mining very large datasets with support vector machine algorithms
TRANSCRIPT

MINING VERY LARGE DATASETS WITH SUPPORT VECTOR
MACHINE ALGORITHMS
François Poulet, Thanh-Nghi Do ESIEA Recherche, 38 rue des Docteurs Calmette et Guérin, 53000 Laval, France
Email: [email protected], [email protected]
Keywords: Data mining, Parallel and distributed algorithms, Classification, Machine learning, Support vector
machines, Least squares classifiers, Newton method, Proximal classifiers, Incremental learning.
Abstract: In this paper, we present new support vector machines (SVM) algorithms that can be used to classify very
large datasets on standard personal computers. The algorithms have been extended from three recent SVMs
algorithms: least squares SVM classification, finite Newton method for classification and incremental
proximal SVM classification. The extension consists in building incremental, parallel and distributed SVMs
for classification. Our three new algorithms are very fast and can handle very large datasets. An example of
the effectiveness of these new algorithms is given with the classification into two classes of one billion
points in 10-dimensional input space in some minutes on ten personal computers (800 MHz Pentium III,
256 MB RAM, Linux).
1 INTRODUCTION
The size of data stored in the world is constantly increasing (data volume doubles every 20 months world-wide) but data do not become useful until some of the information they carry is extracted. Furthermore, a page of information is easy to explore, but when the information becomes the size of a book, or library, or even larger, it may be difficult to find known items or to get an overview. Knowledge Discovery in Databases (KDD) can be defined as the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data (Fayyad et al., 1996).
In this process, data mining can be defined as the particular pattern recognition task. It uses different algorithms for classification, regression, clustering or association. Support Vector Machine (SVM) algorithms are one kind of classification algorithms. Recently, a number of powerful support vector machine (SVM) learning algorithms have been proposed (Bennett and Campbell, 2000). This approach has shown practical relevance for classification, regression or novelty detection. Successful applications of SVMs have been reported for various fields, for example in face identification, text categorization, bioinformatics (Guyon, 1999).
The approach is systematic and properly motivated by statistical learning theory (Vapnik, 1995). SVMs are the most well known algorithms of a class using the idea of kernel substitution (Cristianini and Shawe-Taylor, 2000). SVMs and kernel methodology have become increasingly popular tools for data mining tasks. SVM solutions are obtained from quadratic programming problems possessing a global solution, so that, the computational cost of an SVM approach depends on the optimization algorithm used. The very best algorithms today are typically quadratic and required multiple scans of the data. Unfortunately, real-world databases increase in size: according to (Fayyad and Uthurusamy, 2002), world-wide storage capacity doubles every 9 months. There is a need to scale up learning algorithms to handle massive datasets on personal computers. We have created three new algorithms that are very fast for building incremental, parallel and distributed SVMs for classification. They are derived from the following ones: least squares SVMs classifiers (Suykens and Vandewalle, 1999), finite Newton method for classification problems (Mangasarian, 2001) and incremental SVMs classification (Fung and Mangasarian, 2001). Our three new algorithms can classify one billion points in 10-dimensional input space into two classes in some minutes on ten computers (800 MHz Pentium III, 256 MB RAM, Linux).
© 2004 Kluwer Academic Publishers. Printed in the Netherlands.
177
O. Camp et al. (eds.), Enterprise Information Systems V, 177-184.

ENTERPRISE INFORMATION SYSTEMS V
178
We briefly summarize the content of the paper now. In section 2, we introduce least squares SVMs classifiers, incremental proximal SVMs, and finite Newton method for classification problems. In section 3, we describe our reformulation of the least squares SVMs algorithm for building incremental SVMs. In section 4, we propose the extension of the finite Newton algorithm for building incremental SVMs. In section 5, we describe our parallel and distributed versions of the three incremental algorithms. We demonstrate numerical test results in section 6 before the conclusion in section 7.
Some notations are used in this paper. All vectors will be column vectors unless transposed to row vector by a t superscript. The 2-norm of the vector x will be denoted by ||x||, the matrix A[mxn]will be m trained points in the n-dimensional real space R
n. The classes +1, -1 of m trained points are
denoted by the diagonal matrix D[mxm] of +1, -1. e will be the column vector of 1. w, b will be the coefficients and the scalar of the hyperplane. z will be the slack variable and ν is a positive constant. Idenote the identity matrix.
2 RELATED WORKS
We briefly present a general linear classification task of SVMs and then we summarize three algorithms: least squares SVM, incremental proximal SVM and finite Newton SVM algorithm.
Incremental learning algorithms (Syed et al., 1999), (Cauwenberghs and Poggio, 2001) are a convenient way to handle very large data sets because they avoid to load the whole data set in main memory: only subsets of the data are to be considered at any one time.
2.1 Linear SVMs Classification
Let us consider a linear binary classification task, as depicted in figure 1, with m data points in the n-dimensional input space R
n, represented by the mxn
matrix A, having corresponding labels ±1, denoted by the mxm diagonal matrix D of ±1.
For this problem, the SVMs try to find the best separating plane, i.e. furthest from both class +1 and class -1. It can simply maximize the distance or margin between the support planes for each class (x
tw = b+1 for class +1, x
tw = b-1 for class -1). The
margin between these supporting planes is 2/||w||. Any point falling on the wrong side of its supporting
plane is considered to be an error. Therefore, the SVMs have to simultaneously maximize the margin and minimize the error. The standard SVMs with linear kernel is given by the following quadratic program (1):
min f(z,w,b) = νetz + (1/2)||w||
2
s.t. D(Aw - eb) + z ≥ e (1)
where the slack variable z ≥ 0 and ν is a positive constant.
The plane (w,b) is obtained by the solution of the quadratic program (1). And then, the classification function of a new data point x based on the plane is:
f(x) = sign(wx – b) (2)
2.2 Least squares SVM classifiers
A least squares SVMs classifier has been proposed by (Suykens and Vanderwalle, 1999). It uses an equality instead of the inequality constraints in the optimization problem (1) with a least squares 2-norm error into the objective function f. Least squares SVMs are the solution of the following optimization problem (3):
min f(z,w,b) = (ν/2)||z||2 + (1/2)||w||
2
s.t. D(Aw - eb) + z = e (3)
where the slack variable z ≥ 0 and ν is a positive constant.
Thus substituting z into the objective function fwe get an unconstraint problem (4):
min f(w,b)= (ν/2)||e – D(Aw – eb)||2 + (1/2)||w||
2 (4)
A
A+
xt.w – b = 0
xtw – b = +1
xtw – b = -1
margin = 2/||w||
Figure 1: Linear separation of the datapoints into two classes

MINING VERY LARGE DATASETS WITH SUPPORT VECTOR MACHINE ALGORITHMS
179
For least squares SVMs with linear kernel, the Karush-Kuhn-Tucker optimality condition of (4) will give the linear equation system of (n+1) variables (w,b). Therefore, least squares SVMs is very fast to train because it expresses the training in terms of solving a set of linear equations instead of quadratic programming.
2.3 Proximal SVM classifier and its
incremental version
The proximal SVMs classifier proposed by (Fung and Mangasarian, 2001) also changes the inequality constraints to equalities in the optimization problem (1). However, besides adding a least squares 2-norm error into the objective function f, it changes the formulation of the margin maximization to the minimization of (1/2)||w,b||
2. Thus substituting for z
from the constraint in terms (w,b) into the objective function f we get an unconstraint problem (5):
min f(w,b)= (ν/2)||e – D(Aw–eb)||2 + (1/2)||w,b||
2 (5)
Setting the gradient with respect to (w,b) to zero gives:
[w1 w2 .. wn b]t = (I/ν + E
tE)
-1E
tDe (6)
where E = [A -e]
This expression for (w,b) requires the solution of a system of linear equations. Proximal SVMs is very fast to train.
Linear incremental proximal SVMs is extended from the computation of E
tE and d = E
tDe from the
formulation (6). Let us consider the small blocks of data Ai, Di, we can simply compute E
tE = ΣEi
tEi and
d = Σdi = ΣEitDie. This algorithm can perform the
linear classification of one billion data points in 10-dimensional input space into two classes in less than 2 hours and 26 minutes on a 400 MHz Pentium II (Fung and Mangasarian, 2002). About 30% of the time was spent reading data from disk. Note that all we need to store in memory between two incremental steps is the small (n+1)x(n+1) matrix E
tE and the (n+1)x1 vector d = E
tDe
although the order of the dataset is one billion data points.
2.4 Finite Newton SVMs Algorithm
We return to the formulation of the standard SVMs with a least squares 2-norm error and changing the
margin maximization to the minimization of (1/2)||w,b||
2.
min f(z,w,b) = (ν/2)||z||2 + (1/2)||w, b||
2
s.t. D(Aw - eb) + z ≥ e (7)
where the slack variable z ≥ 0 and ν is a positive constant.
The formulation (7) can be reformulated by substituting for z = (e – D(Aw – eb))+ (where (x)+
replaces negative components of a vector x by zeros) into the objective function f. We get an unconstraint problem (8):
min f(w,b)=(ν/2)||(e–D(Aw–eb))+||2 + (1/2)||w,b||
2 (8)
If we set u = [w1 w2 .. wn b]t and H = [A -e] then
the formulation (8) will be rewritten by (9):
min f(u) = (ν/2)||(e – DHu)+||2 + (1/2)u
tu (9)
O. Mangasarian has developed the finite stepless Newton method for this strongly convex unconstrained minimization problem (9). This algorithm can be described as follows:
where the gradient of f at u is:
∇f(u) = ν(-DH)t(e – DHu)+ + u,
and the generalized Hessian of f(u) is:
∂2f(u) = ν(-DH)
tdiag(e - DHu)'(-DH) + I,
with diag(e - DHu)' denotes the (n+1)x(n+1) diagonal matrix whose j
th diagonal entry is
subgradient of the step function (e - DHu)+.
The sequence {ui} of the algorithm terminates at
the global minimum solution as demonstrated by (Mangasarian, 2001). In almost all the tested cases, the stepless Newton algorithm has given the solution with a number of Newton iterations varying between 5 and 8.
Start with any u0 ∈ R
n+1 and i = 0.
Repeat
1) ui+1
= ui - ∂2
f(ui)
-1∇f(ui)
2) i = i + 1 Until (∇f(u
i-1) = 0)

ENTERPRISE INFORMATION SYSTEMS V
180
3 INCREMENTAL LS-SVMs
We return to the least squares SVMs algorithm with linear kernel as in section 2.1 by changing the inequality constraints to equalities, and substituting for z from the constraint in terms (w,b) into the objective function f. Least squares SVMs involve the solution of the unconstrained optimization problem (4):
min f(w,b)= (ν/2)||e – D(Aw – eb)||2 + (1/2)||w||
2 (4)
Applying the Karush-Kuhn-Tucker optimality condition of (4), the gradient with respect to w,b is set to zero, we obtain the linear equation system of (n+1) variables (w,b):
νAtD(D(Aw – eb) –e) + w = 0
-νetD(D(Aw – eb) –e) = 0
We can reformulate the linear equation system given above as (10):
[w1 w2 .. wn b]t = (I’/ν + E
tE)
-1E
tDe (10)
where E = [A -e], I’ denotes the (n+1)x(n+1) diagonal matrix whose (n+1)
th diagonal entry is zero
and the other diagonal entries are 1.
The solution of the linear equation system (10) will give (w,b). Note that least squares SVMs solving by (10) is very similar to the linear system (6) of the linear proximal SVMs, furthermore, setting to zero the (n+1)
th diagonal
entry of I in the system (6) gives I’ in (10). Therefore, we can extend the least squares SVMs to build the incremental learning algorithm in the same way as the incremental proximal SVMs with linear kernel. We can compute E
tE = ΣEi
tEi and d =Σdi =
ΣEitDie from the small blocks Ai, Di. We can see that
the incremental least squares SVMs algorithm has the same complexity as the incremental proximal SVMs. It can handle very large datasets (at least 10
9
points) on personal computers in some minutes. And we only need to store the small (n+1)x(n+1) matrix E
tE and the (n+1)x1 vector d = E
tDe in
memory between two successive steps.
4 INCREMENTAL FINITE NEW-
TON SVMs
The main idea is to incrementally compute the generalized Hessian of f(u) and the gradient of f(∂2
f(u) and ∇f(u)) for each iteration in the finite Newton algorithm described in section 2.3.
Suppose we have a very large dataset decomposed into small blocks Ai, Di. We can simply compute the gradient and the generalized Hessian of f by the formulation (11) and (12):
∇f(u) = ν(Σ(-DiHi)t(e – DiHiu)) + u (11)
∂2f(u) = ν(Σ(-DiHi)
tdiag(e-DiHiu)'(-DiHi)) + I (12)
where Hi = [Ai -e]
Consequently, the incremental finite Newton algorithm can handle one billion data points in 10-dimensional input space on personal computer. Its execution time is very fast because it gives the solution with a number of Newton iterations varying from 5 to 8. We only need to store a small (n+1)x(n+1) matrix and two (n+1)x1 vectors in memory between two successives steps.
5 PARALLEL AND DISTRIBUTED
INCREMENTAL SVM
ALGORITHMS
The three incremental SVMs algorithms described above are very fast to train in almost cases and can deal with very large datasets on personal computers. However they run only on one single machine. We have extended them to build incremental, parallel and distributed SVMs algorithms on a computer network by using the remote procedure calls (RPC) mechanism. First of all, we distribute the datasets (Ai, Di) on remote servers.
Concerning the incremental proximal and the least squares SVMs algorithms, the remote servers compute independently, incrementally the sums of Ei
tEi and di = Ei
tDie, and then, a client machine will
use these results to compute w and b. Concerning the incremental finite Newton algorithm, the remote servers compute independently, incrementally the sums of:
(-Di Hi)t (e - Di Hi u), and
MINING VERY LARGE DATASETS WITH SUPPORT VECTOR MACHINE ALGORITHMS
181
(-Di Hi)tdiag(e - Di Hi u)'(-Di Hi).
Then a client machine will use these sums to update u for each Newton iteration.
The RPC protocol does not support asynchronous communication. A synchronous request-reply mechanism in RPC requires that the client and server are always available and functioning (i.e. the client or server is not blocked). The client can issue a request and must wait for the server's response before continuing its own processing. Therefore, we have created a child process for parallel waitings on the client side.
The parallel and distributed implementation versions do have significantly speeded up the three incremental versions.
6 NUMERICAL TEST RESULTS
Our new algorithms are written in C / C++ on personal computers (800 MHz Pentium III processor, 256 MB RAM). These computers run on Linux Redhat 7.2. Because we are interested in very large datasets, we focus numerical tests on datasets created by the NDC program from (Musicant, 1998). The first three datasets contain two millions data points in 10-dimensional, 30-dimensional and 50-dimensional input space. We use them to estimate the execution time for varying the number of dimensions.
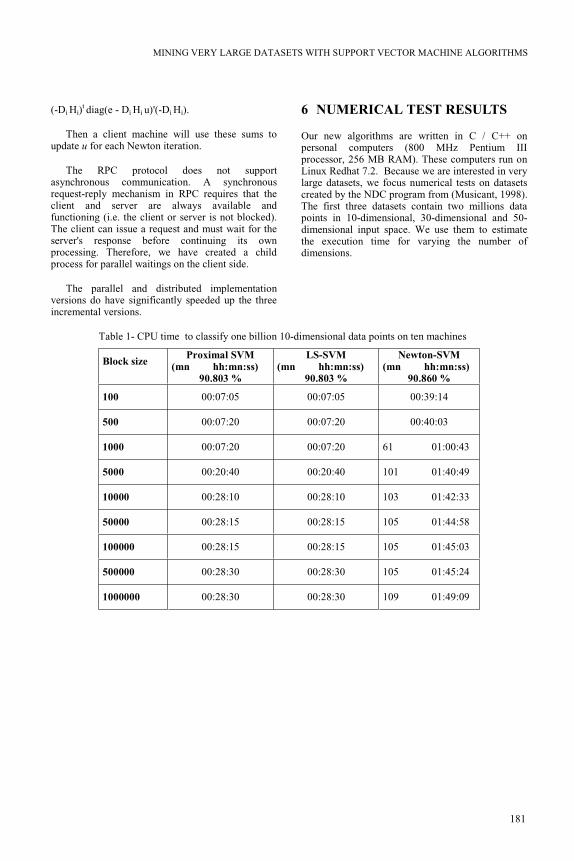
Table 1- CPU time to classify one billion 10-dimensional data points on ten machines
Block size Proximal SVM
(mn hh:mn:ss)
90.803 %
LS-SVM
(mn hh:mn:ss)
90.803 %
Newton-SVM
(mn hh:mn:ss)
90.860 %
100 00:07:05 00:07:05 00:39:14
500 00:07:20 00:07:20 00:40:03
1000 00:07:20 00:07:20 61 01:00:43
5000 00:20:40 00:20:40 101 01:40:49
10000 00:28:10 00:28:10 103 01:42:33
50000 00:28:15 00:28:15 105 01:44:58
100000 00:28:15 00:28:15 105 01:45:03
500000 00:28:30 00:28:30 105 01:45:24
1000000 00:28:30 00:28:30 109 01:49:09
ENTERPRISE INFORMATION SYSTEMS V
182
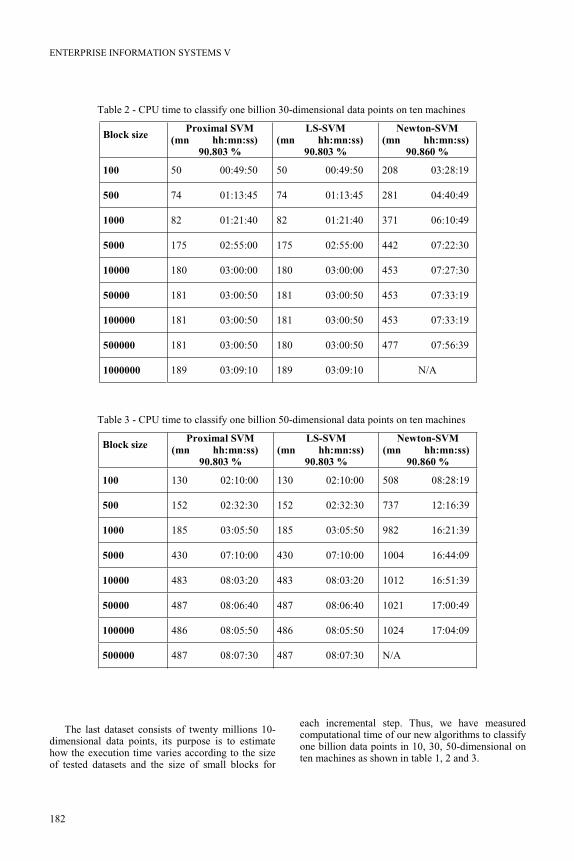
Table 2 - CPU time to classify one billion 30-dimensional data points on ten machines
Block size Proximal SVM
(mn hh:mn:ss)
90.803 %
LS-SVM
(mn hh:mn:ss)
90.803 %
Newton-SVM
(mn hh:mn:ss)
90.860 %
100 50 00:49:50 50 00:49:50 208 03:28:19
500 74 01:13:45 74 01:13:45 281 04:40:49
1000 82 01:21:40 82 01:21:40 371 06:10:49
5000 175 02:55:00 175 02:55:00 442 07:22:30
10000 180 03:00:00 180 03:00:00 453 07:27:30
50000 181 03:00:50 181 03:00:50 453 07:33:19
100000 181 03:00:50 181 03:00:50 453 07:33:19
500000 181 03:00:50 180 03:00:50 477 07:56:39
1000000 189 03:09:10 189 03:09:10 N/A
Table 3 - CPU time to classify one billion 50-dimensional data points on ten machines
Block size Proximal SVM
(mn hh:mn:ss)
90.803 %
LS-SVM
(mn hh:mn:ss)
90.803 %
Newton-SVM
(mn hh:mn:ss)
90.860 %
100 130 02:10:00 130 02:10:00 508 08:28:19
500 152 02:32:30 152 02:32:30 737 12:16:39
1000 185 03:05:50 185 03:05:50 982 16:21:39
5000 430 07:10:00 430 07:10:00 1004 16:44:09
10000 483 08:03:20 483 08:03:20 1012 16:51:39
50000 487 08:06:40 487 08:06:40 1021 17:00:49
100000 486 08:05:50 486 08:05:50 1024 17:04:09
500000 487 08:07:30 487 08:07:30 N/A
The last dataset consists of twenty millions 10-dimensional data points, its purpose is to estimate how the execution time varies according to the size of tested datasets and the size of small blocks for
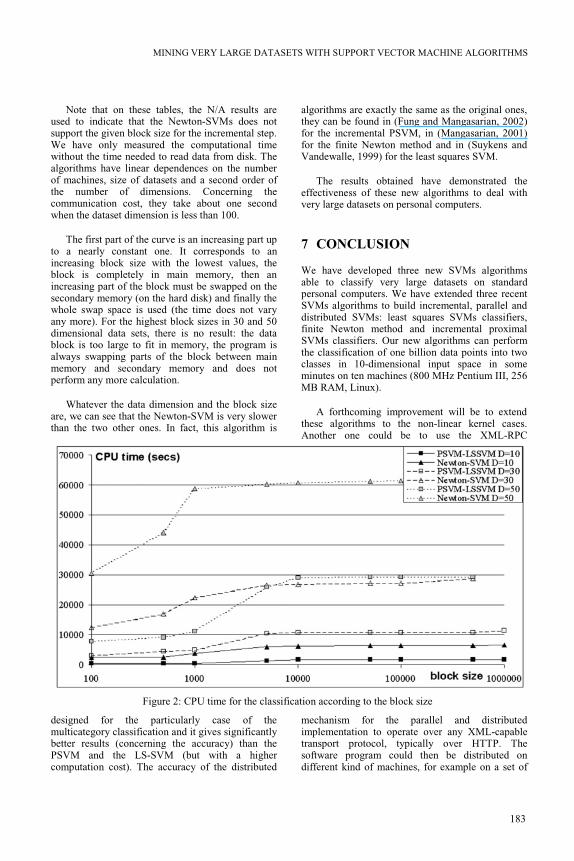
each incremental step. Thus, we have measured computational time of our new algorithms to classify one billion data points in 10, 30, 50-dimensional on ten machines as shown in table 1, 2 and 3.
MINING VERY LARGE DATASETS WITH SUPPORT VECTOR MACHINE ALGORITHMS
183
Note that on these tables, the N/A results are used to indicate that the Newton-SVMs does not support the given block size for the incremental step. We have only measured the computational time without the time needed to read data from disk. The algorithms have linear dependences on the number of machines, size of datasets and a second order of the number of dimensions. Concerning the communication cost, they take about one second when the dataset dimension is less than 100.
The first part of the curve is an increasing part up to a nearly constant one. It corresponds to an increasing block size with the lowest values, the block is completely in main memory, then an increasing part of the block must be swapped on the secondary memory (on the hard disk) and finally the whole swap space is used (the time does not vary any more). For the highest block sizes in 30 and 50 dimensional data sets, there is no result: the data block is too large to fit in memory, the program is always swapping parts of the block between main memory and secondary memory and does not perform any more calculation.
Whatever the data dimension and the block size are, we can see that the Newton-SVM is very slower than the two other ones. In fact, this algorithm is
designed for the particularly case of the multicategory classification and it gives significantly better results (concerning the accuracy) than the PSVM and the LS-SVM (but with a higher computation cost). The accuracy of the distributed
algorithms are exactly the same as the original ones, they can be found in (Fung and Mangasarian, 2002) for the incremental PSVM, in (Mangasarian, 2001) for the finite Newton method and in (Suykens and Vandewalle, 1999) for the least squares SVM.
The results obtained have demonstrated the effectiveness of these new algorithms to deal with very large datasets on personal computers.
7 CONCLUSION
We have developed three new SVMs algorithms able to classify very large datasets on standard personal computers. We have extended three recent SVMs algorithms to build incremental, parallel and distributed SVMs: least squares SVMs classifiers, finite Newton method and incremental proximal SVMs classifiers. Our new algorithms can perform the classification of one billion data points into two classes in 10-dimensional input space in some minutes on ten machines (800 MHz Pentium III, 256 MB RAM, Linux).
A forthcoming improvement will be to extend these algorithms to the non-linear kernel cases. Another one could be to use the XML-RPC
mechanism for the parallel and distributed implementation to operate over any XML-capable transport protocol, typically over HTTP. The software program could then be distributed on different kind of machines, for example on a set of
Figure 2: CPU time for the classification according to the block size

ENTERPRISE INFORMATION SYSTEMS V
184
various remote PCs, Unix stations or any other computer reachable via the web.
REFERENCES
Bennett K. and Campbell C., 2000, “Support Vector
Machines: Hype or Hallelujah?”, in SIGKDD
Explorations, Vol. 2, No. 2, pp. 1-13.
Cauwenberghs G. and Poggio T. 2001, “Incremental and
Decremental Support Vector Machine Learning”, in
Advances in Neural Information Processing Systems
(NIPS 2000), MIT Press, Vol. 13, 2001, Cambridge,
USA, pp. 409-415.
Cristianini, N. and Shawe-Taylor, J., 2000, “An
Introduction to Support Vector Machines and Other
Kernel-based Learning Methods”, Cambridge
University Press.
Fayyad U., Piatetsky-Shapiro G., Smyth P., Uthurusamy
R., 1996, "Advances in Knowledge Discovery and
Data Mining", AAAI Press.
Fayyad, U., Uthurusamy R., 2002, "Evolving Data Mining
into Solutions for Insights", in Communication of the
ACM, 45(8), pp.28-31.
Fung G. and Mangasarian O., 2001, “Proximal Support
Vector Machine Classifiers”, in proc. of the 7th ACM
SIGKDD Int. Conf. on KDD’01, San Francisco, USA,
pp. 77-86.
Fung G. and Mangasarian O., 2002, "Incremental Support
Vector Machine Classification", in proc. of the 2nd
SIAM Int. Conf. on Data Mining SDM'2002
Arlington, Virginia, USA.
Fung G. and Mangasarian O., 2001, "Finite Newton
Method for Lagrangian Support Vector Machine
Classification", Data Mining Institute Technical
Report 02-01, Computer Sciences Department,
University of Wisconsin, Madison, USA.
Guyon I., 1999, "Web Page on SVM Applications",
http://www.clopinet.com/isabelle/Projects/SVM/app-
list.html
Mangasarian O., 2001, "A Finite Newton Method for
Classification Problems", Data Mining Institute
Technical Report 01-11, Computer Sciences
Department, University of Wisconsin, Madison, USA.
Musicant D., 1998, "NDC : Normally Distributed
Clustered Datasets", http://www.cs.cf.ac.uk/Dave/C/
Suykens, J. and Vandewalle J., 1999, "Least Squares
Support Vector Machines Classifiers", Neural
Processing Letters, Vol. 9, No. 3, pp. 293-300.
Syed N., Liu H., Sung K., 1999, "Incremental Learning
with Support Vector Machines", in proc. of the 6th
ACM SIGKDD Int. Conf. on KDD'99, San Diego,
USA.
Vapnik V., 1995, "The Nature of Statistical Learning
Theory", Springer-Verlag, New York.