energy-based unknown intent detection with data manipulation
TRANSCRIPT

Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2852–2861August 1–6, 2021. ©2021 Association for Computational Linguistics
2852
Energy-based Unknown Intent Detection with Data Manipulation
Yawen Ouyang, Jiasheng Ye, Yu Chen, Xinyu Dai∗,Shujian Huang and Jiajun Chen
National Key Laboratory for Novel Software Technology, Nanjing University, China{ouyangyw,yejiasheng,cheny98}@smail.nju.edu.cn
{daixinyu,huangsj,chenjj}@nju.edu.cn
Abstract
Unknown intent detection aims to identify theout-of-distribution (OOD) utterance whose in-tent has never appeared in the training set. Inthis paper, we propose using energy scores forthis task as the energy score is theoreticallyaligned with the density of the input and canbe derived from any classifier. However, high-quality OOD utterances are required duringthe training stage in order to shape the energygap between OOD and in-distribution (IND),and these utterances are difficult to collect inpractice. To tackle this problem, we proposea data manipulation framework to Generatehigh-quality OOD utterances with importanceweighTs (GOT). Experimental results showthat the energy-based detector fine-tuned byGOT can achieve state-of-the-art results ontwo benchmark datasets.
1 Introduction
Unknown intent detection is a realistic and chal-lenging task for dialogue systems. Detecting out-of-distribution (OOD) utterances is critical whenemploying dialogue systems in an open environ-ment. It can help dialogue systems gain a betterunderstanding of what they do not know, whichprevents them from yielding unrelated responsesand improves user experience.
A simple approach for this task relies on the soft-max confidence score and achieves promising re-sults (Hendrycks and Gimpel, 2017). The softmax-based detector will classify the input as OOD ifits softmax confidence score is smaller than thethreshold. Nevertheless, further works demonstratethat using the softmax confidence score might beproblematic as the score for OOD inputs can bearbitrarily high (Louizos and Welling, 2017; Leeet al., 2018).
∗∗ Corresponding author.
Utterance: How much did I spend this week Intent: spending history
Locating Module
Intent-related Word(s): How much did I spend this week
Generating Module
OOD Utterance 1: How much did I drink this week OOD Utterance 2: How much did I lose this week
……
Weighting Module
Figure 1: An overview of our framework GOT. Forthe utterance “How much did I spend this week” fromCLINC150 dataset (Larson et al., 2019). Our locatingmodule locates the intent-related word “spend”. Andthen our generating module generates words “drink”,“lose” to replace it and obtains OOD utterances. Fi-nally, our weighting module assigns a weight for eachof OOD utterances.
Another appealing approach is to use genera-tive models to approximate the distribution of in-distribution (IND) training data and use the likeli-hood score to detect OOD inputs. However, Renet al. (2019) and Gangal et al. (2019) find that like-lihood scores derived from such models are prob-lematic for this task as they can be confounded bybackground components in the inputs.
In this paper, we propose using energy scores(Liu et al., 2020) for unknown intent detection. Thebenefit is that energy scores are theoretically wellaligned with the density of the inputs, hence moresuitable for OOD detection. Inputs with higherenergy scores mean lower densities, which can be

2853
classified as OOD by the energy-based detector.Moreover, energy scores can be derived from anypre-trained classifier without re-training. Never-theless, the energy gap between IND and OODutterances might not always be optimal for differ-entiation. Thus we need auxiliary OOD utterancesto explicitly shape the energy gap between INDand OOD utterances during the training stage (Liuet al., 2020). This poses a new challenge in thatthe variety of possible OOD utterances is almostinfinite. It is impossible to sample all of them tocreate the gap. Zheng et al. (2019) demonstratethat OOD utterances akin to IND utterances, suchas sharing the same phrases or patterns, are more ef-fective, whereas these high-quality OOD utterancesare difficult and expensive to collect in practice.
To tackle this problem, we propose a datamanipulation framework GOT to generate high-quality OOD utterances as well as importanceweights. GOT generates OOD utterances by per-turbing IND utterances locally, which allows thegenerated utterances to be closer to IND. Specifi-cally, GOT contains three modules: (1) a locatingmodule to locate intent-related words in IND utter-ances; (2) a generating module to generate OODutterances by replacing intent-related words withdesirable candidate words, evaluated in two aspects:whether the candidate word is suitable given thecontext, and whether the candidate word is irrele-vant to IND; (3) a weighting module to reduce theweights of potential harmful generated utterances.Figure 1 illustrates the overall process of GOT. Ex-periments show that the generated weighted OODutterances can further improve the performance ofthe energy-based detector in unknown intent de-tection. Our code and data will be available at:https://github.com/yawenouyang/GOT.
To summarize, the key contributions of the paperare as follows:
• We propose using energy scores for unknown in-tent detection. We conduct experiments on real-world datasets including CLINC150 and SNIPSto show that the energy score can achieve compa-rable performance as strong baselines.
• We put forward a new framework GOT to gen-erate high-quality OOD utterances and reweightthem. We demonstrate that GOT can further im-prove the performance of the energy score byexplicitly shaping the energy gap and achievesstate-of-the-art results.
• We show the generality of GOT by applyinggenerated weighted OOD utterances to fine-tunethe softmax-based detector, and the fine-tunedsoftmax-based detector can also yield significantimprovements.
2 Related Work
Lane et al., 2006, Manevitz and Yousef, 2007and Dai et al., 2007 address OOD detection forthe text-mining task. Recently, this problem hasattracted growing attention from researchers (Turet al., 2014; Fei and Liu, 2016; Fei et al., 2016;Ryu et al., 2017; Shu et al., 2017). Hendrycks andGimpel (2017) present a simple baseline that uti-lizes the softmax confidence score to detect OODinputs. Shu et al. (2017) create a binary classi-fier and calculate the confidence threshold for eachclass. Some distance-based methods (Oh et al.,2018; Lin and Xu, 2019; Yan et al., 2020) are alsoused to detect unknown intents as OOD utteranceshighly deviate from IND utterances in their localneighborhood. Simultaneously, with the advance-ment of deep generative models, learning such amodel to approximate the distribution of trainingdata is possible. However, Ren et al. (2019) findthat likelihood scores derived from these modelscan be confounded by background components,and propose a likelihood ratio method to alleviatethis issue. Gangal et al. (2019) reformulate andapply this method to unknown intent detection.
Different from these methods, we introduce theenergy score for this task. Liu et al. (2020) provethat the energy score is theoretically aligned withthe density of the input, and can be derived fromany classifier without re-training, hence desirablefor our task. We further propose a data manipu-lation framework to generate high-quality OODutterances to shape the energy gap between INDand OOD utterances.
Note that there are some related works that alsogenerate OOD samples to improve OOD detectionperformance. Lee et al. (2017) generate OOD sam-ples with Generative Adversarial Network (GAN)(Goodfellow et al., 2014), and Zheng et al. (2019)explore this method for unknown intent detection.However, there are two major distinctions betweenour study and these works. First, they generateOOD utterances according to continuous latentvariables, which cannot be easily interpreted. Incontrast, our framework generates utterances byperforming local replacements to IND utterances,

2854
which is more interpretable to human. Second, ourframework additionally contains a weighting mod-ule to reform the generated utterances. Our work isalso inspired by Cai et al. (2020), which proposesa framework to augment the IND data, while ourframework aims to generate OOD data.
3 Preliminary
In this section, we formalize unknown intent detec-tion task. Then we introduce the energy score, andits superiority and limitations for this task.
3.1 Problem Formulation
Given a training dataset Dtrainin = {(u(i), y(i))}Ni=1
where u(i) is an utterance and y(i) ∈ Yin ={y1, y2, ..., yK} is its intent label. In testing, givenan utterance, unknown intent detection aims to de-tect whether its intent belongs to existing intentsYin. In general, unknown intent detection is anOOD detection task. The essence of all methods isto learn a score function that maps each utteranceu to a single scalar that is distinguishable betweenIND and OOD utterances.
3.2 Energy-based OOD Detection
An energy-based model (LeCun et al., 2006) buildsan energy function E(u) that maps an input u toa scalar called energy score (i.e., E : RD → R).Using the energy function, probability density p(u)can be expressed as:
p(u) =exp(−E(u)/T )
Z, (1)
where Z =∫u exp(−E(u)/T ) is the normalizing
constant also known as the partition function andT is the temperature parameter. Take the logarithmof both side of (1), we can get the equation:
log p(u) = −E(u)/T − logZ. (2)
Since Z is constant for all input u, we can ignorethe last term logZ and find that the energy func-tion −E(u) is in fact linearly aligned with the loglikelihood function, which is desirable for OODdetection (Liu et al., 2020).
The energy-based model has a connection witha softmax-based classifier. For a classificationproblem with K classes, a parametric function fmaps each input u to K real-valued numbers (i.e.,f : RD → RK), known as logits. Logits are used
to parameterize a categorical distribution using asoftmax function:
p(y|u) = exp[fy(u)/T ]∑y′ exp[fy′(u)/T ]
, (3)
where fy(u) indicates the yth index of f(u), i.e.,the logit corresponding the yth class label. Andthese logits can be reused to define an energy func-tion without changing function f (Liu et al., 2020;Grathwohl et al., 2020):
E(u) = −T · log∑y′
exp [fy′(u)/T ]. (4)
According to the above, a classifier can be reinter-preted as an energy-based model. It also means theenergy score can be derived from any classifier.
Due to its consistency with density and accessi-bility, we introduce the energy score for unknownintent detection, and utterances with higher energyscores can be viewed as OOD. Mathematically, theenergy-based detector G can be described as:
G(u; δ, E) =
{IND E(u) ≤ δ,OOD E(u) > δ,
(5)
where δ is the threshold.Although the energy score can be easily com-
puted from the classifier, the energy gap betweenIND and OOD samples might not always be opti-mal for differentiation. To solve this problem, Liuet al. (2020) propose an energy-bounded learningobjective to further widen the energy gap. Specif-ically, the training objective of the classifier com-bines the standard cross-entropy loss with a regu-larization loss:
L = E(u,y)∼Dtrainin
[− logFy(u)] + λ · Lenergy,(6)
where F (u) is the softmax output, λ is the auxiliaryloss weight. The regularization loss is defined interms of energy:
Lenergy = E(u,y)∼Dtrainin
(max(0, E(u)−min))2
+ Eu∼Dtrainout
(max(0,mout − E(u)))2, (7)
which utilizes both labeled IND data Dtrainin and
auxiliary unlabeled OOD data Dtrainout . This term
differentiates the energy scores between IND andOOD samples by using two squared hinge loss withthe margin hyper-parameters min and mout.

2855
Ideally, one has to sample all types of OOD ut-terances to create the gap, which is impossible inpractice. Zheng et al. (2019) demonstrate thatOOD utterances akin to IND utterances could bemore effective, but more difficult to collect. To ad-dress this problem, we propose a data manipulationframework, which can generate these high-qualityOOD utterances and assign each generated utter-ance an importance weight to reduce the impact ofpotential bad generation.
4 Approach
In this section, we will introduce our data manip-ulation framework GOT in detail. GOT aims togenerate high-quality OOD utterances by replacingintent-related words in IND utterances, and thenassign a weight to each generated OOD utterance.Eventually, the weighted OOD utterances can beused to shape the energy gap.
4.1 Locating Module
Since not all words in utterances are meaningful,such as stop words, when generating OOD utter-ances, replacing these words may not change theintent. It is more efficient and effective to replacethose intent-related words. Hence, we design anintent-related score function S to measure how aword w related to an intent y:
S(w, y) =∑
u∈Dtrainy
∑wj∈u
I(wj = w)[log p(wj |w<j , y)
− log p(wj |w<j)], (8)
whereDtrainy is the subset ofDtrain
in , which containsutterances with intent y, I is the indicator function,wj is the jth word in u, and w<j = w1, ..., wj−1.
Given w and y, the intent-related score functionis the sum of the log-likelihood ratios for all w inDtrainy . If w is related to y, w tends to occur more
frequently in Dtrainy than other words. For each
occurrence of w, i.e., wj equals w, p(w|w<j , y)should be higher than p(w|w<j) as the former isadditionally conditioned on the related y, while thelatter is not, hence resulting in a higher S(w, y).In contrast, if w is not related to y, p(w|w<j , y) ismuch less likely to be higher than p(w|w<j), or wtends to have a lower frequency in Dtrain
y , henceS(w, y) is likely to be small. Therefore, S(w, y)can serve as a valid score function to measure howa word w is related to an intent y.
Figure 2: A class-conditional language model to esti-mate p(wj |w<j , y).
With the help of S, given an utterance to bereplaced and its intent label, the locating modulecalculates the intent-related score for each word inthis utterance, and a word with a higher score (i.e.,larger than a given threshold) can be viewed as anintent-related word.
Implementation: We use two generative mod-els to estimate p(wj |w<j , y) and p(wj |w<j) sep-arately. Specifically, we train a class-conditionallanguage model (Yogatama et al., 2017) withDtrain
in
to estimate p(wj |w<j , y), shown in Figure 2. Topredict the word wj , we can combine the hiddenstate hj with the intent embedding from a learnablelabel embedding matrix Ey, then pass it througha fully connected (FC) layer and a softmax layerto estimate the word distribution. In the trainingprocess, the input is the utterance with its intentfrom Dtrain
in , and the training objective is to maxi-mize the conditional likelihood of utterances. Toestimate p(wj |w<j), we directly use pre-trainedGPT-2 (Radford et al., 2019) without tuning. Notethat the whole training process only needs Dtrain
in ,and does not need auxiliary supervised data.
4.2 Generating ModuleAfter detecting intent-related words in the utteranceu, for each of the intent-related words wt, the gen-erating module aims to generate the replacementwords from the vocabulary set to replace wt andobtain OOD utterances. We design a candidatescore function Q to measure the desirability of thecandidate word c:
Q(c;u, wt) = log p(c|w<t,w>t)
− log∑y∈Yin
p(c|w<t, y)p(y). (9)
The first term of the right hand side is the log-likelihood of c conditioned on the context of wt;the higher it is, the more suitable c is given thecontext. The second term of the right hand sideis the negative log of the average likelihoods of cconditioned on the IND label and previous context;

2856
the higher it is, the less relevant c is to IND utter-ances. Therefore, if c has a higher candidate score,that means it fits the context well and has a lowdensity under the IND utterance distribution, thuscan be selected as the replacement word to replacewt. The resulting generated OOD utterance is:
u = {w<t, c,w>t}. (10)
Implementation: Similar with the locating mod-ule, we also do not need auxiliary superviseddata to train the generating module. We usethe same class-conditional language model men-tioned in Section 4.1 to estimate p(c|w<t, y).p(y) is the training set label ratios. To estimatep(c|w<t,w>t), we use pre-trained BERT (Devlinet al., 2018) without tuning.
4.3 Weighting Module
Since we cannot ensure the generation processis perfect, given a generated OOD utterance setDgen
out = {u(i)}Mi=1, there might be some unfavor-able utterances that are useless or even harmfulfor tuning the classifier. To fit these utterances,the generalization ability of the classifier will de-crease. The weighting module aims to assign theseutterances small weights.
We first use Equation 6 as the loss function totrain a classifier by takingDgen
out asDtrainout . Then we
calculate the influence value φ ∈ R (Wang et al.,2020) for each generated utterance u. The influ-ence value approximates the influence of removingthis utterance on the loss at validation samples. Anutterance with positive φ implies that its removalwill reduce the validation loss and strengthen theclassifier’s generalization ability, thus we shouldassign it a small weight. * In particular, given φ,we calculate weight α as follows:
α =1
1 + eγφ
maxφ −minφ
, (11)
where γ ∈ R+ is used to make the weight distri-bution flat or steep, maxφ and minφ are the maxi-mum and minimum influence value of utterancesin Dgen
out .
Implementation: We still do not need auxiliarysupervised data for this module. The validationloss is the cross-entropy loss on the validation set.
*Details about how to calculate the influence can be foundin (Koh and Liang, 2017; Wang et al., 2020).
Algorithm 1 Data Manipulation ProcessInput: Training set Dtrain
in , intent-related score function S,candidate score function Q, intent-related word thresholdε, candidate number K, weight term γ
Output: Generated weighted OOD utterances set Dgwout
1: Dgenout = {} # generated OOD utterances without weights
2: for (u, y) ∈ Dtrainin do
3: for wj ∈ u do4: if S(wj , y) > ε then5: C = top−Kc Q(c;u,wj)6: for c ∈ C do7: u = {w<j , c,w>j}8: Add u into Dgen
out
9: end for10: end if11: end for12: end for13: Dgw
out = {} # generated weighted OOD utterances14: for u ∈ Dgen
out do15: Calculate the weight α by Equation 1116: Add (u, α) into Dgw
out
17: end for18: return Dgw
out
4.4 Overall Data Manipulation ProcessWe summarize the process of GOT in Algorithm1. Line 4 shows that wj can be viewed as an intent-related word for y if S(wj , y) is greater than theintent-related word threshold ε. Line 5 shows thatwe generate K replacement words with the top-KQ(c;u, wt).
4.5 Shape the energy gap with GOTAfter obtaining weighted OOD utterances set Dgw
out,we can explicitly shape the energy gap with them,resulting in IND utterances with smaller energyscores and OOD utterances with higher energyscores. Specifically, we redefine the regulariza-tion loss in Equation 6 as follows and use it tore-train the classifier:
Lenergy = E(u,y)∼Dtrainin
(max(0, E(u)−min))2
+ E(u,α)∼Dgwoutα(max(0,mout − E(u)))2. (12)
In the testing process, we can calculate the en-ergy score for the utterance by Equation 4, andidentify whether it is OOD by Equation 5.
5 Experimental Setup
5.1 DatasetsTo evaluate the effectiveness of the energy scoreand our proposed framework, we conducted exper-iments on two public datasets:
• CLINC150† (Larson et al., 2019): this dataset†https://github.com/clinc/oos-eval

2857
Statistic CLINC150 SNIPS
Train 15000 9385validation 3000 500Test-IND 4500 486Test-OOD 1000 214Test-IND: Test-OOD 4.5: 1 2.3: 1Number of IND classes 150 5
Table 1: Statistics of CLINC150 and SNIPS datasets.
covers 150 intent classes over ten domains. It sup-ports some OOD utterances that do not fall intoany of the system’s supported intents to avoidsplitting unknown intents manually.
• SNIPS‡ (Coucke et al., 2018): this dataset isa personal voice assistant dataset that containsseven intent classes. SNIPS does not explicitlyinclude OOD utterances. We kept two classesSearchCreativeWork and SearchScreeningEventas unknown intents.
Table 1 provides summary statistics about thesetwo datasets. Note that the training set and valida-tion set do not include OOD utterances.
5.2 MetricsWe used four common metrics for OOD detectionto measure the performance. AUROC (Davis andGoadrich, 2006), AUPR In and AUPR Out (Man-ning et al., 1999) are threshold-independent per-formance evaluations and higher values are better.FPR95 is the false positive rate (FPR) when thetrue positive rate (TPR) is 95%, and lower valuesare better.
Considering the smaller proportion of OOD ut-terances in the test set on two datasets, AUPR Outis more informative here.
5.3 BaselinesWe introduce the following classifier-based meth-ods as baselines:
• MSP (Hendrycks and Gimpel, 2017) trains a clas-sifier with IND utterances and uses the softmaxconfidence score to detect OOD utterances.
• DOC (Shu et al., 2017) trains a binary classifierfor each IND intent and uses maximum binaryclassifier output to detect OOD utterances.
• Mahalanobis (Lee et al., 2018) trains a classifierwith softmax loss and uses Mahalanobis distance
‡https://github.com/snipsco/nlu-benchmark
of the input to the nearest class-conditional Gaus-sian distribution to detect OOD utterances.
• LMCL (Lin and Xu, 2019) uses LOF (Bre-unig et al., 2000) in the utterance representationlearned by a classifier. In training, they replacethe softmax loss with LMCL (Wang et al., 2018).
• SEG (Yan et al., 2020) also uses LOF in theutterance representation. In training, they usesemantic-enhanced large margin Gaussian mix-ture loss.
5.4 Implementation DetailsFor a fair comparison, all classifiers used in theabove methods and ours are pre-trained BERT (De-vlin et al., 2018) with a multi-layer perceptron(MLP). We select parameter values based on valida-tion accuracy. For energy score, we follow Liu et al.(2020) to set T as 1, λ as 0.1, min as -8 and mout
as -5. For influence value, we focus on changeson MLP parameters and use stochastic estimation(Koh and Liang, 2017) with the scaling term 1000and the damping term 0.003. For LMCL imple-mentation, we set nearest neighbor number as 20,scaling factor s as 30 and cosine margin m as 0.35,which is recommended by Lin and Xu (2019). ForSEG, we follow Yan et al. (2020) to set margin as1 and trade-off parameter as 0.5.
For our framework, we set candidate numberK as 2, weight term γ as 20. In particular, forCLINC150, we set threshold ε as 150 and gener-ate 100 weighted utterances for each intent. ForSNIPS, we set threshold ε as 1500 and generate1800 weighted utterances for each intent. The dif-ference in settings between two datasets is due tothe different sizes of per intent in the training set.
6 Results and Analysis
In this part, we will show the results of differentmethods on two datasets and offer some furtheranalysis.
6.1 Overall ResultsAs shown in Table 2, we can observe that:
• The energy score can achieve comparable resultson two datasets. Note that on SNIPS dataset,the advantages of the energy score are not asobvious. The reason is that SNIPS dataset isnot as challenging as CLINC150 dataset, mostmethods can achieve good results, such as AUPRout is greater than 0.9.
2858
Method CLINC150 SNIPSAUROC ↑ FPR95↓ AUPR In↑ AUPR Out↑ AUROC ↑ FPR95↓ AUPR In↑ AUPR Out↑
MSP 0.955 0.164 0.990 0.814 0.951 0.370 0.970 0.922DOC 0.943 0.221 0.985 0.790 0.938 0.493 0.956 0.910Mahalanobis 0.969 0.118 0.993 0.871 0.979 0.088 0.989 0.964LMCL 0.962 0.124 0.992 0.810 0.976 0.087 0.987 0.960SEG 0.959 0.152 0.991 0.823 0.974 0.074 0.986 0.948Energy 0.967 0.143 0.991 0.897 0.944 0.497 0.964 0.924Energy + GOT 0.973 0.114 0.993 0.914 0.989 0.039 0.995 0.972Energy + GOT w/o weighting 0.972 0.123 0.992 0.909 0.979 0.083 0.989 0.969
Table 2: AUROC, FPR95, AUPR In, AUPR Out on CLINC150, SNIPS datasets. Best results are in bold. Allresults are averaged across five seeds.
0.0 0.1 0.2 0.3 0.4 0.5Auxiliary loss weight
0.88
0.89
0.90
0.91
0.92
0.93
AUPR
Out
0 20 40 60 80 100# of OOD utterances per intent0.88
0.89
0.90
0.91
0.92
0.93
AUPR
Out
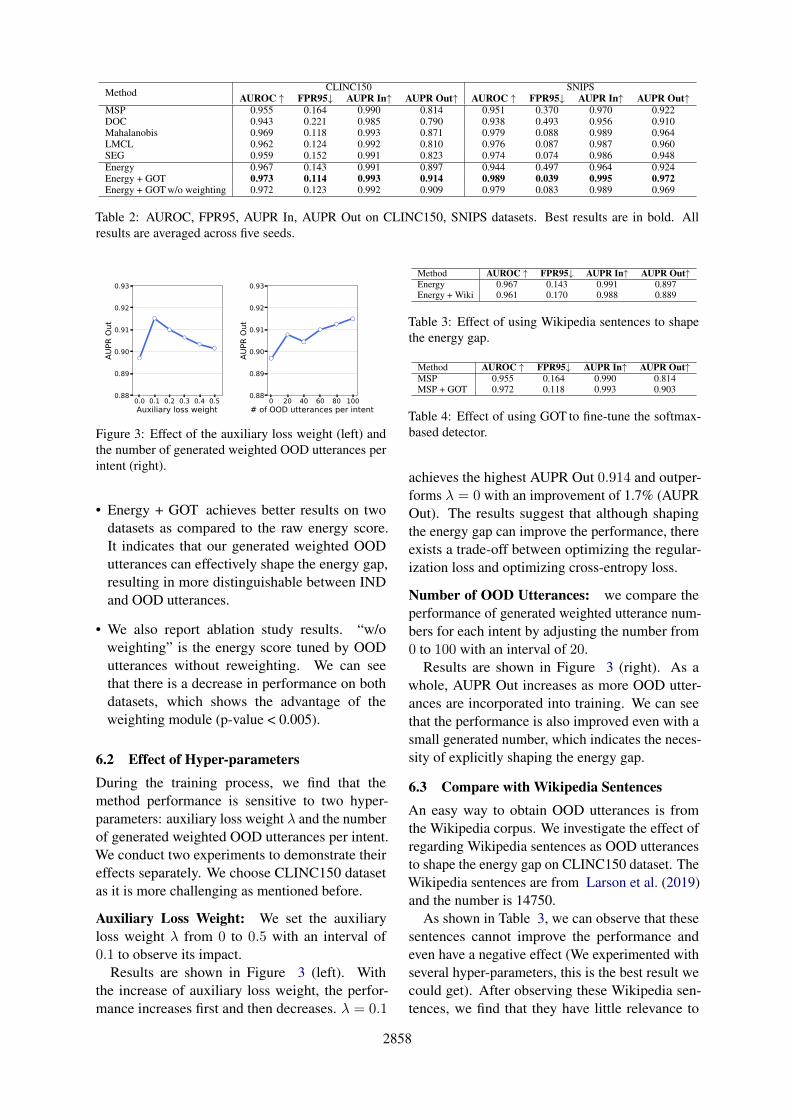
Figure 3: Effect of the auxiliary loss weight (left) andthe number of generated weighted OOD utterances perintent (right).
• Energy + GOT achieves better results on twodatasets as compared to the raw energy score.It indicates that our generated weighted OODutterances can effectively shape the energy gap,resulting in more distinguishable between INDand OOD utterances.
• We also report ablation study results. “w/oweighting” is the energy score tuned by OODutterances without reweighting. We can seethat there is a decrease in performance on bothdatasets, which shows the advantage of theweighting module (p-value < 0.005).
6.2 Effect of Hyper-parametersDuring the training process, we find that themethod performance is sensitive to two hyper-parameters: auxiliary loss weight λ and the numberof generated weighted OOD utterances per intent.We conduct two experiments to demonstrate theireffects separately. We choose CLINC150 datasetas it is more challenging as mentioned before.
Auxiliary Loss Weight: We set the auxiliaryloss weight λ from 0 to 0.5 with an interval of0.1 to observe its impact.
Results are shown in Figure 3 (left). Withthe increase of auxiliary loss weight, the perfor-mance increases first and then decreases. λ = 0.1
Method AUROC ↑ FPR95↓ AUPR In↑ AUPR Out↑Energy 0.967 0.143 0.991 0.897Energy + Wiki 0.961 0.170 0.988 0.889
Table 3: Effect of using Wikipedia sentences to shapethe energy gap.
Method AUROC ↑ FPR95↓ AUPR In↑ AUPR Out↑MSP 0.955 0.164 0.990 0.814MSP + GOT 0.972 0.118 0.993 0.903
Table 4: Effect of using GOT to fine-tune the softmax-based detector.
achieves the highest AUPR Out 0.914 and outper-forms λ = 0 with an improvement of 1.7% (AUPROut). The results suggest that although shapingthe energy gap can improve the performance, thereexists a trade-off between optimizing the regular-ization loss and optimizing cross-entropy loss.
Number of OOD Utterances: we compare theperformance of generated weighted utterance num-bers for each intent by adjusting the number from0 to 100 with an interval of 20.
Results are shown in Figure 3 (right). As awhole, AUPR Out increases as more OOD utter-ances are incorporated into training. We can seethat the performance is also improved even with asmall generated number, which indicates the neces-sity of explicitly shaping the energy gap.
6.3 Compare with Wikipedia SentencesAn easy way to obtain OOD utterances is fromthe Wikipedia corpus. We investigate the effect ofregarding Wikipedia sentences as OOD utterancesto shape the energy gap on CLINC150 dataset. TheWikipedia sentences are from Larson et al. (2019)and the number is 14750.
As shown in Table 3, we can observe that thesesentences cannot improve the performance andeven have a negative effect (We experimented withseveral hyper-parameters, this is the best result wecould get). After observing these Wikipedia sen-tences, we find that they have little relevance to
2859
Intent IND utterance and intent-related word [w] Replacement word Weight
Insurance i need to know more about my health [plan] problems 0.50what [benefits] are provided by my insurance services 0.19
Credit Limit Change can i get a higher limit on my american express [card] ticket 0.46can you [increase] how much i can spend on my visa guess 0.54
Reminder can you list each item on my [reminder] list contacts 0.50what’s on the [reminder] list agenda 0.78
Redeem Rewards walk me through the process of cashing in on [credit] card points those 0.22i have credit card [points] but don’t know how to use them privileges 0.50
Table 5: Weighted OOD utterances generated by GOT on CLINC150 dataset.
0.0 0.2 0.4 0.6 0.8 1.00
2
4
6
Freq
uenc
y
INDOOD
0.0 0.2 0.4 0.6 0.8 1.00
2
4
6
Freq
uenc
y
INDOOD
Figure 4: Histogram of the softmax confidence scorefrom MSP (left) and MSP + GOT (right).
IND utterances. Therefore, simply using Wikipediasentences is unrepresentative and ineffective forshaping the energy gap.
6.4 GOT for Softmax-based Detector
As mentioned in Section 1, when using thesoftmax-based detector, OOD inputs may also re-ceive a high softmax confidence score. To tacklethis problem, Lee et al. (2017) replace the cross en-tropy loss with the confidence loss. The confidenceloss adds the Kullback-Leibler loss (KL loss) onthe original cross entropy loss, which forces OODinputs less confident by making their predictivedistribution to be closer to uniform.
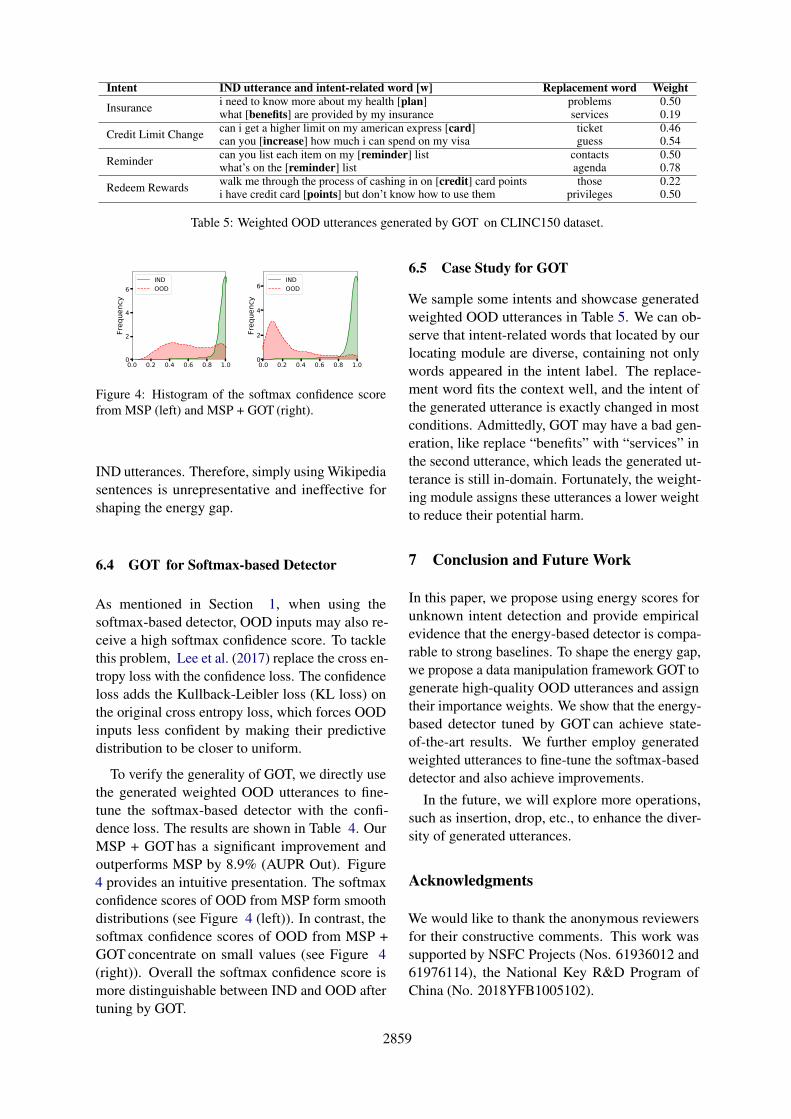
To verify the generality of GOT, we directly usethe generated weighted OOD utterances to fine-tune the softmax-based detector with the confi-dence loss. The results are shown in Table 4. OurMSP + GOT has a significant improvement andoutperforms MSP by 8.9% (AUPR Out). Figure4 provides an intuitive presentation. The softmaxconfidence scores of OOD from MSP form smoothdistributions (see Figure 4 (left)). In contrast, thesoftmax confidence scores of OOD from MSP +GOT concentrate on small values (see Figure 4(right)). Overall the softmax confidence score ismore distinguishable between IND and OOD aftertuning by GOT.
6.5 Case Study for GOT
We sample some intents and showcase generatedweighted OOD utterances in Table 5. We can ob-serve that intent-related words that located by ourlocating module are diverse, containing not onlywords appeared in the intent label. The replace-ment word fits the context well, and the intent ofthe generated utterance is exactly changed in mostconditions. Admittedly, GOT may have a bad gen-eration, like replace “benefits” with “services” inthe second utterance, which leads the generated ut-terance is still in-domain. Fortunately, the weight-ing module assigns these utterances a lower weightto reduce their potential harm.
7 Conclusion and Future Work
In this paper, we propose using energy scores forunknown intent detection and provide empiricalevidence that the energy-based detector is compa-rable to strong baselines. To shape the energy gap,we propose a data manipulation framework GOT togenerate high-quality OOD utterances and assigntheir importance weights. We show that the energy-based detector tuned by GOT can achieve state-of-the-art results. We further employ generatedweighted utterances to fine-tune the softmax-baseddetector and also achieve improvements.
In the future, we will explore more operations,such as insertion, drop, etc., to enhance the diver-sity of generated utterances.
Acknowledgments
We would like to thank the anonymous reviewersfor their constructive comments. This work wassupported by NSFC Projects (Nos. 61936012 and61976114), the National Key R&D Program ofChina (No. 2018YFB1005102).

2860
ReferencesMarkus M Breunig, Hans-Peter Kriegel, Raymond T
Ng, and Jörg Sander. 2000. Lof: identifying density-based local outliers. In Proceedings of the 2000ACM SIGMOD international conference on Manage-ment of data, pages 93–104.
Hengyi Cai, Hongshen Chen, Yonghao Song, ChengZhang, Xiaofang Zhao, and Dawei Yin. 2020. Datamanipulation: Towards effective instance learningfor neural dialogue generation via learning to aug-ment and reweight. In Proceedings of the 58th An-nual Meeting of the Association for ComputationalLinguistics (ACL).
Alice Coucke, Alaa Saade, Adrien Ball, ThéodoreBluche, Alexandre Caulier, David Leroy, ClémentDoumouro, Thibault Gisselbrecht, Francesco Calta-girone, Thibaut Lavril, et al. 2018. Snips voice plat-form: an embedded spoken language understandingsystem for private-by-design voice interfaces. arXivpreprint arXiv:1805.10190.
Wenyuan Dai, Gui-Rong Xue, Qiang Yang, and YongYu. 2007. Co-clustering based classification for out-of-domain documents. In Proceedings of the 13thACM SIGKDD international conference on Knowl-edge discovery and data mining, pages 210–219.
Jesse Davis and Mark Goadrich. 2006. The relation-ship between precision-recall and roc curves. In Pro-ceedings of the 23rd international conference on Ma-chine learning, pages 233–240.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2018. Bert: Pre-training of deepbidirectional transformers for language understand-ing. arXiv preprint arXiv:1810.04805.
Geli Fei and Bing Liu. 2016. Breaking the closedworld assumption in text classification. In Proceed-ings of the 2016 Conference of the North Ameri-can Chapter of the Association for ComputationalLinguistics: Human Language Technologies, pages506–514, San Diego, California. Association forComputational Linguistics.
Geli Fei, Shuai Wang, and Bing Liu. 2016. Learn-ing cumulatively to become more knowledgeable.In Proceedings of the 22nd ACM SIGKDD Inter-national Conference on Knowledge Discovery andData Mining, pages 1565–1574.
Varun Gangal, Abhinav Arora, Arash Einolghozati,and Sonal Gupta. 2019. Likelihood ratios and gen-erative classifiers for unsupervised out-of-domaindetection in task oriented dialog. arXiv preprintarXiv:1912.12800.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza,Bing Xu, David Warde-Farley, Sherjil Ozair, AaronCourville, and Yoshua Bengio. 2014. Generativeadversarial nets. In Z. Ghahramani, M. Welling,C. Cortes, N. D. Lawrence, and K. Q. Weinberger,editors, Advances in Neural Information Processing
Systems 27, pages 2672–2680. Curran Associates,Inc.
Will Grathwohl, Kuan-Chieh Wang, Jörn-Henrik Ja-cobsen, David Duvenaud, Mohammad Norouzi, andKevin Swersky. 2020. Your classifier is secretly anenergy based model and you should treat it like one.International Conference on Learning Representati-nos.
Dan Hendrycks and Kevin Gimpel. 2017. A baselinefor detecting misclassified and out-of-distributionexamples in neural networks. Proceedings of Inter-national Conference on Learning Representations.
Pang Wei Koh and Percy Liang. 2017. Understandingblack-box predictions via influence functions. In In-ternational Conference on Machine Learning, pages1885–1894. PMLR.
Ian Lane, Tatsuya Kawahara, Tomoko Matsui, andSatoshi Nakamura. 2006. Out-of-domain utterancedetection using classification confidences of multi-ple topics. IEEE Transactions on Audio, Speech,and Language Processing, 15(1):150–161.
Stefan Larson, Anish Mahendran, Joseph J. Peper,Christopher Clarke, Andrew Lee, Parker Hill,Jonathan K. Kummerfeld, Kevin Leach, Michael A.Laurenzano, Lingjia Tang, and Jason Mars. 2019.An evaluation dataset for intent classification andout-of-scope prediction. In Proceedings of the2019 Conference on Empirical Methods in Natu-ral Language Processing and the 9th InternationalJoint Conference on Natural Language Processing(EMNLP-IJCNLP), pages 1311–1316, Hong Kong,China. Association for Computational Linguistics.
Yann LeCun, Sumit Chopra, Raia Hadsell, M Ranzato,and F Huang. 2006. A tutorial on energy-basedlearning. Predicting structured data, 1(0).
Kimin Lee, Honglak Lee, Kibok Lee, and JinwooShin. 2017. Training confidence-calibrated classi-fiers for detecting out-of-distribution samples. arXivpreprint arXiv:1711.09325.
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin.2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InS. Bengio, H. Wallach, H. Larochelle, K. Grauman,N. Cesa-Bianchi, and R. Garnett, editors, Advancesin Neural Information Processing Systems 31, pages7167–7177. Curran Associates, Inc.
Ting-En Lin and Hua Xu. 2019. Deep unknown intentdetection with margin loss. In Proceedings of the57th Annual Meeting of the Association for Com-putational Linguistics, pages 5491–5496, Florence,Italy. Association for Computational Linguistics.
Weitang Liu, Xiaoyun Wang, John Owens, and Yix-uan Li. 2020. Energy-based out-of-distribution de-tection. Advances in Neural Information ProcessingSystems, 33.

2861
Christos Louizos and Max Welling. 2017. Multiplica-tive normalizing flows for variational bayesian neu-ral networks. In Proceedings of the 34th Interna-tional Conference on Machine Learning-Volume 70,pages 2218–2227. JMLR. org.
Larry Manevitz and Malik Yousef. 2007. One-classdocument classification via neural networks. Neu-rocomputing, 70(7-9):1466–1481.
Christopher D Manning, Christopher D Manning, andHinrich Schütze. 1999. Foundations of statisticalnatural language processing. MIT press.
Kyo-Joong Oh, DongKun Lee, Chanyong Park, Young-Seob Jeong, Sawook Hong, Sungtae Kwon, and Ho-Jin Choi. 2018. Out-of-domain detection methodbased on sentence distance for dialogue systems. In2018 IEEE International Conference on Big Dataand Smart Computing (BigComp), pages 673–676.IEEE.
Alec Radford, Jeff Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Languagemodels are unsupervised multitask learners.
Jie Ren, Peter J Liu, Emily Fertig, Jasper Snoek, RyanPoplin, Mark Depristo, Joshua Dillon, and BalajiLakshminarayanan. 2019. Likelihood ratios for out-of-distribution detection. In Advances in Neural In-formation Processing Systems, pages 14680–14691.
Seonghan Ryu, Seokhwan Kim, Junhwi Choi, HwanjoYu, and Gary Geunbae Lee. 2017. Neural sentenceembedding using only in-domain sentences for out-of-domain sentence detection in dialog systems. Pat-tern Recognition Letters, 88:26–32.
Lei Shu, Hu Xu, and Bing Liu. 2017. DOC: Deepopen classification of text documents. In Proceed-ings of the 2017 Conference on Empirical Methodsin Natural Language Processing, pages 2911–2916,Copenhagen, Denmark. Association for Computa-tional Linguistics.
Gokhan Tur, Anoop Deoras, and Dilek Hakkani-Tür. 2014. Detecting out-of-domain utterances ad-dressed to a virtual personal assistant. In FifteenthAnnual Conference of the International Speech Com-munication Association.
Feng Wang, Jian Cheng, Weiyang Liu, and Haijun Liu.2018. Additive margin softmax for face verification.IEEE Signal Processing Letters, 25(7):926–930.
Zifeng Wang, Hong Zhu, Zhenhua Dong, Xiuqiang He,and Shao-Lun Huang. 2020. Less is better: Un-weighted data subsampling via influence function.In Proceedings of the AAAI Conference on ArtificialIntelligence, volume 34, pages 6340–6347.
Guangfeng Yan, Lu Fan, Qimai Li, Han Liu, XiaotongZhang, Xiao-Ming Wu, and Albert Y.S. Lam. 2020.Unknown intent detection using Gaussian mixture
model with an application to zero-shot intent clas-sification. In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguistics,pages 1050–1060, Online. Association for Computa-tional Linguistics.
Dani Yogatama, Chris Dyer, Wang Ling, and Phil Blun-som. 2017. Generative and discriminative text clas-sification with recurrent neural networks. arXivpreprint arXiv:1703.01898.
Yinhe Zheng, Guanyi Chen, and Minlie Huang. 2019.Out-of-domain detection for natural language un-derstanding in dialog systems. arXiv preprintarXiv:1909.03862.