efficiently mining frequent embedded unordered trees
TRANSCRIPT

Fundamenta Informaticae 65 (2005) 1–20 1
IOS Press
Efficiently Mining Frequent Embedded Unordered Trees
Mohammed J. Zaki �Computer Science Department
Rensselaer Polytechnic Institute
Troy NY 12180
Abstract. Mining frequent trees is very useful in domains like bioinformatics, web mining, miningsemi-structured data, and so on. In this paper we introduce SLEUTH, an efficient algorithm for min-ing frequent, unordered, embedded subtrees in a database oflabeled trees. The key contributions ofour work are as follows: We give the first algorithm that enumerates all embedded, unordered trees.We propose a new equivalence class extension scheme to generate all candidate trees. We extendthe notion of scope-list joins to compute frequency of unordered trees. We conduct performanceevaluation on several synthetic and real datasets to show that SLEUTH is an efficient algorithm,which has performance comparable to TreeMiner, that mines only ordered trees.
Keywords: Tree Mining, Embedded Trees, Unordered Trees
1. Introduction
Tree patterns typically arise in applications like bioinformatics, web mining, mining semi-structureddocuments, and so on. For example, given a database of XML documents, one might like to mine thecommonly occurring “structural” patterns, i.e., subtrees, that appear in the collection. As another exam-ple, given several phylogenies (i.e., evolutionary trees)from the Tree of Life [16], indicating evolutionaryhistory of several organisms, one might be interested in discovering if there are common subtree patterns.
Whereas itemset mining [1] and sequence mining [2] have beenstudied extensively in the past, re-cently there has been tremendous interest in mining increasingly complex pattern types such as trees [3–7, 17, 21, 25] and graphs [12, 15, 22]. For example, several algorithms for tree mining have been proposed�This work was supported in part by NSF CAREER Award IIS-0092978, DOE Career Award DE-FG02-02ER25538, and NSFgrant EIA-0103708.Address for correspondence: Lally 307, CSCI, RPI, 110 8th St, Troy NY 12180, USA

2 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
recently, which include TreeMiner [25], which mines embedded, ordered trees; FreqT [3], which minesinduced ordered trees, FreeTreeMiner [5] which mines induced, unordered, free trees (i.e., there is nodistinct root); TreeFinder [19], which mines embedded, unordered trees (but it may miss some patterns;it is not complete); and PathJoin [21], uFreqt [17], uNot [4], CMTreeMiner [7] and HybridTreeMiner [6]which mine induced, unordered trees. Our focus in this paperis on a complete and efficient algorithmfor mining frequent, labeled, rooted, unordered, and embedded subtrees.
A
C A
B
B
C
C
C
D
C
B B B
A A A
B
CA
T4T3T2T1
SubtreeEmbedded, Unordered
Figure 1. Embedded Unordered Subtree
We choose to look at labeled rooted trees, since those are thetypes of datasets that are most commonin a data mining setting, i.e., datasets represent relationships between items or attributes that are named,and there is a top root element (e.g., root element in an XML document, the main web page on a site). Weconsider unordered trees, since we might miss some potentially frequent patterns if we restrict ourselvesto ordered trees. Further, many datasets are inherently unordered (like phylogenies, semi-structureddata). Finally, we consider embedded subtrees, which are a generalization of induced subtrees; theyallow not only direct parent-child branches, but also ancestor-descendant branches. As such embeddedsubtrees are able to extract patterns “hidden” (or embedded) deep within large trees which might bemissed by the induced definition. As an example, consider Figure 1, which shows four labeled trees.Let’s assume we want to mine subtrees that are common to all four trees (i.e.,100% frequency). If wemine induced trees only, then there are no frequent trees of size more than one. If we mine embedded,but ordered trees, once again no frequent subtrees of size more than one are found. On the other hand,if we mine embedded, unordered subtrees, then the tree shownin the box is a frequent pattern appearingin all four trees; it is obtained by skipping the “middle” node in each tree. This example shows whyunordered, and embedded trees are of interest.
In this paper we introduce SLEUTH1, an efficient algorithm for the problem of mining frequent,unordered, embedded subtrees in a database of trees. The keycontributions of our work are as follows:1) We give the first algorithm that enumerates all embedded, unordered trees. 2) We propose a new self-contained equivalence class extension scheme to generate all candidate trees. Only potentially frequentextensions are considered, but some redundancy is allowed in the candidate generation to make eachclass self contained. 3) We extend the notion of scope-list joins (first proposed in [25]) for fast frequencycomputation for unordered trees. We conduct performance evaluation on several synthetic dataset and areal weblog dataset to show that SLEUTH is an efficient algorithm, which has performance comparableto TreeMiner [25] that mines only ordered trees.
1SLEUTH is an anagram of the bold letters in the phrase:L isting “Hidden” orEmbeddedUnorderedSubTrees

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 3
2. Preliminaries
Trees A rooted, labeled, tree, T = (V;E) is a directed, acyclic, connected graph, withV = f0; 1,� � � ; ng as the set of vertices (or nodes),E = f(x; y)jx; y 2 V g as the set of edges. One distinguishedvertexr 2 V is designated theroot, and for allx 2 V , there is auniquepath fromr to x. Further,l : V ! L is a labeling function mapping vertices to a set oflabelsL = f`1; `2; � � � g. In anordered treethe children of each vertex are ordered (i.e., if a vertex hask children, then we can designate them as thefirst child, second child, and so on up to thekth child), otherwise, the tree isunordered.
If x; y 2 V and there is a path fromx to y, thenx is called anancestorof y (andy a descendantofx), denoted asx �p y, wherep is the length of the path fromx to y. If x �1 y (i.e.,x is an immediateancestor), thenx is called theparentof y, andy thechild of x. If x andy have the same parent,x andyare calledsiblings, and if they have a common ancestor, they are calledcousins.
We also assume that vertexx 2 V is synonymous with (or numbered according to) its position in thedepth-first (pre-order) traversal of the treeT (for example, the rootr is vertex0). Let T (x) denote thesubtree rooted atx, and lety be the rightmost leaf (or highest numbered descendant) under x. Then thescopeof x is given ass(x) = [x; y℄. Intuitively, s(x) demarcates the range of vertices underx.
SubTrees Given a treeS = (Vs; Es) and treeT = (Vt; Et), we say thatS is anisomorphic subtreeofT iff there exists a one-to-one mapping' : Vs ! Vt, such that(x; y) 2 Es iff ('(x); '(y)) 2 Et. If' is onto, thenS andT are calledisomorphic. S is called aninduced subtreeof T = (Vt; Et), denotedS �i T , iff S is an isomorphic subtree ofT , and' preserves labels, i.e.,l(x) = l('(x));8x 2 Vs. Thatis, for induced subtrees' preserves the parent-child relationships, as well as vertex labels. The inducedsubtree obtained by deleting the rightmost leaf inT is called animmediate prefixof T . The induced treeobtained fromT by a series of rightmost node deletions is called aprefix of T . In the sequel we useprefix to mean an immediate prefix, unless we indicate otherwise.S = (Vs; Es) is called anembedded subtreeof T = (Vt; Et), denoted asS �e T iff there exists a1-to-1 mapping' : Vs ! Vt that satisfies: i)(x; y) 2 Es iff '(x) �p '(y), and ii) l(x) = l('(x)).That is, for embedded subtrees' preserves ancestor-descendant relationships and labels.A (sub)treeof size k is also called ak-(sub)tree. IfS �e T , we also say thatT containsS or S occurs in T .Note that each occurrence ofS in T can be identified by its uniquematch label, given by the sequence'(x0)'(x1) � � �'(xjSj), wherexi 2 Vs. That is a match label ofS is given as the set of matchingpositions inT .
Support Let ÆT (S) denote the number of occurrences (induced or embedded, depending on context) ofthe subtreeS in a treeT . Let dT be an indicator variable, withdT (S) = 1 if ÆT (S) > 0 anddT (S) = 0if ÆT (S) = 0. LetD denote a database (aforest) of trees. Thesupportof a subtreeS in the database isdefined as�(S) =PT2D dT (S), i.e., the number of trees inD that contain at least one occurrence ofS.Theweighted supportof S is defined as�w(S) = PT2D ÆT (S), i.e., total number of occurrences ofSover all trees inD. Typically, support is given as a percentage of the total number of trees inD. A subtreeS is frequentif its support is more than or equal to a user-specifiedminimum support(minsup) value.We denote byFk the set of all frequent subtrees of sizek. In some domains one might be interested inusing weighted support, instead of support. Both of them areallowed our mining approach, but we focusmainly on support.

4 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
Tree Mining Tasks Given a collection of treesD and a user specifiedminsupvalue, several treemining tasks can be defined, depending on the choices among rooted/free, ordered/unordered or in-duced/embedded trees.In this paper we focus on efficiently enumerating all frequent, embedded, un-ordered subtrees inD.
A
B C
induced sub−tree match labels
T S
[5, 5]
[6, 6]
[0, 6]
[1, 5]
[2, 4]
[3, 3] [4, 4]
embedded sub−tree match labels:
A
B
A C
C
BC
6
0
1
2
3 4
5
0
1 2
ordered: {016, 045, 046}
ordered: {016}unordered: {016, 243}
unordered: {016, 045, 046, 043, 243}
Figure 2. An Example: Tree and Subtree
Example 2.1. Consider Figure 2, which shows an example treeT with vertex labels drawn from the setL = fA;B;Cg, and vertices identified by their depth-first number. The figure shows for each vertex, itslabel, depth-first number, and scope. For example, the root is vertex0, its labell(0) = A, and since theright-most leaf under the root is vertex6, the scope of the root iss(0) = [0; 6℄.
ConsiderS; it is clearly an induced subtree ofT . If we look only at ordered subtrees, then the matchlabel ofS in T is given as:012 ! '(0)'(1)'(2) = 016 (we omit set notation for convenience). Ifunordered subtrees are considered, then243 is also a valid match label.S has additional match labelsas an embedded subtree. In the ordered case, we have additional match labels045 and046, and in theunordered case, we have on top of these two, the label043.
Thus the induced weighted support ofS is 1 for ordered and 2 for unordered case. The embeddedweighted support ofS is 3, if ordered, and 5, if unordered. The support ofS is 1 in all cases.
Tree Representation: String Encoding As described in [25], we represent a treeT by its stringencoding, denotedT , generated as follows: Add vertex labels toT in a depth-first preorder traversal ofT , and add a unique symbol$ 62 L whenever we backtrack from a child to its parent. For example, forT shown in Figure 2, its string encoding isA B A C $ B $ $ C $ $ C $. We use the notationT [i℄ todenote the element at positioni in T , wherei 2 [1; jT j℄, andjT j is the length of the stringT .
Database Representation: Scope-ListsWe refer to the tree database in the string encoding format asthe horizontal database. In SLEUTH, we represent the database in the vertical format [25], in which forevery distinct label we store its scope-list, which is a listof tree ids and vertex scopes where that labeloccurs. For label̀, we denote its scope-list asL(`); each entry in the scope list is a pair(t; s), wheret isa tree id (tid) in which̀ occurs, ands is the scope of a vertex with label` in tid t.

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 5
D in Horizontal Format : (tid, string encoding)
D in Vertical Format: (tid, scope) pairs
Tree T1
Database D of 3 Trees
0, [0, 3]1, [1, 3]2, [0, 7]2, [4, 7]
1, [0, 5]1, [2, 2]1, [4, 4]2, [2, 2]2, [5, 5]
1, [5, 5]2, [1, 2]2, [6, 7]
0, [3, 3]1, [3, 3]2, [7, 7]
2, [3, 7]
Tree T0 Tree T2
A
D
B
A
B D
B C
A
C
B
E
A
B C
D
A B C D E
[1,1]
[4,7]
[2,2]
[4, 4] [5,5]
[1,3]
[0,5]
[0,3]
[3,3]
[2,3]
[2,2]
[1,2]
[0,7]
[3,7]
[5,5]
[7,7]
[6,7]
[3, 3]
(T1, B A B $ D $ $ B $ C $)
(T2, A C B $ E A B $ C D $ $ $ $)B C
(T0, A C $ B D $ $)
0, [1, 1]0, [2, 3]
0
1
3
0
1
2 3
4 5
1
2
3
4
5 6
7
2
0
Figure 3. Scope-Lists
Example 2.2. Figure 3 shows a database of 3 trees, along with the horizontal format for each tree, andthe vertical scope-lists format for each label. Consider label A; since it occurs at vertex0 with scope[0; 3℄ in treeT0, we add(0; [0; 3℄) to its scope list.A also occurs inT1 with scope[1; 3℄, and inT2 withscopes[0; 7℄ and[4; 7℄, thus we add(1; [1; 3℄), (2; [0; 7℄) and(2; [4; 7℄) toL(A). In a similar manner, thescope lists for other labels are created.
We use the scope-lists to represent the list of occurrences in the database, for anyk-subtreeS. Letx be the label of the rightmost leaf inS. The scope list ofS consists of triples(t;m; s), wheret is a tidwhereS occurs,s is the scope of vertex with labelx in tid t, andm is a match label for the prefix subtreeof S. Thus our vertical database is in fact the set of scope-listsfor all 1-subtrees (and since they have noprefix, there is no match label).
3. Related Work
Tree mining, being an instance of frequent structure mining, has obvious relation to association [1] andsequence [2] mining. Frequent tree mining is also related totree isomorphism [18] and tree patternmatching [8]. The tree inclusion problem was studied in [13], i.e., given labeled treesP andT , canPbe obtained fromT by deleting nodes? This problem is equivalent to checking ifP is embedded inT .Both subtree isomorphism and pattern matching deal with induced subtrees, while we mine embeddedsubtrees. Further we are interested in enumerating all common subtrees in a collection of trees.
Recently tree mining has attracted a lot of attention. We developed TreeMiner [25] to mine labeled,embedded, and ordered subtrees. The notions of scope-listsand rightmost extension were introducedin that work. TreeMiner was also used in building a structural classifier for XML data [26]. Asai etal. [3] presented FreqT, an apriori-like algorithm for mining labeled ordered trees; they independentlyproposed the rightmost candidate generation scheme. Wang and Liu [20] developed an algorithm to minefrequently occurring subtrees in XML documents. Their algorithm is also reminiscent of the level-wiseApriori [1] approach, and they mine induced subtrees only. There are several other recent algorithms that

6 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
mine different types of tree patterns, which include FreeTreeMiner [5] which mines induced, unordered,free trees (i.e., there is no distinct root); and PathJoin [21], uFreqt [17], uNot [4], and HybridTreeM-iner [6] which mine induced, unordered trees. CMTreeMiner [7] mines maximal and closed induced,unordered trees. TreeFinder [19] uses an Inductive Logic Programming approach to mine unordered,embedded subtrees, but it is not a complete method, i.e, it can miss many frequent subtrees, especially assupport is lowered or when the different trees in the database have common node labels. Our focus hereis on an efficient algorithm to mine the complete set of frequent, embedded, unordered trees.
There has also been recent work in mining frequent graph patterns. The AGM algorithm [12] dis-covers induced (possibly disconnected) subgraphs. The FSGalgorithm [15] improves upon AGM, andmines only the connected subgraphs. Both methods follow an Apriori-style level-wise approach. Re-cent methods to mine graphs using a depth-first tree based extension have been proposed in [22, 23].Another method uses a candidate generation approach based on Canonical Adjacency Matrices [11].The work by Dehaspe et al [10] describes a level-wise Inductive Logic Programming based techniqueto mine frequent substructures (subgraphs) describing thecarcinogenesis of chemical compounds. Workon molecular feature mining has appeared in [14]. The SUBDUEsystem [9] also discovers graph pat-terns using the Minimum Description Length principle. An approach termed Graph-Based Induction(GBI) was proposed in [24], which uses beam search for miningsubgraphs. However, both SUBDUEand GBI may miss some significant patterns, since they perform a heuristic search. In contrast to theseapproaches, we are interested in developing efficient, complete algorithms for tree patterns.
4. Generating Unordered, Embedded Trees
There are two main steps for enumerating frequent subtrees in D. First, we need a systematic way ofgeneratingcandidatesubtrees whose frequency is to be computed. The candidate set should be non-redundant to the extent possible; ideally, each subtree should be generated as most once. Second, weneed efficient ways of counting the number of occurrences of each candidate tree in the databaseD, andto determine which candidates pass theminsupthreshold. The latter step is data structure dependent, andwill be treated later. Here we are concerned with the problemof candidate generation.
B
C B A
BD
B
C B A
B D
B
A
B D
C B
B
A
B D
B C
0
1 2 3
4 5
0
1 2 3
4 5
0
1
2 3
4 5
0
1
2 3
4 5
T1 T2 T3 T4
Figure 4. Some Automorphisms of the Same Graph
Automorphism Group An automorphismof a tree is a isomorphism with itself. LetAut(T ) denotetheautomorphism group, i.e., the set of all label preserving automorphisms, ofT . Henceforth, by auto-morphism, we mean label preserving automorphisms. The goalof candidate generation is to enumerateonly onecanonicalrepresentative fromAut(T ). For an unordered treeT , there can be many automor-phisms. For example, Figure 4 shows some of the automorphisms of the same tree.
Let there be a linear order� defined on the elements of the label setL. Given any two treesX andY , we can define a linear order�, calledtree orderbetween them, recursively as follows: Letrx and

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 7ry denote the roots ofX andY , and let rx1 ; � � � ; rxm and ry1 ; � � � ; ryn denote the ordered list of childrenof rx andry, respectively. Also letT ( rxi ) denote the subtree ofX rooted at vertex rxi . ThenX � Y(alternatively,T (rx) � T (ry)) iff either:
1.) l(rx) < l(ry), or
2.) l(rx) = l(ry), and either a)n � m andT ( rxi ) = T ( ryi ) for all 1 � i � n, i.e., Y is a prefix(not necessarily immediate prefix) of or equal toX, or b) there existsj 2 [1;min(m;n)℄, such thatT ( rxi ) = T ( ryi ) for all i < j, andT ( rxj ) < T ( ryj ).
This tree ordering is essentially the same as that in [17], although their tree coding is different.We can also define acode orderon the tree encodings directly as follows: Assume that the special
backtrack symbol$ > ` for all ` 2 L. Given two string encodingsX andY. We say thatX � Y iffeither:
i.) jYj � jX j andX [k℄ = Y[k℄ for all 1 � k � jYj, or
ii.) There existsk 2 [1;min(jX j; jYj)℄, such that for all1 � i < k, X [i℄ = Y[i℄ andX [k℄ < Y[k℄.Incidentally, a similar tree code ordering was independently proposed in CMTreeMiner [7].
Lemma 4.1. X � Y iff X � Y.Proof Sketch: Condition i) in code order holds ifX andY are identical for the entire length ofY,
but this is true iffY is a prefix of (or equal to)X.Condition ii) holds if and only ifX andY are identical up to positionk � 1, i.e.,X [1; � � � ; k �1℄ = Y[1; � � � ; k � 1℄. This is true iff bothX andY share a common prefix treeP with encodingP = X [1; � � � ; k� 1℄). LetviX (andvjY ) refer to the node in treeX (andY ), that corresponds to positionX [i℄ 6= $ (andY[j℄ 6= $).If k = 1, thenP is an empty tree with encodingP = ;. It is clear thatl(rx) < l(ry) iff X [1℄ < Y[1℄.
If k > 1, thenX [k℄ < Y[k℄, iff one of the following cases is true: A)X [k℄ 6= $ andY[k℄ 6= $: Weimmediately haveX [k℄ < Y[k℄ iff T (vkX) < T (vkY ) iff X < Y . B) X [k℄ 6= $ andY[k℄ = $: let vjX beparent of nodevkX (j < k), and letvjY be the corresponding node inY (which refers toY[j℄ 6= $). Wethen immediately have thatT (vjY ) is a prefix ofT (vjX), sinceX [j; � � � ; k � 1℄ = Y[j; � � � ; k � 1℄, andvjX has an extra childvkX , whereasvjY doesn’t. ut
Given Aut(T ) the canonical representativeT 2 Aut(T ) is the tree, such thatT � X for allX 2 Aut(T ). For anyP 2 Aut(T ) we say thatP is in canonical formif P = T . For example,T = T1for the automorphism groupAut(T1), four of whose members are shown in Figure 4. We can see thatthe string encodingT1 = BAB$D$$B$C$ is smaller thanT2 = BAB$D$$C$B$ and also smallerthan other members.
Lemma 4.2. A treeT is in canonical form iff for all verticesv 2 T , T ( vi ) � T ( vi+1) for all i 2 [1; k℄,where v1; v2; � � � ; vk is the list of ordered children ofv.
Proof Sketch: T is in canonical form implies thatT � X for all X 2 Aut(T ). Assume thatthere exist some vertexv 2 T such thatT ( i) > T ( i+1) for somei 2 [1; k℄, where 1; 2; � � � ; k arethe ordered children ofv. But then, we can obtain treeT 0 by simply swapping the subtreesT ( i) andT ( i+1) under nodev. However, by doing so, we makeT 0 < T , which contradicts the assumption thatT is canonical. ut

8 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
Prefix Extension LetR(P ) = v1v2 � � � vm denote the rightmost path in treeP , i.e., the path from rootPr to the rightmost leaf inP . Given a seed frequent treeP , we can generate new candidatesP ix obtainedby adding a new leaf with labelx to any vertexvi on the rightmost pathR(P ). We call this process asprefix-basedextension, since each such candidate hasP as its prefix tree.
It has been shown that prefix-based extension can correctly enumerate all ordered embedded or in-duced trees [3, 25]. For unordered trees, we only have to do a further check to see if the new extension isthe canonical form for its automorphism group, and if so, it is a valid extension. For example, Figure 5shows the seed treeP , with encodingP = CDA$B (omitting trailing$’s). To preserve the prefix tree,only rightmost branch extensions are allowed. Since the rightmost path isR(P ) = 013, we can extendP by adding a new vertex with labelx any of these vertices, to obtain a new treeP ix (i 2 f0; 1; 3g). Note,how addingx to node2 gives a different prefix tree encodingCDAx, and is thus disallowed, as shownin the figure.
Equivalence Class
Element List: (label, attached to position)
x
x
x x
Class Prefix
3
C
D
2
1
0
B A
Prefix String: C D A $ B
(x, 3) // attached to 3: C D A $ B x $ $ $
(x, 1) // attached to 1: C D A $ B $ x $ $
(x, 0) // attached to 0: C D A $ B $ $ x $
Figure 5. Prefix Extension and Equivalence Class
In [17] it was shown that for any tree in canonical form its prefix is also in canonical form. Thusstarting from vertices with distinct labels, using prefix extensions, and retaining only canonical forms foreach automorphism group, we can enumerate all unordered trees non-redundantly. For each candidate,we can count the number of embedded occurrences in databaseD to determine which are frequent.Thus the main challenges in tree extension are to: i) efficiently determine whether an extension yields acanonical tree, and ii) determine extensions which will potentially be frequent. The former step considersonly valid candidates, whereas the latter step minimizes the number of frequency computations againstthe database.
Canonical Extension To check if a tree is in canonical form, we need to make sure that for each vertexv 2 T , T ( i) � T ( i+1) for all i 2 [1; k℄, where 1; 2; � � � ; k is the list of ordered children ofv.However, since we extend only canonical trees, for a new candidate, its prefix is in canonical form, andwe can do better.
Lemma 4.3. Let P be a tree in canonical form, and letR(P ) be the rightmost path inP . LetP kx be thetree extension ofP when adding a vertex with labelx to some vertexvk in R(P ). For anyvi 2 R(P kx ),let vil�1 and vil denote the last two children ofvi 2. ThenP kx is in canonical form iff for allvi 2 R(P kx ),T ( vil�1) � T ( vil ).
Proof Sketch: LetR(P ) = v1v2 � � � vkvk+1 � � � vm be the rightmost path inP . By Lemma 4.2,P isin canonical form implies that for every nodevi 2 R(P ), we haveT ( vil�1) � T ( vil ).2If vi is a leaf, then both children are empty, and ifvi has only one child, then vil�1 is empty

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 9
B
A
B
C
B
A
B
C
A
B
C
A
C
D
C
0
1
4
5
6
7
10 12
13
11
3
2
8
9 x
14
15
Figure 6. Check for Canonical Form
When we extendP to P kx , we obtain a new rightmost pathR(P kx ) = v1v2 � � � vkvn, wherevn is thenew last child ofvk (with labelx). Thus bothR(P ) andR(P kx ) share the verticesv1v2 � � � vk in common.Note that for anyi > k, vi 2 R(P ) is unaffected by the addition of vertexvn. On the other hand, forall i < k, the last child vil of vi 2 R(P ) (i.e., vi 2 R(P kx )) is affected byvn, whereas vil�1 remainsunchanged. Also fori = k, the last two children ofvk change in treeP kx ; we have vkl�1 = vk+1 and vkl = vn.
SinceP is in canonical form, we immediately have that for allvi 2 fv1; v2; � � � ; vkg, T ( vij ) �T ( vil�1) for all j < l � 1. Thus we only have to compare the new subtreeT ( vil ) with T ( vil�1). IfT ( vil�1) � T ( vil ) for all vi 2 R(P kx ), then by Lemma 4.2, we immediately have thatP kx is in canonicalform. On the other hand ifT ( vil�1) > T ( vil ) for somevi 2 R(P kx ), thenP kx cannot be in canonicalform. ut
According to lemma 4.3 we can check if a treeP kx is in canonical form by starting from the rightmostleaf inR(P kx ) and checking if the subtrees under the last two children for each node on the rightmost pathare ordered according to�. By lemma 4.1 it is sufficient to check if their string encodings are orderedby �. For example, given the candidate treeP 12x shown in Figure 6 which has a new vertex15 withlabelx attached to node12 on the rightmost path, we first compare15 with its previous sibling13. ForT (13) � T (15), we require thatx � C. After skipping node11 (with empty previous sibling), we reachnode0, where we compareT (5) andT (11). ForT (5) � T (11) we require thatx � D, otherwiseP 12xis not canonical. Thus for anyx < D the tree is not canonical. It is possible to speed-up the canonicalitychecking by adopting a different tree coding [17], but here we will continue to use the string encoding ofa tree. The corresponding checks for canonicality based on lemma 4.1 among the subtree encodings areshown below:
Compare 13 and 15:BAAC$$B$$ABCC$$D$$B$$ABCC$$xCompare 5 and 11:BAAC$$B$$ABCC$$D$$B$$ABCC$$x
Based on the check for canonical form, we can determine whichlabels are possible for each rightmostpath extension. Given a treeP and the set of frequent labelsF1, we can then try to extendP with eachlabel fromF1 that leads to a canonical extension. Even though all of thesecandidates are non-redundant(i.e., there are no isomorphic duplicates), this extensionprocess may still produce too many candidatetrees, whose frequencies have to be counted in the databaseD. To reduce the number of such trees, wetry to extendP with a vertex that is more likely to result in a frequent tree,using the idea of a prefixequivalence class.

10 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
Equivalence Class-based ExtensionWe say that twok-subtreesX;Y are in the sameprefix equiva-lence classiff they share the same prefix tree. Thus any two members of a prefix class differ only in thelast vertex. For example, Figure 5 shows the class template for subtrees with the same prefix subtreePwith string encodingP = C D A $ B. The figure shows the actual format we use to store an equiva-lence class; it consists of the class prefix string, and a listof elements. Each element is given as a(x; i)pair, wherex is the label of the last vertex, andi specifies the vertex inP to whichx is attached. Forexample(x; 1) refers to the case wherex is attached to vertex1. The figure shows the encoding of thesubtrees corresponding to each class element. Note how eachof them shares the same prefix up to the(k � 1)th vertex. These subtrees are shown only for illustration purposes; we only store the element listin a class.
Let P be a prefix subtree of sizek � 1; we use the notation[P ℄ to refer to its class (we will usePand its string encodingP interchangeably). If(x; i) is an element of the class, we write it as(x; i) 2 [P ℄.Each(x; i) pair corresponds to a subtree of sizek, sharingP as the prefix, with the last vertex labeledx, attached to vertexi in P . We use the notationP ix to refer to the new prefix subtree formed by adding(x; i) to P .
Let P be a(k � 1)-subtree, and let[P ℄ = f(x;i)jP ix is frequentg be the set of all possible frequentextensions of prefix treeP . Then the set of potentially frequent candidate trees for the class[P ix℄ (obtainedby adding an element(x; i) toP ), can be obtained by prefix extensions ofP ix with each element(y; j) 2[P ℄, given as follows: i)cousin extension: If j � i and jP j = k � 1 � 1, then(y; j) 2 [P ix℄, and inaddition ii)child extension: If j = i then(y; k � 1) 2 [P ix℄.
A
B
C D
A
B
A A A
B B B
C C C
A A
B B D D D
C C
D
D
Element List: (C,1) (D,0)Prefix: A B
Prefix: A B CElement List: (C,2) (C,1) (D,0)
Prefix: A B $ DElement List: (D,2) (D,0)
C1
C4
P2
C3C2
C5
P1
2 2
1
2
3
1
2
1
2
1 2
3
1 2 3
0
P10
P2
11
0C1
0C2
0
C3
3
3
0 0 C5C4
Figure 7. Equivalence Class-based Extension
Example 4.1. Consider Figure 7, showing the prefix classP = AB, which contains 2 elements,(C; 1)and(D; 0). Let’s consider the extensions of first element, i.e., of[P 1C ℄ = [ABC℄. First we must considerelement(C; 1) itself. As child extension, we add(C; 2) (treeC1), and as cousin extension, we add(C; 1)(treeC2). Extending with(D; 0), since0 < 1, we only add cousin extension(D; 0) (treeC3) to [ABC℄.

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 11
When considering extensions of[P 0D℄ = [AB$D℄, we consider(C; 1) first. But sinceC is attached tovertex1, it cannot preserve the prefix treePD. Considering(D; 0), we add(D; 0) as a cousin extensionand(D; 2) as a child extension, corresponding to treesC4 andC5.
The main observation behind equivalence class extension isthat only known frequent elements fromthe same class are used for extendingP ix, which itself is known to be frequent from the previous exten-sion step. Furthermore, we only extendP ix, if it is in canonical form. However, to guarantee that allpossible extensions are members of[P ℄, we have to relax the non-redundant tree generation idea. Thatis, whereas we extend only canonicalP ix, all possible extensions are added to[P ix℄ (which are not nec-essarily canonical). This contrasts with the purely canonical extension approach, where only canonicalextensions are considered. In essence canonical and equivalence class extensions represent a trade-offbetween the number of redundant (isomorphic) candidates generated and the number of potentially fre-quent candidates to count. Canonical extensions generate non-redundant candidates, but many of whichmay turn out not to be frequent. On the other hand, equivalence class extension generates redundantcandidates, but considers a smaller number of (potentiallyfrequent) extensions. In our experiments wefound equivalence class extensions to be more efficient. Oneconsequence of using equivalence classextensions is that SLEUTH doesn’t depend on any particular canonical form; it can work with any sys-tematic way of choosing a representative from an automorphism group. Provided only one representativeis extended, its class contains all information about the extensions that can be potentially frequent. Thiscan provide a lot of flexibility on how tree enumeration is performed.
5. Frequency Computation
SLEUTH uses scope-list joins for fast frequency computation for a new extension. We assume that eachelement(x; i) in a prefix class[P ℄ has a scope-list which stores all occurrences of the treeP ix (obtainedby extendingP with (x; i)). The vertical database contains the initial scope listsL(`) for each distinctlabel `. To compute the scope-lists for members of[P ix℄ we need to join the scope-lists of(x; i) withevery other element(y; j) 2 [P ℄. If the resulting tree is frequent, we insert the element in[P ix℄.
Let sx = [lx; ux℄ be a scope for vertexx, andsy = [ly; uy℄ a scope fory. We say thatsx is strictlylessthansy, denotedsx < sy, if and only if ux < ly, i.e., the intervalsx has no overlap withsy, and itoccurs beforesy. We say thatsx containssy, denotedsx � sy, if and only if lx < ly andux � uy, i.e.,the intervalsy is a proper subset ofsx.
Recall from the equivalence class extension that when we extend element[P ix℄ there can be at mosttwo possible outcomes, i.e., child extension or cousin extension. The use of scopes allows us to computein constant time whethery is a descendant ofx or y is a cousin ofx. We describe below how to computethe embedded support for child and cousin (unordered) extensions, using the descendant and cousin tests.
Descendant Test Given [P ℄ and any two of its elements(x; i) and(y; j). In a child extension ofP ixthe element(y; j) is added as a child of(x; i). For embedded frequency computation, we have to find alloccurrences where labely occurs as a descendant ofx, sharing the same prefix treeP ix in someT 2 D,with tid t. This is called thedescendant test. To check if this subtree occurs in an input treeT with tid t,we search if there exists triples(ty;my; sy) 2 L(y) and(tx;mx; sx) 2 L(x), such that:1) ty = tx = t, i.e., the triples both occur in the same tree, with tidt.2)my = mx = m, i.e.,x andy are both extensions of the same prefix occurrence, with matchlabelm.

12 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
3) sy � sx, i.e.,y lies within the scope ofx.If the three conditions are satisfied, we have found an instance wherey is a descendant ofx in some inputtreeT . We then extend the match labelmy of the old prefixP , to get the match label for the new prefixP ix (given asmy [ lx), and add the triple(ty; fmy [ lxg; sy) to the scope-list of(y; jP j) in [P ix℄.Cousin Test Given [P ℄ and any two of its elements(x; i) and(y; j). In a cousin extension ofP ix theelement(y; j) is added as a cousin of(x; i). For embedded frequency computation, we have to find alloccurrences where labely occurs as a cousin ofx, sharing the same prefix treeP ix in some input treeT 2 D, with tid t. This is called thecousin test. To check ify occurs as a cousin in some treeT with tidt, we need to check if there exists triples(ty;my; sy) 2 L(y) and(tx;mx; sx) 2 L(x), such that:1) ty = tx = t, i.e., the triples both occur in the same tree, with tidt.2)my = mx = m, i.e.,x andy are both extensions of the same prefix occurrence, with matchlabelm.3) sx < sy or sx > sy, i.e., eitherx comes beforey or y comes beforex in depth-first ordering, andtheir scopes do not overlap. This allows us to find the unordered frequency and is one of the crucialdifferences compared to ordered tree mining, as in TreeMiner [25], which only checks ifsx < sy.If these conditions are satisfied, we add the triple(ty; fmy [ lxg; sy) to the scope-list of(y; j) in [P ix℄.
1, 1, [2, 2]2, 0, [2, 2]2, 0, [5, 5]2, 4, [5, 5]
A
B
A
C
0, 0, [2, 3] 0, 0, [1, 1]2, 0, [1, 2]
2, 0, [6, 7]2, 4, [6, 7]
0, [0, 3]1, [1, 3]2, [0, 7]2, [4, 7]
1, [0, 5]1, [2, 2]1, [4, 4]2, [2, 2]2, [5, 5]
1, [5, 5]2, [1, 2]2, [6, 7]
0, [3, 3]1, [3, 3]2, [7, 7]
A B C D
0, [2, 3] 0, [1, 1]
A
B C
0, 02, [1, 1]
2, 02, [6, 7]
2, 45, [6, 7]2, 05, [6, 7]
2, 05, [1, 2]
Figure 8. Scope-list Joins
Example 5.1. Figure 8 shows an example of how scope-list joins work, usingthe databaseD fromFigure 3. The initial class with empty prefix consists of fourfrequent labels (A;B;C, andD), with theirscope-lists. All pairs (not necessarily distinct) of elements are considered for extension.
Two of the frequent trees in class[A℄ are shown, namelyAB$ andAC$. AB$ is obtained by joiningthe scope lists ofA andB and performing descendant tests, since we want to find those occurrences ofB that are within some scope ofA (i.e., under a subtree rooted atA). Let sx denote a scope for labelx.For treeT0 we find thatsB = [2; 3℄ � sA = [0; 3℄. Thus we add the triple(0; 0; [2; 3℄) to the new scopelist. Similarly, we test the other occurrences ofB underA in treesT1 andT2. If a new scope-list occursin at leastminsuptids, the pattern is considered frequent.
The next candidate shows an example of testing frequency of acousin extension, namely, how tocompute the scope list ofAB$C by joining L(AB) andL(AC). For finding all unordered embeddedoccurrences, we need to test for disjoint scopes, withsB < sC or sC < sB , which have the same matchlabel. For example, inT0, we find thatsB = [2; 3℄ andsC = [1; 1℄ satisfy these condition. Thus we addthe triple(0; 02; [1; 1℄) to L(AB$C). Notice that the new prefix match label (02) is obtained by addingto the old prefix match label (0), the position whereB occurs (i.e.,2). The other occurrences are noted inthe final scope-list.

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 13
6. TheSLEUTH Algorithm
Figure 9 shows the high level structure of SLEUTH. The main steps include the computation of the fre-quent labels (1-subtrees) and 2-subtrees, and the enumeration of all other frequent subtrees via recursive(depth-first) equivalence class extensions of each class[P ℄1 2 F2. We will now describe each step insome more detail.
SLEUTH (D,minsup):1. F1 = f frequent 1-subtreesg;2. F2 = f classes[P ℄1 of frequent 2-subtreesg; //create scope-lists3. for all [P ℄1 2 F2 do Enumerate-Frequent-Subtrees([P ℄1 );
ENUMERATE-FREQUENT-SUBTREES([P ℄):4. for each element(x; i) 2 [P ℄ do5. if check-canonical(P ix ) then6. [P ix℄ = ;;7. for each element(y; j) 2 [P ℄ do8. if do-child-extensionthenLd = descendant-scope-list-join((x; i); (y; j));9. if do-cousin-extensionthenL = cousin-scope-list-join((x; i); (y; j));10. if child or cousin extension is frequentthen11. Add(y; j) and/or(y; k � 1) to equivalence class[P ix℄; //add scope-list also12. Enumerate-Frequent-Subtrees([P ix ℄);
Figure 9. SLEUTH Algorithm
Computing F1 andF2: SLEUTH assumes that the initial database is in the horizontal string encodedformat. To computeF1 (line 1), for each labeli 2 T (the string encoding of treeT ), we incrementi’scount in a count array. This step also computes other database statistics such as the number of trees,maximum number of labels, and so on. All labels inF1 belong to the class with empty prefix, given as[P ℄0 = [;℄ = f(i; ); i 2 F1g, and the position indicates thati is not attached to any vertex. Total timefor this step isO(n) per tree, wheren = jT j.
For efficientF2 counting (line 2) we compute the supports of all candidate byusing a 2D integerarray of sizeF1�F1, where nt[i℄[j℄ gives the count of the candidate (embedded) subtree with encoding(i j $). Total time for this step isO(n2) per tree. While computingF2 we also create the verticalscope-list representation for each frequent itemi 2 F1, and before each call ofEnumerate-Frequent-Subtrees ([P ℄1 2 E) (line 3) we also compute the scope lists of all frequent elements (2-subtrees) inthe class.
Computing Fk(k � 3): Figure 9 shows the pseudo-code for the recursive (depth-first) search forfrequent subtrees (ENUMERATE-FREQUENT-SUBTREES). The input to the procedure is a set of elementsof a class[P ℄, along with their scope-lists. Frequent subtrees are generated by joining the scope-lists ofall pairs of elements.
Before extending the class[P ix℄ we first make sure thatP ix is the canonical representative of itsautomorphism group (line 5). If not, the pattern will not be extended. If yes, we try to extendP ix with

14 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
every element(y; j) 2 [P ℄. We try both child and cousin extensions, and perform descendant or cousintests during scope-list join (lines 8,9). If any candidate is frequent, it is added to the new class[P ix℄.This way, the subtrees found to be frequent at the current level form the elements of classes for the nextlevel. This recursive process is repeated until all frequent subtrees have been enumerated. If[P ℄ hasnelements, the total cost is given asO(qn2), whereq is the cost of a scope-list join. The cost of scope-listjoin isO(me2), wherem is the average number of distinct tids in the scope list of thetwo elements, ande is the average number of embeddings of the pattern per tid. The total cost of generating a new class isthereforeO(m(en)2).
In terms of memory management, we need memory to store classes along a path in DFS search. Infact we need to store intermediate scope-lists for two classes at a time, i.e., the current class[P ℄, and anew candidate class[P ix℄. Thus the memory footprint of SLEUTH is not much, unless the scope-listsbecome too big, which can happen if the number of embeddings of a pattern is large. If the lists are toolarge to fit in memory, we can do joins in stages. That is, we canbring in portions of the scope-listsfor the two elements to be joined, perform descendant or cousin tests, and write out portions of the newscope-list.
Lemma 6.1. The equivalence class-based extension inSLEUTH correctly generates all possible em-bedded, unordered, frequent subtrees.
Proof Sketch: We prove the correctness of SLEUTH by induction on the length k of the minedk-subtrees. Let’s consider the base cases. Fork = 1, SLEUTH considers each label and counts itsfrequency, thus all 1-subtrees (F1) are found correctly. Letx; y; z be any three labels (not necessarilydistinct). Fork = 2, SLEUTH considers all possible 2-subtrees of the formxy$, and counts theirfrequency; 2-subtrees are by definition canonical and thus all frequent 2-subtrees are recorded inF2. Fork = 3, SLEUTH considers all 3-subtrees of the formxyz$$ or xy$z$, computes their frequency, andcreates prefix equivalence classes[xy$℄, where each such class containsall frequent extensions ofxy$.The class can contain non-canonical elements, but only canonical elements will be output and consideredfor extension. Thus all possible 3-subtrees are correctly mined.
For the inductive step, let’s assume that SLEUTH mines the set of frequentk-subtrees, organized asa set of prefix-based equivalence classesP, where each classP 2 P has a shared(k � 1) length prefixtree, and consists of all frequent extensions ofP (not necessarily canonical extensions). Also note thatSLEUTH correctly outputs only the canonical frequentk-subtrees from each class.
We will now show that SLEUTH will enumerate all canonical frequent(k + 1)-subtrees. Considerany class[P ℄; let (x; i) and(y; j) be any two elements of the class (not necessarily distinct).From theprevious step we already know thatP ix andP jy (i.e, extensions ofP with (x; i) and(y; j)) are frequent.The equivalence class extension step enumerates all frequent subtrees by using the rightmost path ex-tension, whose correctness has been proved in [3, 25]. SinceSLEUTH extends only canonical subtrees,each new class[P ix℄ has a canonical prefixk-subtreeP ix, and all of its frequent extensions are elementsof the class. Out of these only the canonical(k + 1)-subtrees will be output. This proves that SLEUTHenumerates all possible, embedded, unordered, frequent subtrees. utEquivalence Class vs. Canonical ExtensionsAs described above, SLEUTH uses equivalence classextensions to enumerate the frequent trees. The prefixP is known to be frequent from the previous step,and we extend it only if it is in canonical form. To ensure thatall possible extensions are members of

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 15[P ℄, we had to compromise on non-redundant tree generation, by adding all possible extensions ofP tothe class[P ℄, whether they are canonical or not.
SLEUTH-FKF2 (D,minsup):1. F1 = f frequent 1-subtreesg;2. F2 = f classes[P ℄1 of frequent 2-subtreesg; //create scope-lists3. for all [P ℄1 2 F2 do Enumerate-Frequent-Subtrees([P ℄1 ; F2);ENUMERATE-FREQUENT-SUBTREES([P ℄; F2 ):4. for each element(x; i) 2 [P ℄ do5. [P ix℄ = ;;6. for each element(y; j) 2 [P ℄ [ [x℄, where[x℄ 2 F2 do7. if check-canonical(P ix extended with(y; j)) then8. if do-child-extensionthenLd = descendant-scope-list-join((x; i); (y; j));9. if do-cousin-extensionthenL = cousin-scope-list-join((x; i); (y; j));10. if child or cousin extension is frequentthen11. Add(y; j) and/or(y; k � 1) to equivalence class[P ix℄; //add scope-list also12. Enumerate-Frequent-Subtrees([P ix ℄; F2);
Figure 10. SLEUTH-FKF2 Algorithm
For comparison we implemented another approach, called SLEUTH-FKF2, which performs onlycanonical extensions. The main idea is to extend a canonicaland frequent subtree, with a known frequentsubtree fromF2. The pseudo-code is shown in Figure 10. The computation ofF1 andF2 is the sameas for SLEUTH(lines 1-2). We then callEnumerate-Frequent-Subtrees for each class inF2 (line3). This function takes as input a class[P ℄, all of whose elements are known to be bothfrequent andcanonical. Each member(x; i) of [P ℄ (line 4) is either extended with another element of[P ℄ or withelements in[x℄ (line 6), where[x℄ 2 F2 denotes all possible frequent 2-subtrees of the formxy$; toguarantee correctness we have to extend[P ix℄ with all y 2 [x℄. Note that elements of both[P ℄ and[x℄ represent canonical subtrees, and if the child or cousin extension is canonical (line 7), we performdescendant and cousin joins, and add the new subtree to[P ix℄ if is is frequent. This way, each class onlycontains elements that are both canonical and frequent.
Lemma 6.2. SLEUTH-FKF2 correctly generates all possible embedded, unordered, frequent subtrees.Proof Sketch: The proof is similar to that for SLEUTH. The main differenceis that instead of
storing all possible frequent extensions in a prefix class, SLEUTH-FKF2 stores only the canonical,frequent extensions. To generate new(k + 1) length candidates, all possible rightmost path extensionswith elements ofF2 are considered. If any extension is both canonical and frequent the process continuesto the next level, until all possible embedded, unordered, frequent subtrees have been mined. ut
As we mentioned earlier pure canonical and equivalence class extensions denote a trade-off betweenthe number of redundant candidates generated and the numberof potentially frequent candidates tocount. Canonical extensions generate non-redundant candidates, but many of which may turn out notto be frequent (since, in essence, we joinFk with F2 to obtainFk+1). On the other hand, equivalenceclass extension generates redundant candidates, but considers a smaller number of (potentially frequent)

16 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
extensions (since, in essence, we joinFk with Fk to obtainFk+1). In the next section we compare thesetwo methods experimentally; we found SLEUTH, which uses equivalence class extensions to be moreefficient, than SLEUTH-FKF2, which uses only canonical extensions.
7. Experimental Results
All experiments were performed on a 2.8GHz Pentium 4 processor with 1GB main memory, and witha 250GB, 7200rpms disk, running RedHat Linux 9. Timings are based on total wall-clock time, andinclude all preprocessing costs (such as creating scope-lists).
Synthetic Datasets We constructed a synthetic data generation program to create a database of arti-ficial website browsing behavior [25]. We first construct a master website browsing treeW based onparameters supplied by the user. These parameters include the maximum fanoutF of a node, the maxi-mum depthD of the tree, the total number of nodesM in the tree, and the number of node labelsN . Foreach node in master treeW , we assign probabilities of following its children nodes, including the optionof backtracking to its parent, such that sum of all the probabilities is 1. Using the master tree, one cangenerate a subtreeTi � W by randomly picking a subtree ofW as the root ofTi and then recursivelypicking children of the current node according to the probability of following that link.
We used the following default values for the parameters: thenumber of labelsN = 100, the numberof vertices in the master treeM = 10; 000, the maximum depthD = 10, the maximum fanoutF = 10and total number of subtreesT = 100; 000. We use three synthetic datasets:D10 dataset had all defaultvalues,F5 had all values set to default, except for fanoutF = 5, and forT1M we setT = 1; 000; 000,with remaining default values.
CSLOGS Dataset consists of web logs files collected over 1 month at the CS department. The logstouched 13361 unique web pages within our department’s web site. After processing the raw logs weobtained 59691 user browsing subtrees of the CS department website. The average string encoding lengthfor a user subtree was23:3.
7.1. Performance Evaluation
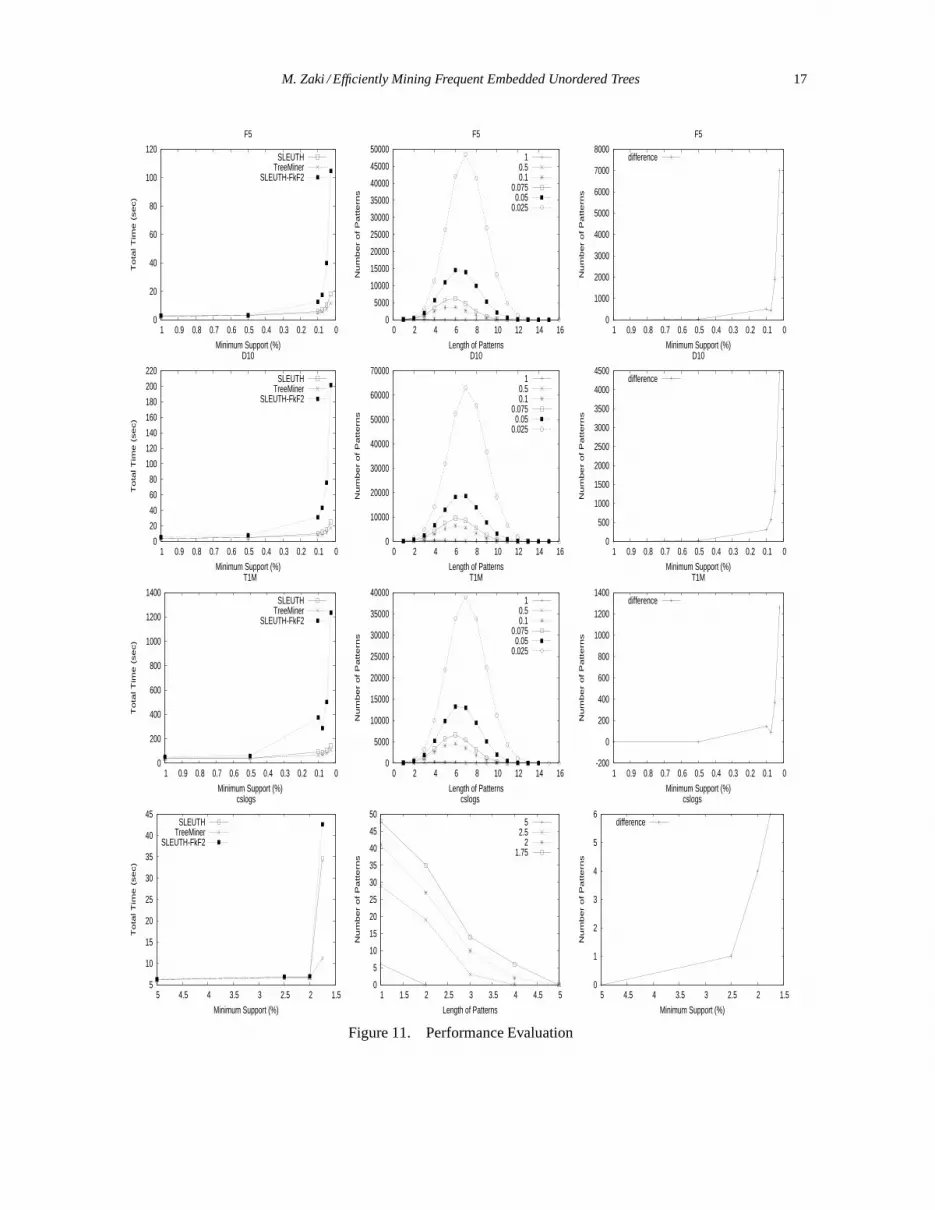
Figure 11 shows the performance of SLEUTH on different datasets for different values of minimum sup-port, and compares the run time against TreeMiner and SLEUTH-FKF2. Note that, whereas SLEUTHand SLEUTH-FKF2 mine unordered embedded patterns, TreeMiner mines ordered embedded patterns.The second column in the figure shows the distribution of frequent embedded, unordered patterns for var-ious supports. Finally the third column shows the difference between the number of frequent embeddedunordered and ordered patterns; a positive value means thatthere are more frequent unordered patternsthan ordered ones.
Let’s consider theF5 dataset. We find that unordered and ordered pattern mining (SLEUTH andTreeMiner, respectively) are comparable, but TreeMiner takes less time. There are two main reasonsfor this behavior. First, the number of unordered patterns is more than ordered patterns for this dataset.Second, SLEUTH needs to perform canonical form tests, whileTreeMiner doesn’t, since for ordered treemining, the automorphism group for a tree only contains one member, the tree itself (Aut(T ) = fTg).
M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 17
0
20
40
60
80
100
120
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Tota
l T
ime (
sec)
Minimum Support (%)
F5
SLEUTHTreeMiner
SLEUTH-FkF2
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
50000
0 2 4 6 8 10 12 14 16
Num
ber
of P
attern
s
Length of Patterns
F5
10.50.1
0.0750.05
0.025
0
1000
2000
3000
4000
5000
6000
7000
8000
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Num
ber
of P
attern
s
Minimum Support (%)
F5
difference
0
20
40
60
80
100
120
140
160
180
200
220
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Tota
l T
ime (
sec)
Minimum Support (%)
D10
SLEUTHTreeMiner
SLEUTH-FkF2
0
10000
20000
30000
40000
50000
60000
70000
0 2 4 6 8 10 12 14 16
Num
ber
of P
attern
s
Length of Patterns
D10
10.50.1
0.0750.05
0.025
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Num
ber
of P
attern
s
Minimum Support (%)
D10
difference
0
200
400
600
800
1000
1200
1400
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Tota
l T
ime (
sec)
Minimum Support (%)
T1M
SLEUTHTreeMiner
SLEUTH-FkF2
0
5000
10000
15000
20000
25000
30000
35000
40000
0 2 4 6 8 10 12 14 16
Num
ber
of P
attern
s
Length of Patterns
T1M
10.50.1
0.0750.05
0.025
-200
0
200
400
600
800
1000
1200
1400
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Num
ber
of P
attern
s
Minimum Support (%)
T1M
difference
5
10
15
20
25
30
35
40
45
1.5 2 2.5 3 3.5 4 4.5 5
Tota
l T
ime (
sec)
Minimum Support (%)
cslogs
SLEUTHTreeMiner
SLEUTH-FkF2
0
5
10
15
20
25
30
35
40
45
50
1 1.5 2 2.5 3 3.5 4 4.5 5
Num
ber
of P
attern
s
Length of Patterns
cslogs
52.5
21.75
0
1
2
3
4
5
6
1.5 2 2.5 3 3.5 4 4.5 5
Num
ber
of P
attern
s
Minimum Support (%)
cslogs
difference
Figure 11. Performance Evaluation

18 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
Looking at the length distribution, we find it to be mainly symmetric across the support values, and also,generally speaking more unordered tree are found as compared to ordered ones, especially as minimumsupport is lowered. Comparing SLEUTHwith SLEUTH-FKF2, we find that there is a big performanceloss for the pure canonical extensions due to the joins ofFk with F2, which result in many infrequentcandidates; SLEUTH-FKF2 can be 5 times slower than SLEUTH. Similar trends are obtained forD10 andT1M datasets; TreeMiner is slightly faster than SLEUTH, whereas SLEUTH can be 5-10times faster than SLEUTH-FKF2. This shows clearly that the strategy of generating some redundantcandidates, but extending only canonical prefix classes is superior to generating many infrequent butpurely canonical candidates.
The web-log datasetCSLOGS has different characteristics for the supports at which we mined.Looking at the pattern length distribution, we find that the number of patterns keep decreasing as lengthincreases. Also there is not much difference between the number of unordered and ordered embeddedtrees. Considering run times, SLEUTH remains faster than SLEUTH-FKF2 and both of them takethe same time as ordered tree mining for higher values of support, but for a low value (1.75%) it takesmuch longer to mine unordered patterns. The reason for this gap is that SLEUTH keeps track of allpossible “unordered” mappings from a candidate to a datasettree. For theCSLOGS dataset, this resultsin longer scope-lists than for TreeMiner, which keeps only the ordered mappings. Longer scope-listslead to higher execution time for the joins.
Summarizing from the results over synthetic and reals datasets, we can conclude that SLEUTH is anefficient, complete, algorithm for mining unordered, embedded trees. Even though it mines more patternsthan TreeMiner, and has to perform canonical form tests, itsperformance is comparable to ordered treemining.
8. Conclusions
In this paper we presented, SLEUTH, the first algorithm to mine all unordered, embedded subtrees ina database of labeled trees. Among our contributions is the procedure for systematic candidate sub-tree generation using self-contained equivalence prefix classes. All frequent patterns are enumeratedby unordered scope-list joins via the descendant and cousintests. We also compared SLEUTH withSLEUTH-FKF2, which also mines unordered, embedded trees, but uses pure canonical extensions. Ourexperiments show that SLEUTH is more efficient than SLEUTH-FKF2, and is generally comparableto TreeMiner, which mines only ordered subtrees, even though SLEUTH has to check if a subtree is incanonical form.
For future work we plan to extend our tree mining framework toincorporate user-specified con-straints. Given that tree mining, though able to extract informative patterns, is an expensive task, per-forming general unconstrained mining can be too expensive and is also likely to produce many patternsthat may not be relevant to a given user. Incorporating constraints is one way to focus the search andto allow interactivity. We also plan to develop efficient algorithms to mine maximal frequent subtreesfrom dense datasets which may have very large subtrees. Finally, we plan to apply our tree miningtechniques to compelling applications, such as finding common tree patterns in phylogenetic data withinbioinformatics, as well as the extraction of structure fromXML documents and their use in classification,clustering, and so on.

M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees 19
References
[1] Agrawal, R., Mannila, H., Srikant, R., Toivonen, H., Verkamo, A. I.: Fast Discovery of Association Rules,Advances in Knowledge Discovery and Data Mining(U. Fayyad, et al, Eds.), AAAI Press, Menlo Park, CA,1996.
[2] Agrawal, R., Srikant, R.: Mining Sequential Patterns,11th Intl. Conf. on Data Engg., 1995.
[3] Asai, T., Abe, K., Kawasoe, S., Arimura, H., Satamoto, H., Arikawa, S.: Efficient Substructure Discoveryfrom Large Semi-structured Data,2nd SIAM Int’l Conference on Data Mining, April 2002.
[4] Asai, T., Arimura, H., Uno, T., Nakano, S.: Discovering Frequent Substructures in Large Unordered Trees,6th Int’l Conf. on Discovery Science, October 2003.
[5] Chi, Y., Yang, Y., Muntz, R. R.: Indexing and Mining Free Trees, 3rd IEEE International Conference onData Mining, 2003.
[6] Chi, Y., Yang, Y., Muntz, R. R.: HybridTreeMiner: An Efficient Algorihtm for Mining Frequent RootedTrees and Free Trees Using Canonical Forms,16th International Conference on Scientific and StatisticalDatabase Management, 2004.
[7] Chi, Y., Yang, Y., Xia, Y., Muntz, R. R.: CMTreeMiner: Mining Both Closed and Maximal Frequent Subtrees,8th Pacific-Asia Conference on Knowledge Discovery and DataMining, 2004.
[8] Cole, R., Hariharan, R., Indyk, P.: Tree pattern matching and subset matching in deterministicO(n log3 n)-time, 10th Symposium on Discrete Algorithms, 1999.
[9] Cook, D., Holder, L.: Substructure discovery using minimal description length and background knowledge,Journal of Artificial Intelligence Research, 1, 1994, 231–255.
[10] Dehaspe, L., Toivonen, H., King, R.: Finding frequent substructures in chemical compounds,4th Intl. Conf.Knowledge Discovery and Data Mining, August 1998.
[11] Huan, J., Wang, W., Prins, J.: Efficient Mining of Frequent Subgraphs in the Presence of Isomorphism,IEEEInt’l Conf. on Data Mining, 2003.
[12] Inokuchi, A., Washio, T., Motoda, H.: An apriori-basedalgorithm for mining frequent substructures fromgraph data,4th European Conference on Principles of Knowledge Discovery and Data Mining, September2000.
[13] Kilpelainen, P., Mannila, H.: Ordered and unordered tree inclusion, SIAM J. of Computing, 24(2), 1995,340–356.
[14] Kramer, S., Raedt, L. D., Helma, C.: Molecular Feature Mining in HIV data, Int’l Conf. on KnowledgeDiscovery and Data Mining, 2001.
[15] Kuramochi, M., Karypis, G.: Frequent Subgraph Discovery, 1st IEEE Int’l Conf. on Data Mining, November2001.
[16] Morell, V.: Web-Crawling up the Tree of Life,Science, 273(5275), aug 1996, 568–570.
[17] Nijssen, S., Kok, J. N.: Efficient Discovery of FrequentUnordered Trees,1st Int’l Workshop on MiningGraphs, Trees and Sequences, 2003.
[18] Shamir, R., Tsur, D.: Faster Subtree Isomorphism,Journal of Algorithms, 33, 1999, 267–280.
[19] Termier, A., Rousset, M.-C., Sebag, M.: TreeFinder: a First Step towards XML Data Mining,IEEE Int’lConf. on Data Mining, 2002.

20 M. Zaki / Efficiently Mining Frequent Embedded Unordered Trees
[20] Wang, K., Liu, H.: Discovering Typical Structures of Documents: A Road Map Approach,ACM SIGIRConference on Information Retrieval, 1998.
[21] Xiao, Y., Yao, J.-F., Li, Z., Dunham, M. H.: Efficient Data Mining for Maximal Frequent Subtrees,Interna-tional Conference on Data Mining, 2003.
[22] Yan, X., Han, J.: gSpan: Graph-based substructure pattern mining,IEEE Int’l Conf. on Data Mining, 2002.
[23] Yan, X., Han, J.: CloseGraph: Mining Closed Frequent Graph Patterns,ACM SIGKDD Int. Conf. on Knowl-edge Discovery and Data Mining, August 2003.
[24] Yoshida, K., Motoda, H.: CLIP: Concept Learning from Inference Patterns,Artificial Intelligence, 75(1),1995, 63–92.
[25] Zaki, M. J.: Efficiently Mining Frequent Trees in a Forest, 8th ACM SIGKDD Int’l Conf. Knowledge Dis-covery and Data Mining, July 2002.
[26] Zaki, M. J., Aggarwal, C.: Xrules: An effective structural classifier for XML data,9th ACM SIGKDD Int’lConf. Knowledge Discovery and Data Mining, August 2003.