ly thuyet thong tin 7 2015
TRANSCRIPT

CHƯƠNG I. KHÁI NIỆM VỀ HỆ THỐNG TRUYỀN TIN
BÀI 1. MÔ HÌNH HỆ THỐNG TRUYỀN TIN
BÀI 2. Thông tin, tín hiệu, dữ liệuThông tin là khái niệm trừu tượng, thể hiện sự cảm nhận vàhiểu biết của con người về thế giới xung quanh. Thông tin cóthể được biến đổi, lưu trữ và truyền từ điểm này sang điểmkhác. Thông tin được con người thu thập một cách trực tiếpbằng các giác quan, cũng có thể được thu thập một cách giántiếp thông qua nhận thức các thông tin do người khác thu thậpvà xử lý. Trong trường hợp thứ hai, thông tin do một người thuthập cần có cách thức để truyền từ điểm này sang điểm khác.Người thu thập thông tin và truyền cho người khác được gọi lànguồn. Người nhận thông tin được gọi là đích. Để thực hiệnđược việc truyền thông tin cần sử dụng một dạng vật chất nàođó để biểu diễn thông tin. Dạng vật chất này gọi là vật mangthông tin (hay còn gọi là phương tiện truyền tin).
Thông tin được biểu diễn bằng sự thay đổi của một trong cácđại lượng biểu diễn tính chất cục bộ của vật mang (ví dụ nhưmức độ dao động của các phần từ trong tín hiệu cơ học, cườngđộ từ trường, điện trường của sóng điện từ). Vật mạng có chứathông tin trong sự thay đổi của một trong các đại lượng của nóvà đây là lần đầu tiên thông tin được gán vào vật mang, Vậtmang có chứa thông tin này sẽ được gọi là dữ liệu. Nhờ dữ liệuthông tin đã được chứa trong một vật hay có thể nói thông tinđã trở thành vật chất và có thể truyền qua môi trường vậtchất.
Mỗi môi trường lan truyền cho phép một vài loại vật chất nhấtđịnh lan truyền qua nó. Vật mang có chứa thông tin được truyềntrong môi trường phù hợp với nó chính là phương tiện để truyềnthông tin và được gọi là tín hiệu. Căn cứ vào thuộc tính củamôi trường truyền tin được sử dụng, có thể có tín hiệu cơ học,tín hiệu điện,tín hiệu quang, ....
1

Tín hiệu là vật mang có chứa thông tin và phù hợp với môitrường lan truyền. Tín hiệu là dạng vật chất của thông tinđược lan truyền. Dữ liệu chỉ là dạng vật chất có chưa thôngtin và chưa chắc đã phù hợp với môi trường lan truyền. Trongnhiều trường hợp bản thân dữ liệu phù hợp để truyền trong môitrường, lúc này nó đóng cả vai trò là tín hiệu. Trong một sốtrường hợp, dữ liệu không phù hợp với môi trường và chúng cầnphải được chuyển đổi thành tín hiệu cho phù hợp với môi trườnglan truyền.
Trong thực tế, có thể có các thông tin liên tục và các thôngtin rời rạc. Thông tin liên tục thường là các thông tin nguyênthủy thu được từ thế giới xung quanh. Thông tin rời rạc thườnglà các thông tin thu được từ các thông tin nguyên thủy sau khiđã qua xử lý. Tín hiệu liên tục là các tín hiệu có thể nhậncác giá trị liên tục và được định nghĩa trên miền thời gianliên tục. Thông tin liên tục khi được biểu diễn bằng tín hiệuliên tục được gọi là dữ liệu liên tục.
Bang I-1: Ví dụ về thông tin tín hiệu dữ liệu liên tục và rời rạc
BÀI 3.Liên tục Rời rạc
Thông tin Nội dung củabản nhạc
Nội dung củavăn bản
Dữ liệu Âm thanh củabản nhạc
Văn bản
Tín hiệu Âm thanh/Tínhiệu điện thoại
Văn bản/Tínhiệu điều khiểntrong máy tính
BÀI 4. Mô hình cơ ban của hệ thống truyền tinMột hệ thống truyền tin phải có tối thiểu 3 bộ phận: nguồntin, kênh truyền tin và đích (bộ phận thu tin). Mô hình nàythường được gọi là mô hình 3 khối được biểu diễn trong Hình I -1.
Nguồn tin là bộ phận chịu trách nhiệm sản sinh ra thông tin.Chất lượng của nguồn tin được đánh giá bằng khối lượng thôngtin mà nguồn tin có thế sinh ra. Kênh truyền tin là thành phần
2

chịu trách nhiệm truyền tin từ đầu kênh đến cuối kênh. Đích(bộ phận thu tin) là nơi tái tạo lại các thông tin ban đầu.Việc tái tạo lại các thông tinban đầu này được gọi là giải bàitoán thu tin.
Hình I-1: Mô hình hệ thống truyền tin
Nếu chỉ có nguồn tin ban đầu tham gia vào kênh truyền tin, bàitoán thu tin được giải quyết một cách hiển nhiên. Trường hợpnày kênh truyền tin được gọi là kênh truyền tin 2 cửa. Tuynhiên, trong thực tế không phải chỉ có nguồn tin ban đầutruyền thông tin vào kênh truyền tin. Có rất nhiều nguồn tinkhác có nguồn gốc tự nhiên có khả năng truyền tin vào kênh.Các nguồn tin này sinh ra thông tin bổ sung, trộn vào thôngtin ban đầu, cản trở việc giải bài toán thu tin. Những thôngtin này được gọi là nhiễu. Các nguồn tin thứ cấp nói trên đượcgọi là nguồn nhiễu. Giá trị thực sự của nhiễu là không xácđịnh, tuy nhiên với một hệ thống truyền tin, các tính chấtthống kê của nhiễu được coi là xác định. Sự ảnh hưởng củanhiễu đến đầu ra của kênh truyền tin có thể được biểu diễnbằng công thức:
( , )rec sendI F I N
Trong đó là thông tin gửi đi, là thông tin nhận đượcở đầu ra, là nhiễu và là hàm đặc trưng của kênh truyềntin.
Yêu cầu của hệ thống truyền tin là thông tin phải được truyềnđi chính xác, hay nói cách khác, thông tin đã được gửi đi ởđầu vào phải được xác định ở đầu ra của kênh truyền tin, vớiđiều kiện có sự tham gia của nhiễu làm tác động lên thông tinđầu ra. Bài toán xác định khi biết gọi làbài toán thu tin. Như vậy bài toán thu tin là bài toán xácđịnh thông tin đầu vào khi biết thông tin đầu ra đã bị phá hủymột phần bởi nhiễu.
3

Ngoài việc đảm bảo có kết quả chính xác cho bài toán thu tin,kênh truyền tin còn phải đảm bảo giải quyết bài toán truyềntin và thu tin trong khoảng thời gian giới hạn. Đây là yêu cầutruyền tin nhanh chóng của một hệ thống truyền tin. Tất nhiên,thời gian truyền tin thực sự phụ thuộc vào yêu cầu của từngbài toán cụ thể. Một bức thư điện tử được nhận sau khi gửi vàiphút được coi là quá chậm, trong khi đó một bức thư tín thôngthường đến tay người nhận sau vài ngày được coi là chấp nhậnđược.
Khi thiết kế, xây dựng triển khai một hệ thống truyền tin,việc đảm bảo truyền tin chính xác, nhanh chóng bị giới hạn bởilượng tài nguyên về băng thông, về khả năng xử lý, về kíchthước của bộ nhớ đệm. Do đó để có thể sử dụng được trong thựctế, các hệ thống truyền tin cần đảm bảo sử dụng các tài nguyênhệ thống một cách có hiệu quả.
Như vậy, 3 yêu cầu chính với một hệ thống truyền tin là truyềntin nhanh chóng, chính xác và hiệu quả.
Để có thể thực hiện được chức năng truyền tin, các thành phầncủa hệ thống truyền tin: nguồn, kênh, đích cần phối hợp vớinhau. Giữa các thành phần này cần có sự đồng bộ về định dạngtín hiệu, khuôn dạng dữ liệu, tốc độ truyền tin và trongtrường hợp cần thiết phải có những cơ chế đồng bộ. Mô hình 3khối nói trên chưa phản ánh được tính chất đồng bộ giữa 3thành phần của kênh truyền tin, đồng thời cũng chưa phản ánhđược cách thức có thể đạt được 3 yêu cầu truyền tin nhanhchóng, chính xác, hiệu quả.
Bộ phát tín hiệu Kênh truyền tin Bộ thu tín hiệu
Nguồn tin Đích tin
Hình I-2: Mô hình hệ thống truyền tin 5 khối
Trong thực tế truyền số liệu, khi quan tâm đến hệ thống vậtlý, người ta thường sử dụng mô hình 5 khối- Hình I -2. Hai
4

bộ phận được bổ sung là bộ phận phát tín hiệu và bộ phận thutín hiệu. Bộ phận phát tín hiệu có chức năng biến đổi thôngtin của nguồn tin thành dạng tín hiêu phù hợp với kênh truyềntin. Bộ phận thu tín hiệu có chức năng biến đổi tín hiệu đầura của kênh truyền tin thành các thông tin phù hợp với bộ phậnthu tin. Ví dụ trong hệ thống điện thoại, để sử dụng môitrường truyền tin là dây điện, chỉ có khả năng lan truyền tínhiệu điện, cần biến đổi thông tin phát ra bởi nguồn tin dướidạng tín hiệu cơ sử dụng bộ phận phát tín hiệu (micro). Tínhiệu thu được tại đầu ra của kênh truyền tin được biến đổithành tín hiệu cơ học để có thể đưa vào đích (tai) bằng thiếtbị thu tín hiệu (loa). Một ví dụ khác là trường hợp phát thanhradio. Để có thể truyền tín hiệu điện từ đi xa, cần có các tínhiệu với tần số đủ lớn. Các tín hiệu điện biểu diễn tiếng nóicó tần số thấp (4Khz) do đó cần được biến đổi bởi một bộ pháttín hiệu để có tần số cao hơn. Tại đích, tín hiệu có tần sốcao hơn này được bộ thu tín hiệu biến đổi về tín hiệu có tầnsố thấp.
BÀI 5. Mô hình truyền thông tinĐể có thể nghiên cứu, tìm hiểu hệ thống truyền tin đảm bảo cácyêu cầu truyền tin nhanh chóng, chính xác, hiệu quả, cần cómột mô hình bao gồm các thành phần thực hiện các yêu cầu nóitrên một cách riêng biệt.
Khi có nhu cầu vận chuyển hàng hóa từ điểm này sang điểm khác,thao tác đầu tiên cần thực hiện là đóng gói hàng hóa vào cácvật chứa cho trước. Thao tác tiếp theo là vận chuyển các vậtđựng đến đích. Tại đích, hàng hóa sẽ được đưa ra khỏi cácthiết bị vận chuyển và dỡ ra khỏi các vật chứa. Có thể thấykhi đóng gói hàng hóa vào các vật chứa, mục tiêu hướng tới sẽlà đảm bảo để số vật chứa cần sử dụng là nhỏ nhất. Ngược lại,trong quá trình vận chuyển, yêu cầu đặt ra là vận chuyển cácvật chứa để không ảnh hưởng, hỏng hóc các hàng hóa chứa bêntrong.
5

M ã hóa kênh Kênh truyền tin Giải m ã kênh
M ã hóa nguồn G iải m ã nguồn
Nguồn tin Đích tin
Hình I-3: Mô hình truyền tin 7 khối
Quá trình truyền tin cũng diễn ra tương tự như vậy. Trước khitruyền tin, cần tìm cách đóng gói các thông tin cần truyền vớimột lượng tài nguyên tối thiểu. Trong quá trình truyền tin,mục tiêu sẽ là đảm bảo để thông tin bị ảnh hưởng các ít cáctốt trong quá trình vận chuyển thông tin. Có thể sử dụng cácphương pháp phát hiện thông tin lỗi, sửa thông tin hỏng,truyền lại các thông tin bị hỏng, ..v..v... Phân tích trên dẫnđến việc biểu diễn hệ thống truyền tin bằng mô hình 7 khối nhưtrong Hình I -3. Trong mô hình này chúng ta không quan tâmđến vấn đề truyền nhận vật mang thông tin (truyền nhận tínhiệu, dữ liệu).
Trong mô hình này, trước khi được truyền lên kênh truyền tin,thông tin được biểu diễn một cách tối ưu nhất, sử dụng lượngtài nguyên tối thiểu. Quá trình này được gọi là quá trình néndữ liệu. Tất nhiên tại điểm đến của thông tin, cần thực hiệnquá trình ngược lại là quá trình giải nén dữ liệu. Việc nén dữliệu chủ yếu dựa vào tính chất, đặc điểm của nguồn tin từ đóđưa ra cách thức biểu diễn tối ưu nhất. Chính vì vậy, nén dữliệu còn được gọi là mã hóa nguồn, giải nén gọi là giải mãnguồn.
Sau khi đã được biểu diễn một cách tối ưu, thông tin cần đượcbảo vệ khi truyền qua kênh truyền tin. Quá trình biến đổi nàyphụ thuộc vào tính chất của kênh truyền tin. Nếu kênh truyềntin có tính chất nhiễu tác động mạnh đến thông tin, khi đó sẽcần lượng tài nguyên lớn để thực hiện các biện pháp bảo vệthông tin. Nếu nhiễu có tác động yếu đến thông tin, khi đó có
6

thể lựa chọn các giải pháp ít tốn kém tài nguyên hơn để bảo vệthông tin. Bộ phận thực hiện nhiệm vụ này được gọi là bộ phậnmã hóa chống nhiễu. Vì việc mã hóa chống nhiễu chỉ phụ thuộcvào kênh truyền tin do đó bộ phận này còn được gọi là mã hóakênh. Thành phần đối xứng tương ứng được gọi là bộ phận giảimã kênh hay giải nén.
Mô hình 7 khối và 5 khối trong các hình vẽ trên phản ánh tínhchất của một hệ thống truyền tin chưa quan tâm đến khía cạnhtín hiệu hoặc dữ liệu. Kênh truyền tin trong mô hình 7 khốithực chất không quan tâm đến biểu diễn tín hiệu của thông tin.Có thể kết hợp các mô hình này để tạo thành mô hình 9 khối(Hình I -4: Mô hình hệ thống truyền tin 9 khối).
M ã hóa kênh Giải m ã kênh
M ã hóa nguồn Giải m ã nguồn
Nguồn tin Đích tin
Bộ phát tín hiệu Kênh truyền tin Bộ thu tín hiệu
Hình I-4: Mô hình hệ thống truyền tin 9 khối
Trong các mô hình nói trên, hầu hết các thành phần của hệthống đều có tính chất xác định: khi biết đầu vào, chắc chắnsẽ xác định được đầu ra. Riêng 2 thành phần là nguồn tin vàkênh truyền tin, không bao giờ có thể xác định được trướcthông tin mà các thành phần này sẽ sản sinh ra. 2 thành phầnnày được gọi là 2 yếu tố bất định của hệ thống truyền tin.Việc nghiên cứu, đánh giá các thành phần này chủ yếu dựa vàocác mô hình xác suất thống kê
7

BÀI 6. Mô hình nguồn tinNguồn tin là tập hợp những tin nguyên thủy (chưa qua một phépbiến đổi nhân tạo nào) ví dụ như tiếng nói, âm nhạc, hình ảnh,các biến đổi khí tượng … Các tin nguyên thủy phần nhiều lànhững hàm liên tục theo thời gian ()f t hoặc là những hàm biếnđổi theo thời gian và một hoặc nhiều thông số khác như hìnhảnh đen trắng ( , ,)h x y t , trong đó ,x y là các toạ độ không gian củahình, hoặc như các thông tin khí tượng: ( ,)ig t trong đó i ,( 1,2,..., )i n là các thông số khí tượng như nhiệt độ, độ ẩm tốc độgió…
Thông thường các tin nguyên thủy mang tính chất liên tục theothời gian và theo mức, nghĩa là có thể biểu diển một thông tinnào đó dưới dạng một hàm ()s t tồn tại trong quãng thời gian T vàlấy các giá trị bất kỳ trong phạm vi min max( , )s s
Những tin nguyên thủy có thể đưa trực tiếp vào kênh để truyềnđi. Cũng có thể bằng những phép biến đổi nhân tạo như rời rạchoá theo thời gian và theo mức rồi đưa vào kênh truyền. Lúcnày tin trước khi vào kênh đã trở thành tin rời rạc. Nguồn tinlúc này gọi là nguồn tin rời rạc và kênh tin được gọi là kênh tin rờirạc để phân biệt với trường hợp đưa tin liên tục vào kênh gọilà nguồn tin liên tục và kênh tin liên tục. Bảng chữ của một ngôn ngữ, cáctin trong hệ thống điện tín, các lệnh điều khiển trong hệthống điều khiển là những tin nguyên thủy có tính chất rờirạc.
Sự phân biệt về bản chất của nguồn rời rạc với nguồn liên tụclà số lượng các tin trong nguồn rời rạc là hữu hạn và số lượngcác tin trong nguồn liên tục không đếm được.
Nói chung các tin rời rạc, hoặc nguyên thủy rời rạc, hoặcnguyên thủy liên tục đã được rời rạc hoá, trước khi đưa vàokênh thông thường đều qua thiết bị mã hoá. Thiết bị mã hoábiến đổi táp hợp tin nguyên thủy thành tập hợp những tin thíchhợp với đặc điểm cơ bản của kênh như khả năng cho qua (thônglượng), tính chất tín hiệu (dạng, cấu trúc phổ, tính thống
8

kê…) và tạp nhiễu. Tóm lại mã hoá là phép biến đổi tính thôngkê và tính chống nhiễu của nguồn tin.
Một bảng các tin xuất phát từ một nguồn tin nào đó đều phảnánh tính chất thống kê của nguồn đó. Bảng tin càng dài sự phảnánh càng trung thực. Chúng ta có thể xem một bảng tin cụ thểlà một thể hiện cụ thể của một nguồn. Vì tại một thời điểm xácđịnh nguồn có thể tạo ra một tin ngẫu nhiên đối với người quansát, nên theo quan điểm toán học có thể xem nguồn tin (nguồntạo ra các tin) là cấu trúc thống kê của một quá trình ngẫunhiên. Như vậy để xác định một nguồn tin, hay nói cách khác đểxác định cấu trúc thống kê của một quá trình ngẫu nhiên, chúngta cần phải biết được các quy luật thống kê qủa quá trình.
Trường hợp một nguồn rời rạc, bảng tin là một dãy các ký hiệukế tiếp của một bộ chữ (bộ ký hiệu ) gồm một số m ký hiệu cóhạn gọi là bộ chữ A:
, 1,2,..., .iA a i m
Bảng tin là một dãy vô hạn hay hữu hạn ở hai phía:
2 1 0 1 2... ...x x x x x x
2 1 0 1 2...x x x x x là ký hiệu , 1,2,...,ia i m bất kỳ của bộ chữ A được phátđi ở thời điểm 2 1 0 1 2, , , , ...t t t t t
Trong thực tế bảng tin có bắt đầu và kết thúc cho nên bảng tinlà một dãy các ký hiệu hữu hạn:
*1 2... nx x x x
*x được gọi là một khối n chiều với các đặc tính thống kê củachúng sẽ xác địng cấu trúc thống kê của nguồn tin. Nói cáchkhác biết được tập hợp các *x (ký hiệu bằng X) và xác suất xuấthiện của các bảng tin *( )p x sẽ quyết định được tính chất thốngkê của nguồn. Do vậy trong trường hợp này nguồn tin là mộttrường xác xuất hữu hạn * *,X p x . Trong một trường hợp hẹphơn, nếu xác suất xuất hiện các ký hiệu trong bảng tin độc lậpvới nhau, chỉ cần biết bộ chữ A và xác suất xuất hiện của các
9

ký hiệu ,i ip a a A cũng đủ để xác định tính chất thống kê củanguồn, lúc đó nguồn là trường xác suất hữu hạn ,A p , ( p viếttắt cho , , 1,2,...,i ip a a A i m ).
Khi chúng ta rời rạc hóa một nguồn liên tục, chúng ta thay mộtthể hiện x t của nguồn (một bảng tin liên tục) bằng một dãyhay một khối n chiều *x nếu thời gian quan sát là hữu hạn.Trong đó bộ chữ A của khối là tập hợp các giá trị lượng tử hoáđược của x t . Như vậy sự rời rạc hoá được thực hiện thông quahai khâu: gián đoạn hoá theo thời gian và lượng tử hoá theomức.
Theo những điều đã trình bày ở trên nguồn tin có cấu trúcthống kê của một quá trình ngẫu nhiên. Mỗi nguồn tin (quátrình ngẫu nhiên ) được xác định bởi một tập giá trị *x và cấutrúc thống kê của chúng *p x . Những nguồn tin thường gặpthường có tính chất của một quá trình ngẫu nhiên dừng và nhiềukhi lại có tính ergodic. Đối với các nguồn tin ergodic mỗi thểhiện (mỗi bảng tin ) ghi nhận được trong một thời gian đủ dàicó thể tiêu biểu cho nguồn và chúng ta có thể căn cứ vào mộtthể hiện để xác định cấu trúc thống kê của nguồn. Điều này cómột ý nghĩa quan trọng trong thực tiễn.
Để nghiên cứu định lượng nguồn tin cũng như hệ thống truyềntin, chúng ta có thể mô hình hoá toán học nguồn tin bằng bốnloại quá trình ngẫu nhiên sau :
- Quá trình ngẫu nhiên liên tục: Nguồn tiếng nói, âm nhạc, hình ảnh làtiêu biểu cho quá trình này. Trong các hệ thống thong tinthoại, truyền thanh truyền hình với các tín hiệu điều biên,điều tần thông thường chúng ta gặp các nguồn như vậy.
- Quá trình ngẫu nhiên rời rạc: Một quá trình ngẫu nhiên liên tục saukhi được lượng tử hoá theo mức sẽ trở thành quá trình này. Mộtngôn ngữ, tín hiệu điện tín, các lệnh điều khiển là nguồn rờirạc loại này.
10

- Dãy ngẫu nhiên liên tục: Đây là trường hợp một nguồn liên tục đãđược gián đoạn hoá theo thời gian, như thường gặp trong các hệthông tin xung điều biên xung (PAM - Pulse AmplitudeModulation), điều pha xung (PPM), điều tần xung (PFM)…
- Dãy ngẫu nhiên rời rạc: Trong các hệ thống thông tin xung có lượngtử hoá như điều biên (pha , tần) xung lượng tử hoá, điều xungmã (PCM).
BÀI 7. Mô hình kênh truyền tinKênh tin có thể được xem xét theo nhiều góc độ. Ở góc độtruyền các tin hiêu, kênh tin được coi là một hệ thống biếnđổi tín hiệu với các đặc trưng tần số và đặc tính xung. Cácđại lượng để đánh giá kênh truyền tin trong trường hợp này sẽlà các đại lượng như: giải thông; độ trễ; độ suy hao; độ méovà sự thay đổi của của đại lượng đó. Ở góc độ truyền thông tincần mô hình hoác các đặc điểm của kênh truyền tin khi truyềnmột thông tin đầu vào thành một thông tin đầu ra. Các đạilượng để đánh giá trong trườn hợp này sẽ là tỷ suất lỗi, tốcđộ truyền tin, thông lượng kênh, ....
Mặc dù có rất nhiều loại môi trường truyền tin khác nhau, tuynhiên trong thực tế thường sử dụng các loại môi trường truyềntin sau đây:
- Dây dẫn đôi
- Dây dẫn đồng trục
- Cáp quang
- Môi trường truyền tin không dây
Các môi trường truyền tin này được đặc trưng bởi các tính chấtnhư: Băng thông, Độ trễ/sự thay đổi của độ trễ, độ suy hao,méo, nhiễu. Bảng sau liệt kê thông số của một số loại môitrường truyền tin
Bang I-2: Một số môi trường truyền tin thông dụng
Giảithông
Suy hao Trễ
11

Dây dẫnđôi
4kHz-1MHz Lớn Lớn
Dây dẫnđồng trục
500MHz1GHz
Lớn Lớn
Cáp quang Rất lớn Khôngđáng kể
Khôngđáng kể
Không dây 2.4-5GHz Thay đổi Thay đổi
Mô hình tín hiệu của kênh truyền tin
Khi quan tâm đến việc tín hiệu truyền qua kênh truyền tin nhưthế nào, kênh truyền tin được đặc trưng bởi đặc tính tần số vàđặc tính xung. Trong miền thời gian, tín hiệu đầu ra được xácđịnh bằng tích chập của tín hiệu đầu vào và đặc tính xung. Cụthể là:
* ()r n v cS t N t S t H t N t
Trong đó là tín hiệu nhận được ở đầu ra, là tín hiệu đầuvào, là đặc tính xung, là phép nhân chập được địnhnghĩa:
*S t H t S t H d
Thành phần là các tín hiệu do các nguồn tin khác truyềnvào kênh truyền tin, được gọi là nhiễu cộng do tính chất cộngvào đầu ra của nó. Nhiễu cộng có thể có nguồn gốc bất kỳ, dođó thông thường nhiễu cộng bao trùm miền tần số lớn, và có phổcông suất đều. Do đó nhiễu cộng còn được gọi là nhiễu trắng.
Thành phần phản ánh sự thay đổi tính chất của kênh truyềntin theo thời gian, ảnh hưởng đến tín hiệu đầu ra bằng hệ sốkhuếch đại, do đó gọi là nhiễu nhân. Nhiễu nhân thường thayđổi chậm hơn so với nhiễu cộng. Trong các hệ thống truyền tinthực tế thường người ta chỉ xem xét nhiễu nhân.
Mô hình tín hiệu của kênh truyền tin thích hợp khi thao tácvới các tín hiệu. Trường hợp muốn nghiên cứu, phân tích đánhgiá kênh truyền tin về mặt thông tin, mô hình tín hiệu sẽ đemlại những tính toán không cần thiết. Do đó trong các trường
12

hợp này thường sử dụng mô hình thông tin của kênh truyền tin.Mô hình này chỉ quan tâm đến việc có xuất hiện hay không xuấthiện các thông tin được xem xét với các điều kiện của kênhtruyền tin đã được “thông tin hóa”.
Xét một ví dụ về kênh truyền tin, đầu vào có thể phân biệt 2ký hiệu 0 và 1, đầu ra cũng có thể sản sinh ra 2 ký hiệu 0 và1. Trong trường hợp lý tưởng, nếu kênh không có nhiễu, khi kýhiệu 0 được truyền đi, trong tất cả các trường hợp đều nhậnđược ký hiệu 0. Tương tự như vậy, xác suất nhận được ký hiệu 1khi gửi ký hiệu 1 đi là 100%. Xác suất để kênh nhầm lẫn, nhậnđược 0 khi gửi 1 và nhận được 1 khi gửi 0 là 0%. Trường hợpkênh có nhiễu, sẽ có khả năng kênh nhầm lẫn, đưa ra ký hiệu 0ở đầu ra khi nhận được ký hiệu 1 hoặc ngược lại. Tính chấtnhiễu, mức độ nhầm lẫn của kênh được phản ảnh bởi các xácsuất này. Như vậy, tác động tính chất điện, tính chất nhiễucủa kênh được tổng hợp thông qua các xác suất nhận được một kýhiệu khi gửi một ký hiệu khác. Các xác suất này được gọi làxác suất chuyển đổi. Trong ví dụ nói trên, kênh truyền tinđược biểu diễn bởi 4 xác suất.
0| 1 ( 1| 0)( 1| 1) ( 0| 0) 1
P Y X P Y X pP Y X P Y x p
p
p
0
1
0
11-p
Hình I-5: Kênh nhị phân đối xứng
Trong trường hợp tổng quát, nếu đầu vào và đầu ra của kênh đềulà các nguồn tin rời rạc. Nếu đầu vào có m tin và đầu ra có ntin thì khi đó tính chất của kênh được biểu diễn bởi cácxác suất chuyển đổi và được gọi là ma trận nhiễu của kênh.
Trở lại với ví dụ về kênh có đầu vào và đầu ra là 0 và 1,trường hợp lý tưởng xác suất chuyển đổi 0 thành 0 và 1 thành 1là 1, 0 thành 1 và 1 thành 0 là 0. Một trường hợp lý tưởngkhác, xác suất chuyển đổi 1 thành 0 là 1 và 0 thành 1 là 0,khi nhận được ký hiệu nào ở đầu ra cũng có thể xác định đượcký hiệu đầu vào. Trường hợp xấu nhất, cả 4 xác suất đều bằng
13

½, khi đó nhận được ký hiệu 0 hay 1 ở đầu ra cũng không thểxác định được đã gửi đi ký hiệu nào ở đầu vào.
14

BÀI 8. CÁC PHÉP BIẾN ĐỔI THÔNG TIN
BÀI 9. Độ đo thông tinTrong những mục về sau của phần lý thuyết thông tin, chúng tasẽ khảo sát lượng đo thông tin của các đại lượng một cách chitiết hơn. Ở đây chúng ta chỉ nêu ra một khái niệm ban đầu vềlượng tin nhằm vật thể hóa thông tin, và cho chúng ta mộtphương tiện để có thể so sánh định lượng các thông tin vớinhau. Từ đấy cũng giúp cho chúng ta dễ nhận thức hơn những chỉtiêu chất lượng đề ra trong khi xây dựng các phương pháp xử lýthông tin (ví dụ phép mã hóa).
Độ đo (Metric) của một đại lượng một giá trị số cho phép xácđịnh độ lớn của đại lượng đó. Một độ đo phải thỏa mãn 2 tínhchất:
- Độ đo không âm.
- Phản ánh thực tế: Đại lượng cần đo càng có ý nghĩa thìgiá trị của độ đo càng lớn.
- Tuyến tính: Độ đo của 2 thực thể phải bằng tổng của 2 độđo nếu ý nghĩa của chúng là độc lập.
Để xác định độ đo thông tin, chúng ta nhận thấy rằng thông tincàng có ý nghĩa khi nó càng hiếm gặp, nên độ lớn của nó phảitỷ lệ nghịch với xác suất xuất hiện của tin. Ví dụ điểm số7/10 cho một thông tin kém ý nghĩa hơn điểm số 70/100, xácsuất xuất hiện của điểm sổ 7/10 là 1/11 lớn hơn nhiều so vớixác suất xuât hiện của điểm số 70/100/ Vậy độ đo thông tinphải là một hàm tỷ lệ nghịch với xác suất xuất hiện tin, haynó là hàm (1/ ( ))if p x cho tin ix có xác suất xuất hiện ( )ip x .
Một tin không cho chúng ta lượng tin nào khi chùng ta đã biếttrýớc về nó hay nó có xác suất (lớn nhất) bằng 1. Ðể xác ðịnhdạng hàm này, chúng ta sử dụng tính chất thứ 3 của ðộ ðo.Chúng ta giả sử rằng có hai tin ix và jx là độc lập thống kê đểmỗi tin không chứa thông tin về tin còn lại. Nếu hai tin có
15

xác suất xuất hiện là ( )ip x và ( )jp x , lượng tin của mỗi tin sẽlà (1/ ( ))if p x , (1/ ( ))jf p x . Giả sử hai tin này cùng đồng thời xuấthiện, ta có tin ( , )i jx x , lượng tin chung của chúng phải bằngtổng lượng tin của từng tin. Khi hai tin đồng thời xuất hiện,xác suất xuất hiện đồng thời của chúng là ( , )i jp x x , và ta có :
(1/ ( , )) (1/ ( )) (1/ ( ))i j i jf p x x f p x f p x
Vì hai tin độc lập thống kê nên:
( , ) ( ). ( )i j i jp x x p x p x
Vậy:
1 1 1( ). ( ) ( ) ( )i j i j
ff fp x p x p x p x
Trong trường hợp này, hàm f phải là hàm dạng loga. Vậy hàm1log ( )ip x là dạng hàm có thể chọn làm độ đo thông tin. Ta cần
kiểm tra tính không âm của hàm này. Vì 0 ( ) 1p x , nên 1/ ( ) 1ip x
hay log(1/ ( ))ip x không âm.
Thêm nữa khi một tín hiệu luôn luôn xuất hiện thì lượng tinnhận được khi này bằng không, ta cần kiểm tra điều kiện này.Rõ ràng khi ( ) 1ip x thì log(1/ ( )) 0ip x .
Vậy hàm log(1/ ( ))ip x được chọn làm độ đo thông tin của một tin củanguồn. Lượng đo thông tin của một tin ix của nguồn thường đượcký hiệu là ( )iI x :
( ) log(1/ ( ))i iI x p x
Tùy vào cơ số của hàm loga này ta sẽ có các đơn vị đo độ lớnthông tin xác định.
Nếu cơ số là 2, đơn vị của độ đo là bít:
2 )(1/ ( )i iI x log p x bit
Nếu cơ số là e, đơn vị của độ đo là nat
16

)(1/ ( )i iI x ln p x nat
Nếu cơ số là 10, đơn vị của độ đo là Hartley
)(1/ ( )( )i iI x lg p x bit hartley
Hiện nay người ta thường dùng đơn vị đo là bit với cơ số củaloga là 2 khi làm việc với các hệ thống xử lý thông tin rờirạc. Với các hệ thống xử lý thông tin liên tục, hoặc khi cầntính đạo hàm, đơn vị nat với cơ số tự nhiên là lựa chọn phùhợp. Cơ số 10 với đơn vị Hartley chỉ có ý nghĩa lịch sử.
BÀI 10. Mã hóaMã hoá là một phép biến đổi cấu trúc thống kê của nguồn. Phépbiến đổi ấy tương đương trên quan điểm thông tin, và nhằm mụcđích cải tiến các chỉ tiêu kỹ thuật của hệ thống truyền tin,tức là giải quyết hai vấn đề cơ bản trong truyền tin. Với kháiniệm mã hoá như trên, thì phép rời rạc hoá là một ví dụ mã hoáđơn giản, biến đổi tin liên tục ở đầu vào thành một lớp tươngđương tin rời rạc ở đầu ra. Chúng ta luôn lưu ý là tương đươngở đây cớ nghĩa là phép biến đổi không thay đổi lượng tin. Vídụ chúng có một nguồn tin có bốn tin đẳng xác suất với sơ đồthông kê như sau:
1 2 3 4A 1 1 1 1
4 4 4 4
a a a a
Lượng tin ( )iI a chứa trong một tin của A bằng:( ) 1.( log1/4) 2 bitiI a
Bằng một phép mã hóa như sau:
1 1 1
2 1 2
3 2 1
4 2 2
a bba bba b ba b b
Chúng ta đổi thành một nguồn tin mới gồm có hai ký hiệu đẳngxác suất:
17

1 2B 1 1
2 2
bb
Lượng tin chứa trong một tin của B cũng vẫn bằng lượng tinchứa trong tin tương ứng của A ví dụ tin 1 1bb tương ứng với tin1a trong A.
Một phép biến đổi thông tin như vậy còn gọi là phép biến đổibảo toàn lượng tin.
Có thể tổng quát hóa ví dụ trên thành bài toán mã hóa nguồntin rời rạc với m tin, bảng tin có chiều dài n. Cần biến đổinguồn tin thành một nguồn tin khác với m’ tin các bảng tin cóchiều dài n’. Để có thể biểu diễn nguồn tin, cần có m’*n’ cácbộ so sánh. Tính chất bảo toàn lượng tin được thể hiện bằngquan hệ:
' 'mlogn mlogn
Bằng đạo hàm có thể thấy 2 giá trị thích hợp của m’ là 2 và 3.Đây cũng là một lý do giải thích tại sao các hệ thống thôngtin số lại sử dụng cơ số 2 để biểu diễn các thông tin.
BÀI 11. Rời rạc hóa nguồn liên tụcTrong các hệ thống truyền tin mà đầu cuối (đầu thu) là nhữngthiết bị xử lý thông tin rời rạc(ví dụ máy tính số) như các hệthống truyền số liệu, hay là các hệ thống thông tin chuyểntiếp điều mã xung, nguồn tin có thể là rời rạc hoặc liên tục.Nếu các nguồn tin là liên tục, nhất thiết trước khi đưa tinvào kênh phải thông qua một phép biến đổi liên tục thành rờirạc. Sau đó sẽ áp dụng các phương pháp mã hoá để đáp ứng đượccác chỉ tiêu kỹ thuật của hệ thống truyền tin cụ thể.
Phép biến đổi nguồn tin liên tục thành rời rạc gồm hai khâu cơbản: một là khâu rồi rạc hoá theo thời gian hay còn gọi làkhâu lấy mẫu, hai là khâu lượng tử hoá theo mức viết tắtlượng tử hóa). Cơ sở lý thuyết của phép biến đổi này gồm cácđịnh lý lấy mẫu và luật lượng tử hoá.
18

Lấy mẫu
Lấy mẫu một hàm tin, có nghĩa là trích từ hàm đó ra các mẫutại những thời điểm thời gian nhất định. Nói một cách khácthay hàm tin liên tục bằng một hàm rời rạc là những mẫu củahàm trên lấy tại những thời điểm gián đoạn. Vấn đề đặt ra ởđây là xét các điều kiện để cho sự thay thế đó là một sự thaythế tương đương (tương đương ở đây là về ý nghĩa thông tin,nghĩa là hàm thay thế không bị mất mát thông tin so với hàmđược thay thế).
Một cách trực quan, tín hiệu hình sin được đặc trưng bởi 3thông số: biên độ, tần số, góc pha. Sau khi lấy mẫu số mẫutrong một chu kỳ phải đảm bảo đủ để xác định 3 thông số nóitrên. Như vậy trong một chu kỳ cần có tối thiểu 3 mẫu, hay nóicách khác, tần số lấy mẫu phải lớn hơn 2 lần tần số của tínhiệu hình sin. Trường hợp tần số lấy mẫu nhỏ hơn, sẽ có nhữnghình sin khác có tần số nhỏ hơn có các giá trị mẫu tương tự.Như vậy nếu lấy mẫu với tần số nhỏ hơn tần số lấy mẫu tốithiểu, ngoài việc không phản ánh được chính xác tín hiệu hìnhsin, còn tạo ra một số các thông tin thứ cấp khác ảnh hưởngđến các tín hiệu hình sin khác.
Tổng quát, với tín hiệu bất kỳ, để có thể lấy mẫu chính xác,tần số lấy mẫu phải lớn hơn 2 lần tần số của thành phần có tầnsố lớn nhất.
Một cách hình thức hơn. một hàm s(t) có phổ hữu hạn, không cóthành phần tần số lớn hơn max có thể được thay thế bằng cácmẫu của nó lấy tại những thời điểm cách nhau một khoảng
max/t
Lượng tử hóa
Kết quả của quá trình lấy mẫu là một chuỗi các giá trị liêntục. Các giá trị này chưa thể lưu trữ trong máy tính. Để cóthể lưu trữ trong các hệ thống thông tin số, cần ánh xạ cácgiá trị này về các giá trị nguyên. Quá trình này gọi là quátình lượng tử hóa. Giả sử hàm s(t) là một thể hiện của một
19

nguồn tin liên tục, có biên độ biến đổi liên tục trong phạm vimin max( , )s s . Ta phân chia phạm vi đó thành một số mức nhất định
đánh số các mức từ min 0 1 2 max, , ,..., ns s s s s s . Việc gián đoạn hóa sựbiến đổi biên độ của s(t) là cho biên độ lấy mức si nhất địnhkhi nó tăng hoặc giảm gần đến mức đó. Như vậy s(t) sẽ trởthành một hàm biến đổi theo bậc thang gọi là hàm lượng tử hóas’(t). Khi số thứ tự các mức đã có quy ước trước, việc gửi đimột hàm liên tục trở thành gửi đi những con số ở những thờiđiểm tương ứng.Theo các con số đó có thể dễ dàng khôi phục lạihàm lượng tử hoá s’(t). Sự chọn lựa các mức thích đáng sẽ làmgiảm sự khác nhau giữa s’(t) và s(t), gọi là sai số lượng tử,đồng thời giảm sai nhầm trong quá trình truyền tin.
Với phép lượng tử hoá, nguồn tin liên tục trở thành rời rạcvới bộ chữ A là tập hợp hữu hạn các mức lượng tử. Một tin(bảng ghi) gửi đi của nguồn sẽ trở thành một dãy hữu hạn cácmức (dưới dạng các con số hoặc các ký hiệu).
Một nguồn tin liên tục sau khi được lấy mẫu và lượng tử hóa sẽtrở thành một nguồn rời rạc. Trong quá trình truyền tin sự tồntại của tạp nhiễu gây tổn thất thông tin là một điều hiểnnhiên. Do vậy sự phân biệt giữa các mức của các trị tức thờicủa tin ()s t đều bị giới hạn bởi ảnh hưởng của tạp nhiễu lớnhoặc bé. Nếu chúng ta cho trị bé nhất của ()s t là mức mà ở đầuthu còn có thể phân biệt được trong nền tạp nhiễu, thì mức đógọi là mức ngưỡng và phải thoả mãn ðiều kiện lớn hõn mức tạpnhiễu trong kênh. Nhý vậy ðể phân biệt ðýợc hai trị tức thời ởnhững mức kế cận của s(t) cũng phải thoả mãn điều kiện nhưvậy, nghĩa là chúng phải lớn hơn nhau một đại lượng lớn hơnhoặc bằng mức ngưỡng, nói cách khác bước lượng tử tối thiểuphải lớn hơn mức tạp nhiễu trong kênh. Khi đã thoả mãn điềukiện này rồi, đứng về quan điểm thông tin nói, việc rời rạchóa nguồn tin liên tục hoàn toàn là một phép biến đổi tươngđương nghĩa là không gây một sự thiệt hại nào về thông tin.
Với quá trình lấy mẫu tần số , lượng tử hóa với mức, saukhi lấy mẫu, trong mỗi đơn vị thời gian sẽ có , giá trịnguyên, mỗi giá trị nguyên cần bít để biểu diễn, như vậy
20

cần bít trong một đơn vị thời gian để có thể biểu diễnchính xác nguồn tin. Đây chính là số đo lượng tài nguyên tốithiểu để biển diễn, lưu trữ, truyền nguồn tin ban đầu đi saukhi đã được rời rạc. Giá trị này càng lớn, nguồn tin rời rạccàng phản ánh chính xác nguồn tin ban đầu. Tuy nhiên, điều nàycũng tương đương với việc chi phí lưu trữ, truyền, xử lý nguồntin sẽ tăng lên.
Tín hiệu tiếng nói có phổ tần số từ 0 đến 4000 Hz. Sai số chấpnhận được khi lượng tử hóa là 1/100. Như vậy để rời rạc hóanguồn tin tiếng nói sẽ cần = 56000 bit. Để truyềnmột nguồn tin rời rạc này sử dụng các xung, giải thông tốithiểu là 28kHz. Tuy nhiên, khi truyền thông tin bằng các tínhiệu rời rác, nếu tín hiệu bị suy hao, các bộ lặp sẽ tái tạolại các thông tin ban đầu, loại bỏ hoàn toàn ảnh hưởng củanhiễu. Ngược lại, với các nguồn tin liên tục, khi tín hiệusuy hao, các bộ khuếch đại sẽ khuếch đại các nhiễu và tínhiệu. Do đó tỷ lệ nhiễu sẽ càng ngày càng tăng lên. Mặt khác,bộ lặp có độ trễ cao hơn so với bộ khuếch đại, do đó ảnh hưởngnhiều hơn đến các tính chất thời gian thực của thông tin.
BÀI 12. Điều chế và giai điều chếTrong các hệ thống truyền tinh liên tục, các tin hình thành từnguồn tin liên tục được biến đổi thành các đại lượng điện (áp,dòng) và chuyển vào kênh ví dụ như trường hợp điện thoại trongthành phố. Khi muốn chuyển các tin ấy qua một cự ly lớn, phảicho qua một phép biến đổi khác gọi là điều chế. Điều chế cónghĩa là chuyển thông tin thành một dạng năng lượng thích hợpvới môi trường truyền lan, trong đó dạng năng lượng được dùngít bị tổn hao và ít bị biến dạng do tác động của nhiễu. Thựcchất của phép điều chế là biến đổi một hoặc nhiều năng lượngđã chọn theo quy luật đặc trưng của thông tin. Ví dụ sự thôngthoại giữa các thành phố với nhau được thực hiện bằng cácđường tải ba, trong đó quy luật thông tin điều khiến sự biếnđổi của một thông số (biên độ, tần số) của năng lượng dòngđiện xoay chiều tần số thấp (vào khoảng vài chục KHz). Thôngtin với cự ly xa hơn sẽ được thực hiện bằng các đường thông
21

tin vô tuyến điện, ở đây quy luật thông tin điều khiển mộthoặc nhiều thông số của năng lượng trường điện từ cao tần.
Đối với các hệ thống truyền tin rời rạc, quy luật mã hiệu điềukhiển một hoặc nhiều thông số của năng lượng được dùng để mangtin. Ví dụ trong trường hợp điện báo thông thường, quy luật mãhiệu điều khiển biên độ dòng một chiều. Với các dạng nănglượng khác như dòng điện xoay chiều hay sóng điện từ, chúng tasẽ có các hệ thống truyền tin bằng điện báo tải ba hoặc thôngtin vô tuyến điện điều chế mã.
Phép điều chế ,ngoài việc chọn năng lượng thích hợp với sựtruyền lan trong môi trường (sóng điện từ) còn có nhiệm vụ làtuỳ theo tính chất của tạp nhiễu trong kênh mà xây dựng một hệthống tín hiệu có độ phân biệt với nhau rõ ràng, để quá trìnhgiải điều chế có thể dễ dàng hơn dù tín hiệu có bị tạp nhiễubiến dạng đi phần nào.
Các phương pháp điều chế thường dùng đối với tin liên tục làđiều chế biên độ (AM - Amplitude Modulation), điều chế đơnbiên (SSB-Single Side Bande), điều chế tần số (FM - FrequencyModulation) và điều chế góc pha (PM – Phase Modulation) caotần. Để tăng tính chống nhiễu người ta còn dùng đến nhữngphương pháp điều chế kép. Ngoài phép điều chế cao tần có thêmmột điều chế phụ như điều chế xung, (điều chế các thông số củamột dãy xung tuần hoàn, có chu kỳ lặp lại thoả mãn điều kiệnđã nêu ra trong định lý lấy mẫu) như điều chế góc pha xung(PPM - Pulse Duration Modulation), điều chế tần số xung (PFM -Pulse Frequency Modulation) và điều chế biên độ xung (PAM -Pulse Amplitude Modulation). Một phương pháp điều chế phụ đượcthường dùng là điều chế mã xung (PCM - Pulse Code Modulation)và điều chế delta (DM - Delta Modulation). Khi đó đã biến tinliên tục thành tin rời rạc và việc điều chế cao tần hoàn toàngiống như trường hợp các hệ thống truyền tin rời rạc.
Những năm gần đây, do sự phát triển của lý thuyết thông tin vàlý thuyết tín hiệu, người ta bắt đầu dùng các tín hiệu dảirộng (tín hiệu giả nhiễu, có phổ và hàm tương quan giống nhiễutrắng). Một phương pháp điều chế được nghiên cứu và áp dụng
22

trong kỹ thuật thông tin một cách có hiệu quả là phương phápđiều chế giả nhiễu.
Đối với tin rời rạc, các phương pháp điều chế cao tần cũnggiống như trường hợp thông tin liên tục, nhưng làm việc giánđoạn theo thời gian, gọi là maníp hay khoá dịch. Cụ thể có cácphương pháp maníp biên độ (ASK - Amplitude Shift Key), maníppha (PSK - Phase Shift Key) và maníp tần số (FSK - FrequencyShift Key). Với PSK và FSK còn có phương pháp maníp pha tươngđối (DPSK - Differential PSK), hoặc là điều chế pha khác vớiquy luật maníp (hằng số trong độ rộng một xung), ví dụ luậttuyến tính hay bình phương trong độ rộng một xung. Điều chếnhiễu cũng được dùng như một điều chế phụ đối với tin rời rạcđể tăng cường tính chống nhiễu của tín hiệu.
Giải điều chế là phép biến đổi ngược của phép điều chế, điềukhác là tín hiệu vào của thiết bị giải điều chế không phải chỉlà tín hiệu đầu ra của thiết bị điều chế, mà là một hỗn hợptín hiệu điều chế và tạp nhiễu. Nhiệm vụ của thiết bị giảiđiều chế là từ trong hỗn hợp đó lọc ra được thông tin dướidạng một hàm điện áp liên tục hoặc là một dãy xung điện rờirạc giống như thông tin ở đầu vào thiết bị điều chế, với saisố trong phạm vi cho phép.
Về phương pháp giải điều chế, nói cách khác phép lọc tin, tuỳtheo hỗn hợp tín hiệu nhiễu và các chỉ tiêu tối ưu về sai số(độ chính xác) phải đạt được mà chúng ta có các phương pháplọc tin thông thường như tách sóng biên độ, tách sóng tần số,tách sóng pha, tách sóng đồng bộ, lọc tin (xác định) liên kết(coherent), lọc tin bằng phương pháp tương quan, lọc tối ưu…
23

CHƯƠNG II. XÁC SUẤT VÀ QUÁ TRÌNH NGẪU NHIÊN
Bài 1. Xác suất
I. Phép thử và sự kiệnXác suất là đại lượng để đo khả năng xuất hiện của một sựkiện. Việc xác định một sự kiện có thể xảy ra hay không đượcthực hiện bằng các phép thử. Các phép thử có thể là lặp lạihoặc không lặp lại. Các phép thử lặp lại là các phép thử màđiều kiện để thực hiện phép thử có thể thiết lập lại mà khôngảnh hưởng đến kết quả của phép thử. Trong xác suất thống kêchỉ quan tâm đến các phép thử lặp lại. Ví dụ: đo điện trở củamột mạch điện, đo điện áp, ...
Khi các phép thử lặp đi lặp lại, các kết quả thu được tạothành một tập hợp các kết quả có thể đạt được. Tập hợp này gọilà tập mẫu. Một sự kiện xảy ra khi kết quả của phép thử thỏamãn một tính chất nào đó. Một tính chất của các phần tử củatập hợp có thể được biểu diễn bởi một tập con của tập hợp đó.Ngược lại, một tập hợp con tương ứng với một tính chất củaphép thử. Như vậy mối quan hệ giữa sự kiện và tập hợp con làmột quan hệ 1-1. Ví dụ khi gieomột con xúc xắc để mô tả chođịnh nghĩa xác suất cổ điển. Gọi {1,2,3,4,5,6}S là tập các giátrị có thể xuất hiện (số lượng các chấm trên xúc xắc). S đượcgọi là không gian kết quả của phép thử. Ta gọi sự xuất hiệncác giá trị của con xúc xắc khi gieo một hay nhiều xúc xắc là1 sự kiện.
Các phép toán trên sự kiện tương tự như các phép toán trên tậpcon. Cụ thể có thể có các quan hệ saugiữa các sự kiện:
- Bù nhau: S\AĀ
- Loại trừ nhau: ;A A A A S
- Phép hợp hai sự kiện A B = C
- Phép giao hai sự kiện A B = C24

Sự kiện A và Ā có tính chất là cùng một thời điểm chỉ có đúngmột sự kiện xảy ra. Các sự kiện như vậy gọi là các sự kiệnloại trừ lẫn nhau. Mở rộng cho nhiều hơn 2 sự kiện. ta có:1 2 3, , , nA A A A là các sự kiện loại trừ lẫn nhau nếu
1
; n
i i jA S A A i j
Các sự kiện một nguồn tin sinh ra một tin trong bảng tin tạothành các sự kiện loại trừ lẫn nhau.
II. Khái niệm xác suấtXác suất của một sự kiện
Ký hiệu: xác suất sự kiện A là P(A) là khả năng xuất hiện sựkiện A khi thực hiện một phép thử có liên quan đến A. Trongthống kê, xác suất được tính bằng công thức:
lim AN
NP AN
Trong đó N là số lần tiến hành phép thử, AN là số lần sự kiệnA xuất hiện.
Từ công thức trên, một vài tính chất của xác suất trở thànhhiển nhiên
0 1P A
1P S
0P
; P A B P A P B A B
Với các sự kiện loại trừ lẫn nhau 1 2 3, , , nA A A A ta có
1( ) 1
n
iP A
Xác suất đồng thời
25

Sự kiện đồng thời của hai sự kiện A và B là sự kiện xuất hiệnkhi và chỉ khi A và B xuất hiện. Xác suất của sự kiện đồngthời được gọi là xác suất đồng thồng của A và B và ký hiệu là( , )P A B hay P AB nếu có thể. Một vài tính chất của xác suất
đồng thời với các sự kiện loại trừ lẫn nhau 1 2 3, , , nA A A A và1 2, ,... nBB B
1
1
,
,
n
i j jim
i j ij
P A B P B
P A B P A
Và
1 1
, 1n m
i ji j
P A B
Hai tính chất đầu tiên cho phép chuyển đổi từ xác suất riêngthành các xác suất đồng thời và ngược lại.
Xác suất có điều kiện. Có nhiều trường hợp cấn xác định xácsuất của các sự kiện với điều kiện một hoặc nhiều sự kiện khácđã xảy ra. Khi có một sự kiện nào đó đã xảy ra, khả năng xuấthiện của các sự kiện khác bị thay đổi. Xác suất xuất hiệntrong trường hợp này được gọi là xác suất có điều kiện ( | )P A B -Xác suất để cho sự kiện A xuất hiện với điều kiện là sự kiện Bđã xuất hiện. Để tính xác suất này, giả định là tiến hành Nphép thử đồng thời với N rất lớn. Phép thử có điều kiện làphép thử thỏa mãn điều kiện B xuất hiện. Như vậy số lượng cácphép thử có điều kiện là * ( )N P B . Trong số các phép thử có điềukiện này, số lần sự kiện A xuất hiện là * ( , )N P A B . Xác suất cóđiều kiện ( , )P A B có thể được tính như sau :
, * ( , )| lim * ( )n
P A B N P A BP A BP B N P B
Nguyên lý xâu chuỗi :
26

1 2 1 2 3 2 3
1 2 3 2 3 2
1 2 3 2 3
, , | , , , ,| , , | , ,| , , | ,
n n n
n n n
n n n
P A A A P A A A A P A A AP A A A A P A A A P A AP A A A A P A A A P A
Tính chất này được gọi là nguyên lý xâu chuỗi của xác suất.
Hai sự kiện độc lập thống kê là hai sự kiện mà việc xuất hiệnhay không của một sự kiện này không ảnh hưởng đến sự xuất hiệncủa sự kiện còn lại. Nói theo ngôn ngữ xác suất:
| * ( , )P A P A B P A P B P A B
Mở rộng cho n sự kiện, 1 2, nA A A là độc lập thống kê khi và chỉkhi :
1 21
, ( )n
n nP A A A P A
III.Định lý BayesTrong một hệ thống truyền tin rời rạc, kênh truyền tin đượcbiểu diễn bởi một ma trận nhiễu. Đầu vào của hệ thống truyềntin được biểu diễn bởi một tập hocpj các sự kiện loại trừ lẫnnhau, mỗi sự kiện tương ứng với việc nguồn tin gửi đi một tintrong bảng tin. Đầu ra của hệ thống xác định bằng tập các sựkiện loại trừ lẫn nhau tương ứng với các sự kiện đầu ra. Cụthể:
1 2, , nA A A là các sự kiện đầu vào.
1 2, , nB B B là các sự kiện đầu ra.
Kênh truyền tin được biểu diễn bằng ma trận nhiễu bao gồm cácxác suất chuyển đổi từ một tin đầu vào thành một tin đầu ra,hay nói cách khác, chính là xác suất để jB xảy ra khi iA đã xảyra. Ký hiệu ( | )j iP B A . Các xác suất này gọi là xác suất tiênnghiệm.
Một quá trình truyền tin được xác định bởi phân bố thống kêđầu vào ( )iP A và tính chất của kênh truyền tin ( | )j iP B A . Khinhận được một sự kiện jB ở đầu ra, để có thể xác định được các
27

sự kiện nào đã xảy ra ở đầu vào, cần xác định các xác suất( | )i jP A B . Các xác suất này gọi là xác suất hậu nghiệm.
Để có thể giải bài toán thu tin trong trường hợp tổng quát,cần xác định được các xác suất hậu nghiệm từ các xác suất tiênnghiệm và phân bố xác suất đầu vào, Điều này được thực hiệnbởi công thức Bayes :
,
1 1
| ( ) | ( )( )| ( ) ( , ) | ( )j i i j i ii j
i j n nj k j j k k
P B A P A P B A P AP A BP A B
P B P A B P B A P A
28

Bài 2. Biến ngẫu nhiên
I. Khái niệm biến ngẫu nhiênĐể có thể sử dụng các công cụ toán học trên các sự kiện, cầnloại bỏ sự ràng buộc của các kết quả thử nghiệm và tập mẫu vớicác giá trị tùy ý. Các giá trị tùy ý này cần được ánh xạ vềcác giá trị số để có thể biểu diễn phép thử bằng các giá trịsố với các xác suất. Một biến có thể nhận các giá trị số vớicác xác suất khác nhau gọi là biến ngẫu nhiên. Một biến ngẫunhiên thường gắn với một phép thử.
Giả thiết rằng một phép thử có tập giá trị S và s là một phầntử của nó, s S, chúng ta sẽ định nghĩa một hàm X(s) có miềnxác định là S và miền giá trị của nó là một khoảng trên trụcthực. Hàm X(s) được gọi là một biến ngẫu nhiên. Ví dụ như nếuchúng ta tung một đồng xu có 2 mặt sấp (H) và ngửa (T), tậpS={H,T}. ta định nghĩa một hàm như sau:
1 ;0 ;
X S HX S T
Đây chính là một biến số ngẫu nhiên có thể lấy giá trị 1 hoặc0 hoặc tùy theo kết quả tung đồng tiền.
Có thể mở rộng cho các phép thử có số lượng kết quả hữu hạn.Mỗi kết quả iS sẽ tương ứng với một giá trị thực ix . Biến ngẫunhiên X(S) khi đó được biểu diễn bằng tập các giá trị ix xuấthiện với các xác suất ( )ip x . Trường hợp này X(S) được gọi làmột biến ngẫu nhiên rời rạc, còn xác suất ( )ip x được gọi làphân bố thống kê của X.
( ) ; ( )i iX S x p x
Trong nhiều trường hợp vật lý, các thực nghiệm sẽ cho một biếncó giá trị liên tục như trong trường hợp đo điện áp nhiễu củabộ khuếch đại điện tử chẳng hạn. lúc này tập giá trị S là liêntục và ta có thể định nghĩa hàm X s s là một biến ngẫu nhiênliên tục.
29

Giả thiết chúng ta đã có biến ngẫu nhiên X, và sự kiện để chobiến ngẫu nhiên X nhỏ hơn một giá trị X x sẽ có một xác suấtxuất hiện nhất định:
, XF x P X x x
Hàm XF x được gọi là hàm phân bố xác suất của biến ngẫu nhiên X.Vì XF x là xác suất xuất hiện nên giá trị của nó cũng nằmtrong dải [0,1]; 0 1XF x , đồng thời 0, 1X XF F . Hàmnày là một hàm không giảm. Hàm phân bố xác suất của biến ngẫunhiên liên tục là một hàm trơn, không giảm theo x.
Đạo hàm p(x) của hàm phân bố xác suất được gọi là hàm mật độphân bố xác suất của biến ngẫu nhiên X. vậy chúng ta sẽ có:
XX
F xp xx
Từ đó có :
1Xp x dx
( )u
X Xp x dx F u
2
1
1 2 ( )x
Xx
p x dx P x X x
Với các biến ngẫu nhiên rời rạc, hàm mật độ phân bố xác suấtđược định nghĩa:
1
( )n
X i ip x p x x x
Trong đó 0, 0, 1t t t dt
là hàm xung chuẩn
II. Biến ngẫu nhiên nhiều chiềuĐặc trưng thống kê của biến ngẫu nhiên nhiều chiều
30

Khi thực hiện đồng thời nhiều phép thử hay một phép thử phứctạp, để hình thức hóa các phép thử này một biến ngẫu nhiênnhiều chiều. Phân bố thống kê của biến ngẫu nhiên nhiều chiềunày sẽ phản ánh sự liên hệ giữa các phép thử. Các kết quả thuđược sẽ được ánh xạ vào một bộ các giá trị thực 1 1(X S ), 2 2(X S), ... Hàm phân bố xác suất và hàm mật độ phân bố xác suất củabiến này được gọi là hàm phân bố xác suất nhiều chiều và hàmmật độ phân bố xác suất nhiều chiều. Với biến ngẫu nhiên haichiều các đặc trưng thống kê trên được định nghĩa như sau:
Hàm phân bố xác suất:
1 2 1 2 1 1 2 2, ( , )X XF x x P X x X x
Hàm mật độ phân bố xác suất:
1 2
1 2
1 21 2
1 2
,( , ) X XX X
dF x xp x x
dx dx
Các tính chất của biến ngẫu nhiên nhiều chiều:
1 2
1 2 1 2-
1 2 2 1-
1 2 1 1 2 2 1 2 1 2
p(x , ) ( )
p(x , ) ( )
( , ) ( , ) ( , )x x
x dx p x
x dx p x
F x x P X x X x p u u du du
Hàm phân bố xác suất có điều kiện Xét 2 biến ngẫu nhiên X1 vàX2 có hàm mật độ phân bố xác suất đồng thời p(x1,x2). Giả sửchúng ta muốn xác định xác suất để biên ngẫu nhiên X1 x1 vớiđiều kiện :
x2 - x2 < X2 x2
Trong đó x2 > 0. Điều đó có nghĩa là chúng ta muốn xac địnhxác suất của sự kiện: (X1 x1|x2 - x2 < X2 x2). Xác suất củasự kiện: 1 1 2 2 2 2(X £x |x Dx X £x ) (X1 x1|x2 - x2 < X2 x2) sẽ bằngxác suất của sự kiện đồng thời :(X1 x1,x2 - x2 < X2 x2)chia cho xác suất của sự kiện (x2 - x2 < X2 x2)
31

1 2
2 22
2 2
1 2 1 21 2 1 2 2
1 1 2 2 22 2 2
2 2
( , )( , ) ( , )( ) ( )( )
x x
x xx
x x
p u u du duF x x F x x xP X x x X x
F x F x xp u du
2x
Chia cả tử số và mẫu số của cho x2 và lấy giới hạn khi x2
0 và nhận được:
1 2
2
1
1 2 1 2 21 2 2
1 1 2 1 22 2
2 2 2
1 2 1
2
( , ) /( , )/( ) ( ) ( )/
( ) /
( , )
( )
x x
x
x
p u u du du xF x x xP X x X F x x
F x xp u du x
p u x du
p x
2=x
Đây là hàm phân bố xác suất của biến ngẫu nhiên X1 trong điềukiện biến X2 đã xác định. Mặt khác F(-|x2) = 0 và F(|x2) = 1.Lấy đạo hàm của biểu thức trên theo x1 được hàm mật độ phân bốxác suất tương ứng p(x1,x2) như sau:
1 21 2
2
( , )( | ) ( )p x xp x x
p x
1 2 1 2 2 2 1 1, ( | ) ( | )p x x p x x p x p x x p x
Các biến ngẫu nhiên độc lập thống kê: Nếu các biến ngẫu nhiênlà kết quả của phép thử chung mà trong đó các phép thử khôngphụ thuộc lẫn nhau thì gọi là các biến ngẫn nhiên độc lậpthống kê. Trong trường hợp này, sự xuất hiện giá trị một biếnnày không phụ thuộc và sự xuất hiện giá trị nào của tất cả cácbiến ngẫu nhiên khác. Theo ngôn ngữ xác suất có :
1 2 1 2
1 2 1 2
, , , ,
n n
n n
F x x x F x F x F xp x x x p x p x p x
32

III.Các giá trị trung bìnhXét biến ngẫu nhiên X được mô tả bởi hàm mật độ phân bố xácsuất p(x). Trị trung bình hay kì vọng toán học của X được địnhnghĩa như sau:
¥
-¥( ) = ( )xE X m xp x dx
Ở đây [.]E ký hiệu của toán tử kỳ vọng toán học (trung bình
thống kê), nó cũng là mômen cấp đầu tiên của biến ngẫu nhiên
X. Một cách tổng quát, mômen cấp n được định nghĩa như sau:
nE(X ) = ( )nx p x dx
Nếu - nxY X m , ở đây mx là giá trị trung bình của X, thì:
¥
-¥( ) [ ( - ) ] ( - ) ( )n n
x xE Y E X m x m p x dx
Giá trị này được gọi là mômen trung tâm cấp n của biến ngẫunhiên X. Khi n=2 thì mômen trung tâm được gọi là độ lệch trungbình bình phương hay sai phương của biến ngẫu nhiên và được kýhiệu x2:
2 2( ) ( )x xx m p x dx
Chú ý rằng kỳ vọng toán học của một hằng số chính là hằng số
đó, chúng ta thu được:
2 2 2 2 2( ) ( ) ( )x xE X E X E X m
Trong trường hợp 2 biến ngẫu nhiên X1 và X2 với hàm mật độ phânbố xác suất đồng thời là p(x1,x2), mômen hợp được định nghĩalà:
1 2 1 2 1 2 1 2( ) ( , )h n h nE X X x x p x x dx dx
33

và mômen trung tâm hợp:
1 1 2 2 1 1 2 2 1 2 1 2[( ) ( ) ] ( ) ( ) ( , )k n k nE X m X m x m x m p x x dx dx
Ở đây i im E X . Đặc biệt quan trọng là mômen hợp và mômentrung tâm hợp ứng với 1k n . Các mômen hợp này được gọi làtương quan và hiệp biến giữa 2 biến ngẫu nhiên 1X và 2X .
Ma trận hiệp biến là ma trận có kích thước n n và các thànhphần là ij . Hai biến ngẫu nhiên được gọi là không tương quanvới nhau nếu i j i j i jE X X E X E X mm . Trong trường hợp đó giátrị hàm hiệp biến ij 0
Khi , i jX X độc lập thống kê với nhau thì chúgn không tương quan,nhưng ngược lại nếu chúng không tương quan thì không nhấtthiết là chúng sẽ độc lập thống kê với nhau.
Hai biến ngẫu nhiên được gọi là trực giao nếu 0i jE X X . Điềunày xảy ra khi iX và jX là không tương quan với nhau và có ítnhất một biến có trị trung bình bằng 0.
IV. Các biến ngẫu nhiên thường gặpPhân bố nhị phân Biến ngẫu nhiên X nhận 2 giá trị 0 và 1 vớixác suất là p và 1-p được gọi là biến ngẫu nhiên nhị phân. Đâylà một biến ngẫu nhiên có phân bố xác suất đơn giản tuy nhiênđược sử dụng rộng rãi để biểu diễn các nguồn tin trong các hệthống thông tin số.
( 0)( 1) 1
P X pP X p
Giá trị trung bình của biến ngẫu nhiên nhị phân:
2
2
[ ] 1[ ] 1
(1 )
X
x
m E X pE X p
p p
Phân bố nhị thức ChoX là 1 biến ngẫu nhiên rời rạc có phân bố nhị phân. Vấn đề đặt
34

ra là xác định hàm phân bố xác suất của 1
n
ii
Y X
, trong đó .
Trước hết chúng ta có nhận xét rằng Y là một tập hợp các sốnguyên từ 0 tới n vì nó là tổng của n số, mà mỗi số là 0 hoặc1, và ta chứng minh dễ dàng rằng hàm mật độ phân bố xác suất
của Y có thể được xác định như sau:
0 0( ) = ( ) ( ) (1 ) ( )
n nk n k
k k
nP y P Y k y k p p y kk
Hàm phân bố xác suất của Y là:
-
0( ) ( ) (1- )
yk n k
k
nF y P Y y p pk
Ở đây | |y là phần nguyên của y. Hai mô men đầu tiên của Y là:
2 2 2
2
1 1Y
E Y npE Y np p n p
np p
và hàm đặc tính là:
1 njvjv p pe
Phân bố đều Hàm mật độ phân bố xác suất và hàm phân bố xácsuất của biến ngẫu nhiên X phân bố đều được trình bày trênhình vẽ. Hai mô men đầu tiên của X là:
2 2
2 2 2
2 ( ) /22
1[ ] ( )21[ ] 3
1 1 = ( )12 2xx m
E X a b
E X a b ab
a b p x e
và hàm đặc tính là:
(jv) = ( )jvb jvae e
jv b a
35

Phân bố Gaussian (phân bố chuẩn) Hàm mật độ phân bố xác suấtcủa một biến ngẫu nhiên phân bố gaussian là:
2 2( ) /21( )2
xx mp x e
Trong đó mx là trị trung bình là 2 là sai phương của biến ngẫu
nhiên. Các mô men trung tâm của biến ngẫu nhiên gaussian là:
1.3... 1 2|0 2| 1
kk
x k
k kE X m
k
Và mô men có thể được biểu diễn qua mô men trung tâm như sau:
0( )
kk i i
k x k ii
E X C m
Tổng của n biến ngẫu nhiên gaussian độc lập thống kê cũng làmột biến ngẫu nhiên gaussian và điều này có thể được giảithích như sau. Đặt:
1
n
ii
Y X
Với iX , i 1, 2, ..., n là những biến ngẫu nhiên gaussian độc lậpthống kê với trị trung bình mi và sai phương i2. Ta tìm ra hàmđặc tính của Y là:
2 2 2 2/2 /2
1 1
i i Yi
n njvm v jvm v y
Y Xi i
jv jv e e
Trong đó:
2 2
1 1,
n n
y i ii i
m m y
Vậy Y cũng là phân bố gaussian với trị trung bình my và saiphương 2y.
V. Giới hạn trên của xác suất ngưỡng Khi đánh giá hiệu quả của một hệ thống thông tin số, thôngthường cần phải xác định miền dưới ngưỡng của hàm mật độ phân
36

bố xác suất. Chúng ta gọi miền này là xác suất ngưỡng. Trong phầnnày chúng ta xét 2 giới hạn trên của xác suất ngưỡng. Giới hạnthứ nhất thu được từ bất đẳng thức Chebyshev, có độ chính xáckhông cao. Giới hạn thứ 2 là giới hạn Chernoff có độ chính xáccao hơn.
Bất đẳng thức Chebyshev Giả thiết X là một biến ngẫu nhiên tùyý với trị trung bình xác định mx và độ lệch trung bình bìnhphương xác định x2, với mọi > 0 ta có:
2
2(| | ) xxP X m
Bất đẳng thức này gọi là bất đẳng thức Chebyshev. Với biếnngẫu nhiên có trị trung bình bằng không – xY X m , định nghĩamột hàm g(Y) như sau:
1( )
0Y
g YY
Do ( )g Y chỉ nhận giá trị 1 hoặc 0 với các xác suất tương ứng(/ / 0)P Y và (/ / )P Y , nên giá trị trung bình của nó là:
[ ( )] (| | )E g Y P Y
Bây giờ ta giả thiết rằng hàm g(Y) bị chặn trên bởi hàm toànphương (Y|)2, nghĩa là:
2( ) ( / )g Y Y
Ta có:
2 2 22
2 2 2 2[ ( )] /( ) y xE YYE g Y E
Do [ ( )]E g Y là xác suất ngưỡng nên ta nhận được bất đẳng thứcChebyshev.
Trong nhiều ví dụ thưc tế, việc sử dụng giới hạn Chebyshev gâyra nhiều sai số. Lý do chủ yếu là do ta đã sử dụng hàm 2(Y/ )không sát với hàm ( )g Y để chặn trên hàm ( )g Y .
37

Giới hạn Chernoff Giới hạn Chebyshev đề cập ở trên có tính tớihàm mật độ phân bố xác suất ngưỡng theo cả 2 phía. Trong nhiềuứng dụng thực tế, chúng ta chỉ quan tâm tới miền dưới mộtngưỡng, trong khoảng (,) hoặc trong khoảng (-,-). Trongtrường hợp như vậy, chúng ta có thể thu được một giới hạn trênchặt nhờ chặn trên hàm ( )g Y bằng một hàm mũ, hàm mũ này có mộttham số được sử dụng khi tối ưu hóa để tìm giới hạn trên chặt.Trong trường hợp chúng ta quan tâm tới xác suất ngưỡng trongkhoảng (,), hàm ( )g Y được chặn trên như sau:
( ) v Yg Y e
trong đó g(Y) được định nghĩa là :
1( )
0Y
g YY
với v 0 là tham số dùng để tối ưu hóa. Giá trị trung bìnhcủa ( )g Y là:
[ ( )] ( ) v YE g Y P Y E e
Giới hạn này đúng với mọi v 0. Giới hạn trên chặt nhất thuđược bằng cách lựa chọn giá trị của v để cực tiểu hóa ( - )( )v YE e .
Điều kiện cần thiết để hàm đạt cực tiểu là: 0v Yd E edv
Thứ tự lấy vi phân và lấy trung bình có thể hoán vị cho nhau,do đó:
( ) 0vY vYv Y v Y v Y vd dE e E e E Y e e E e E edv dv
Từ đó giá trị của v cho ta giới hạn trên chặt thỏa mãn phươngtrình:
0vY vYE Ye E e
Gọi v là nghiệm của . Như vậy từ giới hạn trên của xác suấtngưỡng một phía là:
38

ˆ ˆ( ) .v vYP y e E e
Đây là giới hạn Chernoff cho xác suất ngưỡng trên của các biếnngẫu nhiên rời rạc hay liên tục có trị trung bình bằng không.Có thể thu được theo cách tương tự giới hạn trên ở vùng xácsuất ngưỡng dưới. Kết quả là:
ˆ ˆ( ) .v vYP Y e E e
Trong đó v là nghiệm của và 0 .
VI. Tổng các biến ngẫu nhiên và định lý giớihạn trung tâm
Các vấn đề chúng ta xét ở trên chú trọng đến việc xác định hàmmật độ xác suất của một tổng gồm n biến ngẫu nhiên độc lậpthống kê. Trong phần này chúng ta vẫn quan tâm tới tổng cácbiến ngẫu nhiên độc lập thống kê, nhưng không quan tâm tới hàmmật độ xác suất của từng biến ngẫu nhiên trong tổng. Cụ thểhơn, giả thiết rằng ( 1,2, )iX i n là những biến ngẫu nhiên độclập thống kê và phân bố đồng nhất. Mỗi biến có một trị trungbình hữu hạn mx và sai phương x2. Biến ngẫu nhiên Y được địnhnghĩa như là tổng các biến ngẫu nhiên iX được chuẩn hóa, đượcgọi là mẫu trung bình:
1
1 n
ii
Y Xn
Trước hết chúng ta xác định giới hạn trên của xác suất ngưỡngcủa Y , sau đó chúng ta sẽ chứng minh một định lý quan trọngđối với hàm mật độ phân bố xác suất của Y trong trường hợpgiới hạn khi n dần tới vô hạn.
Biến ngẫu nhiên Y được định nghĩa trong thường gặp trong việcđịnh lượng trị trung bình của một biến ngẫu nhiên X từ nhiềuquan sát cụ thể ( 1,2, )iX i n . Nói cách khác, ( 1,2, )iX i n đượccoi như các mẫu độc lập thu được từ một hàm phân bố ( )XF x và Ylà ước lượng trung bình xm .
Trị trung bình của Y là:
39

i1
1 Xn
y xi
E Y m E mn
và độ lệch trung bình bình phương của Y là:
2
2 2 2 xy yE Y m
n
Với Y được coi như một ước lượng giá trị trung bình mx, chúngta thấy rằng kỳ vọng toán học của nó bằng xm và độ lệch trungbình bình phương 2
y tiến tới không. Phép ước lượng một tham số(trong trường hợp này là xm ), mà tham số ấy hội tụ về giá trịđúng của nó và sai phương hội tụ về khôngkhi n tiến tới vôcùng được gọi là một ước lượng chặt.
Xác suất ngưỡng của biến ngẫu nhiên Y có thể được chặn trênnhờ sử dụng các giới hạn đã được nêu treen. Áp dụng bất đẳngthức Chebyshev cho Y ta có:
2
2
2
21
yy
xi
P Y m
P X mn n
Khi cho n dần tới vô cùng, sẽ trở thành:
1
1lim 0n
i xi
P X mn
n
Như vậy, xác suất để giá trị trung bình ước lượng sai khác vớigiá trị trung bình thật lớn hơn hay bằng (>0) tiến tới khôngkhi n dần tới vô hạn. Đây là luật số lớn. Giới hạn trên hội tụ vềkhông khá chậm (tỉ lệ nghịch với n) nên được gọi là luật suyyếu của các số lớn.
Giới hạn Chernoff áp dụng cho biến ngẫu nhiên Y thu được mộthàm mũ theo n cho ta giới hạn trên chặt của xác suất ngưỡngmột phía. Chúng ta có thể xác định được xác suất ngưỡng của Ylà:
40

1
1 1
1
exp
n
y i xi
n n
i m i mi i
P Y m P X mn
P X n E v X n
Ở đây m xm và 0 . Mặt khác các biến $X_i$ độc lập thốngkê và phân bố đồng nhất, do đó:
1 1
1
exp expm
m i m
n nvn
i m ii i
n nvn vX v vX
i
E v X n e E v X
e E e e E e
Ở đây X biểu thị một biến Xi bất kỳ. Tham số v ứng với giới hạntrên chặt thu được nhờ lấy đạo hàm rồi cho đạo hàm bằng 0, từđó ta thu được phương trình:
vXXe 0vXmE E e
Giải phương trình ta thu được nghiệm v. Giới hạn trên của xácsuất ngưỡng trên là:
ˆ ˆ
1
1 ,mn nv vX
i m m xi
P X e E e mn
Tương tự ta tìm được giới hạn trên của xác suất ngưỡng dướilà:
ˆˆ ,mnvXv
m m xP Y e E m
Định lý giới hạn trung tâm Phần này chúng ta xét một định lýquan trọng được sử dụng nhiều trong thực tế. Định lý này nóitới hàm phân bố xác suất của tổng các biến ngẫu nhiên khi sốbiến ngẫu nhiên tiến tới vô hạn. Có nhiều dạng của định lýnày, chúng ta sẽ chứng minh định lý trong trường hợp các biếnngẫu nhiên Xi, i=1, 2, ..., n độc lập thống kê và có phân bốgiống nhau, mỗi biến sẽ có một trị trung bình hữu hạn mx và độlệch trung bình bình phương xác định x2. Để tiện tính toán,chúng ta định nghĩa một biến ngẫu nhiên chuẩn hóa như sau:
41

, 1,2,...,i xi
x
X mU i n
Ui có trị trung bình bằng không và độ lệch trung bình bìnhphương bằng một. Đặt:
1
1 n
ii
Y Un
Mỗi số hạng trong tổng có trị trung bình bằng không và độ lệchtrung bình bình phương bằng một, như vậy biến ngẫu nhiên chuẩnhóa Y (bởi 1 n) cũng sẽ có trị trung bình bằng không và độlệch trung bình bình phương bằng một. Chúng ta muốn xác địnhhàm phân bố xác suất của Y trong trường hợp giới hạn khi n .
Hàm đặc tính của Y như sau:
1
1exp
i
nni n
jvY iY U U
i
jv U jv jvjv E e En n n
ở đây ký hiệu U biểu thị cho các biến iU có phân bố giốngnhau. Bây giờ chúng ta khai triển hàm đặc trưng dưới dạngchuỗi Taylor như sau:
32
2 331 ...2! 3!
Ujvjv v vj E U E U E U
nn n n
Từ ( ) 0E U và 2( ) 1E U , công thức trên có thể được viết đơn giảnnhư sau:
2 11 ,2U
jv v R v nn nn
Ở đây R(v,n)/n biểu thị cho các số hạng bậc cao. Chúng ta chú ýrằng R(v,n) tiến tới không khi n , ta thu được hàm đặc tínhcủa Y dưới dạng:
42

2 ,1 2
n
YR v nvjv
n n
Lấy loga tự nhiên 2 vế của ta thu được:
2 2 2, , ,1ln ln 1 ...2 2 2 2
n
YR v n R v n R v nv v vjv n n
n n n n n n
Cuối cùng ta lấy giới hạn khi n , trở thành:
2 2lim vY jv e
Đây là hàm đặc tính của một biến ngẫu nhiên gaussian với trịtrung bình bằng không và độ lệch trung bình bình phương bằngmột. Như vậy, chúng ta đã có một kết quả quan trọng là tổngcác biến ngẫu nhiên độc lập thống kê và phân bố giống nhau vớitrị trung bình và độ lệch trung bình bình phương hữu hạn tiếntới một biến ngẫu nhiên gaussian khi n . Vậy định lý giớihạn trung tâm đã được chứng minh.
43

Bài 3. Quá trình ngẫu nhiên
I. Khái niệm quá trình ngẫu nhiênMột thực nghiệm cho chúng ta một kết quả nào đó trong tập hợpcác kết quả có thể : tung đồng xu, gieo con xúc xắc, ...... ;Trong trường hợp này, chúng ta dùng lý thuyết xác suất để đánhgiá kết quả thực ngh
iệm (biến ngẫu nhiên, các giá trị trung bình, phân bố xácsuất, ......). Một thực nghiệm phức tạp hơn, cho chúng ta mộtcác giá trị tại một tập hợp các thời điểm nào đó. Tại mỗi thờiđiểm, giá trị của thực nghiệm là một biến ngẫu nhiên. Giá trịcủa một thời điểm có thể có liên quan đến giá trị tại thờiđiểm khác. Trong trường hợp này, chúng ta không quan tâm nhiềuđến các giá trị riêng rẽ tại từng thời điểm, mà quan tâm đếncác giá trị đồng thời tại tất cả các điểm. Để thực hiện việcnày có thể theo các cách tiếp cận:
Cách tiếp cận hàm số. Hàm số theo thời gian khoảng thời giannào đó. Mỗi lần tiến hành phép thử, thu được một hàm, gọi làhàm mẫu. Tập hợp tất cả các hàm mẫu gọi là không gian mẫu. Quátrình ngẫu nhiên được biểu diễn bằng tập hợp tất cả các hàmmẫu có thể, mỗi hàm mẫu có một xác suất xuất hiện. Cách tiếpcận này mở rộng khái niệm biến ngẫu nhiên, cho phép biến ngẫunhiên có thể nhận các giá trị là các hàm số.
Nếu xem xét quá trình ngẫu nhiên theo thời gian, tại mỗi thờiđiểm thời gian xác định so với mốc đánh giá, trong các phépthử khác nhau sẽ thu được các giá trị khác nhau. Như vậy giátrị của quá trình ngẫu nhiên tại mỗi thời điểm thời gian cóthể coi như một biến ngẫu nhiên. Quá trình ngẫu nhiên được xemxét như một hàm theo thời gian, nhận giá trị là các biến ngẫunhiên.
Như vậy có thể định nghĩa quá trình ngẫu nhiên như một tập(họ)các biến ngẫu nhiên tại các thời điểm khác nhau. Khi gán cácgiá trị cụ thể cho từng biến ngẫu nhiên trong họ ngẫu nhiên
44

nói trên, ta thu được một hàm theo thời gian gọi là hàm mẫu.Tập hợp tất cả các hàm mẫu có thể gọi là không gian mẫu. Khicố định giá trị thời gian t quá trình ngẫu nhiên trở thành mộtbiến ngẫu nhiên. Khi cố định thời gian và hàm mẫu, giá trị củaquá trình ngẫu nhiên là một giá trị số.
II. Đặc trưng thống kê của quá trình ngẫunhiên
Tính chất thống kê của quá trình ngẫu nhiên trước hết phản ánhtrong giá trị của quá trình ngẫu nhiên tại mỗi thời điểm. Giátrị này là một biến ngẫu nhiên có phân bố xác xuất phụ thuộcthời gian. Hàm mật độ phân bố xác suất của biến ngẫu nhiên nàyđược gọi là thống kê bậc 1 của quá trình ngẫu nhiên ( ,)X tp x t . Đểphản ánh mối liên hệ giứa 2 giá trị của quá trình ngẫu nhiêntại hai thời điểm thời gian khác nhau, cần sử dụng hàm mật độphân bố xác suất đồng thời của 2 biến ngẫu nhiên đó. Hàm nàygọi là thống kê bậc 2 của quá trình ngẫu nhiên. Tổng quát, nếuxem xét giá trị của biến ngẫu nhiên tại n thời điểm khác nhau,sẽ có một hàm mật độ phân bố xác suất đồng thời của n biếnngẫu nhiên. Hàm này sẽ có 2n biến, trong đó có n biến tự do vàn biến thời gian. Hàm số này được gọi là thống kê bậc n củaquá trình ngẫu nhiên: 1 2
( , , , )nt t tp x x x .
Các thống kê bậc cao thường rất phức tạp. Sự có mặt của cácbiến thời gian càng làm cho việc nghiên cứu quá trình ngẫunhiên trở thành khó khăn hơn. Trong thực tế, các quá trìnhngẫu nhiên thường có tính chất không phụ thuộc vào mốc thờigian xem xét. Tính chất thống kê khi tiến hành xem xét, đánhgiá thực hiện các phép thử tại một thời điểm không phụ thuộcvào giá trị thời gian tại điểm đó.
Một cách hình thức nếu:
1 2 1 2( , , , ) ( , , , ) ,
n nt t t t t t t t tp X X X p X X X t n
Thì quá trình ngẫu nhiên được gọi là quá trình ngẫu nhiên dừngchặt.
45

III.Giá trị trung bình của quá trình ngẫunhiên
Giá trị trung bình của quá trình ngẫu nhiên tại một thời điểmchính là giá trị trung bình của biến ngẫu nhiên thể hiện quátrình ngẫu nhiên tại thời điểm đó:
[ ]tx tm E x
Nếu quá trình ngẫu nhiên dừng, giá trị trung bình không phụthuộc thời gian t.
Để phản ánh mối tương quan giữa giá trị của quá trình ngẫunhiên tại hai thời điểm khác nhau, sử dụng giá trị tương quangiữa 2 biến ngẫu nhiên tương ứng.
1 2 1 2 1 2 1 2 1 2( , ) ,t t t t t t t tt t E X X x x p x x dx x
Hàm số thu được gọi là hàm tự tương quan của quá trình ngẫunhiên. Trường hợp quá trình ngẫu nhiên dừng, hàm tự tương quanchỉ phụ thuộc vào khoảng cách giữa 2 thời điểm thời gian:
1 2 1 2( , ) ( ) ( )t t t t
Chú ý: ( ) ( ) , như vậy hàm tự tương quan của quá trình ngẫunhiên dừng là hàm chẵn. Ngoài ra khi 1 2t t hoặc 1 2 0t t ,
2(0) ( )tE X đượcc gọi là công suất trung bình của quá trình ngẫunhiên.
Một số quá trình ngẫu nhiên không dừng vẫn có 1 2 1 2( , ) ( ) ( )t t t t
gọi là dừng theo nghĩa rộng.
Hàm tự hiệp biến của quá trình ngẫu nhiên được định nghĩatương tự như hàm tự tương quan.
1 2 1 1 2 2 1 2 1 2, ( ). ( ) ,t tt t E X m t X m t t t m t m t
Trường hợp quá trình ngẫu nhiên dừng:
21 2 1 2,t t t t m
46

Công suất của quá trình ngẫu nhiên dừng được biểu diễn bằnghàm tự tương quan tại 0 (0) . Áp dụng biến đổi Furrier cho hàmtự tương quan có:
2j ff e d
Hàm tự tương quan nhận được khi biến đổi ngược:
2j ff e df
Từ đó
210 () 0f df E X t
Trong , (0) biểu diễn công suất trung bình của quá trình ngẫunhiên, nên f gọi là phổ mật độ công suất của quá trình ngẫunhiên.
Khi xem xét hai quá trình ngẫu nhiên đồng thời, có thể xem xét2 biến ngẫu nhiên đại diện cho 2 quá trình ngẫu nhiên tại cácthời điểm khác nhau. Các hàm tự tương quan, tự hiệp biến trởthành các hàm tương quan chéo, hàm hiệp biến chéo. Công suấttrung bình và phổ mật độ công suất trở thành công suất trungbnh và phổ mật độ công suất chéo. Các biểu thức định nghĩahoàn toàn tương tự.
47

CHƯƠNG III.THÔNG TIN VÀ ĐỊNH LƯỢNG THÔNG TIN
Bài 4. Tốc độ lập tin nguồn rời rạc dừng khôngnhớ
I. Mô hình nguồn rời rạcNguồn tin rời rạc là nguồn sinh ra các thông tin rời rạc. Cácthông tin rời rạc được gọi là các tin. Các tin còn được gọi làcác ký hiệu nguồn. Tập hợp tất cả các tin nguồn tin có thểsinh ra gọi là bảng tin hay bảng ký hiệu. Tập hợp các tinnguồn tin sinh ra trong quá trình phát tin gọi là bản tin.Nguồn tin rời rạc phát các thông tin vào các thời điểm thờigian rời rạc 1 2 3..., , ..., ,...nt t t t . Thông thường chỉ có một số hữu hạnthời điểm có thể quan sát được 1 2 3, , ...,nt t t t . Các thời điểm thườngđược chọn cách đều nhau. Số các tin (ký hiệu) mà nguồn tinsinh ra trong một đơn vị thời gian gọi là tốc độ ký hiệu. Cácbản tin sinh ra có dạng 1 2
... , ,..., ,...nt t tu x x x , trong đó
1 1 2{x ,x ,...,x }t mx X .
Trong trường hợp tổng quát, nguồn tin được biểu diễn bằng bộđôi {u}, {p(u)}U P , trong đó u là các bản tin, còn ( )P u là xácsuất xuất hiện của các bản tin đó. Việc biểu diễn các nguồntin một cách tổng quát như vậy đòi hỏi một không gian lưu trữlớn, do số lượng các bản tin là rất lớn. Chính vì thể, nguồntin thường được xem xét trong một số trường hợp đặc biệt để cócác biểu diễn đơn giản hơn.
Mô hình nguồn rời rạc dừng không nhớ Nguồn rời rạc dừng không nhớ lànguồn mà xác suất xuất hiện của các ký hiệu tại các thời điểmkhông phụ thuộc vào các ký hiệu xuất hiện tại các thời điểmkhác (đặc biệt là các thời điểm ngay sát thời điểm đang xemxét)., đồng thời tính chất thống kê của nguồn không phụ thuộcthời gian. Trong trường hợp này, nguồn tin được biểu diễn bằngbộ {x }, {P(x )}i iX P . Đây là một mô hình đơn giản, tuy nhiên
48

không phải ánh được ràng buộc giữa các ký hiệu sinh ra tại cácthời điểm khác nhau.
Mô hình nguồn rời rạc dừng, có nhớ với bộ nhớ hữu hạn. Để cóthể mở rộng mô hình nguồn không nhớ, có thể bỏ qua không xemxét các ký hiệu xuất hiện tại các thời điểm quá xa nhau. Nhưvậy chỉ cần xem xét các k-1 ký hiệu liên tiếp nhau tác độngthế nào đến ký hiệu xuất hiện ở thời điểm k. Trường hợp nàynguồn được coi là có bộ nhớ k. Các ràng buộc thống kê khôngphụ thuộc thời gian do tính chất dừng của nguồn. Cho biết phânbố xác suất của nguồn khi bắt đầu phát tin, đồng thời biếtđược các ràng buộc thống kê của ký hiệu tại một thời điểm với
1k thời điểm trước đó, có thể xác định xác định phân bố xácsuất tại thời điểm hiện tại. Cách thức biểu diễn này phức tạphơn cách thức biểu diễn nguồn dừng không nhớ, nhưng số lượngthông tin cần lưu trữ là chấp nhận được.
Một trường hợp thường gặp là nguồn có bộ nhớ 1. Xác suất xuấthiện của các ký hiệu chỉ phụ thuộc vào các ký hiệu xuất hiệnngay trước:
1 2 1( | , ...) ( | )
n n n n ni j k i jp x x x p x x
Các xác suất này được biểu diễn bởi ma trận chuyển đổi* ij ( ) ( 1)( | )m m i k j kT p P x x . Gọi xác suất xuất hiện của các ký hiệu
tại thời điểm xuất phát là 0 0( ), 1...iP P x i m . Cần xác định xácsuất xuất hiện của các ký hiệu tại thời điểm k
( ), 1...k kiP P x i m . Thực hiện biến đổi với mỗi xác suất:
( 1) ( 1)
ij ( 1)
( ) ( | ) ( )* ( )
ki ki k j k j
k j
P x P x x P xp P x
Từ công thức nói trên có thể rút ra
1 0* * kk kP P T P T
Như vậy trong trường hợp nguồn tin có nhớ, có thể xác địnhđược phân bố xác suất của các ký hiệu tại mỗi thời điểm, từ đóáp dụng các kết quả đã có với nguồn tin rời rạc dừng khôngnhớ.
49

II. Các loại lượng tinTrong chương 1 đã khẳng định nếu hai sự kiện A,B là độc lậpthống kê thì lượng tin của sự kiện đồng thời bằng tổng lượngtin của hai sự kiện. Trường hợp nếu 2 sự kiện không độc lậpthống kê với nhau, trong thông tin thu được của sự kiện này cóthông tin về sự kiện còn lại. Có thể biểu diễn mối quan hệgiữa thông tin của các sự kiện như hình vẽ
I(A)
I(B)
I(A|B) I(A;B) I(B|A)
I(AB)
III-6: Các loại lượng tin của sự kiện
Tương quan giữa lượng tin của A, lượng tin của B và lượng tincủa AB tạo ra 3 vùng lượng tin mới. Vùng lượng tin chung giữaA và B được ký hiệu là I(A;B), được gọi là lượng tin tương hỗcủa A và B. Lượng tin này phản ánh lượng thông tin về A nhậnđược khi B xảy ra và ngược lại, về B nhận được khi A xảy ra.Hay nói cách khác, đây chính là lượng thông tin chung giữa haisự kiện A và B. Lượng tin này càng lớn thì hai sự kiện A và Bcàng ràng buộc lẫn nhau. Lượng tin tương hỗ có các tính chấtsau đây
( ; ) 0; ( ; ) 0I A B I A B nếu A và B độc lập thống kê
( ; ) ( ); ( ; ) ( ) ( )I A B I A I A B I A A B
Lượng tin về A nhưng không nằm trong B chính là lượng tin cònlại chưa có về A khi B đã xảy ra. Đây chính là lượng tin về Avới điều kiện là B đã xảy ra. Tương tự như với xác suất, lượngtin này được gọi là lượng tin có điều kiện, ký hiệu là ( | )I A B .
50

Như vậy chúng ta đã định nghĩa các lượng tin đồng thời, lượngtin riêng, lượng tin tương hỗ, lượng tin rời rạc. Quan hệ giữacác lượng tin này như sau:
( ; ) ( ) ( | ) ( ) ( | ) ( ) ( ) ( )( | ) ( ) ( ); ( | ) ( ) ( )
I A B I A I A B I B I B A I A I B I ABI A B I AB I B I B A I AB I A
III.Lượng tin trung bình/Entropy nguồn rờirạc
Xét một nguồn tin rời rạc dừng không nhớ. Nguồn có thể phát ram ký hiệu 1 2 3, , ,..., mx x x x với các xác suất 1 2( ), ( ),..., ( ).mp x p x p x Giả sửnguồn phát ra một ký hiệu Lượng tin nguồn sinh ra khi phát raký hiệu ix gọi là lượng tin riêng của ký hiệu và được tính bằngcông thức:
2( ) log ( ( ))( )i iI x p x bit
Lượng tin này cung cấp thông tin về từng ký hiệu, không cungcấp thông tin chung về nguồn tin. Để có được tiêu chí về chấtlượng thông tin do nguồn tin sinh ra, cần lấy giá trị trungbình:
21
( ) ( )log ( ( ))( / )m
i iI X p x p x bit kh
Đại lượng này được gọi là lượng tin trung bình của nguồn tin rờirạc, phản ánh lượng tin trung bình mà nguồn tin sinh ra mỗikhi tạo ra một ký hiệu.
Tính chất của lượng tin trung bình:
- Không âm. Có thể thấy , ( ) 0ii p x . Do đó ( ) 0I X . Trường hợpnếu một ký hiệu nào đó có xác suất xuất hiện 0, ký hiệu này sẽđược loại khỏi biểu thức tính lượng tin trung bình. Do đólượng tin trung bình của một nguồn tin đạt giá trị nhỏ nhất là0, khi tất cả các ký hiệu đều có xác suất bằng 0 và duy nhất 1ký hiệu có xác suất bằng 1.
( ) 0, ( ) 0 : ( ) 1, ( ) 0i jI X I X i p x p x j i
51

Trong trường hợp này, nguồn sinh ra đúng 1 ký hiệu, do đóluôn luôn có thể biết trước được ký hiệu nguồn sẽ sinh ra.Do đó lượng tin trung bình của nguồn tin là 0.
Giá trị lớn nhất của lượng tin trung bình. Ta có:
1 1 1
1 1( )ln( ( )) ( ) ln( ) ln ( ) ) 1 ln( ) ( )
1 1 ln
m m m
i i i ii i
m mp x p x p x m p x mp x p x
mm m
Từ đó:
2 21 1
( )ln( ( )) ln ( )log ( ( )) logm m
i i i ip x p x m p x p x m
Dấu bằng xảy ra khi
1( ) , 1ip x i mm
Như vậy có thể thấy cùng một số lượng ký hiệu trong bảng kýhiệu, nguồn tin có lượng tin trung bình lớn nhất khi các kýhiệu xuất hiện với xác suất bằng nhau và bằng 1/m. Trường hợpnày nguồn tin được gọi là nguồn tin đẳng xác suất. Số lượngcác ký hiệu của bảng ký hiệu càng lớn thì lượng tin trung bìnhlớn nhất càng lớn.
Trong nhiều trường hợp, cần xem xét một chuỗi u gồm J ký hiệuliên tiếp của nguồn tin. Mỗi chuỗi J ký hiệu có thể coi nhưmột ký hiệu của nguồn tin mới có jm ký hiệu. Lượng tin trungbình của nguồn tin mới sẽ là:
21( ) ( )log ( ( )) ( )( / )jmI U p u p u J I X bit kh
Theo một quan điểm khác, trước khi nguồn tin sinh ra một kýhiệu, tồn tại một độ mập mờ về ký hiệu sẽ đýợc sinh ra, đồngthời lýợng tin về ký hiệu đó là 0. Sau khi ký hiệu đã được tạora, độ mập mờ này bằng 0 và nhận được một lượng tin bằng lượngtin của ký hiệu. Như vậy độ mập mờ và lượng tin có ư nghĩangược nhau, nhưng có cùng một số đo. Mở rộng cho nguồn tin,
52

khái niệm lượng tin trung bình được thay thế bằng độ bất địnhtrung bình-entropy của nguồn tin rời rạc:
21
( ) ( )log ( ( ))( / )m
i iH X p x p x bit kh
IV. Tốc độ lập tin và độ dưThông số thống kê cơ bản thứ nhất của nguồn tin là entrôpi,tuỳ thuộc vào cấu trúc thống kê của nguồn. Nhưng sự hình thànhtin nhanh hay chậm để đưa vào kênh lại tuỳ thuộc vào tính chấtvật lý khác của nguồn như quán tính, độ phân biệt, v.v..., chonên số ký hiệu lập được trong một đơn vị thời gian rất khácnhau.
Thông số cơ bản thứ hai của nguồn là tốc độ tạo thông tin-tốcđộ lập tin:
0 /secR n H X bit
Tốc độ lập tin đạt giá trị lớn nhất khi H(X) đạt giá trị lớnnhất ( 2log m)
0 2 log /secR n m bit
Độ dư tuyệt đối của nguồn là tỉ số giữa độ dư của nguồn vàgiá trị cực đại của entrôpi:
max - ( )D H X H X
Độ dư tương đối của nguồn là tỉ số giữa độ dư của nguồn và giátrị cực đại của entrôpi:
max 1- /d H X H X
53

Bài 5. Thông lượng kênh rời rạc
I. Mô hình kênh truyền tinKênh truyền tin là kênh liên tục hoặc kênh rời rạc phụ thuộcvào tính chất liên tục hay rời rạc của đầu vào và đầu ra củakênh. Kênh rời rạc là kênh mà cả đầu vào và đầu ra đều là rờirạc. Kênh rời rạc dừng không nhớ là kênh rời rạc trong đó cáctính chất cúa kênh không phụ thuộc vào thời gian và không phụthuộc vào giá trị của đầu vào và đầu ra tại các thời điểmkhác.
Chương 1 đã trình bày 2 loại mô hình của kênh truyền tin, môhình tín hiệu và mô hình thông tin. Mô hình tín hiệu biểu diễnliên hệ về tín hiệu giữa đầu vào và đầu ra. Mô hình thông tinbiểu diễn mối liên hệ giữa các ký hiệu đầu vào và đầu ra thôngqua ma trận nhiễu. Ví dụ sau đây cho thấy sự liên hệ giữa 2 môhình này. Một nguồn tin có 2 ký hiệu 0 và 1 được truyền trênmột kênh truyền tin bằng mã hóa NRZ. Ký hiệu 0 tương ứng vớimức điện áp 5v, ký hiệu 1 tương ứng với mức điện áp -5v. Trongquá trình truyền, tín hiệu bị ảnh hưởng bởi nhiễu có giá trịlà một biến ngẫu nhiên có mật độ phân bố xác suất p(x).
Tại đầu ra của kênh truyền tin, căn cứ vào mức tín hiệu nhậnđược, bộ phận thu sẽ phải ra quyết định xác định ký hiệu đầura là 0 hay 1. Phương án đơn giản nhất là lựa chọn điện áp ranếu >0 thì ký hiệu đầu ra là 0, nếu <0 thì ký hiệu đầu ra là1.
Xét trường hợp gửi ký hiệu 0 đi. Tín hiệu đầu ra sẽ là mộtbiến ngẫu nhiên có phân bố chuẩn Gauss, có giá trị trung bìnhlà 5. Xác suất để tín hiệu đầu ra lớn hơn 0 là:
5( 0) ( )OP V p x dx
Xác suất để tín hiệu đầu ra nhỏ hơn 0 là:
54

5( 0) ( )OP V p x dx
Xét trường hợp gửi ký hiệu 1 đi. Tín hiệu đầu ra sẽ là mộtbiến ngẫu nhiên có phân bố chuẩn Gauss, có giá trị trung bìnhlà -5. Xác suất để tín hiệu đầu ra lớn hơn 0 là:
5( 0) ( )OP V p x dx
Xác suất để tín hiệu đầu ra nhỏ hơn 0 là:5
( 0) ( )OP V p x dx
Ma trận nhiễu của kênh truyền tin sẽ có dạng:
5
55 5
( ) ( )
( ) ( )
p x dx p x dx
p x dx p x dx
Mặc dù ví dụ này tương đối đơn giản, tuy nhiên có thể thấy từmô hình tín hiệu có thể tính toán để đưa ra được ma trận nhiễuđặc trưng cho kênh truyền tin.
II. Thông lượng kênhĐặc trưng của quá trình truyền tin Quá trình truyền tin được biểu diễnbằng một chuỗi các thao tác gửi các ký hiệu đi ở đầu vào vànhận ký hiệu ở đầu ra. Liên hệ giữa đầu vào và đầu ra được thểhiện bằng ma trận nhiễu. Quá trình truyền tin được đặc trưngbởi phân bố xác suất của nguồn.
Xét một kênh truyền tin rời rạc dừng không nhớ, có m đầu vào
1 2 3, , ,..., mx x x x và n đầu ra 1 2, ,..., ny y y . Tại mỗi thời điểm, khi nguồn
gửi một ký hiệu, ký hiệu này sẽ được biến đổi thành một kýhiệu đầu ra. Quá trình biến đổi bị tác động bởi nhiễu, do đóký hiệu nhận được có thể không tương ứng với ký hiệu đã gửiđi. Đứng trên góc độ thông tin, ký hiệu gửi đi chứa một lượngthông tin bằng với lượng tin riêng của ký hiệu. Trong quá
55

trình truyền, lượng tin này bị phá hủy một phần, chỉ có mộtphần đến được đích. Lượng tin bị phá hủy một phần chính làlượng tin về ký hiệu đầu vào còn chưa nhận được khi nhận đượcký hiệu đầu ra. Lượng tin về ký hiệu đầu vào nhận được ở đầura chính là lượng tin tương hỗ. Hình vẽ chỉ ra sự thay đổi vềlượng tin trong một quá trình truyền đi một ký hiệu.
KênhI(x) I(x;y)
I(x|y)
III-7: Sự thay đổi lượng tin khi truyền một ký hiệu qua kênh truyền tin
Trong việc truyền 1 ký hiệu, lượng tin được truyền qua kênhtruyền tin là: I(x;y). Lượng tin này thay đổi khi ký hiệu đượctruyền và ký hiệu nhận được thay đổi, do đó nó chỉ phản ánhcho quá trình truyền tin tại một thời điểm cụ thể, với một cặpký hiệu đầu vào và đầu ra. Để có thể phản ánh cho cả quá trìnhtruyền tin, cần lấy trung bình trên các cặp ký hiệu:
1 1( ; ) ( , ) ( ; )( / )
m n
i j i jI X Y p x y I x y bit kh
Đại lượng này được gọi là lượng tin tương hỗ trung bình củahai nguồn tin X và Y. Để có thể tính được lượng tin tương hỗ,cần định nghĩa lượng tin đồng thời trung bình:
21 1
( , ) ( , )log ( , )( / )m n
i j i jI X Y p x y p x y bit kh
Và lượng tin có điều kiện trung bình
21 1
21 1
( | ) ( , )log ( | )( / )
( | ) ( , )log ( | )( / )
m n
i j i j
m n
i j i ji
I X Y p x y p x y bit kh
I Y X p x y p y x bit kh
Quan hệ giữa các lượng tin trung bình cũng tương tự như quanhệ các lượng tin, vì phép toán trung bình là phép toán tuyếntính.
56

I(X)
I(Y)
I(X|Y) I(X;Y) I(Y|X)
I(XY)
III-8: Quan hệ giữa các lượng tin trung bình
Các ràng buộc giữa các lượng tin trung bình được biểu diễnbởi:
( ; ) ( ) ( | ) ( ) ( | ) ( ) ( ) ( )( | ) ( ) ( ); ( | ) ( ) ( )
I X Y I X I X Y I Y I Y X I X I Y I XYI X Y I XY I Y I Y X I XY I X
Tương tự như với entropy của một nguồn tin, các entropy đồngthời và entropy có điều kiện của các nguồn tin cũng được tínhbằng độ đo giống như lượng tin, nhưng với ý nghĩa trái ngược.Quan hệ giữa các entropy đồng thời, entropy có điều kiện trong III -8: Quan hệ giữa các lượng tin trung bình được giữnguyên. Công thức trở thành:
( ; ) ( ) ( | ) ( ) ( | ) ( ) ( ) ( )( | ) ( ) ( )( | ) ( ) ( )
I X Y H X H X Y H Y H Y X H X H Y H XYH X Y H XY H YH Y X H XY H X
Tốc độ truyền tin của quá trình truyền tin được tính bởi côngthức:
0 ( ; )outR n I X Y
Trong đó outR là tốc độ truyền tin, 0n là tốc độ ký hiệu, ( ; )I X Y
là lượng tin tương hỗ trung bình, phản ánh lượng tin mà kênhtruyền tin cho qua mỗi khi truyền đi một ký hiệu.
Thông lượng kênh là lượng tin lớn nhất mà kênh có thể cho quatrong một đơn vị thời gian. Thông lượng kênh được tính bằnggiá trị lớn nhất có thể của tốc độ truyền tin
57

0ax ( ; )outX XC maxR m n I X Y
Tỷ lệ giữa tốc độ truyền tin và thông lượng kênh được gọi làhiệu quả sử dụng kênh:
outRHC
Thông lượng kênh không nhiễu Nếu kênh không có nhiễu, tất cả thông tin đều được chuyển tới đầu ra.
( ; ) ( )I X Y I X
0 ( )outR n I X
0 0 0 2( ; ) ( ) logoutX X XC maxR n I X Y maxn I X n mmax
Hiệu quả sử dụng kênh:
2
( )log
R I XHC m
Nếu tốc độ truyền tin chưa bằng thông lượng của kênh, có thểsử dụng các phép mã hóa để tăng hiệu quả của kênh. Xét ví dụsau:
Một nguồn X có 4 ký hiệu và có phân bố xác suất
1 2 3 4, , ,X x x x x , 1 2 3 4( ) 1/2, ( ) 1/4, ( ) 1/8, ( ) 1/8p x p x p x p x
Entropi của X là
( ) ( )log ( ) 7/4X
H X p x p x
Để có Entropi cực đại 2( ) log 4 2maxH X cần có phân bố xác suấtđều cho các ký hiệu. Thực hiện liên tiếp hai phép biến đổi.Phép biến đổi thứ nhất
1 0
2 1 0
3 1 1 0
4 1 1 1
x yx y yx y y yx y y y
58

Xác suất của 0y và 1y là bằng nhau: (7/8)/(7/4) 1/2
Biến đổi nguồn tin thu được thành một nguồn có 4 ký hiệu
0 0 1
1 0 2
0 1 3
1 1 4
y y zy y zy y zy y z
Cả hai phép biến đổi đều bảo toàn lượng tin cho các bản tin.Qua việc thực hiện 2 phép mã hóa này, thông lượng của kênhđược sử dụng tối đa, hiệu quả sử dụng kênh bằng 1. Điều nàyđược giải thích bởi việc phân bố xác suất của nguồn gồm toàncác xác suất « chẵn«, nên có thể sử dụng số ký hiệu nhị phânđúng bằng lượng tin của từng ký hiệu. Khi các xác suất khôngphải là lũy thừa của 2, không thể làm như vậy. Vấn đề đặt ralà hiệu quả tối đa của kênh khi sử dụng các phép biến đổi.Định lý Shannon cho kênh không nhiễu xác định giới hạn củaviệc mã hóa.
Cho kênh truyền tin không nhiễu có thông lượng C, nguồn tin cólượng tin trung bình Ià ( )H X (bit/kh). Như vậy
0 ( ) ( / )max maxC R n H X bit sec . Khi đó:
- Không thể truyền tin nhanh hơn CH (kh/s)
- 0 ò , có thể mã hóa nguồn để truyền tin với tốc độ trung
bình CH ò(ký hiệu/s)
Như vậy sau khi mã hóa tốc độ truyền tin tối đa có thể đạt
được không vượt qua CH (kh/s). Trong nhiều trường hợp, không
thể đạt được đúng tốc độ lập tin này, tuy nhiên luôn luôn cóthể tiệm cận với giá trị đó. Phép mã hóa tương ứng gọi là phépmã hóa tối ưu.
Thông lượng kênh có nhiễu Khi kênh có nhiễu, vấn đề đặt ra làkhi nào có thể truyền tin một cách tin cậy. Định lý Shannoncho kênh không nhiễu thể hiện điều này.
59

Định lý Shannon cho kênh có nhiễu:
Cho nguồn tin có tốc độ lập tin R ,truyền tin vào kênh tin cóthông lượng C ,
- Nếu R C , 0 ò có thể có phương pháp mã hóa để truyềntin với độ sai nhầm ò(bit/s).
- Nếu R C
o 0 ò có thể mã hóa nguồn với sai số R C ò.
o Không tồn tại cách mã hóa với sai số nhỏ hơn R C
Như vậy nếu R C phần dư của nguồn được dùng để bổ sung cácthông tin chống nhiễu. Cần truyền lượng tin lớn hơn so vớilượng tin cần truyền. Nếu R C , phần thông tin không đượctruyền đi sẽ trở thành sai số (tối thiểu). Tồn tại cách mãhóa để có(tiệm cận) sai số tối thiểu
III.Khao sát một số kênh truyền tin thôngdụng
Kênh nhị phân đối xứng là kênh có đầu vào và đầu ra gồm 2 kýhiệu 0 và 1, có ma trận nhiễu đối xứng:
11
p pp p
Giả sử nguồn tin đầu vào có phân bố xác suất ( ,1 )q q . Giả sửkênh truyền tin có tốc độ ký hiệu là 0n . Cần xác định tốc độtruyền tin, thông lượng kênh, hiệu quả sử dụng kênh. Chú ý làtốc độ truyền tin và hiệu quả sử dụng kênh là các đặc điểm củamột quá trình truyền tin còn thông lượng kênh là đặc điểm củakênh
Để có thể tính được tốc độ truyền tin, cần tính được lượng tintương hỗ và lượng tin tương hỗ trung bình. Theo liên hệ giữacác lượng tin, lượng tin tương hỗ trung bình có thể được tínhtheo công thức , cụ thể là:
60

( ; ) ( ) ( | )( ; ) ( ) ( | )( ; ) ( ) ( ) ( )
I X Y I X I X YI X Y I Y I Y XI X Y I X I Y I XY
Công thức thứ 2 có thể tính được lượng tin tương hỗ nhanhnhất.
Trước hết biểu diễn các thông số liên quan đến quá trìnhtruyền tin trong một bảng. Kên truyền tin được đặc trưng bởicác xác suất chuyển đổi, tức là các xác suất có điều kiện củađầu ra với đầu vào đã biết ( | )j ip y x .
P(Y|X)
Đầu vào 0 1
Đầura
0 p 1-p1 1-
pp
P(X) q 1-qSau đó tính các xác suất đồng thời. Từ các xác suất đồng thờitính được xác suất của đầu ra.
P(XY)
Đầu vào 0 1 P(Y)
Đầura
0 pq (1-p)(1-q)
2pq-p-q+1
1 (1-p)q p(1-q) p+q-2pqĐặt 2 1pq p q r . Lượng tin trung bình của đầu ra là:
2 2 2( ) ( ) (1 ) ( )I Y log r log r H r
Trong đó 2( )H r là hàm số xác định lượng tin trung bình củanguồn tin nhị phân với phân bố xác suất ,1r r . Lượng tin cóđiều kiện trung bình ( | )I Y X :
2 2
21 1
2 2 2 2
2 2 2
( | ) ( , ) ( ( | ))
(1 )(1 ) (1 ) (1 ) (1 ) (1 )log (1 )log (1 ) ( )
i j j iI Y X p x y log p y x
pqlog p p q log p p qlog p p q log pp p p p H p
Lượng tin tương hỗ trung bình là:
2 2( ; ) ( ) ( | ) ( ) ( )I X Y I Y I Y X H r H p
Tốc độ lập tin:61

0 2 2( ( ) ( ))outR n H r H p
Thông lượng kênh được xác định bằng tốc độ lập tin lớn nhất:
0 2 2max max( ( ) ( )outX qR n H rC H p
2( )H r đạt giá trị lớn nhất khi 1/2r hay
12 1 (2 1)(2 1) 02pq p q p q
Nếu 1/2p khi đó 1/2r , tốc độ truyền tin và thông lượng kênhđều bằng 0. Trường hợp này kênh là vô dụng
Nếu 1/2p khi đó 0 2(1 ( )C n H p . Hiệu quả sử dụng kênh2 2
2
( ) ( )1 ( )
H r H pHH p
Kênh xóa một ký hiệu là kênh truyền tin có 2 ký hiệu đầu vào0,1 và 3 ký hiệu đầu ra 0,1,E. Ký hiệu E được tạo ra ở đầu rađể báo là thiết bị thu không xác định được ký hiệu nào là kýhiệu đầu vào. Bảng các xác suất chuyển đổi của E có dạng:
P(Y|X)
Đầuvào
0 1
Đầura
0 p 01 0 PE 1-
p1-p
P(X) q 1-qBảng các xác suất đồng thời
P(XY) Đầuvào
0 1 P(Y)
Đầura
0 pq 0 pq1 0 p(1-q) p(1-
q)E (1-
p)q(1-p)(1-q)
1-p
P(X) q 1-qBảng các xác suất có điều kiện của đầu vào khi biết đầu ra:
P(X|Y)
Đầuvào
0 1
62

Đầura
0 1 01 0 1E q (1
-q)P(X) q 1-q
Lượng tin tương hỗ:
2 2 2 2
2
( ; ) ( ) ( | )(1 ) (1 ) (1 ) (1 )(1 ) (1 )
( )
I X Y I X I X Yqlog q q log q p qlog q p q log q
pH q
Tốc độ truyền tin
0 2( )outR n pH q
Thông lượng kênh
ax outXC m R p
Hiệu quả sử dụng kênh
outRH pC
63

Bài 6. Tốc độ lập tin nguồn và thông lượng kênhliên tục
I. Tốc độ lập tin nguồn liên tucBiểu diễn nguồn liên tục dừng, không nhớ Nguồn liên tục là một quátrình ngẫu nhiên liên tục. Để có thể nghiên cứu, xem xét nguồnliên tục cần rời rạc hóa nguồn liên tục. Với điều kiện nguồncó phổ hữu hạn, có thời gian tồn tại hữu hạn, nguồn liên tụccó thể được lấy mẫu với tần số 2 f tại các điểm { }, 1it i n
Nguồn liên tục được biểu diễn bằng tập hợp các thể hiện, mỗithể hiện là một hàm ()x t theo thời gian, được đặc trưng bởi n
giá trị tức thời { }, 1ix i n , được đặc trưng bởi phân bố xác suấtđồng thời 1 2( , , )np x x x , trong đó với nguồn dừng, phân bố xác suấtnày không phụ thuộc thời gian
( ) ( )i it tp x p x
Để đánh giá chất lượng thông tin của một nguồn tin liên tục,cần có các tiêu chí đánh giá như tốc độ lập tin, lượng tintrung bình. Tuy nhiên, các khằng định sau luôn đúng với nguồntin liên tục
- Tại mỗi một thời điểm, giá trị của nguồn liên tục là mộtbiến ngẫu nhiên liên tục có thể nhận vô số giá trị, cácgiá trị này có xác suất xuất hiện cực nhỏ, do đó có lượngtin lớn vô hạn
- Số lượng các giá trị mà nguồn tin có thể sinh ra trongmột đơn vi thời gian là vô hạn.
Như vậy lượng tin vô hạn của nguồn liên tục là vô hạn. Nóicách khác, xác suất để có thể có lại được một thể hiện củanguồn liên tục là cực nhỏ. Như vậy việc định nghĩa lượng tin,lượng tin trung bình, tốc độ lập tin, thông lượng tin không cóý nghĩa vật lý với kênh liên tục.
64

Tuy nhiên, hầu hết các kênh truyền tin liên tục đều được sửdụng để truyền tải các thông tin rời ra. Do đó vẫn cần có mộtđộ đo, cho dù không có ý nghĩa vaantj lý, nhưng vẫn có khảnăng sử dụng để so sánh các kênh truyền tin liên tục với nhauvề khả năng truyền các thông tin rời rạc.vấn đề
Tốc độ lập tin của nguồn tin rời rạc được tính theo côngthức
( )oR n I X
Lượng tin của một nguồn tin rời rạc được tính theo côngthức:
21
( ) ( )log ( ( ))( / )m
i iI X p x p x bit kh
Với các nguồn tin công thức trên có thể được mở rộng bằng:
2( ) ( log ( )I X p x x dx
Giá trị nhỏ nhất của lượng tin là 0. Lượng tin của nguồn tinliên tục bằng 0 khi nguồn phát duy nhất 1 giá trị.
Giá trị lớn nhất của nguồn tin liên tục phụ thuộc vào tínhchất của nguồn tin. Nếu tồn tại các giới hạn trên và dưới củanguồn tin, nguồn tin được gọi là nguồn có công suất cực đạihữu hạn, có lượng tin trung bình lớn nhất khi nguồn tin cóphân bố đều.. Nếu không có cận trên hoặc cận dưới, nguồn tinđược gọi là có công suất trung bình hữu hạn và có lượng tintrung bình lớn nhất khi nguồn có phân bố chuẩn Gauss
Lượng tin lớn nhất của nguồn có công suất cực đại hữu hạn:
max
min
2
2
( ) ( )log ( )
1log ( )
x
x
I X p x p x dx
bitb a
Có thể thấy mặc dù có ý nghĩa vật lý, nhưng lượng tin trungbình có thể dùng để so sánh các nguồn tin liên tục. Trong
65

trường hợp này, nguồn tin nào có biên độ dao động của tín hiệulớn hơn sẽ có lượng tin lớn hơn.
Với lượng tin của nguồn có công suất trung bình hữu hạn avP , 22 ( ) avx p x dx P
,
lượng tin trung bình lớn nhất có giá trị khi nguồn có phân bốchuẩn Gauss. Hàm mật ðộ phân bố xác suất của nguồn có dạng:
2( )1( )2
xx m
av
p x eP
Lượng tin lớn nhất sẽ là
2
2
( ) ( ) ( )[ ln 2 ]21 ( ) ln 2 ( )21 ln 2 ln 22
max avav
avav
av av
xI X I X p x P dxP
x p x dx P p x dxP
P eP
Tốc độ lập tin của nguồn
0 ( ) 2 ( )R n H X fH X
Chú ý là khái niệm tốc độ ký hiệu của nguồn tin rời rạc đãđược thay thế bằng khái niệm 2 f . Tốc độ ký hiệu của nguồncàng lớn, tương ứng với việc tốc độ thay đổi tín hiệu càngnhanh, hay nói cách khác, tần số của tín hiệu càng lớn. Vớimột số nguồn tin trong khi điều chế tần số tín hiệu bị thayđổi, để phản ánh tần số tín hiệu mang thông tin không thể sửdụng tần số tuyệt đối, do đó đại lượng băng thông tín hiệu 2 f
được sử dụng.
Tương tự như lượng tin trung bình của nguồn tin, với 2 nguồntin có thể mở rộng các khai niệm lượng tin trung bình đồngthời, có điều kiện, tương hỗ
Lượng tin đồng thời
( , ) ( , )log ( , )I X Y p x y p x y
66

Lượng tin có điều kiện
( | ) ( , )log ( | )
( | ) ( , )log ( | )
I X Y p x y p x y
I Y X p x y p y x
Lượng tin tương hỗ
( | )( ; ) ( , )log ( )p x yI X Y p x y dxdy
p x
Quan hệ giữa các lượng tin vẫn được bảo toàn như theo III -8: Quan hệ giữa các lượng tin trung bình và công thức .
Cũng tương tự như nguồn tin và kênh tin rời rạc, với nguồn tinvà kênh tin liên tục, các khái niệm entropy đồng thời và cóđiều kiện cũng có độ đo giống như lượng tin. Các quan hệ giữaentropy đồng thời, có điều kiện với lượng tin tương hỗ vẫntuân theo III -8: Quan hệ giữa các lượng tin trung bình vàcông thức .
Như vậy, các khái niệm tốc độ lập tin, lượng tin trung bình,entropy đồng thời, entropy có điều kiện của nguồn tin liên tụclà các khái niệm mở rộng từ các khái niệm tương ứng của nguồntin rời rạc, không có ý nghĩa vật lý tuy nhiên có thể dùng đểso sánh các nguồn tin liên tục với nhau.
II. Thông lượng kênh liên tụcThông lượng kênh liên tục được tính bằng tốc độ truyền thôngtin lớn nhất truyền qua kênh. Tốc độ truyền tin được tính bằngcông thức:
2 ( ; )outR fI X Y
Do đó thông lượng kênh được tính bằng công thức:
max 2 max ( ; )outX XC R f I X Y
67

Bài toán tính toán thông lượng kênh là rất phức tạp. Ở đâychúng ta chỉ xem xét một ví dụ đơn giản. Xét kênh truyền tincó nhiễu cộng. Tín hiệu đầu ra là
() () (), , ,y t x t n t x X y Y n N
giả thiết X và N độc lập thống kê, các nguồn tin đều có côngsuất trung bình hữu hạn. Kênh truyền tin này tuy đơn giảnnhưng có thể phản ánh rất nhiều trường hợp của các kênh truyềntin liên tục trong thực tế.
Vậy
( , ) ( , ) ( , ) ( ) ( )I X Y I X X N I X N I X I N
Mặt khác
( , ) ( ) ( | )I X Y I X I Y X
Vậy ( ) ( | )I N I Y X
Tốc độ lập tin
0[ ( ) ( | )] 2 [ ( ) ( )]R n I Y I Y X f I Y I N
Thông lượng kênh bằng tốc độ lập tin cực đại đầu ra. Cần có( )I Y cực đại để có thông lượng cực đại do đó Y có phân bố
chuẩn. Nhiễu có quá trình phân bố chuẩn, vậy X phải có quátrình phân bố chuẩn. Khi đó
( ) ( ) ln 2 ( ), ( ) ln 2
2 ( ( ) ( )) (1 )max X N N
Xmax
N
I Y I Y e P P I N ePPC R f I Y I N fP
Đây là công thức Shannon cho kênh liên tục. Muốn tăng thônglượng của kênh cần tăng giải thông f hoặc tăng công suất tínhiệu. Tuy nhiên, giải thông không thể tăng vô hạn. Khi giảithông tăng, công suất nhiễu cũng tăng theo
20NP fN
Khi đó
68

22 0log (1 )SPC f N
f
Giới hạn của thông lượng
22 20 0
lim ( ) log 1.443X Xf
P PC eN N
Gọi là giới hạn Shannon cho kênh liên tục. Các hệ thống truyềntin trong thực tế còn cách rất xa giới hạn trên.
69

CHƯƠNG IV. MÃ HIỆU
Bài 7. Cơ sở lý thuyết của mã hiệu
I. Khái niệm mã hiệuQuá trình xử lí thông tin thường bao gồm các giai đoạn:
- Thu thập các thông tin từ một nguồn tin nguyên thủy
- Biến đổi nguồn tin nguyên thủy cho phù hợp với các quátrình xử lí thành các nguồn tin trung gian khác
- Biến đổi ngược từ các nguồn tin thành nguồn tin có dạngban đầu
Trong suốt quá trình biến đổi của thông tin, luôn luôn cầnbiểu diễn thông tin dưới một hình thức nào đó. Để có thể biểudiễn thông tin, ngoài việc phải có môi trường vật lý, còn cầncó các quy tắc để biểu diễn thông tin. Các qui tắc này cầnđược thống nhất giữa các bộ phận trong quá trình xử lý thôngtin. Chương 1 đã đề cập đến phép biến đổi các nguồn tin nóichung sử dụng các qui tắc này. Phép biến đổi được gọi là phépmã hóa theo nghĩa rộng, các qui tắc biến đổi được gọi chung làmã. Ví dụ về mã có thể liệt kê: mã NRZ, Manchester, ....
Trong các hệ thống xử lý thông tin số, các mạch điện chỉ cóthể lưu trữ các ký hiệu rời rạc, thông thường là 2 ký hiệu 0và 1. Do đó để có thể đưa vào xử lý, thông tin cần được biểudiễn bằng các ký hiệu số. Các qui tắc biểu diễn thông tin bằngcác ký hiệu số gọi là mã hiệu. Quá trình biến đổi nguồn tinban đầu thành nguồn tin sử dụng các ký hiệu số gọi là phép mãhóa theo nghĩa hẹp. Quá trình biến đổi nguồn tin sử dụng cácký hiệu số thành nguồn tin ban đầu gọi là quá trình giải mã.Về nguyên tắc quá trình mã hóa và quá trình giải mã đều là cácphép mã hóa, tuy nhiên trong trường hợp biểu diễn thông tinbằng ký hiệu số 2 quá trình này có sự khác nhau cơ bản.
70

Quá trình mã hóa được thực hiện khi thiết bị mã hóa nhận cácký hiệu nguồn và biến đổi thành các chuỗi ký hiệu số. Thôngthường số lượng các ký hiệu trong bảng ký hiệu của nguồn tinlớn hơn nhiều so với số lượng các ký hiệu số sử dụng. Do đómỗi ký hiệu nguồn được ánh xạ với một chuỗi ký hiệu số. Thiếtbị mã hóa cần có bảng mã hóa lưu trữ các ánh xạ này. Quá trìnhmã hóa là quá trình ánh xạ các ký hiệu nguồn thành các chuỗiký hiệu số và ghép lại với nhau.
Quá trình giải mã xảy ra theo trình tự ngược lại. Chuỗi kýhiệu số nhận được sẽ được chia thành các chuỗi ký hiệu con,sau đó các chuỗi ký hiệu con sẽ được ánh xạ theo bảng ánh xạđể trở thành ký hiệu nguồn. Sự khác biệt nằm ở chỗ: quá trìnhghép các chuỗi ký hiệu số thành một chuỗi dài hơn là quá trìnhhiển nhiên, còn quá trình ngược lại, phân táchchuỗi ký hiệu sốthành các chuỗi ký hiệu con có thể có nhiều lời giải. Trườnghợp có nhiều lời giải, mã hiệu được gọi là không phân táchđược. Nếu bài toán phân tách luôn luôn chỉ có một lời giải, mãhiệu được gọi là phân tách được.
Để có thể nghiên cứu sâu hơn về mã hiệu cần có các định nghĩahình thức hơn về cách thức xây dựng mã hiệu cũng như xác địnhtính phân tách được của mã hiệu.
II. Thành phần của mã hiệu Mã hiệu gồm một tập hữu hạn các ký hiệu số, gọi là dấu mã,hay ký hiệu mã. Tập hợp một chuỗi nào đó các dấu mã gọi là tổhợp mã. Trong tập hợp tất cả các tổ hợp mã,
Một tập hợp các tổ hợp mã được xây dựng theo một luật nào đó,gọi là tổ hợp mã có thể (hợp lệ). Luật này thường được định rabởi hệ thống thông tin trung gian. Giả sử thông tin nào đóđược truyền qua một đường truyền quay số theo 8 bit, thì tạiđầu ra, cho dù quá trình truyền tin có lỗi hay không có lỗi,luôn luôn thu được các chuỗi ký hiệu có chiều dài 8 bít.
Trong bảnh ánh xạ, mỗi tin của nguồn nguyên thủy được ánh xạvào đúng một tổ hợp mã. Một tổ hợp mã như vậy gọi là từ mã.
71

Những tổ hợp có thể khác gọi là tổ hợp cấm (tổ hợp không sửdụng). Một dãy từ mã bất kỳ tạo thành một từ thông tin
Ví dụ: Trong mã BCD Binary Coded Decimal ðóng gói, nguồn tinnguyên thủy gồm các tin là các ký hiệu từ 0 9 . Để thuận tiênhơn cho việc biểu diễn các số thập phân trong máy tính màkhông cần phải thực hiện thuật toán chuyển cơ số, mã BCD chophép biểu diễn trực tiếp các chữ số thập phân bằng các chữ sốnhị phân, sử dụng các từ mã có chiều dài 4. Tổ hợp mã có thểlà một chuỗi ký hiệu nhị phân bất kỳ, tuy nhiên tổ hợp mã hợplệ chỉ bao gồm các tổ hợp mã có chiều dài 4. Có tất cả 16 tổhợp mã như vậy. Khi ánh xạ các tổ hợp mã này với các ký hiệunguồn, có 10 tổ hợp mã (ví dụ 0000-1001) tương ứng với 10 kýhiệu nguồn được gọi là từ mã, còn lại 6 tổ hợp ,ã (1010 đến1011) không tương ứng với ký hiệu nguồn nào cả, gọi là tổ hợpmã bị cấm. Khi mã hóa một chuỗi ký hiệu nguồn, ví dụ 2011 khiđó chúng ta có chuỗi từ mã 0010, 0000, 0001, 0001 tạo thành từthông tin 0010000000010001.
Bang 3: Thành phần của mã BCD
Ký hiệunguồn
Tổ hợp mã hợp lệ
0 0000
Các từ mã
1 00012 00103 00114 01005 01016 01107 01118 10009 1001
1010
Tổ hợp mã bị cấm
10111100110111101111
72

III.Thông số của mã hiệuGiả sử nguồn tin ban đầu gồm n ký hiệu 1 2, , , nx x x với các xácsuất tương ứng. Số lượng ký hiệu số trong bảng ký hiệu gọi làcơ số. Số lượng ký hiệu số sử dụng trong mỗi từ mã được gọilà chiều dài của từ mã. Nếu các từ mã có chiều dài bằng nhau,mã hiệu được gọi là mã đều. Nếu không, mã hiệu gọi là mã khôngđều và có chiều dài trung bình của từ mã được tính bằng côngthức:
1( )
L
i ii
n p x n
Ký hiệu L là tổng số từ mã. M là số các tổ hợp mã hợp lệ. NếuL M , mã hiệu gọi là mã đều, nếu L M mã hiệu gọi là mã vơi.R M L : số các tổ hợp bị cấm (không sử dụng). Khi chuyển mộttừ mã qua một kênh truyền tin, luôn luôn thu được một tổ hợpmã hợp lệ. Nếu thu được một tổ hợp bị cấm, quá trình truyềntin đã có lỗi. Nếu thu được một từ mã. Nếu thu được một từ mã,có thể quá trình truyền tin không có lỗi hoặc có lỗi xảy ra
biến một từ mã thành một từ mã khác. Tỷ lệ RM còn được sử dụng
để đánh gái khả năng phát hiện lỗi của mã hiệu.
Để thuận tiện cho việc tìm kiếm các từ mã trong quá trình thựchiện mã hóa và giải mã mỗi từ mã được gán cho một trọng số.Trọng số trực quan nhất của các từ mã là trọng số hệ đếm vịtrí.
Mỗi ký hiệu được gán cho một giá trị gọi là giá trị riêng haytrị của ký hiệu. Ví dụ m ký hiệu có thể được gán các trịtương ứng là 0,1,2 1m . Chỉ số vị trí là số thứ tự của mỗi kýhiệu trong từ mã. Ví dụ: đánh số từ 0, từ phải qua trái.Trọng số vị trí kw : hệ số nhân của từng vị trí ký hiệu k. Vídụ: trong hệ đếm cơ số 10, trọng số của vị trí đầu tiên là 1,thứ 2 là 10, 100, ..... Trọng số (giá trị) của từ mã được tínhbằng công thức:
1(w)
n
k kk
P a w
73

Trong đó 1 2w ... na a a là từ mã, kw là trọng số của vị trí thứ k.
Trong hệ đếm cơ số m 1
0(w)
nk
kk
P a m
Trọng số Hamming của các từ mã được đo bằng số lượng các chữsố khác 0:
( ) |{ 0}|iH w a
Khoảng cách giữa hai từ mã có thể đo bằng nhiều độ đo khoảngcách khác nhau. Có thể đo bằng khoảng cách Euclide, có thể đobằng hiệu giữa hai trọng số, có thể sử dụng một độ đo địnhnghĩa riêng. Khoảng cách Hamming giữa hai từ mã được đo bằngsố vị trí khác nhau giữa 2 từ mã đó:
1 2 1 2( , ) |{ () ()}|HD w w w i w i
Khoảng cách Hamming phản ánh sự khác nhau giữa từ mã và tổ hợpmã nhận được sau khi truyền qua kênh truyền tin. Nếu kênhtruyền tin tin cậy, số lượng bít bị thay đổi nhỏ, khoảng cáchHamming nhỏ. Nếu kênh truyền tin không tin cậy, số lượng bítbị thay đổi lớn, khoảng cách Hamming lớn. Để đảm bảo phát hiệnđược lỗi, phải đảm bảo là khoảng cách giữa các từ mã phải lớnhơn khoảng cách có thể giữa từ mã và tổ hợp mã lỗi tương ứng:
D d
Để sửa được lỗi, các tổ hợp mã bị lỗi của các từ mã khác nhauphải khác nhau, do đó các hình tròn bán kính d phải rời nhau.Do đó:
2D d
Hàm cấu trúc của mã hiệu cho biết phân bố của các từ mã theođộ dài
( ) | |}|{ i iG n w n n
74

Bài 8. Điều kiện để phân tách mã phân táchđược
I. Quá trình giai mã và tính phân tách đượcTính phân tách được Mã hiệu được gọi là phân tách được nếu tấtcả các từ thông tin chỉ có một cách phân tách duy nhất thànhcác từ mã.
Định nghĩa như trên đảm bảo quá trình giải mã luôn luôn có mộtnghiệm duy nhất. Tuy nhiên, rất khó để có thể xác định một mãhiệu có tính phân tách được hay không dựa vào việc kiểm tratất cả các từ thông tin. Đồng thời, việc mã hiệu có sử dụngđược hay không không chỉ phụ thuộc vào tính phân tách được, màcòn phụ thuộc vào việc thời gian phân tách mã có chấp nhậnđược hay không. Để thực hiện được mục đích này, cần phân tíchkỹ quá trình giải mã.
Giả sử một chuỗi ký hiệu nguồn đã được mã hóa thành một từthông tin và gửi đi qua kênh truyền tin. Tại nơi nhận, quátrình giải mã được diễn ra như sau:
- Bộ phận thu tin nhận lần lượt từng dấu ký hiệu mã, ghitạm thời vào bộ nhớ đệm. Nội dung bộ nhớ đệm sẽ được xửlý ở các công đoạn tiếp theo.
- Kiểm tra và tách chuỗi ký hiệu mã thu được thành các từmã nếu có thể
- Chuyển đổi các từ mã thành các ký hiệu của nguồn tin banđầu. Xóa các từ mã đã được giải mã khỏi bộ nhớ đệm. Tiếptục nhận các ký hiệu mã.
- Nếu chưa giải mã được, tiếp tục nhận thêm các ký hiệu mã.
Ở bước 2 bộ phận giải mã cần giải mã bộ nhớ đệm. Nếu chỉ cómột khả năng thỏa mãn khi đó nội dung bộ nhớ đệm có thể giảimã được. Nếu còn hơn 1 khả năng, khi đó cần nhận thêm các kýhiệu mã để loại bỏ một số trong các khả năng còn lại.
75

Cần chú ý là nội dung bộ nhớ đệm không bắt buộc là một từthông tin, mà chỉ là một phần đầu của từ thông tin. Do đó,việc giải mã cần cho một nghiệm duy nhất trong 2 trường hợpsau:
- Nội dung bộ nhớ đệm là một chuỗi từ mã và một phần đầucủa từ mã
- Nội dung bộ nhớ đệm là một chuỗi từ mã và chứa ký hiệucuối cùng của từ thông tin.
Để có thể giải mã được, cần thiết phải lưu trữ một số ký hiệutrong bộ nhớ đệm. Điều này cũng có nghĩa là thời gian từ lúcnhận được một ký hiệu mã cho đến khi từ mã chứa ký hiệu mã nàyđược giải mã phụ thuộc vào kích thước của nội dung bộ nhớ đệm.Do đó kích thước bộ nhớ đệm được gọi là độ trễ giải mã.
II. Bang thử mã Trên cơ sở các khảo sát một quá trình giải mã nói trên,mã hiệu sẽ được xem xét tổng quát với tất cả các quá trìnhgiải mã có thể.
Khi giải mã, thời điểm đầu tiên bộ phận giải mã dừng lại đểxem xét thực sự để giải mã là thời điểm khi nội dung bộ nhớđệm bằng một từ mã 1w . Sẽ có 2 khả năng xảy ra: (i) nếu khôngcó từ mã 2w nào có 1w là phần đầu thì khi đó có thể tiến hànhgiải mã;(ii) nếu có một từ mã 2w nhận 1w là phần đầu, ký hiệu
1 2pw w thì chưa giải mã được do vẫn tồn tại 2 cách phân táchnội dung bộ nhớ đệm. Bộ phận giải mã tiếp tục nhận các ký hiệumã.
Nếu trong quá trình nhận các ký hiệu mã, nếu nội dung bộ nhớđệm không trùng với phần đầu của 2w , hoặc phần còn lại của bộnhớ đệm sau khi bỏ đi 1w không phải là phần đầu của một từ mã,một trong hai trường hợp nói trên bị loại, bộ phận giải mã cóthể tiến hành giải mã. Nếu không, thời điểm tiếp theo bộ phậngiải mã cần lựa chọn là thời điểm nội dung bộ nhớ đệm trùngvới 2w hoặc chuỗi từ mã 1 3,w w .
76

Tại thời điểm này có 2 khả năng giải mã: (i) chuỗi từ mã gồmtừ mã 2w ; (ii) chuỗi từ mã gồm một từ mã 1w và phần đầu của mộttừ mã 3w nào đó. Như vậy điều kiện để có thể tồn tại 2 trườnghợp tại thời điểm này là phần còn lại của bộ nhớ đệm ( 2w ) saukhi đã bỏ đi phần đầu trùng với 1w , ký hiệu 2 1pw w là phần đầucủa 3w .
2 1 3p pw w w
Trường hợp nội dung bộ nhớ đệm trùng với chuỗi từ mã 1 3w w , điềukiện để cả hai trường hợp còn lại là:
23 1w pp w w
Như vậy, đến thời điểm này việc phân tích được hay khônghoàn toàn phụ thuộc vào 2 1pw w . Nói cách khác, nếu có 2 từ mã
2 1', 'w w mà 2 1 2 1' 'p pw w w w , thì kết quả giải mã được hay khôngđều giống nhau.
Quá trình giải mã sẽ tiếp tục như vậy cho đến khi nào mộttrong hai điều kiện giải mã được thỏa mãn.
Trên cơ sở phân tích hình thức quá trình giải mã, có thể lậpbảng theo dõi để từ đó kiểm tra được tính phân tách của mã.
Bảng này sẽ ghi lại tất cả các khả năng có thể của quá trìnhgiải mã tại các thời điểm mà bộ phận giải mã cần cân nhắc tínhgiải mã được của bộ nhớ đệm.
- Cột 1 của bảng sẽ bao gồm tất cả các từ mã
- Cột 2 của bảng sẽ bao gồm tất cả các tổ hợp mã c thỏamãn:
1 2 2 1w ,w | w wpc
- Cột 3 của bảng sẽ được xây dựng từ các phần tử của cột 2.Với mỗi phần tử c của cột 2, phần tử c’ của cột 3 đượcxác định theo 2 cách
w | ' w pc c
77

Hoặc:
w | ' wpc c
Cột 4 được xây dựng tương tự dựa trên cột 3. Cột 1n được xâydựng từ cột n
Bảng thử mã tiếp tục được xây dựng cho đến khi gặp một trongcác trường hợp sau đây:
Thu một cột rỗng Nếu các bước trên không tìm được tổ hợp mãnào phù hợp, bảng thử mã sẽ có một cột rỗng. Hiển nhiên cáccột tiếp theo cũng rỗng. Có thể khẳng định quá trình giải mãđến một số từ mã nào đó chắc chắn sẽ cho nghiệm duy nhất.Trường hợp này mã hiệu phân tách được, độ trễ giải mã hữu hạn.
Thu một từ mã Nếu một tổ hợp mã thu được là từ mã, điều này cónghĩa là tồn tại một từ thông tin có 2 cách phân tách khácnhau. Có thể khẳng định mã hiệu không có tính phân tách.
Thu 2 cột bằng nhau Nếu không rơi vào 2 trường hợp trên, bảngthử mã sẽ có vô số cột. Chú ý là chiều dài các tổ hợp mã trongmỗi cột là hữu hạn, do đó số lượng các tổ hợp của các tổ hợpmã cũng là hữu hạn. Hay nói cách khác, giá trị có thể của cáccột là hữu hạn. Trường hợp bảng thử mã có vô số cột, chắc chắnđến một lúc nào đó có 2 cột có cùng các tổ hợp mã. Khi đó cáccột tiếp theo của 2 cột này cũng có các tổ hợp mã giống nhau:bảng thử mã là tuần hoàn. Trường hợp này có thể chắc chắn làmã hiệu phân tách được, tuy nhiên độ trễ giải mã vô hạn. Cónhững từ thông tin chỉ được giải mã khi nhận được ký hiệu cuốicùng.
Ví dụ về bang thử mã
a. 01,0111, 010, 11101
Cột 1 Cột 2 Cột 3 Cột 401 11 1 11010111 0 111 01-từ mã010 1011101 101
78

Do xuất hiện từ mã ở cột 4 nên mã hiệu là mã không phân táchđược. Thật vậy, từ thông tin 01,0111,01 có thể phân tách mộtcách khác thành chuỗi từ mã 010,11101, do đó mã hiệu là khôngphân tách được.
b. 0, 01, 011, 111
Cột 1 Cột 2 Cột 30 11 101 1 11011111
Cột 2 và cột 3 giống nhau do đó mã hiệu là phân táchđược, độ trễ giải mã vô hạn. Thật vậy, từ thông tin01......1 chỉ có thể được giải mã khi nhận được ký hiệu 1cuối cùng.
c. 01,110,111,0100,0110
Cột 1 Cột 2 Cột 301 10110 0011101000110
Cột thứ 3 rỗng do đó mã hiệu là mã phân tách được với độtrễ giải mã hữu hạn
III.Mã có tính prefix (tiền tố)Nếu bộ mã không có từ mã nào là phần đầu của một bộ mã khác,cột thứ 2 của bảng thử mã rỗng, bộ mã là mã phân tách được vớiđộ trễ giải mã xấp xỉ bằng chiều dài từ mã. Bộ mã như vậy gọilà mã có tính prefix hay đơn giản hơn là mã prefix. Mã prefixcòn được gọi là mã nhanh, mã tức thời, .....
Các thao tác sau đây có thể phá hủy tính prefix của mã hiệu:
- Thu ngắn một từ mã: khi một từ mã bị thu ngắn, nó có thểtrở thành phần đầu của từ mã khác.
- Bổ sung thêm một từ mã: từ mã mới có thể nhận các từ mãđã có là phần đầu.
79

Cả hai thao tác này đều là các thao tác giảm chiều dài trungbình của các từ mã, tăng hiệu suất mã. Như vậy để có được tínhprefix, cần hy sinh một phần hiệu suất. Xem xét kỹ hơn cấutrúc chiều dài của các từ mã.
Hàm cấu trúc của mã prefix
2
1
1 1
1
(1)(2) (1)
( ) ( ) ( )
1 ( )
n nn n j n n j
j j
nj
j
G mG m mG
G n m m G j m m G j
hay
m G j
dấu bằng xảy ra khi ( ) jip x m j .
Ngược lại, nếu dãy số ,1jn j k thỏa mãn
11 j
nn
jm
Thì sẽ tồn tại bộ mã prefix với cơ số m với độ dài của các từmã là jn . Bất đẳng thức này còn gọi là bất đẳng thức Kraft-McMillan.
Có thể thấy để đảm bảo tính chất prefix của mã hiệu, cần hysinh hiệu quả của mã hiệu. Với một mã hiệu có tính prefix, bấtcứ thao tác nào làm tăng hiệu quả mã hiệu như: thu ngắn từ mã,bổ sung từ mã, đều có thể làm mất tính prefix của mã hiệu.
Tuy nhiên, chứng minh sau đây sẽ cho thấy việc áp tính prefixvào mã hiệu không làm thay đổi mã hiêu.
Chúng ta sẽ xem xét bất đẳng thức McMillan với mã phân táchđược. Nâng vế phải của bất đẳng thức lên lũy thừa bậc N
80

21
1 21 1 1 1
min( (
(
)
ax
)
( )
.... ...
( )
ij i iiN
N
Nn n n nnn n n
j i i i
mj
A j
A j
m m m m
A j m
Trong đó ( )A j là số các từ thông tin có chiều dài j . Do các từ thông tin là khác nhau, nêu không có 2 từ thông tin nào ánh xạvào một tổ hợp mã có chiều dài j. Vậy số lượng các từ thông tin có chiều dài j nhỏ hơn số lượng các tổ hợp mã có chiều dàij jm . Từ đó ta có :
21
1 2
ax( ( )1
ax1 1 1
min( ( )) min( ( )
(
)
( )
.... ...
( ) . ax
ij i iiN
N
Nn n n nnn n n
j i i i
m mj j j
A j A j
A j A j
m m m m
A j m m m N m
Trong đó axm là chiều dài lớn nhất của các từ mã. Từ bất đẳngthức trên có thể suy ra :
11j
nn
jm
Theo bất đẳng thức Kraft, tồn tại một mã hiệu có tính prefixcó các chiều dài từ mã là jn . Như vậy bất cứ mã phân tách đượcnào cũng có một mã có tính prefix tương đương. Điều này lýgiải tại sao mã phân tách được không có tính prefix không đượcsử dụng, mà chỉ có mã prefix được dùng trong thực tế.
IV. Các phương pháp phân tách mã thường dùngTrong thực tế, để đơn giản quá trình và thiết bị giải mã, cácphương pháp phân tách mã sau đây thường được sử dụng :
- Phân tách mã sử dụng mã có tính prefix không đều. Phươngpháp này sử dụng các từ mã có chiều dài khác nhau để mãhóa các ký hiệu nguồn, do đó có ưu điểm là có thể thựchiện việc nén dữ liệu bằng các hoán đổi các từ mã cóchiều dài khác nhau với các ký hiệu nguồn có xác suấtxuất hiện khác nhau. Nhược điểm của phương pháp này làviệc giải mã một ký hiệu nguồn phụ thuộc vào việc giải mã
81

ký hiệu trước đó. Nếu vì một lý do nào đó ký hiệu trướcbị lỗi không giải mã được, bộ phận giải mã sẽ không xácđịnh được điểm đầu của từ mã tiếp theo, do đó toàn bộ quátrình truyền tin từ vị trí lỗi là không thực hiện được.Đây là lý do tại sao phương pháp này thường được sử dụngđể lưu trữ cục bộ (do tỷ suất lỗi thấp) và không đượcdùng để truyền tin trực tiếp.
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Từ m ã 1 Từ m ã 2 Từ m ã 3 Từ m ã 4 Từ m ã 5
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Từ m ã 1 Từ m ã 2 Từ m ã 3
IV-9 : Mã phân tách không đều: a. Không có lỗi; b. có lỗi
- Phân tách mã sử dụng mã đều. Sử dụng các từ mã có chiềudài bằng nhau, quá trình phân tách mã trở thành hiển nhiên.Nếu có lỗi xảy ra, vị trí đầu của từ mã tiếp theo vẫn được xácđịnh, không ảnh hưởng đến quá trình truyền tin. Mỗi lỗi xảy rachỉ tác động đến từ mã tương ứng, không tác động đến các từ mãkhác. Tuy nhiên các từ mã có chiều dài bằng nhau hạn chế việcnén dữ liệu, đồng thời các lỗi mất hoặc thừa bít (thường xảyra do sai số thời gian) sẽ không được phát hiện.
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Từ m ã 5Từ m ã 4Từ m ã 3Từ m ã 2Từ m ã 1
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Từ m ã 5Từ m ã 4Từ m ã 3Từ m ã 2Từ m ã 1
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Từ m ã 5Từ m ã 4Từ m ã 3Từ m ã 2Từ m ã 1
IV-10 : Phân tách mã bằng mã đều : a. không có lỗi, b. có lỗi mất từ mã, c. có lỗimất bit
- Phân tách mã sử dụng dấu phân tách. Trong hai phương pháptrên, vấn đề gặp phải là xác định ranh giới giữa các từ mã. Đểđảm bảo luôn luôn xác định được ranh giới giữa các từ mã, bổsung thêm một tổ hợp mã đặc biệt (dấu phân cách) vào cuối của
82

mỗi từ mã. Khi bộ phận giải mã đọc được tổ hợp mã đặc biệtnày, sẽ xác định được đâu là kết thúc của từ mã. Khó khăn màphương pháp này gặp phải là việc lựa chọn dấu phân cách cókích thước đủ nhỏ để không ảnh hưởng quá nhiều đến hiệu suấtmã, đồng thời không xảy ra tình trạng có dấu phân cách trongvùng dữ liệu của mỗi từ mã. Có 2 phương pháp xử lý :
o Mã hóa hai lần (mã hệ thống). Trong số các tổ hợp mãhợp lệ, dùng riêng một số tổ hợp mã làm dấu phântách.
o Tiền xử lý : trước khi nối dấu phân tách vào từ mã,tìm kiến tất cả các tổ hợp giống với dấu phân táchvà đổi thành các tổ hợp khác. Ví dụ trong chuẩnEthernet, các khung dữ liệu kết thúc bằng tổ hợp01111110. Trước khi nối dấu phân cách vào, tất cảcác tổ hợp 011111 trong dữ liệu của khung được đổithành 0111110. Tại bộ phận thu, sau khi đã loại dấuphân cách 01111110, các tổ hợp 0111110 được đổi về011111.
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Dấu phân tách 1
Từ m ã 1
Dấu phân tách 2
Từ m ã 2
0101010101010100000010111110101001010101010101010010101010101010101001010101010101010101010101010100001111011
Từ m ã 1
Dấu phân tách 2
Từ m ã 2
IV-11 : Mã có dấu phân tách
Cần chú ý là cả 3 phương pháp phân tách mã trên đây đều sửdụng mã có tính prefix.
83

Bài 9. Các phương pháp biểu diễn mã
I. Bang mãBang đối chiếu mã.
Bảng đối chiếu mã là cách trình bày đơn giản nhất, liệt kêtrong bảng những tin của nguồn và kèm theo là từ mă tương ứngvới nó. Bảng đối chiếu mã có ưu điểm là cho thấy cụ thể và tứcthời bản tin và từ mã của nó. Nhưng với những bộ mã lớn thìcồng kềnh và khuyết điểm chính là không cho phép thấy các tínhchất quan trọng của bộ mã. Ví dụ bộ đối chiếu mã trong bảngsau:
tin a1 a2 a3 a4 a5
từ mã 00 01 100 1010 1011
Trong một bảng đối chiếu mã, số thứ tự từ mã trong bộ mã là sốthứ tự người ta liệt kê từ mã.
Mặt toạ độ của mã.
Mặt toạ độ mã là một biểu diễn dựa trên hai thông số của từmã, thường là độ dài n và trọng số b để lập một mặt phẳng cóhai toạ độ, trên đó mỗi từ mã được biểu diễn bằng một điểm.Trọng số b của từ mã là tổng trọng số các kí hiệu trong từ mã.
1
0
nk
kk
b a m
với ka là giá trị riêng của kí hiệu thứ k trong từ mã kể từtrái sang phải, với mã nhị phân ka có hai giá trị 0 hoặc 1, klà số thứ tự của kí hiệu trong từ mã, m là cơ số của mã.
Ví dụ
Trọng số của từ mã nhị phân có 4 kí hiệu 1011 bằng:0 1 2 31 2 0 2 1 2 1 2 13b
84

Mỗi từ mã sẽ hoàn toàn xác định khi ta xác định được cặp (n,b) của nó. Như vậy mỗi từ mã được biểu diễn một cặp toạ độ (n,b) duy nhất. Điều này được thể hiện bằng định lý sau:
Định lý: không có hai từ mã mã hoá hai tin khác nhau của cùngmột bộ mã có chiều dài và trọng số bằng nhau.
Chứng minh: nếu hai từ mã có trọng số bằng nhau, 2 từ mã nàychỉ sai khác nhau một số ký hiệu đầu tiên. Tuy nhiên chiều dài2 từ mã bằng nhau. Vậy 2 từ mã trùng nhau.
II. Đồ hình mãCác phương pháp đồ hình sử dụng một đồ hình để biểu diễn mộtmã hiệu. Nó cho phép trình bày mã một cách ngắn gọn hơn bảngmã, đồng thời cho thấy rõ các tính chất quan trọng của mã hiệumột cách trực quan hơn.
Cây mã.
Là một đồ hình gồm các nút và các nhánh. Cao nhất của cây lànút gốc. Từ nút gốc phân ra m nhánh hoặc ít hơn.
Mỗi nút cuối (là nút kết thúc của nhánh đại biểu cho kí hiệucuối cùng của một từ mã) sẽ đại biểu cho một từ mã mà thứ tựcác trị kí hiệu mã là thứ tự các trị trên các nhánh đi từ nútgốc đến nút cuối qua các nút trung gian.
Có thể có những nút cuối mà không có nhánh nào đi ra từ nó, vàcũng có thể có những nút cuối của từ mã này là nút trung giancủa từ mã khác. Mã hiệu có nút cuối trùng với một nút trunggian của từ mã khác sẽ có đặc điểm là từ mã ngắn hơn là phầnđầu của từ mã dài hơn và nó không cho phép phân tách một chuỗimã bất kì thành một dãy duy nhất các từ mã.
Ví dụ cây mã cho bộ mã 00, 01, 100, 1010, 1011.
85

IV-12: Cây mã
Từ ví dụ thấy rằng nhìn vào cây mã ta biết cây mã có phải là đồng đều hay không đồng đều, loại mã đầy hay vơi. Cây mã trên thuộc loại mã không đồng đều.Đồ hình kết cấu.
Đồ hình kết cấu gồm những nút và những nhánh có hướng, đây làmột cách biểu diễn cây mã rút gọn. Một từ mã được biểu diễnbằng một vòng kín xuất phát từ nút gốc theo các nhánh có hướng(chiều mũi tên) qua các nút trung gian rồi về nút gốc. Mỗinhánh đại diện cho một trị của kí hiệu mã. Thứ tự các trị bắtđầu từ nút gốc là thứ tự các kí hiệu mã tính từ bên trái mỗitừ mã.
Ví dụ
IV-13: Đồ hình kết cấu mã
Trên đồ hình kết cấu, trị các nhánh được ghi ở đầu xuất phátcủa nhánh và phía bên trái, dấu V là dấu hoặc (hay là) cónghĩa là một nhánh có thể đại biểu cho trị bên trái hoặc trịbên phải của dấu V; các nút được đánh dấu theo thứ tự xa dầnnút gốc (số ghi trong vòng tròn của nút).
86

Đồ hình kết cấu không những dùng để mô tả bản thân mã mà còndùng để xét cách vận hành thiết bị mã hoá và giải mã như làmột đồ hình trạng thái của thiết bị.
III.Các phương pháp biểu diễn mã tổng quátPhương pháp hình học: các từ mã có độ dài n được biểu diễnbằng một vectơ hay một điểm (đầu mút của vectơ) trong khônggian n chiều. Bộ mã là một hệ điểm trong không gian đó.
Phưong pháp đại số: bộ mã được xem như một cấu trúc đại sốnhất định. Các loại mã sẽ được phân loại và nghiên cứu theocấu trúc đại số sử dụng để biểu diễn bộ mã.
IV. Mã hệ thốngMã hệ thống tổng quát
Mã hệ thống là một loại mã mà mỗi từ mã của nó được xây dựngbằng cách liên kết một số từ mã của bộ mã gốc.
Vì bộ mã gốc có tính phân tách nên bộ mã hệ thống cũng có tínhphân tách. Nếu bộ mã gốc có tính prefix thì bộ mã hệ thốngcũng có tính prefix.
Thông thường lấy một số từ mã của bộ mã gốc làm các tổ hợp tạothành phần đầu của từ mã hệ thống và gọi nó là các tổ hợp sơđẳng. Các tổ hợp còn lại của bộ mã gốc được sử dụng làm các tổhợp kết thúc của từ mã hệ thống và gọi nó là các tổ hợp cuôi.Từ mã của mã hệ thống được tạo ra bằng cách nối các tổ hợp sơđẳng lại với nhau và nối thêm một tổ hợp cuối.
Để biểu diễn mã hệ thống thường biểu diễn các tổ hợp sơ đẳngvà các tổ hợp cuối của nó rồi biểu diễn sự liên kết các tổ hợpnày để tạo thành từ mã. Cách biểu diễn thuận tiện là dùng đồhình kết cấu. Trong đồ hình kết cấu này, chỉ những tổ hợp sơđẳng mới kết thúc ở nút gốc, còn các tổ hợp cuối sẽ kết thúc ởmột nút kết thúc riêng. Từ mã của mã hệ thống sẽ là trình tựcác trị được biểu diễn bằng các nhánh đi từ nút gốc, có thểvòng qua nút gốc một số lần qua các đường đi khác nhau, rồiđến kết thúc ở một nút kết thúc.
87

Việc giải mã đối với mã hệ thống phải qua 2 bước.
Bước một là tách chuỗi kí hiệu nhận được thành chuỗi các tổhợp sơ đẳng và các tổ hợp cuối.
Bước hai là tìm các tổ hợp cuối và xác định điểm kết thúc mãtại đây.
Phương pháp biểu diễn mã hệ thống bằng đồ hình kết cấu: xuấtphát từ nút gốc theo mũi tên các nhánh một cách tuần tự, mỗikhi quay về gốc là kết thúc một tổ hợp sơ đẳng, và khi vàođường cụt là kết thúc tổ hợp cuối cùng, đồng thời kết thúc từmã hệ thống.
Mã hệ thống có tính prefix
Được xây dựng từ một bộ mã gốc có tính prefix bằng cách lấymột số từ mã của mã prefix gốc làm tổ hợp sơ đẳng và các từ mãcòn lại làm tổ hợp cuối. Ghép các tổ hợp sơ đẳng với nhau vànối một trong các tổ hợp cuối vào thành từ mã của mã mới gọilà mã hệ thống có tính prefix.
Ví dụ
Lấy bộ mã prefix 1, 00, 010, 011 làm gốc, trong đó các tổhợp : 1, 00, 010 là tổ hợp sơ đẳng còn 011 là tổ hợp cuối. Cáctừ mã được hình thành như sau đều có thể là từ mã của mã hệthống
1011, 11011, 00011, 100011, 010011, 01001011011
Khi giải mã phải qua hai bước như trên. Ví dụ khi nhận đượctin dưới dạng kí hiệu mã:
010011 010011 100011 01001011011 1011 11011 1011
Bước thứ nhất tách thành dãy:
010-011-010-011-1-00-011-010-010-1-1-011-1011-1-1-011-1-011
Bước thứ hai tách thành dãy tổ hợp mã hệ thống:
88

010011-010011-100011-01001011011-1011-11011-1011
CHƯƠNG V. MÃ HÓA NGUỒN
Bài 10. Mã hóa nguồn rời rạc dừng không nhớ
I. Cơ sở lý thuyết mã hóa nguồn rời rạcdừng không nhớ
Trong chương này, chúng ta chỉ xem xét các mã hiệu với cơ số2. Trường hợp cần thiết, các kết quả với cơ số 2 sẽ được mởrộng với các cơ số khác. Với nguồn rời rạc không nhớ sau thờigian st tạo ra một ký hiệu trong tập hữu hạn các ký hiệu ix ,
1,2,i L . Các ký hiệu có xác suất xuất hiện ( ), 1,2,iP x i L .Entropi cuả nguồn này là:
2 21
( ) ( )log ( ) logL
k kH X P x P x L
Dấu bằng xảy ra khi các ký hiệu có xác suất xảy ra bằng nhau.Lượng thông tin trung bình ứng với mỗi ký hiêu là ( )H X và tốcđộ thông tin là 0 ( )n H X .
Mã hóa với từ mã có độ dài cố định (mã hóa dùng mã đều)
Phương pháp: gán cho mỗi ký hiệu một từ mã. Do có L ký hiệunên để đảm bảo tính duy nhất cần số ký hiệu nhị phân tối thiểulà R với 2logR L khi L là luỹ thừa của 2. Nhận thấy 2log 1R L
khi L không phải là luỹ thừa của 2, trong đó x là phần nguyêncủa x. Kết luận: ( )R H X .
Đánh giá: Hiệu quả của phương pháp mã hoá nguồn rời rạc khôngnhớ xác định bởi tỷ số: ( )/H X R . Vậy khi L là luỹ thừa của haivà các ký hiệu là đẳng xác suất thì ( )H X R , khi đó hiệu quảmã hoá là 100%. Tuy nhiên khi L không phải là luỹ thừa của haithì R sai khác H(X) tối đa là một bit/ký hiệu. Khi 2log L >>1 thìphương pháp mã hoá này có hiệu quả cao. Ngược lại khi 2log L <<1,hiệu quả của phương pháp mã hoá với độ dài từ mã cố định cóthể nâng cao bằng cách mã hoá từng khối gồm J ký hiệu của
89

nguồn. Ðể mã hoá duy nhất ta cần từ mã và nếu gọi N là số kýhiệu mã được sử dụng để mã hoá nguồn thì 2( log )N J L .Gíá trịnguyên nhỏ nhất của N có thể chấp nhận được là 2log 1JN L
.Khi đó số ký hiệu mã trung bình ứng với một ký hiệu của nguồnlà /N J R . Như vậy độ không tối ưu của mã giảm xuống xấp xỉ1/J so với việc mã hoá riêng từng ký hiệu của nguồn. Khi J đủlớn, hiệu quả của phương pháp mã hoá này được đo bằng tỷ số
( )/J H X N rất gần tới đơn vị.
Các phương pháp trên không bị sai số vì ta mã hoá mỗi ký hiệuhay mỗi khối ký hiệu thành một từ mã duy nhất. Loại mã nay gọilà mã không nhiễu.
Giả sử ta muốn giảm R bằng cách bỏ đi điều kiện mã hoá làduy nhất. Ví dụ chỉ một phần trong L khối ký hiệu được mã hoáduy nhất,cụ thể hơn, giả sử 2 1N khối J ký hiệu có xác suấtxuất hiện lớn nhất được mã hoá duy nhất còn lại (2 1)J NL đượcmã hoá thành một từ mã duy nhất. Phương pháp mã hoá này gây raviệc giải mã sai đối với các khối có xác suất xuất hiệnthấp.Gọi eP là xác suất giải mã sai. Dựa trên phương pháp mãhoá này Shanon chứng minh định lý mã hoá nguồn sau:
Định lý mã hóa nguồn 1: Gọi X là một nguồn rời rạc không nhớcó entropi hữu hạn H(X).Các khối J ký hiệu của nguồn được mãhoá thành các từ mã nhị phân có độ dài N. Với mọi 0ò , xácsuất giải mã khối sai eP có thể nhỏ tuỳ ý nếu:
/ ( )R N J H X ò
với J tiến tới vô hạn. Ngược lại nếu ( )R H X ò thì eP dần tớiđơn vị khi J tiến tới vô hạn.
Chứng minh phần thuận
Coi tập hợp các chuỗi ký hiệu nguồn mà ( )| ( )|JI u H UJ
ò là các
chuỗi ký hiệu nguồn ánh xạ vào cùng một từ mã. Cần chứngminh:
90

- Xác suất xuất hiện của các từ mã nói trên có thể bé tùy ý
khi L lớn tùy ý (hiển nhiên, ( )lim ( )JJ
I u H UJ
)
- Các chuỗi ký hiệu còn lại có thể được mã hóa chính xác
với
( )NR H XJ
ò
Thật vậy, nếu gọi tập hợp các ký hiệu còn lại là T . Với mỗiJu T có
( ) ( )JI u H UJ
ò
( ( ) ) ( ( ) )
( )( ) ( )
2 ( ) 2
J
J H U J H UJ
I uH U H UJ
P u
ò ò
ò ò
Chú ý( ( ) )1 ( ) ( ( )) 2 J H U
T J TP T M min P u M ò
Có ( ( ) )2J H U
TM ò
Vậy nếu chọn chuỗi nhị phân có độ dài tối thiểu là ( ( ) )
2log 2 ( ( ) )J H UmN in J H U ò ò
sẽ có ánh xạ 1-1 giữa T và tập các từ mã N ký hiệu nhị phân.
Phép ánh xạ chung sẽ có sai số nhỏ tùy ý ( )| ( )|Je
I uP H UJ
ò
Chứng minh phần đao Chọn ( ( ) 2 )N J H U ò . Với một phép mã hóa bấtkỳ có
( ) ( ) 1eP T P T P , trong đó:
- ( )P T là xác suất để mỗi một chuỗi ký hiệu trong T có mộttừ mã
91

- ( )P T là xác suất để một chuỗi ký hiệu ngoài T có một từmã
- eP Xác suất lỗi (tồn tại chuỗi ký hiệu không có từ mã)
Tổng cộng có 2N từ mã, mỗi từ mã sẽ tương ứng với một từtrong T có xác suất nhỏ hơn ( ( ) )2 J H U ò , vậy xác suất để một từtrong T có một từ mã là
( ( ) 2 )( ( ) ) ( ( ) )2( ) 2 2 2 2J H UJ H U N J H U JP T òò ò ò
Chú ý lim ( ) 0J
P T
. Vậy 1lim eJP
.
Từ định lý này ta thấy số lượng ký hiệu nhị phân trung bình đểmã hoá nguồn rời rạc không nhớ với xác suất giải mã sai nhỏtuỳ bị chặn dưới bởi entropi ( )H X . Ngược lại, nếu ( )R H X thìxác suất giải mã sai tiến tới 100% khi J .
Trong cả hai trường hợp, để đạt được hiệu suất tiệm cận1, cần thực hiện việc mã hóa các ký hiệu nguồn theo từng khối.Kích thước các khối càng dài thì hiệu suất càng gần với 1. Tuynhiên, độ phức tạp của bài toán mã hóa và giải mã tỷ lệ vớilũy thừa của kích thước khối, nên không thể tăng tùy ý kíchthước khối.
Mã hóa với từ mã có độ dài thay đổi (mã không đều)
Trong nhiều hợp các ký hiệu của nguồn không cùng xác suât xuấthiện thì phép mã hoá với độ dài từ mã thay đổi có hiệu quả hơnso với phương pháp mã hoá trên.Ví dụ như mã Morse, các ký hiệucó tần suất xuất hiện nhiều hơn sẽ được gán với từ mã có độdài ngắn hơn và ngược lại: các ký hiệu có xác suất xuất hiệnnhỏ hơn sẽ được gán cho các từ mã có độ dài lớn hơn. Xuất pháttừ ý tưởng này, ta có thể sử dụng xác suất xuất hiện các kýhiệu khác nhau của nguồn trong việc lựa chọn các từ mã dùng đểmã hoá các ký hiệu của nguồn. Loại mã hoá này gọi là mã hoáentropi.
Mục tiêu cơ bản của chúng ta là xây dựng một phương pháp mãhoá có tính hệ thống để tạo ra các từ mã có độ dài thay
92

đổi,giải mã duy nhất và có hiệu quả theo số lượng trung bìnhcác ký hiệu nhị phân ứng với một ký hiệu của nguồn, được địnhnghĩa là:
1( )
L
k kR n P x
Trong đó kx là ký hiệu thứ k của nguồnvà kn là số ký hiệu nhịphân ứng vớI từ mã của kx . Điều kiện tồn tại một mã có tínhprefix được xác định bởi bất đẳng thức Kraft. Bất đẳng thức Kraft:
Điều kiện cần và đủ để tồn tại mã nhị phân với các từ mã cóđộ dài 1 2 Ln n ... n thoả mãn điều kiện prefix là:
12 1k
Ln
Định lý mã hóa nguồn thứ hai của Shannon: Gọi X là một nguồnrời rạc không nhớ với entropi hữu hạn H(X) bit với các kýhiệu. ,1kx k L ,với các xác suất xuất hiện tương ứng ,1kp k L .
i. Có thể xây dựng một mã hiệu nhị phân có tính prefix vàcó độ dài từ mã trung bình R thoả mãn bất đẳng thức:
( ) 1R H X
ii. Với mọi mã hiệu, độ dài từ mã trung bình R thoả mãn bấtđẳng thức:
( )H X R
Chứng minh bất đẳng thức . Có:
2 21 1 1
1 2( ) log logknL L L
k k k kk k kk k
H X R p p n pp p
Sử dụng bất đẳng thức ln 1x x và bất đẳng thức Kraft
2 21 1
2( ) (log ) ( 1)(log )( 2 1) 0k
k
nL Ln
kk kk
H X R e p ep
Dấu bằng xảy ra khi 2 1knkp k L .
93

Chứng minh khẳng định .
Cần tìm một mã hiệu sao cho ( ) 1R H X . Chọn kn sao cho12 2k kn n
kp . Có 21 logk kn p . Vậy:
21 1
(1 log ) 1 ( )L L
k k k kk k
p n p p H X
Trên cơ sở giới hạn lý thuyết trên, các phương pháp mã hóa sẽđược xem xét
II. Mã hóa FanoMột nguồn tin tối ưu là nguồn tin có độ dư bằng 0. Để đảm bảođộ dư gần bằng 0, xác suất xuất hiện của các ký hiệu phải xấpxỉ bằng nhau. Nguồn tin được mã hóa bằng mã hiệu nhị phân, dođó mục tiêu của phương pháp mã hóa Fano-Shannon là tìm cách mãhóa sao cho xác suất của ký hiệu 1 và 0 xấp xỉ bằng nhau.
Để làm như vậy, trước hết chia các chuỗi ký hiệu nguồn thành 2nhóm có xác suất gần bằng nhau. Mã hóa mỗi nhóm bằng 0 hoặc 1.Với mỗi nhóm sau đó lại tìm cách mã hóa bằng 0 và 1 sao choxác suất xuất hiện của 0 và 1 là như nhau. Để làm như vậy lạichia các nhóm thu được thành 2 nhóm có xác suất gần nhau. Quátrình cứ tiếp diễn cho đến khi các nhóm có 1 ký hiệu. Giảithuật mã hóa Fano được mô tả như sau:
- Sắp xếp các ký hiệu theo thứ tự xác suất giảm dần;i=1
- Chia các ký hiệu nguồn thành 2 nhóm liên tục có xác suấtgần bằng nhau
- Gán giá trị ký hiệu ở vị trí thứ i từ trái sang lần lượtlà 0 và 1 cho 2 nhóm.
- Gán i=i+1. Tiếp tục lặp lại bước 2 với từng nhóm cho đếnkhi chỉ có 1 ký hiệu
- Đọc các từ mã bằng các ký hiệu mã hóa từ trái sang phải
Bang 4: Mã hóa Fano
Kýhiệu
Xác suất Chianhóm lần
Chianhóm lần
Chianhóm lần
Chianhóm lần
Từ mã
94

1 (i=1) 2 (i=2) 3 (i=3) 4 (i=4)1x ¼ 0 0 002x ¼ 0 1 013x 1/8 1 0 0 1004x 1/8 1 0 1 1015x 1/16 1 1 0 0 11006x 1/16 1 1 0 1 11017x 1/16 1 1 1 0 11108x 1/16 1 1 1 1 1111
Nhận xét: với cách chia nhóm như trên, mã hiệu luôn luôn đảmbảo tính prefix. Trong ví dụ trên, hiệu suất mã bằng 1. Điềunày có thể giải thích bởi các xác suất của các ký hiệu nguồnđều là lũy thừa của 2.
Bang 5: Mã hóa Fano 2
Kýhiệu
Xácsuất
Chianhómlần 1(i=1)
Chianhómlần 2(i=2)
Chianhómlần 3(i=3)
Chianhómlần 4(i=4)
Chianhómlần 5(i=5)
Từ mã
1x 0,39 0 0 002x 0,21 0 1 013x 0,19 1 0 104x 0,10 1 1 0 1105x 0,06 1 1 1 0 11106x 0,03 1 1 1 1 0 111107x 0,01 1 1 1 1 1 0 11111
08x 0,01 1 1 1 1 1 1 11111
1Trong ví dụ trên, ngoài lựa chọn gồm ký hiệu có xác suất 0,34và ký hiệu có xác suất 0,21 để thành một nhóm ký hiệu có tổngxác suất 0,55, có thể lựa chọn gộp ký hiệu có xác suất 0,34 vàký hiệu có xác suất 0,19 để có tổng xác suất 0,53. Tuy nhiên ởbước tiếp theo sẽ phải tách thành hai nhóm có xác suất là 0,34và 0,19, kém tối ưu hơn so với 2 nhóm như trong ví dụ. Câu hỏiđặt ra là phương pháp nào mã hóa tối ưu hơn, cho hiệu suất mãcao hơn.
95

III.Mã hóa HuffmanTrong các mã hiệu mã hóa từng ký hiệu nguồn, gọi mã hiệu M làmã hiệu tối ưu nhất với chiều dài trung bình của các từ mã là*n . Điều này có nghĩa là với mọi mã hiệu có tính prefix khác
với chiều dài từ mã $n$, luôn luôn có *n n . Các khẳng định sauđây sẽ đúng với mã hiệu tối ưu:
- Từ mã có chiều dài lớn ánh xạ với ký hiệu có xác suấtnhỏ. Một cách hình thức:
- 1 2 1 2( ) ( )p x p x n n
- Thật vậy, giả sử có 1 2 1 2( ) ( ),p x p x n n . Xây dựng một mã hiệumới có chiều dài từ mã $n'*$bằng cách đổi vị trí hai từmã tương ứng với $x_1,x_2$. Khi đó ta có:
1 1 2 2 1 1 2 2
1 1 2 1 12 2 22 11 2
* * ( ) ( ) ( ) ( )( ) ( ) ( ) ( ) ( ( ) ( ))( ) 0
n n p xp x p x n
n p x n p x n p x np x n p x n p x n p x n n
Do đó mã hiệu mới có chiều dài trung bình của các từ mã nhỏhơn mã hiệu cũ, hay nói cách khác mã hiệu mới tối ưu hơn mãhiệu cũ.(dpcm)
- Xét 2 từ mã có chiều dài lớn nhất 1 2,w w . 2 từ mã này phảicó chiều dài bằng nhau.
- Giả sử hai từ mã có chiều dài khác nhau và chiều dài của1w nhỏ hơn chiều dài của 2w . Khi đó tạo từ mã mới 2*w bằng cách
bỏ đi các bít bên phải của 2w cho bằng với 1w . Như vậy chiềudài trung bình của mã hiệu mới nhỏ hơn chiều dài trung bìnhcủa mã hiệu cũ. Mã hiệu mới bảo toàn tính prefix của mã hiệucũ, vì rõ ràng không có từ mã nào là phần đầu của 2w , do đókhông thể là phần đầu của 2*w . Mặt khác 1w cũng không phải làphần đầu của 2w , do đó 2 1*w w . Vậy khi thay thế 2w bằng một từmã mới, thu được mã hiệu có tính prefix và có chiều dài trungbình nhỏ hơn-tối ưu hơn.
- Do đó 2 từ mã dài nhất phải có chiều dài bằng nhau.
96

- Xét 2 từ mã có chiều dài lớn nhất 1 2,w w . 2 từ mã này chỉsai khác nhau đúng 1 ký hiệu tận cùng bên phải.
Xây dựng mã hiệu mới bằng cách bớt đi 2 bít tận cùng bên phảicủa 1 2,w w . Thu được 2 từ mã mới 1 2*, *w w . Mã hiệu mới là mã hiệucó chiều dài trung bình của các từ mã nhỏ hơn. Để cho mã hiệumới không hợp lệ, có thể có các trường hợp sau xảy ra:
- 1 2* *w w khi đó 1 2,w w sai khác nhau đúng một ký hiệu tậncùng bên phải
- 1*w bằng hoặc là phần đầu của một từ mã 3w khác. Dấu bằngkhông thể xảy ra do tính prefix của mã hiệu cũ. Nếu 1*w làphần đầu của 3w , khi đó 31 2 w, ,w w có cùng chiều dài, 1 3,w w saikhác nhau đúng 1 bít cuối cùng.
- Vậy khẳng định đã được chứng minh.
Với khẳng định trên, trong một mã hiệu tối ưu luôn luôn cóhai từ mã có chiều dài dài nhất chỉ sai khác nhau đúng một bítcuối cùng, còn tất cả các bít còn lại bên trái là giống nhau.Thay vì việc đi tìm hai từ mã, bài toán chuyển về tìm một từmã thay thế, với xác suất xuất hiện bằng tổng xác suất xuấthiện của 2 từ mã. Bài toán mã hóa tối ưu nguồn tin có L kýhiệu trở thành bài toán mã hóa nguồn tin có L-1 ký hiệu. Tiếptục lặp lại các bước trên cho đến khi chỉ còn 1 ký hiệu, bàitoán mã hóa tối ưu trở thành hiển nhiên. Đó là ý tưởng mã hóatối ưu của Huffman.
- Giải thuật mã hóa Huffman
- Chọn 2 ký hiệu có xác suất nhỏ nhất
- Mã hóa 2 ký hiệu bằng 0 và 1 ở vị trí tận cùng bên phải
- Thay thế 2 ký hiệu bằng 1 ký hiệu mới có xác suất bằngtổng xác suất của hai ký hiệu nói trên.
- Trở về bước 1 nếu nguồn tin có hơn 1 ký hiệu. Nếu khôngkết thúc quá trình xây dựng mã hiệu.
97

Bang 6: Mã hóa Huffman-1
Kýhiệu
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
1x ¼ ¼ ¼ ¼ ¼ ¼(0)½(0)
1
2x ¼ ¼ ¼ ¼ ¼ ¼(1)
3x 1/8 1/8 1/8 1/8(0) ¼(0)
½ ½(1)
4x 1/8 1/8 1/8 1/8(1)
5x 1/16 1/16(0) 1/8
(0)
¼ ¼(1)6x 1/16 1/16
(1)
7x 1/16(0) 1/8 1/8(1
)8x
1/16(1)
1x 2x 3x 4x 5x 6x 7x 8x00 01 100 101 1100 1101 1110 1111
Bang 7: Mã hóa Huffman-2
Kýhiệu
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
Xácsuất
1x 0,39 0,39 0,39 0,39 0,39 0,39 0,39 0,39(0)
1
2x 0,21 0,21 0,21 0,21 0,21 0,21 0,21(0)
0,61(1)
3x 0,19 0,19 0,19 0,19 0,19 0,19(0)
0,40(1)
4x 0,10 0,10 0,10 0,10 0,10(0)
0,21(1)
5x 0,06 0,06 0,06 0,06(0)
0,11(10
6x 0,03 0,03 0,03(0) 0,05(
1)7x 0,01(0)0,02 0,02(
1)8x 0,01(1)
98

1x 2x 3x 4x 5x 6x 7x 8x
0 10 110 1110 11110 111110 1111110 111111
Mã hóa Huffman với cơ số khác 2.Trong phương pháp mã hóaHuffman với cơ số 2, mỗi lần gộp 2 ký hiệu và thay thế bằngmột ký hiệu mới, số lượng ký hiệu giảm 1. Như vậy chắc chắn sẽcó lúc số lượng ký hiệu nguồn bằng 1. Với mã hóa cơ số m, mỗilần có thể gộp m ký hiệu, số lượng ký hiệu giảm đi m-1. Sẽxuất hiện các trường hợp cần phải gộp ít hơn m-1 ký hiệu. Cầnxác định số lượng các ký hiệu trong lần gộp ít hơn đó và thờiđiểm để gộp. Về số lượng, phép toán về số dư cho ta thấy số kýhiệu gộp trong lần gộp ít hơn là( 1) ( 1) 1L mod m
Về thời điểm, khi gộp các ký hiệu có số lượng ít hơn m, có ảnhhưởng đến hiệu quả mã hiệu, do đó cần tiến hành với các kýhiệu có xác suất nhỏ nhất. Như vậy, giải thuật Huffman với mãhiệu cơ số m sẽ được thực hiện như sau:
- Chọn ( 1) ( 1) 1L mod m ký hiệu có xác suất nhỏ nhất
- Mã hóa ( 1) ( 1) 1L mod m ký hiệu bằng 0,1, , 1m ở vị trí tậncùng bên phải
- Thay thế ( 1) ( 1) 1L mod m ký hiệu bằng 1 ký hiệu mới cóxác suất bằng tổng xác suất của ( 1) ( 1) 1L mod m ký hiệunói trên.
- Nếu nguồn tin có 1 ký hiệu kết thúc quá trình xây dựng mãhiệu.
- Chọn m ký hiệu có xác suất nhỏ nhất.
- Mã hóa m ký hiệu bằng 0,1, , 1m ở vị trí tận cùng bênphải
- Thay thế m ký hiệu bằng 1 ký hiệu mới có xác suất bằngtổng xác suất của m ký hiệu nói trên.
- Trở về bước 5 nếu nguồn tin có hơn 1 ký hiệu. Nếu khôngkết thúc quá trình xây dựng mã hiệu.
99

IV. Mã hóa ShannonCác phương pháp mã hóa nói trên đều đòi hỏi các cấu trúc dữliệu với qui mô 2L . Với khả năng xử lý của máy tính, đòi hỏicó những phương pháp trực tiếp hơn, không thông qua các cấutrúc dữ liệu bậc cao. Với từ mã iw có chiều dài in , xác suấtcủa ký hiệu nguồn tương ứng là ip , theo cách chứng minh bấtđẳng thức Shannon để đảm bảo ( ) 1n H X cần chọn:
2 21
log log 12 2i i
i i in n
i
p n pp
Nói cách khác, ip chính là độ chính xác của một số nhị phân cóin chữ số sau dấu phảy. Như vậy các từ mã iw sẽ tương ứng vớicác khoảng rộng ip . Nhiệm vụ còn lại là tìm các số nhị phântương ứng với từng khoảng. Trong hình vẽ, có thể có các lựachọn về giá trị đặc trưng cho từng khoảng:
- Lấy giá trị đầu khoảng
- Lấy giá trị giữa khoảng
Cho dù lấy ở đầu hay ở giữa khoảng, giá trị đặc trưng này cũngsẽ tạo thành một khoảng bao trùm ra ngoài khoảng đang xem xét.Để đảm bảo cho không có giá trị đặc trưng nào rơi vào mộtkhoảng khác, các khoảng được thực hiện theo thứ tự từ lớn đếnnhỏ. Như vậy giải thuật mã hóa Shannon với lựa chọn giá trịđặc trưng là giá trị đầu khoảng được thực hiện như sau:
- Sắp xếp các xác suất theo thứ tự giảm dần
- Tính các xác suất gộp – giá trị đặc trưng theo công thức1
1()
i
jP i p
- Tính in theo công thức 2 2log log 1i i ip n p
- Khai triển ()P i trong hệ nhị phân với in chữ số nhị phânsau dấu phẩy. Phần lẻ thu được chính là từ mã iw .
Ví dụ được nêu trong Bảng 8 và Bảng 9
100

Bang 8: Mã hóa Shannon-1
Kýhiệu
Xácsuất ( ip )
Xácsuấtgộp( ())P i
inKhaitriểnnhịphân
Từ mã
1x ¼ 0 2 0.00 002x ¼ ¼ 2 0.01 013x 1/8 ½ 3 0.100 1004x 1/8 5/8 3 0.101 101
5x 1/16 ¾ 4 0.1100
1100
6x 1/16 13/16 4 0.1101
1101
7x 1/16(0)
14/16 4 0.1110
1110
8x1/16(1)
15/16 4 0.1111
1111
Bang 9: Mã hóa Shannon-2
Kýhiệu
Xácsuất ( ip )
Xácsuấtgộp( ())P i
inKhaitriểnnhịphân
Từ mã
1x 0,39 0 2 0.00 002x 0,21 0,39 3 0.010 0103x 0,19 0,6 3 0.100 1004x 0,10 0,79 4 0.1100 11005x 0,06 0,89 5 0.11100 11100
6x 0,03 0,95 6 0.111100
111100
7x 0,01 0,98 7 0.1111100
1111110
8x0,01 0,99 7 0.11111
101111110
Có thể thấy mã hóa Shanon cho kết quả không tối ưu bằng cácphương pháp khác, đổi lại, tốc độ tính toán của mã hóa Shannonnhanh hơn. Chú ý là một ký hiệu chỉ cần có giá trị cận trên vàcận dưới của khoảng xác suất là đã có thể xác định được từ mãtương ứng.
101

V. Mã hóa đại sốMặc dù mã hóa Shannon không tối ưu bằng mã hóa Huffman, tuynhiên khi mở rộng cho bài toán mã hóa các khối nhiều ký hiệunguồn, nhược điểm này không còn quan trọng. Khi mã hóa nhiềuký hiệu nguồn theo khối, vấn đề đặt ra là độ phức tạp tínhtoán của quá trình mã hóa và giải mã. Nếu nguồn tin ban đầu cóL ký hiệu, khi mã hóa các khối J ký hiệu sẽ phải mã hóa mộtnguồn tin mới có JL ký hiệu. Độ phức tạp tăng theo hàm mũ!Ngoài ra khi mã hóa từng khối J ký hiệu, độ trễ giải mã tănglên J lần.
Theo phân tích trên, các giới hạn đưa ra bởi các định lýShannon chỉ có ý nghĩa về lý thuyết. Để có thể đưa các kết quảnày vào thực tế, cần giải quyết vấn đề về độ phức tạp nóitrên.
Giả sử mã hóa các ký hiệu nguồn theo từng khối J ký hiệu. Ðểhiệu suất tiệm cận với 1, giá trị J càng lớn càng tốt. Giá trịlớn nhất của J chính là số lýợng ký hiệu nguồn cần truyền đi,nói cách khác, mã hóa tất cả các ký hiệu nguồn cùng một lúc.Độ phức tạp của nguồn tin có JL ký hiệu có nguyên nhân là phảitính JL từ mã. Trong số những từ mã này, chúng ta chỉ cần 1 từmã. Bài toán về độ phức tạp có thể được giải quyết nếu thay vìviệc tính toán tất cả các từ mã bằng việc tính toán đúng từ mãcần thiết. Trong các phương pháp đã nêu trên, chỉ có phươngpháp mã hóa Shannon là cho phép có thể tính toán các từ mã đơnlẻ. Để xác định được từ mã, cần xác định cận trên và cận dướitương ứng với chuỗi ký hiệu.
102

Bắt đầu 0.0 1.0 B 0.2 0.3 I 0.25 0.26 L 0.256 0.258 L 0.2572 0.2576 SPACE 0.25720 0.25724 G 0.257216 0.257220
V-14: Quá trình mã hóa bằng mã đại số
Giả sử chuỗi ký hiệu truyền đi là 1 2 Jx x x . Không mất tính tổngquát và để thuận tiện cho việc tính toán, giả sử các ký hiệunguồn ban đầu là {1,2 , }L . Giả sử các xác suất xuất hiện củacác ký hiệu lần lượt là 1 2, Lp p p . Giả sử các chuỗi ký hiệu cóchiều dài J được sắp xếp theo thứ tự ABC, có nghĩa là chuỗi kýhiệu đầu tiên là 11 1 , chuỗi ký hiệu cuối cùng là LL L . Chuỗiký hiệu đầu tiên sẽ có xác suất là 1
Jp , chuỗi cuối cùng có xác
suất là JLp . Chuỗi ký hiệu đang xem xét có xác suất là
1i
J
xp .
Cần xác định xác suất gộp của chuỗi ký hiệu này. Xác suất nàyđược tính theo công thức:
1 2
1 2
... 1 1
1 2 1 211... 11...1
( ... ) (1 (1 .... )...),J i
in
x x x xJ
J y J i kiy y y
P x x x p P P P P p
103

0.2572167752 B 0.2 0.3 0.10.572167752 I 0.5 0.6 0.1 0.72167752 L 0.6 0.8 0.2 0.6083876 L 0.6 0.8 0.2 0.041938 SPC 0.0 .1 0.1 0.41938 G 0.4 0.5 0.1 0.1938 A 0.2 0.3 0.1 0.938 T 0.9 1.0 0.1
V-15: Giai mã mã đại số
Sau khi đã tính được xác suất gộp, việc tính toán từ mã trởthành hiển nhiên.
Trong thực tế, từ mã được xác định từ xác suất riêng và xácsuất gộp. Tuy nhiên một số nhị phân có thể được biểu diễn bằngmột giá trị và một sai số, như vậy có thể được biểu diễn bởimột khoảng gồm cận trên và cận dưới. Trong trường hợp trên,cận trên là 1 2 1 2( ) ( )J JP x x x p x x x . Gọi ( )D u , trong đó u là mộtchuỗi ký hiệu nguồn bất kỳ là khoảng tương ứng của u. Có
( ) ( )pu v D u D v
Nói cách khác, trong công thức tính khoảng của chuỗi 1 2... Jx x x , cóthể tính dần 1 1 2 1 2( ), ( ), ( )JD x D x x D x x x . Trong quá trình tính, khibiểu diễn cận trên và cận dưới theo cơ số nhất định, vì cácgiá trị này càng ngày càng gần nhau, do đó sẽ có một phần đầuchung. Phần đầu chung này có thể được gửi đi trước, căn cứ vàophần đầu gửi trước này, bộ phận giải mã có thể giải mã đượcmột phần các ký hiệu nguồn đã được mã hóa. Như vậy có thể giảmđược độ trễ giải mã.
Ví dụ: Mã hóa chuỗi BILL GATES sử dụng cơ số 10, với phân bốxác suất như trong bảng.
Space A B E G I L S T0,1 0,1 0,1 0,1 0,1 0,1 0,2 0,1 0,1
104

Quá trình mã hóa được mô tả trong V -14: Quá trình mã hóabằng mã đại số. Quá trình giải mã được nêu trong hình V -15:Giải mã mã đại số.
Bài 11. Mã hóa nguồn rời rạc không dừng có nhớ
I. Entropy nguồn có nhớTrong phần trước ta đã xét việc mã hoá nguồn rời rạc khôngnhớ, bây giờ ta tiếp tục xét tới nguồn mà một dãy các ký hiẹucủa nguồn tạo ra là phụ thuộc thống kê. Ta cũng chỉ xét tớinguồn dừng thống kê trong phần này. Entropi của một khối cácbiến ngẫu nhiên 1 2, .. kX X X là:
)...|()...( 1211
21 i
k
iik XXXXHXXXH
Entropi của một ký hiệu trong một khốI k ký hiệu được địnhnghĩa là:
)..(1)( 21 kk XXXHk
XH
Ta định nghĩa lượng tin trung bình của một nguồn dừng làlượngtin trung bình của một khối ký hiệu của nguồn và có độ lớnbằng entropi của một ký hiệu của nguồn trong khi k tiến tới vôhạn, nghĩa là:
105

( ) lim ( )kkH X H X
Hiệu quả của mã hoá nguồn dừng rời rạc phụ thuộc vào việc mộtkhối các ký hiệu của nguồn được mã hoá thành một từ mã là lớnhay nhỏ.Tuy nhiên, ta thấy rằng thuật toán mã Huffman vàShanon-Fano yêu cầu phải biết hàm mật độ phân bố xác suất đồngthời của khối J ký hiệu của nguồn.
II. Mã hóa nguồn không dừngNguồn không dừng là nguồn có phân bố xác suất thay đổi theothời gian. Tốc độ thay đổi của phân bố xác suất thường nhỏ hơnnhiều so với tốc độ ký hiệu. Như vậy có thể chia quá trìnhtruyền tin thành nhiều đoạn, trong mỗi đoạn có thể coi là phânbố xác suất không thay đổi hoặc thay đổi rất ít, có thể ápdụng được các phương pháp mã hóa đã xem xét ở trên.
Để có thể triển khai được ý tưởng này, các vấn đề sau đây cầnđược giải quyết:
- Xác định các điểm ranh giới giữa các đoạn. Mỗi đoạn tươngứng với một phân bố xác suất và một mã hiệu được xây dựngtừ phân bố xác suất đó. Khi phân bố xác suất thay đổi,đến một mức nào đó mã hiệu không còn phù hợp. Như vậy đểxác định ranh giới giữa các đoạn cần theo dõi sự thay đổicủa phân bố xác suất, sau đó kiểm tra tính phù hợp của mãhiệu hiện tại với phân bố xác suất mới.
- Tính toán một cách hiệu quả mã hiệu mới. Khi có nhu cầusử dụng mã hiệu mới, căn cứ vào phân bố xác suất mới, cầntính được mã hiệu mới. Tuy nhiên phân bố xác suất trênthực tế thay đổi không nhiều, do đó mã hiệu mới cũng thayđổi không nhiều so với mã hiệu cũ. Cần có phương pháp đểtận dụng những từ mã hoặc phần của từ mã giống nhau, giảmkhối lượng tính toán mã hiệu mới.
- Đồng bộ mã hiệu sử dụng với bộ phận nhận tin. Để có thểgiải mã được thông tin khi chuyển sang mã hiệu mới, cầnthông báo và chuyển các thông tin về mã hiệu mới cho bộ
106

phận giải mã. Nếu chuyển cả bảng mã sang cho thiết bịgiải mã, sẽ có ảnh hưởng đến hiệu suất của mã hiệu.
Theo dõi sự thay đổi của phân bố xác suất. Thực tế phân bố xác suất củacác ký hiệu phản ánh bởi tần suất xuất hiện của các ký hiệu.Do đó tại bộ phận mã hóa, ngoài việc mã hóa các ký hiệu cầnghi lại số lần xuất hiện của các ký hiệu. Trên cơ sở số lầnxuất hiện sẽ tính toán xác suất của các ký hiệu. Tuy nhiên,nếu mỗi lần mã hóa một ký hiệu phải tính lại xác suất (thựchiện 1 phép cộng và L phép chia) sẽ ảnh hưởng đến tốc độ mãhóa. Do đó thường phân bố xác suất khi lưu trữ được thay thếbằng tần suất xuất hiện của các ký hiêu. Mỗi khi nhận một kýhiệu chỉ cần cập nhật số lượng ký hiệu đã nhận được. Sau mộtkhoảng thời gian, số lượng ký hiệu sẽ được chia cho một hằngsố để đảm bảo không bị tràn số. Với việc sử dụng tần suất,phương pháp mã hóa Shannon không sử dụng được, chỉ có thể sửdụng phương pháp mã hóa Huffman hoặc Fano. Do tính tối ưu nênphương pháp mã hóa Huffman sẽ được sử dụng.
Theo dõi tính phù hợp của mã hiệu. Cách thức đơn giản nhất để kiểmtra một mã hiệu có phù hợp với phân bố xác suất hiện tại haykhông là tính lại mã hiệu, kiểm tra mã hiệu tính được có giốngmã hiệu cũ hay không. Nếu không giống có nghĩa là mã hiệu mớisẽ được sử dụng. Trong quá trình tính toán, thực tế không phảitính hết tất cả các từ mã, chỉ cần tính một số từ mã là đã cóthể xác định được mã hiệu có phù hợp hay không. Trong mã hóaHuffman, việc xác định mã hiệu có phù hợp hay không phụ thuộcvào một tính chất đặc biệt gọi là sibling của cây mã Huffman.
Cây mã Huffman. Quá trình xây dựng mã Huffman tương đương vớiviệc xây dựng một cây mã theo phương pháp từ dưới lên. Kết quảcủa quá trình là có một cây mã, các nút lá là các nút tươngứng với các ký hiệu nguồn (từ mã), được đánh trọng số bằng tầnsuất xuất hiện của các nút tương ứng. Các nút không phải nútlá là kết quả của việc gộp một số các nút lá và có trọng số làtổng trọng số của các nút lá thuộc cây con. Nếu sắp xếp tất cảcác nút của cây Huffman nhị phân theo thứ tự tăng dần hoặcgiảm dần của xác suất thì các nút anh em bao giờ cũng đứng
107

cạnh nhau. Tính chất này gọi là tính sibling của cây Huffman.Khi tính chất sibling còn được bảo toàn, mã hiệu không thayđổi.
Thay đổi mã hiệu. Khi nhận được một ký hiệu, bộ phận mã hóa cậpnhật tần suất của ký hiệu tại nút lá tương ứng. Tất cả các nútgốc của các cây con chứa nút lá này đều phải được cập nhật.Trong quá trình cập nhật, nếu cho đến nút gốc tính sibling vẫnđược bảo toàn chứng tỏ mã hiệu vẫn còn sử dụng được. Nếu đếnmột cây con nào đó, tính sibling bị phá hủy thì mã hiệu khôngsử dụng được.
Tính toán mã hiệu. Nếu tính chất sibling bị phá hủy, cần tính toánmã hiệu mới. Để không phải tính toán mã hiệu mới, cần chú ýquá trìn xây dựng lại mã hiệu chính là quá trình xây dựng lạicây Huffman. Như vậy nếu có thay đổi giữa cây Huffman mới vàcây Huffman cũ, thì thay đổi này thực chất là để đảm bảo tínhchất sibling. Có thể chủ động thực hiện thay đổi này mà khôngcần tính toán lại cây bằng cách theo dõi tính sibling trêndanh sách sắp xếp các nút của cây. Khi điều kiện sibling bịphá hủy, khi đó có thể đổi chỗ 2 phần tử của danh sách để đảmbảo điều kiện sibling. Tất nhiên khi đó trong cây Huffman, 2cây con tương ứng với 2 nút cũng phải đổi chỗ, trọng số củacác cây con chứa 2 cây con này cũng phải được cập nhật lại.Trong quá trình cập nhật, nếu tính chất sibling bị phá hủy,tiếp tục thực hiện việc hoán vị các phần tử của danh sách vàcây con trong cây Huffman. Quá trình sẽ dừng lại khi đạt đếnnút gốc.
Như vậy, với việc đưa tính chất sibling của cây Huffman vào,các thay đổi cần có của mã hiệu sẽ được phát hiện và được tínhtoán ngay. Tất nhiên khi ứng dụng thực tế còn rất nhiều vấn đềkỹ thuật cần giải quyết như: tạo dần dần cây Huffman từ câyrỗng, các trọng số bằng nhau, ....
Đồng bộ mã hiệu với bộ phận giải mã. Để tránh việc phải gửi cảmã hiệu sang bộ phận giải mã, thông thường bộ phận giải mãcũng theo dõi phân bố xác suất và sự thay đổi mã hiệu. Khi cósự thay đổi mã hiệu ở phía bộ phận mã hóa, chỉ cần thông báo
108

ký hiệu đã gây ra sự thay đổi mã hiệu này cho bộ phận giải mã.Có 2 cách để thực hiện:
- Truyền bằng một mã hóa hoặc ký hiệu đặc biệt (thôngthường là mã hóa chuẩn và sử dụng ký hiệu ESC)
- Truyền bằng mã hiệu cũ. Bộ phận giải mã sử dụng mã hiệucũ, giải mã ra ký hiệu, từ đó có thể cập nhật được mãhiệu.
Phương pháp mã hóa này được gọi là phương pháp mã hóa thíchnghi, mã hóa Huffman động, được dùng rộng rãi để mã hóa điệntín, Telex, ....
III.Mã hóa nguồn có nhớNguồn có nhớ là nguồn có liên hệ thống kê giữa các ký hiệuxuất hiện tại các thời điểm khác nhau. Mã hóa nguồn có nhớ cầntận dụng các mối liên hệ này để tăng hiệu quả của việc mã hóa.Các phương pháp thường dùng là:
Mã hóa đại số. Căn cứ theo phương pháp mã hóa đại số đã trìnhbày ở trên, có thể thực hiện mã hóa đại số cho nguồn có nhớ.Chi tiết cần thay đổi là công thức tính xác suất đồng thời củacác ký hiệu.
Mã hóa sử dụng từ điển. Với nguồn có bộ nhớ hữu hạn k, các tổhợp k ký hiệu sẽ xuất hiện với các xác suất khác nhau, thậmchí một số tổ hợp có xác suất xấp xỉ 0. Do đó thay vì việc mãhóa từng ký hiệu, chúng ta sẽ mã hóa các khối k ký hiệu, sốlượng các khối lúc này sẽ nhỏ hơn kL nhiều, bài toán mã hóatheo các định lý Shannon trở thành khả thi.
Một vấn đề đặt ra là việc đồng bộ bảng mã giữa bộ phận mã hóavà bộ phận giải mã. Mặc dù số lượng các khối nhỏ hơn so vớitrường hợp nguồn không nhớ, tuy nhiên vẫn lớn hơn nhiều so vớimã hóa từng ký hiệu. Thông thường, bảng mã này được dùng chungcho nhiều quá trình truyền tin và được gọi là một từ điển tĩnh.
Một cách tiếp cận khác là xây dựng từ điển cho từng quá trìnhtruyền tin và gửi từ điển cho bộ phận giải mã. Ưu điểm của
109

phương pháp này là kích thước bảng mã nhỏ. Nhược điểm là dưthừa dữ liệu (vừa có từ điển, vừa có mã hóa). Do đó thôngthường chuỗi ký hiệu mã và từ điển được kết hợp với nhau tạothành một từ điển động. Phương pháp mã hóa Lempel-Ziv là mộtphương pháp sử dụng từ điển động.
Phương pháp mã hóa Lempel-Ziv. Nguyên tắc của phương pháp này làchia chuỗi ký hiệu đầu vào thành các từ, không từ nào giống từnào. Các từ này được đưa vào một từ điển và được mã hóa bằngmột danh sách động. Cần chú ý là các từ mới được tạo từ các từcũ + một ký hiệu nguồn, do đó khi mã hóa, các từ mã sẽ đượctạo thành từ số thứ tự của từ mã cũ và ký hiệu mới.
Ví dụ ta xét dãy ký hiệu nhị phân sau:
1 0 10 11 01 00 100 111 010 1000 011001110101100011011
Chia dãy các ký hiệu trên thành các câu như trong bảng từđiển
Vị trí trongtừ điển
Câu Từ mã tươngứng
0001 1 00001
0010 0 00000
0011 10 00010
0100 11 00011
0101 01 00101
0110 00 00100
0111 100 00110
1000 111 01001
1001 010 01010
1010 1000 01110
110

Để giải mã cần phải xây dựng lại từ điển ở phía thu giốngnhư ở phía phát và sau đó là giải mã lần lượt các từ mã nhậnđược. a nhận thấy rằng quá trình mã hoá trong ví dụ trên mãhoá 44 ký hiệu nhị phân của nguồn thành 16 từ mã, mỗi từ mãcó độ dài 5 bit. Như vậy là trong ví dụ này không thực hiệnnén số liệu, đó là do chuỗi ký hiệu được quan sát quá ngắn.Nếu chuỗi ký hiệu được dài ra thêm thì thuật toán sẽ trở nênhiệu quả hơn và có nén số liệu ở đầu ra của nguồn. Vấn đề bâygiờ đặt ra là độ lớn của từ điển là bao nhiêu. Nói chung, độlớn của từ điển chỉ phụ thuộc vào bộ nhớ dùng trong lưu trữ.Để giải quyết vấn đề tràn ô nhớ, bộ mã hoá và bộ giải mã hoácần thống nhất loại bỏ những câu không còn sử dụng nữa và thaythế vào các câu mới. Thuật toán Lempel-Ziv được sử dụng rộngrãi trong việc nén số liệu các tệp trong máy tính. Nhiều tiệních như compress và uncompress trong hệ điều hành UNIX và DOSđược xây dựng trên thuật toán này.
Bài 12. Mã hóa nguồn liên tục
I. Lý thuyết mã hóa nguồn liên tụcNguồn tương tự sinh ra các bản tin ()x t là một thể hiện cụ thểcủa quá trình ngẫu nhiên ()X t . Khi ()X t là một quá trình ngẫunhiên dừng , có dải phổ hữu hạn, ta có thể sử dụng định lý lấymẫu để biểu diễn X(t) qua một chuỗi các mẫu lấy theo tốc độNyquist.
Sử dụng định lý lấy mẫu, tín hiệu ở đầu ra của một nguồn tươngtự được biểu diễn một các tương đương bằng một chuỗi các mẫurời rạc theo thời gian. Sau đó các mẫu được lượng tử hóa theobiên độ và được mã hóa. Một dạng đơn giản của mã hóa là biểudiễn mỗi mức biên độ rời rạc bằng một dãy các kí hiệu nhịphân. Như vậy nếu biên độ tín hiệu có L mức rời rạc , ta cần
2R log L bit cho một mẫu trong trường hợp L là lũy thừa của 2 ,và log2 L 1R khi L không phải là lũy thừa của 2. Mặtkhác , nếu các mức không đồng xác suất xuất hiện và chúng tabiết xác suất của các mức tín hiệu đầu ra thì ta có thể sửdụng phương pháp mã hóa Huffman ( mã hóa theo entropi ) đểtăng hiệu quả mã hóa.
111

Lượng tử hóa biên độ của một mẫu tín hiệu tạo nên hiệu quảtrong việc nén số liệu nhưng đồng thời cũng tạo nên một sự sailệch nào đó của tín hiệu hay còn gọi là sự suy giảm tính trungthực của tín hiệu . Chúng ta cũng xét việc tối thiểu hóa sailệch trong phần này .
II. Hàm tốc độ tạo tin – sai lệchTrong việc lượng tử hóa tín hiệu ta quan tâm trước tiên tới sựsai lệch khi các mẫu của nguồn được lượng tử hóa thành một sốhữu hạn các mức. Sai lệch nghĩa là có một sự sai khác giữa giátrị thực của các mẫu tín hiệu kx với các giá trị lượng tử hóatương ứng kx , được ký hiệu là ,k kd x x .
Đầu ra của nguồn là một quá trình ngẫu nhiên , do đó n mẫu củaX là các biến ngẫu nhiên. Từ đó , ,k kd X X cũng là một biếnngẫu nhiên . Kỳ vọng toán học của nó được định nghĩa là sai sốD:
1
1, ( , ) ,n
kk k k k kk
D E d X X E d x x E d x xn
Đẳng thức cuối cùng chỉ đúng khi quá trình ngẫu nhiên là dừng.Bây giờ giả sử chúng ta có một nguồn không nhớ, đầu ra X làcác mẫu rời rạc , biên độ liên tục cí hàm mật độ phân bố xácsuất p(x), các mẫu tín hiệu được lượng tử hóa theo biên độthành X và sai lệch trên từng mẫu là ,d x x với x X và x X .Tốc độ tạo tin tối thiểu để biểu diễn đầu ra của nguồn khôngnhớ X với sai lệch ≤ D gọi là hàm tốc độ tạo tin _sai lệchR(D) , được định nghĩa :
( / ): ,( ) min ( , )
p x x E d X X DR D I X X
Với ( , )I X X là lượng tin trung bình tương hỗ giữa X và X . Nóichung R(D) giảm thì D tăng và ngược lại.
Một mô hình nguồn thông tin không nhớ, biên độ liên tục haygặp là mô hình nguồn gausian. Trong trường hợp này, Shannon đãchứng minh định lý cơ bản về hàm tốc độ tạo tin-sai lệch sau :
112

Tốc độ tạo tin tối thiểu cần thiết để biểu diễn một nguồn gausian không nhớ, rời rạctheo thời gian, biên độ liên tục trên cơ sở trung bình bình phương sai lệch của từngmẫu là :
2 22
2
1log ( / ) (0 )( ) 20 ( )
x xg
x
D DR DD
với 2x là sai phương của nguồn gausian.
Công thức chỉ ra rằng không cần truyền thông tin khi sai lệchD ≥ 2
x . Đặc biệt khi D = 2x , ta có thể sử dụng các tín hiệu 0
để khôi phục lại tín hiệu. Khi D> 2x có thể dùng các mẫu tín
hiệu nhiễu gausian độc lập thống kê, kỳ vọng toán học bằng 0với sai phương 2
xD để khôi phục lại tín hiệu. Đồ thị của( )gR D được vẽ trên Hình V -16:.
Hàm tốc độ sai số R(D) của một nguồn có liên hệ với định lý mãhóa cơ bản của lý thuyết thông tin sau:
Định lý về mã hóa nguồn với sai lệch cho trước: Tồn tại mộtphương pháp mã hóa nguồn để mã hóa các mẫu của nguồn thành các từ mã vớimột độ sai lệch cho trước D, tốc độ tạo tin tối thiểu R(D) bit/ký hiệu ( mẫu ) đủ đểkhôi phục lại đầu ra của nguồn với sai lệch trung bình sát gần tùy ý tới D .
Như vậy, rõ ràng hàm tốc độ tạo tin-sai lệch R(D) là giới hạndưới của tốc độ tạo tin của nguồn với mức độ sai lệch đã cho.
113

Hình V-16:Tốc độ lập tin của nguồn Gaussian
Hàm tốc độ tạo tin-sai lệch của nguồn gausian không nhớ, biênđộ liên tục.Ta có thể biểu diễn D qua R :
2 2( ) 2 .Rg xD R
Biểu thức của hàm tốc độ tạo tin-sai lệch cho các nguồn khôngnhớ không phải là nguồn gausian tới nay vẫn chưa tìm ra được.Tuy nhiên, người ta đã tìm được giới hạn dưới và giới hạn trêncủa hàm này cho các nguồn không nhớ,rời rạc theo thời gian, cóbiên độ liên tục.
Định lý về giới hạn trên của R(D): Hàm tốc độ tạo tin-sai lệchcủa các nguồn không nhớ , rời rạc theo thời gian, có biên độliên tục có giá trị trung bình bằng 0 và sai phương 2
x hữu hạnđảm bảo sai lệch trung bình bình phương cho trước có giới hạntrên là :
22
21( ) log ,0 |2
xxR D D le
D
Điều này chỉ ra rằng tốc độ thông tin cực đại của nguồngausian lớn hơn tất cả các nguồn khác với cùng mức trung bìnhbình phương sai lệch. Như vậy hàm tốc độ tạo tin-sai lệch củatất cả các nguồn có giá trị trung bình bằng 0 và sai phươnghữu hạn thỏa mãn điều kiện ( ) ( )gR D R D . Tương tự, hàm sai lệch-tốc độ tạo tin của các nguồn như vậy thỏa mãn điều kiện :
2 2( ) ( ) 2 .Rg xD R D R
114

Giới hạn dưới của hàm tốc độ tạo tin-sai lệch cũng tồn tại.Giới hạn này được gọi là giới hạn dưới Shannon cho việc đolường sai lệch theo trung bình bình phương sai lệch như sau :
21*( ) ( ) log 22R D H X eD
H(X) là entropi của nguồn không nhớ có biên độ liên tục. Hàmsai lệch-tốc độ tạo tin tương ứng là :
2 ( )1*( ) 22R H XD R
e
Như vậy , hàm tốc độ tạo tin-sai lệch của các nguồn khôngnhớ , biên độ liên tục có giới hạn trên và giới hạn dưới nhưsau :
*( ) ( ) ( )gR D R D R D
Và tương ứng là hàm sai lệch-tốc độ tạo tin : *( ) ( ) ( )gD R D R D R
Entropi của nguồn gausian không nhớ là :
22
1( ) log 22g xH X e
Như vậy , giới hạn dưới R*(D) trong trở thành Rg(D). Bây giờta biểu diễn D*(R) theo dB và chuẩn hóa bằng cách đặt 2
x =1(hay chia D*(R) cho 2
x ), ta được từ :
hay
10( )10log 6 ( ) ( ) 6[Rg(D)-R*(D)] dB *( )
gg
D RH X H X dB
D R
Ta thấy rằng D*(R) cũng giảm với tốc độ -6dB/bit và entropiH(X) bị giới hạn trên bởi Hg(X).
Ta xét một nguồn gausian có dải thông hữu hạn với mật độ phổ :
115

2( ) /2 ,( W )( ) 0,( W )
xf W fff
Khi tín hiệu đầu ra của nguồn này được lấy mẫu ở tốc độNyquyst, các mẫu không tương quan với nhau và do đó chúng độclập thống kê (do nguồn là gausian). Như vậy nguồn tương đươnglà rời rạc theo thời gian và không nhớ. Hàm tốc độ tạo tin-sailệch cho mỗi mẫu là :
22
2( ) W .log (0 )xg xR D D
D
Hàm sai lệch tốc độ tạo tin tương ứng là : / 2( ) 2 .R W
g xD R
III.Lượng tử hóa vô hướngTrong mã hóa nguồn , bộ lượng tử hóa có thể được tối ưu hóanếu chúng ta biết hàm mật độ xác suất của biên độ tín hiệu ởđầu vào bộ lượng tử . Ví dụ : Giả sử chuỗi {xn}ở đầu vào bộlượng tử có hàm mật độ phân bố xác suất p(x) và đặt L = 2R làsố mức tín hiệu. Ta sẽ thiết kế bộ lượng tử hóa vô hướng tốiưu, làm tối thiểu hóa hàm sai số lượng tử của biến q x x , ởđây x là giá trị lượng tử của x. Gọi ( )f x x là hàm sai lệch taquan tâm. Từ đó, sai lệch trong quá trình lượng tử biên độ tínhiệu là:
D f x x p x dx
Tổng quát , bộ lượng tử hóa tối ưu sẽ làm tối thiểu D bằngcách lựa chọn tối ưu các mức tín hiệu đầu ra và với mỗi khoảngtín hiệu đầu vào sẽ ứng với một mức tín hiệu ở đầu ra của bộlượng tử. Vấn đề tối ưu hóa đã được xem xét bởi Lloyd (1982)và Max (1960 ) và bộ lượng tử hóa tối ưu được gọi là bộ lượngtử hóa Lloyd-Max.
Trong trường hợp tổng quát, nếu tín hiệu vào trong khoảng1k kx x x sẽ ứng với mức tín hiệu ra là kx x . Với bộ lượng tử
116

hóa L mức, các giá trị đầu cuối xo= -∞ , xL = ∞, kết quả sai sốlà :
11
( ).k
k
xL
kk x
D f x x p x dx
Điều kiện cần cho việc tối thiểu hóa sai số D theo {xk}và { kx }là đạo hàm của D theo {xk}và { kx }bằng 0. Kết quả là hệ phươngtrình :
1
1 , 1,2,..,,
( ). 0, 1,2, ,k
k
k k k kx
kx
f x x f x x k L
f x x p x dx k n L
Bộ lượng tử mã hóa các mẫu của một nguồn có biên độ liên tụcthành các mẫu của một nguông có biên độ rời rạc , ta có thể xửlý các biên độ rời rạc như các ký hiệu ,1kX x k L với cácgiá trị xác suất {pk}. Nếu các giá trị biên độ tín hiệu là độclập thống kê , thì nguồn là rời rạc không nhớ có entropi là
21
( ) logL
k kk
H X p p
Kết luận: Bộ lượng tử hóa có thể được tối ưu hóa nếu ta biếthàm mật độ phân bố xác suất của nguồn liên tục . Bộ lượng tửhóa tối ưu 2RL mức gây ra sai số D(R) tối thiểu. Điều đó cóthể đạt được khi mã hóa mỗi mẫu tín hiệu bởi R bit. Tuy nhiên,vẫn có thể mã hóa hiệu quả hơn. Các mẫu ở đầu ra của bộ lượngtử hóa được đặc trưng bởi các xác suất xuất hiện {pk}sẽ được sửdụng trong phương pháp mã hóa Huffman ( mã hóa entropi ). Hiệuquả của phương pháp mã hóa có thể được so sánh qua hàm tốc độtạo tin-sai lệch hay hàm sai lệch-tốc độ tạo tin đối với nguồnrời rạc , biên độ liên tục được đặc trưng bởi hàm mật độ xácsuất.
IV. Lượng tử hóa vectơ : Trong phần trước chúng ta đã xét tới việc lượng tử hóa các mẫutín hiệu ở đầu ra một nguồn có biên độ liên tục, trong đó quá
117

trình lượng tử thực hiện theo từng mẫu. Phần này ta xét tớiviệc lượng tử hóa đồng thời một khối các mẫu tín hiệu hay mộtkhối các tham số tín hiệu. Kiểu lượng tử hóa này được gọi làlượng tử hóa vectơ. Phương pháp lượng tử này được sử dụng rộngrãi trong mã hóa tín hiệu tiếng nói hay trong các hệ thống tintổ ong.
Việc lượng tử hóa vectơ sẽ mang lại hiệu quả cao hơn lượng tửhóa vô hướng, ngay cả khi nguồn có biên độ liên tục và khôngnhớ. Hơn nữa, nếu các mẫu tín hiệu hay các tham số tín hiệu làphụ thuộc thống kê , chúng ta có thể lợi dụng tính chất nàybằng cách lượng tử hóa đồng thời một khối các mẫu hay một khốicác tham số . Phương pháp này có hiệu quả cao hơn phương pháplượng tử hóa vectơ về mặt tốc độ thông tin (tốc độ thông tinthấp hơn).
Vấn đề lượng tử hóa vectơ có thể được diễn giải như sau . Tacó một vectơ n chiều X=[x1,x2 ,…,xn] với giá trị thực , cácthành phần có biên độ liên tục {xk, 1 ≤ k ≤ n } được mô tả bằnghàm mật độ phân bố xác suất đồng thời p(x1,x2,…,xn). Vectơ Xđược lượng tử hóa thành một vectơ X n chiều khác với cácthành phần ,1kx k n . Ta biểu diễn phép lượng tử hóa là Q ,nghĩa là ( )X Q X , X là đầu ra bộ lượng tử hóa vectơ khi đầu vàolà X .
Về cơ bản, việc lượng tử hóa vectơ một khối số liệu có thểđược xem như vấn đề nhận dạng mẫu trong việc phân loại cáckhối số liệu thành các lớp rời rạc hay ô để tối ưu hóa tiêuchuẩn nào đó về độ trung thực. Ví dụ , ta xét việc lượng tửhóa vectơ 2 chiều X=[x1,x2]. Không gian 2 chiều được chia thànhcác ô như trên Hình V -17: Lượng tử hóa véc tơ, các ô là cáchình lục giác đều. Ta kí hiệu tập hợp các vectơ ở đầu ra bộlượng tử là ,1kX k L .
118
x1
x

x1
x
Hình V-17: Lượng tử hóa véc tơ
Tổng quát, việc lượng tử hóa một vectơ X n chiều thành mộtvectơ X n chiều khác tạo ra một sai số lượng tử hay sai lệch( , )d X X . Giá trị trung bình của sai lệch của tập hợp các vectơ
đầu vào X là:
1 1( ) ( , ) ( ) ( , ) ( )
k
L Lk kk k k
k k X C
D P X C E d X X X C P X C d X X p X dX
( )kP X C là xác suất để vectơ X ở trong ô Ck và p(X) là hàm mậtđộ phân bố xác suất đồng thời của n biến ngẫu nhiên. Cũng nhưtrong lượng tử hóa vô hướng, ta có thể cực tiểu hóa D bằngcách chọn các ô , 1 kC k L với mỗi hàm p(X).
Lượng tử hóa vectơ không chỉ giới hạn ở việc lượng tử hóa mộtkhối các mẫu của nguồn tín hiệu vào mà nó còn được sử dụng đểlượng tử hóa tập hợp các tham số của số liệu. Ví dụ như trongmã hóa dự đoán tuyến tính (LPC) , các tham số lấy từ tín hiệulà các hệ số dự đoán, đó là các hệ số của mô hình bộ lọc toàncực của nguồn tạo tín hiệu. Các tham số này được lượng tử hóavectơ với một tiêu chuẩn sai lệch thích hợp nào đó. Trong mãhóa tín hiệu tiếng nói, tiêu chuẩn sai lệch thường là trọnglượng của bình phương sai lệch, ma trận trọng lượng W là matrận tự tương quan chuẩn hóa của tín hiệu vào.
Bây giờ ta trở lại với việc mô hình hóa toán học của vấn đềlượng tử hóa vectơ . Xét việc chia không gian n chiều thành L
119

ô , 1 kC k L sao cho sai lệch trung bình là tối thiểu trêntoàn bộ L mức lượng tử . C ó hai điều kiện cho quá trình tốiưu. Thứ nhất là bộ lượng tử hóa tối ưu sử dụng luật gần nhất đượcdiễn giải dưới dạng toán học :
( ) kQ X X nếu và chỉ nếu: ( , ) ( , )k jD X X D X X k ≠ j , 1 ≤j ≤ L
Điều kiện thứ hai cần thiết cho việc tối ưu hóa là mỗi vectơđầu ra kX được chọn sao cho tối thiểu hóa sai lệch trong ô Ck. Nói cáchkhác , kX là vectơ trong Ck làm cực tiểu biểu thức :
( , ) ( , ) ( )k
k kk kX C
D E d X X X C d X X p X dX
Vectơ kX làm tối thiểu Dk gọi là trung tâm của ô Ck. Như vậycác điều kiện cho việc tối ưu hóa được sử dụng trong việc chiakhông gian n chiều thành các ô , 1 kC k L với điều kiện đãbiết hàm mật độ phân bố xác suất p(X). Nói chung ta muốn cácvectơ mã gần nhau trong miền giá trị hàm mật độ phân bố xácsuất lớn và xa nhau trong miền giá trị hàm mật độ phân bố xácsuất nhỏ.
Ta có thể sử dụng giới hạn trên của sai lệch trong lượng tửhóa vô hướng áp dụng cho từng thành phần của lượng tử hóavectơ để tìm giới hạn trên của sai lệch trong lượng tử hóavectơ. Mặt khác, hiệu quả cao nhất của lượng tử hóa vectơ đượccho bởi hàm tốc độ tạo tin-sai lệch hay hàm sai lệch-tốc độtạo tin.
Hàm sai lệch-tốc độ tạo tin có thể định nghĩa trong lượng tửhóa vectơ như sau: giả sử có vectơ n chiều X từ n mẫu {xm}.Vectơ X được lượng tử hóa thành vectơ , ( )X X Q X . Vectơ X làmột vectơ trong tập các vectơ { kX ,1 ≤ k ≤ L}. Như đã nói , sailệch trung bình D khi biểu diễn X bởi X là E[d(X, X )], vớid(X, X ) là sai lệch theo từng chiều, nghĩa là:
2
1
1( , ) ( )n
kkk
d X X x xn
120

Các vectơ { kX , 1 ≤ k ≤ L}được truyền đi với tốc độ trung bình( )H XRn
(bit/kí hiệu)
( )H X là entropi của nguồn đầu ra bộ lượng tử, được định nghĩanhư sau:
21
( ) ( )log ( )L
i ii
H X p X p X
Với tốc độ trung bình R, sai lệch tối thiểu có thể thực hiệnđược Dn(R) là :
( )( ) min ( , )n Q x
D R E d X X
trong công thức trên R≥ ( )H X /n và giá trị cực tiểu được tínhvới tất cả các khả năng của Q(X). Lấy giới hạn khi n→∞ , tađược :
( ) lim ( )nnD R D R
với D(R) là hàm sai lệch-tốc độ tạo tin .
Các vấn đề nói trên là trong bối cảnh ta đã biết hàm mật độphân bố xác suất đồng thời p(X). Tuy nhiên trong thực tế,người ta thường không tính được p(X). Trong trường hợp đó cóthể chòn các vectơ lượng tử một cách thích hợp từ một tập cácvectơ thử X(m). Giả sử ta đã có một tập M vectơ thử và M >> L.
Một thuật toán ghép gọi là Thuật toán K trung bình (K means algorthm) ,trong trường hợp này thì K=L được áp dụng với các vectơ thử.Thuật toán này chia M vectơ thử thành L tập mà hai điều kiệntối ưu được thỏa mãn. Thuật toán như sau :
B1: Khởi đầu quá trình lặp với i=0, chọn 1 tập hợp các vectơđầu ra (0)kX ,1 ≤ k ≤ L .
B2: Phân các vectơ thử {X(m) , 1 ≤ k ≤ M} thành các lớp {Ck}bằng cách sử dụng luật gần nhất :
()kX C i nếu và chỉ nếu ( , ()) ( , ())k jD X X i D X X i với mọi k≠j
121

B3: Tính lại (Đặt i=i+1) các vectơ đầu ra của tất cả các lớpbằng cách tính trung tâm của các vectơ thử trong mỗi lớp:
1() ( )k
kX Ck
X i X mM
,1 ≤ k ≤ L. Tính sai lệch D(i) của mỗi bước
lặp.
B4: Kết thúc nếu như độ chênh lệch D(i-1)-D(i) đủ nhỏ, nếukhông quay lại B2.
Thuật toán K trung bình hội tụ tới cực tiểu địa phương. Bằngcách lặp lại thuật toán với nhiều tập hợp các vectơ đầu rakhởi đầu (0)kX , ta có thể tìm được cực tiểu toàn cục. Tuynhiên do khối lượng tính toán quá lớn nên ta thường chỉ làm 1vài tập khởi đầu.
Mỗi khi khởi đầu với một tập các vectơ đầu ra { kX , 1 ≤ k ≤L},mỗi vevtơ X(m) được lượng tử hóa thành một vectơ ở đầu ragần nó nhất (theo cách đo lường sai lệch). Nếu việc tính toánđược thực hiện với tất cả L vectơ có thể ở đầu ra { kX } thì thủtục này được gọi là tìm kiếm toàn bộ. Giả thiết số phép tínhcộng và nhân trong mỗi phép thử là n ( thực ra là tỷ lệ với nlà số chiều của vectơ) thì số phép tính cần thực hiện đối vớimột vectơ là C = nL
Nếu L là lũy thừa của 2 thì log2L là số bit cần thiết để biểudiễn cho mỗi vectơ. Gọi R là số bit cần thiết để biểu diễn chomỗi mẫu tín hiệu ( một thành phần hay một chiều của X(m) ) thì
2nR log L . Do đó số phép tính cần thực hiện đối với mỗi vectơlà nRC n.2 Như vậy số lượng phép tính tăng theo hàm mũ với sốchiều không gian và tốc độ bit đối với mỗi chiều, do đó lượngtử hóa vectơ được sử dụng cho việc mã hóa nguồn tốc độ thấpnhư mã hóa các hệ số phản xạ hay các hệ số loga trong phươngpháp LPC.
Ví dụ:
Gọi x1 và x2 là 2 biến ngẫu nhiên có hàm mật độ phân bố xácsuất đồng thời đồng đều:
122

1 21/( , ) ( ) 0
ab X Cp x x p XX C
Với C là miền hình chữ nhật trên hình 5-3-4 (quay 45o so vớiphương ngang)
Nếu ta lượng tử hóa x1 và x2 độc lập và dùng các bước lượng tửnhư nhau Δ thì số các mức cần thiết:
1 2 2a bL L
Số lượng các bit cần thiết để mã hóa vectơ X={x1,x2} là :2
1 2 2 1 2 2 2 2( )log log log 2xa bR R R L L
Hình V-18: Ví dụ về lượng tử hóa vectơ 2 chiều.
Như vậy lượng tử hóa từng thành phần tương đương với lượng tửhóa vectơ với số mức :
2
1 2 2( )2x
a bL L L
Ta nhận thấy rằng phương pháp này tơpng đương với việc phủ kínhình chữ nhật lớn bằng các ô chữ nhật, mỗi ô biểu diễn một
123

miền lượng tử. Do p(X)=0 , nên trừ khi X C phương pháp mãhóa này lãng phí , hay số hình vuông phải sử dụng để phủ là :
2xL’ ab/
Từ đó sự khác nhau về tốc độ số liệu giữa lượng tử hóa vôhướng và lượng tử hóa vectơ là :
2
2( )log 2x xa bR R
ab
Chú ý rằng phép biến đổi tuyến tính (quay 45o) sẽ làm mất quanhệ giữa x1 và x2 và làm cho 2 biến ngẫu nhiên độc lập với nhau.Như vậy lượng tử hóa vectơ và lượng tử hóa vô hướng có hiệuquả như nhau. Nhưng nói chung, lượng tử hóa vectơ xó hiệu quảít nhất là bằng với lượng tử hóa vô hướng.
V. Mã hóa tín hiệu miền thời gian.Có vài kỹ thuật dùng để biếu diễn các đặc tín tín hiệu miềnthời gian. Các kỹ thuật hay dùng nhất được dùng dưới đây
Điều chể xung mã (PCM) x(t) là một thể hiện của nguồn và xn làcác mẫu lấy theo tần số lấy mẫu fs ≥ 2W , W là tần số cao nhấttrong phổ x(t) .Trong mã PCM , mỗi mẫu tín hiệu được lượng tửhóa thành một trong 2R các mức tín hiệu , ở dây R là số ký hiệunhị phân dùng để biểu diễn cho mỗi mẫu . Như vậy tốc độ thôngtin của nguồn là Rfs bit/s. Quá trình lượng tử hóa có mô hìnhtoán học như sau :
n n nx x q
nx là giá trị lượng tử của nx và nq là sai số lượng tử (chúngta thường coi đó là nhiễu cộng). Giả sử bộ lượng tử hóa làđồng đều có quan hệ giữa đầu ra và dầu vào được mô tả trênhình vẽ sau, sai số lượng tử được đặc trưng thống kê bởi hàmmật độ phân bố xác suất đồng đều:
1 1 1( ) 2 2p q q
124

Bước lượng tử là ∆ = 2-R . trung bình bình phương sai số lượngtử là :
2 2 21 1( ) 212 12RE q
Theo thang dB , trung bình phương giá trị của nhiễu là :
2 210 10
110log 10log 2 6R 10.8dB12R
Chúng ta nhận thấy rằng sai số lượng tử giảm 6dB/bit đối vớibộ lượng tử hóa này. Ví dụ với bộ lượng tử hóa 7 bit thì saisố lượng tử là -52.8 dB .
Nhiều nguồn tín hiệu ví dụ như nguồn tín hiệu tiếng nói cótính chất là giá trị biên độ tín hiệu hay nhận giá trị nhỏ hơnlà nhận giá trị lớn. Nhưng bộ lượng tử hóa đồng đều có khoảngcách giữa các bước lượng tử giống nhau mà không phản ánh đượctính chất của tín hiệu. Đối với những tín hiệu như thể sử dụngbộ lượng tử hóa không đồng đều sẽ mang lại hiệu quả cao hơn.Tính chất của bộ lượng tử hóa không đồng đều có thể coi nhưcho tín hiệu qua một thiểt bị phi tuyển để nén biên độ tínhiệu, sau đó cho tín hiệu đã nén qua bộ lượng tử hóa đồng đều.Ví dụ bộ nén loga có quan hệ về biên độ giữa đầu ra và đầu vàonhư sau:
125
Hình V-19: Bước lượng tử

101 | || | log 1
xy
| x|≤1 là biên độ của tín hiệu vào, | y | là biên độ tín hiệura, μ là tham số nén biểu diễn quan hệ giữa |y| và |x| với cácgiá trị khác nhau của μ . Giá trị μ=0 t ương ứng với khôngnén tín hiệu .
Điều chể xung mã visai (DPCM) Trong PCM, mỗi mẫu tín hiệu đượcmã hóa độc lập với tất cả các mẫu khác. Tuy nhiên phần lớn cácnguồn tín hiệu được lấy mẫu ở tốc độ Nyquist hay cao hơn thìgiữa các mẫu liên tiểp có một mối liên hệ đáng kể . Nói cáchkhác, sự sai khác về biên độ giữa các mẫu liên tiếp là khánhỏ. Như vậy có thể xây dựng được một mô hình mã hóa tận dụngdược tính chất này để làm giảm tốc độ số liệu ở đầu ra củanguồn.
Một phương pháp đơn giản là chỉ mã hóa sự sai khác của các mẫutín hiệu liên tiểp thay cho mã hóa từng mẫu độc lập. Do sựchênh lệch giữa các mẫu nhỏ hơn nhiều giá trị biên độ của mộtmẫu lên cần it bit hơn để biểu diễn sự sai khác đó. Cụ thể ,ta có thể dự đoán mẫu hiện tại dựa trên p mẫu trước đó . Đặtxn là giá trị mẫu hiện tại và nx giá trị dự đoán của xn địnhnghĩa như sau:
1 } {ˆ
p
n i n ii
x a x
Như vậy nx là tổ hợp tuyến tính của p mẫu trước ai là các hệ sốcủa bộ dự đoán . các hệ số{ai}được chọn để tối thiểu hóa mộthàm sai lệch nào đó giữa nx và xn .
Hàm lỗi thường dùng trong toán học và thực tể là trung bìnhbình phương sai số (MSE).Với hàm lỗi này , ta chọn {ai}để cựctiểu hóa sai số:
2
2 2
1 1 1 1( ) 2
p p p p
p n n i n i n i n n i i j n i n ji i i j
E e E x a x E x a E x x a a E x x
126

Giả sử đầu ra của nguồn là dừng (theo nghĩa rộng ), tacó thể viểt lại công thức trên như sau :
1 1 1
0 2p p p
p i i ji i j
a i a a i j
m là hàm tự tương quan của các dãy các mẫu tín hiệu {xn}.Cựctiểu hóa p theo {ai}tạo liên hệ các phương trình tuyển tínhsau:
1
, 1,2,p
ii
a i j j j p
Khi hàm tự tương quan n không biết trước một cách tiênnghiệm, ta có thể ước lượng từ mẫu {xn}sử dụng các quan hệsau :
1
1ˆ , 0,1 ,N n
i i ni
n x x n pN
Chú ý rằng chuẩn hóa 1/N phải bỏ đi khi thay ˆ n vào công thức. Hệ phương trình tuyến tính dùng để tìm các hệ số của bộdự đoán được gọi là hệ phương trình Yule-Walker. Thuật toánLevínson và Durbin là loại thụât toán có hiệu quả dùng để giảihệ phương trình đó.
Đầu vào của bộ dự đoán ký hiệu là nx biểu diễn mẫu tín hiệu xn
nhưng bị thay đổi do quá trinh lượng tử đầu ra của bộ dự đoánlà :
1
ˆ p
i n ii
x a x
với sai lệch :
ˆn n ne x x
là tín hiệu vào của bộ lượng tử và đầu ra của bộ lượng tử kíhiệu là ne .Sai số ne được mã hóa thành từ mã và gửi đến phía
127

thu .Sai số lượng tử nx được cộng vào giá trị dự đoán đểđược nx .
Phía thu cũng sử dụng bộ dự đoán như phía phát và giá trị nx
đựoc cộng với ne để thu được nx . Tín hiệu nx được lọc qua mạchlọc thông thấp để thu đựoc tín hiệu x t . Sai số lượng tửbằng:
ˆn n n n n n n nq e e e x x x x
Như vậy , n n nx x q nghĩa là mẫu lượng tử hóa nx sai lệch vớimẫu tín hiệu nx một lượng bằng sai số lượng tư qn độc lập vớibộ dự đóan và do đó sai số không bị dồn .
Người ta có thể cải thiện chất lượng của việc dự đoán bằngcách lọc tuyển tính các giá trị sai số lượng tử cũ .Giá trị dựđoán nx được tính như sau:
1 1
ˆ p m
n i n i i n ii i
x a x be
{bi} là các hệ số của bộ lọc sai số lượng tử .Sơ đồ khối bộ mãhóa và giải mã được trình bày trên Hình V -20: Lượng tử hóamô hình nguồn.
128
Hình V-20: Lượng tử hóa mô hình nguồn

Nhiều nguồn thông tin trong thực tể là nguồn giả dừng(quasistationary). Đặc trưng của nguồn giả dừng là sai phươngvà hàm tự tương quan thay đổi chậm theo thời gian. PCM và DPCMđược thiểt kể trên cơ sở nguồn là dừng thống kê. Hiệu quả củacác phương pháp mã hóa này có thể được cải tiển bằng cách làmcho chúng thay đổi một cách thích nghi với tính thay đổi củachậm của nguồn.
Trong cả hai hệ thống PCM và DPCM , sai số lượng tử qn gây rabởi bộ lượng tử hóa đồng đều với tín hiệu vào giả dừng sẽ chosai phương thay đổi theo thời gian(công suất nhiễu lượng tử ).Sử dụng bộ lượng tử hóa thích nghi sẽ làm giảm giải động củanhiễu luợng tử. Môt phương pháp đơn giản sử dụng cho các bộlượng tử hóa đồng đều là thay đổi bước lượng tử tùy theo saiphương của các mẫu tín hiệu trước. Ví dụ việc ước lượng trongkhoảng thời gian ngắn sai phương của xn được tính từ dãy tínhiệu vào {xn} có thể dùng để thay đổi bước lượng tử. Hình saubiểu diễn bộ lượng tử hóa 3 bit với bước lượng tử thay đổitheo quan hệ :
1n nM n
Trong hệ thống PDCM , bộ dự đoán cũng có thể đựoc thiết kể đểthích nghi với tính chất giả dừng của nguồn tín hiệu . Các hệsố của bộ dự đoán có thể thay đổi tuần hoàn để phản ánh sựthay đổi thống kê của nguồn tín hiệu. Hệ phương trình tuyếntính trong công thức 5-4-9 vẫn như cũ , với việc ước lượngthời gian ngắn các hàm tự tương quan của xn . Các hệ số của bộdự đoán có thể được truyền từ phía phát tới phía thu cùng vớisai số lượng tử ne nhưng sẽ làm tăng tốc độ số liệu trên kênh.Để giải quyết điều đó bộ dự đoán ở phía thu có thể tính các hệsố dự đoán của nình từ ne và
1:
p
n n n i n ii
x x e a x
Nếu ta bỏ qua sai số lượng tử nx sẽ bằng xn . Các hàm tự tươngquan n tính từ nx thưòng đủ để tính các hệ số dự đoán mộtcách khá chính xác, và như vậy tốc độ số liệu sẽ giảm đi.
129

Thay cho việc dùng các khối xử lý dựa trên các hệ số dự đoán{ai} được nói ở trên ta có thể sử dụng các hệ số dự đoán dựatrên thuật toán kiểu gradient đối với từng mẫu tương tự nhưthuật toán gradient cân bằng thích nghi.
VI. Mã hóa tín hiệu miền tần sốTrong phần này chúng ta sẽ trình bày các phương pháp mã hóatín hiệu bằng cách lọc tín hiệu ở đầu ra của nguồn thành nhiềudải tần số và mã hóa riêng rẽ tín hiệu trong từng dải.
Mã hóa băng con (Subband Coding) Trong mã hóa băng con (SBC)đối với tín hiệu tiểng nói hay tín hiệu hình ảnh, tín hiệuđược chia thành nhiều dải băng hẹp và tín hiệu trong miền thờigian ứng với mỗi dải được mã hoa độc lập. Trong mã hóa tiểngnói , dải tần số chứa phần lớn năng lượng của tín hiệu, thêmvào nữa , nhiễu lượng tử ảnh hưởng tới tai người rất thấptrong dải tần số thấp. Như vậy tín hiệu ở băng tần thấp đượcmã hóa bằng nhiều bit còn tín hiệu ở miền tần cao được mã hóabởi ít hơn.
Mã hóa biển đổi thich nghi (Adaptive Tranform Coding). Trongmã hóa biển đổi thích nghi ta chia các mẫu tín hiệu của nguồnthành từng khung T mẫu , sau đó số liêu trong mỗi khung đượcchuyển sang miền tần số rồi mã hóa và truyền đi Tại phía thumỗi khung phổ cấ mẫu tín hiệu sẽ được truyền ngược lại trongmiền thời gian và tín hiệu sẽ dược tổng hợp lại từ các mẫu ởmiền thơì gian rồi cho qua bộ biển đổi D-A. Để mã hóa có hiệuquả, ta dung nhiều bít cho các thành phần phổ quan trọng và ítbít hơn cho các thành phần phổ không quan trọng .
Việc lựa chọn phép biển đổi từ miền thời gian sang miền tần sốphải sa cho các mẫu phổ không liên hệ với nhau. Như vậy thìphép biển đổi Karhunen-Loéve là tối ưu . Nhưng tính toán phépbiển đỏi này quá phức tạp nên người ta thường dùng phép biểnđổi DFT hay nhiều phép biển đỏi Cosin rời rạc DCT (discreteCosin Transform ). HIệu quả phép biển đổi DCT cao hơn nênngười ta thường hay sử dụng phương pháp này
130

VII.Mã hóa mô hình nguồnKhác với các phương pháp đã mã hóa ở trên, cách tiểp cận củaphương pháp mã hóa mô hình nguồn hoàn toàn khác. Trong phươngpháp này, mô hình nguồn được coi là một hệ thống tuyển tính,được kích thích bởi một tín hiệu vào và cho tín hiệu ở đầu ratương ứng. thay cho truyền các mẫu ở nguồn tín hiệu phía thungười ta truyền tham số của hệ thống tuyển tính với các kíchthích đầu vào tương ứng . Nểu số lượng các tham số là nhỏ thìphương pháp mã hóa mô hình nguồn cho phép nén số liệu rấtnhiều.
Phương pháp mã hóa mô hình nguồn được sử dụng một cách rộngrãi nhất là mã hóa dự đoán tuyển tính (LPC). Trong phương phápnày, các mẫu ký hiệu được ký hiệu là xn = 0, 1,…, N-1, coi nhưđược sinh ra từ bộ lọc toàn cực (rời rạc) có hàm truyền đạt:
1
H z1
pk
kk
G
a z
Kích thích hệ thống có thể là một xung, một dãy các xung haycác mẫu của tín hiệu nhiễu trắng có sai phương đơn vị. Trongcác trường hợp đó, giả sử dãy tín hiệu được ký hiệu là vn , n =1, 2,… dãy tín hiệu ra thỏa mãn phương trình sai phân:
1 1, 0,1, , 0
p p
n k n k n n k n kk k
x a x Gv n x a x n
Tổng quát dãy tín hiệu ra xn=0,1,…,N-1 không phải thỏa mãnphương trình sai phân. Nểu đầu vào là dãy tín hiệu nhiễu trắnghay là một xung, ta có thể thực hiện việc ước lượng (dự đoán)xn bằng tổ hợp tuyển tính:
1, 0
p
n k n kk
x a x n
Sai lệch giữa nx và nx :
n1
ˆep
n n n k n kk
x x x a x
131

biểu thị sai lệch giữa giá trị nhận được và giá trị dự đoán.Các hệ số của bộ lọc được lựa chọn để tối thiểu hóa trung bìnhbình phương sai lệch này.
Giả sử tín hiệu vào là dãy tín hiệu nhiễu trắng thì đầu ra củabộ lọc là một dãy ngẫu nhiên cũng như sai lệch en= ˆn nx x Giátrị trung bình của bình phương sai lệch là:
2
2
1 1 1 1( ) 0 2
p p p p
p n n i n i k k mi k k m
E e E x a x a k a a k m
(m) là hàm tự tương quan của dãy tín hiệu xn, n = 1, 2,…, N-1. Để xác định rõ H(z) ta cần xác định hệ số G. Ta có :
2
2 2 2 2
1
p
n n n k n k pk
E Gv G E v G E x a x
ở đây p ta nhận được từ khi thay các hệ số dự đoán tối ưu làlời giải của. Như vậy:
2
10
p
p kk
G a k
Trong thực tể chúng ta thường không biểt hàm tự tương quan củatín hiệu đầu ra của nguồn. Như vậy cho n , ta có thể sử dụngcác giá trị n cho bởi (5-4-10) nhận được từ dãy các mẫu xn, n= 0, 1,…, N-1.
Như đã nói ở trên, thuật toán Levinson-Durbin có thể được sửdụng để tìm ra các hệ số {ai} một cách truy hồi, xuất phát từbộ dự đoán bậc 1 rồi đển bậc p. các phương trình truy hồi đểtìm {ai} là:
132

1
11
12
2
1 1
1 1
1
11 0
ˆ ˆ,i 2,3,..,pˆ
ˆ ˆ ˆ ˆ0 0 1
,1 k i 1ˆ ˆ1
ˆ1 ˆ ˆ, 0ˆ 0
i
i i kk
iii
pp
k iik i
ik i k ii i i k
i ii i
a i ka
G a k a
a a a aa
a
aik, k = 1, 2,…i là các hệ số của bộ dự đoán bậc i. các hệ sốcủa bộ dự đoán bậc p là : ,k 1,2, ,pk pka a , và sai số là :
2
2
1 1
ˆ ˆ ˆ ˆ0 0 1pp
k iik i
G a k a
Ta nhận thấy các phương trình truy hồi không những cho cáctham số của bộ dự đoán bậc p mà còn cho tất cả các tham số củabộ dự đoán có bậc nhỏ hơn p.
Các giá trị sai số i thỏa mãn điều kiện và các hệ số dựđoán iia thỏa mãn điều kiện ii a 1, i 1, 2, , p , các điều kiện nàylà cần và đủ để cho tất cả các điểm cực của H(z) nằm trongđường tròn đơn vị. như vậy hệ là đảm bảo để hệ ổn định.
133

CHƯƠNG VI. MÃ HÓA KÊNH
Bài 13. Cơ sở lý thuyết mã chống nhiễu
I. Mã hóa chống nhiễu theo ShannonTheo định lý mã hóa Shannon khi tốc độ lập tin của nguồn cònnhỏ hơn thông lượng của kênh thì có thể thực hiện được việctruyền tin tin cậy với sai số nhỏ tùy ý. Tuy nhiên, Shannon đềxuất giải pháp thực hiện bằng cách mã hóa từng khối ký hiệu cóđộ phức tạp tính toán khi mã hóa và giải mã tăng theo hàm mũcủa kích thước khối, rất khó có thể cải thiện hiệu năng.
Trong thực tế, để chống nhiễu thường dùng các thông tin bổsung – thông tin điều khiển. Các thông tin điều khiển này đượctính dựa theo các thông tin cần truyền tin. Đến khi nhận đượcthông tin, căn cứ vào các thông tin điều khiển này có thể thựchiện:
- Phát hiện quá trình truyền tin lỗi hay không lỗi (pháthiện lỗi)
- Xác định lại thông tin đã gửi đi dựa vào thông tin lỗi(sửa lỗi)
Phương pháp thứ 2 đảm bảo được việc truyền tin tin cậy, cònphương pháp thứ 1 cần có cơ chế cho phép bộ phận giải mã cóthể thông báo cho bộ phận mã hóa về kết quả của quá trìnhtruyền tin, đồng thời cần một cơ chế để bộ phận mã hóa có thểtruyền lại thông tin bị lỗi. Cơ chế này gọi là cơ chế truyềnlại.
Việc sử dụng phương pháp mã hóa nào, hiệu suất đến đâu phụthuộc vào tính chất của kênh truyền tin. Trong những năm 60-80khi kết nối giữa các máy tính chủ yếu là bằng đường điện thoạiquay số, các mã sửa lỗi, đặc biệt là mã Hamming được sử dụngrộng rãi. Công nghệ mạng cục bộ đảm bảo một tỷ suất lỗi nhỏhơn nhiều so với đường truyền quay số, làm cho mã sửa lỗi trở
134

thành không phù hợp. Mã phát hiện lỗi (mã vòng, mã chẵn lẻ) vàcơ chế truyền lại là giải pháp thích hợp cho trường hợp này.Với các kết nối không dây, khi tính chất của kênh truyền tinthay đổi liên tục, việc sử dụng cơ chế truyền lại không cònphù hợp, cần có các mã sửa lỗi mềm dẻo, thích ứng với các kênhtruyền tin có tính chất khác nhau: mã chập
II. Nguyên tắc mã hóa chống nhiễuSử dụng các thông tin điều khiển, số lượng các tổ hợp mã cóthể nhiều hơn nhiều so với số lượng các từ mã. Khả năng chốngnhiễu của mã cũng lớn hơn nhiều và kèm theo đó là hiệu suất mãsẽ giảm. Các vấn đề cần làm sáng tỏ sẽ là: cơ chế để phát hiệnlỗi và giải mã, ảnh hưởng của số lượng các thông tin điềukhiển đến hiệu suất mã.
Cơ chế phát hiện lỗi. Như ở chương 4 đã đề xuất, việc pháthiện lỗi không được thực hiện một cách hoàn toàn mà dựa trênviệc tổ hợp mã nhận được luôn luôn là một tổ hợp mã hợp lệ.Nếu tổ hợp mã này không phải là từ mã, có thể kết luận được làquá trình truyền tin có lỗi. Ngược lại, nếu tổ hợp mã là từmã, điều này chứng tỏ hoặc quá trình truyền tin không có lỗi,hoặc có một lỗi biến đổi một từ mã thành từ mã khác. Trườnghợp thứ 2 được coi là có lỗi xảy ra nhưng không phát hiệnđươc. Như vậy việc phát hiện lỗi tương đương với việc pháthiên một tổ hợp mã có phải là từ mã hay không. Thông thườngthao tác này được thực hiện dựa trên hàm đặc trưng ( ), ) 0w(F w F
khi và chỉ khi w là từ mã. Cơ chế phát hiện lỗi chỉ đảm bảođược phát hiện được các lỗi có xảy ra hay không. Việc đảm bảotruyền tin tin cậy được thực hiện bằng các cơ chế báo nhận(truyền thông báo cho trạm gửi về kết quả) và truyền lại(truyền lại các từ mã bị lỗi). Phát hiện lỗi, báo nhận vàtruyền lại thích hợp với trường hợp độ tin cậy của kênh truyềntin lớn, khả năng phải kích hoạt tiến trình xử lý lỗi thấp.Trường hợp kênh truyền tin có lỗi, các thao tác xử lý lỗi đặtthêm tải cho kênh truyền tin, trong nhiều trường hợp sẽ làm têliệt hoàn toán hệ thống truyền tin.
135

Cơ chế sửa lỗi Trường hợp khả năng xuất hiện lỗi lớn, để tránhtrường hợp các thao tác xử lý lỗi tạo thêm tải cho hệ thống,cơ chế sửa lỗi được sử dụng. Cơ chế sửa lỗi cho phép xác địnhtừ mã đã bị gửi lỗi dựa trên tổ hợp mã bị lỗi. Để giải quyếttrọn vẹn bài toán này, cần xem xét M*N mối quan hệ giữa các từmã và các tổ hợp mã. Độ phức tạp của bài toán sẽ được cảithiện nếu thay vì tìm từ mã ban đầu xác định sự thay đổi củatừ mã ban đầu. Bài toán sửa lỗi sẽ trở thành bài toán tổngquát với tất cả các từ mã chứ không gắn với một từ mã nào.
1 2(w+e)=S ( ) wF F e S e
Khả năng phát hiện và sửa lỗi. Với một mã hiệu, khả năng pháthiện lỗi được thể hiện bằng khả năng một lỗi tạo ra một từ mãkhác. Khả năng sửa lỗi được thể hiện bằng khả năng hai từ mãlỗi cùng tạo ra một tổ hợp mã lỗi. Hiển nhiên khả năng pháthiện và sửa lỗi được đảm bảo bằng các thông tin điều khiển,hay nói cách khác, bằng việc giảm hiệu suất mã.
Ở một góc độ khác, không có mã hiệu chống nhiễu nào có thể sửahết tất cả các lỗi có thể. Không phải tất cả các lỗi có thểxảy ra khi truyền thông tin qua kênh truyền tin. Ở đây chúngta giả định là một lỗi thay đổi từ mã ít khả năng sẽ xảy ranhiều hơn so với lỗi thay đổi từ mã nhiều. Ví dụ nếu từ tổ hợpmã w’ nhận được, có 2 từ mã có thể sinh ra w’ là w1 và w2 thìtừ mã nào có sai khác so với w’ nhỏ hơn sẽ được chấp nhận.
Như vậy có thể giả định khi truyền một từ mã qua một kênhtruyền tin, các lỗi có thay đổi nhỏ đến từ mã sẽ xảy ra, cáclỗi khác không xảy ra. Đặc tính này của kênh truyền tin đượcbiểu diễn bằng số vị trí lỗi tối đa có thể xảy ra trên mỗi từmã, hay nói cách khác, khoảng cách Hamming tối đa giữa từ mãvà tổ hợp mã bị lỗi sinh ra bởi từ mã d.
Để thực hiện được việc phát hiện và sửa lỗi, các từ mã phảikhác nhau đủ để có thể phân biệt được. Mức độ khác nhau giữacác từ mã được đo bằng khoảng cách Hamming tối thiểu giữa cáctừ mã D.
136

Điều kiện để phát hiện được lỗi sẽ là D d để đảm bảo không cótừ mã nào bị lỗi thành một từ mã khác. Điều kiện sửa lỗi tươngứng sẽ là 2D d .
Ví dụ Mã hiệu gồm 2 từ mã 0,1 có hiệu suất bằng 1, khoảng cáchgiữa các từ mã bằng 1 không có khả năng chống nhiễu. Bất cứmột tác động lỗi nào lên từ mã đều biến từ mã thành một từ mãkhác. Để có thể chống nhiễu, bổ sung 1 bít điều khiển bằng bítthông itn. Khi đó có mã 00,11 có 2 từ mã, khoảng cách tốithiểu giữa các từ mã là 2. Như vậy khi có lỗi xảy ra và chỉ cóđúng 1 bít lỗi, mã này sẽ sửa được lỗi. Để phát hiện lỗi cầnbổ sung thêm 1 bít thành mã hiệu 000,111 với khoảng cách củacác từ mã là 3. Trường hợp này nếu chỉ có 1 bít lỗi có thể xácđịnh được ngay từ mã ban đầu.
III.Các mô hình lỗiĐể có thể phân tích khả năng xử lý lỗi của các mã hiệu chốngnhiễu, cần xác định rõ bối cảnh bị lỗi. Các lỗi được xem xét ởđây là các lỗi dạng Byzantin, khiến cho thông tin bị thay đổi.Thông thường chúng ta xem xét các loại lỗi sau đây:
Lỗi đơn: Các lỗi đơn xảy ra riêng lẻ, không có liên hệ thốngkê với nhau. Được đặc trưng bởi xác suất xảy ra lỗi khi gửimột ký hiệu mã.
Lỗi chùm: là các lỗi xảy ra liên tục, có ràng buộc với nhau vềthống kê. Được đặc trưng bởi độ dài lỗi và xác suất xảy ralỗi.
Các lỗi mất bít, thừa bít được xếp vào dạng lỗi chùm.
Bài 14. Mã tuyến tính
I. Khái niệm và biểu diễnVới mã khối, từ mã được coi là một véc tơ có độ dài cố định.Mã khối là tập hợp các véc tơ này. Độ dài của một từ mã là sốlượng kí hiệu mã có trong từ mã và kí hiệu là n. Mỗi kí hiệumã nhận một giá trị trong bộ kí hiệu có q phần tử. Khi 2q
thì bộ mã là nhị phân. Khi 2q thì bộ mã không phải là nhị
137

phân. Đặc biệt khi 2bq với b là số nguyên dương thì mỗi kíhiệu mã trong từ mã tương đương với một từ mã nhị phân có q
bit. Như vậy mã không nhị phân có độ dài N trong trường hợpnày tương đương với một từ mà nhị phân độ dài n bN .
Ta có thể tạo được 2n tổ hợp nhị phân có độ dài n. Trong đó tacó thể chọn ra M= 2k từ mã (k<n) để tạo ra bộ mã và có thể coikhối dài k bit là khối thông tin được mã hoá. Như vậy khối kbit thông tin được ánh xạ thành một từ mã có độ dài n trongtập M từ mã. Ta gọi mã khối đó là mã khối (n,k) và Rc k/n làtốc độ mã. Số lượng kí hiệu khác 0 trong một từ mã gọi làtrọng lượng của từ mã và tập hợp các giá trị trọng lượng củacác từ mã có trong bộ mã tạo thành sự phân bố về trọng lượngcủa bộ mã. Khi M từ mã có cùng trọng lượng thì gọi là bộ mã cótrọng lượng cố định.
Việc mã hóa và giải mã hoá thực hiện các phép toán cộng vànhân số học trên các từ mã. Các phép toán số học tuân theo cácquy ước của trường đại số với các phần tử là các kí hiệu trongbộ kí hiệu. Trường F là tập hợp các phần tử mà trên tập hợpnày ta định nghĩa được hai phép toán số học gọi là phép cộngvà phép nhân thoả mãn các điều kiện sau sau:
Phép cộng:
Tập hợp F là đóng đối với phép cộng, có nghĩa là nếu a, b Fthì a + b F.
Phép cộng có tính kết hợp, có nghĩa là nếu a, b, c F thì
a + (b + c) = (a + b) + c.
Phép cộng có tính chất giao hoán, có nghĩa là a + b = b + a.
Trong tập hợp có một phần tử gọi là phần tử không kí hiệu là 0mà a + 0 = a.
Mọi phần tử trong tập hợp đều có phần tử đối. Nếu b là mộtphần tử thì phần tử đối, kí hiệu là –b. Phép trừ giữa hai phầntử được định nghĩa là a + (-b).
138

Phép nhân:
Tập F là đóng đối với phép nhân, có nghĩa là nếu a, b thìab F.
Phép nhân có tính kết hợp, có nghĩa là a(bc) = (ab)c.
Phép nhân có tính giao hoán, ab = ba.
Phép nhân có tính phân phối đối với phép cộng, có nghĩa là (a+ b)c = ac + bc.
Tập hợp F có một phần tử gọi là phần tử đơn vị, kí hiệu là 1mà a1 = a với mọi a F.
Mọi phần tử thuộc F, khác 0 đều có nghịch đảo, nếu b F, b 0 thì nghịch đảo của b kí hiệu là b-1 và bb-1 = 1. Phép chiagiữa hai phần tử a và b được định nghĩa là ab-1.
Bộ mã được xây dựng từ một trường có hữu hạn phần tử và trườnghữu hạn có q phần tử gọi là trường Galois và kí hiệu làGF(q). Mọi trường đều có hai phần tử 0 và 1. Như vậy trườngđơn giản nhất là trường GF(2). Phép cộng và phép nhân trêntrường GF(q) được định nghĩa theo phép modulo q và kí hiệu là(mod q). Nếu mq p với m là nguyên dương thì ta có thể mở rộngtrường ( )GF p thành trường ( )mGF p và được gọi là trường mở rộngcủa trường ( )GF p . Phép cộng và phép nhân trên trường mở rộngdựa trên số học modulo p.
Giả sử có hai từ mã Ci và Cj trong mã khối ( , )n k . Sự khác nhaugiữa các kí hiệu tương ứng hay các vị trí tương ứng gọi làkhoảng cách Hamming giữa hai từ mã và kí hiệu la dij. Với i j
thì 0 i jd n . Giá trị nhỏ nhất trong tập i jd gọi là khoảngcách tối thiểu giữa hai từ mã và kí hiệu là mind (còn gọi làkhoảng cách Hamming của từ mã).
Một bộ mã có thể tuyến tính hoặc không tuyến tính. Giả sử Ci vàCj là hai từ mã của bộ mã khối (n,k) và 1 và 2 là hai phầntử nào đó thuộc bộ kí hiệu. Bộ mã là tuyến tính nếu và chỉ nếu1.Ci + 2Cj cũng là một từ mã. Như vậy mọi bộ mã tuyến tính
139

đều chứa từ mã 0 (là từ mã chỉ chứa các kí hiệu mã là 0). Nhưvậy mã có trọng lượng cố định là mã phi tuyến.
Giả sử có một bộ mã khối tuyến tính và kí hiệu Ci, i= 1,2,…., Mlà các từ mã. Kí hiệu C1 là từ mã 0, C1= [00…0] và wr là trọnglượng của từ mã thứ r. Như vậy thì wr chính là khoảng cáchHamming giữa Cr và C1. Khoảng cách giữa hai từ mã Ci và Cj làtrọng lượng của từ mã tổng của Ci và Cj. Sự phân bố của trọnglượng của một bộ mã tuyến tính hoàn toàn đặc trưng cho khoảngcách Hamming của bộ mã. Khoảng cách tối thiểu của bộ mã là:
min r1min{w }
rd
Tập hợp tất cả các véc tơ n chiều tạo nên một không gian véctơ n chiều. Nếu ta chọn một tập hợp ( )k n véc tơ độc lập tuyếntính trong không gian véc tơ S (là không gian véc tơ được xâydựng bởi tất cả các tổ hợp mã có độ dài n cùng với các phéptoán tương ứng) và xây dựng toàn bộ các tổ hợp tuyến tính củacác vectơ này thì sẽ tạo nên không gian con Sc của không gian Scó chiều là k. Mọi tập hợp k vectơ độc lập tuyến tính trong Sc
đều tạo nên cơ sở của không gian vectơ. Xét tất cả các vectơtrong S trực giao với cơ sở của Sc (tức là trực giao với mọivéc tơ trong Sc) thì tập hợp đó tạo ra một không gian con của Svà gọi là không gian không của Sc. Số chiều của Sc là k thì sốchiều của không gian không là n – k. Không gian không của Sc làmột mã tuyến tính khác, có số phần tử là 2n – k và trong mỗi từmã hay mỗi véctơ có n – k bit thông tin.
Mã hiệu tuyến tính với k bít thông tin, có chiều dài các từ mãn với n-k bít điều khiển được biểu diễn bởi tập hợp k từ mã cơsở tạo thành một ma trận gọi là ma trận sinh
1 11 12 1
2 21 22 2
1 2
n
n
k k knk
g g g gg g g g
G
g g gg
Điều kiện cần và đủ để một tổ hợp mã w là từ mã là:
1 2 1 1 2 2, ... :w ...k k ka a a a g a g a g
140

II. Mã hóa, giai mã và phát hiện lỗiXét m1 m2 mkx , x , , x là k bit thông tin được mã hoá thành một từmã mC . Véc tơ k bit thông tin đưa vào bộ mã hoá được kí hiệulà:
m m1 m2 mkX x x x
và đầu ra của bộ mã hoá vectơ:
m m1 m2 mnC c c c
Quá trình mã hóa trong một bộ mã hóa khối tuyến tính có thểđược biểu diễn bằng n phương trình:
mj m1 1j m2 2j mk kjC x g x g x g , j 1, 2, , n
với ijg {0,1} . Các phương trình (10-1-2) được biểu diễn dướidạng ma trận như sau:
m mC X G
Để giảm bớt khối lượng tính toán, ma trận sinh thường đượcchuyển về dạn chuẩn tắc (dạng hệ thống) như sau:
11 12 1
21 22 2
1 2
1 0 0 00 1 0 0
0 0 0 1
n k
n kk
k k kn k
p p pp p p
G I P
p p p
Theo công thức mã hóa m m1 1 m2 2 mk kC x g x g x g , từ mã sẽ códạng
1 2 1... ...,m m mk k nx x x c c với k bít thông tin ở vị trí đầu tiên và n-k bítđiều khiển ở vị trí tận cùng bên phải. Các bít điều khiển đượctính từ tổ hợp tuyến tính của các bít thông tin. Như vậy quátrình mã hóa là quá trình điền các bít thông tin, tính toán vàđiền các bít điều khiển. Việc giải mã đơn thuần chỉ là việctrích xuất các vị trí bít thông tin ra thành các thông tin banđầu. Với ma trận sinh dạng chuẩn tắc, các bít thông tin nằm ởcác vị trí đầu tiên. Với các ma trận sinh dạng khác, vị trícác bít thông tin nằm rải rác trong cả từ mã. Các cột tương
141

ứng với các bít thông tin của ma trận sinh tạo thành một matrận đơn vị.
III.Quá trình phát hiện lỗiTheo nguyên tắc phát hiện và sửa lỗi đã trình bày ở mục trên,để phát hiện lỗi cần phát hiện tổ hợp mã hợp lệ đã nhận đượccó phải là từ mã hay không. Như vậy, cho biết một tổ hợp mã cóchiều dài n, cần xác định xem tổ hợp mã này có phải là từ mãhay không. Cần xác định xem có tồn tại các hệ số , 1ia i k , saocho
1w
k
i ia g
Bài toán phát hiện lỗi chuyển về giải hệ n phương trình tọa độvới k ẩn. Nếu bài toán có nghiệm, tổ hợp mã nhận được là từmã, quá trình truyền tin được coi là không có lỗi. Nếu không,quá trình truyền tin có lỗi.
Việc giải hệ phương trình bậc nhất là phức tạp. Có thể thựchiện cải tiến theo 2 cách. Cách thứ nhất là tính lại từ mã dựatrên các bít thông tin và so sánh với từ mã nhận được. Cáchthứ hai dựa vào tính chất của không gian bù. Từ mã w nằm trongkhông gian của mã hiệu, do đó nó phải vuông góc với tất cả cáctổ hợp mã nằm trong không gian bù. Không gian của mã hiệu có kchiều, vậy không gian bù có n-k chiều. Gọi n-k véc tơ cơ sởcủa không gian bù là 1 2, , n kh h h . Một tổ hợp mã là từ mã khi vàchỉ khi:
w 0, 1ih i n k
Có thể viết lại các đẳng thức
w. 0tH
Trong đó
1
2
...T
n k
hh
H
h
được gọi là ma trận thử của mã hiệu.
142

Cách xác định ma trận thử từ ma trận sinh Một mã hiệu tuyến tính có thểcó nhiều ma trận thử và ma trận sinh. Ứng với một ma trận sinhcó thể có nhiều ma trận thử. Vì vậy bài toán đặt ra là tìm mộtma trận thử. Nếu trong ma trận sinh, các bít thông tin ứng vớimột ma trận đơn vị thì trong ma trận thử, các bít điều khiểncó thể coi là các bít bù của các bít thông tin, do đó cũngtương ứng với một ma trận đơn vị. Như vậy đã có ( )( )n k n k cácgiá trị của ma trận thử. Điều kiện để một ma trận là ma trậnthử của một mã hiệu là các hàng của ma trận thử và các hàngcủa ma trận sinh có tích bằng 0. Do đó có thêm ( )k n k phươngtrình nữa, đủ để xác định ( )k n k bít còn lại của ma trận thử.
Trường hợp ma trận sinh có dwạng chuẩn tắc Ma trận thử sẽ có dạngchuẩn tắc tương tự. Điểm khác biệt là ma trận đơn vị sẽ nằmtận cùng bên phải của ma trận thử.
' n kH P I
Có thể chứng minh ' TP P .
Như vậy quá trình phát hiện lỗi được thực hiện dựa trên matrận thử H. Nếu 0TwH quá trình truyền tin xảy ra không cólỗi. Nếu 0TwH quá trình truyền tin xảy ra đã có lỗi.
IV. Quá trình sửa lỗiQuá trình sửa lỗi là quá trình tái tạo lại từ mã đã bị biếnđổi sau quá trình truyền tin. Giả sử từ mã w sau khi đượctruyền qua kênh đã biến thành từ mã *w . Tại bộ phận thu tin,với *w , ma trận sinh, ma trận thử cần xác định từ mã ban đầu.
Việc phát hiện quá trình truyền tin có lỗi hay không được thựchiện bằng cách tính giá trị của vecto
w *. TS H
Để đơn giản hóa bài toán, thay vì việc xác định w từ các tổhợp *w , chúng ta xác định các thay đổi trên w để tạo ra *w
w*=w e
143

Trong đó e được gọi là cấu hình lỗi. Bài toán xác định wchuyển về bài toán xác định e.
Nhận thấy
. (w * w ) w * wT T T Te H H H H S
Việc xác định e trở thành việc giải phương trình . Đây là mộtphương trình véc tơ với n k tọa độ, có n ẩn, vì vậy khả năngcó vô số nghiệm là rất lớn. Nói cách khác, bài toán sửa tất cảcác lỗi là không thực hiện được. Trong thực tế, hiếm có lỗinào xảy ra mà thay đổi tất cả các bít của từ mã. Như vậy cóthể hạn chế các loại cấu hình lỗi có thể xảy ra. Nếu số lượngcác cấu hình lỗi có thể xảy ra nhỏ hơn số các giá trị của S ,khi đó phương trình sẽ có tối đa một nghiệm. Trong trường hợpnày, bài toán sửa lỗi sẽ được thực hiện như sau:
- Liệt kê tất cả các cấu hình lỗi có thể
- Tính các syndrom cho các cấu hình lỗi. Nếu có 2 syndrombằng nhau, bài toán sửa lỗi không giải được
- Nếu không, khi nhận được một tổ hợp mã *w , tính * TS w H
- Tìm dòng có S trong bảng vừa lập. Xác định e tương ứng
- Từ mã ban đầu là *w e
Ví dụ về mã hiệu tuyến tính và sửa lỗi cho mã hiệu tuyến tinhđược trình bày trong hình VI -21
144

00000010111011011101
11101
011001101010001
Cấu hình lỗi1000001000001000001000001
Syndrom011110100010001
M a trận sinh M a trận thửM ã hiệu
Bảng kề
0101110110
10101 E.H T
110+
VI-21: Ví dụ về mã hiệu tuyến tính (5,2)
V. Thiết kế mã chống nhiễuSố lượng syndrom tối đa có thể có là 2n k . Số cấu hình lỗi cóthể có i lỗi là i
nC . Vậy điều kiện để mã hiệu có thể sửa cáccấu hình lỗi có tối đã r lỗi là:
02
ri n knC
Trường hợp chỉ có một lỗi, biểu thức trở thành
1 2n kn
Ngoài ra, các syndrom chính là tổ hợp của các cột của ma trậnthử. Trường hợp có tối đa r lỗi, các syndrom sẽ là tổ hợp củatối đa r cột.
Bài toán: xây dựng mã hiệu tuyến tính sửa tối đa r lỗi với cáctừ mã chiều dài n.
- Xác định số bit điều khiển và số bít thông tin dựa vàocác công thức và .
145

- Xây dựng ma trận thử. Điều kiện của ma trận thử là khôngcó r cột nào phụ thuộc tuyến tính.
- Xây dựng ma trận sinh từ ma trận thử.
Trong quá trình xây dựng mã hiệu, bước thiết lập ma trận thửlà phức tạp nhất. Nếu 1r , ma trận thử có thể được xây dựngbằng cách lấy một ma trận đơn vị tận cùng bên phải. Các cộtcòn lại được xác định theo nguyên tắc: không có cột toàn 0 vàkhông có 2 cột nào bằng nhau. Nếu 1r , cần đảm bảo không cócột 0 và không có 2r cột nào có tổng bằng 0.
Ví dụ: Xây dựng mã hiệu chiều dài 6, sửa 1 lỗi
Có 2 6 1 7n k . Vì thế mã hiệu là mã (6,3). Ma trận thử sẽ códạng
H=1 0 00 1 00 0 1
x x xx x xx x x
3 cột còn lại không là cột 0, không là cột có 1 ký hiệu 1, vậychỉ có thể là các cột có 2, 3 ký hiệu 1. Một lựa chọn là
H=1 1 0 1 0 01 1 1 0 1 01 0 1 0 0 1
Do đó ma trận sinh của mã hiệu sẽ là
1 0 0 1 1 00 1 0 1 1 10 0 1 1 0 1
VI. Một số loại mã tuyến tính thường gặpMã Hamming có cả mã Hamming nhị phân và không nhị phân vàchúng ta chỉ xét mã nhị phân. Mã Hamming gồm lớp các bộ mãthỏa mãn điều kiện:
m mn,k 2 – 1,2 – 1 – m
trong đó m là số nguyên dương.
146

Ma trận kiểm tra parity H có tính chất đặc biệt giúp chúng tamô tả mã dễ dàng hơn. Đối với mã Hamming (n,k), n= 2m – 1 cộtgồm tất cả các vectơ có m = n – k phần tử trừ vectơ 0. Ví dụnhư mã (7,4) là mã Hamming. Ma trận kiểm tra parity gồm 7vectơ cột là tất cả các véc tơ có độ dài 3 trừ vectơ 0. Nếu tamuốn tạo mã Hamming có tính hệ thống thì ta có thể dễ dàng sắpxếp để có được ma trận kiểm tra parity H và từ đó có ma trậnsinh G. Ta nhận thấy rằng không có hai cột khác nhau nào củama trận H là phụ thuộc tuyến tính. Tuy nhiên với m > 1, ta cóthể tìm được 3 cột của H có tổng bằng 0. Như vậy dmin = 3 đốivới mã Hamming.
Bằng cách thêm bit parity, mã Hamming (n,k) có thể mở rộngthành mã (n + 1,k) với dmin = 4. Mặt khác, mã Hamming có thểthu hẹp lại thành mã (n – l,k – l) bằng cách bỏ đi l hàngtrong ma trận sinh G hay bỏ đi l cột trong ma trận kiểm traparity H. Phân bố trọng lượng của mã Hamming (n,k) được biểudiễn thành dạng đa thức như sau:
( 1) ( 1)2 2
1
1( ) (1 ) (1 ) (1 )1n n ni n
ii
A z A z z n z zn
với Ai là số lượng các từ mã có trọng lượng i.
Mã Hadamard:
Mã Hadamard nhận được từ các hàng của ma trận Hadamard. Matrận Hadamard Mn là ma trận nn (n chẵn), các phần tử là 0
hoặc 1, một hàng bất kì khác các hàng khác chỉ ở 12n vị trí.
Một hàng của ma trận gồm toàn phần tử 0 còn các hàng khác gồm12n phần tử 0 và 12n phần tử 1.
Với n = 2, ma trận Hadamard là:
20 00 1M
Từ ma trận Mn, ta có thể tạo ra ma trận M2n theo quan hệ:147

2n n
nn n
M MM
M M
với nM là ma trận bù của Mn bằng cách thay phần tử 0 bằngphần tử 1 và ngược lại. Ta có:
4
0 0 0 00 1 0 10 0 1 10 1 1 0
M
Ma trận bù của M4 là:
4
1 1 1 11 0 1 01 1 0 01 0 0 1
M
Từ các hàng của M4 và 4M ta tạo ra 8 từ mã độ dài 4. Khoảng
cách tối thiểu dmin = 12n = 2. Ta có thể tạo ra các từ mã n =
2m, 12 min
1log 2 1, 22mk n m d n với m là số nguyên dương.
Mã Golay:
Mã Golay là mã tuyến tính nhị phân (23,12) với dmin = 7. Mởrộng mã Golay bằng cách thêm vào bit parity để trở thành mãnhị phân tuyến tính (24,12) và dmin = 8. Bảng VI -10 liệt kêsự phân bố về trọng lượng của các từ mã trong mã Golay (23,12)và (24,12).
Trọng số Mã (23,12) Mã (24,12)
0
7
8
11
1
253
506
1288
1
0
759
0
148

12
15
16
23
24
1288
506
253
1
0
2576
0
759
0
1
Bang VI-10: Sự phân bố về trọng số của mã Golay.
Bài 15. Mã vòng
I. Khái niệm và biểu diễnMã vòng là mã tuyến tính có tính chất vòng. Tính chất vòngđược thể hiện trong định nghĩa sau:
Một mã hiệu được gọi là mã vòng nếu là mã tuyến tính và:
1 2w ... na a a là từ mã,
2 3 1w* ... na a a a cũng là từ mã.
Các vecto có thể biểu diễn mối quan hệ giữa các bít ở cùng mộtvị trí của các bít khác nhau, tuy nhiên không biểu diễn đượcliên hệ giữa các bít trong cùng một từ mã. Để biểu diễn các từmã của mã vòng, sử dụng tập hợp các đa thức có bậc n-1. Khi đótương ứng với từ mã w chúng ta có:
1 21 2w ( ) ...n n
nx a x a x a
Các phép toán trên từ mã được thực hiện trên các đa thức mộtcách tương tự. Riêng phép nhân hai từ mã, sau khi chuyển thànhphép nhân hai đa thức thì tích thu được sẽ là một đa thức bậc2n-2. Để chuyển đa thức này về bậc n-1 cần sử dụng phép chiamodule cho một đa thức bậc n. Đa thức đơn giản nhất không suybiến là đa thức 1nx .
w( )w *( ) w( ) w *( )mod( 1)nx x x x x
Các khẳng định sau đây là đúng với một từ mã w bất kỳ:
149

- ( )xw x là đa thức của một từ mã1 2 1 2
1 2 2 3 1
2 3 1
xw( ) ( ... )mod( 1) ...( ... )
n n n n nn n
n
x x a x a x a x a x a x a x aP a a a a
- 2 3( ), ( ),....x w x x w x cũng là đa thức của một từ mã
- ( ) ( )Q x w x là đa thức của một từ mã, ( )Q x bất kỳ. Nói cáchkhác, bội của một từ mã là một từ mã.
Trong các đa thức biểu diễn các từ mã, chọn ( )G x là đa thứccó bậc nhỏ nhất. Các khẳng định sau đây đúng với ( )G x
- Một từ mã w bất kỳ tương ứng với đa thức là bội của ( )G x .Lấy ( ) ( ) ( ) ( )w x G x Q x R x . Vì ( )w x và ( ) ( )G x Q x đều là từ mã nên( )R x là từ mã. Bậc của ( )R x nhỏ hơn bậc của ( )G x . Vậy( ) 0.R x
- ( )G x là duy nhất. Nếu *( )G x có tính chất như ( )G x thì*( ) ( ) ( )G x Q x G x . Do ( )G x và *( )G x cùng bậc nên ( ) 1Q x
Như vậy đa thức ( )G x có thể dùng để biểu diễn bất cứ mộtđa thức nào của các từ mã. Ngược lại, một đa thức từ mãbất kỳ phải là bội của ( )G x . Đa thức ( )G x là đa thức sinhcủa mã hiệu.
- Bậc của ( )G x là n k . Điều kiện cần và đủ để ( )w x là từ mãlà:
( ):w ( ) ( ) ( )Q x x Q x G x
Tổng cộng có 2k từ mã, do đó cần có 2k đa thức ( )Q x . Bậc của( )Q x phải là 1k . Vậy bậc của ( )G x là n k .
II. Mã hóa và phát hiện lỗiCác từ mã của mã vòng có dạng w IC , trong đó I là phần thôngtin gồm k bít, còn C là các bít điều khiển, gồm n k bít. Chotrước k bít thông tin I, cần xác định n-k bít điều khiển. Biểudiễn bằng ngôn ngữ đa thức, cần xác định đa thức $I(x)$ saocho
( )| ( )w x G x
150

Trong đó
w ( ) ( ) ( )kx I x x C x
Từ đó suy ra
( ):w( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ) ( )
k
k
Q x x Q x G xI x x C x Q x G xI x x Q x G x C x
Chú ý là bậc của C(x) là k-1, còn bậc của G(x) là k. Vậy
( ) ( ) mod ( )kC x I x x G x
Công thức là công thức mã hóa của mã vòng. Thực tế, đây làphép chia đa thức nhị phân không nhớ. Phép chia này có thểbiểu diễn dưới dạng nhị phân như sau:
.2 modkC I G
Quá trình giải mã được thực hiện bằng cách lấy ra k bít đầutiên. Việc phát hiện lỗi được thực hiện bằng phép chia modulow(x) cho G(x).
Theo định nghĩa, mã vòng là mã đều. Tuy nhiên cả 2 công thức và đều không giới hạn chiều dài của từ mã. Các phép toán đathức có thể mở rộng cho các đa thức bậc lớn hơn n-1. Điều nàygiải thích tại sao trong thực tế mã vòng được sử dụng dướidạng mã không đều.
III.Mã vòng trong thực tếTrong thực tế, mã vòng không bị giới hạn bởi chiều dài từ mã.Vì vậy, các lập luận về tính chống nhiễu của mã cần được phântích lại. Khả năng chống nhiễu của mã vòng sẽ được xem xéttrong các trường hợp sau đây: một lỗi đơn, một lỗi kép, mộtlỗi chùm.
Khi có một lỗi đơn, tổ hợp mã lỗi và từ mã ban đầu sai khácnhau đúng 1 bít. Biểu diễn cấu hình lỗi bằng đa thức ta có:
*( ) w( ) pw x x x
151

Việc có thể phát hiện lỗi hay không phụ thuộc vào việc đa thứcw*(x) có chia hết cho G(x) hay không. Điều này tương đương vớiviệc chọn G(x) sao cho px không chia hết cho G(x). Có thể thấyngay G(x) chỉ cần là một đa thức không suy biến, có hệ số tựdo là thỏa mãn điều kiện này. Đa thức đơn giản nhất, không suybiến, có hệ số tự do là đa thức 1x . Trong trường hợp này mãvòng trở thành mã kiểm tra chẵn lẻ.
Khi có một lỗi kép, cấu hình lỗi dược biểu diễn bằng đa thứcp qx x , trong đó p và q là 2 vị trí lỗi. Bài toán phát hiện lỗi
trở thành xác định G(x) để G(x) không là thừa số của p qx x vớip và q tùy ý. Đã có những đa thức bậc r, không là ước của bấtcứ đa thức nào có dạng 1nx với bậc cỡ 2r .
Khi có một lỗi chùm, cấu hình lỗi được biểu diễn bằng đa thứcq
j
px . Đa thức này có thể chuyển về dạng 1nx . Việc lựa chọn
G(x) tương tự như trong trường hợp trên.
IV. Các cơ chế truyền lạiĐể thực hiện được yêu cầu truyền tin tin cậy, sau khi pháthiện lỗi cần báo cho thiết bị gửi tin và gửi lại thông tin đãbị lỗi. Bộ phận gửi tin cần có cơ chế lưu trữ tạm thời cácthông tin đã gửi đi cho đến khi nào nhận được thông báo thôngtin đã nhận được thành công, chính xác.
Để tiết kiệm bộ nhớ đệm lưu trữ tạm thời các từ mã, chỉ có từmã đang gửi đi được giữ trong bộ nhớ đệm. Không có từ mã nàokhác được gửi đi trong lúc từ mã hiện tại chưa được nhận thànhcông. Khi nhận được từ mã thành công, bộ phận nhận sẽ gửi lạicho bộ phận gửi một thông báo đã nhận được thành công từ mã(báo nhận). Sau một khoảng thời gian (timeout) hoặc khi nhậnđược thông báo từ mã đã bị lỗi, bộ phận gửi sẽ gửi lại từ mã.Cơ chế truyền lại này được gọi là cơ chế dừng và chờ. Ưu điểmcủa cơ chế này là đơn giản, không cần thêm nhiều logic phứctạp và bộ nhớ. Tuy nhiên, trong suốt khoảng thời gian chờ báonhận, bộ phận gửi tin không hoạt động và không thể thực hiệnthao tác nào khác. Ảnh hưởng của khoảng thời gian chờ đợi này
152

có thể được giảm nếu tăng kích thước của từ mã. Tuy nhiên,việc tăng kích thước từ mã dẫn tới xác suất xảy ra lỗi lớnhơn, thời gian chiếm dụng kênh truyền chung lớn hơn.
Cơ chế dừng và chờ không phân biệt được giữa việc mất một từmã và mất báo nhận của từ mã. Trường hợp mất báo nhận có thểdẫn đến tình trạng một từ mã được gửi và được nhận 2 lần. Vấnđề có thể được giải quyết sử dụng cách đánh số các từ mã vàcác báo nhận là 0 và 1 liên tiếp.
Cơ chế cửa số trượt cho phép cùng một lúc có thể gửi đi nhiềutừ mã. Bộ phận mã hóa cần có khả năng lưu trữ các từ mã đangđược gửi đi nhưng chưa nhận được để sẵn sàng gửi lại khi cần.Bộ nhớ đệm có kích thước hữu hạn do đó số lượng các từ mã cóthể gửi đi cùng một lúc là hữu hạn. Sau khi nhận được một từmã, một ô nhớ sẽ được giải phóng và một từ mã khác có thể đượcgửi đi. Hình thành một ‘ô cửa sổ’ trượt trên trục biểu diễncác từ mã sẽ được chuyển đi. Đây là lý do tại sao phương phápnày được gọi là cửa sổ trượt.
Để giảm bớt số lượng các thông báo báo nhận có kích thước nhỏ,hiệu quả thấp, các báo nhận thường được ghép vào các khối dữliệu trong các liên kết dữ liệu 2 chiều. Mỗi từ mã sẽ gồm 2 sốTT, số TT của từ mã gửi đi S và số TT của từ mã đang chờ nhậnR. R báo hiệu là thiết bị đã nhận tốt các từ mã có số TT đếnR-1 và đang chờ nhận từ mã số TT R.
Cơ chế cửa sổ trượt được sử dụng rộng rãi trong việc kiểm soátlỗi, kiểm soát luồng dữ liệu cả ở các giao thức tầng liên kếtdữ liệu và tầng 4, tầng giao vận
Bài 16. Mã chập
I. Khái niệm mã chậpMã chập được tạo ra bằng cách cho dãy thông tin qua một thanhghi dịch tuyến tính có hữu hạn trạng thái. Bộ phận mã hóa cókhả năng nhớ lại các ký hiệu đã truyền đi, tạo ra một ràngbuộc giữa các ký hiệu nguồn đã truyền đi trong các ký hiệu mã.Dựa trên sự ràng buộc này, tại bộ phận giải mã, quá trình phát
153

hiện lỗi và giải mã sẽ được thực hiện. Ưu điểm của phương phápnày so với các loại mã đã xem xét là tính mềm dẻo và hiệu suấtmã. Do việc giải mã, phát hiện lỗi và sửa lỗi được thực hiệndựa trên các ký hiệu mã có ràng buộc với nhau, do đó trongtrường hợp kênh truyền tin có độ tin cậy cao, có thể sử dụngmã chống nhiễu với hiệu suất xấp xỉ 1. Trường hợp kênh có độtin cậy thay đổi, mã chập cho phép thực hiện mã hóa với hiệusuất mã và khả năng chống nhiễu khác nhau, phù hợp với kênhtruyền tin.
Tổng quát, thanh ghi dịch gồm có Kk nhịp mỗi nhịp gồm có k bitvà n bộ tạo hàm đại số tuyến tính. Giả sử số liệu là nhị phânđi vào bộ mã hoá, theo từng nhịp, mỗi nhịp k bit. Đầu ra tươngứng với k bit đầu vào gồm n bit. Như vậy tốc độ mã là Rc=k/nvà tham số K gọi là độ dài ràng buộc của mã chập.
Kk nhÞp
… .1 2 k … .1 2 k 2 … .1 1 kK bit
th«ng tin
+ + + +
3 a21
Tíi bé ®iÒu chÕ
H×nh 10.2.1. Bé m· ho¸ chËp
Một phương pháp để mô tả mã hoá hoá chập là dùng ma trận sinh.Tổng quát, ma trận sinh của mã chập là vô hạn một phía do dãythông tin đầu vào cũng là vô hạn một phía. Một phương phápkhác nữa là ta có thể sử dụng n vector, mỗi vectơ tương ứngvới một bộ cộng modulo 2. Mỗi vectơ có Kk chiều và vị trí thứi là 1 nếu vị trí tương ứng trong thanh ghi dịch nối với bộcộng modulo 2 và là 0 nếu như không nối với bộ cộng.
154

Ví dụ
Xét bộ mã hoá chập với K =3, k=1, n=3 như trên hình 10-2-2.Khởi đầu, số liệu trong thanh ghi dịch toàn là bit 0. Giả sửbit đầu tiên là bít 1và 3 bit ra là bit 111. Bit thứ 2 vào là0 thì 3 bit ra là 001. Nếu bit thứ 3 là 1 thì 3 bit đầu ra sẽlà 100... Giả sử ta đánh số các bộ tạo hàmtạo ra 3 bit đầu ralà 1, 2, 3 và các và các bit đầu ra cũng như thế thì các bộtạo hàm theo thứ tự là g1 = [100], g2 = [101], g3 = [111].Các bộ tạo hàm cho mã này có thể biểu diễn ở dạng cơ số 8 là(4, 5,7).
+
+
1
2
3
Bé m· ho nhËp K = 3, k = 1, n = 3
§Çu ra
+
+
+
1
2
3
§Çu ra
§Çu vµo
Bé m· ho chËpK = 2, k = 2, n = 3
§Çu vµo
VI-22: Ví dụ về mã chập
Xét mã chập tốc độ 2/3 như trên hình VI -22: Ví dụ về mãchập. Đối với mã này, từng cặp 2 bit được đưa vào 2 thanh ghidịch trong mỗi nhịp. Các bộ tạo hàm là g1=[1011], g2=[1101],g3=[1010]. Có ba phương pháp thường dùng để biểu diễn mãchập, đó là cấu trúc cây của mã .
155

000
000000
000
111111
111
aa
cb
001
110d
c
011001
110ba
c111010
101110b
b
d
1
0
A. CÊu tróc c©y cña m· chËp K =3,1/3
æn ®Þnh
101 101 101
000 000 000 000 000
111111
111011
111011
111011
100001
110
010
100001
100001001
110 110010
110
010
a
b
c
d
B. S¬ ®å lí i m· chËp K = 3,1/3
VI-23: Cấu trúc cây của mã
b01
C10
d11
d00000
101
011
010
111
001 100
110
Lưu đồ trạng thái của mã chập
000
(00)
a
000010
c111
101d
b
a
110a
100b001c011d
010(01)b
101a111b010c000d
a
111c
101d
011a001b100c110d
Cấu trúc của mã chập
VI-24: Cấu trúc và lược đồ của mã chập
156

Do đầu ra của bộ mã hoá được xác định bởi đầu vào và các trạngthái của thanh ghi dịch nên ta thu dược lưu đồ trạng thái.Tương ứng với ví dụ trên là lưu đồ trạng thái trong hình 10-2-6.
Ví dụ
Xét mã chập k = 2, n = 3, K = 2, có cấu trúc cây trong và sơđồ lưới trong hình VI -24: Cấu trúc và lược đồ của mã chập.Do độ dài ràng buộc K = 2, ta thấy rằng cấu trúc cây lặp lạisau hai nhịp.
Tổng quát hoá, mã chập có độ dài ràng buộc K, tốc độ k/n đượcđặc trưng bởi 2k nhánh xuất phát từ một nút trong cấu trúc câyvà ( 1)2k K trạng thái trong lưu đồ trạng thái. Ba phương phápbiểu diễn nói trên có thể dùng cho mã chập không nhị phân. Khimột ký hiệu nhận một trong 2kq gia trị có thể thì mã khôngnhị phân có thể được biểu diễn bằng mã nhị phân tương đương.
Ví dụ
Xét mã chập tạo ra bởi bộ mã hoá như hình Hình VI -31:Bộ mãhoá tạo ra mã kép tốc độ 1/2, các tham số mã là K = 2, k = 2,n = 4, Rc=1/2 và các hàm tạo mã là 1 [1010]g , 2 [0101]g , 3 [1110]g
, 4 [1001]g . Trừ sự khác nhau về tốc độ, mã này tương tự như mãtrong ví dụ trên.
157

000
b
c
d
000 000 000
010 010 010 010
aa a a a
111
101
b110
101 111
b b110
101
110
101111 111
011
c c c
100
001
011
101
100001
101
011100001
000
011
d d d
010
100 100 100
000 000010 010
011 011011 011
Sơ đồ lưới K = 2, k = 2, n = 3
Hình VI-25: Sơ đồ lưới của mã chập
Bộ mã tạo ra trong ví dụ này có thể được biểu diễn bằng mãkhông nhị phân một ký hiệu vào bốn mức và hai ký hiệu ra bốnmức.
II. Hàm truyền của mã chậpCác tính chất về khoảng cách và tốc độ sai của mã chập có thểthu được từ lưu đồ trạng thái. Do mã chập là tuyến tính nêntập hợp các khoảng cách từ các dãy mã tạo ra tới dãy mã toànký hiệu 0 giống như tập hợp các khoảng cách tới một dãy mã bấtkỳ khác. Do đó, hoàn toàn không mất tính tổng quát, ta giảthiết đầu vào của bộ mã hoá là dãy mã toàn ký hiệu 0.
Ta sử dụng lưu đồ trạng thái để mô tả phương pháp để nhận dượccác tính chất về khởng cách của mã chập. Đầu tiên ta ký hiệucác nhánh của lưu đồ trạng thái là 0 1D , 1D , 2D , 3D với số mũcủa D là khoảng cách Hamming của dãy tạo ra tới đây tạo ra bởidãy vào toàn ký hiệu 0. Vòng lặp tại nút a có thể bỏ qua vànút a ccược chia làm hai, một nút thể hiện đầu vào và một nút
158

thể hiện đầu ra của lưu đồ trạng thái. Các phương trình trạngthái là:
3
2 2
2
c a b
b c d
d c d
e b
X D X DXX DX DXX D X D XX D X
Hàm truyền của mã được định nghĩa là ( ) /e aT D X X ta có :
66 8 10 12
26
( ) 2 4 8 ...1 2d
dd
DT D D D D D a DD
và( 6)/220
d
devendaodd d
c10
b01
100
d11
a00 00
110
000
010 110 001111
000100
111101
011
001
Lưu đồ trạng thái của mã chập K = 2, k = 2, n = 3
Hình VI-26: Lưu đồ trạng thái của mã chập
159

+ +
12
§Çu vµok = 2
+
+3
4
Bé m· ho¸ chËp K = 2, k = 2, n = 4
Hình VI-27: Bộ mã hóa chập (2,2,4)
Hàm truyền đạt của mã này chỉ ra rằng có một dường với khỏngcách Hamming là 6 tới đường toàn 0 và nhập lại vào đường toàn0 ở một nút nào đó. Trong lưu đồ trạng thái và sơ đồ lướitrong hình 10-2-6 và 10-2-5 ta thấy đưòng đó là acbe. Không còncó đường nào khác có khoảng cách Hamming là 8. Khoảng cách tốithiểu của mã dược gọi là khoảng cách tự do ngắn nhất và ký hiệu là
freed . Trong ví dụ vừa xét, 6freed .
Chúng ta thêm hệ số N vào mọi nhánh tạo ra bởi ký hiệu 1 vànhư vậy khi đi qua những nhánh này, số mũ của N tăng lên 1đơn vị. Chúng ta thêm hệ số J vào mọi nhánh trong lưu đồ trạngthái và như thế thì số mũ của J sẽ chỉ ra số nhánh đi qua từnút a tới nút e.
160

d
b ccaD3 D2D
DD2
D2
Lưu đồ trạng thái cho mã chập K = 3,1/3
d
b ccaD2D
H×nh 10.2.12. L u ®å tr¹ng th¸ i cho m· chËp K = 3,1/3
JDJND2
JND2
JND2
3
2 2
2
c a b
b c d
d c d
e b
X J ND X J NDXX J DX J DXX J ND X J ND XX J D X
3 63 6 4 2 8 5 2 8 5 2 10 6 3 10 7 3 10
2( , , ) 2 ...1 (1 )J NDT D N J J ND J N D J N D J N D J N D J N D
J ND J
Khi chúng ta truyền rất dài, có thể coi là vô hạn và muốn bỏqua tham số J thì ta có thể đặt J = 1.
6
2( , , ) 1 2NDT D N J
ND
6 2 8 3 10 ( 4)/2
62 4 ... d d
dd
ND N D N D a N D
161

Ví dụ : Xét mã chập trong hình 10-2-10 và coi mã là bốn mứcthì khoảng cách từ 0111 tới 0000 là 2. Khi ký hiệu vào là 01được giải mã thành 11 thì đó là sai nhầm 1 ký hiệu. Lưu đồtrạng thái trên hình 10-2-13 và
2 2
2 2
2 2
2( )
b a b c d
c a b c d
d a b c d
e b c a
X NJ D X NJ DX NJ DX NJ D XX NJ D X NJ D X NJ D NJ DXX NJ D X NJ DX NJ D X NJ DXX J D X X X
Hàm truyền là :2 4
23( , , ) 1 2
NJ DT D N JNJ D NJ D
b01
c10
d11
a00
c10
JND2(1110)
JND2(1110)
(0001)JNDJND(0100)
JND2(01111)
(0010)JND
JND2(1111)
JND2 (0110) JND2(1010)
JND2(1001)JND2
(1001)
2JD
2JD(1010)
Lưu đồ trạng thái mã chậpK =2, k = 2, n= 4
b01
c10
d11
a00
c10
JND2 (33)
JND2(12) (11)
JND2(30)
JND2
2JD
2JD(22)
Lưu đồ trạng thái mã chậpK =2, k = 2, n= 4
JND
JD2
JND(03)
(20)JND2(32)
00=001=110=211=3
(21)
(01)
JNDJND2(13)
JND(10)
(02)
JND
(31)
JND2
(23)
VI-28: Lưu đồ trạng thái mã chập với đầu ra nhị phân
Một số loại mã chập khi sử dụng trên kênh BSC thì có một sốlượng hữu hạn sai nhầm sẽ dẫn tới vô hạn lần giải mã sai.Nhưng những loại mã như vậy rất dẽ nhận ra và không được sửdụng trong thực tế.
162

III.Giai mã tối ưu mã chập - Thuật toánViterbi
Giống như với mã khối, bộ mã hoá chập tạo ra các từ mã cố độdài hữu hạn n về cơ bản là một hệ có số trạng thái hữu hạnvàdo đó bộ giải mã tối ưu là bộ ước lượng dãy cực đại khả năng(MLSE). Quá trình giải mã tối ưu mã chập là tìm trong lưới dãycó khả năng lớn nhất. Phụthuộc vào quá trình giải mã là xácđịnh mềm hay xác định cứng mà ta có tốc độ đo tương quan khácnhau. Chúng ta sử dụng mã chập trong sơ đồ lưới hình 10-2-5 đểmô tả thuật toán.
Xét hai đường trong lưới bắt đầu từ trạng thái a nhập lạitrạng thái a sau 3 chuyển đổi, tương ứng với dãy thông tin là000 và 100, các dãy truyền đi tương ứng là 000, 000, 000 và111, 001, 011. Ta kí hiệu các bit truyền đi là {
, 1,2,3; 1,2,3jmc j m } với j là nhánh thứ j và m là bit thứ mtrongnhánh. Ta cũng ký hiệu { , 1,2,3; 1,2,3jmr j m } là đầu ra của bộ giảiđiều chế. Nếu bộ xác định thực hiện xác định cứng thìi đầu racủa mỗi bit là 1 hoặc 0, và nếu việc xác định là mềm và tínhiệu truyền đi là PSK xác định liên kết thì đầu ra của bộ xácđịnh mềm là
(2 1) )jm c jm jmr c n
jmr biểu diễn trắng và c là năng lượng của mỗi bit truyền đi.Độ đo dược định nghĩa cho nhánh thứ j trong đường thứ i là
() ()log ( | ), 1,2,3....i ij j jP Y C j
Như vậy độ đo cho đường thứ i gồm có B nhánh là
() ()
1
Bi i
jj
PM
Nguyên tắc lựa chọn giữa hai dường là chọn đường có độ dài lớnhơn. Nguyên tắc này cực đại hoá xác xuất xác định đúng hay cựctiểu hoá xác suất xác định sai. Ví dụ với giải mã xác địnhcứng với dãy nhận được là {101000100}. Ta ký hiệu i = 0 lànhánh toàn ký hiệu 0 và i = 1 là nhánh xuất phát từ trạng
163

thái a và trở về trạng thái a sau ba chuyển đổi. Độ đo tươngứng với hai đường này là
(0)
(1)6log(1 ) 3log4log(1 ) 5log
PM p pPM p p
Giả sử 1/2p thì ta thấy (0) (1)PM PM . Khoảng cách từ đường dẫntoàn 0 tới dãy nhận được là d = 3 còn từ đường kia tới dãynhận được là d = 5. Như vậy khoảng cách Hamming là độ đo tươngứng với giải mã xác định cứng.
Giả sử giải mã xác định mềm được thực hiện và kênh có nhiễucộng Gaussian thì đầu ra của bộ giải điều chế được mô tả thốngkê bởi
()()
2[ (2 1)]1( | ) exp{ }22
ijm c jmi
jm jmr c
p r c
012N là sai phương của nhiễu trắngvà từ đó độ đo của nhánh
thứ j trong đường thứ i được biểu diễn là
() ()
1(2 1)
ni i
j jm jmm
r c
và trong ví dụ của ta thì độ đo tương ứng với hai đường là3 3(0) (0)1 1
3 3(1) (1)1 1
(2 1)
(2 1)jm jmj m
jm jmj m
CM r c
CM r c
Bây giờ ta xét thuật toán Viterbi. Ta chú ý rằng nếu(0) (1)CM CM thì mọi nhánh tiếp theo xuất phát từ trạng thái a
đều được cộng thêm lượng không đổi là (0)CM hoặc (1)CM . Do đóđường ứng với (1)CM có thể bỏ đi và ta có đường còn lại. Tươngtự , một trong hai đường còn lại ở nút b,c,d có thể bỏ qua.Thủ tục này được lặp lại ở mỗi nhịp.
Tổng quát, với mã chập nhị phân k = 1 thì ta có 12K đường cònlại ở mỗi nhịp và 12K độ đo. Hơn nữa, với mã chập nhị phân vớik bit được đưa vào thanh ghi dịch trong một nhịp thì sơ đồlưới sẽ có ( 1)2k K trạng thái. Như vậy bộ giải mã cần giữ ( 1)2k K
164

đường còn lại và ( 1)2k K độ đo và ở mỗi nhịp có 2K đường tới nút.Do đó số lượng phép tính cần thực hiện tăng theo hàm mũ của kvà K. Độ trễ giải mã và dung lượng bộ nhớ của bộ giả mã sửdụng theo thuật toá này thường rất lớn trong đa số các ứngdụng thực tế. Tuy nhiên ta có thể sửa đổi thuật toán này nhưtrong phần 7-1-4 là độ trễ ở bit mới nhất thoả mãn điều kiện
5K sẽ cho ta kết quả tương đối đúng và chấp nhận được.
IV. Xác suất lỗi của giai mã xác định mềmĐể biểu diễn xác suất xác định sai của mã chập, ta sử dụngtính chất tuyến tính đêr việc biểu diễn được đơn giản. Giảthiết dãy toàn ký hiệu 0được truyền đi và ta xác định xác suấtxác định sai dãy này. Giả thiết ta sử dụng tín hiệu PSK (hoặcbốn mức) và quá trình xác định là liên kết. Độ đo tương quanứng với mỗi đường là
() () ()
1 1 1(2 1)
B B ni i i
j jm jmj j m
CM r c
B là số nhánh trong đường. Ví dụ với đường toàn ký hiệu 0 kýhiệu là i = 0 có độ đo là
(0)
1 1 1 1( )( 1)
B n B n
c jm c n jmj m j m
CM n B n
Chú ý rằng mã chập có thể có độ dài vô hạn và ta định nghĩaxác suất sai của sự kiện thứ nhất là xác suất để một đườngkhác nhập lại với đường dẫn toàn ký hiệu 0 ở nút B có độ đolớn hơn độ đo của đường toàn ký hiệu 0. Giả đường ký hiệu i =1 có khoảng cách tới đường toàn ký hiệu 0 là d, có nghĩa là dcó ký hiệu 1 trong đường i = 1, có khoảng cách tới đường toànký hiệu 0 là d, có nghĩa là có d ký hiệu 1 trong đường i = 1,còn các ký hiệu khác là 0.
(1) (0)2( ) (P d P CM CM (1) (0)( 0)P CM CM (1) (0)
1 1[2 ( ) 0]
B n
jm jm jmj m
P r c c
Do các mã bit trong hai đường là giống nhau trừ d vị trí nên(10-2-18) có thể đơn giản thành:
165

'2
1( ) ( 0)
d
ll
P d P r
với { 'lr } biểu diễn độ dài bộ giải mã với d bit này.
Do { 'lr } là các biến ngẫu nhiên gaussian độc lập thống kê có
phân bố thống kê giống nhau, giá trị trung bình c và sai
phương 012N , như vậy xác suất lỗi để hai đường khác nhau d bit
là
20
2( ) ( ) ( 2 )cb cP d Q d Q R d
N
ở đây 0/b b N là SNR từng bit nhận được và Rc là tốc độ mã.
Chúng ta đã tính xác suất sai của sự kiện thứ nhấtcủa mộtđường có khỏng cách là d so với đường toàn 0 và nhập lại vớiđường toàn 0 tại một nút B nào đó. Ta có thể lấy tổng của (10-2-20) theo tất cả các đường dẫn có thể và thu được giới hạntrên của xác suất lỗi của sự kiện thứ nhất.
2( ) ( 2 )free free
e d d b cd d d d
P a P d a Q R d
Có hai lý do để (10-2-21) là giới hạn trên của xác suất lỗicủa sự kiện thứ nhất. Đầu tiên ta thấy các sự kiện cho xácsuất sai { 2( )P d } là không đồng thời. Điều này ta có thể thấyđược trên lưới. Thứ hai, tổng được lấy theo mọi khả năng freed d
với giả thiết mã chập có độ dài vô hạn. Nếu bộ mã được cấttuần hoàn sau B nút thì ta có thể lấy tổng theo freed d B .
Giới hạn trên trong công thức trên có thể biểu diễn theo cáchkhác nếu ta chú ý đến
2 |b cRb c
R d db c D eQ R d e D
và
( )| Rb ce D eP T D
166

Ta xét xác suất sai bit. Giả sử đường sai được lựa chọn và cácbit thông tin trong đường này bị sai sẽ khác với các bit thôngtin tương ứng trong đường dẫn đúng. Số mũ của N trong hàmtruyền T(D,N) chỉ ra số bit thông tin bị lỗi trong đường sai.Nếu ta nhân 2( )P d với số bit thông tin bị giải mã sai và lấytổng theo d. Hệ số nhân tương ứng với số bit thông tin bị saivới mỗi đường bị lựa chónai là đạo hàm của T(D,N) theo N.
( )( , )free
d f dd
d dP D N a D N
Lấy đạo hàm của T(D, N) theo N và cho N = 1 ta nhận được
1( , )| ( )
free free
d dN d d
d d d d
dT D N a f d D DdN
Như vậy khi k = 1 thì xác suất sai bit bị giới hạn trên bởi
2( ) 2free free
b d d b cd d d d
P P d Q R d
Nếu ta sử dụng giới hạn của hàm Q trong công thức (10-2-22)thì
1,( , )| |R Rb c b c
free
db d D e N D e
d d
dT D NP DdN
khi k > 1 thì xác suất sai tương đương nhận được bằng cáchchia (10-2-26) và (10-2-27) cho k
Việc tính toán các xác suất lỗi ở trên được thực hiện với giảthiết là các bit trong từ mã được truyền đi bằng tín hiệu PSKnhị phân xác định liên kết.. Kết quả cũng đúng khi tín hiệukhi tín hiệu là QPSK xác định liên kết. Khi ta sử dụng các kỹthuật điều chế và giải điều chế khác thì chỉ ảnh hưởng tớiviệc tính 2( )P d chứ không ảnh hưởng tới quá trình tính bP . Khicác ký hiệu là k biit thì xác suất sai bit tương đương đượcnhân thêm với hệ số 12 / 2 1k k như đã nói trong chương 7.
167

V. Xác suất lỗi của giai mã xác định cứngTa xét hiệu quả của thuật toán Viterbi trên kênh BSC. Trongtrường hợp giải mã xác định cứng, các độ đo là các khoảng cáchHamming giữa dãy nhận được và ( 1)2k K dãy còn lại tại mỗi núttrên lưới.
Cũng như phần trên, ta bắt đầu bằng cách xác định xác suất lỗicủa sự kiện thứ nhất. Giả sử đường toàn 0 là đường được truyềnđi. Đường dẫn được so sánh với đường toàn 0 tại một nút B nàođó có khoảng cách d so với đường toàn 0. Nếu d lẻ thì đường sẽ
được chọn nếu số sai trong dãy nhận được nhỏ hơn 1( 1)2 d . Xác
suất lựa chonj đường sai là
2( 1)/2
( ) (1 )d d
k d kkd d
P d p p
Nếu d chẵn thì giải mã sẽ bị sai khi số bit sai vượt quá 12d.
Nếu số sai bằng 12dthì sự lựa chọn sẽ là ngẫu nhiên nên xác
suất sai khi đó là một nửa. Như vậy trong trường hợp d chẵnthì
/2 /22 1/2 1 2
1( ) (1 ) (1 )2d d d
k d k d dk dk d
P d p p p p
Do có nhiều đường với khởng cách khác nhau nhập với đường toàn0 tại một nút nào đó nên giới hạn trên của xác suất lỗi sẽ là
2( )free
e dd d
P a P d
Chúng ta cũng có thể sử dụng giới hạn
/22( ) 4 (1 )dP d p p
ta sẽ nhận được giới hạn kém chặt hơn
/2
4 (1 )4 (1 ) ( )|free
d
e d D p pd d
P a p p T D
168

Bây giờ ta xác định xác suất sai bit. Ta sử dụng số mũ của Ntrong hàm truyền T(D, N). Lấy đạo hàm của hàm này theo N vàđặt N = 1 và chúng ta có :
2( )free
b dd d
P P d
Sử dụng giới hạn kèm chặt của 2( )P d ta sẽ thu được
1, 4 (1 )( , )|b N D p p
dT D NPdN
So sánh xác suất sai của việc giải mã mã chập 1/3, K = 3 củahai phương pháp trên Hình VI -29: so sánh giải mã cứng vàgiải mã mềm đối với mã chập 1/3, K = 3.
169

5
2
5
2
5
2
5
2
5
2
4 6 10 14
G.h.trªn(8-2-20)
SNR tõng bit Y b (JB)
Xc xuÊt sai bÝt Pb
10-1
10-2
10-3
10-4
10-5
10-60 2 8 12
G.m.x.® mÒmG.m.x.®. Cøng
G.h.Ghernoff(8-2-34)
G.h. trªn(8-2-3--3)Víi (8-2-29)Vµ (8-2-28)
Hình VI-29: so sánh giai mã cứng và giai mã mềm đối với mã chập 1/3, K = 3
Cuối cùng, tốc độ sai trung bình theo tập hợp của mã chập trênkênh rời rạc không nhớ được biểu diễn theo tốc độ giới hạn 0R
0
0
_/
02/
( 1) ,1
c
c c
kR R
b cR R R
q qP R Rq
VI. Các tính chất về khoang cách của mã chậpTrong phần này ta ghi ra một số giá trị về khoảng cách tốithiểu, các hàm sinh của một số mã chập nhị phân có độ dài hữuhạn với một số giá trị về tốc độ mã. Các mã nhị phân này làtối ưu theo nghĩa với một tốc độ và độ dài xác định, chúng códfree lớn nhất. Ta có giới hạn trên đơn giản của khoảng cách tựdo tối thiểu của mã chập 1/n là
dfree
1
l1
2min ( 1)2 1l
l K l n
170

Hình VI-30: Mã tỗc độ k/7 có khoang cách tự do lớn nhất
Tốc độ K Hàm sinh dfree Giới hạn trên của dfree
3/43/8
22
131551
254236
612375
476147
48
Bảng 10-2-11:Mã tỗc độ 3/4 và 3/8 có khoảng cách tự do lớnnhất
VII.Mã kép k không nhị phân và mã ghép .Các vấn đề về mã chập chúng ta xem xét tới nay chủ yếu tậptrung vào mã nhị phân sử dụng trên kênh có khả năng sử dụngtín hiệu SPK nhị phân hoặc QPSK xác định liên kết. Tuy nhiêntrong thực tế có những ứng dụng trong đó không thể hay khôngtiện sử dụng các loại tín hiệu này. Trong nhữnng trường hợp đóta sử dụng các kỹ thuật điều chế khác như FSK M mức và giảiđiều chế không liên kết.
Trong phần này ta trình bày một lớp mã không nhị phân gọi làmã kép k (dual k-codes). Loại mã này có thể giải mã tương đối dễbằng thuật toán Viterbi với giải mã xác định mềm hoặc cứng.Loại mã này cũng thích hợp sử dụng làm mã trong và mã ngoàitrong mã ghép.
Bộ mã hoá chập tạo ra mã kép k tốc độ 1/2 được trình bày trênhình 10-2-16. Nó gồm có hai thanh ghi dịch k bit (K=2) và n=2khàm sinh. Đầu ra của bộ mã hoá là hai ký hiệu k bit. Chú ýrằng mã trong ví dụ Hình VI -31:Bộ mã hoá tạo ra mã kép tốcđộ 1/2là mã chập kép 2.
171
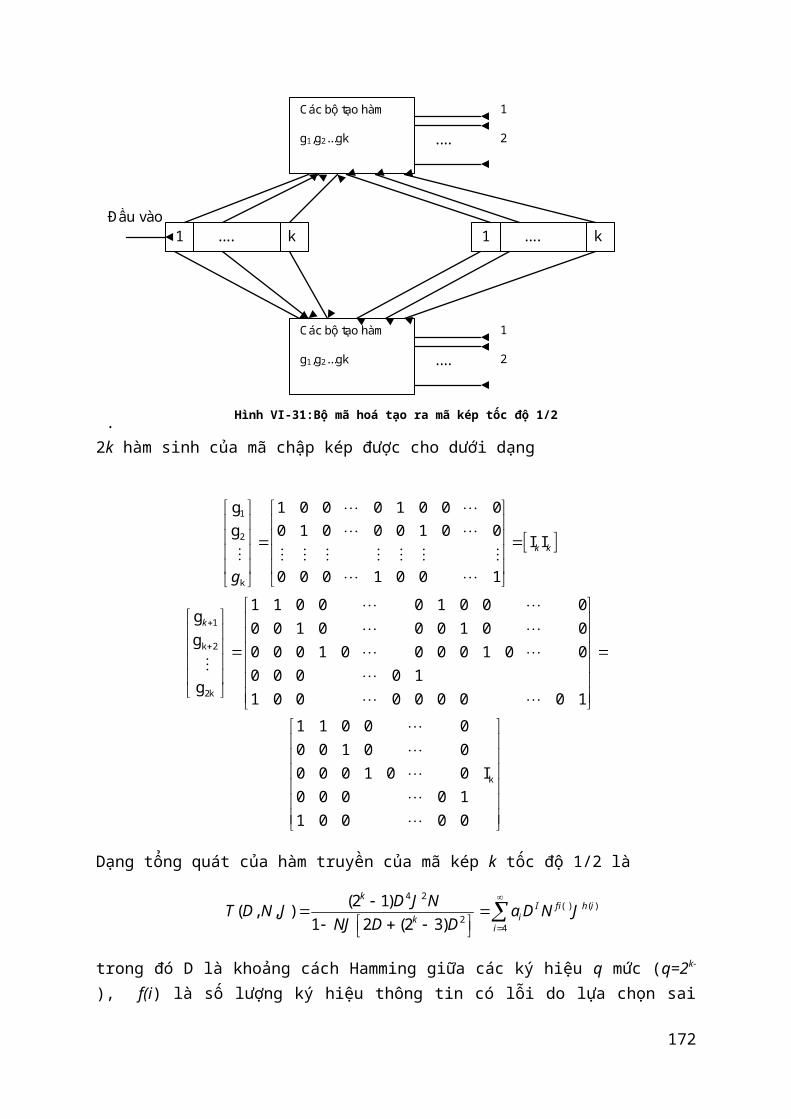
.
....
Các bộ tạo hàm
g1,g2...gk
1
2
...
k
1 .... k
....
Các bộ tạo hàm
g1,g2...gk
1
2
...
Đầu vào
k bit
1 .... k
Hình VI-31:Bộ mã hoá tạo ra mã kép tốc độ 1/2
2k hàm sinh của mã chập kép được cho dưới dạng
1
2
k
g 1 0 0 0 1 0 0 0g 0 1 0 0 0 1 0 0 II
0 0 0 1 0 0 1k k
g
1
k 2
2k
1 1 0 0 0 1 0 0 0g 0 0 1 0 0 0 1 0 0g 0 0 0 1 0 0 0 0 1 0 00 0 0 0 1g 1 0 0 0 0 0 0 0 1
k
k
1 1 0 0 00 0 1 0 00 0 0 1 0 0 I0 0 0 0 11 0 0 0 0
Dạng tổng quát của hàm truyền của mã kép k tốc độ 1/2 là4 2
() ()2
4
(2 1)( , , )1 2 (2 3)
kI fi h i
iki
D J NT D N J a D N JNJ D D
trong đó D là khoảng cách Hamming giữa các ký hiệu q mức (q=2k-
), f(i) là số lượng ký hiệu thông tin có lỗi do lựa chọn sai
172

đường trong lưới, h(i) là số nhánh trong đường. Chú ý rằngkhoảng cách tự do tối thiểu dfree =4 ký hiệu (4k bit).
Mã kép k tốc độ thấp có thể tạo ra theo nhiều cách khác nhau,cách đơn giản nhất là lặp lại các ký hiệu tạo ra bởi tốc độ1/2 r lần , r =1,2,..,m. Nếu ký hiệu trong một nhánh nào đóđược lặp lại r lần thì khoảng cách tương ứng sẽ tăng từ D lênDr. Như vậy hàm truyền của mã kép k tốc độ 1/2r là
4 2
2
(2 1)( , , )1 2 (2 3)
k r
r k r
D J NT D N JNJ D D
Nếu độ dài của dãy thông tin lớn thì tham số độ dài đường Jcó thể đặt bằng 1. Lấy đạo hàm của T(D,N) theo N và đặt N = 1 tacó:
4
1 22 4
( , ) (2 1)|1 2 (2 3)
k ri
N ir k r i r
dT D N D DdN D D
trong đó i là số ký hiệu sai gắn với đường có khoảng cách Di
tới đường toàn 0.Biểu thức trên được sử dụng để tính xác suấtsai của mã kép k trên kênh .
Hiệu qua của mã kép k Giả sử mã kép k được sử dụng cùng vớitín hiệu trực giao M mức và M=2k, kênh có nhiễu cộng trắngGaussian và bộ giải điều chế gồm có M bộ lọc phối hợp. Nếu quátrình giải mã là xác địnhcứng thì hiệu quả của bộ mã được tínhbằng xác suất sai ký hiệu PM.Từ PM ta có thể tính được P2(d).Xác suất sai bit được giới hạn trên bởi
1
24
2 ( )2 1k
b dkd r
P P d
Nếu quá trình giải mã là xác định mềm theo luật bình phươngthì xác suất sai bit cũng được giới hạn trên theo công thức nhưng
1
2 20
1 1 1( ) exp -2 22 1d
b c i b cdi
P d R d K R d
173

và 1 2 10
1 ,!d i d
i llKi
1/2cR r .
Mã ghép Ta xét mã gồm mã khối và mã chập hay hai mã chập vớinhau. Như đã trình bày, mã ngoài thường là mã không nhị phân,mỗi ký hiệu có thể có q=2k giá trị .Mã này có thể là mã khối(Reed-Solomon) hay mã chập kép k. Mã trong có thể là nhị phânhay không phải nhị phân và có thể là mã khối hay mã chập. Nếumã trong là mã chập có độ dài ngấn thì thuật toán Viterbi chophép quá trình giải mã có hiệu quả. Nếu mã trong là mã khốivà bộ giải mã tương ứng xác định mềm thì bộ giải mã tươngứng xác định cứng sau khi nhận được từ mã và đưa kết quả tớibộ giải mã hoá ngoài thì bộ giải mã hoá ngoài phải thực hiệnxác định cứng. Xét ví dụ sau :
Ví dụ
Giả thiết ta có mã ghép gốm có mã kép tốc độ 1/2 là mã ngoàivà mã Hadamard (16,5) là mã trong. Mã kép có khoảng cách tự dotối thiểu Dfree = 4 và mã Hadamard có khoảng cách tối thiểudmin =8 như vậy mã ghép có khoảng cách tối thiểu là 32. Do mãHadamard có 32 từ mã và mã ngoài có 32 ký hiệu, như vậy mỗiký hiệu của bộ mã ngoài chuyển thành một từ mã của mãHadamard. Xác suất sai ký hiệu của bộ giải mã mã trong đượcxác định trong và . Giả thiết giải mã ở bộ giải mã trong làxác định cứng và P32 là xác suất sai từ mã (một ký hiệu ở bộ mãngoài ) thì hiệu quả của bộ mã ngoài và vủa mã ghép được tínhtheo .
7. Thuật toán Fano
Thuật toán Viterbi là thuật toán giải mã tối ưu (thuật toán MLcho toàn bộ dãy) cho mã chập. Tuy nhiên thuật toán này đòi hỏiphải tính 2kK độ đo tại mỗi nút của lưới và lưu trữ 2k(K-1) dãy cònlại , mỗi dãy còn lại có độ dài 5kK bit. Độ phức tạp tính toánvà khối lượng thông tin cần lưu trữ làm cho thuật toán khôngcó hiệu quả khi độ dài ràng buộc lớn.
Thuật toán giải mã dãy Fano tìm đường có nhiều khả năng nhấttrong lưới hay cây bằng cách kiểm tra từng đường, độ đo được
174

tăng lên theo từng nhánh tương ứng với xác suất của tín hiệunhận được từ nhánh đó giống như thuật toán Viterbi ngoại trừmột hằng số âm được thêm vào cho mỗi nhánh. Giá trị của hằngsố được chọn sao cho độ đo tương ứng với nhánh đúng bình quânsẽ tăng còn các nhánh không đúng sẽ giảm bình quân. Bằng cáchso sánh độ đo của các nhánh vơí giá trị ngưỡng thay đổi liêntục, thuật toán sẽ phát hiện và loại bỏ các đường dẫn khôngđúng.
Xét một kênh không nhớ, độ đo của đường thứ i trong cây haylưới từ nhánh đầu tiên tới nhánh thứ B được biểu diễn bởi:
() ()
1 1
B ni i
jmj m
CM
với:()
()2
( | )log ( )i
jm jmijm
jm
p r cK
p r
Trong , jmr là dãy ra của bộ giải điều chế , ()( | )ijm jmp r c là hàm mật
độ phân bố xác suất của jmr với điều kiện mã bit ()ijmc của bit
thứ m trong nhánh thứ j của đường thứ i và K là một hằng sốdương. K được chọn để độ đo của các đường sai sẽ giảm dần vàcủa đường đúng sẽ tăng dần một cách trung bình . Chú ý rằng( )jmp r là độc lập với dãy mã và có thể coi là hằng số.
Ðộ ðo áp dụng cho cả giải mã xác định cứng và mềm có thể tínhđơn giản hơn trong giải mã xác định cứng. Giả sử kênh là BSCthì
()2()
()2
log [2(1 )]log 2
ic jm jmi
jm ic jm jm
p R r cp R r c
jmr là đầu ra của bộ giải điều chế xác định cứng và ()ijmc là bit
mã thứ m của nhánh thứ j trong đường thứ i. Ta thấy rằng đểtính các độ đo thì cần phải biết (hoặc xấp xỉ ) xác suất lỗi.
Ví dụ Giả sử mã nhị phân chập tốc độ 1/3 được truyền trên kênhBSC với p = 0,1 ta có:
175

()()
()0,522,65
ijm jmi
jm ijm jm
r cr c
Để đơn giản việc tính toán các độ đo trong công thức đượcchuẩn hoá và xấp xỉ thành:
()()
()15
ijm jmi
jm ijm jm
r cr c
Do tốc độ mã là 1/3 nên có ba bit ở đầu ra của bộ mã hoá ứngvới mỗi bit đầu vào nên độ đo của một nhánh là:
()ij = 3-6d hay ()i
j =1-2d
với d là khoảng cách Hamming giữa ba bit nhận được với các babit của nhánh. Như vậy ()i
j tương ứng với khoảng cáchHamming giữa các bit nhận được với các bit trong nhánh thứ jcủa đường thứ i.
Hình VI-32: Ví dụ về thuật toán Fano
Khởi đầu bộ giải mã được bắt đầu với một đường đúng bằng cáchtruyền đi vài bit xác định trước. Sau đó nó sẽ tiến từ nút nàytới nút khác, lấy nhánh có xác suất lớn nhất tại mỗi nút vàtăng giá trị cận lên sao cho giá trị cận này không vượt quámột giá trị xác định trước t. Bây giờ giả thiết rằng nhiễutrắng (đối với giải mã xác định mềm ) hay lỗi giải điều chế donhiễu (đối với giải mã xác định cứng) làm cho bộ giải mã chọnmột đường không đúng (Hình VI -32: Ví dụ về thuật toán
176

Fano). Do các giá trị độ đo ứng với đường sai giảm một cáchtrung bình thì độ đo sẽ nhỏ hơn giá trị cận hiện thời (t0 ).Khi điều này xảy ra thì bộ giải mã sẽ quay trở lại và lấy mộtđường khác sao cho có độ đo vượt t0 .Nếu chọn được đường đúng,nó sẽ tiếp tục theo đường này, nếu không, giá trị cận bị giảmđi t và quay trở lại đường ban đầu. Nếu đường ban đầu không cóđộ đo vượt giá trị cận thì bộ giải mã sẽ quay ngược trở lại vàtìm một đường khác. Qúa trình này cứ lặp lại cho tới khi tìmđược đường đúng. Sơ đồ khối của thuật toán được vẽ trong Hình VI -32.
Thuật toán giải mã này cần bộ đệm trong bộ giải điều chế đểlưu trữ số liệu giải mã được. Khi quá trình tìm kiếm kết thúc,bộ giải mã phải xử lý các bit đã giải mã đủ nhanh để xoá bộđệm và lặp lại quá trình tìm kiếm. Tốc độ giới hạn R0 có ýnghĩa quan trọng trong giải mã dãy . Nó là tốc độ để số lượngphép tính ứng với một bit giải mã được tiến tới vô hạn và đượcgọi là thời gian tính toán giới hạn Rcomp.Thực tế thì bộ giải mã dãyFano với thuật toán Viterbi thì thuật toán Fano có độ trễ giảimã lớn hơn, tuy nhiên yêu cầu về bộ nhớ để lưu trữ thì nhỏ hơnvà có hiệu quả với độ dài ràng buộc lớn.
VIII. Một số vấn đề trong thực tế của việcáp dụng mã chập
Từ xác suất sai của giải mã xác suất mềm, ta thấy rằng độ tăngích mã hoá đối với hệ thống sử dụng tín hiệu PSK hay QPSKkhông mã hoá là : độ tăng ích mã hoá log10(Rcdfree) .Ta cũngthấy rằng khoảng cách tự do tối thiểu dfree có thể tăng lênbằng cách giảm tốc độ mã hay tăng độ ràng buộc hay cả hai.Bảng 11 liệt kê độ tăng ích mã hoá thực tế và giới hạn trêncủa độ dài ràng buộc của một số mã chập dùng thuật toánViterbi để giải mã.
Bang 11: Giới hạn trên của độ tăng ích mã hoá đối với giai mã xác định mềm
Mã tốc độ 1/2Mã tốc độ 1/3
177

K
dfree
Giới hạn trêndB
K
dfree
Giới hạn trêndB
3
4
5
6
7
8
9
10
5
6
7
8
9
10
12
12
3,98
4,77
5,44
6,02
6,99
6,99
7,78
7,78
3
4
5
6
7
8
9
10
8
10
12
13
15
16
18
20
4,26
5.23
6,02
6,37
6,99
7,27
7,78
8,24
Bang 12: Độ tăng ích mã hoá với thuật toán Viterbi xác định mềm (dB)
Pb 0/b N Khôngmã hoá (dB)
Rc=1/3
K=7K=8
Rc=1/2
K=5 K=6K =7
Rc=2/3
K=6K=8
Rc=3/4
K=6K=9
10-3
10-5
10-7
6,8
9,6
11,3
4,24,4
5,75,9
6,26.5
3,3 3,53,8
4,3 4,65,1
4,9 5,35,8
2,93,1
4,24,6
4,75,2
2,62,6
3,64,2
3,94,8
178