extended bag of visual words for face detection
TRANSCRIPT
Metadata of the chapter that will be visualized inSpringerLink
Book Title Advances in Computational IntelligenceSeries Title
Chapter Title Extended Bag of Visual Words for Face Detection
Copyright Year 2015
Copyright HolderName Springer International Publishing Switzerland
Corresponding Author Family Name MontazerParticle
Given Name Gholam AliPrefix
Suffix
Division Department of Information Technology Engineering, School of Engineering
Organization Tarbiat Modares University
Address Tehran, Iran
Email [email protected]
Author Family Name SoltanshahiParticle
Given Name Mohammad AliPrefix
Suffix
Division Department of Information Technology
Organization Iranian Research Institute for Information Science and Technology (IranDoc)
Address Tehran, Iran
Email [email protected]
Author Family Name GivekiParticle
Given Name DavarPrefix
Suffix
Division Department of Computer Science
Organization University of Tehran
Address Tehran, Iran
Email [email protected]
Abstract Face detection shows a challenging problem in the field of image analysis and computer vision andtherefore it has received a great deal of attention over the last few years because of its many applications invarious areas. In this paper we propose a new method for face detection using an Extended version of Bagof Visual Words (EBoVW). Two extensions of the original bag of visual words are made in this paper, fist,using Fuzzy C-means instead of K-means clustering and second is, building histogram of words usingmultiple dictionaries for each image. The performances of the original BoVW model with K-means and theproposed EBoVW are evaluated in terms of Area Under the Curve (AUC) and Equal Error Rate (EER) onMIT CBCL Face dataset which is a very large face dataset. The experimental results show the proposedmodel achieves very promising results.

Keywords (separated by '-') Face detection - Bag of visual words - Extended bag of visual words - Scene classification - SIFT - FuzzyC-means

© Springer International Publishing Switzerland 2015 I. Rojas et al. (Eds.): IWANN 2015, Part I, LNCS 9094, pp. 503–510, 2015. DOI: 10.1007/978-3-319-19258-1_41
Extended Bag of Visual Words for Face Detection
Gholam Ali Montazer1(), Mohammad Ali Soltanshahi3, and Davar Giveki2
1 Department of Information Technology Engineering, School of Engineering, Tarbiat Modares University, Tehran, Iran
[email protected] 2 Department of Computer Science, University of Tehran, Tehran, Iran
[email protected] 3 Department of Information Technology,
Iranian Research Institute for Information Science and Technology (Iran Doc), Tehran, Iran [email protected]
Abstract. Face detection shows a challenging problem in the field of image analysis and computer vision and therefore it has received a great deal of atten-tion over the last few years because of its many applications in various areas. In this paper we propose a new method for face detection using an Extended version of Bag of Visual Words (EBoVW). Two extensions of the original bag of visual words are made in this paper, fist, using Fuzzy C-means instead of K-means clustering and second is, building histogram of words using multiple dictionaries for each image. The performances of the original BoVW model with K-means and the proposed EBoVW are evaluated in terms of Area Under the Curve (AUC) and Equal Error Rate (EER) on MIT CBCL Face dataset which is a very large face dataset. The experimental results show the proposed model achieves very promising results.
Keywords: Face detection · Bag of visual words · Extended bag of visual words · Scene classification · SIFT · Fuzzy C-means
1 Introduction
Biometric-based techniques have been born as the most promising option for recogniz-ing individuals in recent years since, instead of authenticating people and granting them access to physical and virtual domains based on passwords, PINs, smart cards, plastic cards, tokens, keys and so forth, these methods examine an individual’s physiological and/or behavioral characteristics in order to determine and/or ascertain his identity. Passwords and PINs are hard to remember and can be stolen or guessed; cards, tokens, keys and the like can be misplaced, forgotten, purloined or duplicated; magnetic cards can become corrupted and unreadable. However, an individual’s biological traits cannot be misplaced, forgotten, stolen or forged. Face detection appears to offer several advan-tages over other biometric methods, a few of which are mentioned here: almost all these technologies require some voluntary action by the user, i.e., the user needs to place his hand on a hand-rest for fingerprinting or hand geometry detection and has to stand in a
Au
tho
r P
roo
f

504 G.A. Montazer et al.
fixed position in front of a camera for iris or retina identification. However, face detec-tion can be done passively without any explicit action or participation on the part of the user since face images can be acquired from a distance by a camera. This is particularly beneficial for security and surveillance purposes. Furthermore, data acquisition in gen-eral is fraught with problems for other biometrics: techniques that rely on hands and fingers can be rendered useless if the epidermis tissue is damaged in some way (i.e., bruised or cracked). Good face detection algorithms and appropriate preprocessing of the images can compensate for noise and slight variations in orientation, scale and illu-mination. Face detection techniques can be broadly divided into three categories based on the face data acquisition methodology: methods that operate on intensity images; those that deal with video sequences; and those that require other sensory data such as 3D information or infra-red imagery [1]. In this paper we focus on face detection from Intensity Images which fall into two main categories: feature based and holistic [2-4]. Feature based approaches first process the input image to identify and extract (and measure) distinctive facial features such as the eyes, mouth, nose, etc. and then compute the geometric relationships among those facial points, thus reducing the input facial image to a vector of geometric features. Standard statistical pattern detection techniques are then employed to match faces using these measurements. Holistic approaches at-tempt to identify faces using global representations, i.e., descriptions based on the entire image at once rather than on local features of the face [1].
Here, we propose a new face detection system using an extended version of Bag of Visual Words (BoVW). Object detection using BoVW model is one of the most ac-ceptable methods for object classification. The BoVW approach has shown acceptable performance because of its fast run time and low storage requirements [5-9]. The key idea is to quantize each extracted key point into one of the visual words, and then represent each image by a histogram of the visual words. To this end, different clus-tering algorithms like K-means are generally used for generating the visual words. Constructing the BoVW from the images involves the following steps: (1) Automati-cally detect regions/points of interest (local patches) and compute local descriptors over these regions/points using some image descriptors, (2) quantize the descriptors into words to form the visual codebook using some clustering techniques, (3) find the occurrences in the image of each specific word in the vocabulary in order to build the BoVW features namely histogram of words and finally (4) Learn the histogram of words using a classifier like SVM, ANN or Adaboost. In this work we implemented BoVW method using dens version of the Scale Invariant Feature Transform descriptor (SIFT) [10]. After obtaining local features called descriptors, a codebook is generated to represent them. The codebook is a group of codes usually obtained by clustering over all descriptors. Typically there are two forms of clustering; hard clustering and soft clustering. The performance of BoVW highly depends on some factors such as the dictionary generation method, size of dictionary, similar words detection, mea-ningless worlds elimination, normalization, similarity measure and classifier. This paper investigates a new method of generating the dictionary of visual words in which multiple dictionaries are used for constructing BoVW using Fuzzy C-means, this approach uses more visual words than original BoVW. In this way more distinctive image features can be captured in a semantic manner. The resulting distribution of descriptors is quantified by using vector quantization to form histogram of words.
Au
tho
r P
roo
f

Extended Bag of Visual Words for Face Detection 505
Compared to the original BoVW our proposed method considerably increases the performance of the algorithm for large scale collection of face images of MIT CBCL dataset with 31022 images.
Regarding improving, extending or modifying feature extraction methods that mostly use SIFT features, some notable works have been done. For instance author in [11], presented a novel framework for detecting, localizing, and classifying faces in terms of visual traits, e.g., sex or age, from arbitrary viewpoints and in the presence of occlusion. All three tasks were embedded in a general viewpoint-invariant model of object class appearance derived from local scale-invariant features, where features were probabilistically quantified in terms of their occurrence, appearance, geometry, and association with visual traits of interest. An appearance model was first learned for the object class, after which a Bayesian classifier was trained to identify the model features indicative of visual traits. The proposed framework can be applied in realistic scenarios in the presence of viewpoint changes and partial occlusion, unlike other techniques assuming data that are single viewpoint, upright, prealigned, and cropped from background distraction.
The rest of the paper is organized as follows. Section 2 discusses the Extended Bag of Visual Words (EBoVW) model. In section 3 experimental results are reported. Finally conclusions are drawn in section 4.
2 Extended Bag of Visual Words
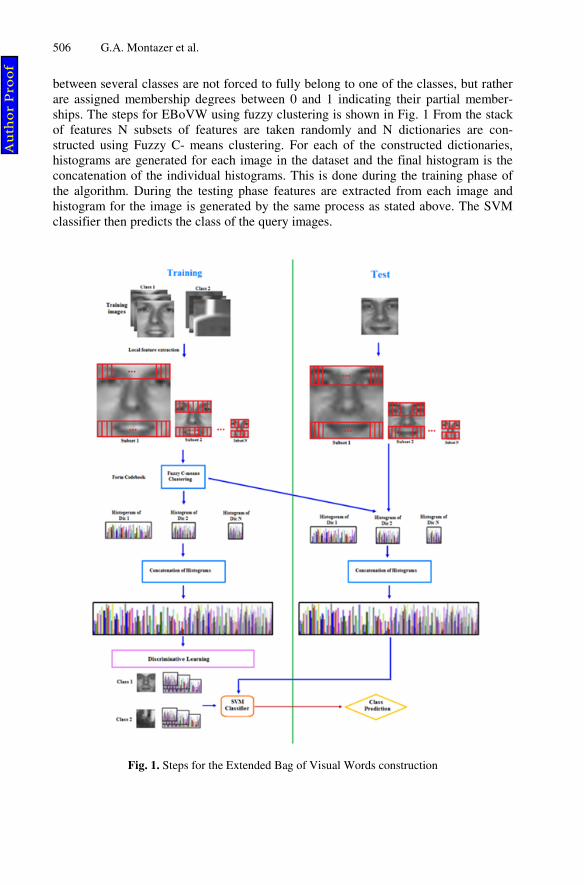
In the original bag of visual words model single dictionary is generated from stack of features. In our proposed extended bag of visual words (EBoVW) multiple dictionaries for each image are constructed so that we can have more visual words and hence EBoVW has significantly increases the performance for large scale image classification problem. Fig. 1 shows the steps of proposed EBoVW model. To this end each dictio-nary is built with a different subset of the image features. So in the implementa-tion of the EBoVW for generating multiple dictionaries the image gets a histogram
from every dictionary which is concatenated to form a single histogram hist. Every feature gets N entries in the histogram hist, one from every dictionary so that more different words are taken from different independent dictionaries while in the original BoVW method more words are taken from the same dictionary. Thus the EBoVW method not only demands less storage than the original method but also its features are more distinctive.
For implementing the proposed EBoVW method first N random possibly overlap-ping subsets of the image features , 1, … , are extracted. Afterwards, a dictionary is computed independently for each subset . Each dictionary has a set of visual words. Then the histogram is computed. Every image feature gets its visual word from every dictionary . Accumulate these visual words as individual words into individual histograms for each dictionary. The final histogram is the concatenation of the individual histograms. In this work, we used Fuzzy C-means clustering for implementing the EBoVW model . Fuzzy C-means (FCM) is a method of clustering which allows one piece of data to belong to two or more clusters. The advantage of soft clustering is that it is insensitive to noise. In many real situations, fuzzy clustering is more natural than hard clustering, as objects on the boundaries
Au
tho
r P
roo
f
506 G.A. Montazer et al.
between several classes are not forced to fully belong to one of the classes, but rather are assigned membership degrees between 0 and 1 indicating their partial member-ships. The steps for EBoVW using fuzzy clustering is shown in Fig. 1 From the stack of features N subsets of features are taken randomly and N dictionaries are con-structed using Fuzzy C- means clustering. For each of the constructed dictionaries, histograms are generated for each image in the dataset and the final histogram is the concatenation of the individual histograms. This is done during the training phase of the algorithm. During the testing phase features are extracted from each image and histogram for the image is generated by the same process as stated above. The SVM classifier then predicts the class of the query images.
Fig. 1. Steps for the Extended Bag of Visual Words construction
Au
tho
r P
roo
f
Extended Bag of Visual Words for Face Detection 507
3 Experimental Results
We present the results of face detection experiments over the images of the MIT CBCL [12]. This dataset consists of 31,022 grayscale images of 2,429 faces and 4,548 non-faces for training and 472 faces and 23,573 non-faces for testing. All of the im-ages with a size of 19×19 pixels. The face images have various illumination condi-tions, facial expressions (e.g., open/closed eyes, smiling/not smiling) and facial details (e.g., glasses/no glasses).
The Bag of visual words model for face detection was implemented using Dense SIFT. 128 dimensional feature vectors used for representing the extracted features. The extracted features are clustered using Fuzzy C-means clustering algorithm and a codebook is generated with each vector in it being a visual word which serves as the basis for indexing the images. Images are then represented as histogram counts of these visual words. For the SVM classifier an exponential kernel of the form expαd was applied, where d is the Euclidean distance between the vectors, and the sca-lar α is determined as described in [13] (we use the LIBSVM package [14] with the trade-off between training error and margin at C 1).
Table 1. Performance comparison (AUC) between original BoVW and EBoVW
Length of feature vector
Original BoVW
EBoVW with 2 Dictionaries
EBoVW with 3 Dictionaries
EBoVW with 4 Dictionaries
128 92.08% 94.05% 94.92% 96.36% 256 92.16% 95.64% 95.87% 96.71 % 512 91.64% 94.67% 95.56% 96.44% 1024 90.60% 94.88% 95.52% 96.54%
Table 2. Performance comparison (EER) between original BoVW and EBoVW
No Of Words Per
Dictionary
Original BoVW
EBoVW with 2 Dictionaries
EBoVW with 3 Dictionaries
EBoVW with 4 Dictionaries
128 14.44% 13.06% 12.09% 10.67% 256 16.53% 12.71% 11.86% 9.96% 512 15.68% 13.11% 11.44% 10.78%
1024 14.19% 11.13% 10.81% 9.32%
In order to evaluate the efficiency of the proposed method two criteria have been
selected from the state-of-the art [15]. Receiver Operating Characteristic (ROC) curve and Equal Error Rate (EER). ROC curve is used to summarize the performance of a biometric verification system. The ROC curve plots, parametrically as a function of the decision threshold, the percentage of impostor attempts accepted (i.e. true positive rate (TPR)) on the x-axis, against the percentage of genuine attempts accepted (i.e. 1 - false positive rate (FPR)) on the y-axis. The ROC curve is threshold independent, allowing performance comparison of different systems under similar conditions. The Area Under the Curve (AUC) is an indicator of the overall quality of a ROC curve. The ROC of the ideal classifier has AUC equal to 1.
Au
tho
r P
roo
f
508 G.A. Montazer et al.
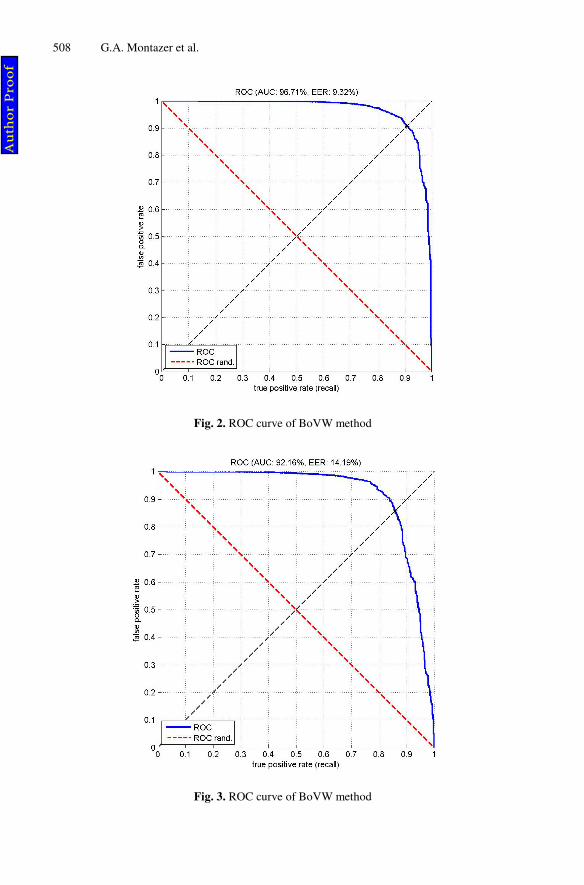
Fig. 2. ROC curve of BoVW method
Fig. 3. ROC curve of BoVW method
Au
tho
r P
roo
f

Extended Bag of Visual Words for Face Detection 509
Another indicator is the Equal Error Rate (EER), the point on the ROC curve that corresponds to have an equal probability of miss-classifying a positive or negative sample. This point is obtained by intersecting the ROC curve with a diagonal of the unit square. The AUC is an overall summary of detection accuracy. AUC equals 0.5 when the ROC curve corresponds to random chance and 1.0 for perfect accuracy. On rare occasions, the estimated AUC is <0.5, indicating that the test does worse than chance. In general, the larger the AUC value, the higher the accuracy of the biometric system. Also, the lower the equal error rate value, the higher the accuracy of the bio-metric system. In our experiments we computed AUC and EER for each experiment as it is shown in Tables 1 and 2. From these tables compared to the original BoVW model, EBoVW model achieves higher performance in terms of both AUC and EER. The best results in both methods were achieved with feature vector of length 1024. In the original BoVW model the best AUC and the best EER are 92.16% and 14.19% and for EBoVW the best AUC and the best EER are 96.71% and 9.32%, respectively. So, more promising results for face detection were obtained by EBoVW while 4 dic-tionaries were used. Fig. 2 and Fig. 3 show plot of ROC for the best results achieved by both BoVW and EBoVW. Also, from the tables we see that by increasing the number of dictionaries the performance of the proposed method increases. Compared to other methods that used MIT CBCL dataset, in [16] authors achieved the best EER of 15.9%. Also authors in [17] stated that their proposed method achieved poor results on MIT CBCL dataset. In [18] authors constructed a new face dataset using MIT CBCL, AR, PIE and Yale datasets. They created this new dataset with different poses, orientations, expressions, lighting conditions, and with or without occlusions. They then rotated, cropped, and re-scaled the face images into the resolution of 24×24 pix-els. They final goal was to design a general learning framework for detecting faces of various poses or under different lighting conditions. They formulated the task as a classification problem over data of multiple classes. Their approach focused on a new multi-class boosting algorithm, called MBHboost, and its integration with a cascade structure for effectively performing face detection.
The only advantage of BoVW over EBoVW is its time complexity. Due to using fuzzy c-means in EBoVW, this method is slightly slower than traditional BoVW.
4 Conclusion
This work introduces an extended version of bag of visual words model. The EBoVW uses multiple dictionary per image and also fuzzy C-mean clustering algorithm to construct histogram of words (feature vectors). In the EBoVW, more words are taken from different independent dictionaries while in the original BoVW model more words are taken from same dictionary. Thus multiple dictionary method has less sto-rage and also more discriminative power than the original one. The experimental re-sults on MIT CBCL face dataset proves the superiority of the proposed method in face detection problem in terms of Area Under the Curve (AUC) and Equal Error Rate (EER). The performance measures used for evaluation increases as the number of dictionary is increased for a particular value of word per dictionary.
Au
tho
r P
roo
f

510 G.A. Montazer et al.
References
1. Jafri, R., Arabnia, H.R.: A Survey of Face Detection Techniques. Journal of Information Processing Systems 5(2) (2009)
2. Brunelli, R., Poggio, T.: Face detection: features versus templates. IEEE Transactions on Pattern Analysis and Machine Intelligence 15, 1042–1052 (1993)
3. Grudin, M.A.: On internal representations in face detection systems. Pattern Detection 33, 1161–1177 (2000)
4. Heisele, B., Wu, P.H.J., Poggio, T.: Face detection: component-based versus global approaches. Computer Vision and Image Understanding 91, 6–21 (2003)
5. Muja, M., Lowe, D.G.: Fast approximate nearest neighbors with automatic algorithm con-figuration. In: VISAPP (2009)
6. Chum, O., Philbin, J., Sivic, J., Isard, M., Zisserman, A.: Total recall: automatic query ex-pansion with a generative feature model for object retrieval. In: ICCV (2007)
7. Jegou, H., Douze, M., Schmid, C.: Hamming embedding and weak geometric consistency for large scale image search. In: Forsyth, D., Torr, P., Zisserman, A. (eds.) ECCV 2008, Part I. LNCS, vol. 5302, pp. 304–317. Springer, Heidelberg (2008)
8. Aly, M., Welinder, P., Munich, M., Perona, P.: Towards automated large scale discovery of image families. In: CVPR Workshop on Internet Vision (2009)
9. Aly, M.: Online learning for parameter selection in large scale image search. In: CVPR Workshop OLCV (2010)
10. Lowe, D.G.: Distinctive image features from Scale-invariant key-points. International Journal of Computer Vision 2(60), 91–110 (2004)
11. Toews, M., Arbel, T.: Detection, Localization, and Sex Classification of Faces from Arbi-trary Viewpoints and under Occlusion. IEEE Transactions on Pattern Analysis and Ma-chine Intelligence 31(9), 1567–1581 (2009)
12. Center for Biological and Computational Learning at MIT (MIT-CBCL) Face Database #1. http://cbcl.mit.edu/cbcl/software-datasets/FaceData2.html
13. Zhang, J., Marszałek, M., Lazebnik, C., Schmid, S.: Local features and kernels for classifi-cation of texture and Scene categories: a comprehensive study. International Journal of Computer Vision 73(2), 213–238 (2007)
14. Chang, C.-C., Lin, C.-J.: LIBSVM : A library for support vector machines. ACM Transac-tions on Intelligent Systems and Technology 2, 27:1–27:27 (2011)
15. Mansfield, A.J., Wayman, J.A.: Best Practices in Testing and Reporting Performance of Biometric Devices (2002)
16. Smeraldi, F.: Ranklets : orientation selective non-parametric features applied to face detec-tion. In: Proceedings of 16th IEEE International Conference on Pattern Detection, vol. 16(3), pp. 379–382 (2002)
17. Zhu, H., Koga, T.: Face Detection based on AdaBoost Algorithm with Local Autocorrela-tions image. IEICE Electronics Express 7(15), 1125–1131 (2010)
18. Lin, Y.Y., Liu, T.-L.: Robust face detection with multi-class boosting. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, pp. 680–687 (2005)
Au
tho
r P
roo
f