hidden truth behind .net's exception handling today
TRANSCRIPT

ON THE INTERPLAY OF .NET AND CONTEMPORARY SOFTWARE ENGINEERING TECHNIQUES
Hidden truth behind .NET’s exception handling today
B. Cabral, P. Sacramento and P. Marques
Abstract: The emergence of exception handling (EH) mechanisms in modern programminglanguages made available a different way of communicating errors between procedures. Foryears, programmers trusted in correct documentation of error codes returned by procedures tocorrectly handle erroneous situations. Now, they have to focus on the documentation of exceptionsfor the same effect. But to what extent can exception documentation be trusted? Moreover, is thereenough documentation for exceptions? And in what way do these questions relate to the discussionon checked against unchecked exceptions? For a given set of Microsoft .NET applications, codeand documentation were thoroughly parsed and compared. This showed that exception documen-tation tends to be scarce. In particular, it showed that 90% of exceptions are undocumented.Furthermore, programmers were demonstrated to be keener to document exceptions they explicitlythrow while typically leaving exceptions resulting from method calls undocumented. Thisconclusion lead to another question: how do programmers use the EH mechanisms available inmodern programming languages? More than 16 different .NET applications were examined inorder to provide an answer. The major conclusion of this work is that exceptions are not beingcorrectly used as an error-handling mechanism. These results contribute to the assessment of theeffectiveness of the unchecked exceptions approach.
1 Introduction
Since the appearance of exception handling (EH) mechan-isms, their importance has been steadily increasing. Beinga part of modern object-oriented programming languagessuch as Sun’s Java and Microsoft’s .NET languages,exceptions have been slowly replacing the error codes thatare widely used in procedural languages such as C.
Whether using error codes or exceptions, if programmersexpect their code to be used by others, or even themselves,they have to spend time and effort documenting theirmethods, explaining the circumstances in which a givenerroneous situation can occur and what methods do workon those events.
This documentation process, being mostly a manual one,is subject to incompleteness and faults. The absence of goodcode documentation is bound to cause programming errors,because unless there is a way of examining the source codeof the software module programmers is interacting with,documentation is all they can trust.
These problems are known to programmers who spendtheir lives wrestling with bad code documentation, andespecially to those used to the old way of error codeidentifiers. Nowadays, error codes can still be used,because in modern programming languages, EH is mostlyan optional way of dealing with erroneous situations [1].Consequently, the full impact of the problem of poordocumentation in modern programming languages is notknown. The purpose of the first part of the analysispresented in this paper is to determine the impact of this
# The Institution of Engineering and Technology 2007
doi:10.1049/iet-sen:20070017
Paper first received 5th February and in revised form 4th October 2007
The authors are with the Department of Engineering Informatica, CISUC,University of Coimbra, Portugal, Polo II – University of Coimbra, Coimbra3030-290, Portugal
E-mail: [email protected]
IET Softw., 2007, 1, (6), pp. 233–250
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
problem. This was done using a specially designed softwaretool to analyse a group of software components written forMicrosoft’s .NET platform [2].
As we will see later in the paper, this analysis steered ustowards the discussion of checked against uncheckedexceptions, which we introduce in Sections 2 and 3 andsubsequently address substantially. Given these approaches,at the present time, this discussion also means Java’s against.NET’s way of dealing with exceptions. Java uses checkedexceptions (Java also allows the usage of uncheckedexceptions for dealing with runtime abnormal situations.).The exceptions’ influence on the functionality of a methodis so significant that it should be explicitly signalled sincethe programmer is forced to handle them. .NET, on theother hand, does not include support for these exceptions –all of them are unchecked – and so, programmers canignore all exceptions that a method throws. In either case,documenting exceptions is important because if program-mers intend to handle an exception, either because they areforced or because they want to, they should know thecircumstances in which the exception may occur in order toprovide accurate handling functionality.
The EH mechanism is far from perfect. In fact, it can beargued that the mechanism is seriously limited if not evenflawed as a programming construct. Problems include thefollowing.
† Programmers throw generic exceptions, making it almostimpossible to properly handle errors and recover fromabnormal situations without shutting down the application.† Programmers catch generic exceptions, not providingproper error handling, making the programs continue toexecute with a corrupt state (relevant in Java). On the otherhand, in some platforms, programmers do not catch enoughexceptions making applications crash even in minor errorsituations (especially relevant in C#/.NET);† Programmers who try to provide proper EH see theirproductivity seriously impaired. A task as simple as
233
at 20:16 from IEEE Xplore. Restrictions apply.

providing EH for writing a file to disk may implycatching and dealing with tens of exceptions (e.g.FileNotFoundException, DiskFullException,SecurityException, IOException etc.). Asproductivity decreases, cost escalates, programmer’smotivation diminishes and, as a consequence, softwarequality suffers.† Providing proper EH can be quite a challenging anderror-prone task. Depending on the condition, it may benecessary to enclose try–catch blocks within loops inorder to retry operations; in some cases, it may be necessaryto abort the program or perform different recoveryprocedures; bizarre situations, like having to use nestedtry–catch blocks to deal with an exception while trying toclose a file on a catch of a finally block, are not uncommon.Dealing with such issues correctly is quite difficult, errorprone and, of course, time-consuming.
The second part of this study provides quantitativemeasures on how programmers are currently using EH inC# and on how the just mentioned problems influence theprogrammers’ task. These results were obtained throughan analysis of several .NET assemblies and their sourcecode. To the best of our knowledge, this is the most compre-hensive study done to date on EH of the .NET platform.
Section 2 presents some background information neededfor a better understanding of the discussed topics. Section 3discusses the related work, which is extensive, and Section 4explains the analysis methodology. Finally, Section 5 showsthe collected results, and Section 6 concludes thediscussion.
2 Background
The target system for this study was the Microsoft .NETplatform [2]. Although EH is similar among differentlanguages and, to some extent, it is possible to extrapolatethe conclusions to other platforms, although there aredifferences. Therefore some background informationneeds to be given on the way EH works, with specialemphasis on .NET.
Try–catch–finally blocks work essentially the same wayin C# as in Java or ‘old’ Cþþ (.NET introduced a languageknown as managed Cþþ, with roughly the same syntax as‘old’ Cþþ, but being a safer language, susceptible totranslation to Microsoft’s Intermediate Language (MSIL).This means that some care is needed when referring toCþþ in the context of .NET.). They protect a portion ofthe code in the sense that if some exception gets thrown inthe try block and a corresponding catch clause exists thatclause is made responsible for the handling of that exception.It is up to the programmer to decide what handling means ineach case. The normal continuation of execution can bepossible in some cases. If a proper clause does not exist,the exception is propagated to the upper method in the callstack. This process continues until such a clause is foundin one of the methods in the call stack or the call stack isemptied, which usually will mean a program crash.
However, EH is more than just try–catch–finally blocks.It also encompasses two important aspects, related to eachother and defined for each platform. One is the conceptualrelation between a method and the exceptions it canthrow; the other is the existence of an obligation of handlingan exception thrown by a method. These aspects aredifferent for the .NET and Java platforms.
In Java [3], programmers can declare some of theexceptions that a given method, m1( ) throws by using thethrows clause in the method’s declaration, and explicitly
234
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
raise exceptions using the throw instruction in themethod’s body. If they use this possibility, exceptioninformation is naturally bound to m1( ) and becomesconnected to that method (it can even be accessed throughreflection). This also has the effect of forcing programmersof another method m2( ), which calls m1( ), to either set upa try–catch–finally block to handle m1( )’s possibly thrownexceptions or declare m2( ) as thrower of those exceptions,using the same process as for m1( ). A Java compiler willrefuse to compile a program in which a programmer doesnot use one of the possibilities for all exceptions thatmethods called by that program are declared to throw.This type of exception is known as a checked exceptionbecause the compiler performs some type checking on itduring compilation. Other exceptions are known asunchecked exceptions. The compiler pays no attention tothem, only the runtime does.
C# has a different approach from Java. There are nochecked exceptions. All exceptions are unchecked.Programmers cannot, even if they wish to, declare a methodas thrower of an exception, and so, the relation between amethod and the exceptions it can throw is weaker. Thus,programmers will never be warned by the compiler if theyforget to handle an exception. Also, another programmerreflectively accessing a method entity has no possibility ofdiscovering which exceptions it may throw. .NET reflectiondoes not give programmers access to exception informationrelated to a method; but a throw instruction still exists,which means programmers can, and do, use it to throwexceptions in methods.
Of course, C# designers did not neglect the fact thatprogrammers need to be aware of a method’s behaviour incertain exceptional circumstances. Their answer resides inspecial documentation tags that programmers can use todocument their code with respect to exceptions.
Specially designed tools can then parse the code lookingfor those tags and generate suitable documentation files. InJava, HTML files are generated by Javadoc [4]. In .NET,custom-formatted XML files are generated by VisualStudio .NET (VS.NET) [5]. A number of other tools canthen convert from this XML to compiled HTML formatand from this to HTML.
The EH code existent in C# and Java applications is avail-able after source code compilation. At Java’s Bytecode and.NET’s IL code level, the information required by the EHmechanisms is kept in tables, being part of the class file orassembly metadata. These table entries identify: the startand end instructions of the protected blocks of code insideeach method; the presence of handlers for the previouslymentioned blocks; the type of exception being handled byeach handler; the start instruction of each handler in Javaand the start and end instruction of each handler in .NET.Furthermore, in Java, it is possible to know which excep-tions a method throws just by looking at the method’smetadata. In .NET, for doing so, it is necessary to performa detailed static analysis of all methods invoked, startingfrom the target method.
There are more differences between the two languages’approaches at a low level. The .NET exception model hasmore functionality available than the one made availableat the C# language level. As an example, .NET’s metadatastructures allow compilers to generate code for filter hand-lers. These handlers allow the execution of code if anassociated conditional expression evaluates to true.
The question that arises from the previous considerationsin the scope of this paper is that of the possibility todetermine, by looking at exception documentation quality,the effectiveness of the unchecked exceptions approach.
IET Softw., Vol. 1, No. 6, December 2007
at 20:16 from IEEE Xplore. Restrictions apply.

3 Related work
The work in this paper was initially inspired by the work ofCandea et al. [6] who alert us to the fact that detailedknowledge of programmers about their software onlyreflects reality to the extent that that the knowledge iscorrect and complete. This, along with the major problemof keeping manually generated documentation in syncwith an evolving system [7], presents a difficulty in buildingrobust software.
Although some authors, like DeVale and Koopman [8],have tried to improve software reliability by techniquesother than exceptions, many others, in what is clearly thedominant trend, have simply accepted exceptions assomething the industry has to live with, having directedtheir efforts towards better ways of using EH mechanisms.Both Robillard and Murphy [9] and Ferreira et al. [10]have tried to improve the use of EH, while avoidingassociated problems, by including such concerns veryearly in the software design methodology. Lippert andLopes [11] suggested using aspect oriented programmingto the same effect, but at the coding level. Others, likeBuhr and Mok [12], tried to improve the EH mechanismby using more elaborated technical mechanisms.
The work in [6], a technique for determining failurepropagation paths by fault injection, and [13], a techniquefor coverage testing of recovery code, through fault injec-tion are, in our view, marred by insufficient applicabilityand extensibility because of their exclusive concern withchecked exceptions (they consider a fault to be a checkedexception). Obviously, such approaches are of little use in.NET and other platforms like Ruby [14] that do not usechecked exceptions at all.
The discussion on checked against unchecked exceptionshas had numerous interesting episodes. Ryder and Soffa [1]present a historical overview of some of the older ones,stating that ‘there is a symbiotic relationship betweensoftware engineering research and the design of EH inprogramming languages’. They trace the roots of EH backto Lisp as early as the mid-1950s and acknowledgeGoodenough’s 1975 seminal work [15] in this field.Interestingly, Ryder and Soffa end by saying that ‘strongtyping in programming languages, desirable in new languagedesigns, was a direct answer to concerns about softwarereliability and correctness’ which agrees with Goodenough’sadvocating of ‘compile-time checking of the completenessof EH’. This means that for at least the last 25 years,checked exceptions have been regarded as good for reliability.But the modern try–catch construction only appeared a littleover 10 years ago in Cþþ [16] and Java, the most popularlanguage to use checked exceptions, in 1996. This meansthat hands-on experience with this topic is still recent.
Robillard and Murphy [9] are critics of the checkedexceptions approach. Using a practical example, theyconclude that ‘although checked exceptions have manybenefits, they can be expensive to implement’. This is dueto the fact that checked exceptions force programmers toalter every method in the call chain, connecting anexception thrower to an exception handler, whenever thegroup of types of exceptions possibly thrown is modified.In the presence of large method call propagation graphs,this is impractical. It can be argued that checked exceptionsclutter the object interfaces and induce complicated catchblocks. On the other hand, checked exceptions could beconsidered as a required language feature for ensuringfault tolerance in applications. In the absence of documen-tation or in the presence of bad documentation, not checkingfor exceptions could mean not documenting exceptions.
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
The unchecked exceptions approach, defended byMicrosoft, seems to imply that the programmers can betrusted to document whatever they see as important. Sunbelieves that this is unreasonable and that a mechanism toenforce reliability is in order. Either way, the special documen-tation tags that both companies introduced tell us that they alsoagree on the importance of good exception documentation.
Cheng and Chen [17] showed that checked andunchecked exceptions can be consistently used: ‘throughthe use of an architectural model, an application canbenefit from a separation of exceptions in terms of recover-ability beyond distinguishing checked and uncheckedexceptions.’ The architectural models presented in [17]help to evaluate and balance conflicting quality require-ments such as modifiability, readability and fault tolerance.The models are useful to guide developers in using checkedand unchecked exceptions in Java.
This paper, besides the analysis of the quality of the docu-mentation, also discusses the way programmers use .NETEH mechanisms. It is a known fact that, since the work ofGoodenough [15] on the definition of a notation for EH,and Cristian [18] on defining its usage, the programminglanguage constructs for handling and recovering from excep-tions have not changed much. Nevertheless, programminglanguage designers have always suggested differentapproaches for implementing these mechanisms.
Several studies have been conducted over the years tovalidate the options taken in different implementations. Forinstance, Garcia et al. [19] did a comparative study on theEH mechanisms available for developing dependablesoftware. Their work consisted of a survey of EH approachesin 12 object-oriented languages. Each programming languagewas analysed with respect to ten technical aspects associatedwith EH constructs: exception representation; external excep-tions in signatures; separation between internal and externalexceptions; attachment of handlers to program constructs(e.g. to statements, objects, methods etc.); dynamism ofhandler binding; propagation of exceptions; continuation ofthe flow control (resumption or termination); clean-upactions (freeing, releasing, or resetting resources); reliabilitychecks and concurrent EH. After the evaluation of all theprogramming languages in terms of exception mechanisms,the major conclusion of the study was that ‘none of the existingexception mechanisms has so far followed appropriate designcriteria’ and that programming language designers were notpaying enough attention to properly supporting error handlingin programming languages.
Reimer and Srinivasan [20] made an extensive analysison the usage of exceptions in large Java applications. Theauthors observed several inappropriate exception usagepatterns that made the maintainability of the applicationsextremely difficult. For instance, many exceptions weresimply swallowed by empty catch handlers; the samehandler was used to handle different kinds of exceptions;exceptions were not being handled close to the source ofthe exception and many handlers provided excessive loginformation, increasing system load.
Other authors like Sinha and Harrold [21], Miller andTripathi [22], Robillard and Murphy [23] also identifiedseveral problems and constraints existent in EH mechan-isms. Because of space constraints, we cannot discuss alltheir findings but we can state that the objective of thisstudy is different from its predecessors. By looking at theway programmers use EH constructs in .NET, we are nottargeting the quality of the mechanisms available but theusage that programmers make of them. The emphasis ison understanding how programmers write EH code, howmuch of the code of an application is dedicated to error
235
t 20:16 from IEEE Xplore. Restrictions apply.

recovery and identifying possible flaws in the usage of EHmechanisms.
One highly influential result in this research area regardsthe results of Cristian [18], which showed that two-thirdsof system crashes in the examined systems were because ofexception failures. This led to the experiences conductedby Maxion and Olszewski [24, 25]. They hypothesised thatthe problem ‘might be rooted in cognitive factors thatimpede the mental generation (or recollection) of exceptioncases that would pertain in a particular situation, resultingin insufficient software robustness’. The authors say thattraditional approaches are limited when dealing with theprogrammer’s inadequate coverage of exceptionalconditions, and they advocate the usage of dependabilitycases as more suitable (‘Dependability cases’ is a method-ology based on taxonomies and memory aids to helpprogrammers to better deal with EH.). To test their hypoth-esis, the authors tested different techniques in severalgroups of people. Their results clearly show that program-mers achieve a better EH coverage in programs if they areprovided with a structure that makes it easier to rememberor generate exception categories and exemplars.Dependability cases provide a framework for thinkingabout what can go wrong, and how to avoid or handlefailures. Prospective approaches achieve better results thanretrospective approaches, such as testing.
The programmers’ ability to predict exceptional eventsand write code to handle these events can be related withtheir experience and knowledge of the application’sdomain. The work of Adelson and Soloway [26] showsthat ‘a designer’s expertise rests on the knowledge andskills which develop with experience in a domain. As aresult, when a designer is designing an object in an unfami-liar domain he will not have the same knowledge and skillsavailable to him as when he is designing an object in a fam-iliar domain’. In this study, Adelson and Soloway analysedthe background expertise and experience of several develo-pers and application designers and tried to find out whatskills drop out and what skills or interactions of skillscome forward as experience with the domain changes.The authors created several design contexts with whichexpert designers were differentially familiar. The paperalso compares the behaviour of novice with expertdesigners. It shows that designers’ experience and theability to create a mental plan for a design eliminate theneed for using other tools and techniques.
4 Analysis
The first part of this section discusses the process weemployed in order to understand to what extent .NET devel-opers actually document their code. The second partexplains the process used for extracting information aboutthe way programmers write exception handling code.
4.1 Strategy for analysing documentation quality
The strategy followed in this work was to take a set ofsoftware components and examine both the binary filecontaining their code looking for unhandled exceptionsand the components’ documentation to evaluate the extentto which one analysis corresponded to the other. To dothis, a specific tool had to be developed, because although.NET provides good reflection mechanisms, no tool couldperform the variety of tasks and analyses aimed for. Thisrequired us to go through every instruction of a component.Since no access to high-level source code could be assumed(important for the analysis of commercial-off-the-shelf
236
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
components), this needed to happen at a lower level. All.NET programs, regardless of the original language theyare written in, are transformed into a low-level commonform known as MSIL or IL, an assembly-like language,which is our real object of analysis. The RuntimeAssembly Instrumentation Library (RAIL) [27] providesus with this kind of access, effectively establishing abridge between .NET reflection, which goes as far as themethod level, and IL code. RAIL was used in the secondpart of this study. But, for the first part, a combination ofMicrosoft’s ILDASM tool, along with simple text parsing,was used for this purpose instead.
Once the tool was ready and hence a mechanism tocompare code and documentation was available, a set ofsoftware components to analyse was chosen. Some ofthese components are core parts of certain applications,whereas others extend the functionality of bigger infrastruc-tures. Some were not built with re-use in mind, whereasothers were built especially for re-use. Finally, the toolwas run for each component and its documentation andresults were gathered. Although the choice of finite set ofapplications to analyse could be a source of bias for theresults in this paper, we are confident that the criteria usedfor the selection were correct. The applications werechosen considering their popularity, number of users,complexity, bug reports, application support given by thedevelopers and availability of source code. Although theexpertise of application designers and programmers todevelop fault-tolerant software could not be assessed, it isnot relevant in the spirit of this study, since it wouldtarget the experiences on a small group of expert program-mers and not on the broader, more common programmerwho has no special training in writing fault-tolerantsoftware but still uses the same tools (available in modernprogramming languages) as the experts.
4.1.1 Analyser tool: The analyser tool is a command-lineprogram written entirely in C#, one of .NET’s high-levellanguages. We only discuss here the characteristics of itthat are relevant for the paper.
As input, the analyser receives a .NET Assembly (a DLLor EXE file) location and optionally a documentation filelocation, in the Visual Studio .NET generated XMLformat. A number of switches can be used to specifydifferent options.
As output, an XML report is generated. The format of thisreport depends on the command-line options but, in general,consists of a list of the methods found in the assembly givenas input. For each of those methods, a number of exceptiondetections are depicted. Each of those exception detectionsrepresents one of two things:
† that an exception not handled by any try–catch blockscan be generated by a given instruction (i.e. line) in themethod’s code (referred to as code exceptions);† that an exception was identified as possibly thrown by amethod in that method’s documentation (referred to asdocumentation exceptions).
They result, respectively, from code analysis anddocumentation analysis. At the end of the report, a largenumber of statistics are displayed, along with some infor-mation about exception classification into groups. Also, ifthe analyser is instructed to do so, it can automaticallycheck the differences between what it detected in the codeand in the documentation. In this case, the report will alsocontain a section dedicated to suspects. Further discussionof suspects will take place later on. For now, it is important
IET Softw., Vol. 1, No. 6, December 2007
at 20:16 from IEEE Xplore. Restrictions apply.

to know that suspects roughly represent exceptiondetections corresponding to situations where the program-mer could have done a better job of documenting his code.
Suspects are important for two reasons. First, the analyseris very thorough in its analysis and although it detects hugeamounts of uncaught exceptions, only a relatively smallnumber can be realistically expected to be documented bya programmer. Secondly, there are situations in which it issimply impossible for the analyser to evaluate whethercode exceptions are documented or not because of theabsence of documentation. So, suspects are a way offiltering the relevant detections.
The documentation analysis process is straightforward. Itconsists of parsing the given documentation looking for thespecific XML tags that identify the documentation of anexception.
The code analysis process is much more complicated. Itconsists of going through an Assembly’s members, ILinstruction by IL instruction, keeping track of entries/exits into/out of try–catch blocks through the use of datastructures such as stacks and queues (See [13] and [26]for more detailed descriptions of some of the techniquesinvolved in this kind of analysis.). For each instruction inthe code, four different types of detection are performed,searching for possible exceptions thrown by that instruction.The first type of detection consists of a simple search in amanually generated dictionary, which associates IL instruc-tions with the exceptions they can throw, as defined in the.NET platform specification [2]. Fig. 1 shows an extractof that dictionary.
We will call this type of detection, IL instructiondetection (ILI)
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
The second type of detection is called method call (MC)detection and is only applied to five IL instructions thatcorrespond to the execution of another method – ‘call,calli, callvirt, newobj and jmp’. For these instructions, weperform documentation parsing looking for exceptiondocumentation for the called method, that is, documentationon the callee’s side.
The third and fourth types of detection are explicit throwdetection (T) and explicit re-throw detection (RT). Theyapply, respectively, to the throw IL instruction and there-throw IL instruction. Explicit throw detection is straight-forward, but explicit re-throw detection involves keepingtrack of the type of the exception being re-thrown, whichis declared at the corresponding catch block (re-throwinstructions only make sense inside catch blocks).
When these four types of detection are concluded, we havea set of exceptions that a given IL instruction can throw. Butobviously, that does not mean that they are not being caught.So, we have to check if the analysis is currently being per-formed inside one or more nested try blocks, to determinewhich of the previously gathered exceptions are beingcaught and which are not. This process requires the completeknowledge of the exception class hierarchies.
Fig. 1 Some lines of the dictionary, adapted
The format is IL instruction/opcode/list of exceptions
Fig. 2 Scheme of the code analysis process
237
t 20:16 from IEEE Xplore. Restrictions apply.

The code analysis process is sketched in Fig. 2. Bothcaught and uncaught exceptions are represented in thefinal report, because it is of interest to check which typesof exception programmers catch and which they do not.
Code and documentation analyses produce two sets ofexception detections. If so instructed, the analyser thenchecks for the differences between these two sets, producinga final set of documented and undocumented exceptiondetections.
4.1.2 Assemblies: Selecting the study’s target assemblieswas the most tedious and difficult part of this work, mainlyfor two reasons: the lack of available and especially popular.NET applications and the lack of proper documentation forthe existing applications.
The first reason is the lack of penetration of the .NET plat-form. In fact, the .NET platform is still an alternative, ratherthan a first choice, for developers and decision-makers. Forthis work, this meant having to search in forums aimed atthe sharing of .NET applications [28], opposed to the moreusual [29].
The second reason is even more serious and penalising,because there were many cases where promising candidateapplications were excluded solely because of lack of properdocumentation, which means the non-existence of VS.NETXML-format files accompanying the assemblies. This canhave two causes: simple skipping of this step by program-mers using VS.NET (or not using of VS.NET at all) or lackof proper documentation tags throughout the source code.
Although the first cause is perfectly possible, especiallyin cases where VS.NET is not used at all (e.g. the Mono[30] development is completely independent of VS.NET),browsing through the source code of the discarded appli-cations clearly indicates that the lack of proper documen-tation is quite common.
Actually, the lack of both proper XML documentationfiles and XML documentation tags in the source codemakes an interesting point towards one of the major findingsof this study: programmers cannot be trusted to documentexceptions.
Six assemblies were chosen as the targets for this study.They span a range of different purposes and sizes. To helpin the characterisation of the assemblies, a division intogroups of similar purpose was created. This division isshown in Table 1.
Table 2 presents a summary of the eight assemblieschosen for this study, identifying their source applicationand emphasising their division into the groups in Table 1.
NAnt [31] is the .NET port of the Ant build tool; NDoc[32] is an extensible code documentation generation toolfor .NET. Because of the size of the applications, only themain assembly of each one was analysed. Even so, exactly
Table 1: Group characterisation
Group Characterisation
applications application assemblies; low
re-use expected; few public
documentation needs
libraries libraries; high re-use expected
and high public
documentation needs
infrastructure infrastructure assemblies;
highest re-use expected and
high documentation needs
238
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
because of their size, they are representative of the rest ofthe code.
SharpZipLib [33] is a .NET data archiving/compressionlibrary supporting all popular standards like Zip, Tar, GZip,BZip and so on, and CpSphere [34] is an implementation ofthe SMTP protocol which can be used to add mail sendingcapabilities to .NET applications. The first library is singleassembly, and that assembly is the target. For CpSphere, themain assembly is selected as a target.
Finally, two of the .NET core platform assemblies werechosen, mainly based on relevance (they are highly used)and documentation availability. Both Mono and Rotor[35] were also considered as sources for the infrastructureassemblies. But, although in the first case the documentationstyle is different from that of VS.NET (Some of Mono’sAssemblies include excellent exception documentationdespite not using Microsoft style documentation tags. Thisjust emphasizes the lack of agreement between differentplayers and the fragility of this method.), in the secondcase, the examined source files (XML documentation isnot included) contained no exception documentation.
4.2 Strategy for analysing EH code
The second objective of this article is to understand howprogrammers use the EH mechanisms available in program-ming languages. The test applications were analysed atsource code level (C#) and at binary level (metadata andIL code) using different processes.
4.2.1 Tools: To perform the source code analysis, a parserwas generated using ‘antlr’ [36], for C#. This parser wasthen modified to extract all the EH codes into one text fileper application. These files were then manually examinedto build reports about the content of exception handlers.
The source code of all applications was examined withone exception. Because of the huge size of Mono, only its‘corlib’ module was processed.
The analysis of the applications source code is not enoughby itself when trying to distinguish between the exceptionsthat the programmer wants to handle and the exceptionsthat might occur at runtime. This is so because the generatedIL code can produce more (and different) exceptions than theones that are declared in the applications source code bymeans of throw and throws statements.
To perform the analysis of the .NET assemblies, adifferent application was developed using the RAIL assem-bly instrumentation library to access assembly metadata andIL code and extract all the information about possiblemethod exceptions, exception handlers and exceptionprotection blocks. All the extracted data were stored on arelational database for easy statistical treatment.
4.2.2 Assemblies: The selection of applications for thesecond part of this study was not limited by the existence
Table 2: Assemblies used in the study
Group Assembly Application
applications NAnt.Core.dll NAnt
NDoc.Core.dll NDoc
libraries SharpZipLib.dll SharpZipLib
CpSphere.Mail.dll CpSphere
infrastructure System.Runtime.Remoting.dll .NET platform
System.XML.dll
IET Softw., Vol. 1, No. 6, December 2007
at 20:16 from IEEE Xplore. Restrictions apply.

of documentation; thus, we were able to increase thenumber of applications that composed our experimentalsubjects. Nevertheless, the code present in the applicationshad to be representative of common programming practiceson the target platform (.NET). Also, care had to be taken sothat these would be ‘real-world’ applications developed forproduction use (i.e. not simply prototypes or beta versions).This was in order not to bias the results towards immatureapplications where much less care with error handlingexists. Finally, in order to be possible to perform differenttypes of analyses, the source code of the applications hadto be available.
Globally, we analysed 16 applications organised in fourcategories according to their nature:
† Libraries: software libraries providing a specificapplication-domain API;† Applications running on servers (Server-Apps): Servlets,JSPs, ASPs and related classes;† Servers: server programs;† Stand-alone applications: desktop programs.
The complete list of applications is shown in Table 3.For each application, only one file (.NET) was analysed.
Table 4 shows the names of the files and packages that wereused in this study. The criteria followed to select these
Table 3: Applications listed by group
Libraries SmartIRC4NET IRC library
Report.NET PDF generation library
Mono (corlib) Open-source CLR
implementation
Nlog Logging library
Server-Apps UserStory.Net Tool for User Story tracking
in Extreme Programming
projects
PhotoRoom ASP.NET web site for
managing on-line photo
albums
SharpWebMail ASP.NET webmail application
that is written in C#
SushiWiki WikiWikiWeb like Web
application
Servers NeatUpload Allows ASP.NET developers
to stream files to disk and
monitor progress
Perspective Wiki engine
Nhost Server for DotNet objects
DCSharpHub Direct connect file sharing
hub
Stand-alone Nunit Unit-testing framework for all
.NET languages
SharpDevelop IDE for C# and VB.NET
projects
AscGen Application to convert images
into high quality ASCII text
SQLBuddy SQL scripting tool for use
with Microsoft SQL Server
and MSDE
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
targets were the size of the files and their relevance in theimplementation of the application core.
5 Results
5.1 Documentation analysis
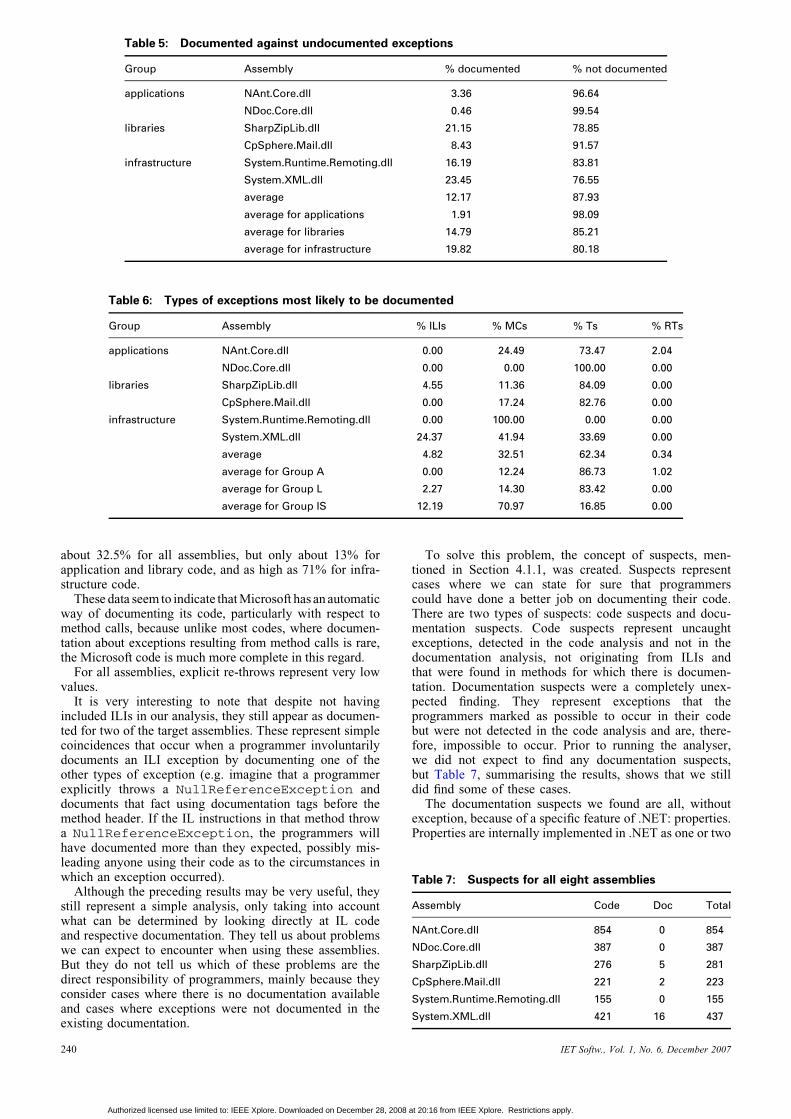
Table 5 summarises the results obtained by running theanalyser for the eight targets, showing the percentage ofdocumented and undocumented exceptions.
ILIs (Section 4.1.1) were not considered in this analysisalthough they represent a huge amount of exceptions. Thisis because we think it is not reasonable to expect program-mers to document them. They are thrown by the low-levelIL instructions at the virtual machine level, which do notcorrespond to problems that the programmer shouldusually deal with. Unfortunately, this means that they canstill cause problems, but it also means that they areusually poorly documented or documented ‘by coincidence’(read ahead for an explanation). Normally, programmerswill only marginally be aware of them.
The results show that for the set of six differentassemblies over 87% of the relevant exceptions that thecode can throw are not documented. For code directedmainly towards the end-user, this value goes up to 98%.For code aimed towards re-use by other programmers(libraries), it stands at about 85%. For infrastructure code,providing basic services for the .NET platform, this valueis still as high as 80%.
Table 6 discriminates the types of exceptions that in theprevious table are mentioned as documented. Thus, itoffers insight into the types of exceptions that programmersare most likely to document.
The four most interesting graphs are also shown in theFig. 3.
More than 60% of the documented exceptions representexplicit throws. This value is about 85% for applicationand library code and about 17% for infrastructure code.This huge discrepancy may be attributed to the presenceof outliers in the target assemblies but is more likely to becaused by very specific documenting styles/procedures ofMicrosoft for the .NET platform.
Most of the other documented exceptions representexceptions that result from method calls. This value is
Table 4: List of assemblies analysed
.NET assemblies Size, kB
Meebey.SmartIrc4net.dll 92
Reports.dll 744
mscorlib.dll 1946
NLog.dll 116
rq.dll (UserStory) 52
PhotoRoom.dll 44
SharpWebMail.dll 144
SushiWiki.dll 88
Brettle.Web.NeatUpload.dll 45
Perspective.dll 96
nhost.exe 20
DCSharpHub.exe 176
nunit.core.dll 84
SharpDevelop.exe 876
Ascgen dotNET.exe 328
SqlBuddy.exe 480
239
t 20:16 from IEEE Xplore. Restrictions apply.
240
Auth
Table 5: Documented against undocumented exceptions
Group Assembly % documented % not documented
applications NAnt.Core.dll 3.36 96.64
NDoc.Core.dll 0.46 99.54
libraries SharpZipLib.dll 21.15 78.85
CpSphere.Mail.dll 8.43 91.57
infrastructure System.Runtime.Remoting.dll 16.19 83.81
System.XML.dll 23.45 76.55
average 12.17 87.93
average for applications 1.91 98.09
average for libraries 14.79 85.21
average for infrastructure 19.82 80.18
Table 6: Types of exceptions most likely to be documented
Group Assembly % ILIs % MCs % Ts % RTs
applications NAnt.Core.dll 0.00 24.49 73.47 2.04
NDoc.Core.dll 0.00 0.00 100.00 0.00
libraries SharpZipLib.dll 4.55 11.36 84.09 0.00
CpSphere.Mail.dll 0.00 17.24 82.76 0.00
infrastructure System.Runtime.Remoting.dll 0.00 100.00 0.00 0.00
System.XML.dll 24.37 41.94 33.69 0.00
average 4.82 32.51 62.34 0.34
average for Group A 0.00 12.24 86.73 1.02
average for Group L 2.27 14.30 83.42 0.00
average for Group IS 12.19 70.97 16.85 0.00
about 32.5% for all assemblies, but only about 13% forapplication and library code, and as high as 71% for infra-structure code.
These data seem to indicate that Microsoft has an automaticway of documenting its code, particularly with respect tomethod calls, because unlike most codes, where documen-tation about exceptions resulting from method calls is rare,the Microsoft code is much more complete in this regard.
For all assemblies, explicit re-throws represent very lowvalues.
It is very interesting to note that despite not havingincluded ILIs in our analysis, they still appear as documen-ted for two of the target assemblies. These represent simplecoincidences that occur when a programmer involuntarilydocuments an ILI exception by documenting one of theother types of exception (e.g. imagine that a programmerexplicitly throws a NullReferenceException anddocuments that fact using documentation tags before themethod header. If the IL instructions in that method throwa NullReferenceException, the programmers willhave documented more than they expected, possibly mis-leading anyone using their code as to the circumstances inwhich an exception occurred).
Although the preceding results may be very useful, theystill represent a simple analysis, only taking into accountwhat can be determined by looking directly at IL codeand respective documentation. They tell us about problemswe can expect to encounter when using these assemblies.But they do not tell us which of these problems are thedirect responsibility of programmers, mainly because theyconsider cases where there is no documentation availableand cases where exceptions were not documented in theexisting documentation.
orized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
To solve this problem, the concept of suspects, men-tioned in Section 4.1.1, was created. Suspects representcases where we can state for sure that programmerscould have done a better job on documenting their code.There are two types of suspects: code suspects and docu-mentation suspects. Code suspects represent uncaughtexceptions, detected in the code analysis and not in thedocumentation analysis, not originating from ILIs andthat were found in methods for which there is documen-tation. Documentation suspects were a completely unex-pected finding. They represent exceptions that theprogrammers marked as possible to occur in their codebut were not detected in the code analysis and are, there-fore, impossible to occur. Prior to running the analyser,we did not expect to find any documentation suspects,but Table 7, summarising the results, shows that we stilldid find some of these cases.
The documentation suspects we found are all, withoutexception, because of a specific feature of .NET: properties.Properties are internally implemented in .NET as one or two
Table 7: Suspects for all eight assemblies
Assembly Code Doc Total
NAnt.Core.dll 854 0 854
NDoc.Core.dll 387 0 387
SharpZipLib.dll 276 5 281
CpSphere.Mail.dll 221 2 223
System.Runtime.Remoting.dll 155 0 155
System.XML.dll 421 16 437
IET Softw., Vol. 1, No. 6, December 2007
t 20:16 from IEEE Xplore. Restrictions apply.

methods (depending on whether the property is read-only ornot), a get_kPropertyl method and, possibly, aset_kPropertyl method. But the documentation tags onlyallow documenting a property as a whole (the internalmethods are completely transparent to the programmer).This carries more than one consequence. First, it meansthat if the documentation is not specific enough (it canexplicitly say that the exception occurs only in setting theproperty), the programmer cannot know if the exceptionoccurs in the getting or the setting of the property.Secondly, it renders attempts to do automatic EH or excep-tion analysis like ours even more difficult, because it isalmost impossible to have the computer read and interpretwhat someone wrote. We chose to have the analysersignal all these cases as suspects.
For the cases where we can state for sure that existingdocumentation is lacking in quality, around 90% ofmissing documentation is related to insufficient accountingof the exceptions that can occur by calling other methods,the rest being explicit throws, which are fairly well docu-mented (as you would expect).
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
Finally, it is possible to compare the numbers presentedin Fig. 3 with Table 8 to get an estimate of the proportionof undocumented cases that are because of the plainabsence of documentation. For this, we can take thenumber of undocumented detections from Fig. 3 (joiningin the values for the other four assemblies) and thenumber of code suspects from Table 8. The results of thiscomparison are shown in Table 9.
Given the way that the analyser statistics were calculated,these numbers can be extrapolated to represent the percentageof methods for which there is no documentation despite theinclusion of documentation for the assembly. There is alarge variability in the results, but there are still cases forwhich more than 50% of the methods did not have documen-tation, including both the Microsoft .Net core platform ones.
5.2 EH code analysis
In the following sections, we will present the results of thesecond part of this study, drawing some observations abouttheir significance. Nevertheless, we should caution that
Fig. 3 Documentation of exceptions in four different assemblies
241
t 20:16 from IEEE Xplore. Restrictions apply.
242
Table 8: Type of detections responsible for code suspects
Assembly Code suspects Number of MCs (%) Number of Ts (%) Number of RTs (%)
NAnt.Core.dll 854 793 (93) 60 (7) 1 (0.1)
NDoc.Core.dll 387 374 (97) 13 (3) 0 (0)
SharpZipLib.dll 276 236 (86) 40 (14) 0 (0)
CpSphere.Mail.dll 221 217 (98) 4 (2) 0 (0)
System.Runtime.Rtg.dll 155 139 (90) 16 (10) 0 (0)
System.XML.dll 421 373 (89) 48 (11) 0 (0)
Authorized lic
Table 9: Proportion of detections because of lack of documentation
Assembly Undocumented
detections
Code
suspects
Lacking
proportion
NAnt.Core.dll 1410 854 39.4%
NDoc.Core.dll 430 387 10.0%
SharpZipLib.dll 328 276 15.9%
CpSphere.Mail.dll 315 221 29.8%
System.Runtime.Rtg.dll 466 155 66.7%
System.XML.dll 911 421 53.8%
although the number of applications that were used was rela-tively large (16), it is not possible to generalise our obser-vations to the whole .NET universe. For that, it would benecessary to have a very significant number of applications,possibly consisting of hundreds of programs. Even so,because of the care taken in selecting the target applications,we believe that the results allow a relevant glimpse intocurrent common programming practices in EH.
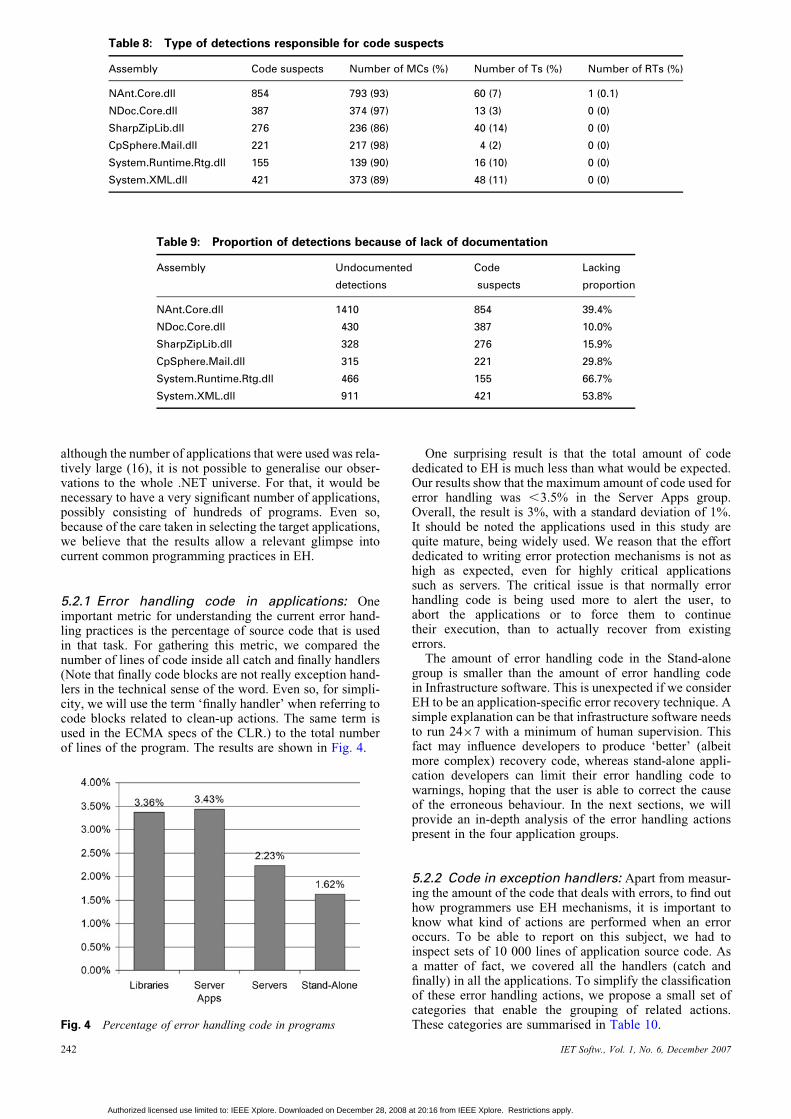
5.2.1 Error handling code in applications: Oneimportant metric for understanding the current error hand-ling practices is the percentage of source code that is usedin that task. For gathering this metric, we compared thenumber of lines of code inside all catch and finally handlers(Note that finally code blocks are not really exception hand-lers in the technical sense of the word. Even so, for simpli-city, we will use the term ‘finally handler’ when referring tocode blocks related to clean-up actions. The same term isused in the ECMA specs of the CLR.) to the total numberof lines of the program. The results are shown in Fig. 4.
Fig. 4 Percentage of error handling code in programs
ensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
One surprising result is that the total amount of codededicated to EH is much less than what would be expected.Our results show that the maximum amount of code used forerror handling was ,3.5% in the Server Apps group.Overall, the result is 3%, with a standard deviation of 1%.It should be noted the applications used in this study arequite mature, being widely used. We reason that the effortdedicated to writing error protection mechanisms is not ashigh as expected, even for highly critical applicationssuch as servers. The critical issue is that normally errorhandling code is being used more to alert the user, toabort the applications or to force them to continuetheir execution, than to actually recover from existingerrors.
The amount of error handling code in the Stand-alonegroup is smaller than the amount of error handling codein Infrastructure software. This is unexpected if we considerEH to be an application-specific error recovery technique. Asimple explanation can be that infrastructure software needsto run 24�7 with a minimum of human supervision. Thisfact may influence developers to produce ‘better’ (albeitmore complex) recovery code, whereas stand-alone appli-cation developers can limit their error handling code towarnings, hoping that the user is able to correct the causeof the erroneous behaviour. In the next sections, we willprovide an in-depth analysis of the error handling actionspresent in the four application groups.
5.2.2 Code in exception handlers: Apart from measur-ing the amount of the code that deals with errors, to find outhow programmers use EH mechanisms, it is important toknow what kind of actions are performed when an erroroccurs. To be able to report on this subject, we had toinspect sets of 10 000 lines of application source code. Asa matter of fact, we covered all the handlers (catch andfinally) in all the applications. To simplify the classificationof these error handling actions, we propose a small set ofcategories that enable the grouping of related actions.These categories are summarised in Table 10.
IET Softw., Vol. 1, No. 6, December 2007
at 20:16 from IEEE Xplore. Restrictions apply.

Note that an exception handler may contain actions thatbelong to more than one category. In fact, this is thecommon case. For instance, a handler can log an error, closea connection and exit the application. These actions are
Table 10: Description of handler’s actions categories
Category Description
empty the handler is empty, has no
code and does nothing more
than cleaning the stack
log some kind of error logging or
user notification is carried out
alternative/static
configuration
in the event of an error or in the
execution of a finally block
some kind of pre-determined
(alternative) object state
configuration is used
throw a new object is created and
thrown or the existing
exception is re-thrown
continue the protected block is inside a
loop and the handler forces it
to abandon the current
iteration and start a new one
return the handler forces the method in
execution to return or the
application to exit. If the
handler is inside a loop, a
break action is also assumed
to belong to this category
rollback the handler performs a rollback
of the modifications
performed inside the
protected block or resets the
state of all/some objects (e.g.
recreating a database
connection)
close the code ensures that an open
connection or data stream is
closed. Another action that
belongs to this category is the
release of a lock over some
resource
assert the handler performs some kind
of assert operation. This
category is separated because
it happens quite a lot. Note
that in many cases, when the
assertion is not successful,
this results in a new exception
being thrown possibly
terminating the application
delegates a new delegate is added
others any kind of action that does not
correspond to the previous
ones
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
represented by three distinct categories: Log, Close andReturn. Thus, in the results, this handler would be classifiedin all these three categories.
Since catch and finally handlers have different purposes,we opted for doing separate counts for each type of handler.Finally, the distribution of handler actions for each appli-cation was calculated as a weighted average according tothe number of actions found in each application. This isso that small applications do not bias the results towardstheir specific error handling strategy.
The results obtained for each application group are shownin the next four graphs.
The graph in Fig. 5 shows the average of results by appli-cation group for catch handlers. In the four applicationgroups 60% to 75% of the total distribution of handleractions is composed of three categories: Empty, Log andAlternative Configuration.
Empty handlers are the most common type of handler inServers, the second largest in Stand-alone applications andthe third largest in Libraries. This result was completelyunexpected in .NET programs since there are no checkedexceptions in the CLR and, therefore, programmers are notobliged to handle any type of exception. Checked exceptionscan sometimes lead lazy programmers to ‘silence exceptions’with empty handlers only to be able to compile their appli-cations. From the analysis of the source code, we concludedthat its usage in .NET is not related with compilation butwith avoiding premature program termination on non-fatalexceptions. A typical example is the presence of severalinline protected blocks containing different ways of perform-ing an operation. This technique assures that if one block failsto achieve its goal, the execution can continue to the next blockwithout any error being generated.
Logging errors is also one of the most common actions inhandlers of all applications. In fact, is the most commonaction in Server-Apps and Stand-alone groups. Consideringweb applications and desktop applications, this typically cor-responds to the generation of an error log, the notification ofthe user about the occurrence of a problem and the abortionof the task. This idea is re-enforced by the value of the Returnaction category in these two application groups which isidentical and the highest of all four groups.
The number of Alternative configuration actions rep-resents the usage of alternative computation or object statereconstruction when the code inside a protected block failsin achieving its objective. These actions are by far themost individualised and specialised of all. In some cases,they are used to completely replace the code inside the pro-tected block.
In the Libraries applications group, Assert operations arethe second most common error handling actions. Assertsensure that if an error occurs, the cause of the error is wellknown and reported to the user/programmer. In Servers,there is also a high distribution value for the Others category.These actions are mainly related with thread stopping andfreeing resources.
Another category of actions with some weight in theglobal distribution is the Throw action. This is mainlybecause of the layered and component-based developmentof software. Layers and components usually have awell-defined interface between them. It is a fairly populartechnique to encapsulate all types of exceptions into onlyone type when passing an exception object between layersor software components. This is typically done with a newthrow.
Empty, Log, Alternative Configuration, Throw andReturn are the actions most frequently found in the catchhandlers of these .NET applications. By opposition,
243
at 20:16 from IEEE Xplore. Restrictions apply.

Fig. 5 Catch handler actions count for .NET programs
Continue, Rollback, Close, Assert, Delegate and Othersactions are rarely used.
Fig. 6 illustrates the results for finally handlers. Thedistribution of the several actions is different from the onefound in catch handlers. Nevertheless, it is clear that themost common handler action category, for all applicationgroups, is Close; that is, finally handlers, in our test suite,are mainly used to close connections and release resources.
Alternative configuration is the second most used handleraction in all application groups with the exception ofLibraries. A typical block of code usually found in finallyhandlers is composed of some type of conditional test thatenables (or not) the execution of some pre-determinedconfiguration. In some cases, this alternative configurationis done while resetting some state. In those cases, theywere classified as Rollback and not Alternative.
Another common category present in finally handlers ofthe applications is Others. These actions include filedeletion, event firing, stream flushing and thread termin-ation, among other less-frequent actions. In Serverapplications, it is also common to reset object’s state orrollback previously done actions.
Finally, on Stand-alone applications, there are someempty finally blocks that we cannot justify since theyperform no easily understandable function.
5.2.3 Exception handler argument classes: Afteridentifying the list of actions performed by handlers, weconcentrated on finding out if there is some relationbetween the handlers for the same type of exceptionclasses. For this, we developed one program to process
244
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
.NET’s IL. This IL code analyser was used to discoverwhat exception classes were most frequently used as catchstatement arguments. We opted to perform this analysis atthis level and not at source code level because it is simplerto obtain this information from assemblies than from C#code.
Fig. 7 shows the most common classes used as the argu-ment of catch instructions for these applications. The resultsare grouped by application type and the values represent theweighted average of the distribution among applications ofthe same group. Thus, programs with the largest number ofhandlers have more weight in the final result.
It is possible to observe that programmers prefer to use themost generic exception classes like System.Exceptionand System.Object for catching exceptions. Note that.NET, not C#, allows any type of object to be used as anexception argument. When the argument clause of a catchstatement is left empty, the compiler assumes that anyobject can be thrown as an exception. This explains thelarge presence of System.Object as argument.
The use of generic classes in catch statements can berelated to two of the most common actions in handlers:Logging and Return. This means that for the largest set ofpossible exceptions that can be thrown, programmers donot have particular EH requirements: they just register theexception or alert the user of its occurrence. Nevertheless,there are a lot of handlers that use more specific exceptionclasses. These different handlers do not have any weightby themselves in the distribution but all the codes thatactually try to perform some error recovery operations areconcentrated around these specialised handlers.
IET Softw., Vol. 1, No. 6, December 2007
t 20:16 from IEEE Xplore. Restrictions apply.
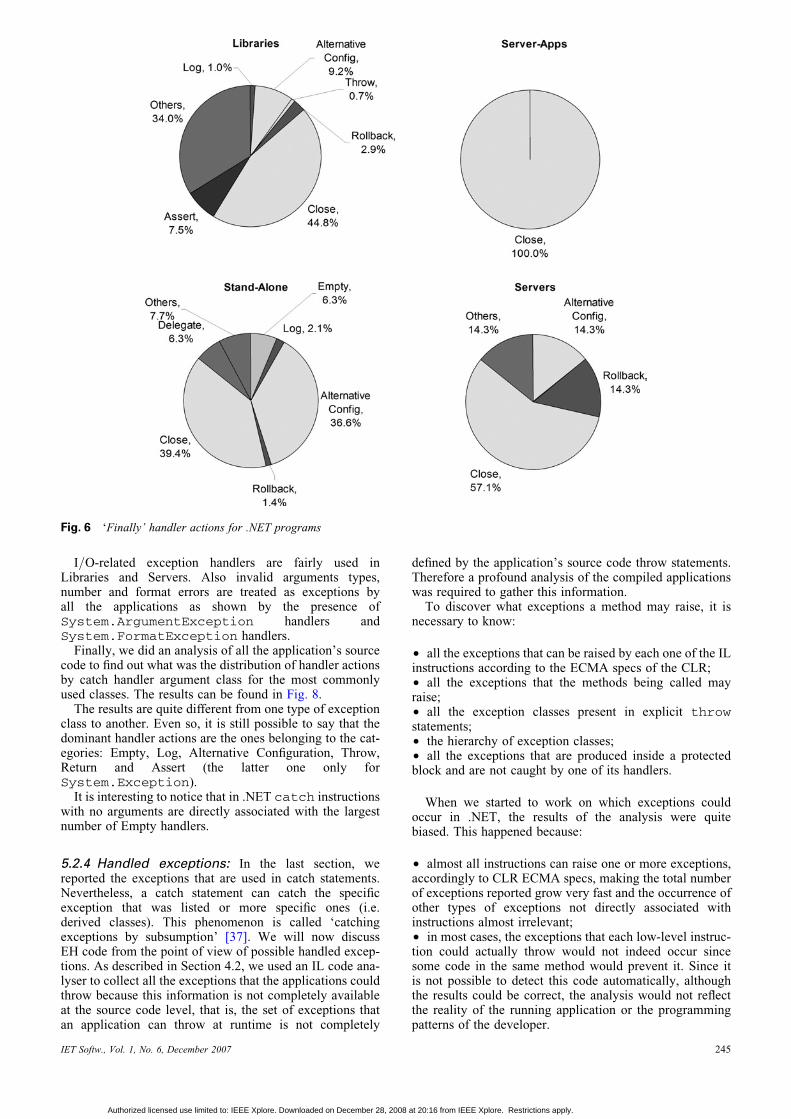
Fig. 6 ‘Finally’ handler actions for .NET programs
I/O-related exception handlers are fairly used inLibraries and Servers. Also invalid arguments types,number and format errors are treated as exceptions byall the applications as shown by the presence ofSystem.ArgumentException handlers andSystem.FormatException handlers.
Finally, we did an analysis of all the application’s sourcecode to find out what was the distribution of handler actionsby catch handler argument class for the most commonlyused classes. The results can be found in Fig. 8.
The results are quite different from one type of exceptionclass to another. Even so, it is still possible to say that thedominant handler actions are the ones belonging to the cat-egories: Empty, Log, Alternative Configuration, Throw,Return and Assert (the latter one only forSystem.Exception).
It is interesting to notice that in .NET catch instructionswith no arguments are directly associated with the largestnumber of Empty handlers.
5.2.4 Handled exceptions: In the last section, wereported the exceptions that are used in catch statements.Nevertheless, a catch statement can catch the specificexception that was listed or more specific ones (i.e.derived classes). This phenomenon is called ‘catchingexceptions by subsumption’ [37]. We will now discussEH code from the point of view of possible handled excep-tions. As described in Section 4.2, we used an IL code ana-lyser to collect all the exceptions that the applications couldthrow because this information is not completely availableat the source code level, that is, the set of exceptions thatan application can throw at runtime is not completely
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
defined by the application’s source code throw statements.Therefore a profound analysis of the compiled applicationswas required to gather this information.
To discover what exceptions a method may raise, it isnecessary to know:
† all the exceptions that can be raised by each one of the ILinstructions according to the ECMA specs of the CLR;† all the exceptions that the methods being called mayraise;† all the exception classes present in explicit throwstatements;† the hierarchy of exception classes;† all the exceptions that are produced inside a protectedblock and are not caught by one of its handlers.
When we started to work on which exceptions couldoccur in .NET, the results of the analysis were quitebiased. This happened because:
† almost all instructions can raise one or more exceptions,accordingly to CLR ECMA specs, making the total numberof exceptions reported grow very fast and the occurrence ofother types of exceptions not directly associated withinstructions almost irrelevant;† in most cases, the exceptions that each low-level instruc-tion could actually throw would not indeed occur sincesome code in the same method would prevent it. Since itis not possible to detect this code automatically, althoughthe results could be correct, the analysis would not reflectthe reality of the running application or the programmingpatterns of the developer.
245
t 20:16 from IEEE Xplore. Restrictions apply.

Fig. 7 .NET classes being used as catch arguments
Fig. 8 Handler action distribution for the most used catch handler classes
To obtain meaningful results, we decided to perform asecond analysis not using all the data from the static analy-sis of IL code instructions. In particular, we filtered a groupof exceptions that are not normally related to the programlogic, and that the programmer should not normallyhandle, and considered the rest. The list of exceptions thatwere filtered (i.e. not considered) is shown in Table 11.
Being aware of the complete list of exceptions that anapplication can raise and of the complete list of handlersand protected blocks, it is possible to find out which arethe most commonly handled exception types. The resultsfor .NET applications are shown in Fig. 9; the values
246
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
represent the average of the results by application groupwhere every application had a different weight in theoverall result according to the total number of results thatthey provided. It is possible to observe that the results arevery different from application group to application group.For instance, in the Libraries group, the most commonlyhandled exceptions are ArgumentNullExceptionand ArgumentException, resulting from bad parameteruse in method invocations. In the remaining three groups,the number one exception type is Exception; this can be asymptom of the existence of a larger and more differentiatedset of exceptions that can occur. If many different
IET Softw., Vol. 1, No. 6, December 2007
at 20:16 from IEEE Xplore. Restrictions apply.
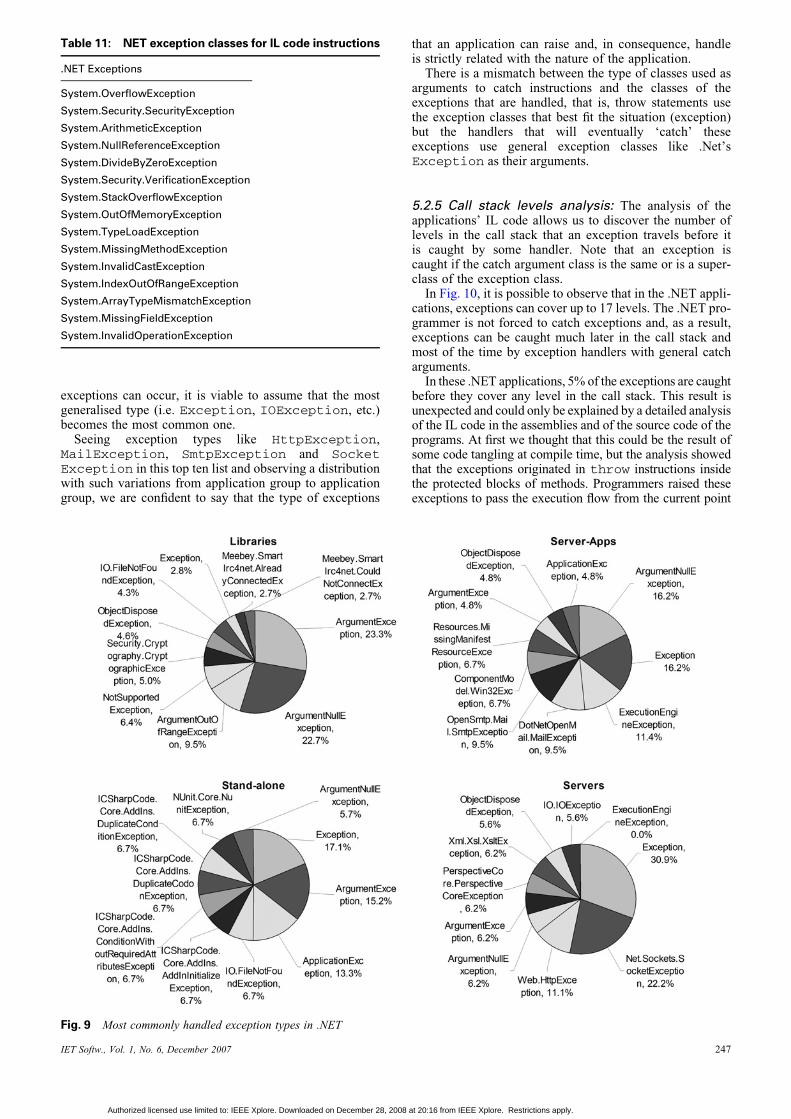
exceptions can occur, it is viable to assume that the mostgeneralised type (i.e. Exception, IOException, etc.)becomes the most common one.
Seeing exception types like HttpException,MailException, SmtpException and SocketException in this top ten list and observing a distributionwith such variations from application group to applicationgroup, we are confident to say that the type of exceptions
Table 11: NET exception classes for IL code instructions
.NET Exceptions
System.OverflowException
System.Security.SecurityException
System.ArithmeticException
System.NullReferenceException
System.DivideByZeroException
System.Security.VerificationException
System.StackOverflowException
System.OutOfMemoryException
System.TypeLoadException
System.MissingMethodException
System.InvalidCastException
System.IndexOutOfRangeException
System.ArrayTypeMismatchException
System.MissingFieldException
System.InvalidOperationException
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
that an application can raise and, in consequence, handleis strictly related with the nature of the application.
There is a mismatch between the type of classes used asarguments to catch instructions and the classes of theexceptions that are handled, that is, throw statements usethe exception classes that best fit the situation (exception)but the handlers that will eventually ‘catch’ theseexceptions use general exception classes like .Net’sException as their arguments.
5.2.5 Call stack levels analysis: The analysis of theapplications’ IL code allows us to discover the number oflevels in the call stack that an exception travels before itis caught by some handler. Note that an exception iscaught if the catch argument class is the same or is a super-class of the exception class.
In Fig. 10, it is possible to observe that in the .NET appli-cations, exceptions can cover up to 17 levels. The .NET pro-grammer is not forced to catch exceptions and, as a result,exceptions can be caught much later in the call stack andmost of the time by exception handlers with general catcharguments.
In these .NET applications, 5% of the exceptions are caughtbefore they cover any level in the call stack. This result isunexpected and could only be explained by a detailed analysisof the IL code in the assemblies and of the source code of theprograms. At first we thought that this could be the result ofsome code tangling at compile time, but the analysis showedthat the exceptions originated in throw instructions insidethe protected blocks of methods. Programmers raised theseexceptions to pass the execution flow from the current point
Fig. 9 Most commonly handled exception types in .NET
247
t 20:16 from IEEE Xplore. Restrictions apply.

in the method to code inside a handler, that is, they use excep-tions purely as a control flow construct.
5.2.6 Handler size: Another interesting measure that weobtain from the analysis of assemblies IL code and metadatawas related to handler’s code size or, more precisely, thecount of opcodes inside a handler.
The graph in Fig. 11 shows that the largest set of handlersin Server-Apps, Servers and Stand-alone applicationsgroups have eight IL Code instructions. In the Librariesgroup, more than 40% of the handlers have three instruc-tions. The second largest set of handlers in all groups hasfive instructions. Obviously, there are bigger handlers, buttheir number is so low that we excluded them from thegraph to improve its reading.
These results made us curious about what was happeningin these handlers and what were the instructions in question.We analysed all the IL codes in all the handlers and foundsome interesting facts:
† In the 526 handlers with size 8, 500 (95%) invoked aDispose( ) method in some object (this method performsapplication-defined tasks associated with freeing, releasingor resetting resources); from this 500, there were twomajor sets of handlers with the exact same opcodes, onewith 329 elements and the other with 166; the remainingfive handlers were different from them; the 500 handlerswere all Finally handlers.† In the set of handlers with five instructions, there were194 elements; 74 disposed of some object; 24 created andraised a new exception; 36 stored some value.† 484 of the 498 handlers of size 3 were Finally handlers;426 handlers had exactly the same opcodes and wereresponsible for closing a database connection; 34 handlers
Fig. 10 Call stack levels for caught exceptions
Fig. 11 Handlers’ size in a number of IL code instructions for.NET
248
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008 a
had the same code and invoked a Finalize method insome object.† The largest set of handlers with size 2 were empty hand-lers that contained no instruction in the source code, thus thecompiler generated actions consisted in cleaning the stackand returning; others re-threw the exception, and the restcalled some Assert method.
These lead us to the conclusion that many of the handlerswith a few instructions are very similar and that the majorityare Finally handlers that do some kind of method dispose orconnection closing.
5.2.7 Types of handlers: Knowing that the majority ofthe handlers with a few instructions were finally blocks,we tried to discover the relation between the total numberof protected blocks, the total number of catch handlersand the total number of finally handlers.
The data in Table 12 show that for the 1565 protectedblocks found in the .NET applications there are 1630handlers; 1144 protected bocks (73%) have finally handlers,but only 29% have catch handlers.
We have observed that the maximum number of catchhandlers per protected block was five for Libraries, threefor Server-apps and two for Stand-alone and Servers. But,for all the applications, the average number of catch hand-lers per try block was one.
6 Conclusions
This paper shows the magnitude of the problems of theabsence of documentation and documentation quality inseveral .NET applications. More emphasis was put on theproblem of documentation quality but Table 9, togetherwith the great difficulties found when collecting assembliesfor this work, is a testimony of the problem ofdocumentation absence.
Regarding documentation quality, in general, 87% of rel-evant exceptions thrown are not documented. These valuesrange from around 80% to almost 98% growing as theamount of re-use expected declines. For the cases where itis possible to state for sure that the existing documentationis lacking in quality, most of the missing data is related toinsufficient accounting of the exceptions that can occur bycalling other methods. The rest are explicit throws, whichare fairly well documented. This fact indicates that theremay be benefits in developing ways of somehow automati-cally documenting methods by following call chainslooking for the exceptions that may be propagated.
Ultimately, this study brings us to the discussion ofchecked against unchecked exceptions. It is quite clearthat further studies need to be performed, not only in.NET, but especially in Java, its main contender. Thatdata will enable a direct comparison of the effect, if any,of using checked exceptions. And despite the claim of thispaper, that a much bigger problem is that of programmersnot sufficiently documenting their code, given the fact thatthe majority of undocumented exceptions relate to method
Table 12: Number of protected blocks, catch handlersand finally handlers
Protected
blocks
Handlers Protected blocks
with finally
handlers
Protected
blocks with
catch handlers
1565 1630 1144 450
IET Softw., Vol. 1, No. 6, December 2007
t 20:16 from IEEE Xplore. Restrictions apply.

calls, those studies might yield more significantconclusions. Why? Because checked exceptions are ameans of getting exception information directly from amethod, not having to manually go through all the chainof calls looking for exceptions, which is one of the down-sides of unchecked exceptions. If the exception informationassociated with the method is accurate (which is very likely,because it is a compile-time check), programmers have oneless excuse for not documenting their code. Furthermore,checked exceptions give us the possibility of improvingtechniques like automatic exception handling and evenautomatic code documentation.
Thus, our opinion is that checked exceptions, or a variationon them, may prove more beneficial for dependability. Ourthought is that checked exceptions will make programmersnot be more inclined to document. But they will at leastmake automation techniques, which seem to deserve a lotof support, much easier. Even so, probably the major con-clusion that can be drawn from the use of exceptions andof the discussion of checked against non-checked exceptionsis that currently the error handling mechanisms available inprogramming languages are not good enough and thatmore research in this important area is needed.
The use of the unchecked model in .NET, and the lack ofproper documentation about exceptions in theseapplications, can be seen as two of the causes for the factthat most of the exception classes used as catch argumentsare quite generic and do not represent specific treatment oferrors, as one would expect. The lack of information aboutthe exceptions that a method may throw can lead the pro-grammer to perform a ‘catch-everything and do nothing’approach when facing problematic method calls. We havealso seen that most of the handlers of these generic catchblocks are empty or are dedicated to log operations. On theother hand, the exception objects ‘caught’ by these handlerscorrespond to very specific types and are closely tied to theapplication’s logic. This demonstrates that although pro-grammers are very concerned in throwing the exceptionobjects that best fit a particular exceptional situation, theyare not so keen in implementing handling code with thesame degree of specialisation. Furthermore, they are alsoreluctant to document these exceptions.
These results show that, in general, exceptions are notbeing correctly used as an error handling tool. This alsomeans that if the .NET programming community at largedoes not use them correctly, probably it is a symptom of aserious design flaw in the mechanism: exception constructs,as they are, are not fully appropriate for handling appli-cation errors. One may argue that the results would havebeen different if the programmers had been educated inthe development of fault tolerant software. But, again, thiswould not represent the broader community of .NET devel-opers. It is not even viable to assume that the large majorityof developers worldwide will ever be educated in such way.
We believe that more work is needed on error handlingmechanisms for programming languages. The C# EH con-structs are the result of more than 30 years of research inthe area. Also, any programmer who tries to develop acode in a programming language such as C# is forced touse exceptions. Programmers do know how exceptions aresupposed to work and should be used. It is not the lack ofthis knowledge that leads them to write catch blocks thatsimply silence exceptions or log the problems. There mustbe other reasons for justifying this practice and some ofthem can be related with the EH mechanism itself. Thecurrent EH mechanisms may indeed have the necessarysemantics for being able to deal with problems, but if theyare too cumbersome for the huge majority of developers to
IET Softw., Vol. 1, No. 6, December 2007
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
use them correctly, then these mechanisms must be revised.Future EH mechanisms should encourage the programmersto adopt the best practices and use sound EH patterns.
In our line of work we are currently approaching theproblem by trying to create automatic EH for the caseswhere ‘benign EH actions’ can be defined (e.g. compressinga file on a disk full exception). In general, we are trying tofree the programmer from the task of writing all the EHcode by hand, forcing the runtime itself to automaticallydeal with the problems whenever possible. A completedescription of the technique is out of scope of this paper,but the interested reader can refer to [38] for a discussionof the approach.
7 Acknowledgments
This investigation was partially supported by the PortugueseResearch Agency – FCT, through the CISUC ResearchCenter (R&D Unit 326/97), and a Ph.D. scholarship (DB/18353/98).
8 References
1 Ryder, B.G., and Soffa, M.L.: ‘Influences on the design of exceptionhandling’, ACM SIGSOFT project on the impact of softwareengineering research on programming language design’, ACMSIGSOFT Softw. Eng. Notes, 2003, 38, (6), pp. 16–22
2 ECMA International: ‘Standard ECMA-335 Common LanguageInfrastructure (CLI), ECMA Standard, 2003
3 Gosling, J., Joy, B., Steele, G., and Bracha, G.: ‘The Java languagespecification’. Sun Microsystems, Inc., Mountain View, California,USA, 2000 ISBN 0-201-31008-21
4 ‘Javadoc tool home page’, available at: http://java.sun.com/j2se/javadoc/
5 ‘Visual studio home’, available at: http://msdn.microsoft.com/vstudio/6 Candea, G., Delgado, M., Chen, M., and Fox, A.: ‘Automatic
failure-path inference: a generic introspection technique for internetapplications’. Proc. 3rd IEEE Workshop on Internet Applications(WIAPP) (IEEE Press, 2003)
7 Brooks, F.P.: ‘The mythical man-month’ (Addison-Wessley, Reading,MA, 1995), Anniversary Edn., ISBN 0-201-8359-59
8 DeVale, J., and Koopman, P.: ‘Robust software – no more excuses’.Proc. Int. Conf. Dependable Systems and Networks 2002 (DSN’02),(IEEE Press, 2002)
9 Robillard, M.P., and Murphy, G.C.: ‘Designing robust Java programswith exceptions’. Proc. 8th ACM SIGSOFT Int. Symp. Foundations ofSoftware Engineering, (ACM Press, 2000), vol. 25, (6)
10 Ferreira, G.R.M., Rubira, C.M.F., and Lemos, R.: ‘Explicitrepresentation of exception handling in the development ofdependable component-based systems’. Proc. 6th IEEE Int. Symp.High Assurance Systems Engineering (HASE’01), (IEEE Press, 2001)
11 Lippert, M., and Lopes, C.: ‘A study on exception detection andhandling using aspect-oriented programming’. Proc. 22nd Int. Conf.Software Engineering, Ireland 2000 (ACM Press, 2000)
12 Buhr, P.A., and Mok, W.Y.R.: ‘Advanced exception handlingmechanisms’, IEEE Trans. Softw. Eng., 2000, 26, (9), pp. 820–836
13 Fu, C., Martin, R.P., Nagaraja, K., Nguyen, T.D., Ryder, B., andWonnacott, D.: ‘Compiler-directed program-fault coverage forhighly available Java internet services’. Proc. 2003 Int. Conf.Dependable Systems and Networks (DSN ’03)(IEEE Press, 2003)
14 ‘Ruby home page’, available at: http://www.ruby-lang.org15 Goodenough, J.B.: ‘Exception handling: issues and a proposed
notation’, Commun. ACM, 1975, 18, (12), pp. 683–69616 Koenig, A., and Stroustrup, B.: ‘Exception handling for Cþþ’ ‘The
evolution of Cþþ: language design in the marketplace of ideas’(MIT Press, 1993)
17 Cheng, Y.C., Chen, C., and Jwo, J.: ‘Exception handling: an architecturemodel and utility support’. Proc. 12th Asia-Pacific Software EngineeringConf. (APSEC’05), Taiwan, China, December 2005
18 Cristian, F.: ‘Exception handling and software fault tolerance’. Proc.FTCS-25, 3 (IEEE, 1996) (reprinted from FTCS-IO 1980, 97–103)
19 Garcia, A., Rubira, C., Romanovsky, A., and Xu, J.: ‘A comparativestudy of exception handling mechanisms for building dependableobject-oriented software’, J. Syst. Softw., 2001, 2, pp. 197–222
20 Reimer, D., and Srinivasan, H.: ‘Analyzing exception usage in largeJava applications’. Proc. ECOOP’03 Workshop on ExceptionHandling in Object-Oriented Systems, July 2003
249
at 20:16 from IEEE Xplore. Restrictions apply.

21 Sinha, S., and Harrold, M.: ‘Analysis and testing of programs withexception-handling constructs’, IEEE Trans. Softw. Eng., 2000, 26,(9), pp. 849–871
22 Miller, R., and Tripathi, A.: ‘Issues with exception handling inobject-oriented systems’. Proc. ECOOP’97, LNCS 1241(Springer-Verlag, 1997), pp. 85–103
23 Robillard, M.P., and Murphy, G.C.: ‘Designing robust JAVAprograms with exceptions’. Proc. 8th ACM SIGSOFT Int.Symp. Foundations of Software Engineering, vol. 25, (ACM Press,2000)
24 Maxion, R.A., and Olszewski, R.T.: ‘Eliminating exception handlingerrors with dependability cases: a comparative, empirical study’, IEEETrans. Softw. Eng., 2000, 26, (9), pp. 888–906
25 Maxion, R.A., and Olszewski, R.T.: ‘Improving software robustnesswith dependability cases’. 28th Int. Symp. Fault-TolerantComputing, Munich, Germany (IEEE Computer Society Press,1998), pp. 346–355
26 Adelson, B., and Soloway, E.: ‘The role of domain experience in softwaredesign’, IEEE Trans. Softw. Eng, 1985, 11, (11), pp. 1351–1360
27 Cabral, B., Marques, P., and Silva, L.: ‘RAIL: code instrumentationfor .NET’. Proc. 2005 ACM Symp. Applied Computing (SAC’05),Santa Fe, New Mexico, USA (ACM Press, 2005)
250
Authorized licensed use limited to: IEEE Xplore. Downloaded on December 28, 2008
28 ‘The code project – free source code and tutorials’, available at: http://www.codeproject.com/
29 ‘Sourceforge.net’, available at: http://sf.net30 ‘Mono’, available at: http://www.go-mono.com31 ‘NAnt – a .NET build tool’, available at: http://nant.sourceforge.net32 ‘NDoc code documentation generator for .NET’, available at: http://
ndoc.sourceforge.net33 SharpZipLib, The Zip, GZip, BZip2 and Tar Implementation For .NET’,
available at: http://www.icsharpcode.net/OpenSource/SharpZipLib/Default.aspx
34 ‘CpSphere Email Component for .NET’, available at: http://www.codeproject.com/dotnet/cpSphereEmailComponent.asp
35 ‘The Microsoft shared source CLI implementation’, available at:http://msdn.microsoft.com/net/sscli
36 Parr, T.: ‘ANTLR – another tool for language recognition’ Universityof San Francisco, 2006, available at: http://www.antlr.org/
37 Robilliard, M.P., and Murphy, G.C.: ‘Static analysis to support theevolution of exception structure in object-oriented systems’, ACMTrans. Softw. Eng. Methodol., 2003, 12, (2), pp. 191–221
38 Cabral, B., and Marques, P.: ‘Making exception handling work’. Proc.Workshop on Hot Topics in System Dependability (HotDep’06),USENIX, Seattle, USA, November 2006
IET Softw., Vol. 1, No. 6, December 2007
at 20:16 from IEEE Xplore. Restrictions apply.