data consistency in distributed systems - is muni
TRANSCRIPT

Masaryk UniversityFaculty of Informatics
Data consistency in distributedsystems
Master’s Thesis
Lenka Heldová
Brno, Spring 2019


Masaryk UniversityFaculty of Informatics
Data consistency in distributedsystems
Master’s Thesis
Lenka Heldová
Brno, Spring 2019


Declaration
Hereby I declare that this paper is my original authorial work, whichI have worked out on my own. All sources, references, and literatureused or excerpted during elaboration of this work are properly citedand listed in complete reference to the due source.
Lenka Heldová
Advisor: doc. Ing. RNDr. Barbora Bühnová Ph.D.
i


Acknowledgements
My acknowledgements belong to my advisor, doc. Ing. RNDr. BarboraBühnová, PhD., for her guidance, inspiration and time she dedicatedme while I was writing this thesis. I would also like to thank to consul-tant, Petr Vala, for valuable consultations, help and time he providedme. Eventually, my gratitude goes to my family and friends who en-couraged and supported me throughout my studies.
iii

Abstract
This master thesis is dedicated to designing of software architecturebased on microservices, for already existing monolithic Volt appli-cation. Much emphasis is given to data consistency and reliabilityin such distributed world that microservices represent. First, Volt it-self and problems of original architecture are introduced. Then alltechnologies and patterns are generally explained and subsequentlylogically connected to resultant architecture design. Last part of thesisis focused on discussion of the created architecture.
iv

Keywords
Microservices, Saga transactions, orchestration-based transactions,Event-sourcing, events storage, Command query responsibility segre-gation, software architecture
v


Contents
Introduction 1
1 Volt application 31.1 Business case . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Software architecture case . . . . . . . . . . . . . . . . . . . 5
1.2.1 Canvas . . . . . . . . . . . . . . . . . . . . . . . . 51.2.2 Front-end . . . . . . . . . . . . . . . . . . . . . . 71.2.3 Back-end . . . . . . . . . . . . . . . . . . . . . . . 71.2.4 Work agent . . . . . . . . . . . . . . . . . . . . . 8
2 Volt as monolith problems 92.1 Team . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2 Event driven business flow . . . . . . . . . . . . . . . . . . 102.3 Canvas modules . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Microservices 133.1 Comparison with monolith . . . . . . . . . . . . . . . . . . 133.2 Services versus libraries . . . . . . . . . . . . . . . . . . . . 163.3 Database per service pattern . . . . . . . . . . . . . . . . . 173.4 Problem with data consistency in microservices . . . . . . . 19
3.4.1 Distributed transactions . . . . . . . . . . . . . . 203.4.2 Eventual consistency . . . . . . . . . . . . . . . . 21
4 Saga transactions 234.1 Choreography-based transactions . . . . . . . . . . . . . . . 24
4.1.1 Roll back . . . . . . . . . . . . . . . . . . . . . . . 254.1.2 Benefits and drawbacks . . . . . . . . . . . . . . 26
4.2 Orchestration-based transactions . . . . . . . . . . . . . . . 274.2.1 Roll back . . . . . . . . . . . . . . . . . . . . . . . 284.2.2 Benefits and drawbacks . . . . . . . . . . . . . . 29
4.3 Choice for our problem . . . . . . . . . . . . . . . . . . . . 30
5 Event-sourcing 315.1 Event store . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2 Command Query Responsibility Segregation (CQRS) . . . . 33
vii

6 From monolith to microservices 376.1 Considerations and prerequisites . . . . . . . . . . . . . . . 376.2 Resilient microservices . . . . . . . . . . . . . . . . . . . . 386.3 Rebuilding . . . . . . . . . . . . . . . . . . . . . . . . . . 396.4 Semantic versioning . . . . . . . . . . . . . . . . . . . . . 42
7 Volt with microservices 457.1 Microservices . . . . . . . . . . . . . . . . . . . . . . . . . 467.2 Data storing and data consistency . . . . . . . . . . . . . . 47
8 Discussion 49
Conclusion 51
Bibliography 53
viii

List of Figures
1.1 Data monitor 41.2 Volt architecture 52.1 Events of Volt application 103.1 Microservices versus monolith [3] 153.2 Database per service pattern 183.3 Data inconsistency 204.1 Choreography-based transactions 244.2 Roll back in choreography-based transactions 264.3 Orchestration-based transactions 274.4 Roll back in orchestration-based transactions 295.1 Command and Query Responsibility Segregation 346.1 Patterns for software resilience [26] 396.2 Module conversion 417.1 Volt architecture with microservices 45
ix


Introduction
Development of technology is progressing very fast these years. Usageof cloud and infrastructure-as-a-service instead of owning all serversand own infrastructure became much more trendy, easier, cheaperand more resilient for bigger companies. The way of developing a soft-ware is changing as well, agile methodology starts to dominate overwell-known "waterfall" approach. That is the reason why traditionalmonolithic style of enterprise applications became less sufficient andnew solutions start to appear.
The goal of this thesis is to design new, more suitable architec-ture of an already existing application, which is being developed inmonolithic style. New architecture is using small independent servicescooperating with each other, microservice style of software architec-ture. The design of new architecture is focusing on data consistency,resilience and scalability.
The thesis is divided into eight chapters. In the first chapter theVolt application, whose architecture is meant to be rebuilt, is intro-duced. The description is provided from two perspectives, businessand software architecture.
The second chapter is dedicated to an explanation of problems,which Volt needs to face as a monolithic application and reasons, whythe rebuilding is an appropriate solution. Three main areas are men-tioned, which are the problems with sizeable team, usage of generalCanvas modules and already existing event-driven Volt’s workflow.
Third, fourth and fifth chapters bring theoretical explanation oftechnologies and patterns, which are suitable to be used with microser-vice software architecture. First of all, microservices themselves andtheir comparison with monolith are introduced. Then Database perservice pattern with its data consistency drawback and right afterSaga transactions as a solution are described. Last but not least, Event-sourcing with logical connection with Command query responsibilitysegregation pattern are highlighted.
Before designing the architecture itself, few very important topicsthat are closely related to microservices architecture are mentioned.At first, there are some considerations and prerequisites, which aregood to think about, before the final decision of taking a journey
1

from monolith to microservices. Another requirement of reliable andresilient architecture is proper fault tolerance mechanism. To close thechapter, taking into account the fact that the thesis is concerned withrebuilding of already existing application, thus the choice of fittingstrategy and versioning for architecture converting is necessary.
Finally, the proposal of Volt’s architecture based on microservicesis designed in Chapter 7. It is accompanied with a figure of sucharchitecture. At the end, a small discussion about the solution andother steps to make is presented.
2

1 Volt application
At first, the Volt application is introduced. This description is necessaryto fully understand the problems of Volt’s monolithic architecture,which are listed in detail in Chapter 2, and therefore imply the needof rebuilding to microservices. Volt is just a pseudonym used for thisthesis, since the real name of the application can not be disclosed dueto the contract with the client, it can not be used here. Volt is describedfrom the business and from the software architecture point of view.
1.1 Business case
From simplified, but for this thesis sufficient, business perspective,Volt is an application which allows a user to input files in specialformats, validate them on several levels, with several rules and afterthat, assemble the right files to create models of an energy networkfor a particular country and timestamp. There is one model for eachhour per day. If some country does not provide or provides erroneousfiles, the application replaces them with suitable files from the past.Final part of this process is to merge all models for Central Europe inorder to produce one big model of the energy network. This processis usually executed multiple times, for example for whole businessday, which means 23-25 times considering day light saving shifts, orfor more business days. These created models are used for the futurepredictions of energy consumption and power flow in Central Europe.
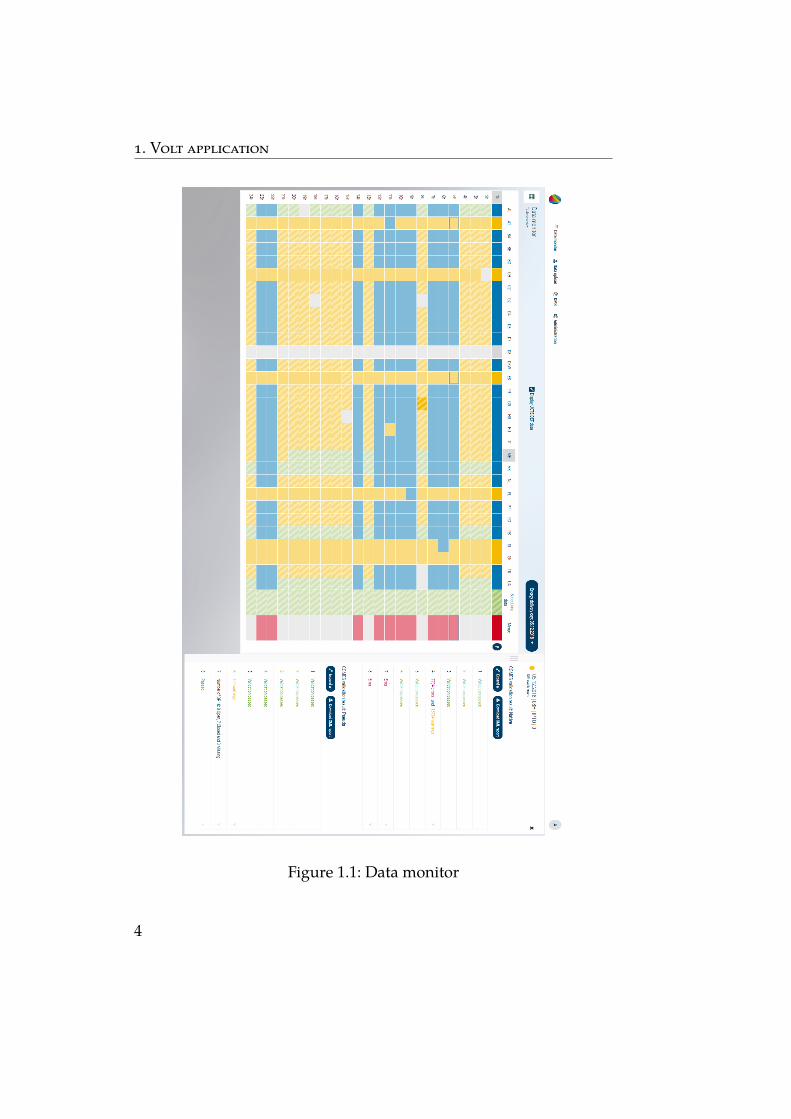
Additionally, all validation result files, merged models and otheroutput files are available for users through the Document managementsystem. User friendly visual results are displayed on Data monitoruse case. This use case is shown in Figure 1.1, results of the validation,merging and data replacement are displayed for a particular businessday. Legend is missing, because there are tool tips on mouse hover.Moreover, there is a right panel, which shows validation details forthe particular model and particular levels and rules.
Finally, there are administration use cases like Wiping data out,Work agents management and About application.
3
1. Volt application
Figure 1.1: Data monitor
4
1. Volt application
1.2 Software architecture case
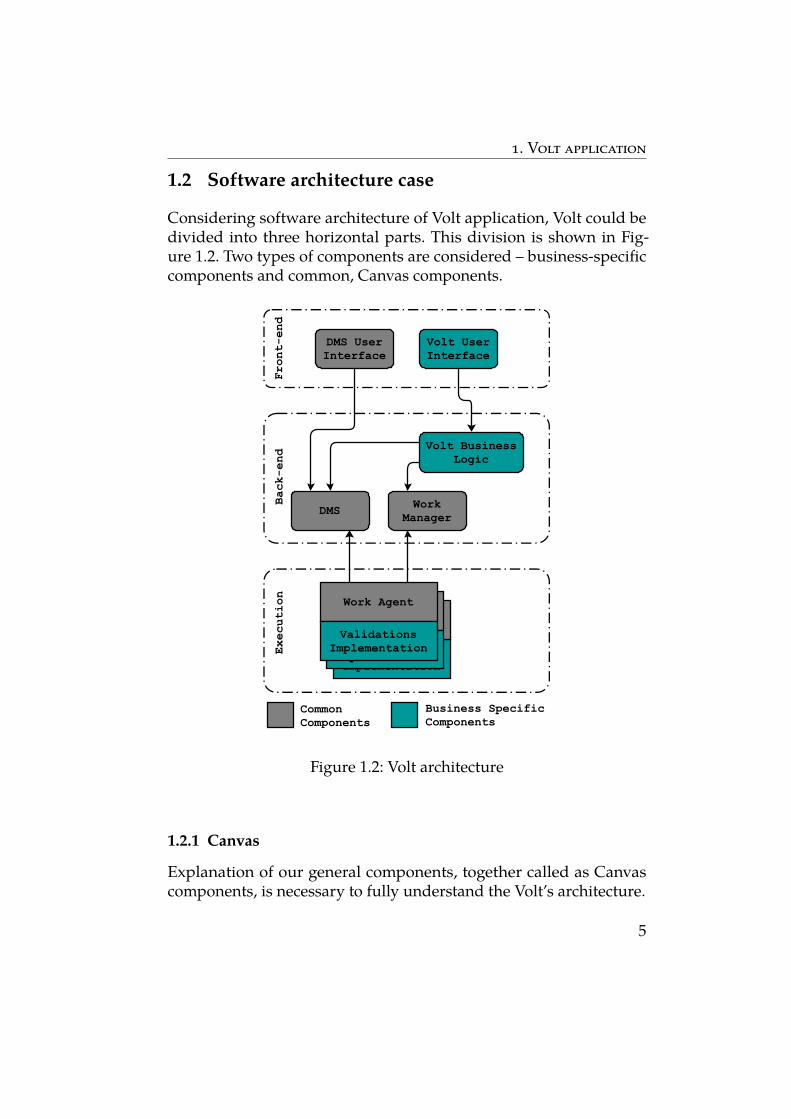
Considering software architecture of Volt application, Volt could bedivided into three horizontal parts. This division is shown in Fig-ure 1.2. Two types of components are considered – business-specificcomponents and common, Canvas components.
Frontend
Backend
Execution
DMS UserInterface
Volt UserInterface
Volt BusinessLogic
DMS WorkManager
ValidationsImplementation
Work Agent Work Agent
ValidationsImplementation
Work Agent
ValidationsImplementation
CommonComponents
Business SpecificComponents
Figure 1.2: Volt architecture
1.2.1 Canvas
Explanation of our general components, together called as Canvascomponents, is necessary to fully understand the Volt’s architecture.
5

1. Volt application
Since Volt is one of the company’s portfolio applications, whichare using the same functionality as Work manager, Document man-agement system and others, following improvements led to a decisionof Canvas components separation:
∙ Enhancing the speed of development — by saving the time todevelop the functionality from scratch.
∙ Reducing the maintenance costs — by having only one codebaseto maintain instead of multiple ones.
∙ Increasing the overall quality — by multiple usage of the com-ponents in more applications, critical Canvas components areproven in various products. Fixes and updates implemented forone product are automatically propagated into other applica-tions.
∙ Standardisation of development — by providing reference ar-chitecture and best practices.
∙ Properly documented software components — the time savedin development is invested into proper documentation of thecomponents.
∙ Independence of software development/maintenance teams— open architecture, comprehensive documentation, usage ofwell-known software design patterns and high level of standard-isation breaks the dependence on specific people/teams. Thecomponents developed by one team are further extended and/ormaintained by other teams.
There are also many drawbacks connected to this extractions likemore complex versioning management, features unification and longerlasting bug fix, but mentioned enhancements outweigh these draw-backs.
Since these described Canvas components have their own code-bases, an application such as Volt uses them as external Java librariesmanaged by dependency management. In cases as Document man-agement system component where graphic user interface is essential,front-end independent component exists as well.
6

1. Volt application
1.2.2 Front-end
On the top of application’s layers, there is a front-end part for user inter-action. In our case this is Angular 6 single page application, consistingof business user interface component and Document managementsystem interface component, from Canvas, attached as an independentmodule.
1.2.3 Back-end
The main part related to this thesis is a back-end part. The back-endpart consists of "main" business logic component and two commonCanvas components – Document management system (DMS) andWork manager component. These two mentioned common compo-nents are used as external Java libraries. Business logic part of Voltapplication was developed as monolithic system consisting of sev-eral modules, which communicate mainly through application events.Each module has its own private database schema, but these schemasare stored in one database. Besides common administrative modulesas Authentication, Core and Settings, Volt has 3 primary business-focused modules:
∙ Data preparation — module responsible for input files downloadusing SFTP protocol, file type recognition (Volt considers 5 filetypes), input files conversion if necessary and preparation ofdata for validation of these files.
∙ Data validation — this module is responsible for orchestrationof the file processing chain. Processing of each file consists ofmultiple steps executed as separate jobs on Work agent. (Workagent is described in Section 1.2.4).
∙ Data replacement and merging — this last but not least moduleserves as storage for the particular models and is also provid-ing the functionality of missing or invalid models replacementbefore the attempt for merging is made.
7

1. Volt application
1.2.4 Work agent
Work agent is a standalone application, created to detach execution ofvalidation algorithms from main back-end part. The main reason forthis choice is scalability. Usually there are multiple Work agents appli-cations attached to one back-end part. Back-end creates specific jobsfor Work agents which are continuously requesting Work managercomponent by REST calls, to obtain a job to be executed by their partic-ular aim. As soon as a processing of the job is done, Work agent sendsresult to back-end, again through REST call. Since results of jobs areunified, this architecture of Work agents unit makes back-end businesspart absolutely independent on validation algorithms implementationand execution.
8

2 Volt as monolith problems
Current monolithic state of Volt was described in Chapter 1. Withgrowing scope of Volt and the team itself, general known monolith’sdisadvantages as hard scalability, necessary release and deploy ofwhole application for every single bug fix, impossibility of reusingsmall modules of application and last but not least time wasting onmeetings caused by too big team, started to outweigh advantages.More general known advantages and disadvantages of monolith andmicroservices are listed in Chapter 3. In this chapter Volt specific prob-lems and facts as a monolith, which led to discussion about changingapplication architecture, are described.
2.1 Team
Despite the fact, that size of the team may seem as just pleasant side-effect benefit of microservices architecture, in case of Volt it was oneof the main reasons to start speculate about microservices. Volt is de-veloping by agile Scrum methodology1, which was perfectly effectiveand suitable until an application scope started to grow rapidly and sothe team. Scrum itself officially recommends from three to nine teammembers to stay effective. Volt team now consists of sixteen peopleplus Scrum master and Product owner which makes meetings anddevelopment itself less effective and slower. Another problem withsuch a big team is that decision making is difficult, since Scrum doesnot have hierarchy of responsibility, the whole team has to agree.
Moreover, Volt team is facing traditional problems with big teamsas losing overview about code changes and others work, merge con-flicts or waiting time until another team member finishes his or herwork and inability to pay attention through long lasting meetings.
1. The Scrum approach to agile software development marks a dramatic departurefrom waterfall management. Scrum and other agile methods were inspired by itsshortcomings. Scrum emphasizes collaboration, functioning software, team selfmanagement, and the flexibility to adapt to emerging business realities. For furtherexplanation of agile approach and Scrum methodology, please read [1] and [2],respectively.
9

2. Volt as monolith problems
All these problems are highlighted by the fact that a part of theteam is working in Prague and another one in Brno. There are, ofcourse, more possibilities to deal with oversized Scrum teams, but thisproblem helped with deciding about rebuilding Volt to microservices-architecture application.
2.2 Event driven business flow
Furthermore, Volt’s business workflow is based on events. Since filesare uploaded into Volt, until the electricity grid of whole CentralEurope is created, by average more than ten events are sent. Eachevent triggers different action to execute.
Datapreparation
module
Workmanager
Datavalidation
module
FILE_UPLOADED_EVENT
FILE_PROCESSED_EVENT
FILE_CONVERTED_EVENT
DMS
MODEL_VALIDATED_EVENT
PROFILE_VALIDATED_EVENT
LOADFLOW_CALCULATED_EVENT
FILE_SAVED_EVENT
MODEL_ASSEMBLED_EVENT
JOB_CREATED_EVENT
Datareplacementand merging
module
JOB_CREATED_EVENT
DATA_REPLACED_EVENT
DATA_MERGED_EVENT
JOB_CREATED_EVENT
Figure 2.1: Events of Volt application
10

2. Volt as monolith problems
Figure 2.1 displays events of Volt application. Simplified, but suffi-cient for the demonstration, business workflow of the Volt applicationis based on these events. In this state of the Volt application, modulesemit events. Listener of these events can be either in same or in anothermodule.
Events are fundamentals for microservices architecture, especiallywith orchestration-based Saga transactions (explained later in Section4.2), which means that process of rebuilding monolith to microservicesshould be significantly easier.
2.3 Canvas modules
Another thing that caused first speculations about microservices isusing of Canvas modules (described in Section 1.2.1) as external Javalibraries. Especially Document management system is often adjustedand fixed module. By usage as an external Java library, after everysuch adjustment the version has to be increased and a new versionbuilt. After this, the new version is used in every application usingDocument management system module. This causes necessity to buildand redeploy whole application. If Document management system isa microservice, such a cycle will not be necessary anymore as long asApplication programming interface (API) stays backwards compatible.
11


3 Microservices
In order to fully understand microservices architecture, this chapteris focused on general theoretical information about microservices, itscomparison to monolith and sketch of data consistency problems insuch architecture. The very good base for this chapter were articlesabout microservices by Martin Fowler and James Lewis [3] and byChris Richardson [4].
The microservices architectural style is a way to develop a singleapplication as a pack of small services. Each of this services is runningits own process and communicating with lightweight mechanisms,often using REST API or event-base communication. These servicesare built and deployed independently. Usually deployable by fullyautomated deployment machinery. These services could be writtenin different programming languages and use different database oranother data stores. Additionally, there is a minimum centralization.
3.1 Comparison with monolith
In the world of enterprise applications, microservice style is consideredas opposite of monolithic style, which is "traditional" style. It would beuseful to compare microservices to monolith to explain these styles.
A monolithic application is built as a single unit. Enterprise ap-plications are often built as three main parts: a front-end part (userinterface), a database and a back-end part (server-side application).The front-end part is usually consisting of HTML pages and Javascriptscripts running in browser on the user’s computer. Database is storingand providing data by application’s instructions.
The server-side application usually handles REST requests andcreates responses for them, executes main business logic, retrievesand updates data from the database. If this server-side applicationis built in a monolithic style, it is a single logical executable unit. Inorder to propagate any changes to the system, building and deployinga new version of the server-side application is necessary. Moreover,if changes to data model are needed, then either all older data has tobe deleted, in order to reinstall database with a new data model, orscript for update of related data has to be created.
13

3. Microservices
Monolithic style of building applications is a logical way to buildthis kind of server-side applications. All logic for each request is run-ning as a single process. Whole application is divided into modules,classes and functions, which can communicate with each other.
Such applications are usually running on developer’s laptop dur-ing development. Before the application is deployed on the productionenvironment, processes as staging, deploying by deployment pipelinesand testing by automated as well as manual tests are applied on testingenvironments. After successful review of new solution, the old oneis decommissioned and replaced in production environment. Scal-ability could be then achieved by running more instances behind aload-balancer.
Monolithic applications can be successful and have own benefits:
∙ Fast development at the beginning.
∙ Easy and straightforward deployment.
∙ Easy automated testing.
But the complications with monolithic applications started to ap-pear as applications are being deployed to the cloud 1. Every littlechange to application causes rebuilding and redeploying of entireapplication – all deployment pipelines have to be run. Some otherdisadvantages of the monolithic architecture are that keeping a goodmodular structure is challenging and devious, it is difficult to preventof changes to impact more modules than is required, which makesrefactoring more difficult, and there is a need to scale entire applica-tion rather than only smaller parts requiring more resources. Fromthe reusability perspective, the disadvantage is obvious, smaller partsor modules cannot be reused among more applications.
All of these problems led software architects to change the wayhow the applications are built – as a set of microservices. One of main
1. According to [5], which refer to few big surveys, cloud computing spending isexpected to grow at better than 6x the rate of IT spending through 2020. Cloudcomputing provides a huge range of advantages compared to a more traditionalset-up. Reduced costs from the reduction in hardware is a key factor for manycompanies as well as the flexibility and the ability for efficient disaster recovery. Formore information and statistics about cloud computing read [5].
14

3. Microservices
benefits of folding such microservices together is fact that servicesare independently deployable and scalable and each service providesa firm boundary. In Figure 3.1 there are shown differences betweenmonolith’s and microservices’ boundaries and scaling.
Figure 3.1: Microservices versus monolith [3]
This approach allows different services to be written in differentprogramming languages and thus developed by different independentteams. Teams can work on a problem or group of problems on theirown. This brings several benefits favored by many developers [6]:
∙ Choice of tool — Each team can use different tool, library orframework suitable for their needs and preferences.
∙ Fast iteration — Since microservices tend, or at least shouldbe small, explored bugs or optimizations can be implementedrelatively quickly. As well as realising a new version. Moreover,experimentation is more accessible, because it is faster and easier.
∙ Ease of refactoring — As opposite with monolithic solutions, mi-croservices tend to be small. That is the reason why rewrites are
15

3. Microservices
an option. The cause may be inappropriate technology, releaseof better framework, old and unreadable code and so on.
∙ Readability and quality of code — As isolated microserviceshave less code, new developers can easily get into it. Moreover,isolated development units tend to be of a higher quality andeasier to be agreed on.
Microservices architecture has its own drawbacks as well, mainlycaused by the fact that such an architecture creates distributed system.The main of them are:
∙ Complex communication between services.
∙ Error handling and possible data inconsistency.
∙ More difficult deployment and monitoring.
Mentioned advantages of microservices architecture together withproblems described in Chapter 2 are reasons why the company decidedto rebuild existing Volt application from monolith to microservices.How to deal with microservices problems is written in Chapter 4,Chapter 5 and Chapter 6. To describe architecture of this rebuilt Voltapplication is the goal of this thesis.
3.2 Services versus libraries
There are more possibilities how to achieve at least few advantageslisted in last section. One of them is usage of external libraries. Speak-ing about libraries, components which are linked to application fromcompilation and using in-memory function calls are being described.While microservices are independent components which have no con-nection to the program except communication mechanisms as webservice requests or remote procedure calls.
The transformation from monolith to microservices can start byusing libraries. Especially shared libraries can bring a lot of advantages[7]:
∙ Strong encapsulation — Implementation is hidden inside com-ponents, this results to highly decoupled parts in the application.
16

3. Microservices
This is very important aspect when different teams are workingon isolated parts.
∙ Well-defined interfaces — Everything that cannot be hidden,must be defined in meaningful APIs between components. Anycomponent can be replaced by any implementation that con-forms to the interface specification.
∙ Explicit dependencies — Modular system means that differentcomponents have to work together as one unit. Relationshipand cooperation between components must be well defined andverifiable.
One of the strongest reasons for using services as components(rather than libraries) is an existence of possibility to deploy microser-vices independently. If an application consists of multiple libraries inone unit, changing of any component will cause the entire applicationto be redeployed. However, if this application is spread over multipleservices, you can expect that many changes in one service will only re-quire redeployment of the changed service. This is not absolute, somechanges may change service interfaces, which can result in necessarycoordination, but the goal of a good microservices architecture is tominimize the impacts through cohesive service boundaries.
3.3 Database per service pattern
This section is focused on data and its persistence used in applicationusing microservices architecture. How should be data stored in sucharchitecture? Restrictions in data persistence are [8]:
∙ Loose coupling — makes possibility for services to be developed,deployed and scaled independently.
∙ Invariants — are needed in some business transactions that spanmultiple services. For example, Data preparation use case mustverify that all files are validated. If some validation fails, it willbe retried or file will not be used.
17

3. Microservices
∙ Multiple-service transactions — query data that is spread acrossmultiple services. For example, when file is uploaded to Volt, itis processed by Data preparation service, saved into Documentmanagement system and validated by Data validation service.
∙ Multiple-service data joins — are necessary in some businesstransactions. For example, find a file (Data preparation service)with its validation result (Data validation service) and content(Document management system).
∙ Different data storage requirements — for different services. Forsome of them may relational database be the best choice but forother could be better to use a NoSQL database such as MongoDB,which is better at storing complex, unstructured data, or Neo4J,designed to efficiently work with graph data.
Widely used solution for these restrictions is Database per servicepattern. With this pattern, each microservice keeps its persistent dataprivate and accessible only via its API. Only transactions of this partic-ular service access its database. Architecture of this pattern is shownin Figure 3.2.
UI
Orchestrator
MicroserviceMicroservice Microservice
DB DBDB
Figure 3.2: Database per service pattern
18

3. Microservices
This pattern brings two main advantages which makes it interest-ing for Volt microservices architecture:
∙ Due to this pattern, services are more loosely coupled - changesto one service’s database do not impact any other services.
∙ Each service can use storage type suiting its needs the best. AsDocument management system stores big files, the relationaldatabase is not the most suitable storage.
But it brings some disadvantages as well [8]:
∙ Quite complicated implementation of multiple-services transac-tions.
∙ Not straightforward implementation of queries that need to joindata from more sources.
∙ Challenging management of multiple types of data storage.
As was already mentioned, microservices have many advantagesworth using this type of architecture, but bring certain complexity aswell, for example with these listed disadvantages. This complexitybrings necessity to consider problems with data consistency.
3.4 Problem with data consistency in microservices
This section is focused on detailed explanation of problem with trans-actions spanning multiple services. Knowledge for writing this sectionwas mainly sourced by work of Grygoriy Gonchar [9] and SebastianPeyrott [10].
As was already described, in microservices with Database per ser-vice pattern, multiple places for data storage exist. In other words,one logical atomic transaction can spread through more than onemicroservice. If one of process participants fails or does not fulfillprerequisites for a successful transaction, data consistency is endan-gered. Suppose Volt application and processing of the uploaded file.If user uploads a file into Volt application, this file is then processedby Data preparation and Data validation service, statuses of file vali-dation are set as pending and if a failure occurs on Work manager or
19

3. Microservices
in communication between services, data is in inconsistent state. Thisinconsistency reflects to statuses of file validation saved in data storesof Data preparation service and Data validation service. Describedsituation is displayed in Figure 3.3.
Datapreparationservice
Datavalidationservice
Workmanager
User
Figure 3.3: Data inconsistency
Therefore, as long as an application has several data storage solu-tions, data consistency has to be taken into account while designing thesystem. For dealing with this problem there are two main approaches:
∙ Distributed transactions
∙ Eventual consistency
3.4.1 Distributed transactions
Mechanisms which ensure that whole series of changes either happenor not, are transactions, they provide data consistency. In the languageof distributed system there are distributed transactions. In general,whole transaction process is managed by transaction manager, which isnotified when system wants to start a transaction. Only after successfulacknowledgement of all transaction process participants, which is sent
20

3. Microservices
to transaction manager, transaction can be performed. There are lots ofways how to implement a transaction manager and the communicationto other participants (two particular implementations are describedin Chapter 4). Distributed transactions are very useful way to ensuredata consistency in the world of smaller applications with small andquick changes.
3.4.2 Eventual consistency
On the other hand, eventual consistency is allowing inconsistenciesfor short time when dealing with the problem of distributed data. Thismeans that systems which work with eventual consistency take intoaccount the inconsistent state of data in some point. This state could betreated in few ways, postponing the operation, using the data in stateit is, or ignoring certain pieces of data. Eventual consistency systemsare more straightforward and easier to implement but not all datamodels or operations fit its semantics. Eventual consistency is moresuitable for systems with bigger and more complicated transactions.
21


4 Saga transactions
While there are use cases in the Volt application, as Model assembling,where all files have to have consistent statuses, eventual consistency asdescribed before is not suitable in whole Volt application. Thus, thischapter is dedicated to distributed transactions. There are many greatsources to get familiar with distributed transactions and particularlySaga transactions, but for this chapter articles by Denis Rosa [11],[12], by Chris Richardson [13] and by Bernd Rücker [14] were used asfundamentals.
One of the most well-known patterns for distributed transactionsis called Saga. The first paper [15] about it was published by HectorGarcia-Molina and Kenneth Salem back in 1987 and since then it hasbeen a popular solution.
Saga is based on a sequence of small local transactions. Each ofthis small transactions updates data in its service. The system triggersfirst step of this sequence and every other step is invoked by the endof the previous one.
Two most extended implementations of Saga transactions fromseveral possibilities are:
∙ Choreography-based transactions — No central operator of thetransaction exists in this case. Each service produces event aftercompletion of particular steps and each service also listens toother service’s events to decide which action should be takenand which not.
∙ Orchestration-based transactions — This implementation ofSaga transactions has a coordinator service, usually called Or-chestrator, that is responsible for centralizing the decision mak-ing and logically sequencing transactions by business logic.
In following sections each listed type of Saga transactions is de-scribed in detail and explained together with its benefits and draw-backs.
23
4. Saga transactions
4.1 Choreography-based transactions
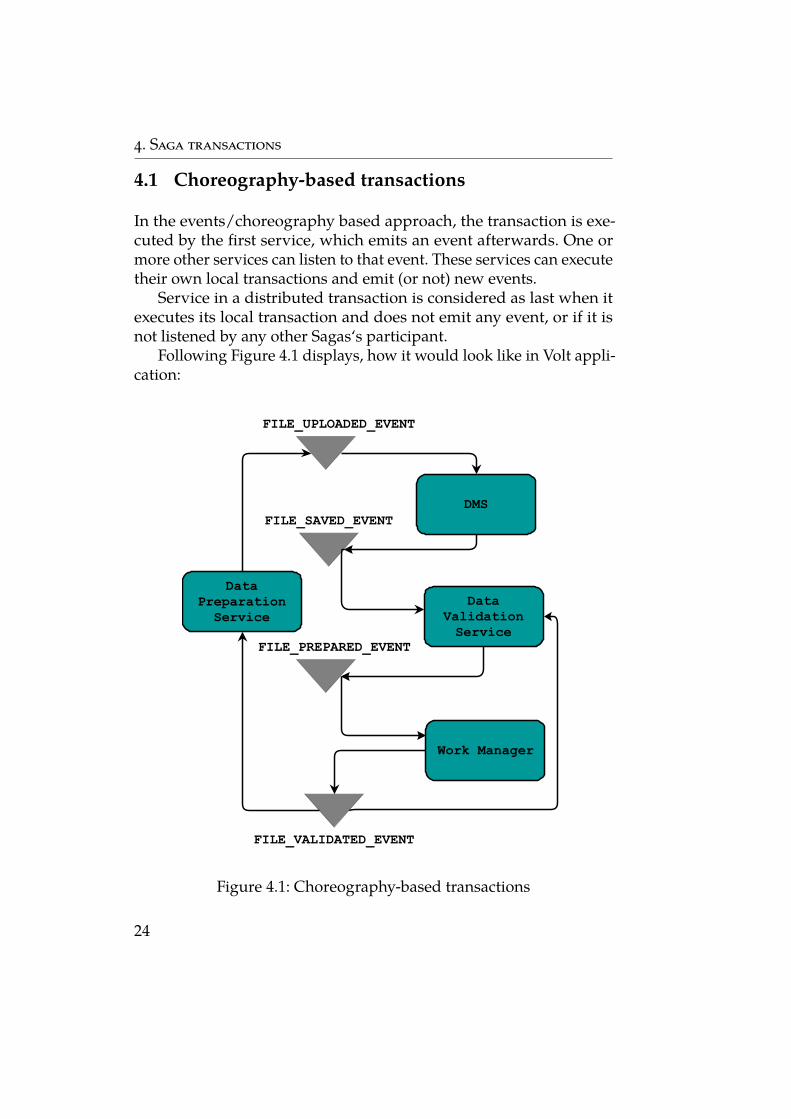
In the events/choreography based approach, the transaction is exe-cuted by the first service, which emits an event afterwards. One ormore other services can listen to that event. These services can executetheir own local transactions and emit (or not) new events.
Service in a distributed transaction is considered as last when itexecutes its local transaction and does not emit any event, or if it isnot listened by any other Sagas‘s participant.
Following Figure 4.1 displays, how it would look like in Volt appli-cation:
DMS
DataValidationService
FILE_UPLOADED_EVENT
DataPreparationService
Work Manager
FILE_SAVED_EVENT
FILE_PREPARED_EVENT
FILE_VALIDATED_EVENT
Figure 4.1: Choreography-based transactions
24

4. Saga transactions
The description for mentioned Figure 4.1:
1. The Data preparation service processes a new file, sets the stateas pending and publishes an event called FILE_UPLOADED_EVENT.
2. The Document management system service listens to FILE_UP-LOADED_EVENT, saves the file and publishes FILE_SAVED_EVENT.
3. The Data validation Service listens to FILE_SAVED_EVENT, savesinformation about file, sets validation status as pending andpublishes FILE_PREPARED_EVENT.
4. The Work manager listens to FILE_PREPARED_EVENT and createsjob for Work agents, when it receives validation results it pub-lishes FILE_VALIDATED_EVENT.
5. Finally, the Data preparation service and Data validation servicelisten to FILE_VALIDATED_EVENT and set the state of the file asvalidated.
In the case above, if the state of the file validation needs to be tracked,Data preparation service could simply listen to all events and updateits state.
4.1.1 Roll back
Figure 4.2 describes how it would look like in a case where a rollback isnecessary. Rolling back distributed transaction is not trivial. Anotheroperation/transaction needs to be implemented to compensate whathas been done before.
Suppose that validation on Work agent has failed during a trans-action to see what the rollback would look like:
1. Work manager produces VALIDATION_FAILED_EVENT.
2. Both Data validation service and Data preparation service listento the previous event:
(a) Data validation service saves information about validationfailure.
25

4. Saga transactions
DMS
DataValidationService
FILE_UPLOADED_EVENT
DataPreparationService
Work Manager
FILE_SAVED_EVENT
FILE_PREPARED_EVENT
VALIDATION_FAILED_EVENT
Figure 4.2: Roll back in choreography-based transactions
(b) Data preparation service set the file state as validationfailed.
It is very important to define a common ID for each transaction.Anytime an event is thrown, all listeners will know which transactionit refers to.
4.1.2 Benefits and drawbacks
Choreography-based transaction pattern is a way to implement Saga’spattern. It is simple and easy to understand, easy to build and its imple-mentation is natural. Loosely coupled participants do not have direct
26

4. Saga transactions
knowledge of each other. The pattern fits very well for transactionswhich involves 2 to 4 steps.
On the other hand, this approach can swiftly become confusingwhen number of steps in transaction is increasing. It is difficult to trackwhich services listen to which events. Furthermore, it also may add acyclic dependency between services because they have to subscribe toeach other’s events.
Eventually, testing can be difficult to implement using this design,because all services need to be running in order to simulate the trans-action behavior.
4.2 Orchestration-based transactions
In the orchestration-based Saga approach, a new service that is re-sponsible for coordination of each participant of the transaction, ie.what to do and when it is introduced. The communication betweenSaga Orchestrator and other services is in a command-reply style.Orchestrator tells them which operation should be performed.
Figure 4.3 shows how orchestration-based transactions could beapplied on the same example:
DMSData
PreparationService
ProcessFile Saga
Orchestrator
SAVE_FILE_CMDChannel
PROCESS_SAGA_REPLYChannel
Message broker
ProcessFileTX
FILE_SAVED_EVENT
FILE_PROCESSED_EVENT
FILE_VALIDATED_EVENT
VALIDATE_FILE_CMDChannel
PROCESS_FILE_CMDChannel
Work Manager
DataValidationService
Figure 4.3: Orchestration-based transactions
27

4. Saga transactions
Enumerated description for Figure 4.3 follows:
1. Data preparation service processes a pending file and asks Pro-cess file Saga Orchestrator to start a transaction of file validation.
2. Orchestrator sends an SAVE_FILE_COMMAND to Document man-agement system, and it replies with a FILE_SAVED_EVENT.
3. Orchestrator sends a PROCESS_FILE_COMMAND to Data validationservice, and it replies with a FILE_PROCESSED_EVENT.
4. Orchestrator sends a VALIDATE_FILE_COMMAND to Work manager,and it replies with a FILE_VALIDATED_EVENT.
In the mentioned case above, Process file Saga Orchestrator knowswhat the needed flow to process a file is. If anything fails, it is alsoresponsible for coordinating the rollback by sending commands toeach participant to undo the previous operation.
A standard way to design a Saga Orchestrator is a state machinewhere each transition corresponds to a command or message. Statemachines are easy to implement and particularly excellent for testing,which makes them to be a great pattern to structure a well-definedbehavior.
4.2.1 Roll back
Rollbacks are much easier when there is an orchestrator machine tocoordinate everything. For demonstration, see Figure 4.4.
1. After a failure on Work agent, Work manager replies to Orches-trator with an VALIDATION_FAILED_EVENT.
2. Orchestrator recognizes that the transaction has failed and startsthe rollback.
(a) In this case, only statuses have to be updated, thereforeOrchestrator sends a VALIDATION_FAILED_COMMAND to Datavalidation service and Data preparation service to set thestate as failed.
28
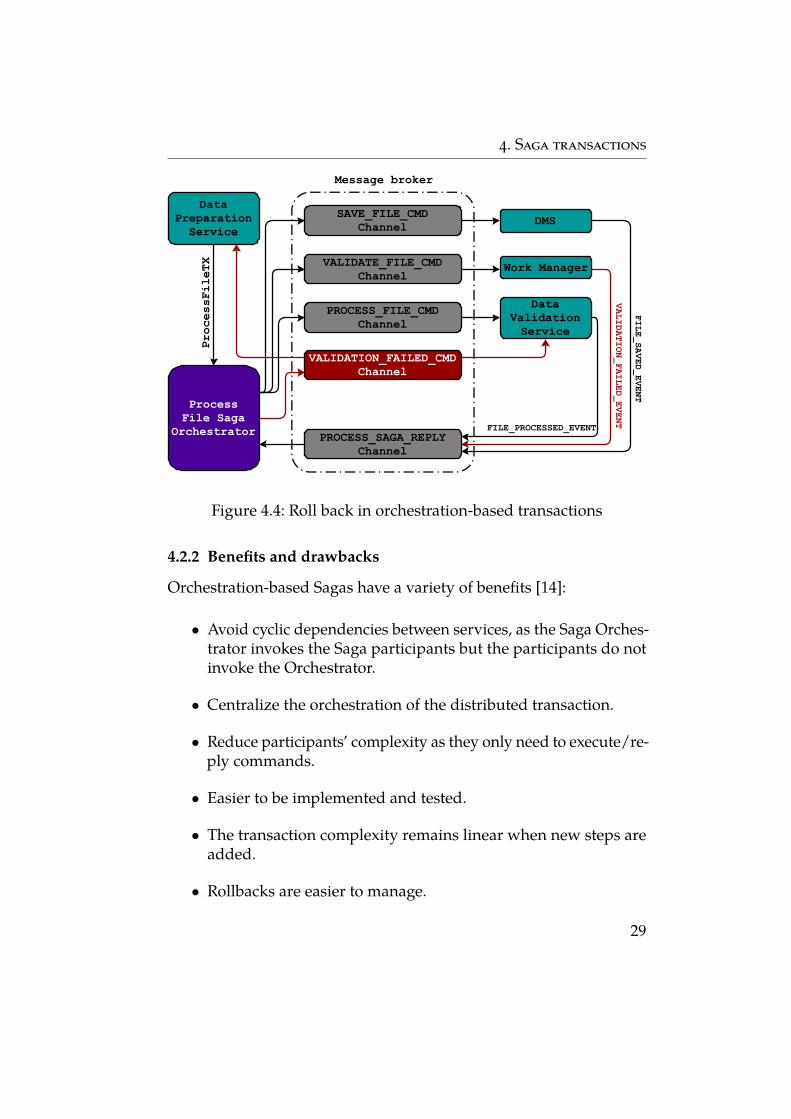
4. Saga transactions
VALIDATION_FAILED_CMDChannel
DMSData
PreparationService
ProcessFile Saga
Orchestrator
SAVE_FILE_CMDChannel
PROCESS_SAGA_REPLYChannel
Message broker
ProcessFileTX
FILE_SAVED_EVENT
FILE_PROCESSED_EVENT
VALIDATION_FAILED_EVENT
VALIDATE_FILE_CMDChannel
PROCESS_FILE_CMDChannel
Work Manager
DataValidationService
Figure 4.4: Roll back in orchestration-based transactions
4.2.2 Benefits and drawbacks
Orchestration-based Sagas have a variety of benefits [14]:
∙ Avoid cyclic dependencies between services, as the Saga Orches-trator invokes the Saga participants but the participants do notinvoke the Orchestrator.
∙ Centralize the orchestration of the distributed transaction.
∙ Reduce participants’ complexity as they only need to execute/re-ply commands.
∙ Easier to be implemented and tested.
∙ The transaction complexity remains linear when new steps areadded.
∙ Rollbacks are easier to manage.
29

4. Saga transactions
∙ If a second transaction is willing to change the same target ob-ject, the Orchestrator can easily put it on hold until the firsttransaction ends.
However, there are some drawbacks as well, one of them is the riskof creating Orchestrator with too much logic, which ends up with astructure where the smart Orchestrator tells the dumb services whatto do.
Another disadvantage of Saga’s orchestration-based is that it mayincrease complexity as there is a need to manage an extra service.Moreover, this is a crucial service of such an architecture, whose un-availability may cause outage of whole system. There is a necessityto create a fault-tolerant mechanism to deal with this problem, moreinformation about such a mechanism is in Section 6.2.
4.3 Choice for our problem
From listed benefits and drawbacks of both types of Saga transactions,it is obvious that choreography-based Saga transactions would notbe sufficient for Volt microservices architecture. The main reason isthat there are far more than 4 steps for one transaction. The usage ofchoreography-based Saga transaction would bring a huge complexityand small scalability. Therefore the usage of orchestration-based Sagatransaction pattern is considered further in this text.
30

5 Event-sourcing
A service typically needs to atomically update the database and pub-lish events. Especially, if it uses the Saga pattern. In order to be reliable,each step of Saga must atomically update the database and publishevents. A good solution to reliably and atomically update the databaseand publish events is to use Event-sourcing. Therefore, this chapteris dedicated to Event-sourcing, stores for events and finally a patterncalled Command query responsibility segregation. Information aboutEvent-sourcing was sourced from Eventuate homepage [16], from Mar-tin Fowler’s web site [17] and from article written by Chris Richardson[18].
Event-sourcing connects publishing events and updating the state.It is radically different approach than the traditional way of persistingan entity - saving its current state. This events sourcing approach canbe also called, event-centric – a business entity is persisted by storinga sequence of events, which change the state. A new event is emittedand added to sequence of events whenever an object’s state changes.Persisting of one event is one operation which means, it is inherentlyatomic. When current state of an entity is queried, it is obtained byreplaying its events.
Events are persisted in an event store. Event store may have morepurposes, it acts as a database of events and it can also behave likea message broker. It provides an application programming interface(API) that enables services to subscribe to events. Each event that ispersisted in the event store is available by this API to all interestedsubscribers. The event store is the main and most important part ofan event-driven microservices architecture.
In this approach, there are more ways how to request an update ofan entity, one of them is an external REST request or another couldbe an event published by another service. These requests are handledby retrieving the entity’s events from the event store, reconstructingthe current state of the entity, updating the entity, and saving the newevents or just saving new events if current state is not necessary forupdating the entity.
The main advantage of Event-sourcing is a number of facilitiesthat can be built on top of it. Concept of Event-sourcing itself brings
31

5. Event-sourcing
guarantee that all changes to the domain objects are initiated by theevent objects. List of few mentioned facilities [17]:
∙ Complete Rebuild — There is a possibility of discarding theapplication state completely and rebuild it by rerunning theevents from the event log on an empty application.
∙ Temporal Query — Determination of the application state ispossible at any point in time. Notionally to do this by startingwith a blank state and rerunning the events up to a particulartime or event. Furthermore, it can be considered multiple time-lines (analogous to branching in a version control system).
∙ Event Replay — If there is a past event, which was incorrect, itcan compute the consequences by reversing it and later eventsand then replaying the new event together with later events. (Orindeed by throwing away the application state and replaying allevents with the correct event in sequence.) The same techniquecan handle events received in the wrong sequence - a commonproblem with systems that communicate with asynchronousmessaging.
In addition, since orchestration-based Saga transactions pattern isbased on events, it is really straightforward and logical to use Event-sourcing along with this pattern.
5.1 Event store
There are lots of possibilities of events stores, as Adam Warski men-tioned in [19]:
When building an event sourced system, there’s a couple of op-tions available when it comes to persistence. First is EventStore, amature, battle-proven implementation. Alternatively, you can useakka-persistence to leverage the scalability of Cassandra together withthe performance of the actor model. Yet another possibility is usingthe good-old relational database, combining the traditional CRUDapproach with events and taking advantage of transactions.
Reading several articles, posts and blogs, for example mentionedarticle by Warski [19] or [20], [21] and [22] shows, that there are many
32

5. Event-sourcing
more possibilities for event storing, each of them with own advantagesand disadvantages. For example Kafka, Axon, Eventuate, PostgreSQL-based Elixir EventStore, which is adapter for open-sourced EventStoreand IBM Db2 Event Store.
Absolutely first decision to make about event storing should bewhich of following storing strategies is the most suitable [19]:
∙ One table/topic per entity — In one table/topic events are storedfor one particular entity. No "where" clause is needed whenasking about particular entity state.
∙ One table/topic per entity type: — In one table/topic events arestored for one entity type. Selecting by entity ID is needed forquerying particular entity state.
∙ One table/topic for everything: All events store in one place.The additional selecting strategies would be probably needed toprevent higher latency when querying particular entity state.
Even after choosing suitable storing strategy, the decision aboutspecific event store would be challenging and comprehensive andthis topic is beyond content of data consistency and microservicesarchitecture itself and therefore is not discussed in more detail in thisthesis.
5.2 Command Query Responsibility Segregation(CQRS)
Traditional CRUD (create, read, update and delete) design works wellwhen only limited business logic is applied to the data operations.Scaffold mechanisms 1 provided by development tools can create dataaccess code very quickly, which can then be customized as required.
However, the traditional CRUD approach has some downsides[23]:
1. Scaffolding is a technique, in which the programmer can specify how the appli-cation database may be used. The compiler or framework uses this specification,together with pre-defined code templates, to generate the final code that the appli-cation can use to create, read, update and delete database entries.
33
5. Event-sourcing
∙ It often happens that there are redundancies caused by differ-ences between the read and write representations of the data,such as additional columns or properties that must be updatedcorrectly even though they are not required as a part of an oper-ation.
∙ Data contention may occur when records stored in collaborativedomain are locked, because multiple actors operate in parallelon the same set of data. In case of optimistic locking, updateconflicts may happen. These risks increase as the complexityand throughput of the system grows.
∙ Managing of security and permissions can become more com-plex because each entity is subject to both read and write opera-tions, which might expose data in the wrong context.
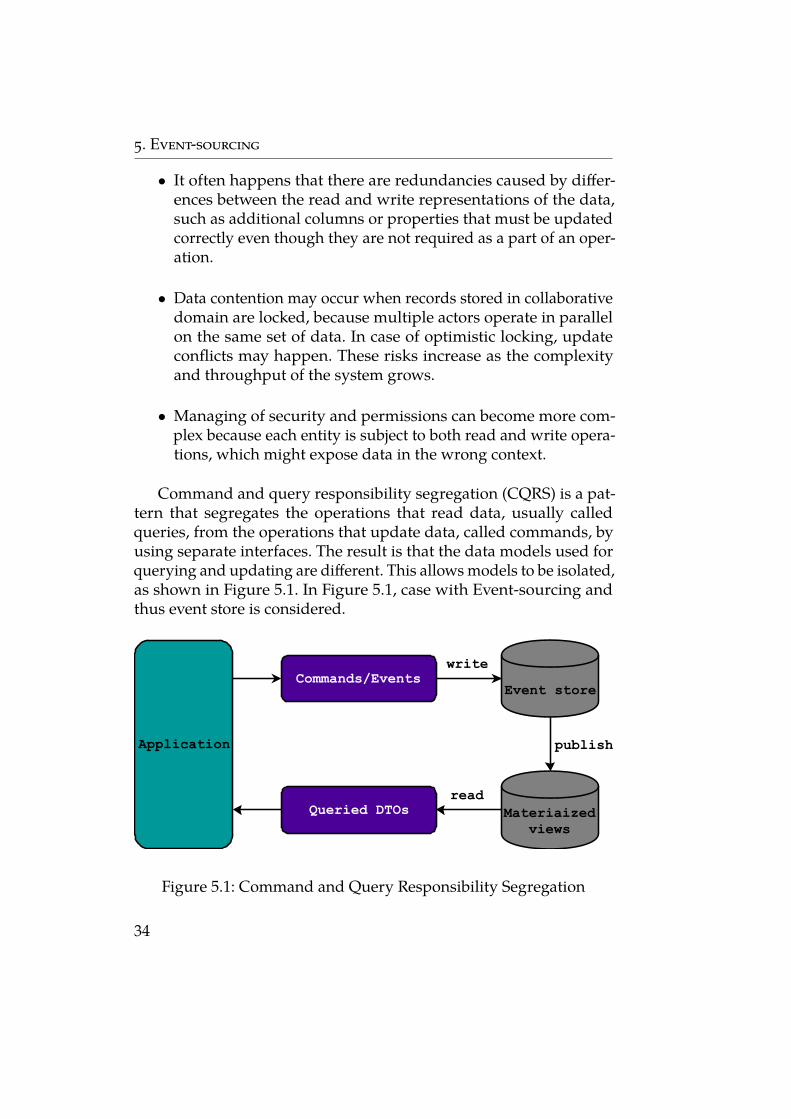
Command and query responsibility segregation (CQRS) is a pat-tern that segregates the operations that read data, usually calledqueries, from the operations that update data, called commands, byusing separate interfaces. The result is that the data models used forquerying and updating are different. This allows models to be isolated,as shown in Figure 5.1. In Figure 5.1, case with Event-sourcing andthus event store is considered.
Event store
Application
Commands/Events write
Queried DTOs read
publish
Materiaizedviews
Figure 5.1: Command and Query Responsibility Segregation
34

5. Event-sourcing
The read data model can be a read-only replica of the write datamodel, or they can have a different structure altogether. Additionally,by using multiple read-only replicas of the read model great increaseof query performance and application User interface responsivenesscan be achieved, especially in distributed scenarios where read-onlyreplicas are located close to the application instances. Some databasesystems provide additional features such as failover replicas to maxi-mize availability.
Separation of the read and write stores also allows each store tobe scaled appropriately to match the load. For example, read storestypically encounter a much higher load than write stores.
A typical approach is to use CQRS with Event-sourcing so that thewrite model is an append-only stream of events driven by executionof commands. These events are used to update materialized views(typically as highly denormalized views) that act as the read model.
There are few issues to mention and consider when using CQRSalong with Event-sourcing [23]:
∙ As with any system where the write and read stores are separate,systems based on this pattern are only eventually consistent.There will be some delay between the event being generated andthe data store being updated.
∙ Using the pattern, a code becomes more complex being able toinitiate and handle events and to assemble or to update the ap-propriate views or objects required by a read model. The CQRStogether with the Event-sourcing pattern can make a success-ful implementation more demanding and must be designedin different way. However, intend of the changes in the data ispreserved thanks to the Event-sourcing, which makes easier tomodel the domain and rebuild views or create new ones.
In our business architecture there is a case when eventually con-sistent state is not acceptable. As example may serve the case, whenassembling of model is started. If there are not all profiles updatedas validated also in read store, assembling would fail. While it is onlyspecial situation, there are few ways how to resolve it. An additionalevent about read model update could be created and published whennecessary or assembling might be retried if it is not started caused
35

5. Event-sourcing
by inconsistency in read model. Another option is to mix usage ofEvent-sourcing with CQRS and traditional relational data storing withtraditional atomic CRUD operations in cases where it fits better.
Even with these additional complexity and issues, described bene-fits of using Event-sourcing and CQRS patterns together would bringwanted value for our microservices architecture.
36

6 From monolith to microservices
While designing new Volt architecture, it is very important to realizethat it will not be developed from scratch. Since Volt has been analready existing functional monolithic application, description of whatto be aware of when breaking a monolith into microservices is worth.
6.1 Considerations and prerequisites
At this state of Volt application, it is very important to realize thatprocess of decomposition of monolith to microservices itself may bringhigh overall cost and may take significant amount of time. Since evenafter considering this as additional disadvantage and closer evaluationof these facts, decomposition is preferable path, there are few moreprerequisites to consider.
The necessity for success with microservices is operational readi-ness maturity whether greenfield services are built or decompositionof an existing system is made. Main requirements are:
∙ On demand access to deployment environment.
∙ Building new kinds of continuous delivery pipelines to indepen-dently build, test, and deploy executable services.
∙ The ability to secure, debug and monitor a distributed architec-ture.
These capabilities imply an important organizational shift – closecollaboration between developers and operations – the DevOpsCul-ture [24]. This collaboration is needed to ensure that provisioningand deployment can be done rapidly, it is also important to ensurequick reaction when monitoring indicates a problem. In particularany incident management needs to involve the development team andoperations, both in fixing the immediate problem and the root-causeanalysis to ensure the underlying problems are fixed. [25]
37

6. From monolith to microservices
6.2 Resilient microservices
Even though microservices architecture isolates failures through de-fined boundaries, there is a high chance of network, hardware, database,or application issues, which will lead to the temporary unavailabilityof a particular service. Unavailability of some service may cause outageof whole application. To avoid or minimize this kind of interruption,there is necessity to build a mechanism for software resilience.
There are so many patterns connected to software fault tolerance,availability, reliability and resilience. Figure 6.1 shows few of thesepatterns divided into 4 groups, which help to achieve:
∙ Loose coupling
∙ Isolation
∙ Latency control
∙ Supervision
Looking at these patterns from different perspectives of view, han-dling of fault, they could be split into another 5 groups [26]:
∙ Detection — Circuit breaker, Timeout, Checksum, Acknowledge-ment, Heartbeat, Leaky bucket, Fail fast
∙ Recovery — Retry, Rollback, Roll-forward, Reset, Failover, Readrepair, Error handler
∙ Treatment — Hot deployments, Small releases
∙ Mitigation — Queue of resources, Fallback, Shed load, Shareload, Deferrable work, Marked data
∙ Prevention — Anti-entropy, Backup request, Diversity, Jitter,Error injection
Description of these patterns could be found in [26]. It would beimpossible and expensive to use all of mentioned patterns. Each ap-plication is different and has own requirements and user’s or client’spriorities, the right resilience mechanism should be designed regard-ing to these requirements and priorities.
38

6. From monolith to microservices
Isolation
Latency Control
Fail Fast
Circuit Breaker
Timeouts
Fan out & quickest reply
Bounded Queues
Shed Load
Bulkheads
Loose Coupling
Asynchronous Communication
Event-Driven
Idempotency
Self-Containment Relaxed Temporal
Constraints
Location Transparency
Stateless
Supervision
Monitor
Complete Parameter Checking
Error Handler
Escalation
Figure 6.1: Patterns for software resilience [26]
Topics as operational readiness maturity, DevOps and designingof fitted resilience mechanism are really important speaking aboutmicroservices architecture and there are lots of articles and videosabout these topics worth exploring, for example DevOps culture byRouan Wilsenach [24], What Is DevOps? [27] by Ernst Mueller and all4 parts of article Patterns for Resilient Architecture by Adrian Hornsby[28]. It was necessary to mention them, but they are out of range ofthis thesis, so they are not further explained or researched.
6.3 Rebuilding
The process of migrating an existing application into microservicesis a form of application modernization. In most cases it is not rec-ommended move to microservices by rewriting the application fromscratch. Instead, it should be incrementally refactored into a set ofmicroservices. As base for this section articles by Chris Richarson [29]
39

6. From monolith to microservices
and post by Zhamak Dehghani [25] serve. There are three strategiesthat could be used for such refactoring [29]:
∙ Implement new functionality as microservices — putting everynew code in a standalone microservice.
∙ Split the presentation components from the business and dataaccess components — splitting the presentation layer from thebusiness logic layers and data access layers.
∙ Convert existing modules in the monolith into services.
Even though all of the mentioned strategies create microservices,first two strategies just prevent monolith to became bigger, only thirdone allows to get rid of monolith itself. So if a goal is to solve problemswith monolith, usage of third strategy, which turns existing moduleswithin the monolith into standalone microservices, is necessary. Witheach new module extracted into a microservice, monolith shrinks.After conversion of enough modules, either the monolith disappearsabsolutely or it becomes small enough to be declared it as just anotherservice.
In Figure 6.2, module extraction and conversion into independentmicroservice is shown. The first step of extracting a module is to definean interface between the module and the monolith, which helps tocreate boundaries between monolith and to-be-extracted module. InFigure 6.2, module Z is a candidate for extraction, thus APIs betweenmodule Z and module Y and between module Z and module X arecreated.
The second refactoring step turns the module into a standaloneservice. To do so, code that enables communication between the mono-lith and the service has to be written. Most known and used ways areevents and REST API.
A large and complex monolithic application usually consists of tensor hundreds of modules, lots of which are candidates for extraction.Figuring out which modules to convert first is often challenging. Beforethose modules which bring the most benefits are converted, the bestway to start is to choose few modules that are easy to extract. Thisapproach helps to become more experienced with microservices ingeneral and the extraction process in particular, easier.
40
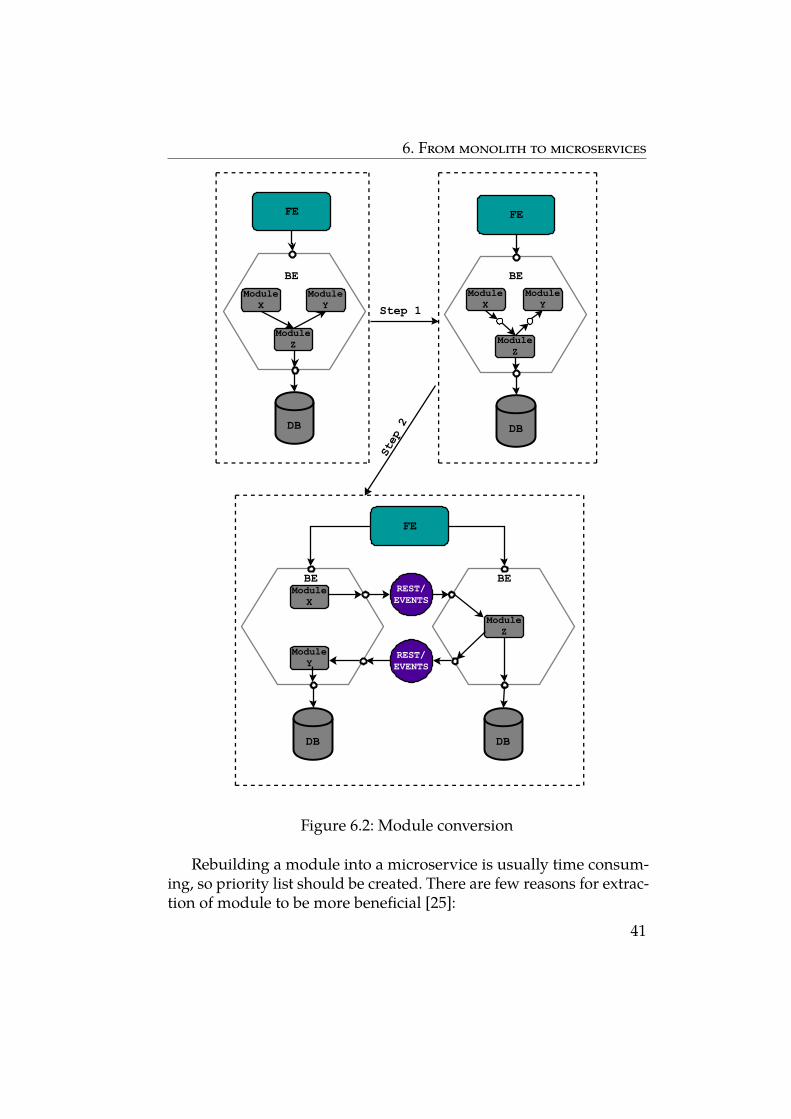
6. From monolith to microservices
BE
ModuleX
ModuleY
ModuleZ
DB
BEModule
XModule
Y
ModuleZ
DB
Step 1
FE FE
BE
DB
BE
ModuleZ
DB
FE
ModuleX
Step 2
ModuleY
REST/EVENTS
REST/EVENTS
Figure 6.2: Module conversion
Rebuilding a module into a microservice is usually time consum-ing, so priority list should be created. There are few reasons for extrac-tion of module to be more beneficial [25]:
41

6. From monolith to microservices
∙ Frequently changing modules — after conversion of a moduleinto a service, it can be developed and deployed independentlyof the monolith, which accelerate the development.
∙ Modules with higher memory requirements — for example,module that has an in-memory database that can be deployedon hosts with larger amounts of memory after conversion intoindependent service.
∙ Modules that implement computationally expensive algorithms— module converted to service could be deployed on host withmore powerful CPU with more threads.
∙ Modules with significantly different storage requirements —new service could use different type of database, for exampleNoSQL MongoDB.
∙ Modules that only communicate with the rest of the applica-tion via asynchronous messages — relatively cheap and easy toconvert into a microservice.
By turning modules with particular resource requirements intomicroservices, application could become much easier to scale.
Often the main motivation of microservices is to have a fast andindependent release cycle. By having dependencies to the monolith(data, logic, APIs), services are coupled to the monolith’s release cycle,that ends up with prohibiting this benefit. Thus, a main principlewhile extracting modules should be to minimize the dependencies ofnewly created microservices to the monolith. One of the major reasonfor moving away from the monolith is expensive and slow refactorof capabilities inside of the monolith. So it is needed to progressivelymove in a direction that unlocks these main capabilities by removingdependencies to the monolith. To ensure that pace of changing newlyformed microservices stays high, a desired state of dependencies isdirection from monolith to microservices.
6.4 Semantic versioning
Another important thing to think about, especially with microservicesarchitecture, is versioning. APIs should stay backwards compatible
42

6. From monolith to microservices
and proper versioning strategy as semantic versioning should be usedto ensure knowledge about risk with version increasing. Semanticversioning, currently the best known and most widely adopted versionscheme, uses a sequence of three digits (X.Y.Z), an optional pre-releasetag and optional build meta tag. In this scheme, risk and functionalityare the measures of significance.
∙ X, major version, high risk — breaking changes with possibleincompatibilities in existing API
∙ Y, minor version, medium risk — new features in a backward-compatible way
∙ Z, patch version, low risk — bugs fixing and all other non-breaking changes
The presence of a pre-release tag (-alpha, -beta) indicates substan-tial risk, as does a major number of zero (0.y.z), which is used toindicate a work-in-progress that may contain any level of potentiallybreaking changes (highest risk).[30]
43

7 Volt with microservices
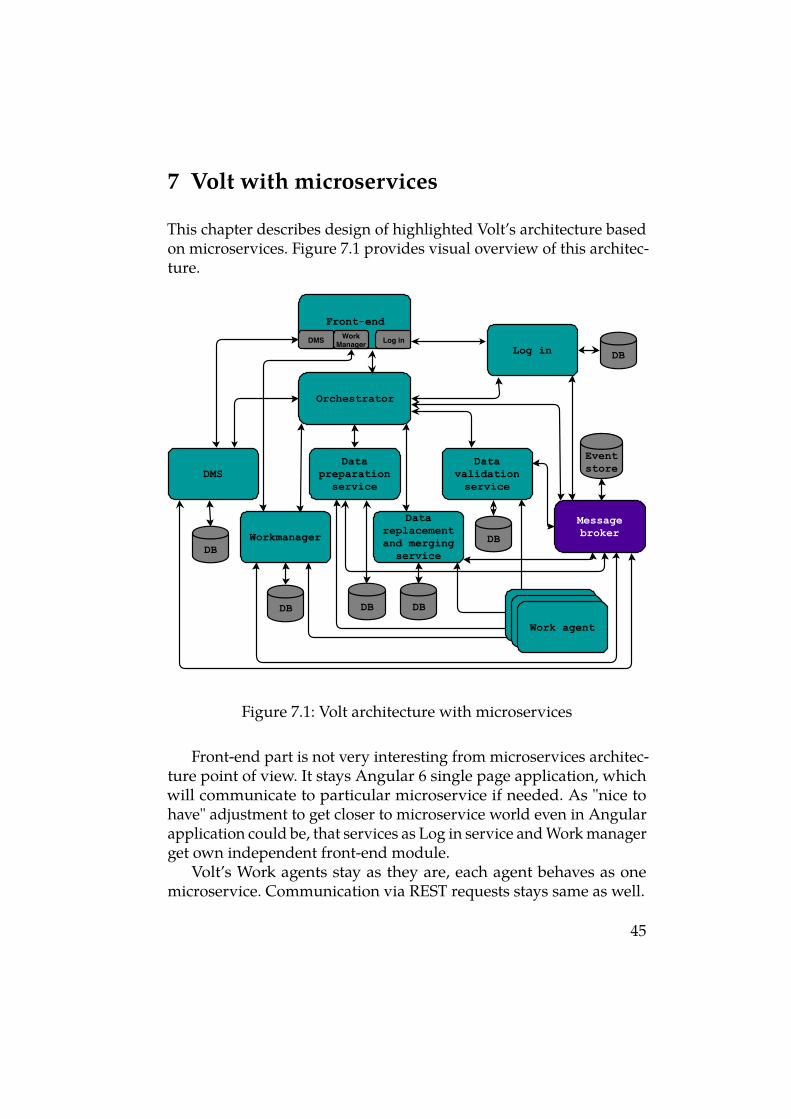
This chapter describes design of highlighted Volt’s architecture basedon microservices. Figure 7.1 provides visual overview of this architec-ture.
Front-end
Orchestrator
WorkManager Log inDMS
DMSData
preparationservice
Login
Workmanager
Datareplacementandmergingservice
Datavalidationservice
DB
DB DB DB
DB
DB
WorkagentWorkagentWorkagent
Messagebroker
Eventstore
Figure 7.1: Volt architecture with microservices
Front-end part is not very interesting from microservices architec-ture point of view. It stays Angular 6 single page application, whichwill communicate to particular microservice if needed. As "nice tohave" adjustment to get closer to microservice world even in Angularapplication could be, that services as Log in service and Work managerget own independent front-end module.
Volt’s Work agents stay as they are, each agent behaves as onemicroservice. Communication via REST requests stays same as well.
45

7. Volt with microservices
7.1 Microservices
Main and the most interesting part described in this chapter is Voltback-end part with microservices architecture. Volt back-end applica-tion will consist of seven independent microservices, each with owndata storage and REST API, by which it communicates to others as wellas to front-end and Work agents. These 7 independent microservices,as Figure 7.1 shows, are:
∙ Orchestrator
∙ Log in service
∙ Document management system
∙ Work manager
∙ Data preparation service
∙ Data validation service
∙ Data replacement and merging service
Services as Document management system, Work manager, Datapreparation service, Data validation service and Data replacementand merging service provide mainly business logic, that is not relevantto architecture itself. Log in services will, as name reveals, take care ofauthentication and authorization of users.
The most decisive service, related to proper implementation of pro-cesses and data consistency, is Orchestrator. This service centralizesof decision making through all Saga-based distributed transactionsand their possible rollbacks. Additionally, Orchestrator will take careof all interactions between back-end and front-end, except front-endinteractions to services, which have own independent front-end mod-ule. If there is in the future demand for detachment of transactionsorchestration and processing of front-end requests based on, for exam-ple size or difficulty of Orchestrator, new service could be introduced.This service would process all front-end requests, which will not havenecessity of distributed transaction.
Microservices will communicate mainly asynchronous way bysubscribing to event channels and by REST requests, which could
46

7. Volt with microservices
be synchronous or asynchronous, depends on concrete suitability.Querying databases and other data stores will be synchronous as well.
7.2 Data storing and data consistency
Since Database per service pattern is crucial for requested indepen-dence of each microservice, there has to be own database, by particularneeds, for all of them (Figure 7.1). To ensure data consistency in suchdistributed microservices of Volt application, orchestration-based Sagatransaction will be used as described in Section 4.2. Reasons why touse orchestration-based instead of choreography-based Saga trans-actions are explained in Section 4.3. Since orchestration-based Sagais based on events, Event-sourcing with Command Query Respon-sibility Segregation will be used in Volt application as well, to takeadvantages, which bring this logical connection. Event-sourcing isfurther explained in Chapter 5. As is written in Section 5.2 eventualconsistency is not suitable for all business cases in Volt application, sotraditional relational model with CRUD operations will be also usedfor suitable entities.
Message broker and event store with cooperation with Orches-trator are the most important part of this Saga-orchestration-event-sourcing based architecture. All listed microservices will be subscribedto message broker’s particular event channel. As was written be-fore, a lot of implementations details depend on chosen platformfor Event-sourcing. In the majority of cases, message broker and eventstores come together. For example, nowadays very popular stream-processing software platform, Apache Kafka, provides immutablecommit log of events, with possibility of subscription, which opensoption to publish data to any number of subscribed services or appli-cations. It also provides durable storage as an event store. In describedarchitecture with CQRS pattern, this durable storage serves as write,but immutable store of events. Then all microservices, with demandof relative information, subscribed to this platform, create own mate-rialized views, as a read store, convenient for own needs. This bringshuge advantage of scalability.
Architecture created of described patterns prevents applicationagainst data inconsistencies, and is able to manage eventually consis-
47

7. Volt with microservices
tent state of data to achieve the best possible performance for usersatisfaction. Furthermore, it offers resilience by possibility of servicesrecovery using Event store.
48

8 Discussion
Architecture of Volt application described in Chapter 7 will serve asprototype for Volt’s rebuilding. As was mentioned in Chapter 6, re-building monolith to microservices is an iterative process and sinceVolt is being developed by agile methodology (agile methodology andScrum are huge topics themselves worth for another theses), require-ments and details may change over time. This is reason, why moredetailed description is not necessary.
However, there are lots of topics which are needed to focus onbefore beginning of the rebuilding process. These topics could begood content of another bachelor or master thesis. Some of them werealready mentioned, but summarizing would be worthy. One of themain decision to make is a choice of events storing strategy, messagebroker and storage itself. Some notes could be found in Section 5.1.In Chapter 7, Apache Kafka serves as an example. It is, however, justone of several possibilities. After that, consideration about whereto use CQRS to improve performance should take place, changes todata model are probable to reach perfect usage of CQRS and Event-sourcing. Furthermore, replacement of relational database for servicesas DMS, where different kind of data storage would be more suitable,is appropriate.
Last but not least, operational readiness maturity and DevOps atti-tude (Section 6.1) as well as designing of resilience and fault tolerancemechanism (Section 6.2) are very important to manage before journeyto microservices architecture.
Moreover, there are, of course, lots of other decisions to make. Onthe one hand, management issues with splitting and managing ofmore teams working on one application. On the other hand decisionsconnected to technology and patterns used with such an architecturestack. For example, authentication and authorization of users amongthe microservices are other huge topics. Additional information aboutauthentication and authorization in microservices architecture is avail-able in articles by Mina Ayoub [31] and by Omar Elgabry [32].
However, achieved goal of this thesis was to choose and properlyconnect patterns to design architecture to ensure desired level of dataconsistency for Volt application with microservices.
49


Conclusion
The goal of this thesis was to design and describe software architecturebased on microservices, for already being developed Volt application.The created architecture is focused on data consistency in distributedworld of microservices as well as on application scalability, reliabilityand flexibility.
At the beginning of the thesis, the Volt application with its currentstate of monolithic application is introduced. Both points of view areconsidered, business and software architecture. Subsequently, reasons,why this state is not suitable anymore are listed. Often adjusted generalmodules, called Canvas modules, ineffectiveness caused by too bigteam and already functional Volt’s workflow based on events werecrucial.
Major part of the thesis focuses on general information and the-oretical knowledge about technologies and patterns used in final ar-chitecture proposal. First of all, microservices with their advantagesand disadvantages are described, followed by comparison with mono-lithic style of software architecture. To emphasize problem of dataconsistency in such distributed system, Database per service pattern,for data storing is mentioned.
As a solution for this problem, Saga transactions with two pos-sible implementations are specified. Both implementations of suchtransactional management are supplemented by examples and figures.Furthermore, since orchestration-based Saga transactions, which applyevents as fundamentals, shows to fit better for designed Volt’s architec-ture, usage of Event-sourcing is beneficial. It allows service recoveryafter failure or correction of past event by replaying stored event. Im-portance of event store choice and storing strategy is explained. To takefull advantage of logical connection between orchestration-based Sagatransactions and Event-sourcing, Command and query responsibilitysegregation pattern is introduced to ensure user satisfied performanceof displaying computed data.
Moreover, there are few essential topics connected to microservicesbeside architecture itself. Prerequisites, as operational readiness ma-turity and understood DevOps approach as well as creating sufficientand suitable fault tolerance mechanism are crucial for developing
51

8. Discussion
functional and resilient application with microservices architecture.In addition, realization of fact that application is meant to be rebuiltinstead of implemented from "green field" is also important. Success ispreceded by designing convenient iterative strategy for converting themonolith into microservices. Consideration of most widely adoptedsemantic versioning for every new created microservice is suggested.
Eventually, Chapter 7 is describing the final proposal of micro-service-based architecture designed by using all mentioned technolo-gies and patterns to achieve desired software architecture for Voltapplication. Particular microservices are introduced with main focuson Orchestrator service as the central of distributed Saga transactions.In addition, data storing and data consistency in connection withEvent-sourcing are mentioned. Proposal is completed by figure ofsuch architecture.
At the end, a small discussion is written, about what is necessaryto focus on before the process of rebuilding Volt into microservices.After that, the architecture created in this thesis could be used for Voltconverting or as an prototype for any other rebuilding of monolithicapplication or for brand-new scalable, reliable, resilient application.
52

Bibliography
1. ALLIANCE, Agile. What is Agile? [online]. 2019 [visited on 2019-16-04].Available from: https://www.agilealliance.org/agile101/.
2. JAMES, Michael. An Empirical Framework For Learning [online]. 2019[visited on 2019-16-04]. Available from: http://scrummethodology.com/.
3. LEWIS, James; FOWLER, Martin. Microservices [online]. 2014 [vis-ited on 2019-07-04]. Available from: https://martinfowler.com/articles/microservices.html.
4. RICHARDSON, Chris. What are microservices? [online]. 2018 [visitedon 2019-07-04]. Available from: https://microservices.io/.
5. WILSON, Victoria. 10 Cloud Computing Statistics You Need To Know[online]. 2018 [visited on 2019-07-04]. Available from: https://www . sysgroup . com / resources / blog / 10 - cloud - computing -statistics-2018.
6. PEYROTT, Sebastian. An Introduction to Microservices, Part 1 [online].2015 [visited on 2019-08-04]. Available from: https://auth0.com/blog/an-introduction-to-microservices-part-1.
7. MAK, Sander. Modules vs. microservices [online]. 2017 [visited on 2019-08-04].Available from: https://www.oreilly.com/ideas/modules-vs-microservices.
8. RICHARDSON, Chris. Pattern: Database per service [online]. 2018 [vis-ited on 2019-08-04]. Available from: https://microservices.io/patterns/data/database-per-service.html.
9. GONCHAR, Grygoriy. Data consistency in microservices architecture [on-line]. 2018 [visited on 2019-08-04]. Available from: https://ebaytech.berlin/data- consistency- in- microservices- architecture-bf99ba31636f.
10. PEYROTT, Sebastian. An Introduction to Microservices, Part 4 [online].2015 [visited on 2019-08-04]. Available from: https://auth0.com/blog/introduction-to-microservices-part-4-dependencies/.
53

BIBLIOGRAPHY
11. ROSA, Denis. How to implement business transactions using Microservices– Part I [online]. 2018 [visited on 2019-08-04]. Available from: https://blog.couchbase.com/saga- pattern- implement- business-transactions-using-microservices-part/.
12. ROSA, Denis. How to implement business transactions using Microservices– Part II [online]. 2018 [visited on 2019-08-04]. Available from: https://blog.couchbase.com/saga- pattern- implement- business-transactions-using-microservices-part-2/.
13. RICHARDSON, Chris. Pattern: Saga [online]. 2018 [visited on 2019-07-04].Available from: https://microservices.io/patterns/data/saga.html.
14. RÜCKER, Bernd. Saga: How to implement complex business transactionswithout two phase commit. [online]. 2017 [visited on 2019-07-04]. Avail-able from: https://blog.bernd- ruecker.com/saga- how- to-implement-complex-business-transactions-without-two-phase-commit-e00aa41a1b1b.
15. GARCIA-MOLINA, Hector; SALEM, Kenneth. Sagas. SIGMOD Rec.1987, vol. 16, no. 3, pp. 249–259. ISSN 0163-5808. Available fromDOI: 10.1145/38714.38742.
16. EVENTUATE. Event Sourcing [online]. 2019 [visited on 2019-08-04].Available from: https://eventuate.io/whyeventsourcing.html.
17. FOWLER, Martin. Event Sourcing [online]. 2005 [visited on 2019-08-04].Available from: https://martinfowler.com/eaaDev/EventSourcing.html.
18. RICHARDSON, Chris. Pattern: Event sourcing [online]. 2018 [visited on2019-08-04]. Available from: https://microservices.io/patterns/data/event-sourcing.html.
19. WARSKI, Adam. Event Sourcing using Kafka [online]. 2018 [visited on2019-08-04]. Available from: https://blog.softwaremill.com/event-sourcing-using-kafka-53dfd72ad45d.
20. HAMMARBÄCK, Jesper. Apache Kafka is not for Event Sourcing [online].2018 [visited on 2019-08-04]. Available from: https://medium.com/serialized- io/apache- kafka- is- not- for- event- sourcing-81735c3cf5c.
54

BIBLIOGRAPHY
21. HARSANYI, Teiva. 1 Year of Event Sourcing and CQRS [online]. 2018[visited on 2019-18-04]. Available from: https://hackernoon.com/1-year-of-event-sourcing-and-cqrs-fb9033ccd1c6.
22. MORRIS, Ben. Designing an event store for scalable event sourcing [on-line]. 2016 [visited on 2019-08-04]. Available from: https://www.ben- morris.com/designing- an- event- store- for- scalable-event-sourcing/.
23. WASSON, Mike et al. Command and Query Responsibility Segregation[online]. 2017 [visited on 2019-16-04]. Available from: https://docs.microsoft.com/en-us/azure/architecture/patterns/cqrs.
24. WILSENACH, Rouan. DevOpsCulture [online]. 2015 [visited on 2019-16-04].Available from: https://martinfowler.com/bliki/DevOpsCulture.html.
25. DEHGHANI, Zhamak. How to break a Monolith into Microservices [on-line]. 2018 [visited on 2019-16-04]. Available from: https://martinfowler.com/articles/break-monolith-into-microservices.html.
26. FRIEDRICHSEN, Uwe. Towards a resilience pattern language [online].2016 [visited on 2019-08-04]. Available from: http : / / bed- con .org/2016/files/slides/bedcon_2016_resilience_pattern_language.pdf.
27. MUELLER, Ernest. What Is DevOps? [online]. 2010 [visited on 2019-08-04].Available from: https://theagileadmin.com/what-is-devops.
28. HORNSBY, Adrian. Patterns for Resilient Architecture [online]. 2018 [vis-ited on 2019-08-04]. Available from: https://medium.com/@adhorn/patterns-for-resilient-architecture-part-1-d3b60cd8d2b6.
29. RICHARDSON, Chris. Refactoring a Monolith into Microservices [on-line]. 2016 [visited on 2019-08-04]. Available from: https://www.nginx.com/blog/refactoring-a-monolith-into-microservices.
30. HOODA, Parikshit. Introduction to Semantic Versioning [online] [visitedon 2019-08-04]. Available from: https://www.geeksforgeeks.org/introduction-semantic-versioning.
31. AYOUB, Mina. Microservices Authentication and Authorization Solutions[online]. 2018 [visited on 2019-05-05]. Available from: https://medium.com/tech-tajawal/microservice-authentication-and-authorization-solutions-e0e5e74b248a.
55

BIBLIOGRAPHY
32. ELGABRY, Omar. Microservices with Spring Boot — Authentication withJWT (Part 3) [online]. 2018 [visited on 2019-05-05]. Available from:https://medium.com/omarelgabrys-blog/microservices-with-spring-boot-authentication-with-jwt-part-3-fafc9d7187e8.
56