recognition of the script in serbian documents using frequency occurrence and co-occurrence analysis
TRANSCRIPT

Hindawi Publishing CorporationThe Scientific World JournalVolume 2013 Article ID 896328 14 pageshttpdxdoiorg1011552013896328
Research ArticleRecognition of the Script in Serbian Documents UsingFrequency Occurrence and Co-Occurrence Analysis
Darko BrodiT1 Zoran N MilivojeviT2 and Hedomir A Maluckov1
1 Technical Faculty in Bor University of Belgrade Vojske Jugoslavije 12 19210 Bor Serbia2 Technical College Nis Aleksandra Medvedeva 20 18000 Nis Serbia
Correspondence should be addressed to Darko Brodic dbrodictfboracrs
Received 18 July 2013 Accepted 21 August 2013
Academic Editors S Bourennane C Fossati and J Marot
Copyright copy 2013 Darko Brodic et al This is an open access article distributed under the Creative Commons Attribution Licensewhich permits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
Any document in Serbian language can be written in two different scripts Latin or Cyrillic Although characteristics of these scriptsare similar some of their statistical measures are quite different The paper proposed a method for the extraction of certain scriptfrom document according to the occurrence and co-occurrence of the script types First each letter is modeled with the certainscript type according to characteristics concerning its position in baseline area Then the frequency analysis of the script typesoccurrence is performed Due to diversity of Latin and Cyrillic script the occurrence of modeled letters shows substantial statisticsdissimilarity Furthermore the co-occurrence matrix is computedThe analysis of the co-occurrence matrix draws a strong marginas a criteria to distinguish and recognize the certain script The proposed method is analyzed on the case of a database whichincludes different types of printed and web documents The experiments gave encouraging results
1 Introduction
Cryptography studies the problems concerning the conver-sion of information from a readable to some other stateIt deals with information which is changing from one toanother state The initial information represents a plain textWhen the information becomes encrypted it is referred as acipher text [1] A substitution cipher is a method of encodingAccording to it the units of plain text are replaced withcipher text [2] They can be single letters pairs of letterstriplets of letters mixtures of the above and so forth Inour application the encryption function is not needed to beinjective [3] due to nature of further statistical analysis Itdoes not matter if it will encrypt two different plain textsinto the same cipher text because decryption of the ciphertext is not considered Hence the cryptography is used onlyas a basis for modeling and analyzing documents written inSerbian language Serbian language represents the Europeanminority language However it is distinct due to its capabilityto be written in Latin and Cyrillic script interchangeablyAccording to the baseline characteristics [4] each letter in thetext file is replaced with the cipher which is taken from theset of four counterparts only The basic idea is to distinguish
the script (Latin or Cyrillic) according to statistical analysisof the cipher text It is accomplished with frequency analysisconcerning occurrence [5] as well as with the method usingstatistical measures extracted from gray-level co-occurrencematrix [6] The letter frequency distribution is a functionwhich assigns each letter a frequency of its occurrence inthe text sample [7] The gray-level co-occurrence matrix(GLCM) have used for the extraction of features needed fortexture classification [8] Nevertheless it can be exploited fora letter co-occurrence in a text document [9] At the finalstage the experiment is made on a custom oriented databasecontaining text from printed and Web documents
The rest of the paper is organized as follows Section 2describes the full procedure of the proposed algorithmSection 3 defines the experiment Section 4 presents theresults from experiment and discusses them Section 5makesa conclusion
2 Proposed Algorithm
The proposed algorithm converts document written in Latinand Cyrillic script which represent the plain text into cipher
2 The Scientific World Journal
Originaldocument
Latindocument
Cyrillicdocument
Encription Encription
Cipher Latindocument
Cipher Cyrillicdocument
Frequencyoccurrence
analysis
Criteria fordecision making
Correctrecognitionof the script
Co-occurrenceanalysis
Frequencyoccurrence
analysis
Co-occurrenceanalysis
Figure 1 The flow of proposed algorithm
text according to predefined encryption based on text linestructure definition Then the equivalent cipher texts aresubjected to the frequency and co-occurrence analysis Theresults of frequency analysis indicated a substantial differencebetween cipher texts obtained from Latin and Cyrillic textSimilarly co-occurrence analysis shows obvious quantitativedisparity in some measures This draws a strong margin as acriterion in order to distinguish and recognize a certain scripttype (Figure 1)
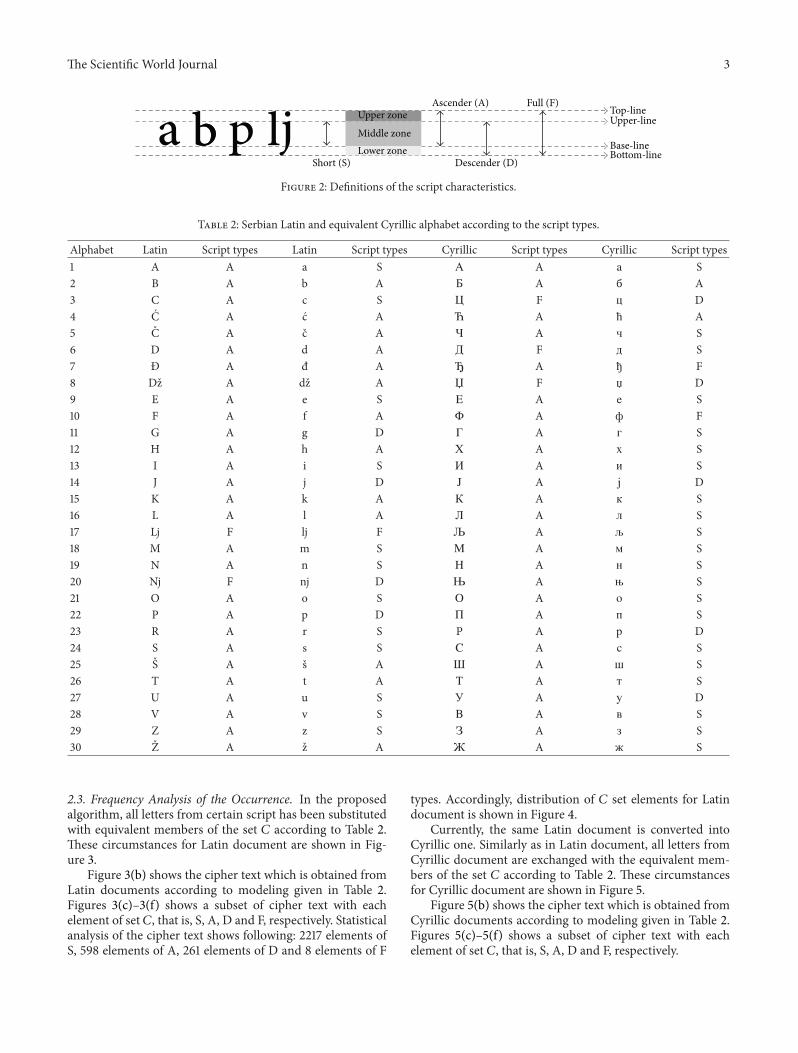
21 Text Line Structure Text in printed and Web documentsis defined as well-formed text type It is characterized bystrong regularity in shape The distances between the textlines are adequate to be split up The words are formedregularly with similar distance Their inter word spacing isdecent as well However in certain script the letters or signshave different position according to its baseline It is shownin Figure 2
From Figure 2 four virtual lines can be defined [4]
(i) The top-line(ii) The upper-line(iii) The base-line and(iv) The bottom-line
Table 1 Definition of script types according to the baselinecharacteristics
Script example Type of script Designationa Short Sb Ascender Aj Descender Dlj Full F
Accordingly a text line can be considered as beingcomposed of three vertical zones [4]
(i) The upper zone(ii) The middle zone and(iii) The lower zoneEach text line has at least a middle zone The upper zone
depends on capital letters and letters with ascenders whilethe lower zone depends on letters with descenders Only afew letters occupy the upper and lower zone
22 Encryption Two different sets are producedThey are119860119871
and 119860119862for Latin and Cyrillic alphabet respectively
119860119871
= ABC Z a b c z
119860119862
= A24 d a 3 5 e
(1)
Each of them consists of 60 elements that is letters whichare valid for Serbian language Furthermore both sets119860
119871and
119860119862are mapped into set 119862
119891119871
119860119871
997891997888rarr 119862
119891119862
119860119862
997891997888rarr 119862
(2)
These mappings are achieved in accordance with the textline area definitionThe structure of text line allows definitionof following script types [4]
(i) Full letter (F) where letter is present in all three zones(ii) Ascender letter (A) where character parts are present
in the upper and middle zones(iii) Descender letter (D) where character parts are
present in the lower and middle zones and(iv) Short letter (S) where character parts are present in
the middle zone onlyAccordingly all letters will be replaced with the cipher
from the following set
119862 = SAD F (3)
All letters can reach certain position which belongs to set119862 with a unique designation according to Table 1
It should be noted that above mappings are surjectiveSerbian language contains 30 letters Each letter in Latin
has a corresponding equivalent letter in Cyrillic Table 2shows Latin and Cyrillic letters as well as theirs designationaccording to Table 1
Statistical analysis of the letters and theirs correspondingtype for Latin and Cyrillic scripts is shown in Table 3
The Scientific World Journal 3
Ascender (A) Full (F)
Short (S) Descender (D)
Upper zone
Middle zoneLower zone
Top-lineUpper-line
Base-lineBottom-line
Figure 2 Definitions of the script characteristics
Table 2 Serbian Latin and equivalent Cyrillic alphabet according to the script types
Alphabet Latin Script types Latin Script types Cyrillic Script types Cyrillic Script types1 A A a S 0 A 1 S2 B A b A 2 A 3 A3 C A c S 4 F 5 D4 C A c A 6 A 7 A5 C A c A 8 A 9 S6 D A d A F S7 ETH A đ A lt A = F8 Dz A dz A gt F D9 E A e S A A S10 F A f A B A C F11 G A g D D A E S12 H A h A H A I S13 I A i S J A K S14 J A j D N A O D15 K A k A P A Q S16 L A l A R A S S17 Lj F lj F T A U S18 M A m S V A W S19 N A n S X A Y S20 Nj F nj D Z A [ S21 O A o S A ] S22 P A p D ^ A _ S23 R A r S P A a D24 S A s S b A c S25 S A s A d A e S26 T A t A f A g S27 U A u S h A i D28 V A v S j A k S29 Z A z S n A o S30 Z A z A p A q S
23 Frequency Analysis of the Occurrence In the proposedalgorithm all letters from certain script has been substitutedwith equivalent members of the set 119862 according to Table 2These circumstances for Latin document are shown in Fig-ure 3
Figure 3(b) shows the cipher text which is obtained fromLatin documents according to modeling given in Table 2Figures 3(c)ndash3(f) shows a subset of cipher text with eachelement of set 119862 that is S A D and F respectively Statisticalanalysis of the cipher text shows following 2217 elements ofS 598 elements of A 261 elements of D and 8 elements of F
types Accordingly distribution of 119862 set elements for Latindocument is shown in Figure 4
Currently the same Latin document is converted intoCyrillic one Similarly as in Latin document all letters fromCyrillic document are exchanged with the equivalent mem-bers of the set 119862 according to Table 2 These circumstancesfor Cyrillic document are shown in Figure 5
Figure 5(b) shows the cipher text which is obtained fromCyrillic documents according to modeling given in Table 2Figures 5(c)ndash5(f) shows a subset of cipher text with eachelement of set 119862 that is S A D and F respectively
4 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 3 Application of the proposed algorithm (a) Original Latin text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 5
Table 3 Statistical analysis of Latin and Cyrillic script types
Script Type of letters Occurrence of script types Distribution of script typesS A D F S () A () D () F ()
Latin Capital letters 0 28 0 2 0 9333 0 667Latin Small letters 12 13 4 1 4000 4333 1333 334Cyrillic Capital letters 0 27 0 3 0 9000 0 1000Cyrillic Small letters 21 2 5 2 7000 667 1666 667
S A D F0
500
1000
1500
2000
2500
Type of scripts
No
Figure 4 Distribution of 119862 setrsquos elements in cipher text obtainedfrom Latin document
Statistical analysis of the Cyrillic document image showsfollowing 2516 elements of S 53 elements of A 445 elementsof D and 26 elements of F types It should be noted that thesum of all 119862 set elements in Latin and Cyrillic document isnot quite identical It is valid due to difference in definition ofletters in two scripts In the Cyrillic script each letter is givenone and only one sign However in Latin script letters suchas dz lj and nj are represented by two letters Distribution of119862 set elements for Cyrillic document is presented in Figure 6
According to Figures 4 and 6 the comparison chart isdrawn It is shown below in Figure 7
Quantification of the script type appearance in a docu-ment written in Latin and Cyrillic is shown in Table 4
It is obvious that the Latin document compared toCyrillicone has slightly smaller number of short (S) descender (D)and full (F) letters Nonetheless the crucial margin is seen inascender (A) letters Hence it can be a measure of confidencefor detection of the script in a document given in Serbianlanguage
24 Co-Occurrence Analysis Let I be the gray scale imagewhich is under consideration It has 119872 row and 119873 columnswhile119879 is the total number of gray levelsThe spatial relation-ship of gray levels in the image I is expressed by the grayscaleco-occurrencematrix (GLCM)C [6 10] HenceC is a matrixthat describes the frequency of one gray level appearing ina specified spatial linear relationship with another gray levelwithin the area of investigation [11] In order to compute aco-occurrence matrixC we considered a central pixel 119868(119909 119910)
with a neighborhood defined by the window of interest Thiswindow is defined by two parameters inter-pixel distance (119889)
and orientation (120579) Typically the choice of 119889 is 1 (one pixel)
while the value of 120579 depends on the neighborhood Becauseof that each pixel has 8 neighbors given at following angles120579 = 0
∘ 45∘ 90∘ 135∘ 180∘ 225∘ 270∘ 315∘ However thecase of neighbors at 120579 = 0
∘ or at 120579 = 180∘ is similar to the
GLCM definition [12] So the choice may fall to 4 neighborspixels at 120579 = 0
∘ 45∘ 90∘ and 135∘ that is horizontal rightdiagonal vertical and left diagonal [13] These orientationsrefer to 4-adjacent pixels at (119909+119889 119910) (119909 119910minus119889) (119909minus119889 119910) and(119909 119910+119889) where119889 is 1 For each pixel of the neighborhood it iscounted the number of times a pixel pair appears specified bythe distance and orientation parameters The (119894 119895)th entry ofC represents the number of occasions a pixel with an intensity119894 is adjacent to a pixel with an intensity 119895 Hence for the givenimage I the co-occurrence matrix C is defined as [14]
119862 (119894 119895) =
119872
sum
119909=1
119873
sum
119910=1
1if 119868 (119909 119910) = 119894
119868 (119909 + Δ119909 119910 + Δ119910) = 119895
0 otherwise
(4)
where 119894 and 119895 are the image intensity values of the image119909 and 119910 are the spatial positions in the image I The offset(Δ119909 Δ119910) is specifying the distance between the pixel-of-interest and its neighbor It depends on the direction 120579 that isused and the distance 119889 at which the matrix is computedThesquarematrixC is of the order119873 Using a statistical approachlike GLCMprovides a valuable information about the relativeposition of the neighboring pixels in an image [12] In orderto normalize matrix C matrix P is calculated as [10]
119875 (119894 119895) =119862 (119894 119895)
sum119873
119894=1sum119873
119895=1119862 (119894 119895)
(5)
The normalized co-occurrence matrix P is obtained bydividing each element of C by the total number of co-occurrence pairs in C
To illustrate the computing of GLCM a four gray levelimage I is usedThe window parameters are 119889 = 1 and 120579 = 0
∘
(horizontal) Initial matrix I is shown in Figure 8The procedure of calculating co-occurrence matrix for
grayscale matrix I (119889 = 1 and 120579 = 0∘) [12] is given in Figure 9
In order to GLCM be applied in our case set 119862 is mappedinto set 119862
119873by bijective function as
119891119862
119862 997891997888rarr 119862119873
(6)
where 119862119873
= 0 1 2 3 Furthermore the neighborhood isgiven as 2-connected (119909 minus 119889 and 119909 + 119889 around 119909 where119889 = 1) According to that the same document in Latin andCyrillic script is converted into cipher text It is shown belowin Figure 10
6 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 5 Application of the proposed algorithm (a) Original Cyrillic text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

2 The Scientific World Journal
Originaldocument
Latindocument
Cyrillicdocument
Encription Encription
Cipher Latindocument
Cipher Cyrillicdocument
Frequencyoccurrence
analysis
Criteria fordecision making
Correctrecognitionof the script
Co-occurrenceanalysis
Frequencyoccurrence
analysis
Co-occurrenceanalysis
Figure 1 The flow of proposed algorithm
text according to predefined encryption based on text linestructure definition Then the equivalent cipher texts aresubjected to the frequency and co-occurrence analysis Theresults of frequency analysis indicated a substantial differencebetween cipher texts obtained from Latin and Cyrillic textSimilarly co-occurrence analysis shows obvious quantitativedisparity in some measures This draws a strong margin as acriterion in order to distinguish and recognize a certain scripttype (Figure 1)
21 Text Line Structure Text in printed and Web documentsis defined as well-formed text type It is characterized bystrong regularity in shape The distances between the textlines are adequate to be split up The words are formedregularly with similar distance Their inter word spacing isdecent as well However in certain script the letters or signshave different position according to its baseline It is shownin Figure 2
From Figure 2 four virtual lines can be defined [4]
(i) The top-line(ii) The upper-line(iii) The base-line and(iv) The bottom-line
Table 1 Definition of script types according to the baselinecharacteristics
Script example Type of script Designationa Short Sb Ascender Aj Descender Dlj Full F
Accordingly a text line can be considered as beingcomposed of three vertical zones [4]
(i) The upper zone(ii) The middle zone and(iii) The lower zoneEach text line has at least a middle zone The upper zone
depends on capital letters and letters with ascenders whilethe lower zone depends on letters with descenders Only afew letters occupy the upper and lower zone
22 Encryption Two different sets are producedThey are119860119871
and 119860119862for Latin and Cyrillic alphabet respectively
119860119871
= ABC Z a b c z
119860119862
= A24 d a 3 5 e
(1)
Each of them consists of 60 elements that is letters whichare valid for Serbian language Furthermore both sets119860
119871and
119860119862are mapped into set 119862
119891119871
119860119871
997891997888rarr 119862
119891119862
119860119862
997891997888rarr 119862
(2)
These mappings are achieved in accordance with the textline area definitionThe structure of text line allows definitionof following script types [4]
(i) Full letter (F) where letter is present in all three zones(ii) Ascender letter (A) where character parts are present
in the upper and middle zones(iii) Descender letter (D) where character parts are
present in the lower and middle zones and(iv) Short letter (S) where character parts are present in
the middle zone onlyAccordingly all letters will be replaced with the cipher
from the following set
119862 = SAD F (3)
All letters can reach certain position which belongs to set119862 with a unique designation according to Table 1
It should be noted that above mappings are surjectiveSerbian language contains 30 letters Each letter in Latin
has a corresponding equivalent letter in Cyrillic Table 2shows Latin and Cyrillic letters as well as theirs designationaccording to Table 1
Statistical analysis of the letters and theirs correspondingtype for Latin and Cyrillic scripts is shown in Table 3
The Scientific World Journal 3
Ascender (A) Full (F)
Short (S) Descender (D)
Upper zone
Middle zoneLower zone
Top-lineUpper-line
Base-lineBottom-line
Figure 2 Definitions of the script characteristics
Table 2 Serbian Latin and equivalent Cyrillic alphabet according to the script types
Alphabet Latin Script types Latin Script types Cyrillic Script types Cyrillic Script types1 A A a S 0 A 1 S2 B A b A 2 A 3 A3 C A c S 4 F 5 D4 C A c A 6 A 7 A5 C A c A 8 A 9 S6 D A d A F S7 ETH A đ A lt A = F8 Dz A dz A gt F D9 E A e S A A S10 F A f A B A C F11 G A g D D A E S12 H A h A H A I S13 I A i S J A K S14 J A j D N A O D15 K A k A P A Q S16 L A l A R A S S17 Lj F lj F T A U S18 M A m S V A W S19 N A n S X A Y S20 Nj F nj D Z A [ S21 O A o S A ] S22 P A p D ^ A _ S23 R A r S P A a D24 S A s S b A c S25 S A s A d A e S26 T A t A f A g S27 U A u S h A i D28 V A v S j A k S29 Z A z S n A o S30 Z A z A p A q S
23 Frequency Analysis of the Occurrence In the proposedalgorithm all letters from certain script has been substitutedwith equivalent members of the set 119862 according to Table 2These circumstances for Latin document are shown in Fig-ure 3
Figure 3(b) shows the cipher text which is obtained fromLatin documents according to modeling given in Table 2Figures 3(c)ndash3(f) shows a subset of cipher text with eachelement of set 119862 that is S A D and F respectively Statisticalanalysis of the cipher text shows following 2217 elements ofS 598 elements of A 261 elements of D and 8 elements of F
types Accordingly distribution of 119862 set elements for Latindocument is shown in Figure 4
Currently the same Latin document is converted intoCyrillic one Similarly as in Latin document all letters fromCyrillic document are exchanged with the equivalent mem-bers of the set 119862 according to Table 2 These circumstancesfor Cyrillic document are shown in Figure 5
Figure 5(b) shows the cipher text which is obtained fromCyrillic documents according to modeling given in Table 2Figures 5(c)ndash5(f) shows a subset of cipher text with eachelement of set 119862 that is S A D and F respectively
4 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 3 Application of the proposed algorithm (a) Original Latin text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 5
Table 3 Statistical analysis of Latin and Cyrillic script types
Script Type of letters Occurrence of script types Distribution of script typesS A D F S () A () D () F ()
Latin Capital letters 0 28 0 2 0 9333 0 667Latin Small letters 12 13 4 1 4000 4333 1333 334Cyrillic Capital letters 0 27 0 3 0 9000 0 1000Cyrillic Small letters 21 2 5 2 7000 667 1666 667
S A D F0
500
1000
1500
2000
2500
Type of scripts
No
Figure 4 Distribution of 119862 setrsquos elements in cipher text obtainedfrom Latin document
Statistical analysis of the Cyrillic document image showsfollowing 2516 elements of S 53 elements of A 445 elementsof D and 26 elements of F types It should be noted that thesum of all 119862 set elements in Latin and Cyrillic document isnot quite identical It is valid due to difference in definition ofletters in two scripts In the Cyrillic script each letter is givenone and only one sign However in Latin script letters suchas dz lj and nj are represented by two letters Distribution of119862 set elements for Cyrillic document is presented in Figure 6
According to Figures 4 and 6 the comparison chart isdrawn It is shown below in Figure 7
Quantification of the script type appearance in a docu-ment written in Latin and Cyrillic is shown in Table 4
It is obvious that the Latin document compared toCyrillicone has slightly smaller number of short (S) descender (D)and full (F) letters Nonetheless the crucial margin is seen inascender (A) letters Hence it can be a measure of confidencefor detection of the script in a document given in Serbianlanguage
24 Co-Occurrence Analysis Let I be the gray scale imagewhich is under consideration It has 119872 row and 119873 columnswhile119879 is the total number of gray levelsThe spatial relation-ship of gray levels in the image I is expressed by the grayscaleco-occurrencematrix (GLCM)C [6 10] HenceC is a matrixthat describes the frequency of one gray level appearing ina specified spatial linear relationship with another gray levelwithin the area of investigation [11] In order to compute aco-occurrence matrixC we considered a central pixel 119868(119909 119910)
with a neighborhood defined by the window of interest Thiswindow is defined by two parameters inter-pixel distance (119889)
and orientation (120579) Typically the choice of 119889 is 1 (one pixel)
while the value of 120579 depends on the neighborhood Becauseof that each pixel has 8 neighbors given at following angles120579 = 0
∘ 45∘ 90∘ 135∘ 180∘ 225∘ 270∘ 315∘ However thecase of neighbors at 120579 = 0
∘ or at 120579 = 180∘ is similar to the
GLCM definition [12] So the choice may fall to 4 neighborspixels at 120579 = 0
∘ 45∘ 90∘ and 135∘ that is horizontal rightdiagonal vertical and left diagonal [13] These orientationsrefer to 4-adjacent pixels at (119909+119889 119910) (119909 119910minus119889) (119909minus119889 119910) and(119909 119910+119889) where119889 is 1 For each pixel of the neighborhood it iscounted the number of times a pixel pair appears specified bythe distance and orientation parameters The (119894 119895)th entry ofC represents the number of occasions a pixel with an intensity119894 is adjacent to a pixel with an intensity 119895 Hence for the givenimage I the co-occurrence matrix C is defined as [14]
119862 (119894 119895) =
119872
sum
119909=1
119873
sum
119910=1
1if 119868 (119909 119910) = 119894
119868 (119909 + Δ119909 119910 + Δ119910) = 119895
0 otherwise
(4)
where 119894 and 119895 are the image intensity values of the image119909 and 119910 are the spatial positions in the image I The offset(Δ119909 Δ119910) is specifying the distance between the pixel-of-interest and its neighbor It depends on the direction 120579 that isused and the distance 119889 at which the matrix is computedThesquarematrixC is of the order119873 Using a statistical approachlike GLCMprovides a valuable information about the relativeposition of the neighboring pixels in an image [12] In orderto normalize matrix C matrix P is calculated as [10]
119875 (119894 119895) =119862 (119894 119895)
sum119873
119894=1sum119873
119895=1119862 (119894 119895)
(5)
The normalized co-occurrence matrix P is obtained bydividing each element of C by the total number of co-occurrence pairs in C
To illustrate the computing of GLCM a four gray levelimage I is usedThe window parameters are 119889 = 1 and 120579 = 0
∘
(horizontal) Initial matrix I is shown in Figure 8The procedure of calculating co-occurrence matrix for
grayscale matrix I (119889 = 1 and 120579 = 0∘) [12] is given in Figure 9
In order to GLCM be applied in our case set 119862 is mappedinto set 119862
119873by bijective function as
119891119862
119862 997891997888rarr 119862119873
(6)
where 119862119873
= 0 1 2 3 Furthermore the neighborhood isgiven as 2-connected (119909 minus 119889 and 119909 + 119889 around 119909 where119889 = 1) According to that the same document in Latin andCyrillic script is converted into cipher text It is shown belowin Figure 10
6 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 5 Application of the proposed algorithm (a) Original Cyrillic text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World Journal 3
Ascender (A) Full (F)
Short (S) Descender (D)
Upper zone
Middle zoneLower zone
Top-lineUpper-line
Base-lineBottom-line
Figure 2 Definitions of the script characteristics
Table 2 Serbian Latin and equivalent Cyrillic alphabet according to the script types
Alphabet Latin Script types Latin Script types Cyrillic Script types Cyrillic Script types1 A A a S 0 A 1 S2 B A b A 2 A 3 A3 C A c S 4 F 5 D4 C A c A 6 A 7 A5 C A c A 8 A 9 S6 D A d A F S7 ETH A đ A lt A = F8 Dz A dz A gt F D9 E A e S A A S10 F A f A B A C F11 G A g D D A E S12 H A h A H A I S13 I A i S J A K S14 J A j D N A O D15 K A k A P A Q S16 L A l A R A S S17 Lj F lj F T A U S18 M A m S V A W S19 N A n S X A Y S20 Nj F nj D Z A [ S21 O A o S A ] S22 P A p D ^ A _ S23 R A r S P A a D24 S A s S b A c S25 S A s A d A e S26 T A t A f A g S27 U A u S h A i D28 V A v S j A k S29 Z A z S n A o S30 Z A z A p A q S
23 Frequency Analysis of the Occurrence In the proposedalgorithm all letters from certain script has been substitutedwith equivalent members of the set 119862 according to Table 2These circumstances for Latin document are shown in Fig-ure 3
Figure 3(b) shows the cipher text which is obtained fromLatin documents according to modeling given in Table 2Figures 3(c)ndash3(f) shows a subset of cipher text with eachelement of set 119862 that is S A D and F respectively Statisticalanalysis of the cipher text shows following 2217 elements ofS 598 elements of A 261 elements of D and 8 elements of F
types Accordingly distribution of 119862 set elements for Latindocument is shown in Figure 4
Currently the same Latin document is converted intoCyrillic one Similarly as in Latin document all letters fromCyrillic document are exchanged with the equivalent mem-bers of the set 119862 according to Table 2 These circumstancesfor Cyrillic document are shown in Figure 5
Figure 5(b) shows the cipher text which is obtained fromCyrillic documents according to modeling given in Table 2Figures 5(c)ndash5(f) shows a subset of cipher text with eachelement of set 119862 that is S A D and F respectively
4 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 3 Application of the proposed algorithm (a) Original Latin text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 5
Table 3 Statistical analysis of Latin and Cyrillic script types
Script Type of letters Occurrence of script types Distribution of script typesS A D F S () A () D () F ()
Latin Capital letters 0 28 0 2 0 9333 0 667Latin Small letters 12 13 4 1 4000 4333 1333 334Cyrillic Capital letters 0 27 0 3 0 9000 0 1000Cyrillic Small letters 21 2 5 2 7000 667 1666 667
S A D F0
500
1000
1500
2000
2500
Type of scripts
No
Figure 4 Distribution of 119862 setrsquos elements in cipher text obtainedfrom Latin document
Statistical analysis of the Cyrillic document image showsfollowing 2516 elements of S 53 elements of A 445 elementsof D and 26 elements of F types It should be noted that thesum of all 119862 set elements in Latin and Cyrillic document isnot quite identical It is valid due to difference in definition ofletters in two scripts In the Cyrillic script each letter is givenone and only one sign However in Latin script letters suchas dz lj and nj are represented by two letters Distribution of119862 set elements for Cyrillic document is presented in Figure 6
According to Figures 4 and 6 the comparison chart isdrawn It is shown below in Figure 7
Quantification of the script type appearance in a docu-ment written in Latin and Cyrillic is shown in Table 4
It is obvious that the Latin document compared toCyrillicone has slightly smaller number of short (S) descender (D)and full (F) letters Nonetheless the crucial margin is seen inascender (A) letters Hence it can be a measure of confidencefor detection of the script in a document given in Serbianlanguage
24 Co-Occurrence Analysis Let I be the gray scale imagewhich is under consideration It has 119872 row and 119873 columnswhile119879 is the total number of gray levelsThe spatial relation-ship of gray levels in the image I is expressed by the grayscaleco-occurrencematrix (GLCM)C [6 10] HenceC is a matrixthat describes the frequency of one gray level appearing ina specified spatial linear relationship with another gray levelwithin the area of investigation [11] In order to compute aco-occurrence matrixC we considered a central pixel 119868(119909 119910)
with a neighborhood defined by the window of interest Thiswindow is defined by two parameters inter-pixel distance (119889)
and orientation (120579) Typically the choice of 119889 is 1 (one pixel)
while the value of 120579 depends on the neighborhood Becauseof that each pixel has 8 neighbors given at following angles120579 = 0
∘ 45∘ 90∘ 135∘ 180∘ 225∘ 270∘ 315∘ However thecase of neighbors at 120579 = 0
∘ or at 120579 = 180∘ is similar to the
GLCM definition [12] So the choice may fall to 4 neighborspixels at 120579 = 0
∘ 45∘ 90∘ and 135∘ that is horizontal rightdiagonal vertical and left diagonal [13] These orientationsrefer to 4-adjacent pixels at (119909+119889 119910) (119909 119910minus119889) (119909minus119889 119910) and(119909 119910+119889) where119889 is 1 For each pixel of the neighborhood it iscounted the number of times a pixel pair appears specified bythe distance and orientation parameters The (119894 119895)th entry ofC represents the number of occasions a pixel with an intensity119894 is adjacent to a pixel with an intensity 119895 Hence for the givenimage I the co-occurrence matrix C is defined as [14]
119862 (119894 119895) =
119872
sum
119909=1
119873
sum
119910=1
1if 119868 (119909 119910) = 119894
119868 (119909 + Δ119909 119910 + Δ119910) = 119895
0 otherwise
(4)
where 119894 and 119895 are the image intensity values of the image119909 and 119910 are the spatial positions in the image I The offset(Δ119909 Δ119910) is specifying the distance between the pixel-of-interest and its neighbor It depends on the direction 120579 that isused and the distance 119889 at which the matrix is computedThesquarematrixC is of the order119873 Using a statistical approachlike GLCMprovides a valuable information about the relativeposition of the neighboring pixels in an image [12] In orderto normalize matrix C matrix P is calculated as [10]
119875 (119894 119895) =119862 (119894 119895)
sum119873
119894=1sum119873
119895=1119862 (119894 119895)
(5)
The normalized co-occurrence matrix P is obtained bydividing each element of C by the total number of co-occurrence pairs in C
To illustrate the computing of GLCM a four gray levelimage I is usedThe window parameters are 119889 = 1 and 120579 = 0
∘
(horizontal) Initial matrix I is shown in Figure 8The procedure of calculating co-occurrence matrix for
grayscale matrix I (119889 = 1 and 120579 = 0∘) [12] is given in Figure 9
In order to GLCM be applied in our case set 119862 is mappedinto set 119862
119873by bijective function as
119891119862
119862 997891997888rarr 119862119873
(6)
where 119862119873
= 0 1 2 3 Furthermore the neighborhood isgiven as 2-connected (119909 minus 119889 and 119909 + 119889 around 119909 where119889 = 1) According to that the same document in Latin andCyrillic script is converted into cipher text It is shown belowin Figure 10
6 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 5 Application of the proposed algorithm (a) Original Cyrillic text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

4 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 3 Application of the proposed algorithm (a) Original Latin text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 5
Table 3 Statistical analysis of Latin and Cyrillic script types
Script Type of letters Occurrence of script types Distribution of script typesS A D F S () A () D () F ()
Latin Capital letters 0 28 0 2 0 9333 0 667Latin Small letters 12 13 4 1 4000 4333 1333 334Cyrillic Capital letters 0 27 0 3 0 9000 0 1000Cyrillic Small letters 21 2 5 2 7000 667 1666 667
S A D F0
500
1000
1500
2000
2500
Type of scripts
No
Figure 4 Distribution of 119862 setrsquos elements in cipher text obtainedfrom Latin document
Statistical analysis of the Cyrillic document image showsfollowing 2516 elements of S 53 elements of A 445 elementsof D and 26 elements of F types It should be noted that thesum of all 119862 set elements in Latin and Cyrillic document isnot quite identical It is valid due to difference in definition ofletters in two scripts In the Cyrillic script each letter is givenone and only one sign However in Latin script letters suchas dz lj and nj are represented by two letters Distribution of119862 set elements for Cyrillic document is presented in Figure 6
According to Figures 4 and 6 the comparison chart isdrawn It is shown below in Figure 7
Quantification of the script type appearance in a docu-ment written in Latin and Cyrillic is shown in Table 4
It is obvious that the Latin document compared toCyrillicone has slightly smaller number of short (S) descender (D)and full (F) letters Nonetheless the crucial margin is seen inascender (A) letters Hence it can be a measure of confidencefor detection of the script in a document given in Serbianlanguage
24 Co-Occurrence Analysis Let I be the gray scale imagewhich is under consideration It has 119872 row and 119873 columnswhile119879 is the total number of gray levelsThe spatial relation-ship of gray levels in the image I is expressed by the grayscaleco-occurrencematrix (GLCM)C [6 10] HenceC is a matrixthat describes the frequency of one gray level appearing ina specified spatial linear relationship with another gray levelwithin the area of investigation [11] In order to compute aco-occurrence matrixC we considered a central pixel 119868(119909 119910)
with a neighborhood defined by the window of interest Thiswindow is defined by two parameters inter-pixel distance (119889)
and orientation (120579) Typically the choice of 119889 is 1 (one pixel)
while the value of 120579 depends on the neighborhood Becauseof that each pixel has 8 neighbors given at following angles120579 = 0
∘ 45∘ 90∘ 135∘ 180∘ 225∘ 270∘ 315∘ However thecase of neighbors at 120579 = 0
∘ or at 120579 = 180∘ is similar to the
GLCM definition [12] So the choice may fall to 4 neighborspixels at 120579 = 0
∘ 45∘ 90∘ and 135∘ that is horizontal rightdiagonal vertical and left diagonal [13] These orientationsrefer to 4-adjacent pixels at (119909+119889 119910) (119909 119910minus119889) (119909minus119889 119910) and(119909 119910+119889) where119889 is 1 For each pixel of the neighborhood it iscounted the number of times a pixel pair appears specified bythe distance and orientation parameters The (119894 119895)th entry ofC represents the number of occasions a pixel with an intensity119894 is adjacent to a pixel with an intensity 119895 Hence for the givenimage I the co-occurrence matrix C is defined as [14]
119862 (119894 119895) =
119872
sum
119909=1
119873
sum
119910=1
1if 119868 (119909 119910) = 119894
119868 (119909 + Δ119909 119910 + Δ119910) = 119895
0 otherwise
(4)
where 119894 and 119895 are the image intensity values of the image119909 and 119910 are the spatial positions in the image I The offset(Δ119909 Δ119910) is specifying the distance between the pixel-of-interest and its neighbor It depends on the direction 120579 that isused and the distance 119889 at which the matrix is computedThesquarematrixC is of the order119873 Using a statistical approachlike GLCMprovides a valuable information about the relativeposition of the neighboring pixels in an image [12] In orderto normalize matrix C matrix P is calculated as [10]
119875 (119894 119895) =119862 (119894 119895)
sum119873
119894=1sum119873
119895=1119862 (119894 119895)
(5)
The normalized co-occurrence matrix P is obtained bydividing each element of C by the total number of co-occurrence pairs in C
To illustrate the computing of GLCM a four gray levelimage I is usedThe window parameters are 119889 = 1 and 120579 = 0
∘
(horizontal) Initial matrix I is shown in Figure 8The procedure of calculating co-occurrence matrix for
grayscale matrix I (119889 = 1 and 120579 = 0∘) [12] is given in Figure 9
In order to GLCM be applied in our case set 119862 is mappedinto set 119862
119873by bijective function as
119891119862
119862 997891997888rarr 119862119873
(6)
where 119862119873
= 0 1 2 3 Furthermore the neighborhood isgiven as 2-connected (119909 minus 119889 and 119909 + 119889 around 119909 where119889 = 1) According to that the same document in Latin andCyrillic script is converted into cipher text It is shown belowin Figure 10
6 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 5 Application of the proposed algorithm (a) Original Cyrillic text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

The Scientific World Journal 5
Table 3 Statistical analysis of Latin and Cyrillic script types
Script Type of letters Occurrence of script types Distribution of script typesS A D F S () A () D () F ()
Latin Capital letters 0 28 0 2 0 9333 0 667Latin Small letters 12 13 4 1 4000 4333 1333 334Cyrillic Capital letters 0 27 0 3 0 9000 0 1000Cyrillic Small letters 21 2 5 2 7000 667 1666 667
S A D F0
500
1000
1500
2000
2500
Type of scripts
No
Figure 4 Distribution of 119862 setrsquos elements in cipher text obtainedfrom Latin document
Statistical analysis of the Cyrillic document image showsfollowing 2516 elements of S 53 elements of A 445 elementsof D and 26 elements of F types It should be noted that thesum of all 119862 set elements in Latin and Cyrillic document isnot quite identical It is valid due to difference in definition ofletters in two scripts In the Cyrillic script each letter is givenone and only one sign However in Latin script letters suchas dz lj and nj are represented by two letters Distribution of119862 set elements for Cyrillic document is presented in Figure 6
According to Figures 4 and 6 the comparison chart isdrawn It is shown below in Figure 7
Quantification of the script type appearance in a docu-ment written in Latin and Cyrillic is shown in Table 4
It is obvious that the Latin document compared toCyrillicone has slightly smaller number of short (S) descender (D)and full (F) letters Nonetheless the crucial margin is seen inascender (A) letters Hence it can be a measure of confidencefor detection of the script in a document given in Serbianlanguage
24 Co-Occurrence Analysis Let I be the gray scale imagewhich is under consideration It has 119872 row and 119873 columnswhile119879 is the total number of gray levelsThe spatial relation-ship of gray levels in the image I is expressed by the grayscaleco-occurrencematrix (GLCM)C [6 10] HenceC is a matrixthat describes the frequency of one gray level appearing ina specified spatial linear relationship with another gray levelwithin the area of investigation [11] In order to compute aco-occurrence matrixC we considered a central pixel 119868(119909 119910)
with a neighborhood defined by the window of interest Thiswindow is defined by two parameters inter-pixel distance (119889)
and orientation (120579) Typically the choice of 119889 is 1 (one pixel)
while the value of 120579 depends on the neighborhood Becauseof that each pixel has 8 neighbors given at following angles120579 = 0
∘ 45∘ 90∘ 135∘ 180∘ 225∘ 270∘ 315∘ However thecase of neighbors at 120579 = 0
∘ or at 120579 = 180∘ is similar to the
GLCM definition [12] So the choice may fall to 4 neighborspixels at 120579 = 0
∘ 45∘ 90∘ and 135∘ that is horizontal rightdiagonal vertical and left diagonal [13] These orientationsrefer to 4-adjacent pixels at (119909+119889 119910) (119909 119910minus119889) (119909minus119889 119910) and(119909 119910+119889) where119889 is 1 For each pixel of the neighborhood it iscounted the number of times a pixel pair appears specified bythe distance and orientation parameters The (119894 119895)th entry ofC represents the number of occasions a pixel with an intensity119894 is adjacent to a pixel with an intensity 119895 Hence for the givenimage I the co-occurrence matrix C is defined as [14]
119862 (119894 119895) =
119872
sum
119909=1
119873
sum
119910=1
1if 119868 (119909 119910) = 119894
119868 (119909 + Δ119909 119910 + Δ119910) = 119895
0 otherwise
(4)
where 119894 and 119895 are the image intensity values of the image119909 and 119910 are the spatial positions in the image I The offset(Δ119909 Δ119910) is specifying the distance between the pixel-of-interest and its neighbor It depends on the direction 120579 that isused and the distance 119889 at which the matrix is computedThesquarematrixC is of the order119873 Using a statistical approachlike GLCMprovides a valuable information about the relativeposition of the neighboring pixels in an image [12] In orderto normalize matrix C matrix P is calculated as [10]
119875 (119894 119895) =119862 (119894 119895)
sum119873
119894=1sum119873
119895=1119862 (119894 119895)
(5)
The normalized co-occurrence matrix P is obtained bydividing each element of C by the total number of co-occurrence pairs in C
To illustrate the computing of GLCM a four gray levelimage I is usedThe window parameters are 119889 = 1 and 120579 = 0
∘
(horizontal) Initial matrix I is shown in Figure 8The procedure of calculating co-occurrence matrix for
grayscale matrix I (119889 = 1 and 120579 = 0∘) [12] is given in Figure 9
In order to GLCM be applied in our case set 119862 is mappedinto set 119862
119873by bijective function as
119891119862
119862 997891997888rarr 119862119873
(6)
where 119862119873
= 0 1 2 3 Furthermore the neighborhood isgiven as 2-connected (119909 minus 119889 and 119909 + 119889 around 119909 where119889 = 1) According to that the same document in Latin andCyrillic script is converted into cipher text It is shown belowin Figure 10
6 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 5 Application of the proposed algorithm (a) Original Cyrillic text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

6 The Scientific World Journal
(a) (b)
(c) (d)
(e) (f)
Figure 5 Application of the proposed algorithm (a) Original Cyrillic text (b) Cipher text according to set 119862 (c) Only ldquoSrdquo text (d) Only ldquoFrdquotext (e) Only ldquoArdquo text (f) Only ldquoDrdquo text
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
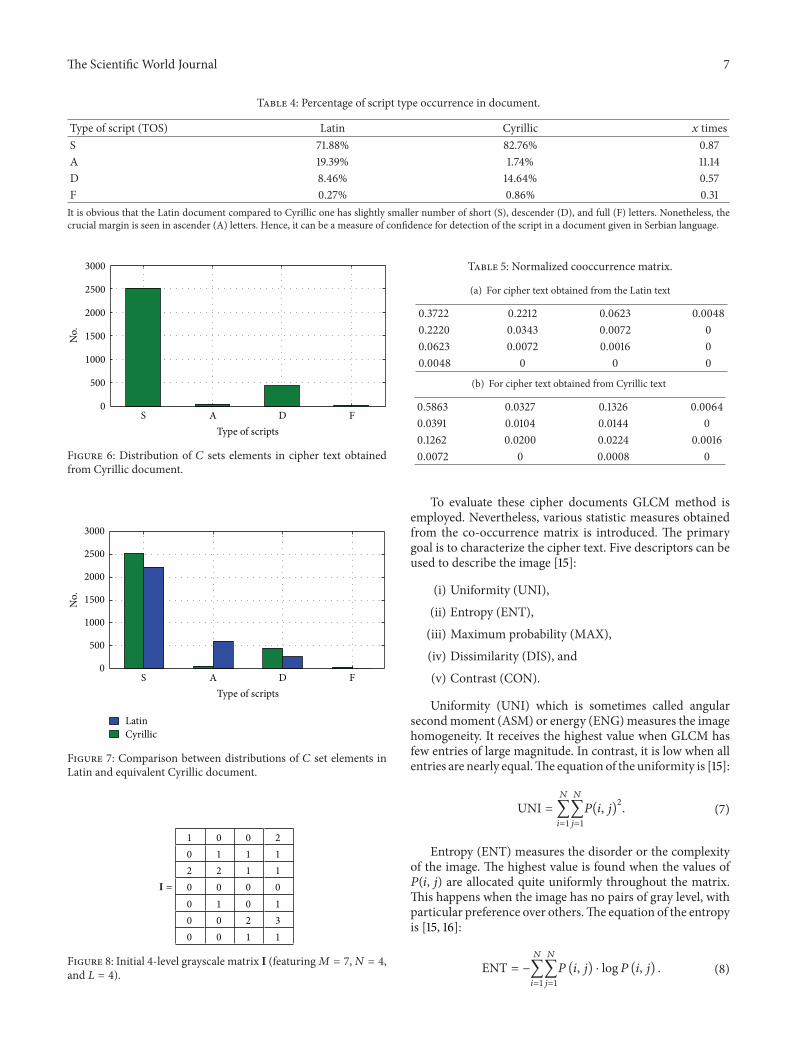
The Scientific World Journal 7
Table 4 Percentage of script type occurrence in document
Type of script (TOS) Latin Cyrillic 119909 timesS 7188 8276 087A 1939 174 1114D 846 1464 057F 027 086 031It is obvious that the Latin document compared to Cyrillic one has slightly smaller number of short (S) descender (D) and full (F) letters Nonetheless thecrucial margin is seen in ascender (A) letters Hence it can be a measure of confidence for detection of the script in a document given in Serbian language
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
No
Figure 6 Distribution of 119862 sets elements in cipher text obtainedfrom Cyrillic document
S A D F0
500
1000
1500
2000
2500
3000
Type of scripts
LatinCyrillic
No
Figure 7 Comparison between distributions of 119862 set elements inLatin and equivalent Cyrillic document
1 0 0 20 1 1 12 2 1 10 0 0 00 1 0 10 0 2 30 0 1 1
I =
Figure 8 Initial 4-level grayscale matrix I (featuring 119872 = 7 119873 = 4and 119871 = 4)
Table 5 Normalized cooccurrence matrix
(a) For cipher text obtained from the Latin text
03722 02212 00623 0004802220 00343 00072 000623 00072 00016 000048 0 0 0
(b) For cipher text obtained from Cyrillic text
05863 00327 01326 0006400391 00104 00144 001262 00200 00224 0001600072 0 00008 0
To evaluate these cipher documents GLCM method isemployed Nevertheless various statistic measures obtainedfrom the co-occurrence matrix is introduced The primarygoal is to characterize the cipher text Five descriptors can beused to describe the image [15]
(i) Uniformity (UNI)(ii) Entropy (ENT)(iii) Maximum probability (MAX)(iv) Dissimilarity (DIS) and(v) Contrast (CON)
Uniformity (UNI) which is sometimes called angularsecondmoment (ASM) or energy (ENG)measures the imagehomogeneity It receives the highest value when GLCM hasfew entries of large magnitude In contrast it is low when allentries are nearly equalThe equation of the uniformity is [15]
UNI =
119873
sum
119894=1
119873
sum
119895=1
119875(119894 119895)2 (7)
Entropy (ENT) measures the disorder or the complexityof the image The highest value is found when the values of119875(119894 119895) are allocated quite uniformly throughout the matrixThis happens when the image has no pairs of gray level withparticular preference over othersThe equation of the entropyis [15 16]
ENT = minus
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot log119875 (119894 119895) (8)
8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

8 The Scientific World Journal
j
i 0 1 2 3 0 6 4 2 0 6 4 2 0 621 421 221 0
1 2 4 0 0 2 4 0 0 221 421 0 02 0 1 1 1 0 1 1 1 0 121 121 1213 0 0 0 0 0 0 0 0 0 0 0 0
(a) (b) (c)
≫ ≫C = P =
Figure 9 Co-occurrence matrix for grayscale matrix I (119889 = 1 and 120579 = 0∘) (a)The number of occasions a pixel with an intensity 119868 is adjacent
to a pixel with intensity 119895 (b) Co-occurrence matrix C (c) Normalized matrix P
(a) (b)
(c) (d)
Figure 10 Document conversion (a) Original Cyrillic text (b) Cipher text obtained fromCyrillic text according to set 119862119873 (c) Original Latin
text (equivalent to Cyrillic one) (d) Cipher text obtained from Latin text according to set 119862119873
Maximum probability (MAX) extracts the most probabledifference between gray scale value in pixels It is defined as[15]
MAX = max 119875 (119894 119895) (9)Dissimilarity (DIS) is a measure of the variation in gray
level pairs of the image It depends on distance from the
diagonal weighted by its probability The equation of thedissimilarity is [15]
DIS =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot1003816100381610038161003816119894 minus 119895
1003816100381610038161003816 (10)
The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

The Scientific World Journal 9
(a) (b)
(c) (d)
Figure 11 Custom-oriented database (a) Printed document in Latin (b) Printed document in Cyrillic (c) Web document in Latin (d) Webdocument in Cyrillic
Contrast (CON) or inertia is a measure of the intensitycontrast between a pixel and its neighbor over the entireimage Hence it shows the amount of local variations presentin the image If the image is constant then the contrast willbe equal 0 The highest value of contrast is obtained whenthe image has random intensity and the pixel intensity and
neighbor intensity are very different The equation of thecontrast is [15 16]
CON =
119873
sum
119894=1
119873
sum
119895=1
119875 (119894 119895) sdot (119894 minus 119895)2 (11)
10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

10 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
100
01
02
03
04
05
06
07
08
09
DocumentsShortDescendingFull
x-ti
mes
(a)
0
2
4
6
8
10
12
14
16
18
Ascending
x-ti
mes
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
Figure 12 The ratio of the script type occurrence (a) short descending and full (b) ascending
Table 6 Cooccurrence descriptors for Latin and Cyrillic cipher text
Serbian language Latin Cyrillic CharacterizationUniformity (energy) 02459 03811 Latin lt CyrillicEntropy minus16298 minus14363 Latin gt CyrillicMaximum probability 03722 05863 Latin lt CyrillicDissimilarity 07356 06669 Latin gt CyrillicContrast 10423 12660 Latin lt CyrillicFrom the above results it is clear that co-occurrence descriptors can fully characterize the difference between Latin andCyrillic scriptThismeans that frequencyanalysis of the occurrence can be supplemented with additional attributes in order to define a strong margin as a criterion to distinguish a certain script
A brief look at the normalized co-occurrence matrix Pfor the same document written in Latin and Cyrillic scripts(text representing the excerpt of the first four paragraphsfrom a document given in Figure 10) shows quite a differentcharacterization The test results are given in Table 5
Furthermore the calculation of five co-occurrencedescriptors shows the values given in Table 6
3 Experiments
For the sake of the experiment a custom-oriented databaseis created It consists of 10 documents These documentsrepresent excerpts from printed and web documents writtenin Serbian language The documents are created in bothscripts Latin and Cyrillic Printed documents are createdfrom PDF documents while web documents are extractedfrom web news The total length of documents given inthe database is approx 75000 letter characters per script(approx 40 pages) The length of printed documents is from2273 to 15840 letter characters Web documents are smallercompared to printed documents Their length is from 1231 to2502 letter characters It should be noted that all documentshave more than 1000 letter characters The example of the
printed and web document from the database is shown inFigure 11
4 Results and Discussion
According to the proposed algorithm all documents fromthe database are converted into equivalent cipher texts andsubjected to the frequency and co-occurrence analysis Firstthe frequency analysis of the script type occurrence in Latinas well as in Cyrillic documents is examined (Table 7) Theobtained results for each document are given in Table 8
The final processing of the results is based on cumulativemeasures like sum average max and min of script typeoccurrence in the database According to that the criteria areestablished All these are shown in Table 9
From cumulative results given in Table 10 some criteriacan be established It can be noted that the biggest marginbetween results are seen in the ratio of ascending letters Thisratio has the value of at least 8 Hence it is the strongestpoint of qualitative characterization and recognition of thecertain script Furthermore the smaller number of short anddescending scripts are common in Latin compared to Cyrillicdocuments At the and full letters are quite rare in a Latindocument However its characterization in criteria form is
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
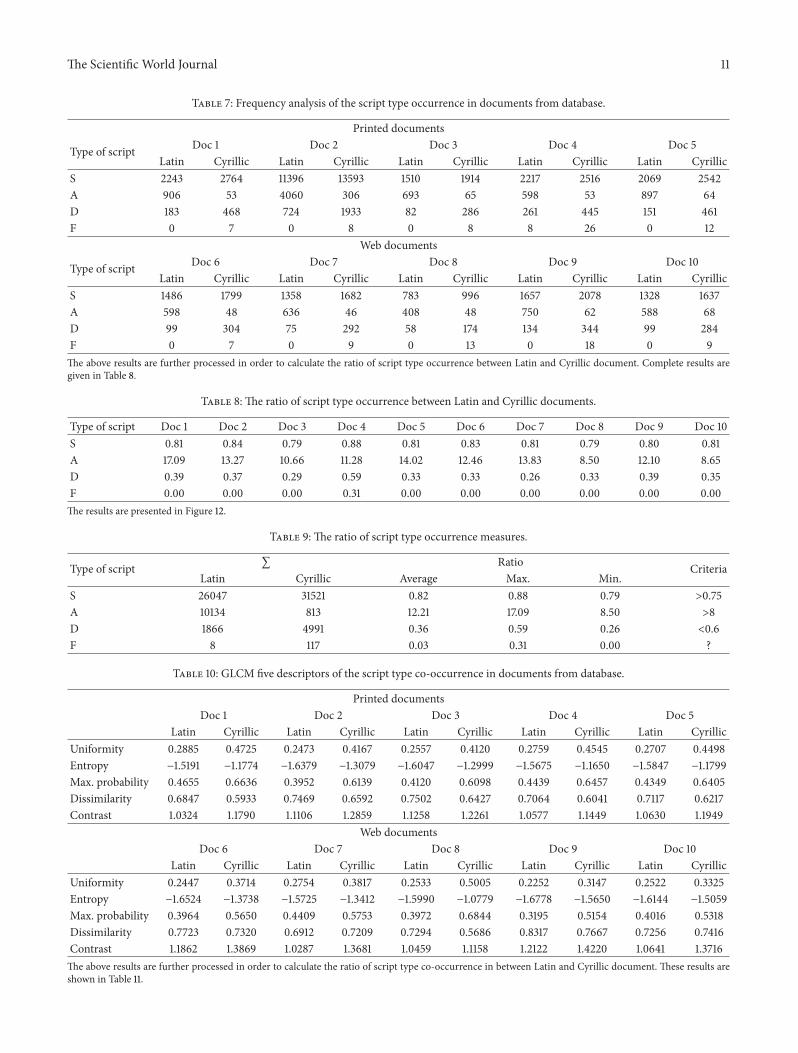
The Scientific World Journal 11
Table 7 Frequency analysis of the script type occurrence in documents from database
Printed documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 2243 2764 11396 13593 1510 1914 2217 2516 2069 2542A 906 53 4060 306 693 65 598 53 897 64D 183 468 724 1933 82 286 261 445 151 461F 0 7 0 8 0 8 8 26 0 12
Web documents
Type of script Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic
S 1486 1799 1358 1682 783 996 1657 2078 1328 1637A 598 48 636 46 408 48 750 62 588 68D 99 304 75 292 58 174 134 344 99 284F 0 7 0 9 0 13 0 18 0 9The above results are further processed in order to calculate the ratio of script type occurrence between Latin and Cyrillic document Complete results aregiven in Table 8
Table 8 The ratio of script type occurrence between Latin and Cyrillic documents
Type of script Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10S 081 084 079 088 081 083 081 079 080 081A 1709 1327 1066 1128 1402 1246 1383 850 1210 865D 039 037 029 059 033 033 026 033 039 035F 000 000 000 031 000 000 000 000 000 000The results are presented in Figure 12
Table 9 The ratio of script type occurrence measures
Type of script sum Ratio CriteriaLatin Cyrillic Average Max Min
S 26047 31521 082 088 079 gt075A 10134 813 1221 1709 850 gt8D 1866 4991 036 059 026 lt06F 8 117 003 031 000
Table 10 GLCM five descriptors of the script type co-occurrence in documents from database
Printed documentsDoc 1 Doc 2 Doc 3 Doc 4 Doc 5
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02885 04725 02473 04167 02557 04120 02759 04545 02707 04498Entropy minus15191 minus11774 minus16379 minus13079 minus16047 minus12999 minus15675 minus11650 minus15847 minus11799Max probability 04655 06636 03952 06139 04120 06098 04439 06457 04349 06405Dissimilarity 06847 05933 07469 06592 07502 06427 07064 06041 07117 06217Contrast 10324 11790 11106 12859 11258 12261 10577 11449 10630 11949
Web documentsDoc 6 Doc 7 Doc 8 Doc 9 Doc 10
Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin Cyrillic Latin CyrillicUniformity 02447 03714 02754 03817 02533 05005 02252 03147 02522 03325Entropy minus16524 minus13738 minus15725 minus13412 minus15990 minus10779 minus16778 minus15650 minus16144 minus15059Max probability 03964 05650 04409 05753 03972 06844 03195 05154 04016 05318Dissimilarity 07723 07320 06912 07209 07294 05686 08317 07667 07256 07416Contrast 11862 13869 10287 13681 10459 11158 12122 14220 10641 13716The above results are further processed in order to calculate the ratio of script type co-occurrence in between Latin and Cyrillic document These results areshown in Table 11
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
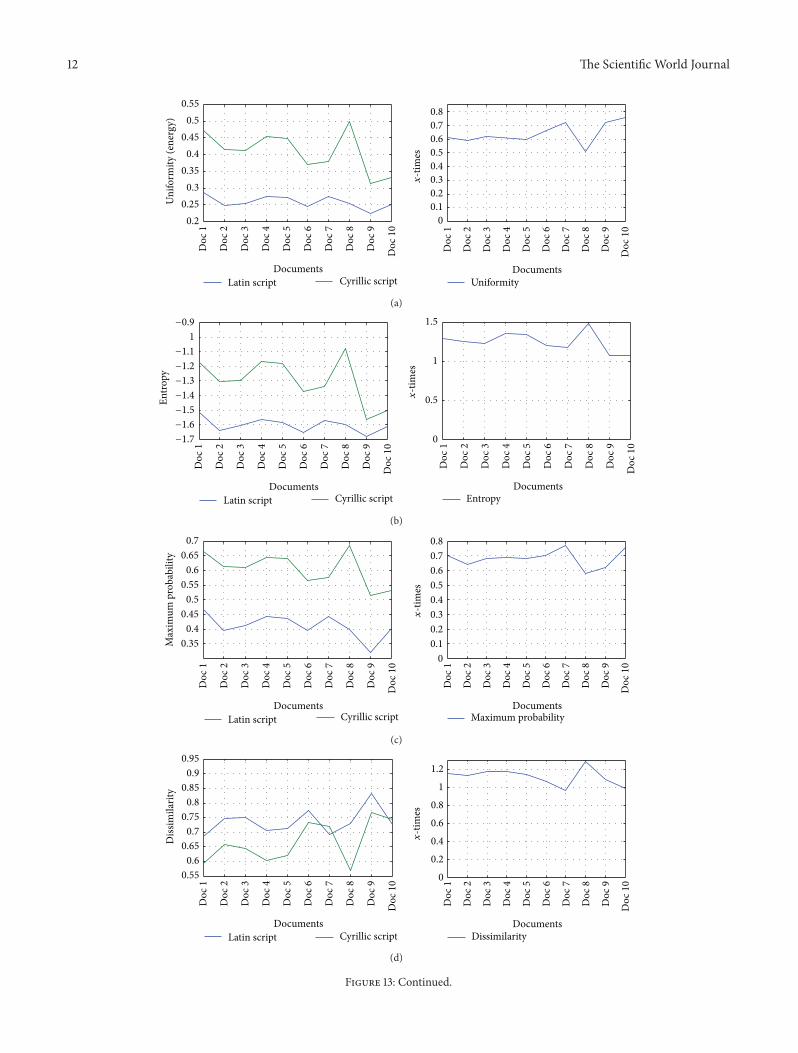
12 The Scientific World Journal
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
00102030405060708
DocumentsUniformity
x-ti
mes
02025
03035
04045
05055
Uni
form
ity (e
nerg
y)
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(a)
Entro
py
0
05
1
15
minus17
minus16
minus15
minus14
minus13
minus12
1
minus11
minus09
x-ti
mes
EntropyDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
(b)
03504
04505
05506
06507
Max
imum
pro
babi
lity
00102030405060708
x-ti
mes
Maximum probabilityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(c)
05506
06507
07508
08509
095
Diss
imila
rity
0
02
04
06
08
1
12
x-ti
mes
DissimilarityDocuments
Latin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(d)
Figure 13 Continued
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
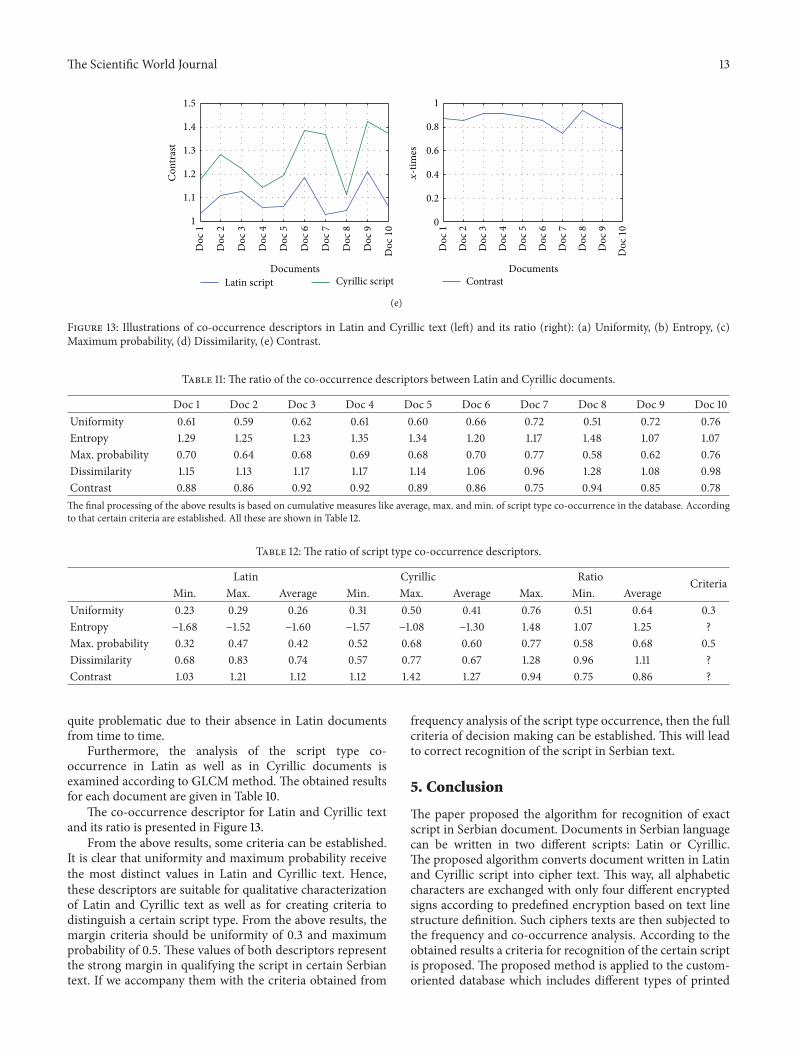
The Scientific World Journal 13
1
11
12
13
14
15
Con
tras
t
0
02
04
06
08
1
Contrast
x-ti
mes
DocumentsLatin script Cyrillic script
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
Documents
Doc
1
Doc
2
Doc
3
Doc
4
Doc
5
Doc
6
Doc
7
Doc
8
Doc
9
Doc
10
(e)
Figure 13 Illustrations of co-occurrence descriptors in Latin and Cyrillic text (left) and its ratio (right) (a) Uniformity (b) Entropy (c)Maximum probability (d) Dissimilarity (e) Contrast
Table 11 The ratio of the co-occurrence descriptors between Latin and Cyrillic documents
Doc 1 Doc 2 Doc 3 Doc 4 Doc 5 Doc 6 Doc 7 Doc 8 Doc 9 Doc 10Uniformity 061 059 062 061 060 066 072 051 072 076Entropy 129 125 123 135 134 120 117 148 107 107Max probability 070 064 068 069 068 070 077 058 062 076Dissimilarity 115 113 117 117 114 106 096 128 108 098Contrast 088 086 092 092 089 086 075 094 085 078The final processing of the above results is based on cumulative measures like average max and min of script type co-occurrence in the database Accordingto that certain criteria are established All these are shown in Table 12
Table 12 The ratio of script type co-occurrence descriptors
Latin Cyrillic Ratio CriteriaMin Max Average Min Max Average Max Min Average
Uniformity 023 029 026 031 050 041 076 051 064 03Entropy minus168 minus152 minus160 minus157 minus108 minus130 148 107 125 Max probability 032 047 042 052 068 060 077 058 068 05Dissimilarity 068 083 074 057 077 067 128 096 111 Contrast 103 121 112 112 142 127 094 075 086
quite problematic due to their absence in Latin documentsfrom time to time
Furthermore the analysis of the script type co-occurrence in Latin as well as in Cyrillic documents isexamined according to GLCM method The obtained resultsfor each document are given in Table 10
The co-occurrence descriptor for Latin and Cyrillic textand its ratio is presented in Figure 13
From the above results some criteria can be establishedIt is clear that uniformity and maximum probability receivethe most distinct values in Latin and Cyrillic text Hencethese descriptors are suitable for qualitative characterizationof Latin and Cyrillic text as well as for creating criteria todistinguish a certain script type From the above results themargin criteria should be uniformity of 03 and maximumprobability of 05 These values of both descriptors representthe strong margin in qualifying the script in certain Serbiantext If we accompany them with the criteria obtained from
frequency analysis of the script type occurrence then the fullcriteria of decision making can be established This will leadto correct recognition of the script in Serbian text
5 Conclusion
The paper proposed the algorithm for recognition of exactscript in Serbian document Documents in Serbian languagecan be written in two different scripts Latin or CyrillicThe proposed algorithm converts document written in Latinand Cyrillic script into cipher text This way all alphabeticcharacters are exchanged with only four different encryptedsigns according to predefined encryption based on text linestructure definition Such ciphers texts are then subjected tothe frequency and co-occurrence analysis According to theobtained results a criteria for recognition of the certain scriptis proposed The proposed method is applied to the custom-oriented database which includes different types of printed
14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

14 The Scientific World Journal
and web documents The experiment shows encouragingresults Possible applications can be seen in the area of webpage recognition
Future work will be toward the recognition of relatedlanguages as well as different languages written in the samescript
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this article (ldquoRecognition of theScript in Serbian Documents using Frequency Occurrenceand Co-occurrence Analysisrdquo by Darko Brodic Zoran NMilivojevic Cedomir A Maluckov)
References
[1] C Smith ldquoBasic cryptanalysis techniquesrdquo Tech Rep SANSInstitute 2001
[2] J Hoffstein J Pipher and J H Silverman An Introductionto Mathematical Cryptography Springer New York NY USA2008
[3] K Ruohonen ldquoMathematical cryptologyrdquo Lecture Notes 2010[4] A Zramdini and R Ingold ldquoOptical font recognition using
typographical featuresrdquo IEEE Transactions on Pattern Analysisand Machine Intelligence vol 20 no 8 pp 877ndash882 1998
[5] P Quaresma ldquoFrequency analysis of the Portuguese languagerdquoTR 2008003 University of Coimbra Portugal 2008
[6] R M Haralick K Shanmugam and I Dinstein ldquoTexturalfeatures for image classificationrdquo IEEE Transactions on SystemsMan and Cybernetics vol 3 no 6 pp 610ndash621 1973
[7] G Jaskiewicz ldquoAnalysis of letter frequency distribution inthe voynich manuscriptrdquo in Proceedings of the InternationalWorkshop (CSampP rsquo11) pp 250ndash261 Putusk Poland 2011
[8] S Cagnoni Evolutionary Image Analysis and Signal Processingvol 213 of Studies in Computational Intelligence SpringerBerlin Germany 2009
[9] R Nosaka C H Suryanto and K Fukui ldquoRotation invariantco-occurrence among adjacent LBPsrdquo in Proceedings of the 11thInternational Conference on Computer Vision (ACCV rsquo11) vol7088 of Lecture Notes in Computer Science pp 82ndash91 DaejeonRepublic of Korea 2011
[10] D A Clausi ldquoAn analysis of co-occurrence texture statistics as afunction of grey level quantizationrdquoCanadian Journal of RemoteSensing vol 28 no 1 pp 45ndash62 2002
[11] A Baraldi and F Parmiggiani ldquoInvestigation of the texturalcharacteristics associated with gray level cooccurrence matrixstatistical parametersrdquo IEEE Transactions on Geoscience andRemote Sensing vol 33 no 2 pp 293ndash304 1995
[12] F R Renzetti and L Zortea ldquoUse of a gray level co-occurrencematrix to characterize duplex stainless steel phases microstruc-turerdquo Frattura ed Integrita Strutturale vol 16 no 5 pp 43ndash512011
[13] R Susomboon D Raicu J Furst and T B Johnson ldquoA Co-occurrence texture semi-invariance to direction distance andpatient sizerdquo in Medical Imaging 2008 Image Processing vol6914 of Procedings of SPIE San Diego Calif USA February2008
[14] A Eleyan and H Demirel ldquoCo-occurrence matrix and itsstatistical features as a new approach for face recognitionrdquo
Turkish Journal of Electrical Engineering and Computer Sciencesvol 19 no 1 pp 97ndash107 2011
[15] D A Clausi and Y Zhao ldquoRapid extraction of image textureby co-occurrence using a hybrid data structurerdquoComputers andGeosciences vol 28 no 6 pp 763ndash774 2002
[16] R Jobanputra and D A Clausi ldquoPreserving boundaries forimage texture segmentation using grey level co-occurringprobabilitiesrdquo Pattern Recognition vol 39 no 2 pp 234ndash2452006
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Antennas andPropagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014