construction collaborative de données lexicales multilingues
TRANSCRIPT

TAL. Volume 42 – n° 4/2001, pages 1 à X
Construction collaborative dedonnées lexicales multilingues
Le projet Papillon
Mathieu Mangeot-Lerebours* — Gilles Sérasset**—Mathieu Lafourcade**** National Institute of InformaticsHitotsubashi 2-1-2-1913 Chiyoda-ku Tokyo 101-8430 [email protected]** GETA-CLIPS — IMAG — Université Joseph FourierBP 53, 38041 Grenoble cedex [email protected]*** TAL-LIRMM — Université de [email protected]
RÉSUMÉ. Résumé
MOTS-CLÉS : mots-clés.
KEY WORDS : keywords.
Note : Article à envoyer le 5 janvier dernier délai àMichael Zock [email protected]
Note : l’article doit faire de 25 à 30 pages

2 TAL. Volume 42 – n° 3/2001
1. Introduction
S : Cet article présente un état de l’art du projetPapillon de construction collaborative sur Internet dedonnées lexicales multilingues.
I : L’intérêt majeur est d’appliquer le paradigme deconstruction du système d’exploitation LINUX,construction collaborative sur Internet par desbénévoles, à celle de données lexicales multilingues quiseront disponibles gratuitement au grand public. Lesenjeux scientifiques sont nombreux. En effet, iln’existe pas à l’heure actuelle de dictionnaire d’usagemultilingue incluant un grand nombre de langues. Quellestructure faut-il adopter pour réduire les efforts deconstruction ? D’autre part, le choix d’interagir avecle serveur à travers le Web pose des problèmes deconstruction d’interfaces pour l’édition et lamanipulation de grandes quantités de données.
P :
2. Motivations du projet
Le projet Papillon fait suite à un premier constat :il n’existe pas à l’heure actuelle de dictionnairefrançais-japonais électroniques et gratuits. De plus,les dictionnaires existants sont en général conçus pourles japonais. La transcription des kanjis (idéogrammesjaponais) est donc la plupart des cas omise. Lesfrancophones ne peuvent donc pas se servir de cesdictionnaires à moins de savoir lire les kanjis. Deplus, d’autres informations necessaries pour lacomprehension des mots japonais font aussi défaut. Ilexiste par exemple, une grande variété de spécificateursnumériques en japonais. Certains échappent à toutelogique. Il est donc indispensable d’y avoir accèslorsque l’on veut utiliser un nom.
Une autre difficulté subsiste dans la construction degrandes quantités de données : les coûts de constructionprohibitifs. Un exemple, le projet Electronic DictionaryResearch (EDR) de construction de dictionnaire japonais-

Construction collaborative de données lexicales multilingues3
anglais a coûté plus de 1200 humains/années. Son prix devente, 140 000 euros environ, est très inférieur auxcoûts réels de construction qui ne seront probablementjamais rentabilisés. Il est cependant encore trop élevépour un particulier. De ce fait, seules des institutionspeuvent l’acquérir.
Pour contourner cette difficulté, nous avons choisid’appliquer le paradigme de construction de LINUX àcelui de l’élaboration de données lexicales : chaqueutilisateur contribue bénévolement à la base lexicale etles ressources sont ensuite disponibles gratuitementpour tous. Les utilisateurs mutualisent leursdictionnaires. Des projets similaires de constructioncollaboratives de données lexicales sur le Web existentparfois depuis plusieurs années. Le projet EDICT deconstruction de dictionnaire japonais-anglais dirigé parJim Breen, professeur à l’université Monash en Australie, a démarré il y a plus de 10 ans. De plus, des projetsparallèles de traduction des gloses dans d’autreslangues comme le français conduit par Jean-MarcDesperrier ont démarré avec succès. D’autres projets deconstruction bilingue de dictionnaires incluant lejaponais ont été lancés plus récemment comme SAIKAM,japonais-thaï et WaDoKuJiten, allemand-japonais. Malgréleur succès, ces projets ont des limitations pour nosobjectifs : la qualité des données et la simplicité desstructures des articles. Edict est un dictionnairejaponais->anglais monodirectionnel. Il est donc trèsdifficile de rechercher une traduction japonaise àpartir de l’anglais. D’autre part, ces projets traitenttoujours de dictionnaires bilingues. La construction dedictionnaires multilingue n’a pas encore à notreconnaissance été abordée dans des projets de ce genre.
Des collaborations existantes entre les membres duprojet de construction de dictionnaires avec d’autreslangues : dictionnaire français-anglais-malais entre leGETA-CLIPS à Grenoble et l’UTMK en Malaisie,dictionnaires français-anglais thaï et français-anglais-vietnamen sur le même modèle d’une part et le projetSAIKAM entre le NII à Tokyo et l’unversité Kasetsart àBangkok, Thaïlande d’autre part, nous ont décidé àétendre le nombre de langues et créer ainsi undictionnaire multilingue. Actuellement, les langues

4 TAL. Volume 42 – n° 3/2001
couvertes sont l’allemand, l’anglais, le français, lejaponais, le lao, le malais, le thaï et le vietnamien.Des discussions sont en cours concernant les languesindiennes et le chinois.
Une autre extension importante du but initial concerneles utilisateurs. Plutôt que de construire undictionnaire pour chaque catégorie d’utilisateurs, ilnous a semblé plus intéressant de construire une baselexicale riche d’informations puis ensuite d’en extrairedes vues personnalisées pour chaque utilisateur oucatégorie d’utilisateur. Nous prévoyons des utilisationsde la base par des humains (débutant, expert,traducteur) mais aussi par des machines (lemmatiseurs,traduction automatique, apprentissage assisté parordinateur, etc.). Pour que les données soientutilsables par des machines, il faut donc prévoir demarquer explicitement toutes les informations.
Le défi est alors lancé : comment construirebénévolement et collaborativement sur le Web undictionnaire multilingue, multiutilisateurs, de qualitéet gratuit.
3. Historique
Ce projet a été lancé en 2000 par Emmanuel Planas etFrançois Brown de Colstoun, chercheurs françaistravaillant au Japon d’une part et Mutsuko Tomokiyo,chercheur japonaise travaillant en France d’autre part.
Note : est-ce que je parle de tous les principauxacteurs ?
Une première réunion des principaux acteurs du projeta eu lieu au Japon en août 2000. Elle a regroupé audépart, des chercheurs issus de la linguistiqueinformatique (issus principalement du laboratoireGETA/CLIPS de Grenoble), plutôt que des linguistes oulexicographes. Cette réunion a servi principalement àdéfinir les bases de la structure du dictionnaire et lesétapes nécessaires au lancement du projet.
Une deuxième réunion a suivi en juillet 2001 àGrenoble, en France. Cette réunion a permis destructurer le projet en s’inspirant de l’organisation du

Construction collaborative de données lexicales multilingues5
W3C : Un comité de pilotage du projet réunit une dizainedes principaux acteurs les plus influents. Ensuite, uneliste des tâches a été établie avec pour chaque tâche,un groupe de travail, un comité directeur, et un cyclede requêtes pour commentaires et recommandations.
Le séminaire Papillon 2002 s’est tenue au Japon enjuillet. Des acteurs reconnus dans le monde de lalinguistique informatique sur le japonais ont rejointle projet : Jim Breen, auteur du dictionnaire EDICT,Francis Bond, chercheur au centre de NTT de Keihanna auJapon, Yves Lepage, chercheur au centre ATR de Keihannaau Japon et Ulrich Appel, auteur du dictionnaireallemand-japonais WaDoKuJiten. Durant ce séminaire, il anottament été décidé que les données du projet seraientdisponibles sous licence de logiciel libre.
Le prochain séminaire aura lieu du 3 au 5 juillet 2003à Sapporo, en marge de la conférence ACL. Le programme,en cours d’élaboration prévoit déjà des ateliers deconstruction d’articles de dictionnaires dans plusieurslangues.
Un des buts du projet étant de produire des ressourceslibres de droits, il est donc difficile de trouver desfinancements. La majorité des acteurs du projet ytravaille donc à temps partiel en plus de leur chargehabituelle. Nous avons cependant pu financer nottamentplusieurs séjours postdoctoraux de français au Japon parle biais de la société japonaise pour la promotion de lascience (JSPS).
4. Macrostructure du dictionnaire Papillon
Pur construire un dictionnaire bilingue, le choixd’une macrostructure composée d’un volume composéd’articles de la langue A traduits vers la langue B etd’un autre volume composé d’articles de la langue Btraduits vers la langue A semble naturel. Mais, lorsquel’on s’attèle à la construction d’un dictionnairemultiligue avec plus de 5 langues au départ, cettesolution n’est rapidement plus envisageable. Pour 5langues, il faudrait alors (n*n-1)/2 = 10 volumes.

6 TAL. Volume 42 – n° 3/2001
Une autre solution utilisée en terminologie avecsuccès (voir la base Eurodicautom du service detraduction de la Communauté Européenne) consiste à neconstruire qu’un volume avec une colonne pour chaquelangue. Chaque terme aura alors un équivalent (et unseul) dans chacune des langues. Cette solution estappliquable en terminologie lorsqu’on traite un domaineparticulier mais elle ne peut être utilisée pour laconstruction d’un dictionnaire d’usage dont le domaineest général et où les mots sont la plupart du tempspolysémiques.
La macrostructure que nous avons choisie provient engrande partie des travaux de thèse de Gilles Sérasset[SER94] et a été expérimentée à petite échelle pour laconstruction de petites bases lexicales multilingues[BLA96]. Elle consiste à construire un volume monolinguepour chaque langue présente dans le dictionnaire puis àrelier chaque sens de mot de chaque article monolingueavec ses correspondants dans les autres langues au moyende liens interlingues (appelés axies pour acceptionsinterlingues) regroupés dans un volume interlingueservant de pivot entre les langues. Cette macrostructurepivot, bien que expérimentée avec succès à petiteéchelle n’a pas encore à notre connaissance étéappliquée à grande échelle pour la construction dedictionnaires généraux à usage humain. Cetteexpérimentation constitue donc pour nous un autre défi àrelever.
À retraduireReal contrastive problems in lexical equivalence (not
to be confused with monolingual polysemy, homonymy orsynonymy as clearly explained in Mel'cuk and Wanner(2001) are handled by way of a special kind of link

Construction collaborative de données lexicales multilingues7
between axies. Figure 2 illustrates this architectureusing a classical example involving "Rice" in 4languages. In this example, we used the word senses asgiven by the "Petit Robert" dictionary for French andthe "Longman Dictionary of Contemporary English" forEnglish. As shown, the French and English dictionariesdo not make any word sense distinction between cookedand uncooked rice seeds. However, this distinction isclearly made in Japanese and Malay. No axie may be usedto denote the union of the word senses for Malay "nasi"and "beras" unless we want to consider them as truesynonyms in Malay (which would be false). Hence, we haveto create 3 different axies: one for the union of "nasi"and å‰î— (gohan), the other for the union of "beras" andïƒ (kome) and one for the union of "rice" and "riz". Alink (non-continuous line in Figure 1 has to be addedbetween the third axies and the others in order to keepthe translation equivalence between the word-senses.
Note that the links between axies do not bear anyparticular semantics and should not be confused withsome kind of ontological links.
Bilingual dictionaries can then be obtained from themultilingual dictionary.
5. Microstructure des articles
Pour la structure des articles, nous aurions pudéfinir notre propre structure. Cependant, il nous asemblé plus judicieux de s’appuyer sur une théorieexistante. Nous avons choisi la lexicographieexplicative et combinatoire, issue de la théorie sens-texte principalement pour les raisons suivantes :
- Cette théorie est indépendante des langues. Ce quipermet entre autres d’avoir une seule structure d’article valable pour toutes les langues.
- Elle apporte un cadre théorique et des outils précis pour distinguer les différents sens sémantiques d’un vocable.
- Il existe déjà des dictionnaires basés sur cette théorie.

8 TAL. Volume 42 – n° 3/2001
La théorie sens-texte a été élaborée en Russie parIgor Mel‘cuk et ses collègues à partir de 1965. Cettethéorie les outils nécessaires pour passer d’une idée(un sens) à sa réalisation dans une langue donnée (letexte). Elle a été développée par la suite àl’Observatoire de la Linguistique Sens-Text (OLST) del’université de Montréal et a donné naissance auDictionnaire Explicatif et Combinatoire (DEC) dufrançais contemporain [MEL84].
Les articles de ce dictionnaire ne sont pas desarticles traditionnels regroupant plusieurs sens. Cesont des lexies. Nous reprenons ici la définition d’unelexie de [POL02] page 41 :
Une lexie, aussi appelée unité lexicale, est un regroupement 1) de mots-formes ou 2) de constructions linguistiques qui ne se distinguent que par laflexion.
Dans le premier cas, il s’agit de lexèmes et dans le second cas, delocutions.
Chaque lexie (lexème ou locution) est associée à un sens donné. Que l’onretrouve dans le signifié de chacun des signes (mots-forms ou constructionslinguistiques) auxquels elle correspond.
Les lexies sont ensuite regroupées en vocables. Nousreprenons ici la définition d’un vocable de [POL02] page42 :
Un vocable est un regroupement de lexies qui sont associées aux mêmessignifiants et qui ont un lien sémantique évident.
Le DEC est actuellement constitué de 4 volumesregroupant 558 vocables en tout. C’est un dictionnaireexpérimental avec une structure assez complexe et qui nepeut (encore) servir à un usage général. C’est pourquoiun projet de simplification du DEC a été lancé récemmentpar Alain Polguère et Igor Mel’cuk avec l'aide desétudiants de l'Observatoire de Linguistique Sens-Textede l'université de Montréal au Canada.
Le projet DiCo [POL00] vise à construire une baselexicale du français de grande taille et à générer àpartir de cette base un dictionnaire d'usage public : leLexique Actif du Français (LAF). La base DiCo est encours de rédaction. Il est prévu à terme d'obtenir

Construction collaborative de données lexicales multilingues9
environ 3 000 vocables ayant chacun plusieurs lexies (enmoyenne trois lexies).
Cette base lexicale est gérée par l'outil FileMaker®.Chaque entrée de la base correspond à une lexie. Unvocable peut avoir une ou plusieurs lexies selon qu'ilest monosémique ou polysémique. Les lexies d'un mêmevocable auront généralement le même nom et les mêmespropriétés grammaticales. chaque lexie est composée dehuit champs différents. Nous donnons dans l'exemple dela figure xxx représentant l'unique lexie du vocablemonosémique MEURTRE le nom de tous les champs suivis deleur valeur.
1. Nom de l'unité lexicale : MEURTRE2. Propriétés grammaticales : nom, masc3. Formule sémantique : action de tuer: ~ PAR
L'individu X DE L'individu Y4. Régime : X = I = de N, A-possY = II = de N, A-poss5. (Quasi-)synonymes: {QSyn} assassinat, homicide#1;
crime6. Fonctions lexicales - {V0} tuer- {A0} meurtrier-adj- {S1} auteur [de ART ~ ]//meurtrier-n /* Nom pour
X*/7. Exemples: La mésentente pourrait être le mobile du
meurtre.8. Idiomes: _appel au meurtre_, _crier au meurtre_Figure xxx : extraits de la lexie MEURTRE de la base
DiCoLes fonctions lexicales de base sont au nombre de 52.
Elles peuvent s’appliquer pour toutes les langues mêmesi quelques fonctions n’auront pas de résultat danscertaines langues. Cette microstructure est doncindépendante des langues.
Depuis la base DiCo, il est possible de générer semi-automatiquement des dictionnaires à usage humain tel quele Lexique Actif du Français (LAF). Ce dictionnaire

10 TAL. Volume 42 – n° 3/2001
tente de rapprocher la lexicographie "théorique" et lalexicographie "commerciale" en utilisant la lexicologieexplicative et combinatoire.
Ce formalisme est très intéressant puisque, à partirdes mêmes données, il permet de produire des ressourcesaussi bien pour des systèmes lexicaux que pour desdictionnaires d'usage grand public. De plus, il permetde populariser la lexicologie explicative etcombinatoire provenant de la théorie sens-texte. Nousavons ici un net progrès par rapport aux autresdictionnaires vus précédemment qui n'étaient destinésqu'à un usage uniquement humain et ne pouvaient donc pasêtre facilement utilisables par une machine sanstransformation.
L'utilisation d'une base de donnée limite cependant lastructuration des entrées en champs. Pour nos besoins,nous avons donc redéfini la structure d’une lexie auformat XML. Ce système de structuration plus élaborénous permet de noter explicitement toute la structuredes articles.
6. Architecture générale de la plateforme
6.1. Cadre théorique de manipulation de données
Gilles Sérasset définit dans sa thèse [SER94] unSystème Universel de gestion de Bases LexicalesMultilingues (SUBLIM). Il consiste principalement endeux langages spécialisés pour la manipulation dedonnées lexicales et d’un langage de vérification decontraintes sur ces données. Ces langages s’exprimentdans une syntaxe tirée de LISP.
LINGARD est un langage de description del’architecture linguistique ou la macrostructure dedictionnaires. Ce language générique permet de définirl’organisation des volumes d’un dictionnaire et lesliens entre ces volumes : dictionnaires monolingues,bilingues, multilingues à structure pivot, etc.
LEXARD est un langage de description de l’architecturelexicale ou la microstructure des articles des

Construction collaborative de données lexicales multilingues11
dictionnaires. Le lexicographe doit pouvoir utilisern’importe quel formalisme pour décrire ses articles.C’est pourquoi LEXARD permet de décrire un grand nombrede types de données différents comme des structures detraits, des arbres, des graphes, des automates, desensembles, des listes, etc. Ce langage n’est donc passpécialisé pour une théorie particulière dereprésentation de données lexicales.
6.2. DML : description de dictionnaires en XML
Malgré la puissance de description de SUBLIM, iln’existait aucune implémentation de ce système. C’estpourquoi nous l’avons repris en l’enrichissant avec leslacunes constatées lors de notre étude [MAN01] puis nousl’avons réexprimé en XML [MAN02a]
We then defined a complete framework for theconsultation and the construction of dictionaries. Theframework is completely generic in order to manageheterogeneous dictionaries with their own properstructures. It is extensively used in Papillon project.The framework consists in the definition of an XMLnamespace called DML (Dictionary Markup Language). Alllexical data of a lexical database can be described withDML elements. The entire hierarchy of the XML files,elements and attributes is described using XML schemataand grouped into the DML namespace. Figure xxx describesthe organisation of the main DML elements. The XMLschemata are available online. This allows users to edit
Database
Entry
DictionaryClientAPI
SupplierAPI
VolumeUser
HistoryGroup
CDM set•headword•pos•pronunciation•translation•example•idiom
Basic Types•boolean•integer•date
function
treegraph
automatonlink
12 TAL. Volume 42 – n° 3/2001
and validate their files online with an XML schemavalidator.Figure xxx : architecture de DML
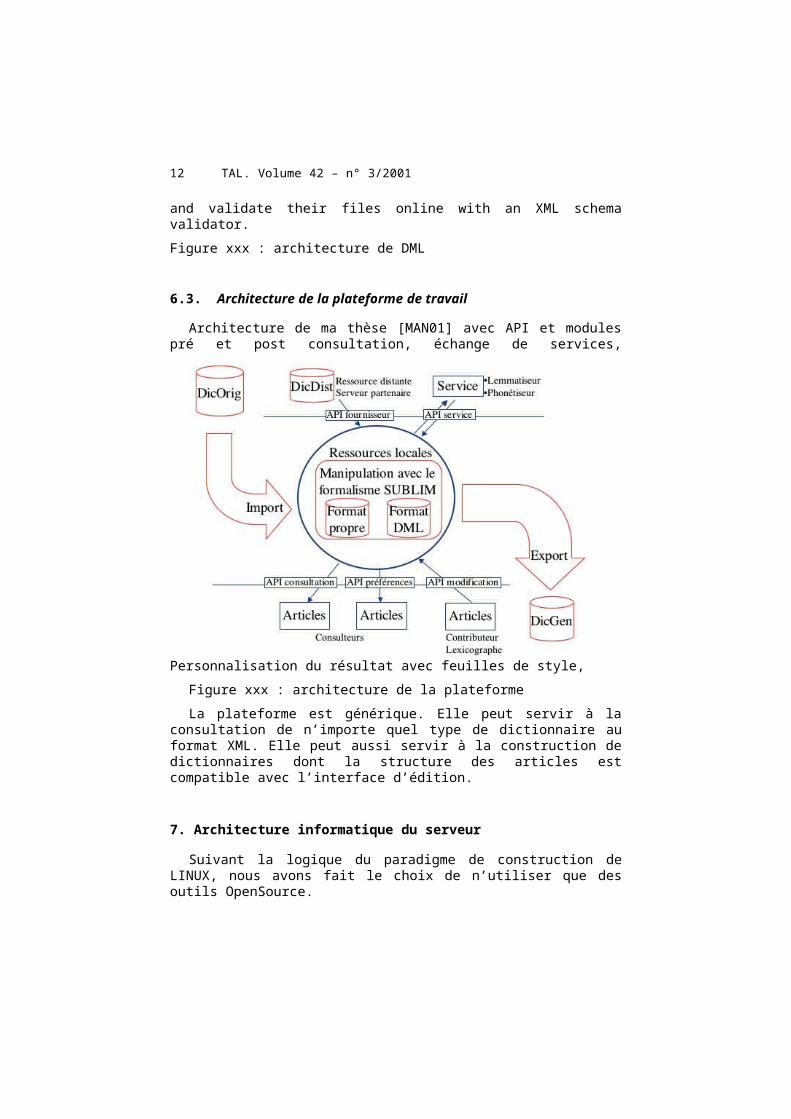
6.3. Architecture de la plateforme de travail
Architecture de ma thèse [MAN01] avec API et modulespré et post consultation, échange de services,
Personnalisation du résultat avec feuilles de style, Figure xxx : architecture de la plateformeLa plateforme est générique. Elle peut servir à la
consultation de n’importe quel type de dictionnaire auformat XML. Elle peut aussi servir à la construction dedictionnaires dont la structure des articles estcompatible avec l’interface d’édition.
7. Architecture informatique du serveur
Suivant la logique du paradigme de construction deLINUX, nous avons fait le choix de n’utiliser que desoutils OpenSource.

Construction collaborative de données lexicales multilingues13
Enhydra, serveur Web d’objets dynamiques en Java,architecture classique de serveur web 3/tiers.
Figure avec plateforme + 3 couches enhydraLa couche de business pour la manipulation des donnéesla couche de présentation pour la communication avec
les clients à travers des pages HTML/CSS/Javascript etdes formulaires HTML/CGIs.
La couche de données data pour le stockage desdonnées. L’architecture de la palteforme est conçue pourêtre indépendante de la couche de données. Les donnéessont pour l’instant stockées dans un SGBD classique.Nous avons choisi PostgreSQL car il répond à notrecahier des charges en gérant de manière transparente lesdonnées multioctets comme du texte en UTF-8. Lacommunication se fait à travers le JDBC. Il est doncpossible de changer de SGBD en limitant lesdéveloppements.
Nous avons ajouté des fonctionnalités pour le travailen communauté :gestion de listes de distributions,entrepôt de documents rédigés par les utilisateursdirectement sur le serveur, etc.
8. Récupération de données existantes
8.1. Gestion des données existantes : limbes, purgatoire et paradis
The lexical data repository of the Papillon project is divided into 4 subdirectories: Administration contains guidelines and administrative
files Limbes (data in original format) Purgatory (data in XML & UTF-8) Paradise (data in Papillon format)The name of the files and directories is normalised in order to allow easy navigation into the repository.All lexical data stored in the repository is free of rights or protected by a GPL-like licence.

14 TAL. Volume 42 – n° 3/2001
8.1.1. Les limbes
This directory contains lexical data in their original format. When a dictionary is received, it is first stored there while waiting to be “recycled”. For each dictionary, we create a metadata file containing all available information concerning the dictionary (name, languages covered, creation date, size, authors, domain,etc.). It is then used to evaluate the quality of the dictionary and to guide the recycling process. These dicitonaries are freely downloadable as they are.
8.1.2. Le purgatoire
The Purgatory directory receives the lexical data once the recuperation process is over. This process consists in converting the lexical data from its original format into XML encoded in UTF-8. To perform this task, we use the RECUPDIC methodology described in Doan-Nguyen (1998)regular expression tools like Perl scripts.If a dictionary is already encoded in XML, the recuperation process consists in mapping the elements ofinformation into CDM elements and storing the correspondence into the metadata file.

Construction collaborative de données lexicales multilingues15
Internet users access these dictionaries as classical online dictionaries, retrieving individual entries by way of requests on the Papillon web site.
8.1.3. Le paradis
The Paradise directory contains only one dictionaryoften called the "Papillon dictionary".
This dictionary has a particular DML structure.Internet users access entries of this dictionary by wayof requests to the Papillon web site.
It is possible to retrieve only one entry, or anysubset of entries in any available output format. The“native” format is the Papillon textual XML DML formatin UTF-8. Users also have ways to add new entries orcorrect existing ones online.
Other purgatory dictionaries may be integrated into thePapillon dictionary with the help of the CDM elements.
8.2. Un mécanisme des pointeurs communs : CDM
The DML framework may be used to encode many differentdictionary structures. Indeed, two dictionary structurescan be radically different. In order to handle suchheterogeneous structures with the same tools, we havedefined a subset of DML element and attributes that areused to identify which part of the different structuresrepresent the same lexical information. This subset iscalled Common Dictionary Markup (CDM). This set is inconstant evolution. If the same kind of information isfound in several dictionaries then a new elementrepresenting this piece of information is added to theCDM set. It allows tools to have access to commoninformation in heterogeneous dictionaries by way ofpointers into the structures of the dictionaries.
Element CDM équivalentTEI FeM OHD NODE
<entry> (entry) <fem-entry> <se> <se><headword> (hom)(orth) <entry> <hw> <hw>

16 TAL. Volume 42 – n° 3/2001
<pronunciation> (pron) <french_pro
n> <pr><ph> <pr><ph>
<etymology> (etym) <etym><syntactic-sense>
(sense level="1")
<sense n=1> <s1>
<pos> (pos)(subc) <french_cat> <pos> <ps>
<lexie> (sense level="2")
<sense n=2> <s2>
<indicator> (usg) <gloss> <id><label> (lbl) <label> <li> <la>
<example> (def) <french_sentence> <ex> <ex>
<definition> (eg) <df>
<translation> (trans)(tr)
<english_equ><malay_equ>
<tr>
<collocate> (colloc) <co>
<link> (xr) <cross_ref_entry> <xr> <xg>
<vg><note> (note) <ann>
8.3. Vecteurs conceptuels pour la fusion de dictionnaires existants
Il est plus facile de corriger des articles existantsque d’écrire un article en partant de zéro. De plus, ilexiste des dictionnaires libres et gratuits surInternet. Partant de ce constat, nous avons mis en placeune méthodologie de récupération de dictionnairesexistants pour construire un squelette de dictionnaire.Les articles seront ensuite révisés et complétés par lescontributeurs.

Construction collaborative de données lexicales multilingues17
9. Adaptation de l’interface de saisie
L’interface de saisie est générée semi-automatiquementà partir d’un schéma XML décrivant l’article à éditer.La génération est contrôlée par l’outil ArtStudio.L’interface ainsi générée s’adapte automatiquement àplusieurs types de plateformes (HTML, WML, CHTML, java,waba, etc).
David et moi avons rédigé des rapports techniquespouvant s’intégrer dans ce cadre. On peut supprimer ceparagraphe si on rajoute des détails sur les vecteursconceptuels.
10. Gestion des contributions
Pour éviter les problèmes de pollution involontaire dela base par des contributions erronées détéctés dans lesprojets de construction collaborative précédents, lescontributions sont d’abord stockées dans l’espaceutilisateur avant d’être révisées par des spécialisteset intégrées définitivement à la base.
Contributions espace utilisateur avant integration,possibilité de visualiser ses contributions et celles deses groupes comme si elles étaient déjà intégré audictionnaire.
Chacun contribue à son niveau.Le volume interlingue de base lexicale est considéré
comme une soupe chaude toujours en évolution. Des agentstravaillent sans cesse à son amélioration.
Les agents automatiques travaillent en tâche de fonden calculant les vecteurs conceptuels de chaque articlerelié à un lien interlingue et les distances entre cesvecteurs.
Les agents humains corrigent et modifient certainsliens en fonction de leurs connaissances. Bien sûr, unlien calculé par un humain aura plus de poids qu’un liencalculé automatiquement.
Comment ne pas être débordé par les vérifications,d’autant plus que les spécialistes devront certainementêtre rémunérés pour leur travail ?

18 TAL. Volume 42 – n° 3/2001
3 solutions peuvent s’appliquer :Les contributeurs peuvent acquérir une note de
confiance au fur et à mesure que leur travail est évaluépositivement. Les contributeurs de confiance pourrontalors intégrer directement leurs contributions à labase.
Il est possible de mettre en place un système de voteet de révision par les pairs : les autres contributeursvoteront sur la qualité d’une contribution.
La troisième solution concerne les agents automatiquesqui travaillent en tâche de fond sur l’évaluation de labase lexicale. Il faut donc mettre en place des systèmesde vérifications de contraintes adaptés à la nouvellearchitecture de la base.
Le projet ne peut réussir sans l’adhésion du grandpublic. Il faut donc prendre grand soin à la mise enœuvre du serveur sous peine de ne pas voir lescontributeurs revenir.
Il faut aussi trouver le moyen de motiver cescontributeurs avec un tableau des meilleurscontributeurs du mois, etc.
11. Vecteurs conceptuels et Amorçage de la base d’acceptions
Nous cherchons à effectuer un travail dedégrossissement en peuplant automatiquement les basesmonolingues et la base d’acceptions (on partlerad’amorçage). Les contributeurs humains sont plus enclinsà participer au projet si un violume de donnéesconséquent est déjà présent. L’amorçage se fait encombinant un certain nombre de resource lexicale. Unexemple de tel croisements est largement illustré par( ??refBond). Cependant, le problème de la selectioncorrecte des différents sens de termes polysémique estun facteur limitant. A l’aide de vecteur conceptuels(ref ML) qui constituent une approche numérique à lareprésentation du sens nous sommes à même d’affectuercette tâche.

Construction collaborative de données lexicales multilingues19
Nous avons utilisé comme ressources monolingues(termes + définitions + vecteurs conceptuels) deuxdictionnaires Français et anglais (accessibles àhttp://www.lirmm.fr/~lafourca) dont les informationssont des compilations de dictionnaires variés (Hachettefrancophones, Thésaurus Larousse, Dictionnairs desynonymes de L’université de Cean, WordNet, Oxford,etc…). Comme ressources bilngues français-anglais nousavons utilisé le FeM et le dictionnaire Oxford.
11.1. Vecteurs conceptuels
Dans le cadre du traitement du sens en TALN, onreprésente les aspects thématiques de segment textuels(documents, paragraphes, etc) à l’aide de vecteursconceptuels (ref ML). Les vecteurs (lexicalisés) ontlargement été utilisés en recherche d’information(Salton, MacGill, 83) et pour la représentation du sensdans le modèle LSI (Deerwester et al, 90). En TAL,(Chauché 90) a proposé un formalisme pour la projectionde la notion de champ sémantique dans un espacevectoriel. Notre modèle en est fortement inspiré.
A partir d’un ensemble de notions élémentaires (lesconcepts), il est possible de construire des vecteurs(dits conceptuels) et de les associer à des itemslexicaux. L’hypothèse forte (originellement discutéedans (Rodget, Kirkpatrick) est que le jeu de conceptsconstitue un ensemble générateur du langage. De façonsimilaire, l’ensemble des concepts consitue un espacegénérateur dans lequel est plongé l’espace vectoriel dessens. L’utilisation de vecteurs permet d’accéder à desfonctions et des propriétés mathématiques bien fondéesauxquelles il est nécessaire d’attacher desinterprétations linguistiques (ou cognitives)raisonnables.
Dans le système à la base de nos expérimentations, lesconcepts sont issues d’un thésaurus (Larousse, 92) où873 idées principales sont identifiées. Cet ensembleconsitute donc un espace générateur pour les itemslexicaux et leur sens. Cet espace n’est probablement paslibre (pas de base vectorielle propre) et donc,n’importe quel terme peut y projeter son ou ses sens.

20 TAL. Volume 42 – n° 3/2001
11.1.1. Principe de la projection thématique
Soit E, un ensemble fini de n concepts. Un vecteurconceptuel V est une combinaison linéaire des élémentsde E. Pour un sens A, le vecteur V(A) est unedescription (en extension) des activations de tous lesconcepts de E. Par exemple, les différents sens de« couper» peuvent être projeter sur les conceptssuivants (ordonnés par intensité décroissante) :
V(« couper ») = (JEU 0.8, LIQUIDE 0.8, CROIX 0.79, PARTIE 0.78,MELANGE 0.78, FRACTION 0.75, SUPPLICE 0.75, BLESSURE 0.75,BOISSON 0.74 …).
En pratique, plus E est grand plus fine sera ladescription, par contre la manipulation sera d’autantmoins aisée. Il est clair, que pour des vecteurs denses(avec peu de composantes valant 0), l’énumération desconcepts est longue et difficile à évaluer. C’estpourquoi, le calcul des vecteurs se fait parapprentissage à partir de définitions. Les définitionsissues de dictionnaires à usages humain (ou encore deliste de synonymes, etc.) sont l’objet d’une analysemorpho-syntaxique dont l’arbre résultat constitue lastructure sur laquelle les vecteurs sont projeté . unrecuit-simulé permet d’obtenir un vecteur global (sur laracine de l’arbre). Les sens des termes présente dans ladéfinition se sont implicitement désambiguïsés parpartage d’information mutuelles (ref ml Sandford).
11.1.2. Distance angulaire
On défini Sim(A,B) comme une distance de similaritéentre deux vecteurs A et B souvent utilisé en recherched’information (Morin 99). On peut exprimer cettefonction comme :
Sim(A, B) = Cos(A,B) = A.B/|A|*|B|Ou “.” Est la produit scalaire. On suppose ici que
toutes les composantes des vecteurs sont positives ounulles. On définit alors la distance angulaire D entredeux vecteurs A et B comme
D(A,B) = arcos(Sim(A,B))Intuitivement, cette fonction constitue une évaluation
de la proximité thématique et est une mesure de l’angle

Construction collaborative de données lexicales multilingues21
entre deux vecteurs. On considérera, en général, qu’unedistance D ≤ π/4 (moins de 45°) indique de A et B sontthématiquement proches et partagent beaucoup deconcepts. Aux alentours de π/2, il n’y a pas de relationentre A et B. D est une vraie distance et vérifie lespropriétés de reflexivité, symétrie et inégalitétriangulaire.
Figure ml : Représentation graphique des termes échange(très polysémique) et cession.
On a par exemple, les angles suivants :DA(profit, profit) = 0DA(profit, bénéfice) = 10°DA(profit, finance) = 19°DA(profit, marché) = 34°
DA(profit, produit) = 33°DA(profit, bien) = 40°DA(profit, tristesse) = 67°DA(profit, joie) = 59°
11.1.3. Opérations sur les vecteurs
Somme de deux vecteurs. Soit A et B deux vecteurs, ondéfinit leur somme normé comme : V = A + B | vi= (ai + bi)/|V|
Cet opérateur est idempotent, car nous avons A+ A = A.Le vecteur nul 0 est par définition l’élement neutre .
Produit termes à termes. Soit A et B deux vecteurs, ondéfinit leur produit termes à ptermes normalisé comme :V = A * B | vi = √(ai * bi)
Cet opérateur est idempotent, et le vecteur 0 estabsorbant.
Contextulisation. Qaund deux termes sont en présence,certains de leur sens se sélectionnent mutuellement. Parexemple, il n’y plus de difficulté à saisir le sensprobable de botte en présente de chaussure. Plus les termessont polysémiques plus la sélectione peut êtredélicates, mais en général deux termes fortementpolysémiques peuvent se conetxtualiser en sélectionnantle sous-ensemble des sens qui sont thématiquementcommuns. Par exemple (à faire)
Soit A un vecteur cible et B un vecteur dit decontexte. On définit la contextualisation de A par B,comme :

22 TAL. Volume 42 – n° 3/2001
Cx(A,B) = A + (A * B)La fonction de contextulistion n’est pas symétrique.
Elle est idempotenete (Cx(A,A) = A) et le vecteur nulest l’élement neutre (Cx(A,0) = A + 0 = X).
?? Figure 3 ml : Représentation géométrique (2D) de lafonction de contextualisation. L’angle alpha representela distance thématique entre les vecteurs A et Bmutuellement contextualisés.
La fonction Cx rapproche les vecteur A et B enproportion à leur intersection. Cette fonction est uneapproche simple permettant d’amplifier les propriétéssaillantes dans un contexte donné. Pour une vecteurd’une terme polysémique, si le vecteur contexte estpertinent, un des sens possibles est activée à traversla contextualisation. Par exemple, le terme anglais bankest ambigü et son vecteur est globalement la moyenneentre les vecteurs des sens river bank et money institution. Sile vecteur de bank est contextualisé par celui de river,alors les concepts du champs sémantique lié à la financeseront considérablement inhibés.
11.2. Peuplement automatique de la base d’acceptions
Afin de peupler automatiquement la base d’acceptions,plusieurs étapdes doivent être considérées. En premierlieu, un amorçage est nécessaire afin de construire unensemble initial d’acceptions. Ensuite, à partir de deux

Construction collaborative de données lexicales multilingues23
dictionnaires bilingues (que l’on nommera source etcible), nous associons chaque ensemble de lexies àl’ensemble de sens correspondants dans le dictionnairemonolingue vectorisé puis enseuite aux accpetions.
11.2.1. Vocabulaire et constaintes
Précisement, nous utiliserons les termes suivants : Unterme est simplement un mot ou plus généralement uneunité lexicale. Ce mot dipose d’un (monosémique) ou deplusieurs sens (polysémique). On parlera de sens, si noussomme dans un contexte monolingue, d’acception sinon. Dansun dictionnaire monolingue nous parlerons d’une entréeet de ses sous-entrées (qui correspondent à des sens),pour un dictionnaire bilingue nous parlerons d’uneassociation et de sous-associations. La problématiqueest bien ici, de rattacher des sens à des acceptions.
L’automatisation nous impose un certains nombre decontraintes en ce qui concerne les lexies, les liens etles acceptions :
1) Il y a, au plus, un seul lien possible d’un sensmonolingue vers une acception. Une terme avec nsens sera indirectement liée à, au plus, nacceptions via ses définitions (lexies). Certainssens peuvent encore ne pas avoir été mis encorrespondance avec une acception.
2) Deux lexies ne peuvent pas être liée à la mêmeacception. Si ces sens sont synonymes, cetterelation sera explicitée à l’aide d’une fonctionlexicales.

24 TAL. Volume 42 – n° 3/2001
Figure ml 4 : L’architecture générale est augmentéd’une base (fictive) de vecteurs conceptuels. Cet basepermet d’associer aux acceptions une représentationthématique calculée à partir de chacuns des vecteursdisponibles dans les base monolingues. Chaque entréesmonolingue est vectorisé, c’est-à-dire qu’un vecteurconceptuel est associé à chaque sens.Un sens monolingueest associé à une et une seule acception. En théoriechaque sens monolingue et chaque acception doit disposerd’un lien. En pratique, le processus de construction(qui est any time) de la base est toujours dans un étatincomplet (c’est-à-dire qu’il existe des objetsorphelins).
.
11.2.2. Amorçage et Liage Lexie-sens
L’ammorcage consite à créer une acception pour chaquesens défini dans le dictionnaire monolingue. Notreapproche consiste à utiliser les vecteurs conceptuel(associé à un sens) pour produire une base de vecteursassociée aux acceptions

Construction collaborative de données lexicales multilingues25
Figure ml 5: Amorçage du peuplement automatique.Chaque sens S d’un dictionnaire monosémique est promusau rang d’acception. Une base de vecteurs liés auxacceptions est crée. Ces vecteurs traduiront lesactivations thématique des acceptions et devront resterraisonnablement proches de leur vecteurs d’origine (côtémonosémique) au fûr et mesure que d’autres dictionnairesmonolingues vectorisés sont rajoutés.
Entrée monolingue et associations bilingue. Onconsidère en toute généralité un dictionnaire bilingueDa-b d’une langue source A vers une langue cible B. Onutilise aussi le dictionnaire inverse Db-a à des fins devalidation croisée. Dans les deux dictionnaires, lastructure (simplifiée) d’une association bilingue est lasuivante :
A(Da-b,w) = San et Sai = (w, cat, glose*, equiv+)Dans le dictionnaire Dab, le terme w est associée à n
définitions (des lexies). Chaque lexie contient : uneinformation morphologique (au moins la catégoriemorphosyntaxique, Nom, Verbe, Adjectif, Adverbe), zéroou plus gloses, et au moins un equivalent dans la languecible. Les gloses sont des termes optionnels quipermettent à l’utilisateur de sélectionner le sens dont

26 TAL. Volume 42 – n° 3/2001
il est question si le terme est polysémique. Ce sont cesmême gloses qui permettent d’associer via les vecteursconceptuels ce sens du dictionnaire bilingue à un sensdu dictionnaire monolingue (en cas d’ambiguité). Unexemple typique d’association bilingue (anglais-français) est :demand ==demand.1 , VT, g{money, explanation, help}, e{exiger, réclamer})demand.2 , VT, g{higher pay}, e{revendiquer, réclamer})demand.3 , N, g{person}, e{demande})demand.4 , N, g{duty, problem, siutation}, e{revendication, réclamation})demand.5 , N, g{for help, for money}, e{demande})
Une entrée générique de nos dictionnaires monolinguesvectorisés est la suivante :
E(Da,w) = Sen et Sei(Dab,w) = (w, cat, def, v)Dans un dictionnaire monolingue vectorisé Da, une
entrée w dispose de n sous-entrées wi (n≥1). Si n=1 leterme w est strictement monosémique (selon cedictionnaire). De façon abusive on qualifiera une sous-entrée de sens. Les sens peuvent être organiséshiérarchiquement, ce qui est reflété par les liens deraffinement dans la base d’acceptions. La définition defest l’information principale à partir de laquelle estcalculé le vecteur conceptuel correspondant (cf ref ml).Dans une approche simlifié, le vecteur global d’unterme est le centroïde des vecteurs de ses sens:
V(E) = 1/n * (V(Se1) + … + V(Sen)Un exemple typique d’entrée monolingue (française) est (définitions issues du dictionnaire Hachette) :exiger == exiger.1, VERBE, #vt# #s=1# Réclamer, en vertu d'un droit réel ou que l'on s'arroge. ( Exiger le paiement de réparations ) -- ( Exiger que ( + subj ) ) ( Il exige qu'on vienne ), V1exiger.2, VERBE, #s=2# ( Sujet nom de chose ) Imposer comme obligation. ( Allez-y, le devoir l'exige ) ( Les circonstances exigent que vous refusiez ). V2

Construction collaborative de données lexicales multilingues27
exiger.2, VERBE, Nécessiter. ( Construction qui exige une main-d'oeuvre abondante ). V3
Le vecteur global pour le terme exiger est : 1/3(V1 +V2+V3).
Appariement Sens-Association . Pour une sous-association Sai = (w, cat, {glose1, gloase2 …}, equiv+)on cacule un vecteur contexte de la façon suivante :
Vc(Sai) = V(glose1) + V(glose2) + …Le vecteur de la glose est le vecteur global,
toutefois on sélectionne les sens dont les catégoriesmorphosyntaxique sont compatibles. Le vecteur associé àSai = (w, cat, {glose1, gloase2 …}, equiv+) est lecalcul de la contextualisation faible (fonction Cx)entre le vecteur issu du dictionnaire monolingue pour wet le vecteur contexte.
Vecteur estimé de Sai = Vcx(Sai) = Cx(V(w), Vc(Sai))A chaque sous-association Sai il est maintenant
poossible d’apparier un vecteur issu du dictionnairemonolingue vectorisé. Il s’agit du vecteur (et donc dusens) qui et le plus proche du vecteur estimé.
V(Sai) = Min(D(V(Se1), Vcx(Sai))
Ainsi, nous avons pu apparier au moins un sous-ensembledes entrée moloingues et des associations bilingues.C’est-à-dire qu’en pratique nous avons pu fournir unevecteur aux associations bilingues ce qui la conditionpour les relier à des acceptions (dans les cas depolysémie). A la fin de ce processus, certains des sensd’un terme du dictionnaire monolingie vectorisédisposent d’un lien unique vers une entrée dudictionnaire bilingue.

28 TAL. Volume 42 – n° 3/2001
?? Figure ml 6 : Processus d’associations de n entréesbilingues vers p entrés monolingues. Chaque entrée teassociation disposent d’un vecteur conceptuel. Lesassociations sont faites par minimisation des distancesentre vecteurs.
11.2.3. Liage Sens-acceptions
Il s’agit ici d’associer un sens Sb du langage cible àune sens du langage souce Sa. Comme un sens est lié demanière univoque à une seule acception A, on étend lelien par transitivité : Sb Sa & Sa A alors Sb A.
On considèrera deux vecteur conceptuel comme“suffisement proche” si leur distance thématique est uninférieur à un seuil t. Plus ce seuil est faible, plus leniveau de confiance du lien vers l’acception est fort.En retour, il risque d’être difficile d’automatiquementréaliser l’association. Un valeur de seuil acceptables’avère être π/4. Les différents situations sont lessuivantes :
Un sens S vers un seul équivalent monosémique. Ce casconsiste à sélectionner directement les term. Lesvecteurs conceptuels ne sont pas utilisé ici, si cen’est pour effectuer une vérification. Si les deuxvecteurs conceptuels ne sont pas raisonnablementproches, un message d’alerte est envoyé au lexicographe.

Construction collaborative de données lexicales multilingues29
Le problème peut aussi bien venir d’une erreur desdictionnaires bilingue, ou qu’un des vecteurs (ou lesdeux) à des activations inadéquates.
Un sens S vers un équivalent polysémique Il faut alorssélectionner le sens equivalent Sb qui pourrait êtreacceptable (fig xx – bas) Un filtre consiste àselectionner les equivalents inverses, puis parmis lessens restant (s’il y en a plusieurs) choisir celui don'tle vecteur est le plus proche.
Un sens S vers plusieurs équivalent polysémique. Cecas est une genéralisation des cas précédents (cf Figxx)
Cas d’erreur L’erreur principale provient de laconsitution d’un ensemble vide. Cela peut arriver si lesinformations dans le dictionnaire bilingue sontinconsistant. On remarquera que cela arrive relativementsouvent en pratique. ?? à dev
?? Fig ml 7 : Partie supérieure - une association directeentre deux equivament monosémique (par exemple babouin baboon). Un avertissement est émis pour lelexicographe si la distance entre les vecteurs est tropimportante. Dans ce cas, il est vraisemblalbe, qu’aumoins un des vecteurs conceptuel ne dispose pasd’activations pertinentes. Partie inférieure – un sens avec unseul équivalent peut être associé à un sous-ensemble dek sens. Seulement le sous-ensemble des sens dont lesvecteurs sont assez proches est retenu.

30 TAL. Volume 42 – n° 3/2001
?? Figure ml 9 : Généralisation des cas précédents. Unsens avec plusieurs équivalents doit être associé à unsous-ensemble des sens de chaque équivalent en languecible.
11.2.4. Netoyage des liens
Le nettoyage des liens consiste à détruire des liensqui aurait été créés abusivement (au vue des contraintesque nous nous somme imposés) et d’en réévaluer certains.Deux cas peuvent se présenter : un sens particulier estlié à plusieurs acceptions), ou une acceptionparticulière est liée à plus d’un sens.
1) Liens multiples. Pour résoudre ce problème, il estnécessaire de créer une acception intermédiaire.The sens est alors lié seulement à la nouvelleacception (les liens précédent sont détruits). Desliens de raffinement de sens sont créés entre lanouvelle acception et les précédentes. (cf figurexx)
2) Sens multiples. Nous avons à choisir parmi lessens lequel doit être retenu comme liable àl’acception, les autres liens étant détruits. Lasélection se fait sur la base du plus prochevecteur.
En toute généralité, les deux situations peuventsurvenir en même temps. The processus de nettoyage etapppliqué itérativement avec une priorité en faveur dela création d’acceptions intermédiaires.

Construction collaborative de données lexicales multilingues31
?? Figure ml 10 : Nettoyage de liens. Partiesupérieure :Liens multiples. Une acception intermédiaireest créeé ainsi que des liens de raffinement de sens.Partie inférieure : Sens multiples. Seul un lien doit êtreconservé. Celui dont les vecteur conceptuels entrel’acception et le sens est le plus proche est retenu.Les autres sens sont orphelins et seront traités par lasuite (identification d’une acception acceptable, oucréation d’une nouvelle acception).
11.2.5. Extensions et discussion
Un certains nombre d’aspects doivent être mentionnéeleur developpement dépassant l’obejt de cet article.
1) les vecteurs des acceptions. Pour chaque acceptionsnous calculons son propre vecteur conceptuel. Cesvecteur est la moyenne des vecteurs des sensmonolingues associés à l’acception. D’autres part,ils sont stockés de façon indépendante à la based’accceptions comme s’il s’agissait d’une basemonolingue (cf Figure ml 5). Ce vecteur sertessentiellement à confirmer ou infirmer uneproposition de liens lors de l’ajout de nouvelleentrées monolingues (à des acceptions déjàexistantes).

32 TAL. Volume 42 – n° 3/2001
2) Pondération des liens. Chaque lien crééautomatiquement se voit attribue une valeur deconfiance (entre 0 et 1). Cette valeur correspond àla similarité entre le vecteur de l’acception etcelui de l’entrée monolingue. Si un lien estconfirmé par le lexicographe, le niveau deconfiance vaut 1. L’exploitation des fonctionslexicales permet de moduler la valeur de confianceattribuée par le système (cf ref SchwabetML).
3) Le processus de peuplement est effectuéitérativement par des agents automomes. Un agentexplorer la base d’accpetions et assaye d’évaluerles liens ou d’en créer. Par exemple, une acceptionpendante (avec un seul lien) doit être reliée à uneentrée monolingue pour chacune des autres langues.Dans le cas d’entrée polysémques ou d’équivamentmultiples, seul les sources monolingues vectorisésnous concerne dans la mesure où seul les vecteursconceptuels sont à la base du processus dedécision. Les entrées orphelines doivent égalementêtre traité par la recherche d’une acceptionadéquate. Le processus est globalement convergentsurtout dans la mesure ou des liens sont fortementcondfirmé par les contributeurs humains.
Nos expériences de croisement de dictionnaires et depeuplement et liage automatique de la based’acceptions nous ont permis dans le cas du français-anglais de générer environ 20000 acceptions dontenviron 15000 était correctement liés. Le resteconsitait en acceptions pendantes (soit du côtéanglais soit du côté français). La plus grandedifficulté concerne les entrées qui ne sont pasdirectement lexicalisé dans une langue. Dans ce cas,l’équivalent se réduit à une phrase explicative ou àun paraphrasage. Ces pseudo-équivalent ne se retrouvepas dans les dictionnaires monolingue équivalent. Parexemple le terme abêtir se traduit par to make stupid, toturn into a moron qui ne consitue par des entrées dudictionnaire monolingue anglais. Afin de régler ceproblème nous avons décider de générer de tellesentrée monolingues qui seront par la suite complétés(en particulier au niveau de leurs fonctionslexiales).

Construction collaborative de données lexicales multilingues33
Une petite frange d’acceptions (moins de 4%) et desens (monolingue français ou anglais) sontincorrectement liés ou disposent de liens dont leseuil de confiance est inférieur à 1/2. Il s’agit engénéral de termes très polysémiques (dont les verbessupport sont un exemple) qui générer beaucoup de formelexicale voire de locutions dont le forme exacte peutêtre sujette à des variations. Cela engendre enparticulier des amas d’acceptions lié par desraffinement de sens. En toute objectivité, l’approchefourni des résultats dans le rappel et important maisdont la précision est parfois médiocre. Enl’occurrence, c’est très exactement la situationsouhaitée où le lexicographe humain peut intervenir.Les termes polysémiques dont les champs sémantiquessont relativement distincts (par exemple un termecomme botte) sont correctement traités par les vecteursconceptuels.Notre approche permet également d’amélirorer laqualités des vecteurs cocneptuels. Il s’agit ici d’uneexploitation du graphe que représente les liens et lesacceptions (et non plus de sa construction). Enparticulier l’apport des lexicographe sur desinformations lexicales permet d’augemnter lapertinence de certains vecteurs ce qui en retouraméliorer les performances du processus de peuplement.
Refml (je n’ai pas inclus les ref à MML, GS, Meltchuk)
[LAF02a] M. Lafourcade, Guessing Hierarchies ans Symbols forWord Meanings through Hyperonyms and Conceptual Vectors.In Procs of OOIS 2002 Workshop, Montpellier, France,September 2002, Springer, LNCS 2426, pp. 84-93.
[LAF02b] M. Lafourcade, Lens effects in autonomousterminology learning with conceptual vectors. In Procs ofSeminar on linguistic meaning representation and theirapplications over the World Wide Web, Penang, Malaysia,12 p.
[LAF02c] M. Lafourcade, D. Schwab, Automatically PopulatingAcception Lexical Database through Bilingual Dictionaries

34 TAL. Volume 42 – n° 3/2001
and Conceptual Vectors. In proc. of PAPILLON-2002, Tokyo,Japan, August 2002
[SCH02a] D. Schwab et M. Lafourcade, Hardening of AcceptionLinks through Vectorized Lexical Functions. In proc. ofPAPILLON-2002, Tokyo, Japan, July 2002
[LAF99] Lafourcade M. et E. Sandford, Analyse etdésambiguïsation lexicale par vecteurs sémantiques. Inproc. of Traitement Automatique du Langage Naturel(TALN'1999), Cargèse, France, Juillet 1999, pp 351-356.
[CHA90] J. Chauché, Détermination sémantique en analysestructurelle :une expérience basée sur une définition dedistance. TAL Information, 31/1, pp 17-24, 1990.
[CHA96] J. Chauché, E. Sandford, D´etermination s´emantiqueen analyse structurelle : une expérience bas´ee sur unedéfinition de distance. Actes de MIDDIM-96, Le Col dePorte, France, August, 1996, pp 56-66.
[DEE90] Deerwester S. et S. Dumais, T. Landauer, G. Furnas,R. Harshman, Indexing by latent semantic anlysis. InJournal of the American Society of Information science,1990, 416(6), pp 391-407.
[LAR92] Larousse. Thésaurus Larousse - des id´ees aux mots,des mots aux id´ees. Larousse, ISBN 2-03-320-148-1, 1992.
[LEH98] Lehmann A. et Martin-Berthet F. Introduction `a lalexicologie. S´emantique et morphologie, Paris, Dunod(Lettres Sup), 1998.
[LYO77] Lyons J. Semantics Cambridge : Cambridge UniversityPress, 1977.
[MOR99] Morin, E. Extraction de liens s´emantiques entretermes à partir de corpus techniques. Thèse de doctorat del’Université de Nantes, 1999.
[PAL76] Palmer, F.R. Semantics : a new introductionCambridge University Press, 1976.
[POL01] Polgu´ere A. Notions de base en lexicologieObservatoire de linguistique sens-texte, 2001.
[QUA01] C. K. Quah and F. Bond and T. Yamazaki Design andConstruction of a machine-tractable Malay-English Lexicon.Proc of AsiaLex, Seoul, 2001, pp 200-205.

Construction collaborative de données lexicales multilingues35
[ROB00] Robert Le Nouveau Petit Robert, dictionnairealphabétique et analogique de la langue française. Ed.Robert, 2000.
[ROD52] Rodget P. Thesaurus of English Words and Phrases.Longman, London, 1852.
[RIL95] Riloff E. and J. Shepherd A corpus-basedbootstrapping algorithm for Semi-Automated semanticlexicon construction. In. Natural Language Engineering5/2, 1995, pp. 147-156.
[SAL83] Salton G. et MacGill M.J. Introduction to modernInformation Retrieval McGraw-Hill, New-York, 1983.
[SCH02b] Schwab D., Lafourcade M. et Prince V. Antonymy andConceptual Vectors, COLING 2002 processings.
[VER92] J. Véronis and N. Ide. A feature-based model forlexical databases. In Proc. of the FourteenthInternational Conference on Computational LinguisticCOLING’92, 1992, Nantes, France, 8 p.
12. Conclusion
13. Bibliographie
[BLA 96] BLANC E., « Une maquette de base lexicale multilingueà pivot lexical: PARAX », Lexicomatique et Dictionnairique, Actes ducolloque LTT, Lyon septembre 1995, ed. AUPELF-UREF, Montréal,Canada, pp. 43-58.
[MAN 01] MANGEOT-LEREBOURS M., Environnements centralisés etdistribués pour lexicographes et lexicologues en contextemultilingue. Thèse de nouveau doctorat, SpécialitéInformatique, Université Joseph Fourier Grenoble I, jeudi27 septembre 2001, 280 p.
[MAN 02a] MANGEOT-LEREBOURS M., « An XML Markup LanguageFramework for Lexical Databases Environments: theDictionary Markup Language », LREC Workshop on International

36 TAL. Volume 42 – n° 3/2001
Standards of Terminology and Language Resources Management, LasPalmas, Islas Canarias, Spain, 28 May 2002, pp 37-44.
[MAN 02b] MANGEOT-LEREBOURS M., SÉRASSET G., « Frameworks,Implementation and Open Problems for the CollaborativeBuilding of a Multilingual Lexical Database. », COLINGWorkshop on Building and Using Semantic Networks SEMANET02, Ed. GraceNgai, Pascale Fung & Kenneth W. Church Taipei, Taiwan, 31August 2002, pp 9-15.A formater
[MEL84] Mel'ãuk, I. A. et al. 1984, 1988, 1992, 1999.Dictionnaire explicatif et combinatoire du françaiscontemporain: Recherches lexico-sémantiques I, II, III, IV.Presses de l'Université de Montréal, Montreal.[POL00] Alain Polguère (2000) Towards a theoretically-motivated general public dictionary of semantic derivations and collocations for French. Proceedings of EURALEX'2000, Stuttgart, pp. 517-527.[POL02] Alain Polguère (2002) Notions de base en lexicologie.OLST-Département de linguistique et de traduction, Universitéde Montréal, 210 p.
[SER 94] SÉRASSET G., SUBLIM: un Système Universel de BasesLexicales Multilingues et NADIA: sa spécialisation auxbases lexicales interlingues par acceptions. Thèse denouveau doctorat, Spécialité Informatique, UniversitéJoseph Fourier Grenoble I, 1994, 280 p
[SER 01] SÉRASSET G., MANGEOT-LEREBOURS M., « Papillon LexicalDatabase Project: Monolingual Dictionaries & InterlingualLinks. », Proc. NLPRS'2001 The 6th Natural Language Processing PacificRim Symposium, Hitotsubashi Memorial Hall, National Centerof Sciences, Tokyo, Japon, 27-30 novembre 2001, vol 1/1,pp. 119-125.
14. Biographie
Mathieu Lafourcade est docteur de l’université Joseph Fourier en informatique. Ilest actuellement maître de conférences à l’université Montpellier II et membre dugroupe Traitements Algorithmiques des Langages du laboratoire LIRMM. Sesactivités de recherche portent sur la mise au point des horloges tournant dans lesens trigonométriques.

Construction collaborative de données lexicales multilingues37
Mathieu Mangeot-Lerebours est docteur de l’université Joseph Fourier enInformatique. Il est actuellement chercheur invité à l’Institut Nationald’Informatique de Tokyo au Japon, financé par la Société Japonaise pour laPromotion de la Science. Se travaux portent sur les environnements de création,manipulation et édition de données lexicales multilingues en collaboration.
Gilles Sérasset est docteur de l’université Joseph Fourier en informatique. Il estactuellement maître de conférences à l’université Joseph Fourier et membre duGroupe d’Études sur la Traduction Automatique du laboratoire CLIPS. Ses activitésde recherche portent sur la confection des carambars à la noix de coco.