estimasi parameter model regresi probit dengan metode
TRANSCRIPT

Estimasi Parameter Model Regresi Probit Dengan Metode Ridge Pada
Data yang Mengandung Multikolinieritas
Sri Irma Yani1*, Anisa2*, Amran3*
Abstrak
Model regresi probit merupakan suatu model regresi yang digunakan ketika variabel respon yang bertipe
kategorik berupa variabel dikotomi yang menunjukkan ada atau tidaknya kriteria atribut dengan menggunakan
nilai 0 atau 1. Terdapat banyak cara yang dapat digunakan untuk mengestimasi parameter model regresi probit,
salah satunya dengan menggunakan metode maximum likelihood estimation (MLE). Namun, ketika terjadi
multikolinieritas antar variabel prediktor, maka variansi semakin membesar yang menyebabkan estimasi dengan
MLE menjadi tidak efisien. Salah satu metode untuk menangani multikolinearitas adalah regresi ridge. Penelitian
ini bertujuan untuk memperoleh estimasi parameter model regresi probit dengan menggunakan metode ridge
pada data yang mengandung multikolinearitas. Pendugaan paremeter pada model regresi probit dengan metode
ridge melibatkan penambahan konstanta bias (𝑘) ke setiap elemen diagonal matriks. Penelitian ini diaplikasikan
pada data kemiskinan kabupaten/kota di Provinsi Sulawesi Selatan tahun 2017. Variabel respon yang bersifat
kategorik dalam penelitian ini yaitu persentase penduduk miskin sesuai indikator kemiskinan dari Badan Pusat
Statistik dan variabel prediktor yaitu faktor-faktor yang mempengaruhi kemiskinan yaitu pengeluaran perkapita,
ketenagakerjaan, fasilitas perumahan dan pendidikan. Hasil yang diperoleh adalah nilai mean square error
(MSE) dari penduga parameter dengan metode ridge sebesar 0.3672 sedangkan dengan metode MLE diperoleh
MSE sebesar 4.5108 dan metode klasik, yaitu metode Ordinary Least Square diperoleh MSE sebesar 10.19. Hal
ini menunjukkan bahwa metode ridge lebih efektif digunakan untuk mengatasi masalah multikolinearitas.
Kata kunci: Regresi Probit, Multikolinieritas, Maximum Likelihood Estimation, Ridge, Mean Square
Error.
ABSTRACT
The probit regression model is a regression model that is used when the response variable with the categorical
type is a dichotomous variable that indicates the presence or absence of attribute criteria using a value of 0 or 1.
There are many ways that can be used to estimate the parameters of the probit regression model, one of them
using the maximum method likelihood estimation (MLE). However, when there is multicollinearity between
predictor variables, the variance will increase which will make estimation with MLE inefficient. One method for
dealing with multicollinearity is ridge regression. The estimation of parameters in the probit regression model
with the ridge method involves adding a bias constant (k) to each diagonal element of the matrix. This study aims
to obtain parameter estimates of probit regression models using the ridge method on data containing
multicollinearity. This study was applied to the poverty data of districts / cities in South Sulawesi Province in
2017. Categorical response variables in this study were the percentage of poor people according to poverty
indicators from the Central Statistics Agency and predictor variables namely factors that influence poverty,
namely expenditure per capita, employment housing and education facilities. The results obtained are the mean
square error (MSE) of the parameter estimator with the ridge method of 0.3672 while the MLE method obtained
by MSE is 4.5108 and the classical method, namely the Ordinary Least Square method obtained by MSE is 10.19.
This shows that the ridge method is more effectively used to overcome multicollinearity problems.
Keywords: Probit Regression, Multicollinearity, Maximum Likelihood Estimation, Ridge, Mean
Square Error.
*Program Studi Statistika, Universitas Hasanuddin
Email : [email protected], [email protected], [email protected]

1. Pendahuluan Model regresi probit adalah model tak linier yang digunakan untuk menganalisis hubungan
antara satu variabel respon dan beberapa variabel bebas, dengan variabel responnya berupa data
kualitatif dikotomi yaitu bernilai 1 untuk menyatakan keberadaan suatu karakteristik dan bernilai
0 untuk menyatakan ketidakberadaan suatu karakteristik [25]. Permasalahan yang sering terjadi
pada regresi probit dengan variabel prediktor lebih dari satu adalah terjadi korelasi antar variabel-
variabel prediktor tersebut yang disebut sebagai multikolinieritas. Hal ini mengakibatkan
penduga/estimator yang dihasilkan menjadi tidak efisien sehingga variansi dari koefisien regresi
menjadi tidak minimum serta variabel prediktor tidak signifikan mempengaruhi variabel respon,
meskipun nilai koefisien determinasinya (R2) tinggi sehingga model yang didapatkan menjadi
kurang layak.
Metode ridge merupakan salah satu metode untuk mengatasi masalah multikolinearitas yakni
dengan cara menambahkan suatu konstanta positif (k) yang kecil pada elemen diagonal matriks
𝑿𝑡𝑿, yang mengakibatkan matriks 𝑿𝑡𝑿 menjadi matriks non-singular. Berdasarkan uraian diatas,
pada penelitian ini penulis mengkaji tentang estimasi parameter model regresi prob it. Sehingga
penulis tertarik untuk mengambil judul penelitian Estimasi Parameter Model Regresi Probit
Dengan Metode Ridge Pada Data yang Mengandung Multikolinieritas.
2. Tinjauan Pustaka
2.1 Estimasi Parameter
Estimasi merupakan suatu pernyataan untuk menduga hubungan mengenai parameter populasi
yang tidak diketahui menggunakan sampel (statistik), dalam hal ini peubah acak yang diambil dari
populasi yang bersangkutan. Jadi dengan estimasi, keadaan populasi dapat diketahui [8]. Adapun
sitat-sifat estimator yang baik adalah sebagai berikut:
1) Unbiased
Suatu hal yang menjadi tujuan dalam mengestimasi adalah estimator harus mendekati nilai
sebenarnya dari parameter yang diduga tersebut.
2) Efisien
Suatu estimator misalkan �̂� dikatakan efisien bagi parameter �̅� apabila penduga tersebut
mempunyai variansi yang kecil.
3) Konsisten
Suatu estimasi dikatakan konsisten apabila nilai estimasi tersebut sama dengan parameter yang
diestimasi.
2.2 Analisis Regresi
Analisis regresi adalah teknik analisis yang mencoba menjelaskan bentuk hubungan antara
peubah-peubah yang mendukung sebab akibat. Prosedur analisisnya didasarkan atas distribusi
probabilitas bersama peubah-peubahnya. Tujuan utama dari analisi regresi adalah untuk
mendapatkan dugaan dari suatu variabel dengan menggunakan variabel lain yang diketahui.
2.2.1 Regresi Linier Berganda
Persamaan model regresi linier dengan 𝑘 variabel bebas diberikan sebagai
𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯+ 𝛽𝑝𝑋𝑝 + 𝜀 (2.1)
dengan,
𝑌 = variabel respon
𝑋1, 𝑋2, … , 𝑋𝑝 = variabel prediktor
𝛽0, 𝛽1, 𝛽2, … , 𝛽𝑝 = parameter

𝜀 = galat
Bila pengamatan 𝑌, 𝑋1, 𝑋2, … , 𝑋𝑝 dinyatakan masing-masing dengan 𝑌𝑖 , 𝑋𝑖1, 𝑋𝑖2, … , 𝑋𝑖𝑝 dan
galatnya 𝜀𝑖, maka Persamaan (2.1) dapat dituliskan sebagai
𝑌𝑖 = 𝛽0 + 𝛽1𝑋𝑖1 + 𝛽2𝑋𝑖2 + ⋯+ 𝛽𝑝𝑋𝑖𝑝 + 𝜀𝑖, 𝑖 = 1,2,… , 𝑛 (2.2)
dengan mean 𝐸(𝜀𝑖) = 0 dan variansinya 𝜎2(𝜀𝑖) = 𝜎2, dan tidak berkorelasi
sehingga kovariansinya 𝐸(𝜀𝑖, 𝜀𝑗) = 0,𝑖 ≠ 𝑗, 𝑖 = 𝑙 = 1,2,… , 𝑛. Apabila dinotasikan dalam bentuk
matriks, menjadi
[
𝑌1
𝑌2
⋮𝑌𝑛
] =
[ 1 𝑋11 … 𝑋1𝑝
1⋮1
𝑋21
⋮𝑋𝑛1
…⋱…
𝑋2𝑝
⋮𝑋𝑝 ]
[
𝛽0
𝛽1
⋮𝛽𝑝
] + [
𝜀1
𝜀2
⋮𝜀𝑛
] (2.3)
Persamaan (2.3) dapat dinyatakan sebagai [17]
𝒀 = 𝑿𝜷 + 𝜺 (2.4)
dengan,
𝒀 = vektor variabel respon (ukuran 𝑛 × 1)
𝑿 = matriks variabel prediktor ukuran (𝑛 × (𝑝 + 1))
𝜷 = vektor parameter (ukuran (𝑝 + 1) × 1)
𝜺 = vektor galat (ukuran 𝑛 × 1)
Persamaan matriks (2.4) dikenal sebagai penyajian matriks model regresi linier (𝑝-variabel).
2.2.1 Regresi Probit
Regresi probit merupakan regresi nonlinier yang digunakan untuk menganalisis hubungan
antara satu variabel respon dengan beberapa variabel prediktor, dengan variabel respon berupa
data kualitatif dikotomi yaitu bernilai 1 untuk menyatakan keberadaan sebuah atribut dan bernilai
0 untuk menyatakan ketidakberadaan sebuah atribut [4]. Menurut Skrondal & Hesketh [23],
regresi probit merupakan modifikasi regresi logistik dengan menetapkan persamaan regresi logit
berdistribusi normal.
Model regresi probit ditunjukkan pada persamaan [13]
𝑦𝑖∗ = 𝑥𝑖′𝜷 + 𝜀𝑖 (2.5)
dengan 𝑦𝑖∗ merupakan variabel laten, 𝑥𝑖 adalah baris ke-i dari 𝑿 yang merupakan matriks berordo
𝑛 × (𝑝 + 1) dengan 𝑝 merupakan banyaknya variabel prediktor, 𝜷 adalah vektor koefisien (𝑝 +
1) × 1 dan 𝜀𝑖 adalah error yang diasumsikan berdistribusi normal. Variabel laten tidak dapat
diamati secara langsung, namun dapat dianalisis melalui variabel dummy sebagai berikut:
𝑦𝑖 = {1, 𝑗𝑖𝑘𝑎 𝑦𝑖
∗ > 0
0, 𝑢𝑛𝑡𝑢𝑘 𝑦𝑖∗ 𝑙𝑎𝑖𝑛𝑛𝑦𝑎
𝑦𝑖 berdistribusi 𝐵𝑒(𝜋𝑖), dengan 𝜋𝑖 = Ф(𝑥𝑖′𝜷) dan Ф adalah fungsi distribusi normal standar.
2.3 Metode Maximum Likelihood Estimator
Metode Maximum Likelihood Estimator (MLE) merupakan metode yang digunakan dalam
menduga parameter regresi logistik. Karena setiap observasi bersifat independen, maka bentuk
umum fungsi likelihood dari distribusi Bernoulli adalah [2]:
𝐿(𝜷) = ∏𝑓(𝑦𝑖)
𝑛
𝑖=1
= ∏ 𝜋𝑖𝑦𝑖(1 − 𝜋𝑖)
1−𝑦𝑖𝑛𝑖=1 (2.6)
dengan

𝜋𝑖 =exp (𝛽0+𝛽1𝑥𝑖1+𝛽2𝑥𝑖2+⋯+𝛽𝑘𝑥𝑖𝑘)
1+exp (𝛽0+𝛽1𝑥𝑖1+𝛽2𝑥𝑖2+⋯+𝛽𝑘𝑥𝑖𝑘)
=exp (∑ 𝛽𝑗𝑋𝑖𝑗)
𝑘𝑗=0
1+exp (∑ 𝛽𝑗𝑋𝑖𝑗)𝑘𝑗=0
=exp (𝑿𝒊𝜷)
1+exp (𝑿𝒊𝜷), 𝑖 = 1,2, … , 𝑛
dengan 𝑿𝒊 = (1, 𝑥𝑖1, 𝑥𝑖2, … , 𝑥𝑖𝑘) dan 𝜷 = (𝛽0 𝛽1 𝛽2 …𝛽𝑘)𝑡
Perhitungan lebih mudah dilakukan dengan memaksimumkan fungsi likelihood yang disebut
fungsi log-likelihood berupa logaritma natural dari fungsi likelihood tersebut, sehingga dituliskan
sebagai:
ℓ = ln 𝐿(𝜷) = ln(∏𝜋𝑖𝑦𝑖(1 − 𝜋𝑖)
1−𝑦𝑖
𝑛
𝑖=1
)
= ∑ {− ln (1 + exp(𝑿𝒊𝜷)) + 𝑦𝑖 𝑿𝒊𝜷}𝑛𝑖=1 (2.7)
Penduga varian dan kovarian diperoleh dari turunan kedua fungsi log likelihood, sebagai
berikut [14]:
𝜕2ℓ
𝜕2𝛽= −∑ (𝑿𝑖
2𝜋𝑖(1 − 𝜋𝑖)) =𝑛𝑖=1 − ∑ (𝑿1
2�̂�𝑖)𝑛𝑖=1
= −𝑿𝑡�̂�𝑿 (2.8)
dengan �̂� = 𝑑𝑖𝑎𝑔[𝜋𝑖(1 − 𝜋𝑖)]
Karena model regresi logistik merupakan fungsi nonlinear, maka proses perhitungan MLE
dapat didekati dengan metode Weighted Least Square (WLS) yang dapat ditulis sebagai berikut:
�̂�𝑊𝐿𝑆 = (𝑿𝑡�̂�𝑿)−1
𝑿𝑡�̂��̂� (2.9)
Metode ini merupakan pengembangan dari metode fisher scoring [2]. Penduga parameter
dengan metode fisher scoring pada iterasi ke-𝑡 + 1 dalam proses iterasi 𝑡= 0, 1, 2 ,... adalah
sebagai berikut :
�̂�𝑡+1 = �̂�𝑡 + 𝑰−1(𝜷𝑡)𝑺(𝜷𝑡) (2.10)
dengan
�̂�𝑡 dan �̂�𝑡+1 : vektor untuk 𝜷 pada iterasi ke-t dan ke-t + 1
𝑰−1(𝜷𝑡) : matriks informasi yang berisi negatif ekspektasi dari turunan kedua ln-likelihood
terhadap 𝜷𝑡
𝑺(𝜷𝑡) : vektor turunan pertama ln-likelihood terhadap 𝜷𝑡
Dari iterasi tersebut akan diperoleh penduga maksimum likelihood untuk �̂� dan �̂� yang
dinotasikan dengan �̂�𝑀𝐿 dan �̂�
�̂�𝑀𝐿 = (𝑿𝑡�̂�𝑿)−1
𝑿𝑡�̂��̂� (2.11)
dengan merupakan vektor yang setiap elemen ke-i bernilai
𝑧𝑖 = ln (𝜋𝑖
1−𝜋𝑖) +
𝑦𝑖−𝜋𝑖
𝜋𝑖(1−𝜋𝑖) (2.12)
2.4 Iterasi Method of Scoring
Iterasi method of scoring adalah salah satu iterasi dari metode nonlinier maximum likelihood
untuk mendapatkan estimasi prameter 𝛽 yang merupakan bagian dari metode fisher scoring
dengan
𝜷(𝑡+1) = 𝜷𝑡 − (𝐸 (𝜕2ℓ
𝜕𝜷𝜕𝜷𝑡 ⃒𝜷𝑡))
−1𝜕ℓ
𝜕𝜷⃒𝜷𝑡 (2.13)
Selanjutnya PDF dari 𝑦𝑖 yang diberikan oleh 𝑿𝑖, 𝜷, dan 𝜎2 berikut :
𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2) =1
𝜎√2𝜋𝑒𝑥𝑝 (−
1
2𝜎2(𝑦𝑖 − 𝑓(𝑿𝑖, 𝜷))2)
= 𝐿𝑖(𝜷, 𝜎2) (2.14)

sebagaimana diketahui Persamaan (2.14), maka dapat dibentuk
ℓ𝑖 = ln𝐿𝑖(𝜷, 𝜎2) = ln 𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2) (2.15)
maka
𝜕ℓ𝑖
𝜕𝜷=
1
𝐿𝑖(𝜷, 𝜎2)
𝜕𝐿𝑖(𝜷, 𝜎2)
𝜕𝜷
=1
𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2)
𝜕𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2)
𝜕𝜷 (2.16)
dari Persamaan (2.16) diperoleh
∫𝜕𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2
)
𝜕𝜷𝑑
∞
−∞𝑦𝑖 = 0
= ∫𝜕ℓ𝑖
𝜕𝜷𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2)𝑑
∞
−∞𝑦𝑖 (2.17)
Selanjutnya turunan parsial pertama Persamaan (2.19) terhadap 𝜷𝑡 dan menyakaman
persamaanya dengan nol sehingga diperoleh, 𝜕
𝜕𝜷𝑡 (∫𝜕ℓ𝑖
𝜕𝜷𝑓(𝑦𝑖|𝑿𝑖, 𝜷, 𝜎2)𝑑
∞
−∞𝑦𝑖) = 0
= 𝐸 (𝜕2ℓ𝑖
𝜕𝜷𝜕𝜷𝑡 +𝜕ℓ𝑖
𝜕𝜷
𝜕ℓ𝑖
𝜕𝜷𝑡)
atau dapat dituliskan sebagai
𝐸 (𝜕2ℓ𝑖
𝜕𝜷𝜕𝜷𝑡) = −𝐸 (𝜕ℓ𝑖
𝜕𝜷
𝜕ℓ𝑖
𝜕𝜷𝑡) (2.18)
2.5 Multikolinieritas
Istilah multikolinieritas diciptakan oleh Ragner Frish yang menyatakan adanya hubungan linier
yang sempurna atau eksak (perfect or exact) di antara variabel-variabel prediktor dalam model
regresi yang menyebabkan variabel prediktor 𝑿 akan mengakibatkan determinan matriks 𝑿𝑡𝑿
pada estimator ordinary least square maupun maximum likelihood mendekati nol sehingga
menjadi singular. [6] menyatakan bahwa hal ini dapat diketahui dari matriks korelasi hasil
pemusatan dan penskalaan matriks X sebagai berikut:
�̂�𝐿𝑆 = (𝑿𝑡𝑿)−1𝑿𝑡𝒀
= [1 𝑟12
𝑟21 1]−1
[𝑟1𝑦
𝑟2𝑦] (2.19)
dengan 𝑟12 adalah koefisien korelasi antara 𝑿1 dan 𝑿2.
Menurut Setiawan dan Kusrini (2010), salah satu ukuran untuk menguji adanya
multikolinieritas adalah Variance Inflation Factors (VIF). VIF merupakan elemen diagonal dari
matriks 𝑿𝑡𝑿.
(𝑿𝑡𝑿)−1 = [
1
1−𝑟122
−𝑟12
1−𝑟122
−𝑟12
1−𝑟122
1
1−𝑟122
] (2.20)
𝑉𝐼𝐹𝑗 = 𝑑𝑖𝑎𝑔(𝑿𝑡𝑿) =1
1−𝑹𝑗2 (2.21)
Pengujian multikolinieritas juga dapat dilakukan dengan menghitung nilai Tolerance (TOL)
dengan persamaan
𝑇𝑂𝐿𝑗 =1
𝑉𝐼𝐹𝑗 (2.22)
Nilai 𝑇𝑂𝐿 < 0.1 mengindikasikan bahwa terjadi multikolinieritas antar variabel prediktor.
Sedangkan nilai VIF dari estimator generalized ridge regression dapat dihitung melalui
persamaan
𝑉𝐼𝐹 = 𝑑𝑖𝑎𝑔 (1
𝑛−1(𝑿𝑡𝑿) − 𝑫𝑲𝑫𝑡)
−1(
1
𝑛−1(𝑿𝑡𝑿)) (
1
𝑛−1(𝑿𝑡𝑿) − 𝑫𝑲𝑫𝑡)
−1 (2.23)

dengan K adalah matriks yang elemen diagonalnya merupakan parameter ridge 𝑘 ≥ 0. D
menyatakan suatu matriks ortogonal dengan 𝑫 = 𝑫−1sedemikian sehingga 𝑫𝑡𝑫 = 𝑰 dan
𝑫𝑡𝑪𝑫 = Ʌ, dengan 𝑪 = 𝑿𝑡𝑿 dan Ʌ merupakan matriks 𝑝 × 𝑝 yang anggota diagonal utamanya
merupakan nilai eigen dari matriks 𝑿𝒕𝑿.
2.6 Metode Ridge
Estimasi ridge untuk koefisien regresi dapat diperoleh dengan menyelesaikan suatu bentuk dari
persamaan normal regresi [10]. Penduga ridge dapat dituliskan sebagai berikut:
�̂�𝑅𝑅 = (𝑿𝑡𝑿 + 𝑘𝑰)−1𝑿𝑡𝒀 (2.24)
Pada dasarnya penduga ridge merupakan metode kuadrat terkecil. Perbedaannya adalah bahwa
pada metode regresi ridge, nilai variabel bebasnya ditransformasikan dahulu melalui prosedur
centering dan rescaling [22].
Pada tahun 1984, R.L Schaefer, L.D Roi dan R.A Wolfe mengembangkan penduga ridge pada
model regresi logistik untuk menangani masalah multikolinearitas dengan metode Lagrange yang
meminimumkan fungsi Weighted Sum of Square Error (WSSE) berikut:
𝑾𝑺𝑺𝑬 = (𝒀 − 𝑿𝜷)𝑡𝑾(𝒀 − 𝑿𝜷) (2.25)
Parameter penting yang membedakan regresi ridge dari metode kuadrat terkecil adalah k.
Parameter ridge k yang relatif kecil ditambahkan pada diagonal utama matriks 𝑿𝑡𝑿, sehingga
koefisien estimator regresi ridge dipenuhi dengan besarnya parameter ridge k. Estimator ridge
diperoleh dengan meminimumkan jumlah kuadrat error untuk model
𝒀 = 𝑿𝜷 + 𝜺 (2.26)
dengan menggunakan metode pengali Lagrange yang meminimumkan fungsi
𝜺𝑡𝜺 = (𝒀 − 𝑿𝜷𝑅𝑅)𝑡(𝒀 − 𝑿𝜷𝑅𝑅) (2.27)
dengan syarat pembatas
𝜷𝑅𝑅𝑡 𝜷𝑅𝑅 − 𝑐2 = 0
𝑮 = (𝒀 − 𝑿𝜷𝑅𝑅)𝑡(𝒀 − 𝑿𝜷𝑅𝑅) + 𝑘(𝜷𝑅𝑅𝑡 𝜷𝑅𝑅 − 𝑐2) (2.28)
yang memenuhi syarat 𝜕𝑮
𝜕𝜷𝑅𝑅| �̂�𝑅𝑅 = 0
−2𝑿𝑡𝒀 + 2𝑿𝑡𝑿�̂�𝑅𝑅 + 2𝑘𝑰�̂�𝑅𝑅 = 0
�̂�𝑅𝑅 = (𝑿𝑡𝑿 + 𝑘𝑰)−1𝑿𝑡𝒀 (2.29)
dengan �̂�𝑅𝑅 = (𝑿𝑡𝑿 + 𝑘𝑰)−1𝑿𝑡𝒀 dengan 0 ≤ 𝑘 ≤ ∞, itulah yang disebut sebagai estimator
regresi ridge. k ≥ 0 aalah nilai konstan yang dipilih sebagai indeks dari kelas estimator. Adapun
model regresi probit dengan metode ridge menggunakan parameter ridge
𝑘 = 𝑚𝑎𝑥 (1
𝑞𝑗) (2.30)
𝑞𝑗 =𝜆𝑚𝑎𝑥
(𝑛−𝑝)�̂�2+𝜆𝑚𝑎𝑥�̂�𝑗2 (2.31)
2.7 Kemiskinan
Masalah kemiskinan merupakan salah satu persoalan mendasar yang menjadi pusat perhatian
pemerintah di negara manapun. Salah satu aspek penting untuk mendukung Strategi
Penanggulangan Kemiskinan adalah tersedianya data kemiskinan yang akurat. Pengukuran
kemiskinan yang dapat dipercaya dapat menjadi instrumen tangguh bagi pengambil kebijakan
dalam memfokuskan perhatian pada kondisi hidup orang miskin. Data kemiskinan yang baik dapat
digunakan untuk mengevaluasi kebijakan pemerintah terhadap kemiskinan, membandingkan
kemiskinan antar waktu dan daerah, serta menentukan target penduduk miskin dengan tujuan
untuk memperbaiki kondisi mereka [3].
Kemiskinan telah menjadi masalah di hampir semua negara, baik negara maju atau negara
yang sedang berkembang. Tingkat kekompleksitas tiap negara berbeda dalam menyelesaikan
masalah kemiskinan. Indonesia sebagai salah satu negara berkembang, angka kemiskinan masih
cukup tinggi. Pemerintah melalui Badan Pusat Statistik (BPS) membuat kriteria kemiskinan, agar
dapat menyusun secara lengkap pengertian kemiskinan sehingga dapat diketahui dengan pasti
jumlahnya dan cara tepat menanggulanginya.
3. Metodologi Penelitian
3.1 Data
Data yang digunakan dalam penelitian ini merupakan data sekunder dari 24 kabupaten/kota
di provinsi Sulawesi Selatan tentang faktor-faktor yang mempengaruhi kemiskinan di Provinsi
Sulawesi Selatan tahun 2017. Sumber data diperoleh dari publikasi BPS berupa buku yang
berjudul “Data dan Informasi Kemiskinan Kabupaten/Kota Tahun 2017”.
Variabel respon Y bersifat kategorik yaitu dengan mengelompokkan kabupaten/kota menjadi
dua kelompok, yakni miskin atau tidak miskin berdasarkan nilai Head Count Index (HCI) Provinsi
Sulawesi Selatan tahun 2016 sebesar 10.34% [9], yaitu: 0 = kabupaten/kota tidak miskin (nilai
HCI dibawah 10,34%)
1 = kabupaten/kota miskin (nilai HCI diatas 10,34%)
Adapun variabel prediktor berdasarkan masing-masing sektor yang
ditampilkan pada Tabel 3.1.
Tabel 3. 1 Variabel penelitian kemiskinan
Sektor Simbol Variabel
- Y (HCI) Persentase penduduk miskin (%)
Pendidikan
X1 Persentase penduduk miskin usia 15 tahun keatas (<SD)
(%)
X2 Angka melek huruf untuk golongan usia 15-55 tahun
(%)
Ketenagakerjaan
X3 Persentase penduduk usia >15 tahun yang tidak bekerja
(%)
X4 Persentase penduduk miskin usia 15 tahun keatas yang
bekerja di sektor pertanian (%)
X5 Persentase penduduk miskin usia 15 tahun keatas yang
bekerja bukan di sektor pertanian (%)
Pengeluaran Perkapita X6 Persentase pengeluaran perkapita penduduk miskin
untuk makanan (%)
Fasilitas Perumahan
X7 Persentase rumah tangga miskin yang menggunakan air
layak (%)
X8 Persentase rumah tangga miskin yang menggunakan
jamban sendiri/bersama (%)
3.2 Metode Analisis
Metode analisis yang digunakan dalam penelitian ini adalah
1. Mendeteksi adanya multikolinieritas pada data dengan menghitung nilai korelasi antar
variabel prediktor (X) dan dengan menghitung nilai VIF serta nilai TOL menggunakan
Persamaan (2.21) dan Persamaan (2.22).
2. Melakukan proses standariasi pada variabel prediktor (X) menggunakan Persamaan

𝑍 =𝑋 − 𝜇
𝜎
3. Melakukan proses pendeskripsian model ke bentuk GLM.
4. Melakukan pendugaan koefisien regresi probit �̂�𝑀𝐿 dengan proses sebagai berikut:
a. Menghitung nilai dugaan awal �̂�𝑀𝐿0 yang diperoleh dari penduga parameter dengan
menggunakan metode Ordinary Least Square (OLS).
b. Menghitung nilai �̂� dan 𝜀 = 𝑦 − �̂�;�̂� = �̂�
c. Menghitung nilai �̂� dan �̂� serta nilai �̂�1 dengan metode MLE menggunakan Persamaan
(2.11)
d. Mengulangi langkah b dan c agar nilai �̂�𝑀𝐿 konvergen hingga m iterasi
�̂�𝑀𝐿𝑚 = (𝑿𝑡�̂�𝑚𝑿)
−1𝑿𝑡�̂�𝑚�̂�𝑚
5. Menghitung nilai eigen dan vektor eitgen dari 𝑿𝑡�̂�𝑚𝑿.
6. Menghitung nilai tetapan 𝑘.
𝑘 = 𝑚𝑎𝑥 (1
𝑞𝑗) dengan 𝑞𝑗 =
𝜆𝑚𝑎𝑥
(𝑛−𝑝)�̂�2+𝜆𝑚𝑎𝑥�̂�𝑗2
7. Melakukan pendugaan koefisien regresi Probit dengan metode ridge, dinotasikan dengan
�̂�𝑅𝑅.
�̂�𝑅𝑅 = (𝑿𝑡𝑾𝑿 + 𝑘𝑰)−1𝑿𝑡𝑾𝑿�̂�𝑀𝐿𝑚
8. Membentuk model regresi Probit.
9. Memeriksa apakah multikolinieritas telah teratasi dengan melakukan uji formal, yakni
dengan menghitung kembali nilai VIF setelah penambahan parameter ridge.
10. Membandingkan hasil estimasi dengan data yang sebenarnya untuk mengetahui kesesuaian
model yang didapatkan. Perbandingan dilakukan dengan mengkategorikan nilai 𝑦𝑖∗, dengan
�̂�𝑖 = {1, 𝑗𝑖𝑘𝑎 𝑦𝑖
∗ > 0
0, 𝑗𝑖𝑘𝑎 𝑦𝑖∗ ≤ 0
11. Penarikan Kesimpulan.
4 Hasil dan Pembahasan
4.1 Estimasi Parameter Model Regresi Probit
Estimasi parameter model regresi probit menggunakan metode ridge diperoleh dengan terlebih
dahulu mendeskripsikan model berupa fungsi distribusi yang dari model ke dalam bentuk GLM,
kemudian dilanjutkan dengan estimasi parameter menggunakan metode MLE. Estimator yang
telah didapatkan kemudian digunakan untuk mengestimasi parameter regresi probit dengan
metode ridge.
Variabel respon 𝑦𝑖(𝑖 = 1,2,… , 𝑛) dalam model regresi probit diasumsikan berdistribusi
Bernoulli dengan peluang sukses 𝜋𝑖 = Ф(𝑥𝑖𝑡, 𝜷), 𝑖 = 1,2,… , 𝑛 dengan Ф adalah fungsi distribusi
normal standar, 𝑥𝑖 adalah kolom ke-i dari matriks X berordo 𝑛 × 𝑝 dengan 𝑝 adalah banyaknya
variabel prediktor, dan 𝜷 adalah matriks berordo 𝑝 × 1.
Karena 𝑦𝑖 berdistribusi Bernoulli dengan peluang sukses 𝜋𝑖, maka dalam bentuk persamaan
dapat dituliskan sebagai
𝑓(𝑦𝑖) = 𝜋𝑖𝑦𝑖(1 − 𝜋𝑖)
1−𝑦𝑖 (4.1)
Untuk mengestimasi parameter 𝜷 digunakan metode MLE setelah mendeskripsikan Persamaan
(4.1) ke dalam bentuk GLM terlebih dahulu.

4.1.1 Deskripsi Model ke Bentuk Generalized Linier Model
Model regresi probit merupakan hasil modifikasi dari model regresi logistik yang merupakan
anggota dari exponential family. Oleh karena itu langkah pertama yang harus dilakukan untuk
mendeskripsikan fungsi distribusi dari variabel respon ke dalam bentuk GLM adalah dengan
menunjukkan bahwa fungsi distribusi tersebut merupakan keluarga eksponensial. Dengan
menggunakan fungsi logaritma natural, Persamaan (4.1) menjadi
ln 𝑓(𝑦𝑖) = 𝑦𝑖 ln(𝜋𝑖) + (1 −𝑦𝑖)ln (1 − 𝜋𝑖)
= 𝑦𝑖 ln (𝜋𝑖
1−𝜋𝑖) + ln(1 − 𝜋𝑖) (4.2)
Persamaan (4.2) dapat dituliskan sebagai
ℓ𝑖 = ln𝑓( 𝑦𝑖) = 𝑦𝑖𝜃𝑖 − 𝑏(𝜃𝑖)
dari 𝜃𝑖 = ln (𝜋𝑖
1−𝜋𝑖), dapat diperoleh 𝜋𝑖 sebagai berikut:
𝜋𝑖 =𝑒𝜃𝑖
1 + 𝑒𝜃𝑖
sehingga,
𝑏(𝜃𝑖) = − ln(1 − 𝜋𝑖) = ln(1 + 𝑒𝜃𝑖) (4.3)
Dari Persamaan (4.3), diperoleh
𝐸(𝑦𝑖) = 𝜋𝑖
dan
𝑉𝑎𝑟(𝑦𝑖) = 𝜋𝑖(1 − 𝜋𝑖)
4.1.2 Estimasi dengan Metode Maximum Likelihood
Metode MLE untuk GLM digunakan pada penduga parameter model yang distribusi
eksponensial. Adapun penduga parameter regresi probit dengan variabel respon mengikuti
distribusi Bernouli diberikan PDF sebagai berikut :
𝑓(𝑦𝑖) = (𝜋𝑖)𝑦𝑖(1 − 𝜋𝑖)
1−𝑦𝑖 , 𝑦 = 0,1 (4.4)
dari Persamaan (4.4) diperoleh fungsi likelihood:
𝐿(𝜷) = ∏ 𝑓(𝑦𝑖)𝑛𝑖=1 = ∏ (
exp (𝑿𝒊𝜷)
1+exp (𝑿𝒊𝜷))
𝑦𝑖(
1
1+exp (𝑿𝒊𝜷))1−𝑦𝑖𝑛
𝑖=1 (4.5)
dan fungsi log-likelihood sebagai berikut :
ℓ = ln 𝐿(𝜷) = ∑ [− ln(1 + exp(𝑿𝑖𝜷)) + 𝑦𝑖𝑿𝑖𝜷]𝑛𝑖=1 (4.6)
turunan pertama dari fungsi log-likelihood terhadap parameter 𝜷 yaitu:
𝜕ℓ
𝜕𝜷⃒𝜷=�̂� = ∑ 𝑿𝑖 [𝑦𝑖 −
(exp(𝑿𝑖�̂�))
1+exp(𝑿𝑖�̂�)]𝑛
𝑖=1 (4.7)
dengan �̂�(𝑥) =(exp(𝑿𝑖�̂�))
1+exp(𝑿𝑖�̂�) atau dalam bentuk matriks dapat dituliskan sebagai:
𝜕ℓ
𝜕𝜷= 𝑿𝑡(𝑦 − �̂�(𝑥)) (4.8)
turunan kedua dari fungsi log-likelihood menghasilkan
𝜕2ℓ
𝜕2𝜷= −∑ (𝑿𝑖
2�̂�𝑖)𝑛𝑖=1
dalam bentuk matriks, dapat dituliskan sebagai:
𝜕2ℓ
𝜕2𝜷= −𝑿𝑡�̂�𝑿 (4.9)
dengan �̂� = 𝑑𝑖𝑎𝑔[�̂�𝑖(1 − �̂�𝑖)]
Iterasi fisher scoring dapat dibentuk ulang menggunakan menjadi
�̂�𝑡+1 = �̂�𝑡+ (𝑿𝑡�̂�𝑿)−1
(𝑿𝑡(𝑦 − �̂�(𝑥))) (4.10)
Persamaan (4.10) dapat dituliskan dalam bentuk matriks sebagai berikut :
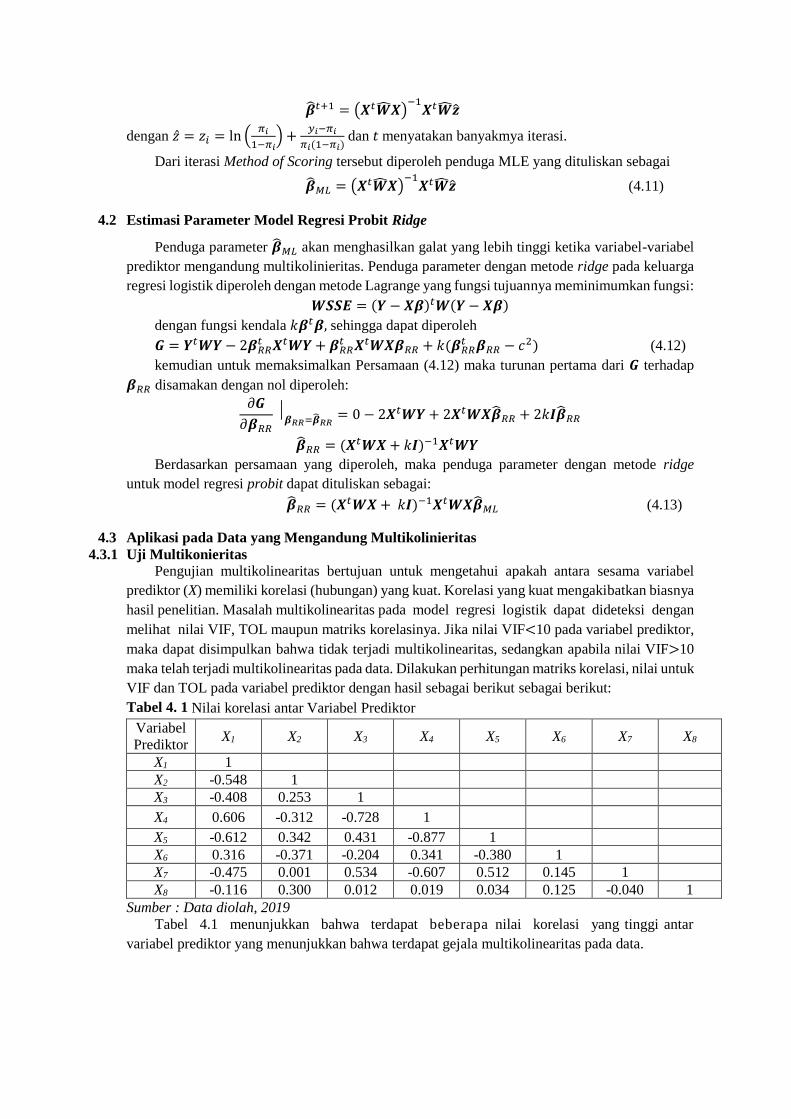
�̂�𝑡+1 = (𝑿𝑡�̂�𝑿)−1
𝑿𝑡�̂��̂�
dengan �̂� = 𝑧𝑖 = ln (𝜋𝑖
1−𝜋𝑖) +
𝑦𝑖−𝜋𝑖
𝜋𝑖(1−𝜋𝑖) dan 𝑡 menyatakan banyakmya iterasi.
Dari iterasi Method of Scoring tersebut diperoleh penduga MLE yang dituliskan sebagai
�̂�𝑀𝐿 = (𝑿𝑡�̂�𝑿)−1
𝑿𝑡�̂��̂� (4.11)
4.2 Estimasi Parameter Model Regresi Probit Ridge
Penduga parameter �̂�𝑀𝐿 akan menghasilkan galat yang lebih tinggi ketika variabel-variabel
prediktor mengandung multikolinieritas. Penduga parameter dengan metode ridge pada keluarga
regresi logistik diperoleh dengan metode Lagrange yang fungsi tujuannya meminimumkan fungsi:
𝑾𝑺𝑺𝑬 = (𝒀 − 𝑿𝜷)𝑡𝑾(𝒀 − 𝑿𝜷)
dengan fungsi kendala 𝑘𝜷𝑡𝜷, sehingga dapat diperoleh
𝑮 = 𝒀𝑡𝑾𝒀 − 2𝜷𝑅𝑅𝑡 𝑿𝑡𝑾𝒀 + 𝜷𝑅𝑅
𝑡 𝑿𝑡𝑾𝑿𝜷𝑅𝑅 + 𝑘(𝜷𝑅𝑅𝑡 𝜷𝑅𝑅 − 𝑐2) (4.12)
kemudian untuk memaksimalkan Persamaan (4.12) maka turunan pertama dari 𝑮 terhadap
𝜷𝑅𝑅 disamakan dengan nol diperoleh:
𝜕𝑮
𝜕𝜷𝑅𝑅⃒𝜷𝑅𝑅=�̂�𝑅𝑅
= 0 − 2𝑿𝑡𝑾𝒀 + 2𝑿𝑡𝑾𝑿�̂�𝑅𝑅 + 2𝑘𝑰�̂�𝑅𝑅
�̂�𝑅𝑅 = (𝑿𝑡𝑾𝑿 + 𝑘𝑰)−1𝑿𝑡𝑾𝒀
Berdasarkan persamaan yang diperoleh, maka penduga parameter dengan metode ridge
untuk model regresi probit dapat dituliskan sebagai:
�̂�𝑅𝑅 = (𝑿𝑡𝑾𝑿 + 𝑘𝑰)−1𝑿𝑡𝑾𝑿�̂�𝑀𝐿 (4.13)
4.3 Aplikasi pada Data yang Mengandung Multikolinieritas
4.3.1 Uji Multikonieritas
Pengujian multikolinearitas bertujuan untuk mengetahui apakah antara sesama variabel
prediktor (X) memiliki korelasi (hubungan) yang kuat. Korelasi yang kuat mengakibatkan biasnya
hasil penelitian. Masalah multikolinearitas pada model regresi logistik dapat dideteksi dengan
melihat nilai VIF, TOL maupun matriks korelasinya. Jika nilai VIF<10 pada variabel prediktor,
maka dapat disimpulkan bahwa tidak terjadi multikolinearitas, sedangkan apabila nilai VIF>10
maka telah terjadi multikolinearitas pada data. Dilakukan perhitungan matriks korelasi, nilai untuk
VIF dan TOL pada variabel prediktor dengan hasil sebagai berikut sebagai berikut:
Tabel 4. 1 Nilai korelasi antar Variabel Prediktor
Variabel
Prediktor X1 X2 X3 X4 X5 X6 X7 X8
X1 1
X2 -0.548 1
X3 -0.408 0.253 1
X4 0.606 -0.312 -0.728 1
X5 -0.612 0.342 0.431 -0.877 1
X6 0.316 -0.371 -0.204 0.341 -0.380 1
X7 -0.475 0.001 0.534 -0.607 0.512 0.145 1
X8 -0.116 0.300 0.012 0.019 0.034 0.125 -0.040 1
Sumber : Data diolah, 2019
Tabel 4.1 menunjukkan bahwa terdapat beberapa nilai korelasi yang tinggi antar
variabel prediktor yang menunjukkan bahwa terdapat gejala multikolinearitas pada data.

Tabel 4. 2 Nilai VIF dan TOL
Variabel VIF TOL Keterangan
X1 2.499 0.400 Tidak Multikolinearitas
X2 1.994 0.501 Tidak Multikolinearitas
X3 11.652 0.086 Multikolinearitas
X4 38.274 0.026 Multikolinearitas
X5 19.957 0.050 Multikolinearitas
X6 1.786 0.560 Tidak Multikolinearitas
X7 2.688 0.372 Tidak Multikolinearitas
X8 1.270 0.787 Tidak Multikolinearitas
Sumber : Data diolah, 2019
Tabel 4.2 menunjukkan bahwa variabel X3, X4 dan X5 memiliki nilai VIF yang lebih besar
dari 10 yaitu masing-masing sebesar 11.652, 38.274 dan 19.957. Nilai TOL yang kurang dari 0.1
terlihat pada variabel X3, X4 dan X5. Dengan demikian dapat disimpulkan bahwa terdapat masalah
multikolinearitas pada model regresi.
4.3.2 Pendugaan Parameter Regresi dengan Metode MLE
Langkah pertama yang dilakukan untuk mengestimasi parameter model dengan metode ridge
adalah dengan menentukan nilai penduga awal yang digunakan menggunakan metode (OLS).
Model regresi yang diperoleh dengan menggunakan metode OLS diberikan sebagai berikut :
𝑦𝑖∗ = −0.3750 − 0.1146𝑋1𝑖 + 0.0386𝑋2𝑖 − 0.2969𝑋3𝑖 − 0.281𝑋4𝑖 − 0.2032𝑋5𝑖
− 0.0889𝑋6𝑖 + 0.0968𝑋7𝑖 − 0.0974𝑋8𝑖
Dengan menggunakan proses iterasi Method of Scoring, dengan nilai dugaan awal dari metode
OLS, maka model regresi yang diperoleh dengan menggunakan metode MLE diberikan sebagai
berikut :
𝑦𝑖∗ = −0.4339 − 0.3836𝑋1𝑖 + 0.0754𝑋2𝑖 − 1. 5450𝑋3𝑖 − 1. 1092𝑋4𝑖 − 1.2081𝑋5𝑖
− 0.2996𝑋6𝑖 + 0.2942𝑋7𝑖 − 0.2694𝑋8𝑖
4.3.3 Pendugaan Parameter Regresi dengan Metode Ridge
Langkah awal dalam proses estimasi menggunakan metode ridge dilakukan dengan pemilihan
nilai konstanta ridge (𝑘). Terdapat beragam metode yang telah dikemukakan peneliti sebelumnya
dalam pemilihan nilai tetapan k. Penduga parameter �̂�𝑅𝑅 dapat diperoleh dengan mengunakan
rumus berikut:
�̂�𝑅𝑅 = (𝑿𝑡𝑾𝑿 + 𝑘𝑰)−1𝑿𝑡𝑾𝑿�̂�𝑀𝐿
Untuk mendapatkan �̂�𝑅𝑅, maka harus ditentukan parameter ridge (𝑘). Dalam hal ini digunakan
𝑘 = 𝑚𝑎𝑥 (1
𝑞𝑗)
dengan 𝑞𝑗 =𝜆𝑚𝑎𝑥
(𝑛−𝑝)�̂�2+𝜆𝑚𝑎𝑥�̂�𝑗2, dan 𝜆𝑚𝑎𝑥 adalah nilai eigen maksimum dari 𝑿𝑡𝑾𝑿, �̂�𝑗
2
didefinisikan sebagai elemen ke-𝑗 dari 𝜸�̂�𝑀𝐿 yang merupakan vektor eigen sedemikian sehingga
𝑿𝒕𝑾𝑿 = 𝜸𝑡Ʌ𝜸, dengan Ʌ yang merupakan matriks diagonal dengan elemen diagonal berupa 𝜆𝑗
dan �̂�2 merupakan jumlah kuadrat sisa dibagi derajat bebas. Adapun persamaannya dapat
dituliskan sebagai berikut :
�̂�2 =∑ (√−2(𝑦𝑖 log �̂�𝑖+(1−𝑦𝑖) log(1−�̂�𝑖)))
2𝑛𝑖=1
𝑛−𝑝−1
Pemilihan koefisien ridge untuk model regresi probit dilakukan dengan memilih nilai 𝑞
yang paling optimal, dimana 𝑞 menjadi optimal saat nilai jumlah kuadrat sisa (�̂�2) besar, sehingga
harus di pilih nilai 𝑞 terkecil. Adapun nilai 𝑞 diperoleh sebagai berikut:

𝒒 =
[ −11.15290.40190.60130.70611.41130.41941.02731.15930.5896 ]
maka diperoleh 𝑘 = 𝑚𝑎𝑥 (1
𝑞𝑗) = 2.4879
Untuk mengetahui model terbaik dari metode pendugaan parameter yang dugunakan,
dilakukan perbandingan nilai MSE masing-masing metode. Adapun perbandingan nilai MSE dan
𝑹𝟐 tiap metode dapat dilihat pada Tabel 4.3 berikut :
Tabel 4. 3 Perbandingan nilai MSE dan 𝑹𝟐 tiap metode pendugaan parameter
No Metode Nilai MSE Nilai 𝑅2
1 OLS 10.19 36.62 %
2 MLE 4.5108 46.16%
3 Ridge 0.3672 63.45%
Sumber : Data diolah, 2019
Berdasarkan perbandingan nilai MSE pada Tabel 4.3, diperoleh nilai MSE terkecil terdapat
pada penduga metode ridge yakni sebesar 0.3672, sehingga dapat disimpulkan bahwa metode
penduga parameter terbaik untuk penduga parameter data kemiskinan di tiap Kabupaten/Kota di
Sulawesi Selatan adalah penduga dengan menggunakan metode ridge. Model regresi probit
dengan metode ridge untuk kasus kemiskinan di tiap Kabupaten/Kota di Sulawesi Selatan dapat
dibentuk sebagai berikut :
𝑦𝑖∗ = −0.1674 − 0.078𝑋1𝑖 + 0.0779𝑋2𝑖 − 0.2265𝑋3𝑖 + 0.181𝑋4𝑖 − 0.01263𝑋5𝑖 − 0.0528𝑋6𝑖
+ 0.0046𝑋7𝑖 − 0.1729𝑋8𝑖
dengan 𝑦𝑖∗ merupakan variabel laten sedemikian sehingga �̂�𝑖 = {
1, 𝑗𝑖𝑘𝑎 𝑦𝑖∗ > 0
0, 𝑗𝑖𝑘𝑎 𝑦𝑖∗ ≤ 0
4.3.4 Uji Multikolinieritas Parameter Ridge
Untuk mengetahui apakah multikolinieritas antar variabel prediktor telah teratasi, maka
dilakukan uji multikolinieritas kembali setelah penambahan parameter ridge. Nilai VIF setelah
penambahan konstanta bias (𝑘), dengan 𝑲 = 𝑘𝑰, maka diperoleh:
𝑉𝐼𝐹 = 𝑑𝑖𝑎𝑔 (1
𝑛 − 1(𝑿𝑡𝑿) − 𝑲)
−1
(1
𝑛 − 1(𝑿𝑡𝑿)) (
1
𝑛 − 1(𝑿𝑡𝑿) − 𝑲)
−1
Perhitungan yang dilakukan menghasilkan VIF dan TOL yang sangat kecil, dapat dilihat pada
Tabel 4.4 berikut:
Tabel 4. 4 Nilai VIF dan TOL setelah penambahan parameter ridge
Variabel VIF TOL Keterangan
X1 0.5664 1.7655 Tidak Multikolinearitas
X2 0.6885 1.4524 Tidak Multikolinearitas
X3 0.5550 1.8018 Tidak Multikolinearitas
X4 0.6745 1.4825 Tidak Multikolinearitas
X5 0.5909 1.6923 Tidak Multikolinearitas
X6 0.6317 1.5830 Tidak Multikolinearitas
X7 0.6872 1.4552 Tidak Multikolinearitas
X8 0.5794 1.7259 Tidak Multikolinearitas
Sumber : Data diolah, 2019
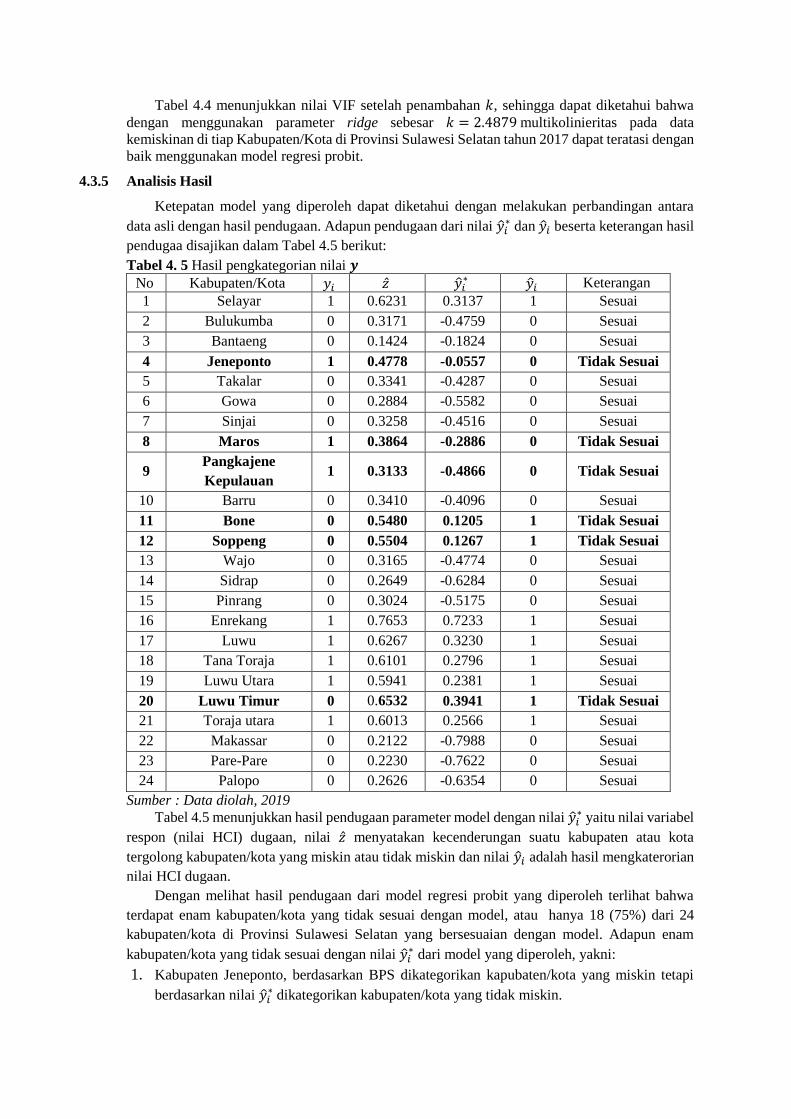
Tabel 4.4 menunjukkan nilai VIF setelah penambahan 𝑘, sehingga dapat diketahui bahwa
dengan menggunakan parameter ridge sebesar 𝑘 = 2.4879 multikolinieritas pada data
kemiskinan di tiap Kabupaten/Kota di Provinsi Sulawesi Selatan tahun 2017 dapat teratasi dengan
baik menggunakan model regresi probit.
4.3.5 Analisis Hasil
Ketepatan model yang diperoleh dapat diketahui dengan melakukan perbandingan antara
data asli dengan hasil pendugaan. Adapun pendugaan dari nilai �̂�𝑖∗ dan �̂�𝑖 beserta keterangan hasil
pendugaa disajikan dalam Tabel 4.5 berikut:
Tabel 4. 5 Hasil pengkategorian nilai 𝒚
No Kabupaten/Kota 𝑦𝑖 �̂� �̂�𝑖∗ �̂�𝑖 Keterangan
1 Selayar 1 0.6231 0.3137 1 Sesuai
2 Bulukumba 0 0.3171 -0.4759 0 Sesuai
3 Bantaeng 0 0.1424 -0.1824 0 Sesuai
4 Jeneponto 1 0.4778 -0.0557 0 Tidak Sesuai
5 Takalar 0 0.3341 -0.4287 0 Sesuai
6 Gowa 0 0.2884 -0.5582 0 Sesuai
7 Sinjai 0 0.3258 -0.4516 0 Sesuai
8 Maros 1 0.3864 -0.2886 0 Tidak Sesuai
9 Pangkajene
Kepulauan 1 0.3133 -0.4866 0 Tidak Sesuai
10 Barru 0 0.3410 -0.4096 0 Sesuai
11 Bone 0 0.5480 0.1205 1 Tidak Sesuai
12 Soppeng 0 0.5504 0.1267 1 Tidak Sesuai
13 Wajo 0 0.3165 -0.4774 0 Sesuai
14 Sidrap 0 0.2649 -0.6284 0 Sesuai
15 Pinrang 0 0.3024 -0.5175 0 Sesuai
16 Enrekang 1 0.7653 0.7233 1 Sesuai
17 Luwu 1 0.6267 0.3230 1 Sesuai
18 Tana Toraja 1 0.6101 0.2796 1 Sesuai
19 Luwu Utara 1 0.5941 0.2381 1 Sesuai
20 Luwu Timur 0 0.6532 0.3941 1 Tidak Sesuai
21 Toraja utara 1 0.6013 0.2566 1 Sesuai
22 Makassar 0 0.2122 -0.7988 0 Sesuai
23 Pare-Pare 0 0.2230 -0.7622 0 Sesuai
24 Palopo 0 0.2626 -0.6354 0 Sesuai
Sumber : Data diolah, 2019
Tabel 4.5 menunjukkan hasil pendugaan parameter model dengan nilai �̂�𝑖∗ yaitu nilai variabel
respon (nilai HCI) dugaan, nilai �̂� menyatakan kecenderungan suatu kabupaten atau kota
tergolong kabupaten/kota yang miskin atau tidak miskin dan nilai �̂�𝑖 adalah hasil mengkaterorian
nilai HCI dugaan.
Dengan melihat hasil pendugaan dari model regresi probit yang diperoleh terlihat bahwa
terdapat enam kabupaten/kota yang tidak sesuai dengan model, atau hanya 18 (75%) dari 24
kabupaten/kota di Provinsi Sulawesi Selatan yang bersesuaian dengan model. Adapun enam
kabupaten/kota yang tidak sesuai dengan nilai �̂�𝑖∗ dari model yang diperoleh, yakni:
1. Kabupaten Jeneponto, berdasarkan BPS dikategorikan kapubaten/kota yang miskin tetapi
berdasarkan nilai �̂�𝑖∗ dikategorikan kabupaten/kota yang tidak miskin.

2. Kabupaten Maros, berdasarkan BPS dikategorikan kapubaten/kota yang miskin tetapi
berdasarkan nilai �̂�𝑖∗ dikategorikan kabupaten/kota yang tidak miskin.
3. Kabupaten Pangkajene Kepulauan, berdasarkan BPS dikategorikan kapubaten/kota yang
miskin tetapi berdasarkan nilai �̂�𝑖∗ dikategorikan kabupaten/kota yang tidak miskin.
4. Kabupaten Bone, berdasarkan BPS dikategorikan kapubaten/kota yang tidak miskin tetapi
berdasarkan nilai �̂�𝑖∗ dikategorikan kabupaten/kota yang miskin.
5. Kabupaten Soppeng, berdasarkan BPS dikategorikan kapubaten/kota yang tidak miskin
tetapi berdasarkan nilai �̂�𝑖∗ dikategorikan kabupaten/kota yang miskin.
6. Kabupaten Luwu Timur, berdasarkan BPS dikategorikan kapubaten/kota yang tidak miskin
tetapi berdasarkan nilai �̂�𝑖∗ dikategorikan kabupaten/kota yang miskin
5 Kesimpulan Berdasarkan analisis data dan pembahasan hasil penelitian, maka dapat ditarik kesimpulan
sebagai berikut:
1. Masalah multikolinieritas pada model regresi prrobit dapat diatasi dengan menggunakan
metode ridge. Penduga parameter model regresi probit dengan metode ridge diperoleh
dengan menggunakan penduga maximum likelihood dengan persamaan sebagai berikut:
�̂�𝑀𝐿 = (𝑿𝑡�̂�𝑿)−1
𝑿𝑡�̂��̂�
selanjutnya diperoleh penduga metode ridge yang melibatkan penambahan satu konstanta
(𝑘) pada setiap elemen diagonal matriks 𝑿𝑡𝑾𝑿, menghasilkan penduga dengan persamaan
sebagai berikut :
�̂�𝑅𝑅 = (𝑿𝑡𝑾𝑿 + 𝑲)−1𝑿𝑡𝑾𝑿�̂�𝑀𝐿
2. Model regresi probit yang terbentuk untuk kasus data kemiskinan di tiap Kabupaten/Kota di
Provinsi Sulawesi Selatan tahun 2017 menggunakan penduga ridge adalah sebaga berikut :
𝑦𝑖∗ = −0.1674 − 0.078𝑋1𝑖 + 0.0779𝑋2𝑖 − 0.2265𝑋3𝑖 + 0.181𝑋4𝑖 − 0.01263𝑋5𝑖
− 0.0528𝑋6𝑖 + 0.0046𝑋7𝑖 − 0.1729𝑋8𝑖
dengan melihat nilai �̂�𝑖∗, yaitu nilai variabel respon (nilai HCI) dugaan yang diperoleh,
terdapat enam kabupaten/kota yang tidak sesuai dengan model, yakni berdasarkan Badan
Pusat Statistik dikategorikan kapubaten/kota miskin tetapi berdasarkan nilai �̂�𝑖∗dikategorikan
sebagai kabupaten/kota yang tidak miskin, begitupun sebaliknya.
Daftar Pustaka [1] Aziz, A. 2010. Ekonometrika Teori & Praktik Eksperimen dengan MATLAB. Malang: UIN-
Maliki Press.
[2] Agresti, A. 2002. Categorical Data Analysis. New York: John Wiley and Sons.
[3] Badan Pusat Statistik. Publikasi: Data dan Informasi Kemiskinan Kabupaten/Kota Tahun
2017. (http://bps.go.id/Publikasi/). Diakses pada tanggal 10 Oktober 2018.
[4] Candra, Y. 2009. Pembentukan Model Probit Bivariat. Semarang: Universitas Diponegoro.
[5] Djalal, N. 2004. Teknik Pengambilan Keputusan. Jakarta: Gasindo.
[6] Draper, N. dan Smith, H. 1992. Analisis Regresi Terapan. Jakarta: PT. Gramedia Pustaka
Umum.
[7] Gujarati, D.N. 2006. Dasar-dasar Ekonometrika. (terj. Eugenia Mardanugraha, Sita
Wardhani, dan Carlos Mangunsong). Jakarta: Salemba Empat.
[8] Hasan, I. 2002. Pokok-pokok Materi Statistik 2 (Statistik Inferensif). Jakarta: Bumi Aksara.
[9] Hasriana. 2016. Pemodelan Kemiskinan Menggunakan Geographically Weighted Logistic
Regression Dengan Fungsi Pembobot Fixed Kernel. Makassar: Universitas Hasanuddin.

[10] Hoerl, A.E. dan Kennard, R.W. 1970. Ridge Regression: Biased Estimation For
Nonorthogonal Problems. Technometrics, 12: 55-67.
[11] Hosmer, D.W. dan Lemeshow, S. 2000. Applied Logistic Regression 2nd Edition. New
York: John Willey and Sons.
[12] Kibria, B.M.G. dan Saleh, A.K.Md.E. 2012. Improving the Estimators of the Parameters of
a Probit Regression Model: A Ridge Regression Approach. Journal of Statistical Planning
and Inference, 142: 1421-1435.
[13] Locking, H., Mansson, K., dan Shukur, G. 2011. Performance of Some Ridge Parameters
for Probit Regression: with Application on Swedish Job Search Data. Journal of
Computational Econometrics, 40: 415-433.
[14] McCullagh, P. dan Nelder, J.A. 1989. Generalized Linear Models. Second Edition. London
New York: Chapman and Hall.
[15] Muliati, A. 2018. Pendugaan Parameter Model Regresi Logistik dengan Metode Ridge.
Makassar: Universitas Hasanuddin.
[16] Myers, R.H. 1990. Classical And Modern Regression With Applications. Boston: PWS-
KENT Publishing Company.
[17] Sembiring, R.K. 1995. Analisis Regresi. Bandung: ITB.
[18] Setiawan dan Kusrini, D.E. 2010. Ekonometrika. Yogyakarta: Andi.
[19] Sunyoto. 2009. Regresi Logistik Ridge: Pada Keberhasilan Siswa SMA Negeri 1 Kediri
Diterima di Perguruan Tinggi Negeri. Surabaya: Institut Teknolni Sepuluh Nopember.
[20] Supranto, J. 2005. Ekonometri. Bogor: Ghalia Indonesia.
[21] Supranto, M.A. 1986. Pengantar Probabilita Dan Statistik Induk. Jakarta: Erlangga.
[22] Wasilaine, T.L., Talakua, M.W., dan Lesnussa, Y.A. 2014. Model Regresi Ridge untuk
Mengatasi Model Regresi Linier Berganda Yang Mengandung Multikolinearitas. Barekeng,
8(1), 31-37.
[23] Widhiarso, W. 2012. Berkenalan dengan Regresi Probit. Yogyakarta: Universitas Gadjah
Mada.
[24] Yitnosumarto. 1990. Dasar-Dasar Statistika. Jakarta: Rajawali.
[25] Young, B. 2003. Penaksir Maksimum Likelihood Bagi Model Probit Dan Model Probit
Bivariat. Bandung: Universitas Katolik Parahyangan.