deliberate word access: an intuition, a roadmap and some preliminary empirical results
TRANSCRIPT

1 23
International Journal ofSpeech Technology ISSN 1381-2416Volume 13Number 4 Int J Speech Technol (2010)13:201-218DOI 10.1007/s10772-010-9078-9
Deliberate word access: an intuition, aroadmap and some preliminary empiricalresults

Int J Speech Technol (2010) 13: 201–218DOI 10.1007/s10772-010-9078-9
Deliberate word access: an intuition, a roadmap and somepreliminary empirical results
Michael Zock · Olivier Ferret · Didier Schwab
Received: 2 March 2010 / Accepted: 21 September 2010 / Published online: 15 October 2010© Springer Science+Business Media, LLC 2010
Abstract No doubt, words play a major role in languageproduction, hence finding them is of vital importance, be itfor writing or for speaking (spontaneous discourse produc-tion, simultaneous translation). Words are stored in a dic-tionary, and the general belief holds, the more entries thebetter. Yet, to be truly useful the resource should contain notonly many entries and a lot of information concerning eachone of them, but also adequate navigational means to re-veal the stored information. Information access depends cru-cially on the organization of the data (words) and the accesskeys (meaning/form), two factors largely overlooked. Wewill present here some ideas of how an existing electronicdictionary could be enhanced to support a speaker/writer tofind the word s/he is looking for. To this end we suggestto add to an existing electronic dictionary an index basedon the notion of association, i.e. words co-occurring in awell balanced corpus, the latter being supposed to repre-sent the average citizen’s knowledge of the world. Beforedescribing our approach, we will briefly take a critical lookat the work being done by colleagues working on auto-matic, spontaneous or deliberate language production,—that
M. Zock (�)Laboratoire d’Informatique Fondamentale (LIF), CNRS &Aix-Marseille Université, Case 901-163 Avenue de Luminy,13288 Marseille Cedex 9, Francee-mail: [email protected]
O. FerretCEA, LIST, Vision and Content Engineering Laboratory,Fontenay-aux-Roses, 92265, Francee-mail: [email protected]
D. SchwabLaboratoire d’Informatique de Grenoble, équipe GETALP,Université Grenoble 2, BP 53, 38041 Grenoble Cedex 9, Francee-mail: [email protected]
is, computer-generated language, simulation of the mentallexicon, or WordNet (WN),—to see how adequate they arewith regard to our goal.
Keywords Lexical access · Index based on associations ·Mental lexicon · Navigation
1 Introduction
We spend a large amount of our lifetime searching: ideas,names, documents, and ‘you just name it’. We will be con-cerned here with the problem of words, or rather, how to findthem (word access) in the place where they are stored: thebrain, or an external resource, a dictionary.
Obviously, a good dictionary is a well-structured reposi-tory with a lot of information concerning words. Yet, whatcounts is not only the coverage, i.e. number of entries or thequality of the information associated with each one of them,but also access support. Because, what is information goodfor, if one cannot access it when needed?
We will present here some ideas of how to enhance anexisting electronic dictionary, in order to help the user tofind the word s/he is looking for. Before doing so we willtake a look at various solutions offered for different produc-tion modes (spontaneous, deliberate and automatic languageproduction), to see their qualities and shortcomings. Let usstart with the latter.
1.1 Related work in the area of natural-language generation
A lot of work has been devoted to lexical issues during thelast twenty years. For excellent surveys see Robin (1990),Stede (1995), Wanner (1996), or Cumming (1986) for someearlier work. Two approaches that have been particularly

202 Int J Speech Technol (2010) 13: 201–218
Fig. 1 Discrimination nets, or, the check list approach
successful were discrimination nets (Goldman 1975) andgraph-rewriting, i.e. pattern-matching (Nogier and Zock1992).
Discrimination nets (Fig. 1) can be seen as a hierarchi-cally ordered set of tests whose outcome determines theword to be chosen. Since the tests are hierarchically ordered,we have, formally speaking, a tree, whose nodes are the con-ditions (tests) and the leaves the outcome, i.e. words
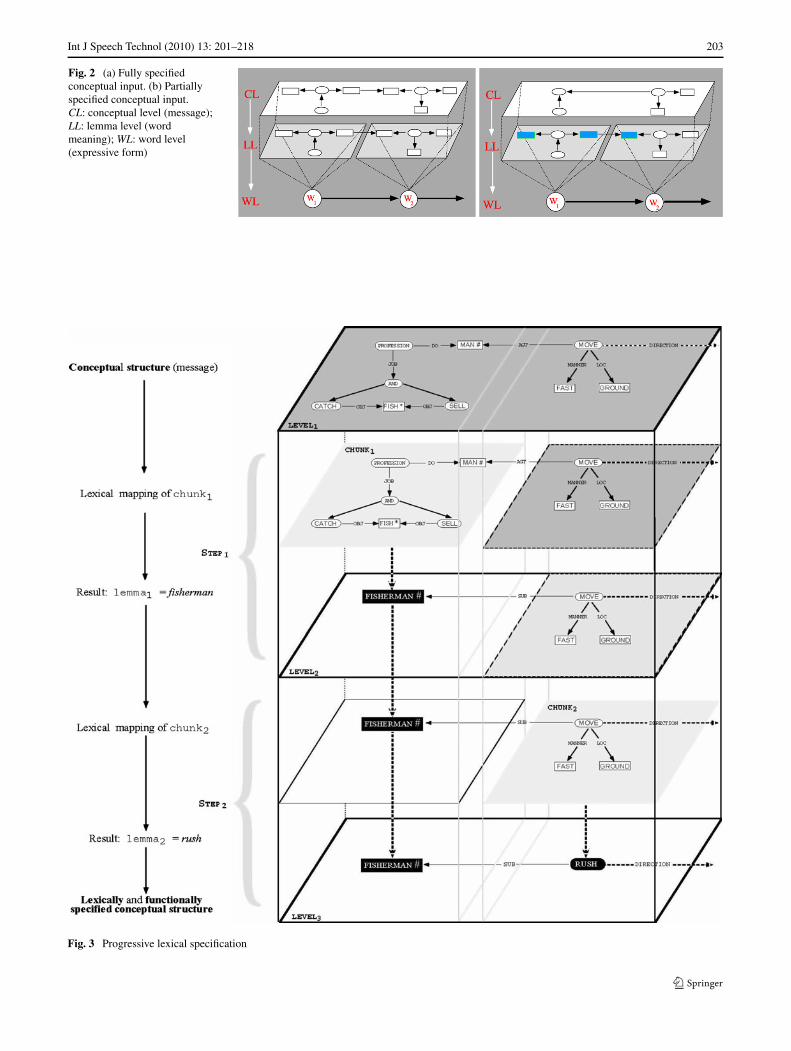
Yet, words are meant to express meanings, which, takentogether form messages. And since the input to the lexical-ization component are meanings, i.e. messages, words aresupposed to express, it is natural to represent both of them(messages and the words’ underlying meaning) by the sameformalism, say, semantic networks or conceptual graphs.According to this view, lexicalization amounts to pattern-matching (Figs. 2 and 3). Lexical items are selected, pro-vided that their underlying content covers at least parts ofthe conceptual input (Figs. 2a and 2b). The process is fin-ished once everything has been covered, i.e. expressed.
To illustrate this conceptually-driven lexicalizationprocess let us take an example from (Zock 1996 and Bate-man and Zock 2003). Suppose your goal were to find themost precise and economic way for expressing the follow-ing content: ‘the man whose profession consists in catch-ing and selling fish moved quickly/towards. . . ’ This messagecould be rewritten by using the words ‘rush’ and ‘fisherman’which express the very same idea as the underlying message,but in a much more compact form. Figure 3 illustrates thisprocess, suggesting by the direction link that more concep-tual information is yet to come. Lexicalization is performedin two steps. During the first only those words are selectedthat pertain to a given semantic field, say, movement. Duringthe next step the lexicalizer selects the term expressing bestthe intended meaning, that is, the most specific term, i.e. theone with maximal coverage.
Unfortunately, the check-list approach as well as lexicalmapping have several shortcomings:
• concerning the checklist approach: discrimination netshave never been developed at a large scale (i.e. for a sub-stantial subset of a lexicon), hence it remains to be shown
that this technique scales up and is well suited for all lex-ical categories. Also, the number of tests needed to locatea word even in a dictionary of moderate size, say 30,000words, is prohibitive. Third, this approach does not al-low for recovery as candidates are progresively eliminatedfrom the list and the set from which to choose precludesredundancies. Last, but not least, the sum of the answersgiven during the tests does not amount to the full meaningof the word towards which the tests converge. To say thatsomething is gazeous does still not reveal what is meantwhen we tell someone that ‘John smokes’.
• concerning pattern matching: the problem with this ap-proach lies in the assumption that messages are com-pletely planned prior to their verbalization, which is, ofcourse, not always the case, in particular if sentences getlong. Yet, what shall we do in case of incomplete concep-tual input (Fig. 2b)?1
Of course, one could claim, that the input, i.e. messageto be expressed, is incomplete prior to lexicalization (Zockand Schwab 2008), and the role of the lexicon is not only toexpress the message, but also to help refining its underspec-ified conceptual fragments (Zock 1996). Given the knownshort-term memory constraints this is not unreasonable. In-deed, there are certainly situations where the author startswith a rough outline or skeleton plan, which is then progres-sively fleshed out with details (see Fig. 2b). For example, thespeaker could have planned roughly the following message[‘PERSON-1 meet PERSON-2 at TIME-T in LOCATION-X’],specifying later on the respective values of the variablesPERSON, TIME, LOCATION, ending up to produce the fol-lowing sentence: ‘The woman I have told you about has mether husband two years ago at John’s birthday party.’
It is interesting to note, that while lexicalization hasbeen a much studied problem in natural language genera-tion (nlg), the issue of lexical access has not been addressedat all. This may be less surprising than it seems at first sight.As a matter of fact, from a strict computational linguisticpoint of view, the whole matter may be a non-issue,2 andas such it is natural that it would not appear in Ward’s listof problems to be addressed (Ward 1988), or in Cahill andReape (1999). Indeed, nlg researchers are interested in theprocessing of information by machines. In other words, theyare interested in the machine point of view (automatic gen-eration).
However, for those who consider lexicalization from apsycholinguistic or man-machine interaction point of view,
1For a sophisticated proposal, see Nicolov (1999).2Computers having a perfect memory, stored information can gener-ally be accessed. Also, programs tend to run serially. Hence, there is(generally) no such thing as competition, problems like interference,confusion or forgetting simply do not occur. Obviously, the situation isquite different for people.
Int J Speech Technol (2010) 13: 201–218 203
Fig. 2 (a) Fully specifiedconceptual input. (b) Partiallyspecified conceptual input.CL: conceptual level (message);LL: lemma level (wordmeaning); WL: word level(expressive form)
Fig. 3 Progressive lexical specification

204 Int J Speech Technol (2010) 13: 201–218
Fig. 4 Dell’s interactive model
things are quite different. There is definitely more to lexi-calization than just choosing words: one has to find them tobegin with. No matter how rich a lexical database may be, itis of little use if one cannot access the relevant informationin time. Lexical access is probably one of the most challeng-ing tasks of language production, be it online (spontaneousdiscourse, oral form) or offline (written form). As we shallsee, this is precisely a point where computers can be of con-siderable help. Before doing so, let us take a look and seewhat psychologists have to say.
1.2 Related work on memory and the mental lexicon
There is an enormous amount of research in psycholin-guistics regarding this issue: a collection of papers editedby Bonin (2004), Levelt (1992), Marslen-Wilson (1979),several monographs (Aitchinson 2003; Jarema et al. 2002;Stemberger 1985), and an overwhelming amount of empir-ical studies, devoted either to lexical access (latencies, er-rors), the tip-of-the tongue phenomenon (Brown and Mc-Neill 1996), or the lexeme/lemma distinction (Kempen andHuijbers 1983; Roelofs 1992). While all these papers dealwith the problem of lexical access, they do not consider theuse of computers for helping people in their task. Yet thisis precisely our goal. While the work done by psychologistsprovides us with inspiration and possibly even with guide-lines, some adaptations will nevertheless be necessary.
The dominant psycholinguistic theories of word produc-tion are all activation-based, multilayered network models.Most of them are implemented, and their focus lies on mod-elling human performance: speech errors or the time course(latencies) as observed during the access of the mental lex-icon. The two best-known models are those of Dell (1986)and Levelt et al. (1999), which take opposing views concern-ing conceptual input (conceptual primitives vs. holistic lex-icalized concepts) and activation flow (one-directional vs.bi-directional).
Dell’s model (Fig. 4) is interactive-activation-based.Starting from a set of conceptual features, the system gener-ates a string of phonemes. Information flow is bi-directional,that is, lower level units can feed back to higher-level com-ponents, possibly causing errors similar to the ones peo-ple tend to make. For example, the system might producerat instead of the intended cat. Indeed, both words shareconceptual and phonological components. Hence, both ofthem are prone to be activated at the same time, leadingthus to potential conflicts. At the conceptual level (from thetop) they share the feature animal, while at the phonologicallevel (from the bottom) they share two phonemes. When thelemma node cat is activated, any of its phonological compo-nents (/k/, /æ/, and /t/) is activated too. The latter two mayfeed back, leading to rat, which may already be primed andbe above baseline due to some information coming from ahigher-level component. Note that this model can producevarious other kinds of speech errors like preservations (e.g.,beef needle soup), anticipations (e.g., cuff of coffee), etc.
Given the distribution of word errors, Dell argues thatspeech generation relies both on retrieval (phrases, phono-logical features, etc.) and synthesis (word/phoneme and pos-sibly morpheme combinations). It is precisely during thislatter process that the mechanism may make mistakes, swap-ping, anticipating or reusing elements.
WEAVER++3 is another computational model. It hasbeen designed to explain how speakers plan and controlthe production of spoken words (Levelt et al. 1999). Themodel is hybrid as it combines a declarative associative net-work and procedural rules with spreading activation andactivation-based rule triggering. Words are synthesized byweaving together various kinds of information.
Like Dell’s model WEAVER++ is activation-based, butinformation flow is one-directional, top-down only. Process-ing is staged in a strictly feed-forward fashion. Starting from
3Acronym standing for ‘Word Encoding by Activation and VERifica-tion’.

Int J Speech Technol (2010) 13: 201–218 205
Fig. 5 Stages in the productionof words
lexicalized concepts (concepts for which a language haswords) it proceeds sequentially to lemma selection, mor-phological, phonological and phonetic encoding, to finishoff with a motor plan, necessary for articulation (see Figs. 5and 6). Unlike the previous model, WEAVER++ accounts pri-marily for reaction time data. Actually, it was developed onthe basis of such data collected during the task of picturenaming. However, more recently the program managed toparallel a number of findings obtained in psycholinguisticsand neurolinguistics where other techniques have been used:chronometry, eye tracking, electrophysiological responsesand neuro-imaging.
Apart from work on the time course of lexical access,there is a large body of work on memory and speech errors,providing the foundations for the above described models.Work on memory has shown that access depends cruciallyon the way information is organized (Collins and Quillian1969; Smith et al. 1974; Baddeley 1982). From speech er-ror literature (Harley 2010; Fromkin 1973; Cutler 1982)we learn, that ease of access depends not only on mean-ing relations,—(word bridges, i.e. associations) or the struc-ture of the lexicon, i.e. the way words are organized in our
mind,—but also on linguistic form (similarity at the differ-ent levels). Researchers collecting speech errors have of-fered countless examples of phonological errors in whichsegments (phonemes, syllables or words) are added, deleted,anticipated or exchanged. Reversals like /aminal/ instead of/animal/, or /carpsihord/ instead of /harpsichord/ are not ran-dom at all, they are highly systematic and can be explained.Examples like the one in Table 1 here below (Fromkin 1973)clearly show that knowing the meaning of a word does notguarantee its access.
1.3 Related work in the area of lexico-graphy (electronicand paper dictio-naries)
Of course, dictionaries are the prime resource for authorssearching for words. But, while there are many dictionaries,only few of them are really well suited for the productivetask. Indeed, most dictionaries have been built for the readerrather than for the writer Yet, to be fair one must say thatthere have been onomasiological attempts ever since the be-ginning of the era of dictionary making, i.e. the middle ofthe 19th century: Thesaurus (Roget 1852), The Chinese and

206 Int J Speech Technol (2010) 13: 201–218
Fig. 6 Fragment of lexicalnetwork
Table 1 Various kinds of speech errors
Error type Intended output Produced output
Anticipations take my bike bake my bike
Preservations pulled a tantrum pulled a pantrum
Reversals Katz and Fodor Fats and Kodor
Misderivations an intervening mode an intervenient mode
Word substitutions before the place before the place
opens closes
Blends grisly + ghastly grastly
English instructor (T’ong 1862), the analogical dictionary(Boissière 1862). Newer work includes the Language Ac-tivator (Summers 1993), the ‘Explanatory CombinatorialDictionary’ (Mel’cuk et al. 1999), WordNet (Miller 1990),MindNet (Richardson et al. 1998) and HowNet (Dong andDong 2006). There is also the work of Fontenelle (1997),Sierra (2000), Moerdijk (2008)), various collocation dictio-naries (BBI, OECD) and Bernstein’s Reverse Dictionary.Finally, there is MEDAL (Rundell 2002), a thesaurus pro-duced with the help of the Sketch Engine (Kilgarriff et al.2004).
While all the work discussed so far started from a con-ceptual input, let us take a look at a tool, designed to contact(enter) the dictionary and to navigate in it by using words.
Actually, this kind of information retrieval or access is theone we are most familiar with.
Of course there are many lexical resources available inelectronic form,4 yet, we will discuss here only WordNet(WN), as it is closest to our goal. WN is quite different fromconventional dictionaries as it is based on psycholinguisticfindings. Rather than multiplying the number of dictionar-ies (one for each use, task or link: definition, synonyms,antonyms, etc.), WN has been built as a single resource(a database) allowing for multiple access paths by follow-ing different links (Miller 1990; Fellbaum 1998). Anotherdifference lies in the fact that lexical entries, i.e. words,are organized as linked synonym sets. There are basicallytwo kinds of links: lexical and semantic. While the formerhold between forms, the latter connect meanings: set in-clusion, i.e. general/specific (hypernymy/ hyponymy), op-posites (antonymy), entailment, and part-of (meronymy/holonymy), etc. Different parts of speech are organized dif-ferently. For example, nouns and verbs are organized intohierarchies, whereas adjectives are arranged in clusters, typ-ically organized around antonymous pairs.
WN has had a tremendeous impact on the field, and it isclearly a major step in the right direction. Nevertheless, it is
4http://www.ilc.cnr.it/EAGLES96/rep2/node1.html.

Int J Speech Technol (2010) 13: 201–218 207
not perfect, and its authors are very well aware of it. Let usmention just some of its shortcomings.5
• The ‘tennis-problem’: words typically occurring together,hence naturally associated (tennis, umpire, racket, court,backhand), are not linked in WN, at least not until veryrecently.
• The lack of syntagmatic relations: “WordNet provides agood account of paradigmatic associations, but containsvery few syntagmatic links. . . . If we knew how to add toeach noun a distinctive representation of the contexts inwhich it is used. . . WordNet would be much more useful.”(Miller, in Fellbaum 1998:33–34). One can’t but agreemore. For a proposal going in this direction see Zock andBilac (2004).
• Incompleteness of links: This applies not only in general,but even within synsets. For a given synset there is nolink between its elements apart from the synonym link.Yet, each element might trigger a different association.Take for example ‘rubbish’ and ‘garbage’. While the for-mer may remind you of a ‘rabbit’ or (horse)-‘radish’, thelatter may evoke the word ‘cabbage’. These cases clearlyillustrate sound-related words.
• The problem of meaning: WN’s underlying structure is alexical matrix whose columns and rows are respectivelymeanings and words. The idea sounds perfect, as it seemsto model the two major access- or communication modes:speaking/writing and listening/reading, taking meaningsand word forms as their respective input. Unfortunately,the column reserved for meanings is not fully functional,i.e. usable by a human user, as meanings are equated withsynsets rather than semantic primes6 i.e. atomic meaningelements, or what we call triggers or source-words (seeSect. 2.1). What information do you give as input whenyour target words are ‘avatar’, ‘tiara’ or eschatology’?While this is already quite a challenge if lookup is per-formed in someone’s mother-tongue it is even more so ifone resorts to a foreign language.
1.4 Discussion
We have presented and commented on three approachesdealing with the problem of the lexicon. One would expectcomplementarities in the quest of achieving a unified view,yet this is far from obvious, the goals and the methods being
5For other criticisms, see Hanks and Pustejovsky (2005), Sharoff(2005).6Of course, one could object that to this day no one has really managedto make a complete list of these semantic primes. See the discussionsin Aitchinson (2003) and Goddard (1998). There have been proposalsthough to use the words of the definition as input when querying thelexicon (Dutoit and Nugues 2002; El-Kahlout and Oflazer 2004), andthis approach seems even to work with Google.
simply too different. All of them capture something relevant,but none of them gives us a unified view.
Concerning the work done in the domain of ‘natural lan-guage generation’, next to nothing can be used in the contextof electronic dictionaries: the issue of word access simplydoes not arise. The assumption being that stored informa-tion can be accessed, which may hold for machines it doesnot always with people. In addition, most of the work doneby natural language generators is based on very small dictio-naries. The resources are often ad-hoc, tailored to the engi-neer’s needs, and the issue of macrostructure (organization)is not addressed at all.
Concerning the work carried out by psychologists, thereare several problems: (a) the size of their dictionaries is ex-tremely small (about 100 entries); (b) the specificities ofthe macrostructure are not spelled out at all; (c) the modelsbeing connectionist, the links cannot be interpreted by hu-mans: all we get are weighted links; (d) the notion of lemmais problematic as it has a completely different meaning de-pending on the community. In lexicology it means a unit,linking meaning and form, whereas in psycholinguistics itis an abstract element. A lemma in this framework meansnothing more than a semantic-syntactic specification (partof speech, and a set of features), but nothing coming closeto a concrete word form, as this is being taken care of by thephonological component, which determines the lexeme.
If one believes in the results produced by psychologistsone is tempted to conclude that people do not have words atall in their mind.7 Notions like ‘words, dictionary, memory’etc. are but metaphors. What we seem to have in our brainsis a set of highly abstract information, distributed all over.By propagating energy rather than data or information,8 wepropagate signals, activating ultimately certain periphericalorgans (larynx, tongue, mouth, lips) in such a way as to pro-duce sounds, that, not knowing better, we call words. An-other way of putting things is to say that our mind is a wordfactory rather than a storehouse, words being synthesizedrather than retrieved.
Concerning the work done by computational lexicogra-phers WN seems to come closest to our ideal with respectto word access. While this resource does not have yet the
7Obviously, this is an extreme position, as, at some point we musthave a way of deciding whether the result produced is indeed an ex-isting word, expressing the idea one had in mind. In order to get aclearer picture concerning this matter one may want to take a closerlook at the debate concerning local vs. distributional representations,debate taking place in connectionist circles, see, for example, S. Lamb(1999:229–232).8Indeed, there is no message passing, transformation or accumulationof information, there is only activation spreading, that is, changes ofenergy levels, call it weights, electronic impulses, or whatever.

208 Int J Speech Technol (2010) 13: 201–218
power or flexibility of a mental lexicon9 it could be improvedin such a way as to get closer to this goal.
We will show in the remainder of this paper a line of re-search we are pursing in order to remedy some of the short-comings mentioned here above. Before doing so, let us takea look at the speaker’s goals and knowledge at the onset ofinitiating search.
2 Search in the dictionary of the future
2.1 A possible search scenario: word access on the basis ofassociations
There are at least two things that people usually know be-fore opening a dictionary:10 the word’s meaning, or at leastpart of it (i.e. part of the definition) and its relation to otherwords or concepts: x is more general/specific than y (hy-ponym/hypernym); x is the equivalent of y (synonym); x isthe opposite of y (antonym), etc. In all these cases x couldbe the source word (the one coming to one’s mind) and ythe target word (the word we are looking for). The relationshere above express mainly conceptual knowledge. Yet, peo-ple seem also to know a lot of things concerning the lexi-cal form (lexeme): number of syllables, beginning/ending ofthe target word, part of speech (noun, verb, adjective, etc.),and sometimes even the gender (Brown and McNeill 1996;Burke et al. 1991; Vigliocco et al. 1997). While, in princi-pal all this information could be used to constrain the searchspace, hence, the ideal dictionary containing be multiple in-dexes, we will deal here only with the semantically and prag-matically related words, that is elements of the definition andthe words’ relations to other concepts or words.
The yet to-be-built (or to-be-enhanced) resource is basedon the age-old notion of association: every idea, conceptor word is connected. In other words, we assume that peo-ple have a highly connected conceptual-lexical network intheir mind. Finding a word amounts thus to entering the net-work at any point by giving the word or concept coming totheir mind (source word) and to follow then the links (as-sociations) leading to the word they are looking for (targetword). In other words, look-up amounts to navigation in ahuge lexical-conceptual space. While this can be one-shotprocess (direct association), it does not need to (indirect as-sociation).
Suppose, you were looking for a word expressing the fol-lowing ideas: superior dark coffee made from beans fromArabia, and that you knew that the target word was nei-ther espresso nor cappuccino. While none of this would lead
9For one it lacks too many of the links known to exist in our mind (seeall the work done on ‘word association’), and secondly, the links arenot quantified and context-sensitive.10Bear in mind that we are dealing here only with the productive sideof language: speaking/writing.
you directly to the intended word, mocha, the information athand, i.e. the word’s definition or some of its elements, couldcertainly be used. In addition, people draw on knowledgeconcerning the role a concept (or word) plays in languageand in real world, i.e. the associations it evokes. For exam-ple, they may know that they are looking for a noun stand-ing for a beverage that people take under certain circum-stances, that the liquid has certain properties, etc. In sum,people have in their mind an encyclopedia: all words, con-cepts or ideas being highly connected. Hence, any one ofthem has the potential to evoke the others. The likelihoodfor this to happen depends, of course, on factors such asfrequency (associative strength), distance (direct vs. indirectaccess), prominence (saliency), etc.
How is this supposed to work for a dictionary user? Sup-pose you wanted to find some word (target word: Tw), yetthe only token coming to your mind were a somehow relatedword (source word: Sw). Starting from this input the systemwould build internally a graph with the Sw at the center andall the words connected to it at the periphery.11 The graphwould be built dynamically depending on the demand. If thelist contains the Tw , search stops, otherwise navigation con-tinues, taking either one of the proposed candidates as thenew starting point or a completely new token. Of course,input could be composed of several words.
Let us take an example. Suppose you were looking for theword mocha (Tw), yet the only token coming to your mindwere computer (Sw). Taking this latter as starting point, thesystem would show all the connected words, for example,Java, Perl, Prolog (programming languages), mouse, printer(hardware), Mac, PC (type of machines), etc. querying theuser to decide on the direction in which to continue to searchby choosing one of the outputs. After all, the user is the onewho knows best which of them comes closest to the Tw .Having started from the Sw computer, and knowing that theTw is neither some kind of software nor a type of computer,s/he would probably choose Java, which is not only a pro-gramming language but also an island. Taking this latter asthe new starting point s/he might choose coffee (since s/heis looking for some kind of beverage, possibly made froman ingredient produced in Java, coffee), and finally mocha,a type of beverage made from these beans. Of course, theword Java might just as well trigger Kawa which not onlyrhymes with the Sw , but also evokes Kawa Igen, a Javanesevolcano, or the argotic word of coffee in French.
As one can see, this approach allows word access viamultiple routes: there are many ways leading to Rome. Inaddition, it takes very few steps to make quite substantialleaps, finding a link (or way) between apparently completely
11Obviously, the more indirectly a word is related with regard to someinput (Sw) the more remote it is from the center. Also, neighborhooddensity may vary according to the nature of the link.

Int J Speech Technol (2010) 13: 201–218 209
Table 2 Triggers, i.e. sourcewords (Sw) and target words(Tw) are respectively on the leftand on the top, links are at theintersection
Coffee Beverage Java1 Java2 Lisp Mac Mocha1 mocha2 mouse1 mouse2
Animal SUBSET
Beverage SUBSET SUBSET
Coffee SUPERSET SUBSET
Computer device SUBSET SUBSET
Computer language ISA ISA
Island ISA
City ISA
unrelated terms. In sum, lexical graphs seem to have thesmall world property of everything being connected witheverything (Barabási 2002; Buchanan 2002), which has asside effect that everything is only at the distance of a fewmouseclicks. Organizing data this way makes navigationfast and flexible, at least more flexible than navigation ina conceptual tree (type hierarchy, ontology) where terms areorganized via ISA links, that is hierarchically. In this lattercase, navigational mistakes can only be repaired via back-tracking.
Of course, one could also have several associations(quasi) simultaneously, e.g., ‘black, delicious, strong, cof-fee, beverage, cappuccino, espresso, Vienna, Starbucks,espresso. . . ’ in which case the system would build a graphrepresenting the intersection of the associations (at dis-tance 1) of the mentioned words.
2.2 Building a semantic map, the ‘lexical matrix’
The main question that we are interested in here is how,or in what terms, to index the dictionary in order to allowfor quick and intuitive access to words. Access should bepossible on the basis of meaning or meaning elements (of-ten words occurring in the target word’s definition), and viasomehow related terms, generally syntagmatic associations.To capture this kind of information we intend to build anassociation matrix (see Table 2) which can be seen as theequivalent of a semantic network or list of tuples.12
The association matrix will contain on one axis all theform elements, i.e. the lemmata or expressions (compounds,etc.) of a given language. We refer to them as target words.On the other axis we will place cues, i.e. trigger-, source-or access-words, that is, the words or concepts capable toevoke the Tw . These are typically the kind of words psychol-ogists have gathered in their association experiments (Jungand Riklin 1906; Deese 1965; Schvaneveldt 1989). Note,
12Note, that each form of representation has its own virtues and short-comings. The matrix and tuples show only directly related words (dis-tance: 1), while semantic networks provide a larger view. Unfortu-nately, these latter are not always very readable because of the greatnumber of (possibly crossing) links.
that instead of putting a Boolean value at the intersectionof the Sw and the Tw , we will put weights and the type oflink holding between the co-occurring terms. This gives usquadruplets. For example, an utterance like ‘this is the keyof the door’ might yield the Sw (key), the Tw (door), the linktype LT (part of), and a weight (say 15).
The fact that we have information concerning the linktype13 and its weight is very important later on, as it allowsthe search engine to cluster by type the possible answersto be given in response to a user query (word(s) providedas input) and to rank them. Since the number of hits, i.e.words from which the user must choose, may be substantial(depending on the degree of specification of the input), it isimportant to group and rank them to ease navigation, allow-ing the user to find directly and quickly the desired word,or at least the word with which to continue search (indirectassociation).
Obviously, different word senses (homographs), requiredifferent entries (mouse: animal vs. mouse: computer de-vice), but so will synonyms, as every word-form, synonymor not, is likely to be evoked by a different key- or access-word (similarity of sound).14
Every relation between a Sw and a Tw . requires an extraline. Whether more than one line is needed in the case ofa link being expressed by various linguistic resources (‘thelock of the door’ vs. ‘the door’s lock’ vs. ‘the door has alock’) is an open empirical question.
13Links are sensitive to direction. For example, the relationship be-tween ‘coffee-beverage’ and ‘beverage-coffee’ is not the same, it isinverse (subset vs. superset). Hence, ideally both types of relationshipshould appear in the table (Table 2). Nevertheless, we have includedonly one of them, assuming that the starting point be the Tw . For ex-ample, ‘coffee’ is related to ‘beverage’ via a subset link, meaning that‘coffee’ is a particular kind of beverage. If we started from the cue- ortrigger word, ‘beverage’ would be linked to ‘coffee’ via a superset rela-tion, meaning that ‘beverage’ is the name of the class of which ‘coffee’is an instance. One should note that in the table here above we mentiononly direct relations (distance = 1). For instance, ‘mocha2 is a subsetof ‘coffee’ which in its turn is a subset of ‘beverage’. Hence, giventhis transitivity one may well conclude that ‘mocha2 is also a subset of‘beverage’.14See the rubbish/garbage example at the end of Sect. 1.3.
210 Int J Speech Technol (2010) 13: 201–218
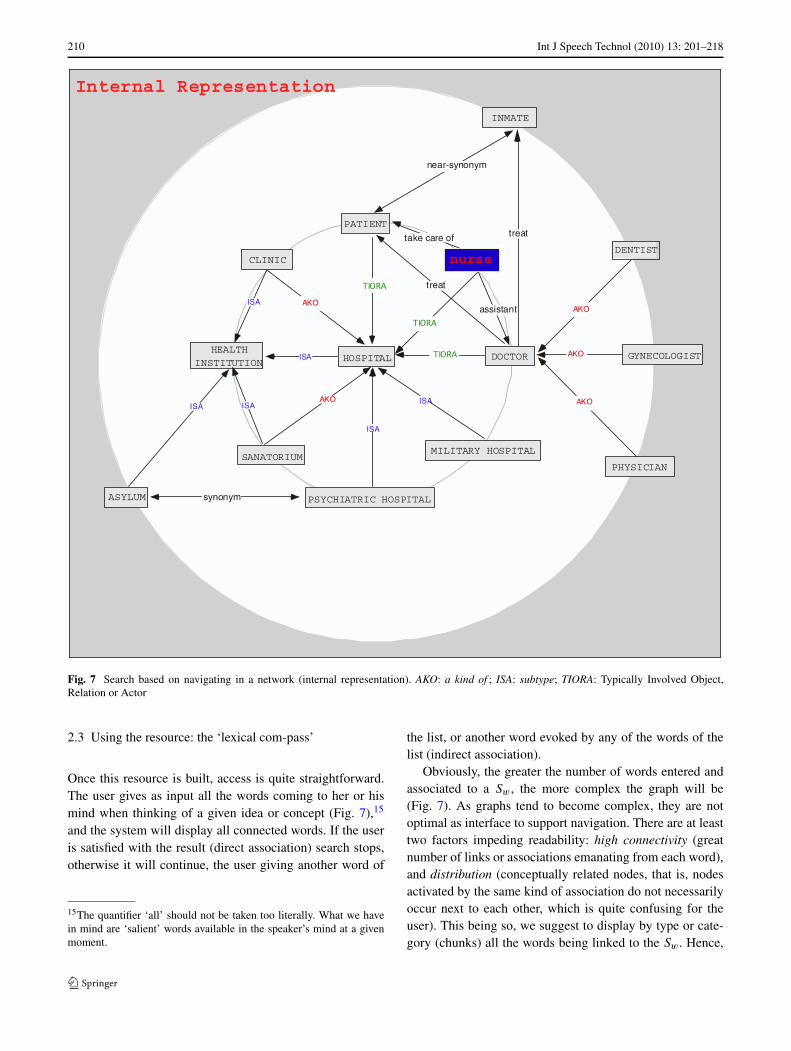
Fig. 7 Search based on navigating in a network (internal representation). AKO: a kind of ; ISA: subtype; TIORA: Typically Involved Object,Relation or Actor
2.3 Using the resource: the ‘lexical com-pass’
Once this resource is built, access is quite straightforward.The user gives as input all the words coming to her or hismind when thinking of a given idea or concept (Fig. 7),15
and the system will display all connected words. If the useris satisfied with the result (direct association) search stops,otherwise it will continue, the user giving another word of
15The quantifier ‘all’ should not be taken too literally. What we havein mind are ‘salient’ words available in the speaker’s mind at a givenmoment.
the list, or another word evoked by any of the words of thelist (indirect association).
Obviously, the greater the number of words entered andassociated to a Sw , the more complex the graph will be(Fig. 7). As graphs tend to become complex, they are notoptimal as interface to support navigation. There are at leasttwo factors impeding readability: high connectivity (greatnumber of links or associations emanating from each word),and distribution (conceptually related nodes, that is, nodesactivated by the same kind of association do not necessarilyoccur next to each other, which is quite confusing for theuser). This being so, we suggest to display by type or cate-gory (chunks) all the words being linked to the Sw . Hence,

Int J Speech Technol (2010) 13: 201–218 211
Fig. 8 Proposed candidates,grouped by family, i.e.according to the nature of thelink
rather than displaying all the connected words as a huge flatlist, we suggest to present the words in hierarchically orga-nized clusters, the links of the graph becoming the nodes ofthe tree (Fig. 8). Since the same word may occur at variouslevels (for example, a word like ‘coffee’ may be connectedboth to ‘beverage’ and to ‘major export product’) our treesdo not have the shortcomings as Goldman’s work (Sect. 1.1).Indeed, our trees allow for recovery
This kind of presentation seems clearer and less over-whelming for the user, as it allows for categorical search,which is a lot faster than search in a huge bag of words. Ofcourse, this supposes that the user knows to which categorya word belongs to, and that the labels, i.e. link names arewell chosen. This is crucial, as the names must be meaning-ful, i.e. be interpretable by the user (which is not really thecase in our example here). Figure 8 presents graphically therationale outlined here above, except that the Sw and Tw arenot computer and mocha but hospital and nurse.
As one can see, the fact that the links are labeled has somevery important consequences:
• While maintaining the power of a highly connected graph(possible cyclic navigation), it has at the interface levelthe simplicity of a tree: each node points only to data ofthe same type, i.e. to the same kind of association.
• With words being presented in clusters, navigation can beaccomplished by clicking on the appropriate category.
The assumption being that the user generally knows towhich category the target word belongs (or at least, he canrecognize within which of the listed categories it falls), and
that categorical search is in principle faster than search in ahuge list of unordered (or, alphabetically ordered) words.16
2.4 A roadmap
Obviously, in order to allow for this kind of access, the re-source has to be built accordingly. To this end at least fourproblems have to be solved.
Corpus: We need a well-balanced corpus. Since the corpusis supposed to represent the user’s world knowledge, thislatter must reflect this knowledge in the corpus. In otherword, the corpus must contain a little bit of everything nor-mal people know concerning the world in general and spe-cific events like sports, politics, geography, etc.
Indexing: words have to be indexed in terms of the associ-ations they evoke. This means that we need to discover thetrigger words and their associates. Next to using the kind ofassociation lists gathered by psychologists, one may try tobuild this kind of information bottom-up, via corpora andby using a collocation extractor tool like the one here inFig. 9.
Ranking: the weight of the link needs to be determined(relative frequency). This is important for ranking the as-sociated words. Ideally, the weight is (re-)computed on thefly to take into account contextual variations. A given word,say Java, is likely to evoke quite different associations de-pending on the context: coffee vs. programming.
16Even though very important, at this stage we shall not worry toomuch for the names given to the links. Indeed, one might questionnearly all of them. What is important is the underlying rationale: helpusers to navigate on the basis of symbolically qualified links. In realitya whole set of words (synonyms, of course, but not only) could expressthe semantics of a given a link.

212 Int J Speech Technol (2010) 13: 201–218
Identification and naming the links: Associations mustnot only be identified, but also be labeled. This is vitalfor navigation. Qualifying, i.e. typing the links is the hard-est task, yet it is very important for navigation. Frequencyalone is not only of limited use (people cannot interpretproperly numerical values in a context like this), it is evenmisleading: two terms of very similar weight (say, ‘mouse’and ‘PC’) may belong to entirely different categories (com-puter device vs. type of computer), hence choosing one in-stead of the other may have important consequences for theremainder of navigation, i.e. finding or failing to find thedesired word.
Next to building the resource, one needs also to thinkabout how to perform search. We will only briefly touch herethis very important point.
3 Some preliminary results
So far we have identified only problems and goals, let usnow turn to see some preliminary results. The first one dealswith automatic link extraction,17 while the second dealswith search.
3.1 Automatic extraction of topical relations
3.1.1 Definition of the problem
We have argued in the previous sections that word accesscan be supported via lexical associations. In this section,we address the issue of acquiring automatically from cor-pora syntagmatic relations generally absent from lexical re-sources, even in WordNet. We call them topical relations(Ferret 2002), as they link words being part of a given topic,situation or scenario. Word-pairs like doctor–hospital, bur-glar–policeman or plane–airport, are typical examples incase.
Various authors (Harabagiu and Moldovan 1998; Man-dala et al. 1999; Agirre et al. 2001; Magnini and Cavagliá2000, or Avancini et al. 2003) have tried to endow WordNetwith topical knowledge. However, all these approaches arelimited by the fact that they rely too heavily on some of themore sophisticated features of WordNet, like the definitionsassociated with the synsets. Hence, they make it difficult togeneralize to contexts where lexical resources are far lessdeveloped. In addition, the kind of knowledge they acquireare not relations.
Since our goal is different, we have chosen not to rely onany significant resource, all the more as we would like ourmethod to be applicable to a wide array of languages. In con-sequence, we took an incremental approach (Ferret 2006):starting from a network of lexical co-occurrences collectedfrom a large corpus, we used these latter to select potentialtopical relations by using a topic analyzer.
17For more details see Ferret and Zock (2006).
Fig. 9 Ferret’s collocation extractor (1998)
3.1.2 From a network of co-occurrences to a set of TopicalUnits
We start by extracting lexical co-occurrences from a corpusto build a network. To this end we follow the method intro-duced by Church and Hanks (1990), i.e. by sliding a windowof a given size over texts. The parameters of this extractionwere set in such a way as to catch the most obvious topicalrelations: the window was fairly large (20-words wide), andwhile it took text boundaries into account, it ignored the or-der of the co-occurrences. Like Church and Hanks (1990),we used pointwise mutual information, with a normalizationin our case, to measure the cohesion between two words.
This network is used by TOPICOLL (Ferret 2002),a topic analyzer, which performs simultaneously three tasks:
• it segments texts into topically homogeneous segments;• it selects in each segment the most representative words
of its topic;• it proposes a restricted set of words from the co-occur-
rence network to expand the selected words of the seg-ment.
These three tasks rely on a common mechanism: a win-dow is moved over the text to be analyzed in order to limitthe focus space of the analysis. This latter contains a lem-matized version of the text’s plain words. For each positionof this window, we select only words of the co-occurrencenetwork that are linked to at least three other words of thewindow (see Fig. 10). This leads to select both words that arein the window (first order co-occurrents) and words comingfrom the network (second order co-occurrents).
The number of links between the selected words of thenetwork, called expansion words, and those of the window

Int J Speech Technol (2010) 13: 201–218 213
Fig. 10 Selection and weighting of words from the co-occurrence net-work
are a good indicator of the topical coherence of the window’scontent. Hence, when their number is small, a topic shift canbe assumed. This is the basic principle underlying our topicanalyzer. The words selected for each position of the win-dow are summed, to keep only those occurring in 75% of thepositions of the segment. This allows reducing the numberof words selected from non-topical co-occurrences. Once acorpus has been processed by TOPICOLL, we obtain a setof segments and a set of expansion words for each of them.The association of the selected words of a segment and itsexpansion words is called a Topical Unit (TU). Since bothsets of words are selected by relying on topical homogene-ity, the co-occurrences between them are more likely to betopical relations than in our initial network.
3.1.3 Filtering of Topical Units
Before recording the co-occurrences in the TUs, the unitsare filtered twice. The first filter aims at discarding hetero-geneous TUs, which can arise as a side effect of a docu-ment whose topics are so intermingled that it is impossibleto get a reliable linear segmentation of the text. We considerthis to occur when for a given text segment, no word canbe selected as a representative of its topic. Moreover, weonly keep the TUs that contain at least two words from theiroriginal segment. Since topics are defined here as a config-uration of words, their identification cannot be based on asingle word.
The second filter is applied to the expansion words ofeach TU in order to increase their topical homogeneity. Theprinciple of the filtering of these words is the same as theone of their selection described in the previous section: anexpansion word is kept if it is linked in the co-occurrencenetwork to at least three words of the TU. Moreover, a se-lective threshold is applied to the frequency and the cohe-sion of the co-occurrences supporting these links. For in-stance in 3, which shows an example of a TU after its fil-
Table 3 Content of a filtered Topical Unit
Text words Expansion words
surveillance police_judiciaire
(watch) (judiciary police)
téléphonique écrouer
(telephone) (to imprison)
juge garde_à_vue
(judge) (police custody)
policier écoute_téléphonique
(policeman) (phone tapping)
brigade juge_d’instruction
(squad) (examining judge)
enquête contrôle_judiciaire
(investigation) (judicial review)
placer (to put)
tering, écrouer (to imprison) is selected, because it is linkedin the co-occurrence network to the words of the text juge(judge), policier (policeman) and enquête (investigation),with a frequency and cohesion higher than 15 and 0.15 re-spectively.
3.1.4 From Topical Units to a network of topical relations
After the filtering, a TU gathers a set of words supposed tobe strongly coherent from the topical point of view. Next,we record the co-occurrences between these words for allthe TUs remaining after filtering. Hence, we get a large setof co-occurrences that are more likely to express topical re-lations than the ones contained in the initial network. Never-theless, a significant number of non-topical co-occurrencesremains, given the fact that filtering the TUs is an unsuper-vised process. The frequency of a co-occurrence in this caseis given by the number of TUs containing both words simul-taneously. No distinction concerning the origin of the wordsof the TUs is made.
The network of topical co-occurrences built from TUs isa subset of the initial network. However, it also contains co-occurrences that are not part of it, i.e. co-occurrences thatwere not extracted from the corpus used for building theinitial network, or co-occurrences whose frequency was toolow in this corpus. Only some of these ‘new’ co-occurrencesare topical. Since it is difficult to assess globally which onesare interesting, we have decided to focus our attention onlyon the co-occurrences of the topical network already presentin the initial network.
Thus, we only use the network of topical co-occurrencesas a filter for the initial co-occurrence network. Before do-ing so, we filter the topical network in order to discard

214 Int J Speech Technol (2010) 13: 201–218
Table 4 Co-occurrents of theword acteur (actor) with acohesion of 0.16 (theco-occurrents removed by ourfiltering method are underlined)
Word Freq. Word Freq. Word Freq. Word Freq.
scène 884 théâtral 62 cynique 26 scénique 14
(stage) (dramatic) (cynical) (theatrical)
théâtre 679 scénariste 51 miss 20 Chabol 13
(theater) (scriptwriter) (miss) (Chabol)
réalisateur 220 comique 51 parti_pris 16 Tchekov 13
(director) (comic) (bias) (Tchekov)
cinéaste 135 oscar 40 monologue 15 allocataire 13
(film-marker) (oscar) (monolog) (beneficiary)
comédie 104 film_américain 38 revisiter 14 satirique 13
(comedy) (american film) (to revisit) (satirical)
costumer 63 hollywoodien 30 gros_plan 14
(to dress up) (Hollywood) (close-up)
co-occurrences whose frequency is too low, that is, co-occurrences that are unstable and not representative. We setthe threshold experimentally to 5 by relying on the results ofTOPICOLL for topic segmentation (see next section) basedon this filtered network. Finally, the initial network is fil-tered by keeping only co-occurrences present in the topicalnetwork. Their frequency and cohesion are taken from theinitial network. While the frequencies given by the topicalnetwork are potentially interesting with respect to topicalsignificance, we do not use them, as the results of the fil-tering of TUs are too hard to evaluate.
3.1.5 Results and evaluation
We applied the method described here above to an initial co-occurrence network extracted from a corpus of 24 months ofLe Monde, a major French newspaper. The size of the corpuswas around 39 million words. The initial network contained18,958 words and 341,549 relations. The first run produced382,208 TUs. After filtering, we kept 59% of them. Thenetwork built from these TUs was made of 11,674 wordsand 2,864,473 co-occurrences. 70% of these co-occurrenceswere new with regard to the initial network; hence they werediscarded. Finally, we got a filtered network of 7,160 wordsand 183,074 relations, which represents a cut of 46% of theinitial network. A qualitative study showed that most of thediscarded relations are non-topical. This is shown in Table 4,which gives the high cohesion co-occurrents of the wordacteur (actor) together with the result of their filtering byour method. For instance, the words cynique (cynical) orallocataire (beneficiary) are cohesive co-occurrents of theword actor, even though they are not topically linked to it.While these words are filtered out, we do keep words likegros_plan (close-up) or scénique (theatrical), which topi-cally cohere with acteur (actor) even though their frequencyis lower than the one of the discarded words.
Table 5 TOPICOLL’s results with different networks
Initial Topical filtering Frequency filtering
Error (Pk) 0.20 0.21 0.25
In order to evaluate more objectively our work, we com-pared the quantitative results of TOPICOLL with the initialnetwork and its filtered version. The evaluation shows thatthe performance of the segmenter18 remains stable whenwe use a topically filtered network (see Table 5; the differ-ence between 0.20 and 0.21 being statistically not signifi-cant according to a one-side t-test with a null hypothesis ofequal means). Moreover, it also shows, with statistical sig-nificance, that a network filtered only by frequency and co-hesion performs less well with respect to topic segmentationthan the topically filtered network while the size of the twois comparable. Hence, one may conclude that our method isan effective way of selecting topical relations.
In the next section, we try to provide some empirical ev-idence of a claim made early on: knowledge does not implyaccess.
3.2 Search: knowledge vs. access
The goal of the experiment described here below is to showtwo things: (1) the fact that one has knowledge, i.e. that in-formation has been stored, does not guarantee its access, asthis may also depend on the search method;19 (2) accessi-bility may depend on intrinsic characteristics of the resource
18This performance is expressed by the Pk metric (Beeferman et al.1999), which is a classical measure for evaluating the accuracy of top-ical segmenters. In the context of this paper, the main thing to know isthat it is an error metric. As a consequence, low values are better thanhigh values.19For more details, see Zock and Schwab (2008, 2010).

Int J Speech Technol (2010) 13: 201–218 215
Table 6 Outputs varyingaccording to the query and theresource
Input Output from WordNet Output from Wikipedia
wine 488 words: grape, sweet, serve, France,small, fruit, dry, bottle, produce, red,bread, hold, . . .
1845 words: alcoholic, country, God, cha-racteristics, regulation, grape, appella-tion, system, bottled, like, christian, track,. . .
harvest 30 words: month, fish, grape, revolutio-nary, calendar, festival, butterfish, dollar,person, make, wine, first, . . .
983 words: produce, grain, autumn,farms, energy, cut, combine, ground, bal-ance, rain, amount, rich, . . .
wine + harvest 6 words: make, fish, grape, someone, com-memorate, person
45 words: grape, vintage, bottle, produce,fermentation, juice, Beaujolais, taste, viti-culture, France, Bordeaux, vineyard, . . .
where search takes place (nature of the data, weight, index,organization).
To check our claims we have run a simple experiment.Only one lexical function was used: neighborhood (f neig).Applying this function produces the set of co-occurringterms within a given window (sentence or a paragraph). Inother words, the result produced by the system and returnedto the user is the intersection of the application of f neig tothe SWs . Let us see how this function, applied to differentcorpora (WordNet and Wikipedia), may yield different suc-cess rates concerning word access.
3.2.1 WordNet and Wikipedia as corpus
There are many good reasons to use WordNet (WN) for ourpurpose. For one, there are many extensions. The one weare using, eXtended WN (Mihalcea and Moldovan 2001)spares us the trouble to use definitions as raw text. Hence, allwords are identified with their WN senses and their part ofspeech. Despite these qualities this kind of corpus presentstwo kind of problems (a) size: the corpus remains smallas it contains only 63,941 different words; (b) the corpuslacks many syntagmatic associations encoding encyclopedicknowledge. This last point is precisely one of the strengthsof Wikipedia (WP).
WP is a multilingual encyclopedia, freely accessible onthe Web. For our experiment we have chosen the Englishversion which at May 12, 2008 contained 2,369,180 entries.While WP covers well encyclopedic or syntagmatic rela-tions, it is only raw text. Hence problems like the followingneed to be addressed: word segmentation (the lexical con-cept hot dog is not the same as hot and dog or its sum),lemmatisation (verbs, nouns, adverbs and adjectives are onlyused in their canonical form), creation of a stoplist (be, do,thing are too common words to be useful, hence they areremoved). Given the fact that we considered only a smallsubset of WP (1000 documents), our experiments are veryrudimentary. The documents were produced as result to agiven input. For example, the term wine, produced a list ofabout 72,000 words.
3.2.2 Building the necessary resources
Building the resource requires processing a corpus andbuilding linked lists of SWs and TWs , that is, triples (Sw , Tw ,weight) with Sw and Tw being co-occurring terms in a spec-ified window, and weight the number of times of their co-occurrence.20 While window-size varies with text genre, theoptimal window-size being an open, empirical question, wedecided to use in this context the following two windows:definitions for WN and the paragraphs for WP.
WN, or, more precisely, eXtended WN spares us the trou-ble of preprocessing, hence triples can be built directly. Asmentioned already, the situation is different in the case ofWP. This being so we use a preprocessor to convert WP’sHTML pages into plain text. Next, a part-of-speech tagger21
annotates all the words under consideration. This allows usto filter out all irrelevant words and to keep but a bag ofwords, that is, the nouns, adjectives, verbs and adverbs oc-curring in the paragraph. These items will be used to fill thetriplets.
While we could start arbitrarily from any page, we havechosen wine for our experiment. Given this input, we applythe algorithm outlined here above to pick then randomly anoun within the page received as output to fetch a new pageon Wikipedia. This process is repeated until a given samplesize is obtained (in our case, 1000 pages). Of course, in-stead of picking randomly a noun, we could have decided toprocess all the nouns of a given page, and to add then incre-mentally the nouns of the next pages. Yet, doing this wouldhave led us to privilege a specific topic (in our case ‘wine’)instead of a more general one.
20Actually, we need a fourth kind of information: the nature of the link.Using only the very generic neighborhood function (f neig), we did notaddress this very important point in this work.21http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/.

216 Int J Speech Technol (2010) 13: 201–218
3.2.3 A small experiment
We have developed a website as a Java servlet. Interac-tions are quite straightforward: people can add or deletea word from the current list of triggers, i.e. source-words(SW ). The example here below shows that with very fewwords, hence very quickly, we can obtain the desired tar-get word (TW ). Given some input, the system provides theuser with a list of words co-occurring with the SW , the can-didate target-words (TW ). The output is an ordered list ofwords, with the order depending on the overall score, i.e.number of co-occurrences between the SW and the TW . Forexample, if the SW wine and harvest co-occur with the TW
bunch respectively 5 and 8 times, then the overall score ofco-occurrence of bunch is 13: ((wine, harvest), bunch, 13).Hence, all words with a higher score will precede it, whilethe others will follow it.
Here above are the examples extracted from the WN cor-pus. Our goal was to find the word vintage. Trigger wordsare wine and harvest, yielding respectively 488 and 30 hits,i.e. words. As one can see harvest is a better access termthan wine. Combining the two will reduce the list to 6 items.Please note that the TW vintage is not among them, eventhough it does exist in WordNet, which illustrates nicely thefact that storage does not guarantee accessibility (Sinopal-nikova and Smrz 2006). Looking at Table 6 allows you tosee that the results have improved considerably with WP.The same input, wine evokes many more words (1845 asopposed to 488). For harvest we get 983 hits instead of 30(the intersection containing 62 words), and combining thetwo reduces the set to 45 items among which we will find,of course, the target word. We hope that this example is clearenough to convince the reader that it makes sense to use realtext as corpus to extract information (associations) peopleare likely to give when looking for a word. To be fair to-wards WN, one must say though, that, had we built the re-source differently, for example, had we included the maincomponents of the word’s definition (gloss) or the definitionof its hypernyms we would certainly get vintage, as the termwine is contained in the definition of vintage.
Concerning this last point we should mention that wehave taken into account all the glosses or definitions in thecase of WN, while considering only a small subset of WP(0.05%), extending this range might offer some interestingperspectives.
4 Conclusion
Our starting point has been a well known search problem,finding the needle in a haystack, that is words in a lexicon.Indeed, one of the most vexing problems in speaking or writ-ing is the fact that one knows a given word, yet one fails to
access it when needed. This kind of failure, often referred toas dysnomia or Tip of the Tongue-problem, occurs not onlyin communication, but also in other activities of everydaylife. Being basically a search problem, it is likely to occurwhenever we look for something that exists in real world(objects) or our mind: dates, phone numbers, past events,peoples’ names, or ‘you-just-name-it’.
In order to find a solution we turned to experts havingworked on related problems: engineers interested in com-puterized language production, psychologists studying themental lexicon, computational linguists working on elec-tronic dictionaries. Having taken a closer look at their workwe felt that there were gaps that needed to be filled. Wehave presented here a roadmap describing how this mightbe achieved. We have also presented some empirical work,showing that progress is possible, though, given the com-plexity of the task, more work is needed. Some problemsbeing rooted in the lack of adequate corpora, others beingintrinsically difficult research problems (identification of thenature of links). Despite all this, we hope that our ideas willinspire others to accept the challenge and help us to buildthe ‘map’ and the ‘lexical compass’ of tomorrow. Buildingan index based on the notion of association should be help-ful for many tasks (information access, word finding, brain-storming, subliminal communication) and various people.While wordhunters are certainly among the most concerned,this kind of resource should also be valuable for psycholo-gists, as it allows them to see what people do when look-ing for a word. Navigational strategies reveal in slow mo-tion what our brain does seemingly without any effort andin a split of a second. Put differently, it shows to some ex-tent how search is performed in the mental lexicon, whilerevealing the word we are looking for. What can we ask formore?
References
Agirre, E., Ansa, O., Martinez, D., & Hovy, E. (2001). EnrichingWordNet concepts with topic signatures. In NAACL’01 workshopon WordNet and other lexical resources: applications, extensionsand customizations.
Aitchinson, J. (2003). Words in the mind: an introduction to the mentallexicon. Oxford: Blackwell.
Avancini, H., Lavelli, A., Magnini, B., Sebastiani, F., & Zanoli, R.(2003). Expanding domain-specific lexicons by term categoriza-tion. In 18th ACM symposium on applied computing (SAC-03).
Baddeley, A. (1982). Your memory: a user’s guide. Baltimore: Pen-guin.
Barabási, A. (2002). Linked: the new science of networks. Cambridge:Perseus.
Buchanan, M. (2002). Nexus: small worlds and the groundbreakingtheory of networks. New York: W.W. Norton.
Bateman, J., & Zock, M. (2003). Natural language generation. InR. Mitkov (Ed.), Handbook of computational linguistics (pp. 284–304). Oxford: Oxford University Press.
Beeferman, D., Berger, A., & Lafferty, J. (1999). Statistical models fortext segmentation. Machine Learning, 34(1), 177–210.

Int J Speech Technol (2010) 13: 201–218 217
Boissière, P. (1862). Dictionnaire analogique de la langue française :répertoire complet des mots par les idées et des idées par les mots,Paris.
Bonin, P. (2004). Mental lexicon: some words to talk about words. NewYork: Nova Science Publishers.
Brown, R., & McNeill, D. (1996). The tip of the tongue phenomenon.Journal of Verbal Learning and Verbal Behaviour, 5, 325–337.
Burke, D. M., MacKay, D. G., Worthley, J. S., & Wade, E. (1991).On the tip of the tongue: what causes word finding failures inyoung and older adults? Journal of Memory and Language, 30,542–579.
Cahill, L., & Reape, M. (1999). Lexicalisation in applied NLG systems(p. 9). Brighton: ITRI.
Church, K., & Hanks, P. (1990). Word association norms, mutual infor-mation, and lexicography. Computational Linguistics, 16(1), 177–210.
Collins, A., & Quillian, L. (1969). Retrieval time from semantic mem-ory. Journal of Verbal Learning and Verbal Behavior, 8, 240–247.
Cumming, S. (1986). The lexicon in text generation. ISI: 86–168.Cutler, A. (Ed.) (1982). Slips of the tongue and language production.
Amsterdam: Mouton.Deese, J. (1965). The structure of associations in language and
thought. Baltimore: Johns Hopkins Press.Dell, G. S. (1986). A spreading-activation theory of retrieval in sen-
tence production. Psychological Review, 93, 283–321.Dong, Z., & Dong, Q. (2006). HOWNET and the computation of mean-
ing. London: World Scientific.Dutoit, D., & Nugues, P. (2002). A lexical network and an algorithm to
find words from definitions. In F. van Harmelen (Ed.), ECAI2002,Proceedings of the 15th European conference on artificial intelli-gence, Lyon (pp. 450–454).
El-Kahlout, I. D., & Oflazer, K. (2004). Use of wordnet for retrievingwords from their meanings. In 2nd Global WordNet conference,Brno.
Fellbaum, C. (1998). WordNet: an electronic lexical database andsome of its applications. Cambridge: MIT Press.
Ferret, O. (2002). Using collocations for topic segmentation and linkdetection. In COLING 2002 (pp. 260–266).
Ferret, O. (2006). Building a network of topical relations from a cor-pus. In LREC 2006.
Ferret, O., & Zock, M. (2006) Enhancing electronic dictionaries withan index based on associations. In ACL’06: Proceedings of the21st international conference on computational linguistics andthe 44th annual meeting of the ACL (pp. 281–288).
Fontenelle, T. (1997). Using a bilingual dictionary to create semanticnetworks. International Journal of Lexicography, 10(4):275–303.
Fromkin, V. (Ed.) (1973). Speech errors as linguistic evidence. TheHague: Mouton Publishers.
Goddard, C. (1998). Bad arguments against semantic primitives. The-oretical Linguistics, 24(23), 129–156.
Goldman, N. (1975). Conceptual generation. In R. Schank (Ed.), Con-ceptual information processing. Amsterdam: North-Holland.
Hanks, P., & Pustejovsky, J. (2005). A pattern dictionary for naturallanguage processing’ in revue française de linguistique appliquée10 (2).
Harabagiu, S., & Moldovan, D. (1998). Knowledge processing on ex-tended WordNet. In C. Fellbaum (Ed.), WordNet: an electroniclexical database and some of its applications (pp. 379–405) Cam-bridge: MIT Press.
Harley, T. (2010). Talking the talk. New York: Psychology Press.Jarema, G., Libben, G., & Kehayia, E. (2002). The mental lexicon.
Brain and Language, 81.Jung, C., & Riklin, F. (1906). Experimentelle Untersuchungen Über
Assoziationen Gesunder. In Jung, C. G. (Ed.), Diagnostische As-soziationsstudien (pp. 7–145) Leipzig: Barth.
Kempen, G., & Huijbers, P. (1983). The lexicalization process in sen-tence production and naming: Indirect election of words. Cogni-tion, 14, 185–209.
Kilgarriff, A., Rychly, P., Smrz, P., & Tugwell, D. (2004). The sketchengine. In Proceedings of the eleventh EURALEX internationalcongress, Lorient, France (pp. 105–116).
Lamb, S. (1999). Pathways of the brain: the neurocognitive basis oflanguage. Amsterdam: John Benjamins.
Levelt, W. (1992). Accessing words in speech production: stages,processes and representations. Cognition, 42, 1–22.
Levelt, W. J. M., Roelofs, A., & Meyer, A. S. (1999). A theory of lex-ical access in speech production. Behavioral and Brain Sciences,22, 1–75.
Magnini, B., & Cavaglia, G. (2000). Integrating subject field codesinto WordNet. In Second international conference on languageresources and evaluation, Athenes, Geece (pp. 1413–1418).
Mandala, R., Tokunaga, T., & Tanaka, H. (1999). ComplementingWordNet with Roget’s and corpus-based thesauri for informationretrieval. In EACL99.
Marslen-Wilson, W. (Ed.) (1979). Lexical representation and process,Bradford book. Cambridge: MIT Press.
Mel’cuk, I., Arbatchewsky-Jumarie, N., Iordanskaja, L., Mantha, S.,& Polguère, A. (1999). In Recherches lexico-séman-tiques IV.Dictionnaire explicatif et combinatoire du français contemporain.Montréal: Les Presses de l’Université de Montréal.
Mihalcea, R., & Moldovan, D. (2001). Extended WordNet: progressreport. In NAACL 2001—workshop on WordNet and other lexicalresources, Pittsburgh, USA.
Miller, G. A. (Ed.) (1990). WordNet: an on-line lexical database. Inter-national Journal of Lexicography, 3(4), 235–244.
Moerdijk, F. (2008). Frames and semagrams; meaning description inthe general dutch dictionary. In Proceedings of the thirteenth Eu-ralex international congress, EURALEX, Barcelona.
Nicolov, N. (1999). Approximate text generation from non-hierarchicalrepresentation in a declarative framework. PhD dissertation, uni-versity of Edinburgh.
Nogier, J. F., & Zock, M. (1992). Lexical choice by pattern matching.Knowledge Based Systems, 5(3), 200–212.
Richardson, S. W., Dolan, B., & Vanderwende, L. (1998). MindNet:acquiring and structuring semantic information from text. In ACL-COLING’98 (pp. 1098–1102).
Robin, J. (1990). A survey of lexical choice in natural language genera-tion. Technical Report CUCS 040-90, Dept. of Computer Science,University of Columbia.
Roelofs, A. (1992). A spreading-activation theory of lemma retrievalin speaking. In Cognition, 42, 107–142. W. Levelt (Ed.) Specialissue on the lexicon.
Roget, P. (1852). Thesaurus of English words and phrases. London:Longman.
Rundell, M. (2002). Macmillan English dictionary for advanced learn-ers. Oxford: Macmillan.
Sharoff, S. (2005). The communicative potential of verbs of ‘away-from’ motion in English and Russian. Functions of Language,12(2), 203–238.
Schvaneveldt, R. (Ed.) (1989). Pathfinder Associative Networks: stud-ies in knowledge organization. Norwood: Ablex.
Sierra, G. (2000). The onomasiological dictionary: a gap in lexicogra-phy. In Proceedings of the ninth Euralex international congress,IMS, Universität Stuttgart (pp. 223–235).
Sinopalnikova, A., & Smrz, P. (2006). Knowing a word vs. access-ing a word: Wordnet and word association norms as interfaces toelectronic dictionaries. In Proceedings of the third internationalWordNet conference, Korea (pp. 265–272).
Smith, E., Shoben, E., & Rips, L. (1974). Structure and process in se-mantic memory: a featural model for semantic decisions. Psycho-logical Review, 81, 214–241.

218 Int J Speech Technol (2010) 13: 201–218
Stede, M. (1995). Lexicalization in natural language generation: a sur-vey. Artificial Intelligence Review, 8, 309–336.
Stemberger, N. (1985). The lexicon in a model of speech production.New York: Garland.
Summers, D. (1993). Language Activator: the world’s first productiondictionary. London: Longman.
T’ong, T.-K. (1862). Ying ü tsap ts’ün (The Chinese and English in-structor). Canton.
Vigliocco, G., Antonini, T., & Garrett, M. F. (1997). Grammatical gen-der is on the tip of Italian tongues. Psychological Science, 8, 314–317.
Wanner, L. (1996). Lexical choice in text generation and machinetranslation. Machine Translation, 11, 3–35. Choice. L. W. (Ed.)Special Issue on Lexical.
Ward, N. (1988). Issues in word choice. COLING-88, Budapest.Zock, M., & Bilac, S. (2004). Word lookup on the basis of associa-
tions: from an idea to a roadmap. In Proc. of coling workshop:Enhancing and using dictionaries, Geneva (pp. 29–35).
Zock, M., & Schwab, D. (2010). Lexical access, a search problem. InCogalex-2, Beijing.
Zock, M., & Schwab, D. (2008). Lexical access based on underspeci-fied input. In Cogalex-1, coling workshop, Manchester.
Zock, M. (1996). The power of words in message planning,COLING, Copenhagen, 990-5. http://acl.ldc.upenn.edu/C/C96/C96-2167.pdf.