marketing attribution at internetstores –
TRANSCRIPT

MARKETING ATTRIBUTION AT INTERNETSTORES –
Whitepaper

2
Über Internetstores:
Als einer der führenden, digitalen Fachhändler für Bike und Outdoor bringt Internetstores jeden Tag Tausende Menschen in ganz Europa aufs Rad und in die Natur. Reichweitenstarke Plattformen wie fahrrad.de, Bikester, Probikeshop, CAMPZ und Addnature bieten mehr als 1.300 Marken und über 130.000 Produkte – direkt online verfügbar, komfortabel bezahl- oder finanzierbar, bequem nach Hause oder an den Wunschort geliefert. Neben weltweit führenden Top-Brands aus den Bereichen Fahrrad, E-Bike und Outdoor vertreibt Internetstores zudem exklusive und ausgezeichnete Produktlinien etwa von VOTEC, FIXIE Inc., Ortler und Serious. Das starke Online-Business wird ergänzt durch lokale Stores in Deutschland, Schweden und Frankreich sowie durch ein wachsendes Netzwerk an stationären und mobilen Servicepartnern.
Internetstores ist Teil der SIGNA Sports United und beschäftigt an den europäischen Unternehmensstandorten Stuttgart, Berlin, Lyon und Stockholm rund 800 Mitarbeiterinnen und Mitarbeiter.
Über CI.Bureau:
Als Digital Beratung unterstützen wir Sie maßgeschneidert bei der Sammlung, Verknüpfung, Interpretation und dem Einsatz kundenzentrierter Daten zur Ausrichtung von Produkten, Services, internen Prozessen und Marketingmaßnahmen auf Ihre Kunden.
Gemeinsam entwerfen wir mit Ihnen kundenzentrierte Geschäftsprozesse, planen und begleiten deren Umsetzung. Neben der Konzeption und Realisierung von datengetriebenen Technology Stacks entwickeln wir moderne Datenprodukte und -services. CI.Bureau hilft Ihnen, geschäftsrelevante Potenziale für den Einsatz von Machine Learning Algorithmen zu identifizieren und bringt diese in die automatisierte Anwendung. Zu unseren Mandanten zählen namhafte Unternehmen aus den Bereichen E-Commerce, Multichannel Retail, Unterhaltungsindustrie sowie Energieversorgung.

3
Inhaltsverzeichnis
1. Management Summary 4
2.1 Aufgaben und Ziele 7
2.2 Prozesskomponenten 8
3. Make or Buy at Internetstores 11
4. Marketing Attribution at Internetstores 15
4.1 Solution Architecture 16
4.2 Attributionsmodell 19
4.3 Erkenntnisse und Ergebnisse 22
5. Fazit & Ausblick 23
Kontakt 24

MANAGEMENT SUMMARY –
Marketing Attribution at Internetstores

5
1. Management Summary
Kundenzentrierung und damit die Fokussierung und Ausrichtung des Geschäftsmodells sowie sämtlicher Aktivitäten auf die Bedürfnisse der Kundschaft birgt enorme Potenziale für eine Verbesserung des Kundenerlebnisses und der Kundenbindung. Gleichzeitig schafft sie entscheidende Wettbewerbsvorteile in einem sich stets verändernden Marktumfeld.
Speziell im Marketing ist dieser Trend nicht mehr aufzuhalten. Die zunehmende Anwendung von Technologie und die Verwendung von Daten erlaubt dabei eine personalisierte, individualisierte und orchestrierte Interaktion entlang der individuellen Customer Journey, nicht nur bei der bestehenden Kundschaft, sondern ebenfalls in der Akquisition von neuen Kund*innen. Neben dieser potenziellen Zunahme an Effektivität steigt gleichzeitig der Anspruch an eine Beurteilung der Marketingeffizienz entlang eben dieser Customer Journey durch Marketing Attribution. Marketing Attribution ist dabei keineswegs nur ein Tool, welches von einzelnen Funktionen eines Unternehmens genutzt wird, sondern es ist vielmehr ein zentraler Geschäftsprozess, der sich in eine kundenzentrierte Marketingstrategie einordnet und die funktionsübergreifende Wirklichkeit für eine kundenorientierte Wertschöpfung abbildet.
Aufgrund der Bedeutung und notwendigen Passgenauigkeit muss die Entscheidung für und die Definition dieses Prozesses beim Unternehmen liegen. Gleichzeitig ist die Frage zu klären, ob Umsetzung und Betrieb von einzelnen Prozesskomponenten über externe Tools und Dienstleistungen ausgelagert werden können, ohne auf eine notwendige Flexibilität und Transparenz verzichten zu müssen. Mit beratender Unterstützung durch CI.Bureau ist Internetstores die nächsten Schritte in der Weiterentwicklung dieses Prozesses gegangen.
Im ersten Teil dieses Whitepapers wird Marketing Attribution als Geschäftsprozess sowohl hinsichtlich seiner Aufgaben und Ziele als auch seiner einzelnen Prozesskomponenten idealtypisch beschrieben. Auf der Basis des Prozessverständnisses wird im darauffolgenden Teil die Internetstores-spezifische “Make or Buy”-Entscheidung über einzelne Komponenten erörtert. Im dritten Teil wird die technologische Umsetzung in Eigenentwicklung näher beschrieben. Neben der datenbasierten Lösungsarchitektur wird dabei auch im Speziellen auf die Entwicklung eines Attributionsmodells eingegangen. Das Whitepaper schließt mit einer Zusammenfassung der wesentlichen Erkenntnisse und zeigt die konkreten sowie langfristigen nächsten Schritte bei Internetstores auf.

MARKETING ATTRIBUTION ALS GESCHÄFTSPROZESS –
Marketing Attribution at Internetstores

7
2.1 Aufgaben und Ziele
Für die Bewertung des Erfolgs von Marketingmaßnahmen ist es entscheidend, mehr als nur die letzte Interaktion der jeweiligen Nutzer*innen mit der Marke zu berücksichtigen. Hinter diesem allgemeinen Konsens steckt das intuitive Verständnis für die Customer Journey, also die Phasen individueller Nutzer*innen, die diese auf dem Weg zum gewünschten Ziel durchlaufen, und damit die Erkenntnis, dass unterschiedliche Marketingkanäle in diesen verschiedenen Phasen eine differenzierte Wirkung entfalten (siehe Abb. 1).
Abb. 1: Der Sales Funnel als konzeptionelle Darstellung von Customer Journeys
Insofern besteht die Aufgabe von Marketing Attribution darin, Marketing-Touchpoints, unter Berücksichtigung der Phase und im Vergleich zu allen anderen Touchpoints, in der nutzerindividuellen Customer Journey verursachungsgerecht zu bewerten. Daraus leitet sich das Ziel von Marketing Attribution ab – die optimierte Budgetallokation und damit eine Steigerung der Effizienz. Langfristig sollen so Marketingkosten reduziert oder Umsatzerlöse bei gleichbleibendem Mitteleinsatz maximiert werden.
TRIGGER & AWARENESS
RESEARCH & COMPARE
CONVERSION
LOYALTY & RETENTION
WO
RD OF M
OUTH / BRAN
D AWAREN
ESS
SEARCH
SEARCH
SEARCH
SEARCH
DISPLAY
DISPLAY
DISPLAY
DISPLAY
8
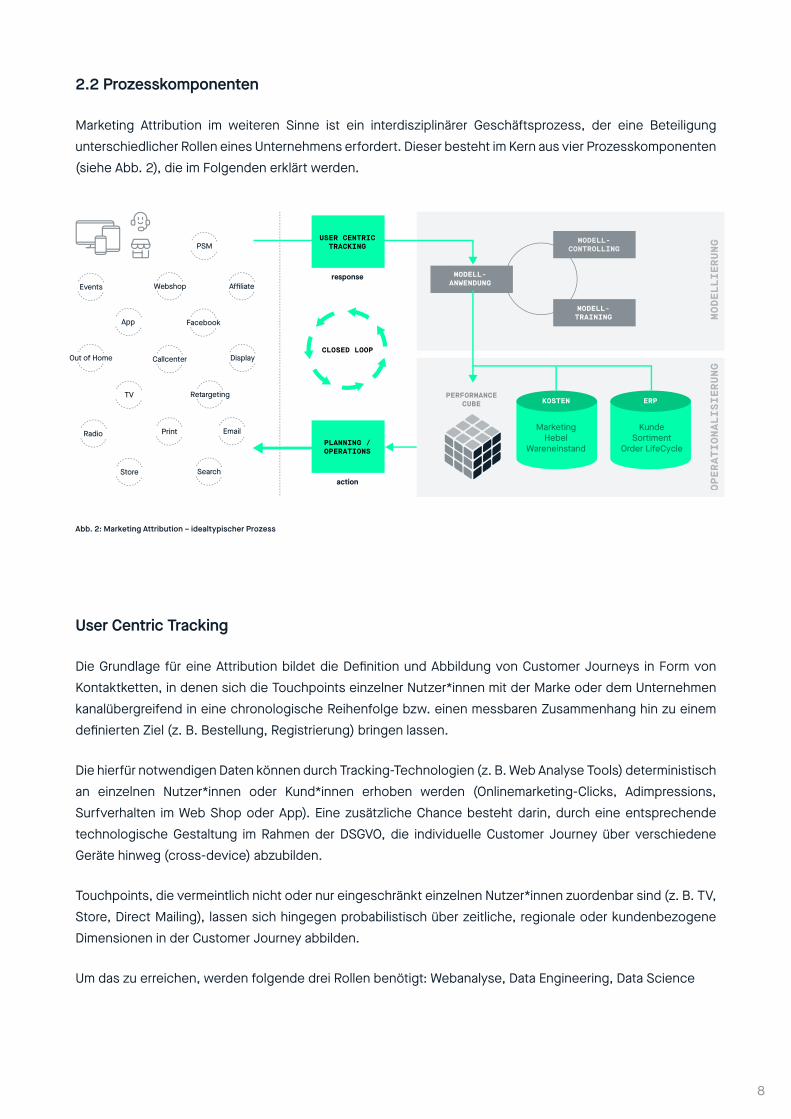
2.2 Prozesskomponenten
Marketing Attribution im weiteren Sinne ist ein interdisziplinärer Geschäftsprozess, der eine Beteiligung unterschiedlicher Rollen eines Unternehmens erfordert. Dieser besteht im Kern aus vier Prozesskomponenten (siehe Abb. 2), die im Folgenden erklärt werden.
Abb. 2: Marketing Attribution – idealtypischer Prozess
User Centric Tracking
Die Grundlage für eine Attribution bildet die Definition und Abbildung von Customer Journeys in Form von Kontaktketten, in denen sich die Touchpoints einzelner Nutzer*innen mit der Marke oder dem Unternehmen kanalübergreifend in eine chronologische Reihenfolge bzw. einen messbaren Zusammenhang hin zu einem definierten Ziel (z. B. Bestellung, Registrierung) bringen lassen.
Die hierfür notwendigen Daten können durch Tracking-Technologien (z. B. Web Analyse Tools) deterministisch an einzelnen Nutzer*innen oder Kund*innen erhoben werden (Onlinemarketing-Clicks, Adimpressions, Surfverhalten im Web Shop oder App). Eine zusätzliche Chance besteht darin, durch eine entsprechende technologische Gestaltung im Rahmen der DSGVO, die individuelle Customer Journey über verschiedene Geräte hinweg (cross-device) abzubilden.
Touchpoints, die vermeintlich nicht oder nur eingeschränkt einzelnen Nutzer*innen zuordenbar sind (z. B. TV, Store, Direct Mailing), lassen sich hingegen probabilistisch über zeitliche, regionale oder kundenbezogene Dimensionen in der Customer Journey abbilden.
Um das zu erreichen, werden folgende drei Rollen benötigt: Webanalyse, Data Engineering, Data Science
PSM
Webshop
Out of Home Callcenter Display
TV
Print Email
Store Search
Radio
Retargeting
App
Events
MODE
LLIE
R UNG
OPER
ATI O
NALI
SIER
UNG
USER CENTRICTRACKING
MODELL-ANWENDUNG
PERFORMANCECUBE KOSTEN ERP
MODELL-CONTROLLING
MODELL-TRAINING
PLANNING /OPERATIONS
response
action
CLOSED LOOP
MarketingHebel
Wareneinstand
KundeSortiment
Order LifeCycle

9
Modellierung
Die Attribution im engeren Sinne befasst sich mit der Frage der verursachungsgerechten Verteilung eines erreichten Ziels bzw. dessen monetären Werts auf die beteiligten Kontaktpunkte in der Customer Journey. Das Werkzeug hierfür bietet ein Attributionsmodell. Dabei wird zwischen statischen und dynamischen Modellen unterschieden. Statische Modelle folgen eindimensional, d.h. ausschließlich auf die Kontaktposition bezogen, einem definierten Regelwerk (z. B. First- / Last-Click, U-Modell / Badewanne, gleichverteilt, linear ansteigend).Dynamische Modelle werden multidimensional, d.h. neben der Kontaktposition mit weiteren Bewertungsdimensionen, auf der Basis statistischer Algorithmen auf das Verteilungsproblem mathematisch trainiert und angewendet. Während statische Modelle recht einfach, transparent und nachvollziehbar sind, können sie nur unzureichend in ihren Annahmen validiert werden, und sind somit zu Teilen willkürlich. Dynamische Modelle hingegen lassen sich bereits bei der Entwicklung, aber auch im laufenden Betrieb, hinsichtlich ihres Wahrheitsgehalts überprüfen – sie sind somit überwachbar (Modellcontrolling). Je nach Wahl der statistischen Methode und dem Grad der Komplexität dieser, verlieren statistische Algorithmen an Transparenz und Nachvollziehbarkeit. Da es bei der Verwendung der Daten in letzter Konsequenz um eine Umverteilung des Marketingbudgets geht, kann eine Blackbox an dieser entscheidenden Stelle zu einem Akzeptanzproblem unter den beteiligten, budgetverantwortlichen Rollen (z. B. Online Marketing, CRM, Controlling) kommen. Dieser Herausforderung kann durch zielgerichtete Analysen und Visualisierungen, d.h. durch nachgelagerte Schaffung von Transparenz, entgegengetreten werden.Während statische, journeybasierte Modelle häufig für die ersten Gehversuche bei dem Thema Attribution in Eigenregie verwendet werden, haben sich dynamische Modelle vor allem auch bei den kommerziellen Anbietern als State of the Art durchgesetzt.
Innerhalb des Unternehmens benötigte Rollen: Data Engineering, Data Science
Operationalisierung
Im Rahmen der Operationalisierung muss der durch ein Attributionsmodell bereitgestellte Verteilungsschlüssel in handlungsrelevantes Wissen übersetzt werden. Die Handlungsrelevanz leitet sich dabei grundsätzlich von den fachlichen bzw. technischen Anforderungen der zu versorgenden Fachabteilungen und Tools ab. Die Aufgabe der Operationalisierung lässt sich insofern als Anreicherung der Attribution mit spezifischen Bewertungsdimensionen und Kennzahlen beschreiben. Zusätzlich zu den im Tracking gemessenen Informationen erfolgt hierbei eine Anreicherung der Customer Journeys mit Informationen aus unternehmensinternen oder -externen Datenquellen. Damit beispielsweise auf abgeschlossenen und attribuierten Bestellungen eine KUR (Kosten-Umsatz-Relation) abgebildet werden kann, müssen zum einen die Marketingkosten aus den entsprechenden Tools bzw. Kanälen (z. B. Google Ads, Facebook Ads, usw.) standardmäßig extrahiert und zum anderen die weitere zeitliche Entwicklung dieser Bestellungen (Auslieferung, Storno, Retoure) aus unternehmensinternen Systemen (ERP) verknüpft werden. Die Kostenpositionen lassen sich hierbei beliebig nach unternehmensindividueller Anforderung und Datenverfügbarkeit bis hin zu einem attribuierten, betriebswirtschaftlichen Deckungsbeitrag erweitern. Gleichzeitig können auch weitere Prognosemodelle bereitgestellt werden, die beispielsweise die Zeit zwischen Bestellung und potenzieller Retoure durch eine Vorhersage überbrücken oder einen prognostischen CLV (Customer-Lifetime-Value) auf Kundenebene in eine attribuierte Steuerung überführen.

10
Neben betriebswirtschaftlichen Steuerungsgrößen wird die Attribution um relevante Bewertungsdimensionen angereichert. Dies können z. B. Sortimentsdimensionen an den angesehenen oder bestellten Produkten, geo-basierte Informationen für eine Verknüpfung mit dem Stationärgeschäft oder Kundendimensionen, wie z.B. Soziodemographika oder Kundensegmente, sein. Das Ergebnis der Operationalisierung ist schlussendlich die Bereitstellung eines einzigen multidimensionalen Datenwürfels (Performance Cube) als Single Source of Truth, der für unterschiedliche Abteilungen und Tools in spezifische Datensichten gedreht werden kann. Während SEA-Manager*innen die Performance auf Kampagnen-, AdGroup- oder Keyword-Ebene umtreibt, möchten Marketingverantwortliche eine Rentabilitätsaussage auf Marketingkanalebene erheben. Interessiert SEO-Verantwortliche der Impact von organischen Suchen auf bestimmten Seitentypen, möchten Category Manager*innen in der langen Reihe die Performance der Vermarktung bestimmter Sortimente verfolgen. Neben einer kanal- und funktionsübergreifenden Wahrheit liefert die einheitliche Datensicht gleichzeitig die analytische Basis zum Verständnis des Zusammenspiels unterschiedlicher Touchpoints und Kanäle in der Customer Journey und damit zur Generierung handlungsrelevanten, kundenzentrierten Wissens.
Für den Einsatz werden folgende Rollen benötigt: Data Engineering – Business Analytics – Controlling – Channel Management
Planning & Operations
Für eine operative Planung und Steuerung müssen Personen und Tools zur richtigen Zeit, in der richtigen Frequenz, mit den für sie steuerungsrelevanten Informationen versorgt werden.Neben der Bereitstellung unterschiedlicher Datensichten in Form von Standard Reportings und Visualisierungen für menschliche Betrachter*innen, spielt die Versorgung von Marketing-Tools eine entscheidende Rolle bei der Erreichung eines Effizienzgewinns in der operativen Steuerung. Während viele Tools ihre eigene eingeschränkte Performancesicht, quasi in Silos, als Steuerungsgrundlage zur Verfügung stellen, besteht hier zwingend die Notwendigkeit, die durch eine zentrale Marketing Attribution generierte Wahrheit bis in diese Tools und damit in die Steuerung zu tragen. Eine wachsende Anzahl an Tools erlaubt den programmatischen Upload von extern attribuierten Conversions für eine Anwendung in toolspezifischen Dashboards und Optimierungsszenarien. Gleichzeitig müssen auf der Basis der attribuierten Performance Steuerungsimplikationen standardmäßig für die Arbeit mit solchen Tools bereitgestellt werden, die über keine programmatische Schnittstelle verfügen. Hierfür benötigte Rollen sind: Data Engineering – Business Analytics – Controlling – Channel Management
Closed Loop
Die konsequente operative und analytische Umsetzung der oben genannten Prozesskomponenten führt zu einem geschlossenen Regelkreis aus Ursache und Wirkung und damit zu einem unternehmensweiten Instrument für eine kanalübergreifende, da kundenzentrierte, Bewertung und Effizienzsteigerung von Marketingmaßnahmen. In technischer Hinsicht wird der Regelkreis über den Betrieb einer automatisierten und regelmäßigen Datenbewirtschaftung abgebildet, die standardmäßig tagesaktuell, in einzelnen Szenarien sogar untertägig erfolgen kann.

MAKE OR BUY AT INTERNETSTORES –
Marketing Attribution at Internetstores
3. Make or Buy at Internetstores

12
Internetstores hatte bereits einige Erfahrungen mit einem statischen, journey-basierten Modell in Eigenentwicklung gesammelt. Zusätzlich waren Teile der weiteren Prozesskomponenten (Operationalisierung und Steuerung) bereits umgesetzt. Demnach bestanden die Kernanforderungen in einer Verbesserung des Modellierungsansatzes sowie in einer Ausweitung der kundenzentrierten Analysemöglichkeiten und der handlungsrelevanten Erkenntnisse in der Operationalisierung. Damit sollte die unternehmensweite Akzeptanz und Nutzung in der Planung und Steuerung gesteigert werden.
Während der Umsetzungsschwerpunkt zunächst auf den nutzerindividuellen, digital messbaren Touchpoints liegen sollte, wurden bereits Anforderungen für eine Berücksichtigung indirekt messbarer Touchpoints (z. B. TV oder Branding) formuliert. Gleichzeitig sollte eine Lösung prospektiv auf alle nationalen und internationalen Shop Brands übertragbar und umsetzbar sein.
Internetstores verfügt über die notwendigen fachlichen Rollen und technischen Fähigkeiten für eine Eigenentwicklung der gesamten Prozesskette. Aus dieser Ausgangslage heraus, bestand für Internetstores weniger die originäre Frage zwischen Make or Buy, sondern vielmehr die Einschätzung, ob gewichtige Gründe bei der Abbildung einzelner Prozesskomponenten gegen eine Eigenentwicklung sprechen könnten.
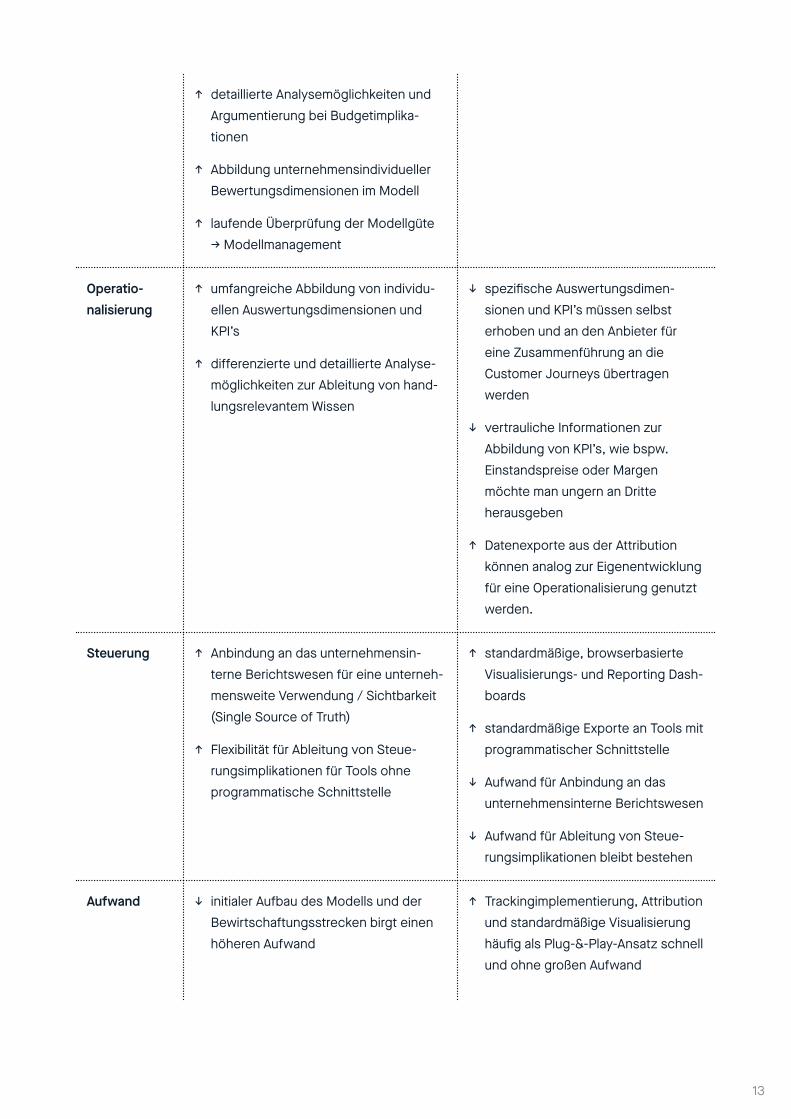
Tabelle 1 beschreibt im Folgenden die Abwägung der Vor- und Nachteile der Eigenentwicklung im Vergleich zur Nutzung von Drittanbieter-Tools.
Kriterium Make Buy (Drittanbieter-Tools)
Tracking ↑ Verwendung der Datenexporte aus bestehendem Webanalyse Tool möglich
↑ Etablierter Prozess und Verantwor-tungsbereich
↑ Beobachtung und Sicherstellung der Datenqualität in eigenen Händen
↑ Flexibilität zukünftiger Erweiterungen
↓ Anbindung und Pflege eines zusätz-lichen, anbieterseitigen Trackings im Online-Shop
↓ Datenqualität nicht unmittelbar erfassbar / bewertbar
↑ Erfahrung in der nutzerzentrierten Datenerhebung
↑ standardmäßige Schnittstellen zur Anbindung indirekt messbarer Touchpoints (z.B. TV)
Attribution ↓ Ausbaufähiges Know-how beim Thema Attribution- Modelling
↑ Wahl eines einfacheren Algorithmus zur Einarbeitung sowie Nachvollziehbarkeit und Transparenz
↑ Aufbau von Wissen und Erfahrung im eigenen Unternehmen
↓ State of the Art, aber Blackbox-Algo-rithmus – schwer bzw. überhaupt nicht nachvollziehbar → potentielles Akzeptanzproblem
↓ keine Individualisierung der Bewer-tungsdimensionen möglich
↑ Datenexporte von attribuierten Customer Journeys möglich
13
↑ detaillierte Analysemöglichkeiten und Argumentierung bei Budgetimplika-tionen
↑ Abbildung unternehmensindividueller Bewertungsdimensionen im Modell
↑ laufende Überprüfung der Modellgüte → Modellmanagement
Operatio-nalisierung
↑ umfangreiche Abbildung von individu-ellen Auswertungsdimensionen und KPI’s
↑ differenzierte und detaillierte Analyse-möglichkeiten zur Ableitung von hand-lungsrelevantem Wissen
↓ spezifische Auswertungsdimen-sionen und KPI’s müssen selbst erhoben und an den Anbieter für eine Zusammenführung an die Customer Journeys übertragen werden
↓ vertrauliche Informationen zur Abbildung von KPI’s, wie bspw. Einstandspreise oder Margen möchte man ungern an Dritte herausgeben
↑ Datenexporte aus der Attribution können analog zur Eigenentwicklung für eine Operationalisierung genutzt werden.
Steuerung ↑ Anbindung an das unternehmensin-terne Berichtswesen für eine unterneh-mensweite Verwendung / Sichtbarkeit (Single Source of Truth)
↑ Flexibilität für Ableitung von Steue-rungsimplikationen für Tools ohne programmatische Schnittstelle
↑ standardmäßige, browserbasierte Visualisierungs- und Reporting Dash-boards
↑ standardmäßige Exporte an Tools mit programmatischer Schnittstelle
↓ Aufwand für Anbindung an das unternehmensinterne Berichtswesen
↓ Aufwand für Ableitung von Steue-rungsimplikationen bleibt bestehen
Aufwand ↓ initialer Aufbau des Modells und der Bewirtschaftungsstrecken birgt einen höheren Aufwand
↑ Trackingimplementierung, Attribution und standardmäßige Visualisierung häufig als Plug-&-Play-Ansatz schnell und ohne großen Aufwand

14
↑ Skalierbarkeit des Implementierungs- und Betriebsaufwandes bei Anbindung zusätzlicher Shop Brands nach initialer Blaupause
↓ unternehmensspezifische Operatio-nalisierung bei begrenzten Möglich-keiten nur mit Implementierungs- und Betriebsaufwand möglich
↓ Kosten der Toolnutzung steigen vermeintlich mit Ausweitung auf weitere Shop Brands
Flexibilität ↑ flexible Anpassung und Erweiterung des gesamten Prozesses liegt in den eigenen Händen
↓ nicht oder nur schwer beein-flussbare externe Abhängigkeit → kein unmittelbarer Einfluss auf Anpassungen und Feature-Erwei-terungen
Tabelle 1: Vor- und Nachteile: Marketing Attribution - Make or Buy
Eine grundlegende Erkenntnis aus der Gegenüberstellung der Vor- und Nachteile ist, dass Marketing Attribution als Geschäftsprozess effizient über einen externen Anbieter abgebildet werden kann, solange der Funktionsumfang des Anbieters ausreichend für die eigenen Anforderungen ist. Verlässt das Unternehmen diesen Standard und verfolgt eine maßgeschneiderte Individualisierung, d. h. es behält die Definitionshoheit des Geschäftsprozesses, wird die Fachabteilung auch mit einem externen Anbieter einen nicht wesentlich geringeren Aufwand aufbringen müssen als in der Eigenentwicklung.
Vor dem Hintergrund der im Unternehmen vorhandenen Skills ließ sich die Frage des Make or Buy im Wesentlichen auf den Bereich “Attribution” eingrenzen. Vorteile für die Nutzung eines externen Anbieters in diesem Bereich lagen klar bei der Erfahrung in einer nutzerzentrierten Datenerhebung, in Modellierung und Einsatz von erprobten statistischen Algorithmen sowie der Möglichkeit mit Datenexporten eine anschließende Operationalisierung in Eigenregie durchzuführen.
Demgegenüber stand die Tatsache, dass Internetstores zunächst in einen Know-how Aufbau beim Thema dynamische Attribution investieren müsse, um dieses mittel- bis langfristig in Eigenregie bewerkstelligen zu können. In dieser Abwägung war die Entscheidung für einen langfristigen Aufbau von Know-how und einer damit verbundenen Flexibilität in der Individualisierung des gesamten Geschäftsprozesses bei maximaler Transparenz und zusätzlichem Wissensgewinn gefallen. Um den Prozess des Know-how-Aufbaus maßgeblich zu beschleunigen und zügig zu einer ersten Umsetzung zu kommen, ließ sich Internetstores sowohl bei der Justierung des Gesamtprozesses als auch in der initialen technischen Umsetzung entscheidender Prozesskomponenten durch CI.Bureau unterstützen.

MARKETING ATTRIBUTION AT INTERNETSTORES –
Marketing Attribution at Internetstores
4. Marketing Attribution at Internetstores

16
Das Ziel bei der technischen Abbildung des Geschäftsprozesses war es, eine Informationsarchitektur aufzubauen, die über den Use Case Marketing Attribution hinaus auch auf andere datengetriebene, kundenzentrierte Anwendungsfälle flexibel erweiterbar ist.
4.1 Solution Architecture
Abb. 3: Solution Architecture Marketing Attribution
Die Informationsarchitektur zur Abbildung des Geschäftsprozesses “Marketing Attribution” beinhaltet im Wesentlichen folgende fünf Komponenten (siehe Abbildung 3).
Data Sources
Die für den Geschäftsprozess notwendigen Datenquellen werden für den Data Stack angebunden und extrahiert. Um die Customer Journeys abzubilden, werden die Bewegungsdaten aus dem Onlineshop benötigt. Diese werden über eine bei Internetstores bestehende Google Analytics-Implementierung gemessen und bereitgestellt. Neben den Bestellungen und externen Marketingeinsprüngen sind hier vor allem Interaktionen der Nutzer*innen mit dem Onlineshop (z. B. Suche, Navigation, Produktdetailseitenansichten, Warenkorb-Interaktion) für die Abbildung von Bewertungsdimensionen im Attributionsmodell von hoher Relevanz. Für die Operationalisierung werden Kosten- und Performancedaten aus dem Marketing Toolstack (Suchmaschinen, Preisvergleich und Display Advertising) über regelmäßige API-Abfragen bereitgestellt und bewirtschaftet.
Weiterhin werden Daten aus dem ERP-Backend, welche bereits in einem Datawarehouse erfasst und verarbeitet werden, für den Attributionsprozess extrahiert und bereitgestellt. Hier sind vor allem solche Informationen von Bedeutung, die nicht über das Web Analytics Tracking erfasst werden (können) – beispielsweise
DATA SOURCESDATA STACK
DATAACTIVATION
STORAGE-LAYER(DATALAKE)
DATA SCIENCESTACK TRAINING
CODE REPRO DEPLOYMENT SCHEDULING
CONTROLLING APPLICATION
AUTOMATIONPIPELINE
LOAD-LAYER(STAGING)
BASE-LAYER(DATA MODEL)
BUSINESS-LAYER
(INFORMATION-MARTS)
ON-PREM
Analysis |Prototyping
BusinessIntelligence
MarketingToolstack
Data StudioWeb Analytics
Storage BigQuery
MarketingToolstack
ERP /Datawarehouse
events | visitsreferrer | campaigns
orders
Search
PriceComparison
Display impressionsclicks | costs
orderscustomers (pseud.)
products
ReportingCubes
DataFeeds

17
Kund*innensegmente, Prognosen, Stornos und Retouren von Bestellungen, Sortimentsdimensionen sowie Margen und Deckungsbeiträge der bestellten Artikel.Durch die Zusammenführung dieser Informationen mit den attribuierten Customer Journeys können im Rahmen der Operationalisierung Marketing-relevante Kennzahlen abgebildet (z. B. Click Through Rate, Conversion Rate, KUR, ROAS, usw.) und mit relevanten Auswertungsdimensionen auf Kund*innen- bzw. Produktebene angereichert werden.
Data Stack
Die Schlüsselkomponente für eine Datenintegration, -modellierung und regelmäßige automatisierte Bewirtschaftung wird durch den Data Stack abgebildet. Aufgrund der durch das Webtracking erzeugten großen Datenmengen stellte sich bei der Wahl der Technologie vor allem die Frage nach kostengünstiger Skalierbarkeit bei gleichzeitiger Berücksichtigung vorhandener Skills in der Datenmodellierung (Python, SQL). Der Vorzug einer Cloud-basierten Lösung im Vergleich zu einer Hardware- bzw. Lizenzerweiterung der bestehenden On-premise Datenbanktechnologie war hierfür die naheliegende Entscheidung. Auf Basis des Vergleichs mit anderen Cloud-Anbietern fiel die Wahl auf die Google Cloud Platform. Hier wurden zunächst die Module Cloud Storage (als kostengünstiger Objektspeicher) sowie Bigquery (als serverloses, vollständig verwaltetes, skalierbares und kostengünstiges Cloud Data Warehouse) für die Lösungsarchitektur herangezogen. Im Vergleich zu Redshift von AWS und Synapse Analytics von Azure zeichnet sich Google Bigquery vor allem dadurch aus, dass durch ein On-Demand Preismodell keine anfänglichen Investitionskosten anfallen. Sizing & Planning sowie Overprovisioning durch eine automatisierte Skalierung entfallen vollständig. Einen weiteren Vorteil bietet Bigquery durch bestehende Datenintegrationen aus Tools im Google Stack. So existieren z. B. standardmäßig Datentransfer-Features aus Google Analytics und Google Ads, die mithilfe weniger Einstellungen aktiviert werden können. Der Datenbewirtschaftungsprozess wird über eine Multi-Layer-Architektur abgebildet. Im Storage Layer werden dabei aus den Datenquellen extrahierte Rohdaten-Files langfristig und kostengünstig gespeichert. Im Load Layer (Staging) werden diese Files als “federated external tables” mit Metadaten angereichert und stehen damit als Tabellen in Bigquery zur Verfügung. Abfragen auf externe Tabellen sind in Bigquery kostenlos. Ein großer Teil der Datenintegration (Typkonvertierung, Deduplizierung, Cleansing, Deltabetrachtung, Transformation, usw.) kann damit direkt in SQL-Skripten umgesetzt werden. Es bedarf hierbei keines weiteren Tools.Im Base Layer werden somit Tabellen als wiederverwendbare Basis-Entitäten in Form von Geschäftsobjekten (z. B. Orders, Visits, external Calls, Customer Journeys, Costs, Financials usw.) bewirtschaftet und durch entsprechende Schlüssel verknüpfbar gemacht. Neben der Marketing Attribution kann der Base Layer so zukünftig auch für andere Use Cases als Ausgangspunkt verwendet und erweitert werden. Der Business Layer beinhaltet grundsätzlich Use-Case-spezifische Datamarts, d. h. aus der Kombination relevanter Basis-Entitäten und gegebenenfalls mit statistischen Algorithmen veredelte, prozessierte Datentransformationen, die für eine spezifische Anwendung aufbereitet werden. Aus der Anwendung des Attributionsmodells auf die modellierten Customer Journeys und deren anschließenden Anreicherung mit Kosten- und Backenddaten im Rahmen der Operationalisierung wird der Performance Cube als Single Source of Truth persistiert.

18
Data Activation
Im Rahmen der Data Activation werden nach dem Push- oder Pull-Prinzip die Abnehmer*innen mit den für sie relevanten Datensichten aus dem Performance Cube versorgt. Gegeben einer nativen Konnektivität zwischen Bigquery und Google Datastudio kann letzteres vor allem für eine Visualisierung von Adhoc-Analysen und Prototyping von Datensichten genutzt werden. Weiterhin werden standardisierte Reportingsichten für eine Weiterverarbeitung bzw. Visualisierung im Business Intelligence zur Verfügung gestellt. Die Versorgung des Marketing Toolstacks erfolgt dabei über Datenfeeds, die programmatisch an die jeweiligen Tools überstellt werden (z. B. Google Ads).
Data Science Stack
Als technologische Basis für den Data Science Stack wurde auf bereits intern verwendete On-premise Ressourcen zurückgegriffen, wohl wissentlich, dass Google Cloud hier eine Cloud-native Umgebung zur Abbildung von Machine Learning Workflows bereitstellt (z. B. AI-Platform, Vertex-AI). Damit fiel die Wahl auf eine weniger komplexe Methode für das Attributionsmodell (siehe Kapitel 4.1 Attributionsmodell). Durch die Nutzung bestehender Ressourcen war folglich eine schnelle Umsetzung möglich. Der Data Science Stack besteht hauptsächlich aus drei Komponenten, die das Training, die Überwachung (Controlling) und die Anwendung (Application) des Attributionsmodells beinhalten. Im Rahmen des Modelltrainings werden basierend auf dem Base Layer Trainingsdaten aufgebaut und Modelle experimentell trainiert, bewertet und iterativ weiterentwickelt. Qualifiziert sich ein Modell, wird dieses für eine Anwendung im Regelprozess verfügbar gemacht. Aufgrund der bereits oben erwähnten Wahl einer weniger komplexen Methode, kann die Anwendung des Modells innerhalb von Bigquery (in Database) abgebildet werden, sodass ein Technologiebruch an dieser Stelle vermieden und die Skalierbarkeit in der Datenverarbeitung ausgenutzt werden kann. Für eine laufende Überwachung der Modellqualität wird das im Einsatz befindliche Modell automatisiert und regelmäßig hinsichtlich seiner Erklärungsgüte bewertet. Besteht der Bedarf einer Neujustierung des Modells z. B. aufgrund sich ändernder Verhaltensweisen in den gemessenen Daten, wird wieder ein Trainingsprozess angestoßen, der in einer Aktualisierung des produktiven Modells mündet. Damit schließt sich der Modell-Management-Regelkreis.
Automation Pipeline
Analog zum Data Science Stack wurde für eine Automation Pipeline ebenfalls auf bestehende Ressourcen zurückgegriffen. Die Google Cloud Platform bietet auch hierfür verschiedene Cloud-native Komponenten an (z. B. Cloud Composer, Cloud Data Flow), die sich für einen späteren Einsatz qualifizieren können.Neben einer Verwaltung des Quellcodes und der Abbildung eines Deployment-Prozesses ist hier vor allem die automatisierte Steuerung der gesamten Datenbewirtschaftungskette in zeitlicher und logischer Abfolge von besonderer Bedeutung.

19
4.2 Attributionsmodell
Herausforderung
Wie bereits erwähnt, gibt es eine Vielzahl von statistischen Methoden, um sich einer mathematischen Lösung des Attributionsproblems anzunähern (siehe beispielsweise Abbildung 4).
Allen gemein ist dieselbe Herausforderung, den Einfluss von Marketing-Touchpoints oder generell die Interaktion mit der Marke in der Customer Journey, welche mit einem definierten Ziel endet (z. B. Conversion), zu erklären und quantifizierbar zu machen. Da es sich um eine von Vorhinein festgelegte, zu lernende Aufgabe handelt, kommen ausschließlich Methoden aus dem Bereich des überwachten Lernens in Frage. Die Methoden unterscheiden sich dabei hinsichtlich ihrer Art und Weise in der Modellierung der Zusammenhänge zwischen den erklärenden Variablen (Interaktionen in der Customer Journey) und der zu erklärenden Variable (Ziel). Mögliche Unterschiede liegen z. B. in der Abbildung linearer vs. nicht-linearer Zusammenhänge, einer Schätzung mithilfe frequentistischer im Vergleich zu bayesianischer Verfahren oder in der Periodizität der Trainingsdaten (inkrementell/Online vs. Batch). Während der Methodenanspruch beim überwachten Lernen gewöhnlich in der bestmöglichen Klassifizierung bzw. Vorhersage der Zielvariable liegt, gilt das Augenmerk in der Attribution darüber hinaus einer realitätsnahen Schätzung der Einflussfaktoren, die für die Anwendung des Attributionsmodells maßgeblich ist.
Komplexität vs. Transparenz
Abb. 4: Methodenwahl
Vereinfacht lässt sich die Methodenwahl auf zwei Dimensionen reduzieren:
1. Komplexität – benötigtes Know-how in der Modellierung und technischen Umsetzung für Produktionsumgebungen → Umsetzungsgeschwindigkeit.
2. Transparenz – Nachvollziehbarkeit der Modell-Mechanik bzw. Interpretation der Ergebnisse → Akzeptanz
DECISION TREES REGRESSIONREGRESSION
MARKOV CHAINS
MIXTURE MIXTURE MODELSMODELS
SURVIVAL SURVIVAL ANALYSISANALYSIS
DEEP DEEP LEARNINGLEARNING
TRANSPARENZ KOMPLEXITÄT

20
Während die Unterschiede in der Erklärungsgüte bei den “klassischen” Methoden eher gering bis moderat ausfallen dürften, steht hierbei ein Leistungs- und Erklärungssprung eines Deep-Learning-Ansatzes außer Frage. Dieser ist hinsichtlich Transparenz und Komplexität in der Entwicklung und Anwendung jedoch deutlich anspruchsvoller.Am Beispiel der Edge Cases in Abbildung 4 können die Herausforderungen in Komplexität und Transparenz der Methode greifbar gemacht werden. Während sich die Wege (Verästelungen und Blätter) bei Entscheidungsbäumen fast schon durch bloßes Lesen nachvollziehen lassen, ist die Interpretation nichtlinearer Zusammenhänge in mehrschichtigen Deep Neural Networks noch ein relativ junges Forschungsgebiet (Explainable Artificial Intelligence). Neben der Transparenz wirkt sich das in gleichem Maße auf die Komplexität einer Extraktion der Einflussfaktoren aus, die für die bereits genannte Übersetzung in eine Attributionsleistung einzelner Kontakte in der Journey notwendig ist. Gleichzeitig besteht ein großer Unterschied in den technischen Anforderungen eines Modelltrainings. Während sich einfachere Algorithmen in angemessener Zeit sogar auf gut ausgestatteten Desktop- bzw. Notebook-PCs berechnen lassen, ist für ein effizientes Training von Deep-Learning-Algorithmen eine Verwendung von GPUs oder TPUs notwendig.
Realitätsnähe
Die bereits erwähnte “Realitätsnähe” der durch ein Modell quantifizierten Einflussfaktoren lässt sich im statistischen Sinne in eine möglichst unverzerrte Schätzung der erklärenden Variablen übersetzen. Systematische Abweichungen in den Einflussgrößen führen in letzter Konsequenz zu einer verzerrten Attribution und gegebenenfalls zu einer nicht optimalen Budgetallokation. Wie in anderen Anwendungsgebieten gibt es auch bei der Attributionsmodellierung Risiken systematischer Abweichungen, die für eine Methodenwahl bzw. eine Vorverarbeitung der Trainingsdaten von besonderer Bedeutung sind. Beispielhaft seien hier drei wichtige potenzielle Ursachen systematischer Abweichungen erläutert:
1. Survivorship Bias
Nach dem Survivorship Bias werden Wahrscheinlichkeiten eines Erfolgs systematisch überschätzt, da erfolgreiche Zustände stärker sichtbar sind als nicht erfolgreiche. Bezogen auf die Attribution besteht das Risiko eines Survivorship Bias, wenn für die Modellierung ausschließlich die erfolgreichen, also z. B. mit einem Kauf abgeschlossenen, Journeys betrachtet und somit die nicht erfolgreichen außen vor gelassen werden (z. B. Markov Chain nur auf erfolgreichen Customer Journeys). Für einen Suvivorship Bias können ebenso “Selbstselektionseffekte” in den erklärenden Variablen ursächlich sein. Das gängige Nutzerverhalten, einen Online-Kauf noch kurz vor Abschluss mit einem gültigen Gutschein zu verbessern, lässt sich anhand vermehrter Einsprünge über Gutschein-Affiliates vor dem Kauf beobachten. Dieses Verhalten kann in nicht erfolgreichen Journeys in diesem Umfang nicht festgestellt werden, sodass ein Modell keine andere Wahl hat, als dieses Verhalten hinsichtlich der Erklärung des Kaufs zu belohnen. Intelligente Analysen und Filter in der Datenvorverarbeitung können hier Abhilfe schaffen.
2. Omitted Variable Bias
Der Omitted Variable Bias tritt auf, wenn relevante erklärende Variablen in einem Modell nicht berücksichtigt werden, der Effekt der ausgelassenen Größe aber durch andere, mit ihr korrelierten, im Modell vorhandenen Variablen kompensiert wird. Die Wahrscheinlichkeit einer solchen Verzerrung ist als recht hoch anzusehen, da sich nicht alle latenten Effekte, die Einfluss auf eine Kaufentscheidung haben, überhaupt messen lassen.
21
3. Multikollinearität
Multikollinearität ist eine statistische Eigenschaft, bei der eine erklärende Variable stark mit einer oder mehreren anderen erklärenden Variablen korreliert. Grundsätzlich kann davon ausgegangen werden, dass alle gemessenen Realdaten davon in irgendeiner Form betroffen sind. Bestimmte statistische Methoden können mit Multikollinearität besser umgehen als andere. Bei der Regressionsanalyse zum Beispiel ist die Auswirkung für die Prognoseleistung des gesamten Modells eher gering, kann aber zu einer Verzerrung der trainierten Einflussstärke einzelner Variablen und damit zu einer fehlerhaften Attribution führen.
Methodenwahl
Um der Kernanforderung an Transparenz und Nachvollziehbarkeit gerecht zu werden, fiel die Methodenwahl bei Internetstores auf die logistische Regression. Die logistische Regression ist ein statistisch robustes, gut dokumentiertes und umfassend erprobtes Verfahren, sowohl in der Forschung als auch in der Anwendungspraxis. In seinen Grundzügen ist es auch Laien gut zugänglich bzw. vermittelbar. Gleichzeitig profitiert es von unzähligen Implementierungen und Erweiterungen in gängigen Programmiersprachen. Die relativ einfache, mathematische Formulierung ermöglicht ein effizientes Training auf moderat skalierten Rechenressourcen sowie eine skalierbare Anwendung in der Produktionsumgebung auf großen Datenmengen.
Die logistische Regression ist im Kern linear, ermöglicht jedoch durch die Anwendung einer Link-Funktion (Logit, Probit usw.) und einer damit einhergehenden Berechnung von Wahrscheinlichkeiten, die Abbildung einer zusätzlich differenzierten Dynamik in der Attribution. Bezogen auf die Herausforderung systematischer Abweichungen optimiert die logistische Regression auf eine binär-kodierte Zielvariable (d. h. 0 oder 1). Neben den erfolgreichen Journeys finden hiermit auch die nicht-erfolgreichen Journeys Berücksichtigung. Um potenziellen Verzerrungen in den Parameterschätzungen gerecht zu werden, wird ein Ensemble-Ansatz verfolgt, bei dem die Zusammenhänge nicht aus einem einzigen Modelltraining quantifiziert werden, sondern ein Gesamturteil über potenziell mehrere hundert bis tausend Einzelmodell-Trainings aggregiert wird.
Feature Dimensionen
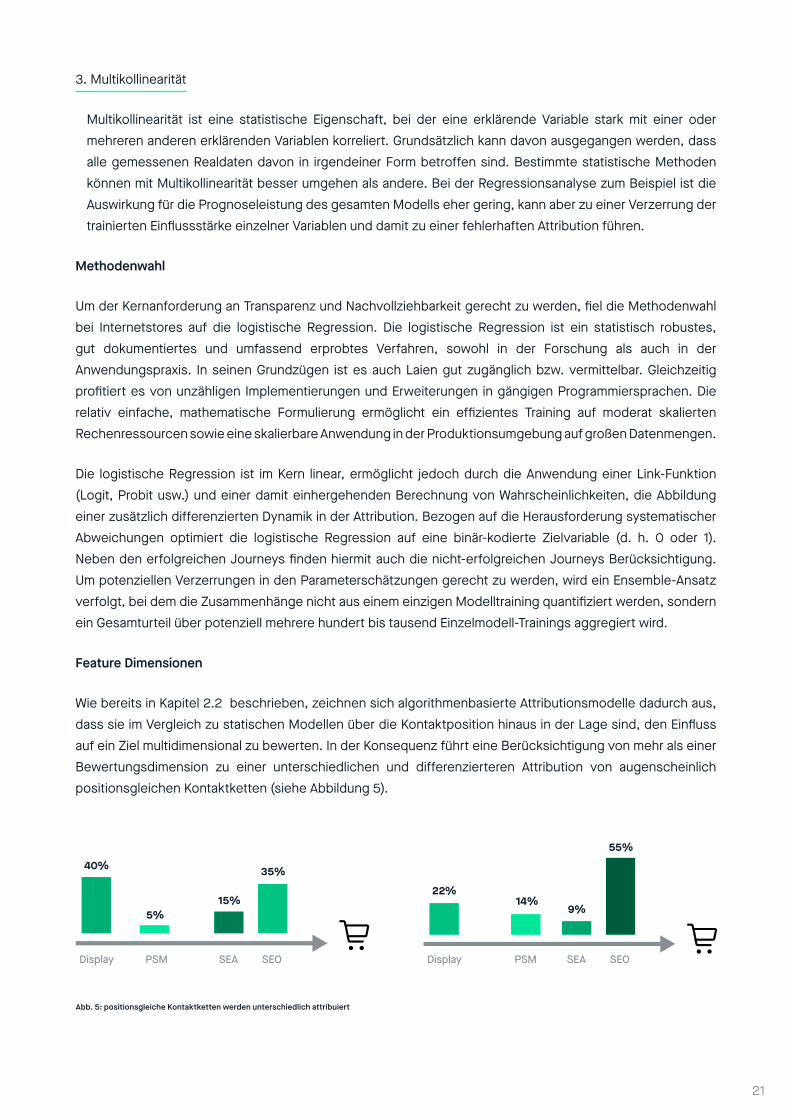
Wie bereits in Kapitel 2.2 beschrieben, zeichnen sich algorithmenbasierte Attributionsmodelle dadurch aus, dass sie im Vergleich zu statischen Modellen über die Kontaktposition hinaus in der Lage sind, den Einfluss auf ein Ziel multidimensional zu bewerten. In der Konsequenz führt eine Berücksichtigung von mehr als einer Bewertungsdimension zu einer unterschiedlichen und differenzierteren Attribution von augenscheinlich positionsgleichen Kontaktketten (siehe Abbildung 5).
40%
Display PSM SEA SEO
5%15%
35%
Display PSM SEA SEO
14%9%
55%
22%
Abb. 5: positionsgleiche Kontaktketten werden unterschiedlich attribuiert

Die Bewertungsdimensionen finden über erklärende Variablen (Features) Eingang in das Attributionsmodell. Die genaue Spezifizierung ihrer Ausprägungen zur Verbesserung der Robustheit und Erklärungsgüte eines Modells ist Aufgabe des Data Scientists und unter der Disziplin Feature Engineering geläufig. Feature Engineering ist dabei ein experimenteller Prozess, bei dem es nicht sofort die eine Lösung gibt, sondern über iterative Entwicklungsschritte das Feature Setup immer wieder angepasst, bewertet und verbessert wird. Im Rahmen der Modellentwicklung bei Internetstores wurden hierbei verschiedene Feature Dimensionen berücksichtigt (siehe Abbildung 6).
Abb. 6: Bewertungsdimensionen für die Attribution
Neben der bereits erwähnten Position eines Kontaktes innerhalb der nutzerindividuellen Journey, wurden hierbei auch Features evaluiert, welche sich aus dem Kanaltyp des Kontaktes, der Reihenfolge im Vergleich zu anderen Kontakten, dem verwendeten Endgerät, bekannten Nutzereigenschaften und der Journeylänge (z. B. Zeit und Anzahl Kontakte) ableiten ließen. Die weit gefasste Dimension Zeit ließ sich dabei in verschiedene Blickwinkel aufteilen. So kann Zeit eine Bedeutung hinsichtlich einer Tages-, Wochen- oder Monatszeit sowie einer zeitlichen Einordnung eines Kontaktes im Vergleich zu anderen Kontakten oder der Journey als Ganzes entfalten. Die Dimension Engagement beschreibt zudem solche erklärenden Variablen, die auf der Basis des im Onlineshop gemessenen Nutzerverhaltens eine kontaktspezifische, differenzierte Interaktionstiefe berücksichtigen. Letzteres bezieht sich dabei nicht nur auf den eigentlichen Kontakt, sondern auf das durch den Kontakt induzierte Verhalten im Onlineshop.
4.3 Erkenntnisse und Ergebnisse
Im Vergleich zum zuvor im Einsatz befindlichen statischen Modell (Badewanne) war eine deutliche Verschiebung in der Gewichtung der Kanäle im Rahmen der Attribution zu verzeichnen. Da dieser Vergleich eine Rückschau ist und die dynamische Attribution an dieser Stelle lediglich eine alternative, dafür realitätsnähere Performancesicht abbildet, verbietet sich zu diesem Zeitpunkt von einer Performancesteigerung in einzelnen Kanälen zu sprechen. Noch konkreter gesagt: Der ex-post Vergleich findet auf gemessenen Journeys statt, deren Marketingkontakte nicht nach dem neuen Modell gesteuert wurden. Es ist insofern nicht ausreichend, lediglich auf Dashboards mit alternativen Attributionen zu “starren” und daraus einen Performancegewinn
ATTRIBUTION
REIHE
NFOLGE POSITION
KANALNUTZER
DEVICEJOURNY LÄ
NGE
ZEIT
ENGAGEMENT

abzuleiten, der so nie realisiert wurde. In diesem Bewusstsein führt erst eine konsequente Umsetzung des beschriebenen geschlossenen Regelkreises aus Messung, Modellanwendung, Operationalisierung und Steuerung zu einem echten Performancegewinn im Marketing. Gleichwohl konnten in der Rückschau bereits Erkenntnisse aus den Journeys abgeleitet und damit handlungsrelevante Insights für eine differenzierte Steuerung generiert werden. So konnten Unterschiede in den Customer Journeys hinsichtlich gekaufter Produktkategorien bei fahrrad.de sichtbar gemacht werden. Zusammengefasst zeigt sich, dass Journeys von Fahrradkäufen im Mittel deutlich länger als Journeys von reinen Zubehörkäufen bzw. Käufen einzelner Komponenten sind. Diese Erkenntnis ist speziell für eine Weiterentwicklung von kundenzentrierten Marketing-Kampagnen und eine Verbesserung der User Experience (z. B. Guided Selling) wichtig.Weiterhin konnte durch eine Verknüpfung von Customer Journeys mit Informationen zur Produktverfügbarkeit betrachteter Artikel eine veränderte Kampagnengestaltung in Google Shopping analytisch fundiert werden.
5. Fazit & Ausblick
Internetstores konnte im Rahmen der Eigenentwicklung den Geschäftsprozess Marketing Attribution auf einer performanten und wiederverwendbaren technologischen Basis abbilden. Das Attributionsmodell wurde transparent, nachvollziehbar und kontrollierbar verbessert. Durch eine Anreicherung der Customer Journeys mit handlungsrelevanten Informationen wurden umfangreiche, kundenzentrierte Analysemöglichkeiten geschaffen, deren Potenzial es in Zukunft auszuschöpfen gilt. Der Grundstein für eine breitere, unternehmensweite Akzeptanz und Nutzung einer Single Source of Truth ist damit gelegt. Gleichzeitig wird der Geschäftsprozess im Rahmen der Weiterentwicklung der Marketing Organisation hin zu einer Kundenzentrierung einen wesentlichen Beitrag leisten.
Für die Zukunft ist der sukzessive Rollout des technischen und fachlichen Prozesses auf alle Shop-Brands angedacht. Zusätzlich werden bereits zu diesem Zeitpunkt Konzepte und Lösungswege zur Erweiterung der Attribution um nicht direkt messbare Kanäle (TV, Branding) für eine holistische, datenbasierte Bewertung des Marketings erarbeitet.
FAZIT & AUSBLICK –rketing Attribution at Internetstores

Internetstores GmbHFriedrichstraße 670174 Stuttgart VERTRETEN DURCHThomas Spengler (CCO) KONTAKTTel +49 (0)711/93305-555E-Mail [email protected]
CI.Bureau GmbH & Co. KGDuvenstedter Berg 1922397 Hamburg
Amtsgericht Hamburg HRA 120485
Vertretungsberechtigte Geschäftsführer:Lars Schümann und Alexander Frerichs
[email protected]+49 176 571 023 05
Kontakt