lembar pengesahan
TRANSCRIPT

LEMBAR PENGESAHAN

AYAT AL-QURAN

MOTTO

ABSTRAK

KATA PENGANTAR

DAFTAR ISI

DAFTAR TABEL

DAFTAR GAMBAR

BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Saat ini banyak sekali karyawan yang ingin
memiliki penghasilan lebih dari setiap pekerjaan yang
dia lakukan salah satunya adalah mengambil waktu
tambahan yang dimana biasa disebut dengan jam lembur,
jam lembur sendiri di definiskan sebagai waktu untuk
melakukan pekerjaan, dapat dilaksanakan siang hari
dan/atau malam hari. Namun biasanya jam lembur ini juga
telah di tetapkan oleh perusahaan untuk setiap karyawan
yang bekerja di perusahaan tertentu. Dalam pelaksanaan
jam lembur disini para karyawan dapat mendapatkan
tambahan uang atau sering disebut dengan insentif sama
halnya dengan pengupahan yang diberikan kepada karyawan
yang melakukan akhitifitas tambahan salam melakukan
pekerjaannya seperti jam lembur, namun disini di
jelaskan bahwa setiap jam lembur yang dilakukan oleh
setiap karyawan akan mendapatkan upah tambahan.
Insentif yang di berikan oleh karyawan berdeda-
beda tergantung pada prestasi yang di lakukannya.
Penelitian bertujian untuk dapat mengetahui ada
pengaruh jam lembur yang di lakukan setiap karyawan
dengan intensif yang diterima. Dengan fungsi utama dari
insentif adalah untuk memberikan tanggungjawab dan
dorongan kepada karyawan. Dalam hal ini, untuk

menentukan apakah ada pengaruh jam lembur terhadap
pendapatan insentif disini salah satunya adalah
menggunakan teknik analisis dapat dianalisis pengaruh
beberapa variabel terhadap variabel lainnya dalam waktu
yang bersamaan untuk menjelaskan hubungan antar
variabel, dimana hubunga teknik analisis digunakan
untuk mempelajari antara jam lembur dengan pendapatan
intensif. Sehingga dengan analisis disini dapat
memprediksi jumlah intensif yang di terima karyawan
dengan mempertimbangkan jam lembur yang di lakukan.
Dengan adanya kasus tersebut dapat diidentifikasi
variabel penyebab dan akibat, bahwa yang menjadi
variabel penyebab (X) adalah jam lembur karyawan dan
variabel akibat (Y) adalah jumlah pendapatan insentif.
1.2 Perumusan Masalah
Perumusan masalah disini terkait dengan kasus yang
ada untuk pembuatan laporan akhir dengan kasus mengenai
pengaruh jam lembur terhadap pendapatan insentif :
1. Bagaimana mengevaluasi hasil menggunakan Teknik
Analisis Statistik ?
2. Bagaimana pengaruh jam lembur karyawan terhadap
pendapatan insentif karyawan?
1.3 Maksud dan Tujuan Penelitian
Maksud dari penelitian ini adalah pengaruh jam
lembur karyawan terhadap pendapatan insentif karyawan.

Tujuannya untuk mengetahui asumsi yang digunakan
dalam regresi linier sederhana dan untuk memprediksikan
nilai variabel regresi.
1. Dapat mengevaluasi hasil menggunakan Teknik
Analisis Statistik
2. Dapat mengetahui dan mengambil kesimpulan
pengaruh jam lembur karyawan terhadap pendapatan
insentif karyawan.
1.4 Pembatasan Masalah
Pembatasan masalah dalam penelitian digunakan
untuk lebih melihat kepada :
1. Data yang digunakan dalam penelitian ini adalah
data sekunder yaitu data yang diperoleh atau
dikumpulkan dari berbagai sumber yang telah ada,
yang di dapat dari data sebuah kantor Dinas di
Kalimantan Barat.
2. Dimana objek penelitian disini adalah Jam Lembur
yang di sini menjadi variabel X dan Jumlah
Insentif menjadi variabel Y.
3. Alat penunjang dalam penelitian dan pembuatan
laporan disini menggunakan software IBM SPSS 22.
1.5 Sistematika Penulisan
Pada proses penyusunan untuk menyelesaikan laporan
akhir Statistik Bisnis Industri II, yaitu sebagai
berikut :
BAB I Pendahuluan

Pada bab ini berisi tentang latar belakang dari
penyusunan laporan akhir, perumusan masalah yang akan
dianalisa dan tujuan dari pengolahan dan perhitungan
data yang telah didapat, serta sistematika penulisan
laporan akhir.
BAB II Landasan Teori
Pada bab ini berisi tentang penjelasan teori-teori
yang berhubungan dengan studi kasus mengenai pengaruh
jam lembur terhadap jumlah insentif karyawan serta
teori yang berhubungan dengan praktikum Statistik
Bisnis Industri II.
BAB III Kerangka Pemecahan Masalah
Pada bab ini berisi tentang penjelasan menganai
kerangka pemecahan masalah yang diinterpretasikan
melalui flowchart disertai dengan uraian pemecahan
masalah.
BAB IV Pengumpulan dan Pengolahan Data
Pada bab ini berisi tentang gambaran umum
Laboratorium Manajemen Kualitas, pengumpulan data yang
terdiri dari data objek penelitian dan data pretest, dan
pengolahan data mengenai perhitungan parameter
populasi, perhitungan ukuran pemusatan data,
perhitungan ukuran penyebaran data, pengukuran
dispersi, skewness, dan kurtosis, pengujian kenormalan,
penentuan koefisien regresi, uji hipotesis dan
penaksiran selang koefisien regresi, penentuan

koefisien korelasi, uji hipotesis dan penaksiran selang
koefisien korelasi, dan analisis variansi.
BAB V AnalisisPada bab ini akan membahas tentang hasil
perhitungan dan pengolahan data yaitu analisis
perhitungan parameter populasi, perhitungan ukuran
pemusatan data, perhitungan ukuran penyebaran data,
analisis pengujian kenormalan, analisis penentuan
koefisien regresi, analisis uji hipotesis dan
penaksiran selang koefisien regresi, analisis penentuan
koefisien korelasi, analisis uji hipotesis dan
penaksiran selang koefisien korelasi, dan analisis
variansi.
BAB VI Kesimpulan dan Saran
Pada bab ini dipaparkan tentang kesimpulan data yang
sudah diolah, serta memberikan jawaban dari perumusan
masalah yang ada dan Saran yang akan di berikan untuk
khasus yang dipilih dengan hasil dari pengolahan data
yang ada.

BAB II
LANDASAN TEORI
2.1 Teori Jam Lembur & Insentif
2.1.2 Jam Lembur
Menurut KEPMEN Pasal 1 Ayat 1 (2004: 1), waktu
kerja lembur adalah waktu kerja yang melebihi tujuh jam
sehari dan 40 jam satu minggu untuk enam hari kerja
dalam satu minggu atau delapan jam sehari dan 40 jam
satu. Minggu untuk lima hari kerja dalam satu minggu
atau waktu kerja pada hari istirahat mingguan dan atau
pada hari libur resmi yang ditetapkan.
Menurut KEPMEN Pasal 3 Ayat 1 (2004: 2), waktu
kerja lembur hanya dapat dilakukan paling banyak tiga
jam dalam satu hari dan 14 jam dalam satuminggu.
Menurut KEPMEN Pasal 8 Ayat 1 (2004: 2),
perhitungan upah lembur didasarkan pada upah bulanan.
Menurut KEPMEN Pasal 8 Ayat 2 (2004: 2), cara
menghitung upah sejam adalah 1/173 kali upah sebulan.
Menurut KEPMEN Pasal 11 (2004: 1), cara
perhitungan upah kerja lembur sebagai berikut.
1. Kerja lembur dilakukan pada hari kerja.
a.Untuk jam kerja lembur pertama harus dibayar
upah sebesar 1,5 kali upah sejam.
b.Untuk setiap jam kerja lembur berikutnya harus
dibayar upah sebesar dua kali upah sejam.

2. Apabila kerja lembur dilakukan pada hari
istirahat mingguan dan/atau hari libur resmi untuk
waktu kerja enam hari kerja 40 jam seminggu.
a. Perhitungan upah kerja lembur untuk tujuh jam
pertama dibayar dua kali upah sejam, dan jam
kedelapan dibayar tiga kali upah sejam dan jam
lembur kesembilan dan kesepuluh dibayar empat
kali upah sejam.
b. Apabila hari libur resmi jatuh pada hari
kerja terpendek perhitungan upah lembur lima jam
pertama dibayar dua kali upah sejam, jam keenam
3 (tiga) kali upah sejam dan jam lembur ketujuh
dan kedelapan 4 (empat) kali upah sejam.
2.1.3 Insentif
Pengertian yang umum, insentif adalah kompensasi
khusus yang dirancang untuk memotivasi kinerja luar
biasa (superior performance). Dalam bahasa yang lebih
sederhana insentif dapat diartikan sebagai bonus diluar
gaji. Kompensasi dalam bentuk insentif ini mempunyai
kaitan langsung dengan motivasi (jadi insentif
diberikan guna meningkatkan motivasi).
Insentif diberikan tergantung dari prestasi atau
produksi. Kompensasi insentif dibedakan atas:
Bonus Utuh (lump-sump), yaitu pembayaran kas sekali
waktu/tunai atau hak untuk membeli saham
perusahaan berdasarkan kinerja.

Pembagian Keuntungan (profit sharing), yaitu pemberian
bonus berdasarkan keuntungan perusahaan.
Pembagian Pendapatan (gain sharing), yaitu pemberian
bonus karena berhasit melampaui target kinerja
yang ditetapkan atau terjadi efisiensi kerja.
Pembayaran atas Pengetahuan Yang Dimiliki (pay for
knowledge), yaitu pemberian kenaikan upah/gaji atas
keterampilan atau pekerjaan baru yang mereka
kuasai.
Menurut Para ahli pengertian insentif, berikut ini
beberapa diantaranya:
1. Andrew F. Sikula: insentif ialah sesuatu yang
mendorong atau mempunyai kecenderungan untuk
merangsangsuatu kegiatan, insentif adalah motif-
motif dan imbalan-imbalan yang dibentuk untuk
memperbaiki produksi.
2. Heidjrachman: Pengupahan insentif dimaksudkan
untuk memberikan upah/gaji yang berbeda karena
prestasi kerja yang berbeda.
3. Adams dan Hicks: Insentif adalah semua bentuk
imbalan dan hukuman (punishments) yang diterima oleh
para pemberi layanan (providers) sebagai konsekuensi
dari organisasi tempat mereka bekerja, institusi
yang mereka operasionalkan, dan intervensi-
intervensi yang mereka lakukan.

2.2 Statistik Deskriptif
Statistik deskriptif merupakan salah satu merode
dalm kajian ilmu statistika metode ini dipergunakan
untuk menggambarkan dan menganalisis data dengan cara
menghitung/mengolah sekurang-kurangnya satu statistik
sampel, dengan cara menyusun sejumlah grafik dan tabel,
dan dengan cara membandingkan hasil yang diperoleh
dengan data lainnya.
2.2.1 Konsep Dasar Statistika
Terdapat banyak definisi yang diberikan untuk
menjelaskan pengertian dari statistika (statistics) atau
ilmu statistik. Salah satunya diberikan oleh Sudjana
(2013) yang mengatakan bahwa statistik adalah
“Pengetahuan yang berhubungan dengan cara-cara
pengumpulan data, pengolahan atau penganalisisannya dan
penarikan kesimpulan berdasarkan kumpulan data dan
penganilisisan yang dilakukan”.
Untuk dapat mempelajari statistik lebih lanjut,
perlu dipahami terlebih dahulu mengenai beberapa konsep
dasar yang berkaitan dengan statistika tersebut. Adapun
sejumlah konsep dasar yang perlu dipahami tersebut
antara lain.
1. Data, adalah sekumpulan angka atau keterangan yang
tersusun dan didapatkan melalui pengukuran, hasil
perhitungan ataupun hasil kerja dari badan tertentu
(Sudjana, 2013).

2. Populasi, adalah kumpulan dari seluruh elemen
sejenis tetapi dapat dibedakan satu sama lain karena
karakteristiknya (Supranto, 2008). Perbedaan-
perbedaan itu disebabkan karena adanya nilai
karakteristik yang berlainan. Misalnya, seluruh
karyawan perusahaan merupakan suatu populasi. Disini,
elemennya berupa orang, yaitu karyawan perusahaan.
Walaupun jenisnya sama, namun karakteristiknya secara
keseluruhan akan berlainan, misalnya pendidikan, masa
kerja, jumlah anak, gaji pokok, dan lain sebagainya.
Ukuran populasi tersebut bisa berhingga (finite
population) ataupun yang tidak terhingga (infinite
population). Nilai sebenarnya dari suatu sifat populasi
ini disebut dengan parameter populasi, yang
dilambangkan dengan sejumlah huruf latin, seperti
μ,σ,π dan lain sebagainya.3. Sampel acak (random sample), adalah sampling yang
pemilihan elemen-elemen populasinya dilakukan secara
acak atau random (Supranto, 2008). Pemilihan
dilakukan dengan menggunakan lotere, undian atau
tabel bilangan acak (table of random number). Ukuran
sampel biasanya berhingga dan cukup kecil yang
bertujuan untuk mengurangi waktu pengumpulan data dan
biaya, namun lebih besar ukuran sampel akan menambah
tingkat akurasi dari estimasi parameter. Nilai dari
sampel disebut dengan “statistik” (statistic), yakni
suatu angka yang dihitung dari data sampel dan

digunakan untuk mengestimasi suatu parameter
populasi, yang biasanya tidak diketahui. Statistik
ini biasanya dilambangkan oleh suatu huruf romawi
seperti s, t, p, x. Sebagai contoh, misalnya untuk
contoh kependudukan maka sampel merupakan sebagian
dari penduduk kota yang diteliti.
4. Variabel, adalah karakteristik populasi yang
diamati. Dilambangkan dengan huruf kapital dan dapat
diklasifikasikan menjadi variabel diskret, dan
variabel kontinu. Variabel diskret, hanya dapat
mengasumsikan suatu nilai terbatas yang tentu.
Contohnya, sejumlah orang yang bekerja (misalkan X),
dapat merupakan suatu bilangan bulat (integer) 0, 1,
2, dan seterusnya. Variabel kontinu dapat mengasumsikan
suatu bilangan diantara dua batas (limit), ukuran
tinggi badan misalnya merupakan salh satu contoh
variabel kontinu. Kenyataan yang seringkali
menunjukkan bahwa variabel kontinu terlihat sebagai
variabel diskret, terjadi karena variabel tidak dukur
seakurat mungkin. Jika diakatakan bahwa tinggi badan
seseorang adalah 175 cm, ini bukanlah diskret, tetapi
kontinu. Karena sebenarnya 175 cm adalah 174,79.
Terdapat dua tahapan utama dalam statistika, yakni
statistika deskriptif (descriptive statistics), dan statistika
inferentif (inferential statistics). Statistika deskriptif,
menggambarkan dan menganalisis data dengan cara
menghitung/mengolah sekurang-kurangnya satu statistik

sampel, dengan cara menyusun sejumlah grafik dan tabel,
dan dengan cara membandingkan hasil yang diperoleh
dengan data lainnya. Setelah tahapan ini selesai, maka
statistika inferentif mengintepretasikan hasil tersebut
dengan menggunakan alat (tools) statistika, pengalaman,
pengetahuan umum (common sense), dan pemahaman umum dari
proses yang dipelajari.
2.2.2 Penyajian Data
Data yang telah dikumpulkan, baik berasal dari
populasi maupun smapel, untuk keperluan pelaporan dan
atau analisis selanjutnya, perlu diatur, disusun, dan
disajikan dalam bentuk yang jelas dan singkat sehingga
mempermudah pemahaman. Secara umum terdapat dua cara
penggambaran data yang seringkali digunakan dalam
statistika, yakni cara tabel dan grafik atau diagram.
Sebagai bahan rujukan lebih lanjut mengenai format
penyajian data statistika dapat dilihat pada Sudjana
(2013).
2.2.2.1 Tabel
Tabel merupakan bentuk penggambaran data dalam
bentuk baris dan kolom. Adapun bentuk tabel ini beragam
sesuai dengan kebutuhan yang ada.
2.2.2.2 Grafik/Diagram
Grafik atau diagram merupakan bentuk penyajian
data dalam bentuk gambar. Terdapat beberapa jenis
grafik atau diagram, yang dibedakan berdasarkan bentuk
visualnya. Diantara grafik tersebut antara lain diagram

batang, diagram garis, diagram pastel/lingkaran,
diagram pencar dan lain-lain.
2.2.2.3 Distribusi Frekuensi
Untuk dapat memahami data dengan mudah, harus
disajikan dalam bentuk yang ringkas dan jelas. Salah
satu cara untuk meringkas data adalah dengan distribusi
frekuensi. Distribusi frekuensi merupakan
pengelompokkan data ke dalam beberapa kelompok (kelas)
dan kemudian dihitung banyakanya data yang masuk
kedalam tiap kelas (Supranto, 2008). Distribusi
frekuensi atau yang disebut juga dengan histogram, bisa
digunakan untuk data yang dikelompokkan atau tidak.
Dara yang tidak dikelompokkan (ungrouped data) biasanya
digunakan untuk suatu variabe diskret. Nilai variabel
diletakkan pada sumbu absis (sumbu x) dan skala
frekuensi pada sumbu ordinat (sumbu y). Seringkali
distribusi frekuensi data tidak terkelompok, kurang
memberikan gambaran bagaimana data terdistribusi karena
perbedaan setiap nilai membuat frekuensi setiap data
sangat kecil. Untuk meningkatkan efesiensi dalam
mempelajari sejumlah variabel, data tersebut dapat
dikelompokkan menjadi sejumlah kelas (cells). Untuk
membuat daftar distribusi frekuensi dengan panjang
kelas yang sama, langkah pengerjaan yang harus
dilakukan adalah sebagai berikut:
1. Mengurutkan data dari yang terkecil hingga yang
terbesar.

2. Menentukan rentang (R) kelas, dengan cara:
R = Xmaks - Xmin
..................................................
.............(2.1)
3. Menentukan banyak kelas interval yang diperlukan
Banyak Kelas = 1 + 3,3 log n
..........................................(2.2)
4. Menentukan panjang kelas interval (p) dengan cara:
5. Menentukan batas kelas, yakni setelah nilai
setengah unit pengukuran yang lebih akurat
daripada nilai yang diamati.
6. Menentukan nilai tengah setiap kelas dengan cara:
Nilai tengah = 12 (Batas atas kelas + Batas bawah kelas)
...........(2.3)
2.2.3 Ukuran Pemusatan dan Penyebaran Data
Dalam tendesi pemusatan data akan dipelajari
mengenai rata-rata (mean), modus (mode) dan median
(median), selain itu akan dipelajari juga tentang
kuartil, desil dan persentil. Sedangkan dalam tendensi
penyebaram data (dispersion) akan dipelajari tentang
rentang (range), simpangan baku (standard deviation) dan
variansi (variance). Selain itu, pada tulisan ini hanya
akan dibahas mengenai ukuran pada data yang telah
dikelompokkan
2.2.3.1 Ukuran Pemusatan Data
Dalam bagian ini akan dipelajari mengenai
perhitungan rata-rata (mean), nilai tengah (median),

nilai terbanyak (modus) dan nilai perempat (quartile),
persepuluh (desil), perseratus (persentile).
Rata-rata
Rata-rata (mean/average/expected value) adalah nilai
yang mewakili himpunan atau sekelompok data (a set of
data) yang pada umumnya cenderung terletakdi tengah
suatu kelompok data yang telah disusun menurut besar
kecilnya niali (Supranto, 2008). Beberapa jenis rata-
rata yang sering digunakan ialah rata-rata hitung
(aritmetic mean), rata-rata ukur (geometric mean) dan rata-
rata harmonik (harmonic mean). Dalam tulisan ini, hanya
akan dibahas mengenai rata-rata hitung (seterusnya
sebut saja rata-rata) saja, sedangakn untuk jenis rata-
rata lain dapat dirujuk pada Sudjana (2013). Rata-rata
( X ) (baca: eks bar) untuk sampel, dan µ (baca: miu)
untuk rata-rata populasi. Jadi X adalah statistik
sedangkan µ adalah parameter untuk menyatakan rata-
rata.
.........................................
......................(2.4)
Dimana: Xi = Nilai tengah kelas
n = Banyak data
Dan bila memperhitungkan frekuensi setiap kelas

.........................................
...................... (2.6)
Dimana: Xi = Nilai tengah kelas
ƒi = Frekuensi kelas
Median
Kalau ada sekelompok nilai sebanyak n diurutkan
mulai dari yang terkecil X1 sampai dengan yang terbesar
Xn, maka nilaiyang ada ditengah disebut dengan median
(Me).
.................................
................................. (2.7)
Dimana:
Lo = Batas bawah dari kelas median dimana median
berada
n = Jumlah data
p = Panjang kelas interval
= Frekuensi kelas median
F = Jumlah frekuensi dengan tanda kelas lebih
kecil dari tanda kelas
Median
Modus
Modus (Mo) dari suatu kelompok nilai adalah nilai
kelompok yang memiliki frekuensi tertinggi. Atau nilai
yang paling banyak terjadi di dalam suatu kelompok

nilai. Nilai modus diperoleh dengan menggunakan
persamaan berikut.
..................................
........................... (2.8)
Dimana:
Lo = Batas bawah dari kelas modus
b1 = Selisih antara frekuensi kelas modus dengan
frekuensi tepat satu
kelas sebelum kelas modus
b2 = Selisih antara frekuensi kelas modus dengan
frekuensi tepat satu
kelas sesudah kelas modus
p = Panjang kelas interval
Kuartil, Desil dan Persentil
Bila median membagi data menjadi dua kelompok yang
sama, maka kuartil (Q) membagi data menjadi empat
bagian yang sama, desil (D) membagi menjadi sepuluh
bagian yang sama dan persentil (P) menjadi seratus
bagian yang sama. Bila data tersebut belum ikelompokkan
nilai kuartil, desil, dan persentil diperoleh dengan
menggunakan persamaan berikut.
..........................................
................................ (2.9)
Dengan catatan

Kuartil : L = 4 ; i= 1, 2, 3
dimana, n= 4
Desil : L = 10 ; i= 1, 2, 3, ..., 9
dimana, n= 10
Persentil: L = 100 ; i= 1, 2, 3, ..., 99
dimana, n= 100
Untuk data yang telah dikelompokkan ke dalam
distribusi frekuensi, ketiga pengukuran tersebut dapat
diperoleh dengan menggunakan persamaan berikut ini.
- Kuartil
...............................
............... (2.10)
- Desil
..............................
................(2.11)
- Persentil

.............................
............... (2.12)
Dimana:
Lo = Batas bawah dari kelas kuartil, desil,
persentil
p = Panjang kelas interval
= Frekuensi kelas kuartil, desil, persentil
= Jumlah semua frekuensi kelas sebelum
kelas kuarti, desil dan persentil
2.2.3.2 Ukuran Penyebaran Data
Dalam bagian ukuran penyebaran data (dispersion)
akan dipelajari tiga ukuran, yakni nilai jarak (range),
nilai rata-rata simpangan (mean deviation), nilai
simpangan baku (standard deviation), bilangan baku
(standardized value) dan koefisien variasi (coefficient of
variation).
Nilai Jarak
Bila suatu kelompk nilai (data) telah disusun
menurut urtan yang terkecil (Xi) sampai dengan yang
terbesar (Xn), maka untuk menghitung nilaijarak (R)
dipergunakan persamaan 2.13, yaitu

R= Xmaks.- Xmin
.......................................................
................ (2.13)
Rata-rata Simpangan
Rata-rata simpangan (RS) adalah rata-rata dari nilai
absolut simpangan antara data (Xi) dengan nilai rata-
ratanya (x). Rata-rata simpangan ini selanjutnya dapat
dirumuskan sebagai berikut.
RS= 1/n x Σ I xi -
xI.....................................................
.................. (2.14)
Simpangan Baku
Simpangan baku merupakan salah satu ukuran dispersi
yang diperoleh dari akar kuadrat variansi. Sedangkan
variansi adalah rata-rata dari kuadrat simpangan baku
setiap pengamatan terhadap rata-ratanya (Supranto,
2008). Lambang yang digunakan untuk varians adalah “σ2”
(baca: sigma kuadrat) untuk populasi, dan “s2” untuk
sampel. Persamaan yang digunakan untuk mencari nilai s2
adalah sebagai berikut.
................................
...............................(2.15)
Dan bila memperhitungkan frekuensi setiap kelasnya
persamaan yang digunakan adalah

....................................
............................ (2.16)
Karena simpangan baku merupakan akar variansi,
maka
Atau,
....................................
............................. (2.17)
Dimana: S2 = Variansi
S = Simpangan Baku
Bilangan Baku
Misalkan terdapat suatu sampel berukuran n dengan
data x1, x2, x3, ..., xn sedangkan rata-ratanya = (x)
dan simpangan bakunya= s, maka nilai bilangan baku (Zi)
diperoleh dengan menggunakan persamaan berikut ini.
..........................................
..............................................(2.18)
Dari nilai z ini kemudian dapat dihitung nilai
rata-rata dan simpangan baku yang baru, dan dari
perhitungan akan diperoleh jika rata-rata (xz) selalu
bernilai atau mendekati nilai nol (0). Sedangkan nilai
simpangan bakunya selalu bernilai atau mendekati nilai
satu (1).

Koefisien variansi
Simpangan baku mempunyai satuan yang sama dengan
satuan data aslinya, hal ini merupakan suatu kelemahan
bila ingin membandingkan dua kelompok data, misalnya
berat 100 ekor kuda dengan berat 100 ekor kelinci.
Walaupun nilai simpangan baku untuk berat kuda lebih
besar daripada simpangan baku kelinci, namun belum
tentu data berat kuda lebih heterogen (beragam) atau
lebih bervariasi daripada berat kelinci. Untuk itu,
dalam membandingkan dua kelompok data dipergunakan
koefisien variasi (kv), yang bebas dari satuan data
asli, untuk sampel nilai koefisien variasi diperoleh
dengan menggunakan persamaan.
.............................................
................................................ (2.19)
Jika ada dua kelompok data dengan kv1 dan kv2,
dimana kv1 > kv2, maka ini berarti kelompok pertama
lebih bervariasi atau lebih heteogen daripada kelompok
kedua.
2.2.4 Momen, Kemiringan dan Kurtosis
Apabila terdapat sekelompok data sebanyak n: x1,
x2, x3, ...., xn, maka yang disebut momen ke r (Mr)
dapat dirumuskan sebagai berikut.

.....................................
..................................... (2.20)
Dan bila memperhitungkan frekuensi setiap kelasnya,
persamaan tersebut dapat ditulis.
...................................
................................... (2.21)
Momen ketiga dan keempat, yaitu M3 dan M4 masing-
masing berguna untuk mengukur kemiringan (skewness) dan
keruncingan (kurtosis) dari suatu distribusi frekuensi.
2.2.4.1 Ukuran Kemiringan
Kemiringan data diukur pada suatu sumbu vertikal.
Dimana, kemiringan tersebut berhubungan dengan letak
dari rata-rata, median dan modus. Kemiringan data
tersebut dapat dikategorikan ke dalam tiga jenis bentuk
data.
1. Data simetris: rata-rata, median dan modus
terletak pada garis yang sama. (a3 = 0)
2. Data miring ke kanan: median terletak diantara
rata-rata dan modus, dengan letak modus di
sebelah kiri. (a3 > 3)
3. Data miring ke kiri: median terletak diantara
rata-rata dan modus, dengan modus di sebelah
kanan. (a3 < 3)

Secara diagramatis kemiringan dapat digambarkan
sebagai berikut.
Gambar 2. 1 Ukuran Kemiringan (di modifikasi dari Supranto, 2008)
Ukuran kemiringan (α3) dapat diperoleh dengan
menggunakan dua pendekatan pertama, pendekatan Pearson,
dan kedua pendekatan momen. Penedekatan pertama
diperoleh dengan menggunakan persamaan berikut.
Kemiringan Pearson tipe pertama
......................................
.........................................(2.22)
Kemiringan Pearson tipe kedua,
.....................................
.......................................(2.23)
Sedangkan bila menggunakan pendekatan Momen,
kemiringan dapat ditulis,
α3 =
.......................................................
....................................(2.24)

2.2.4.2 Ukuran Keruncingan
Dilihat dari tingkat keruncingannya (α4) kurva
distribusi frekuensi dibagi menjadi 3, yaitu leptokurtis
(puncalk sangat runcing), platykurtis (puncak agak datar),
dan mesokurtis (puncak tidak begitu runcing). Secara
diagramatis ketiga jenis kurva dapat digambarkan
sebagai berikut.
Gambar 2. 2 Ukuran Keruncingan (di modifikasi dari Supranto, 2008)
Untuk memperoleh nilai α4 ini dapat dipergunakan
pendekatan momen yang dapat ditulis.
a4 =
.......................................................
.................................... (2.25)
2.3 Teori Peluang
Peluang (probability) dapat diartikan sebagai
kemungkinan terjadinya suatu kejadian sebagai hasil
percobaan statistika seperti itu dinilai dengan
menggunakan sekumpulan bilangan real dari 0 sampai 1
(Walpole dan Myers 1995). Untuk tiap titik pada ruang
sampel dikaitkan suatu peluang sedemikian rupa,
sehingga jumlah semua bobot sama dengan l. Bila kita
yakin bahwa suatu titik sampel tertentu kemungkinan

besar akan terjadi, maka bobotnya seharusnyalah dekat
dengan 1. Sebaliknya, bobot yang hampir nol diberikan
pada titik sampel yang kecil sekali kemungkinannya
terjadi. Dalam banyak percobaan, seperti pelantunan
suatu mata uang atau dadu, tiap titik sampel
berkemungkinan sama untuk muncul dan karenanya diberi
bobot yang sama pula. Titik di luar ruang sampel (yang
menggambarkan kejadian sederhana yang tak mungkin
terjadi) diberi bobot nol. Untuk menentukan peluang
suatu kejadian A, semua bobot titik sampel dalam A
dijumlahkan. Jumlah ini dinamakan peluang A dan
dinyatakan dengan P(A).
P (A )=nN ................................................
.......................................................
. (2-1)
Peluang ini dapat dinyatakan dalam bentuk desimal,
semisal 0.25. Selain itu peluang dapat juga dinyatakan
dalam bentuk persentase tertentu, semisal 65 % dan
sebagainya.
2.3.1 Teori Himpunan
Suatu himpunan (set) adalah sekumpulan dari
sejumlah objek tertentu, dimana objek-objek yang berada
dalam satu himpunan tersebut bisanya memiliki sejumlah
kesamaan tertentu. Sedangkan himpunan bagian (subset)
adalah kumpulan objek, yang merupakan bagian dari suatu
himpunan. Sebagai contoh misalnya himpunan A adalah

jumlah mahasiswa di seluruh kampus UNISBA, sedangakan
subset a misalnya jumlah mahasiswa di Fakultas Teknik
Industri UNISBA.
Semesta (universe) dilambangkan "S", atau himpunan
semesta adalah kumpulan dari seluruh objek yang
diteliti, jadi suatu himpunan merupakan subset bagi
suatu himpunan semesta. Suatu himpunan yang tidak
memiliki objek disebut himpunan kosong, dan
dilambangkan dengan huruf latin Ø (phi).
2.3.1.2 Diagram Venn dan Operasi Himpunan
Diagram Venn merupakan suatu diagram yang dapat
menjelaskan secara grafis dari sejumlah himpunan dan
bagaimana hubungan diantara himpunan-himpunan tersebut.
Terdapat tiga operasi himpunan yang berguna dalam
memahami teori peluang. Berikut ini dijelaskan mengenai
masing-masing operasi dan diagram venn yang
menggambarkannya.
Gambar Diagram Ven (a) Gabungan, (b) Irisan, (c) Komplemen
Gabungan (union) (gambar 2.1 a). Gabungan dari dua
himpunan merupakan suatu himpunan yang mengandung
seluruh elemen dari kedua himpunan, dan dilambangkan
dengan simbol "∪” Misalnya: A = {a,b,c} dan B = {b,d,f,g}
Maka : A ∪ B = {a,b,c,d,f,g}

Irisan (intersection) (gambar 2.1 b) . Irisan dari dua
himpunan adalah himpunan yang mengandung elemen yang
terdapat di kedua himpuan dan dilambangkan ∩,untuk.contoh diatas A ∩B = {c}
Komplemen (complement) (gambar 2.1 c). Komplemen
dari suatu himpunan merupakan himpunan yang memiliki
elemen diluar himpunan tersebut tapi masih merupakan
elemen himpunan semesta. Misalnya S = {a,b,..., j},
maka komplemen himpunan A adalah A’ = {e,f,g,h,i,j} dan
(A ∪B)' = {e,g,i,j}.2.3.1.3 Ruang Sampel dan Peluang Suatu Kejadian
Suatu daftar mengenai seluruh hasil yang mungkin
dari suatu percobaan, merupakan himpunan semesta, dan
disebut dengan ruang sampel (S). Anggota dari S ini
disebut dengan elemen, dan suatu subset dari S disebut
dengan kejadian (event). Suatu kejadian biasanya
merupakan perhatian utama, namun pemahaman mengenai
ruang sampel tetap saja diperlukan untuk mempelajari
kejadian lain pada ruang sampel yang sama.
2.3.1.4 Aksioma-aksioma Peluang
Suatu aksioma merupakan suatu pembuktian, yang
telah terbukti kebenarannya. Tiga aksioma dasar seluruh
perhitungan peluang dari suatu ruang sampel S dan dua
kejadian A dan B akan diperlihatkan berikut ini, P ()
dipergunakan untuk melambangkan peluang.
1. Bernilai Positif, setiap kejadian memiliki peluang
non negatif

P (A) ≥ 0
2. Kepastian, peluang dari ruang sampel adalah bernilai
1
P (S) = 1
3. Gabungan, peluang gabungan dari sejumlah kejadian
yang saling terpisah (mutually eclusive) adalah
penjumlahan dari peluang setiap kejadiannya
P (A∪B) = P (A) + P (B), Jika, A ∩ B = Ø2.3.1.5 Aturan Peluang
Terdapat sejumlah aturan peluang yang mungkin
dapat ditulis dan dibuktikan. Berikut ini dijelaskan
beberapa diantara aturan yang penting (Blank, 1986).
1. 0 ≤ P (A) ≤ 1
2. P (Ø) = 0
3. P (A) ≤ P (B), jika A merupakan subset dari B
4. P (A’) = 1 – P (A)
5. P (A∪B) = P (A) + P(B) – P (A ∩ B)Aturan terakhir akan berlaku jika himpunan A dan B
memiliki himpunan irisan. Namun bila A dan B tidak
memiliki himpunan irisan maka aturan yang berlaku
adalah seperti pada aksioma ketiga peluang.
2.3.1.6 Peluang Besyarat dan Kejadian Bebas
Peluang terjadinya suatu kejadian B bila diketahui
bahwa A telah terjadi disebut kejadian bersyarat
(conditional events) dan dinyatakan dengan P(B|A). Lambang
P(B|A) biasanya dibaca "peluang terjadi bila diketahui
A terjadi" atau lebih sederhana lagi" peluang B, bila A

diketahui. Secara matematis, persamaan yang dapat
digunakan untuk mencari P(B|A) adalah sebagai berikut.
P (B|A )=P(A∩B)P(A)
bilaP (A )>0 ...........................
............................ (2-2)
Berdasarkan persamaan 2.2 diatas dapat dibangun
suatu persamaan baru, yakni peluang irisan, dari dua
buah kejadian dimana kedua-duanya saling bergantung
(dependent). Persamaan P(A ∩ B) dapat ditulis sebagaiberikut.
Jadi peluang A dan B terjadi serentak sama dengan
peluang A terjadi dikalikan dengan peluang terjadinya B
bila A terjadi. Karena kejadian A ∩ B dan B ∩ A
ekivalen, maka berlaku
P(A∩B) = P(B∩A) = P(B)P(A|B)Dengan kata Iain, tidaklah menjadi soal kejadian
yang mana disebut A dan yang disebut B.
2.3.1.7 Variabel Acak
Variabel atau peubah acak merupakan suatu fungsi
yang mengaitkan suatu bilangan real pada setiap unsur
dalam mang sampel (Walpole, 1995). Contoh : Suatu
peubah acak biasanya dinotasikan dengan huruf besar
misalnya A,B,X,Y dan seterusnya sedangkan harganya
dengan huruf kecil misalnya a,b,x,y dst.
Bila x menyatakan kemungkinan jumlah anak laki
yang lahir bila pasangan suami istri merencanakan punya
2 anak sudah cukup maka nilai x yang mungkin dari
peubah acak X adalah pada Tabel

Contoh Variabel Acak
KejadianPP LP
PL LL
X0 1
1 2
2.3.1.8 Aturan Bayes
Teorema Bayes memainkan peranan yang penting dalam
penggunaan probabilitas bersyarat dan kejadian bebas.
Misalkan kejadian B1, B2, ......, Bk merupakan suatu
sekatan ruang sampel T dengan P(Bi) ≠+ 0 untuk i =
1,2,....,k. Misalkan A suatu sembarang dalam T dengan
P(A) ≠ 0. Maka:
P (Br|A )= P(Br∩A)
∑i=1
kP(Bi∩A)
=P (Br )P(A∨Br)
∑i=1
kP (Bi)P¿¿¿
....................
........................ (2-3)
untuk r = 1,2,..., k.
2.3.2 Permutasi dan Kombinasi
Bila kita mempunyai sebanyak n buah iłem, kemudian
n buah iłem tersebut akan disusun kedalam r cara,
dimana r < n, maka banyaknya cara yang dapat dilakukan
dapat ditentukan melalui dua cara:
1. Urutan penyusunan diperhatikan, yang dikenal dengan
model permutasi

2. Urutan penyusunan tidak diperhatikan, yang dikenal
dengan model kombinasi
Misalnya terdapat tiga buah bola, katakan bola A,
B, dan C. Tentukan banyak cara menyusun tiga bola
tersebut ke dalam dua posisi, baik menurut cara satu
ataupun cara dua
1. Bila menggunakan cara permutasi dimana urutan
diperhatikan, maka tiga bola tersebut dapat disusun
sebagai berikut: AB, AC, BC, BA, CA, CB. Atau
sebanyak 6 cara, perhatikan jika menggunakan cara
ini AB ≠ BA. Dengan menggunakan persamaan matematis
cara menyusun n item kedalam r cara dengan
memperhatikan urutan penyusunannya dapat ditulis
sebagai berikut :
nPr ¿n!
(n−r )!
....................................................
............................................ (2-4)
Dimana : nPr permutasi dari sebanyak n item yang
disusun ke dałam posisi sebanyak r posisi. Dimana n
≥ r.
2. Bila menggunakan cara kombinasi dimana urutan tidak
diperhatikan, maka tiga bola tersebut dapat disusun
sebagai berikut: AB, AC, BC. Atau sebanyak 3 cara,
perhatikan jika menggunakan cara ini AB = BA. Dengan
menggunakan persamaan matematis cara menyusun n item

kedalam r cara dengan memperhatikan urutan
penyusunannya dapat ditulis sebagai berikut
nCr ¿ n!r! (n−r)!
....................................................
.......................................... (2-5)
2.3.3 Distribusi Peluang
Distribusi peluang adalah tabel, gambar atau
persamaan yang menggambarkan atau mendeskripsikan
nilai-nilai yang mungkin dari peubah acak dan peluang
yang bersesuaiannya (Peubah Acak Diskret) atau
kepadatan (Peubah Acak Kontinu).
2.3.3.1 Distribusi Peluang Diskret
Himpunan pasangan terurut (x, f(x)) merupakan
suatu fungsi peluang, fungsi massa peluang atau
distribusi peluang peubah acak diskret X, untuk setiap
kemungkinan hasil x (Walpole/Myers, 1995).
1. f(x)>0
2. ∑x=a
bf (x)=1
3. P (X=x) = f(x)
2.3.3.2 Distribusi Hipergeometrik
Dipergunakan untuk memecahkan masalah penarikan
sampel tanpa pengembalian
Ada n benda
k benda diberi nama sukses

Sisanya n-k benda gagal. Dicari peluang memilih x
sukses dari sebanyak k yang tersedia , bila sampel
acak ukuran n diambil dari N benda.
Sifat percobaan hipergeometrik
Sampel acak ukuran n diambil dari N benda
Sebanyak k benda dapat diberi nama sukses sedangkan
sisanya N-k, diberi nama gagal
Asumsi yang diperhatikan dalam distribusi
hipergeometrik adalah sebagai berikut:
1. Terdapat n kali percobaan dalam suatu sampel dari
suatu populasi terbatas berukuran N
2. Hanya terdapat dua hasil sukses atau gagal
3. Jumlah sukses populasi diketahui
Parameter dari distribusi ini terdiri dari tiga
parameter, yaitu .
• N (ukuran populasi),
• D (jumlah kejadian sukses), dan
• n (ukuran sampel).
Secara matematis peluang ditemukannya x (sukses)
dalam sampel berukuran n yang diambil dari populasi
berukuran N, dengan D (sukses), dimana nilai D
diketahui dapat ditulis sebagai berikut.
h (x;N,n,D)=[Dx][N−D
n−x][Nn]
..............................
....................................... (2-6)

Sedangkan nilai rata-rata dan standar deviasi dari
distribusi ini dapat dicari dengan menggunakan
persamaan berikut
μ=nDN ............................................
......................................................
(2-7)
σ2=N−nN−1
nDN (1−
DN ) ..................................
........................................ (2-8)
2.3.3.3 Distribusi Binomial
Dalam distribusi hipergeometrik ukuran populasi
dan jumlah kejadian sukses dalam populasi tersebut
diketahui, namun bagaimana menghitung nilai peluang
ditemukannya x sukses dalam suatu sampel berukuran n,
dimana ukuran populasinya jauh lebih besar dinadingkan
nilai n dan kejadian sukses dalarn populasi tersebut
tidak ketahui. Untuk menjawabnya kita dapat menggunakan
pendekatan distribusi binomial, dengan asumsi sebagai
berikut.
1. Terdapat n kali percobaan Bernauli
2. Hanya terdapat dua hasil yang mungkin dalarn
setiap kali percobaan
3. Peluang setiap kejadian adalah konstan, dalam
setiap kali percobaan
Parameter dari distribusi ini terdiri dari dua
jenis parameter, yakni n (ukuran sampel), p (proporsi
atau peluang kejadian sukses), dan q (proporsi atau

peluang gagal; q=l-p). Peluang terjadinya kejadian
sukses sebanyak x kali, pada sampel berukuran n, dengan
peluang kejadian sukses sebesar p, dapat dicari
menggunakan persamaan matematis berikut ini.
b (x;n,p )=[nx]pxqn−x ................................
...................................... (2-9)
Sedangkan nilai rata-rata dan standar deviasi dari
distribusi ini dapat dicari
dengan menggunakan persamaan berikut
μ=E (X )=np ........................................
.......................................... (2-10)
σ2=V (X )=npq ......................................
........................................ (2-11)
2.3.3.4 Distribusi Poison
Suatu percobaan Poisson mendapat namanya dari
proses Poisson dan memiliki sifat berikut
1. Banyaknya hasil yang terjadi dalam suatu selang
waktu atau daerah tertentu tidak terpengaruh oleh
(bebas dari) apa yang terjadi pada selang waktu atau
daerah lain yang terpisah. Dalam hubungan ini proses
Poisson dikatakan tak punya ingatan.
2. Peluang terjadinya suatu hasil (tunggal) dalam
selang waktu yang amat pendek atau daerah yang tidak
tergantung pada banyaknya hasil yang terjadi di luar
selang waktu atau daerah tersebut.

3. Peluang terjadinya lebih dari satu hasil dalam
selang waktu yang pendek atau daerah yang sempit
tersebut dapat di abaikan.
Banyaknya hasil X dalam suatu percobaan Poisson
disebut suatu peubah acak Poisson dan distribusi
peluangnya disebut distribusi Poisson. Rataan banyaknya
hasil dihitung dari μ=¿ λ t, bila t menyatakan 'waktu'
atau 'daerah' khas yang menjadi perhatian. Karena
peluangnya tergantung pada λ , laju terjadinya hasil
akan kita nyatakan dengan lambang p(x; λ t).
Poison terjadi dengan asumsi sebagai berikut.
1. Terdapat n kali percobaan bebas
2. Hanya terdapat satu kejadian yang diamati
3. Peluang yang konstan dalam setiap kali percobaan
4. Peluang terjadinya lebih dari satu kejadian teramati
dalam setiap percobaan dapat diabaikan.
Sifat percobaan Poison:
1. Banyaknya sukses terjadi dalam suatu selang waktu
atau daerah tertentu tidak terpengaruh oleh apa yang
terjadi pada selang waktu atau daerah lain yang
dipilih (bebas).
2. Peluang terjadinya suatu sukses (tunggal) dalam
selang waktu yang amat pendek atau dalam daerah yang
kecil sebanding dengan panjang selang waktu atau
besarnya daerah dan tidak tergantung pada banyaknya
sukses yang terjadi di luar selang waktu atau daerah
tersebut.

3. Peluang terjadinya lebih dari satu sukses dalam
selang waktu yang pendek atau daerah yang sempit
tersebut dapat diabaikan.
Parameter dari distribusi ini terdiri dari satu
jenis parameter, yakni λ (rata-rata). Secara matematis
peluang ditemukannya kejadian khusus sebanyak x kali,
dengan rata-rata terjadinya kejadian dalam unit yang
diamati, adalah konstan sebesar λ dapat ditulis.
P (X )=P (X=x )=e−¿❑x
x!¿ .................................
..................... (2-12)
dengan x 0, 1, 2, 3, ...., sedangkan e = sebuah
bilangan konstan yang jika dihitung hingga 4 desimal e
= 2,7183 dan λ (baca : lambda) = sebuah bilangan
tetap.
Sedangkan nilai rata-rata dan standar deviasi dari
distribusi ini dapat dicari dengan menggunakan
persamaan berikut
μ=¿ ..............................................
.......................................................
. (2-13)
σ=√❑ ............................................
.................................................. (2-
14)
2.3.3.5 Distribusi Peluang Kontinu
Ada banyak jenis distribusi peluang variable random
kontinu yang dikenal dalam ilmu probabilitas, seperti:

Distribusi normal,
Chi-kuadrat
Distribusi F
Distribusi t dll.
Distribusi frekuensi normal merupakan distribusi
yang paling sering digunakan dalam statistik.
Suatu peubah acak kontiniu mempunyai peluang nol
pada setiap titik x. Karena itu, distribusi peluangnya
tak mungkin disajikan dalam bentuk tabel. Kendati
distribusi peluang peubah acak kontinu tidak dapat
disajikan dalam bentuk tabel, mungkin dapat disajikan
dalam bentuk rumus. Rumus seperti itü tentunya
merupakan fungsi dari nilai yang berbentuk bilangan
(numerik) dari peubah kontinu X dan karena itu akan
dinyatakan dengan lambang fungsi f(x). Fungsi f(x)
adalah fungsi padat peluang peubah acak kontiniu X,
yang didefiniskan di atas himpunan semua bilangan real
R, bila :
1. f(X) ≥ 0 untuk semua x ∈ R.
2. ∫−∞
∞
f (x)dx=1
3. P (a<X<b )=∫a
b
f (x )dx
2.3.3.6 Distribusi Normal
Distribusi nomal merupakan distribusi peluang
kontinu yang terpenting dalam seluruh bidang statistika
(Walpole dan Myers, 1995). Kurva normal standar adalah
kurva nomal yang sudah diubah menjadi distribusi nilai

Z, dimana distribusi tersebut akan mempunyai μ=0 dan
standar deviasi σ=1. Variabel normal standar Z adalah
Z=NilaivariabelrandomRata−ratavariabelrandom
Standardeviasivariabelrandom
Atau : z=(x−μ)/σKurva distribusi normal kontinu dibuat sedemikian
rupa sehingga luas daerah di bawah kurva itu yang
dibatasi oleh x = x1 dan x = x2 sama dengan peluang
bahwa variabel acak x mengambil nilai antara x = x1 dan
x = x2. Jadi kurva normal daerah P(x1<x<x2) dinyatakan
oleh daerah yang diarsir. Untuk mengetahui berbagai
luas di bawah kurva normal standar maka digunakan Tabel
Luas Kurva Nomıal Standar.
Ciri-ciri distribusi normal :
1. Kurvanya membentuk garis lengkung yang halus.
2. Simetris terhadap rata-rata μ.3. Kedua ujungnya (ekor) semakin mendekati sumbu x
tetapi tidak pernah memotong.
4. Jarak titik belok kurva tersebut dengan sumbu
simetrisnya sama dengan σ.5. Luas daerah di bawah lengkungan kurva normal dari
-∞ sampai +∞ sama dengan 1 atau 100%.Distribusi ini memiliki dua parameter, yakni nilai
rata-rata (μ) untuk parameter lokasi, dan standar
deviasi (σ) untuk parameter skala. Untuk menghitungluas daerah dibawah kurva normal, dapat digunakan
persamaan matematis berikut ini.

P (xi<X<x2 )=∫x1
x2n (x;μ,σ )dx ...........................
....................... (2-15)
¿1
√2πσ∫x1
x2
e−(
12
) [x−μ¿¿σ ]2
dx ...............................
............................... (2-16)
Perhitungan luas daerah dengan menggunakan
persamaan diatas, dirasa cukup menyulitkan, oleh karena
itu nilai dari setiap variabel acak, dapat
ditransfonnasikan kedalam bentuk bilangan baku (Z).
Variabel Z diperoleh dengan menggunakan persamaan
berikut ini.
Z=X−μσ ..........................................
....................................................
(2-17)
Dengan menggunakan nilai bilangan baku diatas maka
persamaan luas daerah kurva normal selanjutnya dapat
ditulis sebagai berikut.
P (x1<X<x2 )= 1√2πσ
∫x1
x2
e−(
12
)[x−μ¿¿σ ]2
dx
= 1√2π
∫e−z2/2dz=∫z1
z2
n (z;0,1 )dz
=
P(Z1<Z<Z2) ............................................
....................... (2-18)
Walaupun dengan menggunakan nilai bilangan baku,
proses perhitungan menjadi lebih mudah, namun

penggunaan integral, dirasa masih menyulitkan bagi
sebagian orang dalam menghitung daerah normal, untuk
mempermudahnya nilai peluang ini dapat dilihat pada
tabel normal, atau dengan menggunakan bantuan perangkat
lunak.
2.3.3.7 Distribusi X2
Distribusi X2 (baca: Chi Square) biasanya
digunakan dalam pengujian hipotesis statistika, dan
sejak pengujian menjadi hal yang utama dalam aplikasi
statistika keteknikan, pemahaman Distribusi X2 ini
menjadi suatu hal yang penting.
Distribusi ini memiliki satu buah parameter bentuk
(shape), yakni parameter derajat kebebasan (v : baca
nu), derajat kebebasan ini merupakan suatu parameter
yang digunakan pada sejumlah distribusi kontinu, nilai
v adalah hasil pengurangan antara ukuran sampel n
dengan jumlah parameter populasi k. Secara matematis v
dapat ditulis.
v = n – 1
.......................................................
....................................... (2-19)
Untuk menentukan luas daerah dibawah kurvanya
dapat digunakan persamaan fungsi kepadatan sebagai
berikut.

f (x )={ 1
2v2 (v2
)
xv
2−1e−x /2} ...............................
................................ (2-20)
Sama halnya dengan pdf normal, perhitungan diatas
akan cukup menyulitkan, karenanya untuk menentukan luas
kurva ini dapat juga dilakukan dengan menggunakan
bantuan tabel, atau perangkat lunak komputer. Sementara
untuk menghitung nilai rataan dan variansinya dapat
dilakukan dengan menggunakan persamaan berikut.
μ=vdanσ2=2v ........................................................................... (2-21)
2.3.3.8 Distribusi-t
Jika ukuran sampel kecil (n < 30), nilai dari S2
berfluktuasi clari satu sampel ke sampel yang Iain dan
distribusi dari variabel random tidak lagi merupakan
distribusi normal standar. Bila x dan s2 masing-masing
adalah nilai tengah dan ragam suatu contoh acak
berukuran n yang diambil dan suatu populasi normal
dengan nilai tengah μdan ragam σ2, merupakan sebuah
mlai peubah acak T yang mempunyai distribusi t dengan v
= (n — 1) derajat bebas.
Misalkan Z peubah acak normal baku dan V peubah
acak Chi square dengan derajat kebebasan v. Bila Z dan
V bebas, maka distribusi peubah acak T, bila

T= z√V /v ..........................................
................................................... (2-
22)
Diberikan oleh
h (t )=¿
Γ[ (v+1)/2 ]
Γ(v /2)√πv (1+t2v )
−(v+1)/2
....................................................
(2-23)
Ini dikenal dengan nama distribusi-t dengan derajat
kebebasan v.
Ciri khusus dari distribusi ini adalah bahwa
distribusi t tergantung pada suatu parameter yang
disebut derajat kebebasan (degrees offreedom). Jika
derajat bebas meningkat maka perbedaan distribusi t
dengan distribusi normal baku semakin kecil.
Dalam menurunkan distribusi t, akan kita misalkan
bahwa sampel acaknya berasal dari populasi normal. Maka
:
t=x−μσ /√n ..........................................
....................................................
(2-24)
2.3.3.9 Distribusi-F
Distribusi yang tergantung pada dua buah derajat
kebebasan. Salah satu distribusi yang terpenting dalam
statistika terapan ialah ditsribusi-F, yang

didefinisikan sebagai rasio dari dua variabel
independen chi-square random yang masing-masing dibagi
dengan derajat kebebasannya. Sehingga, dapat ditulis :
F=U /v1
V /v2 ...........................................
................................................... (2-
25)
U dan V menyatakan dua peubah acak bebas yang masing-
masing berdistribusi chi square dengan derajat
kebebasan v1dan v2. Maka distribusi peubah acak F=U /v1
V /v2
, diberikan oleh
h (f )=¿
{ Γ[ (v1+v2 )/2 ](v1/v2 )
v1 /2fv1 /2−1
Γ(v1 ¿2)Γ(v2 ¿2)(1+v1f /v2)( v1+v2 )/2
0 }, 0 < f < ∞ untuk
nilai lainnya
Perhitungan diatas akan cukup menyulitkan.
Sehingga, untuk menentukan luas kurva ini dapat juga
dilakukan dengan menggunakan bantuan tabel, atau
perangkat lunak komputer.
2.4 Pendahuluan
Pada modul sebelumnya pembahasan ditekankan pada
sifat-sifat sampel dari rataan sampel dan variansi
sampel. Tujuannya ialah untuk meletakkan dasar agar
memungkinkan para statistikawan menarik kesimpulan
tentang parameter-populasi dari data percobaan. Sebagai
contoh, Teorema Limit Pusat memberi informasi tentang
distribusi dari rataan sampel X. Distribusinya

mengandung rataan populasi. Jadi setiap kesimpulan yang
ditarik mengenai dari suatu rata-rata sampel yang
diamati haruslah tergantung pada pengetahuan tentang
distribusi sampel ini. Di modul ini kita mulai secara
resmi membahas garis besar dari tujuan inferensi
statistik, kemudian diikuti dengan membahas
permasalahan penaksiran parameter populasi.
2.4.1 Inferensia Statistik
Teori inferensi statistik terdiri atas metode
untuk menarik inferensi atau proses pcngambilan
kesimpulan tentang parameter populasi berdasarkan
analisa pada sampel. Proses ini menggunakan sampel
statistik untuk menduga atau menaksir hubungan
parameter populasi yang tidak di ketahui. Kecenderungan
yang sekarang adalah membedakan metode klasik dan
metode Bayes dalam menaksir parameter populasi. Dalam
metode klasik, inferensi didasarkan scpenuhnya pada
informasi yang diperoleh melalui sampel acak yang
diambil dari populasi. Metode Bayes menggunakan
pengetahuan subjektif sebelumnya mengenai distribusi
peluang parameter yang tak diketahui bersama dengan
informasi yang diberikan oleh data sampel.
Inferensi statistik dapat dibagi dalam dua bagian
besar: penaksiran dan pengujian hipotesis. Untuk
membedakan kedua bagian ini dengan jelas, pandanglah
contoh berikut. Seorang pedagang yang akan memasarkan
produksi barunya ingin menaksir proporsi sesungguhnya

calon pembeli dengan menanyakan pendapat pada sampel
acak ukuran 100 dari calon pembeli. Proporsi calon
pernbeli yang mau membeli barangnya dalam sampel dapat
digunakan sebagai taksiran proporsi calon pembeli
sesungguhnya dalam populasi. Pengetahuan tentang
distribusi sampel proporsi memungkinkan kita menentukan
derajat ketepatan taksiran tersebut. Masalah ini masuk
bagian penaksiran.
Sekarang pandanglah kasus seorang ibu yang ingin
menentukan apakah sabun cuci Rinso mencuci lebih unggul
daripada B29. Dia mungkin menghipotesiskan bahwa Rinso
lebih baik daripada B29, dan setelah mengadakan
pengujian secukupnya, si ibu menerima atau menolak
hipotesis. Dalam contoh ini parameter tidak ditaksir,
tapi sebagai gantinya kita ingin mendapat keputusan
yang benar mengenai hipotesis yang ditetapkan
sebelumnya. Untuk itu kita juga menggunakan teori
sampel untuk mendapatkan suatu ukuran ketepatan
keputusan yang diambil.
2.4.2 Penentuan Ukuran Sampel dan Teori Penaksiran
Statistika berusaha untuk menyimpulkan populasi,
untuk itu perilaku dari populasi ini dipelajari
berdasarkan data yang diambil baik secara sensus maupun
sampling. Dalam kenyataannya, mengingat sejumlah
faktor, penarikan kesimpulan perilaku suatu populasi
berdasar suatu sampel yang dianggap representatif
menjadi alternatif yang kerap dipilih. Perilaku

populasi yang akan ditinjau disini hanyalah mengenai
parameter populasi, dan sampel yang akan digunakan
merupakan suatu sampel acak, dari nilai statistik
sampel ini kemudian akan disimpulkan bagaimana perilaku
dari parameter.
2.4.2.1 Tingkat Kepercayaan dan Ketelitian
Istilah kepercayaan (confìdence) dan ketelitian atau
keberartiaan (significance), merupakan istilah yang akan
sering ditemukan dalam bahasan statistika induktif
(inference statistics). Tingkat kepercayaan menyangkut
tingkat keyakinan (faith) terhadap kesimpulan yang
bersifat statistika, sedangkan tingkat ketelitian
menyangkut pada tingkat kecurigaan atau
ketidakpercayaan (mistrust) terhadap hal yang sama.
Tingkat kepercayaan dapat didefinisikan sebagai derajat
(degree) jaminan (assurance) bahwa suatu pernyataan
statistika yang khusus, adalah benar dalam suatu
kondisi tertentu. Sedangkan tingkat keyakinan adalah
derajat ketidakpastian mengenai suatu pernyataan
statistika dalam kondisi yang sama untuk menentukan
tingkat kepercayaan. (Walpole,E., 1995).
Tingkat ketelitian dilambangkan dengan α (0 ≤ α ≤
l) dan tingkat kepercayaan dengan 1 - α. Secara
matematis dapat ditulis, jika
Tingkat kepercayaan + Tingkat ketelitian = 1
(1−α )+α=1..........................................
........................................ (2-1)

Jika ketelitian α = 0.05, kepercayaan adalah 1 -
0.05 = 0.95. Jika dalam bentuk persentase kepercayaan
adalah 100 (l - α) = 95%. Dalam kasus ini kesimpulan
atau pernyataan diharapkan akan keliru tidak lebih lima
kali dalam seratus percobaan.
Secara grafis ketelitian dapat ditunjukan dua
jenis ketelitian, yakni ketelitian satu arah (one tail)
dan ketelitian dua arah (two tail). Ketelitian satu arah,
menempatkan daerah α dalam satu arah, baik daerah lebih
rendah (lower) atau lebih tinggi (upper), dan sisanya
mempakan kepercayaan 1 - α. Sedangkan pada dua arah
menempatkan α/2 pada masing-masing arah, dan
kepercayaan 1 – α diantara kedua daerah tersebut.
2.4.2.2 Penentuan Ukuran Sampel
Ketika parameter populasi di taksir (estimated),
suatu sampel berukuran n harus dihitung, dan bukannya
ditebak sehingga nilai parameter yang ditaksir akan
lebih akurat. Akurasi secara statistika memiliki dua
aspek:
Tingkat kepercayaan 1 – α.
Persyaratan kecermatan (precision) h. Jumlah
simpangan dari nilai sesungguhnya yang dinyatakan dalam
bentuk unit nyata atau dalam bentuk persentase.
Pernyataan akurasi itu misalnya "saya ingin 98%
percaya jika taksiran µ tidak melebihi 10 inc dari
panjang sesungguhnya" atau "saya ingin 98% percaya jika
taksiran µ tidak melebihi 5% dari panjang

sesungguhnya". Pernyataan pertama di nyatakan dalam
suatu unit nyata (10 inc) sedangkan pernyataan kedua
dinyatakan dalam bentuk persentase (5%). Dalil limit
pusat untuk rata-rata sampel dan distribusi normal
baku.
z=x−μσ ............................................
.....................................................
(2-2)
Digunakan untuk menghitung ukuran sampel yang
diperlukan. Variabel z pada persamaan 2.2 merupakan
distribusi normal baku untuk ketelitian dua arah. Nilai
h = x - µ merupakan persyaratan kecermatan dalam unit
nyata, dan σp adalah simpangan baku dari parameter yang
ditaksir. Dengan mensubsitusikan h untuk x - µ dan
simpangan baku dari rata-rata σX untuk σp.
g=
zαzσ
√n.............................................
................................................. (2-3)
maka,
n=( zα
zσg )
2
...........................................
............................................. (2-4)
Taksiran σ diperoleh dari data masa lalu atau dari
percobaan suatu sampel kecil. Ukuran sampel yang
melampaui n akan lebih memberikan kepercayaan dan

kecermatan. Dengan menggunakan persamaan binomial nilai
n dapat juga diperoleh dengan menggunakan persamaan
berikut.
n=z2p(1−p)
h2 ........................................
................................................. (2-5)
Disamping menggunakan pendekatan diatas penentuan
ukuran sampel juga dapat ditentukan menurut cara atau
metode pengambilan sampel, untuk keperluan tersebut
dapat dilihat lebih lanjut pada bahasan teori sampling
di sejumlah referensi.
2.4.3 Penaksiran Titik dan Penaksiran Selang
Taksiran titik (point estimate) adalah suatu nilai
tunggal yang diambil dari suatu sampel untuk menaksir
suatu parameter populasi. Misal X= 12.5 kg, mempakantaksiran titik untuk rata-rata populasi µ. Pada
taksiran ini tidak terdapat kaitan dengan peluang,
sehingga akurasinya tidak dapat diketahui.
Statistik yang digunakan untuk mendapatkan
taksiran titik disebut penaksir atau fungsi keputusan.
Jadi fungsi keputusan S2, yang merupakan fungsi peubah
acak, ialah suatu penaksir σ2 dan taksiran S2 ialah
'tindakan' yang diambil. Sampel yang berlainan umumya
akan menghasilkan tindakan atau taksiran yang berlainan
pula.
Taksiran selang (interval estimate) merupakan suatu
pernyataan peluang yang menyatakan jika suatu parameter

populasi berada diantara dua nilai yang dihitung.
Misalnya kita percaya 95% jika µ berada diantara 1.75
dan 2.38 kg atau dapat ditulis P (1.75 ≤ µ ≤ 2.38).
Kasus ini adalah contoh dari penaksiran dua arah,
dengan kepercayaan sebesar 95%. Secara umum penaksiran
selang dua arah dengan suatu tingkat kepercayaan 1 - α.
P (Batas bawah ≤ Parameter ≤ Batas atas) = 1 – α
............................... (2-6)
Penaksiran ini dapat juga dilakukan pada satu
arah, baik lebih besar, maupun lebih kecil. Penaksiran
satu arah tersebut dapat dinyatakan sebagai berikut
P (Batas bawah ≤ Parameter) = 1 – α
.................................................. (2-
7)
P (Parameter ≤ Batas atas) = 1 – α
.................................................. (2-
8)
Makin lebar selang kepercayaan makin yakin pula
kita bahwa selang tersebut mengandung parameter yang
tidak diketahui (Walpole,E.,1986,hal 208). Sehingga
lebih baik percaya 95% bahwa rata-rata umur suatu
transitor televisi antara 6 sampai 7 tahun daripada
percaya 99% bahwa umur antara 3 sampai 10 tahun.
Idealnya, lebih disenangi selang pendek dengan derajat
kepercayaan yang tinggi. Kadang-kadang, pembatasan
dalam ukuran sampel tidak memungkinkan mendapat selang

yang sempit tanpa mengorbankan sedikit derajat
kepercayaan.
2.4.3.1 Penaksiran Selang Untuk Rataan Populasi
Untuk dapat menaksir suatu rata-rata populasi
dapat dilakukan terhadap dua kondisi. Kondisi pertama
bila nilai µ dan σ diketahui, sedangkan pada kondisi
kedua nilai µ dan σ tidak diketahui. Menurut Walpole
(1995) kondisi pertama dapat terjadi karena, kedua
nilai dapat diganti dengan nilai asalkan ukuran
sampelnya ≥ 30. Untuk kondisi ini digunakan pendekatan
distribusi normal, sehingga diperoleh taksiran selang
untuk rata-rata sebagai berikut
P(−zα /2<Z<zα /2) = 1 – α
.......................................................
....... (2-9)
Dimana nilai Zhitung dituliskan sebagai berikut :
x−μσ /√n..............................................
.......................................................
(2-10)
Sehingga didapat sebagai berikut:
P [−zα /2<x−μσ /√n
<zα /2] = 1 – α
.......................................................
(2-11)
Selang kepercayaan untuk µ ; σ diketahui bila Xrataan sampel acak berukuran n dari suatu populasi

dengan variansi σ2 yang diketahui, maka selang
kepercayaan (1 - α) 100% untuk µ ialah
X−zα /2σ√n
<μ<X+zα /2σ√n...............................
......................... (2-12)
Untuk menaksir µ dengan derajat ketepatan yang
lebih tinggi diperlukan selang yang lebih besar
(Walpole,E., 1995,).
Untuk kondisi kedua dimana nilai σ tidak
diketahui, yang berarti ukuran sampel < 30, maka
taksiran dapat dilakukan dengan menggunakan pendekatan
distribusi t, sehingga diperoleh persamaan taksiran
selang terhadap rataan, sebagai berikut
P(−tα /2<T<tα/2) = 1 – α
.......................................................
..... (2-13)
Dimana Thitung dituliskan sebagai berikut :
x−μs/√n..............................................
.......................................................
(2-14)
Sehingga didapat persarnaan sebagai berikut:
P [−tα /2<x−μs/√n
<tα /2] = 1 – α
.......................................................
. (2-15)
Dengan mengalikan tiap suku dalam persamaan dengan
S/√n, lalu dikurangi dengan X, dan kemudian dikalikan

dengan - 1, maka akan diperoleh persamaan taksiran
selang terhadap rataan sebagai berikut
X−tα /2S√n
<μ<X+tα /2S√n...............................
........................ (2-16)
2.4.3.2 Selisih rata-rata dua populasi
Selain terhadap kedua kondisi diatas penaksiran
selang terhadap rataan dapat juga dilakukan terhadap
rataan dengan kondisi sebagai berikut
Selang kepercayaan untuk menaksir selisih dua rataan
dimana nilai σ12dan σ2
2diketahui
(X1−X2 )−Zα /2√ σ12
n1+σ22
n2<μ1−μ2<(X1−X2 )+Zα /2√ σ12
n1+σ22
n2..... (2-17)
Bila ukuran sampel kecil, maka distribusi t harus
digunakan kembali untuk mencari selang kepercayaan
yang akan berlaku bila distribusi populasinya hampir
normal
Selang kepercayaan untuk menaksir selisih dua rataan
dimana nilai σ12 =σ2
2tidak diketahui
(X1−X2)−ts /2sp√ 1n1
+1n2
<μ1−μ2<(X1−X2 )+ts /2sp√ 1n1
+1n2
.. (2-18)
Selang kepercayaan untuk menaksir selisih dua rataan
dimana nilai σ12 ≠σ2
2tidak diketahui dan merniliki
ukuran sampel yang kecil (<30)
(X1−X2 )−tα /2√ s12
n1+s22
n2<μ1−μ2<(X1−X2 )+tα /2√ s12
n1+s22
n2....... (2-
19)

Bila tα/2 nilai distribusi-t dengan derajat kebebasan
v=( s1
2
n1+s22
n2)2
[( s12n1 )2
/(n1−1)]+[( s22n2 )2
/(n2−1)]2.4.4 Penaksiran Selang Untuk Proporsi Populasi
Penaksiran titik untuk proporsi p dalam suatu
percobaan binomial diberikan oleh statistik p = x/n
dengan x menyatakan banyaknya yang berhasil dalam n
usaha. Jadi, proporsi sampel p= x/n akan digunakansebagai taksiran titik untuk parameter p.
P(−zα /2<Z<zα /2) = 1 –
α.................................................
........... (2-20)
Dengan Z dituliskan sebagai berikut: p−p
√Pq /n, sehingga
didapat persamaan:
P(−zα /2<p−p
√Pq/n<zα /2) = 1 –
α.................................................
.... (2-21)
Dengan mengalikan tiap suku dalam persamaan dengan
√ p q /n, lalu dikurangi dengan p (proporsi yang berhasildalam sampel acak ukuran n) dan kemudian dikalikan
dengan - 1, maka akan diperoleh persamaan taksiran
selang terhadap proporsi dari suatu populasi adalah
sebagai berikut

P(p−zα /2√pqn <P<p+zα /2√pqn ) = 1 – α
................................. (2-22)
Dimana p = x/n dan q didapat dari q=1−p. Dengandemikian persamaan taksiran selang terhadap proporsi
dari suatu populasi dapat dituliskan sebagai berikut.
p−zα/2√ pqn <P<p+zα /2√ p qn .............................
......................... (2-23)
2.4.4.1 Menaksir selisih dua proporsi
Pandangan persoalan menaksir selisih dua parameter
binomial Pı dan P2. Penaksiran titik untuk selisih dua
proporsi Pı - P2, adalah statistic p1−p2. Jadi, selisih
kedua proporsi sampel, p1−p2, akan digunakan sebagai
taksiran titik untuk Pı - P2. Sedangkan untuk menaksir
selisih dari dua proporsi dapat dilakukan dengan
menggunakan persamaan sebagai berikut.
(p1−p2 )−zα /2√ p1q1
n1+p2q2
n2<Pı−P2<(p1−p2)+zα /2√ p1q1
n1+p2q2
n2
(2-24)
2.4.4.2 Penaksiran Selang Untuk Variansi
Untuk menaksir nilai variansi populasi dapat
digunakan pendekatan distribusi dengan persamaan selang
kepercayaan sebagai berikut.
P (X1−α/22 <X2<Xα /2
2 ) = 1 – α
.......................................................
(2-25)
Dimana X2 dituliskan :

(n−1)S2σ2 ...........................................
......................................................
(2-26)
Sehinga didapat :
P(X1−α/22 <
(n−1)S2
σ2 <Xα /22 ) = 1 – α
............................................... (2-27)
Bagilah setiap suku dengan persamaan (n−1)S2, dankemudian balikkan setiap suku, maka persamaan taksiran
selang untuk variansi dari suatu populasi dapat
dituliskan sebagai berikut.
(n−1)S2Xα /22 <σ2<
(n−1)S2
X1−α /22 ................................
....................................... (2-28)
2.4.5 Pengujian Hipotesis
Benar atau salahnya suatu hipotesis tidak akan
pemah diketahui dengan pasti, kecuali bila kita
memeriksa seluruh populasi. Tentu saja, dalam
kebanyakan situasi hal itu tidak mungkin dilakukan.
Oleh karena itu, kita dapat mengambil suatu contoh acak
dari populasi tersebut dan menggunakan informasi yang
dikandung contoh itu untuk memutuskan apakah hipotesis
tersebut kemungkinan besar benar atau salah. Bukti,
dari contoh, yang tidak konsisten dengan hipotesis yang
dinyatakan tentu saja membawa kita pada penolakan
hipotesis tersebut, sedangkan bukti yang mendukung
hipotesis akan membawa pada penerimaannya. Perlu

ditegaskan di sini bahwa penerimaan suatu hipotesis
statistik adalah merupakan akibat tidak cukupnya untuk
menolaknya, dan tidak berimplikasi bahwa hipotesis itu
pasti benar. Misalnya, dalam pelemparan sekeping uang
logam sebanyak 100 kali, kita mungkin ingin'menguji
hipotesis bahwa uang itu setimbang. Dikatakan dalam
parameter populasi, kita ingin menguji hipotesis bahwa
proporsi munculnya Sisi gambar adalah p = 0.5 bila uang
itu dilemparkan terus-menerus tanpa henti-hentinya.
Meskipun seandainya uang logam itu setimbang, kejadian
munculnya sisi gambar 48 kali bukanlah hal yang
mengejutkan. Hasil yang demikian itu tentu saja
mendukung hipotesis bahwa p — 0.5. Tetapi kita juga
dapat mengatakan bahwa hasil yang demikian itu
konsisten dengan hipotesis bahwa p — 0.45. Jadi, dalam
menerima hipotesis itu, satu-satunya yang dapat kita
pastikan adalah bahwa munculnya proporsi munculnya sisi
gambar yang sesungguhnya tidak terlalu jauh berbeda
dari setengah. Bila ke-100 lemparan itu hanya
menghasilkan 35 sisi gambar, maka kita mempunyai cukup
bukti untuk menolak hipotesis itu. Mengingat bahwa
peluang memperoleh 35 sisi gambar atau kurang dari itu
dalam 100 lemparan uang yang setimbang kira-kira
sebesar 0.002, berarti telah terjadi suatu kejadian
yang jarang sekali terjadi, atau kita benar dalam
menyimpulkan bahwa p = 0.5.

Meskipun kita akan sangat sering menggunakan
istilah "menerima" dan "menolak", tetapi perlu disadari
bahwa penolakan suatu hipotesis berarti menyimpulkan
bahwa hipotesis itu salah, sedangkan penerimaan suatu
hipotesis semata-mata mengimplikasikan bahwa kita tidak
mempunyai bukti untuk mempercayai sebaliknya. Karena
pengertian ini, statistikawan atau peneliti sering
mengambil sebagai hipotesisnya suatu pernyataan yang
diharapkan akan ditolak.
Pengujian hipotesis dilakukan untuk menggunakan
sejumlah data statistik sampel dan pengetahuan mengenai
distribusi statistika, untuk membuat suatu kesimpulan
mengenai populasi yang diwakili oleh sampel tersebut.
Penyimpulan itu dapat mengenai nilai parameter populasi
atau mengenai pdf dari populasi tersebut.
Hipotesis adalah suatu pernyataan statistika
mengenai menerima atau menolak. Hipotesis statistik
adalah pernyataan atau dugaan mengenai satu atau lebih
populasi. Hipotesis ini dapat merumuskan mengenai
rataan, variansi, perbedaan dari sejumlah rataan, atau
bentuk pdf. Terdapat dua jenis hipotesis untuk setiap
pengujian statistika. Pertama dan yang terpenting
adalah Ho (hipotesis nol). Hipotesis
alternatif/tandingan (Hl) secara otomatis akan diterima
bila pengujian menunjukan Ho harus ditolak. Suatu
hipotesis nol mengenai suatu parameter populasi akan
selalu dinyatakan sedemikian rupa sehingga parameter

tersebut tertentu nilainya secara tepat, sedangkan
hipotesis alternatif/ tandingan memungkinkan beberapa
nilai. Jadi, bila Ho menyatakan hipotesis nol p = 0.5
untuk populasi binomial, hipotesis tandingan Hi mungkin
salah satu dari p > 0,5,p < 0,5 atau p ≠ 0,5.
Seperti pada penaksiran interval, pengujian
hipotesis ini juga menggunakan dua jenis pengujian.
Pertama pengujian dua arah, dan yang kedua pengujian
satu arah, dimana pada setiap jenisnya digunakan suatu
tingkat kepercayaan tertentu.
Pengujian hipotesis ini walau telah dilakukan
dengan benar, namun tetap saja memiliki galat (error)
atau kesalahan. Dalam pengujian hipotesis dikenal dua
jenis kesalahan, yakni galat jenis I (α) dan galat
jenis Il (β). Kesalahan galat jenis I terjadi jika kitamenolak Ho dan menerima H1, padahal sesungguhnya Ho
yang benar, sedangkan galat jenis Il terjadi ketika
kita menerima Ho yang sebenarnya hipotesis itu salah.
Peluang melakukan galat jenis I disebut taraf
nyata uji tersebut dan dilambangkan dengan α. Peluang
menggunakan galat jenis II, yang dilambangkan dengan β,tidak mungkin dihitung kecuali bila kita memiliki
hipotesis alternatif yang spesifik.
2.4.5.1 Uji Satu-Arah dan Dua-srall
Uji satu arah
Suatu uji hipotesis statistik yang alternatifnya
bersifat satu-arah, seperti

H0: θ = θ0
H1: θ>θ0
Atau mungkin:
H0: θ = θ0
H1: θ<θ0
Disebut uji satu-arah. Wilayah kritik bagi
hipotesis altefnatif θ>θ0 terletak seluruhnya di ekor
kanan sebaran tersebut, sedangkan wilayah kritik
bagi hipotesis alternatif θ<θ0 terletak seluruhnya di
ekor kiri.
Uji dua arah
Uji hipotesis statistik yang alternatifnya bersifat
dua-arah, seperti
H0: θ = θ0
H1: θ ≠ θ0
Disebut uji dua-arah, karena wilayah kritiknya
dipisah menjadi dua bagian yang ditempatkan di masing-
masing ekor sebaran statistik ujinya. Hipotesis
alternatif θ ≠ θ0 menyatakan bahwa θ>θ0 atau θ<θ0.
Hipotesis nol, H0, akan selalu dituliskan dengan
tanda kesamaan sehingga menspesifikasi suatu nilai
tunggal. Dengan cara demikian, peluang melakukan galat
jenis I dapat dikendalikan. Apakah kita harus
menggunakan uji satu-arah atau dua-arah, bergantung
pada kesimpulan yang akan ditarik bila H0 ditolak.
Lokasi wilayah kritiknya dopat ditentukan hanya setelah
hipotesis altematif H1 dinyatakan.

2.4.5.2 Langkah-langkah Pengujian Hipotesis
Untuk membuat suatu kesimpulan statistika,
prosedur-prosedur standar berikut ini dapat dilakukan.
Prosedur tersebut adalah :
1. Tentukan penyataan hipotesis, kembangkan bentuk
eksak dari H0 dan Hl. Tentukan pula jenis pengujian
yang akan dilakukan, apakah satu atau dua arah
2. Pilih tingkat ketelitian yang akan digunakan.
3. Hitung statistik sampel dan lakukan penaksiran
parameter. Satu atau lebih statistik mungkin
diperlukan untuk menyusun pengujian.
4. Hitung nilai statistik pengujian atau disebut juga
statistik hitung.
5. Tentukan daerah penerimaan dan daerah kritis dari
statistik uji.
6. Putuskan apakah H0 diterima atau ditolak (terima H0
bila statistik hitung berada pada daerah penerimaan
dan tolak jika berada didaerah kritis).
2.4.5.3 Pengujian Hipotesis untuk Rataan
Salah satu bentuk penggunaan uji hipotesis yang
paling sering digunakan adalah pengujian untuk
menentukan apakah rataan sejumlah sampel adalah sama,
lebih, atau kurang dari suatu nilai lain yang spesifik.
Seluruh pengujian rataan ini menggunakan statistik uji
z dan t, yang membedakan penggunaan keduanya terletak
pada tiga hal berikut.

Apakah data yang diuji tersebut merupakan data
satu atau dua sampel, dan bila dari dua data apakah
keduanya berasal dari satu sumber, bila ya maka kedua
sampel tersebut tidak bebas, tapi berpasangan.
• Apakah nilai standar deviasi σ diketahui, atau
harus ditaksir
• Apakah ukuran sampel kecil atau besar, besar bila
n ≥ 30
Pengujian Rataan untuk Satu Sampel dengan Nilai σ
Diketahui
Untuk melakukan pengujian rataan dari satu sampel
dengan nilai σ diketahui, baik ukuran sampel besar atau
kecil. Serta rataan dengan nilai σ tidak diketahui tapi
ukuran sampelnya besar digunakan statistik uji z dengan
menggunakan persamaan :
z= x−μσ /√n...........................................
................................................... (2-
29)
Pengujian Rataan untuk Satu Sampel dengan Nilai σ
Tidak Diketahui
Untuk melakukan pengujian rataan dari satu sampel
dengan nilai σ tidak diketahui, dan ukuran sampel kecil
yaitu n < 30 digunakan statistik uji t dengan
menggunakan persamaan :

t=x−μ0s /√n
...........................................
................................................... (2-
30)
Pengujian Rataan untuk Dua Sampel Saling Bebas
dengan Nilai σ Diketahui
Untuk melakukan pengujian rataan dari dua sampel
saling bebas dengan nilai σ dari kedua populasi
diketahui, baik ukuran sampel besar atau kecil. Serta
dua rataan dengan nilai σ tidak diketahui tapi ukuran
sampelnya besar digunakan statistik uji z dengan
menggunakan persamaan
Z=(x1−x2 )−(μ1−μ2)
√ σ12
n1+σ22
n2
..................................
.......................................... (2-31)
Berdistribusi normal baku. Jelas, bila dianggap
bahwa σ1=σ2=σ, maka statistik diatas menyusut menjadi
Z=(x1−x2 )−(μ1−μ2)
σ√ 1n1
+1n2
..................................
......................................... (2-32)
Kedua statistik diatas merupakan dasar bagi
pengembangan prosedur uji yang menyangkut dua rataan.
Kesamaannya dengan selang kepercayaan dan kemudahan
memperluasnya dari kasus uji menyangkut satu rataan

menyederhanakan pekerjaan kita. Hipotesis dua arah
menyangkut dua rataan dapat ditulis secara umum sebagai
H0 : µ1 - µ2 = d0
Distribusi yang digunakan ialah distribusi dari uji
statistik dibawah H0. Nilai x1 dan x2 dihitung dan untuk
σ1 dan σ2 yang diketahui maka uji statistiknya
berbentuk
z=(x1−x2 )do
√σ12
n1+σ22
n2
Pengujian Rataan untuk Dua Sampel Saling Bebas
dengan Nilai σ Tidak Diketahui
Untuk melakukan pengujian rataan dari dua sampel
dengan nilai σ kedua populasi tidak diketahui, dan
ukuran sampel kecil digunakan statistik uji t dengan
menggunakan persamaan :
t=(x1−x2 )−do
Sp√ 1n1+ 1n2
......................................
............................................... (2-32)
Untuk
Sp2=
S12 (n−1 )+S2
2(n2−1)n1+n2−2
................................
........................................ (2-33)
Pengujian Rataan Untuk Dua Sampel Berpasangan

Untuk menguji rataan dari dua buah sampel yang
berpasangan digunakan statistik uji t dengan persamaan
statistik uji sebagai berikut :
T=D−μDSd√n
...........................................
................................................. (2-
34)
Bila D dan Sd peubah acak yang menyatakan rataan
sampel dan simpangan baku dari selisih pengamatan dalam
satuan percobaan. Seperti pada uji-t gabungan.
Anggapannya ialah bahwa pengamatan dari tiap populasi
adalah normal. permasalahan dua-sampel pada dasarnya
disederhanakan menjadi permasalahan satu sampel dengan
menggunakan selisih dl, d2, ..., dn. Jadi hipotesisnya
berbentuk
H0 : µD = d0
Uji statistik hasil perhitungan menjadi
t=d−d0
Sd√n...........................................
................................................... (2-
35)
2.4.5.4 Pengujian Hipotesis untuk Variansi
Dalam seluruh pengujian terhadap rataan dua buah
sampel, sejumlah asumsi mengenai kesamaan atau
ketidaksamaan variansi adalah sangat diperlukan.
Seluruh pengujian mengenai variansi ini menggunakan dua
statistik uji apakah itu statistik uji atau statistik

uji F. Perbedaan penggunaan dua statistik uji tersebut
terletak dalam dua hal berikut ini.
Apakah data berasal dari satu atau dua buah
sampel, jika satu gunakan statistik uji jika dua
gunakan statistik uji F.
Apakah data berasal dari populasi normal, jika ya
bisa diproses, jika tidak, suatu n diperlukan untuk
penaksiran.
Pengujian Variansi Satu Sampel
Untuk menguji variansi dari sebuah sampel
berukuran n dengan H0 digunakan statistik uji yang
memiliki derajat kebebasan v = n - 1, adapun persamaan
statistik uji yang digunakan adalah sebagai berikut.
x2=(n−1)S2
σ02 ........................................
............................................... (2-36)
Pengujian Variansi Dua Sampel
Untuk menguji variansi dari dua buah populasi
normal, digunakan statistik uji F dengan persamaan
statistik uji sebagai berikut.
F=S12
S22.............................................
................................................... (2-
37)
Dengan

V1 = n1 – 1
.......................................................
................................... (2-38)
V2 = n2 – 2
.......................................................
................................... (2-39)
Pengujian Hipotesis untuk Proporsi
Dalam melakukan pengujian proporsi digunakan
pendekatan statistik uji z, yakni dengan menggunakan
pendekatan normal terhadap binomial. Pendekatan ini
biasanya akurat jika np > 5 dan nq > 5 tetapi bila
ukuran sampel terlalu kecil untuk menggunakan
pendekatan normal ini distribusi normal harus
digunakan. (Walpole,E.,1995,).
2.4.5.5 Pengujian Proporsi Satu Sampel
Uji hipotesis yang menyangkut proporsi banyak
dipakai dalam berbagai bidang. Politisi tentunya
tertarik untuk mengetahui beberapa bagian dari pemilih
yang akan mendukungnya dalam pemilihan mendatang.
Pengusaha pabrik berkepentingan mengetahui proporsi
yang cacat dalam suatu pengiriman prodüksinya. Penjudi
bergantung pada pengetahuannya mengenai proporsi hasil
yang dia anggap akan menguntungkannya.
Disini akan dibahas persoalan pengujian hipotesis
bahwa proporsi sukses dalam suatu percobaan binomial
sama dengan suatu nilai tertentu. Yaitu, akan diuji
hipotesis nol H0 bahwa P = P0, bila p parameter

distribusi binomial tersebut. Hipotesis tandingan
mungkin salah satu dari P < P0, P > P0, atau p ≠ P0.
Untuk menguji proporsi satu buah sampel berukuran
n dengan H0. Digunakan pendekatan statistik uji z
dengan persamaan statistik uji sebagai berikut.
z=P−P0
σp...........................................
................................................... (2-
40)
Dimana
σp=√P0(1−P0)
n......................................
............................................. (2-41)
Pengujian Proporsi Dua Sampel
Untuk menguji proporsi dua buah sampel dengan H0.
digunakan pendekatan statistik uji z dengan persamaan
statistik uji sebagai berikut (Walpole).
z=p1−p2
√p q[( 1n1 )+(
1n2 )]..................................
.............................................. (2-
42)
Keterangan: p = Total proporsi sampel p1 = Proporsi
sampel pertama q=1−p2.4.6 Uji Kesesuaian
Pada pembahasan pengujian hipotesis sebelumnya,
kita melakukan pengujian terhadap parameter populasi

seperti rataan, variansi, dan proporsi. Pada bagian uji
kesesuaian (goodness of fitting test) kita akan melakukan
penyimpulan terhadap distribusi populasi dari data yang
dikumpulkan. Dari sampel yang diambil kita akan menguji
suatu hipotesis nol dalam bentuk umum berikut.
Ho : sampel berasal dari distribusi tertentu
Distribusi yang diuji dapat berupa sembarang
distribusi apakah distribusi yang telah dikenal, atau
distribusi yang dibangun oleh seorang statistikawan.
Hipotesis tandingan selalu dalam bentuk berikut.
Hl : sampel tidak berasal dari distribusi tertentu
Terdapat dua jenis pengujian distribusi yang akan
dibahas pada bagian ini.
Kedua jenis pengujian tersebut adalah sebagai berikut.
Uji, dengan menggunakan pendekatan statistik
Uji Kolmogorov-Smirnov (K-S), yang merupakan
pengujian yang bersifat non parametrik, atau tidak
memerlukan suatu statistik uji tertentu.
2.4.6.1 Uji Kesesuaian Untuk Distibusi Diskret
Uji x2 menggunakan uji statisik dalam
penyelesaiannya, dimana distribusi kesesuaian x2
digunakan dalam melakukan uji ini. Untuk melakukan
pengukuran pada uji ini, maka formula yang digunakan
adalah sebagai berikut :
x2=∑i=1
k (Oi−Ei)2
Ei......................................
........................................ (2-43)

Keterangan :
K = jumlah perbedaan nilai dari varibel
Oi = nilai frekuensi pengamatan
Ei = nilai frekuensi teoritis yang diharapkan
Nilai Ei dibentuk dari ukuran sampel dan peluang
dari distribusi hipotesis yang dituliskan sebagai
berikut :
Ei=nPi............................................
................................................. (2-
44)
Sejak fungsi kepadatan x2 digunakan untuk uji
kesesuaian, parameter tingkat kebebasan harus
ditentukan. Seperti (Johnson,A. 1996,hal 301)
v=(k−1)(r−1)......................................
..................................... (2-45)
Dimana r adalah jumlah parameter dari uji
hipotesis yang di estimasi dari data sampel (baris) dan
K menyatakan kolom percobaan. Secara umum untuk
melakukan uji kesesuaian tahapan pengujiannya hampir
sama dengan uji hipotesis.
2.4.6.2 Frekuensi Pemeriksaan Minimum Untuk Statistik
X2
Nilai frekuensi ei yang diharapkan untuk digunakan
dalam uji kecocokan minimum memiliki frekuensi sebanyak
5, untuk perkiraan keakuratan dalam X2 jika dimungkinkan
dapat dilakukan kombinasi antara nilai ei dan oi dengan
jaminan nilai ei> 5.

2.5 Regresi Linier Dengan Kuadrat Terkecil (Least
Squares)
Susunan dari sebuah garis eye-baled yang melalui
titik-titik yang diplot dalam sebuah grafik adalah satu
cara tepat membentuk baris data. Bagaimanapun juga,
jika bentuk garis jadi kemungkinan terbaik dan jika ada
sebuah persamaan garis tersebut, Regresi adalah
pendekatan yang tepat.
"Regresi adalah model hubungan antara dua variabel atau lebih,
yaitu antara variabel bargantung (dependent variable), dengan
variabel bebasnya (independent variable) " (Supangat, 2010).
"Persamaan regresi adalah persamaan matematik yang
memungkinkan untuk meramalkan nilai-nilai suatu peubah tak
bebas dari nilai-nilai satu atau lebih peubah bebas. Regresi
diterapkan pada semua jenis peramalan, dan tidak harus
berimplikasi suatu regresi mendekati nilai tengah populasi
(Walpole, 1995).
S=∑ei2=∑ (Yi−Yi)
2............................
............................... (2-1)
Gambar 2. 3 Persamaan Garis Regresi Linier

Oleh karena itu, metode kuadrat terkecil (method of
least squares) sekali lagi akan digunakan untuk
menempatkan garis pada data yang diamati, sehingga
bentuk dari persamaan regresi adalah sebagai berikut :
Y=a+bX.......................................................................................... (2-2)

Dimana : a = Titik tolak Y.
b = Kemiringan dari garis regresi (kenaikan
atau penurunan Y' untuk setiap perubahan
satu-satuan X) atau koefısiensi regresi,
yang mengukur besarnya pengaruh X
terhadap Y kalau X naik satu unit.
X = Nilai tertentu dari variabel bebas.
Y = Nilai yang diukur atau dihitung pada
variabel tidak bebas.
Regresi atau bentuk kurva yang menggunakan
sepasang data (Xi, Yi) persamaan (2-1) untuk menentukan
sebuah persamaan yang menerangkan hubungan matematis
antar dua variabel. X adalah variabel bebas biasa
karena belum terpilih dan nilai tetap (non-random). Y
adalah variabel tidak bebas atau jawaban yang acak
untuk setiap nilai X.
Teknik dengan kuadrat terkecil membuat asumsi
tertentu :
1. Tidak ada kesalahan dalam nilai Xi, karena itu data
pengamatan. Variabel Xtidak ada kesalahan.
2. Distribusi normal tampak pada setiap Xi jika
beberapa nilai Yi didapatkan.
3. Distribusi normal adalah bebas dari yang lainnya.
4. Variansi normal (σ2) ada pada setiap nilai Xi
adalah sama.
5. Kemiringan kuadrat terkecil melalui rata-rata µi
distribusi normal pada setiap Xi.

Garis atau regresi dengan kuadrat terkecil
memiliki hubungan matematis yang dikembangkan hanya
mengunakan nilai Xi yang ditentukan, perhitungan diluar
batas ini akan beresiko. Tidak ada jaminan bahwa
distribusi normal untuk nilai Y akan mengikuti asumsi
diatas.
2.5.1.1 Penentuan Koefisinsi Regresi
Jika sebuah hubungan garis lurus diasumsikan
terbaik antara X dan Y, model matematis untuk i = 1, 2,
. , n adalah :
Yi=α+βXi+ei.......................................
......................................... (2-3)
Dimana nilai ei atau S adalah kesalahan acak mengenai
garis. Penaksir terbaik α dan βadalah α= a dan β = bdari persamaan :
Yi=a+bXi..........................................
............................................... (2-4)
Dimana Yiadalah penaksiran dari persamaan regresi.
Persamaan (2-1) dan persamaan (2-4) bisa digunakan pada
persamaan a dan b menggunakan metode kuadrat terkecil.
(Minimasi)
∑i=1
nei2=S=∑
i=1
n(Yi−Yi)
2=∑ [Yi−(a−bXi)]2...................
...... (2-5)
Secara serentak solusi dari a dan b dari persamaan
normal diberikan :

b=
n∑i=1
nxiyi−(∑
i=1
nxi)(∑
i=1
nyi)
n∑i=1
nxi2−(∑
i=1
nxi)
2............................
................................... (2-6)
a=∑i=1
nyi−b∑
i=1
nxi
n....................................
............................................ (2-7)
Nilai dari a dan b disubstitusikan kedalam persamaan
(2-4) untuk mendapatkan persamaan Yi.
Jika persamaan normal pertama (2-4) dengan Y, kitaakan dapatkan :
Y=∑Yn
=nan
+bXi
nY=a+bX......................................
........................................ (2-8)
Gambar 2. 4 Mode Regresi Linier Pergeseran Awal Pada (X,Y)
Gambar 2.2 menunjukan tujuan dari pergeseran untuk
mencapai hubungan yang lebih mudah dalam penggunaan
yang konstan.

Jika regresi linier digunakan, sebuah hubungan
linier diasumsikan antara variabel X dan Y, dan model
untuk i = l, 2, ..., n adalah :
Yi=α+βXiDimana α adalah titik tolak y dan β adalah kemiringan.Jika estimator kuadrat terkecil â = a dan β = b
digunakan, ini mungkin bergeser dari awal ke titik (
X,Y), seperti ditunjukan pada gambar 2.2, dan samaberasal dari hubungan sederhana untuk konsistensi.
Tanpa disebutkan translasi awal, modelnya adalah :
Yi=a+bXi..........................................
............................................... (2-9)
dan dengan translasi adalah :
Y−Y=a'+b(X−X)....................................
................................. (2-10)
Setelah a dan b ditentukan, beberapa nilai X dapat
digunakan dalam persamaan regresi untuk menentukan
nilai harapan Y , yang mana nilai rata-rata dari sebuahdistribusi normal ditempatkan pada nilai X. Langkah-
langkah gambaran penggunaan teknik regresi .
l. Menghitung X dan Y.
1. Peroleh nilai dan jumlah X−X, (X−X )2dan Y−Y.
2. Hitung a dan b menggunakan persamaan (2-6) dan (2-
7)
3. Substitusikan b dan a kedalam persamaan dan tulis
kembali persamaan kedalam bentuk Yi=a+bXi.

4. Selesaikan Y menggunakan nilai X yang diberikan
dan plot persamaan.
2.5.1.2 Selang Kepercayaan Garis Regresi
Garis regresi yang sesuai, diterangkan pada bagian
persamaan (2-1), melalui rata-rata distribusi normal
pada setiap pengamatan nilai X. Data persamaan Yi=a+bXi
, dan sekitar garis regresi variansi Sy2 yang digunakan
dalam interval persentase tingkat kepercayaan (1 – α)
dalam empat nilai terkecil yang berbeda. Pertama kita
akan diskusikan penaksiran interval dalam Y, yang manarata-rata nilai pengamatannya pada setiap nilai X.
Batas ditemukan pada Yuntuk setiap nilai X, dan batas
simetris yang ditunjukan pada gambar 2.3. Variansi
untuk setiap rata-rata nilai Y adalah:
Sy2=Sy
2[ 1n+(X−X)2
∑ (X−X)2 ]........................................................................ (2-11)
X dalam perhitungan adalah nilai untuk setiap interval
yang tersusun, jadi Sy2 yang baru dihitung untuk setiap
nilai X.
Penaksiran interval ( θ ), yang tersusun
menggunakan distribusi t dengan derajat kebebasan v = n
- 2 dan two-tail α, adalah :Y−tsY<θ<Y+tsY ....................................
........................................ (2-12)

Interval selalu berhimpit pada X. Untuk menjaga
kepercayaan yang sama berawal duri nilai X, intervalyang didapat lebih jauh.
Gambar 2. 5 Interval Kepercayaan Pada Rata-rata Nilai Yi Pada Tiap Nilai
Pengamatan Xi
Jika X baru bernilai X0 disubstitusikan pada
persamaan regresi dan Y sebagai nilai prediksi untuknilai selanjutnya, interval tersusun dalam penaksiran
nilai Y0. Interval ini terlihat seperti diatas, lebih
jauh karena dihitung untuk satu nilai Y, bukan untukrata-rata. Sering kali nilai X tidak teramati ketika
data telah terkumpul dan dan dihitung.
Variansi untuk satu nilai Y0akan dinotasikan oleh
S02 dan sama dengan :
S02=Sy2[1+
1n
+(X0−X)2
∑ (X−X)2 ]................................................................. (2-13)
Ini juga menggunakan distribusi t untuk derajat
kepercayaan v = n - 2 dan two tail α :

Y−ts0<θ<Y+ts0 ....................................
......................................... (2-14)
Dimana Y0=a+bX0 dari persamaan regresi. Untuk
menghitung satu batas interval Y untuk nilai X0 lebih
dari seluruh bentuk kipas kurva pada gambar 2.3.
Cacatan bahwa S02 pada persamaan (2-13) lebih besar dari
Sy2 pada persamaan (2-11), oleh jumlah Sy
2.
Penaksiran interval mungkin juga menetapkan titik
tolak dan kemiringan b menggunakan distribusi t dengan
derajat kebebasan v = n - 2. Formulasinya :
Tabel 2.1 Standar Deviasi Sa dan Sb
ParameterPenaksiran
IntervalTitik Tolak
aa±tsa
Kemiringan
bb±tsb
2.5.1.3 Uji Hipotesis Koefisiensi Regresi
Dalam pembuatan beberapa tipe dari kesimpulan
statistik mengenai regresi, ini perlu menghitung
sekitar garis regresi variansi, (Sy2 = rata-rata kuadrat

penyimpangan sekitar regresi atau rata-rata kuadrat
residu) seperti :
Sy2=
JumlaherrorkuadratDerajatkebebasan
=∑ei
2
v
¿∑ (Yi− Yi)
2
n−2........................................
............................................ (2-15)
Penghitungan persamaan (2-11) dan derajat kepercayaan v
= n - 2 karena ini memerlukan dua titik untuk
menentukan sebuah garis tertentu, jadi 2 derajat
kebebasan hilang.
Untuk menguji nilai a dan b dari garis Yi = a + bXi
menghadapi beberapa nilai hipotesis a0 atau b0. ini
digunakan jika beberapa kriteria tipe telah tersusun
dalam sebuah garis atau set data yang Iain untuk
dibandingkan. Distribusi t digunakan untuk menguji
kinerja untuk setiap nilainya. Jika nilai hipotesis b0
= 0 diterima, garis regresi memiliki kemiringan 0, jadi
variabel X dan Y adalah bebas dan garis kesesuaian
adalah tanpa nilai.
Hipotesis Dua Bagian, uji statistik t, dan derajat
kebebasan teringkas dalam tabel 2.1. Dalam kasus Iain,
jika perhitungan t melebihi nilai dari nilai tabel
distribusi t untuk sebuah two-tail α, kemudian tolak Ho.Tabel 2.2 Uji Statistik untuk Titik Tolak dan Garis Regrasi
Hipotesi
s
Standar Deviasi a atau
b
Uji Statistik
t
Derajat
Kebebasan

H0 : a ≠
a0
H0 : a ≠+
a0
Sa=[Sy2(1n+
X2
∑(Xi−X)2 )]1/2
t=[a−a0 ]Sa
v ≠ n - 2
H0 : b ≠
b0
H0 : b ≠+
b0
Sb=[Sy2( X2
∑ (Xi−X)2 )]1/2
t=[b−b0 ]Sb
v ≠ n - 2
Adapun langkah umum dalam pengujian hipotesis,
dimana prosedurnya antara lain :
1. Tentukan pernyataan hipotesis, kembangkan bentuk
eksak H0 dan H1. Tentukan pula jenis pengujian
yang akan dilakukan, apakah satu atau dua arah.
2. Pilih tingkat ketelitian yang akan digunakan.
3. Hitung statistik sampel dan lakukan penaksiran
parameter. Satu atau lebih statistik mungkin
diperlukan untuk menyusun pengujian.
4. Hitung nilai statistik pengujian atau disebut juga
statistik hitung.
5. Tentukan daerah penerimaan dan daerah krisis dari
statistik uji.
6. Putuskan apakah diterima atau ditolak (Terima H0
bila statistik hitung berada pada daerah
penerimaan dan penolakan H0 jika berada di daerah
kritis).

Gambar 2. 6 Daerah Penerimaan Oner-tail (satu arah)
Gambar 2. 7 Daerah Penerimaan Two-tail (dua arah)
2.5.2 Analisis Korelasi
Korelasi merupakan suatu hubungan antara satu
variabel dengan variabel Iainnya. Hubungan antara
variabel tersebut bisa secara korelasi dan bisa juga
secara kausal. Jika hubungan tersebut tidak menunjukkan
sifat sebab akibat, maka korelasi tersebut dikatakan
korelasional, artinya sifat hubungan variabel satu
dengan variabel Iainnya tidak jelas mana variabel sebab
dan mana variabel akibat. Sebaliknya, jika hubungan
tersebut menunjukkan sifat sebab akibat, maka
korelasinya dikatakan kausal, artinya jika variabel
yang satu merupakan sebab, maka variabel Iainnya
merupakan akibat.

Materi pada bagian ini akan membantu melakukan
pembelajaran sebuah korelasi dan menginterprestasikan
hasil. Penggunakan analisis koefisiensi korelasi linier
telah dikenalkan, juga korelasi nonlinier dan korelasi
multiple linier diperkenalkan.
Analisis korelasi adalah studi yang membahas tentang derajat
hubungan antara variabel-variabel (Sudjana,2013).
Ukuran yang dipakai untuk mengetahui derajat
hubungan, terutama untuk data kuantitatif, dinamakan
koefisien korelasi. Ini mungkin menggunakan studi hubungan
misal seperti IQ dan pendidikan, kelelahan dan angka
produksi, temperatur dan tekanan, dan Iain sebagainya.
Seperti analisis regresi, studi korelasi biasanya
berkonsentrasi pada hubungan linier. Hasil dari studi
korelasi adalah indikator yang baik, tentang seberapa
baiknya garis regresi menjelaskan variasi atas
tanggapan variabel Y. Walaupun regresi Y adalah acak
dan variabel bebas X tetap, analisis korelasi
memberikan informasi untuk studi regresi.
Secara umum korelasi dapat dibagi menjadi 7
(tujuh), yaitu:
1. Korelasi Positif
Korelasi positif adalah tingkat hubungan antara
dua variabel yang mempunyai ciri, bahwa
perubahan variable independent x (variabel bebas x)
diikuti oleh perubahan variable dependent y (variabel
tak bebas y) secara "searah".

2. Variabel Negatif
Variabel negarif adalah tingkat hubungan antara
dua variabel yang mempunyai ciri, bahwa perubahan
variabel independent x (variabel bebas x) diikuti
oleh perubahan variabel dependent y (variabel tak
bebas y) secara "berlawanan".
3. Korelasi sederhana
Korelasi sederhana adalah tingkat hubungan yang
terjadi antara 2 (dua) variabel saja.
4. Korelasi Multipel (Multiple Corelation)
Korelasi multipel adalah tingkat hubungan yang
terjadi antara 2 (dua) variabel atau lebih.
Misalnya pada model regresi multipel (y = a0+ a1x1
+ a1x2 + e), maka dan pengertian dari pernyataan
diatas adalah: tingkat hubungan antara y dan x1
atau tingkat hubungan antara y dan x2 atau tingkat
hubungan antara X1 dan x2.
5. Korelasi Sempurna (Perfect Corelation)
Maksud dan pengertian dari korelasi sempurna
adalah suatu kondisi bahwa setiap variabel bebas x
akan terdapat pada setiap nilai variabel tidak
bebas y nya. Hal ini dapat diartikan pula, bahwa
garis regresi yang terbentuk dalam data yang
tersebar (terdistrubusi) adalah merupakan tempat
kedudukan dari rata-rata dimaksud, sehingga nilai
r nya - 1 atau r = -1.
6. Korelasi tidak semurna (Inperfect Corelation)

Korelas antara 2 (dua) variabel dikatakan tidak
sempurna, jika titik-titik yang tersebar tidak
terdistribusi tepat pada satu garis lurus.
7. Kolerasi yang mustahil (Nonsense Coleration)
Kolerasi antara variabel yang seolah-olah ada tapi
tidak ada.
Sebuah grafik pengamatan data untuk dua variabel
acak X dan Y disebut diagram pencar (Gambar 2.6).
Walaupun korelasi nonlinier dan analisis regresi
dimungkinkan, banyak waktu untuk sebuah hubungan linier
cukup untuk menjelaskan banyak bagian dari variasi
data. Tidak ada hubungan Sebab-Akibat yang menaksir
studi kolerasi.
Gambar 2. 8 Grafik Umum Diagram Tebar yang Digunakan dalam Analisis
Korelasi
2.5.2.1 Penentuan Koefisien Korelasi
Hubungan antara dua variabel diukur menggunakan
koefisien korelasisederhana r, juga disebut koefisien
korelasi produk-momen Pearson. Nilai r didefinisikan
sebagai tingkat kekuatan hubungan antara dua variabel

atau lebih (besarnya konstribusi yang diberikan oleh
variabel yang mempengaruhi), baik secara langsung
maupun tidak langsung. Secara umum r didefinisikan
sebagai:
r=(VariansiyangditentukanTotalvariansi )1/2
......................
................................. (2-16)
Untuk korelasi linier pasangan data (Xi,, Yi) untuk i
= 1, 2, ..., n pengamatan menggunakan perhitungan r (i
dihilangkan) :
r=n∑xy−∑x∑ y
√¿¿¿..................................
....................... (2-17)
Beberapa penyajian r, dengan acuan seperti :
Range : - 1 ≤ r ≤ 1
r = ± 1 : Korelasi linier sempurna (Gambar
2.7.a)
r = 0 : Tidak ada hubungan linier, tidak
berkorelasi (Gambar 2.7.b)
r > 0: Kemiringan positif antara X dan Y
r mendekati + 1 : Kecenderungan linier positif kuat
(Gambar 2.7.c)
r< 0 : Kemiringan negatif antara X dan Y
r mendekati – 1 : Kecenderungan linier negatif kuat
(Gambar 2.7.d)
Dimensi : Tidak ada, dimensi X dan Y tidak
terlihat

Translasi : r sama tertinggal jika variabel
banyak oleh penambahan tetapnya
Jika r = ± 1 dan garis regresi membentuk data,
bentuk yang sempurna dan kesalahan (error) jumlah, sama
dengan persamaan (2-1) akan sama dengan 0. Jika r = 0
variabelnya tidak berkorelasi, tidak ada kecenderungan
linier yang dapat dibedakan. Variabel ini bebas karena
r = 0, tapi variabel ini benar bahwa dua variabel bebas
dengan r = 0.
Gambar 2. 9 Diagram Tebar Koefesiensi Korelasi
2.5.2.2 Uji Hipotesis Koefisien Korelasi
Untuk menentukan perhitungan nilai untuk
signifikasi statistik r atau sama dengan nilai p0, cara
pengujian hipotesis digunakan untuk menguji :
H0 : p = p0 vs H1 : p ≠ p0

Dimana p adalah nilai populasi dari dari
koefisiensi korelasi sebagai estimasi oleh sampel nilai
r. Uji hipotesis ini diilustrasikan diatas, perbedaan
uji statistik dari distribusi t atau distribusi normal
(z) harus digunakan untuk menguji H0 tergantung pada
nilai p0. Jika nilai p0 adalah 0 dan jika H0 ditolak,
korelasi dari data yang signifikasi dengan 100(1 - α)
persen tingkat kepercayaan. Untuk menghitung statistik,
jawaban pertama dari pertanyaan dan gunakan hubungan
dari tabel 2.3.
1. Dengan ukuran sampel (n< 30) atau lebih? Jika
sampel kecil, tapi distribusi normal dapat
diasumsikan untuk data, menggunakan perhitungan
statistik dengan sampel besar. Jika p ≠ p0 dan n <
30, tambah data atau asumsikan normal.
2. Dalam ketidakberlakuan hipotesis H0 : p = p0 , p0
menuju 0, atau beberapa nilai bukan nol?
Statistik t dalam persamaan 2-17 dengan derajat
kebebasan v = n - 2. Pengujian satu sisi, ini biasanya
menampilkan pengujian dua sisi untuk korelasi.
Jika menghitung nilai t dan dan z yang melebihi nilai
tabulasi, H0 ditolak.Tabel 2.3 Uji Statistik untuk Menguji Koefisiensi Korelasi
Ukura
n
Sampe
l
Nilai p0
dalam H0
Tipe dari
Uji
Statistik
Uji Statistik
Nomor
Persamaa
n

Kecil 0 Tr√n−2√1−r2 (2-18)
Besar 0 Zr√n−2√1−r2 (2-19)
Besar Bukan 0 Z √n−32
ln[( 1+r1−r )(1−p0
1+p0 )] (2-20)
2.5.2.3 Koefisien Determinasi
Definisi umum dari koefisien korelasi r, mungkin
digunakan untuk menghitung pecahan dari variasi total
data yang dipindahkan oleh sebuah persamaan regresi
linier atau bukan. Kuadrat r disebut koefisiensi dengan
ketentuan :
r2=Variansiyangditentukan
TotalvariansiKoefisien determinasi adalah ukuran (besaran) yang
menyatakan tingkat kekuatan hubungan dalam bentuk
persen (%). Besaran ini dinyatakan dalam nitasi R.
Dimana:
R =
r2.....................................................
............................................. (2-21)
Peninjauan dari tipe variansi dihadirkan dalam
sebuah analisis regresi. Dalam penjumlahan akar
kuadrat, r2 ditulis :
r2=SSRSST
=∑ ( Y−Y )2
∑ (Y−Y )2...................................
.......................................... (2-22)

Dimana : Y = Ditentukan dari persamaan regresi
Y = Rata-rata dari nilai pengamatan Y
Nilai r2, yang memiliki rentang 0 ≤ r2 ≤ 1 , berisi
lampiran banyak perhitungan regresi.
Harus dilaksanakan bahwa akar persamaan 2-22 dan
koefisiensi korelasi dalam persamaan 2-23 bertepatan
ketika regresi linier digunakan. Persamaan 2-23
memberikan hasil bilangan yang sama pada kurva
kesesuaian baru, karena hanya pasangan data asli (Xi,
Yi) digunakan, bukan menentukan Y dalam persamaan
2-22. Jika tipe persamaan nonlinier menjadi
ketidaksesuaian data, distribusi r dihitung sebagai
akar kuadrat r2 dalam persamaan 2-22. Hubungannya
disebut koefisiensi korelasi umum.
r=[∑ (Y−Y)2
∑ (Y−Y)2 ]1/2
.....................................
............................................ (2-23)
2.5.3 Analisis Variansi
Pada bagian ini mendiskusikan mengenai teknik dan
penggunaan Analisis Variansi (ANOVA). Model matematik
yang diasumsikan, hipotesis yang diuji, dan tabel
lengkap ANOVA yang diberikan untuk satu dan dua faktor
ANOVA. Dasar pemikiran Analisis Variansi (ANOVA),
diikuti pertimbangan situasi. Empat mesin dapat
digunakan untuk memproduksi produk alumunium yang sama.

Lima sampel ketebalan i (i = 1, 2, 3, 4, 5) diambil dari
setiap mesin j (j = 1, 2, 3, 4). Ketebalan dari semua
mesin menggunakan persamaan statistik atau jika "akibat
mesin" membuat beberapa perbedaan ketebalan dari yang
lainnya. Kita menunjuk mesin sebagai perawatan, karena
setiap mesin berbeda cara terhadap perlakuan produknya.
Jika hanya ada dua mesin, pengujian rata-rata dapat
digunakan, tetapi apabila lebih dari dua analisis lebih
efektif menggunakan teknik analisis variansi.
Pada dasarnya ANOVA dapat dibagi menjadi 2
kelompok besar yaitu :
a. Beberapa kelompok yang dihadapi merupakan bagian
dari satu independent variabel (variabel bebas).
Kondisi ini yang sering disebut dengan single factor
experiment (analisis variansi satu arah).
b. Beberapa kelompok yang dihadapi merupakan
pembagian dari beberapa independent variabel
(variabel bebas). Kondisi ini yang sering disebut
dengan two factor experiment (analisis variansi dua
arah).
Dalam bagian ini kita mendiskusikan singkat
mengenai :
a) Dasar model ANOVA,
b) Uji hipotetsis,
c) Pembagian total variansi, dan
d) Bagaimana tabel ANOVA disiapkan dan digunakan
untuk memperoleh hasil yang bersangkutan dengan

hipotesis. Semua keperluan ANOVA ditampilkan,
dengan tanpa melihat kelengkapan disain
penelitian.
Untuk pemecahan permasalahan empat mesin diatas,
model linier dirumuskan :
xij=μ+Tj+eij.......................................
........................................ (2-24)
Dimana : xij = Nilai pengamatan i dari mesin j
μ = Rata-rata keseluruhan ketebalan untuk
semua mesin.
Tj = Akibat dari mesin j dalam penambahan
rata-rata keseluruhan µ
eij = Akibat acak untuk pengamatan i dari
mesin j
Jika rata-rata ketebalan 5 cm banyak produk i = 3 dalam
2 mesin (j = 2) dengan akibat mesin - 0,3 dan akibat
acak + 0,1 cm, kemudian X32 = 5,0 - 0,3 + 0,1 = 4,8 cm.
Jumlah semua akibat perlakuan disumsikan 0 ketika ANOVA
digunakan. Ditulis sebagai :
∑j=1
kTj=0...........................................
.............................................. (2-25)
Dimana j = 1, 2, ..., k adalah perlakuan, yang
berasal dari pemisahan populasi. Populasi ini adalah
produk alumunium yang dibuat oleh setiap mesin pada
contoh tersebut.

Akibat perlakuan Tj adalah sebuah variabel acak,
jadi persamaan 2-20 disebut juga model acak akibat.
Dalam ANOVA setiap Tj diasumsikan berdistribusi N(0,σT2 ¿.
Variansi σT2sama untuk semua perlakuan, kesalahan
hipotesis diuji bukan sebagai akibat perlakuan yang
ditampilkan. Oleh karena itu :
H0 : Tj = 0 untuk semua perlakuan j
Diuji dengan alternatif hipotesis :
H1 : Tj ≠ 0untuk beberapa perlakuan j
Jika satu atau beberapa mesin membuat produk dengan
perbedaan statistik dari yang Iain, H0 ditolak.
Partisi variansi total dipenuhi oleh pemisahan
jumlah total kuadrat SST untuk data pengamatan. SST
selalu jumlah kuadrat dari perbedaan antar setiap Xij
dan tinggi rata-rata X .
SST=∑j∑i
(Xij−X)2...................................
................................... (2-26)
Tinggi rata-rata X adalah :
∑j=1
k
∑i=1
n Xij
kn..........................................
............................................. (2-27)
Dimana perlakuan k dan pengamatan n per perlakuan. Dua
sumber variansi dalam model persamaan 2-26 meliputi
SST. Salah satunya perbedaan diakibatkan akibat mesin
Tj, perlakuan antara jumlah kuadrat SST, yang ditulis :

SSTr=∑jn(Xj−X)2....................................
................................... (2-28)
Dimana : n = Bilangan pengamatan per sampel (i = l,
2, ..., n)
Xj= Rata-rata nilai pengamatan untuk setiap perlakuan j
Kedua adalah efek acak eij yang terjadi dengan setiap
mesin (perlakuan) karena karakteristik spesifiknya.
Hasil dalam perlakuan ini, atau kesalahan, jumlah
kuadrat SSE.
SSE=∑j∑i
(Xij−Xj)2..................................
................................... (2-29)
Dimana Xj telah dijelaskan sebelumnya. Bisa ditunjukan
bahwa SST adalah jumlah dari persamaan 2-28 dan 2-29 :
SST=SSTr+SSE
SSE=∑j∑i
¿¿¿........ (2-30)
Penjumlahan ini digunakan dalam bagian berikutnya untuk
memperoleh hasil ANOVA; yang akan ditulis kembali dalam
bentuk hitungan yang lebih mudah.
Hasil ANOVA diperoleh dari perhitungan nilai
distribusi F untuk setiap stiap sumber variasi kecuali
kesalahan total dan acak. Rata-rata kuadrat dihitung
dari setiap jumlah kuadrat kecuali total. Nilai rata-
rata kuadrat tidak lebih dari taksiran variansi, jadi
jumlah rata-rata dibagi dengan derajat kebebasan v yang
sesuai. Untuk MSTr, antar perlakuan derajat kebebasan
vTr, adalah bilangan perlakuan k kurang 1 :

MSTr=SSTRvTr
=SSTrk−1....................................
....................................... (2-31)
Untuk kesalahan rata-rata kuadrat vE total derajat
kebebasan nk - 1, kurang vTr atau vE = k(n - 1). Kemudian
:
MSE=SSEvE
=SSE
k(n−1)...................................
........................................ (2-32)
Semua hasilnya dimasukan dalam sebuah tabel ANOVA
seperti tabel 3.4. Jika perhitungan nilai F melebihi
nilai tabel B-6 untuk pemilihan nilai a dengan derajat
kebebasan vTr dan vE, H0 tidak diterima dan akibat
perlakuan akan disampaikan. Kesimpulan ini berarti
bahwa satu mesin paling kecil memproduksi ketebalan
material yang berbeda.
Tabel 2.4 Bentuk Umum Tabel ANOVA
Sumber
Variansi
Derajat
Kebebasa
n
Jumlah
Kuadrat
Rata-rata
KuadratNilai F
Antar
Perlakukan
(Tj)
k – 1 SSTR MSTr=SSTrk−1
MSTr
MSE
Kesalahan
(eij)k (n - 1) SSE MSE=
SSEk(n−1)
Total Kn – 1 SST ≠ SSTr + SSE

2.5.3.1 Analisis Variansi Satu Arah
Perlakuan membedakan tingkatan faktor, yang mana
menarik pemikiran sebuah ANOVA. Jika hanya satu faktor,
seperti tipe mesin, tingkat tekanan, tingkat
temperatur, dsb, akan disampaikan sebuah faktor yang
digunakan. Juga disebut satu arah ANOVA. Lebih lanjut
lagi, disainnya lengkap sembarang jika tidak ada
batasan yang ditempatkan dalam pemilihan sampel acak
dari tingkat perlakuan k. Bagian ANOVA ini
mengasumsikan model pada persamaan 2-24 yang hasil yang
disampaikan pada bentuk tabel 2.4. Ini mungkin menulis
ulang syarat jumlah kuadrat dalam persamaan 2-26 pada
persamaan 2-25 dalam bentuk yang lebih mudah digunakan.
Langkah-langkah dibawah ditampilkan dalam penulisan
kembali bentuk dan rancangan prosedur untuk menampilkan
satu arah ANOVA untuk pengamatan i = l, 2, ..., n dan
perlakuan j = l, 2, ..., k.
1. Tulis model asumsi, ketidakberlakuan hipotesis dan
tingkatan a.
2. Hitung jumlah seluruh pengamatan dan masukan
syarat T :
T=∑j∑iXij.........................................
............................................. (2-
33)
3. Hitung jumlah total kuadrat :

SST=∑j∑iXij2 −
T2
nk...................................
....................................... (2-34)
Dimana T dari persamaan 2-35. Derajat kebebasannya
vT = nk - 1.
4. Hitung perlakuan antar jumlah kuadrat :
SSTr=∑j
Xj2
n−T2
nk.....................................
......................................... (2-35)
Dimana : Xj2 = Kuadrat jumlah Xij untuk setiap
perlakuan j.
= (∑i Xij)2
Derajat kebebasannya adalah vTr = k - l.
5. Tentukan kesalahan jumlah kuadrat dan derajat
kebebasan dengan mengurangi:
SSE=SST−SSTrvE=vT−vTr
6. Tempatkan hasilnya dalam tabel 2.4 dan hitung
nilai rata-rata kuadrat dengan persamaan 2-31 dan
persamaan 2-32.
7. Tentukan nilai F untuk akibat perlakuan dan
bandingkan dengan nilai susunan tabel untuk v1 = k
- 1 dan v2 = k(n - l). Terima atau tolak hipotesis
akibat ketidakberlakuan.

2.5.3.2 Analisis Variansi Untuk Persamaan Regresi
Faktor tunggal ANOVA digunakan untuk menguji
signifikansi model multipel (atau simpel) regresi
linier umumnya berbentuk :
Yi=a+b1Xi1+b2Xi2+…+bkXik............................
.................... (2-36)
Dimana Yi (i = 1, 2, ..., n) adalah nilai pengamatan
analisator pada Xij dalam persamaan 2-36. Nilai bj
mengestimasi koefisiensi βj, pada bab sebelumnya.
Signifiknsi keseluruhan regresi mengurangi uji
hipotesis :
H0:b1=b2=…=bk=0..................................
.............................. (2-37)
H0 tidak diterima dengan metode rata-rata ANOVA pada
satu bj terkecil bukan nilai statistik sama dengan 0,
jadi pada satu Variabel Xj terkecil bukan variabel
bebas Y oleh karena itu regresinya penuh arti. Tentu
beberapa variabel Xj yang Iain ditambahkan sedikit atau
tidak satupun untuk menjelaskan hubungannya dengan
variabel Y.
Untuk membentuk ANOVA pada persamaan regresi,
mempertimbangkan perlakuan koefisiensi regresi bj dan
menggunakan tabel 2.4, tapi menempatkan variasi antar
perlakuan dengan regresi.
1. Tulis model regresi, tidak ada hipotesis,
pemilihan tingkatan a.

2. Hitung bentuk T dengan jumlah dari rata-rata semua
nilai pengamatan Y :
T=∑iYi...........................................
..................................................
(2-38)
3. Hitung total jumlah kuadrat menggunakan :
SST=∑iYi2−
T2
n ......................................
......................................... (2-39)
Dengan derajat kebebasan vT = n – 1.
4. Tentukan kesalahan jumlah kuadrat dengan :
SSE=∑i
¿¿..........................................
................................... (2-40)
Derajat kebebasan vE = n - k - 1, dimana k adalah
anggota nilai b dalam H0
5. Hitung regresi jumlah kuadrat SSR dengan
mengurangi :
SSR=SST−SSE.......................................
........................................ (2-41)
Derajat kebebasannya vk = k. Alternatif SSR
dihitung menggunakan persamaan:
SSR=∑i
¿¿..........................................
................................... (2-42)
6. Masukan hasilnya pada bentuk tabel 2.4 dan hitung
rata-rata kuadrat untuk regresi dan kesalahannya.

7. Tentukan nilai F untuk akibat regresi bandingkan
dengan nilai tabel distribusi F untuk v1 = vR dan v2
= vE. Terima H0 jika nilai perhitungan tidak
melebihi nilai tabel pada tingkat signifikansi a.
2.5.3.3 Analisis Variansi Dua Arah
Disain sebuah pengamatan sering untuk menguji
pemisahan dua atau lebih wilayah (disebut ruang dalam
ANOVA) karena ketiadaan ruangan dalam satu ruang.
Beberapa contoh :
Data Pengamatan Perlakuan RuangReaksi waktu
alarmAlarm asap Ruang asap
Roda jarak
bermil-milMerk ban Kendaraan
Kecacat Produk Temperatur proses Garis proses
Gambar 2. 10 Empat Perlakuan (Alarm)Ditempatkan Acak Dengan Setiap
Ruangan (Kamar)
Karena pengamatan ditampilkan oleh setiap ruang,
ini memungkinkan sebuah efek ruangan yang diisikan dan
dianalisis dalam ANOVA. Sebuah contoh, diduga empat
merk alarm asap diuji dalam lima ruang asap berbeda
lebih baik dari semua dalam sat ruangan. Gambar 2.7

diacak dengan setiap ruang (ruangan), dan satu dari
setiap tipe alarm dimasukan dalam setiap ruang.
Dalam satu faktor ANOVA dengan tingkat perlakuan Tj
(j = l, 2, ..., k) masih utama, tetapi model asumsi
sekarang diisi ruang akibat Bi (i = 1, 2, ..., n) :
Xij=μ+Tj+Bi+eij....................................
.................................. (2-23)
Untuk model persamaan semua ruang mengandung pengamatan
k, satu untuk setiap perlakuan. Jika tidak semua
perlakuan dapat diisi dalam setiap blok, satu
ketidaklengkapan analisis ruang acak ditamplikan.
Hipotesis gagal dari tidak ada akibat perlakuan,
sebelumnya berbentuk,
H0:T1=T2=…=Tk=0.............................
....................... (2-24)
Hipotesis dari tidak ada akibat ruangan, seperti,
H0:B1=B2=…=Bn=0
Mungkin juga diuji. Karena Tj dan akibat Bi, ANOVA
disebut analisis dua arah, dan jumlah kuadrat untuk
ruang SSBI diisikan dengan mengurangi hanya kesalahan
jumlah kuadrat SSE, bukan yang lainnya. Langkah yang
diberikan untuk analisis satu cara dibenarkan dengan
tiga alternatif. Pertama, beri nama kembali langkah 4
ke langkah 4a dan isikan langkah 4b.
4b. Hitung ruang antara jumlah kuadrat :

SSBI=∑i
Xi2
k−T2
nk................................
.................................. (2-25)
Dimana Xi2 = Kadrat dari jumlah Xij untuk setiap
pengamatan i.
¿(∑i Xij)2
Derajat kebebasan vBI = n - 1.
Kedua, langkah 5 ditulis kembali untuk mengurangi
kesalahan jumlah kuadrat untuk menampung SSBI :
5.Tentukan SSE adn vE dengan mengurangi :
SSE=SST−SSTr−SSBt.............................
......................... (2-26)
vE=vT−vTr−vBI=(k−1)(n−1)
Jadi, derajat kebebasan dalam langkah 7 untuk nilai F
sekarang v1 = k - 1 dan v2= (k – 1)(n - 1)

BAB III
KERANGKA PEMECAHAN MASALAH
3.1 Kerangka Pemecahan Masalah
Berikut adalah flowchart pembuatan laporan akhir
yang ditampilkan dalam bentuk flowchart . flowchart kerangka
kerja praktikum dapat di lihat pada Gambar:

Gambar 3. 1 Flowchart Pemecahan Masalah
3.2 Uraian Pemevahan Masalah
Laporan akhir di sini memiliki beberapa tahapan
yang di lakukan untuk mendapatkan hasil dari data yang
telah di mana data tersebut harus di olah sesuai
tahapan di bawah ini, yang di mana di sini telah di
buat flowchart dan akan di jelaskan sebagai berikut :

Studi Pendahuluan
Pada studi pendahuluan laporan akhir disini di
mana kegiatan penelitian harus memahami tentang apa
khasus yang diambil untuk laporan akhir yang harus di
pahami mulai dari latar belakang masalah, perumusan
masalah, maksud dan tujuan penelitian hingga pembatasan
dan sumber data yang di dapatkan untuk khasus tersebut.
Menentukan Rumusan Masalah & Pembatasan Masalah
Pada rumusan masalah di sini harus memahami apa
dari masalah dari khasus yang di ambil sehingga nanti
dapat dengan mudah untuk mengambil tujuan dari
penelitan yang di lakukan, dan untuk pembatasan masalah
di sini lebih di utamakan untuk pembatasan masalah
dalam penelitian digunakan untuk lebih melihat kepada
objek pengamatan agar lebih cepat untuk mencapai tujuan
dan dapat menarik kesimpulan sesuai dengan tujuan yang
ingin dicapai. Pembatasan masalah dalam penelitian ini
adalah penunjang penelitian digunakan software IBM SPSS
22.
Landasan Teori
Landasan teori disini menjelaskan teori apa saja
yang digunakan dalam penulisan laporan, dimana teori
disini antara lain teori mengenai Jam Lembur ,
Insentif, dan teori mengenai praktikum SBI II teori
tentang statistika deskriptif, teori peluang dan
distribusi peluang, statistika inferensial dan teknik
analisis statistik.

Pengumpulan Data
Pengumpulan data yang dilakukan dengan cara
mengambil data yang telah ada di sebuah kantor dinas di
Kalimantan Barat. Peneliti melakukan pengumpulan data
yang nantinya data tersebut akan diolah. Pengumpulan
data yang digunakan dalam penelitian laporan akhir ini
merupakan data Sekunder yaitu data yang diperoleh atau
dikumpulkan dari berbagai sumber yang ada.
Pengolahan Data
Untuk mengolah data-data tersebut menggunakan
teknik analisis statistik untuk mengetahui hubungan jam
lembur dengan pendapatan insentif karyawan, sehingga
dapat memprediksi jumlah insentif yang di dapat dari
banyaknya waktu lembur yang di lakukan. Berdasarkan
kasus tersebut dapat diidentifikasi variabel penyebab
dan akibat, bahwa yang menjadi variabel penyebab (X)
adalah jam lembur dan variabel akibat (Y) adalah
pendapatan insentif pengolahan dilakukan dengan cara
perhitunga parameter populasi, perhitungan ukuran
pemusatan data, perhitungan ukuran penyebaran
data,pengukuran dispersi, skewness, dan kurtosis,
pengujian kenormalan, penentuan koefisien regresi,
penentuan koefisien korelasi, uji hipotesis dan
penaksiran selang koefisien korelasi, dan analisis
variansi.

Analisis Hasil Pengamatan
Analisis di sini di lakukan dari hasil pengolahan
data dari khasus yang telah dipilih, menganalisis data
yang telah diperoleh , menganalisis data dari analisis
regresi linier dengan kuadrat terkecil, analisis
korelasi, dan analisis variansi.
Kesimpulan & Saran
Kesimpulan dari laporan akhir ini adalah hasil dari
tujuan yang telah di dapatkan dan diberi kesimpulan
apakah telah mencapai tujuan yang diinginkan dan saran
untuk hasil akhir yang didapat dan diberi saran sesuai
dengan yang seharusnya dilakukan.

BAB IV
PENGUMPULAN DAN PENGOLAHAN DATA
4.1 Gambaran Umum Laboratorium Manajemen Kualitas
Gambaran umum di sini menjelaskan tentang sejarah
singkat dan srtuktur organisasi laboratorium manajemen
kualitas.
4.1.2 Sejarah Singkat Laboratorium Manajemen
Kualitas
Kehadiran teknologi yang mampu mengangkat nilai
hidup manusia ditengah-tengah budaya masyarakat, perlu
digalakkan penerapannya disemua sektor pada tingkat,
skala dan jenis industri. Maka dari itu pengendalian
kualitas sebagai suatu ilmu yang sangat diperlukan
untuk memberikan dan memenuhi kebutuhan-kebutuhan
manusia berjalan seiring dengan perkembangan teknologi.
Banyaknya keputusan mengenai masalah yang
berhubungan dengan kualitas atau mutu diperlukan dalam
suatu proses pembuatan produk. Dalam membuat keputusan-
keputusan semacam itu ingin diperiksa perbandingan
ekonomis antara alternatif yang sedang diperiksa.
Teknik-teknik pengendalian kualitas dapat memberikan
suatu sumbangan yang berguna bagi penelitian ekonomis
semacam itu.
Banyaknya permasalahan yang sering kita hadapi
didunia industri mendorong para dosen Teknik Industri
Universitas Islam Bandung untuk memberikan dan

mengaplikasikan beberapa mata kuliah keahlian yang ada
di jurusan Teknik Industri salah satunya berupa
praktikum, sehingga dapat memberikan pengetahuan
tambahan kepada mahasiswa.
Praktikum Manajemen Kualitas berawal pada tahun
2001. Pertama kali diadakan di Laboratorium Perancangan
Sistem Kerja dan Ergonomi. Laboratorium ini baru
berdiri sendiri pada bulan September 2001, dengan 10
asisten dan melaksanakan 3 macam praktikum, yaitu
Praktikum Statistik Industri 1, Praktikum Pengendalian
Kualitas dan Praktikum Aplikasi Perangkat Lunak.
4.1.2 Visi, Misi, Tujuan dan Sasaran Laboratorium
Manajemen Kualitas
1. Visi dari laboratorium Manajemen Kualitas yaitu:
Menjadi tempat penyelenggaraan eksperimen dalam
bidang manajemen kualitas yang mampu bersaing di
tingkat daerah dan nasional.
2. Misi dari laboratorium Manajemen Kualitas yaitu:
Membantu mahasiswa dalam memecahkan masalah
ilmiah pada bidang manajemen kualitas.
Memberikan kemampuan lapangan (eksperimental)
kepada mahasiswa dalam bidang manajemen
kualitas.
Meningkatkan pemeberdayaan tenaga akademik
melalui penyelenggaraan penelitian, penulisan
artikel ilmiah, penyusunan bahan ajar, dan
pubilkasi di tingkat nasional.

3. Tujuan
Meningkatkan penguasaan dan keterampilan dalam
bidang Manajemen Kualitas melalui pendidikan,
pelatihan dan pengabdian kepada masyarakat.
Mengembangkan metodelogi Manajemen Kualitas
melalui kegiatan penenlitian.
4. Sasaran
Pembelajaran
Meningkatkan kualitas pemebelajaran keiilmuaan
Manajemen Kualitas.
Meningkatkan SDM laboratorium melalui pendidikan
formal dan non formal (kursus, seminar, on the job
traininag, dll).
Penelitian
Menumbuhkan minat penelitian di kalangan dosen dan
mahasiswa.
Menjalin kerjasama dengan instansi baik pemerintah
maupun swasta untuk melaksanakan penelitian
bersama.
Mempublikasikan hasil penelitian dan pengembangan
ke media lokal, nasional, dan internasional.
Mensosialisasikan hasil penelitian mengenai system
produktivitas dan efisiensi baik yang dihasilkan
oleh laboratorium maupun pihak lain.
Pengabdian

Menigkatkan peran serta dalam perbaikan Manajemen
Kualitas pada sistem manufaktur Nasional dan
menumbuhkan industry kecil.
Mengadakan pelatihan tentang Manajemen Kualitas.
4.1.3 Program dan Kegiatan
Program
Perbaikan kegiatan praktikum dan penelitian bagi
mahasiswa.
Pembinaan dan pengembangaan mata kuliah.
Peningkatan penelitian dan penerapan hasil
akumulasi pengetahuan dan keterampilan.
Peningkatan kompetensi dalam penguasaan sistem
produktivitas dan efisiensi.
Peningkatan citra Laboratorium Manajemen Kualitas
dan Program Studi Teknik Industri UNISBA.
Kegiatan
1. Pembelajaran
a. Pembinaan Praktikum: Statistik Bisnis Industri
II, Perancangan Sistem Manufaktur (Perancngan
Produk dan Perencanaan Proses), Perancangan Sistem
Perusahaan (Pengendalian Kualitas).
b. Pembinaan Mata Kuliah: Wajib dan Pilihan,
diantaranya:
Statistik Industri I
Statistik Industri II
Pengendalian Kualitas

Sistem Produksi*
Perancangan Sistem Kerja*
Manajemen Kualitas dan Hubungan Pelanggan*
Manajemen Hijau
*) Laboratorium Manajemen Kualitas turut
berkepentingan dalam pembinaan mata kuliah
tersebut.
c. Penulisan Hand-out/ diktat/ buku ajar untuk mata
kuliah
d. Pengembangan Wawasan Manajemen Kualitas.
e. Pembinaan staf pengajar dan calon staf pengajar.
2. Penelitian dalam Manajemen Kualitas
a. Penelitian Tugas Akhir mahasiswa Sarjana
b. Penelitian individual staf pengajar/kelompok
c. Peran serta seminar dan publikasi tingkat
Nasional dan Internasional
d. Penyelenggara Seminar/Workshop pada tingkat
Lokal dan Nasioanal
e. Menjalin kerjasama penelitian dengan instansi
pemerintah maupun swasta (masyarakat industri)
3. Pengabdian kepada masyarakat
a. Pelatihan
b. Kerjasama keilmuan/pendidikan
c. Kompetensi Sistem Produktivitas dan Citra
Laboratorium (dicapai melalui kegiatan- kegiatan
pada butir 1, 2, dan 3).

4.1.4 Lingkup Manajemen Kualitas
1) Fasa Perancangan
Sistem Design
Persyaratan Pelanggan (Customer Requirements).
Karakteristik Kualitas (Quality Characteristic).
Desain konsep (Conceptual Design).
Inovasi Produk (Product Innovation).
Parameter dan Toleransi (Parameter & Tolerance).
Design
Matoda Taguchi (Taguchi Methods): Turunan Fungsi
Kualitas (Quality Loss Function).
Desain untuk Manufaktur, Keandalan dan Perawatan
(Design for Manufacturability, Realibity &
Maintainability) menggunakan QFD: Analisa dan
dampak dari jenis kesalahan (Failur mode effect &
analysis)
2) Fasa Produksi
Pengendalian Proses (Process Control):
- Menjalankan proses yang singkat (Short run
process)
- Proses yang bermacam-macam (Multivariate process)
- Grafik urutan proses (Sequential process chart)
Proses pemeriksaan yang otomatis (Automated
process Inspection):
- Sampel Penerimaan (Accepted Sampling)
- Pemeriksaan dalam Proses (In-process Inspection)

- Komputer yang dirancang untuk pemeriksaan
(Computer aided inspection)
Pengujian perawatan kecepatan daya tahan
(Accelerated life testing Maintenance):
Berdasarkan Waktu (Time Based), Berdasarkan
Penggunaan (Used based), Berdasarkan Keadaan
(Condition Based), Berdasarkan Hasil Desain
(Design-out).
3) Fasa Pasca Produksi
Garansi Produk (Product Warranty): Garansi Satu
Dimensi (One Dimensional Warranty) dan Garansi Dua
Dimensi (Two Dimensional Warranty)
Kontrak Pelayanan (Service Contracts): Kebijakan
Satu Dimensi (One Dimensional Policy) & Kebijakan
Dua Dimensi (Two Dimensional Policy)
Keandalan Operasional (Operational Reliability):
- Waktu daya tahan yang diinginkan (Expected life
time)
- Pertumbuhan keandalan (Realibity growth)
- Faktor-faktor yang aman (Safety factors)
- Kecenderungan analisis pohon kesalahan pada
produk (Fault tree analysis Product Liability):
Turunan Kualitas Keuangan (Financial Quality
Loss)
Jaminan Kualitas (Quality System):
- Sistem Kualitas (Quality System)
Manajemen Kualitas Total

ISO 9000
Audit kualitas (Quality Audit)
- Siklus kualitas dan kemajuan kualitas
(Quality Circles dan Quality Improvement):
Siklus Demingg (Deming cycle), Kaizen,
Rekayasa ulang (Reengineering).
- Sistem lingkungan yang terfokus pada pengguna
(Customer oriented Enviroment System):
Produksi Bersih (Clean Production) dan ISO
14000.

4.1.5 Struktur Organisasi Laboratorium Managemen
Kualitas
4.2 Pengumpulan Data
Pengumpulan data yang dilakukan dengan cara
mengambil data yang telah ada di sebuah kantor. Oleh
karena itu, data yang digunakan dalam penelitian
laporan akhir ini merupakan data Sekunder yaitu data
yang diperoleh atau dikumpulkan dari berbagai sumber
yang telah ada, yang di dapat dari data sebuah kantor
Dinas di Kalimantan Barat.

4.2.1 Data Objek Penelitian
Berikut ini adalah data objek penelitian yaitu Jam
Lembur dan jumlah Insentif yang di dapatkan :Tabel 4. 1 Data Penelitian
No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22

26 20 19
27 19 18
28 18 20
29 18 20
30 20 20
4.2.2 Data Pretest
Uji Validasi
Uji Validitas konstruk dapat dilakukan dengan
menghitung korelasi antara masing-masing pernyataan
dengan skor total yang menggunakan rumus teknik
korelasi “product moment”
r=n∑xy−∑x∑ y
¿¿¿
r=(30x11401 )−(569x596)
{[ (30x10913 )−(569)2 ] [ (30x12028 )−(596)2 ]}12
=0,64
Keterangan :
r = Korelasi Product Moment
X = Skor Pernyataan
Y = Skor Total Seluruh Pernyataan
XY = Skor Pernyataan Dikalikan Skor Total
N = Jumlah Responden Pretesr
Variabel dinyatakan valid apabila rhitung > rtabel.
Adapun rekapitulasi hasil wawancara untuk responden
adalah sebagai berikut :
Tabel 4. 2 Rekapitulasi Hasil Penelitian

No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22
26 20 19
27 19 18
28 18 20
29 18 20
30 20 20

Tabel 4. 3 Perhitungan Uji Validitas
No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
X Y X.Y
1 14 15 196 225 210
2 14 17 196 289 238
3 20 19 400 361 380
4 20 25 400 625 500
5 17 16 289 256 272
6 20 19 400 361 380
7 21 19 441 361 399
8 20 18 400 324 360
9 19 21 361 441 399
10 20 20 400 400 400
11 18 20 324 400 360
12 17 15 289 225 255
13 20 20 400 400 400
14 17 20 289 400 340
15 23 23 529 529 529
16 20 20 400 400 400
17 17 17 289 289 289
18 20 20 400 400 400
19 16 18 256 324 288
20 22 22 484 484 484
21 19 24 361 576 456
22 20 24 400 576 480
23 20 23 400 529 460
24 20 22 400 484 440
25 20 22 400 484 440
26 20 19 400 361 380
27 19 18 361 324 342

28 18 20 324 400 360
29 18 20 324 400 360
30 20 20 400 400 400
Jumla
h569 596 10913 12028 11401
r=n∑xy−∑x∑ y
¿¿¿
r=(30x11401 )−(569x596)
{[ (30x10913 )−(569)2 ] [ (30x12028 )−(596)2 ]}12
=0,64
Berdasarkan hasil perhitungan diatas, dapat
dilihat sebesar 0,64 sedangkan nilai r tabel menurut
tabel angka kritik untuk N -2 yaitu 30-2 = 28 dan taraf
signifikan 5% maka nilai r tabel yaitu 0,361. Karena
rhitung > rtabel = 0,64 > 0,361 maka variabel dinyatakan
Valid, hal ini berarti bahwa variabel tersebut dapat
dijadikan data untuk pengolahan selanjutnya.
Uji Reliability
Keandalan (realiability) didefinisikan sebagai
seberapa jauh pengukuran bebas dari varian kesalahan
acak (free from random error variance). Reliabilitas dapat
juga dikatakan sebagai tingkat kepercayaan hasil suatu
pengukuran. Pengukuran reliabilitas bertujuan untuk
menunjukkan kestabilan dan kekonsistenan alat ukur
dalam mengukur konsep yang ingin diukur. Uji
reliabilitas dilakukan dengan menggunakan software SPSS
22.0. nilai koefisien reabilitas (Alpha Cronbach)

berkisar antara 0 hingga 1. Makin besar koefisien ini
maka makin besar keandalan alat ukur yang digunakan.
Reliability Statistics
Cronbach'sAlpha
Cronbach'sAlpha Based
onStandardized
ItemsN ofItems
.772 .783 2
Item-Total StatisticsScale Meanif ItemDeleted
ScaleVariance ifItem Deleted
CorrectedItem-TotalCorrelation
SquaredMultiple
Correlation
Cronbach'sAlpha if
Item DeletedVAR00001 19.8667 6.464 .643 .414 .VAR00002 18.9667 4.171 .643 .414 .
Scale Statistics
Mean VarianceStd.
DeviationN ofItems
38.8333 17.316 4.16126 2Gambar 4. 1 Output Uji Reliability
4.2.3 Data Hail PengukuranTabel 4. 4 Data Penelitian
No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19
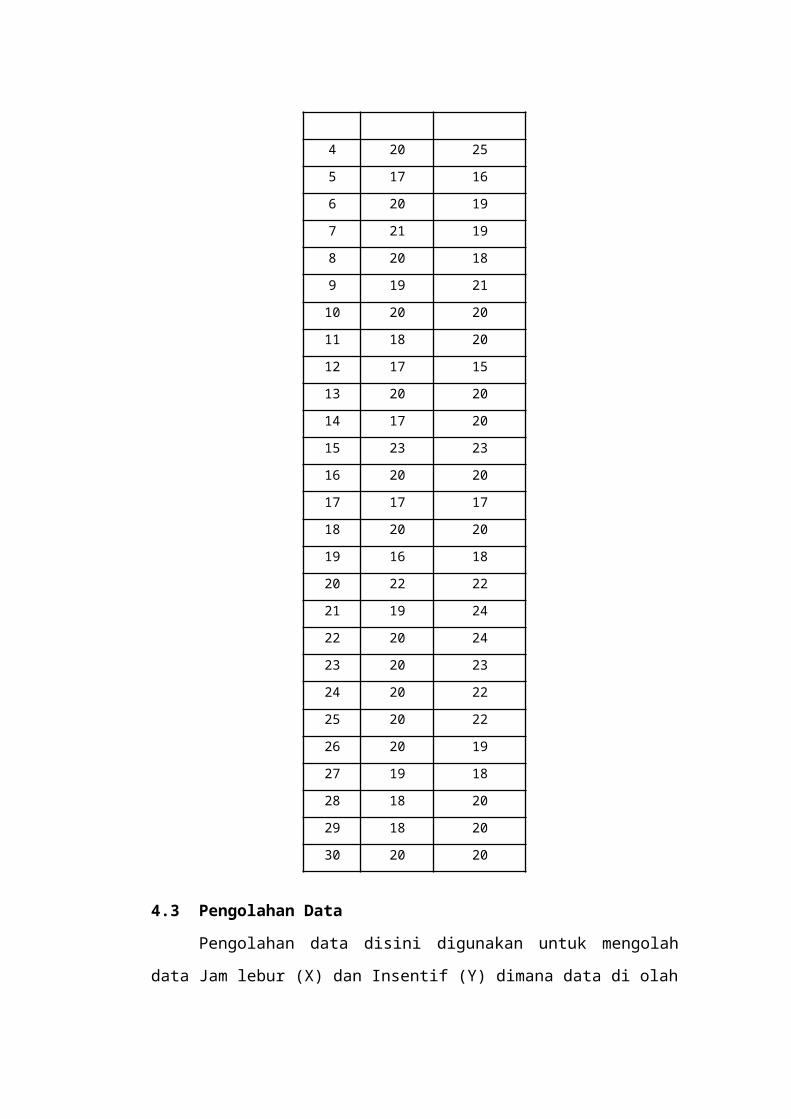
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22
26 20 19
27 19 18
28 18 20
29 18 20
30 20 20
4.3 Pengolahan Data
Pengolahan data disini digunakan untuk mengolah
data Jam lebur (X) dan Insentif (Y) dimana data di olah

sehingga mendapatkan hasil dan dapat disimpulkan apakah
dua variabel tersebut memiliki pengaruh satu sama
lainnya Pegolahan data disini antara lain :
4.3.1 Perhitungan Parameter Populasi
Dalam penelitian ini akan digunakan tingkat
kepercayaan sebesar 95%, tingkat akurasi 5% dan
simpangan baku 2,04. Dengan demikian ukuran sampel yang
diperlukan pada penelitian ini adalah sebagai berikut.
α = 0,05 ; Nilai Z (Dua Arah) = 1,96 (Tabel
Distribusi Normal)
n = zσα=(1,96x2,040,05 )=30,12≈ 30 sampel
Jadi banyaknya sampel yang harus diambil dalam
penelitian sebanyak 30 sampel.
NoJam Lembur
(X)
Insentif
(Rp.1000.000) (Y)
1 14 15
2 14 17
3 20 19
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
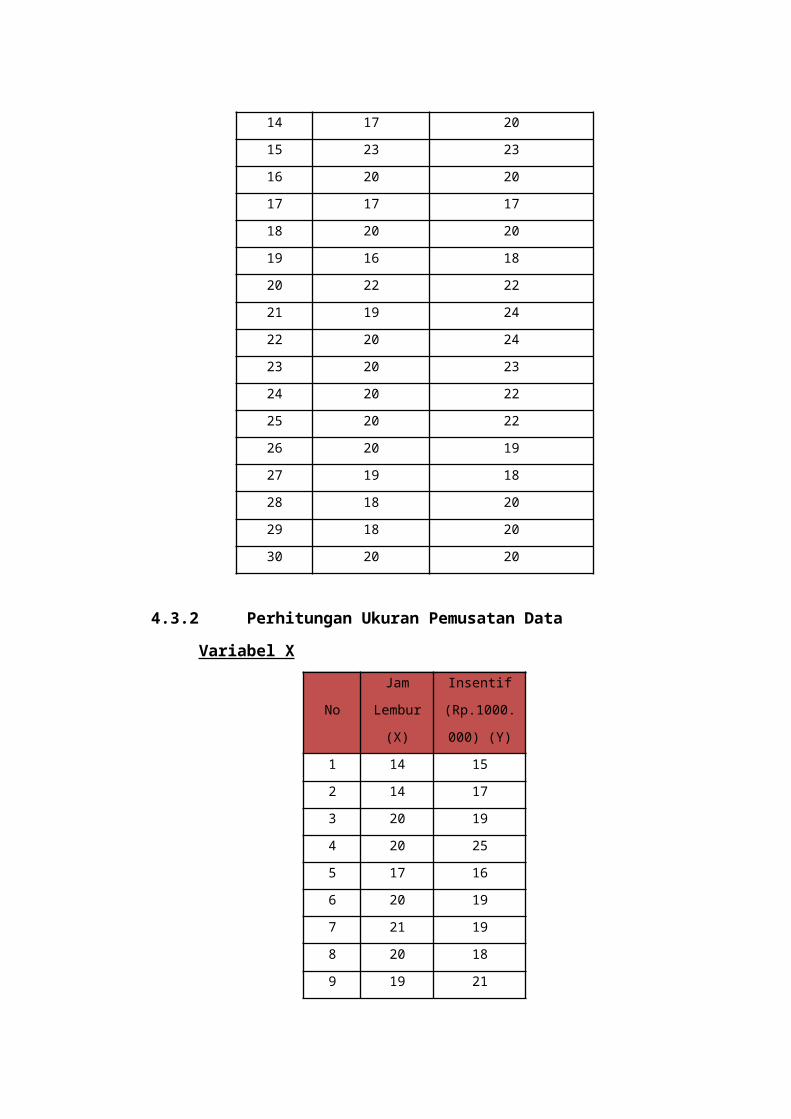
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22
26 20 19
27 19 18
28 18 20
29 18 20
30 20 20
4.3.2 Perhitungan Ukuran Pemusatan Data
Variabel X
No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
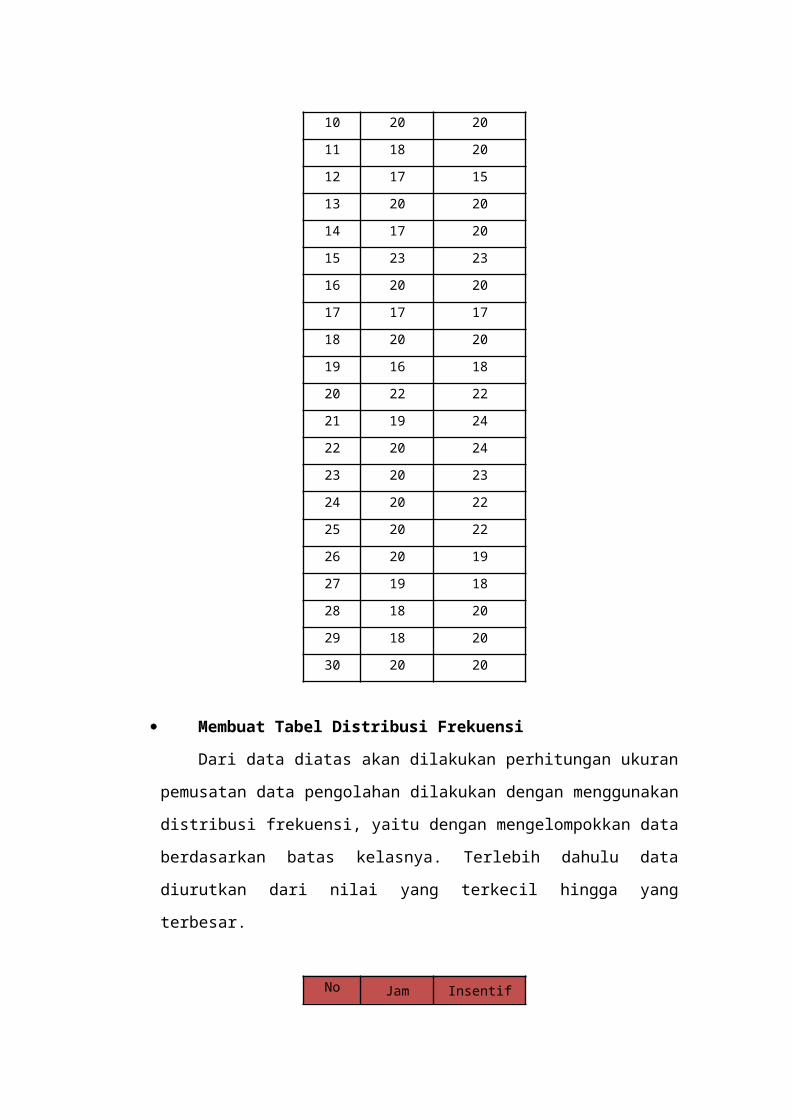
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22
26 20 19
27 19 18
28 18 20
29 18 20
30 20 20
Membuat Tabel Distribusi Frekuensi
Dari data diatas akan dilakukan perhitungan ukuran
pemusatan data pengolahan dilakukan dengan menggunakan
distribusi frekuensi, yaitu dengan mengelompokkan data
berdasarkan batas kelasnya. Terlebih dahulu data
diurutkan dari nilai yang terkecil hingga yang
terbesar.
No Jam Insentif

Lembur
(X)
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22
26 20 19
27 19 18
28 18 20
29 18 20
30 20 20

Setelah data diurutkan dari nilai terkecil hingga
terbesar, kemudian melakukan pengolahan data
menggunakan tabel distribusi frekuensi. Ada empat
langkah dalam membuat tabel distribusi frekuensi.
Keempat langkah tersebut yaitu sebagai berikut :
Menghitung rentang (Range/R)
R = Nilai data Maksimum – Nilai data Minimum
R = 23 – 14 = 9
Menghitung Jumlah Kelas Interval (k)
Menentukan banyak kelas interval yang diperlukan.
Banyak kelas adalah 6 – 10 kelas untuk data kurang
dari 50, dan 10 – 20 kelas untuk data sejumlah 50
atau lebih. Data yang diperoleh dari hasil
pengukuran sebanyak 30 data. Berdasarkan jumlah
tersebut maka diambil jumlah kelas interval sebanyak
5 kelas.
Menentukan Panjang Kelas Interval (p)
p = R/k
p = 9/6 = 1,8≈ 2jadi, panjang kelas intervalnya 2. Berdasarkan nilai
p tersebut dapat ditentukan bahwa kelas pertama
adalah 14 – 15
Menentukan Batas Kelas
Pilih ujung ujung bawah kelas interval pertama.
Untuk ini bisa diambil sama dengan data terkecil
atau nilai data yang lebih kecil dari data terkecil
tetapi selisishnya harus kurang dari panjang kelas

yang telah ditentukan. Selanjutnya daftar
diselesaikan dengan menggunakan harga-harga yang
telah dihitung.
Untuk Interval ke-1
Batas Bawah = 14 – 0,5 = 13,5
Batas Atas = 15 + 0,5 = 15,5
Menentukan Nilai Tengah
Nilai Tengah = ½ (Batas bawah kelas + batas atas
kelas )
Nilai tengah = ½ (13,5 + 15,5)
= 14,5
Tabel TabulasiInterval
Kelas Tabulasi
Freku
ensi14 - 15 II 216 - 17 IIIII 518 - 19 IIIII I 6
20 - 21
IIIII
IIIII
IIIII 1522 - 23 II 2
Urutan kelas interval disusun mulai dari terkecil
terus ke bawah sampai nilai data terbesar. Berturut-
turut mulai dari atas, diberi nama kelas interval
pertama, kelas interval kedua,…, kelas interval
terakhir.
Membuat Grafik Histogram, Poligon, dan Kurva
Frekuensi

Grafik Histogram
13,5 - 15,5
15,5 - 17,5
17,5 - 19,5
19,5 - 21,5
21,5 - 23,5
0
4
8
12
16Grafik Histogram
Batas Kelas
Frek
uens
i
Grafik Poligon
13,5 - 15,5
15,5 - 17,5
17,5 - 19,5
19,5 - 21,5
21,5 - 23,5
0
4
8
12
16Grafik Poligon
Batas Kelas
Frek
uens
i
Variabel Y
No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19

4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22
26 20 19
27 19 18
28 18 20
29 18 20
30 20 20
Membuat Tabel Distribusi Frekuensi
Dari data diatas akan dilakukan perhitungan ukuran
pemusatan data pengolahan dilakukan dengan menggunakan
distribusi frekuensi, yaitu dengan mengelompojjan data

berdasarkan batas kelasnya. Terlebih dahulu data
diurutkan dari nilai yang terkecil hingga yang
terbesar.
No
Jam
Lembur
(X)
Insentif
(Rp.1000.
000) (Y)
1 14 15
2 14 17
3 20 19
4 20 25
5 17 16
6 20 19
7 21 19
8 20 18
9 19 21
10 20 20
11 18 20
12 17 15
13 20 20
14 17 20
15 23 23
16 20 20
17 17 17
18 20 20
19 16 18
20 22 22
21 19 24
22 20 24
23 20 23
24 20 22
25 20 22

26 20 19
27 19 18
28 18 20
29 18 20
30 20 20
Setelah data diurutkan dari nilai terkecil hingga
terbesar, kemudian melakukan pengolahan data
menggunakan tabel distribusi frekuensi. Ada empat
langkah dalam membuat tabel distribusi frekuensi.
Keempat langkah tersebut yaitu sebagai berikut :
Menghitung rentang (Range/R)
R = Nilai data Maksimum – Nilai data Minimum
R = 25 – 15 = 10
Menghitung Jumlah Kelas Interval (k)
Menentukan banyak kelas interval yang diperlukan.
Banyak kelas adalah 6 – 10 kelas untuk data kurang
dari 50, dan 10 – 20 kelas untuk data sejumlah 50
atau lebih. Data yang diperoleh dari hasil
pengukuran sebanyak 30 data. Berdasarkan jumlah
tersebut maka diambil jumlah kelas interval
sebanyak 6 kelas.
Menentukan Panjang Kelas Interval (p)
p = R/k
p = 10/6 = 1,6 ≈ 2jadi, panjang kelas intervalnya 2. Berdasarkan
nilai p tersebut dapat ditentukan bahwa kelas
pertama adalah 15 – 16

Menentukan Batas Kelas
Pilih ujung ujung bawah kelas interval pertama.
Untuk ini bisa diambil sama dengan data terkecil
atau nilai data yang lebih kecil dari data
terkecil tetapi selisishnya harus kurang dari
panjang kelas yang telah ditentukan. Selanjutnya
daftar diselesaikan dengan menggunakan harga-harga
yang telah dihitung.
Untuk Interval ke-1
Batas Bawah = 15 – 0,5 = 14,5
Batas Atas = 16 + 0,5 = 16,5
Menentukan Nilai Tengah
Nilai Tengah = ½ (Batas bawah kelas + batas atas
kelas )
Nilai tengah = ½ (14,5 + 16,5)
= 15,5
Tabel TabulasiInterval
Kelas Tabulasi
Frekuen
si15 – 16 III 317 – 18 IIIII 5
19 – 20
IIIII
IIIII III 1321 – 22 IIII 423 – 24 IIII 425 – 26 I 1
Urutan kelas interval disusun mulai dari terkecil
terus ke bawah sampai nilai data terbesar. Berturut-
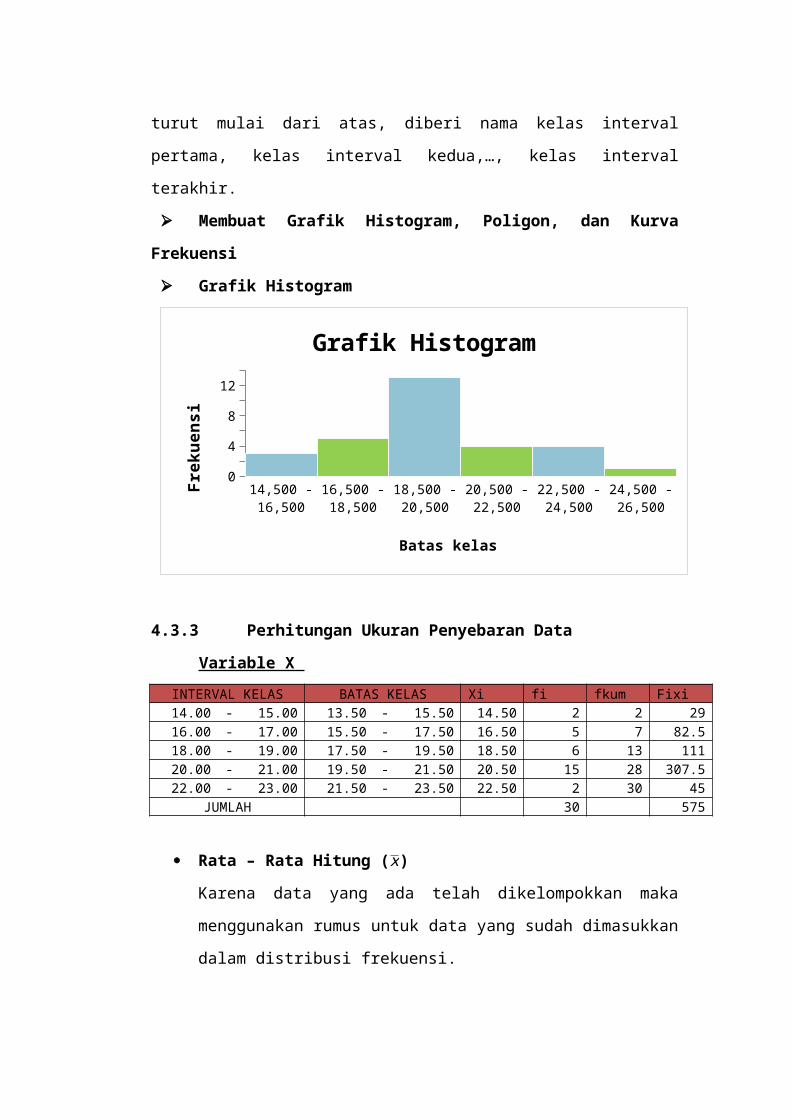
turut mulai dari atas, diberi nama kelas interval
pertama, kelas interval kedua,…, kelas interval
terakhir.
Membuat Grafik Histogram, Poligon, dan Kurva
Frekuensi
Grafik Histogram
14,500 - 16,500
16,500 - 18,500
18,500 - 20,500
20,500 - 22,500
22,500 - 24,500
24,500 - 26,500
0
4
8
12
Grafik Histogram
Batas kelas
Frek
uens
i
4.3.3 Perhitungan Ukuran Penyebaran Data
Variable X INTERVAL KELAS BATAS KELAS Xi fi fkum Fixi14.00 - 15.00 13.50 - 15.50 14.50 2 2 2916.00 - 17.00 15.50 - 17.50 16.50 5 7 82.518.00 - 19.00 17.50 - 19.50 18.50 6 13 11120.00 - 21.00 19.50 - 21.50 20.50 15 28 307.522.00 - 23.00 21.50 - 23.50 22.50 2 30 45
JUMLAH 30 575
Rata – Rata Hitung (x)Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi.

x=∑ fixi∑fi
Dimana:
= Frekuensi untuk kelas interval ke-i
= Nilai dari titik tengah
x=∑ fixi∑fi = 56930 = 18,97
Median (Me)
Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi.
Me=Lo+p((n2 )−F❑
) Dimana:
Lo = Batas bawah dari kelas median dimana median
berada
n = Jumlah data
p = Panjang kelas interval
= Frekuensi kelas median
F = Jumlah semua frekuensi kelas sebelum kelas
yang mengandung Median
Me=Lo+p((n2 )−F❑
) = 19,5+2((302 )−13
15 )= 19,77 Modus (Mo)

Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi.
Mo=Lo+p( b1b1+b2 )
Dimana:
Lo = Batas bawah dari kelas modus
b1 = Selisih antara frekuensi kelas modus dengan
frekuensi tepat satu kelas sebelum kelas
modus
b2 = Selisih antara frekuensi kelas modus dengan
frekuensi tepat satu
kelas sesudah kelas modus
p = Panjang r kelas interval
Mo=Lo+p( b1b1+b2 ) = 19,5+2( 9
9+13 ) = 20,32 Menghitung Kuartil
Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi (baik kuartil, desil,
maupun persentil).
Qi=Lo+p( i.n4 −∑ F
fkuartil ) Dimana:
i = 1,2,3
Lo = Batas bawah dari kelas kuartil
f = Frekuensi kuartil Ke-i

ΣF = Jumlah semua frekuensi kelas sebelum kelas
kuartil
Misal nilai Q1 yaitu , Q1 = ¼ x jumlah total data
= ¼ x 30
= 7,5, cari fkum sampai total
(kumulatif) dari frekuensi
pada tebel berjumlah ≥ 8,75
Q1 = 17,5 + 2 (7,5−76 ) = 17,67
Q2 = 19,5 + 2 (15−1315 ) = 19,77Q3 = 19,5 + 2 (22,5−1315 )= 20,77
Menghitung Desil
Di=Lo+p( i.n10−∑ F
fkuartil ) Mis : nilai D6, yaitu ; D6 = 6/10 x jumah total
data = 6/10 x 30 = 18. Cari fkum sampai total
(kumulatif) dari frekuensi pada tebel berjumlah ≥
18. Didapat pada tebel adalah kelas ke 3.
D1=15,5+2( 30.110−2
5 ) = 15,90D2=15,5+2( 30.210
−2
5 ) = 17,01

D3=17,5+2( 30.310−7
6 ) = 18,17D4=17,5+2( 30.410
−7
6 ) = 19,17D5=19,5+2( 30.510
−13
15 ) = 19,77D6=19,5+2( 30.610
−13
15 ) = 20,17D7=19,5+2( 30.710
−13
15 ) = 20,57D8=19,5+2( 30.810
−13
15 ) = 20,97D9=19,5+2( 30.910
−13
15 ) = 21,37 Menghitung Persentil
Pi=Lo+p( i.n100−∑ F
fkuartil ) P5=13,5+2( 5.30100
−0
2 ) = 15,00

P31=17,5+2( 31.30100−7
6 ) = 18,27P50=19,5+2( 50.30100
−13
15 ) = 19,77P93=19,5+2( 93.30100
−13
15 ) = 21,49P95=21,5+2( 95.30100
−28
2 ) = 22,00Variable Y
INTERVAL KELAS BATAS KELAS Xi fi fkum Fixi15.00 - 16.00 14.50 - 16.50 15.50 3 3 46.517.00 - 18.00 16.50 - 18.50 17.50 5 8 87.519.00 - 20.00 18.50 - 20.50 19.50 13 21 253.521.00 - 22.00 20.50 - 22.50 21.50 4 25 8623.00 - 24.00 22.50 - 24.50 23.50 4 29 9425.00 - 26.00 24.50 - 26.50 25.50 1 30 25.5
JUMLAH 30 593
Rata – Rata Hitung (x)Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi.
x=∑ fixi∑fi
Dimana:
= Frekuensi untuk kelas interval ke-i
= Nilai dari titik tengah

x=∑ fixi∑fi = 59630 = 19,87
Median (Me)
Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi.
Me=Lo+p((n2 )−F❑
) Dimana:
Lo = Batas bawah dari kelas median dimana median
berada
n = Jumlah data
p = Panjang kelas interval
= Frekuensi kelas median
F = Jumlah semua frekuensi kelas sebelum kelas
yang mengandung Median
Me=Lo+p((n2 )−F❑
) = 18, 5 +2((302 )−813 ) = 19,42
Modus (Mo)
Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi.
Mo=Lo+p( b1b1+b2 )
Dimana:
Lo = Batas bawah dari kelas modus

b1 = Selisih antara frekuensi kelas modus dengan
frekuensi tepat satu kelas sebelum kelas
modus
b2 = Selisih antara frekuensi kelas modus dengan
frekuensi tepat satu
kelas sesudah kelas modus
p = Panjang r kelas interval
Mo=Lo+p( b1b1+b2 ) = 18,5+2( 8
8+9 ) = 19,30 Menghitung Kuartil
Karena data yang ada telah dikelompokkan maka
menggunakan rumus untuk data yang sudah dimasukkan
dalam distribusi frekuensi (baik kuartil, desil,
maupun persentil).
Qi=Lo+p( i.n4 −∑ F
fkuartil ) Dimana:
i = 1,2,3
Lo = Batas bawah dari kelas kuartil
f = Frekuensi kuartil Ke-i
ΣF = Jumlah semua frekuensi kelas sebelum kelas
kuartil
Misal nilai Q1 yaitu , Q1 = ¼ x jumlah total data
= ¼ x 30
= 7,5, cari fkum sampai total
(kumulatif) dari frekuensi
pada tebel berjumlah ≥ 8,75

Q1 = 16,5 + 2 (7,5−35 ) = 18,03
Q2 = 18,5 + 2 (15−813 ) = 19,42Q3 = 20,5 + 2 (22,5−214 )= 21,14
Menghitung Desil
Di=Lo+p( i.n10−∑ F
fkuartil ) Mis : nilai D6, yaitu ; D6 = 6/10 x jumah total
data = 6/10 x 30 = 18. Cari fkum sampai total
(kumulatif) dari frekuensi pada tebel berjumlah ≥
18. Didapat pada tebel adalah kelas ke 3.
D1=14,5+2( 30.110−0
3 ) = 16,20D2=16,5+2( 30.210
−3
5 ) = 17,52D3=18,5+2( 30.310
−8
13 ) = 18,63D4=18,5+2( 30.410
−8
13 )= 19,02D5=18,5+2( 30.510
−8
13 )= 19,42

D6=18,5+2( 30.610−8
13 )= 19,81D7=¿ 18,5+2( 30.710
−8
13 )= 20,20D8=20,5+2( 30.810
−21
4 )= 21,78D9=22,5+2( 30.910
−25
4 ) = 23,35 Menghitung Persentil
Pi=Lo+p( i.n100−∑ F
fkuartil ) P5=14,5+2( 5.30100
−0
3 ) = 15,35P31=18,5+2( 31.30100
−8
13 ) = 18,67P50=18,5+2( 50.30100
−8
13 ) = 19,42P93=22,5+2( 93.30100
−25
4 ) = 23,73
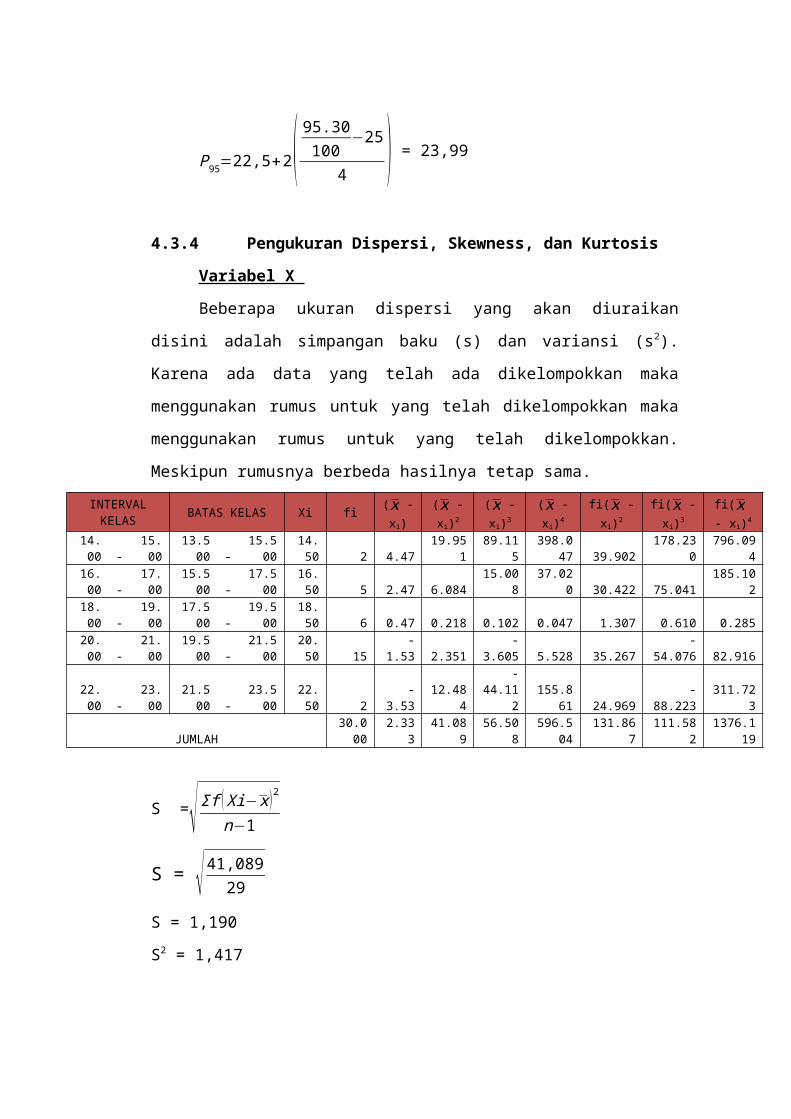
P95=22,5+2( 95.30100−25
4 ) = 23,994.3.4 Pengukuran Dispersi, Skewness, dan Kurtosis
Variabel X
Beberapa ukuran dispersi yang akan diuraikan
disini adalah simpangan baku (s) dan variansi (s2).
Karena ada data yang telah ada dikelompokkan maka
menggunakan rumus untuk yang telah dikelompokkan maka
menggunakan rumus untuk yang telah dikelompokkan.
Meskipun rumusnya berbeda hasilnya tetap sama. INTERVALKELAS BATAS KELAS Xi fi (x -
xi)(x -xi)2
(x -xi)3
(x -xi)4
fi(x -xi)2
fi(x -xi)3
fi(x - xi)4
14.00 -
15.00
13.500 -
15.500
14.50 2 4.47
19.951
89.115
398.047 39.902
178.230
796.094
16.00 -
17.00
15.500 -
17.500
16.50 5 2.47 6.084
15.008
37.020 30.422 75.041
185.102
18.00 -
19.00
17.500 -
19.500
18.50 6 0.47 0.218 0.102 0.047 1.307 0.610 0.285
20.00 -
21.00
19.500 -
21.500
20.50 15
-1.53 2.351
-3.605 5.528 35.267
-54.076 82.916
22.00 -
23.00
21.500 -
23.500
22.50 2
-3.53
12.484
-44.11
2155.8
61 24.969-
88.223311.72
3
JUMLAH30.000
2.333
41.089
56.508
596.504
131.867
111.582
1376.119
S =√Σf (Xi−x)2
n−1
S = √41,08929
S = 1,190
S2 = 1,417
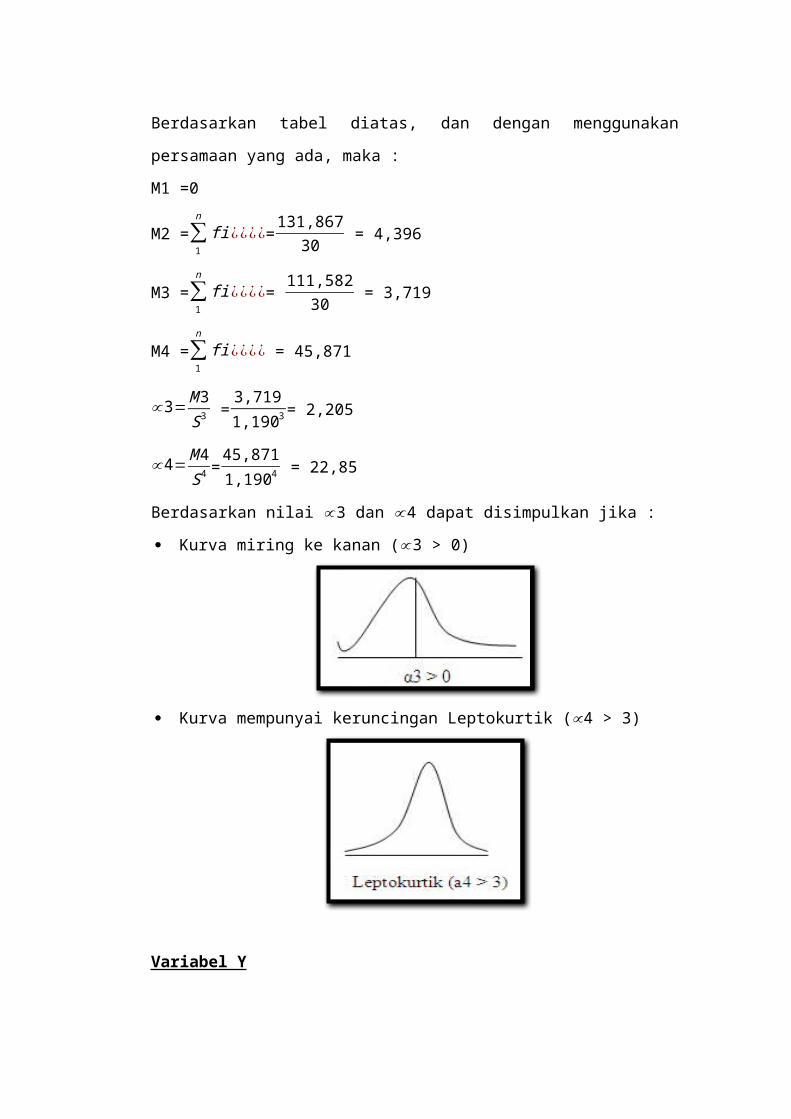
Berdasarkan tabel diatas, dan dengan menggunakan
persamaan yang ada, maka :
M1 =0
M2 =∑1
nfi¿¿¿¿=131,86730 = 4,396
M3 =∑1
nfi¿¿¿¿= 111,58230 = 3,719
M4 =∑1
nfi¿¿¿¿ = 45,871
∝3=M3S3 =
3,7191,1903= 2,205
∝4=M4S4 =
45,8711,1904 = 22,85
Berdasarkan nilai ∝3 dan ∝4 dapat disimpulkan jika :
Kurva miring ke kanan (∝3 > 0)
Kurva mempunyai keruncingan Leptokurtik (∝4 > 3)
Variabel Y

Beberapa ukuran dispersi yang akan diuraikan
disini adalah simpangan baku (s) dan variansi (s2).
Karena ada data yang telah ada dikelompokkan maka
menggunakan rumus untuk yang telah dikelompokkan maka
menggunakan rumus untuk yang telah dikelompokkan.
Meskipun rumusnya berbeda hasilnya tetap sama.
S =√Σf¿¿¿¿
S = √72,40729
S = 1,580
S2 = 2,497INTERVALKELAS BATAS KELAS Xi fi (x -
xi)(x -xi)2
(x -xi)3
(x -xi)4
fi(x -xi)2
fi(x -xi)3
fi(x -xi)4
15.00 -
16.00
14.50 -
16.50
15.50 3 4.37 19.068 83.263
363.580 57.203
249.788
1090.740
17.00 -
18.00
16.50 -
18.50
17.50 5 2.37 5.601 13.256 31.372 28.006 66.280
156.862
19.00 -
20.00
18.50 -
20.50
19.50 13 0.37 0.134 0.049 0.018 1.748 0.641 0.235
21.00 -
22.00
20.50 -
22.50
21.50 4
-1.63 2.668 -4.357 7.117 10.671
-17.429 28.468
23.00 -
24.00
22.50 -
24.50
23.50 4
-3.63 13.201
-47.964
174.269 52.804
-191.85
6697.07
7
25.00 -
26.00
24.50 -
26.50
25.50 1
-5.63 31.734
-178.77
11007.0
75 31.734
-178.77
11007.0
75
JUMLAH30.00
-3.80
0 72.407
-134.52
41583.4
32182.16
7-
71.3482980.4
58
Berdasarkan tabel diatas, dan dengan menggunakan
persamaan yang ada, maka :
M1 =0
M2 =∑1
nfi¿¿¿¿=182,16730 = 2,414

M3 =∑1
nfi¿¿¿¿= −71,348
30 = -2,378
M4 =∑1
nfi¿¿¿¿ = 99,349
∝3=M3S3 =
−2,3781,5803 = - 0,6028
∝4=M4S4 =
99,3491,5804 = 15,937
Berdasarkan nilai ∝3 dan ∝4 dapat disimpulkan jika :
Kurva miring ke kiri (∝3< 0)
Kurva mempunyai keruncingan Leptokurtik (∝4 > 3)
4.3.5 Pengujian Kenormalan
Variabel X
Dari data diatas maka dilakukan uji kesesuaian
untuk mengetahui apakah data yang ada berdistribusi
normal atau tidak. Dengan derajat kebebasan 0,05 nilai
σ = 2,042 dan nilai µ = 18,97.

Solusi : Ho = Data Berdistribusi Tidak Normal
H1 = Data Tidak Berdistribusi Normal INTERVAL KELAS BATAS KELAS Xi fi fkum14.00 - 15.00 13.50 - 15.50 14.50 2 216.00 - 17.00 15.50 - 17.50 16.50 5 718.00 - 19.00 17.50 - 19.50 18.50 6 1320.00 - 21.00 19.50 - 21.50 20.50 15 2822.00 - 23.00 21.50 - 23.50 22.50 2 30
JUMLAH 30
Langkah pertama adalah dengan menghitung luas
dibawah kurva normal yang dihipotesiskan yang berada
antara berbagai batas kelas. frekuensi harapan paling
sedikit sebesar 5, maka dilakukan penggabungan Oi.
BATAS KELAS fi OiGABUNGAN
13.50 - 15.50 2 715.50 - 17.50 517.50 - 19.50 6 619.50 - 21.50 15 1721.50 - 23.50 2
Untuk Batas Kelas Peratama
Z1 = 13,55–18,97
2,042 = -2,677 dan Z2 =
15,5–18,972,042 = -1,679
Sehingga P (-1,679< Z < -2,677) = 0,045 – 0,004 = 0,041
Jadi frekuensi harapan untuk kelas pertama adalah :
ei = (0,041)(30) = 1,233
Untuk Batas Kelas Kedua
Z2 = 15,5–18,97
2,042 = -1,697 dan Z3 = 17,5–18,97
2,042 = 0,718

Sehingga P (0,718< Z <1,697) = 0,236 – 0,045 = 0,192
Jadi frekuensi harapan untuk kelas kedua adalah :
ei = (0,192)(30) = 5,746
Untuk Batas Kelas Ketiga
Z3 = 17,5–18,97
2,042 = 0,718 dan Z4 = 19,5–18,97
2,042 = 0,261
Sehingga P (0,261 < Z <0,718) = 0,603 – 0,236 = 0,367
Jadi frekuensi harapan untuk kelas ketiga adalah :
ei = (0,367)(30) = 9,216
Untuk Batas Kelas Keempat
Z4 = 19,5–18,97
2,042 = 0,261 dan Z5 = 21,5–18,97
2,042 = 1,240
Sehingga P (1,240< Z <0,261) = 0,893 – 0,603= 0,290
Jadi frekuensi harapan untuk kelas keempat adalah :
ei = (0,290)(30) = 8,687
Untuk Batas Kelas Kelima
Z5 = 21,5–18,97
2,042 = 1,230 dan Z6 = 23,5–18,97
2,042 = 2,220
Sehingga P (2,220< Z <1,230) = 0,987 – 0,893 = 0,094
Jadi frekuensi harapan untuk kelas kelima adalah :
ei = (0,094)(30) = 2,826
BATAS KELAS fi
OiGABUNGAN
Z1HITUNG
Z2HITUNG
Z1TABEL
Z2TABEL P EI EI
GABUNGAN13.500 -
15.500 2
7-2.677 -1.697 0.004 0.045
0.041
1.233
6.979
15.5 - 17.5 5 -1.697 -0.718 0.045 0.236 0.1 5.74

00 00 92 617.500 -
19.500 6 6 -0.718 0.261 0.236 0.603
0.367
11.000 11.000
19.500
-
21.500
15 17 0.261 1.240 0.603 0.893
0.290
8.687 11.51321.5
00 -
23.500 2 1.240 2.220 0.893 0.987
0.094
2.826
Dari hasil perhitungan diatas terlihat bahwa jumlah
seluruh selang terlah berubah dari 6 menjadi 3 sehingga
derajat kebebasannya menjadi v = 1. Nilai X2 akan
menjadi
x2=∑i=1
k¿¿¿
x2=¿¿ + ¿¿ + ¿¿
= 4,888
Dari tabel x0,051 dengan V = 1 didapat nilai 3,8414.
Karena nilai x2 hitung lebih besar daripada nilai x2
tabel. Maka, dapat disimpulkan H0 ditolak yaitu data
tidak berdistribusi normal.
Variabel Y
Dari data diatas maka dilakukan uji kesesuaian
untuk mengetahui apakah data yang ada berdistribusi
normal atau tidak. Dengan derajat kebebasan 0,05 nilai
σ = 2,542 dan nilai µ = 19,87.
Solusi : Ho = Data Berdistribusi Tidak Normal
H1 = Data Tidak Berdistribusi Normal INTERVAL KELAS BATAS KELAS Xi fi fkum
15.00 - 16.00 14.500
- 16.500 15.50 3 3
17.00 - 18.00 16.500
- 18.500 17.50 5 8

19.00 - 20.00 18.500
- 20.500 19.50 13 21
21.00 - 22.00 20.500
- 22.500 21.50 4 25
23.00 - 24.00 22.500
- 24.500 23.50 4 29
25.00 - 26.00 24.500
- 26.500 25.50 1 30
JUMLAH 30
Langkah pertama adalah dengan menghitung luas
dibawah kurva normal yang dihipotesiskan yang berada
antara berbagai batas kelas. frekuensi harapan paling
sedikit sebesar 5, maka dilakukan penggabungan Oi.
BATAS KELAS fi OiGABUNGAN
14.500
- 16.500 38
16.500
- 18.500 5
18.500
- 20.500 13 13
20.500
- 22.500 4
922.500
- 24.500 4
24.500
- 26.500 1
Untuk Batas Kelas Peratama
Z1 = 14,5–19,87
2,542 = - 2,111 dan Z2 =
16,5–19,872,542 = - 1,324
Sehingga P(- 1,324< Z <-2,111) = 0,093 – 0,017 = 0,075

Jadi frekuensi harapan untuk kelas pertama adalah :
ei = (0,075)(30) = 2,260
Untuk Batas Kelas Kedua
Z2 = 16,5–19,87
2,542 = - 1,324 dan Z3 = 18,5–19,872,542 =
0,534
Sehingga P 0,534< Z <-1,324) = 0,295 – 0,093 = 0,203
Jadi frekuensi harapan untuk kelas kedua adalah :
ei = (0,203)(30) = 6,082
Untuk Batas Kelas Ketiga
Z3 = 18,5–19,87
2,542 = 0,538 dan Z4 = 20,5–19,87
2,542 = 0,249
Sehingga P (0,249< Z <- 0,538) = 0,598 - 0,249 = 0,303
Jadi frekuensi harapan untuk kelas ketiga adalah :
ei = (0,303)(30) = 9,087
Untuk Batas Kelas Keempat
Z4 = 20,5–19,87
2,542 = 0,249 dan Z5 = 22,5–19,87
2,542 = 1,036
Sehingga P (1,036< Z <0,249) = 0,850 – 0,598 = 0,251
Jadi frekuensi harapan untuk kelas keempat adalah :
ei = (0,251)(30) = 7,544
Untuk Batas Kelas Kelima
Z5 = 22,5–19,87
2,542 = 1,036 dan Z6 = 24,5–19,87
2,542 = 1,822

Sehingga P (1,822< Z < 1,036) = 0,966 – 0,850 = 0,116
Jadi frekuensi harapan untuk kelas kelima adalah :
ei = (0,116)(30) = 3,479
Untuk Batas Kelas Keenam
Z6 = 24,5–19,87
2,542 = 1,822 dan Z7 = 26,5–19,87
2,542 = 2,609
Sehingga P (2,609< Z <1,822) = 0,995 – 0,966 = 0,030
Jadi frekuensi harapan untuk kelas keenam adalah :
ei = (0,030)(30) = 0,890
BATAS KELAS fi OiGABUNGAN
Z1HITUNG
Z2HITUNG
Z1TABEL
Z2TABEL P EI EI
GABUNGAN14.500
-
16.500 3 8 -2.111 -1.324 0.017 0.093
0.075
2.260 8.34216.5
00 -
18.500 5 -1.324 -0.538 0.093 0.295
0.203
6.082
18.500
-
20.500 13 13 -0.538 0.249 0.295 0.598
0.303
9.087 9.087
20.500
-
22.500 4
9
0.249 1.036 0.598 0.8500.251
7.544
11.91322.500
-
24.500 4 1.036 1.822 0.850 0.966
0.116
3.479
24.500
-
26.500 1 1.822 2.609 0.966 0.995
0.030
0.890
Dari hasil perhitungan diatas terlihat bahwa
jumlah seluruh selang terlah berubah dari 6 menjadi 3
sehingga derajat kebebasannya menjadi v = 1. Nilai X2
akan menjadi
x2=∑i=1
k¿¿¿
x2=¿¿ + ¿¿ + ¿¿
= 2,411

Dari tabel x0,051 dengan V = 1 didapat nilai 3,8414.
Karena nilai x2 hitung lebih kecil dari pada nilai x2
tabel maka disimpulkan terima H0 merupakan distribusi
normal.
4.3.6 Penentuan Koefisien Regresi
Dapatkan Koefisien a dan b
Langkah-langkah dalam menentukan hasil dari
koefisien (persamaan) regresi didapatkan dari:Data Pengamatan
No X Y X2 X.Y1 14 15 196 2102 14 17 196 2383 20 19 400 3804 20 25 400 5005 17 16 289 2726 20 19 400 3807 21 19 441 3998 20 18 400 3609 19 21 361 39910 20 20 400 40011 18 20 324 36012 17 15 289 25513 20 20 400 40014 17 20 289 34015 23 23 529 52916 20 20 400 40017 17 17 289 28918 20 20 400 40019 16 18 256 28820 22 22 484 48421 19 24 361 45622 20 24 400 480

23 20 23 400 46024 20 22 400 44025 20 22 400 44026 20 19 400 38027 19 18 361 34228 18 20 324 36029 18 20 324 36030 20 20 400 400Tot
al569 596 10913 11401
b=
n∑i=1
nxiyi−(∑i=1
nxi)(∑i=1
nyi)
n∑i=1
nxi2−(∑i=1
nxi)
2
¿(30×11401 )−(569x596)
(30x10913 )−(569)2=0,80
a=∑i=1
nyi−b∑
i=1
nxi
n .
¿596−(0,80x569)
30=4,68
Buat persamaan regresi linier
Ῡi¿a+bXῩi = 4,68 + 0,80 Xi
4.3.7 Uji Hipotesis Dan Penaksiran Selang
Koefisiensi Regresi
Uji hipotesis dilakukan pada kedua koefisien
tersebut yaitu koefisien a dan koefisien b, dimana
langkahnya antara lain:

Menentukan pernyataan hipotesis dengan bentuk eksak
H0 dan H1
Lakukan untuk pengujian dua arah (Two Tail)
H0 : Adanya hubungan antar variabel
H1 : Tidak ada hubungan antar variabel
Pengujian terhadap koefisien a
H0 : 4,68 = 0 dengan H1 : -4,68≠ 0
Pengujian terhadap koefisien b
H0 : 0,80 = 0 dengan H1 : -0,80 ≠ 0
Hitung nilai perhitungan statistik
Masukkan setiap nilai pengamatan (X = Jam Lembur )
terhadap persamaan garis regresi sederhana di atas dan
penyimpanan (error) masing-masing nilai pengamatannya.
Contoh perhitungan untuk pernyataan ke-1
Ŷi = 4,68 + 0,80 Xi
Ŷi = 4,68 + 0,80 (14) = 15,89
(Yi - Ῡ)2 = (15 - 15,89)2 = 0,79
(Xi – X)2 = (14 – 18,97)2 = 24,70
Sehingga didapatkan seluruh nilai persamaan garis
regresi sederhana tersebut :Rekapan Data Persamaan Garis Regresi Sederhana
No X Y Ŷ (Xi –
Xbar)2
(Yi -
Ŷ)2
1 14 15 15,89 24,70 0,792 14 17 15,89 24,70 1,233 20 19 20,69 1,06 2,874 20 25 20,69 1,06 18,545 17 16 18,29 3,88 5,256 20 19 20,69 1,06 2,87

7 21 19 21,49 4,12 6,228 20 18 20,69 1,06 7,269 19 21 19,89 0,00 1,2210 20 20 20,69 1,06 0,4811 18 20 19,09 0,94 0,8212 17 15 18,29 3,88 10,8413 20 20 20,69 1,06 0,4814 17 20 18,29 3,88 2,9215 23 23 23,10 16,24 0,0116 20 20 20,69 1,06 0,4817 17 17 18,29 3,88 1,6718 20 20 20,69 1,06 0,4819 16 18 17,49 8,82 0,2620 22 22 22,30 9,18 0,0921 19 24 19,89 0,00 16,8622 20 24 20,69 1,06 10,9323 20 23 20,69 1,06 5,3224 20 22 20,69 1,06 1,7125 20 22 20,69 1,06 1,7126 20 19 20,69 1,06 2,8727 19 18 19,89 0,00 3,5828 18 20 19,09 0,94 0,8229 18 20 19,09 0,94 0,8230 20 20 20,69 1,06 0,48Tota
l569,00 596,00 596,00 120,97 109,90
Derajat kebebasannya (V) = n-2 = 30-2 = 28
Sr2=
∑i=1
n(Yi−Yi)
2
n−2 =109,9028
=3,925
Nilai uji statistik koefisien a:

Sa=[Sr2(1n+
X2
∑ (Xi−X)2 )]1/2
=[3,925( 130+18,972120,97 )]
1/2
=3,436
t=[a−a0 ]Sa
=(4,68)−03,436
=1,362
Nilai uji statistik koefisien b:
Sb=[Sr2( X2
∑ (Xi−X)2 )]1/2
=[3,925( 18,972
120,97 )]1/2
=3,417
t=[b−b0 ]Sb
=(0,80)−03,417
=0,234
Menentukan daerah penerimaan dan daerah kritis uji
statistik
Daerah penerimaan untuk dua arah dengan tingkat
ketelitian (α ¿=0,025 dan derajat kebebasan V = n-2
= 30-2 = 28, pada tabel distribusi t didapatkan
nilai t = ± 2,3684 (-2,3684 < t < 2,3684)
Simpulan putusan terhadap hasil
Untuk koefisien a diketahui nilai t hitung adalah
1,362 sedangkan nilai t tabel adalah ± 2,3684 (-
2,3684 < t < 2,3684)

Daerah Kritis Koefisien a
t hitung berada didalam daerah penerimaan, maka
keputusannya Terima H0 dan simpulkan bahwa ada hubungan
antar variabel.
Untuk koefisien b diketahuin nilai t hitung adalah
0,234 sedangkan nilai t tabel adalah ± 2,3684 (-2,3684
< t < 2,3684)
Gambar 4. 2 Simpulan Putusan Terhadap Hasil Untuk Koefisien b
t hitung berada didalam daerah penerimaan, maka
keputusannya Terima H0 dan simpulkan bahwa ada hubungan
antar variabel.
Hitung nilai kesalahan (error)
Dari tabel perhitungan di atas didapatkan jumlah
kesalahan (error) adalah :
S=∑i=1
nei2=∑
i=1
n(Yi−Yi)
2

Sy2=
∑ (Yi−Yi)2
n−2=109,9028
=3,925
Contoh perhitungan untuk pernyataan ke-1:
Sy2=[Sy
2(1n+(Xi−X)2
∑ (Xi−X)2 )]1/2
Sy2=[3,925( 130+
24,70120,97 )]
1/2
Sy=0,97
Nilai t tabel dua arah didapatkan dari tabel
distribusi t dengan derajat kepercayaan V = n-2 =
30-2 = 28, nilainya adalah ±2,3684, sehingga
batasannya (θ) adalah:Ŷi = 4,68 + 0,80 Xi
Ŷi = 4,68 + 0,80 (14) = 15,89
Ŷ – tsŷ < θ < Ŷ + tsŷ15,89 - (2,3684)(2,286) < θ < 15,89 + (2,3684)
(2,286)
13,60 < θ < 18,18Berikut adalah rekapitulasi perhitungan:
Rekapan Data Kesalahan (Error)
No X Y Ŷ (Xi –
Xbar)2
(Yi
-
Ŷ)2
SŶ(Ŷ-
tsŷ)
(Ŷ+t
sŷ)Ket
1 14 1515,8
924,70 0,79
0,9
7
13,6
0
18,1
8
Didal
am
2 14 1715,8
924,70 1,23
0,9
7
13,6
0
18,1
8
Didal
am3 20 19 20,6 1,06 2,87 0,4 19,7 21,6 Didal

9 1 3 6 am
4 20 2520,6
91,06
18,5
4
0,4
1
19,7
3
21,6
6
Dilua
r
5 17 1618,2
93,88 5,25
0,5
1
17,0
9
19,4
9
Didal
am
6 20 1920,6
91,06 2,87
0,4
1
19,7
3
21,6
6
Didal
am
7 21 1921,4
94,12 6,22
0,5
1
20,2
8
22,7
1
Didal
am
8 20 1820,6
91,06 7,26
0,4
1
19,7
3
21,6
6
Didal
am
9 19 2119,8
90,00 1,22
0,3
6
19,0
4
20,7
5
Dilua
r
10 20 2020,6
91,06 0,48
0,4
1
19,7
3
21,6
6
Didal
am
11 18 2019,0
90,94 0,82
0,4
0
18,1
4
20,0
4
Didal
am
12 17 1518,2
93,88
10,8
4
0,5
1
17,0
9
19,4
9
Didal
am
13 20 2020,6
91,06 0,48
0,4
1
19,7
3
21,6
6
Didal
am
14 17 2018,2
93,88 2,92
0,5
1
17,0
9
19,4
9
Dilua
r
15 23 2323,1
016,24 0,01
0,8
1
21,1
8
25,0
2
Didal
am
16 20 2020,6
91,06 0,48
0,4
1
19,7
3
21,6
6
Didal
am
17 17 1718,2
93,88 1,67
0,5
1
17,0
9
19,4
9
Didal
am
18 20 2020,6
91,06 0,48
0,4
1
19,7
3
21,6
6
Didal
am
19 16 1817,4
98,82 0,26
0,6
5
15,9
6
19,0
2
Didal
am

20 22 2222,3
09,18 0,09
0,6
5
20,7
5
23,8
5
Didal
am
21 19 2419,8
90,00
16,8
6
0,3
6
19,0
4
20,7
5
Dilua
r
22 20 2420,6
91,06
10,9
3
0,4
1
19,7
3
21,6
6
Dilua
r
23 20 2320,6
91,06 5,32
0,4
1
19,7
3
21,6
6
Dilua
r
24 20 2220,6
91,06 1,71
0,4
1
19,7
3
21,6
6
Dilua
r
25 20 2220,6
91,06 1,71
0,4
1
19,7
3
21,6
6
Dilua
r
26 20 1920,6
91,06 2,87
0,4
1
19,7
3
21,6
6
Didal
am
27 19 1819,8
90,00 3,58
0,3
6
19,0
4
20,7
5
Didal
am
28 18 2019,0
90,94 0,82
0,4
0
18,1
4
20,0
4
Didal
am
29 18 2019,0
90,94 0,82
0,4
0
18,1
4
20,0
4
Didal
am
30 20 2020,6
91,06 0,48
0,4
1
19,7
3
21,6
6
Didal
amTot
al
569,
00
596,
00
596,
00120,97
109,
90
14,
57
561,
51
630,
49
4.3.8 Penentuan Koefisien Korelasi
Untuk menentukan hubungan dari beberapa variabel
diatas, dicari koefisiensi korelasinya menggunakan
produk momen Pearson.Koefisien Korelasi
No X Y X2 Y2 X.Y1 14 15 196 225 210

2 14 17 196 289 2383 20 19 400 361 3804 20 25 400 625 5005 17 16 289 256 2726 20 19 400 361 3807 21 19 441 361 3998 20 18 400 324 3609 19 21 361 441 39910 20 20 400 400 40011 18 20 324 400 36012 17 15 289 225 25513 20 20 400 400 40014 17 20 289 400 34015 23 23 529 529 52916 20 20 400 400 40017 17 17 289 289 28918 20 20 400 400 40019 16 18 256 324 28820 22 22 484 484 48421 19 24 361 576 45622 20 24 400 576 48023 20 23 400 529 46024 20 22 400 484 44025 20 22 400 484 44026 20 19 400 361 38027 19 18 361 324 34228 18 20 324 400 36029 18 20 324 400 36030 20 20 400 400 400Tota
l569 596 10913 12028 11401
r=n∑xy−∑x∑ y
¿¿¿

r=(30x11401 )−(569x596)
{[ (30x10913 )−(569)2 ] [ (30x12028 )−(596)2 ]}12
=0,64
Nilai r = 0,64 (r > 0; positif) berarti ada
kenaikan korelasi linier antara variabel X dan Y. Garis
linier ditampilkan pada gambar berikut:
0 2 4 6 8 10 12024681012
Garis Regresi Linier
(X.Y)
4.3.9 Uji Hipotesis dan Penaksiran Selang Koefisien
Korelasi
Menentukan pernyataan hipotesis dengan bentuk eksak
H0 dan H1
Dilakukan untuk pengujian dua arah (two tail)
H0 : adanya hubungan antara variabel
H1 : Tidak adanya hubungan antar variabel
Pengujian terhadap koefisien r:
H0 : 0,64= 0 dengan H1 : 0,64 ≠ 0
Hitung nilai perhitungan statistik
Sampel statistik yang ditentukan adalah sebanyak
n=30 dengan nilai r = 0,64.

t=r√n−2√1−r2
t=0,64√30−2√1−0,642
=4,446
Menentukan daerah penerimaan dan daerah kritis uji
statistik
Derajat penerimaan untuk dua arah dengan tingkat
ketelitian (α) = 0,04 dan derajat kepercayaan v = n-2 = 30-2 = 28 pada tabel distribusi t didapatkan
nilai t = 2,3684 (-2,3684 < t < 2,3684).
Simpulan terhadap putusan hasil
Untuk koefisien t diketahui nilai t hitungnya adalah
4,446 sedangkan t tabel adalah ± 2,3684 (-2,3684 < t
< 2,3684) maka:
Daerah Kritis Korelasi
t hitung berada didalam daerah penerimaan, maka
keputusannya terima H1 dan simpulkan bahwa tidak ada
hubungan antar variabel.
4.3.10 Analisis Variansi
Langkah-langkah dalam penulisan bentuk dan
rancangan prosedur untuk menampilkan ANOVA untuk
persamaan regresi antara lain:

Menentukan Model Pengamatan ANOVA
Ŷi = 4,68 + 0,80 Xi
Hipotesisnya adalah:
H0 : b1 = 0
Dengan ketentuan tingkat ketelitian adalah α=0,025
dijadikan taraf atau tingkat signifikan.
Hitung Nilai Perhitungan Statistik
Daripersamaan T=∑iYi didapatkan nilainya adalah :
ANOVA Persamaan Regresi
No X Y Y2 Ŷ(Y -
Ŷ)2
1 14 15225,00
015,890 0,792
2 14 17289,00
015,890 1,232
3 20 19361,00
020,690 2,856
4 20 25625,00
020,690 18,576
5 17 16256,00
018,290 5,244
6 20 19361,00
020,690 2,856
7 21 19361,00
021,490 6,200
8 20 18324,00
020,690 7,236
9 19 21441,00
019,890 1,232
10 20 20400,00
020,690 0,476

11 18 20400,00
019,090 0,828
12 17 15225,00
018,290 10,824
13 20 20400,00
020,690 0,476
14 17 20400,00
018,290 2,924
15 23 23529,00
023,100 0,010
16 20 20400,00
020,690 0,476
17 17 17289,00
018,290 1,664
18 20 20400,00
020,690 0,476
19 16 18324,00
017,490 0,260
20 22 22484,00
022,300 0,090
21 19 24576,00
019,890 16,892
22 20 24576,00
020,690 10,956
23 20 23529,00
020,690 5,336
24 20 22484,00
020,690 1,716
25 20 22484,00
020,690 1,716
26 20 19361,00
020,690 2,856
27 19 18 324,00 19,890 3,572

0
28 18 20400,00
019,090 0,828
29 18 20400,00
019,090 0,828
30 20 20400,00
020,690 0,476
Tota
l569 596
12028,
000
595,92
0109,907
Hitung Jumlah Pengamatan
T=∑iYi=Y1+Y2+…Yn=596
∑ Yi2 = 12028
Hitung Jumlah Kuadrat
SST=∑iYi2−
T2
n =12028−(596)2
30=187,467
Hitung Jumlah Kuadrat Kesalahan (error)
SSE=∑iei2=∑ (Y−Ŷ)2=109,907
Dengan derajat kebebasannya adalah:
VE = n – k – 1 = 30 – 1 – 1 =28
Hitung Nilai Perhitungan Statistik
Substraksi jumlah kesalahan (error) kuadrat:
SSR = SST – SSE = 187,467– 109,907 = 77,560
Dengan derajat kebebasan adalah :
VR = k = 1Sumber Variansi
Sumber
Variansi
Derajat
Kebebas
an
Jumla
t
Kuadr
Rata-
Rata
Kuadra
Nilai
F

at tAntar
Variabel1
77,56
077,560
19,75
9
Kesalahan
(error)28
109,9
07
3,9252
429
Total 29187,4
67
Menentukan Daerah Penerimaan dan Daerah Krisis Uji
Statistik
Daerah penerimaan untuk dua arah dengan tingkay
ketelitian (α)=0,025 dengan V1 = VR = 1 dan V2 = 28,
pada tabel distribusi F didapatkan nilai F = 5,6096.
Simpulan Putusan Terhadap Hasil
Untuk nilai F diketahui nilai F hitung adalah 19,759
; sedangkan nilai F tabel ± 5,6096 (-5,6096 < F <
5,6096)
Gambar 4. 3 Simpulan Putusan Terhadap Hasil F Hitung
Karena F hitung berada luar daerah penerimaan, maka
putusannya adalah terima H1 .

BAB V
ANALISIS
5.1 Perhitungan Parameter Populasi
Dalam melakukan suatu penelitian hal yang utama
dilakukan yaitu menentukan parameter populasi untuk
dijadikan objek penelitian. Untuk mendapatkan populasi
yang harus didapatkan dibutuhkannya menentukan tingkat
kepercayaan, tingkat ketelitian, dan simpangan baku
terhadap data tersebut. Menentukan sampel dapat
menggunakan rumus dengan mengkalikan antara nilai Z
tabel normal dengan simpangan baku dan membaginya
dengan tingkat ketelitian, sehingga didapatkan sampel
yang diperlukan untuk penelitian yaitu sebesar 30,12
dibulatkan menjadi 30 sampel.
5.2 Perhitungan Ukuran Pemusatan Data
Pemusatan data ini yaitupengolahan data dengan
menggunakan distribusi frekuensi yang dimana dibutuhkan
perhitungan-perhitungan seperti menghitung rentang (R),
jumlah kelas interval (k), panjang kelas interval (p),
menentukan batas kelas, dan nilai tengah. Dengan
langkah awal mengurutkan data dari yang terkecil hingga
terbesar lalu dapat mulai perhitungan. Pada variabel X
pada kasus ini yaitu jam lembur diperoleh hasil rentang
yaitu 9, jumlah kelas sebanyak 6 dengan sampel sebanyak
30 data, dan panjang kelas 2, maka dapat dibuatnya
tabel tabulasi yang terdiri dari interval kelas,
tabulasi, dan frekuensi.. Pada variabel Y yaitu

insentif pekerja didaptkan hasil rentang yaitu 10,
jumlah kelas sebanyak 6, panjang kelas yaitu 2, batas
kelas dengan mengurangi 0,5 untuk batas bawah dn
menambah 0,5 untuk batas atas, nilai tengan dengan cra
menambhakan batas bawah dan batas atas dan dikalikan
setengah. Diperoleh hasil tersebut dibuatnya grafik
histogram dan poligon yang menggambarkan hubungan
antara batas kelas dan frekuensi sehingga lebih
memudahkan dalam membaca terhadap data tersebut.
5.3 Perhitungan Ukuran Penyebaran Data
Ukuran penyebaran terdiri atas mean, median,
modus, kuartil, desil, dan persentil. Mean (rata – rata
hitung) merupakan nilai yang dapat mewakili keseluruhan
variable pada data. Nilai mean pada variable x sebesar
18,97 dan untuk variable y sebesar 19,87. Median
merupakan nilai tengah yang terdapat pada data, dari
variable x didapatkan nilai median sebesar 19,77,
sedangkan untuk variable y sebesar 19,42. Modus adalah
nilai yang sering muncul pada data. Pada variable x
didapatkan nilai modus sebesar 20,32 dan pada variable
y sebesar 19,30. Kuatil adalah nilai yang membagi data
menjadi emapat bagian, kuartil terdiri atas 4. Kuartil
satu (Q1), kuartil dua (Q2), dan kuartil tiga (Q3). Pada
variable x nilai Kuartil satu (Q1) 17,67 , kuartil dua
(Q2) 19,77, dan kuartil tiga (Q3) 20,77.
Desil merupakan nilai yang mebagi data menjadi 10
bagian, desil terdiri atas sembilan. Untuk variable x

nilai desil satu (D1) sebesar 15,90, desil dua (D2)
sebesar 17,01, desil tiga (D3) sebesar 18,17, desil
empat (D4) sebesar 19,17, desil lima (D5) sebesar
19,77, desil enam (D6) sebesar 20,17, desil tujuh (D7)
sebesar 20,57, desil delapan (D8) sebesar 20,97, dan
desil sembilan (D9) sebesar 21,37. Untuk variable y
nilai desil satu (D1) sebesar 16,20, desil dua (D2)
sebesar 17,52, desil tiga (D3) sebesar 18,63, desil
empat (D4) sebesar 19,02, desil lima (D5) sebesar
19,42, desil enam (D6) sebesar 19,81, desil tujuh (D7)
sebesar 20,20, desil delapan (D8) sebesar 21,78, dan
desil sembilan (D9) sebesar 23,35. Penyebaran data yang
terakhir adalah persentil. Persentil merupakan nilai
yang membagi data menjadi 100 bagian. Untuk persentil
pada penyebaran data ini, terdapat lima perhitungan
persentil, yaitu persentil lima (P5) sebesar 15,00,
persentil tigapuluh satu (P31) sebesar 18,27, persentil
limapuluh (P¿¿50)¿sebesar 19,77, persentil sembilanpuluh
tiga (P¿¿93)¿sebesar 21,49 ,dan persentil sembilanpuluh
lima (P¿¿95)¿ sebesar 22,00 untuk variable x. sedangkan
untuk variable y yaitu persentil lima (P5) sebesar
15,35, persentil tigapuluh satu (P31) sebesar 18,67,
persentil limapuluh (P¿¿50)¿sebesar 19,42, persentil
sembilanpuluh tiga (P¿¿93)¿sebesar 23,73,dan persentil
sembilanpuluh lima (P¿¿95)¿ sebesar 23,99.
Dari penyabaran data tersebut kemudian digambarkan
kedalam kurva kemiringan dan kurva keruncingan. Untuk

variable x Kurva miring ke kanan (∝3 > 0) dan
keruncingan Leptokurtik (∝4 > 3). Hal ini didapat kan
karna nilai ∝3 sebesar 2,205 dan nilai ∝4 sebesar
22,8. Untuk variable y Kurva miring ke kiri (∝3< 0)
dan keruncingan Leptokurtik (∝4 > 3). Dengan nilai ∝3
sebesar - 0,6028 dan nilai ∝4 sebesar 15,937
5.4 Pengujian Kenormalan
Pengujian kenormalan merupakan pengujian atas data
variable x dan y, apakah data yang ada berdistribusi
normal atau tidak. Untuk variable x dengan nilai σ =
2,042 dan nilai µ = 18,97 Dari hasil perhitungan
terlihat bahwa jumlah seluruh selang terlah berubah
dari 5 menjadi 3 sehingga derajat kebebasannya menjadi
v = 1. Nilai X2 akan menjadi 4,88 sehingga dapat
disimpulkan H0 ditolak yaitu data tidak berdistribusi
normal. Untuk variable y dengan nilai σ = 2,542 dan
nilai µ = 19,87. Dari hasil perhitungan terlihat bahwa
jumlah seluruh selang terlah berubah dari 6 menjadi 3
sehingga derajat kebebasannya menjadi v = 1. Nilai X2
akan menjadi 2,411 sehingga dapat disimpulkan H0
diterima yaitu data berdistribusi normal.
5.5 Penentuan Koefisiensi Regresi
Dari hasil yang didapat dalan pengolahan data aitu
Ῡi = 4,68 + 0,80 Xi dimana 0,80 adalah koefisien arah
regresi linier dan di mana koefisien ini merupakan
perubahan rata-rata variabel Y (4,68) untuk setiap
perubahan variabel X yaitu jam lembur. Dimana perubahan

disini adalah bertambah karena nilai dari variabel b
adalah positif. Regresi dengan X menyatakan variabel
bebas dan Y variabel terikat sering dinamakan sebagai
regresi Y atas X atau sebaliknya. Variabel tak bebas Y
dalam regresi telah dinyatakan oleh simbol Ŷ yang mana
digunakan untuk menbedakan denga Y hasil amatan dan Ŷ
yang di dapat dari regresi.
5.6 Uji Hipotesis dan Penaksiran Selang Koefisiensi
Regresi
Dan telah di dapatkan dari hasil pengolahan data
untuk Jam lembur & Insentif yang di mana niali b adalah
0,80 bertanda posistif sehingga kita dapat menyatakan
bahwa setiap X (Jam Lembur) bertambah, maka rata-rata
insentif bertambah dengan hasil nilai a adalah 4,68.
Dan di perkirakan dari hasil Ŷi = 4,68 + 0,80 (14) =
15,89 bahwa di perkirakan rata-rata dari jam lembur dan
insentif disini 15,89 dari 14 jam lembur yang di
hasilkan. Dimana data di hitung dari data pertama
hingga terakhir itu di sebut interpolasi, dan jika di
masukan harga Y di luar batas daerah ruang gerak
pengamatan merupakan ekstrapolasi dalam menentukan
ekstrapolasi harus di lakukan dengan pertimbangan
penuh. Resio selalu timbul terkecuali kita tau bahwa
regresi sama berlaku untuk Y di luar ruang gerak
pengamatan. Dan hasil akhir di mana b & a bertanda
positif dan a dan b untuk menentukan t hitung, dan t
hitung dari kedua variabel berada didalam daerah

penerimaan, maka keputusannya terima H0 dan simpulkan
bahwa ada hubungan antar variabel.
5.7 Penentuan Koefisiensi Korelasi
Dapat dianalisis variabel X mengalami kenaikan,
maka variabel Y akan ikut naik, nilai koefisien
korelasi mendekati +1 (positif Satu) dan pasangan data
variabel X dan variabel Y memiliki korelasi linear
positif yang kuat/erat.
Dari hasil pengolahan data didapatkan r sebesar
0,64 maka di artikan bahwa kriteria hubungan antara
variabel X dan variabel Y berkorelasi sedang. Untuk
hasil dari diagram pencar atau sering di sebut garis
regresi linear di dapatkan garis naik artinya hubungan
positif antara variabel x (jam lembur) dengan variabel
y (insentif).
5.8 Uji Hipotesis dan Penaksiran Selang Koefisiensi
Korelasi
Hasil dari uji hipotesis dan penaksiran selang
koefisiensi korelasi didapatkan nilai thitung adalah
4,446 dari hasil tersebut dapat disimpulkan dengan
nilai ttabel 2,368 maka tidak ada hubungan antara
variabel X (jam lembur) dengan variabel Y (insentif).
5.9 Analisis Variansi
Analisis variansi disini dipengaruhi oleh nilai
SST yaitu jumlah kuadrat perlakuan yang berfungsi untuk
mengukur keragaman antara terata sampel dan SSE jumlah
kuadrat kesalahan yang dimana SSE berfungsi untuk

mnegukur keragaman dalam sampel. Dari hasil perhitungan
didapatkan Fhitung > Ftabel, maka H0 ditolak dan H1 diterima
yang berarti ada pengaruh yang signifikan antara
variabel independen X (jam lembur) secara bersama-sama
terhadap variabel dependen Y (insentif). H0 : b1 = 0
artinya tidak ada pengaruh dari variabel independen
secara bersama-sama terhadap variabel dependen.

BAB VI
KESIMPULAN DAN SARAN
6.1 Kesimpulan
Berdasarkan hasil pengolahan data dan analisis dapat
disimpulkan bahwa:
- Penelitian yang dilakukan yaitu mengenai ‘Pengaruh
Jam Lembur terhadap Jumlah Insentif Karyawan
Dinas Pertambangan & Energi Provinsi Kal-Bar.
Dimana penelitian bertujuan untuk dapat mengetahui
adakah pengaruh jam lembur yang di lakukan setiap
karyawan dengan intensif yang diterima, dengan
dapat diidentifikasi variabel penyebab dan akibat,
yang menjadi variabel penyebab (X) adalah jam
lembur karyawan dan variabel akibat (Y) adalah
jumlah pendapatan insentif.
- Dalam penelitian laporan akhir ini pengumpulan
data yang digunakan merupakan data Sekunder karena
data diperoleh dari data yang sudah tersedia dan
ada di salah satu kantor Dinas di Kal-Bar. Objek
pengamatan nya yaitu jam lembur (X) terhadap
insentif (Y) dengan jumlah data masing-masing
variabel terdapat 30 sampel.
- pengolahan data yang dilakukan pada saat
pengerjaan LA apa aja?
Untuk menguji analisis dibutuhkannya pengolahan
data sehingga diperoleh keputusan analisis yang

- berdasrkan pengolahan data apakah variabel x sama
y ada pengaruhnya ? sertakan alasannya.
- Dari hasil pengamatan serta pengolahan dengan
rumus yang ditentukan didapatkan nilai-nilai yang
dibutuhkan dalam penarikan analisis.
6.2 Saran

DAFTAR PUSTAKA
