speech perception and generalization across speakers and accents
TRANSCRIPT

Speech perception and generalization across talkers andaccents
Kodi WeatherholtzUniversity of Rochester
Department of Brain and Cognitive SciencesCorresponding author: [email protected]
T. Florian JaegerUniversity of Rochester
Departments of Brain and Cognitive Sciences, Computer Science, and Linguistics
DRAFT as of July 17, 2015. Please do not cite or quote without authors’ permission.Feedback is always welcome! If you would like to share this manuscript feel free to ask for themost up-to-date version.
Contents
Summary 2
Introduction 2
To what extent are there invariant aspects of speech? 4Acoustic invariance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4Articulatory / motor invariance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
How is the speech signal adjusted during the early stages of processing? 8Normalization as an automatic auditory process . . . . . . . . . . . . . . . . . . . . . . 10Category-intrinsic vs. category-extrinsic normalization . . . . . . . . . . . . . . . . . . 13Normalization and learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
How do listeners make use of the statistical distribution of variability? 14Talker perception and speech processing . . . . . . . . . . . . . . . . . . . . . . . . . . 15Adaptation and perceptual/distributional learning . . . . . . . . . . . . . . . . . . . . . 16
Conclusions 18
References 19
Further Reading 32

SPEECH PERCEPTION AND GENERALIZATION 2
Summary
The seeming ease with which we usually understand each other belies the complexity of theprocesses that underlie speech perception. One of the biggest computational challenges is that dif-ferent talkers realize the same speech categories (e.g., /p/) in physically different ways. We reviewthe mixture of processes that enable robust speech understanding across talkers despite this lack ofinvariance. These processes range from automatic pre-speech adjustments of the distribution of en-ergy over acoustic frequencies (normalization) to implicit statistical learning of talker-specific prop-erties (adaptation, perceptual recalibration), to the generalization of these patterns across groups oftalkers (e.g., gender differences).
Introduction
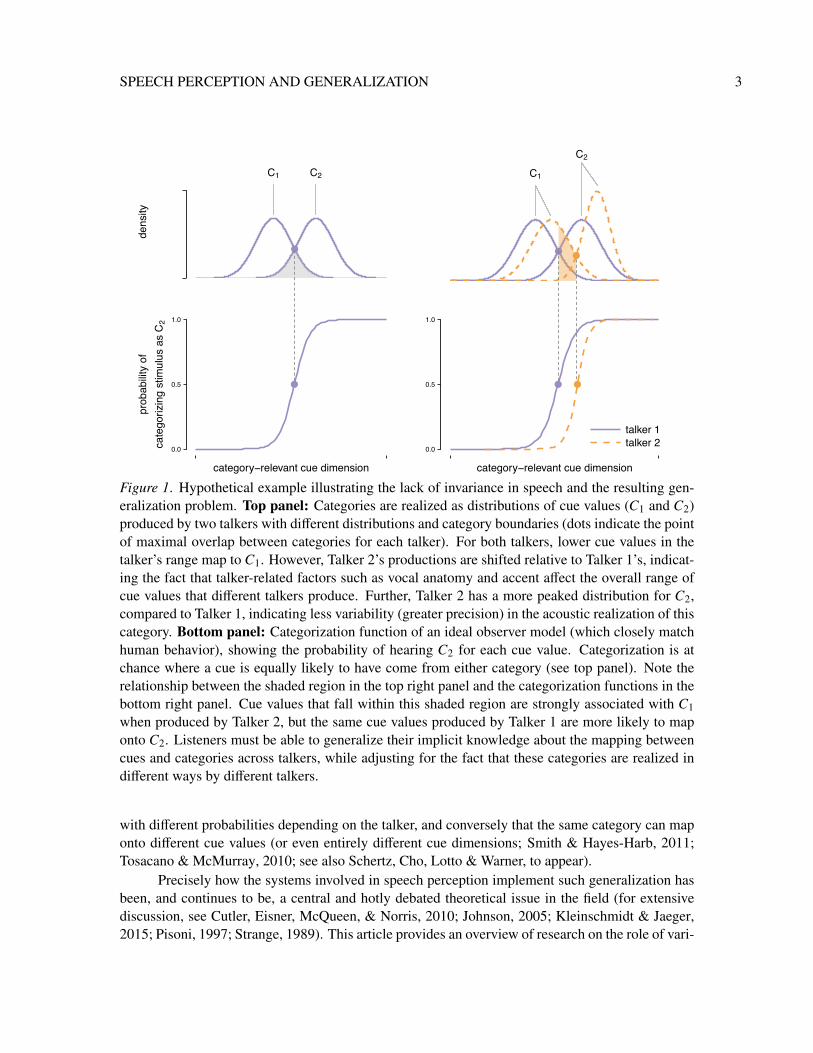
The overarching goal of speech perception research is to explain how listeners recognize andcomprehend spoken language. One of the biggest challenges of speech perception is the lack of aone-to-one mapping between acoustic information in the speech signal and linguistic categories inmemory. This so-called lack of invariance in speech (Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967) stems from a host of factors (see Klatt, 1986, for an overview). The physicalproperties of speech sounds produced by a given talker vary across productions due to factors suchas tongue position, jaw position and the temporal coordination of articulators (Stevens, 1972; seealso Marin, Pouplier, & Harrington, 2010), as well as articulatory carefulness in formal versus ca-sual speech (Lindblom, 1990), speaking rate, emotional state (Protopapas & Lieberman, 1997), andthe degree of coarticulation with adjacent sounds (see Ladefoged, 1980; Öhman, 1966). Further,when comparing across talkers, variability arises due to differences in anatomical structures such asvocal tract length and vocal fold size (Fitch & Giedd, 1999; Peterson & Barney, 1952), as well asdifferences due to age (Lee, Potamianos, & Narayanan, 1999), gender (Perry, Ohde, & Ashmead,2001), idiolectal articulatory gestures (Ladefoged, 1989), and regional or non-native accent (Labov,Ash, & Boberg, 2006). As a result, the physical realization of the same speech category can dif-fer greatly over time, especially when produced by different talkers (Hillenbrand, Getty, Clark, &Wheeler, 1995; Peterson & Barney, 1952; Potter & Steinberg, 1950). For example, an adult female’sproduction of /S/ might be very similar to an adult male’s production of /s/ due to the influence ofvocal tract size on spectral center of gravity (one of the primary cue dimensions that indicates placeof articulation for fricatives). Further, one talker’s realization of the vowel /E/ (as in said) mightsound like another talker’s realization of the vowel /æ/ (as in sad) due to cross-dialectal differencesin the realization of these vowels. Figure 1 illustrates this many-to-many mapping problem for ahypothetical category contrast.
The lack of invariance in speech leads to an inference and generalization problem. To achieveperceptual constancy in the face of highly variable speech input, listeners must be able to generalizeknowledge about the sound structure of their language across words, phonological contexts, talkers,accents, and speaking styles. Indeed, despite the ubiquity of variability in speech, listeners tend tounderstand native speakers of their language with surprisingly little difficulty. That is, listeners tendto succeed in mapping acoustic input to the linguistic categories intended by the talker. Even inextreme cases, such as listening to a talker with a heavy foreign accent amid a noisy background,listeners can often overcome initial perceptual difficulties to comprehend speech (e.g., Bradlow &Bent, 2008; Clarke & Garrett, 2004). To overcome such differences, the speech perception systemmust be able to adjust for the fact that the same physical cue values map onto different categories
SPEECH PERCEPTION AND GENERALIZATION 3
●
C1 C2
0
0.23
dens
ity
● ●
C1
C2
0.0
0.1
0.2
0.3
−7.491105 18.616095
●
0.0
0.5
1.0
category−relevant cue dimension
prob
abilit
y of
cate
goriz
ing
stim
ulus
as
C2
● ●
0.0
0.5
1.0
category−relevant cue dimension
talker 1talker 2
Figure 1. Hypothetical example illustrating the lack of invariance in speech and the resulting gen-eralization problem. Top panel: Categories are realized as distributions of cue values (C1 and C2)produced by two talkers with different distributions and category boundaries (dots indicate the pointof maximal overlap between categories for each talker). For both talkers, lower cue values in thetalker’s range map to C1. However, Talker 2’s productions are shifted relative to Talker 1’s, indicat-ing the fact that talker-related factors such as vocal anatomy and accent affect the overall range ofcue values that different talkers produce. Further, Talker 2 has a more peaked distribution for C2,compared to Talker 1, indicating less variability (greater precision) in the acoustic realization of thiscategory. Bottom panel: Categorization function of an ideal observer model (which closely matchhuman behavior), showing the probability of hearing C2 for each cue value. Categorization is atchance where a cue is equally likely to have come from either category (see top panel). Note therelationship between the shaded region in the top right panel and the categorization functions in thebottom right panel. Cue values that fall within this shaded region are strongly associated with C1when produced by Talker 2, but the same cue values produced by Talker 1 are more likely to maponto C2. Listeners must be able to generalize their implicit knowledge about the mapping betweencues and categories across talkers, while adjusting for the fact that these categories are realized indifferent ways by different talkers.
with different probabilities depending on the talker, and conversely that the same category can maponto different cue values (or even entirely different cue dimensions; Smith & Hayes-Harb, 2011;Tosacano & McMurray, 2010; see also Schertz, Cho, Lotto & Warner, to appear).
Precisely how the systems involved in speech perception implement such generalization hasbeen, and continues to be, a central and hotly debated theoretical issue in the field (for extensivediscussion, see Cutler, Eisner, McQueen, & Norris, 2010; Johnson, 2005; Kleinschmidt & Jaeger,2015; Pisoni, 1997; Strange, 1989). This article provides an overview of research on the role of vari-

SPEECH PERCEPTION AND GENERALIZATION 4
ability in speech perception. We focus primarily on talker variability and the issue of cross-talkergeneralization. However, as we note throughout the discussion, the mechanisms for coping withtalker variability also play a role in how listeners cope with within-talker contextual variability (seeNusbaum & Magnuson, 1997, for further discussion of this point). We aim to provide an overviewof the critical concepts and debates in this domain of research; to chart significant historical de-velopments; to emphasize underlying assumptions and the evidence that supports or opposes thoseassumptions; and to highlight overlap among lines of research that are often viewed as orthogonalor opposing. We organize the current discussion around four questions that have guided researchon talker variability: (i) To what extent are there invariant aspects of speech? (ii) How is the speechsignal adjusted during (the early stages of) processing? (iii) How do listeners make us of the statis-tical distribution of variability across talkers, such as systematic variation due to a talker’s accent,sex or other social group membership? And (iv) how is such information learned? We conclude byindicating important directions for future research.
To what extent are there invariant aspects of speech?
Early approaches to the issue of talker variability in speech perception assumed that acousticvariability in the realization of speech sounds was perceptual “noise” that obscures the abstract sym-bolic content of the linguistic message. To understand how listeners achieve perceptual constancywhen confronted with noisy input, a large body of research focused on identifying invariant aspectsof speech that uniquely identify phonemic categories (e.g., Fowler, 1986; Ladefoged & Broadbent,1957; Peterson, 1952; Shankweiler, Strange, & Verbrugge, 1975). According to this approach, lis-teners’ ability to generalize the sound structure of their language across talkers—i.e., to recognizephysically different speech signals from different talkers as instances of the same speech category—is the result of the perceptual system focusing on or extracting invariant aspects of speech andignoring variability due to the talker’s idiolect, accent or vocal anatomy/physiology.
Acoustic invariance
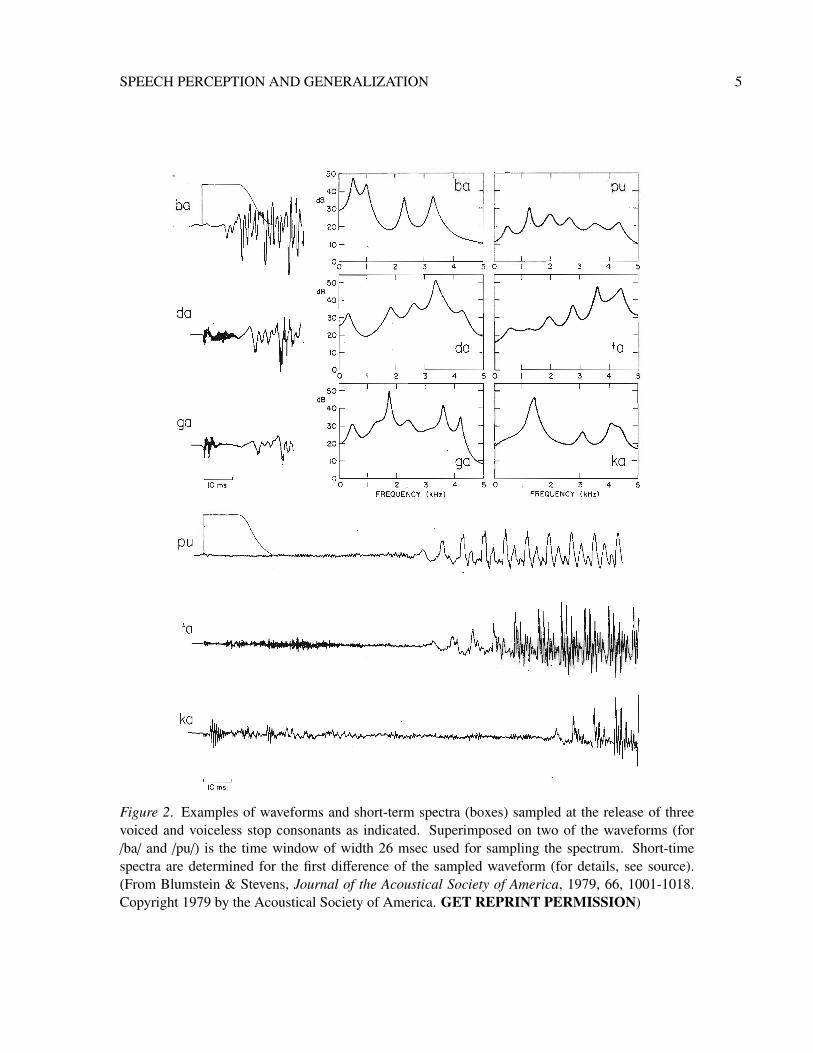
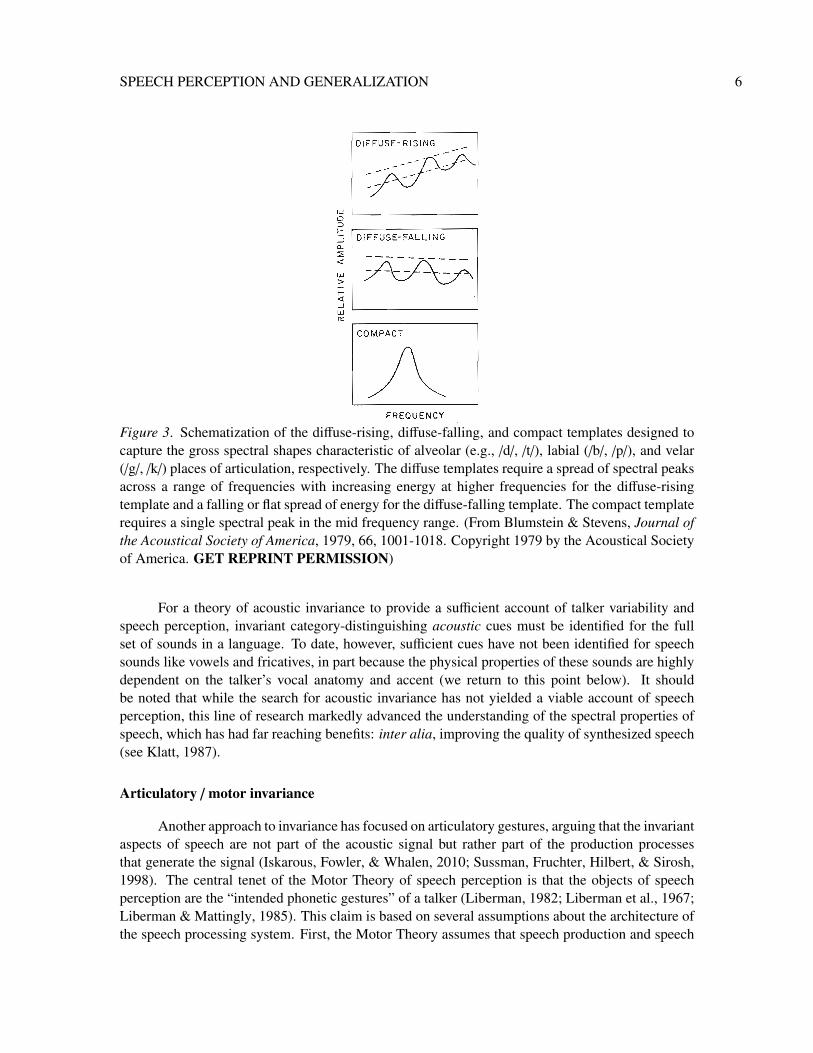
Within this tradition, some researchers assumed the existence of and aimed to identify in-variant acoustic information in the speech signal: that is, category-specific acoustic cues that areproduced the same by all talkers (Cole & Scott, 1974; Fant, 1960). The theory of acoustic invari-ance is most fully elaborated for stop consonants (e.g., /b/, /d/, /g/, etc.; Kewley-Port, 1983; Lahiri,Gewirth, & Blumstein, 1984; Walley & Carrell, 1983). Several studies argued that the shape of thespectrum (the distribution of energy as a function of frequency) at the release of a stop consonantis an invariant cue to place of articulation (Halle, Hughes, & Radley, 1957; Stevens & Blumstein,1977, 1978; Zue, 1976). As shown in Figures 2 and 3, the gross shape of the short-term spectrumat the time of burst release is diffuse and either falling or flat for labial consonants (e.g., /b/), diffuseand rising for alveolar consonants (e.g., /d/), and compact for velar consonants (e.g., /g/). Thus, itwas proposed that a perceptual mechanism that samples the short-term spectra at the time of burst re-lease can reliably distinguish stop consonants with a place of articulation contrast (see, e.g., Stevens& Blumstein, 1981). Indeed, early automatic phoneme recognition systems that implemented sucha mechanism achieved considerable accuracy in classifying stop consonants produced by differenttalkers (Searle, Jacobson, & Rayment, 1979). For further elaboration of acoustic invariance for stopconsonant place of articulation, see research on formant transitions (e.g., Delattre, Liberman, &Cooper, 1955; Story & Bunton, 2010)
SPEECH PERCEPTION AND GENERALIZATION 5
Figure 2. Examples of waveforms and short-term spectra (boxes) sampled at the release of threevoiced and voiceless stop consonants as indicated. Superimposed on two of the waveforms (for/ba/ and /pu/) is the time window of width 26 msec used for sampling the spectrum. Short-timespectra are determined for the first difference of the sampled waveform (for details, see source).(From Blumstein & Stevens, Journal of the Acoustical Society of America, 1979, 66, 1001-1018.Copyright 1979 by the Acoustical Society of America. GET REPRINT PERMISSION)
SPEECH PERCEPTION AND GENERALIZATION 6
Figure 3. Schematization of the diffuse-rising, diffuse-falling, and compact templates designed tocapture the gross spectral shapes characteristic of alveolar (e.g., /d/, /t/), labial (/b/, /p/), and velar(/g/, /k/) places of articulation, respectively. The diffuse templates require a spread of spectral peaksacross a range of frequencies with increasing energy at higher frequencies for the diffuse-risingtemplate and a falling or flat spread of energy for the diffuse-falling template. The compact templaterequires a single spectral peak in the mid frequency range. (From Blumstein & Stevens, Journal ofthe Acoustical Society of America, 1979, 66, 1001-1018. Copyright 1979 by the Acoustical Societyof America. GET REPRINT PERMISSION)
For a theory of acoustic invariance to provide a sufficient account of talker variability andspeech perception, invariant category-distinguishing acoustic cues must be identified for the fullset of sounds in a language. To date, however, sufficient cues have not been identified for speechsounds like vowels and fricatives, in part because the physical properties of these sounds are highlydependent on the talker’s vocal anatomy and accent (we return to this point below). It shouldbe noted that while the search for acoustic invariance has not yielded a viable account of speechperception, this line of research markedly advanced the understanding of the spectral properties ofspeech, which has had far reaching benefits: inter alia, improving the quality of synthesized speech(see Klatt, 1987).
Articulatory / motor invariance
Another approach to invariance has focused on articulatory gestures, arguing that the invariantaspects of speech are not part of the acoustic signal but rather part of the production processesthat generate the signal (Iskarous, Fowler, & Whalen, 2010; Sussman, Fruchter, Hilbert, & Sirosh,1998). The central tenet of the Motor Theory of speech perception is that the objects of speechperception are the “intended phonetic gestures” of a talker (Liberman, 1982; Liberman et al., 1967;Liberman & Mattingly, 1985). This claim is based on several assumptions about the architecture ofthe speech processing system. First, the Motor Theory assumes that speech production and speech

SPEECH PERCEPTION AND GENERALIZATION 7
perception are tightly linked and share the same representations. Second, this theory assumes thatspeech sounds are represented in the brain as “invariant motor commands that call for movementsof the articulators through certain linguistically significant configurations” (Liberman & Mattingly,1985, p.2, emphasis added): e.g., [m] is described as a combination of a labial gesture and a velum-lowering gesture. While the abstract category-specific motor commands are assumed to be invariant,the physical execution of these commands (i.e., articulation) naturally varies across utterances andtalkers. Thus, Liberman & Mattingly (1985, p. 3) argue that:
“[t]o perceive an utterance is to perceive a specific pattern of intended gestures. Wehave to say ‘intended gestures,’ because, for a number of reasons (coarticulation beingmerely the most obvious), the gestures are not directly manifested in the acoustic signalor in the observable articulatory movements. It is thus no simple matter ... to definespecific gestures rigorously or to relate them to their observable consequences.”
As this quotation indicates, one of the challenges faced by motor theory is to provide an explicitaccount for how listeners extract abstract gestural information (e.g., invariant motor commands, orintended gestures) from the speech input.
One answer to this challenge holds that the objects of speech perception are the actual phys-ical gestures produced by a talker, rather than the intended gestures (see the Direct Realist view ofspeech perception, which is broadly related to the Motor Theory, but differs in many of the basicassumptions; Best, 1995; Fowler, 1986, 1991; J. J. Gibson, 1966). For physical gestures to be theobjects of speech perception, these gestures must be “perceivable” even when listeners have no vi-sual information about the physical production of speech sounds (e.g., when talking on the phone orlistening to the radio). Research in the field of automatic speech recognition has demonstrated thatarticulatory gestures can be recovered from the acoustic signal, without any corresponding visualarticulatory information (see Schroeter & Sondhi, 1994, for a review), and that these recovered ges-tures can indeed guide speech recognition (e.g., Mitra, Nam, Epsy-Wilson, Saltzman, & Goldstein,2012).
Any theory of speech perception based on articulatory recovery must (at minimum) accountfor anatomical and postural differences between talkers; otherwise, acoustic variation resulting fromsuch factors might be wrongly attributed to differences in the movement of articulators, or viceversa. One proposal concerning talker variability and articulatory recovery (see e.g., McGowan &Cushing, 1999; McGowan & Berger, 2009) starts from the assumption that speech perception re-lies on an internal articulatory model, which comprises a talker-independent representation of thehuman vocal tract, along with knowledge of the acoustic consequences that result from different ges-tural configurations. When listeners hear speech, talker-specific anatomical features are estimatedfrom the speech signal (for estimation methods, see e.g., Hogden, Rubin, McDermott, Katagiri,& Goldstein, 2007), and these estimates are used to adjust the internal vocal tract representation.Articulatory gestures can then be recovered by comparing the observed speech input to the outputof different configurations of the adjusted internal model. McGowan and Cushing (1999) demon-strated that this approach aids the recovery of category-relevant articulatory movements from maleand female talkers who differ, inter alia, in vocal tract length and palette height.
There is a considerable body of empirical evidence showing that the perception of speechsounds is indeed influenced by information about the physical production of those sounds (for ex-tensive discussion, see Galantucci, Fowler, & Turvey, 2006; Vroomen & Baart, 2012), such as visualinformation about articulatory movements—as in the case of the classic McGurk effect (McGurk &

SPEECH PERCEPTION AND GENERALIZATION 8
MacDonald, 1976)—or haptic information gathered by touching a talker’s face during articulation(Fowler & Deckle, 1991; Sato, Cavé, Ménard, & Brasseurc, 2010). These findings indicate thatspeech production can provide information that guides speech perception (as claimed by auditorytheories of speech processing that include a role for motor knowledge; see Figure 4a). However,these findings are insufficient to support the claim that articulatory gestures form the basis of speechperception (see Figure 4b). In fact, there are several reasons to doubt this claim.
One of the main issues with gesture-based theories is that speech production and speechperception can be disrupted independently, which calls into question the assumption that productionis required for perception. For example, expressive aphasia, also known as Broca’s aphasia, is alanguage disorder that is characterized by severe disruption of speech production processes as aresult of brain damage (e.g., a brain lesion or stroke), but often only mild, if any, disruption toperception and comprehension processes (see, e.g., Naeser, Palumbo, Helm-Estabrooks, Stiassny-Eder, & Albert, 1989). The linguistic abilities of expressive aphasics are particularly problematic forthe Motor Theory, given that this theory assumes motor-based representations of speech categoriesthat are shared between production and perception (Hickok, Costanzo, Capasso, & Miceli, 2011;Lotto, Hickok, & Holt, 2009; though see Wilson, 2009 for a counterargument).
Further evidence for a dissociation between perception and production comes from studiesthat demonstrate human-like speech perception phenomena in animals, despite the fact that theanimals being tested lack the anatomical apparati to produce speech. For example, chinchillas showhuman-like categorical perception of speech sounds—e.g., abrupt rather than gradual changes inperception of voiced /d/ and voiceless /t/ when tokens are varied along a voice onset time continuum(Kuhl & Miller, 1975). Many animals also show a human-like ability to differentiate phonologicalcategories while ignoring talker-related variability in the realization of those categories: e.g., zebrafinches (Ohms, Gill, Van Heijningen, Beckers, & ten Cate, 2010); ferrets (Bizley, Walker, King, &Schnupp, 2013); rats (Eriksson & Villa, 2006); chinchillas (Burdick & Miller, 1975); cats (Dewson,1964). It is unlikely that these animals evolved to have a mental representation of the human vocaltract or specialized knowledge of the motor commands used to produce speech sounds. Thus, thefindings from these animal studies pose a challenge for theories that place gesture-based knowledgeat the center of speech perception (for discussion, see Kriengwatana, Escudero, & ten Cate, 2015).
How is the speech signal adjusted during the early stages of processing?
A third approach to variability in the realization of speech categories proposes that invarianceis achieved via perceptual processes that warp or transform the speech signal. This approach is oftenreferred to as normalization: speech perception is taken to effectively normalize variability by inter-preting certain aspects of the speech signal in relation to other aspects: e.g., adjusting the perceptionof voice onset times based on the talker’s speaking rate (Newman & Sawusch, 1996), or adjustingthe perceived distribution of energy at different frequencies based on an estimate of the talker’svocal tract size (see Johnson, 2005, for a review of talker normalization). In other words, unlikethe accounts in the previous section that were—at least in their original conceptions—concernedwith absolute acoustic or articulatory invariance, normalization accounts are often concerned withrelational invariance (e.g., Sussman, 1989).
Before discussing the merits and limitations of normalization approaches, we begin witha detailed example that illustrates one of the core phenomena addressed by this line of research:

SPEECH PERCEPTION AND GENERALIZATION 9
7 Baker, E. et al. (1981) Interaction between phonological and semanticfactors in auditory comprehension. Neuropsychologia 19, 1–15
8 Utman, J.A. et al. (2001) Mapping from sound to meaning:reduced lexical activation in Broca’s aphasics. Brain Lang. 79,444–472
9 Meister, I.G. et al. (2007) The essential role of premotor cortex in speechperception. Curr. Biol. 17, 1692–1696
10 D’Ausilio, A. et al. (2009) The motor somatotopy of speech perception.Curr. Biol. 19, 381–385
11 Wilson, S.M. and Iacoboni, M. (2006) Neural responses to non-nativephonemes varying in producibility: evidence for the sensorimotornature of speech perception. Neuroimage 33, 316–325
12 Davis, M.H. and Johnsrude, I.S. (2007) Hearing speech sounds: top-down influences on the interface between audition and speechperception. Hear. Res. 229, 132–147
1364-6613/$ – see front matter ! 2009 Elsevier Ltd. All rights reserved.doi:10.1016/j.tics.2009.06.001 Available online 29 July 2009
Letters Response
Response to Wilson: What does motor cortexcontribute to speech perception?
Gregory Hickok1, Lori L. Holt2 and Andrew J. Lotto3
1 Cognitive Sciences, University of California, SSPA4109, Mail Code: 5100, Irvine, CA 92697, USA2 Department of Psychology and Center for the Neural Basis of Cognition, 5000 Forbes Avenue, Pittsburgh, PA 15213, USA3 Speech, Language and Hearing Sciences, University of Arizona, 1131 E. 2nd Street, P.O. Box 210071, Tucson, AZ 85721-0071, USA
Although the main goal of our paper [1] was to argueagainst mirror neurons as a possible instantiation of theMotor Theory of speech, we also presented evidence insupport for an alternative auditory theory of speech per-ception. That is, we promoted a model as in Figure 1a andagainst that represented in Figure 1b. Wilson [2] does notdispute this central position. Instead he argues that speechproduction regions could have a top-down influence onperception. We agree wholeheartedly and would add thatspeech production systems are not the only source of top-down information. As Wilson hints, lexical-semantic infor-mation can also influence perception, and visual speechinformation is known to have dramatic effects [3] – argu-ably to a much greater extent than motor information.Although some authors attribute the influence of visualspeech entirely to motor activity [4], there is evidence that‘direct’ cross-sensory integration (visual-to-auditory) is themore robust source of influence [5].
It seems that the only point of dispute raised byWilson isone of terminology. We suggested that the motor system isnot ‘necessary’ for speechperception;Wilson suggests that itis. By our use of the termwemean that it is possible, at leastundersomecircumstances, foraccurate speechperception tooccur without the influence of the motor system. Evidencefor this claim comes from the fact that even large left frontallesions that reduce speech production to nil or stereotypedoutput do not produce considerable impairments in speechrecognition [6]; that deactivating the entire left hemispherein Wada procedures produces mutism yet results in only a7.5% error rate in discriminating minimal phonemic pairs(hearing ‘bear’ and pointing to a matching picture amongphonemic distractors [7]); that the failure to develop speechproduction does not preclude normal receptive speechdevelopment [8,9], and that infants as young as 1-month-old exhibit sophisticated speech perception ability includingcategorical perceptionwell before they acquire the ability tospeak [10].
It is a fair criticism that many studies demonstratingpreserved auditory comprehension in Broca’s aphasics donot implement tight controls on contextual information.However, (i) this indicates the auditory system in concert
Figure 1. Coarse schematic models of speech perception illustrating thefundamental difference between auditory and motor theories of speechperception. (a) Schematic of an auditory theory. Acoustic speech input activatesauditory-phonological networks, which in turn activate lexical-conceptualnetworks. (b) Schematic of a motor theory. Acoustic speech input must makecontact with motor speech systems to access lexical-conceptual networks.Corresponding author: Holt, L.L. ([email protected]).
Update Trends in Cognitive Sciences Vol.13 No.8
330
Figure 4. Coarse schematic models of speech perception illustrating the fundamental differencebetween auditory and motor theories of speech perception. (a) Schematic of an auditory theory.Acoustic speech input activates auditory-phonological networks, which in turn activate lexical-conceptual networks. (b) Schematic of a motor theory. Acoustic speech input must make con-tact with motor speech systems to access lexical-conceptual networks. (From Hickok, Holt &Lotto, Trends in Cognitive Science, 2009, 13(8), 330-331. Copyright 2009 by Elsevier Inc. GETREPRINT PERMISSION)
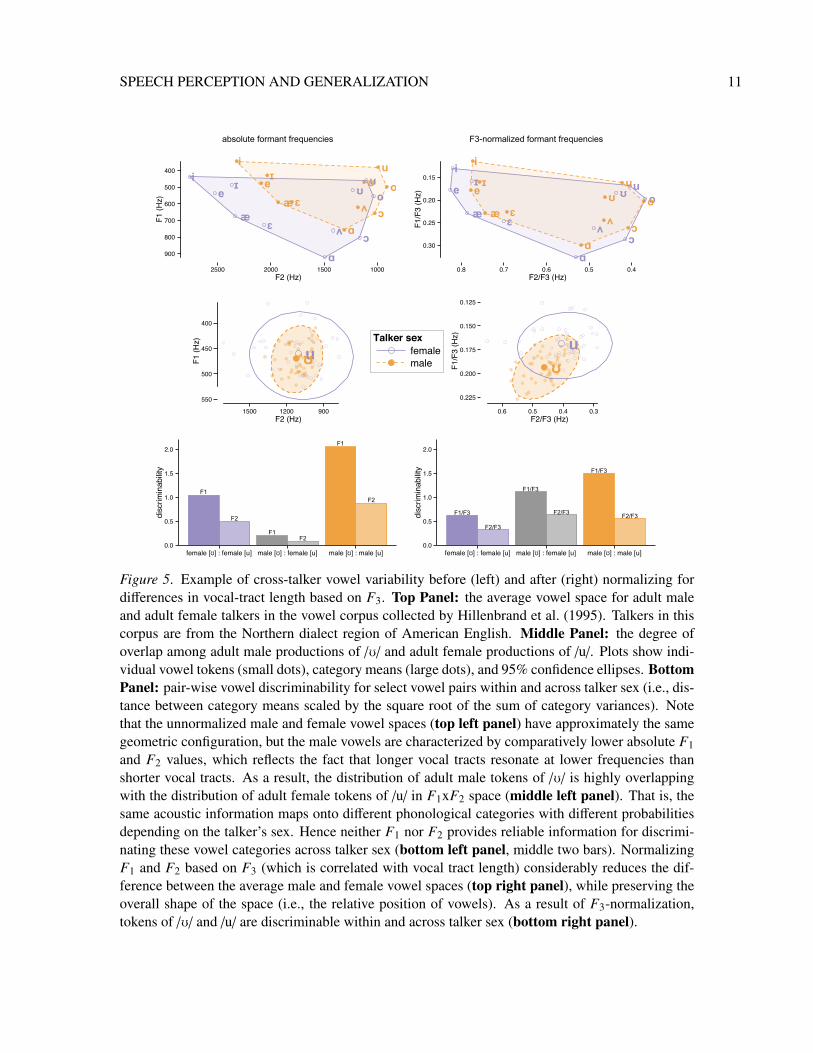
vowel variability resulting from the talker’s vocal anatomy/physiology.1 Consider first that adultmen tend to have longer vocal tracts than adult women due to laryngeal descent (i.e., the loweringof the larynx in the throat) during puberty (Fitch & Giedd, 1999). Longer vocal tracts resonate atlower frequencies than shorter vocal tracts (Chiba & Kajiyama, 1941). Thus, vowel productionsfrom adult men tend to be characterized by formants (acoustic resonances of the vocal tract) atlower frequencies than corresponding vowels produced by adult females (see the top left panel ofFigure 5; see also Huber, Ash, & Johnson, 1999). This biological difference has consequences forvowel perception. The first and second formants (F1 and F2) vary systematically by vowel type
1Much of the normalization literature has focused on vowels (see reviews by Adank, Smits, & van Hout, 2004;Johnson, 2005). Vowels are a considerable source of variation across talkers and the spectral properties of vowels arecomparatively well understood. Fewer studies have investigated normalization of consonants (Holt, 2006; Johnson, 1991;Mann & Repp, 1980) and lexical tone (Fox & Qi, 1990; Huang & Holt, 2009; Moore & Jongman, 1997).

SPEECH PERCEPTION AND GENERALIZATION 10
(Ladefoged, 1980) and are two of the primary cue dimensions used in vowel identification (Fox,Flege, & Munro, 1995; Verbrugge, Strange, Shankweiler, & Edman, 1976; Yang & Fox, 2014): forexample, the vowel /u/ (as in the word suit) is characterized by a lower F1 and (in many varietiesof English) F2 than the vowel /U/ (as in the word soot). As a result of laryngeal descent, and henceformant lowering, the F1 and F2 of an adult male’s realization of /U/ (the vowel with the relativelyhigher formants) might match the F1 and F2 of an adult female’s realization of /u/, as shown in themiddle left panel of Figure 5 (see also Hillenbrand et al., 1995; Peterson & Barney, 1952).2
This example highlights several facts. First, with few exceptions, there is not a one-to-onemapping between category-relevant acoustic cues and linguistic categories: e.g., one talker’s [u] isanother talker’s [U]. Second, anatomical differences across talkers have a systematic influence onthe acoustic realization of speech sounds: e.g., there is a relationship between vocal tract lengthand resonance frequencies. Third, talkers with the same dialect maintain the same structural rela-tionships among speech sounds: e.g., the contrast between the vowels /u/ and /U/ and the relativeposition of these vowels in acoustic-phonetic space. According to the normalization approach, thespeech perception system copes with acoustic variability by capitalizing on relational aspects ofspeech. In other words, it is not the absolute value of category-relevant speech cues that matters forspeech perception, but rather the relationship among various cues.
Normalization as an automatic auditory process
Normalization has a long history in research on speech perception, and a number of relatednormalization mechanisms have been proposed (see, e.g., Barreda, 2012; Irino & Patterson, 2002;Zahorian & Jagharghi, 1993; Nearey, 1989; Strange, 1989; Nordström & Lindblom, 1975; Lobanov,1971; Joos, 1948; Lloyd, 1890a). Some accounts are purely auditory, such as ratio-based accounts3
in which category-relevant speech cues (e.g., F1 and F2 for vowels) are normalized based on acous-tic correlates of the talker’s vocal tract length, such as a talker’s fundamental frequency (F0) or thirdformant (F3; Bladon, Henton, & Pickering, 1984; Claes, Dologlous, Bosch, & van Compernolle,1998; Halberstam & Raphael, 2004; Miller, 1989; Monahan & Idsardi, 2010; Nordström & Lind-blom, 1975; Peterson, 1961; Sussman, 1986; Syrdal & Gopal, 1986). Figure 5 shows an exampleof F3-normalization in which the F1 and F2 from a set of American English vowels (left panel) areconverted to F1/F3 and F2/F3 ratios (right panel), which dramatically reduces vocal tract-relatedvariability across talkers with the same accent (see Monahan & Idsardi, 2010 for further discussion).Other normalization accounts assume an articulatory basis for speech perception. For example, inMcGowan and Cushing’s (1999) articulatory recovery model (see above), vocal tract normalizationis the first step in extracting category-relevant gestural information from the speech signal. What themajority of these proposals share is the belief that normalization of the speech signal results from
2As we discuss below, biological changes are not sufficient to explain cross-linguistic variance in the formant structurebetween male and female talkers (Johnson, 2007).
3 The general ratio-based proposal traces to the work of Richard John Lloyd in the late 1800s (Lloyd, 1890a,b, 1891,1892). To quote from Lloyd’s doctoral thesis: “the great implied postulate of the organic system of phonetics ... [is that]like articulations produce like sounds. ... For if half-a-dozen human beings, of identical type but widely differing size,all articulate a given vowel exactly in a given way, it is then clear that mathematically speaking, these six examples ofthe configuration of that vowel will be a series of similar figures. Now if this be true, whether vowel resonance be singleor double or even more complex, it is certain that the pitch of that resonance or body of resonances will vary exactly inproportion to the relative size of the configuration from which it proceeds” (Lloyd, 1890a, p. 172, emphasis added). Here,Lloyd outlines the earliest account of F0 normalization, in which vowel formants are scaled by the talker’s fundamentalfrequency (F0), which is the acoustic correlate of perceived pitch.
SPEECH PERCEPTION AND GENERALIZATION 11
absolute formant frequencies F3-normalized formant frequencies
Talker sexfemalemale
ææ
ɑ
ɑ
ee
ɛ
ɛ
ii
ɪɪ
oo
ɔ
ɔ
uu
ʊʊ
ʌ
ʌ
400
500
600
700
800
900
1000150020002500F2 (Hz)
F1 (H
z)
æ æ
ɑɑ
e e
ɛɛ
i i
ɪ ɪoo
ɔɔ
uuʊʊ
ʌʌ
0.15
0.20
0.25
0.30
0.40.50.60.70.8F2/F3 (Hz)
F1/F
3 (H
z)
uʊ
400
450
500
550
90012001500F2 (Hz)
F1 (H
z) uʊ
0.125
0.150
0.175
0.200
0.225
0.30.40.50.6F2/F3 (Hz)
F1/F
3 (H
z)
F1
F2
F1F2
F1
F2
0.0
0.5
1.0
1.5
2.0
female [ʊ] : female [u] male [ʊ] : female [u] male [ʊ] : male [u]
discrim
inability
F1/F3
F2/F3
F1/F3
F2/F3
F1/F3
F2/F3
0.0
0.5
1.0
1.5
2.0
female [ʊ] : female [u] male [ʊ] : female [u] male [ʊ] : male [u]
discrim
inability
Figure 5. Example of cross-talker vowel variability before (left) and after (right) normalizing fordifferences in vocal-tract length based on F3. Top Panel: the average vowel space for adult maleand adult female talkers in the vowel corpus collected by Hillenbrand et al. (1995). Talkers in thiscorpus are from the Northern dialect region of American English. Middle Panel: the degree ofoverlap among adult male productions of /U/ and adult female productions of /u/. Plots show indi-vidual vowel tokens (small dots), category means (large dots), and 95% confidence ellipses. BottomPanel: pair-wise vowel discriminability for select vowel pairs within and across talker sex (i.e., dis-tance between category means scaled by the square root of the sum of category variances). Notethat the unnormalized male and female vowel spaces (top left panel) have approximately the samegeometric configuration, but the male vowels are characterized by comparatively lower absolute F1and F2 values, which reflects the fact that longer vocal tracts resonate at lower frequencies thanshorter vocal tracts. As a result, the distribution of adult male tokens of /U/ is highly overlappingwith the distribution of adult female tokens of /u/ in F1xF2 space (middle left panel). That is, thesame acoustic information maps onto different phonological categories with different probabilitiesdepending on the talker’s sex. Hence neither F1 nor F2 provides reliable information for discrimi-nating these vowel categories across talker sex (bottom left panel, middle two bars). NormalizingF1 and F2 based on F3 (which is correlated with vocal tract length) considerably reduces the dif-ference between the average male and female vowel spaces (top right panel), while preserving theoverall shape of the space (i.e., the relative position of vowels). As a result of F3-normalization,tokens of /U/ and /u/ are discriminable within and across talker sex (bottom right panel).

SPEECH PERCEPTION AND GENERALIZATION 12
automatic, low-level (precategorical) auditory processes (Huang & Holt, 2011; Sjerps, McQueen,& Mitterer, 2013; Sussman, 1986; Watkins & Makin, 1996).
This belief is motivated in part by how the peripheral auditory system perceives the frequencycontent of speech. In humans (and other mammals), sound frequency discrimination begins in thecochlea. The basilar membrane, which is part of the cochlea, is tonotopically organized, mean-ing that different regions respond to different frequencies. Specifically, hair cells that are positionedfurther along the membrane respond to progressively lower frequencies.4 Building on these basic as-pects of sound perception, Potter and Steinberg (1950, p. 812) proposed that “within limits, a certainspatial pattern of stimulation on the basilar membrane may be identified as a given sound regardlessof position along the membrane.” In other words, Potter and Steinberg proposed a ratio-based ac-count of normalization in which the auditory system perceives the relationship among co-occurringformants, rather than perceiving individual formants. In a similar vein, Sussman (1986) developeda simulation-based model of vowel normalization and representation that involved “combination-sensitive neurons”, which integrate information from multiple formants before mapping the normal-ized input to abstract representations of vowel categories.
One of the most compelling pieces of behavioral evidence for automatic low-level normaliza-tion of speech comes from experiments showing context-dependent perceptual shifts. In a seminalstudy, Ladefoged and Broadbent (1957), found that perception of a target utterance—a word thatwas relatively ambiguous between “bit” (with an [I]) and “bet” (with an [E]) due to the frequencyof F1—shifted depending on the formant structure of the preceding carrier phrase. Ladefoged andBroadbent manipulated the F1 and F2 of all vowels in the carrier phrase, either lowering or raisingthem. The lowered or raised F1 and F2 across vowels in the carrier phrase thus suggested a talkerwith a relatively longer or shorter vocal tract, respectively. Ladefoged and Broadbent found thatthis manipulation affected the perception of the target vowel (which was physically identical acrossconditions): when the carrier phrase had raised vowel formants, the target tended to be heard as“bit”; when the carrier phrase had lowered formants, the same target tended to be heard as “bet”.That is, listeners interpreted the vowel in the target word as relative to the talker’s vowel space (notethat [I] has a lower F1 than [E]). Thus, the speech perception system compensated for talker-relatedvariability as revealed in the preceding utterance (see also Ladefoged, 1989).
Building on this seminal finding, Holt and colleagues (Holt, 2005, 2006; Huang & Holt,2009) demonstrated that the same perceptual shift occurs even when the carrier phrase is replacedwith a series of non-speech sine-wave tones. In these experiments, a constant speech target wasinterpreted as relatively higher when preceded by a series of pure tones sampled from a distributionof low frequency tones and as relatively lower when preceded by a series of tones drawn from adistribution of high frequency tones. The fact that both speech and non-speech contexts elicit thisshift suggests that at least vowel normalization results from general low-level auditory processesthat are sensitive to the relational properties of the acoustic input (as opposed, e.g., to higher-levelprocesses that adjust the mapping between auditory percepts or phonetic features and phonologicalcategories; Laing, Liu, Lotto, & Holt, 2012).
4The frequency-position map appears to be logarithmic over most of the cochlea’s range of frequency sensitivity(Greenwood, 1961). Thus, converting the frequency scale to mel or Bark, which are units of measurement that are (ap-proximately) logarithmically related to frequency, is a type of normalization that aims to capture the biological structureof the inner ear and the psychophysics of sound perception.

SPEECH PERCEPTION AND GENERALIZATION 13
Category-intrinsic vs. category-extrinsic normalization
While there is widespread agreement that normalization is an automatic low-level process,one dimension along which normalization proposals differ is the type of information that is used toperform the normalization (for discussion, see Ainsworth, 1975; Johnson, 1990). Category-extrinsicprocedures involve normalizing a category token based on an external frame of reference, such asinformation from the preceding utterance or context (Holt, 2005, 2006; Sjerps et al., 2013). In anearly but highly influential proposal, Joos (1948, p. 61) argued that vowel information is perceptu-ally evaluated on a talker-specific “coordinate system” that the listener “swiftly constructs” basedon information from other vowels from the same talker. By contrast, category-intrinsic proceduresrely exclusively on information from a given category token to normalize that token. An exampleof category-intrinsic normalization is calculating the interval between adjacent formants of a givenvowel token in order to isolate the relative pattern of formants independent of the absolute formantfrequencies (e.g., F2 - F1, F1 - F0; Syrdal & Gopal, 1986).
Research on the role of F0 in talker normalization serves to highlight the complementarityof category-intrinsic and category-extrinsic approaches. F0 results from the periodic pulsing of thevocal folds and is correlated with vocal cord size and (indirectly) with vocal tract size. F0 there-fore provides a vowel-intrinsic reference point for normalizing variability due to the talker’s vocalanatomy (for various instantiations of this approach, see. e.g., Hirahara & Kato, 1992; Johnson,2005; Katz & Assmann, 2001; Syrdal & Gopal, 1986). However, one limitation of vowel-intrinsicF0 normalization is that listeners can recognize vowels with a high degree of accuracy even whenF0 is not present in the signal (Tartter, 1991), as in the case of whispered speech (i.e., there is noperiodic pulsing of the vocal folds during whispered speech because the vocal folds are held tight).Vowel-extrinsic F0 normalization (Miller, 1989) provides a potential solution because the formantsin whispered vowels could be normalized based on an aggregate measure of the talker’s fundamentalfrequency, calculated over previous tokens in which F0 was present.
The evidence discussed above suggests that normalization involves sensitivity to both syn-tagmatic relationships—e.g., the relationship between a given speech sound and aspects of the sur-rounding context—and paradigmatic relationships—e.g., the relationships among category-internalsources of information. This leaves open the possibility that listeners draw on a wide variety of cues,possibly weighing them in accordance to their informativity. This possibility receives some supportfrom a review of proposed vowel normalization algorithms, which found that vowel-extrinsic pro-cedures performed better than vowel-intrinsic procedures in achieving relational invariance (Adanket al., 2004). Since category-extrinsic information is more available and plentiful than category-intrinsic information (the latter is limited, by definition), extrinsic cues are a priori more likely toyield reliable information about talker-related sources of variation, and hence to provide a stablebaseline for normalization.
Normalization and learning
While low-level normalization algorithms have been shown to reduce talker-related acous-tic variability, particularly due to vocal anatomy, this approach has been met with a number ofcriticisms. We briefly review some of the most important criticisms (for extensive discussion, seeJohnson, 1997, 2005). Then we discuss an aspect of these criticisms that has received comparativelylittle attention: the relationship between normalization and learning.

SPEECH PERCEPTION AND GENERALIZATION 14
One criticism of normalization accounts is that instance-specific details of perceived speechare retained in long-term memory and influence subsequent speech processing (Bradlow, Nygaard,& Pisoni, 1999; Goldinger, 1996; Palmeri, Goldinger, & Pisoni, 1993; Schacter & Church, 1992),which indicates that acoustic variability is not “filtered out” during the early stages of process-ing. These findings spurred a tremendous body of research into speech perception. According toepisodic (Goldinger, 1996, 1998) and exemplar-based approaches (Johnson, 1997; Pierrehumbert,2002; Pisoni, 1997)), detailed representations of speech episodes play a central role in how listenerscope with talker variability.
Two related criticisms of normalization accounts come from cross-linguistic studies. First,the exact difference between adult male and adult female vowel formants varies across languagesand cannot be reduced to differences in vocal anatomy (Johnson, 2007; see also Bladon et al., 1984;Johnson, 2005). This suggests that cultural factors such as gender-norms contribute to patterns ofvariation in speech, above and beyond biologically-determined variation, such as sex-based vocaltract differences after puberty. As further evidence of this point, boys and girls in some culturesshow adult-like differences in speech production (e.g., boys producing lower formants) long beforelaryngeal descent during puberty (Johnson, 2005; Lee et al., 1999; Perry et al., 2001). Second,normalization procedures that are effective in reducing inter-talker variability when applied to datafrom one language are not necessarily equally effective when applied to corresponding data fromanother language (see, e.g., Disner, 1980).
These cross-linguistic findings raise questions about how low-level normalization processescome into existence. A priori, there are at least three logically possible scenarios: (i) normaliza-tion involves a genetically-determined invariant mapping from genetically-determined cues to cate-gories; (ii) normalization involves a variable mapping function from genetically-determined cues tocategories, with the mapping function being learned through exposure; (iii) normalization is simplythe use of an invariant mapping function to relate cues to categories, but both the cues and the natureof the mapping function are learned from exposure (e.g., learning that F0 and F3 are related to thetalker’s vocal anatomy/physiology and hence can help normalize source-related variability; and fur-ther learning how these cues vary due to cultural factors in the listeners’ target language). The firstof these scenarios seems unlikely in light of the cross-linguistic evidence cited above. The other twoscenarios involve some degree of learning, which is typically not discussed in the normalization lit-erature and is often conceptualized as incompatible with accounts of automatic low-level processes.However, there is increasing evidence that even some of the lowest level cellular mechanisms in thehuman perceptual system appear to learn and adapt (Brenner, Bialek, & de Ruyter van Steveninck,2000; Fairhall, Lewen, Bialek, & de Ruyter van Steveninck, 2001). Taken together, these criticismssuggest that learning processes (e.g., learning of language-specific or talker-specific variation) playan important role in how the speech perception system copes with variability and how listeners areable to generalize knowledge of the sound structure of their language across talkers and utterances.We turn to this issue in the next section.
How do listeners make use of the statistical distribution of variability?
A prominent line of recent research on talker variability and perceptual constancy capital-izes on the fact that variability in speech is the rule, rather than the exception, by adopting a viewof human perception that is dynamic, adaptive, and context-sensitive (see Bradlow & Bent, 2008;Clayards, Tanenhaus, Aslin, & Jacobs, 2008; Eisner & McQueen, 2005; Kraljic & Samuel, 2006;Maye, Werker, & Gerken, 2002; Pisoni, 1997; Pisoni & Levi, 2007). Indeed, this is increasingly

SPEECH PERCEPTION AND GENERALIZATION 15
how cognitive scientists see all of the brain, even low-level perceptual areas (Gutnisky & Dragoi,2008; Sharpee et al., 2006; Stocker & Simoncelli, 2006). Instead of searching for inherently in-variant properties of speech, this approach seeks to understand how the systems involved in speechperception track, learn, and respond to patterns of variation in the environment (for extensive dis-cussion, see Kleinschmidt & Jaeger, 2015; Samuel & Kraljic, 2009). This approach is based on thefundamental belief that the distribution of variability associated with speech categories—and thefact that different talkers can have different distributions (see Figure 1)—is highly informative. AsPisoni (1997, p. 10) explains, “stimulus variability is, in fact, a lawful and highly informative sourceof information for the perceptual process; it is not simply a source of noise that masks or degradesthe idealized symbolic representation of speech in human long-term memory.”
A similar point was noted by Liberman & Mattingly (1985): “systematic stimulus variationis not an obstacle to be circumvented or overcome in some arbitrary way; it is, rather, a source ofinformation about articulation that provides important guidance to the perceptual process” (p. 14-15,emphasis added). For Liberman and Mattingly, who were proponents of motor theory (see above),the primary focus was on the types of information provided by phonological context: e.g., in the caseof coarticulation, systematic variation in formant transitions between a stop consonant and vowelprovide information about consonant place of articulation. The research discussed below extendsbeyond sources of information provided by phonological context to include any source of systematicvariation in speech: e.g., a talker’s age, sex, gender, accent, speaking rate, or idiosyncratic speechpatterns.
We begin by discussing evidence that speech perception is guided by listeners’ knowledgeof how variability is distributed in the world (e.g., how patterns of pronunciation variation are dis-tributed across talkers and social groups). We then discuss research concerned with the learningmechanisms that enable listeners to achieve this sensitivity to the distributional aspects of speech.
Talker perception and speech processing
Sociolinguistic research over the last several decades has shown that listeners have richand structured knowledge about the distribution of variability across groups of talkers (see e.g,.Campbell-Kibler, 2007; Clopper & Pisoni, 2004b, 2007; Labov, 1966; Preston, 1989). Listeners usethis social knowledge to help generalize knowledge of the sound structure of their language acrosstalkers (see Foulkes & Hay, 2015, for a recent overview). This line of research has demonstratedthat speech perception can be influenced by expectations about the talker’s dialect background (Hay,Nolan, & Drager, 2006; Niedzielski, 1999), age (Drager, 2011; Hay, Warren, & Drager, 2006;Koops, Gentry, & Pantos, 2008; see also Walker & Hay, 2011), socio-economic status (Hay, War-ren, & Drager, 2006), and ethnicity (Staum Casasanto, 2008)—in cases where these social attributescovary statistically with patterns of pronunciation variation in the target language.
For example, Hay and colleagues found that unprompted expectations about an unfamiliartalker—based on visually-cued social attributes of the talker—influenced perception of vowel vari-ation in New Zealand English (Hay, Warren, & Drager, 2006). In New Zealand English, the diph-thongs /i@/ and /e@/ (as in the words near and square, respectively) are in the process of merging.This change-in-progress is most advanced among younger speakers and members of lower socio-economic groups, whereas older and more affluent speakers tend to maintain the vowel contrast. Inone study, Hay, Warren, & Drager (2006) presented listeners with minimal pairs like beer and bareproduced by New Zealand talkers who maintained the vowel distinction. Photographs were used tomanipulate the perceived age and socio-economic status of the talkers. Results of a two-alternative

SPEECH PERCEPTION AND GENERALIZATION 16
forced-choice identification task (e.g., did the talker say the word beer or bare?) showed that identi-fication accuracy was worse when the talker appeared to be younger or from a lower socioeconomicgroup than when the talker appeared to be older or more affluent (see also Drager, 2011). That is,when the talker appeared to belong to a social group with merged vowels, the target stimuli tended tobe treated as homophonous, creating uncertainty about the intended word and resulting in a higherrate of identification ‘errors’.5 Crucially, since the speech stimuli were identical across conditions,the difference in identification accuracy can only stem from listeners’ expectations based on thevisually-cued attributes of the talker.
Niedzielski (1999) found that simply informing listeners about a talker’s ostensible regionalbackground led to differences in how the same physical vowel stimulus was perceived (see also Hay& Drager, 2010). In this study, listeners from Detroit, Michigan heard target words containing araised variant of the diphthong /aw/ (e.g., about pronounced more like “a boat”), a phenomenonknown as Canadian Raising. The listeners’ task was to identify the best match between the vowel inthe stimulus word and one of six synthesized vowel tokens, which ranged from a standard-soundingrealization of /aw/ to a raised vowel variant. When told the speaker was from Canada, rather thanDetroit, listeners were more likely to match the target vowel to one of the raised variants on thesynthesized continuum, reflecting the fact that Detroit residents attribute Canadian Raising to thespeech of Canadians and are virtually unaware of this feature in their own speech.
Sensitivity to the covariance between social factors and the realization of speech categoriesdoes not stop at the level of social group membership. Listeners have also been found to be sensitiveto talker-specific patterns of variation (Creel, 2014; Goldinger, 1996; Kraljic, Brennan, & Samuel,2008; Kraljic & Samuel, 2006, 2007; for relevant discussion, see Creel & Bregman, 2011). Using anexposure-test paradigm, Nygaard and colleagues (Nygaard, Sommers, & Pisoni, 1994) found thatlisteners were better able to recognize new words produced by familiar talkers than words producedby unfamiliar talkers, as indicated by identification accuracy at test for words in noise (see alsoNygaard & Pisoni, 1998). The fact that the benefits of exposure generalizes to new words fromthe familiar talkers indicates that listeners learn and use knowledge of talker-specific pronunciationpatterns to guide processing of new tokens from those talkers. Trude and Brown-Schmidt (2012)found that when listening to multiple familiar talkers who produce different variants of the samespeech category, providing listeners with talker-indexical cues on each trial (e.g., a picture of thetalker or a snippet of speech that did not contain the target speech category) facilitated the use ofknowledge of talker-specific pronunciation variation.
Taken together, the findings discussed above indicate that listeners’ knowledge about the dis-tribution of variability within and across talkers and social groups provides a rich backdrop againstwhich to evaluate speech. Listeners can capitalize on this knowledge to predict the likelihood withwhich certain speech cues map to higher-level linguistic categories.
Adaptation and perceptual/distributional learning
In order for talker-specific or group-based information to be useful in speech perception, lis-teners must first learn the patterns of variation that are associated with particular talkers or groups
5The observed increase in uncertainty is actually expected under an ideal observer model that draws on implicit beliefsabout the covariance between the social factors and the realization of the near and square vowels (cf. Kleinschmidt &Jaeger, 2015). The ‘errors’, too (defined as deviation from the answer intended by the design) are expected under an idealobserver model that draws on implicit knowledge of this covariance.

SPEECH PERCEPTION AND GENERALIZATION 17
of talkers. A tremendous body of research—much of it in recent years—has investigated the mech-anisms that track and respond to patterns of variation in speech input (see Aslin & Newport, 2012;Samuel & Kraljic, 2009). The conceptual foundations of this research can be traced in part to sem-inal work on perceptual learning by James and Eleanor Gibson in the 1950s and 60s (E. J. Gibson,1969; J. J. Gibson & Gibson, 1955). E. J. Gibson (1969, p. 3) defined perceptual learning as “anincrease in the ability to extract information from the environment, as a result of experience andpractice with stimulation coming from it”. The premise of this view is that perception is fundamen-tally shaped by the perceiver’s existing knowledge and past experiences in such a way as to facilitateprocessing of the input, rather than being an objective translation of the physical world into units ofperception. The appeal of this view for theories of speech perception is that speech categories (e.g.,/b/ vs. /d/, /u/ vs. /U/) need not be distinguished by a fixed set of acoustic, articulatory or relationalinvariants. Rather, through experience with specific talkers or groups of talkers, listeners can learnthe cue dimensions and distributions of cue values that are relevant for distinguishing speech cate-gories produced by those talkers (Bejjanki, Clayards, Knill, & Aslin, 2011; Clayards et al., 2008;Kleinschmidt & Jaeger, 2015; Maye et al., 2002). In other words, the speech perception systemadapts. For the present discussion, we use the term adaptation to refer to the outcome of a learningmechanism (see Goldstone, 1998 for an ontology of perceptual learning mechanisms).6
One of the classic demonstrations of perceptual learning for speech is that listeners dynami-cally recalibrate phonetic category boundaries in response to variation in the speech input (Bertel-son, Vroomen, & de Gelder, 2003; Norris, McQueen, & Cutler, 2003). For example, when listenersencounter a talker whose realization of /s/ is acoustically ambiguous between [s] and [f], listen-ers adjust their category boundary to perceive the otherwise ambiguous stimulus as /s/ (i.e., as aninstance of the category intended by the talker). This phonetic recalibration effect can be drivenby lexical knowledge, such as hearing the ambiguous sound in a disambiguating lexical context:e.g., hearing “platypu[?sf]” for platypus, an /s/-final word with no /f/-final counterpart (Kraljic &Samuel, 2005; McQueen, Cutler, & Norris, 2006; Norris et al., 2003)). Phonetic recalibration canalso be driven by visual information: e.g., hearing a sound that is acoustically ambiguous between[b] and [d], but seeing the talker produce the labial closure for [b] (Bertelson et al., 2003); seeVroomen & Baart, 2012 for a recent review), and by statistical knowledge about contingenciesamong acoustic-phonetic cues (Idemaru & Holt, 2011).
Perceptual learning for speech helps listeners cope with talker variability by tailoring speechperception processes to patterns of variation in the input. As evidence of pattern abstraction, adap-tation to atypical segmental variation ([?sf] for /s/) generalizes to new words that are pronouncedwith the segmental variant (Maye et al., 2008; McQueen et al., 2006; Mitterer, Chen, & Zhou, 2011;Mitterer, Scharenborg, & McQueen, 2013; Sjerps & McQueen, 2010; Weatherholtz, 2015; see alsoGreenspan, Nusbaum, & Pisoni, 1988). This finding of generalization indicates that listeners ab-stracted over the trained word forms to learn a sublexical pattern of variation, as opposed to simplyencoding the atypical word forms experienced during training (e.g., “platypu[?sf]” for platypus;McQueen et al., 2006).
6The terms perceptual learning and adaptation have been variously defined in speech perception research (and moregenerally in the field of cognitive psychology). Sometimes perceptual learning refers to long-lasting changes in how theperceptual system processes incoming stimulus information, while adaptation is taken to refer to relatively short-termadjustments (see Goldstone, 1998), based on bottom-up information (Eisner, 2012, but see Kleinschmidt & Jaeger, underreview). In yet other cases, adaptation is considered the behavioral outcome of any type of learning mechanism that tracksand responds to properties of the environment (see Kleinschmidt & Jaeger, 2015; see also Bradlow & Bent, 2008; Fine &Jaeger, 2013; Maye, Aslin, & Tanenhaus, 2008).

SPEECH PERCEPTION AND GENERALIZATION 18
A central question in this line of research concerns the conditions under which pattern ab-straction is talker-specific versus talker-independent (see Bradlow & Bent, 2008; Kraljic & Samuel,2007; Reinisch & Holt, 2014). Both can be beneficial. For example, when adapting to talker-specificidiosyncracies, an ideal adapter should learn a talker-specific pattern of variation, but when adaptingto patterns of variation that occur across talkers (e.g., dialect or accent variation), an ideal adaptershould learn talker-independent pronunciation variation in order to generalize learning to new talk-ers with the same dialect or accent. There is some evidence that human listeners behave in waysthat are qualitatively and quantitatively similar to ideal adapters (Kleinschmidt & Jaeger, 2015).For example, exposure to multiple talkers with the same accent or dialect facilitates cross-talkergeneralization by helping listeners distinguish talker-independent patterns of variation from inter-talker variability in the realization of those patterns. This effect of exposure conditions on learningoutcomes has been observed for a range of perceptual learning phenomenon: adapting to foreign-accented speech (Bradlow & Bent, 2008; Gass & Varonis, 1984; Sidaras, Alexander, & Nygaard,2009); learning new perceptual categories, such as Japanese-learners of English acquiring the /l/-/r/contrast (Lively, Logan, & Pisoni, 1993; Logan, Lively, & Pisoni, 1991), and learning to classifytalkers by regional dialect (Clopper & Pisoni, 2004a).
Some results suggest that multi-talker exposure is a necessary pre-condition for talker-independent adaptation (Bradlow & Bent, 2008; Lively et al., 1993). For example, Bradlow andBent (2008) found that listeners who were familiarized to five Mandarin-accented English talkerswere subsequently able to generalize learning to a novel talker with this accent, indicating talker-independent adaptation. However, when listeners were initially familiarized to a single Mandarin-accented English talker, adaptation was talker-specific: i.e., listeners were subsequently better ableto understand the trained talker’s speech in noise, but accent adaptation did not generalize acrosstalkers. By contrast, several studies concerned with phonetic recalibration have found cross-talkergeneralization of perceptual learning following exposure to a single talker (Eisner & McQueen,2005; Kraljic & Samuel, 2006, 2007; see also Weatherholtz, 2015). The likelihood of cross-talkergeneralization following exposure to a single talker seems to depend largely on the acoustic simi-larity between the familiar and new talkers (Kraljic & Samuel, 2007; Reinisch & Holt, 2014). Thus,when listeners do not have evidence that a particular pattern of variation is systematic across talkers(as in the case of single talker exposure), listeners appear to adapt talker-specifically and only gener-alize learning to acoustically similar tokens produced by other talkers (i.e., generalization based onstimulus similarity). But when listeners have evidence of variation that is systematic across talkers(as in the case of multi-talker exposure), listeners adapt by learning talker-independent patterns ofvariation (see Kleinschmidt & Jaeger, 2015; Weatherholtz, 2015 for additional discussion).
Conclusions
Research in speech perception has come a long way in understanding how variable speechinput is mapped to linguistic categories in memory: from simply assuming invariance to modeling ahighly complex, layered system that draws on statistical information in the speech signal. We havediscussed several aspects of the speech perception system that enable listeners to cope with talkervariability: sensitivity to articulatory gestures (and recovery of articulatory information from thespeech signal), normalization, memory for episodic detail, and perceptual and distributional learningmechanisms that are sensitive to patterns of variation in speech. At least some of these mechanismsare automatic and appear to operate during the early stages of processing (i.e., pre-categorical, pre-speech mechanisms). It is an open question to what extent these early processes involve learning:

SPEECH PERCEPTION AND GENERALIZATION 19
for example, learning early in development that F0 and F3 are correlated with vocal tract lengthand, hence, learning that these cue dimensions can be used to normalize variability resulting fromindividual differences in vocal anatomy. Similarly, it is an open question as to how flexible low-levelprocesses are. While there is evidence that low-level auditory processes engage in distributionallearning (for discussion, see Kleinschmidt & Jaeger, under review), it is not yet known whetherthe types of distributional learning involved in adapting to talker and accent variability are neurallycoded early (for discussion, see Goslin, Duffy, & Floccia, 2012) and further whether sensitivity tocovariation between social factors and speech cues is partly due to low-level processes.
The debate between normalization accounts and episodic/exemplar-based accounts of speechperception warrants further discussion. The fact that episodic details of speech stimuli are retainedin memory and affect speech perception is one of the primary challenges to normalization accounts(Johnson, 2005). However, it is important to note that, in principle, abstracting away from vari-ance is orthogonal to whether fine acoustic details are retained in memory. That is, normalizationaccounts that aim to identify relational invariants (e.g., vowel formant ratios that are stable acrosstalkers) do not, in principle, require fine-grained stimulus details to be “filtered out”, forgotten orotherwise inconsequential for speech perception. Thus, the fact that speech perception is sensitiveto episodic detail indicates that normalization accounts, as typically formulated, are insufficient,but does not rule out normalization altogether. Likewise, episodic and exemplar-based theories(e.g., (Goldinger, 1996; Johnson, 1997)) do not provide a straightforward account for some of thestrongest evidence of normalization—i.e., that speech sounds are interpreted relative to frequencyinformation in the surrounding context, even when this “context” is non-speech sine-wave tones(Laing et al., 2012). Thus, like normalization accounts, episodic models alone are insufficient toexplain how the speech perception system copes with variability, despite evidence that episodic in-formation plays an important role in recognition and categorization processes (Bradlow et al., 1999;Palmeri et al., 1993).
We take the integration of these sometimes conflicting—though not necessarilyincompatible—views to be one of the big open questions in research on speech perception. In-tegrating these views will be critical in understanding how low-level pre-speech and higher-levelspeech processes jointly achieve relative invariance—the ability to robustly recognize speech cate-gories across talkers.
References
Adank, P., Smits, R., & van Hout, R. (2004). A comparison of vowel normalization procedures forlanguage variation research. Journal of the Acoustical Society of America, 116(5), 3099-3107.doi: 10.1121/1.1795335
Ainsworth, W. A. (1975). Intrinsic and extrinsic factors in vowel judgements. In G. Fant &M. A. A. Tatham (Eds.), Auditory analysis and perception of speech (p. 103-111). London:Academic Press.
Aslin, R. N., & Newport, E. L. (2012). Statistical learning: From acquiring specific items toforming general rules. Current Directions in Psychological Science, 21, 170-176. doi: 10.1177/
0963721412436806

SPEECH PERCEPTION AND GENERALIZATION 20
Barreda, S. (2012). Vowel normalization and the perception of speaker changes: An explorationof the contextual tuning hypothesis. Journal of the Acoustical Society of America, 132(5), 3453-3464. doi: 10.1121/1.4747011
Bejjanki, V. R., Clayards, M., Knill, D. C., & Aslin, R. N. (2011). Cue integration in categoricaltasks: Insights from audio-visual speech perception. PLOS One, 6(5), e19812. doi: 10.1371/
journal.pone.0019812
Bertelson, P., Vroomen, J., & de Gelder, B. (2003). Visual recalibration of auditory speechidentification: A McGurk after effect. Psychological Science, 14, 592-597. doi: 10.1046/
j.0956-7976.2003.psci_1470.x
Best, C. T. (1995). A direct realist view of cross-language speech perception. In W. Strange (Ed.),Speech perception and linguistic experience: Theoretical and methodological issues (p. 171-204).Timonium, MD: New York Press.
Bizley, J. K., Walker, K. M. M., King, A. J., & Schnupp, J. W. H. (2013). Spectral timbre perceptionin ferrets: Discrimination of artificial vowels under different listening conditions. Journal of theAcoustical Society of America, 133(1), 365-376. doi: 10.1121/1.4768798
Bladon, R. A. W., Henton, C. G., & Pickering, J. B. (1984). Towards an auditory theory of speakernormalization. Language Communication, 4(1), 59-69. doi: 10.1016/0271-5309(84)90019-3
Bradlow, A. R., & Bent, T. (2008). Perceptual adaptation to non-native speech. Cognition, 106(2),707-729. doi: 10.1016/j.cognition.2007.04.005
Bradlow, A. R., Nygaard, L. C., & Pisoni, D. B. (1999). Effects of talker, rate, and amplitudevariation on recognition memory for spoken words. Perception & Psychophysics, 61(2), 206-219. doi: 10.3758/BF03206883
Brenner, N., Bialek, W., & de Ruyter van Steveninck, R. R. (2000). Adaptive rescaling maximizesinformation transmission. Neuron, 26(3), 695-702. doi: 10.1016/S0896-6273(00)81205-2
Burdick, C. K., & Miller, J. D. (1975). Speech perception by the chinchilla: Discrimination ofsustained /a/ and /i/. Journal of the Acoustical Society of America, 58(2), 415-427. doi: 10.1121/
1.380686
Campbell-Kibler, K. (2007). Accent, (ING), and the social logic of listener perception. AmericanSpeech, 82(1), 32-64. doi: 10.1215/00031283-2007-002
Chiba, T., & Kajiyama, M. (1941). The vowel: Its nature and structure. Tokyo: Tokyo PublishingCompany.
Claes, T., Dologlous, I., Bosch, L. T., & van Compernolle, D. (1998). A novel feature transforma-tion for vocal tract length normalization in automatic speech recognition. IEEE Transactions onSpeech and Audio Processing, 6(6), 549-557. doi: 10.1109/89.725321
Clarke, C., & Garrett, M. F. (2004). Rapid adaptation to foreign-accented English. Journal of theAcoustical Society of America, 116, 3647-3658. doi: 10.1121/1.1815131

SPEECH PERCEPTION AND GENERALIZATION 21
Clayards, M., Tanenhaus, M. K., Aslin, R. N., & Jacobs, R. A. (2008). Perception of speechreflects optimal use of probabilistic speech cues. Cognition, 108(3), 804-809. doi: 10.1016/
j.cognition.2008.04.004
Clopper, C. G., & Pisoni, D. B. (2004a). Effects of talker variability on perceptual learning ofdialects. Language and Speech, 47(Pt 3), 207-239. doi: 10.1177/00238309040470030101
Clopper, C. G., & Pisoni, D. B. (2004b). Homebodies and army brats: Some effects of earlylinguistic experience and residential history on dialect caegorization. Language Variation andChange, 16, 31-48. doi: 10.1017/S0954394504161036
Clopper, C. G., & Pisoni, D. B. (2007). Free classification of regional dialects of American English.Journal of Phonetics, 35, 421-438. doi: 10.1016/j.wocn.2006.06.001
Cole, R. A., & Scott, B. (1974). Toward a theory of speech perception. Psychological Review,81(4), 348-374. doi: 10.1037/h0036656
Creel, S. C. (2014). Preschoolers’ flexible use of talker information during word learning. Journalof Memory and Language, 73, 81-98. doi: 10.1016/j.jml.2014.03.001
Creel, S. C., & Bregman, M. R. (2011). How talker identity relates to language processing. Lan-guage and Linguistics Compass, 5(5), 190-204. doi: 10.1111/j.1749-818X.2011.00276.x
Cutler, A., Eisner, F., McQueen, J. M., & Norris, D. (2010). How abstract phonemic categories arenecessary for coping with speaker-related variation. In C. Fougeron, B. Kühnert, M. D’Imperio,& N. Vallée (Eds.), Laboratory phonology 10 (p. 91-111). Berlin: de Gruyter.
Delattre, P. C., Liberman, A. M., & Cooper, F. S. (1955). Acoustic loci and transitional cuesfor consonants. Journal of the Acoustical Society of America, 27(4), 769-773. doi: 10.1121/
1.1908024
Dewson, J. H. (1964). Speech sound discrimination by cats. Science, 144(3618), 555-556. doi:10.1126/science.144.3618.555
Disner, S. F. (1980). Evaluation of vowel normalization procedures. Journal of the AcousticalSociety of America, 67(1), 253-261. doi: 10.1121/1.383734
Drager, K. (2011). Speaker age and vowel perception. Language and Speech, 54, 99-121. doi:10.1177/0023830910388017
Eisner, F. (2012). Perceptual learning in speech. In N. Seel (Ed.), Encyclopedia of the science oflearning (p. 2583-2584). Berlin: Springer.
Eisner, F., & McQueen, J. M. (2005). The specificity of perceptual learning in speech processing.Perception & Psychophysics, 67(2), 224-238. doi: 10.3758/BF03206487
Eriksson, J. L., & Villa, A. E. P. (2006). Learning of auditory equivalence classes for vowels byrats. Behavioural Processes, 73(3), 348-359. doi: 10.1016/j.beproc.2006.08.005
Fairhall, A. L., Lewen, G. D., Bialek, W., & de Ruyter van Steveninck, R. R. (2001). Efficiency andambiguity in an adaptive neural code. Nature, 412(23), 787-792. doi: 10.1038/35090500

SPEECH PERCEPTION AND GENERALIZATION 22
Fant, G. (1960). Acoustic theory of speech production. The Hague: Mouton.
Fine, A. B., & Jaeger, T. F. (2013). Evidence for implicit learning in syntactic comprehension.Cognitive Science, 1-14. doi: 10.1111/cogs.12022
Fitch, W. T., & Giedd, J. (1999). Morphology and development of the human vocal tract: Astudy using magnetic resonance imaging. Journal of the Acoustical Society of America, 106(3),1511-1522. doi: 10.1121/1.427148
Foulkes, P., & Hay, J. (2015). The emergence of sociophonetic structure. In B. MacWhinney &W. O’Grady (Eds.), The handbook of language emergence. Hoboken, NJ: John Wiley & Sons,Inc. doi: 10.1002/9781118346136.ch13
Fowler, C. A. (1986). An event approach to the study of speech perception from a direct-realistperspective. Journal of Phonetics, 14, 3-28.
Fowler, C. A. (1991). Auditory perception is not special: We see the world, we feel the world, weheard the world. Journal of the Acoustical Society of America, 89, 2910-2915. doi: 10.1121/
1.400729
Fowler, C. A., & Deckle, D. J. (1991). Listening with eye and hand: Cross-modal contributions tospeech perception. Journal of Experimental Psychology: Human Perception and Performance,17(3), 816-821. doi: 10.1037/0096-1523.17.3.816
Fox, R. A., Flege, J. E., & Munro, M. J. (1995). The perception of English and Spanish vowelsby native English and Spanish listeners: A multidimensional scaling analysis. Journal of theAcoustical Society of America, 97(4), 2540-2551. doi: 10.1121/1.411974
Fox, R. A., & Qi, Y.-Y. (1990). Context effects in the perception of lexical tone. Journal of ChineseLinguistics, 18, 261-283.
Galantucci, B., Fowler, C. A., & Turvey, M. T. (2006). The motor theory of speech perceptionreviewed. Psychonomic Bulletin & Review, 13(3), 361-377. doi: 10.3758/BF03193857
Gass, S., & Varonis, E. M. (1984). The effect of familiarity on the comprehensibility of nonnativespeech. Language Learning, 34(1). doi: 10.1111/j.1467-1770.1984.tb00996.x
Gibson, E. J. (1969). Principles of perceptual learning and development. New York: Appleton-Century-Crofts.
Gibson, J. J. (1966). The senses considered as perceptual systems. Boston, MA: Houghton-Mifflin.
Gibson, J. J., & Gibson, E. J. (1955). Perceptual learning: Differentiation or enrichment? Psycho-logical Review, 105, 251-279. doi: 10.1037/h0048826
Goldinger, S. D. (1996). Words and voices: Episodic traces in spoken word identification andrecognition memory. Journal of Experimental Psychology: Learning, Memory, & Cognition,22(5), 1166-1183. doi: 10.1037/0278-7393.22.5.1166
Goldinger, S. D. (1998). Echoes of echoes? an episodic theory of lexical access. PsychologicalReview, 105, 251-279. doi: 10.1037/0033-295X.105.2.251

SPEECH PERCEPTION AND GENERALIZATION 23
Goldstone, R. L. (1998). Perceptual learning. Annual Review of Psychology, 49, 585-612. doi:10.1146/annurev.psych.49.1.585
Goslin, J., Duffy, H., & Floccia, C. (2012). An ERP investigation of foreign and regional accentprocessing. Brain and Language, 122(2), 92-102. doi: 10.1016/j.bandl.2012.04.017
Greenspan, S. L., Nusbaum, H. C., & Pisoni, D. B. (1988). Perceptual learning of synthetic speechproduced by rule. Journal of Experimental Psychology: Learning, Memory & Cognition, 14(3),421-433. doi: 10.1037/0278-7393.14.3.421
Greenwood, D. D. (1961). Auditory masking and the critical band. Journal of the AcousticalSociety of America, 33(4), 484-502. doi: 10.1121/1.1908699
Gutnisky, D. A., & Dragoi, V. (2008). Adaptive coding of visual information in neural populations.Nature, 452(13), 220-224. doi: 10.1038/nature06563
Halberstam, B., & Raphael, L. J. (2004). Vowel normalization: The role of fundamental frequencyand upper formants. Journal of Phonetics, 32, 423-434. doi: 0.1016/j.wocn.2004.03.001
Halle, M., Hughes, G. W., & Radley, J.-P. A. (1957). Acoustic properties of stop consonants.Journal of the Acoustical Society of America, 29(1), 107-116. doi: 10.1121/1.1908634
Hay, J., & Drager, K. (2010). Stuffed toys and speech perception. Linguistics, 48(41), 865-892.doi: 10.1515/LING.2010.027
Hay, J., Nolan, A., & Drager, K. (2006). From fush to feesh: Exemplar priming in speech percep-tion. The Linguistic Review, 23, 351-379. doi: 10.1515/TLR.2006.014
Hay, J., Warren, P., & Drager, K. (2006). Factors influencing speech perception in the context of amerger-in-progress. Journal of Phonetics, 34, 458-484. doi: 10.1016/j.wocn.2005.10.001
Hickok, G., Costanzo, M., Capasso, R., & Miceli, G. (2011). The role of Broca’s area in speechperception: Evidence from aphasia revisited. Brain and Language, 119(3), 214-220. doi: 10.1016/j.bandl.2011.08.001
Hillenbrand, J., Getty, L. A., Clark, M. J., & Wheeler, K. (1995). Acoustic characteristics ofAmerican English vowels. Journal of the Acoustical Society of America, 97(5), 3099-3111. doi:10.1121/1.411872
Hirahara, T., & Kato, H. (1992). The effect of F0 on vowel identification. In Y. Tohkura,E. Vatikiotis-Bateson, & R. Sagisaka (Eds.), Speech perception, production and linguistic struc-ture (p. 89-112). Tokyo: Ohmsha Publishing.
Hogden, J., Rubin, P., McDermott, E., Katagiri, S., & Goldstein, L. (2007). Inverting mappingsfrom smooth paths through Rn to paths through Rm: A technique applied to recovering articulationfrom acoustics. Speech Communication, 49(5), 361-383. doi: 10.1016/j.specom.2007.02.008
Holt, L. L. (2005). Temporally nonadjacent nonlinguistic sounds affect speech categorization.Psychological Science, 16(4), 305-312. doi: 10.1111/j.0956-7976.2005.01532.x

SPEECH PERCEPTION AND GENERALIZATION 24
Holt, L. L. (2006). Speech categorization in context: Joint effects of nonspeech and speech precur-sors. Journal of the Acoustical Society of America, 119(6), 4016-4026. doi: 10.1121/1.2195119
Huang, J., & Holt, L. L. (2009). General perceptual contributions to lexical tone normalization.Journal of the Acoustical Society of America, 125(6), 3983-3994. doi: 10.1121/1.3125342
Huang, J., & Holt, L. L. (2011). Evidence for the central origin of lexical tone normalization.Journal of the Acoustical Society of America, 129(3), 1145-1148. doi: 10.1121/1.3543994
Huber, J. E., Ash, E. T. S. G. M. C. T. A., & Johnson, K. (1999). Formants of children, women,and men: The effects of vocal intensity variation. Journal of the Acoustical Society of America,106(3), 1532-1542. doi: 10.1121/1.427150
Idemaru, K., & Holt, L. L. (2011). Word recognition reflects dimension-based statistical learning.Journal of Experimental Psychology: Human Perception and Performance, 37, 1939-1956. doi:10.1037/a0025641
Irino, T., & Patterson, R. D. (2002). Segregating information about the size and shape of the vocaltract using a time-domain auditory model: The stabilised wavelet-Mellin transform. SpeechCommunication, 36(3-4), 181-203. doi: 10.1016/S0167-6393(00)00085-6
Iskarous, K., Fowler, C. A., & Whalen, D. H. (2010). Locus equations are an acoustic expressionof articulator synergy. Journal of the Acoustical Society of America, 128(4), 2021-2032. doi:10.1121/1.3479538
Johnson, K. (1990). The role of perceived speaker identity in F0 normalization of vowels. Journalof the Acoustical Society of America, 88(2), 642-654. doi: 10.1121/1.399767
Johnson, K. (1991). Differential effects of speaker and vowel variability on fricative perception.Language and Speech, 34, 265-279. doi: 10.1177/002383099103400304
Johnson, K. (1997). Speech perception without speaker normalization. In K. Johnson & J. W. Mul-lennix (Eds.), Talker variability in speech processing (p. 146-165). San Diego: Academic Press.
Johnson, K. (2005). Speaker normalization in speech perception. In D. B. Pisoni & R. E. Remez(Eds.), The handbook of speech perception (p. 363-389). Oxford: Blackwell.
Johnson, K. (2007). Resonance in an exemplar-based lexicon: The emergence of social identity andphonology. Journal of Phonetics, 34(4), 485-499. doi: 10.1016/j.wocn.2005.08.004
Joos, M. A. (1948). Acoustic phonetics. Language, 24, 1-136.
Katz, W. F., & Assmann, P. F. (2001). Identifiation of children’s and adults’ vowels: Intrinsicfundamental frequency, fundamental frequency dynamics, and presence of voicing. Journal ofPhonetics, 29(1), 33-51. doi: 10.006/jpho.2000.0135
Kewley-Port, D. (1983). Time-varying features as correlates of place of articulation in stop conso-nants. Journal of the Acoustical Society of America, 73, 1779-1793. doi: 10.1121/1.388813

SPEECH PERCEPTION AND GENERALIZATION 25
Klatt, D. H. (1986). The problem of variability in speech recognition and models of speech per-ception. In J. S. Perkell & D. H. Klatt (Eds.), Invariance and variability in speech processing(p. 300-319). Hillsdale, NJ: Lawrence Erlbaum Associates.
Klatt, D. H. (1987). Review of text-to-speech conversion for English. Journal of the AcousticalSociety of America, 82(3), 737-793. doi: 10.1121/1.395275
Kleinschmidt, D. F., & Jaeger, T. F. (n.d.). Re-examining selective adaptation: Fatiguing featuredetectors, or distributional learning? (manuscript under review)
Kleinschmidt, D. F., & Jaeger, T. F. (2015). Robust speech perception: Recognize the familiar,generalize to the similar, and adapt to the novel. Psychological Review. doi: 10.1037/a0038695
Koops, C., Gentry, E., & Pantos, A. (2008). The effect of perceived speaker age on the percep-tion of PIN and PEN vowels in Houston, Texas. University of Pennsylvania Working Papers inLinguistics: Selected Papers from NWAV 36, 12, 91-101.
Kraljic, T., Brennan, S. E., & Samuel, A. G. (2008). Accommodating variation: Dialects, idiolects,and speech processing. Cognition, 107, 54-81. doi: 10.1016/j.cognition.2007.07.013
Kraljic, T., & Samuel, A. G. (2005). Perceptual learning for speech: Is there a return to normal?Cognitive Psychology, 51, 141-178. doi: 10.1016/j.cogpsych.2005.05.001
Kraljic, T., & Samuel, A. G. (2006). Generalization in perceptual learning for speech. PsychonomicBulletin and Review, 13, 262-268. doi: 10.3758/BF03193841
Kraljic, T., & Samuel, A. G. (2007). Perceptual adjustments to multiple speakers. Journal ofMemory and Language, 56, 1-15.
Kriengwatana, B., Escudero, P., & ten Cate, C. (2015). Revisiting vocal perception in non-humananimals: A review of vowel discrimination, speaker voice recognition, and speaker normalization.Frontiers in Psychology, 15(1543), 1-13. doi: 10.3389/fpsyg.2014.01543
Kuhl, P. K., & Miller, J. D. (1975). Speech perception by the chinchilla: Voiced- voiceless distinc-tion in alveolar plosive consonants. Science, 190(4209), 69-72. doi: 10.1126/science.1166301
Labov, W. (1966). The social stratification of English in New York City. Washington, D.C.: Centerfor Applied Linguistics.
Labov, W., Ash, S., & Boberg, C. (2006). The atlas of North American English. Berlin: Mouton deGruyter.
Ladefoged, P. (1980). What are linguistic sounds made of? Language, 56(3), 485-502. doi:10.2307/414446
Ladefoged, P. (1989). A note on “information conveyed by vowels”. Journal of the AcousticalSociety of America, 85(5), 2223-2224. doi: 10.1121/1.397821
Ladefoged, P., & Broadbent, D. E. (1957). Information conveyed by vowels. Journal of theAcoustical Society of America, 29, 98-104.

SPEECH PERCEPTION AND GENERALIZATION 26
Lahiri, A., Gewirth, L., & Blumstein, S. E. (1984). A reconsideration of acoustic invariance forplace of articulation in diffuse stop cosonants: Evidence from a cross-language study. Journal ofthe Acoustical Society of America, 76(2), 391-404. doi: 10.1121/1.391580
Laing, E. J. C., Liu, R., Lotto, A. J., & Holt, L. L. (2012). Tuned with a tune: Talker normalizationvia general auditory processes. Frontiers in Psychology, 3(203). doi: 10.3389/fpsyg.2012.00203
Lee, S., Potamianos, A., & Narayanan, S. S. (1999). Acoustics of children’s speech: Developmentalchanges of temporal and spectral parameters. Journal of the Acoustical Society of America,105(3), 1455-1468. doi: 10.1121/1.426686
Liberman, A. M. (1982). On finding that speech is special. American Psychologist, 37, 148-167.doi: 10.1037/0003-066X.37.2.148
Liberman, A. M., Cooper, F. S., Shankweiler, D. P., & Studdert-Kennedy, M. (1967). Perceptionof the speech code. Psychological Review, 74(6), 431-461. doi: 10.1037/h0020279
Liberman, A. M., & Mattingly, I. G. (1985). The motor theory of speech percepion revised.Cognition, 21(1), 1-36. doi: 10.1016/0010-0277(85)90021-6
Lindblom, B. (1990). Explaining phonetic variation: A sketch of the H&H theory. In W. J. Hard-castle & A. Marchal (Eds.), Speech production and speech modelling (p. 403-439). KluwerAcademic Publishers. doi: 10.1007/978-94-009-2037-8_16
Lively, S. E., Logan, J. S., & Pisoni, D. B. (1993). Training Japanese listeners to identify English/r/ and /l/: II. The role of phonetic environment and talker variability in learning new perceptualcategories. Journal of the Acoustical Society of America, 94, 1242-1255. doi: 10.1121/1.408177
Lloyd, R. J. (1890a). Some researches into the nature of vowel-sound. Liverpool, England: Turnerand Dunnett.
Lloyd, R. J. (1890b). Speech sounds: Their nature and causation (I). Phonetische Studien, 3,251-278.
Lloyd, R. J. (1891). Speech sounds: Their nature and causation (II-IV). Phonetische Studien, 4,37-67, 183-214, 275-306.
Lloyd, R. J. (1892). Speech sounds: Their nature and causation (V-VII). Phonetische Studien, 5,1-32, 129-141, 263-271.
Lobanov, B. (1971). Classification of Russian vowels spoken by different speakers. Journal of theAcoustical Society of America, 49, 606-608. doi: 10.1121/1.1912396
Logan, J. S., Lively, S. E., & Pisoni, D. B. (1991). Training japanese listeners to identify English/r/ and /l/: A first report. Journal of the Acoustical Society of America, 89(2), 874-876. doi:10.1121/1.1894649
Lotto, A., Hickok, G., & Holt, L. L. (2009). Reflections on mirror neurons and speech perception.Trends in Cognitive Science, 13(3), 110-114. doi: 10.1016/j.tics.2008.11.008

SPEECH PERCEPTION AND GENERALIZATION 27
Mann, V. A., & Repp, B. H. (1980). Influence of vocalic context on perception of the [s]-[S]distinction. Perception & Psychophysics, 23(3), 213-228. doi: 10.3758/BF03204377
Marin, S., Pouplier, M., & Harrington, J. (2010). Acoustic consequences of articulatory variabilityduring the productions of /t/ and /k/ and its implications for speech error research. Journal of theAcoustical Society of America, 127(1), 445-461. doi: 10.1121/1.3268600
Maye, J., Aslin, R., & Tanenhaus, M. (2008). The Weckud Wetch of the Wast: Lexical adaptationto a novel accent. Cognitive Science, 32, 543-562. doi: 10.1080/03640210802035357
Maye, J., Werker, J. F., & Gerken, L. (2002). Infant sensitivity to distributional information canaffect phonetic discrimination. Cognition, 82(3), B101-B111. doi: 10.1016/S0010-0277(01)00157-3
McGowan, R. S., & Berger, M. A. (2009). Acoustic-articulatory mapping in vowels by locallyweighted regression. Journal of the Acoustical Society of America, 126(4). doi: 10.1121/1.3184581
McGowan, R. S., & Cushing, S. (1999). Vocal tract normalization for mid-sagittal articulatoryrecovery with analysis-by-synthesis. Journal of the Acoustical Society of America, 106(2), 1090-1105. doi: 10.1121/1.427117
McGurk, H., & MacDonald, J. (1976). Hearing lips and seeing voices. Nature, 264, 746-748. doi:10.1038/264746a0
McQueen, J. M., Cutler, A., & Norris, D. (2006). Phonological abstraction in the mental lexicon.Cognitive Science, 30, 1113-1126. doi: 10.1207/s15516709cog0000_79
Miller, J. D. (1989). Auditory-perceptual interpretation of the vowel. Journal of the AcousticalSociety of America, 85, 2114-2134. doi: 10.1121/1.2029825
Mitra, V., Nam, H., Epsy-Wilson, C., Saltzman, E., & Goldstein, L. (2012). Recognizing articu-latory gestures from speech for robust speech recognition. Journal of the Acoustical Society ofAmerica, 131(3), 2270-2287. doi: 10.1121/1.3682038
Mitterer, H., Chen, Y., & Zhou, X. (2011). Phonological abstraction in processing lexical-tonevariation: Evidence from a learning paradigm. Cognitive Science, 35(1), 184-197. doi: 10.1111/
j.1551-6709.2010.01140.x
Mitterer, H., Scharenborg, O., & McQueen, J. M. (2013). Phonological abstraction withoutphonemes in speech perception. Cognition, 129(2), 356-361. doi: 10.1016/j.cognition.2013.07.011
Monahan, P. J., & Idsardi, W. J. (2010). Auditory sensitivity to formant ratios: Toward an accountof vowel normalization. Language and Cognitive Processes, 25(6), 808-839. doi: 10.1080/
01690965.2010.490047
Moore, C. B., & Jongman, A. (1997). Speaker normalization in the perception of Mandarin Chinesetones. Journal of the Acoustical Society of America, 102(3), 1864-1877. doi: 10.1121/1.420092

SPEECH PERCEPTION AND GENERALIZATION 28
Naeser, M. A., Palumbo, C., Helm-Estabrooks, N., Stiassny-Eder, D., & Albert, M. L. (1989).Severe nonfluency in aphasia: Role of the medical subcallosal fasciculus and other white matterpathways in recovery of spontaneous speech. Brain, 112(1), 1-38. doi: 10.1093/brain/112.1.1
Nearey, T. M. (1989). Static, dynamic, and relational properties in vowel perception. Journal ofthe Acoustical Society of America, 85(5), 2088-2113. doi: 10.1121/1.397861
Newman, R. S., & Sawusch, J. S. (1996). Perceptual normalization for speaking rate: Effects oftemporal distance. Perception & Psychophysics, 58(4), 540-560. doi: 10.3758/BF03213089
Niedzielski, N. (1999). The effect of social information on the perception of sociolinguis-tic variables. Journal of Language and Social Psychology, 18(1), 62-85. doi: 10.1177/
0261927X99018001005
Nordström, P.-E., & Lindblom, B. (1975). A normalization procedure for vowel formant data. InProceedings of the 8th International Congress of Phonetic Sciences (p. 212).
Norris, D., McQueen, J. M., & Cutler, A. (2003). Perceptual learning in speech. Cognitive Psy-chology, 47(2), 204-238. doi: 10.1016/S0010-0285(03)00006-9
Nusbaum, H., & Magnuson, J. (1997). Talker normalization: Phonetic constancy as a cognitiveprocess. In K. Johnson & J. W. Mullennix (Eds.), Talker variability in speech processing (p. 109-132). New York, NY: Academic Press.
Nygaard, L. C., & Pisoni, D. B. (1998). Talker-specific learning in speech perception. Perception& Psychophysics, 60(3), 355-376. doi: 10.3758/BF03206860
Nygaard, L. C., Sommers, M. C., & Pisoni, D. B. (1994). Speech perception as a talker-contingentprocess. Psychological Science, 5(1), 42-46. doi: 10.1111/j.1467-9280.1994.tb00612.x
Öhman, S. E. G. (1966). Coarticulation in VCV utterances: Spectrographic measurements. TheJournal of the Acoustical Society of America, 39(1), 151-168. doi: 10.1121/1.1909864
Ohms, V. R., Gill, A., Van Heijningen, C. A. A., Beckers, G. J. L., & ten Cate, C. (2010). Zebrafinches exhibit speaker-independent phonetic perception of human speech. Proceedings of theRoyal Society B, 277, 1003-1009. doi: 10.1098/rspb.2009.1788
Palmeri, T. J., Goldinger, S. D., & Pisoni, D. B. (1993). Episodic encoding of voice attributes andrecognition memory for spoken words. Journal of Experimental Psychology: Learning, Memoryand Cognition, 19(2), 309-328. doi: 10.1037//0278-7393.19.2.309
Perry, T. L., Ohde, R. N., & Ashmead, D. H. (2001). The acoustic bases for gender identificationform children’s voices. Journal of the Acoustical Society of America, 109(6), 2988-2998. doi:10.1121/1.1370525
Peterson, G. E. (1952). The information-bearing elements of speech. Journal of the AcousticalSociety of America, 24, 629-637. doi: 10.1121/1.1906945
Peterson, G. E. (1961). Parameters of vowel quality. Journal of Speech and Hearing Research,4(1), 10-29. doi: 10.1044/jshr.0401.10

SPEECH PERCEPTION AND GENERALIZATION 29
Peterson, G. E., & Barney, H. L. (1952). Control methods used in a study of the vowels. Journal ofthe Acoustical Society of America, 24, 175-184. doi: 10.1121/1.1917300
Pierrehumbert, J. B. (2002). Word-specific phonetics. In C. Gussenhoven & N. Warner (Eds.),Laboratory phonology vii (p. 101-139). Berlin: Mouton de Gruyter.
Pisoni, D. B. (1997). Some thoughts on ‘normalization’ in speech perception. In K. Johnson &J. W. Mullennix (Eds.), Talker variability in speech processing (p. 9-33). San Diego: AcademicPress.
Pisoni, D. B., & Levi, S. V. (2007). Some observations on representations and representationalspecificity in speech perception and spoken word recognition. In G. Gaskell (Ed.), The oxfordhandbook of psycholinguistics (p. 3-18). Oxford University Press.
Potter, R. K., & Steinberg, J. C. (1950). Toward the specification of speech. Journal of theAcoustical Society of America, 22, 807-820. doi: 10.1121/1.1906694
Preston, D. R. (1989). Perceptual Dialectology: Nonlinguists’ Views of Areal Linguistics. Provi-dence, RI: Foris.
Protopapas, A., & Lieberman, P. (1997). Fundamental frequency of phonation and perceivedemotional stress. Journal of the Acoustical Society of America, 101(4), 2267-2277. doi:10.1121/1.418247
Reinisch, E., & Holt, L. L. (2014). Lexically-guided phonetic retuning of foreign-accented speechand its generalization. Journal of Experimental Psychology: Human Perception and Perfor-mance, 40(2), 539-555. doi: 10.1037/a0034409
Samuel, A. G., & Kraljic, T. (2009). Perceptual learning for speech. Attention, Perception, &Psychophysics, 71(6), 1207-1218. doi: 10.3758/APP.71.6.1207
Sato, M., Cavé, C., Ménard, L., & Brasseurc, A. (2010). Auditory-tactile speech perception incongenitally blind and sighted adults. Neuropsychologia, 48(12), 3683-3686. doi: 10.1016/
j.neuropsychologia.2010.08.017
Schacter, D. L., & Church, B. A. (1992). Auditory priming: Implicit and explicit memory for wordsand voices. Journal of Experimental Psychology: Learning, Memory, and Cognition, 18(5), 915-930. doi: 10.1037/0278-7393.18.5.915
Schertz, J., Cho, T., Lotto, A., & Warner, N. (to appear). Individual differences in phonetic cue usein production and perception of a non-native contrast. Journal of Phonetics.
Schroeter, J., & Sondhi, M. M. (1994). Techniques for estimating vocal-tract shapes from thespeech signal. IEEE Transactions on Speech and Audio Processing, 2(1), 133-150. doi: 10.1109/
89.260356
Searle, C. L., Jacobson, J. Z., & Rayment, S. G. (1979). Stop consonant discrimination based onhuman audition. journal of the acoustical society of america. Journal of the Acoustical Society ofAmerica, 65(3), 799-809. doi: 10.1121/1.382501

SPEECH PERCEPTION AND GENERALIZATION 30
Shankweiler, D., Strange, W., & Verbrugge, R. (1975). Speech and the problem of perceptual con-stancy. In R. Shaw & J. Bransford (Eds.), Perceiving, acting, and knowing: Toward an ecologicalpsychology (p. 315-345). Hillsdale, NJ: Erlbaum.
Sharpee, T. O., Sugihara, H., Kurgansky, A. V., Rebrik, S. P., Stryker, M. P., & Miller, K. D. (2006).Adaptive filtering enhances information transmission in visual cortex. Nature, 439(23), 936-942.doi: 10.1038/nature04519
Sidaras, S., Alexander, J. E. D., & Nygaard, L. C. (2009). Perceptual learning of systematic variationin Spanish-accented speech. Journal of the Acoustical Society of America, 125(5), 3306-3316.doi: 10.1121/1.3101452
Sjerps, M. J., & McQueen, J. M. (2010). The bounds of flexibility in speech perception. Journal ofExperimental Psychology: Human Perception and Performance, 36(1), 195-211. doi: 10.1037/
a0016803
Sjerps, M. J., McQueen, J. M., & Mitterer, H. (2013). Evidence for precategorical extrinsic vowelnormalization. Attention, Perception, & Psychophysics, 75(576-587). doi: 10.3758/s13414-012-0408-7
Smith, B. L., & Hayes-Harb, R. (2011). Individual differences in the production and perceptionof the voicing contrast by native and non-native speakers of English. Journal of Phonetics, 39,115-120. doi: 10.1016/j.wocn.2010.11.005
Staum Casasanto, L. (2008). Does social information influence sentence processing? In Proceed-ings of the 30th annual meeting of the cognitive science society. Washington, D.C..
Stevens, K. N. (1972). The quantal nature of speech: Evidence from articulatory-acoustic data. InE. E. David & P. B. Denes (Eds.), Human communication: A unified view (p. 51-66). New York:McGraw-Hill.
Stevens, K. N., & Blumstein, S. E. (1977). Onset spectra as cues for consonantal place of articula-tion. Journal of the Acoustical Society of America, 61, S48. doi: 10.1121/1.2015732
Stevens, K. N., & Blumstein, S. E. (1978). Invariant cues for place of articulation in stop consonants.Journal of the Acoustical Society of America, 64(5), 1358-1368. doi: 10.1121/1.382102
Stevens, K. N., & Blumstein, S. E. (1981). The search for invariant acoustic correlates of phoneticfeatures. In P. Eimas & J. L. Miller (Eds.), Perspectives on the study of speech (p. 1-38). Hillsdale,NJ: Erlbaum.
Stocker, A. A., & Simoncelli, E. P. (2006). Sensory adaptation within a bayesian frameworkfor perception. In Y. Weiss, B. Schölkopf, & J. Platt (Eds.), Advances in neural informationprocessing systems (Vol. 18, p. 1291-1298). Cambridge, MA: MIT Press.
Story, B. H., & Bunton, K. (2010). Relation of vocal tract shape, formant transitions, and stopconsonant identifiation. Journal of Speech, Language and Hearing Research, 53(6), 1514-1528.doi: 10.1044/1092-4388(2010/09-0127

SPEECH PERCEPTION AND GENERALIZATION 31
Strange, W. (1989). Dynamic specification of coarticulated vowels spoken in sentence context.Journal of the Acoustical Society of America, 85, 2135-2153. doi: 10.1121/1.397863
Sussman, H. M. (1986). A neuronal model of vowel normalization and representation. Brain andLanguage, 28(1), 12-23. doi: 10.1016/0093-934X(86)90087-8
Sussman, H. M. (1989). Neural coding of relational invariance in speech: Human language analogsto the barn owl. Psychological Review, 96(4), 631-642. doi: 10.1037/0033-295X.96.4.631
Sussman, H. M., Fruchter, D., Hilbert, J., & Sirosh, J. (1998). Linear correlates in the speechsignal: The orderly output constraint. Behavioral and Brain Sciences, 21(2), 241-299. doi:10.1017/S0140525X98001174
Syrdal, A., & Gopal, H. (1986). A perceptual model of vowel recognition based on the auditoryrepresentation of American English vowels. Journal of the Acoustical Society of America, 79,1086-1100. doi: 10.1121/1.393381
Tartter, V. C. (1991). Identifiability of vowels and speakers from whispered syllables. Perception& Psychophysics, 49(4), 365-372. doi: 10.3758/BF03205994
Tosacano, J. C., & McMurray, B. (2010). Cue integration with categories: Weighting acousticcues in speech using unsupervised learning and distributional statistics. Cognitive Science, 34(3),434-464. doi: 10.1111/j.1551-6709.2009.01077.x
Trude, A. M., & Brown-Schmidt, S. (2012). Talker-specific perceptual adaptation during on-line speech perception. Language and Cognitive Processes, 27(7-8), 979-1001. doi: 10.1080/
01690965.2011.597153
Verbrugge, R. R., Strange, W., Shankweiler, D. P., & Edman, T. R. (1976). What informationenables a listener to map a talker’s vowel space? Journal of the Acoustical Society of America,60(1), 198-212. doi: 10.1121/1.1919793
Vroomen, J., & Baart, M. (2012). Phonetic recalibration in audiovisual speech. In M. M. Murray& M. T. Wallace (Eds.), The neural bases of multisensory processes (chap. 19). Boca Raton, FL:CRC Press.
Walker, A., & Hay, J. (2011). Congruence between ‘word age’ and ‘voice age’ faciltiates lexicalaccess. Laboratory Phonology, 2(1), 219-237. doi: 10.1515/labphon.2011.007
Walley, A. C., & Carrell, T. D. (1983). Onset specta and formant transition in the adult’s andchild’s pereption of place of articulation in stop consonants. Journal of the Acoustical Society ofAmerica, 73(3), 1011-1022. doi: 10.1121/1.389149
Watkins, A. J., & Makin, S. J. (1996). Effects of spectral contrast on perceptual compensationfor spectral-envelope distortion. Journal of the Acoustical Society of America, 99(6), 3749-3757.doi: 10.1121/1.414981
Weatherholtz, K. (2015). Perceptual learning of systemic cross-category vowel variation (Unpub-lished doctoral dissertation). The Ohio State University.

SPEECH PERCEPTION AND GENERALIZATION 32
Wilson, S. M. (2009). Speech perception when the motor system is compromised. Trends inCognitive Science, 13(8), 329-330. doi: 10.1016/j.tics.2009.06.001
Yang, J., & Fox, R. A. (2014). Perception of english vowels by bilingual Chinese-English andcorresponding monolingual listeners. Language and Speech, 57(2), 215-237. doi: 10.1177/
0023830913502774
Zahorian, S. A., & Jagharghi, A. J. (1993). Spectral-shape features versus formants as acousticcorrelates for vowels. Journal of the Acoustical Society of America, 94(4), 1966-1982. doi:10.1121/1.407520
Zue, V. W. (1976). Acoustic characteristics of stop consonants: A controlled study (Unpublisheddoctoral dissertation). MIT, Cambridge, MA.
Further Reading
[see attached document]