cost-optimal aws deployment configuration for ... - is muni
TRANSCRIPT

Masaryk UniversityFaculty of Informatics
Cost-optimal AWS DeploymentConfiguration for
Containerized Event-drivenSystems
Master’s Thesis
Martin Sisák
Brno, Spring 2021

Masaryk UniversityFaculty of Informatics
Cost-optimal AWS DeploymentConfiguration for
Containerized Event-drivenSystems
Master’s Thesis
Martin Sisák
Brno, Spring 2021

This is where a copy of the official signed thesis assignment and a copy of theStatement of an Author is located in the printed version of the document.

Declaration
Hereby I declare that this paper is my original authorial work, whichI have worked out on my own. All sources, references, and literatureused or excerpted during elaboration of this work are properly citedand listed in complete reference to the due source.
Martin Sisák
Advisor:Mgr. Kamil Malinka, Ph.D.
i

Acknowledgements
First, I would like to thank my parents for their love and supportduring my studies, because without them I would not make it, as theyhave stood by me no matter what.I would like to thank my academic advisor Mgr. Kamil Malinka, Ph.D.for his good advice and willingness to help during the whole year.And last but not least, I would like to thank my colleague, friend andconsultant of this thesis Mgr. Tomáš Sezima, for his good advice andhelpfulness throughout the year.
ii

Abstract
This thesis aims to find cost optimal deployment configuration forcloud hosted, containerized, non-uniformly utilized event driven sys-tems. The motivation behind this thesis is that such systems are stillchallenging to be designed cost-efficiently, mostly because of complexpricing schemes that reflect cloud intrinsic limitations. First part ofthe thesis introduce the general context of cloud computing, togetherwith the key areas of interest that have the biggest impact on the re-sulting costs. As this thesis is focused on the AWS cloud, in next partare described AWS services that contributes to the cost of proposedsolution. Based on such gathered knowledge, a decision tree appa-ratus is introduced, aimed to help finding the most performant andcost-optimal solution. With an application of proposed methodology,AWS deployment configuration is designed and implemented as aninfrastructure scheme prototype for running the event-driven con-tainerized workloads in AWS. At the end, performance and cost ofproposed solution is measured and confronted with the expectations.
iii

Keywords
cloud computing, cost optimization, AWS, Infrastructure as a Code
iv

Contents
Introduction 1
1 Problem definition 21.1 Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Requirements . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Background 42.1 Cloud computing . . . . . . . . . . . . . . . . . . . . . . 42.2 Serverless computing . . . . . . . . . . . . . . . . . . . . 72.3 Event-driven architecture and microservices . . . . . . 82.4 Containerization . . . . . . . . . . . . . . . . . . . . . . . 92.5 Container orchestration . . . . . . . . . . . . . . . . . . 10
3 General cost-optimization strategies 123.1 General principles . . . . . . . . . . . . . . . . . . . . . . 123.2 Compute . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1 On-demand vs. Reserved instances . . . . . . . . 143.2.2 Spare capacity . . . . . . . . . . . . . . . . . . . . 153.2.3 Overprovisioning and rightsizing . . . . . . . . 163.2.4 Idle resources . . . . . . . . . . . . . . . . . . . . 173.2.5 Autoscaling . . . . . . . . . . . . . . . . . . . . . 18
3.3 Networking . . . . . . . . . . . . . . . . . . . . . . . . . 18
4 AWS cost-optimization considerations 214.1 General principles . . . . . . . . . . . . . . . . . . . . . . 214.2 AWS account . . . . . . . . . . . . . . . . . . . . . . . . . 224.3 Compute . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.3.1 AWS operational responsibility model . . . . . . 234.3.2 Amazon EC2 . . . . . . . . . . . . . . . . . . . . 234.3.3 Amazon EKS . . . . . . . . . . . . . . . . . . . . 284.3.4 Amazon ECS . . . . . . . . . . . . . . . . . . . . 294.3.5 Comparison of Amazon EKS and ECS . . . . . . 314.3.6 AWS Fargate . . . . . . . . . . . . . . . . . . . . . 324.3.7 Comparison of EC2 and Fargate . . . . . . . . . 354.3.8 AWS Lambda . . . . . . . . . . . . . . . . . . . . 35
4.4 Networking . . . . . . . . . . . . . . . . . . . . . . . . . 44
v

4.4.1 AWS Regions and Availability Zones . . . . . . . 444.4.2 Amazon Virtual Private Cloud . . . . . . . . . . 454.4.3 NAT Gateway . . . . . . . . . . . . . . . . . . . . 464.4.4 AWS PrivateLink and VPC endpoints . . . . . . 474.4.5 Amazon Elastic Container Registry . . . . . . . . 484.4.6 Data transfer . . . . . . . . . . . . . . . . . . . . 49
4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5 AWS deployment schemes 505.1 Workload types . . . . . . . . . . . . . . . . . . . . . . . 505.2 Workload orchestration . . . . . . . . . . . . . . . . . . . 515.3 Networking . . . . . . . . . . . . . . . . . . . . . . . . . 515.4 AWS Step Functions . . . . . . . . . . . . . . . . . . . . . 525.5 Amazon EC2 . . . . . . . . . . . . . . . . . . . . . . . . . 525.6 Amazon EKS - EC2 integration . . . . . . . . . . . . . . 535.7 Amazon ECS - EC2 integration . . . . . . . . . . . . . . 545.8 Amazon EKS - Fargate integration . . . . . . . . . . . . 545.9 Amazon ECS - Fargate integration . . . . . . . . . . . . 555.10 AWS Lambda . . . . . . . . . . . . . . . . . . . . . . . . 565.11 Decision trees . . . . . . . . . . . . . . . . . . . . . . . . 57
5.11.1 Compute . . . . . . . . . . . . . . . . . . . . . . . 585.11.2 Networking . . . . . . . . . . . . . . . . . . . . . 62
5.12 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6 Interpretation of findings 686.1 Application of methodology . . . . . . . . . . . . . . . . 68
6.1.1 Compute . . . . . . . . . . . . . . . . . . . . . . . 686.1.2 Networking . . . . . . . . . . . . . . . . . . . . . 68
6.2 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . 69
7 Implementation 727.1 Infrastructure as a Code . . . . . . . . . . . . . . . . . . 72
7.1.1 AWS CloudFormation . . . . . . . . . . . . . . . 727.1.2 AWS Cloud Development Kit . . . . . . . . . . . 73
7.2 Description of implementation of AWS Lambda solution 747.3 Workflow . . . . . . . . . . . . . . . . . . . . . . . . . . . 797.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . 80
vi

8 Cost evaluation 818.1 Cost evaluation methods . . . . . . . . . . . . . . . . . . 81
8.1.1 Analytical methods . . . . . . . . . . . . . . . . . 818.1.2 Holistic methods . . . . . . . . . . . . . . . . . . 82
8.2 Performance and Cost evaluation . . . . . . . . . . . . . 828.2.1 AWS Lambda solution . . . . . . . . . . . . . . . 828.2.2 AWS EKS with Fargate launch type solution . . 868.2.3 Conclusion . . . . . . . . . . . . . . . . . . . . . 88
9 Discussion 90
Bibliography 92
vii

List of Tables
3.1 Qualitative comparison between on-demand an reservedinstances [26]. 15
4.1 vCPU and memory combinations available for Pods runningon Fargate using EKS [68] 33
viii

List of Figures
2.1 Popularity of the term "serverless computing" reported viaGoogle Trends 7
2.2 Using Virtual Machines vs. using containers to isolateapplications [14] 10
3.1 Overprovisioning of cloud resources [34] 173.2 AWS 2021 Global infrastructure map [43] 204.1 Amazon Web Services operational responsibility model of
compute services [47] 234.2 EC2 instance types categorized by their processor type and
by their ideal general use case [48] 264.3 Amazon EKS workflow [55] 284.4 Amazon ECS workflow [59] 304.5 ECS scheme with both Fargate and EC2 launch types 334.6 Isolation model for the AWS Lambda [80] 384.7 Cold start durations per image extra size [82] 405.1 Decision tree aimed to help with choosing the most suitable
AWS compute service for different types of workload 585.2 Ratio between price and amount of invocations per hour for
the short-lived workload using AWS Lambda and AWSFargate 61
5.3 Ratio between price and increasing amount of requestedresources in AWS Lambda and AWS Fargate 62
5.4 Difference between routing traffic through AWS PrivateLinkand NAT Gateway 63
5.5 Decision tree aimed to help with choosing the most suitableAWS networking service for different types of workload 66
7.1 AWS VPC Resource defined in the CloudFormationtemplate 73
7.2 Cloud Development Kit scheme of presented solution 767.3 Architectural scheme of presented solution 787.4 Workflow diagram of the presented solution 798.1 AWS CloudWatch log stream containing logs of an AWS
Lambda function 83
ix

8.2 Log record of one invocation of a Lambda functioninstance 84
8.3 Architectural scheme of the AWS EKS with Fargate launchtype solution 86
8.4 Execution time of containerized workload in AWS EKS withFargate launch type using AWS Step Functions 87
8.5 Number of invocations of tested AWS Lambda function 88
x

Introduction
Throughout the last decade cloud computing allowed for dramaticcost reductions thanks to serverless offerings that go hand in handwith the pay-per-use pricing model. This masters thesis aims to findcost-optimal deployment configuration for cloud hosted, container-ized, non-uniformly utilized event-driven systems.
There is a large amount of subjects and inputs that have an impacton the solution to this type of a problem. The goal of this thesis isto first describe the context from the general point of view of cloudcomputing, find out what needs to be taken into consideration to comeup with the cost optimal solution, and demonstrate feasibility of pro-posed methodology on the practical proof of concept, through thelargest cloud service provider: Amazon Web Services (AWS).
Since there is very little distinguishing one cloud provider fromanother [1], an attempt has been made to keep the thesis as genericas possible, making it potentially also useful for readers who prefer,for example Microsoft Azure over AWS. Moreover, since pricing ofindividual AWS services changes on daily basis, distilled recommen-dations are more reflective to modern trends than to concrete pricinglists.
The added value of this thesis is to have the requirements, inputs,and boundaries, that affects the cost and performance of these typeof systems, summarized and described in one place. Together withthe working proof of concept, implemented through the largest cloudprovider on the current market, it would be possible to find the costoptimal solution, based on the system inputs defined by the user.
1

1 Problem definition
This diploma thesis strives to formalize a cost optimal AWS deploy-ment configuration for event-driven containerized workloads. How-ever, cost optimality must not be achieved at the expense of cleansolution design, supported by industry best practices, making theproblem hard to be formalized. This Chapter provides the contextof the problem, its background and requirements placed upon thedesired solution.
1.1 Context
This diploma thesis is being developed in cooperation with the com-pany Datamole. Story behind the problem comprises of so-called Datato Information (D2I) algorithms, data processing pipelines responsi-ble for analytics over sensor data produced by electron microscopes.Such Python (Pandas) extract - transform - load (ETL) microservicesare designed as event-driven, stateless, containerized workloads, al-lowing for great level of freedom when deciding on where and how itshould be hosted.
At this moment, D2I pipelines are hosted by an on-premise infras-tructure that is reaching its limits. Therefore, decision has beenmade toinvestigate cloud deployment options, while having the price in mindas a decision driving force. That said, the biggest challenge behindthis problem is to make a research of cloud-agnostic cost optimizationstrategies in the various cloud environment key fields, investigate rel-evant AWS services which could possibly contribute to the solutionand come up with several AWS design patterns, for running the event-driven containerized workloads in AWS cloud. As the outcome of thisthesis, one deployment configuration will be chosen and confrontedwith the requirements placed upon the desired system. As a proof ofconcept, this solution will be implemented and deployed into the AWScloud environment. For proving the feasibility and cost-efficiency ofthe chosen solution, a cost evaluation process will be placed upon it.
In summary, this diploma thesis should provide the cost-efficientsolution for running the event-driven containerizedworkloads in AWScloud environment, which would be adhering the AWS best practices
2

1. Problem definitionand guidelines, and would fulfill the system requirements placedupon it, which are being described in the following section.
1.2 Requirements
The aim of this thesis is to expose architecture design principles tobe followed when striving for a cost optimal cloud deployments. Par-ticularly, deployment configuration has to be found for a category ofsystems that share following properties:
• System comprises of distributed, containerized, loosely coupledworkloads
• Such services are stateless, idempotent and horizontally scal-able by design
• Load placed upon the system is non-uniform, system compo-nents might be idle for prolonged period of time
• Container management must rely on some "off the shelf" or-chestrator
• Containers’ CPU and memory demands are known prior todeployment, workload takes typically couple of seconds tocomplete
• Communication betweenmicroservices is event-based, servicesare out-of-order & at-least-once delivery tolerant
• Workloads are not Internet facing, Internet connectivity is, how-ever, needed
• For sake of simplicity system does not integrate with monitor-ing, tracing and/or logging services
Since an operational burden associated with the currently used on-premise infrastructure stood behind many customer-facing problems,it has been emphasized that serverless solution is preferred over man-ually maintained deployment schemes, if price allows.
3

2 Background
There are several technical areas this thesis is dealing with. It spansmultiple domains, from cloud computing and serverless computing,through event-driven architecture and microservices, to containeriza-tion and container orchestration. Therefore, for better understandingof the context, the following Chapter aims to provide the basic intro-duction to each of these areas.
2.1 Cloud computing
Cloud computing has shaped the way in which software and IT in-frastructure are used by consumers. Since its emergence, industry or-ganisations, governmental institutions, and academia have embracedit and its adoption has seen a rapid growth. Cloud computing hasenabled new businesses to be established in a shorter amount of time,has facilitated the expansion of enterprises across the globe, has ac-celerated the pace of scientific progress, and has led to the creation ofvarious models of computation for pervasive and ubiquitous applica-tions, among other benefits, says the manifesto from Association forComputing Machinery [2].
National Institute of Standards and Technology defined cloud com-puting as a model for enabling ubiquitous, convenient, on-demandnetwork access to a shared pool of configurable computing resources(e.g., networks, servers, storage, applications, and services) that canbe rapidly provisioned and released with minimal management effortor service provider interaction [3].
There are five essential characteristics of cloud computing de-scribed in the NIST article:
• On-demand self-service: A consumer can provision cloud re-sources as needed, without requiring human interaction witheach service provider.
• Broad network access: Cloud resources are available and ac-cessible over the network.
4

2. Background• Resource pooling: Cloud providers computing resources are
pooled to serve multiple consumers, with different physicaland virtual resources dynamically assigned and reassignedaccording to consumer demand.
• Rapid elasticity: Resources can be elastically provisioned andreleased (in some cases automatically), to satisfy consumersfluctuating demand.
• Measured service: Usage of cloud resources can be monitored,controlled, and reported, providing transparency for both theprovider and consumer of the utilized service.
The aforementioned model, described by NIST, is composed of threeservice models:
• Software as a Service (SaaS): SaaS offers the highest level ofabstraction and allows users to access applications runningon cloud infrastructure [2]. The applications are accessiblethrough e.g. web browser, or program interface. User does notmanage or control the underlying cloud infrastructure [3]. SaaSapplications are for example Dropbox1 or Slack2.
• Platform as a Service (PaaS): This model is tailored for usersthat require more control over their IT resources [2]. User doesnot manage or control the underlying cloud infrastructure, buthas control over the deployed applications and possibly overconfiguration settings for the application-hosting environment[3]. PaaS providers are for example Openshift3 or Heroku4.
• Infrastructure as a Service (IaaS): IaaS allows user to accessand control computing resources, such as processing, storagesand networks, where user is able to deploy and run arbitrarysoftware [3]. This model is not only the foundation for SaaSand PaaS, but it has also been the pillar of cloud computing in
1. https://dropbox.com2. https://slack.com3. https://openshift.com4. https://heroku.com
5

2. Backgroundgeneral [2]. The examples of IaaS providers are Amazon WebServices (AWS)5 or Microsoft Azure6.
According to the NIST definition of cloud computing [3], definedcloud model is composed of four deployment models.
First is referred to as a private cloud, which is aimed to be used bya single organization comprising multiple consumers, e.g. businessunits.
Second model is described as a community cloud, and it is meantto be used exclusively by a specific community of consumers fromorganizations that have shared concerns.
Both private and community cloud can be owned, managed andoperated by one or more of the organizations, a third party, or somecombination of them. They may exist on premises, which are by defi-nition operated and maintained within (or in proximity to) the userorganization [4], or off premises. On-premise and serverless solutionswill be discussed more in the next section.
Third deployment model is public cloud. Its infrastructure is pro-visioned for open use by the general public. Public clouds can saveusers from the expensive costs of having to purchase, manage, andmaintain on-premises hardware and application infrastructure - thecloud service provider is held responsible for all management andmaintenance of the system [5]. Top three public cloud providers areAmazon Web Services (AWS), Microsoft Azure and Google CloudPlatform (GCP), where AWS is particularly dominant on the market[6]. This thesis is focused on services and solutions offered by publiccloud providers, together with working model demonstrated throughAWS.
There also exists a possibility of having the hybrid cloud, which isa composition of two or more distinct cloud infrastructures (private,community, or public), that remain unique entities, but are boundtogether by some standardized or proprietary technology [3].
5. https://aws.amazon.com6. https://azure.microsoft.com/
6

2. Background
2.2 Serverless computing
There are different ways of how to approach the server architecture.On the one hand, there is an on-premise approach. Servers are locatedon the premises of the company. That means a physical server hostedat the company, or a data center the company has their servers at. Inthis setup, the company has full responsibility of all the security as-pects and maintenance, but has the full control over the infrastructure[7].
As it was mentioned in the Chapter 1, throughout the last coupleof years, a new and compelling paradigm for the deployment of cloudapplications has been emerging, called serverless computing. It hasbeen largely due to the recent shift of enterprise application archi-tectures to containers and microservices [8] (discussed more in thenext sections). This claim can be substantiated by report from GoogleTrends, showing increasing popularity of term "serverless computing"over the last five years:
Figure 2.1: Popularity of the term "serverless computing" reported viaGoogle Trends
According to the researchers [8], despite of using the word "server-less", servers are still needed, developers just do not need to concernthemselves with managing them. Decisions, such as the number ofservers and their capacity, are taken care of by the serverless platform,with server capacity automatically provisioned as needed by the work-load. This provides an abstraction where computation (in the form ofa stateless function) is detached from where it is going to run.
Serverless are in fact a sub-category of cloud solutions. A differencebetween cloud and serverless solutions is that with cloud, user have
7

2. Backgroundhis own server, albeit a virtual one. In a serverless solution he has not.
In a serverless solution, the code is triggered by events. Instead ofmaintaining a server, it is possible to upload the code to the cloud andlet it trigger each function based on events, such as someone upload-ing a file to a storage [7]. The event-driven architecture is describedmore in the section 2.5.
Serverless can also be called Function as a Service, or FaaS. Twopopular examples are AWS Lambda and Google Cloud Functions [7].
Serverless delivers exact units of resources in response to a demandfrom the application. With traditional cloud computing, the computerresources are dedicated to user whether he is using them or not whilewith serverless, one can dynamically pull only what he needs from avast ocean of resources [9].
2.3 Event-driven architecture and microservices
There are a lot of architecture patterns, that are used to organize soft-ware systems. For sake of the thesis, only event-driven, loosely coupledmicroservices are considered. This section describes more the event-driven architecture, microservices and how these paradigms can beused together. As the AIP Conference Proceedings publication says[10], microservices and event-driven architecture are preferred tech-niques for implementing modern scalable cloud applications.
"Microservices are an architectural pattern that structures an ap-plication as a collection of small, loosely coupled services that operatetogether to achieve a common goal. Because they work independently,they can be added, removed, or upgraded without interfering withother applications" [11].
An event-driven architecture (EDA) is distributed asynchronousarchitecture pattern, comprised by a set of high-cohesive components,that asynchronously react to events to perform a specific task [12].
According to this publication [10], in EDA, each microservice pub-lishes an event when something notable happens. The other microser-vices subscribe to the events, which they are interested to. An eventcan be defined as a significant change in state. Events can be used toimplement business transactions that span multiple services. Trans-actions can be represented by a series of steps where each step is a
8

2. Backgroundmicroservice, which updates or creates a business entity and publishesan event that triggers the next step.
In other words, event-driven microservices allow for real-time mi-croservices communication, enabling data to be consumed in the formof events before they’re even requested [11].
Since components of the system whose deployment configurationis being sought have known and finite life-span, they could be alsoregarded to as tasks or jobs. By definition, job can be referred as a "unitof work" - generally either a "task" or a "service" [13].
Requirements formulated in the Chapter 1 also mention expectedsystem utilization, stating that the load has non-uniform distribution.In context of event-driven system, a fact is being emphasized thatthere might be prolong periods of time where no messages are beingexchanged, possibly for hours or even days.
2.4 Containerization
The key challenge when deploying an application is to assure thattarget host environment share the configuration with the environmentused during development and/or testing. For this reason, multiplecontainerization strategies have been implemented that allow for seam-less portability. As a first attempt, virtualization has been introducedthat allowed (micro)services to run in a dedicated, portable operatingsystem. However, this solution has a weakness in scaling, which iswhy an abstraction on process level called containerization found itsway into application management mainstream.
A process running in container runs inside the hosts OS, like allthe other processes, but it is still isolated from other processes. Fromthe process perspective, it looks like it is the only one running processon the host machine [14].
9

2. Background
Figure 2.2: Using Virtual Machines vs. using containers to isolateapplications [14]
To wrap it up, a container is single isolated process running in thehost OS, consuming only the resources that the application runningin the container consumes, without the overhead of any additionalprocesses [14].
To reduce the space of possible cost-optimization strategies, dis-cussed systems from the Chapter 1 are expected to be composed ofDocker containers only. According to the survey [15], 92 percent ofworkloads managed by major cloud providers rely on Docker. Dockerwas also voted as number two (right after Linux) in ’Most Loved’ andnumber one among ’Most Wanted’ platforms in the 2020 StackOver-flow Survey [16]. Taking these facts into account, such simplificationseems reasonable.
2.5 Container orchestration
Containerized applications are in majority being deployed on a clus-ter of compute nodes, rather than on a single machine. As organi-zations are increasingly relying on containerization technology to
10

2. Backgrounddeploy diverse workloads, it creates the need for container orches-tration middleware [17]. Container orchestration makes it possibleto define how to select, deploy, monitor, and dynamically controlthe containerized systems and applications [18]. These orchestrationplatforms are responsible for managing and deploying the variousdistributed applications packaged as containers efficiently on a set ofhosts [17].
As the survey shows, Kubernetes is by far the most widely used or-chestration platform [19]. Major public cloud providers are followingthe trend, offering services to manage Kubernetes environments, forexample AWS Elastic Kubernetes Service, Google Kubernetes Engineor Azure Kubernetes Service.
However, competing orchestrators, especially those that offer seam-less cloud integration, are becoming more and more popular [19].Amazon Elastic Container Service, Google Container Engine andAzure Container Service are taking prominent places among the con-tainer orchestrators used by various organizations. With this in mind,these services are also need to be considered in finding the cost optimalsolution.
11

3 General cost-optimization strategies
When it comes to costs, amount of contributing factors is vast. Thereare a lot of types of business costs, and every part of the businessis associated with different types of costs, from production up tillmarketing and even sales [20]. Many costs may be quantifiable, be-cause they can be easily observed, but other costs must be estimatedor specifically allocated.
Costs can be optimized on many organizational levels, whichmakes the optimality requirement very hard to be satisfied. For in-stance, underdimensioned infrastructure might seem cost efficient butindirect expenses on resulting incidents could make such architectureextremely pricey. To reduce the space of considered possibilities, thisthesis focuses primarily on fees associated with utilized services, yetkeeps operational simplicity as its secondary objective.
As stated on the AWS re:Invent 2020 convention, cost optimizationis not always a trade-off for performance and availability. It is a matterof understanding the pricing options, using the right tools for man-aging capacity, and taking advantage of guidance and best practices[21].
Therefore, this Chapter summarizes the key areas of interest thathave the biggest impact on the solution price and depicts general,cloud agnostic cost optimization strategies. These could be applied toa target organization, environment or account, without giving up onstability, reliability, resiliency and other aspects of properly designedsystems.
3.1 General principles
Cost optimizing costs goes hand in hand with lots of tools and tech-niques that organizations can use. But it can become an overwhelminglandscape. And since tools are not omnipotent, there are several fun-damental high-level principles, that organizations, no matter the size,can follow to make sure they are getting the most out of the cloud[22].
People and processes play a crucial part in the cost optimiza-tion process in the organization. The initial step should be to create
12

3. General cost-optimization strategies
company-wide standards, that outline desired service-level profitabil-ity, reliability, and performance [23]. It can be done by a team, or aninvidividual, who has a responsibility of cost management and costoptimization activities, and should establish and maintain a culture ofcost awareness in the company [24]. Some of the papers recommendestablishing a tiger team1 to kickstart this initiative and to continueworking on adhering the defined standards [22].
It is difficult to implement aforementioned standards retroactively.That is the reason why is it important to integrate standardized pro-cesses from the beginning and ensure that they are systematically andconsistently enforced. For best results and best practices, responsiblepeople should meet on regular basis, reviewing usage trends and ad-justing the forecasting as necessary.
One of the fixes to overcome the problems like unexpected spikein bill or long-term rise in costs, is to organize and structure the costsin a relation to company business needs. Cloud providers offer billingreports to have a clear look at granular cost details [23]. Another im-portant approach is attributing the costs back to the departments andteams by labeling the resources, based on the predefined business met-rics. Without labeling resources, it is incredibly difficult to decipherhow much it cost. But with having resources labeled, it is possible totrack their spending overtime, for example by building own customdashboards [22].
Establishing a partnership between key finance and technologystakeholders can create a shared understanding of organizationalgoals and can lead to developing mechanisms for financial successin variable spend cloud computing model. In other words, these twoestablishments have near real-time insight into cloud usage and cost,and can collaborate on forecasting future cost and usage, to align orbuild organizational budget [24].
There is a broad set of cloud-based products, that public cloudproviders offer, including computing, networking, storage, securityand others. Each of these categories has its own specifics and options,where the cost can be optimized, or the other way, cost can incrementrapidly. The next sections are describing in more detail the publiccloud offerings in two key areas most relevant for this thesis, being
1. https://www.lucidchart.com/blog/what-is-a-tiger-team
13

3. General cost-optimization strategies
computing and networking field, and explaining how can be the costof the final solution optimized through them.
3.2 Compute
Modern cloud providers offer a large amounts of computing powerand provide numerous services, that allow users to run their work-loads according to their requirements and needs.
The deployment of a service in a public cloud provider is alwayssupported by a group of virtual machines (VMs), which host the re-quired software for the service. These machines are deployed on theprovider’s virtualization infrastructure. The offer of VMs by a provideris usually known as aforementioned Infrastructure as a Service (IaaS).
VMs can use different combinations of computational resources(such as number of virtual cores, memory, etc.) for their deployment.These are frequently referred to as VM types, which are different withevery public cloud provider. Each VM type has an established priceper time unit and can reach certain level of performance for a givenapplication [25].
Vast majority of compute engines offered by public cloud providersis charged based on memory and CPU consumption. That said, pricereduction strategies, described in the this Chapter, aim to effectivelyutilize the available computational power.
3.2.1 On-demand vs. Reserved instances
With regard to pricing, two main categories of Virtual Machines canbe considered: on-demand instances and reserved instances.
On-demand is the basic offering of public cloud providers, andimplies that the user is only charged for the time the VM is running,requiring a per-hour usage fee, without any up-front payment or long-term commitment. As an alternative, offerings such as Amazon EC2Reserved Instances, Azure Reservations, Google Cloud Committedare available, that allow for significant price reduction in exchange forcommitment between the user and service provider. The user agreesto pay for the instance for a determined time period (for example,a year, or three years), regardless of whether the VM is used or not
14

3. General cost-optimization strategies
[25]. The providers guarantee cost savings compared to the same on-demand instance at the end of the commitment time [26]. The longerreservation, the bigger savings.
Table 3.1: Qualitative comparison between on-demand an reservedinstances [26].
On-demand Instances Reserved InstancesPay as-you-go (hourly fee) Upfront fee and hourly feeFor flexibility For cost savingsAlmost no need for planning Need careful planning
Reserved instances payment options that public cloud providers offerare very similar. There is a possibility of upfront payments, or regularpayments on a monthly basis. For example, Amazon Web Servicesoffer these three types of payment [27]:
• No upfront: User is billed a discounted hourly rate for everyhour within the term.
• Partial upfront: A portion of the cost must be paid up frontand the remaining hours in the term are billed at a discountedhourly rate.
• All upfront: Full payment is made at the start of the term, withno other costs or additional hourly charges incurred for theremainder of the term.
Reserved instances with a higher upfront payment provide greater dis-counts. With more purchase of reserved instances, volume discountsbegin to apply that let the user save even more.
3.2.2 Spare capacity
Spare capacitymodels, also referred to as spot instances, are frequentlycited as one of the top ways to save money on public cloud. It is a pur-chasing option that allows users to take advantage of spare capacityat a significantly low price. Variations of spot instances are offeredacross different public cloud providers [28].
15

3. General cost-optimization strategies
The idea of spare capacity is to provide users the provider’s un-used computing capacity, with the notable discount. But these spotinstances have an important caveat. Reliability is not guaranteed, asthe cloud provider can interrupt these instances at short notice toreclaim capacity back [29]. However, cloud providers offer variousnotification systems and advisors to notice user on spot instance re-moval. That said, with careful management, spare capacity can beuseful in batch processing, high performance computing, big data,test and development environments or containerized workloads. Ingeneral, they are best-suited for short-lived workloads, able to handleoccasional interruptions [30].
All major public cloud providers offers spare capacity solutions,which differ in several aspects, for example in notification time beforeinstance removal, percentage of savedmoney compared to on-demandinstances, or in degree of integration with other cloud services. Ama-zon offers EC2 Spot Instances, which was the first spare capacity so-lution among all public cloud providers, being available since 2009.Microsoft Azure offers Spot Virtual Machines2, and Google Cloud hasits Preemptible Virtual Machines3.
3.2.3 Overprovisioning and rightsizing
In cloud computing, provisioning means equipping the virtual ma-chine instances with everything it needs to run IT services. It can beCPU cores, memory, storage capacity, storage performance, operatingsystem and networking bandwidth. One of the easiest ways to wastebudget money is by paying more than needed, without realising it,and this is the case of overprovisioning [31]. Effective approach to-wards overprovisioning is rightsizing.
Cloud right-sizing enables significant cost savings and power sav-ings by tuning the amount of active resources to handle the currentworkload [32].
It is a continuous analysis of instances performance, usage needsand patterns. The outcome is turning off the idle instances (describedmore in the next subsection), or rightsizing instances that are eitheroverprovisioned or poorly matched to the workload. To continually
2. https://docs.microsoft.com/en-us/azure/virtual-machines/spot-vms3. https://cloud.google.com/compute/docs/instances/preemptible
16

3. General cost-optimization strategies
achieve cost optimization, right-sizing should be an ongoing process,because the cloud resource needs are always changing [33].
On Figure 3.1, there is a graph showing overprovisioning of cloudresources over time, with demand smaller than actual provisionedcapacity.
.Figure 3.1: Overprovisioning of cloud resources [34]
3.2.4 Idle resources
Every year, an exorbitant amount of money is wasted on idle cloudresources. These are resources, that are provisioned and being paidfor, but they are not actually being used. Idle resources are a hugeproblem, that clogs up cloud environment and drain the budget.
In terms of cloud compute engines, virtual machine instancesare the most typical example of the resources frequently left run-ning, when they are not being used. Especially instances used in non-production purposes like development, testing and QA [35]. Thisthesis is mostly focused on resources capable of hosting containerizedworkloads, however, there might be many resource types responsiblefor such wasting, such as relational databases, backups or load bal-
17

3. General cost-optimization strategies
ancers.Cloud providers offer several services to identify and recommend
instances that are being idle or underutilized, such as AWS Com-pute Optimizer, Microsoft Azure Advisor, or Compute Engine Recom-mender for resource rightsizing by Google Cloud.
3.2.5 Autoscaling
Autoscaling is a process of automatically increasing or decreasing thecomputational resources provided for a cloud workload based on itsneed. The primary benefit of well configured and managed autoscal-ing is that workload gets exactly the cloud computational resourcesit requires at any given time [36]. That said, user pays for the com-putational resources he needs and when he needs them, which cansignificantly lower the solution cost.
All major public cloud providers provide autoscaling capabilities.Amazon Web Services offers EC2 Auto scaling, the autoscaling fea-ture of Google Cloud is called Instance groups and Azure providesVirtual Machine scale sets. All of these services provide the same corecapability of horizontal scaling of the computational resources, and allof them has the capability to group VM instances into groups whoseproperties could be managed centrally.
3.3 Networking
Fundamental need of cloud-based solutions users is a constant connec-tion to the internet and the ability to push data over cloud platforms.That said, networking is a backbone. Every task, if useful, need toexchange data with various upstream and downstream producers orconsumers. Such data flow is then typically charged, depending onmultiple factors. In general, there are twoways of charging the user fordata transfer: for moving the data between the cloud and the Internet,or moving the data within the cloud services.
Most of the public cloud providers allow users to input the data tothe cloud for free, but will charge large networking fees for movingthe data outside the cloud environment [37]. With this in mind, thefirst thing of networking cost optimisation is to monitor what goes in
18

3. General cost-optimization strategies
and out of the cloud platform. One of the ways to govern it is throughlogging the flow of Virtual Private Cloud4 (VPC).
These logs keep tracking of flows sent and received by the VMinstances inside the VPC. These log entries record details contain infor-mation such as source IP, destination IP, and bytes sent and receivedfor each network connection. In AWS and Google Cloud, such serviceis called VPC Flow logs. Microsoft Azure provides such functionalityas a part of a Network Watcher service, in a feature called Networksecurity group flow logs. Besides cost optimization, these services canbe used for network monitoring, cloud forensics and real-time securityanalysis [38].
Transfers that send data out over the Internet are billed at region-specific and tiered data transfer rates. Tiered pricing means with moredata transferred, less is going to be payed for certain amount, e.g.number of TB [39]. All major public cloud providers are using theconcepts of regions and availability zones.
Regions are the physical geographical locations of the cloud datacenters, distributed around the world. Regions are designed to becompletely isolated from the others. Different regions offer differentservice qualities in terms of latency, solutions portfolios, and costs [40].Customers can choose the region closest to them, so they can reducethe network latency as much as possible for the end-users. Not allregions are created equally, as some have more services available thanthe others. Usually, the newest services start on a fewmain regions andthen pop up in other regions later. Not all regions have equal prices,so using built-in cloud calculators can help to estimate the rough costof services in different regions, and prices of the individual regionsvary from provider to provider [41].
Within each region, there are multiple, isolated locations, calledAvailability Zones. Each Availability Zone comprises of one or mul-tiple data centers, and no single data center is shared between mul-tiple Availability Zones. Availability Zones have independent powersources, networking, and cooling resources. If the compute instancesare distributed across multiple Availability Zones and one instancefails, the architecture can be designed so that an instance in another
4. https://www.cloudflare.com/learning/cloud/what-is-a-virtual-private-cloud/
19

3. General cost-optimization strategies
Availability Zone can handle the requests [41]. Within an Availabil-ity Zone, its data centers are hooked up to each other over privateredundant low-latency, high-speed fibre network links [42]. Using asingle-zone architecture in regions with higher costs, and multi-zonearchitecture where the traffic costs are lower, can in general lead tolower prices, but one need to weigh any potential network cost savingswith the availability implications of a single-zone architecture [38].
Figure 3.2: AWS 2021 Global infrastructure map [43]
Keeping the traffic private directly impacts data transfer prices.Costs are higher when data are transferred using a public IP addressesas compared to using a private IP addresses [44].
In conclusion, keeping all traffic within same region leads to lowerprices. If traffic needs to exit a region, it is best to choose the regionwith the lowest data transfer rates that makes most sense for the busi-ness requirements. Having all the traffic within the same AvailabilityZone and in the same Virtual Private Cloud using private IP addresses,contributes to maximum networking cost optimization [39].
20

4 AWS cost-optimization considerations
As the Chapter 3 says, there are a lot of ways how to save or squandermoney in such a living thing as cloud environment. As this thesis isprimarily focused on the AmazonWeb Services, this Chapter serves asa natural continuation of the third General cost-optimization strategiesChapter, but focuses on the services offered by the AWS.
Gathered information span over key networking and computeAWS resources, providing an end-to-end high-level overview of as-pects, that contribute to cost of solutions that utilize it.While this thesisfocuses on event-driven containerized workloads, depicted servicescould be used in numerous other contexts, possibly making followingparagraphs also useful to readers whose needs more or less differfrom requirements placed upon this thesis.
4.1 General principles
AWS provides a Well-Architected Framework, which helps to under-stand the decisions made while building workloads on AWS. It pro-vides architectural best practices for designing and operating reliable,secure, efficient, and cost-effective workloads in the cloud. It demon-strates a way to consistently measure the architectures against bestpractices and identify areas for improvement [45].
AWS Well-Architected Framework is based on five pillars:• Operational Excellence• Security• Reliability• Performance Efficiency• Cost Optimization
AWS cost-optimization best practices are summarized through CostOptimization Pillar, a high-level overview of strategies to be adoptedby modern, cloud native systems. This paper is intended for those in
21

4. AWS cost-optimization considerations
technology, from chief technology officers (CTOs) and chief financialofficers (CFOs), through architects and developers, to business ana-lysts and operation teammembers. It does not provide implementationdetails of architectural patterns, however, it does include references toappropriate resources [45].
4.2 AWS account
AWS account allows for logical separation of AWS resources createdand managed by certain user. When resources are created and man-aged in an AWS account, it provides administrative capabilities foraccess and billing.
Using multiple AWS accounts is a best practice for scaling the AWSenvironment, as it provides a natural billing boundary for costs, iso-lates resources for security, gives flexibility or individuals and teams,in addition to being adaptable for new business processes [46]. How-ever, for sake of simplicity the belowmentioned cost-optimizationparadigms do not take multi-account or multi-cloud deploymentstrategies into consideration.
4.3 Compute
AWS cloud provides its functionality through more than two hundredservices - managed online applications that are capable of solvingvirtually any software engineering problem. Each of these servicesdiffers in the purpose of use, and each of them has its own pricingmodel. For running event-driven containerized workloads, several ofthe AWS compute services can be used. To have theworkloads runningin the most cost-optimized way, one has to decide which service is themost suitable for the very workload.
In this section, AWS compute services are described, together withthe use cases they are most suitable for, taking into account theirpricing models and schemes. However, presented approaches are notto be followed blindly. Depicted simplifications could help decidingon appropriate strategies, but it is always necessary to interpret thefindings in context of concrete software project, being team knowledge,preference or technical debt.
22

4. AWS cost-optimization considerations
4.3.1 AWS operational responsibility model
Figure 4.1: Amazon Web Services operational responsibility model ofcompute services [47]
AWS services in general differ in the level of operational responsi-bility, which is the degree of responsibility for operating andmanagingthe concrete service. At the bottom of this model, there are virtual ma-chines, which are completely operated by the user on his on-premiseinfrastructure. As moving to the right part of the model, there areservices like Amazon EC2, AWS Elastic Beanstalk, Amazon EKS andECS, AWS Fargate and on the top of the model there is AWS Lambda,which is a serverless solution, where almost all the managing andoperational responsibility is delegated to the cloud provider [47].
As the number of AWS Compute services is quite large1, for thesake of simplicity and sustainability, only the most suitable ones werechosen, i.e. services that are the most relevant to the problem of thisthesis.
4.3.2 Amazon EC2
Amazon EC2 is the AWS concept of Virtual Machines, which can be re-ferred to as instances. According to the latest AWS re:Invent conference[48], there are more than 350 EC2 instance types to support virtuallyany workload.
These types are divided into multiple categories, such as instancesfor General purpose, Compute optimized and Memory optimizedinstances, or instances suited for Accelerated computing, or Storageoptimized instances, et cetera. For the purpose of this thesis, onlythe first three categories - General purpose, Compute optimized andMemory optimized instances - are going to be considered.
1. https://aws.amazon.com/products/compute/
23

4. AWS cost-optimization considerations
Storage optimized instances are primarily meant to be used by ap-plications that require high, sequential read and write access to verylarge data sets on local storage hence they are not a good fit for statelessworkloads. Accelerated Computing instances make use of hardwareaccelerators to increase performance of GPU heavy workloads. Whilenot explicitly stated in Chapter 3, solved problem is known to be CPUintensive and therefore would not benefit from such instance capabili-ties.
Use cases
The amount of possibilities of running the consideredworkloads usingAmazon Elastic Compute Cloud (Amazon EC2) is large. The mostbasic one is to have Docker and Kubernetes installed on self-managedcluster of EC2 instances. In terms of operational responsibility model,described above, this solution takes the closest place to the On-premisearchitecture, because of minimal operational responsibility delegatedto the cloud provider. That said, a burden of maintenance responsi-bility lies almost fully on user’s shoulders. That comes into conflictwith the serverless ambition of the targeted solution, which leaves self-managed container orchestration machinery backed by EC2 instancesout of consideration.
EC2 instances could also be used as a computational power to AWSmanaged container orchestrators, being Amazon Elastic KubernetesService2 (EKS) and Amazon Elastic Container Service3 (ECS). Pricingand other characteristics of the resulting cluster then reflect the typesof EC2 instances used. With choosing to run them on a cluster of EC2instances, the final cost and performance is based on the choice ofunderlying EC2 instance types, which the cluster is composed of.
With this in mind, in the following sections are described the idealuse cases for specific EC2 instance types, which are relevant for theobjectives of this thesis, together with their purchase options andpricing.
2. https://aws.amazon.com/eks/pricing/3. https://aws.amazon.com/ecs/pricing/
24

4. AWS cost-optimization considerations
Amazon EC2 instance characteristics
As it was mentioned before, Amazon EC2 provides a wide selectionof instance types optimized to fit different use cases. Instance typescomprise varying combinations of CPU andmemory capacity, togetherwith other parameters such as storage capacity and networking, andgives user the flexibility to choose the appropriate mix of resourcesfor his applications. Each instance type includes one or more instancesizes, allowing user to scale the resources to the requirements of thetarget workload [49].Proper categorization of instance types is crucial for choosing themost suitable one for each of the considered workloads, because everyinstance type has different use case and pricing model.
Processor types
The aforementioned General purpose, Compute optimized and Mem-ory optimized EC2 instances are powered by various Intel and AMDprocessors, as well as AWS Gravitons - processors custom built byAmazon Web Services [49]. According to the re:Invent4 2020, if cost isthe primary constraint, there are several recommendations on whichprocessor type to use.
EC2 instance types M6g, C6g and R6g, which are the General pur-pose, Compute and Memory optimized instances running on AWSGraviton processor, are offering 20% lower cost and up to 40% higherperformance, over M5, C5, and R5 instances respectively, which arerunning on the Intel processor. These findings are based on AWS in-ternal testing of workloads with varying characteristics of computeand memory requirements. [50].
For users having preference in AMD processors, AWS offers in-stance types running on AMD processor, which are 10% cheaper thencomparable Intel based instances [51, 52].
If user’s primary constraint is cost, EC2 instance types runningon AWS Graviton are the best price/performance solution. With lesslimited budget, one may consider using other instance types and pro-cessors, depending on the type, use case or primary constraint of hisworkload.
4. https://reinvent.awsevents.com/
25

4. AWS cost-optimization considerations
Figure 4.2: EC2 instance types categorized by their processor type andby their ideal general use case [48]
General purpose instance types
General purpose instances provide a balance of compute, memoryand networking resources, and can be used for a variety of diverseworkloads. These instances are ideal for applications that use theseresources in equal proportions such as web servers and code reposito-ries [49].
T3a and T4g instances are suitable for a broad set of burstable gen-eral purpose workloads, with the ability to burst CPU usage at anytime for as long as required. They are the best fit for micro-services,low-latency interactive applications, small and medium databases,virtual desktops, development environments, code repositories, orbusiness-critical applications.
Ideal uses cases of M5a and M6g general purpose instances aresmall and medium databases, application servers or data processingtasks that require additional memory [49].
Compute optimized instance types
Compute Optimized instances are ideal for compute bound applica-tions that benefit from high performance processors. Instance types
26

4. AWS cost-optimization considerations
C5a and C6g are an ideal fit for the high performance computing, batchprocessing, distributed analytics or even gaming [49].
Memory optimized instance types
Memory optimized instances are designed to deliver fast performancefor workloads, that need to process large data sets in memory. TheR5a and R6g instances are the most suitable for memory-intensiveapplications such as real time big data analytics, high performancedatabases or in-memory caches [49].
Amazon EC2 purchase options
There are four relevant ways of paying for EC2 instances: On-demand,Reserved instances, Spot instances and Saving plans. While the first threeoptions are described in the Chapter 3 as the model occuring acrossvarious clouds, Saving Plans is AWS specific offering. It is a flexiblepricing model that offer low prices on EC2 usage (and also applies toAWS Fargate and AWS Lambda usage), in exchange for a commitmentto a consistent amount of usage for a 1 or 3 year term [53].
All of the EC2 purchase options measure their prices in $ per hourfor every up and running EC2 instance, and prices vary for differentEC2 instance types. As the EC2 purchase options have different pricingmodels, they also have different recommendations for usage.
On-demand instances are recommended for short-term, stateful &spiky, or unpredictable workloads that cannot be interrupted. Theyare also recommended for testing newly developed applications [52].According to re:Invent 2020 statistics, On-demand instances are mostlybeing utilized for the types of workloads like video streaming, gamingservers or interactive streaming [21].
Reserved instances and Saving plans are recommended for users whocan commit to using EC2 over a 1 or 3 year term to reduce their totalcomputing costs [52]. They are being mostly utilized for known andsteady-state workloads like databases [21].
Spot instances are recommended for users with urgent computingneeds for large amounts of additional capacity [52]. They are an idealfit for stateless, flexible, fault-tolerant applications, such as big data,containerized workloads, CI/CD, stateless web servers or high perfor-
27

4. AWS cost-optimization considerations
mance computing [54].Amazon EC2 also participates in AWS Free Tier, which includes
750 hours of Linux and Windows EC2 Micro Instances, each monthfor one year [52].
4.3.3 Amazon EKS
Amazon Elastic Kubernetes Service (Amazon EKS) is a managedservice used to run Kubernetes on AWS without needing to install,operate, and maintain the Kubernetes control plane or nodes.
An Amazon EKS cluster consists of two primary components: EKScontrol plane and nodes that are registered with the control plane.That means EKS runs Kubernetes as a separate control plane that islayered on top of AWS services, and consists of control plane nodesthat run the Kubernetes software. EKS runs and scales the Kubernetescontrol plane for each cluster across multiple AWS Availability Zonesto ensure high availability. EKS automatically scales control planeinstances based on load and detects and replaces unhealthy ones andit provides automated version updates and patching for them. EachAmazon EKS cluster control plane is single-tenant and unique [55].
When user creates newKubernetes cluster using EKS, it establishesthe control plane and Kubernetes API in the selected underlying in-frastructure. This allows the user to deploy workloads using nativeKubernetes tooling, like kubectl5 or Helm6 [56].
Figure 4.3: Amazon EKS workflow [55]
5. https://kubernetes.io/docs/reference/kubectl/overview/6. https://helm.sh/
28

4. AWS cost-optimization considerations
Kubernetes runs workloads by placing containers into Pods to runon nodes [57]. EKS cluster can schedule these Pods on any combina-tion of Self-managed nodes, EKS Managed node groups and AWSFargate.
One can deploy one or more nodes into a node group. A nodegroup is one or more Amazon EC2 instances that are deployed in anAmazon EC2 Auto Scaling group. Self-managed nodes have higheroperational overhead, but in return they provide flexibility in configur-ing the underlying infrastructure. EKSManaged node groups simplifythe creation and management of EKS node groups, because they aredesigned to automate the provisioning and lifecycle management ofnodes. On the other hand, they reduce user options for instance andnode configuration [58]. AWS Fargate is described in more detail laterin this Chapter.
4.3.4 Amazon ECS
Amazon Elastic Container Service (Amazon ECS) is an AWS specificcontainer management service which is used for running, stoppingand managing containers on an underlying ECS cluster. An AmazonECS cluster is a logical grouping of tasks or services, and it is possibleto launch it on one or more EC2 instances or on AWS Fargate.
For specifying the Kubernetes objects, Amazon EKS uses Kuber-netes manifests, most often provided as files in the .yaml format. Onthe other hand, Amazon ECS has its own syntax, in form of ECS taskdefinitions.
A task definition is a text file (in JSON format) that describes oneor more containers (up to a maximum of ten) that form the applica-tion. The task definition can be thought of as an application blueprint,specifying various parameters, such as which containers should beused, which ports should be opened for the application, or what datavolumes should be used with the containers in the task.
A task is the instantiation of a task definition within a cluster. Aftercreating a task definition for the application within Amazon ECS, it ispossible to specify the number of tasks to run on the ECS cluster. Forplacing these tasks within the cluster, the Amazon ECS task sched-uler is responsible, and there are several different scheduling options
29

4. AWS cost-optimization considerations
available. For example it is possible to define a service that runs andmaintains a specified number of tasks simultaneously.
On each container instance within an ECS cluster runs the con-tainer agent, which sends information about the resource utilizationand tasks currently running on it to Amazon ECS. It is responsible forfor starting and stopping tasks, whenever it receives a request fromECS [59].
Figure 4.4: Amazon ECS workflow [59]
30

4. AWS cost-optimization considerations
4.3.5 Comparison of Amazon EKS and ECS
Both AWS fully managed container orchestration services support abroad array of compute options and have deep integration with otherAWS services, but yet they have some differences [60].
With Amazon ECS, the control plane is not a user’s concern. Alsobecause ECS was specifically designed for the AWS environment, itenables user to build, deploy, or migrate his containerized applicationsvia the familiar AWS management console. In contrast, with AmazonEKS, user need to interact with Kubernetes to deploy the containerizedapplications, so more expertise and operational knowledge is needed.The key advantage of EKS-managed workload is that it runs in everyKubernetes distribution regardless of cloud environment [61].
To deploy applications either on Amazon ECS or Amazon EKS,the application components must be architected to run in containers.Containers are created from a read-only template called an image. Im-ages are typically built from a Dockerfile, which is a plaintext file thatspecifies all of the components that are included in the container. Afterbeing built, these images are stored in a container registry, fromwherethey then can be downloaded and run. Both Amazon EKS and ECSsupport Amazon Elastic Container Registry (Amazon ECR), or othercontainer registries such as Docker Hub, or self-hosted registries[59,62].
The price-wise difference is that with ECS, there are no additionalcharges, but with EKS, user pay $0.10 per hour for each EKS clustercreated. [63, 64]. This does not have to be as expensive as it sounds,because users can take the advantage of a single cluster to runmultipleapplications by utilizing Kubernetes namespaces and IAM7 security,by logically separating workloads by IAM policies [65]. Both Ama-zon EKS and ECS offers two launch typemodels relevant for this thesis:one or more Amazon EC2 instances and serverless AWS Fargate. Inboth ways, user will pay for the resources used by his workloads. Ei-ther it is payed for amount of vCPU and memory in Fargate launchtypemodel, or for the up and running EC2 instances in the EC2 launchtype model, which depends on the chosen EC2 purchase option.
In conclusion, Amazon EKS is better option under three essentialconditions:
7. https://aws.amazon.com/iam
31

4. AWS cost-optimization considerations
• If developing and operating large projects, where many userswill work on several deployments and products simultaneously.
• If multicloud or hybrid cloud options are on the table, becauseof better compatibility.
• If applications are Kubernetes-native and users are experiencedwith Kubernetes.
On the other hand, ECS is better option:• For users looking for a free control plane and easy-to-use API.• For smaller projects or users unexperienced with containeriza-
tion and microservices.• For an AWS-native solution easily integrated with other AWS
solutions [56].To summarize, users adopting containers at scale seeking for simplic-ity should focus on Amazon ECS. On the other hand, Amazon EKSprovides the flexibility of Kubernetes with the security and resiliencyof being an AWS managed service that is optimized for customersbuilding highly available services [60].
4.3.6 AWS Fargate
AWS Fargate is a serverless compute engine for containers, as it re-moves the need to provision and manage servers and let user specifyand pay for resources per application [66]. AWS Fargate works bothwith Amazon ECS and Amazon EKS.
Amazon EKS Fargate Integration
When running containers on Fargate using Amazon EKS, there areseveral conditions that need to be complied with. Before schedulingPods on AWS Fargate in the EKS cluster, user must define at least oneFargate profile, to specify which Pods should run on Fargate whenthey are launched [67].
Kubernetes allows defining requests, which is a minimum amount
32

4. AWS cost-optimization considerations
,Figure 4.5: ECS scheme with both Fargate and EC2 launch types
of vCPU and memory resources that are allocated to each container ina Pod. Pods are being scheduled by Kubernetes to ensure that at leastthe requested resources for each Pod are available on the computeresource. When Pods are being scheduled on Fargate, the amount ofvCPU and memory reserved within the Pod specification determinehowmuch CPU and memory to provision for the specific Pod [68]. AsFargate runs each Pod in an isolated environment, each Pod runningon Fargate gets its own worker node [69].
Table 4.1: vCPU andmemory combinations available for Pods runningon Fargate using EKS [68]
vCPU value Memory value0.25 vCPU 0.5 GB, 1 GB, 2 GB0.5 vCPU 1 GB, 2 GB, 3 GB, 4 GB1 vCPU 2 GB, 3 GB, 4 GB, 5 GB, 6 GB, 7 GB, 8 GB2 vCPU Between 4 GB and 16 GB in 1-GB increments4 vCPU Between 8 GB and 30 GB in 1-GB increments
33

4. AWS cost-optimization considerations
Amazon ECS Fargate Integration
Using Fargate with Amazon ECS is more simple than with AmazonEKS. After packaging the application in a container and creating thetask definition, one has to specify the requested CPU and memoryrequirements for the task. Each Fargate task has its own isolationboundary and does not share the underlying kernel, CPU resourcesor memory resources with another task.
When first using Amazon ECS, a default cluster is created. Anotherclusters can then be created additionally. In the end, a service forlaunching and maintaining a specified number of copies of the taskin the cluster needs to be configured. After that, Fargate is ready tolaunch the containerized application on Amazon ECS [70].
Pricing
With AWS Fargate, there are no upfront fees. User is only charged forresources requested, even though resulting Fargate node might beoverprovisioned for hosted workload. In other words, if a containerthat needs 2 GB of memory ends up being deployed to a Fargate nodewith 8 GB of memory, user would still be charged for all the node’sresources, regardless of actual memory used. Pricing is calculatedbased on the vCPU and memory resources used from the time userstarts to download the container image until the Amazon ECS taskor Amazon EKS Pod terminates, rounded up to the nearest second. Aminimum charge of 1 minute applies, with per second pricing.
Just like Amazon EC2 instances, Fargate supports Spot and Com-pute Savings Plan pricing options. Compute Savings Plan is availablefor both Amazon ECS and EKS, while Fargate Spot is currently onlysupported by ECS [71].
Quotas
With AWS Fargate, one can launch up to 1000 concurrent ECS tasksand EKS Pods running on Fargate On-Demand and 1000 concurrentECS tasks running on Fargate Spot. These are default quotas (alsocommonly known as limits) for an AWS account in a given AWS Re-gion, but one can always raise these values even further to meet the
34

4. AWS cost-optimization considerations
application needs by requesting a quota increase [72].
4.3.7 Comparison of EC2 and Fargate
For long-running workloads with known and steady demands, prop-erly configured EC2 instances (of a properly chosen EC2 instance type)would represent more cost-efficient hosting environment than Fargate.The same applies for fault-tolerant workloads where EC2 Spot yieldsbetter savings than Fargate Spot. However, operational overhead as-sociated with EC2 backed clusters could justify usage of Fargate asdemonstrated by its increasing popularity [73].
Running ECS or EKS on the Fargate or EC2 instances, both havingcomparable CPU and memory resources available, have several differ-ences. The advantage of Fargate launch type decreases as its computeand memory utilization approaches the capacity of the comparableEC2 instance. That said, for steady-state, predictable workloads thatuse a higher proportion of the instance CPU and memory, EC2 canbe a more cost-effective choice, as it is possible to simply select theinstance type for which tasks can optimally use the available resources.On the other hand, for highly dynamic workloads, where right-sizingand scaling EC2 infrastructure introduces the risks of under or over-provisioning, the flexibility in cost and operation provided by Fargatewould be beneficial [74].
In general, for sustained, predictable tasks, a highly utilized EC2-based launch could help to optimize costs, since there can be selectedthe instance type best suited for the required task capacity at a lowercost than Fargate with the same capacity. EC2 is simply a better choicewhere one can maximize the utilization of a cluster of EC2 instances.If cluster utilization falls under certain thresholds, which depends onthe workload and its requirements, then AWS Fargate is the betteroption [74].
4.3.8 AWS Lambda
AWS Lambda is a serverless compute service which let user run acode without a need to provision or manage hosting servers. The code
35

4. AWS cost-optimization considerations
can be run for virtually any application or backend service, with zeroadministration. It can be uploaded as a ZIP file or a container image,and Lambda automatically allocates compute execution power andruns the code based on the incoming request or event, for any scaleof traffic [75]. Compressed ZIP file uploads must be no larger than50MB, and container images can be up to size of 10GB.
AWS Lambda natively supports Java, Go, PowerShell, Node.js, C#,Python, and Ruby code, and provides a Runtime API which allowsuser to use any additional programming languages to author theLambda functions [76].
Lambda function
The code uploaded and run on AWS Lambda is called AWS Lambdafunction. Each function has associated configuration information,such as its name, description, entry point, and resource requirements.Lambda functions can include libraries, even native ones.
The Lambda function must be written in a “stateless” style, i.e. itshould assume there is no affinity to the underlying compute infras-tructure. On the other hand, each Lambda function receives 500MB ofnon-persistent disk space in its own /tmp directory. And while AWSLambda’s programming model is stateless, Lambda code can accessstateful data by calling other web services, such as Amazon S38 orAmazon DynamoDB9.
In the AWS Lambda resource model, the amount of memory forthe function is chosen by the user, and are allocated proportionalCPU power. For example, choosing 256MB of memory allocates ap-proximately twice as much CPU power to the Lambda function asrequesting 128MB of memory, and half as much CPU power as choos-ing 512MB of memory [76]. In other words, an increase in memorysize triggers an equivalent increase in CPU available to the function.Memory can be set from 128MB to 10240 MB, in 1MB increments [77].
AWS Lambda function can be configured to run up to 15 minutesper execution. The timeout can be set to any value between 1 secondand 15 minutes.
Lambda function code can be set up to automatically trigger from
8. https://aws.amazon.com/s3/9. https://aws.amazon.com/dynamodb/
36

4. AWS cost-optimization considerations
other AWS services or call it directly from any web or mobile app [76].What events from which relevant AWS services can trigger an AWSLambda function is described in the next section.
AWS events
AWS Lambda integrates with other AWS services to invoke functions.User can configure triggers to invoke a function in response to resourcelifecycle events, respond to incoming HTTP requests, consume eventsfrom a queue, or run on a schedule [78].
Some services, such as Amazon S3, allow for direct integrationwith Lambda, triggering functions on service specific events, e.g. S3object deletion. User defined custom events could then be propagatedto Lambda through native integration with AWS message queues(brokers) such as Simple Queue Service (SQS), Amazon Kinesis orAmazon EventBridge. Also, AWS Lambda exposes HTTP API thatcould be used for trigerring the functions from external sources.
Each service that integrateswith Lambda sends data to the functionin JSON as an event. The structure of the event document is differentfor each event type, and contains data about the resource or requestthat triggered the function. Lambda runtimes convert the event intoan object and pass it to the function as an input parameter [76].
Execution environment
Lambda invokes the function in an execution environment, whichacts as a container to a secure and isolated runtime environment. Theexecution environment manages the resources required to run thefunction. The execution environment also provides lifecycle supportfor the function’s runtime and any external extensions associated withthe function.
After creation of Lambda function the configuration informationis specified, such as the amount of memory available and the max-imum execution time allowed for the function. Lambda uses suchinformation to set up the execution environment. The runtime of afunction and each external extension are processes that run within theexecution environment. That said, permissions, resources, credentials,
37

4. AWS cost-optimization considerations
and environment variables are shared between the function and theextensions [79].
Execution environments are run on hardware virtualized virtualmachines (MicroVMs) which are dedicated to a single AWS account.Execution environments are never shared across functions and Mi-croVMs are never shared across AWS accounts [80].
Figure 4.6: Isolation model for the AWS Lambda [80]
Cold start and warm start
Before setting up the execution environment, AWS Lambda servicedownloads the to-be-executed code, being either S3 hosted ZIP file oran image hosted on Amazon Elastic Container Registry (ECR), beingcompliant with the Open Container Initiative (OCI) standard. Thenthe execution environment is created with the memory, runtime, andconfiguration specified. These two steps are frequently referred to asa cold start.
After execution of a function completes, the execution environ-ment is frozen. Lambda service retains the execution environment fora non-deterministic period of time, to improve resource managementand performance [81]. There is no predefined threshold after the en-vironment gets recycled, nonetheless, the lifetime is approximatelybetween 5 and 7 minutes [82]. The length of this environment’s life-time is influenced by factors such as the amount of memory allocated
38

4. AWS cost-optimization considerations
to the function and the size of the code deployment package. Thelarger these resources are, the longer the environment persists in theready state.
During this time, if another request arrives for the same function in-stance, AWS Lambda service may reuse the environment. This secondrequest typically finishes quicker, since the execution environmentalready exists and it is not necessary to repeat the cold start steps again.This is called a warm start. In general, the Lambda service optimizesthe execution of functions to reduce the number of cold starts.
However, it is not possible to target a warm environment explic-itly (for example using service API). It is Lambda’s responsibility todetermine the optimal strategy based upon internal queueing andoptimization factors.
According to Amazon analysis, cold Lambda starts typically occurin under 1% of all invocations, and the duration of a cold start variesfrom under 100 milliseconds to over 1 second [81]. Depicted perfor-mance holds regardless of programming language used. However,for containerized workloads, cold starts are slightly more demanding,taking roughly 600 to 1400 milliseconds.
User is able to set the memory that gets allocated to a single in-stance of a function. Most language runtimes have no measurabledifference in cold start duration for different instance sizes. However,.NET functions pose as an exception, as the more memory the instancehas allocated, the faster the startup time [82].
Adding dependencies to the Lambda function packaged as ZIP file,thus increasing the package size, will further increase the cold startduration. Functions with many dependencies can be 5-10 times slowerto start. On the other hand, container image size does not influencethe cold start duration [82].
39

4. AWS cost-optimization considerations
Figure 4.7: Cold start durations per image extra size [82]
Important thing is that an update of the code in a Lambda functionor a change in the functional configuration results in the cold start ofthe next invocation. Any existing environments running a previousversion of the function are reaped to ensure that only the new versionof the code is used.
To ensure the lowest possible latency and to have predictable starttimes of the workloads, Provisioned concurrency is the recommendedsolution, preferred for production workloads [81].
Provisioned concurrency
In AWS Lambda, concurrency is the number of requests that yourfunction is serving at any given time. When a function is invoked,Lambda allocates an instance of it to process the event. When thefunction code finishes running, it can handle another request. If thefunction is invoked again while a request is still being processed, an-other instance is allocated, which increases the function’s concurrency[83].
Provisioned concurrency gives user a greater control over hisserverless applications.When enabled, Provisioned concurrency keepsfunctions initialized and hyper-ready to respond in double-digit mil-liseconds [76]. In other words, Provisioned concurrency initializes a
40

4. AWS cost-optimization considerations
requested number of execution environments so that they are preparedto respond to your function’s invocations and reduces the number ofcold starts [83].
There is an additional pricing model for Lambda functions withenabled Provisioned concurrency, described in the following Pricingsubsection.
Pricing
AWS Lambda usage is charged per number of requests for the Lambdafunctions and per the duration - the time it takes for the code to finish.Lambda counts a request each time it starts executing in response toan event notification or invoke call, including also the test invokesfrom the AWS console. Unlike Fargate, Lambda does not charge usersfor code (or container image) download period, billed duration onlyspans actual execution, rounded up to the nearest 1 millisecond.
When Provisioned concurrency is enabled for the Lambda function,it is charged for the configured amount of concurrency and for theconfigured period of time. It is calculated from the time when it isenabled on the function until it is disabled, rounded up to the nearest5 minutes. If Provisioned concurrency is enabled and the Lambdafunction has been executed, user also pay for requests and durationtime, as it is with the function with disabled Provisioned concurrency.
AWS Lambda also participates in the Compute Savings Plans. Itis similar as with Amazon EC2 or AWS Fargate, Savings Plans offerlower prices in exchange for a commitment to a consistent amountof usage (measured in $ per hour) for a 1 or 3 year term. With AWSLambda, Compute Savings Plans can save up to 17%, but it only paysoff for predictable, consistent workloads.
AWS Free Tier is also applicable, where AWS Lambda free usagetier includes 1M free requests per month and 400,000 GB-seconds ofcompute time per month [77].
Container image support
As mentioned before, besides uploading the code as ZIP file, AWSLambda enables users to package and deploy functions as containerLinux-based images. Lambda supports all Linux distributions, such
41

4. AWS cost-optimization considerations
as Alpine, Debian, and Ubuntu [84].Container images have to implement the AWS Lambda Runtime
API. Runtime API is a simple HTTP-based protocol with operations toretrieve invocation data, submit responses, and report errors [85]. Inevery container image compatible with AWS Lambda, there need tobe a Runtime Interface Client, which manages the interaction betweenLambda and the function code [86].
User can use one of the AWS base images for Lambda to build thecontainer image for a function code. The base images are preloadedwith a AWS Lambda Runtime Interface Client and other componentsrequired to run a container image on Lambda. User just have to add afunction code and dependencies to the base image and package it as acontainer image.
There is also a possibility to use an arbitrary base image, but asmentioned before, it has to implement the Runtime API. Using a cus-tom base image, one can leverage the open-source Runtime InterfaceClient for each of the supported Lambda runtimes, to make the imagecompatible with Lambda Runtime API. Supported Lambda runtimesare Node.js, Python, Java, .NET, Go and Ruby [86].
There are few important things about AWS Lambda containerimage support, that have to be mentioned:
• Lambda uses Amazon Elastic Container Registry10 (AmazonECR) as the underlying code storage for functions defined ascontainer images, so a function may not be invocable when theunderlying image is deleted from ECR [76].
• Container image must be able to run on a read-only filesystem.However, function code can access a writable /tmp directorywith 512 MB of storage. [84].
• Container images, once deployed to AWS Lambda, will be im-mutable and the service will not patch or update the image.However, AWS will release an AWS base images when any newmanaged runtime becomes available. These published imageswill be patched and updated along with updates to the AWSLambda managed runtimes. So user can pull and use the latest
10. https://aws.amazon.com/ecr/
42

4. AWS cost-optimization considerations
base image, re-build the container image and deploy to AWSLambda via Amazon ECR. This allows users to build and testthe updated images and runtimes, prior to deploying the imageto production [76].
Deploying container images to AWS Lambda can be done in the fol-lowing steps. One has to package the Lambda function code and de-pendencies as a container image, using tools such as the Docker CLI.Then, the image needs to be uploaded to the container registry hostedon Amazon ECR. And finally, Lambda function (with a granted accessto the ECR) can be created by using all familiar Lambda interfacesand tools, such as the AWS Management Console, the AWS CLI, theAWS CDK or AWS CloudFormation [85, 76], which are going to bedescribed in more detail in the following Chapter.
Comparison of AWS Lambda and Fargate
As already mentioned, AWS Lambda and AWS Fargate both supportcontainer images. However, there are some differences that need tobe pointed out and understood, in order to choose the more suitableservice for concrete scenario.
With both AWS Lambda and Fargate, if configured correctly, usersonly pay for what they use. Fargate, however, introduces a 1-minuteminimum entry barrier which makes it an inconvenient and priceytool for lightweight, short-lived workloads. One should also keep inmind that Fargate does not cache images and download period isbilled, so further costs might be incurred.
Both of the services are highly scalable, but Lambda can simplysit idle and then burst into thousands of tasks per second, because itscales seamlessly on per-request basis. It is a great fit for applicationswith bursty workloads, that need to switch from idle to full capacityand back. Fargate, on the other hand, integrates with Amazon EKSand ECS that allow for better fine-tuning of scaling strategies.
Depending upon the resource requirements, onemay find Lambdaslightly limiting. As mentioned before, Lambda executions are limitedto 15 minutes and may only consume up to 10 GB of RAM. If consid-ered system consists of long-running, memory demanding workloads,that have to be managed in a serverless fashion, Fargate is the pre-ferred option.
43

4. AWS cost-optimization considerations
Lambda comes with native integration with more than a hundredAWS services [85]. Event-driven use cases, like running the code ev-erytime a new file arrived in S3, or triggering the function when newmessage arrives in Amazon Kinesis Stream11 or Amazon SQS12, arebetter served from a Function as a Service mechanism (FaaS), whichAWS Lambda is. Such use cases would require more wiring for Fargatetasks, which makes AWS Lambda a better choice.
Lambda’s native integration with various AWS services can beutilized for the purpose of container orchestration. When an arbitraryevent triggers the container-based Lambda function, Lambda orches-trates running of the workload by running appropriate amount ofcontainers to safely and efficiently handle the workload. This topicis described in more detail in the following Chapters, together withthe findings and results based on infrastructure scheme prototypeimplemented in AWS.
Overall, Lambda shines for unpredictable or inconsistent work-loads and applications easily expressed as isolated functions, triggeredby events in other AWS services [85, 87].
4.4 Networking
AWS provides broad set of networking services with various function-alities, from building a cloud network, through its scaling to securingthe network traffic. Since all AWS managed deployments rely on un-derlying networking layer, relevant costs have to made explicit, asintended by the following Chapter.
4.4.1 AWS Regions and Availability Zones
AWShas the concept of Region, which is a physical location around theworld, where are the data centers clustered. Each group of logical datacenters is called an Availability Zone. Each AWS Region consists ofmultiple, isolated and physically separated Availability Zones withina geographic area. Each of these Availability Zones has independentpower and they are connected with ultra-low latency networks. This
11. https://aws.amazon.com/kinesis/data-streams/12. https://aws.amazon.com/sqs/
44

4. AWS cost-optimization considerations
gives the user the ability to produce more fault-tolerant, scalable andhighly available solutions, that would be impossible with only onedata center in a Region [88].
4.4.2 Amazon Virtual Private Cloud
Amazon Virtual Private Cloud (VPC) is a service enabling user todefine a logically isolated virtual network, where he is able to launchAWS resources. The following are the key concepts for VPC [89]:
• Subnet: A range of IP addresses in a VPC.
• Route table: A set of rules, called routes, that are used to de-termine where network traffic is directed.
• Internet Gateway: Gateway attached to the VPC to enable com-munication between resources in the VPC and the internet.
• NAT Gateway: Managed Network Address Translation (NAT)service for resources in a private subnet to access the internet.
• VPC endpoint: Enables private connection of resources withina VPC to supportedAWS services without requiring an InternetGateway, NAT devices or VPN.
• CIDR block: Classless Inter-Domain Routing. An internet pro-tocol address allocation and route aggregation methodology.
When creating a VPC, the range of IPv4 addresses for the VPCmust beprovided in the form of a CIDR block, for example 10.0.0.0/16, whichwould be primary CIDR block for the VPC. By default, all VPCs andtheir subnets must be associated with IPv4 CIDR blocks, and IPv6CIDR block can be optionally associated with the VPC.
A VPC spans all of the Availability Zones in the Region, where it isplaced. After creating aVPC, one ormore subnets can be placed in eachAvailability Zone. When creating a subnet, CIDR block for the subnetneeds to be specified, which is a subset of the aforementioned VPCCIDR block. Each subnet within a VPC must reside entirely withinone Availability Zone and cannot span multiple zones.
Each subnet has to be associated with a route table, which specifies
45

4. AWS cost-optimization considerations
the allowed routes for outbound traffic leaving the subnet. VPC comesautomatically with the main route table, which controls the routingfor all subnets that are not explicitly associated with any other routetable. If a subnet’s traffic is routed to an internet gateway, the subnet isknown as a public subnet. If resource in a public subnet should commu-nicate with the internet, it should have specified public IPv4 or IPv6address respectively. If a subnet does not have a route to the internetgateway, the subnet is known as a private subnet [90].
Pricing
There are no additional charges for creating and using the AmazonVPC itself [91]. But other services used in context of VPC, such asNAT Gateway or PrivateLink has their own pricing models, describedin the following sections.
4.4.3 NAT Gateway
NAT Devices enables resources in a private subnet to connect to theinternet (for example, for software updates) or otherAWS services, butprevent the internet from initiating connections with these resources.A managed NAT Device offered by AWS is called NAT Gateway.To create a NAT Gateway, two things has to be specified:
• Public subnet in which the NAT Gateway should reside.
• Exactly one Elastic IP address to be associated with the NATGateway. It is a static, public IPv4 address designed for dynamiccloud computing. After associating with the NAT Gateway, itcannot be changed.
After NAT Gateway is created, one has to update the route table asso-ciated with one or more VPC private subnets to point internet-boundtraffic to the NAT gateway. This enables resources in these privatesubnets to communicate with the internet [92].
46

4. AWS cost-optimization considerations
Pricing
NAT Gateway is charged for every hour that it is provisioned andavailable inside the VPC. Each partial hour consumed is billed asa full hour. Also data processing is charged for each GB processedthrough the NAT gateway, regardless of the traffic’s source or desti-nation. Together with data processing charges, standard AWS datatransfer are charged for all data transferred via the NAT gateway [91].Data transfer charges are being described in more detail in the nextsection.
4.4.4 AWS PrivateLink and VPC endpoints
AWS PrivateLink is a technology that enables private access to servicesrunning in the VPC by using private IP addresses. Traffic between theVPC and the other services does not leave the Amazon network [93].
VPC endpoints are virtual devices. They are horizontally scaled,redundant, and highly available VPC components. They allow com-munication between instances in the VPC and other services withoutimposing availability risks. VPC endpoint enables to privately connectthe VPC to supported AWS services and VPC endpoint services pow-ered by AWS PrivateLink without requiring an internet gateway, NATdevice or VPN connection. Resources in the VPC also do not requirepublic IP addresses for communication with these services.
From the VPC endpoint types, for purposes of this thesis is rele-vant the VPC Interface endpoint type, which serves as an entry pointfor traffic destined to services in VPC. It is a network interface with aprivate IP address from the IP address range of the subnet, and it ispowered by AWS PrivateLink [93].
Pricing
User of AWS PrivateLink is billed for each hour that VPC endpointremains provisioned in his VPC, in each Availability Zone. Each par-tial VPC endpoint-hour consumed is billed as a full hour, and suchhourly billing stops when the VPC endpoint is deleted. Data process-ing charges apply for each GB processed through the VPC endpoint.The charged rates depends on the type of endpoint used: Interface
47

4. AWS cost-optimization considerations
endpoints are usually cheaper, with lower price for Data processing[94].
4.4.5 Amazon Elastic Container Registry
Amazon Elastic Container Registry (ECR) is an AWS managed con-tainer image registry service. ECR eliminates the need to operateown container repositories or scaling the underlying infrastructure. Itsupports both private and public container image repositories, andintegrates with Amazon ECS, EKS, Fargate, Lambda and Docker CLI[95]. Amazon ECR comprises of the following components [96]:
• Registry: Provided to each AWS account and enables to createimage repositories and store images in them.
• Repository: Contains Docker images, Open Container Initia-tive (OCI) images and OCI compatible artifacts. Repositorypolicies serves to control the access to the repositories and im-ages within them.
• Authorization token: To work with private repositories, it isfirst needed to authenticate to Amazon ECR registries as anAWS user before pushing and pulling the images.
• Image: It is possible to push and pull container images to theECR repositories.
Pricing
With Amazon ECR, there are no upfront fees or commitments. Userpays only for the amount of data stored in public or private repositoriesanddata transferred to the Internet. Data transferred out fromaprivaterepository is billed to the AWS account that owns it. On the otherhand, data transferred out from a public repository is free to a certainthreshold and can be done anonymously. Beyond this threshold, datatransfer is billed to the AWS account that downloads from the publicrepository. Storing data is always billed to the account that owns therepository, either private or public [97].
48

4. AWS cost-optimization considerations
4.4.6 Data transfer
Amazon Web Services charges certain prices for moving the data inand out of the cloud environment. When talking about the data trans-fer costs, AWS Compute and Networking services mentioned in thisChapter are in their pricingmodels referring to the standardAWSDatatransfer rates. These can be found in the pricing model of On-demandEC2 instances.
All data transferred into the AWS from Internet are for free. Datatransferred out from AWS to Internet is charged for a certain price perGB, which is based on amount of GB or TB transferred to Internet permonth.
There is also a certain price per GB for transferring the data be-tween different AWS regions. Transferring data between most of theAWS services in the same AWS Region is for free. Also AWS Servicesaccessed via PrivateLink endpoints will incur PrivateLink charges,mentioned in the previous section.
Data transferred in and out from public or Elastic IPv4 addressin the same region is charged for certain price in each direction. Thesame goes with transferring the data in and out from an IPv6 addressin a different VPC [98].
4.5 Conclusion
In conclusion, there are many AWS services capable of satisfyingrequirements summarized in the Chapter 1. Moreover, each of thedepicted services has its own pricing scheme that can be oftenmislead-ing at a first. As a result, utilizing context and principles describedin previous Chapters, several AWS deployment schemes has beendesigned, which are going to be described in the following Chapter.
49

5 AWS deployment schemes
Taking into consideration the findings summarized in the previousChapters, several AWS deployment schemes have been drafted. Theyaim to help finding the cost-optimal AWS infrastructure setup for run-ning event-driven containerized workloads in AWS cloud, fulfillingthe requirements from Chapter 1 and at the same time adhering theAWS best practices and guidelines. However, reader is advised to in-terpret such patterns with having the full picture in mind: while someof the decisions might make resulting system cost optimal, it mightalso make it practically unusable.
This Chapter focuses on describing the considered workload typesand workload orchestration. As the next step, individual design pat-terns are presented and moreover, decision trees are presented atthe end of this Chapter, further simplifying decision making whenopting for cost optimized host infrastructure configuration. Finally,proposed deployment configurations are confronted with require-ments captured in the Chapter 1 and alleged cost-optimal solution isdetermined.
5.1 Workload types
For purposes of this thesis, two types of workloads are going to beconsidered:
• Reactive, triggered workloads
• Long-running workloadsReactive workloads are also regarded to as jobs or tasks. Their keycharacteristics is that they run to completion. In another words, oncetrigger (being typically a message, or grouping of messages) is pro-cessed, relevant container is terminated. Long-running workloads arealso regarded to as services. They, on the other hand, run continuouslyand listen on source queues for new messages proactively. While theformer approach provides an obvious opportunity to save costs, it alsointroduces a need for rather complex workload orchestration.
50

5. AWS deployment schemes
5.2 Workload orchestration
Reactive workflows rely on workflow orchestrators, which are exter-nal components that trigger respective containers whenever relevantevent is encountered, e.g. a message is received. This makes it a com-plementary apparatus to container orchestrators, such as EKS, whoseresponsibility is to manage relevant containers’ lifecycle. Workfloworchestration could be implemented on several system levels, havingit externalized, so that coupling between system components is keptat necessary minimum.
In context of Amazon Web Services, AWS Step Functions can beused. It is a reliable way to coordinate components and step throughthe functions of the application. Step Functions manages the opera-tions and underlying infrastructure to help ensuring that an applica-tion is available at any scale [99].
Step Functions could be considered as a standard for orchestrationof AWS services, that do not natively integrate with AWS triggers,such as message brokers. Both EKS and ECS, container orchestratorsdiscussed in previous Chapters, are examples of such services. AWSLambda, on the other hand, provides its own workload orchestrationlayer, so event sources such as Simple Queue Services (SQS) or SimpleNotification Service (SNS) could be configured as triggers directly,through AWS Lambda service API.
5.3 Networking
As per requirements stated in the Chapter 1, workloads must not bereachable from Internet, yet must be able to reach Internet hostedresources. That said, each of the AWS design pattern should rely onprivate networking and private subnets as much as possible, with thehelp of services such as AWS NAT Gateway and AWS PrivateLink.
For the sake of simplicity, to keep networking boundaries and costseasy to reason about, systemwhose deployment configuration is beingsought is only expected to exchange data with three external compo-nents: Internet hosted endpoints (only for the download purposes),message broker and container registry. Factors like logs, monitoringmetrics and data traffic in the context of storages are not taken into
51

5. AWS deployment schemes
account and for the sake of this thesis are considered out of scope.When talking about the incoming messages, regardless of the de-
sign pattern, the cost for the incoming traffic in form of the messagesis negligible, because the number of messages is, as per the statedrequirements, small. The networking cost implications should be con-sidered only once throughput reaches roughly megabytes daily.
Therefore, the key cost-affecting networking aspect, reflected bysubsequent access patterns is workload image handling. Workloadimages might be gigabytes in size and, therefore, significantly con-tribute to relevant VPC’s traffic flows. This is especially true if targetedcontainer orchestrator does not support image caching, in which casethe workload’s image might be re-downloaded with every message.
5.4 AWS Step Functions
AWS Step Functions is a serverless orchestration service that helps tocoordinate components of distributed applications and microservicesas a visual workflow, in form of a series of event-driven steps.
Step Functions are based on so-called state machines and tasks. Astate machine is a workflow. A task is a state in a workflow that repre-sents a single unit of work that another AWS service performs. Eachstep in a workflow is a state. Using Step Functions, one can examinethese steps to make sure that the application runs in order and asexpected [100].
AWS StepFunctions pricing is based on the number of state transi-tions required to execute the application. Step Functions counts a statetransition each time a step of the workflow is executed. AWS Free Tieralso applies, allowing for 4000 free state transitions per month [101].
5.5 Amazon EC2
Running event-driven containerized workloads on the self-managedcluster of EC2 instances, with self-managed Docker and Kubernetes,have several different obstacles and consequences. Maintaining, oper-ating and regularly updating the EC2 cluster, together with all servicesrunning on it, would be a responsibility of the user. That said, suchsolution could hardly be considered serverless and operable.
52

5. AWS deployment schemes
All of the above applies to both reactive and long-running work-load types. As for reactive workloads, custom development would benecessary to orchestrate the microservices, since self managed Kuber-netes nor Docker integrate with Step Functions out of the box. [102].
Taking into account all of the above, running event-driven con-tainerized workloads on self-managed cluster of EC2 instances is notgoing to be considered for this thesis.
5.6 Amazon EKS - EC2 integration
When discussing possibility to run reactive workloads on AmazonElastic Kubernetes Service with EC2 cluster launch type, there are twooptions to be considered.
Technically, it would be possible to spin up cluster nodes, beingEC2 instances, on per message basis. This type of solution would havea potential to offload the cluster of non-utilized nodes while taking anadvantage of cheap computational power that EC2 instances are, but itwould be immensely hard to operate. Cost efficiency of the solution isalso to be challenged, because such one-off nodes, depending on EC2instance type used, would likely take charged minutes to be createdand to join the cluster [103]. This type of solution is not going to beconsidered for any type of workload.
Second possibility is to start a new Kubernetes Pod with new con-tainer for every incoming message. Such approach is implementableusing AWS Step Functions, which would act as a workflow orches-trator: a service responsible for submitting relevant workloads intoKubernetes cluster on per message basis. After the workload is com-pleted, Amazon EKS would be responsible for termination of relevantPods [104].
There are several disadvantages of this solution, for example start-ing a new Pod in EKS takes considerable amount of time. Necessityof using Step Functions makes the deployment configuration moreexpensive and also adds additional complexity to it. Also, cluster ofEC2 instances would be charged, even if there are no Pods running,making cost-efficiency of such setup questionable. Possible use of EC2autoscaling could help, but it would also introduce complexity and,therefore, operational costs that would be have to taken into consider-
53

5. AWS deployment schemes
ation.For scenarios where long-running workflows are preferred and as-
suming that resource demands of such services are well known priorto deployment, EKS launched on cluster of EC2 instances might rep-resent the sweet spot of easily operable, yet cost-efficient deploymentscheme.
5.7 Amazon ECS - EC2 integration
When it comes to running reactive or long-running event-driven con-tainerized workloads on Amazon ECS with Amazon EC2 launch type,the principles to be followed are the same as depicted in previousChapter.
The main difference is in the technologies themselves. As men-tioned in the Chapter 4, Amazon EKS requires Kubernetes knowledgeand is more of a flexible solution, while ECS is AWS specific technol-ogy, focusing more on simplicity and on being more user friendly.Final cost for ECS-backed deployments could be cheaper compared toEKS, because in contrary to ECS, Amazon EKS charges 0.10$ per hourfor each cluster created [64].
5.8 Amazon EKS - Fargate integration
As it was mentioned in section concerning EC2 launch type for Ama-zon EKS, it is possible to start a new Kubernetes Pod with new con-tainer for every incoming message. But since Fargate runs each Pod inan isolated environment, each Pod running on Fargate gets its ownworker node. That said, new Fargate node with Kubernetes Pod wouldbe started for each message incoming to the messaging queue. In asense, this could be considered an analogy to the aforementionedscenario, where new EC2 instance joins EKS cluster on per-messagebasis, but in a managed manner.
This solution has several obstacles, such as a need for a Step Func-tions as a workflow orchestrator, being an additional service to thesolution, resulting in higher cost and complexity. Moreover, startinga new Pod in EKS using Fargate takes time, approximately 30-45 sec-
54

5. AWS deployment schemes
onds for a node to be created and registered. Moreover, newly createdFargate node needs to be provided with respective Docker image. Itspulling might, depending on its size, take another valuable seconds.Putting it all together, it takes roughly a minute for the node and con-tainer to be started. [105].
One of the biggest drawbacks of this solution that makes it unfea-sible, is that the time needed for an image to be pulled is, accordingto Fargate pricing model, charged. Moreover, since images needs tobe downloaded from external sources, being typically ECR, on per-message basis, considerable amount of money could be spent on re-sulting traffic [106]. That said, the ideal strategy would be to set upthe Private Link and VPC endpoints between EKS and ECR, and avoidusing NAT Gateway. While being a cheaper alternative to NAT Gate-way based setup, this approach is still to be considered cumbersomeand unnecessarily costly1.
Even if the startup time of EKS Pod would be in milliseconds, inFargate, user is charged for the whole first minute no matter what. Onthe other hand, AWS Fargate charges the requested amount of vCPUand memory. Another big advantage is that usage of AWS Fargatereduces operational complexity to necessary minimum.
From perspective of long-running workloads, same principles ap-ply, except for the need for Step Functions, because these workloadsread the messages directly from the messaging queue. The advan-tage over cluster consisting of EC2 instances would then be very little.Operational complexity would be smaller, but there would be higherservice costs. Assuming that considered long-running workloads havepredictable resource demands and could, therefore, be hosted by astatic cluster, Fargate usage is not to be advised. The biggest benefit ofusing Fargate over EC2 is that user does not have to determine pre-cisely the size of the underlying cluster and its nodes, as AWS Fargatedoes it for him automagically.
5.9 Amazon ECS - Fargate integration
For both considered types of workloads, the same principles appliesas for running the workloads on Amazon EKS on AWS Fargate.
1. https://github.com/aws/containers-roadmap/issues/696
55

5. AWS deployment schemes
The biggest difference is the same as with the EKS on EC2 launchtype and ECS on EC2 launch type. Amazon EKS, being Kubernetesbased service, allows for nearly environment agnostic deployments,but does not integrate with the cloud as seamlessly as ECS does. Be-cause of an EKS charge of 0.10$ per hour for each cluster created,running the considered workloads on Amazon ECS on Fargate launchtype may be in the end cheaper.
5.10 AWS Lambda
AWS Lambda support for running functions packaged as containerimages makes the service an interesting alternative to established con-tainer orchestrators that ECS and EKS are. Especially, for event-drivenworkloads that face unpredictable loads, AWS Lambda promises tobe cost-optimal, yet highly performant fit. This assumption is basedon several advantages that AWS Lambda offers.
AWS Lambda is a purely serverless service, which shields userfrom managing and operating the underlying infrastructure. Thereis no need for using AWS Step Functions or any other workload or-chestrator, because AWS Lambda integrates seamlessly with majorityof AWS native message brokers and event sources. For example, fea-sibility case study presented in Chapter 7, relies on Amazon SimpleQueue Service (SQS).
With AWS Lambda there is no need for container orchestrator,because AWS Lambda as a service acts as an orchestrator itself, beingnatively integrated with AWS Elastic Container Registry. Lambda candeploy containers on user’s behalf, manages their lifecycle and retriestheir executions in case of a failure.
AWS Lambda is responsible for reading the incoming messagesfrom the input queue, their following batching and distributing amongthe number of run containers. Number of launched containers andnumber of Lambda function invocations are also determined by theAWS Lambda, based upon the actual workload requirements.
The containers images are being cached, so there is no need tore-download the image with every new execution, which gives thissolution a big advantage over the aforementioned solutions. That said,when traffic is allowed to leave for Internet, there is no need for setting
56

5. AWS deployment schemes
up the PrivateLink between Lambda and the Amazon ECR, whichreduces the overall complexity and cost of this solution.
The startup time of AWS Lambda, during which the containerimage and the function code is being prepared for execution, takeslow hundreds of milliseconds, making it by two orders of magnitudefaster and consequently cheaper than analogical solution based onFargate. Moreover, such preparation period is not being billed, mak-ing the service even more appealing. Lambda is a serverless service,where user is charged on pay-per-use basis. So without the need ofadditional services like Step Functions and PrivateLink, the final costof the solution would be calculated only for the usage of Lambda,being number of requests for the function, and the duration it takesfor the code to execute (based on the amount of memory allocated tothe function).
However, AWS Lambda has one disadvantage, being that Lambdaexecutions are limited to 15 minutes. This makes AWS Lambda an un-feasible solution for running long-running event driven containerizedworkloads.
5.11 Decision trees
As a result of the depicted principles, decision trees described inthis section strive for providing a high-level view on the problematic,while reflecting general and AWS specific cost optimization principlesdescribed in previous Chapters.
57

5. AWS deployment schemes
5.11.1 Compute
Figure 5.1: Decision tree aimed to help with choosing themost suitableAWS compute service for different types of workload
58

5. AWS deployment schemes
For purposes of this thesis, finding a serverless solution is a pre-ferred option over manually maintained deployment schemes, if priceallows. Taking into account also the fact, that space of EC2 instancespricing is simply too vast, following pricing aspects of two depictedserverless services are to be considered when striving for cost-optimalconfiguration.
AWS Fargate is charged for requested amount of vCPU and mem-ory, from the start of downloading the image, until the ECS Task orEKS Pod is terminated, rounded up to the nearest second. Aminimumcharge of 1 minute applies. Also, Fargate startup time has to be con-sidered for its significant price-wise impact, together with the chargesapplied for every created cluster when using EKS.
As a result, described context could be translated into the followingequation:
p = MAX(ih ∗ 160
, dh + sh) ∗ (pv + pm) + e (5.1)
where:p = Hourly price of Fargate usageih = Number of Fargate invocations per hourdh = Duration of Fargate usage in hourssh = Duration of Fargate startup in hourspv = Price of the vCPU requested per hourpm = Price of the memory requested per houre = Price of the EKS cluster per hour, if utilized
AWS Lambda is charged for the number of invocations (requests) ofthe function, and for the duration time it takes for the code to finish. Formore sparsely workloads, AWS Lambda Free Tier includes 1 millionof free requests and 400000 seconds combined with allocated amountof memory (GB-second) of free compute time per month.
For workloads exceeding the monthly Free Tier quotas, describedcontext resulted in the following equation:
p = (ih ∗ pr) + (dh ∗ gs ∗ pgs) (5.2)
where:
59

5. AWS deployment schemes
p = Hourly price of Lambda usageih = Number of Lambda invocations per hourdh = Duration of Lambda usage per hour (in seconds)gs = Amounf of requested memory in GBpr = Price of 1 million of Lambda requestspgs = Price of every GB-second
For demonstration purposes, following simulated scenario utilizingreactive workload is considered. Hosting environment, being AWSLambda function or EKS managed Pod, offers 1 vCPU and 2 GBs ofmemory. Test system then comprises of a single workload that forevery and each incomingmessage takes two seconds to complete. Nev-ertheless, for configuration that relies on AWS Fargate, such durationneeds to be further extended by roughly 60 seconds that are neededand thus billed, to provision underlying infrastructure .
Such values have then been used for parametrization of the afore-mentioned equations, together with EU West 1 (Ireland) region spe-cific AWS Lambda and AWS Fargate pricing from May 17 2021. As aresult, a graph has been created that presents overall compute costs fordifferent system loads, depicted as numbers of messages processed inan hour.
For sake of an example, to compare raw costs associated with bothofferings, AWS Lambda’s free tier is not considered. Also, it is neededto keep in mind that presented visualizations are taking into accountcompute related costs only, concealing image pull and workflow or-chestration relevant charges that would make AWS Fargate supportedsolution even more expensive.
60

5. AWS deployment schemes
Figure 5.2: Ratio between price and amount of invocations per hourfor the short-lived workload using AWS Lambda and AWS Fargate
Aforementioned chart shows that for given example, usage of AWSLambda yields better results. This applies for systems that share qual-ities depicted in the first thesis chapter, workloads that take minutesto complete would, however, likely be a better fit for AWS Fargate asits long startup time would become a less burden. In another words,solution based on AWS Fargate would have been cheaper comparedto AWS Lambda if there wasn’t for service specific shortcomings.
On the following graph is displayed the non-linear dependencybetween price paid for increasing amount of resources requestedthrough AWS Lambda and AWS Fargate. As it was mentioned, forshort-running workloads, it is advantageous and cost-optimal to useAWS Lambda, because of the AWS Fargate startup time, which has tobe taken into account. However, with increasing length of time thatworkloads need for completion, trend is changing and AWS Fargate isbecoming more feasible option.
61

5. AWS deployment schemes
Figure 5.3: Ratio between price and increasing amount of requestedresources in AWS Lambda and AWS Fargate
5.11.2 Networking
From the networking perspective, it is recommended to create logi-cally isolated virtual network Amazon Virtual Private Cloud (VPC),to launch AWS services in. Such VPC may be comprised of certainnumber of private and public subnets, depending on user’s choiceand his workload requirements.
As discussed in previous Chapters, VPC components, such as rout-ing tables or private or public subnets, are mostly free of charge. This,however, does not apply for AWS PrivateLink and NAT Gateways that- if misconfigured - could significantly contribute to resulting solutioncosts.
NAT Gateway provides Internet connectivity to resources in pri-vate subnets, but prevents such resources from being exposed to the in-ternet. AWS PrivateLink, on the other hand, allows for private commu-nication between AWS resources, without traffic being routed throughinternet.
If using AWS PrivateLink, for every resource to be connected a
62

5. AWS deployment schemes
Figure 5.4: Difference between routing traffic throughAWSPrivateLinkand NAT Gateway
PrivateLink endpoint has to be created. In another words, there willbe as many endpoints associated (and thus billed) with targeted pri-vate subnet, as there are services to be consumed. Alternatively (or inaddition), traffic originating from the considered resources could berouted through a NAT Gateway, typically instantiated on per-publicsubnet basis.
As a natural first step when deciding on which service to use, oneneeds to confront networking requirements of workloads hosted ina private subnet with service capabilities. If Internet connectivity isrequired, NAT Gateway is the preferred option.
There can also occur an option that resources in private subnets donot require internet connectivity, yet are tolerant to scenarios wheretraffic leaves AWS network and is routed through the Internet. In suchcase, it is up to the user to choose whether he wants to route trafficthrough PrivateLink instances per service or through NAT Gateways
63

5. AWS deployment schemes
per private subnet. As pricing of these two services slightly differs,following aspects are to be considered when striving for cost-optimalconfiguration.
PrivateLink is charged per every VPC endpoint per hour and perevery GB of data processed. That said, there are multiple variablesthat affects the final price:
• Number of VPC endpoints (one per service in private subnet)• Price per VPC endpoint per hour (different across various AWS
regions)• Expected GB of data to process through PrivateLink• Price per GB of data processed
NAT Gateway’s pricing scheme follows similar paradigm. Individualinstances are charged per every NAT Gateway per hour and per GB ofdata processed, which results in the following price-affecting variables:
• Number of NAT Gateways (one per public subnet)• Price per NAT Gateway per hour (different across various AWS
regions)• Expected GB of data to process through NAT Gateway• Price per GB of data processed
As a result, depicted context could be translated into the following setof equations:
(p ∗ ph) + (g ∗ pg) = (n ∗ nh) + (g ∗ ng) (5.3)where:p = number of VPC endpoints (one per service in private subnet)n = number of NAT Gateways (one per public subnet)g = expected GB of data to process through PrivateLink or NAT Gatewayph = price per VPC endpoint per hourpg = price per GB of data processed through PrivateLinknh = price per NAT Gateway per hourng = price per GB of data processed through NAT Gateway
64

5. AWS deployment schemes
Assuming dimensioning proposed in the following Chapter 7, for Eu-rope (Ireland) AWS region hosted VPC, consisting of two public andtwo private subnets that exchange 1 GB of data per hour, with pricesfrom Amazon VPC pricing list from 17 May 2021, the parametrizationwould be as follows:
(p ∗ 0.011) + (1 ∗ 0.01) = (2 ∗ 0.048) + (1 ∗ 0.048)p = 12.1818
(5.4)
where:n = 2g = 1
ph = 0.011$pg = 0.01$nh = 0.048$ng = 0.048$
(5.5)
The result of this example equation says, that for setup with 2 publicsubnets and expected 1 GB of data to be processed, it is cheaper andpreferable to use AWS PrivateLink instead of NAT Gateway in a sce-nario with 12 and less services. For 13 services and more, it would becheaper to use NAT Gateways.
In general, this equation is helpful in a case that resources in pri-vate subnets do not require internet connectivity and traffic does nothave to stay within the AWS network. Such multivariate equivalencecould then be used as a guideline when choosing between PrivateLinkand NAT Gateway.
As a conclusion, a decision tree for choosing themost suitable AWScompute service for different types of workload has been proposed,taking into account also the depicted set of equations.
5.12 Conclusion
Every deployment context depicted in this Chapter has its pros andcons, that needs to be evaluated in context of requirements placedupon the desired deployment configuration.However, generally speak-ing, all of the options could be a match for event-driven containerized
65

5. AWS deployment schemes
Figure 5.5: Decision tree aimed to help with choosing themost suitableAWS networking service for different types of workload
workloads under certain conditions.For running the reactive type of workloads, the best possible so-
lution for the purposes of this thesis is running containers in AWSLambda, with utilizing Amazon ECR as Docker image registry andAmazon SQS as messaging queue service. For long-running work-loads, established container orchestrators, being EKS and ECS relyingon EC2 launch type, are the cost-optimal fit.
As written in the solution requirements in the Chapter 1, this thesisis focusing on non-uniform workloads, that can be idle for prolongedperiod of time and take typically couple of seconds to complete. Thatsaid, only the reactive type of workloads is to be considered. But thisAWS Design patterns Chapter should serve as the point of supportfor users who want to run the aforementioned workloads on AWS,regardless of the workload type and requirements placed upon thesolution.
Therefore, AWS Lambda solution for running the reactive event-driven containerized workloads in AWS should be confronted with
66

5. AWS deployment schemes
the requirements defined in the Chapter 1, to prove that it fulfills therequirements placed upon this thesis. That is described in detail inthe following Chapter, which serves as the interpretation of findingsand natural conclusion of the previous five Chapters.
67

6 Interpretation of findings
6.1 Application of methodology
Decision trees presented in the previous Chapter’s conclusion aimto help user with choosing the most suitable compute and network-ing AWS services that meet the requirements placed upon his typeof workloads. In the following section is described the applicationof such methodology as a transition through the presented decisiontrees, taking into account this thesis requirements.
6.1.1 Compute
In the compute decision tree, the first level of decision-making is basedonwhether the workload is stateful and/or highly utilized.Workloads,of which the considered system should be comprised of, have beensaid to be stateless, and load placed upon such system is non-uniform,where system components might be idle for prolonged period of time.Therefore, EC2 launch type is not going to be considered.
Such reasoning leads to another crossroad, where next decision isto be made on a serverless service. As per thesis requirements, CPUand memory demands of considered containerized workloads areknown prior to deployment, and workloads take typically couple ofseconds to complete. Workloads, therefore, do not require more than10 GB of memory, nor do they take more than 15 minutes to run. Thatsaid, AWS Lambda turns out to be the most suitable solution, leavingAWS Fargate launch type out of consideration.
6.1.2 Networking
From the networking perspective, first level of decision-making in thenetworking tree is to choosewhether the consideredworkloads requirethe Internet connectivity in the Virtual Private Cloud private subnets.As per requirements placed upon this thesis, such workloads are notInternet facing, Internet connectivity is, however, needed. That said,
68

6. Interpretation of findings
choice of NAT Gateway as a networking service over AWS PrivateLinkturns out to be the one meeting the thesis requirements.
6.2 Conclusion
Applying the knowledge described in the previous Chapters, a deci-sion has been made to choose AWS Lambda as a final solution for run-ning the event-driven containerized workloads in AWS in cost-optimalfashion. In this conclusion, this solution is going to be confronted withthe requirements placed upon this thesis to confirm that they are ful-filled by using this AWS deployment scheme.
Whole solution is comprised of distributed, loosely coupled con-tainerized workloads. AWS Lambda functions are packaged as con-tainer images and stored in Amazon ECR, container image registrynatively integrated with Lambda function. Such Lambda functions arebeing executed for every message incoming to the messaging queueservice Amazon SQS.
Management of the containers is delegated to third party orches-trator, which is in this case responsibility of AWS Lambda itself. Work-loads have been said to be stateless, persistence layer is, therefore, notconsidered, yet easily pluggable if needed.
Such workloads have to be idempotent, meaning that they haveto yield exactly the same output every time triggered for duplicatesof certain message. Such guarantee further simplifies requirementsplaced upon relevant workload orchestrator, allowing for naive retrystrategies and at-least-once message delivery approach [107]. AWSLambda functions also allow for seamless queue utilization-basedhorizontal scaling, making it a great fit for context-less workloads,that share properties described in the requirements in a Chapter 1[76].
Load placed upon this system is non-uniform, meaning that it isnot steady and predictable. Occasional spikes can occur, and systemcomponents might be idle for prolonged period of time. AWS Lambdais a serverless service and its pay-per-use pricing model is an idealfit for such type of workloads. When system components are idle,meaning that no messages are coming to the input messaging queuefor some prolonged period of time, AWS Lambda costs virtually noth-
69

6. Interpretation of findings
ing, but fees may apply for ECR hosted images. Arguably, describedservice characteristics make AWS Lambda a cost-optimal solution tothe solved problem.
AWS Lambda’s considerable disadvantage lies in its execution time,being limited to only 15 minutes. But for the purposes of this thesissuch limit seems acceptable, as requirements state that consideredworkloads take typically couple of seconds to complete. CPU andmemory requirements of the containers are known prior to deploy-ment, and are expected to fit into 10240MBmemory and 6 vCPU limitsof AWS Lambda, as it has not been explicitly stated that workloads inquestion have anomalous demands.
When a newmessage arrives in Amazon SQS queue, AWS Lambdais being triggered to run the function packaged as container image.That said, communication between services is event-based. Servicesused are tolerant to possible out-of-order message delivery. However,it is also possible to further support ordering guarantees by relying onSQS First In First Out (FIFO) queues or alike concepts implementedin AWS message brokers [108].
Workloads have to be at-least-once delivery tolerant, which is acomplement to the aforementioned idempotent property, because itcan happen that some input messages can arrive to the messagingqueue twice, as exactly-once delivery guarantee is technically veryhard (if not impossible) to be achieved. Amazon SQS service provideat-least-once message delivery [109].
Consideredworkloads can not be Internet facing, however, internetconnectivity is needed. For this purpose, private subnets have beencreated in ad-hoc Virtual Private Cloud (VPC), and AWS Lambdafunctions configured to run within such subnets. Internet connec-tivity is assured by VPC Internet gateway. NAT Gateway then givesresources within the VPC private subnet access to the internet, butprevent the internet from initiating connections with these resources.
For sake of simplicity, this solution does not have to integrate withmonitoring, tracing and logging services. Being an AWS native service,AWS Lambda reports on its executions through AWS CloudWatchautomatically. For more lightly used systems comprising of low hun-dreds of Lambda functions, the amount of execution metrics and logsharvested is expected to fall within the scope of AWS Free Tier.
To demonstrate the feasibility of the proposed design principles,
70

6. Interpretation of findings
this solution is implemented as AWS infrastructure scheme prototype,and it is described in more detail in the following Chapter.
71

7 Implementation
In order to demonstrate feasibility of cost optimization principles de-picted in previous Chapters, proposed infrastructural context is tobe implemented, deployed to AWS and confronted with its allegedtheoretical qualities.
This Chapter is intended to present the proposed scheme in thefollowing manner. First, reader will be confronted with design of theimplemented solution, technologies and frameworks used. The imple-mentation of AWS Lambda-based cost-optimal infrastructure schemeprototype for running the event-driven containerized workloads inAWS cloud is then described in the second section of this Chapter.
7.1 Infrastructure as a Code
Deployment configuration should be described through Infrastructureas a Code (IaaC) means for reproducibility and ease of evaluation,since other approaches, such as manual configuration through AWSconsole, AWS Elastic Beanstalk or AWS Lightsail might introduce re-sources on user’s behalf without him knowing. Presented implemen-tation is utilizing AWS Cloud Development Kit (CDK) developmentframework and, therefore, AWS CloudFormation service.
Infrastructure as a Code (IaaC) paradigm proposes to manage andprovision cloud resources through code, instead of through manualprocesses. IaaC makes it easier to edit and distribute the infrastruc-ture configuration [110]. For AWS, the built-in choice for IaaC is AWSCloudFormation.
7.1.1 AWS CloudFormation
AWSCloudFormation enables to define cloud resources in orderly andpredictable fashion, in either JSON or YAML formatted text files calledCloudFormation templates. These templates require a specific syntax andstructure, that depends on the types of resources being created andmanaged.
ACloudFormation template is deployed into theAWS environment
72

7. Implementation
as a stack. Stack is then manageable through CloudFormation HTTPAPI, which is for convenience reasons also accessible through high-level AWS resources such as AWS console or AWSCLI. One can updatethe stack if changes are needed to the resources running in it. Beforemaking changes to resources, CloudFormation allows for generating achange set, which is a summary of the proposed changes. Change setsenable to see how changes might impact the running resources beforeimplementing them. In case of a problem, infrastructure changes arebeing automatically rolled back to the pre-deployment state [111].
Figure 7.1: AWS VPC Resource defined in the CloudFormation tem-plate
7.1.2 AWS Cloud Development Kit
The AWS Cloud Development Kit (AWS CDK) is an open sourcesoftware development framework for modeling and provisioning thecloud application resources using familiar programming languages,
73

7. Implementation
like Python, .NET. TypeScript, etc. AWS CDK utilizes AWS CloudFor-mation in the background to provision resources in a safe and repeat-able manner. One can use supported languages to define reusablecloud components known as Constructs, which are then being com-posed into Stacks and Applications [112].
CDK Construcs are basic building blocks of AWS CDK applica-tions, representing a cloud component and encapsulating everythingthat CloudFormation needs to create the component. AWS CDK in-cludes the Construct library, which contains constructs representingAWS resources.
L1 or low-level constructs directly represent all resources availablein AWS CloudFormation. Using these resources, one must explicitlyconfigure all resource properties, which requires a complete under-standing of the details of the underlying AWS CloudFormation re-source model.
L2 or higher-level constructs provide similar functionality, but pro-vide the boilerplate logic,which needs to be implemented bydeveloperwhen using L1 constructs. They reduce the need to know all the detailsabout the AWS resources they represent, while providing conveniencemethods which make it simpler to work with the resource. Imple-mented solution of this thesis is utilizing only these L2 constructs.
The unit of deployment in AWS CDK is also called a stack. All AWSresources defined within the scope of a stack, either directly or indi-rectly, are provisioned as a single unit, and any number of stacks canbe defined in one AWS application. All constructs that provision infras-tructure resources must be defined within the scope of a stack. Suchstacks are then being defined within a scope of AWS CDK application,to allow their deployment into the AWS environment. Each instanceof a stack in AWS CDK app is explicitly or implicitly associated withan environment. An environment is the target AWS account and regioninto which the stack is intended to be deployed [113].
7.2 Description of implementation of AWS Lambdasolution
To demonstrate feasibility of proposed design principles, an infras-tructure scheme prototype has been implemented, as an AWS CDK
74

7. Implementation
Python project utilizing multiple AWS services. This solution shouldserves as an approximate model of the considered system, for whichthis thesis strives to find the cost-optimal solution.For implementation of the application were used the higher-level L2constructs, that simplify the solution and spare the user from resource(and CloudFormation) specific details. Solution is configured to runin one AWS account, in the Europe (Ireland) AWS region. ProposedAWS CDK application is comprised of two Stacks.
First stack consists of three CDK custom constructs, namely forcreating instances of Amazon VPC, Amazon SQS queues and AWSLambda functions. This stack serves as the main, deployment stack.
First VPC custom Construct defines an AWS VPC that spans thewhole region. It automatically divides the default VPC CIDR range,and creates 2 public and 2 private subnets, being a reasonable defaultfor purposes of this thesis. Network routing for the public subnets isautomatically configured to allow outbound access directly via an In-ternet Gateway. Network routing for the private subnets is configuredto allow outbound access via a set of resilient NAT Gateways, one perpublic subnet.Second CDK custom constructs acts an abstraction of a message queue.In this implementation, AWS SQS FIFO queues are used. The orderin which messages are sent and received to and from the FIFO queueis preserved, even though alleged system’s components are said tobe out-or-order delivery tolerant. Message is delivered once and re-mains available until a consumer processes and deletes it. Moreover,in specified deduplication interval, messages with identical contentare treated as duplicates, thus deduplicated by SQS service. FIFOqueues were chosen also for the support of message groups, whichallow multiple ordered message groups within a single queue. Suchqueues then serve as the event sources for containerized workloadsdefined as Lambda functions.
Last but not least, third custom CDK construct describes actualworkloads. Construct implementation then utilizes containerizedAWSLambda function, as proposed byprevious thesis Chapters.When suchLambda function is invoked, AWS Lambda runs the handler method.This method is defined in the standalone Python script, accompaniedby a Dockerfile, that targets such method as an entry point. For thissolution, an AWS-provided base image preloaded with Python run-
75
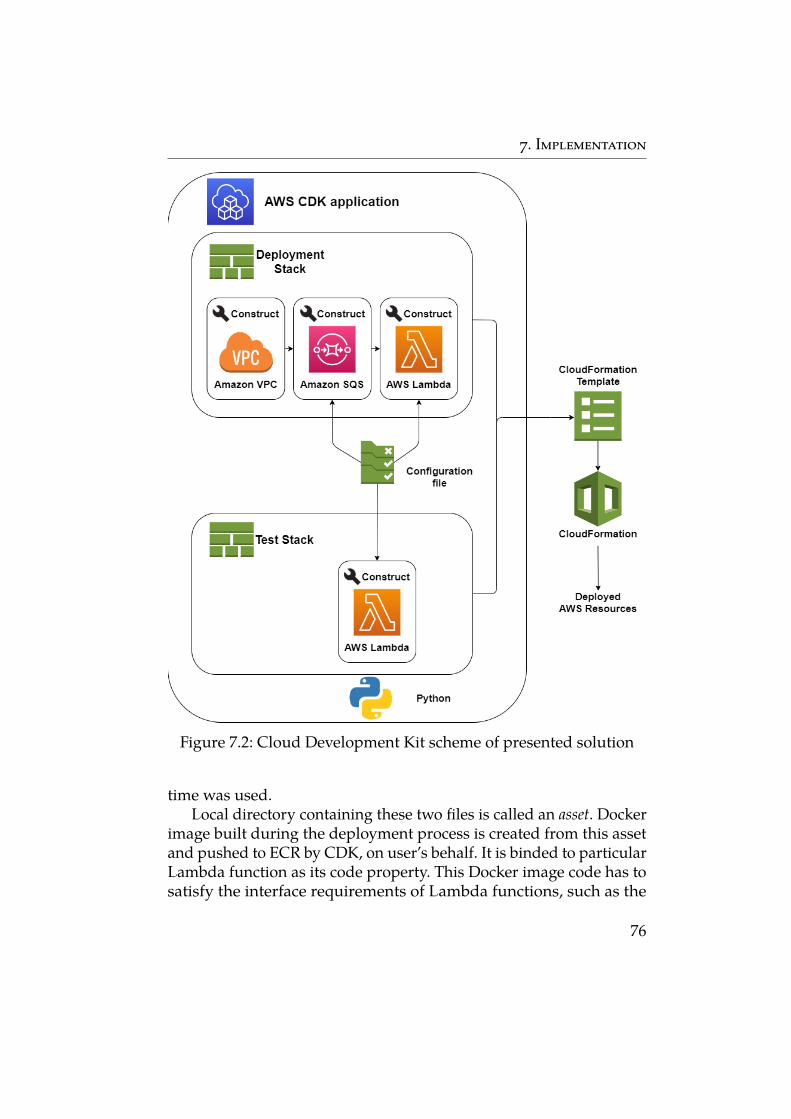
7. Implementation
Figure 7.2: Cloud Development Kit scheme of presented solution
time was used.Local directory containing these two files is called an asset. Docker
image built during the deployment process is created from this assetand pushed to ECR by CDK, on user’s behalf. It is binded to particularLambda function as its code property. This Docker image code has tosatisfy the interface requirements of Lambda functions, such as the
76

7. Implementation
aforementioned handler method. For sake of simplicity, all of the testworkflows make use of a single "hello world" Docker image.
With building a Docker image in a deployment time comes also au-tomatic creation of anAmazon Elastic Container Registry (ECR) repos-itory for CDK assets. After built, an image is automatically pushed tothis repository and bound to the particular Lambda function.
Each of these Lambda functions has an AWS IAM Role associatedwith it, that grants it permissions needed to publish logs into AWSCloudWatch and interconnect with respective Virtual Private Cloud(VPC). All Lambda functions are configured to run in the VPC privatesubnets.
Such workloads has associated an event source mappings withthem, which is a Lambda resource that reads from an event source andinvokes the function. For purposes of this solution, the event sourcesare the SQS queues defined in the aforementioned custom Construct.
This solution is configurable through a YAML file, where parame-ters of all the considered workloads (Lambda functions) are defined,such as AWS region, path to the Dockerfile, names of the ingress andegress queues and amount of memory to be allocated to each of theLambda functions. This configuration file should serve as an entrypoint for defining the parameters for the application. The idea behindis to have the solution as generic as possible, allowing application usersto specify theirs own system components and dependencies betweensuch components, by simply updating the configuration. Such gener-icity preserves the possibility of chaining of the individual workloads,utilizing the various combinations of SQS queues as event sources ofthe workloads.
Second CDK stack aims to demonstrate capabilities of the solutionby provisioning its entry point (ingress only) queues with predefinednumber of test messages. Such machinery is designed in a way, thatmessages are only being loaded into the ingress queues, that do notact as the egress queue of any other workload. This Lambda functionis configured to be created from an asset directory and uploaded tothe AWS as a ZIP file.
77

7. Implementation
Figure 7.3: Architectural scheme of presented solution
All workloads and test loader function run in a private subnets ofthe defined VPC. Amazon ECR CDK assets repository and all of theSQS queues run outside of the VPC, and are connected with relevantprivate subnets via NAT Gateway instances.
78

7. Implementation
7.3 Workflow
A workload is triggered every time a message arrives into the SQSingress queue defined as its event source. Test messages are then beinggenerated and emitted by aforementioned Lambda function, throughmeans of AWS Python SDK, which is also regarded to as Boto3.
When workload is invoked, an ECR image associated with thisfunction is pulled (and cached), and the handler method defined inthe image is run. Since SQSwas chosen as the most suitable messagingqueue for this solution, the code in a Lambda function handler methodis written with respect to relevant AWS service (SQS) interfaces, uti-lizing the Boto3 for interacting with relevant egress SQS queues. Suchconfiguration of workloads is described in the configuration YAMLfile. When the message arrive to the workload’s ingress queue, "helloworld" container used for sake of the demonstration either send themessages further to the list of egress queues if configured, or reportson successful execution through standard output.
Performance of these Lambda functions in form of monitored met-rics and logs are visible in AWS CloudWatch service.
Workflow of this whole machinery is illustrated on the followingdiagram:
Figure 7.4: Workflow diagram of the presented solution
79

7. Implementation
7.4 Conclusion
This Chapter serves as the a guide through the implementation of amodel solution for the considered systems, being AWS CDK-basedproject utilizing various AWS services, such as AWS Lambda, AWSSQS, Amazon VPC and Amazon ECR. Evaluation of the actual costand performance of this proposed solution, and its comparison withthe another possible solution is described in the next Chapter 8.
80

8 Cost evaluation
To demonstrate that implemented solution is feasible for purposesof this thesis and that it fulfills its requirements, performance andcosts have been measured and compared with alternative approaches.Namely, AWS Lambda based deployment configuration is confrontedwith its closest competitor, which is a setup that relies on AmazonEKS backed by AWS Fargate launch type.
8.1 Cost evaluation methods
To evaluate costs of Amazon Web Services cloud hosted workloads,one could rely on variety of different approaches. A natural first stepis to confront alleged system’s specification with pricing list of in-dividual AWS services, for example using AWS Pricing Calculator1.After some time, such estimate could be confronted with actual spend-ings through AWS Compute Optimizer2, or similar tools that analyzehistorical spending. To reduce the number of iterations needed foroptimal setup to be achieved, one could also rely on third, holisticstrategy where costs are not being evaluated on level of individualservices, but rather on level of system architecture, designed to beas close to problem relevant AWS guidelines and best practices aspossible. For sake of this thesis, the third option has been chosen asthe only one feasible.
8.1.1 Analytical methods
Analytical methods assume that problem could be, on a theoreticallevel, reduced to cost-contributing aspects, such as CPU utilization,memory demands or number of requests, that are then to be used asinputs to cost-determining equations, based on AWS service specificpricing lists. To make such attempts easier, AWS offers AWS PricingCalculator tool that requires from user the alleged system’s character-istics and, in response, provides relevant price estimate.
1. https://calculator.aws/2. https://aws.amazon.com/compute-optimizer/
81

8. Cost evaluation
It is very challenging, if not impossible, to think of all the cost-contributing factors prior to system deployment. For example, whileit might be easy to determine number of EKS clusters needed, onewould likely struggle to reason about how underlying inter-node traf-fic contributes to final networking costs. For that reason, such simpleanalytical methods are not considered as reliable cost indicators andhave, therefore, not been used as a primary guideline when designingimplemented solution.
8.1.2 Holistic methods
In practice, reasoning about system costs and attempts to optimizethem on basis of aspects such as number of requests, CPU used, mem-ory consumed etc., can lead to misleading conclusions that do notreflect complexity of system as a whole. As a consequence, systemsmight be designed that are cost-optimal, yet unusable.
For that reason, this thesis adheres to holistic cost evaluation strat-egy which gives different cost weights to different high-level concepts,based on a ratio between actual price and complementary aspects, suchas operability, stability and resilience. The key problem is that suchratio inevitably reflects system designer’s preferences, often basedon aspects that could not be formalized, such as experience. Hencethe thesis Chapters 3-5 aim to shape the boundaries that should beobeyed in order to achieve a configuration that represents an optimumbetween cost-optimality and maintainability.
8.2 Performance and Cost evaluation
8.2.1 AWS Lambda solution
Implementation of proposed AWS Lambda solution comprises of sev-eral Lambda functions. To ease further analysis, however, performanceand costs are being measured for one of the AWS Lambda functioninstances only.
82

8. Cost evaluation
Performance
For purposes of the experiment, load of 100 messages was sent at onceto the ingress SQS queue.When Lambda functionwas triggered by theincoming messages, it divided 100 messages into 18 batches (functioninvocations), and these batches were distributed between 3 containers(function instances).
Therefore, for each of the three function instances AWS Lambdahad to create the execution environment and execute the cached ECRDocker image function code 18 times across the three available func-tion replicas. Such slicing and dicing, e.g. number of messages perbatch or number of available instances, is, on user’s behalf, determinedby AWS Lambda service in attempt to balance throughput, resourcedemands and therefore costs [114].
AWS Lambda automatically monitors its functions and sends func-tion metrics to Amazon CloudWatch service, where a log stream iscreated for each instance of the function.
Log streams contain logs for every and each Lambda function
Figure 8.1: AWS CloudWatch log stream containing logs of an AWSLambda function
invocation, such as duration of the execution and ratio between allo-cated and used memory. Logs also report on function initialisationphase, allowing for detailed analysis of durations associated with dif-
83

8. Cost evaluation
ferent components of cold start procedure, such as image downloador environment bootstrapping.
Every log contains the information about the billed duration, beinga sum of initialisation time and duration of the execution for the firstinvocation of each instance, or only the duration of the execution forevery other invocation of each instance, rounded up to the nearestmillisecond. Number of function invocations equals to the number ofbilled requests.
REPORTRequestId: f18aee67-bedb-538c-96b4-b774e7360e54Duration: 801.99 msBilled Duration: 1859 msMemory Size: 128 MB MaxMemory Used: 69 MBInit Duration: 1056.26 ms
Figure 8.2: Log record of one invocation of a Lambda function instance
Logs of "hello world" AWS Lambda functions introduced in practi-cal part of this thesis then revealed that for Docker images that are172 megabytes in size, having 128 megabytes of memory allocated,respective function’s cold start took roughly 700 milliseconds, makingthe setup superior to discussed alternatives by almost two orders ofmagnitude.
Cost
Proposed solution is comprised of several AWS services whose uti-lization is affecting the final cost. However, for a real world systems,taking into account considered network traffic, compute costs wouldbe the key determinant to the solution’s price.
Within the AWS Free tier, AWS Lambda service includes one mil-lion of free requests per month and 400000 seconds combined withallocated amount of memory (GB-second) of free compute time permonth. Such amount of computational power might not only be suffi-cient for demonstrative purposes but has a potential to meet demandsof actual more lightly used system described in the Chapter 1. That
84

8. Cost evaluation
said, depending on the actual system utilization, this thesis mighthave described the ultimate, completely free solution. Still, one couldpush the boundaries further by applying following AWS Lambda per-formance, and thus price, optimization best practices.
For sake of simplicity, Python Lambda runtime has been chosenfor implementation of demonstratory system. Generally, compiled lan-guages run codemore quickly than interpreted languages but can takelonger to initialize. For small functions with basic functionality, oftenan interpreted language is better suited for the fastest total executiontime, and therefore the lowest cost [115].
Invocation frequency is a major factor in determining cost. Depend-ing on the event source for the function, there are various controlsto lower the total number of invocations. AWS SQS was chosen asmessaging service, for its native integration with AWS Lambda. Andon top of that, SQS queues has a batch size property, which deter-mines the number of items in an SQS queue sent to Lambda per oneinvocation. Increasing this number reduces the number of Lambdafunction invocations. It is then possible to aggregate more data permessage sent to SQS to process more data in fewer invocations [115].
When using the AWS-provided base images, AWS Lambda cachesthem proactively, so they do not have to be downloaded with everyfunction execution. Despite the fact that AWS-provided base imagesare typically larger than other minimal container base images, thedeployment time may still be shorter when compared to third-partybase images, which may not be cached.
Another thing is that the AWS-provided base images are stable. Asthe base image is at the bottom layer of the container image, anychanges require other layers to be rebuilt and redeployed. Fewerchanges to the base image mean fewer re-builds and re-deployments,which can reduce build costs [116].
Together with natural integration with a wide spectrum of AWSservices, the key factor of choosing AWS Lambda above the other com-pute services, is the price-performance ratio. AWS Lambda createsthe execution environment and pulls the cached Docker image withthe function code in a hundreds of milliseconds. It is a huge advantagefor running the non-uniform, event-driven workloads which typicallytakes short time to complete.
85

8. Cost evaluation
8.2.2 AWS EKS with Fargate launch type solution
Following the guidelines depicted in Chapter 5, deployment configu-ration scheme that relies on Elastic Kubernetes Service (EKS) backedby AWS Fargate has also been considered.
This solution comprises of AWS Step Functions as the workloadorchestrator, utilizing AWS EventBridge as an event source. In AWSStep Functions a state machine is defined, responsible for runningthe AWS EKS job, which runs the Pod in AWS Fargate. Kubernetesthen downloads the sample Docker image, comparable with the imageused in the AWS Lambda solution, and starts the Job.
Figure 8.3: Architectural scheme of the AWS EKS with Fargate launchtype solution
Performance
Since AWS Step Functions do not offer native integrationwith AmazonSQS, AWS EventBridge was used. However, such decision introduces
86

8. Cost evaluation
several technology specific limitations that make message batchingand scaling difficult to be implemented. In another words, with AWSEventBridge, target workflows have to be triggered for every and eachincoming message.
Once message arrives, relevant Step Functions workflow is trig-gered and EKS cluster is instructed deploy relevant workload by cre-ating a Kubernetes Job. Since AWS Fargate is used, a new cluster nodeis created, joined, and made a target for resulting Pod. Then, con-tainer hosted logic is executed. However, this process takes more thana minute to complete, making the solution roughly hundred timesslower than the one built on top of AWS Lambda.
Figure 8.4: Execution time of containerized workload in AWS EKSwith Fargate launch type using AWS Step Functions
Cost
There are multiple factors affecting the resulting price. Most notably,AWS Fargate node is billed based on requested vCPU and mem-ory, with one minute minimum. However, one also need to considercharges for EKS cluster and workflow orchestrator, being AWS StepFunctions.
Therefore in this case, user is charged for approximately 65 sec-onds, even when the actual run of the workload without creating andregistering the EKS node with Fargate Pod took only a hundreds ofmilliseconds. But even if the whole machinery that took place beforerunning the containerized workload took only couple of milliseconds,
87

8. Cost evaluation
in Fargate there still applies a minimum charge of 1 minute.Moreover, AWS Fargate does not cache Docker images, so they
have to be downloaded every time the EKS Pod starts. This can havevery big impact on the networking prices of the solution.
8.2.3 Conclusion
Based on performance and cost evaluation depicted in this Chapter,AWS Lambda solution seem superior and it highly overperforms theother considered AWS EKS with Fargate launch type solution. For fur-ther confirmation of such claim, following stress test was performed.
To ingress SQS queue, which acted as an event source for the testedLambda function, were sent 10, 100, 1000, 5000, 10000 and 20000 mes-sages, with 30 seconds wait time between each of the loads, and withmessages batched by ten. As can be seen on the graph, AWS Lambda
Figure 8.5: Number of invocations of tested AWS Lambda function
scaling is seamless, as it determined the number of function invoca-tions based upon the actual workload requirements, being the amountof incoming messages. Moreover, Lambda function processed suchamount of more than 35000 messages in about 7 minutes. Besides that,such experiment costs nothing because it falls under the quotas ofAWS Free Tier.
88

8. Cost evaluation
As it was mentioned in this Chapter, AWS EKS backed by Fargatesolution is utilizing AWS EventBridge as an event source, where thetargeted workflows have to be triggered for every and each incomingmessage. Besides that, since AWS Fargate is used, a new cluster nodeper message is created for every Fargate Pod. Taking into account thatsuch process takes more than a minute to complete and EKS clusterwith more than a 1000 nodes would be immensely expensive, leadsto conclusion that such solution is simply too pricey and extremelyunwieldy.
89

9 Discussion
This diploma thesis aimed to formalize a cost optimal AWS deploy-ment configuration for non-uniformly utilized, event-driven container-ized workloads.
First part of the thesis introduced the reader to the general contextof the cloud computing and other relevant services that this thesisis dealing with, such as containerization, event-driven architectureand microservices. As the next step, the key areas of interest that havethe biggest impact on the solution price, being the compute and net-working field, were summarized, depicting the general, cloud agnosticcost-optimization strategies.
As this thesis is focused on the AWS cloud, the natural next stepwas to introduce relevant compute and networking AWS services, toprovide an end-to-end high-level overview of aspects, that contributeto cost of solutions that utilize it.
Based on such gathered knowledge, several AWS deploymentschemes utilizing the aforementioned AWS services were introduced,together with a decision tree apparatus, aimed to help finding themost performant and cost-optimal solution. Such decision trees werethen confronted with system requirements placed upon this thesis.Based on the application of proposed methodology, an AWS Lambda-based deployment configuration was designed, and implemented asan infrastructure scheme prototype for running the event-driven con-tainerized workloads in AWS cloud.
Depicted solution was then confronted with its closest competitor,a system relying on Amazon EKS backed by AWS Fargate. As a resultof such comparison, AWS EKS-based solution was outperformed byAWS Lambda, which also turned out to be the most cost-optimal solu-tion.
In conclusion, information gathered throughout the first five Chap-ters of the thesis was utilized in designing a decision tree apparatus,aimed to help finding the desired AWS deployment configuration,which in the end turned out to be the most performant and cost-optimal for problem that this thesis was dealing with.
However, there are several areas, which were decided not to beintroduced in this thesis, such as storage or security, as the space of
90

9. Discussion
considered possibilities would increase exponentially. As a next stepin the future, proposed solution could be extended with such fields.
Also, it had been emphasized that this thesis would prefer server-less solution over manually maintained deployment schemes, be-cause of an operational burden associated with the currently usedon-premise infrastructure. For this reason, solutions that requiredhigh maintainability and operability were not taken into account.
Event-driven, containerized workloads are, nowadays, consideredde-facto an industry standard for decentralized, highly scalable appli-cations, and cost optimization of such systems will, therefore, likelyremain a trending topic - and the very fact that Amazon introducedcontainer support to AWS Lambda proofs it.
This thesis uses holistic methods to achieve its goals, which meansto be concerned with the complete system as a whole, rather thananalyzing the smaller details. Next step could be to iterate from suchmethods to formalized analytical model, which transform the pro-posed decision trees into a framework or tool, based upon the pro-vided input requirements.
AWS offers lot of architectural guidelines and recommendations,which exhort users to save money in cloud, which may seem counter-productive from the AWS point of view, but in the end opposite is true.The lower the barrier is for users to architect solutions that are cost-efficient, the higher the chances that such workloads would end upbeing hosted by a cloud. That said, such proposed framework wouldbe beneficial for both the community and Amazon Web Services.
91

Bibliography
1. A Cloud Services Comparison Of The Top Three IaaS Providers.CloudHealth.Available also from: https://www.cloudhealthtech.com/blog/cloud-services-comparison.
2. BUYYA, Rajkumar; SRIRAMA, Satish Narayana; CASALE, Giu-liano; CALHEIROS, Rodrigo, et al. A Manifesto for Future Gen-eration Cloud Computing: Research Directions for the NextDecade. 2018, p. 2. Available from doi: 10.1145/3241737.
3. MELL, Peter; GRANCE, Timothy. The NIST Definition of CloudComputing. 2011, pp. 2–3. Available from doi: 10.6028/NIST.SP.800-145.
4. WINKLER, Till J.; BROWN, Carol V. Horizontal Allocation ofDecision Rights for On-Premise Applications and Software-as-a-Service. 2013, p. 20. Available from doi: 10.2753/MIS0742-1222300302.
5. What is a public cloud? Microsoft Azure. Available also from:https://azure.microsoft.com/en-us/overview/what-is-a-public-cloud/.
6. AWS vs. Azure vs. Google: 2021 Cloud Comparison. MicrosoftAzure. Available also from: https : / / www . datamation .com/cloud- computing/aws- vs- azure- vs- google- cloud-comparison.html.
7. Serverless vs Cloud vs On-prem. Detectify. Available also from:https://blog.detectify.com/2019/03/09/serverless-vs-cloud-vs-on-prem/.
8. BALDINI, Ioana; CASTRO, Paul, et al. Serverless Computing:Current Trends and Open Problems. 2017, pp. 1–4. Availablefrom doi: 10.1007/978-981-10-5026-8_1.
9. What’s the Difference Between Cloud Computing and Serverless?NorthStack. Available also from: https://northstack.com/cloud-computing-vs-serverless/.
92

BIBLIOGRAPHY10. ZHELEV, Svetoslav; ROZEVA, Anna. Using microservices and
event driven architecture for big data stream processing. 2019.Available from doi: 10.1063/1.5133587.
11. Event-Driven Microservices. Confluent, Inc., 2020. Available alsofrom: https://www.confluent.io/resources/event-driven-microservices/.
12. LAIGNER, Rodrigo et al. From a Monolithic Big Data Systemto a Microservices Event-Driven Architecture. 2020. Availablefrom doi: 10.1109/SEAA51224.2020.00045.
13. Upstart Ubuntu: Intro, Cookbook and Best Practices. Upstart, 2014.Available also from: http://upstart.ubuntu.com/cookbook/#concepts-and-terminology.
14. LUKŠA, Marko. Kubernetes in Action. Manning Publications,2018. isbn 9781617293726.
15. Barriers to Container Adoption Persist, Survey Finds. EnterpriseAI.Available also from: https://www.enterpriseai.news/2015/06/17/barriers-to-container-adoption-persist-survey-finds/.
16. 2020 Developer Survey. StackOverflow, 2020. Available also from:https://insights.stackoverflow.com/survey/2020.
17. RODRIGUEZ, Maria; BUYYA, Rajkumar. Container Orches-tration With Cost-Efficient Autoscaling in Cloud ComputingEnvironments. 2020. Available from doi: 10.4018/978-1-7998-2701-6.ch010.
18. CASALICCHIO, Emiliano. Container Orchestration: A Survey.Springer, Cham, 2018. isbn 978-3-319-92377-2. Available fromdoi: 10.1007/978-3-319-92378-9_14.
19. What the data says about Kubernetes deployment patterns. The NewStack, 2018. Available also from: https://thenewstack.io/data-says-kubernetes-deployment-patterns/.
20. 10 Types of Business Costs. Marketing91. Available also from:https://www.marketing91.com/10- types- of- business-costs/.
93

BIBLIOGRAPHY21. SCHMUTZER, Chad. Optimize compute for performance and cost.
AWS re:Invent 2020, 2020-12-03. Available also from: https://www.youtube.com/watch?v=L173l1RdVxs.
22. Cloud cost optimization: principles for lasting success. GoogleCloud. Available also from: https : / / cloud . google . com /blog/topics/cost-management/principles-of-cloud-cost-optimization.
23. 5 Leading Principles of Cloud Cost Optimization. Maven Wave.Available also from: https://www.mavenwave.com/blog/5-leading-principles-of-cloud-cost-optimization/.
24. FITZSIMONS, Philip; BESH, Nathan, et al. Cost OptimizationPillar: AWS Well-Architected Framework. 2020. Available alsofrom: https : / / docs . aws . amazon . com / wellarchitected /latest/cost-optimization-pillar/wellarchitected-cost-optimization-pillar.pdf.
25. DÍAZ, José Luis; ENTRIALGO, Joaquín; GARCÍA, Manuel;GARCÍA, Javier; GARCÍA, Daniel Fernando. Optimal alloca-tion of virtual machines in multi-cloud environments withreserved and on-demand pricing. 2017. Available from doi:10.1016/j.future.2017.02.004.
26. NODARI, Andrea. Cost Optimization in Cloud Computing. 2015.Available also from: http : / / urn . fi / URN : NBN : fi : aalto -201509184326. MA thesis. Aalto University.
27. Reserved Instances payment options. AWS. Available also from:https://docs.aws.amazon.com/whitepapers/latest/cost-optimization- reservation- models/reserved- instances-payment-options.html/.
28. Spot Instances Can Save Money – But Are Cloud Customers TooScared to Use Them? ParkMyCloud. Available also from: https://www.parkmycloud.com/blog/spot-instances/.
29. MAAYAN, Gilad David. The complete guide to spot instances onAWS, Azure and GCP. Data Centre Dynamics. Available alsofrom: https://www.parkmycloud.com/blog/idle- cloud-resources/.
94

BIBLIOGRAPHY30. SCHONBERG, Zev. Understanding Excess Cloud Capacity: Ama-
zon EC2 Spot Instances vs. Azure Low-Priority VM vs. Google Pre-emptible VM vs IBM Transient Servers. NetApp. Available alsofrom: https://spot.io/blog/amazon-ec2-spot-vs-azure-lpvms-vs-google-pvms-vs-ibm-transient-servers/.
31. How to avoid overprovisioning: Don’t waste money on IaaS! Spice-Works. Available also from: https://community.spiceworks.com/cloud/article/overprovisioning-servers-iaas.
32. ALAMRO, Sultan et al. CRED: Cloud Right-Sizing to Meet Exe-cution Deadlines and Data Locality. In: 2016 IEEE 9th Interna-tional Conference on Cloud Computing (CLOUD). 2016, pp. 686–693. Available from doi: 10.1109/CLOUD.2016.0096.
33. Right Sizing: Provisioning Instances to Match Workloads. Spice-Works. Available also from: https://aws.amazon.com/aws-cost-management/aws-cost-optimization/right-sizing/.
34. LEI, Wei; CHUAN, Foh; BINGSHENG, He; JIANFEI, Cai. To-wards Efficient Resource Allocation for Heterogeneous Work-loads in IaaS Clouds. 2015. Available from doi: 10.1109/TCC.2015.2481400.
35. 4 Types of Idle Cloud Resources That Are Wasting Your Money. Park-MyCloud. Available also from: https://www.parkmycloud.com/blog/idle-cloud-resources/.
36. HILLIER, Andrew. Cloud Autoscaling Explained. Densify.Available also from: https://www.densify.com/articles/autoscaling.
37. SMITH, Jared. Comparing Data Egress Fees Among CloudProviders. HostDime, 2021-02-08. Available also from: https://www.hostdime.com/blog/data-egress-fees-cloud/.
38. Best Practices For Network Cost Optimisation On Cloud. AIM.Available also from: https://analyticsindiamag.com/best-practicesfor-network-cost-optimisation-on-cloud/.
39. AWS Data Transfer Costs: Hidden Network Transfer Costs and Whatto Do About Them. NetApp. Available also from: https://cloud.netapp.com/blog/aws-cvo-blg-aws-data-transfer-costs-solving-hidden-network-transfer-costs/.
95

BIBLIOGRAPHY40. Availability Regions and Zones for AWS, Azure & GCP. BMC blogs.
Available also from: https://www.bmc.com/blogs/cloud-availability-regions-zones/.
41. AWS Regions and Availability Zones: The Simplest ExplanationYou Will Ever Find Around. Cloud Academy. Available alsofrom: https://cloudacademy.com/blog/aws-regions-and-availability-zones-the-simplest-explanation-you-will-ever-find-around/.
42. What are cloud regions and availability zones? DXC.technology.Available also from: https://blogs.dxc.technology/2018/04/17/what-are-cloud-regions-and-availability-zones/.
43. Global Infrastructure: The Most Secure, Extensive, and ReliableGlobal Cloud Infrastructure, for all your applications. AWS. Avail-able also from: https://aws.amazon.com/about-aws/global-infrastructure/.
44. Data Transfer Costs; Everything You Need To Know. CloudManagement Insider. Available also from: https : / / www .cloudmanagementinsider . com / data - transfer - costs -everything-you-need-to-know/.
45. Cost Optimization Pillar - AWS Well-Architected Framework.AWS. Available also from: https://docs.aws.amazon.com/wellarchitected/latest/cost-optimization-pillar/.
46. AWS Organizations FAQs. AWS. Available also from: https://aws.amazon.com/organizations/faqs/.
47. CASALBONI, Alex. Performance tuning and cost optimization forserverless web applications. AWS DevDay 2020, 2016-10-15.
48. MEHTA-DESAI, Ishita. Selecting the right Amazon EC2 instancefor your workloads. AWS re:Invent 2020, 2020-12-03. Availablealso from: https://youtu.be/q5Dn9gcmpJg.
49. Amazon EC2 Instance Types. AWS. Available also from: https://aws.amazon.com/ec2/instance-types/.
50. AWS Graviton Processor. AWS. Available also from: https://aws.amazon.com/ec2/graviton/.
96

BIBLIOGRAPHY51. Amazon EC2 instances featuring AMD EPYC processors. AWS.
Available also from: https://aws.amazon.com/ec2/amd/.52. Amazon EC2 Pricing. AWS. Available also from: https://aws.
amazon.com/ec2/pricing/.53. Saving Plans. AWS. Available also from: https://aws.amazon.
com/savingsplans/.54. Best practices for EC2 Spot. AWS. Available also from: https:
//docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-best-practices.html.
55. What is Amazon EKS? AWS. Available also from: https://docs.aws.amazon.com/eks/latest/userguide/what-is-eks.html.
56. ÖZAL, Serkan. Amazon ECS vs. Amazon EKS: The Ultimate Show-down. The New Stack, 2021-01-19. Available also from: https://thenewstack.io/amazon-ecs-vs-amazon-eks-the-ultimate-showdown/.
57. Nodes. Kubernetes. Available also from: https://kubernetes.io/docs/concepts/architecture/nodes/.
58. BRUNER, Karen. Guide to Designing EKS Clusters for Better Se-curity. StackRox. Available also from: https://www.stackrox.com/post/2020/03/guide- to- eks- cluster- design- for-better-security/.
59. What is Amazon Elastic Container Service? AWS. Available alsofrom: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/Welcome.html.
60. SINGH, Deepak. Amazon ECS vs Amazon EKS: making senseof AWS container services. AWS, 2020-11-05. Available alsofrom: https://aws.amazon.com/blogs/containers/amazon-ecs - vs - amazon - eks - making - sense - of - aws - container -services/.
61. STARMER, John. Amazon ECS vs EKS : Which One Is Best ForYour Application. Opsani, 2020-07-30. Available also from: https://opsani.com/blog/amazon- ecs- vs- eks- which- one- is-best-for-your-application/.
97

BIBLIOGRAPHY62. Amazon ECR: Private images. AWS. Available also from: https:
/ / docs . aws . amazon . com / AmazonECR / latest / userguide /images.html.
63. Amazon Elastic Container Service pricing. AWS. Available alsofrom: https://aws.amazon.com/ecs/pricing/.
64. Amazon EKS pricing. AWS. Available also from: https://aws.amazon.com/eks/pricing/.
65. BERKMAN, Jackie. Amazon ECS vs EKS: Which Service is Rightfor You. Mission Cloud Services, 2021-01-19. Available also from:https://www.missioncloud.com/blog/amazon-ecs-vs-eks-which-service-is-right-for-you.
66. AWS Fargate FAQs. AWS. Available also from: https://aws.amazon.com/fargate/faqs/.
67. AWS Fargate profile. AWS. Available also from: https://docs.amazonaws . cn / en _ us / eks / latest / userguide / fargate -profile.html.
68. AWS Fargate pod configuration. AWS. Available also from: https:/ / docs . amazonaws . cn / en _ us / eks / latest / userguide /fargate-pod-configuration.html.
69. EKS Data Plane. AWS. Available also from: https : / / aws .github.io/aws- eks- best- practices/reliability/docs/dataplane/.
70. Getting Started with Amazon ECS on AWS Fargate. AWS. Avail-able also from: https://docs.aws.amazon.com/AmazonECS/latest/userguide/fargate-getting-started.html.
71. AWS Fargate Pricing. AWS. Available also from: https://aws.amazon.com/fargate/pricing/.
72. AWS Fargate increases default resource count service quotasto 1000. AWS, 2021-02-16. Available also from: https ://aws.amazon.com/about- aws/whats- new/2021/02/aws-fargate - increases - default - resource - count - service -quotas-to-1000/.
98

BIBLIOGRAPHY73. EC2 or AWS Fargate? AWS. Available also from: https :
/ / containersonaws . com / introduction / ec2 - or - aws -fargate/.
74. BECK, Julia et al. Theoretical cost optimization by Amazon ECSlaunch type: Fargate vs EC2. AWS. Available also from: https://aws.amazon.com/blogs/containers/theoretical-cost-optimization- by- amazon- ecs- launch- type- fargate- vs-ec2/.
75. AWS Lambda. AWS. Available also from: https://aws.amazon.com/lambda/.
76. AWS Lambda FAQs. AWS. Available also from: https://aws.amazon.com/lambda/faqs/.
77. AWS Lambda Pricing. AWS. Available also from: https://aws.amazon.com/lambda/pricing/.
78. Using AWS Lambda with other services. AWS. Available also from:https://docs.aws.amazon.com/lambda/latest/dg/lambda-services.html#intro-core-components-event-sources.
79. AWS Lambda execution environment. AWS. Available alsofrom: https://docs.aws.amazon.com/lambda/latest/dg/runtimes-context.html.
80. BESWICK, James.Operating Lambda: Building a solid security foun-dation – Part 1. AWS Compute Blog. Available also from: https:/ / aws . amazon . com / blogs / compute / operating - lambda -building-a-solid-security-foundation-part-1/.
81. BESWICK, James. Operating Lambda: Performance optimization– Part 1. AWS Compute Blog, 2021-04-26. Available also from:https : / / aws . amazon . com / blogs / compute / operating -lambda-performance-optimization-part-1/.
82. SHILKOV, Mikhail. Cold Starts in AWS Lambda. MikhailShilkov, 2021-01-05. Available also from: https://mikhail.io/serverless/coldstarts/aws/.
83. Managing concurrency for a Lambda function. AWS. Available alsofrom: https://docs.aws.amazon.com/lambda/latest/dg/configuration-concurrency.html.
99

BIBLIOGRAPHY84. Creating Lambda container images. AWS. Available also from:
https://docs.aws.amazon.com/lambda/latest/dg/images-create.html.
85. Running Container Images in AWS Lambda. AWS. Availablealso from: https : / / www . pulumi . com / blog / aws - lambda -container-support/.
86. Runtime support for Lambda container images. AWS. Available alsofrom: https://docs.aws.amazon.com/lambda/latest/dg/runtimes-images.html.
87. REHEMÄGI, Taavi. How to Deploy AWS Lambda with Docker Con-tainers. Hackernoon, 2021-01-07. Available also from: https://hackernoon.com/how-to-deploy-aws-lambda-with-docker-containers-e51j3141.
88. Regions and Availability Zones. AWS. Available also from: https:/ / aws . amazon . com / about - aws / global - infrastructure /regions_az/.
89. What is Amazon VPC? AWS. Available also from: https://docs.aws.amazon.com/vpc/latest/userguide/what-is-amazon-vpc.html.
90. VPCs and subnets. AWS. Available also from: https://docs.aws.amazon.com/vpc/latest/userguide/VPC_Subnets.html.
91. Amazon VPC pricing. AWS. Available also from: https://aws.amazon.com/vpc/pricing/.
92. NAT gateways. AWS. Available also from: https://docs.aws.amazon.com/vpc/latest/userguide/vpc-nat-gateway.html.
93. VPC endpoints. AWS. Available also from: https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints.html.
94. AWS PrivateLink pricing. AWS. Available also from: https://aws.amazon.com/privatelink/pricing/.
95. Amazon Elastic Container Registry FAQs. AWS. Available alsofrom: https://aws.amazon.com/ecr/faqs/.
96. What is Amazon Elastic Container Registry. AWS. Available alsofrom: https://docs.aws.amazon.com/AmazonECR/latest/userguide/what-is-ecr.html.
100

BIBLIOGRAPHY97. Amazon Elastic Container Registry pricing. AWS. Available also
from: https://aws.amazon.com/ecr/pricing/.98. Amazon EC2 On-Demand Pricing: Data Transfer. AWS. Available
also from: https : / / aws . amazon . com / ec2 / pricing / on -demand/.
99. Implementing Microservices on AWS. AWS. Available also from:https : / / docs . aws . amazon . com / whitepapers / latest /microservices-on-aws/microservices-on-aws.html.
100. What is AWS Step Functions?AWS. Available also from: https://docs.aws.amazon.com/step-functions/latest/dg/welcome.html.
101. AWS Step Functions Pricing. AWS. Available also from: https://aws.amazon.com/step-functions/pricing/.
102. Supported AWS Service Integrations for Step Functions. AWS.Available also from: https://docs.aws.amazon.com/step-functions/latest/dg/connect-supported-services.html.
103. Amazon EC2: Instance Lifecycle. AWS. Available also from: https://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/ec2-instance-lifecycle.html.
104. Introducing AWS Step Functions integration with Amazon EKS.AWS. Available also from: https : / / aws . amazon . com /blogs / containers / introducing - aws - step - functions -integration-with-amazon-eks/.
105. [EKS/Fargate] request: Improve Fargate Node Startup Time. GitHub,Inc. (AWS), 2019-12-13. Available also from: https://github.com/aws/containers-roadmap/issues/649.
106. [Fargate/ECS] [Image caching]: provide image caching for Fargate.GitHub, Inc. (AWS), 2020-01-14. Available also from: https://github.com/aws/containers-roadmap/issues/696.
107. Lambda Retry Mechanics. Dashbird. Available also from: https://dashbird.io/knowledge-base/aws-lambda/retries-and-idempotency/.
101

BIBLIOGRAPHY108. BESWICK, James. New for AWS Lambda – SQS FIFO as an event
source. AWS. Available also from: https://aws.amazon.com/blogs/compute/new- for- aws- lambda- sqs- fifo- as- an-event-source/.
109. Amazon SQS FAQs. AWS. Available also from: https://aws.amazon.com/sqs/faqs/.
110. What is Infrastructure as Code (IaC)? RedHat. Available also from:https://www.redhat.com/en/topics/automation/what-is-infrastructure-as-code-iac.
111. AWS CloudFormation concepts. AWS. Available also from:https : / / docs . aws . amazon . com / whitepapers / latest /introduction-devops-aws/aws-cloudformation.html.
112. What is the AWS CDK?AWS. Available also from: https://docs.aws.amazon.com/cdk/latest/guide/home.html.
113. AWS Cloud Development Kit: Concepts. AWS. Available also from:https://docs.aws.amazon.com/cdk/latest/guide/core_concepts.html.
114. AWS Lambda function scaling. AWS. Available also from: https://docs.aws.amazon.com/lambda/latest/dg/invocation-scaling.html.
115. BESWICK, James. Operating Lambda: Performance optimiza-tion – Part 3. AWS Compute blog. Available also from:https : / / aws . amazon . com / blogs / compute / operating -lambda-performance-optimization-part-3/.
116. SUTTER, Rob. Optimizing Lambda functions packaged as containerimages. AWS Compute blog. Available also from: https://aws.amazon.com/blogs/compute/optimizing-lambda-functions-packaged-as-container-images/.
102