high-throughput analysis of large microscopy image datasets on cpu-gpu cluster platforms
TRANSCRIPT

High-throughput Analysis of Large Microscopy Image Datasets on CPU-GPUCluster Platforms
George Teodoro1,3, Tony Pan1, Tahsin M. Kurc1, Jun Kong1, Lee A. D. Cooper1,Norbert Podhorszki2, Scott Klasky2, and Joel H. Saltz1,3
1Center for Comprehensive Informatics, Emory University, Atlanta, GA2Scientific Data Group, Oak Ridge National Laboratory, Oak Ridge, TN3College of Computing, Georgia Institute of Technology, Atlanta, GA
Abstract—Analysis of large pathology image datasets offerssignificant opportunities for the investigation of disease mor-phology, but the resource requirements of analysis pipelineslimit the scale of such studies. Motivated by a brain cancerstudy, we propose and evaluate a parallel image analysisapplication pipeline for high throughput computation of largedatasets of high resolution pathology tissue images on dis-tributed CPU-GPU platforms. To achieve efficient executionon these hybrid systems, we have built runtime support thatallows us to express the cancer image analysis application as ahierarchical data processing pipeline. The application is imple-mented as a coarse-grain pipeline of stages, where each stagemay be further partitioned into another pipeline of fine-grainoperations. The fine-grain operations are efficiently managedand scheduled for computation on CPUs and GPUs usingperformance aware scheduling techniques along with severaloptimizations, including architecture aware process placement,data locality conscious task assignment, data prefetching, andasynchronous data copy. These optimizations are employed tomaximize the utilization of the aggregate computing powerof CPUs and GPUs and minimize data copy overheads. Ourexperimental evaluation shows that the cooperative use ofCPUs and GPUs achieves significant improvements on topof GPU-only versions (up to 1.6×) and that the executionof the application as a set of fine-grain operations providesmore opportunities for runtime optimizations and attains betterperformance than coarser-grain, monolithic implementationsused in other works. An implementation of the cancer imageanalysis pipeline using the runtime support was able to processan image dataset consisting of 36,848 4Kx4K-pixel imagetiles (about 1.8TB uncompressed) in less than 4 minutes (150tiles/second) on 100 nodes of a state-of-the-art hybrid clustersystem.
Keywords-Image Segmentation Pipelines; GPGPU; CPU-GPU platforms;
I. INTRODUCTION
Analysis of large datasets is a critical, yet challengingcomponent of scientific studies, because of dataset sizes andthe computational requirements of analysis applications. So-phisticated image scanner technologies developed in the pastdecade have revolutionized biomedical researchers’ abilityto perform high resolution microscopy imaging of tissuespecimens. With a state-of-the-art scanner, a researcher cancapture color images of up to 100Kx100K pixels rapidly.
This allows a research project to collect datasets consistingof thousands of images, each of which can be tens ofgigabytes in size. Processing of an image consists of severalsteps of data and computation intensive operations suchas normalization, segmentation, feature computation, andclassification. Analyzing a single image on a workstationcan take several hours, and processing a large dataset cantake a very long time. Moreover, a dataset may be analyzedmultiple times with different analysis parameters and algo-rithms to explore different scientific questions, to carry outsensitivity studies, and to quantify uncertainty and errors inanalysis results. These requirements create obstacles to theutilization of microscopy imaging in research and healthcareenvironments and significantly limit the scale of microscopyimaging studies.
The processing power and memory capacity of graph-ics processing units (GPUs) have rapidly and significantlyimproved in recent years. Contemporary GPUs provideextremely fast memories and massive multi-processing capa-bilities, exceeding those of multi-core CPUs. The applicationand performance benefits of GPUs for general purposeprocessing have been demonstrated for a wide range ofapplications [1]. As a result, hybrid systems with multi-coreCPUs and multiple GPUs are emerging as viable high perfor-mance computing platforms for scientific computation [2].This trend is also fueled by the availability of programmingabstractions and frameworks, such as CUDA1 and OpenCL2,that have reduced the complexity of porting computationalkernels to GPUs. Nevertheless, taking advantage of hybridplatforms for scientific computing still remains a challengingproblem. An application developer needs to be concernedabout efficient distribution of computational workload notonly across cluster nodes but also among multiple CPUcores and GPUs on a hybrid node. The developer also hasto take into account the relative performance of applicationoperations on CPUs and GPUs. Some operations are moresuitable for massive parallelism and generally achieve higher
1http://nvidia.com/cuda2http://www.khronos.org/opencl/

GPU-vs-CPU speedup values than other operations. Suchperformance variability should be incorporated into schedul-ing decisions. On top of these challenges, the applicationdeveloper has to minimize data copy overheads when datahave to be exchanged between application operations. Thesechallenges often lead to underutilization of the power ofhybrid platforms.
In this work, we propose and evaluate parallelizationstrategies and runtime runtime support for efficient executionof large scale microscopy image analyses on hybrid clustersystems. Our approach combines the coarse-grain dataflowpattern with the bag-of-tasks pattern in order to facilitatethe implementation of an image analysis application from aset of operations on data. The runtime supports hierarchicalpipelines, in which a processing component can itself bea pipeline of operations, and implements optimizations forefficient coordinated use of CPUs and GPUs on a computingnode as well as for distribution of computations acrossmultiple nodes. The optimizations studied in this paperinclude data locality conscious and performance variationaware task assignment, data prefetching, asynchronous datacopy, and architecture aware placement of control processesin a computation node. Fine-grain operations that constitutean image analysis pipeline typically involve different dataaccess and processing patterns. Consequently, variability inthe amount of GPU acceleration of operations is likely toexist. This requires the use of performance aware schedulingtechniques in order to optimize the use of CPUs and GPUsbased on speedups attained by each operation.
We evaluate our approach using image datasets from braintumor specimens and an analysis pipeline developed forstudy of brain cancers on a state-of-the-art hybrid cluster,where each node has multi-core CPUs and multiple GPUs.Experimental results show that coordinated use of CPUsand GPUs along with the runtime optimizations results insignificant performance improvements over CPU-only andGPU-only deployments. In addition, multi-level pipelinescheduling and execution is faster than a monolithic im-plementation, since it can leverage the hybrid infrastructurebetter. Applying all of these optimizations makes it possibleto process an image dataset at 150 tiles/second on 100 hybridcompute nodes.
II. APPLICATION DESCRIPTION
The motivation for our work is the in silico studies ofbrain tumors [3]. These studies are conducted to find bettertumor classification strategies and to understand the biologyof brain tumors, using complementary datasets of high-resolution whole tissue slide images (WSIs), gene expressiondata, clinical data, and radiology images. WSIs are capturedby taking color (RGB) pictures of tissue specimens stainedand fixated on glass slides. Our group has developed WSIanalysis applications to extract and classify morphologyand texture information from images, with the objective of
exploring correlations between tissue morphology, genomicsignatures, and clinical data [3]. The WSI analysis appli-cations share a common workflow which consists of thefollowing core stages: 1) image preprocessing tasks suchas color normalization, 2) segmentation of micro-anatomicobjects such as cells and nuclei, 3) characterization of theshape and texture features of the segmented objects, and4) machine-learning methods that integrate information fromfeatures to classify the images and objects. In terms ofcomputation cost, the preprocessing and classification stages(stages 1 and 4) are inexpensive relative to the segmentationand feature computation stages (stages 2 and 3). The currentimplementation of the classification stage works at imageand patient level and includes significant data reductionprior to the actual classification operation which decreasesdata and computational requirements. The segmentation andfeature computation stages, on the other hand, may operateon hundreds to thousands of images with resolutions rangingfrom 50K×50K to 100K×100K pixels and on 105 to 107
micro-anatomic objects (e.g., cells and nuclei) per image.Thus, we target the segmentation and feature computationstages in this paper.
The segmentation stage detects cells and nuclei and de-lineates their boundaries. It consists of several componentoperations, forming a dataflow graph (see Figure 1). Theoperations in the segmentation include morphological re-construction to identify candidate objects, watershed seg-mentation to separate overlapping objects, and filtering toeliminate candidates that are unlikely to be nuclei based onobject characteristics. The feature computation stage derivesquantitative attributes in the form of a feature vector forthe entire image or for individual segmented objects. Thefeature types include pixel statistics, gradient statistics, edge,and morphometry. Most of the features can be computedconcurrently in a multi-threaded or parallel environment.
III. APPLICATION PARALLELIZATION FOR HIGHTHROUGHPUT EXECUTION
The workflow stages described in the previous sectionwere originally implemented in MATLAB. To create highperformance versions of the segmentation and feature com-putation stages, we first implemented GPU-enabled versions,as well as C++-based CPU versions, of individual operationsin those stages (Section III-A). We then developed a runtimemiddleware and methods that combine the bag-of-tasks andcoarse-grain dataflow patterns for parallelization across mul-tiple nodes and within each CPU-GPU node (Section III-B).Finally, we incorporated a set of runtime optimizations toreduce computation time and use CPUs and GPUs in acoordinated manner on each compute node (Section III-C).
A. GPU-based Implementations of Operations
We used existing implementations from OpenCV [4]library or from other research groups, or implemented our

Figure 1. Pipeline for segmenting nuclei in a whole slide tissue image and computing their features. The input to the pipeline is an image or image tile.The output is a set of features for each segmented nucleus.
own if no efficient implementations were available. TheMorphological Open operation, for example, is availablein OpenCV [4] and is implemented using NVIDIA Per-formance Primitives (NPP) [5]. The Watershed operation,on the other hand, has only a CPU implementation in theOpenCV library. We used the GPU version developed byKorbes et. al. [6] for this operation. A list of core operationssupported by our current implementation along with thesources of the CPU/GPU implementations is presented inTable I.
Several of the methods we developed in the segmentationstage have irregular data access and processing patterns.The Morphological Reconstruction (MR) [7] and DistanceTransform algorithms are used as building blocks in anumber of these methods. These algorithms can be effi-ciently executed on a CPU using a queue structure. In thesealgorithms, only the computation performed in a subset ofthe elements (active elements) from the input data domaineffectively contribute to the output. Therefore, to reduce thecomputation cost, the active elements are tracked using acontainer, e.g., a queue, so that only those elements areprocessed. When an element is selected for computation, itis removed from the set of active elements. The computationof the active element involves its neighboring elements on agrid, and one or more of the neighbors may be added to theset of active elements as a result of the computation. Thisprocess continues until stability is reached; i.e., the containerof active elements becomes empty. To port these algorithmsto the GPU, we have implemented a hierarchical and scalablequeue to store elements (pixels) in fast GPU memoriesalong with several optimizations to reduce execution time.We refer the reader to the following manuscripts [8], [9]for implementation details. The queue-based implementa-tion resulted in significant performance improvements overpreviously published GPU-enabled versions of the MR al-gorithm [10]. Our implementation of the distance transformresults in a distance map equivalent to that of Danielsson’salgorithm [11].
The connected component labeling operation (BWLabel)was implemented using the union-find pattern [12]. Con-ceptually, the BWLabel with union-find first constructs aforest where each pixel is its own tree. It then merges treescorresponding to adjacent pixels by inserting one tree as abranch of the other. The trees are merged only when theadjacent pixels have the same mask pixel value. During a
Table ISOURCES OF CPU AND GPU IMPLEMENTATIONS OF OPERATIONS IN
THE SEGMENTATION AND FEATURE COMPUTATION STAGES.
Pipeline operation CPU source GPU source
RBC detection OpenCV and Vincent [7] ImplementedMorph. Reconstruction (MR)Morph. Open OpenCV (by a 19x19 disk) OpenCVReconToNuclei Vincent [7] MR ImplementedAreaThreshold Implemented ImplementedFillHolles Vincent [7] MR Implemented
Pre-Watershed Vincent [7] MR and OpenCV Implementedfor distance transformationWatershed OpenCV Korbes [6]BWLabel Implemented Implemented
Features comp. Implemented. Implemented.OpenCV(Canny) OpenCV(Canny)
merge, the roots of two trees are compared by the labelvalues. The root with the smaller label value remains theroot, while the other is grafted onto the new root. After allthe pixels have been visited, pixels belonging to the samecomponent are on the same label tree. The label can thenbe extracted by flattening the trees and reading the labels.The output of this operation in the computation pipeline,shown in Figure 1, is a labeled mask containing all of thesegmented objects.
The operations in the feature computation stage consistof pixel and neighborhood based transformations that areapplied to the input image (Color deconvolution, Canny,and Gradient) and computations on individual objects (e.g.,nuclei) segmented in the segmentation stage. The featurecomputations on objects are generally more regular and com-pute intensive than the operations in the segmentation stage.This characteristics of the feature computation operationslead to better GPU acceleration [13].
B. Parallelization on Distributed CPU-GPU machines
The image analysis application encapsulates multiple pro-cessing patterns. First, each image can be partitioned intorectangular tiles, and the segmentation and feature compu-tation steps can be executed on each tile independently. Thisleads to a bag-of-tasks style processing pattern. Second, theprocessing of a single tile can be expressed as a hierarchicalcoarse-grain dataflow pattern. The segmentation and featurecomputation stages are the first level of the dataflow struc-ture. The second level is the set of fine-grain operations thatconstitute each of the coarse-grain stages. This formulationis illustrated in Figure 1.

The hierarchical representation lends itself to a separationof concerns and enables the use of different schedulingapproaches at each level. For instance, it allows for thepossibility of exporting second level operations (fine-grainoperations) to a local scheduler on a hybrid node, as opposedto describing each pipeline stage as a single monolithic taskthat should entirely be assigned to a GPU or a CPU. In thisway, the scheduler can control tasks at a finer granularity,account for performance variations across the finer graintasks within a node, and assign them to the most appropriatedevice.
In order to support this representation, our implementationis built on top of a Manager-Worker model, shown inFigure 2, that combines the bag-of-tasks style execution withthe coarse-grain dataflow execution pattern. The applicationManager creates stage instances, each of which are repre-sented by a tuple, (input data chunk, processing stage),and builds the dependencies among them to enforce thecorrect pipeline execution. This dependency graph is notcompletely known prior to execution, thus is built dynam-ically at runtime. For instance, after the segmentation ofa tile, the feature extraction for that particular chunk ofdata is only dispatched for computation if a certain numberof objects were segmented. Since stage instances may becreated as a consequence of the computation of other stageinstances, it is possible to create loops as the dependencygraph may be reinstantiated dynamically.
Figure 2. Overview of the multi-node parallelization strategy.
The granularity of tasks assigned to the applicationWorker nodes is equal to stage instances, i.e., a segmentationor feature computation stage instance in our case. Thetasks are scheduled to the Workers using a demand-drivenapproach. Stage instances are assigned to the Workers forexecution in the same order the instances are created, and theWorkers continuously request work as they finalize the exe-cution of the previous instances (see Figure 2). In practice, asingle Worker is able to execute multiple application stagesconcurrently, and the sets of Workers shown in Figure 2 arenot necessarily disjoint. All the communication among theprocesses is done using MPI.
Since a Worker (see Figure 3) is able to use all CPUcores and GPUs in a node concurrently, it may ask for
multiple stage instances from the Manager in order to keepall computing devices busy. The maximum number of stageinstances assigned to a Worker at a time is a configurablevalue (Window size). The Worker may request multiple stageinstances in one request or in multiple requests; in the lattercase, the assignment of a stage instance and the retrievalof necessary input data chunks can be overlapped with theprocessing of an already assigned stage instance.
Figure 3. A Worker is a multi-thread process. It uses all the devices ina hybrid node via the local Worker Resource Manager, which coordinatesthe scheduling and mapping of operation instances assigned to the Workerto CPU cores and GPUs.
The Worker Communication Controller (WCC) moduleruns on one of the CPU cores and is responsible forperforming any necessary communication with the Man-ager. All computing devices used by a Worker are con-trolled by a local Worker Resource Manager (WRM). Whena Worker receives a stage instance from the applicationManager and instantiates the pipeline of finer-grain op-erations in that pipeline instance, each of the fine-grainoperation instances, (input data, operation), is dispatchedfor execution with the local WRM. The WRM maps the(input data, operation) tuples to the local computingdevices as the dependencies between the operations areresolved. In this model of a Worker, one computing threadis assigned to manage each available CPU computing coreor a GPU. The threads notify the WRM whenever theybecome idle. The WRM then selects one of the tuples readyfor execution with operation implementation matching theprocessor managed by that particular thread. When all theoperations in the pipeline related to a given stage instanceare executed, a callback function is invoked to notify theWCC. The WCC then notifies the Manager about the end ofthat stage instance and requests more stage instances. Duringa stage instance destruction phase, it could also instantiateother stages instances as necessary.
C. Efficient Cooperative Execution on CPUs and GPUs
This section describes optimizations that address smartassignment of operations to CPUs and GPUs and datamovement between those devices.

1) Performance Aware Task Scheduling (PATS): Thestage instances (Segmentation or Feature Computation) as-signed to a Worker create many finer-grain operation in-stances. The operation instances need to be mapped toavailable CPU cores and GPUs efficiently in order to fullyutilize the computing capacity of a node. Several recentefforts on task scheduling in heterogeneous environmentshave targeted machines equipped with CPUs and GPUs [14],[15], [16]. These works address the problem of partitioningand mapping tasks between CPUs and GPUs for applicationsin which operations (or tasks) achieve consistent speedupswhen executed on a GPU vs on a CPU. The previousefforts differ mainly in whether they use off-line, on-line, orautomated scheduling approaches. However, when there aremultiple types of operations in an application, the operationsmay have different processing and data access patterns andattain different amounts of speedup on a GPU.
In order to use performance variability to our advantage,we have developed a strategy, referred here to as PATS(formerly PRIORITY scheduling) [13]. This strategy assignstasks to CPU cores or GPUs based on an estimate of the rela-tive performance gain of each task on a GPU compared to itsperformance on a CPU core and on the computational loadsof the CPUs and GPUs. In this work, we have extended thePATS scheduler to take into account dependencies betweenoperations in an analysis workflow.
The PATS scheduler uses a queue of operation instances,i.e., (data element, operation) tuples, sorted based on therelative speedup expected for each tuple. As more tuplesare created for execution with each Worker and pendingoperation dependencies are resolved, more operations arequeued for execution. Each new operation is inserted in thequeue such that the queue remains sorted (see Figure 3).During execution, when a CPU core or GPU becomes idle,one of the tuples from the queue is assigned to the idledevice. If the idle device is a CPU core, the tuple withthe minimum estimated speedup value is assigned to theCPU core. If the idle device is a GPU, the tuple with themaximum estimated speedup is assigned to the GPU. ThePATS scheduler relies on maintaining the correct relativeorder of speedup estimates rather than the accuracy ofindividual speedup estimates. Even if the speedup estimatesof two tasks are not accurate with respect to their respectivereal speedup values, the scheduler will correctly assign thetasks to the computing devices on the node, as long as theorder of the speedup values is correct.
Time based scheduling strategies, e.g., heterogeneousearliest finish time, have shown to be very efficient forheterogeneous environments. The main reason we do not usea time based scheduling strategy is that most operations inour case have irregular computation patterns and data depen-dent execution times. Estimating execution times for thoseoperations would be very difficult. Thus, our schedulingapproach uses relative GPU-vs-CPU speedup values, which
we have observed are easier to estimate, have less variance,and lead to better scheduling in our example application.
Although we provide CPU and GPU implementations ofeach operation in our implementation, this is not necessaryfor correct execution. When an operation has only oneimplementation, CPU or CPU, the scheduler can restrictthe assignment of the operation to the appropriate type ofcomputing device.
2) Data Locality Conscious Task Assignment (DL): Thebenefits of using a GPU for a certain computation arestrongly impacted by the cost of data transfers between theGPU and the CPU before the GPU kernel can be started.In our execution model, input and output data are welldefined as they refer to the input and output streams ofeach stage and operation. Leveraging this structure, we haveextended the base scheduler in order to promote data reuseand avoid penalties due to excessive data movement. Afteran operation assigned to a GPU has finished, the schedulerexplores the operation dependency graph and searches foroperations ready for execution that can reuse the data alreadyin the GPU memory. If the operation speedups are notknown, the scheduler always chooses to reuse data insteadof selecting another operation that does not reuse data.For the case where speedup estimates for operations areavailable, the scheduler searches for tasks that reuse datain the dependency graph, but it additionally takes intoconsideration other operations ready for execution. Althoughthose operations may not reuse data, it may be worthwhileto pay the data transfer penalties if they benefit more fromexecution on a GPU than the operations that can reusethe data. To choose which operation instance to execute inthis situation, the speedup of the dependent operations withthe best speedup (Sd) is compared to that of the operationwith the best speedup (Sq) that does not reuse the data.The dependent operation is chosen for execution, if Sd ≥Sq × (1 − transferImpact). Here transferImpact is areal value between 0 and 1 and represents the fraction of theoperation execution time spent in data transfer. We currentlyrely on the programmer to provide such an estimate, but weplan to automate this step in a future work.
3) Data Prefetching and Asynchronous Data Copy: Datalocality conscious task assignment reduces data transfersbetween CPUs and GPUs for successive operations in apipeline. However, there are moments in the executionwhen data still have to be exchanged between these devicesbecause of scheduling decisions. In those cases, data copyoverheads can be reduced by employing pre-fetching andasynchronous data copy. New data can be copied to theGPU in parallel to the execution of the computation kernelon a previously copied data [17]. In a similar way, resultsfrom previous computations may be copied to the CPU inparallel to a kernel execution. In order to employ both dataprefetching and asynchronous data copy, we modified theruntime system to perform the computation and communi-
cation of pipelined operations in parallel. The execution ofeach operation using a GPU in this execution mode involvesthree phases: uploading, processing, and downloading.Each GPU manager thread in the WRM pipelines multipleoperations through these three phases. Any input data neededfor another operation waiting to execute and the results froma completed operation are copied from and to the CPU inparallel to the ongoing computation in the GPU.
IV. EXPERIMENTAL EVALUATION
A. Experimental Setup
We have evaluated the runtime system, optimizations,and application implementation using a distributed memoryhybrid cluster, called Keeneland [2]. Keeneland is a NationalScience Foundation Track2D Experimental System and has120 nodes in the current configuration. Each computationnode is equipped with a dual socket Intel X5660 2.8 GhzWestmere processor, 3 NVIDIA Tesla M2090 (Fermi) GPUs,and 24GB of DDR3 RAM (See Figure 4). The nodes areconnected to each other through a QDR Infiniband switch.
Figure 4. Architecture of a Keeneland node.
The image datasets used in the evaluation were obtainedfrom brain tumor studies [3]. Each image was partitionedinto tiles of 4K×4K pixels. The codes were compiled using“gcc 4.1.2”, “-O3” optimization flag, OpenCV 2.3.1, andNVIDIA CUDA SDK 4.0. The experiments were repeated3 times. The standard deviation in performance results wasnot observed to be higher than 2%. The input data werestored in the Lustre filesystem.
B. Performance of Application Operations on GPU
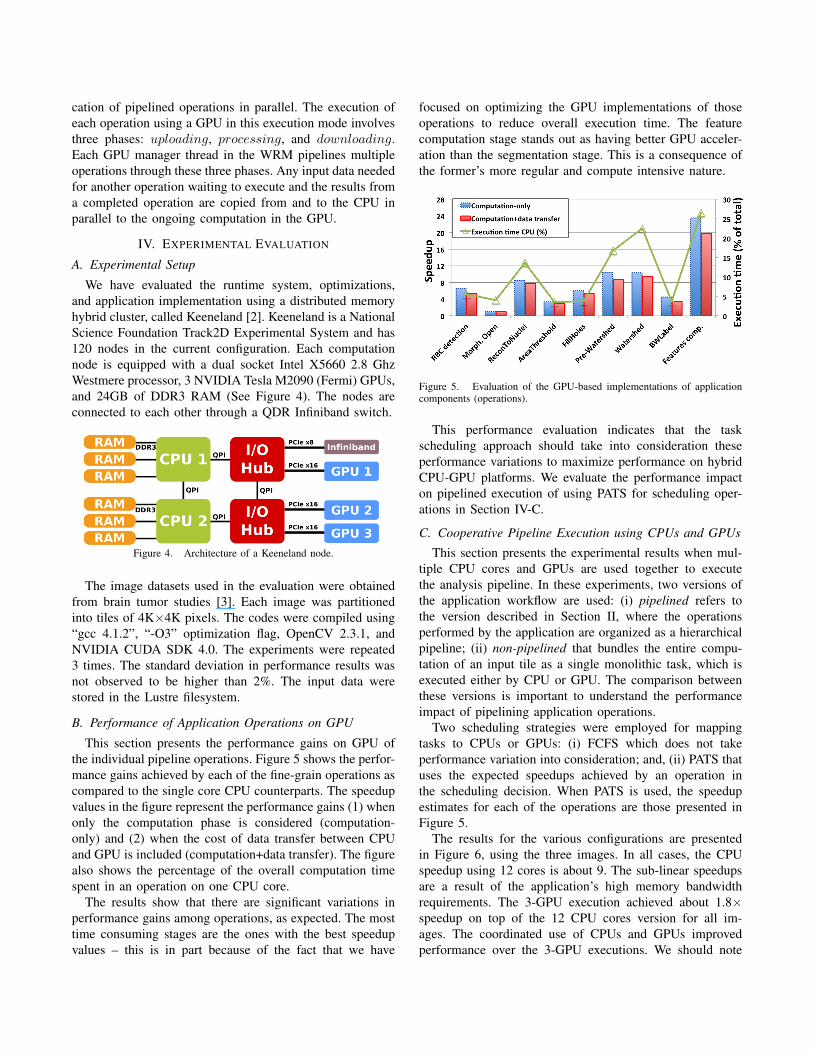
This section presents the performance gains on GPU ofthe individual pipeline operations. Figure 5 shows the perfor-mance gains achieved by each of the fine-grain operations ascompared to the single core CPU counterparts. The speedupvalues in the figure represent the performance gains (1) whenonly the computation phase is considered (computation-only) and (2) when the cost of data transfer between CPUand GPU is included (computation+data transfer). The figurealso shows the percentage of the overall computation timespent in an operation on one CPU core.
The results show that there are significant variations inperformance gains among operations, as expected. The mosttime consuming stages are the ones with the best speedupvalues – this is in part because of the fact that we have
focused on optimizing the GPU implementations of thoseoperations to reduce overall execution time. The featurecomputation stage stands out as having better GPU acceler-ation than the segmentation stage. This is a consequence ofthe former’s more regular and compute intensive nature.
Figure 5. Evaluation of the GPU-based implementations of applicationcomponents (operations).
This performance evaluation indicates that the taskscheduling approach should take into consideration theseperformance variations to maximize performance on hybridCPU-GPU platforms. We evaluate the performance impacton pipelined execution of using PATS for scheduling oper-ations in Section IV-C.
C. Cooperative Pipeline Execution using CPUs and GPUs
This section presents the experimental results when mul-tiple CPU cores and GPUs are used together to executethe analysis pipeline. In these experiments, two versions ofthe application workflow are used: (i) pipelined refers tothe version described in Section II, where the operationsperformed by the application are organized as a hierarchicalpipeline; (ii) non-pipelined that bundles the entire compu-tation of an input tile as a single monolithic task, which isexecuted either by CPU or GPU. The comparison betweenthese versions is important to understand the performanceimpact of pipelining application operations.
Two scheduling strategies were employed for mappingtasks to CPUs or GPUs: (i) FCFS which does not takeperformance variation into consideration; and, (ii) PATS thatuses the expected speedups achieved by an operation inthe scheduling decision. When PATS is used, the speedupestimates for each of the operations are those presented inFigure 5.
The results for the various configurations are presentedin Figure 6, using the three images. In all cases, the CPUspeedup using 12 cores is about 9. The sub-linear speedupsare a result of the application’s high memory bandwidthrequirements. The 3-GPU execution achieved about 1.8×speedup on top of the 12 CPU cores version for all im-ages. The coordinated use of CPUs and GPUs improvedperformance over the 3-GPU executions. We should note
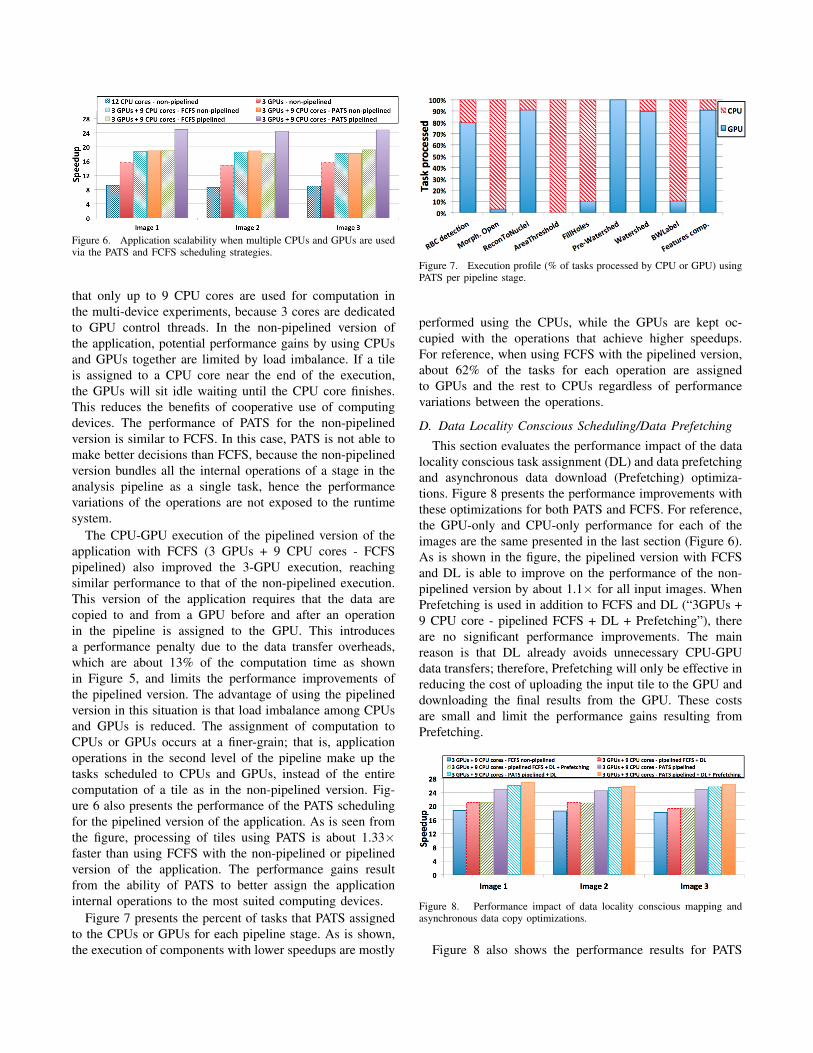
Figure 6. Application scalability when multiple CPUs and GPUs are usedvia the PATS and FCFS scheduling strategies.
that only up to 9 CPU cores are used for computation inthe multi-device experiments, because 3 cores are dedicatedto GPU control threads. In the non-pipelined version ofthe application, potential performance gains by using CPUsand GPUs together are limited by load imbalance. If a tileis assigned to a CPU core near the end of the execution,the GPUs will sit idle waiting until the CPU core finishes.This reduces the benefits of cooperative use of computingdevices. The performance of PATS for the non-pipelinedversion is similar to FCFS. In this case, PATS is not able tomake better decisions than FCFS, because the non-pipelinedversion bundles all the internal operations of a stage in theanalysis pipeline as a single task, hence the performancevariations of the operations are not exposed to the runtimesystem.
The CPU-GPU execution of the pipelined version of theapplication with FCFS (3 GPUs + 9 CPU cores - FCFSpipelined) also improved the 3-GPU execution, reachingsimilar performance to that of the non-pipelined execution.This version of the application requires that the data arecopied to and from a GPU before and after an operationin the pipeline is assigned to the GPU. This introducesa performance penalty due to the data transfer overheads,which are about 13% of the computation time as shownin Figure 5, and limits the performance improvements ofthe pipelined version. The advantage of using the pipelinedversion in this situation is that load imbalance among CPUsand GPUs is reduced. The assignment of computation toCPUs or GPUs occurs at a finer-grain; that is, applicationoperations in the second level of the pipeline make up thetasks scheduled to CPUs and GPUs, instead of the entirecomputation of a tile as in the non-pipelined version. Fig-ure 6 also presents the performance of the PATS schedulingfor the pipelined version of the application. As is seen fromthe figure, processing of tiles using PATS is about 1.33×faster than using FCFS with the non-pipelined or pipelinedversion of the application. The performance gains resultfrom the ability of PATS to better assign the applicationinternal operations to the most suited computing devices.
Figure 7 presents the percent of tasks that PATS assignedto the CPUs or GPUs for each pipeline stage. As is shown,the execution of components with lower speedups are mostly
Figure 7. Execution profile (% of tasks processed by CPU or GPU) usingPATS per pipeline stage.
performed using the CPUs, while the GPUs are kept oc-cupied with the operations that achieve higher speedups.For reference, when using FCFS with the pipelined version,about 62% of the tasks for each operation are assignedto GPUs and the rest to CPUs regardless of performancevariations between the operations.
D. Data Locality Conscious Scheduling/Data Prefetching
This section evaluates the performance impact of the datalocality conscious task assignment (DL) and data prefetchingand asynchronous data download (Prefetching) optimiza-tions. Figure 8 presents the performance improvements withthese optimizations for both PATS and FCFS. For reference,the GPU-only and CPU-only performance for each of theimages are the same presented in the last section (Figure 6).As is shown in the figure, the pipelined version with FCFSand DL is able to improve on the performance of the non-pipelined version by about 1.1× for all input images. WhenPrefetching is used in addition to FCFS and DL (“3GPUs +9 CPU core - pipelined FCFS + DL + Prefetching”), thereare no significant performance improvements. The mainreason is that DL already avoids unnecessary CPU-GPUdata transfers; therefore, Prefetching will only be effective inreducing the cost of uploading the input tile to the GPU anddownloading the final results from the GPU. These costsare small and limit the performance gains resulting fromPrefetching.
Figure 8. Performance impact of data locality conscious mapping andasynchronous data copy optimizations.
Figure 8 also shows the performance results for PATS
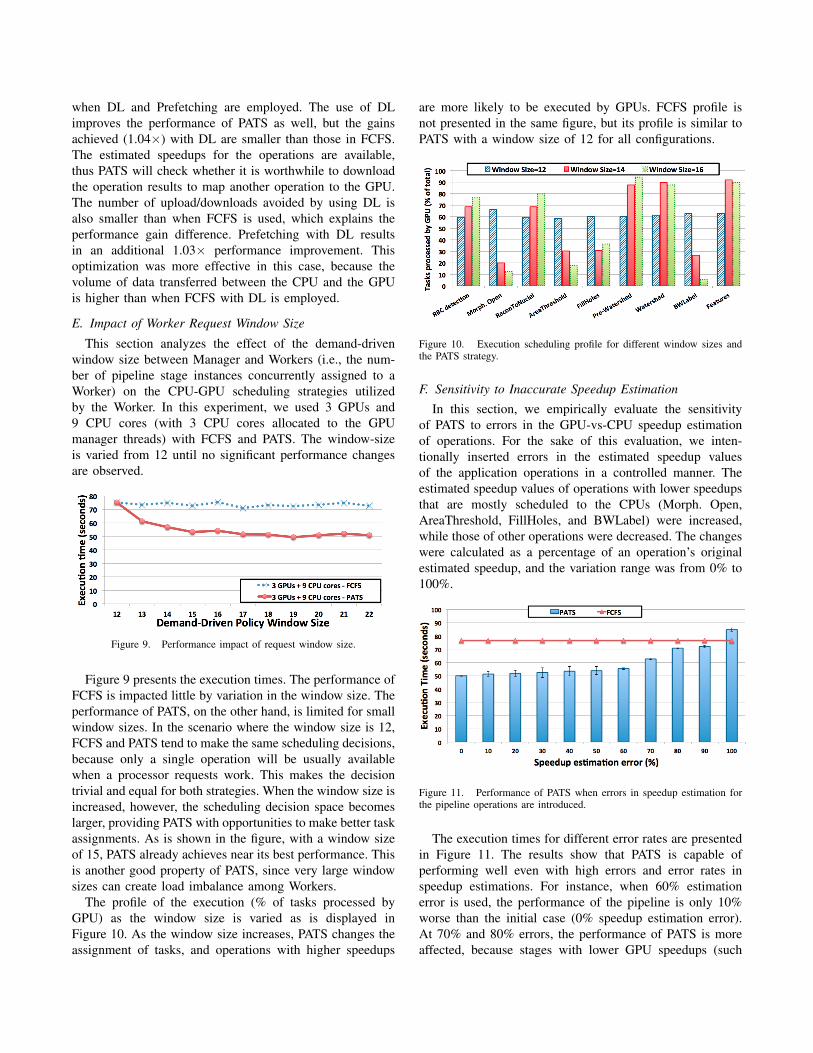
when DL and Prefetching are employed. The use of DLimproves the performance of PATS as well, but the gainsachieved (1.04×) with DL are smaller than those in FCFS.The estimated speedups for the operations are available,thus PATS will check whether it is worthwhile to downloadthe operation results to map another operation to the GPU.The number of upload/downloads avoided by using DL isalso smaller than when FCFS is used, which explains theperformance gain difference. Prefetching with DL resultsin an additional 1.03× performance improvement. Thisoptimization was more effective in this case, because thevolume of data transferred between the CPU and the GPUis higher than when FCFS with DL is employed.
E. Impact of Worker Request Window Size
This section analyzes the effect of the demand-drivenwindow size between Manager and Workers (i.e., the num-ber of pipeline stage instances concurrently assigned to aWorker) on the CPU-GPU scheduling strategies utilizedby the Worker. In this experiment, we used 3 GPUs and9 CPU cores (with 3 CPU cores allocated to the GPUmanager threads) with FCFS and PATS. The window-sizeis varied from 12 until no significant performance changesare observed.
Figure 9. Performance impact of request window size.
Figure 9 presents the execution times. The performance ofFCFS is impacted little by variation in the window size. Theperformance of PATS, on the other hand, is limited for smallwindow sizes. In the scenario where the window size is 12,FCFS and PATS tend to make the same scheduling decisions,because only a single operation will be usually availablewhen a processor requests work. This makes the decisiontrivial and equal for both strategies. When the window size isincreased, however, the scheduling decision space becomeslarger, providing PATS with opportunities to make better taskassignments. As is shown in the figure, with a window sizeof 15, PATS already achieves near its best performance. Thisis another good property of PATS, since very large windowsizes can create load imbalance among Workers.
The profile of the execution (% of tasks processed byGPU) as the window size is varied as is displayed inFigure 10. As the window size increases, PATS changes theassignment of tasks, and operations with higher speedups
are more likely to be executed by GPUs. FCFS profile isnot presented in the same figure, but its profile is similar toPATS with a window size of 12 for all configurations.
Figure 10. Execution scheduling profile for different window sizes andthe PATS strategy.
F. Sensitivity to Inaccurate Speedup Estimation
In this section, we empirically evaluate the sensitivityof PATS to errors in the GPU-vs-CPU speedup estimationof operations. For the sake of this evaluation, we inten-tionally inserted errors in the estimated speedup valuesof the application operations in a controlled manner. Theestimated speedup values of operations with lower speedupsthat are mostly scheduled to the CPUs (Morph. Open,AreaThreshold, FillHoles, and BWLabel) were increased,while those of other operations were decreased. The changeswere calculated as a percentage of an operation’s originalestimated speedup, and the variation range was from 0% to100%.
Figure 11. Performance of PATS when errors in speedup estimation forthe pipeline operations are introduced.
The execution times for different error rates are presentedin Figure 11. The results show that PATS is capable ofperforming well even with high errors and error rates inspeedup estimations. For instance, when 60% estimationerror is used, the performance of the pipeline is only 10%worse than the initial case (0% speedup estimation error).At 70% and 80% errors, the performance of PATS is moreaffected, because stages with lower GPU speedups (such
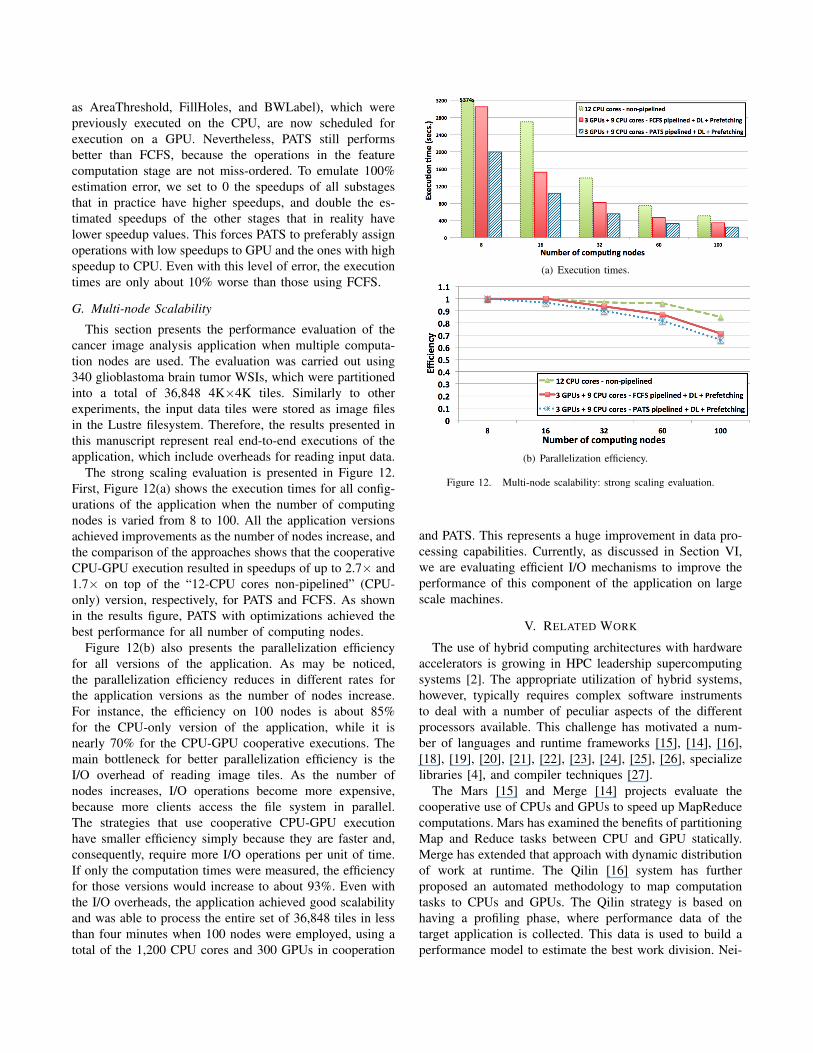
as AreaThreshold, FillHoles, and BWLabel), which werepreviously executed on the CPU, are now scheduled forexecution on a GPU. Nevertheless, PATS still performsbetter than FCFS, because the operations in the featurecomputation stage are not miss-ordered. To emulate 100%estimation error, we set to 0 the speedups of all substagesthat in practice have higher speedups, and double the es-timated speedups of the other stages that in reality havelower speedup values. This forces PATS to preferably assignoperations with low speedups to GPU and the ones with highspeedup to CPU. Even with this level of error, the executiontimes are only about 10% worse than those using FCFS.
G. Multi-node Scalability
This section presents the performance evaluation of thecancer image analysis application when multiple computa-tion nodes are used. The evaluation was carried out using340 glioblastoma brain tumor WSIs, which were partitionedinto a total of 36,848 4K×4K tiles. Similarly to otherexperiments, the input data tiles were stored as image filesin the Lustre filesystem. Therefore, the results presented inthis manuscript represent real end-to-end executions of theapplication, which include overheads for reading input data.
The strong scaling evaluation is presented in Figure 12.First, Figure 12(a) shows the execution times for all config-urations of the application when the number of computingnodes is varied from 8 to 100. All the application versionsachieved improvements as the number of nodes increase, andthe comparison of the approaches shows that the cooperativeCPU-GPU execution resulted in speedups of up to 2.7× and1.7× on top of the “12-CPU cores non-pipelined” (CPU-only) version, respectively, for PATS and FCFS. As shownin the results figure, PATS with optimizations achieved thebest performance for all number of computing nodes.
Figure 12(b) also presents the parallelization efficiencyfor all versions of the application. As may be noticed,the parallelization efficiency reduces in different rates forthe application versions as the number of nodes increase.For instance, the efficiency on 100 nodes is about 85%for the CPU-only version of the application, while it isnearly 70% for the CPU-GPU cooperative executions. Themain bottleneck for better parallelization efficiency is theI/O overhead of reading image tiles. As the number ofnodes increases, I/O operations become more expensive,because more clients access the file system in parallel.The strategies that use cooperative CPU-GPU executionhave smaller efficiency simply because they are faster and,consequently, require more I/O operations per unit of time.If only the computation times were measured, the efficiencyfor those versions would increase to about 93%. Even withthe I/O overheads, the application achieved good scalabilityand was able to process the entire set of 36,848 tiles in lessthan four minutes when 100 nodes were employed, using atotal of the 1,200 CPU cores and 300 GPUs in cooperation
(a) Execution times.
(b) Parallelization efficiency.
Figure 12. Multi-node scalability: strong scaling evaluation.
and PATS. This represents a huge improvement in data pro-cessing capabilities. Currently, as discussed in Section VI,we are evaluating efficient I/O mechanisms to improve theperformance of this component of the application on largescale machines.
V. RELATED WORK
The use of hybrid computing architectures with hardwareaccelerators is growing in HPC leadership supercomputingsystems [2]. The appropriate utilization of hybrid systems,however, typically requires complex software instrumentsto deal with a number of peculiar aspects of the differentprocessors available. This challenge has motivated a num-ber of languages and runtime frameworks [15], [14], [16],[18], [19], [20], [21], [22], [23], [24], [25], [26], specializelibraries [4], and compiler techniques [27].
The Mars [15] and Merge [14] projects evaluate thecooperative use of CPUs and GPUs to speed up MapReducecomputations. Mars has examined the benefits of partitioningMap and Reduce tasks between CPU and GPU statically.Merge has extended that approach with dynamic distributionof work at runtime. The Qilin [16] system has furtherproposed an automated methodology to map computationtasks to CPUs and GPUs. The Qilin strategy is based onhaving a profiling phase, where performance data of thetarget application is collected. This data is used to build aperformance model to estimate the best work division. Nei-

ther of these solutions (Mars, Merge, and Qilin), however,are able to take advantage of distributed systems.
PTask [28] provides OS abstractions for execution oftasks, called ptasks, on GPU equipped machines. It treatsGPUs as first class resources and provides methods forscheduling tasks to GPUs, fairness, and isolation. Appli-cations are represented using a data-flow model. Our ap-proach differs from Ptask in several ways. A task in ourframework is dynamically bound to a GPU or CPU duringexecution. ptasks in the PTask framework, on the otherhand, cannot be re-targeted. Our PATS scheduler employsa different priority metric, the relative performance of (data,oper) on GPU vs CPU, for mapping tasks to processors.These optimizations are targeted at improving throughput.We also allow for cyclic and dynamic dependency graphs,hierarchical pipelines, and multi-node execution. We believePTask and our system could co-exist and benefit from eachother.
Efficient execution of applications on distributed CPU-GPU equipped platforms has been an objective of severalprojects [23], [24], [25], [26], [22], [29], [30]. Ravi etal. [24], [26] proposes techniques for automatic translationof generalized reductions to CPU-GPU environments viacompile-time techniques, which are coupled with runtimesupport to coordinate execution. The runtime system tech-niques employ auto-tuning approaches to dynamically par-tition tasks among CPUs and GPUs. The work by Hartleyet al. [25] is contemporary to Ravi’s and proposes runtimestrategies for divisible workloads. The OmpSs [29] supportsefficient asynchronous execution of dataflow applicationsautomatically generated by compiler techniques from serialannotated code. OmpSs statically binds the tasks to one ofthe available processors, while our approach dynamicallyschedules tasks to processors during execution according tothe performance benefits and device suitability of tasks.
DAGuE [23] and StarPU [18], [31] are frameworks thatsupport execution of regular linear algebra applications onCPU-GPU machines. These systems represent an applicationas a DAG of operations and ensure that dependencies arerespected. They offer different scheduling policies, includingthose that prioritize computation of critical paths in thedependency graph in order to maximize parallelism. Theyinclude support for multi-node execution and assume thatthe application DAG is static and known before execution.This structure fits well with regular linear algebra applica-tions, but is a limitation that prevents their use in irregularand dynamic applications such as ours. In our application,the dependency graph representing the application must bedynamically built during the execution, as the computationof the next stage of the analysis pipeline may depend on theresults of the current stage. For instance, the entire featurecomputation should not be computed, if nuclei are not foundin the segmentation stage. Additionally, neither of the previ-ous solutions allow for the representation of the application
as a multi-level pipeline, which is key to achieving highperformance with fine-grain task management.
Our work targets a scientific data analysis pipeline, includ-ing the GPU/CPU implementations of several challengingirregular operations. In addition, we develop support forexecution of applications that can be described as a multi-level pipeline of operations, where coarse-grain stages aredivided into fine-grain operations. In this way, we canleverage variability in the amount of GPU acceleration offine-grain operations that was not possible in the previousworks. We also investigate a set of optimizations that includedata locality aware task assignment. This optimization dy-namically groups operations that present good performanceaccording to the current set of tasks ready to execute on amachine, instead of doing it statically prior to execution as inour previous work [13]. Data prefetching and asynchronousdata transfer optimizations are also employed in order tomaximize computational resource utilization.
VI. CONCLUSIONS AND FUTURE DIRECTIONS
Hybrid CPU-GPU cluster systems offer significant com-puting and memory capacity to address the computationalneeds of large scale scientific analyses. In this paper, wehave developed an image analysis application that can fullyexploit such platforms to achieve high-throughput data pro-cessing rates. We have shown that significant performanceimprovements are achieved when an analysis applicationcan be assembled as pipelines of fine-grain operations, ascompared to bundling all internal operations in one ortwo monolithic methods. The former allows for exportingapplication processing patterns more accurately to the run-time environment and empowers the middleware system tomake better scheduling decisions. Performance aware taskscheduling coupled with function variants enable efficientcoordinated use of CPU cores and GPUs in pipelinedoperations. Performance gains can further be increased onhybrid systems through such additional runtime optimiza-tions as locality conscious task mapping, data prefetching,and asynchronous data copy. Employing a combinationof these optimizations, our application implementation hasachieved a processing rate of about 150 tiles per secondwhen 100 nodes, each with 12 CPU cores and 3 GPUs, areused. These levels of processing speed make it feasible toprocess very large datasets and would enable a scientist toexplore different scientific questions rapidly and/or carry outalgorithm sensitivity studies.
The current implementation of the classification step (step4 in Section II) clusters images into groups based onaverage feature values per image. The average feature valuescan be computed by maintaining on each compute nodea running sum of the feature values of segmented objectsfor each image. The partial sums on the nodes can thenbe accumulated in a global sum operation, and the averagefeature values per image can be computed. Thus, the amount

of data transferred from the feature computation step tothe classification step is relatively small. However, thereare cases when the output from a stage, or even from anoperation, needs to be staged to disk. For example, studyingthe sensitivity to input parameters and algorithm variationsof output from the segmentation stage would require us toexecute multiple runs. It might not be possible, due to timeand resource constraints, to maintain output from a run inmemory until all the runs have been completed. The outputfrom a stage in a single run or multiple runs may alsoneed to be stored on disk for inspection or visualizationat a later time. As a future work, in order to support theI/O requirements in such cases, we are developing an I/Ocomponent based on a stream-I/O approach, drawing fromfilter-stream networks [32], [33], [34], [35], [36] and datastaging [37], [38]. This implementation facilitates flexibility.The I/O processes can be placed on different physicalprocessors in the system. For example, if a system hadseparate machines for I/O purposes, the I/O nodes couldbe placed on those machines. Moreover, the implementationallows us to leverage different I/O sub-systems. In additionto POSIX I/O in which each I/O process writes out itsbuffers independent of other I/O nodes, we have integratedADIOS [39] for data output. ADIOS is shown to be efficient,portable, and scalable on supercomputing platforms and fora range of applications. We are in the process of carryingout initial performance evaluations of the I/O component.
ACKNOWLEDGMENT
This work was supported in part byHHSN261200800001E from the National Cancer Institute,R24HL085343 from the National Heart Lung and BloodInstitute, by R01LM011119-01 and R01LM009239 fromthe National Library of Medicine, RC4MD005964 fromNational Institutes of Health, and PHS UL1RR025008 fromthe Clinical and Translational Science Awards program.This research used resources of the Keeneland ComputingFacility at the Georgia Institute of Technology, whichis supported by the National Science Foundation underContract OCI-0910735.
REFERENCES
[1] NVIDIA, “GPU Accelerated Applications,” 2012.[Online]. Available: http://www.nvidia.com/object/gpu-accelerated-applications.html
[2] J. S. Vetter, R. Glassbrook, J. Dongarra, K. Schwan, B. Loftis,S. McNally, J. Meredith, J. Rogers, P. Roth, K. Spafford,and S. Yalamanchili, “Keeneland: Bringing HeterogeneousGPU Computing to the Computational Science Community,”Computing in Science and Engineering, vol. 13, 2011.
[3] L. A. D. Cooper, J. Kong, D. A. Gutman, F. Wang, S. R.Cholleti, T. C. Pan, P. M. Widener, A. Sharma, T. Mikkelsen,A. E. Flanders, D. L. Rubin, E. G. V. Meir, T. M. Kurc,C. S. Moreno, D. J. Brat, and J. H. Saltz, “An integrative
approach for in silico glioma research,” IEEE Trans BiomedEng., vol. 57, no. 10, pp. 2617–2621, 2010.
[4] G. Bradski, “The OpenCV Library,” Dr. Dobb’s Journal ofSoftware Tools, 2000.
[5] NVIDIA, NVIDIA Performance Primitives(NPP), 11 Febru-ary 2011. [Online]. Available: http://developer.nvidia.com/npp
[6] A. Korbes, G. B. Vitor, R. de Alencar Lotufo, and J. V.Ferreira, “Advances on watershed processing on GPU archi-tecture,” in Proceedings of the 10th International Conferenceon Mathematical Morphology, ser. ISMM’11, 2011.
[7] L. Vincent, “Morphological grayscale reconstruction in imageanalysis: Applications and efficient algorithms,” IEEE Trans-actions on Image Processing, vol. 2, pp. 176–201, 1993.
[8] G. Teodoro, T. Pan, T. M. Kurc, L. Cooper, J. Kong, andJ. H. Saltz, “A Fast Parallel Implementation of Queue-based Morphological Reconstruction using GPUs,” EmoryUniversity, Center for Comprehensive Informatics TechnicalReport CCI-TR-2012-2, January 2012.
[9] G. Teodoro, T. Pan, T. Kurc, J. Kong, L. Cooper, and J. Saltz,“Efficient Irregular Wavefront Propagation Algorithms onHybrid CPU-GPU Machines,” Parallel Computing, 2013, toappear.
[10] P. Karas, “Efficient Computation of Morphological GreyscaleReconstruction,” in MEMICS, ser. OASICS, vol. 16. SchlossDagstuhl - Leibniz-Zentrum fuer Informatik, Germany, 2010.
[11] P.-E. Danielsson, “Euclidean distance mapping,” ComputerGraphics and Image Processing, vol. 14, pp. 227–248, 1980.
[12] V. M. A. Oliveira and R. de Alencar Lotufo, “A Study onConnected Components Labeling algorithms using GPUs,” inSIBGRAPI, 2010.
[13] G. Teodoro, T. M. Kurc, T. Pan, L. A. Cooper, J. Kong,P. Widener, and J. H. Saltz, “Accelerating Large Scale Im-age Analyses on Parallel, CPU-GPU Equipped Systems,” in26th IEEE International Parallel and Distributed ProcessingSymposium (IPDPS), 2012, pp. 1093–1104.
[14] M. D. Linderman, J. D. Collins, H. Wang, and T. H. Meng,“Merge: a programming model for heterogeneous multi-coresystems,” SIGPLAN Not., vol. 43, no. 3, pp. 287–296, 2008.
[15] B. He, W. Fang, Q. Luo, N. K. Govindaraju, and T. Wang,“Mars: A MapReduce Framework on Graphics Processors,”in Parallel Architectures and Compilation Techniques, 2008.
[16] C.-K. Luk, S. Hong, and H. Kim, “Qilin: Exploiting paral-lelism on heterogeneous multiprocessors with adaptive map-ping,” in 42nd International Symposium on Microarchitecture(MICRO), 2009.
[17] T. B. Jablin, P. Prabhu, J. A. Jablin, N. P. Johnson, S. R.Beard, and D. I. August, “Automatic CPU-GPU communi-cation management and optimization,” in Proceedings of the32nd ACM SIGPLAN conference on Programming languagedesign and implementation, ser. PLDI ’11, 2011, pp. 142–151.

[18] C. Augonnet, S. Thibault, R. Namyst, and P.-A. Wacrenier,“Starpu: A unified platform for task scheduling on heteroge-neous multicore architectures,” in Euro-Par ’09: Proceedingsof the 15th International Euro-Par Conference on ParallelProcessing, 2009, pp. 863–874.
[19] G. F. Diamos and S. Yalamanchili, “Harmony: an executionmodel and runtime for heterogeneous many core systems,”in Proceedings of the 17th international symposium on Highperformance distributed computing, ser. HPDC ’08. NewYork, NY, USA: ACM, 2008, pp. 197–200.
[20] G. Teodoro, R. Sachetto, O. Sertel, M. Gurcan, W. M. Jr.,U. Catalyurek, and R. Ferreira, “Coordinating the use of GPUand CPU for improving performance of compute intensiveapplications,” in IEEE Cluster, 2009, pp. 1–10.
[21] N. Sundaram, A. Raghunathan, and S. T. Chakradhar, “Aframework for efficient and scalable execution of domain-specific templates on GPUs,” in IPDPS ’09: Proceedingsof the 2009 IEEE International Symposium on Parallel andDistributed Processing, 2009, pp. 1–12.
[22] G. Teodoro, T. D. R. Hartley, U. Catalyurek, and R. Fer-reira, “Run-time optimizations for replicated dataflows onheterogeneous environments,” in Proc. of the 19th ACMInternational Symposium on High Performance DistributedComputing (HPDC), 2010, pp. 13–24.
[23] G. Bosilca, A. Bouteiller, T. Herault, P. Lemarinier, N. Saeng-patsa, S. Tomov, and J. Dongarra, “Performance Portability ofa GPU Enabled Factorization with the DAGuE Framework,”in 2011 IEEE International Conference on Cluster Computing(CLUSTER), sept. 2011, pp. 395 –402.
[24] V. Ravi, W. Ma, D. Chiu, and G. Agrawal, “Compiler and run-time support for enabling generalized reduction computationson heterogeneous parallel configurations,” in Proceedings ofthe 24th ACM International Conference on Supercomputing.ACM, 2010, p. 137146.
[25] T. D. R. Hartley, E. Saule, and U. V. Catalyurek, “Automaticdataflow application tuning for heterogeneous systems,” inHiPC. IEEE, 2010, pp. 1–10.
[26] X. Huo, V. Ravi, and G. Agrawal, “Porting irregular reduc-tions on heterogeneous CPU-GPU configurations,” in 18thInternational Conference on High Performance Computing(HiPC), dec. 2011, pp. 1 –10.
[27] S. Lee, S.-J. Min, and R. Eigenmann, “OpenMP to GPGPU:a compiler framework for automatic translation and opti-mization,” in PPoPP ’09: Proceedings of the 14th ACMSIGPLAN symposium on Principles and practice of parallelprogramming, 2009, pp. 101–110.
[28] C. J. Rossbach, J. Currey, M. Silberstein, B. Ray, andE. Witchel, “Ptask: operating system abstractions to managegpus as compute devices,” in Proceedings of the Twenty-ThirdACM Symposium on Operating Systems Principles, ser. SOSP’11. New York, NY, USA: ACM, 2011, pp. 233–248.
[29] J. Bueno, J. Planas, A. Duran, R. Badia, X. Martorell,E. Ayguade, and J. Labarta, “Productive Programming ofGPU Clusters with OmpSs,” in 2012 IEEE 26th InternationalParallel Distributed Processing Symposium (IPDPS), may2012, pp. 557 –568.
[30] G. Teodoro, T. Hartley, U. Catalyurek, and R. Ferreira,“Optimizing dataflow applications on heterogeneous environ-ments,” Cluster Computing, vol. 15, pp. 125–144, 2012.
[31] C. Augonnet, O. Aumage, N. Furmento, R. Namyst, andS. Thibault, “StarPU-MPI: Task Programming over Clustersof Machines Enhanced with Accelerators,” in The 19th Euro-pean MPI Users’ Group Meeting (EuroMPI 2012), ser. LNCS,S. B. Jesper Larsson Traff and J. Dongarra, Eds., vol. 7490.Vienna, Autriche: Springer, 2012.
[32] R. H. Arpaci-Dusseau, E. Anderson, N. Treuhaft, D. E. Culler,J. M. Hellerstein, D. A. Patterson, and K. Yelick, “Cluster I/Owith River: Making the Fast Case Common,” in IOPADS ’99:Input/Output for Parallel and Distributed Systems, Atlanta,GA, May 1999.
[33] B. Plale and K. Schwan, “Dynamic Querying of StreamingData with the dQUOB System,” IEEE Trans. Parallel Distrib.Syst., vol. 14, no. 4, pp. 422–432, 2003.
[34] V. S. Kumar, P. Sadayappan, G. Mehta, K. Vahi, E. Deelman,V. Ratnakar, J. Kim, Y. Gil, M. W. Hall, T. M. Kurc, andJ. H. Saltz, “An integrated framework for performance-basedoptimization of scientific workflows,” in HPDC, 2009, pp.177–186.
[35] T. Tavares, G. Teodoro, T. Kurc, R. Ferreira, D. Guedes, W. J.Meira, U. Catalyurek, S. Hastings, S. Oster, S. Langella, andJ. Saltz, “An Efficient and Reliable Scientific Workflow Sys-tem,” IEEE International Symposium on Cluster Computingand the Grid, vol. 0, pp. 445–452, 2007.
[36] G. Teodoro, T. Tavares, R. Ferreira, T. Kurc, J. Meira, Wagner,D. Guedes, T. Pan, and J. Saltz, “A run-time system forefficient execution of scientific workflows on distributed en-vironments,” International Journal of Parallel Programming,vol. 36, pp. 250–266, 2008.
[37] C. Docan, M. Parashar, and S. Klasky, “Dataspaces: an in-teraction and coordination framework for coupled simulationworkflows,” in HPDC, 2010, pp. 25–36.
[38] H. Abbasi, M. Wolf, G. Eisenhauer, S. Klasky, K. Schwan,and F. Zheng, “Datastager: scalable data staging services forpetascale applications,” Cluster Computing, vol. 13, no. 3, pp.277–290, 2010.
[39] J. F. Lofstead, S. Klasky, K. Schwan, N. Podhorszki, andC. Jin, “Flexible IO and integration for scientific codesthrough the adaptable IO system (ADIOS),” in CLADE, 2008,pp. 15–24.