implementation of a multi-lingual control of home appliance
TRANSCRIPT

37
Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
ADEBISI John Adetunji Department of Electrical Electronics and Computer Engineering
University of Lagos, Akoka, Nigeria.
GBOLADE Olatunde Oluwatosin Department of Electrical Electronics and Computer Engineering
University of Lagos, Akoka, Nigeria.
BABAJIDE Samuel Afolabi Department of Computer Science and Engineering
Obafemi Awolowo University, Ile-Ife. Nigeria Abstract. There have been recent advances in the field of multilingual speech recognition and these breakthroughs have seen significant adoption in voice-controlled home automation systems. Spontaneous response to instructions from home appliances is a major challenge of voice recognition systems. This requirement involves a range of complex hardware and software design processes. The existing systems do not consider specific geographical regions especially the western parts of the world. As such, there is a very little support for local languages in Nigeria. This work presents a multilingual voice recognition system for controlling home appliances; allowing intuitive response from specific devices to for Nigerian people. It provides support for the major languages in the country including English, Yoruba, and Igbo and allows the control of multiple appliances. The system is achieved by using the Elechouse Voice Recognition Module V3 in conjunction with an Arduino Uno Microcontroller which in turn controls the state of the connected appliances. Speech collected through the microphone is passed into the voice recognition module and it compares the voice sample against previously stored commands. A corresponding control signal is sent by the microcontroller on successful recognition of the voice command. The project was evaluated to measure the accuracy of the constructed system in successfully controlling an appliance natively once a registered voice command is uttered. The results showed an accuracy of about 86% in quiet environments and 52% in noisy environments based on the system response in terms of speed and accuracy of response to voice commands in the selected languages. Key words: Multilingual, Voice recognition, Home Appliance, Microcontroller
Adebisi A., Gbolade O., Babajide A. (2021) Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback . In: Odumuyiwa V., Oladejo B., Onifade O., David, A. (eds) Transition from Observation to Knowledge to Intelligence (TOKI 2021) - Human - Data Interaction in an Artificial World, pp 37-54, Lagos, ISKO-WA, 2021.

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
38
1. Background Study
Home automation has witnessed increased development and
adoption in recent times. This development assist people especially the
working class, nursing mothers and all those involved in multitasking
to be more efficient with their time while controlling appliances
seamless using their voices. Many tools have been developed to help
automate basic tasks around the home and offices, hence giving people
more time to focus on productive work as outlined in Kraljevic et al,
(2018). To assist physically challenged, elderly men and women and
mothers who may be caught up with multiple home tasks, home
automation systems have developed rapidly to allow easy control of
lights, heating and cooling systems, alarm systems, security cameras,
sprinkler systems and several other appliances within the home. Most
home automation systems provide remote monitoring and access. The
connected appliances can be viewed and monitored through internet
connected devices like smartphones, tablets to mention few. While a
large proportion of the population is computer literate and have no
problem using these remote devices, there is still need to cater for those
who might not be as discussed in Ali et al, (2017).
AlShu'eili et al, (2011) stated breakthroughs in artificial intelligence
have greatly helped to achieve this task, specifically in the fields of
natural language processing. It is now possible for machines to
understand and process human languages, translate and even
summarize it. The development of voice assistants such as Siri, Alexa
and Cortana only help to underscore these advances. Voice recognition
and control has now become one of the most important features in home
automation systems. Considering the global trend, a lot of the world’s
population speak multiple languages, however many voice recognition
products still cater to a singular language. Hence this research designed,
constructed and evaluate a prototype for a multilingual speech control
interface, for multiple appliances.
1.1. Significance
This work improves upon existing voice-controlled home
automation systems by allowing users to interact with it in multiple

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 39
languages. This is especially useful in areas where the language of
preference is not English or they speak comfortably in more than one
language such as Nigeria. It provides SMART control of multiple
appliances connected to the automation system in an intuitive manner
rather than the control of just a single appliance as it is in many
automation systems. The home automation system detects user’s
speech and whenever a recognized phrase is identified it triggers
corresponding action to switch appliances on or off. With speech
recognition, people seeking comfort and physically challenged people
can control their appliances with much more ease.
2. Theoretical Framework
Researchers over the years have studied several approaches to
achieve accurate speech recognition. In this section, several of these
models will be explored while detailing each’s drawbacks and
improvements over the other models. The Dynamic Time Warping
algorithm was widely used until the discovery of Hidden Markov
Models which has been largely utilized in recent times. Breakthroughs
in artificial intelligence specifically deep learning have also allowed for
the use of neural networks to develop even more sophisticated speech
recognition models. The speech recognition modules used in the
various cases such as the Google Speech API, Microsoft Azure,
Amazon AWS or custom designed modules responsible for the speech-
to-text conversion and make a comparative review of the several
systems.
2.1. Hidden Markov Models
The most relevant and widely used model in speech recognition
today is the Hidden Markov models (HMMs). It is a statistically-based
approach that outputs a sequence of symbols. A speech signal can be
seen as a piecewise signal or even a short-time stationary process. This
makes HMMs well suited for speech analysis. This is detailed in Niesler
and Willett (2008). HMMs can be automatically trained, are
computationally feasible and easy to use making them very popular. For

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
40
speech recognition, the Hidden Markov model outputs a sequence of
real-valued vectors which are n-dimensional, once every 10
milliseconds. The HMM will have for each of its state a statistical
distribution giving a likelihood/probability to each observed vector.
Each word/phoneme will have its own unique output distribution; the
final HMM for the sequence of words is obtained by summing together
the individual hidden trained models for all the words. This is the basis
of the most common method of speech recognition using HMMs. State-
of-the-art speech recognition systems utilize several combinations of
these standard techniques to gain improved results over the basic
approach outlined above and is shown in Caesar (2012).
HMM acoustic models tend to underestimate the acoustic
probability hence little weight is given to the language model. To solve
this problem the language model is scaled by an empirically determined
constant s. This is called the Language Model Scale Factor (LMSF).
The weighting has a side effect on inserting words. Hence, a scaling
factor p, was added to penalize word insertions. This is called the word
insertion penalty (WIP) which is also empirically obtained.
Then the likelihood of a word occurring becomes: Ẃ = 𝑎𝑟𝑔 max
𝑤𝑃(𝑊|𝑶)𝑃(𝑊)𝑠|𝑊|𝑝 (2.1)
In the log domain, the total likelihood is obtained as 𝑙𝑜𝑔|𝑤| Ẃ = 𝑙𝑜𝑔 |𝑤 |𝑃(𝑶|𝑊) + 𝑠 𝑙𝑜𝑔 |𝑤|𝑃(𝑊) + 𝑝 (2.2)
|W| represents the length of the word sequence W, s is the LMSF
(usually in the range 5 to 15) and p is the WIP (usually in the range 0 to
20). A separate notation can be used depending on whether the local or
global posterior probabilities are being considered. The global posterior
probability is given as 𝑃(𝑀|𝑶, 𝜃) where M is the model assumed model
O and parameters 𝜃 . Equation 2.3 Shows the global posterior
probability in terms of the local posterior probabilities: 𝑃 (𝑀|𝑶) = ∑ ∑ 𝑃(𝑞𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 , 𝑀|𝑶)𝐿
𝑙𝑛=1𝐿𝑙1=1 (2.3)
The posterior probability and the modal can be further decomposed
into the product of the language models and an acoustic model:

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 41
𝑃(𝑞𝑙11 , . . . , 𝑞𝑙𝑛
𝑛 , 𝑀|𝑶) = 𝑃(𝑞 𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 |𝑶)𝑃(𝑀|𝑶, 𝑞𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 ) (2.4)
≅ 𝑃(𝑞 𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 |𝑂)𝑃(𝑀, 𝑞𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 ) (2.5)
Where the acoustic model is 𝑃(𝑞𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 |𝑂) and 𝑃(𝑀, 𝑞𝑙1
1 , . . . , 𝑞𝑙𝑛𝑛 )
is the language model. Equation (2.4) can be modified to obtain:
𝑃(𝑀|𝑂) ∑ [ ∏ 𝑃( 𝑞 𝑙𝑛𝑛 | 𝑂 𝑛−𝑐
𝑛+𝑑 ) 𝑃( 𝑞 𝑙𝑛
𝑛 |𝑀)
𝑃( 𝑞 𝑙𝑛𝑛 )
𝑁𝑛 ] 𝑃(𝑀)𝑙1…...,𝑙𝑛 (2.6)
The hybrid HMM according to Lin et al, (2013) is based on the local posterior probability, and 𝑂 𝑛−𝑐
𝑛+𝑑 is limited to the local context only.
Bayes rule, showed that:
𝑃( 𝑂 𝑛−𝑐𝑛+𝑑 | 𝑞 𝑙𝑛
𝑛 )
𝑃( 𝑂 𝑛−𝑐𝑛+𝑑 )
= 𝑃( 𝑞 𝑙𝑛
𝑛 | 𝑂 𝑛−𝑐𝑛+𝑑 )
𝑃( 𝑞 𝑙𝑛𝑛 )
(2.7)
Equation 2.8 can be obtained as:
𝑃(𝑀|𝑂) = ∑ [ ∏ 𝑃( 𝑂 𝑛−𝑐𝑛+𝑑 | 𝑞 𝑙𝑛
𝑛 ) 𝑃( 𝑞 𝑙𝑛
𝑛 |𝑀)
𝑃( 𝑂 𝑛−𝑐𝑛+𝑑 )
𝑁𝑛 ] 𝑃(𝑀)𝑙1…...,𝑙𝑛 (2.8)
This is based on local likelihood; this is called the standard HMM as in Caesar (2012).
2.2. Dynamic Time Warping Algorithm
Niesler and Willett (2008) describe an alternate but less reliable
model for speech recognition is the Dynamic time warping (DTW)-
based approach. It was prevalently used for voice recognition but has
been widely replaced by the more efficient HMM-focused approach.
Dynamic time warping algorithm measures the similarity between two
distinct sequences varying in time or speed. In general, it helps to
determine the optimal matching between two sequences. This sequence
alignment approach is often employed in the context of HMMs.

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
42
2.3. Neural Networks
The emergence of neural networks as an effective acoustic
modelling approach came about in the late 1980s. They have then seen
significant adoption in many areas of speech/voice recognition
including phoneme classification, audiovisual speech recognition,
speaker adaptation and even isolated word recognition. According to
Lopez-Moreno et al, (2014) when neural networks are used for the
estimation of speech feature segments, they allow for discriminative
training in a very efficient way. However, despite their relative
effectiveness in classifying isolated words and individual phonemes
i.e., short-time units, early neural networks were seldom successful in
continuous recognition tasks. This was due to their limited ability to
effectively model time dependencies.
2.4. Empirical Review
In this section, methods employed in implementing multilingual
speech recognition systems starting from earlier developed approaches
were progressively explore and move on to current state-of-the-art
methods. Project where voice recognition has been integrated to
achieve control of the connected appliances were considered.
Adebisi et.al., (2021) worked on a multi-channel solution which
provides a suitable backup to the cloud is a viable solution to serve as a
failsafe plan in case of hardware eventualities. This work focuses on the
design and construction of a real-time power and data backup
surveillance system for security of lives and properties. Construction of
a sufficient power bank backup system was developed in real time with
average power outage duration in Nigeria considered. It shared similar
methodology with this work but more of security solution than home
automation.
Kumar et al, (2018) proposed a cost-effective and performance
efficient virtual assistant for home automation. The project used ideas
from Artificial Intelligence, Speech Recognition and Internet of Things.
The system receives voice commands from the user and responds

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 43
through voice by itself. It can retrieve dates, weather conditions, time,
return search results and play specific music tracks from the internet.
Node-MCU are responsible for controlling the appliances after
receiving commands from Raspberry Pi microcontroller. The
Raspberry Pi processes the voice input received through the
microphone, converts it into text and executes it. A python script puts
the whole system together as it contains both the speech-to-text and
text-to-speech code. Finally, the Node-MCU is coded with Arduino to
control the appliances.
Othman (2017) proposed using a voice controlled personal assistant
using the Alexa Voice Service (AVS) speech recognition engine
provided by Amazon. The author also used a Raspberry Pi as the
microcontroller responsible for command processing similar to the
method proposed in (Adebisi et al 2021). AVS is used as both the
speech-to-text engine for converting the audio into text form and also
as the Text-to-Speech engine for vocally outputting the retrieved
information. The system achieved a speech recognition accuracy of
92% and was very easy to implement due to the flexibility of the AVS
API.
In Matarneh et al, (2017) several existing speech recognition
systems were explored and compared. It focused on two main classes
namely open source and closed-source systems. The closed-source
refers to proprietary software with no access to the source code. Only
the binary versions are distributed. Under this class the Google Speech
Recognition API is present, Microsoft Speech API, Siri, Yandex speech
kit and Dragon Mobile SDK. The comparisons were based on accuracy,
speed, performance, response time, API and compatibility. The analysis
of these various systems allows us to make informed decisions when
choosing an appropriate one. The tests found CMU Sphinx to be the
most attractive open-source voice recognition system however it
requires a large initial database. Of the closed systems, the most
accurate was found to be Dragon but due to its complex API, Google
speech API was more attractive. In general, the closed systems were

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
44
found to be more accurate than the open-source voice recognition
systems.
Caesar (2012) proposed a multilingual speech recognition technique
that entails first detecting the language present in the audio signal. Then,
the outcome of the language identification determines which of the
available monolingual speech recognizers will be activated and passed
the voice input. The paper also proposed a method for the language
identification. It involved estimating the language posterior
probabilities giving the input signal using hierarchical multi-layer
perceptron in combination with hidden Markov models. The case study
was the Media-Parl speech corpus which consisted of recorded speech
in both Swiss-French and Swiss-German. The experiments showed that
using language identification to determine the appropriate speech
recognizer to be used significantly improves upon using a single
universal speech recognizer capable of recognizing multiple language
such as in Niesler and Willett (2008).
Niesler and Willett (2008) worked on a multilingual speech
recognition system to identify four different South African languages.
It showed specifically how to identify English, Zulu, Afrikaans and
Xhosa using a single recognition pass with a set of HMMs. The paper
shows the effect of using discriminatively trained acoustic models on
the language identification process and the in-language recognition
accuracy. To achieve this, they optimized the acoustic model
parameters of the speech recognizer by maximizing the value of the
training data posterior probability through a process called maximum
likelihood (ML) parameter estimation. This was achieved
computationally using the Baum-Welch algorithm at a low cost. It
suggests other discriminative measures which may produce better
parameter estimates resulting in better recognition accuracy.
Discriminative training proved to be computationally expensive and
showed no marked improvement in recognition accuracy overall the
baseline acoustic models. Finally code-mixing (using words from
multiple languages) seemed to have lower recognition accuracy rates. The studies have shown that systems that incorporate Deep Neural
Networks in combination with Hidden Markov models achieve the

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 45
highest speech recognition accuracy. A comparative review of many
commercial speech recognition systems was also conducted. The
Google Speech Recognition Application Programing Interface (API)
seemed to be the most favored due to its high accuracy rate and easy to
use interface.
2.5. Formulation of Speech Recognition
First is the division of the continuous speech waveform into frames
of constant length (~25ms). Each frame is then represented as a discrete
parameter vector. It is assumed that for the duration of a single vector
(i.e. frame) the waveform is stationary. This approximation helps to
easily formulate the problem. For each word in the speech signal, 𝑶 = 𝑜1𝑜2 · · · 𝑜𝜏 is a sequence of parameter vectors where 𝐨𝐭 is taken at a
time t ∈ {1, . . . , τ} . Ẃ = 𝑎𝑟𝑔 max
𝑤𝑃(𝑊|𝑶) (3.1)
Where Ẃ refers to the recognized word, then P means the probability
measure and 𝑊 = 𝑤1 … 𝑤𝑘 represents a word sequence. Bayes’ Rule
allows us to transform (3.1) into a calculable form:
𝑃(𝑊|𝑶) = (𝑃(𝑶|𝑊). 𝑃(𝑊))/𝑃(𝑶) (3.2)
Where 𝑃(𝑶|𝑊) signifies the acoustic model and 𝑃(𝑊) is the
language model. It can be inferred then that determining the most
probable word in the speech sample depends only on the likelihood
𝑃 (𝑶|𝑊) as shown in Niesler and Willett (2008).
3. Proposed System Architecture
The architecture of the proposed multilingual voice-controlled
automation system is depicted in Figure 3.1. It shows the flow of
operation from the collection of speech through the microphone to the
control of the connected appliances.

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
46
Figure1: Block Diagram of the Voice Controlled Automation System
The Arduino is powered by a 5V DC supply. The voice commands
are spoken by the user and are recorded by a microphone. The speech
input is then passed along to the voice recognition module where the
speech signal is matched against the pre-recorded trained voice
samples. After the successful recognition of a voice command, the
microcontroller actuates the corresponding connected appliance such as
setting off the alarm, turning ON/OFF the light and fan. (a)
3.1. Implementation
A simple collar type microphone was used for this project to capture
audio by converting observed sound waves into electrical energy
variations. The obtained signal was then amplified as an analogue signal
converted into a digital signal for further processing by a computer or
an audio device. Elechouse voice recognition module V3 was used for
the speech recognition process in the proposed system. It allows any
sound to be trained as a command. It is a two way controlled mechanism
with relatively moderate voltage requirement with easy speaking
recognition module compare to other voice recognition boards. In
addition. Elechouse supports up to 80 voice commands and up to seven
can work at the same time with trained commands. Table 4.1 shows the
breakdown of identified languages and selected appliances used for
testing during the implementation. This gives us the flexibility to train
the system to recognize commands spoken in English, Yoruba, Igbo and
Hausa and any other language of choice. The V3 module also has
recognition accuracy of 99% when used under ideal conditions (i.e. in

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 47
low noise levels). It can store up to 80 commands in its library and
recognize a total of 7 commands at the same time.
3.3.1 Arduino Microcontroller
The microcontroller used for the proposed system is the Arduino-
Uno microcontroller shown in Figure 1. It comes with an Integrated
Development Environment (IDE) which runs on a PC and allows users
write programs in C or C++ programming languages. This is where
most of the logic behind this project is implemented. The Arduino
microcontroller, powered by 5V DC, 16 MHz clock speed; is based on
the Atmega328 and has 14 digital and output pins with 6 analogue
inputs.
Figure 1: Arduino-Uno microcontroller
(Source: www.store.arduino.cc/arduino-uno-rev3)
A 5V 4-channel relay module, an electrical device that acts as a
switch allowing current passage act as the connecting interfacing
between the microcontroller and the devices. In addition to Arduino
Microcontroller, other components were identified. The voice
recognition module was trained with a diverse set of voices and
language samples. The voice recognition module chosen for this project
is the Elechouse V3 recognition module. Samples from three (3)
speakers were taken (one for each of the identified languages) to utter
voice commands so as to properly train the voice module. These voice
commands specify the operation to perform on the mentioned
appliance. The software implementation of the project consisted of
training the voice recognition module and writing a program to control
the connected appliances on recognition of a voice command. The voice

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
48
commands were recognized in each of the languages alongside the
appliance to be controlled. Table 1 shows the breakdown of the
applicable voice commands in the respective languages.
Table 1: All Identified Voice Commands
APPLIANCE ENGLISH YORUBA IGBO
LED/BULB “Light on” “tan ina” “gbanye ọkụ”
“Light off” “pa ina” “gbanyụọ ọkụ”
FAN “Fan On” “tan fan” “gbanye fan”
“Fan Off” “pa fan” “gbanyụọ fan”
BUZZER “Buzzer On” “tan buzzer” “gbanye
buzzer”
“Buzzer Off” “pa buzzer” “gbanyụọ
buzzer”
On successful matching of both commands, a prompt stating
“success” show. A snapshot of this process is shown in Figure 2. The
voice command has now been stored and ready for use. To verify that
the voice command has indeed been stored at the specified address, the
“record” command is typed, followed by the address. If the record is
already trained, it shows “record --> trained”.
To enable intuitive control of the appliances, the components are
first connected to the Arduino and the Arduino is programmed to
control them after successful recognition of a voice command. The
program written in C programming language was stored in a file called
“Vr_Control_Appliances”. The program code snippet as shown in
Figure 3.

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 49
Figure 2: Voice Recognition Module Training
Figure 3: Microcontroller program code
4. Results Discussion
To determine the performance of the system, the accuracy of the
system in recognizing voice commands and then controlling the
corresponding appliance is a major focus. In carrying out this
effectively, evaluation partitions were created. These partitions include
testing in a quiet environment, testing in a noisy environment and
testing using random/unregistered voice samples. In all aforementioned
partitions, the tests are carried out for each of the languages. For each
Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
50
voice command, a total of 6 experimental trials as shown in Tables 2
and 3 are conducted to effectively measure the accuracy of the system
in responding to the command i.e. controlling the corresponding
appliance. A ‘1’ signifies success while a ‘0’ indicates failure. Several
voice commands (made up of turn/off commands in three different
languages for each of the connected appliance).
Table 2: Yoruba Voice Commands’ Test in a Quiet Environment
S/
N
Voice
Command
Experimental trials Total
Responses
1 2 3 4 5
1. tana 1 1 0 1 1 4
2. pana 1 1 1 1 0 4
3. tan-fan 0 0 1 1 1 3
4. pa-fan 1 0 1 1 0 3
5. tan-buzz 0 1 1 0 1 3
6. pa-buzz 1 1 1 1 1 5
Table 3: Igbo Voice Commands’ Test in a Quiet Environment
S/N Voice
Command
Experimental trials Total
Responses
1 2 3 4 5
1. gbanyeku 1 0 1 0 1 3
2. gbanyoku 0 1 1 1 1 4
3. gbanye-fan 0 1 1 0 1 3
4. gbanyo-fan 1 0 1 1 0 3
5. gbanye-
buzz
1 1 1 1 1 5
6. gbanyo-
buzz
1 1 0 1 1 4
From the tests conducted in a quiet environment, the results showed
that the English voice commands were more easily recognized when
compared to that of Yoruba and Igbo. The tests on English voice
commands attained a system response rate of about 80% while that of
J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 51
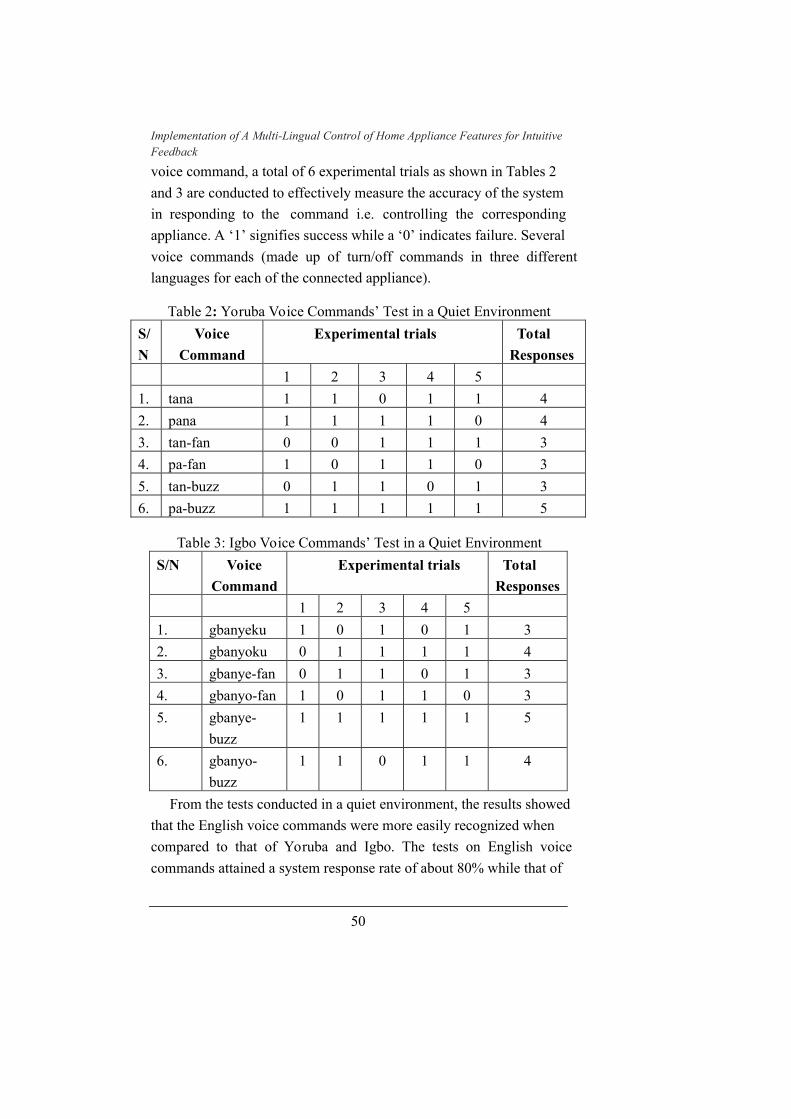
Yoruba was about 73.3% response and Igbo 70% as depicted in Figure
4.
Figure 4: Response Rate of System in Quiet Environment
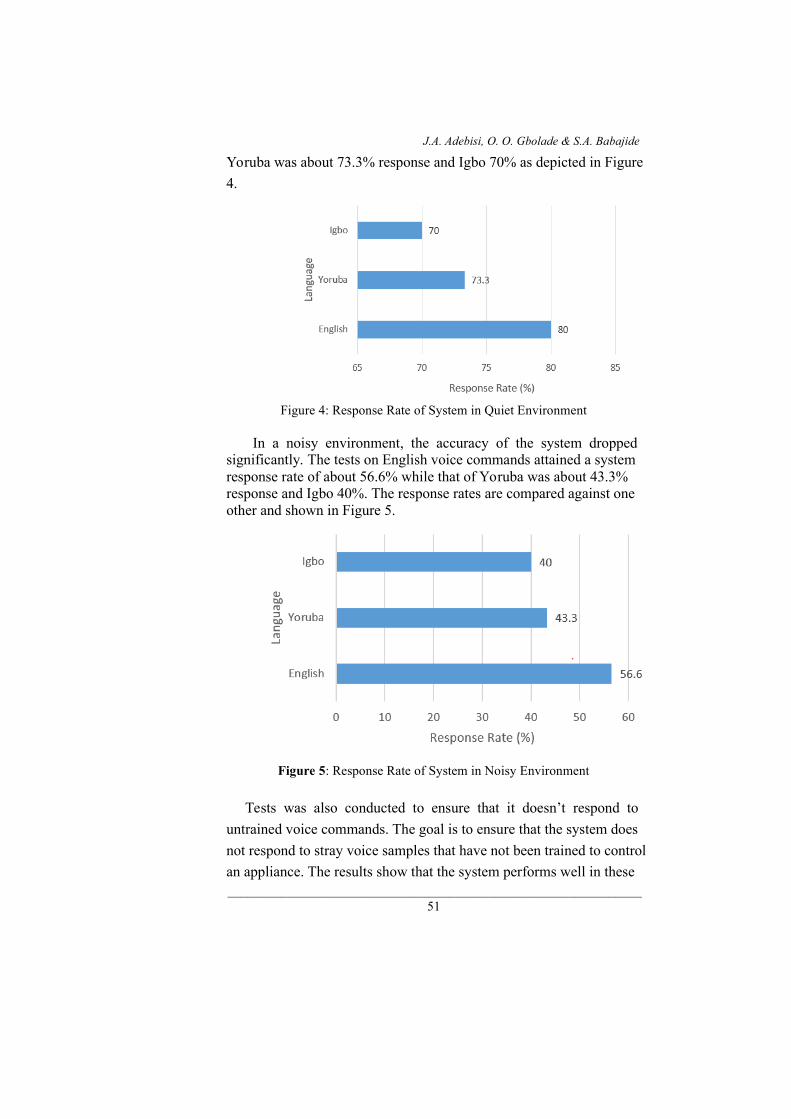
In a noisy environment, the accuracy of the system dropped significantly. The tests on English voice commands attained a system response rate of about 56.6% while that of Yoruba was about 43.3% response and Igbo 40%. The response rates are compared against one other and shown in Figure 5.
Figure 5: Response Rate of System in Noisy Environment
Tests was also conducted to ensure that it doesn’t respond to
untrained voice commands. The goal is to ensure that the system does
not respond to stray voice samples that have not been trained to control
an appliance. The results show that the system performs well in these

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
52
instances. Furthermore, results show that the system performs
extremely well in these instances by not acting on any of these stray
commands irrespective of how similar they might be to registered ones.
5. CONCLUSION
This work designed and constructed an intuitive multilingual voice
recognition for the control of home appliances. Most previous work in
this area are limited to a single language (English) while this project has
been able to effectively implement a multilingual voice recognition
system. The project was evaluated to measure the accuracy of the
constructed system in successfully controlling an appliance natively
once a registered voice command is uttered. The results showed an
accuracy of about 86% in quiet environments and 52% in noisy
environments based on the system response in terms of speed and
accuracy of response to voice commands in the selected languages.
Although the result of this work can be applied in other western part of
the world as it is configurable; the proposed solution has sufficiently
addressed the challenge of using local language to control basic home
appliances when the need arises. In future, effort will be put in place to
implement control of appliances in even more local Nigerian languages
and beyond to assist the elderly ones, handicaps among other categories
of citizen as the case may be.
List of References
Adebisi, J. A., Abdulsalam, K. A., & Adams, I. O. (2021). Multi-Power
Source and Cloud-Backup Enabled Security Framework for
Surveillance in Nigeria. In IOP Conference Series: Earth and
Environmental Science (Vol. 730, No. 1, p. 012005). IOP
Publishing.
Ali, A. T., Eltayeb, E., and Abusail, E. A. (2017). Voice Recognition
Based Smart Home Control System. International Journal of
Engineering Inventions.

J.A. Adebisi, O. O. Gbolade & S.A. Babajide
______________________________________________________________ 53
AlShu'eili, H., Gupta, G. S., and Mukhopadhyay. (2011). Voice
Recognition Based Wireless Home Automation System. Kuala
Lumpur, Malaysia: International Conference on Mechanotrics.
Caesar, H. (2012). Integrating language identification to improve
multilingual speech recognition (No. REP_WORK). Idiap.
Gonzalez-Dominguez, J., Eustis, D., Lopez-Moreno, I., Senior, A.,
Beaufays, F., and Moreno, P. (2014). A Real-Time End-to-End
Multilingual Speech. IEEE.
Kraljevic, L., Russo, M., and Stella, M. (2018). Voice Command
Module for Smart Home Automation. International Journal of
Signal Processing.
Kumar, K., Jayalakshmi, J., and Prasanna, K. (2018). A Python based
Virtual Assistant using Raspberry Pi for Home Automation.
International Journal of Electronics and Communication
Engineering.
Lopez-Moreno, I., Gonzalez-Dominguez, J., Plchot, O., Martinez, D.,
Gonzalez-Rodriguez, J., and Moreno, P. (2014). Automatic
Language Identification Using Deep Neural Networks. IEEE
International Conference on Acoustic, Speech and Signal Processing
(ICASSP).
Matarneh, R., Maksymova, S., and Lyashenko, V. V. (2017). Speech
Recognition Systems: A Comparative Review. IOSR Journal of
Computer Engineering.
Niesler, T., and Willett, D. (2008). Language Identification and
Multilingual Speech Recognition using Discriminatively Trained
Acoustic Models. South Africa: Department of Electrical and
Electronics Engineering, University of Stellenbosch.
Othman, E. (2017). Voice Controlled Personal Assistant Using
Raspberry Pi. International Journal of Scientific and Engineering
Research.
Sabah, F., Jyoti, S., Miskin, P., and Sarvagya, M. (2018). Design and
Implementation of Voice Controlled Home Automation Using Iot.
International Conferene on Recent Trends in Engineering Science
and Management.

Implementation of A Multi-Lingual Control of Home Appliance Features for Intuitive Feedback
54