ijirae::audio clustering
TRANSCRIPT

International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 205
AUDIO CLUSTERING Venkatesh Deshak Arunkumar Kanthi M.tech Student, Asst.Professor, PDACE-GULBARGA PDACE-GULBARGA
Abstract --- In the age of digital information, audio data has become an important part in many modern computer applications. Audio clustering has been becoming a focus in the research of audio processing and pattern recognition. While classification aims at assigning predefined class labels to the data, clustering aims at dividing the data into classes based on their similarity without predefined class labels. Gaussian mixture model (GMM) is one of the clustering method that has been widely used in fields of data mining, pattern recognition and information processing. In this project, we present an approach to audio clustering, based on EM Algorithm with Gaussian Mixture Model. This algorithm is simple and practical and is quite sensitive to initial values and the number of its components needs to be given a priori. Keywords --- Audio clustering, GMM, EM Algorithm, MFCC, GFCC, LPC
I. INTRODUCTION II.
Clustering is the process of grouping together similar objects. The resulting groups are called clusters. Clustering algorithms group data points according to various criteria. The various clustering algorithms are based on some assumptions in order to define a partitioning of a data set. Clustering is one of the most useful method in the data mining process for discovering groups and identifying interesting distributions and patterns in the underlying data. Thus, the main concern in the clustering process is to reveal the organization of patterns into sensible groups, which allow us to discover similarities and differences, as well as to derive useful inferences about them. Clustering makes it possible to look at properties of whole clusters instead of individual objects - a simplification that might be useful when handling large amounts of data.
In this project, the approach to audio clustering, based on EM Algorithm with Gaussian Mixture is proposed. This method is one of Model-based methods, it is very popular as iteration and refinement algorithm, also can be used to obtain parameter estimations. It greatly reduces the maximum likelihood estimate of computational complexity. The E-step is defined as the evaluation of this expectation, and the M-step of the EM algorithm is to maximize the expectation which was computed in the E-step. Both of them implicitly and automatically determine the direction and distance of each step. Audio features representing the audio information can be extracted from the audio signal at the segmental level. The segmental features are the features extracted from short segments of the audio signal. These features represent the short-time spectrum of the audio signal. The selected features include linear prediction coefficients (LPC), mel-frequency cepstral coefficients (MFCC) and Gama-tone filter bank coefficients(GFCC).
III. PROPOSED SYSTEM
Fig. 1: Proposed Audio clustering system
2.1) Pre-treatment
a) Pre-emphasis
In order to flatten audio spectrum, a pre-emphasis filter is used before spectral analysis. Its aim is to compensate the high-frequency part of the audio signal that was suppressed during the sound production mechanism.

International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 206
The most used filter is a high-pass FIR filter described in the below equation (1).
2.2) Feature Extractor
a) Frame Blocking
The audio signal is divided into a sequence of frames where each frame can be analyzed independently and represented by a single feature vector. Since each frame is supposed to have stationary behavior, a compromise, in order to make the frame blocking, is to use a 100 ms window applied at 50 ms intervals.
Fig. 2 : Frame blocking
b) Windowing
In order to reduce the discontinuities of the audio signal at the edges of each frame, a window is applied to each one. The most common used window is Hamming window, described in equation (3).
…(2)
c) DFT computation
The third step of MFCC extraction process is to compute the Fast Fourier Transform (FFT) of each frame and obtain its magnitude. The FFT is a computationally efficient algorithm of the Discrete Fourier Transform (DFT).
d) Filter bank
i. MFCC
Next stage is Mel-filter bank analysis where Mel-scale frequency can be approximate by
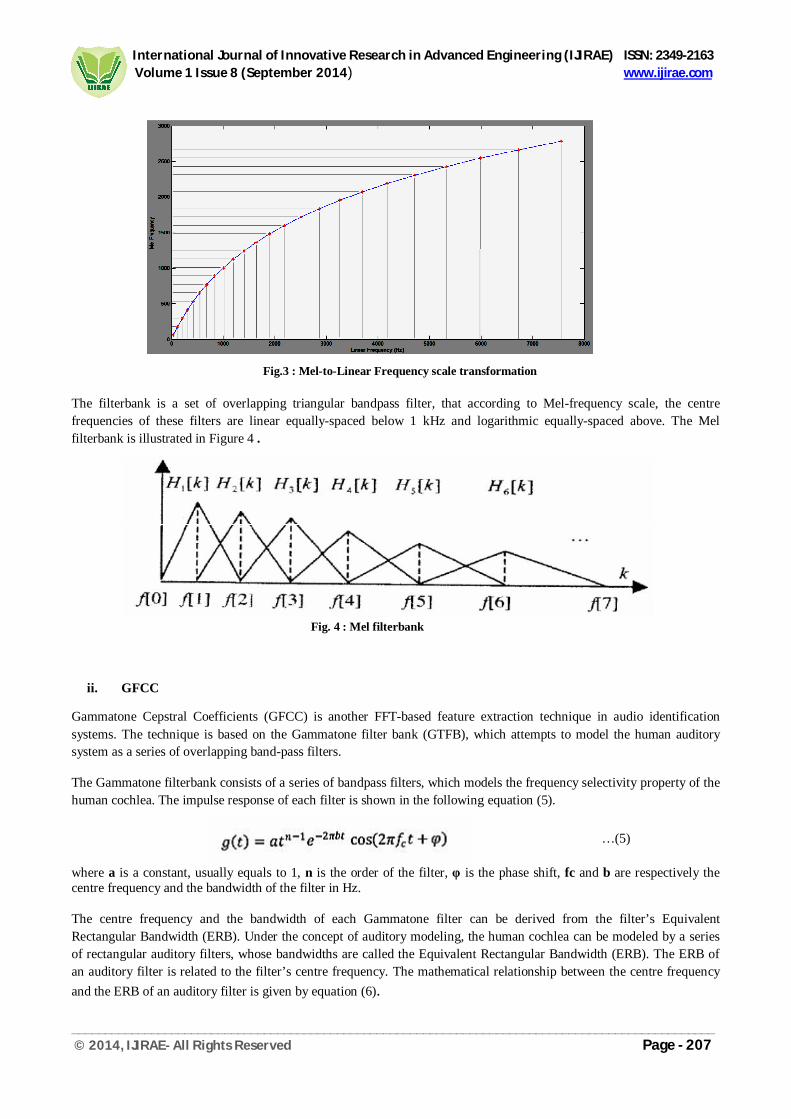
…(3) This non-linear transformation can be seen in Figure 3. It shows that equally spaced values on Mel-frequency scale correspond to non-equally spaced frequencies. This is the inverse function of the Eq. (3) which is given by Eq. (4):
…(4)
International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 207
Fig.3 : Mel-to-Linear Frequency scale transformation
The filterbank is a set of overlapping triangular bandpass filter, that according to Mel-frequency scale, the centre frequencies of these filters are linear equally-spaced below 1 kHz and logarithmic equally-spaced above. The Mel filterbank is illustrated in Figure 4 .
Fig. 4 : Mel filterbank
ii. GFCC
Gammatone Cepstral Coefficients (GFCC) is another FFT-based feature extraction technique in audio identification systems. The technique is based on the Gammatone filter bank (GTFB), which attempts to model the human auditory system as a series of overlapping band-pass filters.
The Gammatone filterbank consists of a series of bandpass filters, which models the frequency selectivity property of the human cochlea. The impulse response of each filter is shown in the following equation (5). …(5) where a is a constant, usually equals to 1, n is the order of the filter, φ is the phase shift, fc and b are respectively the centre frequency and the bandwidth of the filter in Hz. The centre frequency and the bandwidth of each Gammatone filter can be derived from the filter’s Equivalent Rectangular Bandwidth (ERB). Under the concept of auditory modeling, the human cochlea can be modeled by a series of rectangular auditory filters, whose bandwidths are called the Equivalent Rectangular Bandwidth (ERB). The ERB of an auditory filter is related to the filter’s centre frequency. The mathematical relationship between the centre frequency and the ERB of an auditory filter is given by equation (6).
International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 208
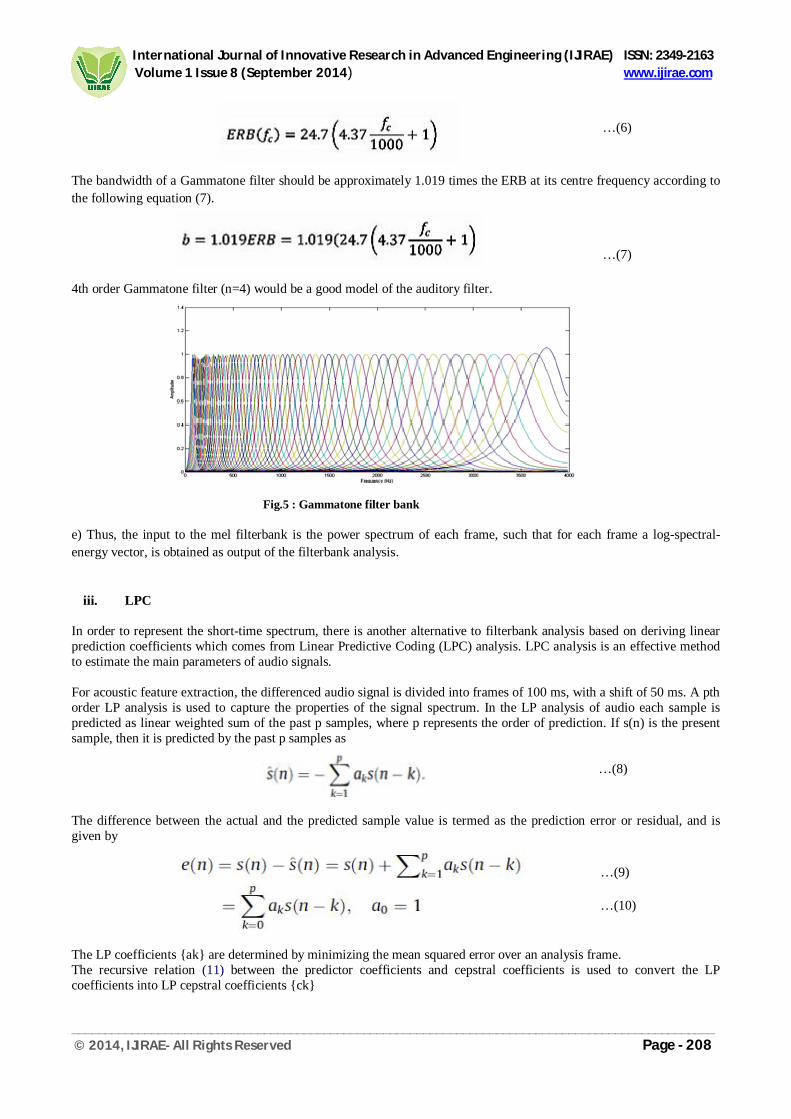
…(6) The bandwidth of a Gammatone filter should be approximately 1.019 times the ERB at its centre frequency according to the following equation (7). …(7) 4th order Gammatone filter (n=4) would be a good model of the auditory filter.
Fig.5 : Gammatone filter bank
e) Thus, the input to the mel filterbank is the power spectrum of each frame, such that for each frame a log-spectral-energy vector, is obtained as output of the filterbank analysis.
iii. LPC
In order to represent the short-time spectrum, there is another alternative to filterbank analysis based on deriving linear prediction coefficients which comes from Linear Predictive Coding (LPC) analysis. LPC analysis is an effective method to estimate the main parameters of audio signals. For acoustic feature extraction, the differenced audio signal is divided into frames of 100 ms, with a shift of 50 ms. A pth order LP analysis is used to capture the properties of the signal spectrum. In the LP analysis of audio each sample is predicted as linear weighted sum of the past p samples, where p represents the order of prediction. If s(n) is the present sample, then it is predicted by the past p samples as
…(8) The difference between the actual and the predicted sample value is termed as the prediction error or residual, and is given by …(9)
…(10)
The LP coefficients {ak} are determined by minimizing the mean squared error over an analysis frame. The recursive relation (11) between the predictor coefficients and cepstral coefficients is used to convert the LP coefficients into LP cepstral coefficients {ck}

International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 209
…(11)
where σ2 is the gain term in the LP analysis and D is the number of LP cepstral coefficients. 2.3) GMM based EM algorithm
Gaussian Mixture Models (GMM) was firstly found by Douglas A. Reynolds and Richard C Rose in 1995. Gaussian Mixture Models consist of a set of local Gaussian modes. Different Gaussian distributions represent different domain of feature space, and have different output characteristics. Gaussian Mixture Models try to describe a complex system using the combination of all the Gaussian clusters or mixtures, instead of using a single model. The mixture or cluster of Gaussian model represents a dataset by a set of mean and covariance matrix. The centre of each class is placed at the mean and has a Gaussian which extends as described by its matrix.
Fig 6 : Example of GMM model Figure depicts an example of a Gaussian mixture, the individual weighted Gaussian components PDFs are shown using dashed lines whereas the over PDF (the sum of the components) is shown using a solid line. Summary of Gaussian Mixture Model The basic idea of GMM is that each object is approximated by a Gaussian distribution. We assume the observed sample is: X = {x1,x2….xn}, If fk(xiIϴk) satisfies the Gaussian distribution, parameter ϴk is composed of mean value µk and covariance matrix Ʃk .Density function is as follow
…(12)
The distribution P could be described by a sum of weighted average of G Gaussian density functions: …(13)
Πk is the K-th Gaussian distribution of weights at the moment T. In addition Πk ≥ 0, ∑ 휋푘 = 1
Gaussian Mixture based on EM Algorithm applied in Audio Clustering.

International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 210
The purpose of the audio classification and clustering is to attribute audio to a certain sort of audio type. During the identification task, given a sample of audio test, we should find its model and its corresponding model λi , which makes the feature vector set X of audio to be identified with the maximum posterior probability p(λi/X). Suppose that there are N kinds of audio. Corresponding to N kinds of candidate audio, the Gaussian mixture model parameters respectively set as λ1, λ2, …. λn. Audio to be identified whose vector set is assign as X = {xl, x2,…xT}. According to Bayesian theory, posterior probability …(14)
Priori probability of audio i is p(λi) , p(X) is the probability density of feature vector sets X of all audio types. Under the condition that the audio is of i type, when feature vector sets is X is p(X/λi). p(λi/X) represents the posterior probability of i type when feature vector set is X. Discriminant result is given by the next Maximum posterior probability criterion: …(15) i* indicates the discriminant result.
In the proposed method, priori probability of samples is unknown, and it is rational to assume that the probability of each audio sample is the same:
…(16)
n=1,2,·,N. To each sample. p(X) of formula (15) is equal, thus, formula (16) equivalent to:
…(17) At this point, maximum a posterior probability rule turns into maximum-likelihood criterion. Here, we use the following equation to identify audio used to test with audio library.
…(18) …(19)
Here we specify the steps of Gaussian Mixture based on EM algorithm which can be applied in audio clustering as follow: Given a Gaussian mixture model, the goal is to maximize the likelihood function with respect to the parameters.
1) Initialize the means µk, covariances Ʃk and mixing coefficients Πk, and evaluate the initial value of the log likelihood.
2) E step. Evaluate the responsibilities using the current parameter values
…(20)

International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163 Volume 1 Issue 8 (September 2014) www.ijirae.com
_________________________________________________________________________________________________ © 2014, IJIRAE- All Rights Reserved Page - 211
3) M step. Re-estimate the parameters using the current responsibilities
…(21)
…(22)
…(23)
where
4) Evaluate the log likelihood
…(24)
and check for convergence of either the parameters or the log likelihood. If the convergence criterion is not satisfied return to step 2.
IV. EXPERIMENTS AND RESULTS
In this project we concatenated audio clips with the Audacity software to make it a single audio clip. It is passed through pre-emphasis FIR filter with a coefficient of 0.97 then divided the single concatenated audio clip into frames of 100 ms with the overlapping of 50ms. Hamming window is applied to each frame. Than we calculated the MFCC, GFCC and LPC features to each frame having 12 dimensional vectors for MFCC and LPC and 22 dimensional vectors for GFCC. Then applied GMM based EM algorithm with number mixtures equal to number of audio clips took at initial time. Initial value of mean(µk) is assigned by k-means clustering algorithm, covariance matrix(Ʃk) is selected as matrix of 1’s in each row and column, and mixture weights(Πk) of equal probability, By checking log likelihood condition we get the clustered indexes of each frame.
V. CONCLUSION
Currently, there is so much study is going on data clustering. In this paper, we make a further study on audio clustering with Gaussian Mixture based on EM Algorithm using different feature extraction. Mel-frequency cepstral coefficient(MFCC) and Gammatone cepstral coefficient(GFCC), Linear prediction cepstrum coefficient(LPC) are calculated as features to characterize audio content and then clustered using GMM based EM algorithm.
REFERENCES:
[1]. Christopher M. Bishop, “Pattern Recognition and Machine Learning”, Springer Science, Business Media, 2006 [2]. Yunhui Wang, Xiaoqing Yu, Wengen Wang, Liang Liu, “The Research Of Audio Clustering With Gaussian Mixture Based
On EM Algorithm”, IEEE transaction,2011 [3]. Ramani S. Pilla and Bruce G. Lindsay. “Alternative EM methods for nonparametric finite mixture models.” Biometrika
(2001) 88 (2): 535-550. [4]. Guorong Xuan, Wei Zhanf and Peiqui Chai, “Em Algorithms Of Gaussian Mixture Model And Hidden Markov Model”,
IEEE transition 2009 [5]. Douglas A. Reynolds, “Robust Text independent speaker identification using Gaussian mixture speaker model” , IEEE
transaction,1995 [6]. S. Chandrakala and C Chandrashekhar, “Model based clustering of audio clips using Gaussian mixture models”, IEEE
transition,2009.