optimizing dataflow applications on heterogeneous environments
TRANSCRIPT

Noname manuscript No.(will be inserted by the editor)
Optimizing dataflow applications on heterogeneousenvironments
George Teodoro · Timothy D. R. Hartley ·
Umit V. Catalyurek · Renato Ferreira
Received: date / Accepted: date
Abstract The increases in multi-core processor par-allelism and in the flexibility of many-core accel-erator processors, such as GPUs, have turned tra-ditional SMP systems into hierarchical, heteroge-neous computing environments. Fully exploiting theseimprovements in parallel system design remains anopen problem. Moreover, most of the current toolsfor the development of parallel applications for hi-erarchical systems concentrate on the use of only asingle processor type (e.g., accelerators) and do notcoordinate several heterogeneous processors. Here,we show that making use of all of the heteroge-neous computing resources can significantly improveapplication performance. Our approach, which con-sists of optimizing applications at run-time by effi-ciently coordinating application task execution onall available processing units is evaluated in the con-text of replicated dataflow applications. The pro-posed techniques were developed and implementedin an integrated run-time system targeting both intra-and inter-node parallelism. The experimental resultswith a real-world complex biomedical applicationshow that our approach nearly doubles the perfor-mance of the GPU-only implementation on a dis-tributed heterogeneous accelerator cluster.
George Teodoro· Renato FerreiraDept. of Computer ScienceUniversidade Federal de Minas Gerais, BrazilTel.: +55-31-34095840E-mail:{george,renato}@dcc.ufmg.br
Timothy D. R. Hartley· Umit V. CatalyurekDepts. of Biomedical Informatics, andElectrical & Computer EngineeringThe Ohio State University, Columbus, OH, USATel.: +90-614-292-4778E-mail:{hartleyt, umit}@bmi.osu.edu
Keywords GPGPU· run-time optimizations·filter-stream
1 Introduction
An important current trend in computer architec-ture is increasing parallelism. This trend is turn-ing traditional distributed computing resources intohierarchical systems, where each computing nodemay have several multi-core processors. At the sametime, manufacturers of modern graphics processors(GPUs) have increased GPU programming flexibil-ity, garnering intense interest in using GPUs forgeneral-purpose computation; under the right cir-cumstances, GPUs perform significantly better thanCPUs. In light of these two trends, developers whowant to make full use of high-performance comput-ing (HPC) resources need to design their applica-tions to run efficiently on distributed, hierarchical,heterogeneous environments.
In this paper, we propose techniques to efficientlyexecute applications on heterogeneous clusters ofGPU-equipped, multi-core processing nodes. We eval-uate our method in the context of thefilter-streamprogramming model, a type of dataflow where ap-plications are decomposed into filters that may runon multiple nodes of a distributed system. The ap-plication processing occurs in the filters, and filterscommunicate with one another by using unidirec-tional logical streams. By using such a dataflowprogramming model, we expose a large number ofindependent tasks which can be executed concur-rently on multiple devices. In our filter-stream run-time system, filters are multithreaded, and can in-clude several implementations of their processingfunction, in order to target different processor types.

2
The speedup GPUs can achieve as compared toCPUs depends on the type of computation, amountof work, input data size, and application param-eters. Additionally, in the dataflow paradigm, thetasks generated to be performed by the filters toachieve the application’s goals are not necessarilyknown prior to execution. To support these types ofapplications, the decision about where to run eachtask has to be made at run-time, when the tasksare created. Our approach assigns tasks to devicesbased on the relative performance of that device,with the aim of optimizing the overall executiontime. While in previous work [39], we consideredintra-node parallelism, in the original version of thispaper [37] and here we consider both intra-nodeand inter-node parallelism. We also present new tech-niques for on-line performance estimation and han-dling data transfers between the CPU and the GPU.Our main contributions are:
– A relative performance estimation module forfilter-stream tasks based on their input parame-ters.
– An algorithm for efficiently coordinating datatransfers, enabling asynchronous data transfersbetween the CPU and the GPU;
– A novel stream communication policy for het-erogeneous environments that efficiently coor-dinates the use of CPUs and GPUs in clustersettings;
Although an important active research topic, gen-erating code for the GPU is beyond the scope of thispaper. We assume that the necessary code to runthe application on both the CPU and the GPU areprovided by the programmer and we focus on theefficient coordination of the execution on hetero-geneous environments, as most of the related workrelegates this problem to the programmer and ei-ther focuses only on the accelerator performance orassumes the speedup of the device is constant forall tasks. For GPU programming we refer to theCUDA [23] toolkit and mention other GPU pro-gramming research based on compiler techniques[18,26], specialized libraries [7,12,21], or appli-cations [34]. Also, though we focus on GPUs andCPUs, the techniques are adaptable for multiple dif-ferent devices.
The rest of the paper is organized as follows:in Section 2 we present our use case and motivat-ing application. Section 3 presents the Anthill, theframework used for evaluation of the proposed tech-niques, and how it has been extended to target mul-tiple devices. Section 4 presents our performanceestimation approach and Section 5 describes the run-
time optimizations. An extensive experimental eval-uation is presented in Section 6 and the conclusionsare summarized in Section 7.
2 Motivating application
For this work, our motivating application is the Neu-roblastoma Image Analysis System (NBIA), a real-world biomedical application developed by Sertelet al. [31]; we also will use this application to eval-uate the performance of our technique. Neuroblas-toma is a cancer of the sympathetic nervous systemaffecting mostly children. The prognosis of the dis-ease is currently determined by expert pathologistsbased on visual examination under a microscope oftissue slides. The slides can be classified into differ-ent prognostic groups determined by the differenti-ation grade of the neuroblasts, among other issues.
The process of manual examination by patholo-gists is error-prone and very time-consuming. There-fore, the goal of NBIA is to assist in the determina-tion of the prognosis of the disease by classifyingthe digitized tissue samples into different subtypesthat have prognostic significance. The focus of theapplication is on the classification of stromal devel-opment as either stroma-rich or stroma-poor, whichis one of the morphological criteria in the disease’sprognosis that contributes to the categorization ofthe histology as favorable and unfavorable [32].
Since the slide images can be very high reso-lution (over 100K x 100K pixels of 24-bit color),the first step in NBIA is to decompose the imageinto smaller image tiles that can be processed in-dependently. Next, the image analysis uses a multi-resolution strategy that constructs a pyramid rep-resentation [28], with multiple copies of each im-age tile from the decomposition step with differ-ent resolutions. As an example, a three-resolutionpyramid of an image tile could be constructed with(32 × 32), (128 × 128), and (512 × 512) images;each higher-resolution image is simply a higher-resolution version of the actual tile from the overallimage. NBIA analyzes each tile starting at the low-est resolution, and will process the higher-resolutionimages unless the classification satisfies some pre-determined criterion.
The classification of each is based on statisticalfeatures that characterize the texture of tissue struc-ture. To that end, NBIA first applies a color spaceconversion to the La*b* color space, where colorand intensity are separated, and enabling the use ofEuclidean distance for feature calculation. The tex-ture information is calculated using co-occurrencestatistics and local binary patterns (LBPs), which

3
Fig. 1 NBIA Flow Chart
help characterize the color and intensity variationsin the tissue structure. Finally, the classification con-fidence at a particular resolution is computed usinghypothesis testing; either the classification decisionis accepted or the analysis resumes with a higherresolution, if one exists. The result of the imageanalysis is a classification label assigned to eachimage tile indicating the underlying tissue subtype,e.g., stroma-rich, stroma-poor, or background. Fig-ure 1 shows the flowchart for the classification ofstromal development. More details on the NBIAcan be found in [31].
The NBIA application was originally implementedin the filter-stream programming model as a set offive components: (i) Image reader, which reads tilesfrom the disk; (ii) Color conversion, which con-verts image tiles from the RGB color space to theLa*b* color space; (iii) Statistical features, whichis responsible for computing a feature vector of co-occurrence statistics and LBPs; (iv) Classifier, whichcalculates the per-tile operations and conducts a hy-pothesis test to decide whether or not the classifi-cation is satisfactory; and (v) Start/Output, whichcontrols the processing flow. The computation startsby tiles at the lowest resolution, and only restartscomputations for tiles at a higher resolution if theclassification is insufficient, according to the Clas-sifier filter. This loop continues until all tiles havesatisfactory classifications, or they are computed atthe highest resolution. Since the Color conversionand Statistical feature filters are the most computa-tionally intensive, they were implemented for GPUs.For our experiments, we started from the originalimplementations of the neuroblastoma applicationsfor both GPU and CPU except that we utilize bothresources simultaneously at run-time. There is nosignificant difference in the application code, ourchanges only affect the run-time support libraries.
NBIA was chosen as our motivating applica-tion because it is an important real-world and com-plex classification system that we believe to have askeleton similar to a broad class of applications. Itsapproach to divide the image into several tiles thatcan be independently processed through a pipelineof operations is found, for instance, in several im-
age processing applications. Furthermore, the multi-resolution processing strategy which concurrentlygenerates tasks with different granularities duringthe execution time is also present in various researchareas as computer vision, image processing, medicine,and signal processing [13,15,22,28].
In our experience with the filter-stream program-ming model, most applications are bottleneck free,and the number of active internal tasks are higherthan the available processors [8,11,17,35,40,43].Thus, the proposed approach to exploit heteroge-neous resources consists of allocating multiple tasksconcurrently to processors where they will performthe best, as detailed in Section 3. Also, the com-putation time of applications’ tasks dominates theoverall application execution time, so the cost of thecommunication latency is offset by the speedups onthe computation. Although these premises are validfor a broad range of applications, there is also inter-esting work on linear algebra computation for mul-ticore processors [33], for instance, including het-erogeneous computing with GPUs [2], where theamount of application’s concurrent tasks are smallerthan the number of processors. The authors improvedapplication performance by using scheduling algo-rithms that take into account the task dependencies,in order to increase the number of concurrent ac-tive tasks, hence allowing them to take advantageof multicore systems.
3 Anthill
Anthill is a run-time system based on the dataflowmodel and, as such, applications are decomposedinto processing stages, calledfilters, which commu-nicate with each other using unidirectionalstreams.The application is then described as a multi-graphrepresenting the logical interconnection of the fil-ters [4]. At run time, Anthill spawns instances ofeach filter on multiple nodes of the cluster, whichare called transparent copies. Anthill automaticallyhandles run-time communication and state partition-ing among transparent copies [36].
4
When developing an application using the filter-stream model tasks and data parallelism are exposed.Task parallelism is achieved as the application isbroken up in a set of filters, which independentlyperform their specific transformations in a pipelinefashion. Data parallelism, on the other hand, can beobtained by creating multiple (transparent) copiesof each filter and dividing the data to be processedamong them. In Figure 2 we show a typical Anthillapplication.
Fig. 2 Anthill Application
The filter programming abstraction provided byAnthill is event-oriented. The programmer providesfunctions that match input buffers from the multi-ple streams to a set of dependencies, creating eventqueues. Anthill run-time controls the non-blockingI/O issues that are necessary. This approach derivesheavily from the message-oriented programming model [6,24,42].
The programmer also provides handling func-tions for each of the events on a filter which are au-tomatically invoked by the run-time. These events,in the dataflow model, amount to asynchronous andindependent tasks and as the filters are multithreaded,multiple tasks can be spawned provided there arepending events and compute resources. This featureis essential in exploiting the full capability of cur-rent multicore architectures, and in heterogeneousplatforms it is also used to spawn tasks on multipledevices. To accomplish that, Anthill allows the userto provide for the same event multiple handlers foreach specific device.
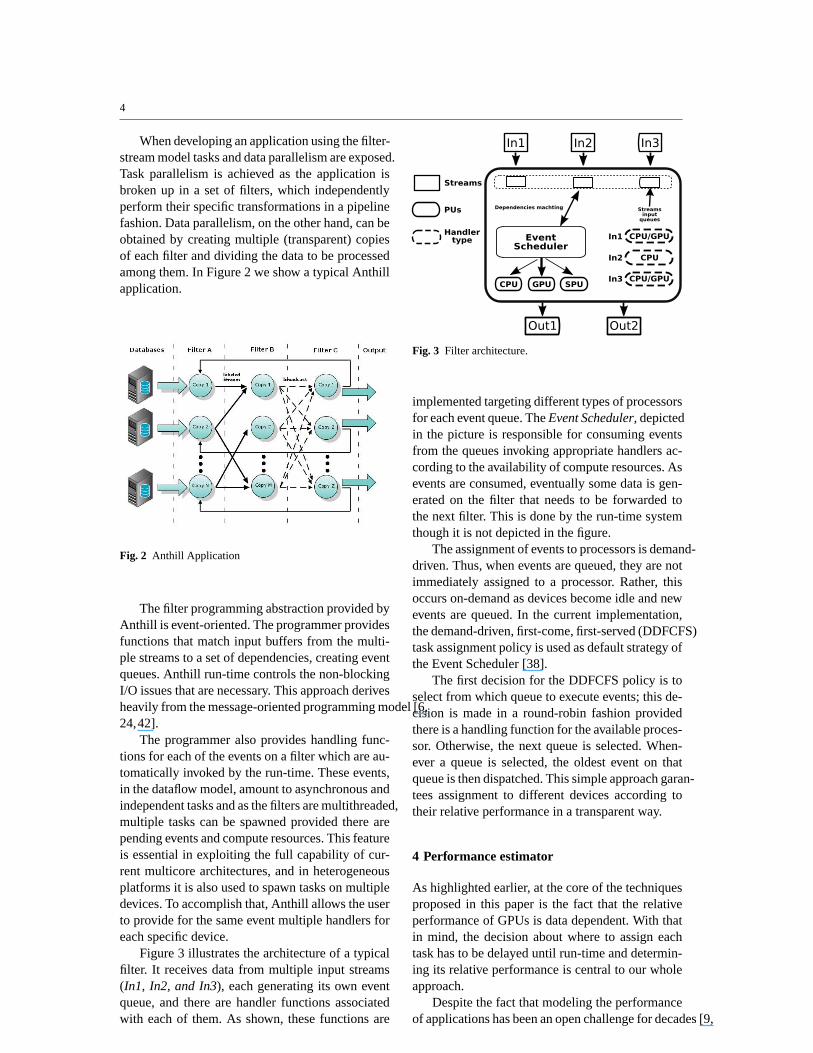
Figure 3 illustrates the architecture of a typicalfilter. It receives data from multiple input streams(In1, In2, and In3), each generating its own eventqueue, and there are handler functions associatedwith each of them. As shown, these functions are
Fig. 3 Filter architecture.
implemented targeting different types of processorsfor each event queue. TheEvent Scheduler, depictedin the picture is responsible for consuming eventsfrom the queues invoking appropriate handlers ac-cording to the availability of compute resources. Asevents are consumed, eventually some data is gen-erated on the filter that needs to be forwarded tothe next filter. This is done by the run-time systemthough it is not depicted in the figure.
The assignment of events to processors is demand-driven. Thus, when events are queued, they are notimmediately assigned to a processor. Rather, thisoccurs on-demand as devices become idle and newevents are queued. In the current implementation,the demand-driven, first-come, first-served (DDFCFS)task assignment policy is used as default strategy ofthe Event Scheduler [38].
The first decision for the DDFCFS policy is toselect from which queue to execute events; this de-cision is made in a round-robin fashion providedthere is a handling function for the available proces-sor. Otherwise, the next queue is selected. When-ever a queue is selected, the oldest event on thatqueue is then dispatched. This simple approach garan-tees assignment to different devices according totheir relative performance in a transparent way.
4 Performance estimator
As highlighted earlier, at the core of the techniquesproposed in this paper is the fact that the relativeperformance of GPUs is data dependent. With thatin mind, the decision about where to assign eachtask has to be delayed until run-time and determin-ing its relative performance is central to our wholeapproach.
Despite the fact that modeling the performanceof applications has been an open challenge for decades [9,

5
16,41], we believe the use of relative fitness to mea-sure performance of the same algorithm or work-load running on different devices is accurate enough,and is far easier to predict than execution times.However, this task should not be left to the appli-cation programmer, but rather, should be part of thesystem and so we propose thePerformance Estima-tor.
The proposed solution, depicted in Figure 4, usesa two-phase strategy. In the first phase, when a newapplication is implemented, it is benchmarked fora representative workload and the execution timesare stored. The profile generated in this phase con-sists of the application input parameters, targeteddevices and execution times, and construes a train-ing dataset that is used during the actual perfor-mance prediction.
Fig. 4 Anthill relative performance estimator.
The second phase implements a model learn-ing algorithm, and can employ different strategiesto estimate the targeted relative performance. How-ever, it is important to notice that modeling the be-havior of applications based on their inputs is be-yond any basic regression models. Also, it is be-yond the scope of this paper to study this specificproblem and propose a final solution. Rather, wepropose an algorithm which we have validated ex-perimentally and which was shown to yield suffi-cient accuracy for our decision making.
Our algorithm uses kNN [10] as the model learn-ing algorithm. When a new application task is cre-
ated, thek nearest executions in our profile are re-trieved based on a distance metric on the input pa-rameters and their execution times are averaged andused to compute the relative speedup of the taskon the different processors. The employed distancemetric for the numeric parameters first normalizesthem, dividing each value by the highest value ofeach dimension, and then uses an Euclidian dis-tance. The non-numeric attributes, on the other hand,gives a distance of 0 to attributes with completematch, or 1 otherwise.
For the purpose of evaluating the effectivenessof the Performance Estimator, we evaluated six rep-resentative applications (described in Table 1) withthe technique discussed above. The evaluation hastwo main purposes: (i) to understand if the pro-posed technique performs an acceptable estimation;and, (ii) to discuss our insights that relative perfor-mance (speedup) is easier to predict sufficiently ac-curately than execution times. The results shownwere obtained by performing a first-phase bench-mark using a workload of 30 jobs, which are ex-ecuted on both the CPU and the GPU. The esti-mator errors are calculated using a 10-fold cross-validation, andk = 2 was utilized as it achievednear-best estimations for all configurations.
The average speedup error for each applicationis shown in Table 1. First of all, our methodology’saccuracy was high, since the worst-case error is nothigher than 14%, while the average error among allthe applications is only 8.52%. In our use case ap-plication, whose accuracy was about average, thiserror level does not impact the performance becauseit is sufficient to maintain the optimal order of thetasks. We also used the same approach to estimatetask execution times for the CPU, using the sameworkload as before. During this second evaluation,we simply computed the predicted execution timesas the average of thek nearest samples’ executiontimes. The CPU execution time error is also shownin the same table; those errors are much higher thanthe speedup errors for all applications, although thesame prediction methodology is employed.
This empirical evaluation is interesting for dif-ferent reasons: (i) as our task assignment relies onrelative performance estimation, it should performbetter for this requirement than for time-based strate-gies; (ii) the speedup can also be used to predictexecution times of an application in different run-time environments. For instance, if the executiontime in one device is available, the time in a sec-ond processor could be calculated utilizing the rel-ative performance between them. The advantage ofthis approach is that the estimated execution time

6
Benchmark Speedup avg. error (%) CPU Time avg. error (%) Description App. source
Black-Scholes 2.53 70.50 European option price CUDA SDK [23]N-body 7.34 11.57 Simulate bodies iterations CUDA SDK [23]
Heart Simulation 13.79 41.97 Simulate electrical heart activity [27]kNN 8.76 21.18 Find k-nearest neighbors Anthill [38]Eclat 11.32 102.61 Calculate frequent itemsets Anthill [38]
NBIA-component 7.38 30.35 Neuroblastoma (Section 2) [11,29]
Table 1 Evaluating the performance estimator prediction.
error would be equal to the error of the predictedspeedup.
We believe that relative performance is easier topredict, because it abstracts effects like conditionalstatements or loop breaks that highly affect the ex-ecution time modeling. Moreover, the relative per-formance does not try to model the application it-self, but the differences between devices when run-ning the same program.
5 Performance optimizations
In this section we discuss several run-time tech-niques for improving the performance of replicateddataflow computations, such as filter-stream appli-cations, on heterogeneous clusters of CPU- and GPU-equipped machines. First, we present our approachto reduce the impact of data transfers between theCPU and the GPU by using CUDA’s asynchronouscopy mechanism. Next, in Section 5.2, we presenta technique to better coordinate CPU and GPU uti-lization. Lastly, in Section 5.3, we propose a novelstream communication policy that improves the per-formance of heterogeneous clusters, where com-puting nodes have different processors, by coordi-nating the task assignment.
5.1 Improving CPU/GPU data transfers
The limited bandwidth between the CPU and theGPU is a critical barrier for efficient execution ofGPU kernels, where for many applications the costof data transfer operations is comparable to the com-putation time [34]. Moreover, this limitation hasstrongly influenced application design, increasingthe programming challenges.
An approach to reduce GPU idle time duringdata transfers is to overlap the them with usefulcomputation. Similar solutions have been used inother scenarios, where techniques such as doublebuffering are used to keep processors busy whiledata is transferred among memory hierarchies ofmulticore processors [30]. The approach employedin this work is also based on the overlapping of
communication and computation, but on NVidia GPUsdouble buffering may not be the most appropriatetechnique because these devices allow multiple con-current transfers among CPU and GPU. Moreover,in all but the most recent GPUs, prior to the newNVidia Fermi GPUs in its Tesla version, these con-current transfers are only possible in one direction,from CPU to GPU or from GPU to CPU; two con-current transfers in different directions are not sup-ported. Thus, the problem of providing efficient datatransfer becomes challenging, as the performancecan only be improved up to a saturation point by in-creasing the number of concurrent transfers. Unfor-tunately, the optimal number of concurrent trans-fers varies according to the computation/communicationrates of the tasks been processed and the size of thetransferred data. We show this empirically in Sec-tion 6.2.
The solution of overlapping communication withcomputation to reduce processor idle time consistsof assigning multiple concurrent processing eventsto the GPU, overlapping the events’ data transferswith computation, and determining the number ofevents that maximizes the application performance.We assume that the data to be copied from the CPUto the GPU are the data buffers received through thefilter input streams. For the cases where the GPUkernel’s input data is not self-contained in the re-ceived data buffers, the copy/format function canbe rewritten according to each filter’s requirements.
After copying the GPU kernel’s input data tothe GPU, and after running the kernel, it is typi-cally necessary to copy the output results back tothe CPU and send them downstream. During thisstage, instead of copying the result itself, the pro-grammer can use the Anthill API to send the outputdata to the next filter, passing the address of the dataon the GPU to the run-time environment. With thepointer to this data, Anthill can transparently startan asynchronous copy of the data back to the CPUbefore sending it to the next filter. It is also impor-tant to highlight that our asynchronous copy mech-anism uses the Stream API of CUDA SDK [23],and that each Anthill event is associated with a sin-gle CUDA stream.

7
Algorithm 1 Algorithm to control the CPU/GPUdata transfers
concurrentEvents = 2; streamStepSize = 2;stopExponetialGrowth = 0;while notEndOfWork do
for i := 0, eventId = 0; i< concurrentEvents; i++doif event← tryToGetNewEvent()then
asyncCopy(event.data, event.GPUData, ...,event.cuStream)activeEvents.insert(eventId++, event)
end ifend forfor i := 0; i < activeEvents.size; i++do
proc(event[i])end forfor i := 0; i < activeEvents.size; i++do
event← activeEvents.getEvent(i)waitStream(event.cuStream)asyncCopy(event.outGPUData, event.outData, ...,event.cuStream)
end forfor i := 0; i < activeEvents.size; i++do
event← activeEvents.getEvent(i)waitStream(event.cuStream)send(event)activeEvents.remove[i]
end forcurThroughput← calcThroughput()if currentThroughput> lastThroughputthen
concurrentEvents += streamStepSize;if stopExponetialGrowth6= 1 then
streamStepSize *= 2;end if
end ifif curThroughput< lastThroughput &concurrentEvents> 2 then
if streamStepSize> 1 thenstreamStepSize /=2 ;
end ifif stopExponetialGrowth== 0 then
stopExponetialGrowth = 1;streamStepSize /=2 ;
end ifconcurrentEvents -= streamStepSize;
end ifend while
Because application performance can be dra-matically influenced by GPU idle time, we proposean automated approach to dynamically configurethe number of concurrent, asynchronous data copiesat run-time, according to the GPU tasks’ perfor-mance characteristics. Our solution is based on anapproach that changes the number of concurrentevents assigned to the GPU according to the through-put of the application. Our algorithm (Algorithm 1)starts with two concurrent events and increases thenumber until the GPU’s throughput begins to de-crease. The previous configuration is then saved,and with the next set of events, the algorithm con-tinues searching for a better number of concurrentdata copies by starting from the saved configura-
tion. In order to quickly find the saturation point,the algorithm increases the number of concurrentdata copies exponentially until the GPU throughputbegins to decrease. Thereafter, the algorithm makesa binary search for the best configuration betweenthe current and last value ofconcurrentEvents.After that phase, it simply makes changes by oneconcurrent data copy at a time.
Most of the recent NVidia GPUs only allowconcurrent transfers in one direction, our algorithmhas been designed with this in mind. To maximizeperformance given this limitation, it schedules mul-tiple concurrent transfers from the CPU to the GPU,executes the event processing, and finally sched-ules all transfers of the data back to the CPU. Abarrier is used at the end of this processing chainto stop concurrent transfers in different directionsfrom occurring. If data transfers in each directionare not grouped, the asynchronous, concurrent datacopy mechanism is not used, and the GPU driverdefaults to the slower synchronous copy version.
The new NVidia Fermi GPUs, on the other hand,have added the capability to handle multiple datatransfers in both directions concurrently, from CPUto GPU and GPU to CPU, with dual overlappedmemory transfer engines. Thus, when using thesenewer processors, it possible to exploit the trans-fer mechanism without grouping data transfers ineach direction, as is done in our three loop algo-rithm shown before. However, the proposed algo-rithm to dynamically control the number of con-current data being transferred/processed is still use-ful for Fermi Tesla GPUs, as this value still im-pacts the performance. Thus, when using these newGPUs, the three loops from the original algorithmcan be merged into a single loop, since it is possibleto have asynchronous transfers in both directions.Although not shown in the algorithm, we guaran-tee that the number ofconcurrentEvents is neversmaller than 1, and its maximum size is boundedby the available memory.
5.2 Intra-filter task assignment
The problem of assigning tasks in heterogeneousenvironments has been the target of research for along time [1–3,5,14,15,19]. Recently, with the in-creasing ubiquity of GPUs in mainstream comput-ers, the scientific community has examined the useof nodes with CPUs and GPUs in more detail. InMars [12], an implementation of the MapReduceprogramming model for CPU- and GPU-equippednodes, the authors evaluate the collaborative use ofCPUs and GPU where the Map and Reduce tasks

8
are divided among them, when using a fixed rel-ative performance between the devices. The Qilinsystem [21] argues that the processing rates of sys-tem processors depend on the input data size. Bygenerating a model of the processing rates for eachof the processors in the system during a trainingphase, Qilin determines how best to split the workamong the processors for successive executions ofthe application, considering that application inter-nal tasks have the same relative performance. How-ever, for certain classes of applications, such as ourimage analysis application, the processing rates ofthe various processors are data-dependent, meaningthat such a static partitioning will not be optimal forthese cases.
Indeed, in dataflow applications, there are manyinternal tasks which can exhibit these data-dependentperformance variations, and we experimentally showthat taking these variations into account can signifi-cantly improve application performance. Heteroge-neous processing has been previously studied [15],but in this work the authors target methods to mapand schedule tasks onto heterogeneous, parallel re-sources where the task execution times do not varyaccording to the data. Here, we show that this data-dependent processing rate variability can be lever-aged to give applications extra performance.
In order to exploit this intra-filter task hetero-geneity, we then proposed and implemented a taskassignment policy, called demand-driven dynamicweighted round-robin (DDWRR) [39] in the AnthillEvent Schedulermodule, previously shown in Sec-tion 3. As in DDFCFS, the assignment of eventsto devices is demand-driven: the ready-to-executetasks are shared among the processors inside a sin-gle node and are only assigned when a processorbecomes idle, and the first step of selecting fromwhich stream to process events is done in round-round fashion.
The main difference between DDWRR and DDFCFSis in the second phase, when an event is chosenfrom the selected stream. In this phase, DDWRRchooses events according to a per-processor weightthat may vary during the execution time. This valueis the computed estimation of the event’s perfor-mance when processed by each device. For exam-ple, this value could be the event’s likely executiontime speedup for this device when compared to abaseline processor (e.g., the slowest processor inthe system). During the execution, this weight isthen used to order ready-to-execute events for eachdevice. The employed ordering sorts events fromhighest to lowest weight for each device. As thespeedup of all tasks of the baseline processor is 1,
tasks with the same speedup are ordered addition-ally using the inverse value of the best speedup theyachieve in any of the available devices. The ideais that if a given processorX can choose amonga set of tasks with the same speedup, the selectedtask should have the worst performance when pro-cessed in any of other available devices of the sys-tem should be selected.
Figure 5 presents the DDWRR tasks orderingfor 5 tasks:t1, t2, t3, t4 andt5, created in this or-der in a given filter instance. As shown, for the CPUbaseline processor, the tasks’ relative performanceis 1. The GPU queue is built inserting tasks in de-creasing order according to the speedup over thebaseline CPU processor. Therefore, sincet1 andt3 have the same relative performance, the oldestcreated task (t1) is inserted first. The CPU queue,meanwhile, uses the inverse of GPU speedup tocreate its ordering, as all tasks have the same CPUrelative performance because it is the baseline. Giventhe task ordering shown in the figure, during execu-tion when a certain processor is available, the firstevent in the queue for this type of device is chosen,and the selected task is removed from other queues.
Fig. 5 DDWRR: task ordering per device type, having CPUas baseline processor.
Therefore, DDWRR assigns events in an out-of-order fashion, but instead of using it for specu-lative execution or to reduce the negative impact ofdata dependencies [25], it is used to sort the eventsaccording to their suitability for each device. It isalso important to highlight that DDWRR does notrequire an exact speedup value for each task be-cause it is only necessary to have a relative orderingof events according to their performance. The esti-

9
mator described in Section 4 has sufficient accuracyfor our purposes.
5.3 Inter-filter optimizations: on-demand dynamicselective stream
On distributed systems, performance is heavily de-pendent upon the load balance as the overall exe-cution time is that of the slowest node. Our previ-ous techniques deal only with the events receivedin a single instance of a filter. To optimize globally,however, when there are multiple instances of a fil-ter, we need to consider which of those instancesshould receive and process the messages we send.
We present a novel stream communication pol-icy to optimize filter-stream computations on dis-tributed, heterogeneous, multi-core, multi-acceleratorcomputing environments. To fully utilize and achievemaximum performance on these systems, filter-streamapplications have to satisfy two premises that mo-tivate the proposed policy:(i) the number of databuffers at the input of each filter should be highenough to keep all the processors busy, making itpossible to exploit all of the available resources, butnot so high as to create a load imbalance amongfilter instances;(ii) the data buffers sent to a filtershould maximize the performance of the processorsallocated to that filter instance.
Based on these premises, we propose an on-demand dynamic selective stream (ODDS) policy.This stream policy implements ann×m on-demanddirected communication channel fromn instancesof a producer filterFi to m instances of a con-sumer filterFj . As such, ODDS implements a pol-icy where each instance of the receiver filterFj canconsume data at different rates according to its pro-cessing power.
Because instances ofFj can consume data atdifferent rates, it is important to determine the num-ber of data buffers needed by each instance to keepall processors fully utilized. Moreover, as discussedpreviously, the number of buffers kept in the queueshould be as short as possible to avoid load imbal-ance across computing nodes. These two require-ments are obviously contradictory, which poses aninteresting challenge. Additionally, the ideal num-ber of data buffers in the filter’s input queue may bedifferent for each filter instance and can change asthe application execution progresses. Not only dothe data buffers’ characteristics change over time,but the communication times can vary due to theload of the sender filter instances, for example. ODDSis comprised of two components: Dynamic Queue
Adaptation Algorithm (DQAA) and Data Buffer Se-lection Algorithm (DBSA). DQAA is responsiblefor premise(i), where as DBSA is responsible forpremise(ii). In the next two subsections we de-scribe these two algorithms in more detail.
5.3.1 Dynamic Queue Adaptation Algorithm(DQAA)
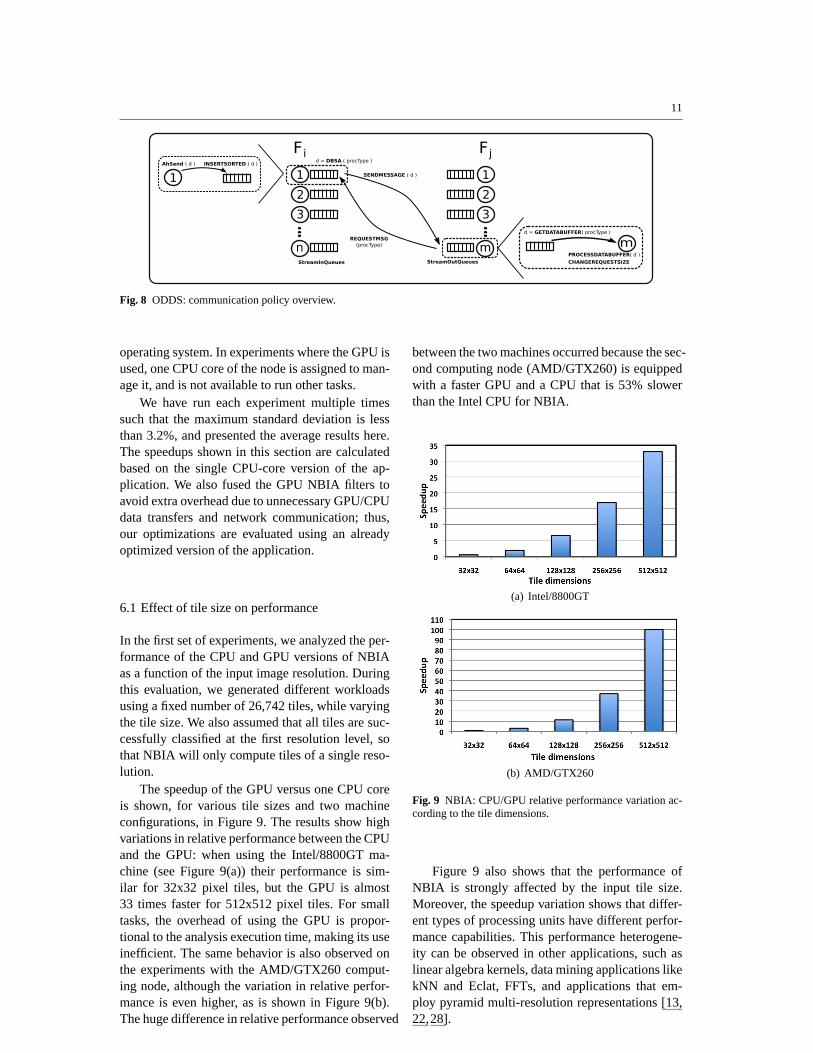
Our solution to control the queue size on the re-ceiver side derives from concepts developed by Brakmo etal. for TCP Vegas [20], a transport protocol whichcontrols flow and congestion in networks by contin-uously measuring network response (packet roundtrip times) and adjusting the transmission window(number of packets in transit). For our purposes,we continuously measure both the time it takes fora request message to be answered by the upstreamfilter instance and the time it takes for a processorto process each data buffer, as detailed in Figure 6.Based on the ratio of the request response time tothe data buffer processing time, we decide whetherthe length of theStreamRequestSize (the num-ber of data buffers assigned to a filter instance, whichincludes those data buffers being transferred, al-ready received and queued) must be increased, de-creased or left unaltered. The alterations are the re-sponsibility of the threadThreadWorker , that com-putes its target request size after finishing the pro-cessing of each of its data buffers and updates thecurrent request size if necessary.
In parallel, theThreadRequesterthread observesthe changes in therequestsize and the target streamrequest size for eachThreadWorker . Wheneverthe requestSize falls below the target value, in-stances of the upstream filter are contacted to re-quest more data buffers, which are received andstored in the filterStreamOutQueue. While theserequests occur for eachThreadWorker , theStream-OutQueue creates a single queue with the receiveddata buffers. Once all of the buffers residing in thesharedStreamOutQueue have been received, thequeue also maintains a queue of data buffer pointersfor each processor type, sorted by the data buffers’speedup for that processor.
5.3.2 Data Buffer Selection Algorithm (DBSA)
Our approach for selecting a data buffer to senddownstream is based on the expected speedup valuewhen a given data buffer is processed by a certaintype of processor. This algorithm is similar to theone described earlier to select a task for a given de-vice, and it also relies on the Performance Estima-tor to accomplish that.

10
Algorithm 2 ThreadWorker (proctype, tid)for all proctype, targetrequestsize(tid) = 1,requestsize(tid) = 0 do
while notEndOfWork doif |StreamOutQueue(proctype)| > 0 then
d←GETDBUFFER(StreamOutQueue(proctype))requestsize(tid)−−timetoprocess← PROCESSDATA BUFFER(d)targetlength← requestlatency
timetoprocess
if targetlength > |targetrequestsize(tid)| thentargetrequestsize(tid) + +
end ifif targetlength < |targetrequestsize(tid))|then
targetrequestsize(proctype)−−end if
end ifend while
end for
Algorithm 3 ThreadRequester (proctype,tid)while notEndOfWork do
while |requestsize(tid)| < targetrequestsize(tid) dop← CHOOSESENDER (proctype)sendtime← TIMENOW ( )SENDMESSAGE(REQUESTMSG(proctype),p)m← RECEIVEMESSAGE(p)recvtime← TIMENOW ( )if m 6= ∅ then
d← m.data
INSERT(StreamOutQueue, d)requestlatency ← recvtime− sendtime
requestsize(tid) + +end if
end whileend while
Fig. 6 Receiver Threads
Whenever an instance of filterFj demands moredata from its input stream, the request includes in-formation about the processor type which causedthe request to be issued (because, according to Fig-ure 6, theThreadRequesterwill generate specificrequest messages for each event handler thread).Upon receipt of the data request, the upstream filterinstance will select, from among the queued databuffers, the best suited for that processor type.
The algorithm we propose, which runs on thesender side of the stream, maintains a queue of databuffers that is kept sorted by the speedup for eachtype of processor versus the baseline processor. Whenthe instance ofFi which received a request choosesand sends the data buffer with the highest speedupto the requesting processor, it removes the samebuffer from all other sorted queues. On the receiverside, as stated above, a shared queue is used to min-
Algorithm 4 ThreadBufferQueuerwhile notEndOfWork do
if StreamInQueue 6= ∅ thend← GETDATA BUFFER(StreamInQueue)INSERTSORTED(d,SendQueue)
end ifend while
Algorithm 5 ThreadBufferSenderwhile notEndOfWork do
if ∃requestmsg thenproctype← requestmsg.proctype
requestor ← requestmsg.sender
d← DBUFFERSELECTALG(SendQueue,proctype)SENDMESSAGE(DATA MSG(d),requestor)
end ifend while
Fig. 7 Sender Threads
imize the load imbalance between the processorsrunning in the system.
In Figure 7, we show the operation of DBSA.The threadThreadBufferQueuer is activated eachtime the filterFi’s instance sends a data buffer throughthe stream. It inserts the buffer in theSendQueue
of that node with the computed speedups for eachtype of processor. Whenever a processor runningan instance ofFj requests a data buffer from thatfilter instanceFi, the threadThreadBufferSenderprocesses the request message, executes DBSA andsends the selected data buffer to the requesting fil-terFj . Figure 8 shows an overview of the proposedstream policy, including messages exchanged whendata is requested from filterFj to Fi, and the algo-rithms executed on each side to control data buffersqueue sizes.
6 Experimental Results
We have carried out our experiments on a 14-nodePC cluster. Each node is equipped with one 2.13 GHzIntel Core 2 Duo CPU, 2 GB main memory, and asingle NVIDIA GeForce 8800GT GPU. The clusteris interconnected using switched Gigabit Ethernet(Intel/8800GT). We have also executed some ex-periments on single compute nodes, the first beingequipped with dual quad-core AMD Opteron 2.00 GHzprocessors, 16 GB of main memory, and a NVidiaGeForce GTX260 GPU (AMD/GTX260). The sec-ond single node, equipped with a dual NVidia TeslaC2050, has been used to evaluate the dual over-lapped memory transfer engines available on thisFermi based GPU. All of these systems use the Linux
11
Fig. 8 ODDS: communication policy overview.
operating system. In experiments where the GPU isused, one CPU core of the node is assigned to man-age it, and is not available to run other tasks.
We have run each experiment multiple timessuch that the maximum standard deviation is lessthan 3.2%, and presented the average results here.The speedups shown in this section are calculatedbased on the single CPU-core version of the ap-plication. We also fused the GPU NBIA filters toavoid extra overhead due to unnecessary GPU/CPUdata transfers and network communication; thus,our optimizations are evaluated using an alreadyoptimized version of the application.
6.1 Effect of tile size on performance
In the first set of experiments, we analyzed the per-formance of the CPU and GPU versions of NBIAas a function of the input image resolution. Duringthis evaluation, we generated different workloadsusing a fixed number of 26,742 tiles, while varyingthe tile size. We also assumed that all tiles are suc-cessfully classified at the first resolution level, sothat NBIA will only compute tiles of a single reso-lution.
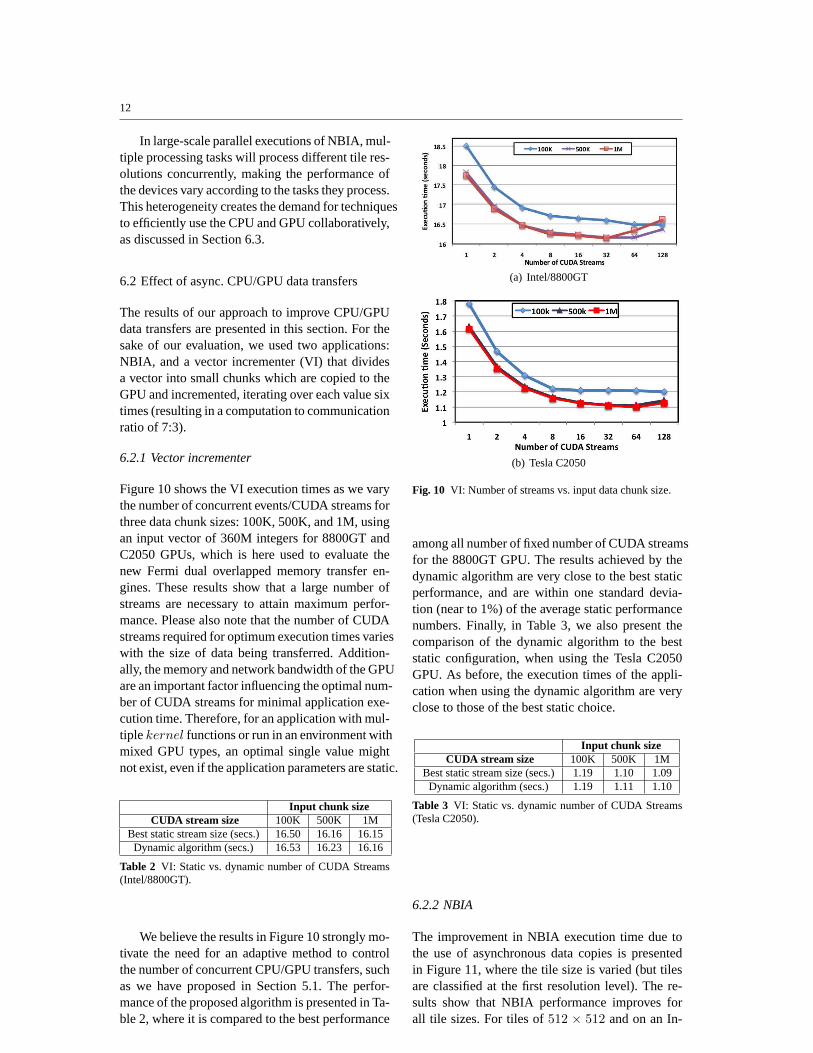
The speedup of the GPU versus one CPU coreis shown, for various tile sizes and two machineconfigurations, in Figure 9. The results show highvariations in relative performance between the CPUand the GPU: when using the Intel/8800GT ma-chine (see Figure 9(a)) their performance is sim-ilar for 32x32 pixel tiles, but the GPU is almost33 times faster for 512x512 pixel tiles. For smalltasks, the overhead of using the GPU is propor-tional to the analysis execution time, making its useinefficient. The same behavior is also observed onthe experiments with the AMD/GTX260 comput-ing node, although the variation in relative perfor-mance is even higher, as is shown in Figure 9(b).The huge difference in relative performance observed
between the two machines occurred because the sec-ond computing node (AMD/GTX260) is equippedwith a faster GPU and a CPU that is 53% slowerthan the Intel CPU for NBIA.
(a) Intel/8800GT
(b) AMD/GTX260
Fig. 9 NBIA: CPU/GPU relative performance variation ac-cording to the tile dimensions.
Figure 9 also shows that the performance ofNBIA is strongly affected by the input tile size.Moreover, the speedup variation shows that differ-ent types of processing units have different perfor-mance capabilities. This performance heterogene-ity can be observed in other applications, such aslinear algebra kernels, data mining applications likekNN and Eclat, FFTs, and applications that em-ploy pyramid multi-resolution representations [13,22,28].
12
In large-scale parallel executions of NBIA, mul-tiple processing tasks will process different tile res-olutions concurrently, making the performance ofthe devices vary according to the tasks they process.This heterogeneity creates the demand for techniquesto efficiently use the CPU and GPU collaboratively,as discussed in Section 6.3.
6.2 Effect of async. CPU/GPU data transfers
The results of our approach to improve CPU/GPUdata transfers are presented in this section. For thesake of our evaluation, we used two applications:NBIA, and a vector incrementer (VI) that dividesa vector into small chunks which are copied to theGPU and incremented, iterating over each value sixtimes (resulting in a computation to communicationratio of 7:3).
6.2.1 Vector incrementer
Figure 10 shows the VI execution times as we varythe number of concurrent events/CUDA streams forthree data chunk sizes: 100K, 500K, and 1M, usingan input vector of 360M integers for 8800GT andC2050 GPUs, which is here used to evaluate thenew Fermi dual overlapped memory transfer en-gines. These results show that a large number ofstreams are necessary to attain maximum perfor-mance. Please also note that the number of CUDAstreams required for optimum execution times varieswith the size of data being transferred. Addition-ally, the memory and network bandwidth of the GPUare an important factor influencing the optimal num-ber of CUDA streams for minimal application exe-cution time. Therefore, for an application with mul-tiplekernel functions or run in an environment withmixed GPU types, an optimal single value mightnot exist, even if the application parameters are static.
Input chunk sizeCUDA stream size 100K 500K 1M
Best static stream size (secs.)16.50 16.16 16.15Dynamic algorithm (secs.) 16.53 16.23 16.16
Table 2 VI: Static vs. dynamic number of CUDA Streams(Intel/8800GT).
We believe the results in Figure 10 strongly mo-tivate the need for an adaptive method to controlthe number of concurrent CPU/GPU transfers, suchas we have proposed in Section 5.1. The perfor-mance of the proposed algorithm is presented in Ta-ble 2, where it is compared to the best performance
(a) Intel/8800GT
(b) Tesla C2050
Fig. 10 VI: Number of streams vs. input data chunk size.
among all number of fixed number of CUDA streamsfor the 8800GT GPU. The results achieved by thedynamic algorithm are very close to the best staticperformance, and are within one standard devia-tion (near to 1%) of the average static performancenumbers. Finally, in Table 3, we also present thecomparison of the dynamic algorithm to the beststatic configuration, when using the Tesla C2050GPU. As before, the execution times of the appli-cation when using the dynamic algorithm are veryclose to those of the best static choice.
Input chunk sizeCUDA stream size 100K 500K 1M
Best static stream size (secs.) 1.19 1.10 1.09Dynamic algorithm (secs.) 1.19 1.11 1.10
Table 3 VI: Static vs. dynamic number of CUDA Streams(Tesla C2050).
6.2.2 NBIA
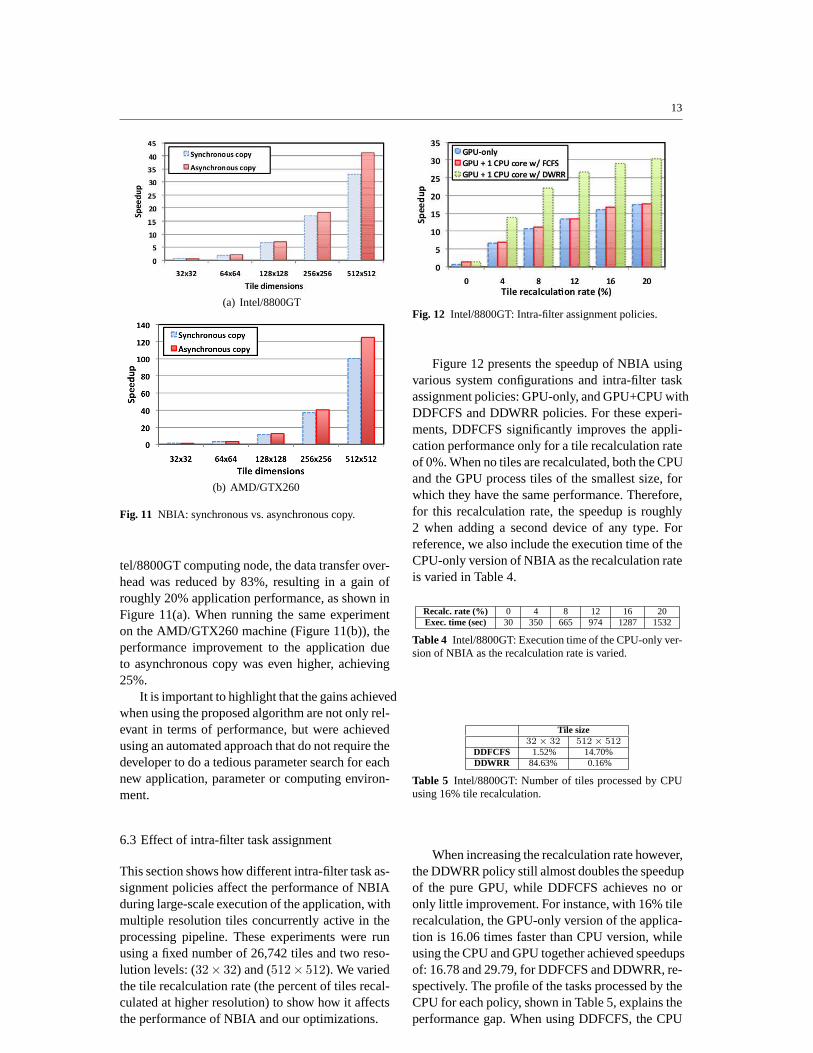
The improvement in NBIA execution time due tothe use of asynchronous data copies is presentedin Figure 11, where the tile size is varied (but tilesare classified at the first resolution level). The re-sults show that NBIA performance improves forall tile sizes. For tiles of512 × 512 and on an In-
13
(a) Intel/8800GT
(b) AMD/GTX260
Fig. 11 NBIA: synchronous vs. asynchronous copy.
tel/8800GT computing node, the data transfer over-head was reduced by 83%, resulting in a gain ofroughly 20% application performance, as shown inFigure 11(a). When running the same experimenton the AMD/GTX260 machine (Figure 11(b)), theperformance improvement to the application dueto asynchronous copy was even higher, achieving25%.
It is important to highlight that the gains achievedwhen using the proposed algorithm are not only rel-evant in terms of performance, but were achievedusing an automated approach that do not require thedeveloper to do a tedious parameter search for eachnew application, parameter or computing environ-ment.
6.3 Effect of intra-filter task assignment
This section shows how different intra-filter task as-signment policies affect the performance of NBIAduring large-scale execution of the application, withmultiple resolution tiles concurrently active in theprocessing pipeline. These experiments were runusing a fixed number of 26,742 tiles and two reso-lution levels: (32× 32) and (512× 512). We variedthe tile recalculation rate (the percent of tiles recal-culated at higher resolution) to show how it affectsthe performance of NBIA and our optimizations.
Fig. 12 Intel/8800GT: Intra-filter assignment policies.
Figure 12 presents the speedup of NBIA usingvarious system configurations and intra-filter taskassignment policies: GPU-only, and GPU+CPU withDDFCFS and DDWRR policies. For these experi-ments, DDFCFS significantly improves the appli-cation performance only for a tile recalculation rateof 0%. When no tiles are recalculated, both the CPUand the GPU process tiles of the smallest size, forwhich they have the same performance. Therefore,for this recalculation rate, the speedup is roughly2 when adding a second device of any type. Forreference, we also include the execution time of theCPU-only version of NBIA as the recalculation rateis varied in Table 4.
Recalc. rate (%) 0 4 8 12 16 20Exec. time (sec) 30 350 665 974 1287 1532
Table 4 Intel/8800GT: Execution time of the CPU-only ver-sion of NBIA as the recalculation rate is varied.
Tile size32 × 32 512 × 512
DDFCFS 1.52% 14.70%DDWRR 84.63% 0.16%
Table 5 Intel/8800GT: Number of tiles processed by CPUusing 16% tile recalculation.
When increasing the recalculation rate however,the DDWRR policy still almost doubles the speedupof the pure GPU, while DDFCFS achieves no oronly little improvement. For instance, with 16% tilerecalculation, the GPU-only version of the applica-tion is 16.06 times faster than CPU version, whileusing the CPU and GPU together achieved speedupsof: 16.78 and 29.79, for DDFCFS and DDWRR, re-spectively. The profile of the tasks processed by theCPU for each policy, shown in Table 5, explains theperformance gap. When using DDFCFS, the CPU
14
processed some tiles of both resolutions, while DDWRRschedules the majority of low resolution tiles to theCPU, leaving the GPU to focus on the high resolu-tion tiles, for which it is far faster than the CPU.The overhead due to the task assignment policy,including our on-line performance estimation, wasnegligible.
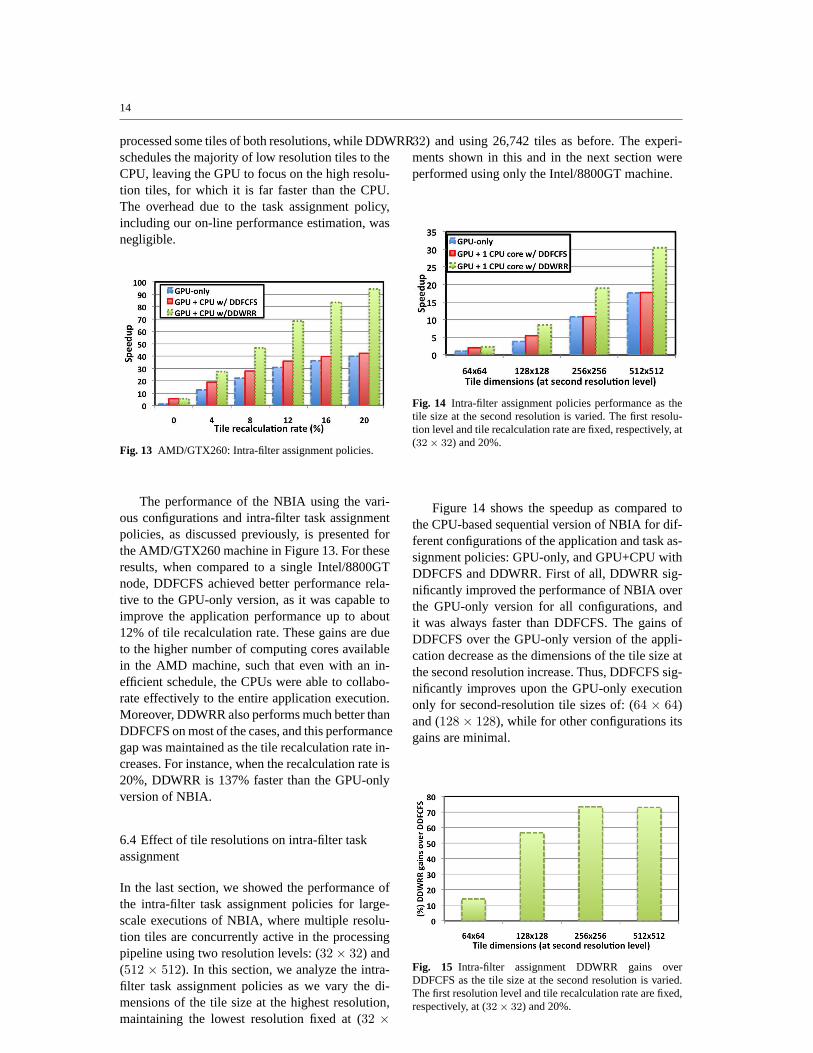
Fig. 13 AMD/GTX260: Intra-filter assignment policies.
The performance of the NBIA using the vari-ous configurations and intra-filter task assignmentpolicies, as discussed previously, is presented forthe AMD/GTX260 machine in Figure 13. For theseresults, when compared to a single Intel/8800GTnode, DDFCFS achieved better performance rela-tive to the GPU-only version, as it was capable toimprove the application performance up to about12% of tile recalculation rate. These gains are dueto the higher number of computing cores availablein the AMD machine, such that even with an in-efficient schedule, the CPUs were able to collabo-rate effectively to the entire application execution.Moreover, DDWRR also performs much better thanDDFCFS on most of the cases, and this performancegap was maintained as the tile recalculation rate in-creases. For instance, when the recalculation rate is20%, DDWRR is 137% faster than the GPU-onlyversion of NBIA.
6.4 Effect of tile resolutions on intra-filter taskassignment
In the last section, we showed the performance ofthe intra-filter task assignment policies for large-scale executions of NBIA, where multiple resolu-tion tiles are concurrently active in the processingpipeline using two resolution levels: (32× 32) and(512 × 512). In this section, we analyze the intra-filter task assignment policies as we vary the di-mensions of the tile size at the highest resolution,maintaining the lowest resolution fixed at (32 ×
32) and using 26,742 tiles as before. The experi-ments shown in this and in the next section wereperformed using only the Intel/8800GT machine.
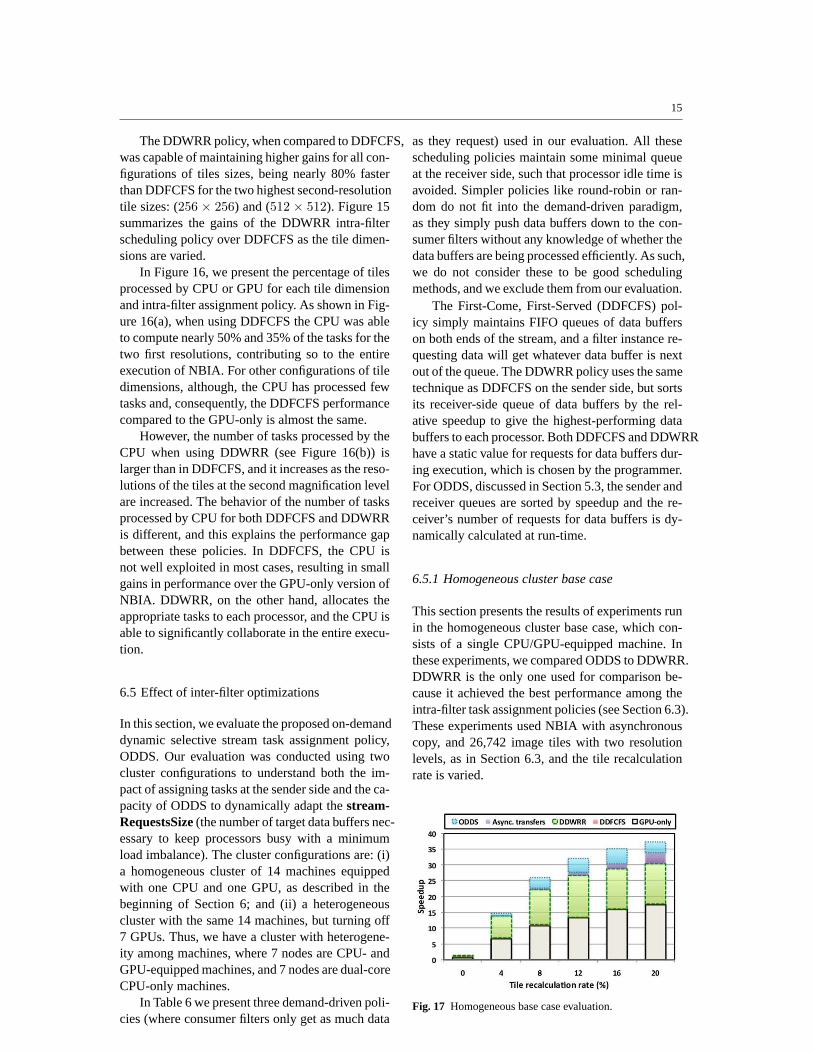
Fig. 14 Intra-filter assignment policies performance as thetile size at the second resolution is varied. The first resolu-tion level and tile recalculation rate are fixed, respectively, at(32× 32) and 20%.
Figure 14 shows the speedup as compared tothe CPU-based sequential version of NBIA for dif-ferent configurations of the application and task as-signment policies: GPU-only, and GPU+CPU withDDFCFS and DDWRR. First of all, DDWRR sig-nificantly improved the performance of NBIA overthe GPU-only version for all configurations, andit was always faster than DDFCFS. The gains ofDDFCFS over the GPU-only version of the appli-cation decrease as the dimensions of the tile size atthe second resolution increase. Thus, DDFCFS sig-nificantly improves upon the GPU-only executiononly for second-resolution tile sizes of: (64 × 64)and (128 × 128), while for other configurations itsgains are minimal.
Fig. 15 Intra-filter assignment DDWRR gains overDDFCFS as the tile size at the second resolution is varied.The first resolution level and tile recalculation rate are fixed,respectively, at (32× 32) and 20%.
15
The DDWRR policy, when compared to DDFCFS,was capable of maintaining higher gains for all con-figurations of tiles sizes, being nearly 80% fasterthan DDFCFS for the two highest second-resolutiontile sizes: (256 × 256) and (512 × 512). Figure 15summarizes the gains of the DDWRR intra-filterscheduling policy over DDFCFS as the tile dimen-sions are varied.
In Figure 16, we present the percentage of tilesprocessed by CPU or GPU for each tile dimensionand intra-filter assignment policy. As shown in Fig-ure 16(a), when using DDFCFS the CPU was ableto compute nearly 50% and 35% of the tasks for thetwo first resolutions, contributing so to the entireexecution of NBIA. For other configurations of tiledimensions, although, the CPU has processed fewtasks and, consequently, the DDFCFS performancecompared to the GPU-only is almost the same.
However, the number of tasks processed by theCPU when using DDWRR (see Figure 16(b)) islarger than in DDFCFS, and it increases as the reso-lutions of the tiles at the second magnification levelare increased. The behavior of the number of tasksprocessed by CPU for both DDFCFS and DDWRRis different, and this explains the performance gapbetween these policies. In DDFCFS, the CPU isnot well exploited in most cases, resulting in smallgains in performance over the GPU-only version ofNBIA. DDWRR, on the other hand, allocates theappropriate tasks to each processor, and the CPU isable to significantly collaborate in the entire execu-tion.
6.5 Effect of inter-filter optimizations
In this section, we evaluate the proposed on-demanddynamic selective stream task assignment policy,ODDS. Our evaluation was conducted using twocluster configurations to understand both the im-pact of assigning tasks at the sender side and the ca-pacity of ODDS to dynamically adapt thestream-RequestsSize(the number of target data buffers nec-essary to keep processors busy with a minimumload imbalance). The cluster configurations are: (i)a homogeneous cluster of 14 machines equippedwith one CPU and one GPU, as described in thebeginning of Section 6; and (ii) a heterogeneouscluster with the same 14 machines, but turning off7 GPUs. Thus, we have a cluster with heterogene-ity among machines, where 7 nodes are CPU- andGPU-equipped machines, and 7 nodes are dual-coreCPU-only machines.
In Table 6 we present three demand-driven poli-cies (where consumer filters only get as much data
as they request) used in our evaluation. All thesescheduling policies maintain some minimal queueat the receiver side, such that processor idle time isavoided. Simpler policies like round-robin or ran-dom do not fit into the demand-driven paradigm,as they simply push data buffers down to the con-sumer filters without any knowledge of whether thedata buffers are being processed efficiently. As such,we do not consider these to be good schedulingmethods, and we exclude them from our evaluation.
The First-Come, First-Served (DDFCFS) pol-icy simply maintains FIFO queues of data bufferson both ends of the stream, and a filter instance re-questing data will get whatever data buffer is nextout of the queue. The DDWRR policy uses the sametechnique as DDFCFS on the sender side, but sortsits receiver-side queue of data buffers by the rel-ative speedup to give the highest-performing databuffers to each processor. Both DDFCFS and DDWRRhave a static value for requests for data buffers dur-ing execution, which is chosen by the programmer.For ODDS, discussed in Section 5.3, the sender andreceiver queues are sorted by speedup and the re-ceiver’s number of requests for data buffers is dy-namically calculated at run-time.
6.5.1 Homogeneous cluster base case
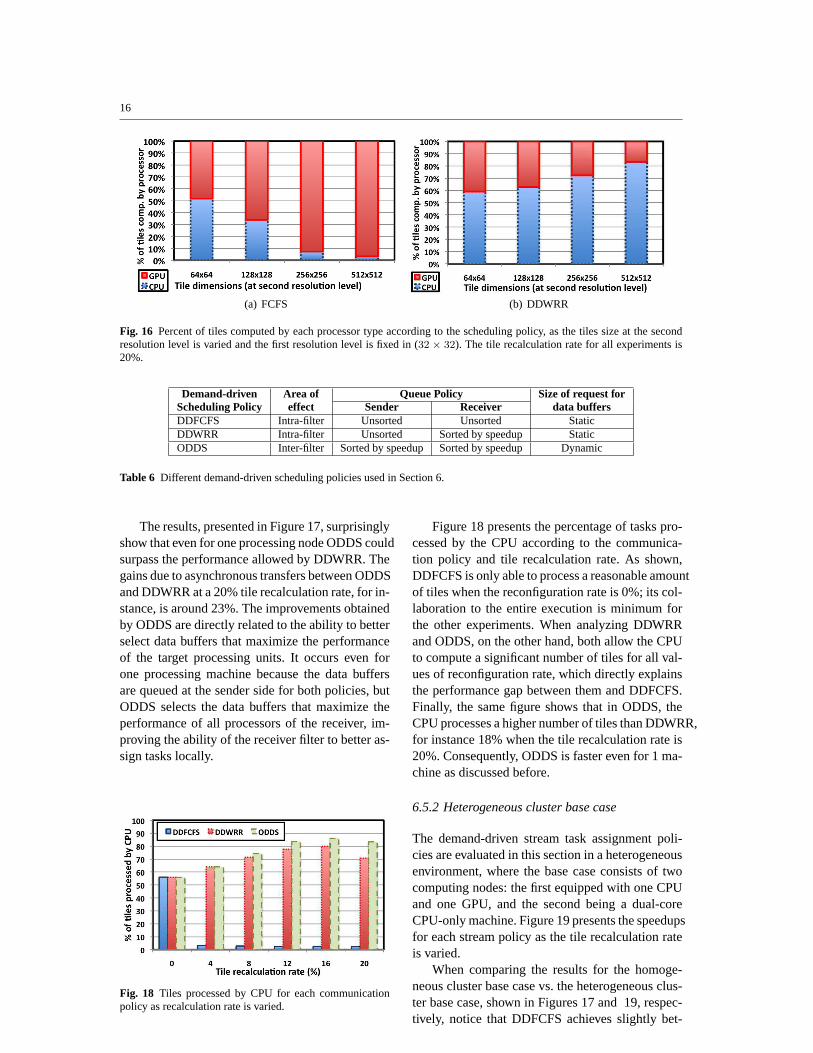
This section presents the results of experiments runin the homogeneous cluster base case, which con-sists of a single CPU/GPU-equipped machine. Inthese experiments, we compared ODDS to DDWRR.DDWRR is the only one used for comparison be-cause it achieved the best performance among theintra-filter task assignment policies (see Section 6.3).These experiments used NBIA with asynchronouscopy, and 26,742 image tiles with two resolutionlevels, as in Section 6.3, and the tile recalculationrate is varied.
Fig. 17 Homogeneous base case evaluation.
16
(a) FCFS (b) DDWRR
Fig. 16 Percent of tiles computed by each processor type according to the scheduling policy, as the tiles size at the secondresolution level is varied and the first resolution level is fixedin (32 × 32). The tile recalculation rate for all experiments is20%.
Demand-driven Area of Queue Policy Size of request forScheduling Policy effect Sender Receiver data buffersDDFCFS Intra-filter Unsorted Unsorted StaticDDWRR Intra-filter Unsorted Sorted by speedup StaticODDS Inter-filter Sorted by speedup Sorted by speedup Dynamic
Table 6 Different demand-driven scheduling policies used in Section 6.
The results, presented in Figure 17, surprisinglyshow that even for one processing node ODDS couldsurpass the performance allowed by DDWRR. Thegains due to asynchronous transfers between ODDSand DDWRR at a 20% tile recalculation rate, for in-stance, is around 23%. The improvements obtainedby ODDS are directly related to the ability to betterselect data buffers that maximize the performanceof the target processing units. It occurs even forone processing machine because the data buffersare queued at the sender side for both policies, butODDS selects the data buffers that maximize theperformance of all processors of the receiver, im-proving the ability of the receiver filter to better as-sign tasks locally.
Fig. 18 Tiles processed by CPU for each communicationpolicy as recalculation rate is varied.
Figure 18 presents the percentage of tasks pro-cessed by the CPU according to the communica-tion policy and tile recalculation rate. As shown,DDFCFS is only able to process a reasonable amountof tiles when the reconfiguration rate is 0%; its col-laboration to the entire execution is minimum forthe other experiments. When analyzing DDWRRand ODDS, on the other hand, both allow the CPUto compute a significant number of tiles for all val-ues of reconfiguration rate, which directly explainsthe performance gap between them and DDFCFS.Finally, the same figure shows that in ODDS, theCPU processes a higher number of tiles than DDWRR,for instance 18% when the tile recalculation rate is20%. Consequently, ODDS is faster even for 1 ma-chine as discussed before.
6.5.2 Heterogeneous cluster base case
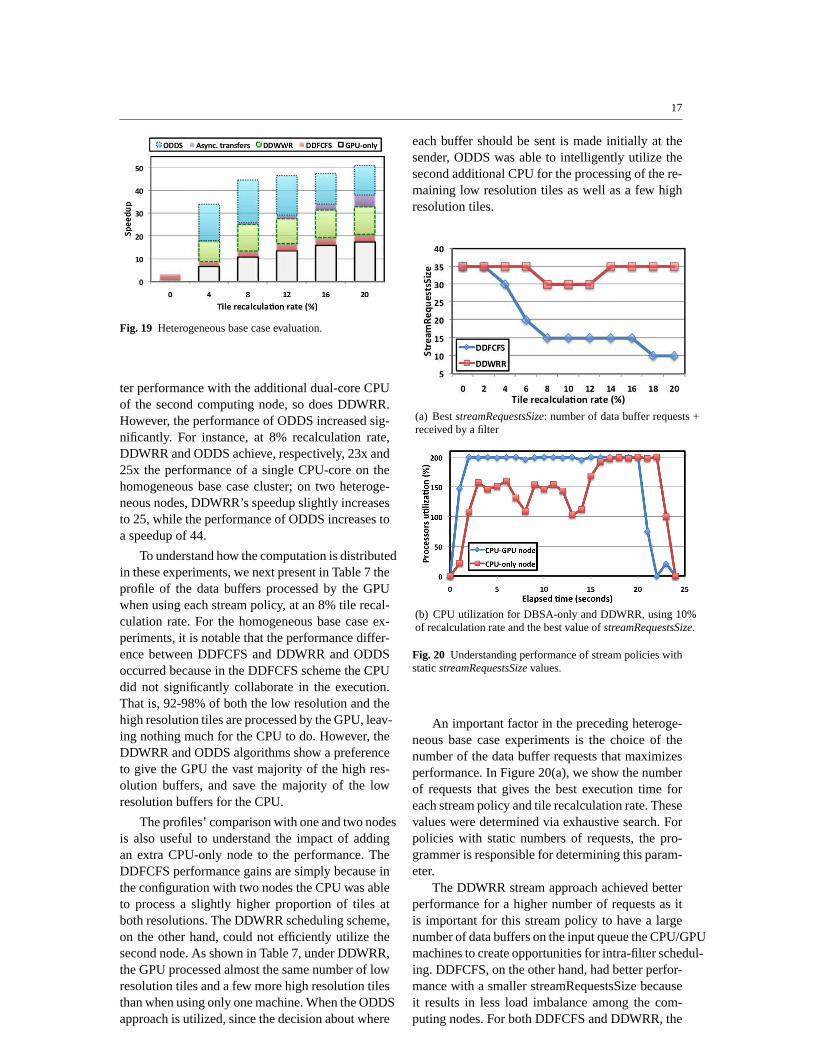
The demand-driven stream task assignment poli-cies are evaluated in this section in a heterogeneousenvironment, where the base case consists of twocomputing nodes: the first equipped with one CPUand one GPU, and the second being a dual-coreCPU-only machine. Figure 19 presents the speedupsfor each stream policy as the tile recalculation rateis varied.
When comparing the results for the homoge-neous cluster base case vs. the heterogeneous clus-ter base case, shown in Figures 17 and 19, respec-tively, notice that DDFCFS achieves slightly bet-
17
Fig. 19 Heterogeneous base case evaluation.
ter performance with the additional dual-core CPUof the second computing node, so does DDWRR.However, the performance of ODDS increased sig-nificantly. For instance, at 8% recalculation rate,DDWRR and ODDS achieve, respectively, 23x and25x the performance of a single CPU-core on thehomogeneous base case cluster; on two heteroge-neous nodes, DDWRR’s speedup slightly increasesto 25, while the performance of ODDS increases toa speedup of 44.
To understand how the computation is distributedin these experiments, we next present in Table 7 theprofile of the data buffers processed by the GPUwhen using each stream policy, at an 8% tile recal-culation rate. For the homogeneous base case ex-periments, it is notable that the performance differ-ence between DDFCFS and DDWRR and ODDSoccurred because in the DDFCFS scheme the CPUdid not significantly collaborate in the execution.That is, 92-98% of both the low resolution and thehigh resolution tiles are processed by the GPU, leav-ing nothing much for the CPU to do. However, theDDWRR and ODDS algorithms show a preferenceto give the GPU the vast majority of the high res-olution buffers, and save the majority of the lowresolution buffers for the CPU.
The profiles’ comparison with one and two nodesis also useful to understand the impact of addingan extra CPU-only node to the performance. TheDDFCFS performance gains are simply because inthe configuration with two nodes the CPU was ableto process a slightly higher proportion of tiles atboth resolutions. The DDWRR scheduling scheme,on the other hand, could not efficiently utilize thesecond node. As shown in Table 7, under DDWRR,the GPU processed almost the same number of lowresolution tiles and a few more high resolution tilesthan when using only one machine. When the ODDSapproach is utilized, since the decision about where
each buffer should be sent is made initially at thesender, ODDS was able to intelligently utilize thesecond additional CPU for the processing of the re-maining low resolution tiles as well as a few highresolution tiles.
(a) BeststreamRequestsSize: number of data buffer requests +received by a filter
(b) CPU utilization for DBSA-only and DDWRR, using 10%of recalculation rate and the best value ofstreamRequestsSize.
Fig. 20 Understanding performance of stream policies withstaticstreamRequestsSizevalues.
An important factor in the preceding heteroge-neous base case experiments is the choice of thenumber of the data buffer requests that maximizesperformance. In Figure 20(a), we show the numberof requests that gives the best execution time foreach stream policy and tile recalculation rate. Thesevalues were determined via exhaustive search. Forpolicies with static numbers of requests, the pro-grammer is responsible for determining this param-eter.
The DDWRR stream approach achieved betterperformance for a higher number of requests as itis important for this stream policy to have a largenumber of data buffers on the input queue the CPU/GPUmachines to create opportunities for intra-filter schedul-ing. DDFCFS, on the other hand, had better perfor-mance with a smaller streamRequestsSize becauseit results in less load imbalance among the com-puting nodes. For both DDFCFS and DDWRR, the
18
Config. Homogeneous base case Heterogeneous base caseScheduling DDFCFS DDWRR ODDS DDFCFS DDWRR ODDSLow res.(%) 98.16 17.07 6.98 84.85 16.72 0High res.(%) 92.42 96.34 97.89 85.67 92.92 97.62
Table 7 Percent of tiles processed by the GPU at each resolution/stream policy.
best performance was achieved in a configurationwhere processor utilization is not maximum dur-ing the whole execution. For these policies, leav-ing processors idle may be better than requestinga high number of data buffers and generating loadimbalance among filter instances at the end of theapplication’s execution.
Figure 20(b), shows the processors utilizationfor DDWRR and DBSA at the sender side, with afixed and best size ofstreamRequestsSize. As shown,the better perfomance of this stream communica-tion policy is achieved in a configuration where thehardware is not fully utilized. This observation, asdiscussed before, motivated the development of DQAAto dynamically calculate the appropriate value ofstreamRequestsSizefor each computing node ac-cording to its characteristics. Moreover, DQAA andDBSA were then coupled to create the ODDS streamcommunication policy for heterogeneous environ-ments first proposed in the earlier version of thiswork [37].
In contrast to both DDFCFS and DDWRR, ODDScan adapt the number of data requests according tothe processing rate of each receiver filter instance,providing it the ability to better utilize the proces-sors during the whole execution (see Figure 21(a)).To show this, we show in Figure 21(b) how ODDSchanges the streamRequestsSize dynamically in oneexecution of the NBIA application. This experimentused a 10% reconfiguration rate. As expected, thestreamRequestsSize varies as the execution proceeds,adapting to the slack in each queue. It is especiallydramatic that at the end of the execution where thereis a build-up of higher-resolution data buffers to becomputed. It is this build-up of the higher-resolutiondata buffers (and their longer processing times onthe CPU-only machine) which causes DQAA to re-duce the number of requests of the CPU-only ma-chine, reducing the load imbalance among the com-puting nodes at the tail end of the application’s ex-ecution.
6.5.3 Scaling homogeneous and heterogeneouscases
Finally, in this section, we show NBIA performanceas the number of machines is increased for each
(a) CPU utilization for ODDS
(b) ODDS data requests size
Fig. 21 ODDS execution detailed.
cluster type. The scaling of the homogeneous clus-ter was done by simply increasing the number ofnodes, while for the heterogeneous cluster 50% ofthe computing nodes are equipped with both a CPUand a GPU, and the other 50% are without the GPUs.The results have been performed using 267,420 im-age tiles with two resolution levels, as before. Weused an 8% tile recalculation rate, and the speedupsare calculated according to a single CPU-core ver-sion of the application.
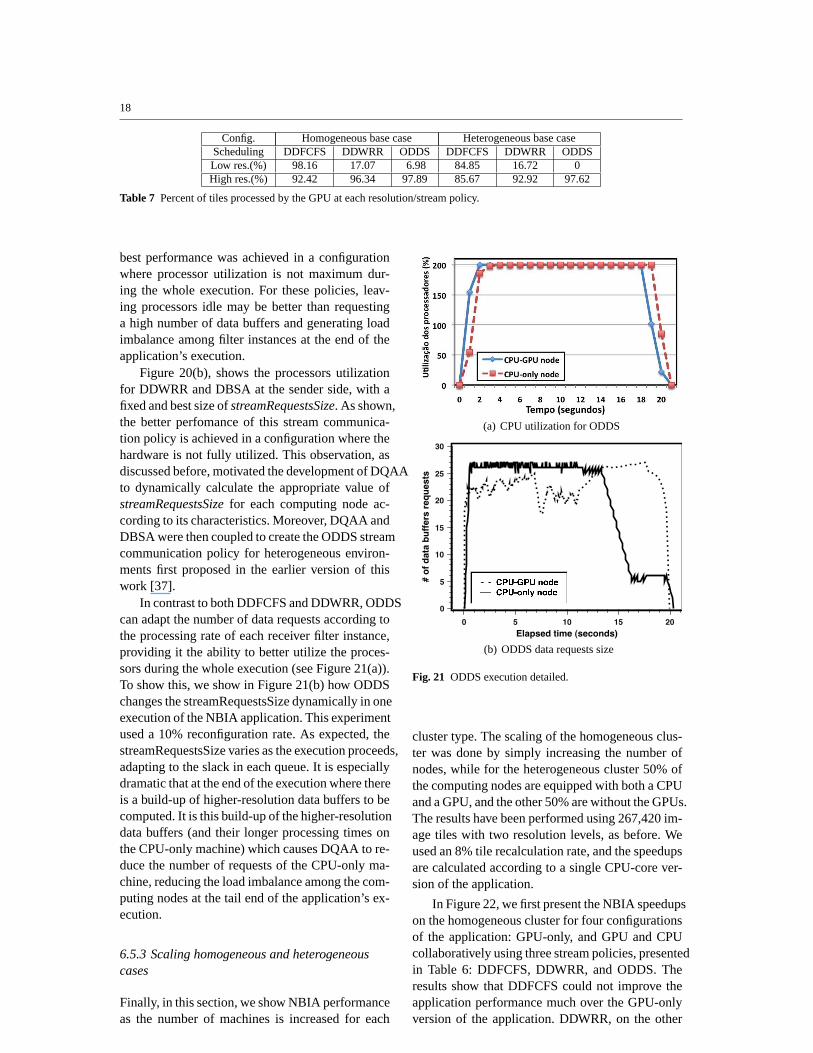
In Figure 22, we first present the NBIA speedupson the homogeneous cluster for four configurationsof the application: GPU-only, and GPU and CPUcollaboratively using three stream policies, presentedin Table 6: DDFCFS, DDWRR, and ODDS. Theresults show that DDFCFS could not improve theapplication performance much over the GPU-onlyversion of the application. DDWRR, on the other
19
Fig. 22 Scaling homogeneous base case.
hand, doubled the performance of the GPU-onlyconfiguration. Further, the ODDS was 15% fasterthan DDWRR even in the homogeneous environ-ment as it can better choose which data buffers tosend to requesting processors, due to its knowledgeof downstream processors’ performance character-istics.
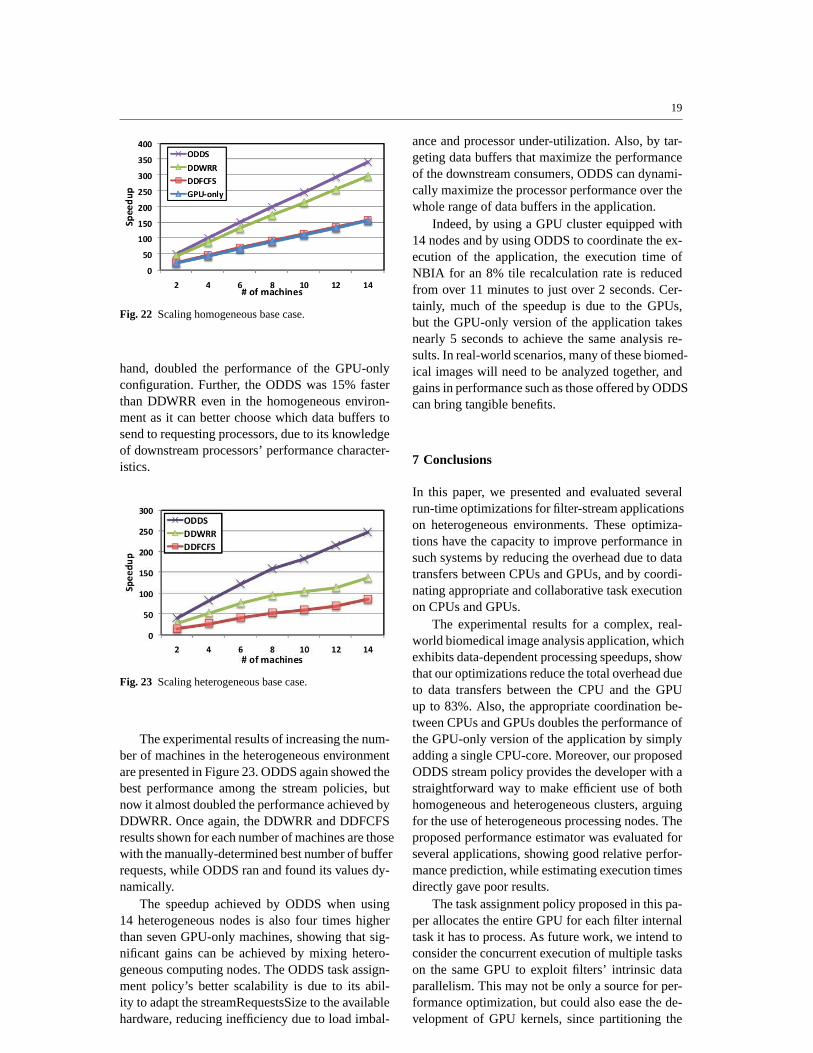
Fig. 23 Scaling heterogeneous base case.
The experimental results of increasing the num-ber of machines in the heterogeneous environmentare presented in Figure 23. ODDS again showed thebest performance among the stream policies, butnow it almost doubled the performance achieved byDDWRR. Once again, the DDWRR and DDFCFSresults shown for each number of machines are thosewith the manually-determined best number of bufferrequests, while ODDS ran and found its values dy-namically.
The speedup achieved by ODDS when using14 heterogeneous nodes is also four times higherthan seven GPU-only machines, showing that sig-nificant gains can be achieved by mixing hetero-geneous computing nodes. The ODDS task assign-ment policy’s better scalability is due to its abil-ity to adapt the streamRequestsSize to the availablehardware, reducing inefficiency due to load imbal-
ance and processor under-utilization. Also, by tar-geting data buffers that maximize the performanceof the downstream consumers, ODDS can dynami-cally maximize the processor performance over thewhole range of data buffers in the application.
Indeed, by using a GPU cluster equipped with14 nodes and by using ODDS to coordinate the ex-ecution of the application, the execution time ofNBIA for an 8% tile recalculation rate is reducedfrom over 11 minutes to just over 2 seconds. Cer-tainly, much of the speedup is due to the GPUs,but the GPU-only version of the application takesnearly 5 seconds to achieve the same analysis re-sults. In real-world scenarios, many of these biomed-ical images will need to be analyzed together, andgains in performance such as those offered by ODDScan bring tangible benefits.
7 Conclusions
In this paper, we presented and evaluated severalrun-time optimizations for filter-stream applicationson heterogeneous environments. These optimiza-tions have the capacity to improve performance insuch systems by reducing the overhead due to datatransfers between CPUs and GPUs, and by coordi-nating appropriate and collaborative task executionon CPUs and GPUs.
The experimental results for a complex, real-world biomedical image analysis application, whichexhibits data-dependent processing speedups, showthat our optimizations reduce the total overhead dueto data transfers between the CPU and the GPUup to 83%. Also, the appropriate coordination be-tween CPUs and GPUs doubles the performance ofthe GPU-only version of the application by simplyadding a single CPU-core. Moreover, our proposedODDS stream policy provides the developer with astraightforward way to make efficient use of bothhomogeneous and heterogeneous clusters, arguingfor the use of heterogeneous processing nodes. Theproposed performance estimator was evaluated forseveral applications, showing good relative perfor-mance prediction, while estimating execution timesdirectly gave poor results.
The task assignment policy proposed in this pa-per allocates the entire GPU for each filter internaltask it has to process. As future work, we intend toconsider the concurrent execution of multiple taskson the same GPU to exploit filters’ intrinsic dataparallelism. This may not be only a source for per-formance optimization, but could also ease the de-velopment of GPU kernels, since partitioning the

20
task among the GPU’s execution units would be ob-viated. The performance estimator is another focusfor future work, where we plan to evaluate moresophisticated model learning algorithms and to usethe current prediction model in other contexts.
Acknowledgements This work was partially supported byCNPq, CAPES, Fapemig, and INWeb; by the DOE grantDE-FC02-06ER2775; by AFRL/DAGSI Ohio Student- Fac-ulty Research Fellowship RY6-OSU-08-3; by the NSF grantsCNS-0643969, OCI-0904809, OCI-0904802 and CNS-0403342;and computing time from the Ohio Supercomputer Center.
References
1. Arpaci-Dusseau, R.H., Anderson, E., Treuhaft, N.,Culler, D.E., Hellerstein, J.M., Patterson, D., Yelick,K.: Cluster I/O with River: Making the fast case com-mon. In: IOPADS ’99: Input/Output for Parallel andDistributed Systems (1999)
2. Augonnet, C., Thibault, S., Namyst, R., Wacrenier,P.A.: Starpu: A unified platform for task schedulingon heterogeneous multicore architectures. In: Euro-Par’09: Proceedings of the 15th International Euro-ParConference on Parallel Processing. pp. 863–874 (2009)
3. Berman, F.D., Wolski, R., Figueira, S., Schopf, J., Shao,G.: Application-level scheduling on distributed hetero-geneous networks. In: Supercomputing ’96: Proceed-ings of the 1996 ACM/IEEE conference on Supercom-puting. p. 39 (1996)
4. Beynon, M., Ferreira, R., Kurc, T.M., Sussman, A.,Saltz, J.H.: DataCutter: Middleware for filtering verylarge scientific datasets on archival storage systems. In:IEEE Symposium on Mass Storage Systems. pp. 119–134 (2000)
5. Beynon, M.D., Kurc, T., Catalyurek, U., Chang, C.,Sussman, A., Saltz, J.: Distributed processing of verylarge datasets with DataCutter. Parallel Comput. 27(11),1457–1478 (2001)
6. Bhatti, N.T., Hiltunen, M.A., Schlichting, R.D., Chiu,W.: Coyote: a system for constructing fine-grain config-urable communication services. ACM Trans. Comput.Syst. 16(4), 321–366 (1998)
7. Buck, I., Foley, T., Horn, D., Sugerman, J., Fatahalian,K., Houston, M., Hanrahan, P.: Brook for gpus: streamcomputing on graphics hardware. ACM Trans. Graph.23(3), 777–786 (2004)
8. Catalyurek, U., Beynon, M.D., Chang, C., Kurc,T., Sussman, A., Saltz, J.: The virtual microscope.IEEE Transactions on Information Technology inBiomedicine 7(4), 230–248 (2003)
9. Fahringer, T., Zima, H.P.: A static parameter based per-formance prediction tool for parallel programs. In: ICS’93: Proceedings of the 7th international conference onSupercomputing. pp. 207–219 (1993)
10. Fix, E., Hodges, J.: Discriminatory analysis, nonpara-metric discrimination, consistency properties. Com-puter science technical report, School of AviationMedicine, Randolph Field, Texas (1951)
11. Hartley, T.D., Catalyurek, U.V., Ruiz, A., Ujaldon, M.,Igual, F., Mayo, R.: Biomedical image analysis on a co-operative cluster of gpus and multicores. In: 22nd ACMIntl. Conference on Supercomputing (Dec 2008)
12. He, B., Fang, W., Luo, Q., Govindaraju, N.K., Wang, T.:Mars: A mapreduce framework on graphics processors.In: Parallel Architectures and Compilation Techniques(2008)
13. Hoppe, H.: View-dependent refinementof progressive meshes. In: SIGGRAPH97 Proc. pp. 189–198 (Aug 1997),http://research.microsoft.com/ hoppe/
14. Hsu, C.H., Chen, T.L., Li, K.C.: Performance effectivepre-scheduling strategy for heterogeneous grid systemsin the master slave paradigm. Future Gener. Comput.Syst. (2007)
15. Iverson, M., Ozguner, F., Follen, G.: Parallelizing ex-isting applications in a distributed heterogeneous envi-ronment. In: 4th Heterogeneous Computing Workshop(HCW’95) (1995)
16. Kerbyson, D.J., Alme, H.J., Hoisie, A., Petrini, F.,Wasserman, H.J., Gittings, M.: Predictive performanceand scalability modeling of a large-scale application.In: Supercomputing ’01: Proceedings of the 2001ACM/IEEE conference on Supercomputing (CDROM).pp. 37–37 (2001)
17. Kurc, T., Lee, F., Agrawal, G., Catalyurek, U., Ferreira,R., Saltz, J.: Optimizing reduction computations in adistributed environment. In: SC ’03: Proceedings of the2003 ACM/IEEE conference on Supercomputing. p. 9(2003)
18. Lee, S., Min, S.J., Eigenmann, R.: OpenMP to GPGPU:a compiler framework for automatic translation andoptimization. In: PPoPP ’09: Proceedings of the 14thACM SIGPLAN symposium on Principles and practiceof parallel programming. pp. 101–110 (2009)
19. Linderman, M.D., Collins, J.D., Wang, H., Meng, T.H.:Merge: a programming model for heterogeneous multi-core systems. SIGPLAN Not. 43(3), 287–296 (2008)
20. Low, S., Peterson, L., Wang, L.: Understanding tcp ve-gas: A duality model. In: In Proceedings of ACM Sig-metrics (2001)
21. Luk, C.K., Hong, S., Kim, H.: Qilin: Exploiting par-allelism on heterogeneous multiprocessors with adap-tive mapping. In: 42nd International Symposium on Mi-croarchitecture (MICRO) (2009)
22. Maes, F., Vandermeulen, D., Suetens, P.: Comparativeevaluation of multiresolution optimization strategies formultimodality image registration by maximization ofmutual information. Medical Image Analysis 3(4), 373– 386 (1999)
23. NVIDIA: NVIDIA CUDA SDK (2007), http://nvidia.com/cuda
24. O’Malley, S.W., Peterson, L.L.: A dynamic network ar-chitecture. ACM Trans. Comput. Syst. 10(2) (1992)
25. Patkar, N., Katsuno, A., Li, S., Maruyama, T., Savkar,S., Simone, M., Shen, G., Swami, R., Tovey, D.: Mi-croarchitecture of hal’s cpu. IEEE International Com-puter Conference 0, 259 (1995)
26. Ramanujam, J.: Toward automatic parallelization andauto-tuning of affine kernels for gpus. In: Workshop onAutomatic Tuning for Petascale Systems (July 2008)
27. Rocha, B.M., Campos, F.O., Plank, G., dos Santos,R.W., Liebmann4, M., Haase, G.: Simulations of theelectrical activity in the heart with graphic processingunits. Accepted for publication in Eighth InternationalConference on Parallel Processing and Applied Mathe-matics (2009)
28. Rosenfeld, A. (ed.): Multiresolution Image Processingand Analysis. Springer, Berlin (1984)
29. Ruiz, A., Sertel, O., Ujaldon, M., Catalyurek, U., Saltz,J., Gurcan, M.: Pathological image analysis using the

21
gpu: Stroma classification for neuroblastoma. In: Proc.of IEEE Int. Conf. on Bioinformatics and Biomedicine(2007)
30. Sancho, J.C., Kerbyson, D.J.: Analysis of DoubleBuffering on two Different Multicore Architectures:Quad-core Opteron and the Cell-BE. In: Interna-tional Parallel and Distributed Processing Symposium(IPDPS) (2008)
31. Sertel, O., Kong, J., Shimada, H., Catalyurek, U.V.,Saltz, J.H., Gurcan, M.N.: Computer-aided prognosisof neuroblastoma on whole-slide images: Classificationof stromal development. Pattern Recognition, SpecialIssue on Digital Image Processing and Pattern Recog-nition Techniques for the Detection of Cancer 42(6)(2009)
32. Shimada, H., Ambros, I.M., Dehner, L.P., ichi Hata, J.,Joshi, V.V., Roald, B.: Terminology and morphologiccriteria of neuroblastic tumors: recommendation by theinternational neuroblastoma pathology committee. Can-cer 86(2) (1999)
33. Song, F., YarKhan, A., Dongarra, J.: Dynamic taskscheduling for linear algebra algorithms on distributed-memory multicore systems. In: SC ’09: Proceedings ofthe Conference on High Performance Computing Net-working, Storage and Analysis (2009)
34. Sundaram, N., Raghunathan, A., Chakradhar, S.T.:A framework for efficient and scalable execution ofdomain-specific templates on gpus. In: IPDPS ’09: Pro-ceedings of the 2009 IEEE International Symposium onParallel and Distributed Processing. pp. 1–12 (2009)
35. Tavares, T., Teodoro, G., Kurc, T., Ferreira, R., Guedes,D., Meira, W.J., Catalyurek, U., Hastings, S., Oster, S.,Langella, S., Saltz, J.: An efficient and reliable scien-tific workflow system. IEEE International Symposiumon Cluster Computing and the Grid 0, 445–452 (2007)
36. Teodoro, G., Fireman, D., Guedes, D., Jr., W.M., Fer-reira, R.: Achieving multi-level parallelism in filter-labeled stream programming model. In: The 37th In-ternational Conference on Parallel Processing (ICPP)(2008)
37. Teodoro, G., Hartley, T.D.R., Catalyurek, U., Ferreira,R.: Run-time optimizations for replicated dataflows onheterogeneous environments. In: Proc. of the 19th ACMInternational Symposium on High Performance Dis-tributed Computing (HPDC) (2010)
38. Teodoro, G., Sachetto, R., Fireman, D., Guedes, D.,Ferreira, R.: Exploiting computational resources in dis-tributed heterogeneous platforms. In: 21st InternationalSymposium on Computer Architecture and High Per-formance Computing. pp. 83–90 (2009)
39. Teodoro, G., Sachetto, R., Sertel, O., Gurcan, M., Jr.,W.M., Catalyurek, U., Ferreira, R.: Coordinating the useof GPU and CPU for improving performance of com-pute intensive applications. In: IEEE Cluster (2009)
40. Teodoro, G., Tavares, T., Ferreira, R., Kurc, T., Meira,W., Guedes, D., Pan, T., Saltz, J.: Run-time supportfor efficient execution of scientific workflows on dis-tributed environmments. In: International Symposiumon Computer Architecture and High Performance Com-puting. Ouro Preto, Brazil (October 2006)
41. Vrsalovic, D.F., Siewiorek, D.P., Segall, Z.Z.,Gehringer, E.F.: Performance prediction and cali-bration for a class of multiprocessors. IEEE Trans.Comput. 37(11) (1988)
42. Welsh, M., Culler, D., Brewer, E.: Seda: an architec-ture for well-conditioned, scalable internet services.SIGOPS Oper. Syst. Rev. 35(5), 230–243 (2001)
43. Woods, B., Clymer, B., Saltz, J., Kurc, T.: A parallel im-plementation of 4-dimensional haralick texture analysisfor disk-resident image datasets. In: SC ’04: Proceed-ings of the 2004 ACM/IEEE conference on Supercom-puting (2004)