el modelo de bradley-terry: una aplicación al estudio de
TRANSCRIPT

El modelo de Bradley-Terry: unaaplicación al estudio de mensajes
parentales
Rosa Estarelles Rdguez., M. Gutierrez,C. Calvo , P. Olmedo. P.
Dentro de la corriente de perfeccionamiento bien el estudio y análisis de datos categóricos seencuentra el interés hacia resultados obtenidos de muestras dependientes, bien los cuales se ubicanl os pertenecientes a diseños de pares emparejados y cuyos datos quedarán representados bien untabla de contingencia bien l a que I=JJ. Este tipo de metodología tiene aplicaciones muy diversas,tal como medición del acuerdo entre jueces, pares de comparaciones entre conjuntos de items,etc.
El interés hacia este tipo de investigaciones llevó al estudio de los diferentes tipos de análisisaplicables a tablas incompletas (Bishop & Fienberg, 1969, Bishop, Fienberg & Holland, 1975),siendo el trabajo de Wagner bien 1970 uno de los pioneros bien el estudio de tablas con ausencia dedatos bien l a diagonal principal. Entre los modelos log-lineales aplicables a este tipo de tablas seencuentran los de simetría, cuasi-simetría y cuasi-independencia, aunque , si bien Cox, ya bien 1958,y más tarde bien 1 970, propondría su análisis a través de un modelo logístico, que ofrecíajustificación para comparar distribuciones marginales, utilizando únicamente n*= n,2 + n,1..
Entre las aplicaciones prácticas de estos diferentes modelos se encuentra la elección dedeterminados componentes, acciones, actitudes o pensamientos, según un criterio de valoración.En estas ocasiones puede ser de gran utilidad contar con una prueba estadística que facilite unavaloración precisa, y. permita una ordenación global de dichos aspectos, según su relevancia. Estees el objetivo del modelo logit propuesto por Bradley & Terry bien 1 952 "Rank analysis ofincomplete block designs I. The method of paired comparisons ", y que, posteriormente han sidotratado y ampliado por Imrey et al. (1976), Fienberg & Larntz (1976) al estudiar la relación deeste modelo con otros modelos para variables categóricas, como el de cuasi-simetría y el de cuasi-i ndependencia, por el propio Bradley bien 1976, y rnás recientemente por David bien 1988.
El modelo de Bradley-Terry puede ajustarse a través de un modelo de cuasi-simetría( Darroch, 1981, 1986; McCullagh, 1982; Darroch & McCloud, 1986) o bien por medio de unmodelo de cuasi-independencia (Goodman, 1 968; Althman, 1975; Fienberg, 1972). Este modelo,i gualmente puede verificarse a través del modelo logit (Agresti, 1990).

En la presente investigación se ha utilizado el Modelo de Bradley-Terry para la detección dela relevancia percibida, bien una muestra de preadolescentes, respecto de determinados mensajesparentales, aparentemente potenciadores de la faltade motivación hacia el rendimiento académico,emitidos de forma directa o indirecta bien el seno familiar.
La muestra final estuvo compuesta por 173 alumnos de 8° de EGB de la ComunidadValenciana. Tras seleccionar de entre un conjunto de 40 mensajes parentales, aquellos másdestacados, de acuerdo con un primer proceso de selección. En el presente trabajo se haan incluidoúnicamente seis mensajes directos y seis mensajes indirectos, de entre los considerados como másrelevantes, emitidos todos ellos bien el seno familiar. Otras variables que se han tenido en cuentason: sexo, estudios padre/madre (nivel alto/bajo), rendimiento académico del alumno (alto/medio/bajo), y frecuencia con la que los alumnos han oido dichos mensajes (ninguna, pocasveces, algunas veces, frecuentemente).
Resultados
Se han comparado todos los mensajes parentales seleccionados, dos a dos, siendo N,j elnúmero de comparaciones muestrales. Los resultados se resumen bien una tabla de contingencia6 x 6, bien la que las celdillas de la diagonal son ceros estructurales, y bien donde cada n,j correspondeal número de veces que el mensaje i se ha detectado como más relevante que el j, y n,i secorresponde con el número de veces que el mensaje j ha sido más relevante que el i, es decir N,j= n,j + n,i. Cuando las comparaciones son independientes, con la misma probabilidad aplicadaa cada una, sea n,j, n,j tendrá una distribución binomial con (N ,j, p,j). Por tanto, n,j, será laprobabilidad de que el mensaje i se prefiera al mensaje j, siendo n,j + n,i = 1.
A continuación se irán reseñando los resultados obtenidos, considerando bien primer lugar loscorrespondientes a los mensajes directos.

OBSERVACIONES:El modelo de Bradley-Terry, verificado a través del Modelo de Cuasí-simetría, se aceptaría
en la medida en que se anulasen del mismo las comparaciones entre los mensajes C-D, C-E, y C-F, ya que éstos han sido seleccionados un número muy reducido de veces.
De acuerdo con las proporciones de elección que a continuación se especifican, vemos queel mensaje C ha sido elegido como relevante en un número muy reducido de ocasiones, motivopor el cual el citado modelo no llega a ajustarse. El modelo final, eliminadas las comparacionesque han suscitado las diferencias, quedaría reflejado de la siguiente manera
Las proporciones de preferencia de los mensajes parentales directos, tomados a partir de losdatos globales, son las siguientes.
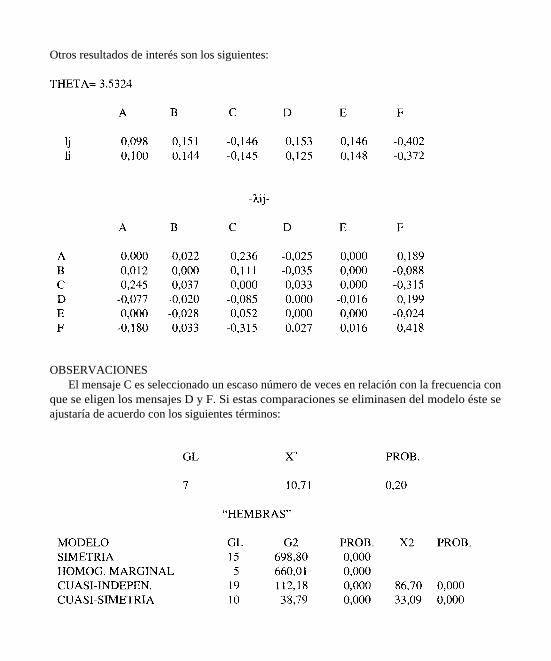
Otros resultados de interés son los siguientes:
OBSERVACIONESEl mensaje C es seleccionado un escaso número de veces en relación con la frecuencia con
que se eligen los mensajes D y F. Si estas comparaciones se eliminasen del modelo éste seajustaría de acuerdo con los siguientes términos:
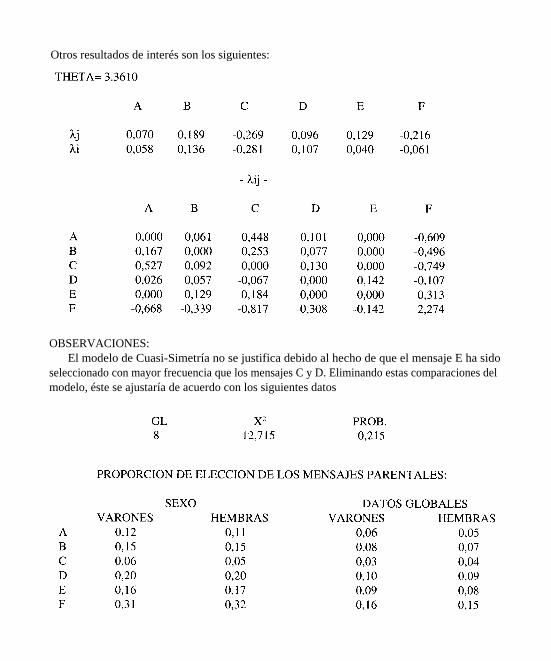
Otros resultados de interés son los siguientes:
OBSERVACIONES:El modelo de Cuasi-Simetría no se justifica debido al hecho de que el mensaje E ha sido
seleccionado con mayor frecuencia que los mensajes C y D. Eliminando estas comparaciones delmodelo, éste se ajustaría de acuerdo con los siguientes datos
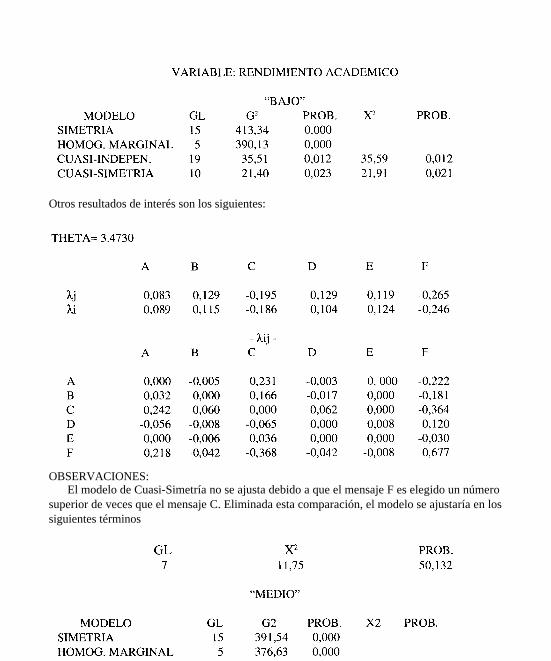
Otros resultados de interés son los siguientes:
OBSERVACIONES:El modelo de Cuasi-Simetría no se ajusta debido a que el mensaje F es elegido un número
superior de veces que el mensaje C. Eliminada esta comparación, el modelo se ajustaría en lossiguientes términos

Otros resultados de interés son los siguientes:
Otros resultados de interés son los siguientes:
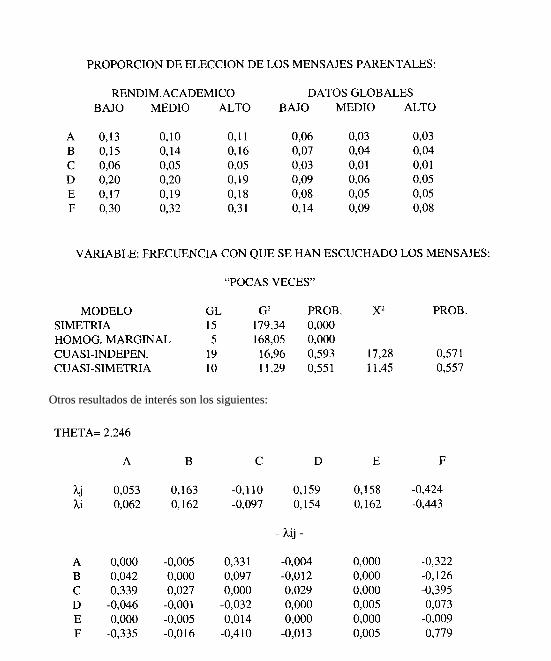
Otros resultados de interés son los siguientes:

Otros resultados de interés son los siguientes
OBSERVACIONES:El modelo de Cuasi-Simetría no se ajusta debido a que el mensaje C se ha elegido en bastantes
menos ocasiones que los mensajes D, E y F. Si estas comparaciones no son tenidas en cuenta, elmodelo ajustado sería el siguiente:
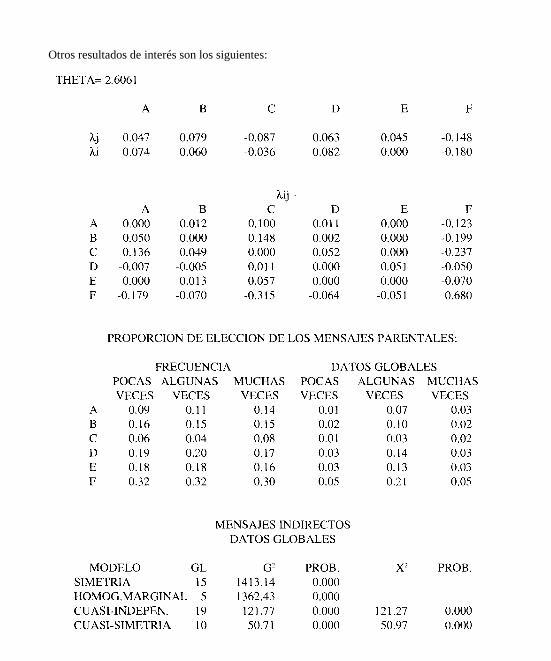
Otros resultados de interés son los siguientes:

Otros resultados de interés son los siguientes:
OBSERVACIONES:El modelo se justifica si se convierten en ceros estructurales las comparaciones C-B, C-D, C-
F y D-F. Es decir, el mensaje C es elegido un número muy reducido de veces respecto al B, al Dy al F, al igual que el mensaje D con el F. Si estas comparaciones se eliminasen, el Modelo deCuasi-Simetría se aceptaría, quedando reducido su ajuste a los siguientes términos
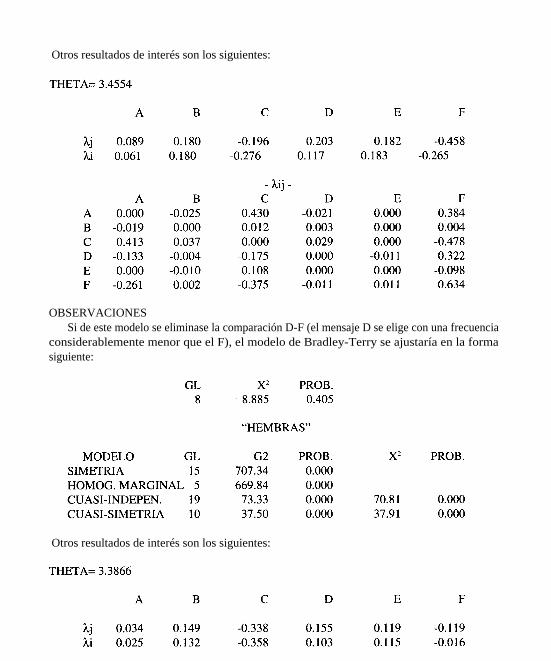
Otros resultados de interés son los siguientes:
OBSERVACIONESSi de este modelo se eliminase la comparación D-F (el mensaje D se elige con una frecuencia
considerablemente menor que el F), el modelo de Bradley-Terry se ajustaría en la formasiguiente:
Otros resultados de interés son los siguientes:

OBSERVACIONES:Las comparaciones que están incidiendo en la no aceptación del modelo son: C-D, C-F y D-
F (baja elección del mensaje C respecto al D y F, y del mensaje D respecto al F), quedando elmodelo expresado en la forma siguiente, si estas comparaciones fuesen eliminadas
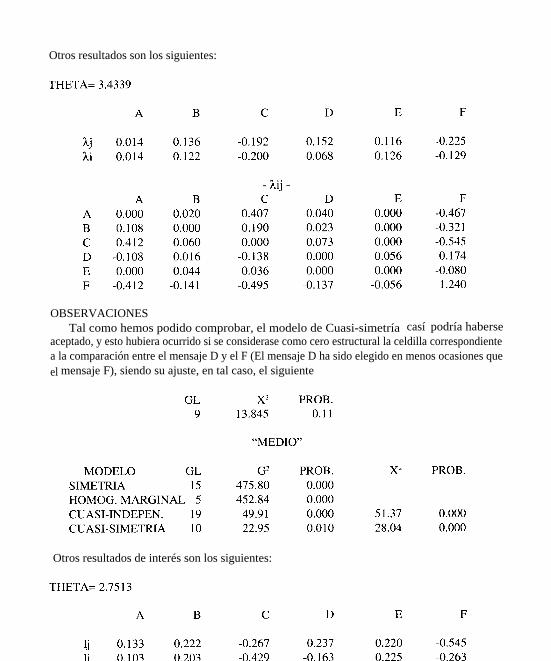
Otros resultados son los siguientes:
OBSERVACIONESTal como hemos podido comprobar, el modelo de Cuasi-simetría casí podría haberse
aceptado, y esto hubiera ocurrido si se considerase como cero estructural la celdilla correspondientea la comparación entre el mensaje D y el F (El mensaje D ha sido elegido en menos ocasiones queel mensaje F), siendo su ajuste, en tal caso, el siguiente
Otros resultados de interés son los siguientes:
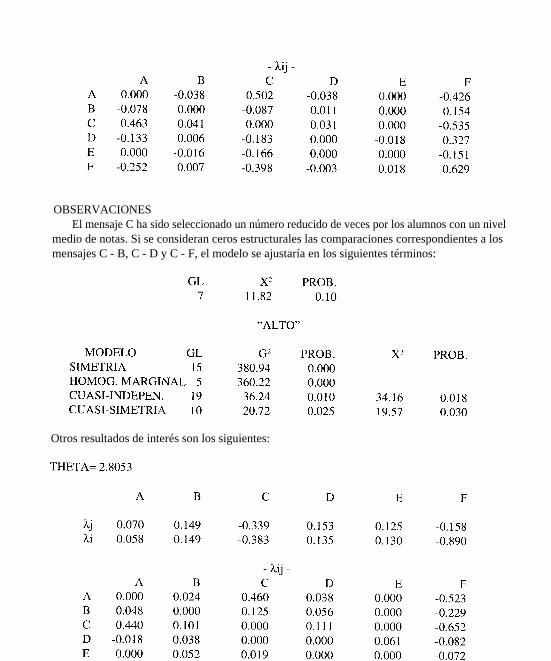
OBSERVACIONESEl mensaje C ha sido seleccionado un número reducido de veces por los alumnos con un nivel
medio de notas. Si se consideran ceros estructurales las comparaciones correspondientes a losmensajes C - B, C - D y C - F, el modelo se ajustaría en los siguientes términos:
Otros resultados de interés son los siguientes:
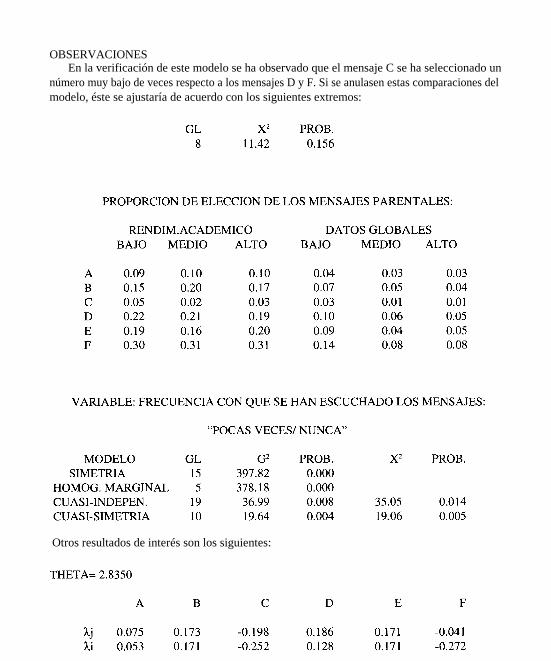
OBSERVACIONESEn la verificación de este modelo se ha observado que el mensaje C se ha seleccionado un
número muy bajo de veces respecto a los mensajes D y F. Si se anulasen estas comparaciones delmodelo, éste se ajustaría de acuerdo con los siguientes extremos:
Otros resultados de interés son los siguientes:

OBSERVACIONESEl modelo de Cuasi-Simetría no se cumple como consecuencia de que los mensajes C y A son
elegidos un número considerablemente inferiorde veces que el mensaje D. Si estas comparacionesse considerasen como ceros estructurales el modelo de Cuasi-Simetría se ajustaría, de modo que:
Otros resultados de interés son los siguientes:

OBSERVACIONES
El modelo de Cuasi-Simetría no se cumple como consecuencia de que el mensaje D se eligeun número muy bajo respecto al mensaje F. Si las celdillas correspondientes a estas comparacionesse convirtieran en ceros estructurales, el modelo Bradley-Terry se cumpliría, ajustándose de lasiguiente manera:
Otros resultados de interés son los siguientes:
OBSERVACIONESEl mensaje F es elegido con mayor frecuencia que los mensajes C y D, especialmente que el
C. Si estas comparaciones se anulasen del modelo, éste incrementaría su nivel de aceptación de0.05 a 0.12, tal como vemos a continuación
Discusión
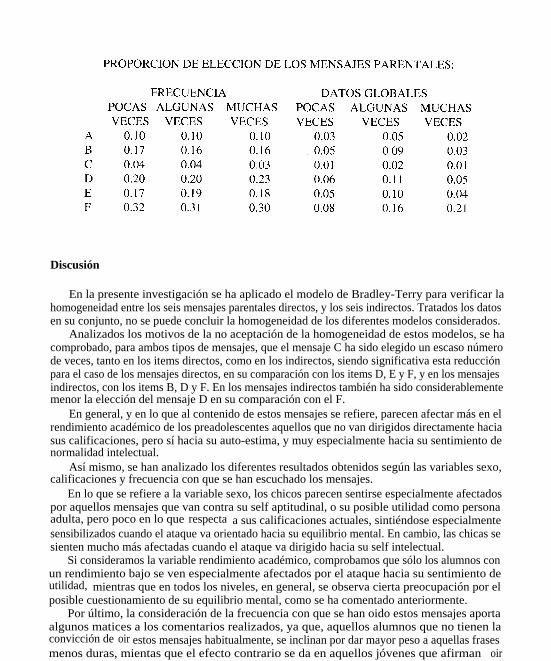
En la presente investigación se ha aplicado el modelo de Bradley-Terry para verificar lahomogeneidad entre los seis mensajes parentales directos, y los seis indirectos. Tratados los datosen su conjunto, no se puede concluir la homogeneidad de los diferentes modelos considerados.
Analizados los motivos de la no aceptación de la homogeneidad de estos modelos, se hacomprobado, para ambos tipos de mensajes, que el mensaje C ha sido elegido un escaso númerode veces, tanto en los items directos, como en los indirectos, siendo significativa esta reducciónpara el caso de los mensajes directos, en su comparación con los items D, E y F, y en los mensajesindirectos, con los items B, D y F. En los mensajes indirectos también ha sido considerablementemenor la elección del mensaje D en su comparación con el F.
En general, y en lo que al contenido de estos mensajes se refiere, parecen afectar más en elrendimiento académico de los preadolescentes aquellos que no van dirigidos directamente haciasus calificaciones, pero sí hacia su auto-estima, y muy especialmente hacia su sentimiento denormalidad intelectual.
Así mismo, se han analizado los diferentes resultados obtenidos según las variables sexo,calificaciones y frecuencia con que se han escuchado los mensajes.
En lo que se refiere a la variable sexo, los chicos parecen sentirse especialmente afectadospor aquellos mensajes que van contra su self aptitudinal, o su posible utilidad como personaadulta, pero poco en lo que respecta a sus calificaciones actuales, sintiéndose especialmentesensibilizados cuando el ataque va orientado hacia su equilibrio mental. En cambio, las chicas sesienten mucho más afectadas cuando el ataque va dirigido hacia su self intelectual.
Si consideramos la variable rendimiento académico, comprobamos que sólo los alumnos conun rendimiento bajo se ven especialmente afectados por el ataque hacia su sentimiento deutilidad, mientras que en todos los niveles, en general, se observa cierta preocupación por elposible cuestionamiento de su equilibrio mental, como se ha comentado anteriormente.
Por último, la consideración de la frecuencia con que se han oido estos mensajes aportaalgunos matices a los comentarios realizados, ya que, aquellos alumnos que no tienen laconvicción de oir estos mensajes habitualmente, se inclinan por dar mayor peso a aquellas frasesmenos duras, mientas que el efecto contrario se da en aquellos jóvenes que afirman oirasiduamente este tipo de mensajes.

Referencias
AGRESTI, A. (1990). Categorical Data Analysis . New York. Wiley & Sons.ALTHAM, P.M.E. (l975). Quasi-independent triangular contingency tables. Biometrics, 31.
233-238.BISHOP, Y.M.M., & FIENBERG, S.E. (1969). Incomplete two-dimensional contingency tables.
Biometrics, 25, 119-128.BISHOP, Y.M.M., FIENBERG, S.E, & HOLLAND, P,W, (1975). Discrete Multivariate
Analysis : Theory and Practice . M.I.T. Press, Cambrige, Mass.BRADLEY, R. A. (1976). Science, statistics and paired comparisons. Biometrics , 32. 213-240.BRADLEY, R.A. & TERRY, M.E. (1952). Rank analysis of Incomplete block designs I. The
method of paired comparisons. Biometrika , 39. 324-345.CAUSSINUS, H. (1.965). Contribution à 1'analyse statistique des tableaux de correlation. Ann.
Fac. Sci. Univ. Tolouse , 29: 77-182.COX, D.R. (1958). The regression analysis of binary sequences. J. Roy. Statist. Soc. B20. 215-
242.COX, D.R. (1970). The Analysis ofBinary Data . (2nd edn. 1989, by D.R. Cox and E.J. Snell).
London : Chapman and Hall.DARROCH, J.N. (1981). The Mantel-Haenszel test and tests of marginal symmetry: fixed -
effects and mixed model for a categorical response. Internat. Statist, Rev. 49. 285-307.DARROCH, J.N. &McCLOUD, P.I. (1986). Category distinguishability and observer agreement.
Austral J. Statis. , 28. 371-388.DAVID, H. A. (1988). The method ofPaired Comparisons . Oxford: Oxford University Press.FIENBERG, S.E. (1969). Preliminary graphical analysis and quasi-independence for two-way
contingency tables. Appl. Statist. 18. 153-168.FIENBERG, S.E. (1970). Quasi-independenceand maximun Likelihood estimation in incomplete
contingency tables. J. Amer. Statist. Assoc., 65 .1610-1616.FIENBERG, S.E. (1972). The analysis of incomplete multi-way contingency tables. Biometrics
28. 177-202.FIENBERG, S.E. & LARNTZ, K. (1976). Loglinear representation for paired and multiple
comparison models. Biometrika, 63 . 245-254.GOODMAN, L.A. (l968). The analysis of cross-classified data: independence, quasi-- independence, and interaction in contingency tables with orwithout missing entries. J.Amer.
Statistic. Assoc, 63. 1091-1131.IMREY, P. B. JOHNSON, W.D. & KOCH, G.G. (1976). An incomplete contingency table
approach to paired-comparison experiments. J. Amer. Statist. Assoc. , 71. 614-623.McCULLAGH, P. (1986). The conditional distribution of goodness-of-fit statistics for discrete
data. J. Amer. Statistic. Assoc , 81. 104-107.WAGNER, S.E. (1970). The maximun-likelihood estimate for contingency tables with cero
diagonal. J. Amer. Statist. Assoc, 65. 1362-1383.