mips assembly - computing systems laboratory
TRANSCRIPT

Systems Virtualization
Steven HandUniversity of Cambridge
ACACES Summer School, July 2010
Virtualization is…• … a word frequently used in computer science
– … and with a variety of meanings!
• A rough definition:– Virtualization involves providing an artificial view of
underlying resources to higher level entities
– Aims to provide abstraction, isolation, sharing
• For example, virtual memory in an OS gives each process its own “memory”– Conceptually separate from each other
– In practice, share underlying real resource (RAM)
• In this course, we’re interested in virtualization of a complete computer system (e.g. a PC)
Virtual Machine Monitor (VMM)
Physical Host
Physical Host Physical Host Physical Host Physical Host
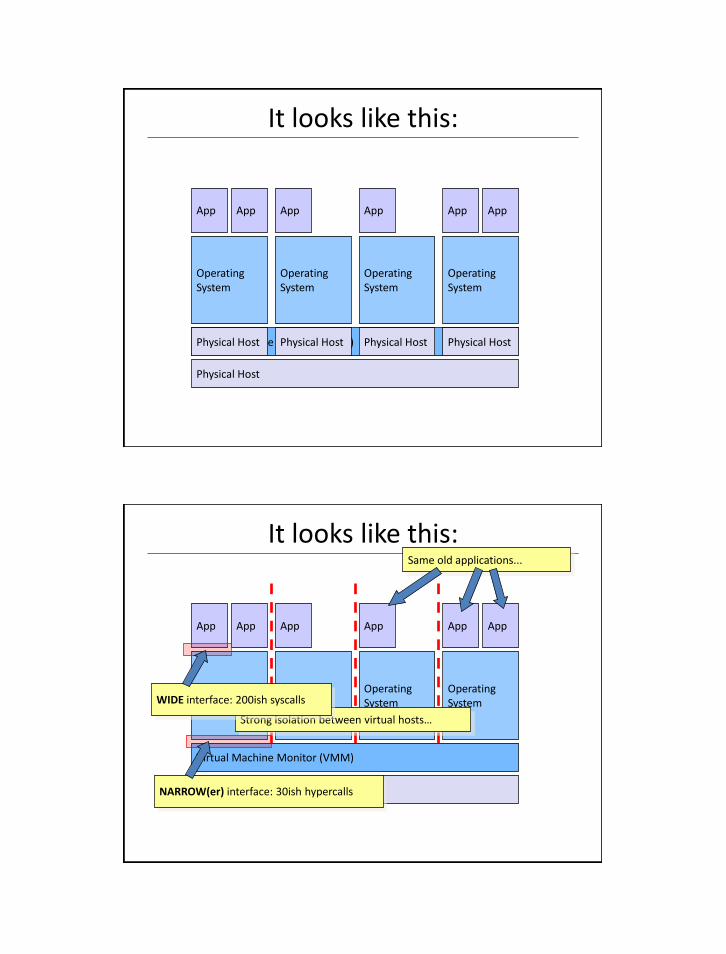
It looks like this:
Operating System
Operating System
Operating System
Operating System
App App App App App App
Physical Host
It looks like this:
Operating System
Operating System
Operating System
Operating System
App App App App App App
Virtual Machine Monitor (VMM)
Same old applications...
Strong isolation between virtual hosts…
WIDE interface: 200ish syscalls
NARROW(er) interface: 30ish hypercalls

Why it’s a big deal…
• Businesses like it because…
– It saves money (fewer machines, ...)
– It eases management (dialable resources, “one click” machine deployment, ...)
• Desktop OSes like it because…
– Good way to contain the nasties.
– More control for application developers.
• Systems researchers like it because…
– Makes it easy to build new operating systems...
– (or to play with existing ones)
Just to be clear:• This is not about JVMs (or .NET VMs, or …)
– These are designed to run application programs
– The “virtual machine” abstraction bears little resemblance to a real machine
• This is not about OS-level containers or zones– These virtualize name-spaces, but share one OS
• This is not even about simulators/emulators– These provide the abstraction of a “real” system, but
typically for development or legacy purposes
– (don’t run user code directly on real CPU)
• This is about running multiple independent OS instances on a single physical machine

Virtualization Possibilities
• Value-added functionality from outside OS:
– Firewalling / network IDS / “inverse firewall”
– VPN tunnelling; LAN authentication
– Virus, malware and exploit scanning
– OS patch-level status monitoring
– Performance monitoring and instrumentation
– Storage backup and snapshots
– Local disk as just a cache for network storage
– Carry your world on a USB stick
– Multi-level secure systems
Course Outline
• Primary focus will be on virtual machine monitors (VMMs)
– A VMM is software which provides one or more virtual machines (VMs), each of which runs an OS
– We’ll also use hypervisor as a synonym for VMM
• To start with, let’s briefly review OS structures:
– Earliest operating systems were “monolithic”
– 1970s: Unix pioneered notion of the kernel
• Just the essentials in privileged mode
• Everything else (e.g. shell, login, etc) a process
– 1980s: Introduction of the microkernel

Kernels (lhs) & Microkernels (rhs)
• New concept in early 1980‘s: simplify kernel– modularity: support multiprocessors, distributed computing– move functions to user-space servers, access servers via (IPC)
Microkernel Benefits• Multiprocessor support:
– Servers can be scheduled anywhere– Only require spin-locks in small microkernel
• Real-time support: – Small kernel allows predictable performance – Use RM / EDF (aperiodic tasks for best effort)
• Modularity:– Easy to replace – or evolve – functionality– (and get extensibility too via user-space servers)
• Portability: – Machine dependent code limited to kernel
• Security: – Small kernel easier to verify

The Mach Microkernel
• Developed at CMU 1985- (Rashid, Bershad, …)• Aimed to support diverse architectures:
– including multiprocessors & heterogeneous clusters!– hence used message-based IPC (as per RIG, Accent)
• Also targeted compatibility with 4.3BSD, OS/2, …
Mach Abstractions
• Tasks (unit of protection) & Threads (unit of scheduling)• IPC based on ports and messages:
– Port is a generic reference to a resource – Implemented as a buffered communications channel– IPC is asynchronous: message passing between threads

Mach Implementation• All resources accessed via IPC
– Protection achieved via port capabilities
– send right, send-once right, receive right• send of a receive right “teleports” endpoint
– Messages can be in-band if small, or passed by reference if larger (i.e. via virtual address region)
• (mostly) machine independent memory management via memory objects– Send IPC to memory object to satisfy page fault
– Since message-based, can even be over network!
• Compatibility layers in unprivileged servers– Mach ‘reflects’ system calls via IPC upcalls
Microkernel Reality• Looks good on paper, but in practice performance was
very poor:– many user-kernel crossings => expensive– flexible asynchronous IPC introduces latency– machine-independent parts lack optimization – e.g. Chen (SOSP'93) compared Mach to Ultrix:
• worse locality affects caches and TLBs• large block copies thrash memory system
• Other benefits all a bit “proof-by assertion” – e.g. ‘small kernel’ => simplicity, security, modularity, etc…
• Basic dilemma:– if too much in kernel, lose benefits– if too little in kernel, too costly
• By mid 90’s, most people had given up...

L3/L4: Making Microkernels Perform
• Liedtke (SOSP'95) claims that problems were a failure in implementation, not in concept
• To fix, you simply have to:
1. minimise what should be in the kernel; and
2. make those primitives really fast.
• The L3 (and L4, SOSP'97) systems provided just:
– recursive construction of address spaces
– threads and basic thread scheduling
– synchronous local IPC
– unique identifier support
• Hand-coded in i486 assembly code!
L3/L4 Design & Implementation• Address spaces support by three primitives:
1. Grant: give pages to another address space2. Map: share pages with another address space3. Flush: take back mapped or granted pages
• Threads execute with address space:– characterised by set of registers– micro-kernel manages thread -> address space binding
• IPC is synchronous message passing between threads:– highly optimised for i486 (3us vs Mach's 18us)– interrupts handled as messages too
• Does it work? '97 paper getpid() comparison:
• Q: are these micro-benchmarks useful? what about portability?
System Time Cycles
Linux 1.68s 223
L4Linux 3.95s 526
MkLinux (Kernel) 15.41s 2050
MkLinux (User) 110.60s 14710

The Exokernel (MIT, 1995-)
• “Exterminate All OS Abstractions!” since they:– deny application-specific optimization– discourage innovation – impose mandatory costs
• Leads to Exokernel: minimal resource multiplexor on top of which applications “choose” their own OS abstractions…
Building an Exokernel• Key idea: separate concepts of protection and abstraction
– Protection is required for safety– Abstraction is about convenience– Typically conflated in existing OSes, e.g. filesystem instead of
block-device access; sockets instead of raw network
• If protect at lowest level, can let applications choose their own abstractions (file system or DB or neither; netw proto)
• Exokernel itself just multiplexes “raw” hardware resources; applications link against library OS to provide abstractions=> get extensibility, accountability & performance.
• Still need some “downloading”:– Describe packets you wish to receive using DPF; exokernel
compiles to fast, unsafe, machine code– Untrusted Deterministic Functions (UDFs) allow exokernel to
sanity check block allocations.
• Lots of cheezy performance hacks (e.g. Cheetah)

Nemesis (Cambridge, 1993-)• OS designed for soft
real-time applications
• Three principles: – Isolation: explicit
guarantees to apps
– Exposure: multiplex real resources
– Responsibility: apps must do data path
• NTSC is minimal resource multiplexor– Just does real-time
scheduling & events
– No device drivers
• Alpha, x86, ARM
Nemesis versus Exokernel• Both are vertically-structured OSes:
– Small bit at bottom does secure multiplexing – Applications choose functionality to suit them
• Differences in motivation: – Exokernel: extensibility & performance– Nemesis: real-time (accountability) & minimality
• Differences in virtual addressing: – Exokernel: Unix-style address space per application– Nemesis: Single address space (64 bits) shared by entire
system … but protection domains per application
• Differences in linkage: – Exokernel: standard C library – Nemesis: strongly-typed IDL, module name space
• And of course, differences in marketing ;-)

Virtual Machine Monitors
• An alternative system software structure
• Use virtual machine monitor (or hypervisor) to share h/w between multiple OSes
• Why virtualize?
– H/W too powerful
– OSes too bloated
– Compatibility
– Better isolation
– Better manageability
– Cool and froody
Virtual Machine Monitor
Hardware
Virtual Machine
OS
App
Virtual Machine
OS
App
IBMs VM/CMS
• VMM idea pioneered by IBM
– 1960’s: IBM researchers propose VM for OS 360
– 1970’s: implemented on System/370
– 1990’s: VM/ESA for ES9000
– 2000’s: z/VM for System Z
• VMM provides OS with:
– Virtual console
– Virtual processor
– Virtual (physical) memory
– Virtual I/O devices IBM Mainframe
IBM VM/370
CMS MVS CMS CMS
App App App App

IBMs VM/CMS
• Key technique is trap-and-emulate:– Run guest OS (in virtual machine) in user mode
– Most instructions run directly on real hardware
– Privileged instructions trap to VMM, which emulates the appropriate behaviour
• Need some additional software to emulate memory management h/w, I/O devices, etc
• IBM’s VM provides complete virtualization – can even run another VMM
– (and people do – up to 4-levels deep!!)
• Success ascribed to extreme flexibility
Formal Requirements• “Formal Requirements for Virtualizable Third
Generation Architectures”– Popek and Goldberg, Comm. ACM 17 (7), 1974
• Defined a virtual machine as an efficient, isolatedduplicate of the real machine– Duplicate: environment provided is essentially identical to
that provided by real machine• Some caveats about timing, total #resources, etc
– Efficient: programs run in this environment with at worst only minor decreases in speed
– Isolated: VMM is in total control of all resources
• VMs provided either a Type 1 (“bare metal”) VMM or a Type 2 (“hosted”) VMM– (term “hypervisor” originally described just Type 1, but
now used to refer to both types interchangeably ;-)

Formal Requirements• Defined 3 sets of instructions for a machine M• P(M) are the privileged instructions
– An instruction is privileged if it traps when executing it in user-mode, but not if executing in kernel-mode
• S(M) are the sensitive instructions, comprising– Control Sensitive: those which attempt to change
processor mode or (e.g.) MMU-related values; and– Location Sensitive: those whose behavior depends on
current operating mode or memory location
• I(M) = innocuous (i.e. non-sensitive) instructions• Proved can build a VMM for M if S(M) P(M)
– If so, we say that M is classically virtualizable– i.e. trap-and-emulate where we de-privilege OS:
I(M) runs direct; S(M) traps & VMM emulates
And then…?• VMMs incredibly successful in industry, but
mostly ignored by academic researchers– Instead did microkernels (& extensibility, etc)
• Can be ascribed to a difference in focus
• VMMS: – Focus on pragmatism, i.e. make it work!
– Little design freedom (hardware is the spec)
– Few chances to write research papers
• Microkernels:– Focus on ‘architectural purity’
– Design whatever you want
– Write a paper about each design decision ;-)

Similarities and Differences• Both approaches advocate:
– A small lowest layer with simple well-defined interfaces,– Strong isolation/security between components; and – Claim benefits of modularity, extensibility, robustness, security
• But: Different entity multiplexed by lowest layer:– VMMs: operating systems (few, big)
– uKerns: tasks or threads (many, small)
• But: Different basic abstractions provided:– VMMs: closely aligned with hardware so have explicit CPU
upcalls, maskable asynchronous events, etc
– uKerns: somewhat higher level, so get threads, transparent preemption, capabilities, synchronous IPC
• But: Different support for address spaces:– VMMs: >1 address space per scheduled entity
– uKerns: >1 scheduled entity per address space
Interim Summary• Systems virtualization is about “faking out” an
entire computer so that – Can run multiple independent operating systems
– Can consolidate workloads on powerful hardware
– Can introspect / manage / protect OSes + Apps
• Old technology (dating back to IBM late 60s)– Very successful in industry, ignored by academia
– VMMs similar to - yet different from - uKerns
• Classic Virtualization (Popek & Goldberg)– VMM runs directly on host (Type 1), or as app (Type 2)
– De-privilege OS (run it in user-space)
– Trap on privileged instructions, emulate in VMM

Disco (Stanford, 1995)
• VMM idea regained popularity in mid 90’s
• Disco was designed to support cc-NUMA:
– Commodity OSes didn’t do well on NUMA
– Tricky to modify them successfully…
– … but even trickier to write a new OS from scratch
• Instead use Disco hypervisor (VMM):
– Disco manages inter-processor interconnect, remote memory access, allocation, etc
– Fakes out UP or SMP virtual machine on top
– (Mostly) unmodified commodity OS runs in VM
Disco Architecture
• Virtual CPU looks like a real MIPS 10000– Trap-and-emulate for privileged instructions (including
TLB fill: ‘physical’->‘machine’ mapping)
– Some changes to OS (buffer cache, NIC) for sharing
• Also enables use of special-purpose OSes…

VMware
• Startup founded 1998 by Stanford Disco dudes
• Basic idea: virtual machines for x86
• One problem: x86 not classically virtualizable!– Visibility of privileged state.
• e.g. guest can observe its privilege level via %cs.
– Not all sensitive instructions trap.• e.g. privileged execution of popf (pop flags) modifies
on-chip privileged state…
• … but doesn’t trap if executed in user mode!
=> cannot just use trap-and-emulate
• However this doesn’t mean we can’t virtualize an x86 processor…
VMware Insight• In order to virtualize, we just need to ensure that
VMM can detect instructions in S(M)– Then can replace with appropriate emulation
• For example, could interpret x86 instructions– As execute, update a model of CPU privileged state
(e.g. MMU information) => safety easy to attain.
• But would be too slow (so not efficient)• VMware solution: dynamic binary rewriting
– Basically JIT compilation where input comprises x86 instructions, and output is also some x86 instructions!
– Innocuous instructions usually translated 1-to-1
• Only need to worry about kernel code– Use trap-and-emulate to track user/kernel transitions

VMware: CPU virtualization• DBR: translate at run-time, and on-demand
– Laziness avoids issues of code versus data
• Works on translation units (TUs): up to 12 x86 instructions (or less if hit control flow insn)– Translate from x86 to { safe-subset of x86 }– Sensitive instructions replaced with either explicit
traps, or user-space emulation code– Each TU turns into a compiled code fragment: CCF
• Adaptive: – Macro CCF’s built up over time (hoist checks)– Can coalesce multiple co-dependent traps into one – Can “inline” emulation code in some cases
• Can be fragile (imprecise) => not 100% compat
VMware: CPU virtualization
• For some workloads, can be better than native (“hotspot” specialization)

VMware: Memory & I/O• Shadow page tables used to track the “physical”
to “machine” address mapping:– Need to translate guest page tables into usable ones– Much more difficult than Disco (MIPS) since x86 has
hardware defined page tables• e.g. accessed and dirty bits; 32/PAE/64; superpages; etc.
– Similar tricks needed for segmentation
• DBR and shadowing lead to a performance hit...• Emulating I/O devices hurts even more
– VMware address this by writing special device drivers for display, NIC, etc
• Modern CPUs have hardware support to help with various aspects (VT/SVM, EPT/NPT)– But a good s/w VMM can sometimes outperform
Denali (U. Washington, 2001)• Motivation: new application domains
– pushing dynamic content code to caches, CDNs– application layer routing (or peer-to-peer)– deploying measurement infrastructures
• Use VMM as an isolation kernel– security isolation: no sharing across VMs– performance isolation: VMM supports fairness mechanisms (e.g. fair
queuing and LRP on network path), static memory allocation
• Aim for decent overall performance by using paravirtualization– full x86 virtualization needs gory tricks– instead invent “new” x86-like ISA– write/rewrite OS to deal with this
• Only a proof of concept implementation:– Isolation kernel based on Flux OSKit– Can only run copies of one specially-constructed single-user guest OS
with user-space TCP/IP stack plus user-level threads package– (cannot run commodity operating systems)– No SMP, no protection, no disk, no QoS

XenoServers (Cambridge, 1999-)• Vision: XenoServers scattered across globe,
usable by anyone to host services, applications, ...– Location is key, not cycles (so not quite ‘the cloud’)
• Use Xen hypervisor to allow the running of arbitrary untrusted code (including OSes)– No requirement for particular language or framework
• Crucial insight:– use SRT techniques to guarantee resources in time
and space, and then charge for them.
– share and protect CPU, memory, network, disks
• Sidestep Denial of Service
• Use paravirtualization, but real operating systems
Xen 1.0• Work on Xen started in late 2001 / early 2002• Xen 1.0 was small (<50K LOC):
– 16-bit start-up code (re-used from linux)– SRT scheduler (BVT), scheduler activations and events– device drivers for timers, NICs, IDE, SCSI.
• Special guest OS (Domain 0) started at boot time:– privileged interface to Xen to manage other domains
• Physical memory allocated at start-of-day:– guest uses buffered updates to manipulate page-tables– aware of “real” addresses => bit awkward
• Interrupts converted into events:– write to event queue in domain– domain “sees” events only when activated
• GuestOSes run own scheduler off virtual or real-time timer• Asynchronous queues used for network and disk

Xen 1.0 Architecture
Unmodified User-
Level Application
Software
Ported ‘Guest’
Operating Systems
Xen Hypervisor
Hardware
Domain 0 Domain 1 Domain 2 Domain 3
• (Xen 1.0 Figure from SOSP 2003 Paper)
Para-Virtualization in Xen
• Xen extensions to x86 arch
– Like x86, but Xen invoked for privileged ops
– Avoids binary rewriting
– Minimize number of privilege transitions into Xen
– Modifications relatively simple and self-contained
• Modify kernel to understand virtualised env.
– Wall-clock time vs. virtual processor time
• Desire both types of alarm timer
– Expose real resource availability
• Enables OS to optimise its own behaviour

x86 CPU virtualization (32-bit)
• Xen runs in ring 0 (most privileged)
• Ring 1/2 for guest OS, 3 for user-space
– GPF if guest attempts to use privileged instr
• Xen lives in top 64MB of linear addr space
– Segmentation used to protect Xen as switching page tables too slow on standard x86
• Hypercalls jump to Xen in ring 0
– Indirection via hypercall page allows flexibility
• Guest OS may install ‘fast trap’ handler
– Direct user-space to guest OS system calls
MMU Virtualization
• Xen supports 3 MMU virtualization modes
– *1+. Direct (“Writable”) pagetables
– [2]. Shadow pagetables
– [3]. Hardware Assisted Paging
• OS Paravirtualization compulsory for [1], optional (and very beneficial) for [2] and [3]
• In all cases, need to distinguish between
– Virtual addresses (per-process per-VM)
– Pseudo-physical addresses (per -VM); and
– Machine addresses (per actual machine)

MMU Virtualization
Pseudo-Physical MemoryPseudo-Physical Memory
Virtual Machine 1 Virtual Machine 2
Machine Memory(reserved for VMM)
Process A Process B Process X Process Y
Para-Virtualizing the MMU• Guest OSes aware of virtual, pseudo-physical and
machine addresses– Keep a “P2M table” which translates pfns -> mfns
• Hence guest can allocate and manage own PTs– High-level kernel functions concerned with pfns
– Architecture-specific code does final translation
• Guest OS is not trusted tho: – Hypercall to install a new PT base (%cr3)
– Xen has M2P table which can check if entries ok (owned by guest; not writeable mapping to PT)
• Xen marks all page table pages read-only– Will trap on any guest write to a PTE...

Writeable Page Tables : 1 – Write fault
MMU
Guest OS
Xen VMM
Hardware
page fault
first guest
write
guest reads
Virtual → Machine
Writeable Page Tables : 2 – Emulate?
MMU
Guest OS
Xen VMM
Hardware
first guest
write
guest reads
Virtual → Machine
emulate?
yes

Writeable Page Tables : 3 – or Unhook
MMU
Guest OS
Xen VMM
Hardware
guest reads
Virtual → MachineXguest writes
Writeable Page Tables : 4 – First Use
MMU
Guest OS
Xen VMM
Hardware
guest reads
Virtual → MachineXguest writes
page fault

Writeable Page Tables : 5 – Re-Hook
MMU
Guest OS
Xen VMM
Hardware
guest reads
Virtual → Machineguest writes
validate
Xen 1.0: MMU Micro-Benchmarks
L X V U
Page fault (µs)
L X V U
Process fork (µs)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
lmbench results on Linux (L), Xen (X), VMWare Workstation (V), and UML (U)

Xen 1.0: System Performance
L X V U
SPEC INT2000 (score)
L X V U
Linux build time (s)
L X V U
OSDB-OLTP (tup/s)
L X V U
SPEC WEB99 (score)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
Benchmark suite running on Linux (L), Xen (X), VMware Workstation (V), and UML (U)
• Macroscopic performance shows less degradation
The Evolution of Xen• Xen 2 (Nov 04) included many changes, e.g
– Moved device drivers into driver domains– Support for live migration of virtual machines (see later)
• Xen 3 (Dec 05) first included:– SMP guests– H/W-assisted full virtualization (VT, SVM)– 32/36/64-bit support
• Many enhancements since: – 32-on-64, COW storage, XSM, VTD, instruction emulation,
shadow2, HAP, NUMA, page sharing, …– Releases for client (XCI) and cloud (XCP)
• Latest stable releases: – Xen 4.0 (April 2010), Xen 3.4.3 (May 2010)– More info (and code!) from http://www.xen.org/

Interim Summary• Systems virtualization revisited in mid 90’s
– 1995 - Disco for cc-NUMA prototype system
– 1998 - VMware set-up to do virtualization on x86
• x86 is problematic: not classically virtualizable!– Conceptually can still interpret / simulate, but
performance will be poor (e.g. Bochs)
– VMware use dynamic binary rewriting
– Xen uses paravirtualization
• Both techniques work, both have pros & cons– DBR is fragile, and can have high overhead
– PV requires OS changes, but usually performs better
• Performance highly dependent on workload
Xen 4.0 Architecture
Event Channel Virtual MMUVirtual CPU Control IF
Hardware (SMP, MMU, physical memory, Ethernet, SCSI/IDE)
NativeDeviceDrivers
GuestOS(XenLinux)
Device Manager & Control s/w
VM0
GuestOS(XenLinux)
UnmodifiedUser
Software
VM1
Front-EndDevice Drivers
GuestOS(XenLinux)
UnmodifiedUser
Software
VM2
Front-EndDevice Drivers
UnmodifiedGuestOS(WinXP))
UnmodifiedUser
Software
VM3
Safe HW IF
Xen Virtual Machine Monitor
Back-End
HVM
x86_32
x86_64
IA64
AGP
ACPI
PCISMP
Front-EndDevice Drivers
SMP Guest Kernels
• Xen supports multiple VCPUs
– Virtual IPI’s sent via Xen event channels
– Currently (Xen 4.0) up to 128 VCPUs supported
• Simple hotplug/unplug of VCPUs
– From within VM or via control tools
– Dynamically optimize one active VCPU case by binary patching spinlocks to nops
• Extra care needed to synchronize TLBs
• Handling virtual time (TSC + PT) also tricky
• NB: many applications have poor SMP scalability
– often better to run multiple instances each own VM!
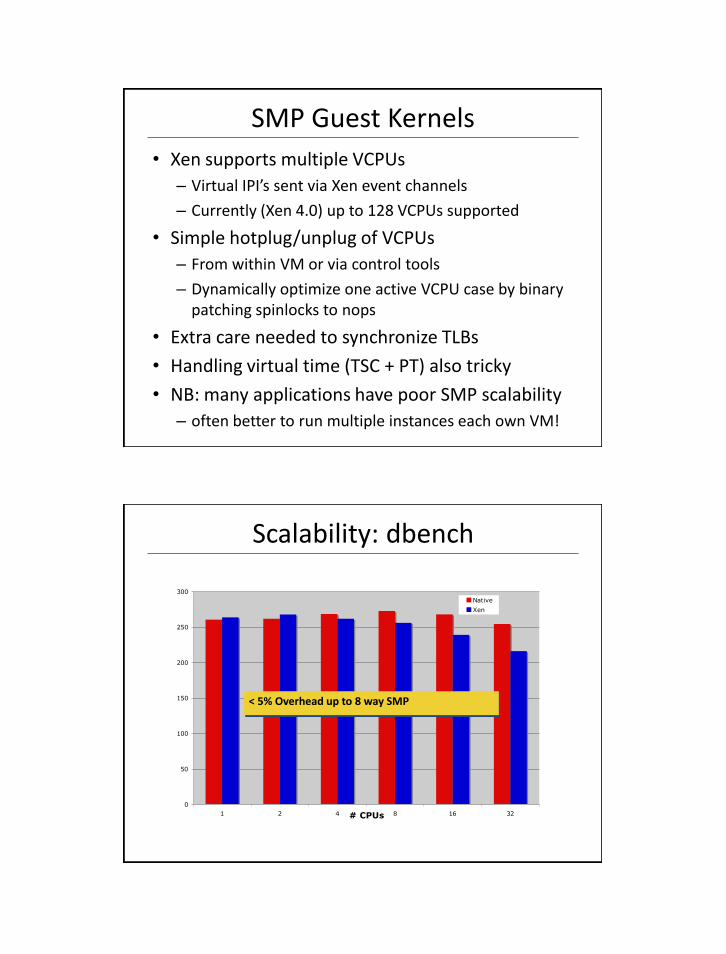
Scalability: dbench
0
50
100
150
200
250
300
1 2 4 8 16 32# CPUs
Native
Xen
< 5% Overhead up to 8 way SMP

Scalability: kernel build
0
50
100
150
200
250
300
350
1 2 4 6 8
Tim
e (
s)
Native
Xen
32b PAE; Parallel make,
4 processes per CPU
5%
8%
13%
18% 23%
# Virtual CPUs
I/O Architecture• Xen IO-Spaces delegate guest OSes protected
access to specified h/w devices– Virtual PCI configuration space
– Virtual Interrupts
– (Need IOMMU for full DMA protection)
• Devices are virtualised and exported to other VMs via Device Channels– Safe asynchronous shared memory transport
– ‘Backend’ drivers export to ‘frontend’ drivers
– Net: use normal bridging, routing, iptables
– Block: export any blk dev e.g. sda4,loop0,vg3
• (Infiniband / Smart NICs for direct guest IO)

Driver Domains
Event Channel Virtual MMUVirtual CPU Control IF
Hardware (SMP, MMU, physical memory, Ethernet, SCSI/IDE)
NativeDeviceDriver
GuestOS(XenLinux)
Device Manager & Control s/w
VM0
NativeDeviceDriver
GuestOS(XenLinux)
VM1
Front-EndDevice Drivers
GuestOS(XenLinux)
UnmodifiedUser
Software
VM2
Front-EndDevice Drivers
GuestOS(XenBSD)
UnmodifiedUser
Software
VM3
Safe HW IF
Xen Virtual Machine Monitor
Back-End Back-End
DriverDomain
Device Channel Interface

Isolated Driver VMs
• Run device drivers in separate domains
• Detect failure e.g. illegal access, timeout, etc
• Kill domain, restart
• e.g. 275ms outage from failed Ethernet driver
0
50
100
150
200
250
300
350
0 5 10 15 20 25 30 35 40
time (s)
Hardware Virtualization• Paravirtualization has fundamental benefits
– e.g. MS chose paravirtualization for Hyper-V – but is limited to OSes with PV kernels.
• DBR lets you run unmodified OSes– but has performance and completeness issues
• Since 2007 have new CPUs from Intel and AMD– Introduces host mode and guest mode– VMM runs in host mode, and sets up VMCB per VM– New instruction vmrun to switch to guest mode
• When in guest mode, various events cause vmexits– Essentially a trap to the hypervisor– Set of events configurable, but can include ‘difficult’
instructions… or these can directly update shadow state– Basically enables a classic trap-and-emulate hypervisor

Hardware Virtualization
• Definitely a help… but CPU is only part of the system: must also handle memory & I/O
Transparent MMU Virtualization
• Unmodified OS expects contiguous chunks of physical memory (e.g. E820 map)…– but VMM must share between many OSes
• Hence need to dynamically translate between guest physical and ‘real’ physical addresses– i.e. pseudo-physical to machine translation
• Use shadow page tables to mirror guest OS page tables (and implicit ‘no paging’ mode)– Guest reads/writes what it thinks are the real PTs
– VMM tracks, and constructs PT for real MMU
– Must back propagate accessed & dirty bits too

MMU Virtualization: Shadow-Mode
MMU
Accessed &
dirty bits
Guest OS
VMM
Hardware
guest writes
guest reads Virtual → Pseudo-physical
Virtual → Machine
Updates
Shadow Page Table Algorithms• Simplest algorithm simply walks guest PT and
makes a shadow version– On write to PT base (%cr3), trap into VMM
– Starting at root, for every PT• Allocate a shadow page
• For each PTE in original PT, translate guest PFN to MFN
• Store translated PTE (merge bits) in shadow page
• Write protect source PT
– When finished, update hw %cr3 with shadow root
– On %cr3 switch, discard existing shadows + rebuild
• This has problems with time overhead, space overhead, and correctness ;-)
• In practice, more sophisticated algorithms used…

Shadow Page Table Optimizations• Keep dynamic cache of shadow page table pages,
indexed by VM + %cr3– Can keep shadows across context switches
• Supports guest-level PT sharing (not root)
– Can tweak size of cache on per-VM basis to trade memory for performance
– Need care to ensure notice when PTs are demoted (how?)
• Allow “out of sync” shadow page tables– Basically same trick as writeable page tables– Works very well for fork(), mmap() etc
• Emulate faulting instruction, performing guest physical -> machine translation on the fly– Only a limited x86 emulator required– Can always fall back to copy-mode is cannot emulate
• Fast revalidate (track unchanged regions of guest PT)
Shadow Page Table Complications
• There’s a lot more gore to worry about:– 2, 3, or 4-level PTs with 32-bit or 64-bit PTEs
– 32-bit mode guests on 36- or 64-bit hardware
– superpages at various levels
– linear page tables (recursive maps)
– protected mode & big real mode
– interactions with segmentation and PAT
– multiple-VCPUs and TLB shootdown issues
• All feasible, and with high performance…
• … but shadow page table code is generally some of the most complex in any VMM!

Hardware Assisted Paging• Recently AMD NPT/Intel EPT added to respective CPUs • Hardware handles translation with nested pagetables
– guest PTs managed by guest in normal way– Guest physical to machine tables managed by VMM
• Can increases the number of memory accesses to perform a TLB fill pagetable walk by factor of 5 (gulp!)– Hopefully less through caching partial walks– But reduces the effective TLB size
• Current implementations seem to do rather worse than shadow PTs (e.g. 15%)– Big SMP guests do relatively better due to no s/w locking
• TLB flush paravirtualizations essential
• However H/W will improve: TLBs will get bigger, caching more elaborate, prefetch more aggressive
• And considerably simpler in any case…
Transparent I/O Virtualization
• Finally we need to solve the I/O issue– non-PV OSes don’t know about VMM
– hence run ‘standard’ PC ISA/PCI drivers
• Just emulate devices in software?– complex, fragile and non-performant…
– … but ok as backstop mechanism.
• Better: – add PV (or “enlightened”) device drivers to OS
– well-defined driver model makes this easy
– (network, block, USB ok; trickier for e.g. GPU!)
– get PV performance benefits for I/O path
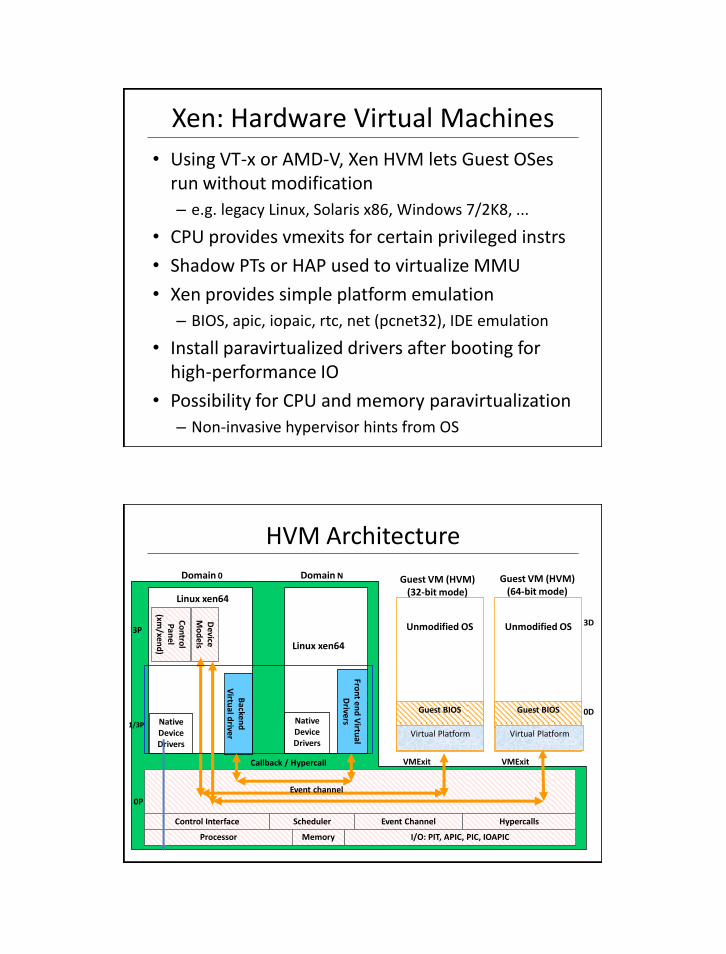
Xen: Hardware Virtual Machines
• Using VT-x or AMD-V, Xen HVM lets Guest OSesrun without modification
– e.g. legacy Linux, Solaris x86, Windows 7/2K8, ...
• CPU provides vmexits for certain privileged instrs
• Shadow PTs or HAP used to virtualize MMU
• Xen provides simple platform emulation
– BIOS, apic, iopaic, rtc, net (pcnet32), IDE emulation
• Install paravirtualized drivers after booting for high-performance IO
• Possibility for CPU and memory paravirtualization
– Non-invasive hypervisor hints from OS
NativeDevice Drivers
Co
ntro
l P
anel
(xm/xen
d)
Fron
t end
Virtu
al D
rivers
Linux xen64
Device
Mo
dels
Guest BIOS
Unmodified OS
Domain N
Linux xen64
Callback / Hypercall VMExit
Virtual Platform
0D
Backen
dV
irtual d
river
Native Device Drivers
Domain 0
Event channel
0P
1/3P
3P
I/O: PIT, APIC, PIC, IOAPICProcessor Memory
Control Interface Hypercalls Event Channel Scheduler
Guest BIOS
Unmodified OS
VMExit
Virtual Platform
3D
Guest VM (HVM)(32-bit mode)
Guest VM (HVM)(64-bit mode)
HVM Architecture

Progressive Paravirtualization
• Hypercall API available to HVM guests
• Selectively add PV extensions to optimize
– Network and Block IO
– XenAPIC (event channels)
– MMU operations
• multicast TLB flush
• PTE updates (faster than page fault)
• page sharing
– Time (wall-clock and virtual time)
– CPU and memory hotplug
NativeDevice Drivers
Co
ntro
l P
anel
(xm/xen
d)
Fron
t end
Virtu
al D
rivers
Linux xen64
De
vice
Mo
dels
Guest BIOS
Unmodified OS
Domain N
Linux xen64
Callback / Hypercall VMExit
Virtual Platform
0D
Backen
dV
irtual d
river
Native Device Drivers
Domain 0
Event channel
0P
1/3P
3P
I/O: PIT, APIC, PIC, IOAPICProcessor Memory
Control Interface Hypercalls Event Channel Scheduler
FE Virtu
al D
rivers
Guest BIOS
Unmodified OS
VMExit
Virtual Platform
FE Virtu
al D
rivers
3D
PIC/APIC/IOAPICemulation
Guest VM (HVM)(32-bit mode)
Guest VM (HVM)(64-bit mode)
Progressive Paravirtualization

0
100
200
300
400
500
600
700
800
900
1000
ioemu PV-on-HVM PV
Mb/s
rx tx
HVM I/O Performance
Measured with ttcp
(1500 byte MTU)
Emulated I/O PV on HVM Pure PV
NativeDevice Drivers
Co
ntro
l P
anel
(xm/xen
d)
Fron
t end
Virtu
al D
rivers
Linux xen64
Guest BIOS
Unmodified OS
Domain N
Linux xen64
Callback / Hypercall
VMExit
Virtual Platform
0D
Guest VM (HVM)(32-bit mode)
Backen
dV
irtual d
river
Native Device Drivers
Domain 0
Event channel
0P
1/3P
3P
I/O: PIT, APIC, PIC, IOAPICProcessor Memory
Control Interface Hypercalls Event Channel Scheduler
FE Virtu
al D
rivers
Guest BIOS
Unmodified OS
VMExit
Virtual Platform
Guest VM (HVM)(64-bit mode)
FE Virtu
al D
rivers
3D
IO Emulation IO Emulation
De
vice
Mo
dels
PIC/APIC/IOAPICemulation
Xen 4: Even better HVM Emulation

Interim Summary• Systems Virtualization aims to make efficient,
isolated, duplicates of the real machine– CPU, MMU, Devices
• Can virtualize CPU via: – traditional trap-and-emulate (RISC, new x86); – dynamic binary rewriting (VMw, qemu(?)); or– paravirtualization (Xen, Denali)
• MMU easy for RISC, harder if h/w page tables– Can paravirtualize; shadow; or use h/w support
• Devices: – Software emulation (slow & fragile, but often needed)– Paravirtualized I/O (even if guest not PV); or – Hardware support (e.g. VT-d, SR-IOV, ..)
Four Case Studies
• Virtualization is a powerful technique
– One extra-level of indirection solves everything…
• Next up we’ll cover four example uses:
– #1 Live Migration of Virtual Machines
– #2 Enhanced Virtual Block Devices
– #3 Demand-Emulation for Dynamic Taint-Tracking
– #4 Enlightened Page Sharing

#1. VM Relocation : Motivation
• VM relocation enables:
– High-availability
• Machine maintenance
– Load balancing
• Statistical multiplexing gain
Assumptions
• Networked storage
– NAS: NFS, CIFS
– SAN: Fibre Channel
– iSCSI, network block dev
– drdb network RAID
• Good connectivity
– common L2 network
– L3 re-routeing
Storage

Challenges
• VMs have lots of state in memory
• Some VMs have soft real-time requirements
– E.g. web servers, databases, game servers
– May be members of a cluster quorum
Minimize down-time
• Performing relocation requires resources
Bound and control resources used
Relocation Strategy
Stage 0: pre-migration
Stage 1: reservation
Stage 2: iterative pre-copy
Stage 3: stop-and-copy
Stage 4: commitment
VM active on host ADestination host selected(Block devices mirrored)
Initialize container on target host
Copy dirty pages in successive rounds
Suspend VM on host ARedirect network trafficSynch remaining state
Activate on host BVM state on host A released

Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 1

Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 1

Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 2

Pre-Copy Migration: Round 2
Pre-Copy Migration: Round 2

Pre-Copy Migration: Round 2
Pre-Copy Migration: Round 2

Pre-Copy Migration: Final
Writable Working Set
• Pages that are dirtied must be re-sent
– Super hot pages
• e.g. process stacks; top of page free list
– Buffer cache
– Network receive / disk buffers
• Dirtying rate determines VM down-time
– Shorter iterations → less dirtying → …

Rate Limited Relocation
• Dynamically adjust resources committed to performing page transfer
– Dirty logging costs VM ~2-3%
– CPU and network usage closely linked
• E.g. first copy iteration at 100Mb/s, then increase based on observed dirtying rate
– Minimize impact of relocation on server while minimizing down-time
Web Server Relocation
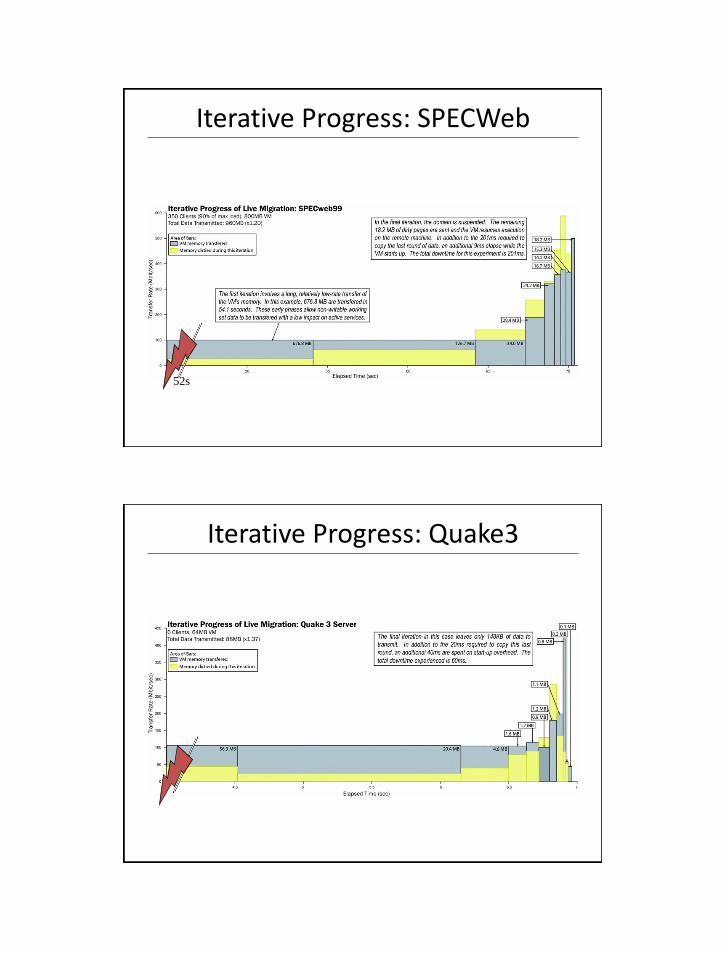
Iterative Progress: SPECWeb
52s
Iterative Progress: Quake3

Quake 3 Server relocation
#2. Virtual Disk Storage
• Originally, people used LVM Logical Volumes to store guest virtual disk images today
– Not as intuitive as using files
– Copy-on-write and snapshot support not ideal
• However storing disk images in files using Linux’s “loop” driver doesn’t work well...
• The “Blktap” driver (Xen 3.0.3+) provides an alternative :
– Allows all block requests to be serviced in user-space using zero-copy AIO approach

Blktap and tapdisk plug-ins
• Plugins for qcow, vhd, vmdk and raw• Native qcow format supports:
– Sparse allocation– Copy-on-write– Encryption– Compression
• Great care taken over metadata write ordering
RHUL 23/02/07 102
Blktap IO performance

103
Parallax: Virtual block mappings
• Each virtual image is the root of a mapping trie.
• No write sharing.
• Snapshots are immutable.
• Similar to what happens inside a filer, but visible.
Root A Root BSnapshot!
Data
L2
L1
Storage VMs aggregate to form a storage service. A single administrative role manages filers, disks, drivers, etc.

#3. Taint-based protection
• A generalized attack vector on desktops is the eventual execution of downloaded code.
• Idea: What if we prevented downloaded data from ever executing?
• Not just devices: Memory + CPU as well.
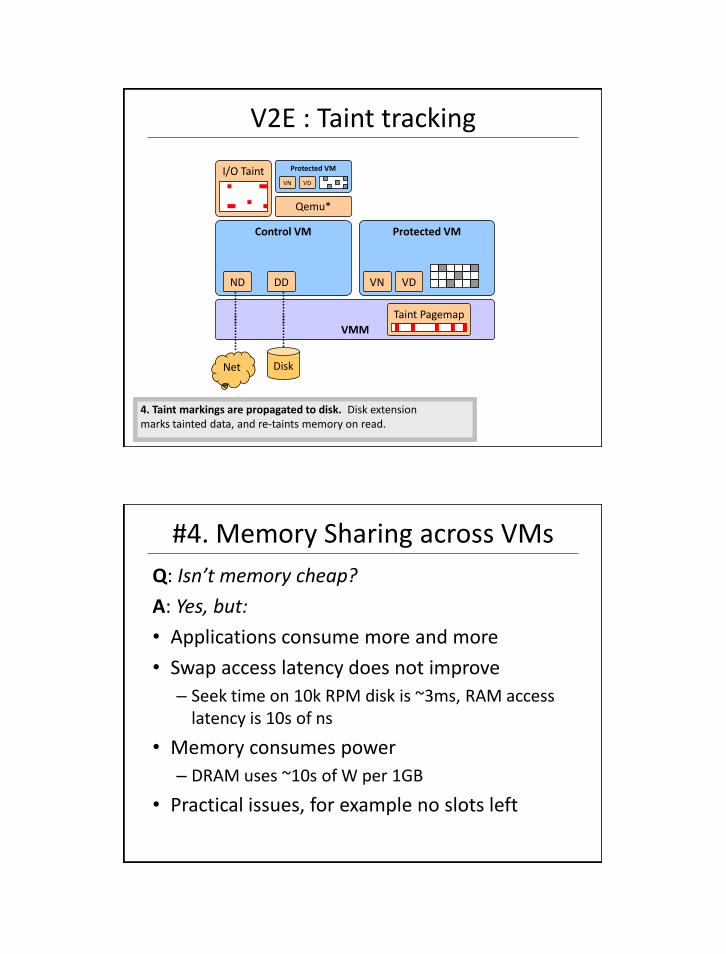
V2E : Taint tracking
VMM
Control VM
DD
DiskNet
ND
Protected VM
VN VD
I/O Taint
Taint Pagemap
1. Inbound pages are marked as tainted. Fine-grained taintDetails in extension, page-granularity bitmap in VMM.2. VM traps on access to a tainted page. Tainted pagesMarked not-present. Throw VM to emulation.
Qemu*
Protected VM
VN VD
3. VM runs in emulation, tracking tainted data. Qemumicrocode modified to reflect tainting across data movement.4. Taint markings are propagated to disk. Disk extensionmarks tainted data, and re-taints memory on read.
V2E : Taint tracking
VMM
Control VM
DD
DiskNet
ND
I/O Taint
Taint Pagemap
1. Inbound pages are marked as tainted. Fine-grained taintDetails in extension, page-granularity bitmap in VMM.2. VM traps on access to a tainted page. Tainted pagesMarked not-present. Throw VM to emulation.
Qemu*
3. VM runs in emulation, tracking tainted data. Qemumicrocode modified to reflect tainting across data movement.4. Taint markings are propagated to disk. Disk extensionmarks tainted data, and re-taints memory on read.
Protected VM
VN VD
Protected VM
VN VD
#4. Memory Sharing across VMs
Q: Isn’t memory cheap?
A: Yes, but:
• Applications consume more and more
• Swap access latency does not improve
– Seek time on 10k RPM disk is ~3ms, RAM access latency is 10s of ns
• Memory consumes power
– DRAM uses ~10s of W per 1GB
• Practical issues, for example no slots left

Memory in VMMs
• VMMs must divide finite physical memory between some number of VMs
• Can overcommit by promising VMs more memory in aggregate than is actually available
• If memory overcommitted– More (idle?) VMs can be supported, but …
– Paging in the VMM
– Double paging
• If memory not overcommitted– Guests run their own MM policies
– Allocations can still be changed with balloons
Memory sharing in VMMs
• Identically configured VMs (OS, apps, etc) can share a lot of identical data
– Hence working set of all VMs less than the sum of individual working sets
• Memory sharing saves memory
– Extra memory increases page cache sizes
– Less I/O, thus better performance
• If a similar VM is already running, footprint of new VM is reduced
– makes deployment of new VMs cheaper

Memory sharing in VMMs
• It looks like this:
Guest
Operating
System
Guest
Operating
System
‘Pseudo-physical’ memory
Machine memory
Copy-on-write memory sharing
Surplus
memory
Sharing Requirements
• Sharing clearly has potential benefit, although need to be careful to maintain isolation
– Don’t want behaviour (or “contents of”) VM1 to be able to adversely affect VM2
– (Similar problem in OS-level sharing, but isolation less required – or at least expected! – there)
• To implement, need to solve four problems:
– 1. Detecting potentially sharable memory
– 2. How to track sharing, and detect “breaking”
– 3. Deciding what do to with surplus memory
– 4. Reclaiming memory when needed

Detecting Sharing Opportunities• Simplest approach is page scanning
– VMM loops through all physical memory, runs SHA-1 hash (or similar), and looks for duplicates
– If duplicate detected, update shadow page tables of relevant VMs to point to single machine page
• Unfortunately page scanning can suffer from high overhead (CPU load, caches)– Hence typically rate-limit the scanning… but now less
effective at finding opportunities
• Another option is to interpose on the I/O path– i.e. check only pages loaded from [virtual] disk– Much lower overhead, but may miss some chances– In practice get 70-90% of all possible meaningful
sharing via I/O interposition
Tracking Sharing & Breaking
• Tracking sharing is relatively straightforward
– Use standard CoW tricks from OS, but now in shadow page tables instead of guest ones
– Some care needed regarding e.g. superpagemappings, low-level PTE attributes, …
• Breaking is detected by a write-protect fault from one of the sharing VMs
– Need to find a new machine page, and update the relevant page table
– Problem: how to find a new page?

Page Reclamation• Three possibilities:
– 1. Paging in the hypervisor– 2. Memory Ballooning– 3. Ephemeral (or “transcendental”) memory
• Hypervisor-level paging is problematic:– complicates the hypervisor, and breaks isolation– But sometimes required as a fall-back
• Memory ballooning requires PV driver in guest– Guest “gives back” memory that it doesn’t require – Issues with unresponsive or uncooperative guest
• Ephemeral memory also requires PV driver– Guest must nominate some memory as reproducible– VMM can then reclaim without notification
• In practice, tend to use combination of all three
Using Surplus Memory• Simplest way is to put surplus memory to
common use (e.g. shared buffer cache)
• For load balancing, however, better to distribute surplus memory between VMs– E.g. VMs with phase-shifts in workloads
– Need to be careful not to break isolation
• Fairest is to give each VM a sharing entitlement– For each page shared between n VMs, each VM
receives an entitlement of (1/n)
– (entitlement adjusted dynamically at runtime)
– Can “borrow” up to floor(entitlement) from VMM
– If borrow k pages, must give k ephemeral as collateral

VMMs: Conclusions• Old technique having recent resurgence:
– really just 1 VMM between 1970 and 1995– now at least 10 under development
• Why popular today?– OS static size small compared to memory– (sharing can reduce this anyhow)– security at OS level perceived to be weak– flexibility (and “extensibility”) as desirable as ever
• Emerging applications:– Virtual Portable Machines:
• Run VMM on servers, desktops, laptops, etc• As commute, move personal VM to convenient location
– Multi-level secure systems: • many people run VPN from home to work, but machine shared for
personal use => risk of viruses, information leakage, etc• instead run VM with only VPN access
– Data-center management & The CloudTM
ReadingEarly papers on VMMs; and microkernels, and other architectures.• PDP-10 Virtual machines, Galley, Proc. ACM SIGARCH-SIGOPS
Workshop on Virtual Computer Systems, Cambridge, Mass., 1969• Proceedings of the workshop on virtual computer systems, March
1973, Cambridge Mass, [Entire Proceedings are of interest!]• Formal Requirements for Virtualizable Third Generation
Architectures, Popek & Goldberg, CACM 17(7), 1974 • The Impact of Operating System Structure on Memory System
Performance, Chen and Bershad, ACM SOSP 1993• On Micro-Kernel Construction, Liedtke, ACM SOSP 1995• Exterminate All Operating System Abstractions, Engler et al, HotOS
1995• The Performance of Microkernel-based Systems, Haertig et al, ACM
SOSP 1997• Application Performance and Flexibility on Exokernel Systems,
Kaashoek et al, SOSP 1997• Self-Paging in the Nemesis Operating System, Hand, OSDI 1999

Reading• The modern VMM era
– Disco: Running Commodity Operating Systems on Scalable Multiprocessors, Bugnion et al, ACM SOSP 1997
– Analysis of the Intel Pentium's Ability to Support a Secure Virtual Machine Monitor, Robin et al, USENIX Security 2000
– Scale and Performance in the Denali Isolation Kernel, Whitaker et al, OSDI 2002
– Xen and the Art of Virtualization, Barham et al, ACM SOSP 2003
– A Comparison of Hardware and Software Techniques for x86 Virtualization, Adams & Agesen, ACM ASPLOS 2006
– Hardware Virtualization with Xen, Hand et al, USENIX ;login magazine 32(1), February 2007
– The Cost of Virtualization, Drepper, ACM Queue (6)1, January/February 2008
Reading• Topics in Systems Virtualization:
– Live Migration of Virtual Machines, Clark et al, ACM NSDI 2005
– Practical Taint-based Protection using Demand Emulation, Ho et al, EuroSys 2006
– Performance and Security Lessons Learned from Virtualizing the Alpha Processor, Computer Architecture News, 35(2), May 2007
– Parallax: Virtual Disks for Virtual Machines, Meyer at al, Eurosys 2008
– Remus: High Availability via Asynchronous Virtual Machine Replication, Cully et al, ACM NSDI 2008
– Satori: Englightened Page Sharing, Milos et al, USENIX 2009
– NOVA: A MicrohypervisorBased Secure Virtualization Architecture, Steinberg & Kauer, EuroSys 2010