shallow techniques for argument mining - irit
TRANSCRIPT

Clos, J.,Wiratunga,N.,Massie,S.,&Cabanac,G. (inpress).Shallowtechniquesfor argument mining. ECA’15: Proceedings of the 1st European Conference onArgumentation: Argumentation and Reasoned Action. Studies in Logic andArgumentation(Vol.___,pp.___-___).London,UK:CollegePublications.
1
Shallowtechniquesforargumentmining
JÉRÉMIECLOSRobertGordonUniversity,UK
NIRMALIEWIRATUNGARobertGordonUniversity,[email protected]
STEWARTMASSIE
RobertGordonUniversity,[email protected]
GUILLAUMECABANAC
UniversitédeToulouse,[email protected]
Argumentmininghasrecentlyemergedasapromisingfieldatthe frontiers of the argumentation and text miningcommunities. However, most techniques developed withinthatfielddonotscaletolargeramountsofdata,deprivingusfor example of valuable insights in large-scale discussionforums. On two social media datasets, we study differentlightweight scalable text mining techniques used within thesentiment analysis community and their applicability to theargumentminingproblem.
KEYWORDS:argumentmining,sentimentanalysis,textmining
1.INTRODUCTION
TheadventoftheWeb2.0hasseenamassiveincreaseinuser-generateddataintheformofcommentsandmessagessuchastheonesdisplayedinFigure1.Increasinglyitistheplatformofchoiceforpublicdebate and conversation, but its traditional “document-centric” focusandassociatedsearchandbrowsemethodsarelessfitforpurpose.Forexample,inFigure1itisnotsufficienttoonlysearchforkeywordsbut

2
insteadbeinfluencedbythetree-likethreadstructureenforcedbyusersrespondingtootherusercomments.
Figure1:ExcerptfromacommenttreewhereusersdiscussUKpolitics.
New research fields such as sentiment analysis and topic modellinghavethusemergedinordertofillthisneedforbetterandmoreintuitiveways to help users browse through large amounts of data. Whilevaluable, these techniques inevitably fall short of meeting therepresentational requirementswhendealingwith conversational data.For instance, sentiment analysis is only concerned with projectingdocuments on a negative to positive opinion dimension, and topicmodellingisfocusedonanalysingacorpusandidentifyingcentraltopicsNeitherareinterestedintheconversationaldynamics.
Argument mining is able to discover knowledge that wouldallow us to detect justifications for common opinions, generate fine-grained debate graphs for complex political issues or refine commonopinion mining algorithms. There are however many challenges inadapting argument mining algorithms to the scale of the Social Web.Current approaches either rely on computationally expensive NLPtechniquesoronhumanannotations,neitherofwhicharetransferabletoa real timeanalysissettingwhere largevolumesofdata,absenceofreliableknowledgesourcesandinformallanguagearethenorm.
In this paper we propose to relax the requirements of anargumentminingalgorithmbyrestrictingtheargumentminingtasktoatarget (another argument/expressionof opinion)detectionand stance(whetheritsupportsorattacksthetarget)classificationtask,leveragingexisting literature in the sentiment analysis and opinion mining. Ourcontribution is threefold: firstly, we build a novel dataset based on

3
onlinecomments fromtheReddit1 socialwebsiteandanoisy labellingprocess. Secondly, we experiment using three standard unsupervisedsentimentanalysis approaches inorder tomeasurehowwell they canapproximate the stance classification part of the argument miningprocess. Thirdly and finally, we improve a PMI-based classifier byincorporating contextual clues in a simple but intuitive way into theclassificationprocess.
Insection2wedetail therelationshipbetweenargumentation,argument mining and information retrieval, thus justifying andcontextualizingourapproach. Insection3weexplaintheclassificationapproaches that are being compared, as well as the approach we areproposingasanincrementalimprovementoveranaivetechniquebasedonstrengthofassociation.Insection4theexperimentalmethodologyispresented, together with details of a new dataset, generated for thepurposeofthisresearch.Finally,beforeconcludinginsection6,section5willanalysetheresultsfromthecomparativestudy.2.BACKGROUNDANDRELATEDWORKSOur approach to argument mining is inspired by text analysis andrepresentation schemes which are commonly used in informationretrieval. Rather than linguistic rigor, we aim to use knowledge-lightrepresentations that can still provide insight about the discussion. Asexplainedintheprevioussection,weseektorebuildtheargumentationgraph underlying a discussion by making the following simplifyingassumptions:allcommentshaveanargumentativevalue,andthetargetof a comment is always the comment to which it is replying. For thepurposeofbuildingabipolarargumentationgraph,welooselyassigntothe"attack"relationshipdefinedbyDung(Dung,1995)thesemanticsofoverall disagreement, and to the "support" relationship defined byCayrol and Lagasque-Schiex (Cayrol and Lagasquie-Schiex, 2005) thesemanticsofoverallagreement.
Theneedtoscaleclassificationtolargeamountsofdatarequiresa simple conceptual representation of arguments, such as the oneproposed in PragmaticArgumentationTheory (PAT) (VanEemeren etal., 1996;Hutchby,2013).Fittinga complexmodelof argumentwouldbecomputationallyexpensiveandnotfitthecolloquialnatureofsocialmediacontentandit isthusdeemedpreferabletouseamoreaccurateandsimplermodel.
PATdefinesanargumentasanopinionatedpieceoftextwhichcan arise in the presence of two elements: (1) a target, being someotheractionbyanotheractorwhichhasbeencalledout ;(2)astance,
1http://www.reddit.com

4
i.e.whetheritissupportingorattackingthetarget.Webypassthetargetdetectionstepandfocusonstanceclassification,whichallowsustousetechniques from text mining and sentiment analysis (Pang and Lee,2008),consideringstanceofanargumentanalogoustothesentimentofanopinionatedtext.
Figure2:IllustrationofhowtheRedditcommentingsystemforcestheusertoplacetheircommentunderthecontribution
Figure 2 illustrates the way the system incites users to insert theircommentundertherelevantsectionofthediscussionbypresentingitinathreadedstructure,allowingustotreattheargumentminingproblemasaclassification task.Forexample, thecommentpostedbyUser3 inFigure 2 is in agreement with the comment posted by User 2, whichmakesitasupportingstatement.2.1ArgumentminingArgumentmininghasbeenapproachedintheliteratureasthestudyofmethodsandtechniques todetectargumentativediscourseunits, theirrole in the argumentation process and how they relate to otherargumentativediscourseunits (Peldszus andStede, 2013). Earlyworkfocused on representing arguments in a restricted manner (Cohen1987),butthefirststepstowardsanautomatedtreatmentofargumentmining (PalauandMoens,2009;MochalesandMoens,2011)aimed tominelegaltextusingsupervisedlearningtechniques.Moreparticularly,Palau and Moens (Palau and Moens, 2009) performed a three-stepargument analysis by firstly detecting argumentative sentences,

5
secondly identifying whether they were part of a conclusion or apremise, and thirdly classifying the relationships between thesesentences, thus trying to mine argumentative structure in these legaltexts. Cabrio and Villata (Cabrio and Villata, 2012) on the other handmadeuseoftextualentailmentandsemanticsimilarityfeaturesinordertotrainaclassifiertorecognizeattackingarguments,inlinewithDung'sabstract argumentation framework (Dung, 1995). Similar work alongthese lines studied the use of context-free grammars (Wyner et al.,2010) to extract arguments but did not handle the detection of theirrelationshipswith other arguments, since legal textsmainly dealwithcasesofmonologicalargumentation.Howevertheseapproachesdonottransferwell to socialmediabecauseof their relianceon idiosyncraticfeatures and complex learning methods such as support vectormachines(SVM)(Bishop,2006).
Otherworks fromtheargumentminingcommunity focusedonbridging it to the field of opinion mining (Villalba and Saint-Dizier,2012) and studied the use of reasoning patterns in user-contributedreviews. They did not however direct their study towards theautomated detection of arguments themselves within these textualreviewsandinsteadfocusedonadescriptiveanalysis,makingthemnotdirectlyrelevanttoourwork.2.2StanceclassificationStance classification becomes relevant to argumentmining because ofits binary classification nature. However most techniques used in theliteraturebasetheirworkontrainingacomplexclassifierusingalargenumber of computationally expensive features (Boltuzic and Snajder,2014;Anandetal.,2011;Abbottetal.,2011;SomasundaranandWiebe,2010; Walker et al., 2012a) or are performed on automaticallytranscribed text (Wang et al., 2011) or non-conversational content(Bousmalisetal.,2013)withlimitedapplicabilitytoWeb2.0.
Muchclosertoourapproach,Yinetal.(Yinetal.,2012)usedalogisticregressionclassifiertrainedonsomewhatcomplexfeaturesandrelatedthenotionoflocalandglobalstances,buildingtheglobalstanceof a post by computing a sequence of local stances between that postandthefirstappearanceofthetopicofdiscussion
Cardie and Wang (Wang and Cardie, 2014) took a differentapproach to the stance classification problem in that they used anisotonicconditionalrandomfield-basedtechniquetodetectlocalstance.However, they still required a significant training phase and need alarge collectionof idiosyncratic features,whichnegates theportabilityoftheirapproach.

6
2.2SentimentanalysisandargumentminingThe field of sentiment analysis (Pang and Lee, 2008) also treats thebinary classification of large text corpora along the axis ofpositivity/negativity.Twomainfamiliesofmethodologiesemerge:
• Supervisedsentimentanalysis involvestheuseofsupervisedmachine learning techniques in order to perform sentimentclassification.Traditionalalgorithmsknownfortheirversatilityand performance on text classification tasks areMaxEnt, SVM,and Naive Bayes (Pang et al., 2002). These algorithms aretrained on training data in order to produce a model able toclassifyfuturetestdata.
• Lexicon-based sentiment analysis involves thelearning/buildingoflexicons,whicharelook-uptablesoftermswithstrengthsofassociationscoresfordifferentclasses,aswellascombinationrules(Taboadaetal.,2011).Testdataisdirectlyfed to the lexicon-based classifier which uses the combinationrulesinordertocomputethescoresofeachclass(positiveandnegative)basedonthepresenceoftermsfromthelexicon.
Ourworkcanbeput incontextbetweentheargumentminingandthestance detection communities, as we aim for the detection ofrelationships between textual entities with the bipolar semantics ofCayrol and Lagasquie-Schiex (Cayrol and Lagasquie-Schiex, 2005) butdosobyattributingdifferentsemanticstotheirrelations.3.SHALLOWTECHNIQUESFORARGUMENTMININGWerefertotherelationshipbetweenacommentanditsdirectparentasthe conversational context of that comment. Our goal is to take intoaccount, for all comments, a progressively deeper level of theirconversational contextandstudy its effecton theoverall classificationaccuracy. As such, we will review the approaches according to theirlevel of context-informedness as well as their degree of supervision.Here context-informedness refers to the extent towhich the approachusesinformationthatisexternaltothecomment,andsupervisionreferstotheextenttowhichthealgorithmrequiresahuman-labelleddatasetinordertowork.3.1Argumentminingaslexicon-basedclassificationIn itsmostbasic form,argumentminingcanbeseenasaclassificationtask, where the classes are either support or attack. This basic formentails that any piece of text can be classified by itselfwithout taking

7
into account any notion of conversational context, by simply applyingstandard text representation techniques and mapping thisrepresentation into the class codomain. contains simple lexicon-basedclassification(referredtoasPMILex).
Asimplewaytoreliablyclassifyinstancesistheuseofalexicon.Becausetheredoesnotexistamanuallybuiltlexiconoflocalstance,wecompute it on a distant-labelled dataset using normalized pointwisemutual information (NPMI) as a measure of strength of associationbetweentermsandtheirclass.
𝑁𝑃𝑀𝐼 𝑥, 𝑦 = 𝑃𝑀𝐼 𝑥, 𝑦
− log 𝑝 𝑥, 𝑦
𝑃𝑀𝐼 𝑥, 𝑦 = log (𝑝 𝑥, 𝑦 )𝑝 𝑥 𝑝(𝑦)
This classification rule classifies a user comment x on the basis of amaximized sum of associations between each of its terms t and eachclassc.Noticethatthetermclassassociationscannowbeexploitedasalexicon.
While this approach is sensible to create a general purposelexicon, it suffers some flaws in the following cases: (1) if noneof thetermsused in the child post has an argumentative value or is presentwithin the lexicon, no classification is possible, and (2) some termsmight end up with an undeserved score because they accidentallyappearmore frequentlywithin comments of one class. For example ifnon-argumentative terms such as "Monday" accidentally co-occur toooftenwithinoneclass,theywillbemisconstruedasbeingindicativeofthatclass.3.2.Context-awaremethodsforargumentclassificationThepreviousmethodprovidedasimplemappingfromasetoftermstoaclasslabel,wenowexploredifferentwaystoconsidercontextduringthe classification.This context canoriginate fromeither the sentimentcontained within the comment, or the conversation that contains thecomment. Sentiment-guidedmethods dealwith the sentiment context,i.e. the sentiment that is expressed within the terminology andgrammatical structure used in the text. Within the context of adiscussion,thissentimentisakintoaglobalstancetakenbytheauthorof that textwith respect to the topic at hand. Conversational context-aware methods on the other hand are focused on representing therelationshipbetweenacommentand itsconversationalcontext, inour

8
situation its parent post. They do so either by detecting attack orsupport against the author of the parent comment (Wang and Cardie,2014)orbymodifyingtheimportanceofsometermsbasedtheparentcomment(theproposedapproaches).3.2.1Sentiment-guidedmethodsSentiment methods provide a means to use emotive context to inferargumentstance,byassumingthestanceofacommentasequivalenttoits sentiment orientation. We employ a simple sentiment analysisalgorithmbasedona lexicon(EsuliandSebastiani,2006) towhichwewillrefertoasSENTLEX.Itoperatesbylookinguppositiveandnegativevaluesoftermspresentinthecommentandsummingthemseparatelyintoapositiveandanegativescore.Theclassificationruleisbasedonasimple comparison: a higher positive strength implies a supportivecomment, andhighernegative strength impliesanattacking comment.We use the SMARTSA algorithm (SSA) developed byMuhammad et al.(Muhammad et al., 2013) as an extension of traditional lexicon-basedsentiment analysis techniques taking into account additional linguisticfactorssuchasthepresenceofspecialtermscalledmodifiersthatalterthe class values of terms in their vicinity by exaggerating them(amplifiers), reducing them (diminishers) or inversing their polarity(negators).
Sentiment-guided methods assume that global stance of thecomment, i.e. how its author feels about the discussion topic, can beusedinplaceofitslocalstance,i.e.howitsauthorfeelsabouttheparentcomment. As such they present some flaws whenever (1) those twostancesdonotalign,(2)thestanceisexpressedinasentiment-neutralWAY, or (3) the overall sentiment of the sentence ends up beingbalanced.Thefollowingexamplesillustratetheseflaws:
(1) "I completely disagreewith you, thismoviewas very good and Ienjoyed every minute of it." Here we can see that the authorexpresses a positive opinion by disagreeingwith the author oftheparentcomment,thusmakinganattackingstatement.
(2) "Thereisnothingintheworldthatwillmakemeseethesituation
your way." In this comment there is no positive or negativeterminology used, while the sentence is written with anattackingstance.
(3) "Iagreethattheactingwasgood,butIamstilldisappointedthat
thedialoguesweresopoorlywritten."Herenegativeandpositive

9
sentiments are equally used, but the stance should besupporting.
3.2.2Conversationalcontext-awaremethodsWe explore conversational context-aware methods using theUnsupervisedSentimentSurfacealgorithm(USS).USSisextendedfromCardieandWang (Wang&Cardie,2014)andusesa shallow linguisticanalysis to compute the average distance between second personpronouns and positive or negative terms. The classification comparesthoseaveragedistances,classifyingthecommentasattackingifnegativetermsareonaverageclosertosecondpersonpronounsandsupportingotherwise.USSworksontheintuitionthatthestanceofthecommentiscontainedwithinexplicitreferencestotheparentposts:suchreferencescan be analyzed by detecting second person pronouns (e.g. "you","your", etc.) and their polarity by searching their grammaticalneighborhoodforsentiment-bearingterminology.
Forexample, "Idon'tagreewithyouand I thinkyouropinion iswrong"wouldbe interpretedasanattackingstatementbecauseof theoverwhelming proximity of negative terms ("don't", "wrong") nearsecond person pronouns ("you", "your"). This approach can also giveflawed results when there is ambiguity contained in the text in thefollowing: (1) when a positive (respectively negative) term isaccidentally closed to a second person pronounwhich is semanticallylinked to a negative (respectively positive) term (2) when a morecomplex sentence structure is used where the polarity of a term isimplicitly negated, or (3) whenever no second person pronouns orsentiment-bearingtermsareused.Thefollowingexamplesillustratethefirsttwocases:
(1) "I like you, but you are wrong." Here we can see that𝑑 𝑙𝑖𝑘𝑒, 𝑦𝑜𝑢 < 𝑑(𝑦𝑜𝑢,𝑤𝑟𝑜𝑛𝑔) where d is a distance function,whichwouldclassifythisinstanceasasupportingstatement.
(2) "Icanbarelytoleratethatyoubelieveyourselftoberight."Here
the sentence structure puts yourself very close to right, whichwillclassifythesentenceasasupportingstatement.However,itisclearunderahumaneyethatthesentencehasadisapprovingtone.
The USS approach is based on the assumption that over a significantnumber of sentences these errors would cancel each other out andresultinagoodoverallclassificationaccuracy.

10
3.2.3Context-informedfeaturevectorenrichmentTermvectorrepresentationisaconvenientwaytoworkwithtextdatabecause of its simplicity and versatility (more details can be found in(Manningetal.,2008)).Itiscompatiblewithlexicon-basedclassificationaswellasmorestandardsupervisedclassifiersandextremelycommonin text classification. In this section we use conversational context toalterthatfeaturevectorofacommentbasedonitsparentcomment.Weexperiment using two basic variations of this alteration. Theclassificationruleweuseistoassigntheclasslabelcthatmaximizestheassociationscorebetweenaninstancexandc.Theassociationscoreiscomputeddifferentlyaccordingtotheenrichmentscheme.
𝐶𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑐𝑎𝑡𝑖𝑜𝑛 𝑥 = 𝐴𝑟𝑔𝑀𝑎𝑥![𝐴𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑖𝑜𝑛𝑆𝑐𝑜𝑟𝑒 𝑥, 𝑐 ]Intersection-basedvector enrichment.Weused a lexicon computedsimilarlytothesimplePMIlexicondiscussedinaprevioussection,andcomputetheassociationscorebetweenaninstancexandaclasscasthesumofNPMIscoresbetweenalltermstwithcwheretispresentinboththe x and its parent p(x).
𝐴𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑖𝑜𝑛𝑆𝑐𝑜𝑟𝑒! 𝑥, 𝑐 = 𝑁𝑃𝑀𝐼(𝑡, 𝑐)!∈!∩! !
Union-basedvectorenrichment.Wemodifytheclassificationruleandcompute the association score as the sumofNPMI scores between allterms twithagivenclasscwhere t ispresent ineither the instancexand its parent p(x).
𝐴𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑖𝑜𝑛𝑆𝑐𝑜𝑟𝑒! 𝑥, 𝑐 = 𝑁𝑃𝑀𝐼(𝑡, 𝑐)!∈!∪! !
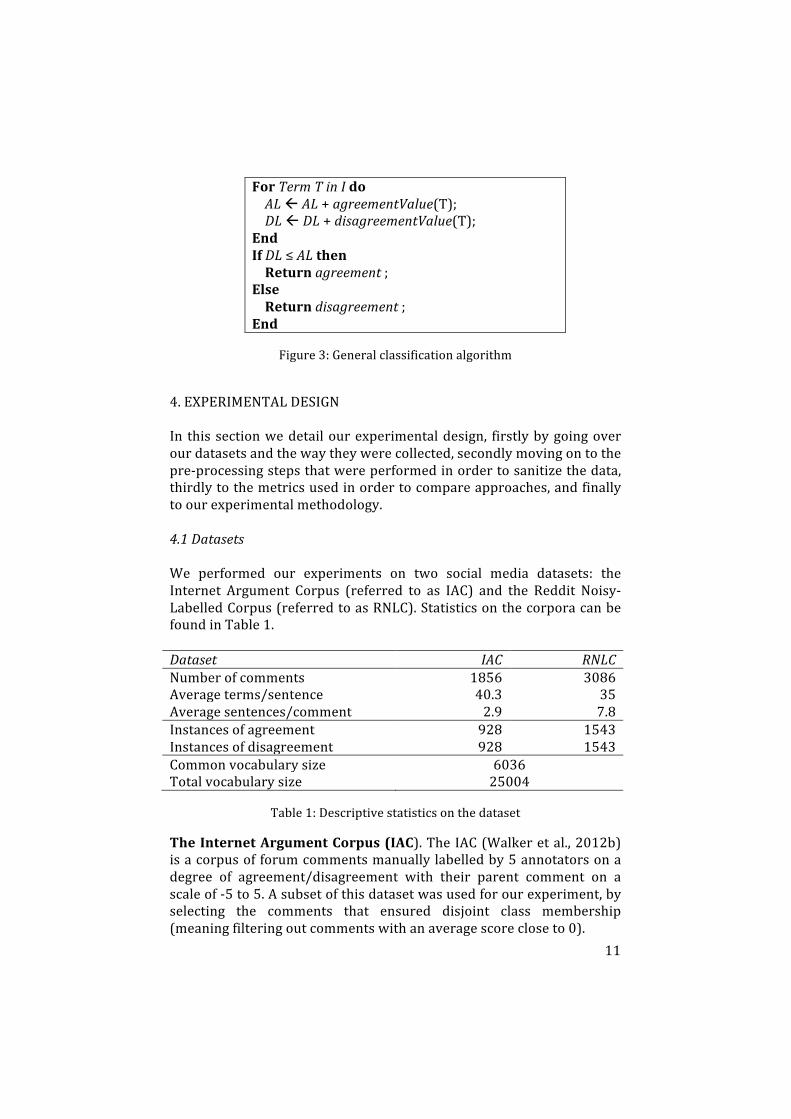
The algorithm described in Figure 3 represents the generalclassification algorithmof our approaches,where the changing part isthe way the instance I is created from the comments P and C. Theclassificationisdonebyasimplesummationofterms,whichisahighlyscalableoperationwithanegligiblecomputationalcost.
Data:ChildcommentCandparentcommentPResult:AclasslabelLCreateinstanceIfromPandC;ALß0;DLß0;
11
ForTermTinIdoALßAL+agreementValue(T);DLßDL+disagreementValue(T);EndIfDL≤ALthenReturnagreement;ElseReturndisagreement;End
Figure3:Generalclassificationalgorithm
4.EXPERIMENTALDESIGNIn this sectionwedetailourexperimentaldesign, firstlybygoingoverourdatasetsandthewaytheywerecollected,secondlymovingontothepre-processingstepsthatwereperformedinordertosanitizethedata,thirdlytothemetricsusedinordertocompareapproaches,andfinallytoourexperimentalmethodology.4.1DatasetsWe performed our experiments on two social media datasets: theInternet Argument Corpus (referred to as IAC) and the Reddit Noisy-LabelledCorpus(referredtoasRNLC).StatisticsonthecorporacanbefoundinTable1.Dataset IAC RNLCNumberofcomments 1856 3086Averageterms/sentence 40.3 35Averagesentences/comment 2.9 7.8Instancesofagreement 928 1543Instancesofdisagreement 928 1543Commonvocabularysize 6036Totalvocabularysize 25004
Table1:Descriptivestatisticsonthedataset
TheInternetArgumentCorpus(IAC).TheIAC(Walkeretal.,2012b)isacorpusofforumcommentsmanuallylabelledby5annotatorsonadegree of agreement/disagreement with their parent comment on ascaleof-5to5.Asubsetofthisdatasetwasusedforourexperiment,byselecting the comments that ensured disjoint class membership(meaningfilteringoutcommentswithanaveragescorecloseto0).

12
TheRedditNoisy-LabelledCorpus(RNLC).TheRNLCisanewcorpus of comments extracted from the Reddit and automaticallylabelled with a binary class using evidence contained within thecomments.Explicitexpressionssuchas"I[positiveadverb]agree"and"I[positiveadverb]disagree"variationswereusedtodetectevidenceofacommentbelongingtoaclass.Inthecaseofthepresenceofconflictingevidence, i.e. expressions acting as strong evidence towards bothclasses,thecommentswerenotconsidered.Remainingcommentswereautomaticallyassigned to their respective classand the correspondingsentences were deleted from the comments in order to avoid a classbias advantage. That labelling process is inspired from distantsupervisionlearning(Mintzetal.,2009)wherebyhighlydiscriminativeexpressionsareusedasclasslabelproxies.
Bothdatasetswerepre-processedby removing comments thatwere deemed as non-constructive because of their limited length. Athresholdwasempiricallychosenbasedonahumanobservationofthedataandall commentscomposedof less than20wordsand/orwithavocabulary of less than 10 words were considered as noise andremovedfromthedata.
Nostemmingwasappliedduetotheunreliablevocabularyusedinsocialmedia,meaningthatarule-basedprocedureforwouldreunifyterms thatare semanticallydistantand thus remove information fromthedatasets.For thesamereasonno lemmatizationwasapplied,sincedictionary-basedlemmatizerswouldatbestbeineffectiveandatworstdetrimentaltoourapproach.
Finally, in the absence of information about the real classdistribution, we artificially enforced a uniform class distribution bysubsamplingthemajorityclass.4.2EvaluationmetricsandexperimentalprotocolWe chose classification accuracy as our evaluation metric becausebalanced data renders other thresholdmetrics (such as F1-Score) lessmeaningfulandusedthestandard10-Foldcross-validationprotocolformachine learning experiments (Bishop, 2006) for both our distantlylearned approaches and our unsupervised approaches in order topreserveasfairacomparisonaspossible.5.RESULTANDDISCUSSIONTheresultsshowninTable2showthatwhileastandardlexiconbuiltona background corpuswith a simple bag-of-words representation doesnot significantly outperform standard sentiment analysis or stanceclassification techniques, changing the representation of the instances

13
by adding some form of context improves our classification accuracyagain by a significantmargin (+5.7% compared to a similar approachwithout context and +7.8% compared to the best baseline).Dataset/Method SentLex SentLex SmartSA USSIAC 0.5042 0.5260 0.5147 0.5061RNLC 0.4670 0.4664 0.4522 0.4718
PMILex PMILex+inter PMILex+union0.5362 0.5899 0.56960.4843 0.5304 0.5043
Table2:Accuracyofthecomparedapproaches.
Wenotethatbetweenthetwoapproachestointroducecontext
inthebagofwordsrepresentation,thebestaccuracywasgivenbytheapproachusingthe intersectionof thebagofwordsrepresentationsofchild and parent comments rather than the union (which preservesmoreinformation).Apossiblereasonforthisisthattheintersectionofbagsofwordspreservetopicallyrelevanttermswhichcanthenbeusedintheclassificationprocess.Inthecontextofclassifyingargumentativestance, such result implies that evidence of this stance is containedwithincommoninformationpresentinbothchildandparentcomment.
However, this does not account for the fact that the union ofbags of words outperforms the standard methods while potentiallyaddingnoiseintotherepresentation.Thisleadsustothinkthatfurtherrefinement of the model could be done by using a term weightingschemeasamiddlegroundbetweenaddinginformationusingtheunionoperatorandfilteringinformationusingtheintersectionoperator.
Theaccuracyscoreshoweverwhilebeinganimprovementoverthe baselines are too low for an operational context. More work isrequired in improving the naive way in which we added context atclassificationtime.6.CONCLUSIONArgumentmininginthecontextofclassificationhasmuchtogainfromshallow techniques borrowed from information retrieval, text miningand sentiment analysis research. A comparative analysis ofrepresentationtechniquesforclassifyingtheparent-childrelationshipsin threaded posts show that sentiment analysis approaches can besuccessfully adopted for argument mining provided that theconversational-contextiscapturedinrepresentationschemes.Weshow

14
that the simplebag-of-words representation contextualisedbyparent-child vocabulary intersection leads to significant improvements overcomparable baseline approaches. Following on from these results weaim to explore conversational-contextual enrichments that can furtherimproverepresentationforargumentclassification.Forthisinadditiontotheparent-childsinglelevelrelationship,weintendexploringfurtherlevelsofcontextsuchasfromsiblingstoancestors.REFERENCESAbbott,R.,Walker,M.,Anand,P.,FoxTree, J.E.,Bowmani,R.,&King, J.(2011,
June). How can you say such things?!?: Recognizing disagreement ininformalpolitical argument. InProc of theWorkshoponLanguages inSocialMedia(pp.2-11).AssociationforComputationalLinguistics.
Anand,P.,Walker,M.,Abbott,R.,Tree,J.E.F.,Bowmani,R.,&Minor,M.(2011,June).Catsruleanddogsdrool!:Classifyingstanceinonlinedebate.InProc 2nd workshop on computational approaches to subjectivity andsentimentanalysis(pp.1-9).AssociationforComputationalLinguistics.
Bishop,C.M.(2006).Patternrecognitionandmachinelearning.Springer.Boltuzic, F., & Šnajder, J. (2014, June). Back up your stance: Recognizing
arguments inonlinediscussions. InProceedingsof theFirstWorkshoponArgumentationMining(pp.49-58).
Bousmalis,K.,Mehu,M.,&Pantic,M.(2013).Towardstheautomaticdetectionof spontaneous agreement and disagreement based on nonverbalbehaviour: A survey of related cues, databases, and tools.Image andVisionComputing,31(2),203-221.
Cabrio, E., & Villata, S. (2012, July). Combining textual entailment andargumentation theory for supporting online debates interactions.InProc of the 50th Annual Meeting of the ACL: Short Papers-Volume2(pp.208-212).AssociationforComputationalLinguistics.
Cayrol,C.,&Lagasquie-Schiex,M.C.(2005).Ontheacceptabilityofargumentsin bipolar argumentation frameworks. InSymbolic and quantitativeapproaches to reasoning with uncertainty(pp. 378-389). SpringerBerlinHeidelberg.
Cohen, R. (1987). Analyzing the structure of argumentative discourse.Computationallinguistics,13(1-2),11-24.
Dung,P.M.(1995).Ontheacceptabilityofargumentsanditsfundamentalrolein nonmonotonic reasoning, logic programming and n-persongames.Artificialintelligence,77(2),321-357.
Esuli,A.,&Sebastiani,F.(2006,May).Sentiwordnet:Apubliclyavailablelexicalresourceforopinionmining.InProcofLREC(Vol.6,pp.417-422).
Hutchby, I. (2013).Confrontation talk: Arguments, asymmetries, and power ontalkradio.Routledge.
Manning,C.D.,Raghavan,P.,&Schütze,H. (2008).Introductionto informationretrieval(Vol.1,p.496).Cambridge:Cambridgeuniversitypress.
Mintz,M.,Bills,S.,Snow,R.,&Jurafsky,D.(2009,August).Distantsupervisionforrelationextractionwithoutlabelleddata.InProcoftheJointConfof

15
the47thAnnualMeetingoftheACLandthe4thIntlJointConfonNLPoftheAFNLP:Volume2-Volume2(pp.1003-1011).ACL.
Mochales, R., & Moens, M. F. (2011). Argumentation mining.ArtificialIntelligenceandLaw,19(1),1-22.
Muhammad,A.,Wiratunga,N.,Lothian,R.,&Glassey,R.(2013).Domain-BasedLexiconEnhancement forSentimentAnalysis. InSMA@BCS-SGAI (pp.7-18).
Palau,R.M.,&Moens,M.F.(2009,June).Argumentationmining:thedetection,classificationandstructureofargumentsintext.InProcofthe12thintlconfonAIandlaw(pp.98-107).ACM.
Pang,B.,&Lee,L.(2008).Opinionminingandsentimentanalysis.Foundationsandtrendsininformationretrieval,2(1-2),1-135.
Pang, B., Lee, L., & Vaithyanathan, S. (2002, July). Thumbs up?: sentimentclassificationusingmachinelearningtechniques.InProcoftheACL-02conferenceonEmpiricalmethodsinNLPVolume10(pp.79-86).ACL.
Peldszus, A., & Stede, M. (2013). From argument diagrams to argumentationmining in texts: A survey.Int Journal of Cognitive Informatics andNaturalIntelligence(IJCINI),7(1),1-31.
Somasundaran,S.,&Wiebe, J. (2010, June).Recognizingstances in ideologicalon-line debates. InProc of the NAACL HLT 2010 Workshop onComputational Approaches to Analysis and Generation of Emotion inText(pp.116-124).ACL.
Taboada,M.,Brooke,J.,Tofiloski,M.,Voll,K.,&Stede,M.(2011).Lexicon-basedmethods for sentiment analysis.Computational linguistics,37(2), 267-307.
Van Eemeren, F. H., Grootendorst, R., Jackson, S., & Jacobs, S. (1993).Reconstructingargumentativediscourse.
Villalba,M.P.G.,&Saint-Dizier,P.(2012,September).SomeFacetsofArgumentMiningforOpinionAnalysis.InCOMMA(pp.23-34).
Walker, M. A., Anand, P., Abbott, R., & Grant, R. (2012, June). Stanceclassification using dialogic properties of persuasion. InProc of theNorthAmericanChapteroftheACL:HumanLanguageTechnologies(pp.592-596).AssociationforComputationalLinguistics.
Walker,M.A.,Tree,J.E.F.,Anand,P.,Abbott,R.,&King,J.(2012).ACorpusforResearchonDeliberationandDebate.InLREC(pp.812-817).
Wang, L., & Cardie, C. (2014). Improving agreement and disagreementidentification in online discussions with a socially-tuned sentimentlexicon.ACL2014,97.
Wang, W., Yaman, S., Precoda, K., Richey, C., & Raymond, G. (2011, June).Detectionofagreementanddisagreementinbroadcastconversations.In Proc of the 49th Annual Meeting of the ACL: Human LanguageTechnologies:shortpapers-Volume2(pp.374-378).ACL.
Wyner,A.,Mochales-Palau,R.,Moens,M.F.,&Milward,D.(2010).Approachestotext mining arguments from legal cases(pp. 60-79). Springer BerlinHeidelberg.
Yin,J.,Thomas,P.,Narang,N.,&Paris,C.(2012,July).Unifyinglocalandglobalagreementanddisagreementclassificationinonlinedebates.InProcofthe 3rd Workshop in Computational Approaches to Subjectivity andSentimentAnalysis(pp.61-69).ACL.