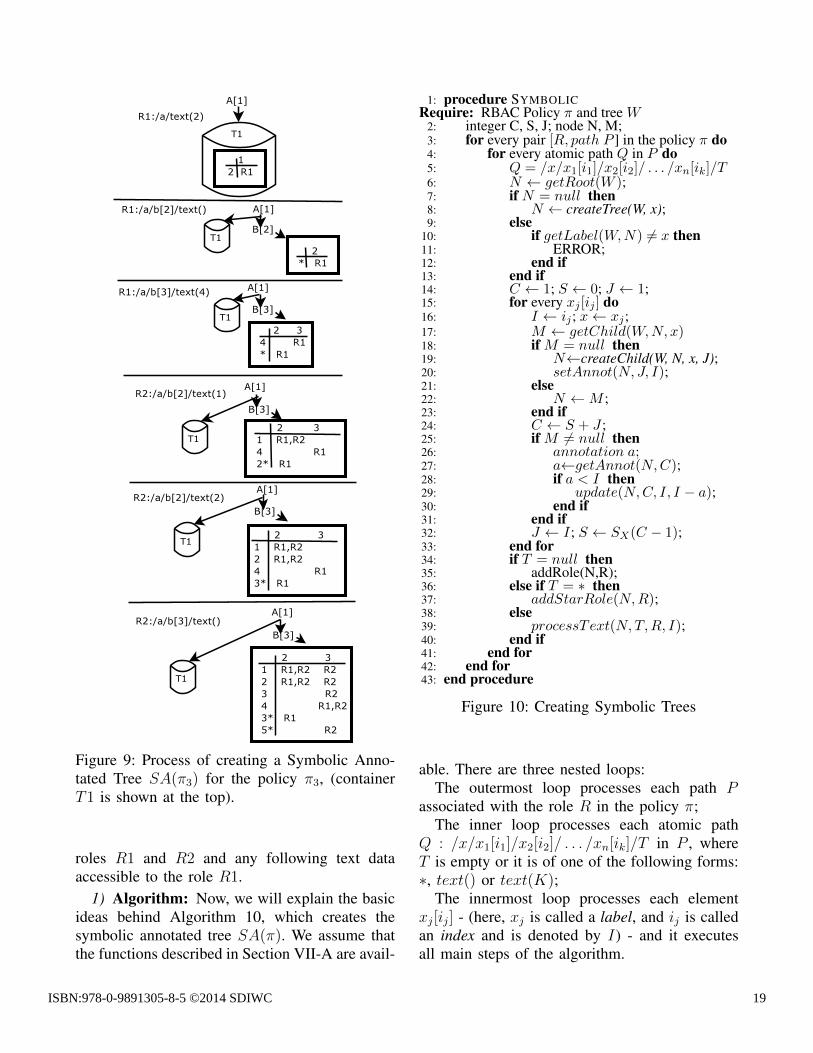
Figure 9: Process of creating a Symbolic Anno-tated Tree SA(π3) for the policy π3, (containerT1 is shown at the top).
roles R1 and R2 and any following text dataaccessible to the role R1.
1) Algorithm: Now, we will explain the basicideas behind Algorithm 10, which creates thesymbolic annotated tree SA(π). We assume thatthe functions described in Section VII-A are avail-
1: procedure SYMBOLICRequire: RBAC Policy π and tree W
2: integer C, S, J; node N, M;3: for every pair [R, path P ] in the policy π do4: for every atomic path Q in P do5: Q = /x/x1[i1]/x2[i2]/ . . . /xn[ik]/T6: N ← getRoot(W );7: if N = null then8: N ← createTree(W, x);9: else
10: if getLabel(W,N) 6= x then11: ERROR;12: end if13: end if14: C ← 1; S ← 0; J ← 1;15: for every xj [ij ] do16: I ← ij ; x← xj ;17: M ← getChild(W,N, x)18: if M = null then19: N←createChild(W, N, x, J);20: setAnnot(N, J, I);21: else22: N ←M ;23: end if24: C ← S + J ;25: if M 6= null then26: annotation a;27: a←getAnnot(N,C);28: if a < I then29: update(N,C, I, I − a);30: end if31: end if32: J ← I; S ← SX(C − 1);33: end for34: if T = null then35: addRole(N,R);36: else if T = ∗ then37: addStarRole(N,R);38: else39: processText(N,T,R, I);40: end if41: end for42: end for43: end procedure
Figure 10: Creating Symbolic Trees
able. There are three nested loops:The outermost loop processes each path P
associated with the role R in the policy π;The inner loop processes each atomic path
Q : /x/x1[i1]/x2[i2]/ . . . /xn[ik]/T in P , whereT is empty or it is of one of the following forms:∗, text() or text(K);
The innermost loop processes each elementxj[ij] - (here, xj is called a label, and ij is calledan index and is denoted by I) - and it executesall main steps of the algorithm.
ISBN:978-0-9891305-8-5 ©2014 SDIWC 19

The algorithm uses the following global vari-ables: the tree SA(π) and the current node Nin this tree. and three integer variables; C, whichrepresents the position of the current annotation inthe annotation list A for N ; S, which representsthe sum of all annotations in A, from the firstposition to C − 1; and J , which represent thevalue of the index from the previous step of theloop. The algorithm traverses in sync the path Qand the tree SA(π), performing some basic errorchecking (and calling the procedure ERROR)and updating the tree if necessary. Correctness ofthe algorithm follows from the fact that each itemstarts from the position SX(C − 1) + 1.
Figure 11: Tracing of creation of a SymbolicAnnotated Tree SA(π1)
Example 5: Figure 11 shows the trace the in-nermost loop of the Algorithm 10, and shows onthe right hand-side the components of the patha[1]/b[2]/c[3]/d[1]/e[1]/f [2]/g[1] and values ofvariables C, S and J used to create a symbolicannotated tree, and this tree is shown at the left-hand side. For each non-zero annotation A inany node X and its child Y , lines from A toannotations in Y show the item for A; e.g., forthe 2nd annotation for the node C[1, 3, 4] (equalto 3), annotations at positions 2, 3 and 4 in D.Thin arrow indicate the current annotation.
C. Multi-encrypted Tree
The module PM uses a symbolic annotatedtree and a streamed XML document D to create a
multi-encrypted tree MA(D, π) by applying thefollowing process:
1) While D is being streamed, pessimisticassumptions made in creating SA(D, π)are verified and corrected. In particular,the information about symbolic segments isused to create segments. Each container isdivided into one or more segments (basedon symbolic segments and the informationfrom D). Not all symbolic segments willactually be used to create segments, andadditional segments representing text con-tainers not specified by the policy may becreated;
2) Each segment is compressed with a back-end compressor;
3) Key pairs are generated based on rolesattached to nodes and segments. All nodesand segments that are not available to ev-erybody are encrypted and for each listR of roles in the policy π, PM createstwo keyrings: KU(R) consists of publickeys for the role R and KP (R) consistsof private keys for the role R. Note thata key pair for a list R s.t. R consists ofmore than one role, corresponds to keysfor the intersection of roles, i.e., elementsaccessible to more than one role; e.g., forR = R1, R2 a new key pair (ku, kp) willbe used for elements accessible in R1 andR2;
4) Keys are assigned integer key numbers cor-responding to keys; e.g., for keys k1, ..., kn,key numbers are 1, ..., n.
5) Segments and nodes that will be encryptedare labeled by key numbers;
6) Each query may require more than one keyto perform decryption, e.g., the result ofthe query may include the intersection ofmore than one role and thus will be splitinto sub-queries such that each sub-querywill require a single key. The authorizeduser will receive a mapping from the listof sub-queries associated with any basicquery for this user so that they can useappropriate private keys in her possession.
ISBN:978-0-9891305-8-5 ©2014 SDIWC 20

Thus, for any role R and a basic query Qtaken from the XPath from the role R in thepolicy π, PM creates a list of sub-queriesQ1, ..., Qm and a mapping M(Q) from thelist of private keys from KP (R) to the listof key numbers;
7) There is one additional master key pair(MU,MP ). For any basic query and theassociated list of sub-queries, this list andthe mapping M(Q) are encrypted with thepublic master key MU , forming E(Q). Theannotated tree is first compressed and thenencrypted with the public master key MU ,hiding the structure to un-authorized users,and forming the final version of the multi-encrypted tree MA(D, π);
8) The user authorized to be in role R willreceive KP (R) and MP , and then she willuse MP to decrypt MA(D, π) and E(Q),and KP (R) to decrypt answers to queries.
Example 6: Figures 12, 13 and 14 show multi-encrypted trees for the document D from Figure 2and respectively the instantiated policy π1, π2and π3 from Example 2. Text containers that donot show segments represent un-encrypted textcontainers from Figure 3. Segments are labeled bynumbers representing keys. In this example, thefollowing key pairs are generated for each policy:
For the policy π1, key 1 is for the list of rolesR1, R2 and key 2 is for the role R2.
For the policy π2, key 1 is for the list of rolesR1, R2, key 2 is for the role R2 and key 3 is forthe role R3.
For the policy π3, key 1 is for the role R1, key2 is for the role R2 and key 3 is for the rolesR1, R2.
Figure 12: Multi-encrypted Tree MA(D, π1) forthe document D and the policy π1
Figure 13: Multi-encrypted Tree MA(D, π2) forthe document D and the policy π2
Figure 14: Multi-encrypted Tree MA(D, π3) forthe document D and the policy π3
Segments and nodes not labeled by key num-bers are not encrypted and represent parts of thetree, which are accessible to everybody; otherwisethey are encrypted using the key corresponding tothe key number. Note the each time the minimalnumber of keys is generated, e.g., for the policyπ1 there will be only two keys.
1) Algorithms: This section provides thealgorithms to create the multi-encrypted treeMA(D, π) for a non-cyclic XML document D.Parts of this algorithm are based on the algorithm,which maps a labeled tree D into an annotatedtree, see [22]. However, since the entire text datain a container cannot be compressed and have tobe analyzed to split containers into segments, theoriginal algorithm has been modified, using the
ISBN:978-0-9891305-8-5 ©2014 SDIWC 21

information about text data stored in the symbolicannotated tree. Nodes in the symbolic annotatedtree are used for the following two purposes: (1)Error checking, e.g., signalling an error if in thesymbolic annotated tree there is a child B[4] ofthe root but in D there are only three childrenof the root labeled by b; and (2) Assigning keys,based on roles that label nodes in the symbolicannotated tree.
In this paper, a simplified version of the al-gorithm is shown, with error checking omitted.The symbolic annotated tree SA(π) can be usedto create a mapping T (π) from the set Q(π) ofs-paths to the lists of roles, and s-paths of theform s−path/text to text containers that storesymbolic segments (nodes and text containers tobe visible to all users are omitted). For example,for the tree SA(π3)from Figure 9 the set Q(π3)= {a/text, a/b/text}, and T (π3)(a/text) = T1,T (π3)(a/b/text) = T2, where T2 denotes thesymbolic text container for the node B[3]. For thefull version, with error checking, a synchronoustraversal of the symbolic annotated tree SA(π)and the DFS-traversal of the incoming XMLdocument D can be used (recall that SAX-parsingresults in the DFS-traversal).The following notations will be used in Algo-rithm 15:
• JpK denotes the s-path for the path p• x(n) denotes a node x labeled by n in D• X(n)[A] denotes an annotated node X la-
beled by n with the annotation A• for the path p ∈ D and a node x ∈ D, p/x
denotes the path p extended by /x• p↓ denotes the path p except its last element• P denotes the set of four-tuples: (s-path JpK,
graph G(JpK), the current node X0(JpK) inG(JpK), integer key number K(JpK) repre-senting an integer value assigned to a key).The graph and current node may be empty,and the key number is equal to 0 if the noderepresented by JpK is not to be encrypted.
There are two steps in the process of creatinga multi-encrypted tree, respectively implementedby Algorithm 15 and Algorithm 17. Algorithm 15uses functions defined in Section VII-B and it
1: procedure TRAVERSERequire: p0 = /root of D, empty G(Jp0K) X0(Jp0K),
K(Jp0K) = 02: while true do3: if root is4: current node and no nodes then5: close all current segments; return;6: end if7: if moving down to text then8: perform text processing;9: go up; continue;
10: end if11: if moving down to node x then12: p1← p0/x;13: if insertP (p1) then14: // p1 is a new path15: X1←16: insertG(p0, label of x,Ann(p0));17: if X0(Jp0K) 6= ∅ then18: addArc(X0(Jp0K), X1, p0);19: end if20: else// p1 is already defined21: X1←22: memberG(Jp0K, label of x);23: add1 to X1′s last annotation;24: if roleKind(p1) = 0 then25: k ← getKey(getRoles(p1));26: PsetKey(X1, k);27: end if28: updateG(p1);29: if X0(Jp0K)6=∅30: & X1 6=X0(Jp0K) then31: addArc(X0(Jp0K), X1, Jp0K);32: else33: X0(Jp0K)← X1;34: end if35: end if36: X0(Jp0K)← X1;37: p0← p1;38: else// moving up to the node x39: X0(p0)← ∅;40: p0← p0↓;41: end if42: end while43: end procedure
Figure 15: Algorithm which maps an XML docu-ment D to a set P and associated graphs withkeys attached. Text datasets are split into seg-ments and compressed. For functions used hereSection VII-B
ISBN:978-0-9891305-8-5 ©2014 SDIWC 22

performs a depth-first search traversal of the inputdocument, moving down and up, which corre-sponds to SAX-parsing of the streamed document.These actions would be triggered by entering thebeginning of the element, i.e., < x and the endof the element, i.e., < /x. When this algorithmcompletes its actions, i.e., when parsing of D isperformed, every s-path has an associated graphof annotated nodes, and every data container issplit into segments, each of which is individuallycompressed and encrypted. The Algorithm 15 isinitialized by setting the node x0 to be the root ofD and p0 to be the path /x0. Then it performs aloop, maintaining the current path p0 in D and theset P , and moving down and up until it reachesthe root node and there are no more un-visitedchildren of the root. The following invariants aremaintained: (1) The current node X0(p0↓) is notnull; (2) If the algorithm moves down to the nodex, such that the path p/x already exists, then thereexists a unique annotated node X in the graphG(Jp0K) which has the same label as the label ofx. Once the algorithm complete their actions, theset P stores the set of s-paths for D. However,nodes are not encrypted since they have to beused in the second step that uses data createdby the first step to perform a topological sortof graphs (for the description as to why this isneeded, see [22]), then encrypt nodes and finallycreate a multi-encrypted tree.Text Processing Now, let us explain textprocessing, line 8 of the Algorithm 15, andhow symbolic segments are used to create seg-ments. Recall that a symbolic segment SS is atriple (sub-container number SS(C), text num-ber SS(T ), non-empty list of roles SS(R)),and let us call a trigger(R) a pair (C, T )for which there exists a symbolic segment SSwith SS(C), SS(T ), SS(R). Segments will al-ways store compressed text values (i.e., thesevalues are sent to the segment through the text,back-end compressor), and they are optionallylabeled by key numbers and encrypted by thekey corresponding to the key number. Text valuesfor a node X are split into segments using thefollowing procedure. A list L of segments for X
will be created, and until processing text valuesfor X has been completed, one segment will becurrent. Two integer values are maintained duringtext processing for X: the sub-container numberC corresponding to X[C] and the text number Tindicating the number of the currently processedtext value within the current sub-container. Ini-tially, L is empty, C = 1, T = 1, a segmentS is created and becomes current. If there is atrigger(R) for the pair (C, T ) then a key k for thelist R, with the key number n(k), is fetched, andgenerated if necessary (when S will be closed,i.e., cease to be current, it will be appended tothe list L. In addition, S will be encrypted withk and labeled with k(n)); otherwise S will notbe labeled and encrypted. When the first textvalue for X is encountered, it is sent to S. Untilprocessing text values for X has been completed,the following actions are executed. When a newtext value t for X is encountered, values for Cand T are updated. If there is a trigger(R1)for the new pair (C, T ) and R1 is differentfrom the R used in trigger(R) then the currentsegment will be closed (appended to the list andencrypted, as describes above), a new segment Swill be created, a key k for the list R1, withthe key number n(k), is fetched, and generatedif necessary. Finally, the text t is sent to S.
Example 7: To explain the above procedure,consider the symbolic annotated tree from Fig-ure 9. Here, the symbolic segment SS1 for thenode A[1] indicates that there is a trigger(R1) for(1, 2). Therefore, the text t1 is stored in a single,un-encrypted segment, the text t2 is stored in asingle segment encrypted with the key number 1,and texts t3 and t4 are both stored in a single,un-encrypted segment (see Figure 14).
Figure 16: Symbolic annotated tree for D fromExample 1.
ISBN:978-0-9891305-8-5 ©2014 SDIWC 23

Example 8: Table I shows the trace of theexecution of Algorithm 15 for the document Dfrom Example 1. The symbolic annotated tree forthe RBAC policy from this example is shown inFigure 16. The current annotated node X0(p) (ifany) is underlined. If the tuple (path q, G(q))has not changed, then it is not shown again. Theaction of going down to the node x is shown as ↓xand the action of going up to the node x is shownas ↑x. Each q ∈ P will represent a node of theannotated tree, and the annotated nodes from thegraph G(q) will represent children of these nodes.
Algorithm 17 inputs the output of the Al-gorithms 15 and produces the multi-encryptedannotated tree.
D. CLIENT-BASED AND SERVER-BASEDPROCESSING
Until this point, we considered only the client-based version. However, in some cases, the seg-ment to be encrypted may contain a very shorttext, and therefore its compression will not beefficient; see Example 7. Our future work willconsider an alternative, i.e., a hybrid version,for which in some cases the user can decryptthe view they are entitled to access by usinga key in their possession, but in other cases,they have to request the view from the server.Thus, DRBAC policies may be implemented intwo ways: (1) the client-based access, in which
Move P G(JpK) K(JpK) Segments↓t1 /a A[1] A[1]:{t1}↓b1 /a/b A[1]:B[1]↓t4 B[1]:{t4}↑a↓t2 A[1]:{t1,t2}↓b2 A[1]:B[2]↓t5 B[2]:{t4,t5}↑a↓t3 k1 A[1]:{t1,t2}, {t3}↑a A[1]:{t1,t2}, {t3}
Table I: Trace of the execution of Algorithm 15.The current segment is underlined (it is open andnot compressed). After ↓t3, the segment {t1,t2} iscompressed and encrypted with the key k1. Oncethe algorithm completes, all open segments (here,{t4,t5} and {t3}) are compressed and encryptedwith new keys.
1: procedure TRAVERSE(Finalize)Path p, NodeX
Require: Initially p = \root, X = root(label ofthe root of D)[1], labeled by integer 0
2: sortG(p); // now G(JpK) is a chain3: make nodes in G(JpK) children of X4: for every node X1 in G(JpK) do5: p1← p/(label of X1);6: if G(Jp1K) 6= ∅ then7: Finalize(p1, X1);8: end if9: end for
10: encrypt(X,K(JpK));11: end procedure
Figure 17: Algorithm which uses a set P andassociated graphs to create the multi-encryptedtree MA(D, π). Compressed nodes are beingencrypted. For the description of functions usedhere see Section VII-C.
the user receives the multi-encrypted annotatedtree through an insecure channel and then willdecrypt views using one of their keys; or (2) thehybrid-based access, in which the user receivessome views through a secure channel. There isa trade-off between these two versions: limitedcompression ratio with the single communicationwith the server (the client-based version) vs. highcompression ratio (the hybrid-based version) withthe additional communication with the server. Theabove solution is feasible because while texts areincoming to be processed by the SAX parser, theirlength is known before they are completely read.Therefore, in the hybrid version, the length of thecoming string can be used as a predictor as tohow efficient text compression will be.
For the hybrid version, there are two kinds ofsegments, called units. The server-side units storeshort strings which will not be efficiently com-pressed; such units are encrypted with a system-defined key. Therefore, server-side units resemblematerialized views, except they are always veryshort and consequently do not affect the effi-ciency. The client-side units are used as describedin previous sections of this paper. At this point, itis not clear whether the hybrid version would bebetter than the client-side version; only extensivetesting can provide the definite answer to this
ISBN:978-0-9891305-8-5 ©2014 SDIWC 24

question.
VI. CONCLUSIONS AND FUTURE WORKThis paper presents a novel idea of using com-pression combined with encryption to provide asuccinct and secure implementation of DRBACpolicies for schema-less XML documents. Nocomparison with other similar systems designedfor succinct, compression-focused, role-based en-cryption has been provided, since no such systemsexist.
In our future work, we will remove variouslimitations described in this paper, e.g., apply ourtechnique to arbitrary (cyclic or not) XML docu-ments and extend the set of allowable queries. Inaddition, we will investigate generalizations of theapproach presented, to develop the schema-based,parameterized, secure and compressed publishingtechniques.
To test the security of our approach, we willdetermine wether or not it is possible to exploitthe knowledge of similar paths, especially if thereis a segment filled with fixed sized strings. Finally,we will complete the implementation of the de-scribed technique and test its effectiveness usinga specialized corpus of XML documents.
VII. APPENDIXA. Part 1.
1) Functions operating on trees:label getLabel(Tree W,Node n); returnsthe label of the the node n;node getRoot(Tree W ); returns the root ofW , or null if the tree is emptynode createTree(Tree W, label lab); cre-ates a new tree W , with the root labeled bylab and annotation [1], and returns the root;node getChild(Tree W, node N, labellab); returns a child of the node N in Wlabeled by lab, or null if there is no suchchild;node createChild(Tree W, node N, labellab, int annot); creates a new child of Nlabeled by lab and with annot annotations,each of which is equal to 0;
2) Functions operating on annotations:int getAnnot(node N, int pos); returns the
annotation of the node N at position pos;setAnnot(node N , int pos, int v); sets theannotation of the node N at position pos tov;update(node N, int ann, int new, intmore), which first appends more annota-tions (each equal to 0) to the annotation listof each child of the node N , and then setsthe annotation at position ann of N to new;
3) Functions operating on roles, subtrees andkeys:addRole(node N , role R), which adds therole R to the list of roles that labels N , orperforms no actions if R is already in thislist;addStarRole(node N , role R), which addsthe role R to the list of roles that labels N ,or performs no actions if R is already in thislist. In addition, it adds the special node ∗labeled by R as a child of N , and traversesthe subtree labeled at N , adding the role Rto the list of roles that labels any node inthis subtree and creating the special node ∗labeled by R as a child;
4) Functions operating on texts:processText(node N, role R, text T, intpos), which, based on the text T , creates orupdates symbolic segments within the sub-container number pos of the node N andlabels them with the role R.
B. Part 2.1) Functions operating on the set P:
bool insertP (path p) returns false if JpK ∈P; otherwise it inserts JpK into P , setsG(JpK) to be an empty graph, GX0(JpK)to null, K(JpK) to 0, and returns true;Annotatednode insertG(path p, labeln, annotation A); inserts a new nodeX(n)[A] to G(JpK) and returns it;node memberG(path p, label n) returns theunique node X in G(JpK) such that X islabeled with n;addArc(node X1, node X2, path p) adds anew arc connecting X1 and X2 in G(JpK);annotation Ann(path p) if the path p isof the form \root or the sum S of all
ISBN:978-0-9891305-8-5 ©2014 SDIWC 25

annotations of of the node X0(Jp↓K) isequal to 1 then return 1, otherwise returnthe annotation consisting of S occurrencesof ”0”, followed by ”1”.updateG(path p) for each node X inG(JpK) add 0 after the last annotation ofX
2) Functions operating on roles and keys:int roleKind(path p); returns 0 if p is notvalid in the symbolic annotated tree, 1 ifp is valid and the node pointed to by p islabeled with roles, and 2 if p is valid and ppoints to the text value.RoleList getRoles(path p); assumes thatp points to the node and returns the list ofroles associated with this node;PsetKeyN(node X, int k); assign to X aninteger key number k
C. Part 3.
To generate keys, the following approach isused. Let RR denote a single role, or a listof different roles (from the policy). During theDFS-traversal, the system maintains a mapping Vbetween every RR and a key pair (V is initiallyempty). When an element node or a segment inthe tree labeled by RR is encountered and if RRis not empty, the mapping V is consulted, and ifV (RR) is undefined, then a new key pair (pk, pr)is generated. Then for V (RR) = (pk, pr) thisnode/segment is encrypted with the key pk, andif RR consists of a single role R, the key pr isadded to the keyring KP (R) and the key pk isadded to the keyring KU(R); otherwise if RRconsists of roles R1, . . . , Rk then for each roleRi, 1 ≤ i ≤ k, the key pr is added to KP (Ri)and the key pk is added to the keyring KU(R).
To assign integer numbers to keys, the mappingI is maintained (initially I is empty), and a keycounter kc (initially set to 1). Whenever a newkey k is generated, I(kc) is set to k, and the valueof kc is incremented by one.sortG(path p) performs a topological sort ofG(JpK);In addition to functions listed before, the follow-ing functions are assumed to be available:
1) Functions operating on keys and imple-menting the mapping V :key GetKey(roleList R); if there are nokeys associated with R then generate a newkey pair (pk, pr). Then add pk and pr asdescribed above, and finally return pk.
2) Functions encrypting:encrypt(node X, int key k); if k 6= 0 thenencrypt X with the public key with thekey number kint SgetKeyN(roleList RR); return a keynumber for the list of roles RR, 0 if RRis empty, and generate a new key pair andthe corresponding key number of necessary;
REFERENCES
[1] RBAC, “Role based access control (RBAC) androle based security,” http://csrc.nist.gov/rbac, 2012,retrieved March 2013 from http://csrc.nist.gov/rbac.[Online]. Available: http://csrc.nist.gov/rbac
[2] D. F. Ferraiolo, R. Sandhu, S. Gavrila, D. R. Kuhn,and R. Chandramouli, “Proposed NIST standard forrole-based access control,” ACM Trans. Inf. Syst.Secur., vol. 4, no. 3, pp. 224–274, Aug. 2001. [Online].Available: http://doi.acm.org/10.1145/501978.501980
[3] S. Osborn, R. Sandhu, and Q. Munawer, “Configuringrole-based access control to enforce mandatory anddiscretionary access control policies,” ACM Trans.Inf. Syst. Secur., vol. 3, no. 2, pp. 85–106, May2000. [Online]. Available: http://doi.acm.org/10.1145/354876.354878
[4] XML, “Extensible markup language (XML) 1.0 (Fifthedition),” http://www.w3.org/TR/REC-xml/, 2012, re-trieved on June 20, 2013.
[5] I. Fundulaki and M. Marx, “Specifying accesscontrol policies for XML documents with XPath,” inProceedings of the ninth ACM symposium on Accesscontrol models and technologies, ser. SACMAT’04. New York, NY, USA: ACM, 2004, pp. 61–69. [Online]. Available: http://doi.acm.org/10.1145/990036.990046
[6] J. Wang and S. L. Osborn, “A role-based approach toaccess control for XML databases,” in Proceedingsof the ninth ACM symposium on Access controlmodels and technologies, ser. SACMAT ’04. NewYork, NY, USA: ACM, 2004, pp. 70–77. [Online].Available: http://doi.acm.org/10.1145/990036.990047
ISBN:978-0-9891305-8-5 ©2014 SDIWC 26

[7] XPath, “XML Path Language (XPath,” http://www.w3.org/TR/xpath/, 2013, retrieved on June 20, 2013.[Online]. Available: http://www.w3.org/TR/xpath/
[8] G. Miklau and D. Suciu, “Controlling access topublished data using cryptography,” in Proceedingsof the 29th international conference on Very largedata bases - Volume 29. VLDB Endowment, 2003,pp. 898–909. [Online]. Available: http://dl.acm.org/citation.cfm?id=1315451.1315528
[9] E. Bertino and E. Ferrari, “Secure and selectivedissemination of XML documents,” ACM Trans.Inf. Syst. Secur., vol. 5, no. 3, pp. 290–331, Aug.2002. [Online]. Available: http://doi.acm.org/10.1145/545186.545190
[10] E. Bertino, B. Carminati, E. Ferrari, B. Thuraising-ham, and A. Gupta, “Selective and authentic third-party distribution of XML documents,” Knowledgeand Data Engineering, IEEE Transactions on, vol. 16,no. 10, pp. 1263–1278, 2004.
[11] E. Damiani, S. De Capitani di Vimercati,S. Paraboschi, and P. Samarati, “A fine-grainedaccess control system for XML documents,”ACM Trans. Inf. Syst. Secur., vol. 5, no. 2,pp. 169–202, May 2002. [Online]. Available:http://doi.acm.org/10.1145/505586.505590
[12] P. Devanbu, M. Gertz, A. Kwong, C. Martel,G. Nuckolls, and S. G. Stubblebine, “Flexibleauthentication of XML documents,” in Proceedingsof the 8th ACM conference on Computer andCommunications Security, ser. CCS ’01. New York,NY, USA: ACM, 2001, pp. 136–145. [Online].Available: http://doi.acm.org/10.1145/501983.502003
[13] T. Muldner, G. Leighton, and J. Miziołek, “Usingmulti-encryption to provide secure and controlled ac-cess to XML documents,” Extreme markup languages,2006.
[14] AES, “Advanced encryption standard,” http://csrc.nist.gov/publications/fips/fips197/fips-197.pdf, 2012,retrieved March 2013. [Online]. Available: http://csrc.nist.gov/publications/fips/fips197/fips-197.pdf
[15] L. Hartmut and D. Suciu, “XMill: an efficient com-pressor for XML data,” ACM Special Interest Groupon Management of Data (SIGMOD) Record, vol. vol.29, no. 2, pp. pp. 153–164, 2000. [Online]. Available:http://portal.acm.org/citation.cfm?id=335405
[16] P. Tolani and J. Haritsa, “XGRIND: a query-friendlyXML compressor,” International Conference on DataEngineering (ICDE)’ 02, pp. 225–234, 2002.
[17] A. Arion, A. Bonifati, I. Manolescu, andA. Pugliese, “XQueC: A query-conscious compressedXML database,” ACM Trans. Internet Technol.,vol. 7, no. 2, May 2007. [Online]. Available:http://doi.acm.org/10.1145/1239971.1239974
[18] M. Johnson, D. Wagner, and K. Ramchandran, “Oncompressing encrypted data without the encryp-tion key,” IEEE Transactions on Signal Processing,vol. 52, no. 10, pp. 2992–3006, Oct. 2004.
[19] T. Muldner, C. Fry, J. Miziołek, and S. Durno,“XSAQCT: XML queryable compressor,” in Balisage:The Markup Conference, Montreal, Canada, August2009.
[20] T. Muldner, C. Fry, J. Miziołek, and S. Durno,“SXSAQCT and XSAQCT: XML QueryableCompressors,” in Structure-Based Compression ofComplex Massive Data, ser. Dagstuhl SeminarProceedings, S. M. S. Bottcher, M. Lohrey andW. Rytter, Eds., no. 08261, 2008. [Online]. Available:http://drops.dagstuhl.de/opus/volltexte/2008/1673
[21] GZIP, “The gzip home page,” http://www.gzip.org,2012, retrieved on June 20, 2013.
[22] T. Muldner, J. Miziołek, and T. Corbin, “AnnotatedTrees and their Applications to XML Compression,”in The Tenth International Conference on Web Infor-mation Systems and Technologies. Barcelona, Spain:WEBIST, 2014.
ISBN:978-0-9891305-8-5 ©2014 SDIWC 27