automatic assessment technologies to support drums practicing
TRANSCRIPT

Automatic assessment technologies to support drums practicing
Amoroacutes Cortiella Maciagrave
Curs 2020-2021
Treball de Fi de Grau
Director Xavier Serra
GRAU EN ENGINYERIA EN SISTEMES AUDIOVISUALS
Bachelorrsquos Degree on Audiovisuals Systems EngineeringUniversitat Pompeu Fabra
Automatic assessment technologies tosupport drums practicing
Maciagrave Amoroacutes i Cortiella
Supervisor Xavier Serra
May 2021
Contents
1 Introduction 1
11 Motivation 1
12 Existing solutions 2
13 Identified challenges 3
131 Guitar vs drums 3
132 Dataset creation 4
133 Signal quality 4
14 Objectives 5
15 Project overview 5
2 State of the art 6
21 Signal processing 6
211 Feature extraction 6
212 Data augmentation 8
22 Sound event classification 9
221 Drums event classification 9
23 Digital sheet music 11
24 Software tools 11
241 Essentia 12
242 Scikit-learn 12
243 Lilypond 12
244 Pysimmusic 13
245 Music Critic 13
25 Summary 13
3 The 40kSamples Drums Dataset 14
31 Existing datasets 14
311 MDB Drums 15
312 IDMT Drums 15
32 Created datasets 16
321 Music school 16
322 Studio recordings 18
33 Data augmentation 22
34 Drums events trim 23
35 Summary 23
4 Methodology 24
41 Problem definition 24
42 Drums event classifier 25
421 Feature extraction 26
422 Training and validating 27
423 Testing 31
43 Music performance assessment 33
431 Visualization 33
432 Files used 35
5 Results 36
51 Tempo limitations 37
52 Saturation limitations 40
53 Evaluation of the assessment 43
6 Discussion and conclusions 47
61 Discussion of results 47
62 Further work 48
63 Work reproducibility 49
64 Conclusions 50
List of Figures 51
List of Tables 53
Bibliography 54
A Studio recording media 57
B Extra results 60
Acknowledgement
I would like to express my sincere gratitude to
bull Xavier Serra for supervising this project
bull Vsevolod Eremenko Eduard Vergeacutes and the MTG for helping me whenever I
have needed it
bull Sepe Martiacutenez and the Stereodosis team for helping me record a drums dataset
Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Bachelorrsquos Degree on Audiovisuals Systems EngineeringUniversitat Pompeu Fabra
Automatic assessment technologies tosupport drums practicing
Maciagrave Amoroacutes i Cortiella
Supervisor Xavier Serra
May 2021
Contents
1 Introduction 1
11 Motivation 1
12 Existing solutions 2
13 Identified challenges 3
131 Guitar vs drums 3
132 Dataset creation 4
133 Signal quality 4
14 Objectives 5
15 Project overview 5
2 State of the art 6
21 Signal processing 6
211 Feature extraction 6
212 Data augmentation 8
22 Sound event classification 9
221 Drums event classification 9
23 Digital sheet music 11
24 Software tools 11
241 Essentia 12
242 Scikit-learn 12
243 Lilypond 12
244 Pysimmusic 13
245 Music Critic 13
25 Summary 13
3 The 40kSamples Drums Dataset 14
31 Existing datasets 14
311 MDB Drums 15
312 IDMT Drums 15
32 Created datasets 16
321 Music school 16
322 Studio recordings 18
33 Data augmentation 22
34 Drums events trim 23
35 Summary 23
4 Methodology 24
41 Problem definition 24
42 Drums event classifier 25
421 Feature extraction 26
422 Training and validating 27
423 Testing 31
43 Music performance assessment 33
431 Visualization 33
432 Files used 35
5 Results 36
51 Tempo limitations 37
52 Saturation limitations 40
53 Evaluation of the assessment 43
6 Discussion and conclusions 47
61 Discussion of results 47
62 Further work 48
63 Work reproducibility 49
64 Conclusions 50
List of Figures 51
List of Tables 53
Bibliography 54
A Studio recording media 57
B Extra results 60
Acknowledgement
I would like to express my sincere gratitude to
bull Xavier Serra for supervising this project
bull Vsevolod Eremenko Eduard Vergeacutes and the MTG for helping me whenever I
have needed it
bull Sepe Martiacutenez and the Stereodosis team for helping me record a drums dataset
Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Contents
1 Introduction 1
11 Motivation 1
12 Existing solutions 2
13 Identified challenges 3
131 Guitar vs drums 3
132 Dataset creation 4
133 Signal quality 4
14 Objectives 5
15 Project overview 5
2 State of the art 6
21 Signal processing 6
211 Feature extraction 6
212 Data augmentation 8
22 Sound event classification 9
221 Drums event classification 9
23 Digital sheet music 11
24 Software tools 11
241 Essentia 12
242 Scikit-learn 12
243 Lilypond 12
244 Pysimmusic 13
245 Music Critic 13
25 Summary 13
3 The 40kSamples Drums Dataset 14
31 Existing datasets 14
311 MDB Drums 15
312 IDMT Drums 15
32 Created datasets 16
321 Music school 16
322 Studio recordings 18
33 Data augmentation 22
34 Drums events trim 23
35 Summary 23
4 Methodology 24
41 Problem definition 24
42 Drums event classifier 25
421 Feature extraction 26
422 Training and validating 27
423 Testing 31
43 Music performance assessment 33
431 Visualization 33
432 Files used 35
5 Results 36
51 Tempo limitations 37
52 Saturation limitations 40
53 Evaluation of the assessment 43
6 Discussion and conclusions 47
61 Discussion of results 47
62 Further work 48
63 Work reproducibility 49
64 Conclusions 50
List of Figures 51
List of Tables 53
Bibliography 54
A Studio recording media 57
B Extra results 60
Acknowledgement
I would like to express my sincere gratitude to
bull Xavier Serra for supervising this project
bull Vsevolod Eremenko Eduard Vergeacutes and the MTG for helping me whenever I
have needed it
bull Sepe Martiacutenez and the Stereodosis team for helping me record a drums dataset
Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

241 Essentia 12
242 Scikit-learn 12
243 Lilypond 12
244 Pysimmusic 13
245 Music Critic 13
25 Summary 13
3 The 40kSamples Drums Dataset 14
31 Existing datasets 14
311 MDB Drums 15
312 IDMT Drums 15
32 Created datasets 16
321 Music school 16
322 Studio recordings 18
33 Data augmentation 22
34 Drums events trim 23
35 Summary 23
4 Methodology 24
41 Problem definition 24
42 Drums event classifier 25
421 Feature extraction 26
422 Training and validating 27
423 Testing 31
43 Music performance assessment 33
431 Visualization 33
432 Files used 35
5 Results 36
51 Tempo limitations 37
52 Saturation limitations 40
53 Evaluation of the assessment 43
6 Discussion and conclusions 47
61 Discussion of results 47
62 Further work 48
63 Work reproducibility 49
64 Conclusions 50
List of Figures 51
List of Tables 53
Bibliography 54
A Studio recording media 57
B Extra results 60
Acknowledgement
I would like to express my sincere gratitude to
bull Xavier Serra for supervising this project
bull Vsevolod Eremenko Eduard Vergeacutes and the MTG for helping me whenever I
have needed it
bull Sepe Martiacutenez and the Stereodosis team for helping me record a drums dataset
Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

51 Tempo limitations 37
52 Saturation limitations 40
53 Evaluation of the assessment 43
6 Discussion and conclusions 47
61 Discussion of results 47
62 Further work 48
63 Work reproducibility 49
64 Conclusions 50
List of Figures 51
List of Tables 53
Bibliography 54
A Studio recording media 57
B Extra results 60
Acknowledgement
I would like to express my sincere gratitude to
bull Xavier Serra for supervising this project
bull Vsevolod Eremenko Eduard Vergeacutes and the MTG for helping me whenever I
have needed it
bull Sepe Martiacutenez and the Stereodosis team for helping me record a drums dataset
Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Acknowledgement
I would like to express my sincere gratitude to
bull Xavier Serra for supervising this project
bull Vsevolod Eremenko Eduard Vergeacutes and the MTG for helping me whenever I
have needed it
bull Sepe Martiacutenez and the Stereodosis team for helping me record a drums dataset
Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Abstract
This project is focused in the development of automated assessment tools for the
support of musical instrument learning concretely drums learning The state of
the art on music performance assessment has advanced in the last years and the
demand for online learning resources has increased The goal is to develop software
that listens to a student reading a music sheet with drums then evaluates the audio
recording giving some feedback on the tempo and reading accuracy First a review
of the previous work on different topics is made Then a drums event dataset
is created as well as a classifier and a performance assessment pipeline has been
developed focused on giving feedback through a visualization of the waveform in
parallel with the exercise score Results suggests that the classifier can generalize
with new audios despite this there is a large margin to improve the classification
results Furthermore there are some limitations in terms of maximum tempo to
classify correctly the events and the amount of saturation that the system can afford
to ensure a correct prediction Finally a discussion introduces the idea of a teacher
that follows the same process as the pipeline proposed thinking if this is a correct
approach to the problem and if this is a fair way to evaluate the system in a task
that we do differently with more information than one audio
Keywords Automatic assessment Signal processing Music information retrieval
Drums Machine learning
Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Chapter 1
Introduction
The field of sound event classification and concretely drums events classification has
improved the results during the last years and allows us to use this kind of technolo-
gies for a more concrete application like education support [1] The development of
automated assessment tools for the support of musical instrument learning has been
a field of study in the Music Technology Group (MTG) [2] concretely on guitar
performances implemented in the Pysimmusic project [3] One of the open paths
that proposes Eremenko et al [2] is to implement it with different instruments
and this is what I have done
11 Motivation
The aim of the project is to implement a tool to evaluate musical performances
specifically reading scores with drums One possible real application may be to sup-
port the evaluation in a music school allowing the teacher to focus on other items
such as attitude posture and more subtle nuances of performance If high accuracy
is achieved in the automatic assessment of tempo and reading a fair assessment of
these aspects can be ensured In addition a collaboration between a music school
and the MTG allows the use of a specific corpus of data from the educational insti-
tution program this corpus is formed by a set of music sheets and the recordings of
the performances
1
2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

2 Chapter 1 Introduction
Besides this I have been studying drums for fourteen years and a personal motivation
emerges from this fact Learning an instrument is a process that does not only rely
on going to class there is an important load of individual practice apart of the class
indeed Having a tool to assess yourself when practicing would be a nice way to
check your own progress
12 Existing solutions
In terms of music interpretation assessment there are already some software tools
that support assessing several instruments Applications such as Yousician1 or
SmartMusic2 offer from the most basic notions of playing an instrument to a syllabus
of themes to be played These applications return to the students an evaluation that
tells which notes are correctly played and which are not but do not give information
about tempo consistency or dynamics and even less generates a rubric as a teacher
could develop during a class
There are specific applications that support drums learning but in those the feature
of automatic assessment disappears There are some options to get online drums
lessons such as Drumeo3 or Drum School4 but they only offer a list of videos impart-
ing lessons on improving stylistic vocabulary feel improvisation or technique These
applications also offer personal feedback from professional drummers and a person-
alized studying plan but the specific feature of automatic performance assessment
is not implemented
As mentioned in the Introduction automatic music assessment has been a field
of research at the MTG With the development of Music Critic5 an assessment
workflow is proposed and implemented This is useful as can be adapted to the
drums assessment task
1httpsyousiciancom2httpswwwsmartmusiccom3httpswwwdrumeocom4httpsdrumschoolappcom5httpsmusiccriticupfedu
13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

13 Identified challenges 3
13 Identified challenges
As mentioned in [2] there are still improvements to do in the field of music as-
sessment especially analyzing expressivity and with advanced level performances
Taking into account the scope of this project and having as a base case the guitar
assessment exercise from Music Critic some specific challenges are described below
131 Guitar vs drums
As defined in [4] a drumset is a collection of percussion instruments Mainly cym-
bals and drums even though some genres may need to add cowbells tambourines
pailas or other instruments with specific timbres Moreover percussion instruments
are splitted in two families membranophones and idiophones membranophones
produces sound primarily by hitting a stretched membrane tuning the membrane
tension different pitches can be obtained [5] differently idiophones produces sound
by the vibration of the instrument itself and the pitch and timbre are defined by
its own construction [5] The vibration aforementioned is produced by hitting the
instruments generally this hit is made with a wood stick but some genres may need
to use brushes hotrods or mallets to excite specific modes of the instruments With
all this in mind and as stated in [1] it is clear that transcribing drums having to
take into account all its variants and nuances is a hard task even for a professional
drummer With this said there is a need to simplify the problem and to limit the
instruments of the drumset to be transcribed
Returning to the assessment task guitars play notes and chords tuned so the way
to check if a music sheet has been read correctly is looking for the pitch information
and comparing it to the expected one Differently instruments that form a drumset
are mainly unpitched (except toms which are tuned using different scales and tuning
paradigms) so the differences among drums events are on the timbre A different
approach has to be defined in order to check which instrument is being played for
each detected event the first idea is to apply machine learning for sound event
classification
4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

4 Chapter 1 Introduction
Along the project we will refer to the different instruments that conform a drumkit
with abbreviations In Table 1 the legend used is shown the combination of 2 or
more instruments is represented with a rsquo+rsquo symbol between the different tags
Instrument Kick Drum Snare Drum Floor tom Mid tom High tomAbbreviation kd sd ft mt ht
Instrument Hi-hat Ride cymbal Crash cymbalAbbreviation hh cy cr
Table 1 Abbreviationsrsquo legend
132 Dataset creation
Keeping in mind the last idea of the previous section if a machine learning approach
has to be implemented there is a basic need to obtain audio data of drums Apart
from the audio data proper annotations of the drums interpretations are needed in
order to slice them correctly and extract musical features of the different events
The process of gathering data should take into account the different possibilities that
offers a drumset in terms of timbre loudness and tone Several datasets should be
combined as well as additional recordings with different drumsets in order to have
a balanced and representative dataset Moreover to evaluate the assessment task
a set of exercises has to be recorded with different levels of skill
There is also the need to capture those sounds with several frequency responses in
order to make the model independent of the microphone Also those samples could
be processed to get variations of each of them with data augmentation processes
133 Signal quality
Regarding the assignment we have to take into account that a student will not be
able to record its interpretations with a setup as the used in a studio recording most
of the time the recordings will be done using the laptop or mobile phone microphone
This fact has to be taken into account when training the event classifier in order
to do data augmentation and introduce these transformations to the dataset eg
introducing noise to the samples or amplifying to get overload distortion
14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

14 Objectives 5
14 Objectives
The main objective of this project is to develop a tool to assess drums interpretations
of a proposed music sheet This objective has to be split into the different steps of
the pipeline
bull Generate a correctly annotated drums dataset which means a collection of
audio drums recordings and its annotations all equally formatted
bull Implement a drums event sound classifier
bull Find a way to properly visualize drums sheets and their assessment
bull Propose a list of exercises to evaluate the technology
In addition having the code published in a public Github6 repository and uploading
the created dataset to Freesound7 and Zenodo8 will be a good way to share this work
15 Project overview
The next chapters will be developed as follows In chapter 2 the state of the art is
reviewed Focusing on signal processing algorithms and ways to implement sound
event classification ending with music sheet technologies and software tools available
nowadays In chapter 3 the creation of a drums dataset is described Presenting the
use of already available datasets and how new data has been recorded and annotated
In chapter 4 the methodology of the project is detailed which are the algorithms
used for training the classifier as well as how new submissions are processed to assess
them In chapter 5 an evaluation of the results is done pointing out the limitations
and the achievements Chapter 6 concludes with a discussion on the methods used
the work done and further work
6httpsgithubcom7httpsfreesoundorg8httpszenodoorg
Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Chapter 2
State of the art
In this chapter the concepts and technologies used in the project are explained
covering algorithm references and existing implementations First signal process-
ing techniques on onset detection and feature extraction are reviewed then sound
event classification field is presented and its relationship with drums event classifica-
tion Also the principal music sheet technologies and codecs are presented Finally
specific software tools are listed
21 Signal processing
211 Feature extraction
In the following sections sound event classification will be explained most of these
methods are based on training models using features extracted from the audio not
with the audio chunks indeed [6] In this section signal processing methods to get
those features are presented
Onset detection
In an audio signal an onset is the beginning of a new event it can be either a
single note a chord or in the case of the drums the sound produced by hitting one
or more instruments of the drumset It is necessary to have a reliable algorithm
6
21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

21 Signal processing 7
that properly detects all the onsets of a drums interpretation With the onsets
information (a list of timestamps) the audio can be sliced to analyze each chunk
separately and to assess the tempo consistency
It is important to address the challenge in a psychoacoustical way as the objective
is to detect the musical events as a human will do In [7] the idea of perceptual
onset for percussive instruments is defined as a time interval between the physical
onset and the moment that the maximum level is reached In [8] many methods are
reviewed focusing on the differences of performance depending on the signal Non
Pitched Percussive instruments are better detected with temporal methods or high-
frequency content methods while Pitched Non Percussive instruments may need to
take into account changes of energy in the spectrum distribution as the onset may
represent a different note
The sound generated by the drums is mainly percussive (discarding brushesrsquo slow
patterns or malletrsquos build-ups on the cymbals) which means that is formed by a
short transient followed by a short decay there is no sustain As the transient is a
fast change of energy it implies a high-frequency content because changes happen
in a very little frame of time As recommended in [9] HFC method will be used
Timbre features
As described in [10] a feature denotes in some way a quantity or a value Features
extracted by processing the audio stream or transformations of that (ie FFT)
are called low-level descriptors these features have no relevant information from a
human point of view but are useful for computational processes [11]
Some low-level descriptors are computed from the temporal information for in-
stance the zero-crossing rate tells the number of times the signal crosses the zero
axis per second the attack time is the duration of the transient and temporal cen-
troid the energy distribution of an event during the time Other well known features
are the root median square of the signal or the high-frequency content mentioned
in section 211
8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

8 Chapter 2 State of the art
Besides temporal features low-level descriptors can also be computed from the fre-
quency domain Some of them are spectral flatness spectral roll-off spectral slope
spectral flux ia
Nowadays Essentialsquos library offers a collection of algorithms that reliably extracts
the low-level descriptors aforementioned the function that englobes all the extrac-
tors is called Music extractor1
212 Data augmentation
Data augmentation processes refer to the optimization of the statistical representa-
tion of the datasets in terms of improving the generalization of the resultant models
These methods are based on the introduction of unobserved data or latent variables
that may not be captured during the dataset creation [12]
Regarding this technique applied to audio data signal processing algorithms are
proposed in [13] and [14] that introduces changes to the signals in both time and
frequency domains In these articles the goal is to improve accuracy on speech and
animal sound recognition although this could apply to drums event classification
The processes that lead best results in [13] and [14] were related to time-domain
transformations for instance time-shifting and stretching adding noise or harmonic
distortion compressing in a given dynamic range ia Other processes proposed
were focused on the spectrogram of the signal applying transformations such as
shifting the matrix representation setting to 0 some areas or adding spectrograms
of different samples of the same class
Presently some Python2 libraries are developed and maintained in order to do audio
data augmentation tasks For instance audiomentations3 and the GPU version
torch-audiomentations4
1httpsessentiaupfedustreaming_extractor_musichtml2httpswwwpythonorg3httpspypiorgprojectaudiomentations0604httpspypiorgprojecttorch-audiomentations
22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

22 Sound event classification 9
22 Sound event classification
Sound Event Classification is the task of detecting and recognizing sound events in
an audio stream [15] As described in [10] this task can be approached from two
sides on one hand the perceptual approach tries to extract the timbre similarity to
cluster sounds as how we perceive them on the other hand the taxonomic approach
is determined to label sound events as they are defined in the cultural or user biased
taxonomies In this project the focus is on the second approach as the task is to
classify sound events in the drums taxonomy (ie kick drum snare drum hi-hat)
Also in [] many classification methods are proposed Concretely in the taxonomy
approach machine learning algorithms such as K-Nearest Neighbors Support Vector
Machines or Neural Networks All of them using features extracted from the audio
data as explained in section 211
221 Drums event classification
This section is divided into two parts first presenting the state-of-the-art methods
for drum event classification and then the most relevant existing datasets This
section is mainly based on the article [1] as it is a review of the topic and encompasses
the core concepts of the project
Methods
Focusing on the taxonomic drums events classification this field has been studied for
the last years as in the Music Information Retrieval Evaluation eXchange5 (MIREX)
has been a proposed challenge since 20056 In [1] a review of the main methods
that have been investigated is done The authors collect different approaches such
as Recurrent Neural Networks proposed in [16] Non-Negative matrix factorization
proposed in [17] and others real-time based using MaxMSP7 as described in [18]
5httpswwwmusic-irorgmirexwikiMIREX_HOME6httpswwwmusic-irorgmirexwiki2005Audio_Drum_Detection_Results7httpscycling74comproductsmax
10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

10 Chapter 2 State of the art
It is needed to mention that the proposed methods are focused on Automatic Drum
Transcription (ADT) of drumsets formed only by the kick drum snare drum and
hi-hat ADT field is intended to transcribe audio but in our case we have to check
if an audio event is or not the expected event this particularity can be used in our
favor as some assumptions can be made about the audio that has to be analyzed
Datasets
In addition to the methods and their combinations the data used to train the
system plays a crucial role As a result the dataset may have a big impact on the
generalization capabilities of the models In this section some existing datasets are
described
bull IDMT-SMT-Drums [19] Consists of real drum recordings containing only
kick drum snare drum and hi-hat events Each recording has its transcription
in xml format and is publicly avaliable to download8
bull MDB Drums [20] Consists of real drums recordings of a wide range of genres
drumsets and styles Each recording has two txt transcriptions for the classes
and subclasses defined in [20] (eg class Hi-hat Subclasses Closed hi-hat
open hi-hat pedal hi-hat) It is publicly avaliable to download9
bull ENST-Drums [21] Consists of real drum audio and video recordings of dif-
ferent drummers and drumsets Each recording has its transcription and some
of them include accompaniment audio It is publicly available to download10
bull DREANSS [22] Differently this dataset is a collection of drum recordings
datasets that have been annotated a posteriori It is publicly available to
download11
Electronic drums datasets have not been considered as the student assignment is
supposed to be recorded with a real drumset8httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml9httpsgithubcomCarlSouthallMDBDrums
10httpspersotelecom-paristechfrgrichardENST-drums11httpswwwupfeduwebmtgdreanss
23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

23 Digital sheet music 11
23 Digital sheet music
Several music sheet technologies have been developed since the first scorewriter
programs from the 80s Proprietary softwares as Finale12 and Sibelius13 or open-
source software as MuseScore14 and LilyPond15 are some options that can be used
nowadays to write music sheets with a computer
In terms of file format Sibelius has its encrypted version that can only be read and
written with the software it can also write and read MusicXML16 files which are
not encrypted and are similar to an HTML file as it contains tags that define the
bars and notes of the music sheet this format is the standard for exchanging digital
music sheet
Within Music Criticrsquos framework the technology used to display the evaluated score
is LilyPond it can be called from the command line and allows adding macros that
change the size or color of the notes The other particularity is that it uses its own
file format (ly) and scores that are in MusicXML format have to be converted and
reviewed
24 Software tools
Many of the concepts and algorithms aforementioned are already developed as soft-
ware libraries this project has been developed with Python and in this section the
libraries that have been used are presented Some of them are open and public and
some others are private as pysimmusic that has been shared with us so we can use
and consult it In addition all the code has been developed using a tool from Google
called Collaboratory17 it allows to write code in a jupyter notebook18 format that
is agile to use and execute interactively
12httpswwwfinalemusiccom13httpswwwavidcomsibelius14httpsmusescoreorg15httpslilypondorg16httpswwwmusicxmlcom17httpscolabresearchgooglecom18httpsjupyterorg
12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

12 Chapter 2 State of the art
241 Essentia
Essentia is an open-source C++ library of algorithms for audio and music analysis
description and synthesis [23] it can also be installed as a Python-based library
with the pip19 command in Linux or compiling with certain flags in MacOS20 This
library includes a collection of MIR algorithms it is not a framework so it is in the
userrsquos hands how to use these processes Some of the algorithms used in this project
are music feature extraction onset detection and audio file IO
242 Scikit-learn
Scikit-learn21 is an open-source library for Python that integrates machine learning
algorithms for regression classification and clustering as well as pre-processing and
dimensionality reduction functions Based on NumPy22 and SciPy23 so its algorithms
are easy to adapt to the most common data structures used in Python It also allows
to save and load trained models to do inference tasks with new data
243 Lilypond
As described in section 23 LilyPond is an open-source songwriter software with
its file format and language It can produce visual renders of musical sheets in
PNG SVG and PDF formats as well as MIDI files to listen to the compositions
LilyPond works on the command line and allows us to introduce macros to modify
visual aspects of the score such as color or size
It is the digital sheet music technology used within Music Criticrsquos framework as
allows to embed an image in the music sheet generating a parallel representation of
the music sheet and a studentrsquos interpretation
19httpspypiorgprojectpip20httpsessentiaupfeduinstallinghtml21httpsscikit-learnorg22httpsnumpyorg23httpswwwscipyorgscipylibindexhtml
25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

25 Summary 13
244 Pysimmusic
Pysimmusic is a private python library developed at the MTG It offers tools to
analyze the similarity of musical performances and uses libraries such as Essentia
LilyPond FFmpeg24 ia Pysimmusic contains onset detection algorithms and a
collection of audio descriptors and evaluation algorithms By now is the main eval-
uation software used in Music Critic to compare the recording submitted with the
reference
245 Music Critic
Music Critic is a project from the MTG intended to support technologies for online
music education facilitating the assessment of student performances25
The proposed workflow starts with a student submitting a recording playing the
proposed exercise Then the submission is sent to the Music Criticrsquos server where
is analyzed and assessed Finally the student receives the evaluation jointly with
the feedback from the server
25 Summary
Music information retrieval and machine learning have been popular fields of study
This has led to a large development of methods and algorithms that will be crucial
for this project Most of them are free and open-source and fortunately the private
ones have been shared by the UPF research team which is a great base to start the
development
24httpswwwffmpegorg25httpswwwupfeduwebmtgtech-transfer-asset_publisherpYHc0mUhUQ0G
contentid229860881maximizedYJrB-usp7YV
Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Chapter 3
The 40kSamples Drums Dataset
As stated in section 132 having a well-annotated and balanced dataset is crucial to
get proper results In this section the 40kSamples Drums Dataset creation process is
explained first focusing on how to process existing datasets such as the mentioned
in 221 Secondly introducing the process of creating new datasets with a music
school corpus and a collection of recordings made in a recording studio Finally
describing the data augmentation procedure and how the audio samples are sliced
in individual drums events In Figure 1 we can see the different procedures to unify
the annotations of the different datasets while the audio does not need any specific
modification
31 Existing datasets
Each of the existing datasets has a different annotation format in this section the
process of unifying them will be explained as well as its implementation (see note-
book Dataset_formatUnificationipynb1) As the events to take into account
can be single instruments or combinations of them the annotations have to be for-
matted to show that events properly None of the annotations has this approach
so we have written a function that filters the list and joins the events with a small
1httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
14
31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

31 Existing datasets 15
difference of time meaning that they are played simultaneously
Music school Studio REC IDMT Drums MDB Drums
audio + txt
Sibelius to MusicXML
MusicXML parser to txt
Write annotations
AnnotationsAudio
Figure 1 Datasets pre-processing
311 MDB Drums
This dataset was the first we worked with the annotation format in txt was a key
factor as it was easy to read and understand As the dataset is available in Github2
there is no need to download it neither process it from a local drive As shown in
the first cells of Dataset_formatUnificationipynb data from the repository can
be retrieved with a Python wrapper of the Github API3
This dataset has two annotations files depending on how deep the taxonomy used
is [20] In this case the generic class taxonomy is used as there is no need to
differentiate styles when playing a given instrument (ie single stroke flam drag
ghost note)
312 IDMT Drums
Differently to the previous dataset this one is only available downloading a zip
file4 It also differs in the annotation file format which is xml Using the Python
2httpsgithubcomCarlSouthallMDBDrums3httpspypiorgprojectgithubpy4httpswwwidmtfraunhoferdeenbusiness_unitsm2dsmtdrumshtml
16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

16 Chapter 3 The 40kSamples Drums Dataset
package xmltodict5 in the second part of Dataset_formatUnificationipynb the
xml files are loaded as a Python dictionary and converted to txt format
32 Created datasets
In order to expand the dataset with more variety of samples other methods to get
data have been explored On one hand with audio data that has partial annotations
or some representation that is not data-driven such as a music sheet that contains
a visual representation of the music but not a logic annotation as mentioned in
the previous section On the other hand generating simple annotations is an easy
task so drums samples can be recorded standalone to create data in a controlled
environment In the next two sections these methods are described
321 Music school
A music school has shared its docent material with the MTG for research purposes
ie audio demos books in pdf format music sheet in Sibelius format As we can
see in Figure 1 the annotations from the music school corpus are in Sibelius format
this is an encrypted representation of the music sheet that can only be opened with
the Sibelius software The MTG has shared an AVID license which includes the
Sibelius software so we were able to convert the sib files to musicxml MusicXML
is not encrypted and allows to open it and read so a parser has been developed to
convert the MusicXML files to a symbolic representation of the music sheet This
representation has been inspired by [24] which proposes a system to represent chords
MusicXML parser
As mentioned in section 23 MusicXML format is based on ordering the visual
information with tags creating a tree structure of nested dictionaries In the first cell
of XML_parseripynb6 two functions are defined ConvertXML2Annotation reads
the musicxml file and gets the general information of the song (ie tempo time
5httpspypiorgprojectxmltodict6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterXML_parseripynb
32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

32 Created datasets 17
measure title) then a for loops throughout all the bars of the music sheet checking
whereas the given bar is self-defined the repetition of the previous one or the begin
or end of a repetition in the song (see Figure 2) in the self-defined bar case the bar
indeed is passed to an auxiliar function which parses it getting the aforementioned
symbolic representation
Figure 2 Sample drums score from music school drums grade 1
In Figure 2 we can see a staff in which the first bar has been written and the three
others have a symbol that means rsquorepetition of the previous barrsquo moreover the
bar lines at the beginning and the end represents that these four bars have to be
repeated therefore this line in the music score represents an interpretation of eight
bars repeating the first one
The symbolic representation that we propose is based in [24] defines each bar with
a string this string contains the representations of the events in the bar separated
with blank spaces Each of the events has two dots () to separate the figure (ie
quarter note half note whole note) from the note or notes of the event which
are separated by a dot () For instance the symbolic representation of the first bar
in Figure 2 is F4A44 F4A44 F4A44 F4A44
In addition to this conversion in parse_one_measure function from XML_parser
notebook each measure is checked to ensure that fully represents the bar This
means that the sum of the figures of the bar has to be equal to the defined in the
time measure the sum of the events in a 44 bar has to be equal to four quarter
notes
Symbolic notation to unified annotation format
As we can see in Figure 1 once the music scores are converted to the symbolic
representation the last step is to unify the annotations with the used in sections 31
18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

18 Chapter 3 The 40kSamples Drums Dataset
This process is made in the last cells of Dataset_formatUnification7 notebook
A dictionary with the translation of the notes to drums instrument is defined so
the note is already converted Differently the timestamp of each event has to be
computed based on the tempo of the song and the figure of each event this process
is made with the function get_time_steps_from_annotations8 which reads the
interpretation in symbolic notation and accumulates the duration of each event
based on the figure and the tempo
322 Studio recordings
At this point of the dataset creation we realized that the already existing data
was so unbalanced in terms of instances per class some classes had around two
thousand samples while others had only ten This situation was the reason to
record a personalized dataset to balance the overall distribution of classes as well
as exercises with different accuracy when reading simulating students with different
skill levels
The recording process took place on April 16 and 17 at Stereodosis Estudio9 (Sants
Barcelona) the first day was intended to mount the drumset and the microphones
which are listed in Table 2 in Figure 3 the microphone setup is shown differently
to the standard setup in which each instrument of the set has its microphone this
distribution of the microphones was intended to record the whole drumset with
different frequency responses
The recording process was divide into two phases first creating samples to balance
the dataset used to train the drums event classifier (called train set) Then recording
the studentsrsquo assignment simulation to test the whole system (called test set)
7httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_formatUnificationipynb
8httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4scriptsdrumspyL9
9httpswwwstereodosiscom
32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

32 Created datasets 19
Microphone Transducer principleBeyerdynamic TG D70 Dynamic
Shure PG52 DynamicShure SM57 Dynamic
Sennheiser e945 DynamicAKG C314 CondenserAKG C414 CondenserShure PG81 CondenserSamson C03 Condenser
Table 2 Microphones used
Figure 3 Microphone setup for drums recording
Train set
To limit the number of classes we decided to take into account only the classes
that appear in the music school subset this decision was motivated by the idea of
assessing the songs from the books so only classes of the collection of songs were
needed to train the classifier In Figure 4 the distribution of the selected classes
before the recordings is shown note that is in logarithmic scale so there is a large
difference among classes
20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

20 Chapter 3 The 40kSamples Drums Dataset
Figure 4 Number of samples before Train set recording
To organize the recording process we designed 3 different routines to record depend-
ing on the class and the number of samples already existing a different routine was
recorded These routines were designed trying to represent the different speeds dy-
namics and interactions between instruments of a real interpretation In Appendix
A the routines scores are shown to write a generic routine a two lines stave is used
the bottom line represents the class to be recorded and the top line an auxiliary
one The auxiliary classes are cymbals concretely crashes and rides whose sound
remains a long period of time and its tail is mixed with the subsequent sound events
bull Routine 1 (Fig 31) This routine is intended for the classes that do not include
a crash or ride cymbal and has a small number of classes (ie lt500)
bull Routine 2 (Fig 32) This routine does not include auxiliary events as it is
intended for classes that include crash or ride cymbal whose interaction with
itself is intrinsic
bull Routine 3 (Fig 33) This is a short version of routine 1 which only repeats
each bar two times instead of four is intended for classes which not include a
crash or ride cymbal and has a large number of classes (ie gt500)
32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

32 Created datasets 21
Routines 1 and 3 were recorded only one time as we had only one instrument of each
of the classes differently routine 2 was recorded two times for each cymbal as we
was able to use more instances of them different cymbals configurations used can
be seen in Appendix A in Figures 34 35 and 36
After the Train set recording the number of samples was a little more balanced as
shown in Figure 5 all the classes have at least 1500 samples
0
1000
2000
3000
ht+kd
kd+m
t
ht
mt
ft+sd
ft+kd
+sd
cr+sd
ft
cr+kd
cr
ft+kd
hh+k
d+sd
kd+s
d
cy+s
d
cy
cy+k
d sd
kd
hh+s
d
hh+k
d
hh
recorded before record
Figure 5 Number of samples after Train set recording
Test set
The test set recording tried to simulate different students performing the same song
in the same drumset to do that we recorded each song of the music school Drums
Grade Initial and Grade 1 playing it correctly and then making mistakes in both
reading and rhythmic ways After testing with these recordings we realized that we
were not able to test the limits of the assessment system in terms of tempo or with
different rhythmic measures So we proposed two exercises of groove reading in 44
and in 128 to be performed with different tempos these recordings have been done
in my study room with my laptoprsquos microphone
22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

22 Chapter 3 The 40kSamples Drums Dataset
33 Data augmentation
As described in section 212 data augmentation aims to introduce changes to the
signals to optimize the statistical representation of the dataset To implement this
task the aforementioned Python library audiomentations is used
The library Audiomentations has a class called Compose which allows collecting
different processing functions assigning a probability to each of them Then the
Compose instance can be called several times with the same audio file and each time
the resulting audio will be processed differently because of the probabilities In
data_augmentationipynb10 a possible implementation is shown as well as some
plots of the original sample with different results of applying the created Compose
to the same sample an example of the results can be listened in Freesound11
The processing functions introduced in the Compose class are based in the proposed
in [13] and [14] its parameters are described
bull Add gaussian noise with 70 of probability
bull Time stretch between 08 and 125 with a 50 of probability
bull Time shift forward a maximum of 25 of the duration with 50 of probability
bull Pitch shift plusmn2 semitones with a 50 of probability
bull Apply mp3 compression with a 50 of probability
10httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterdata_augmentationipynb
11httpsfreesoundorgpeopleMaciaACpacks32213
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
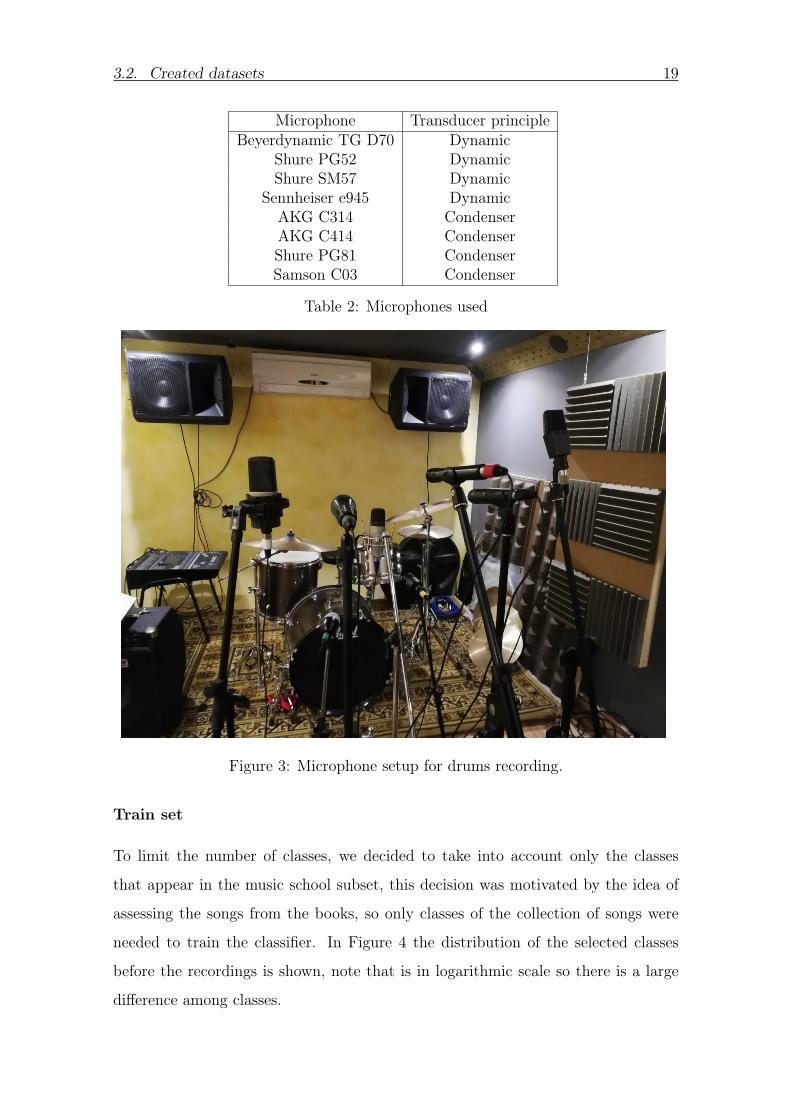
34 Drums events trim 23
34 Drums events trim
As will be explained in section 421 the dataset has to be trimmed into individual
files to analyze them and extract the low-level descriptors In the Dataset_feature
Extractionipynb12 notebook this process has been implemented slicing all the
audios with its annotations each dataset separately to sight-check all the resultant
samples and detect better which annotations were not correct
35 Summary
To summarize a drums samples dataset has been created the one used in this
project will be called the 40k Samples Drums Dataset Nonetheless to share this
dataset we have to ensure that we are fully proprietary of the data which means
that the samples that come from IDMT MDBDrums and MusicSchool datasets
cannot be shared in another dataset Alternatively we will share the 29k Samples
Drums Dataset formed only by the samples recorded in the studio This dataset will
be available in Zenodo13 to download the whole dataset at once and in Freesound
some selected samples are uploaded in a pack14 to show the differences among mi-
crophones
12httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterDataset_featureExtractionipynb
13httpszenodoorgrecord4958592YMmNXW4p5TZ14httpsfreesoundorgpeopleMaciaACpacks32397
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
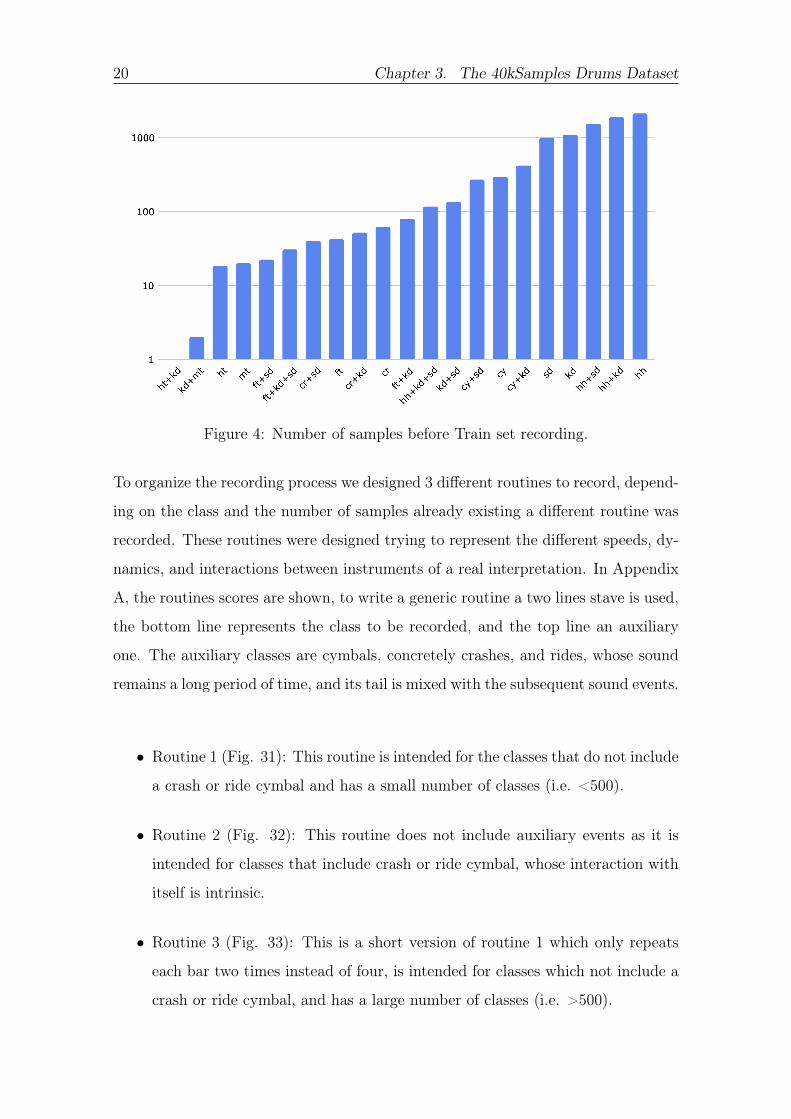
Chapter 4
Methodology
In this chapter the methodologies followed in the development of the assessment
pipeline are explained In Figure 6 the proposed pipeline diagram is shown it is
inspired by [2] Each box of the diagram refers to a section in this chapter so the
diagram might be helpful to get a general idea of the problem when explaining each
process
The system is divided into two main processes First the top boxes correspond to
the training process of the model using the dataset created in the previous chapter
Secondly the bottom row shows how a student submission is processed to generate
some feedback This feedback is the output of the system and should give some
indications to the student on how has performed and how can improve
41 Problem definition
To check if a student reads correctly a music sheet we need some tool to tag which
instruments of the drumset is playing for each detected event This leads us to
develop and train a Drums events classifier if this tool ensures a good accuracy
when classifying (ie lt95) we will be able to properly assess a studentrsquos recording
If the classifier has not enough accuracy the system will not be useful as we will not
be able to differentiate among errors from the student and errors from the classifier
24
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
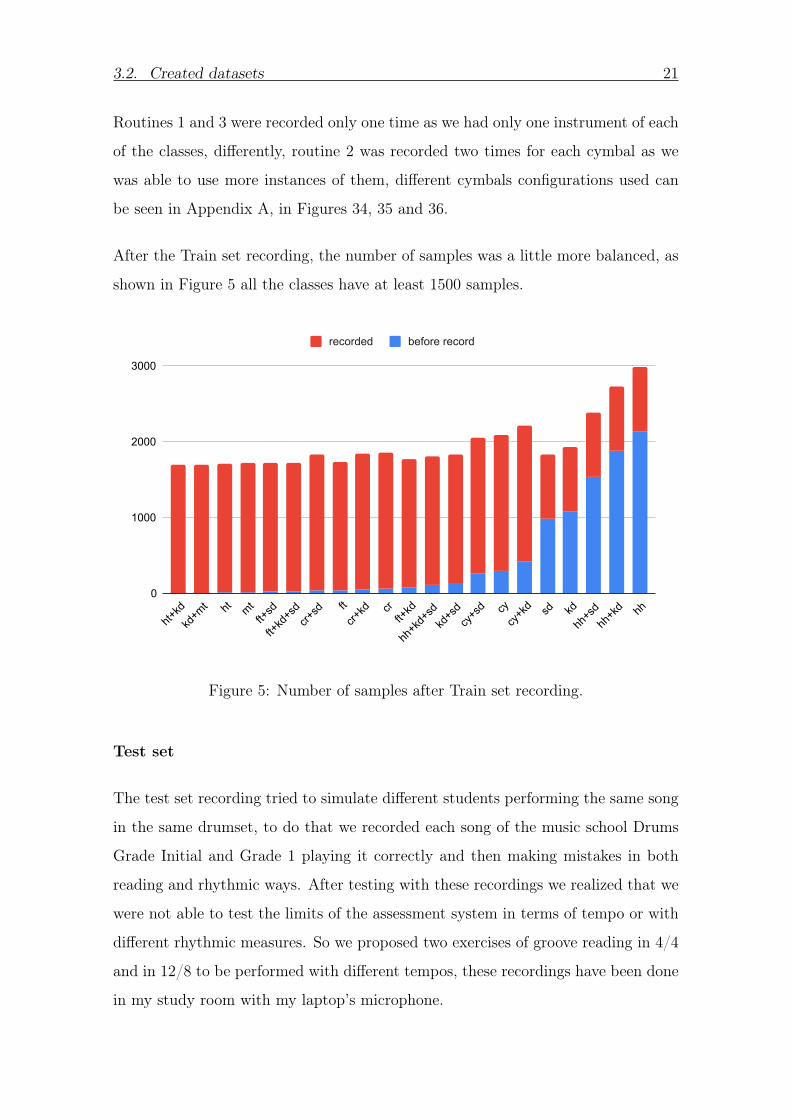
42 Drums event classifier 25
Assessments
Music Scores
Studentsrsquo performances
Annotations
Audio recordings
Dataset
Feature extraction
Drums event classifier training
Performanceassessment
training
Feature extraction
Performanceassessment
inference
New studentrsquos recording
Visualization Performancefeedback
Figure 6 Proposed pipeline for a drums performance assessment system inspiredby [2]
For this reason the project has been mainly focused on developing the aforemen-
tioned drums event classifier and a proper dataset So developing a properly as-
sessed dataset of drums interpretations has not been possible nor the performance
assessment training Despite this the feedback visualization has been developed as
it is a nice way to close the pipeline and get some understandable results moreover
the performance feedback could be focused on deterministic aspects as telling the
student if is rushing or slowing in relation to a given tempo
42 Drums event classifier
As already mentioned this section has been the main load of work for this project
because of the dependence of a correct automatic transcription in order to do a
reliable assessment The process has been divided into 3 main parts extracting
26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

26 Chapter 4 Methodology
the musical features training and validating the model in an iterative process and
finally validating the model with totally new data
421 Feature extraction
The feature extraction concept has been explained in Section 211 and has been
implemented using the MusicExtractor()1 method from Essentiarsquos library
MusicExtractor() method has to be called passing as a parameter the window and
hope sizes that will be used to perform the analysis as well as a filename of the event
to be analyzed The function extract_MusicalFeatures()2 has been implemented
to loop a list of files and analyze each of them to add the extracted features to a
csv file jointly with the class of each drum event At this point all the low-level
features were extracted both mean and standard deviation were computed across
all the frames of the given audio filename The reason was that we wanted to check
which features were redundant or meaningful when training the classifier
As mentioned in section 34 the fact that MusicExtractor() method has to be
called with a filename not an audio stream forced us to create another version of
the dataset which had each event annotated in a different audio file with the corre-
spondent class label as a filename Once all the datasets were properly sliced and
sight-checked the last cell of the notebook were executed with the correspondent
folder names (which contains all the sliced samples) and the features saved in differ-
ent csv one for each dataset3 Adding the number of instances in all the csv files
we get 40228 instances with 84 features and 1 label
1httpsessentiaupfedureferencestd_MusicExtractorhtml2httpsgithubcomMaciACtfg_DrumsAssessmentblobe81be958101be005cda805146d3287eec1a2d5a4
scriptsfeature_extractionpyL63httpsgithubcomMaciACtfg_DrumsAssessmenttreemasterdataslices
features
42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

42 Drums event classifier 27
422 Training and validating
As mentioned in section 22 some authors have proposed machine learning algo-
rithms such as Support Vector Machines (SVM) and K-Nearest Neighbours (KNN)
to do sound event classification also some authors have developed more complex
methods for drums event classification The complexity of these last methods made
me choose the generic ones also to try if it were a good way to approach the problem
as there is no literature concretely on drums event classification with SVM or KNN
The iterative process of training and validating the aforementioned methods has
been the main reference when designing the 40k Drums samples dataset the first
times we tried the models we were working with the classes distribution of Figure
4 as commented this was a very unbalanced dataset and we were evaluating the
classification inference with the accuracy formula 41 that did not take into account
the unbalance in the dataset The accuracy computation was around 92 but the
correct predictions were mainly on the large classes as shown in Figure 7 some
classes had very low accuracy (even 0 as some classes has 10 samples 7 used to
train an 3 to validate which are all bad predicted) but having a little number of
instances affects less to the accuracy computation
accuracy(y y) =1
nsamples
nsamplesminus1sumi=0
1(yi = yi) (41)
Otherwise the proper way to compute the accuracy in this kind of datasets is the
balanced accuracy it computes the accuracy for each class and then averages the
accuracy along with all the classes as in formula 42 where wi represents the weight
of each class in the dataset This computation lowered the result to 79 which was
not a good result
wi =wisum
j 1(yj = yi)wj
(42)
balanced-accuracy(y y w) =1sumwi
sumi
1(yi = yi)wi
28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

28 Chapter 4 Methodology
Figure 7 Confusion matrix after training with the dataset in Figure 4
Another widely used accuracy indicator for classification models is the f-score which
combines the precision and the recall of the model in one measure as in formula
43 Precision is computed as the number of correct predictions divided by the total
number of predictions and recall is the number of correct predictions divided by the
total number of predictions that should be correct for a given class
F_measure =precisiontimes recallprecision+ recall
(43)
Having these results led us to the process of recording a personalized dataset to
extend the already existing (See section 322) With this new distribution the
results improved as shown in Figure 8 as well as better balanced accuracy and f-
score (both 89) Until this point we were using both KNN and SVM models to
compare results and the SVM performed always 10 better at least so we decided
to focus on the SVM and its hyper-parameter tunning
42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

42 Drums event classifier 29
Figure 8 Confusion matrix after training with the dataset in Figure 5 and parameterC = 1
The C parameter in a support vector machine refers to the regularization this
technique is intended to make a model less sensitive to the data noise and the
outliers that may not represent the class properly When increasing this value to
10 the results improved among all the classes as shown in Figure 9 as well as the
accuracy and f-score (both 95)
At that point the accuracy of the model was pretty good but the 88 on the snare
drum class was somehow a problem as is one of the most used instruments in the
drumset jointly with the hi-hat and the kick drum So I tried the same process
with the classes that include only the three mentioned instruments (ie hh kd sd
hh+kd hh+sd kd+sd and hh+kd+sd) Reducing the number of classes improved
the overall accuracy and f-score to 977 and concretely the sd accuracy to 96 as
shown in Figure 10
30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

30 Chapter 4 Methodology
Figure 9 Confusion matrix after training with the dataset in Figure 5 and parameterC = 10
Figure 10 Confusion matrix after training with the dataset in Figure 5 and param-eter C = 10 but only hh sd and kd classes
42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

42 Drums event classifier 31
The implementation of the training and validating iterative process has been de-
veloped in the Classifier_trainingipynb4 notebook First loading the csv files
with the features extracted in Dataset_featureExtractionipynb then depend-
ing on which subset of classes will be used the correspondent instances and filtered
and to remove redundant features the ones with a very low standard deviation are
deleted (ie std_dev lt 000001) As the SVM works better when data is normalized
the standard scaler is used to move all the data distributions around 0 and ensuring
a standard deviation of 1
In the next cells the dataset is split into train and validation sets and the training
method from the SVM of sklearn is called to perform the training when the models
are trained the parameters are dumped in a file to load the model a posteriori and
be able to apply the knowledge learned to new data This process was so slow on
my computer so we decided to upload the csv files to Google Drive and open the
notebook with Google Collaboratory as it was faster and is a key feature to avoid
long waiting times during the iterative train-validate process In the last cells the
inference is made with the validation set and the accuracy is computed as well as
the confusion matrix plotted to get an idea of which classes are performing better
423 Testing
Testing the model introduces the concept of onset detection until now all the slices
have been created using the annotations but to assess a new submission from
a student we need to detect the onsets and then slice the events The function
SliceDrums_BeatDetection5 does both tasks as explained in section 211 there
are many methods to do onset detection and each of them is better for a different
application In the case of drums we have tested the rsquocomplexrsquo method which finds
changes in the frequency domain in terms of energy and phase and works pretty
well but when the tempo increase there are some onsets that are not correctly de-
tected for this reason we finally implemented the onset detection with the HFC4httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterClassifier_
trainingipynb5httpsgithubcomMaciACtfg_DrumsAssessmentblob9422e71a998d3cd0a6c7f03e92a8b0c6f6dac869
scriptsdrumspyL45
32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

32 Chapter 4 Methodology
method This method computes for each window the HFC as in equation 44 note
that high-frequency bins (k index) weights more in the final value of the HFC
HFC(n) =sumk
|Xk[n]|2lowastk (44)
Moreover the function plots the audio waveform jointly with the onsets detected to
check if it has worked correctly after each test In Figures 11 and 12 we can see two
examples of the same music sheet played at 60 and 220 bpm in both cases all the
onsets are correctly detected and no false detection occurs
Figure 11 Onsets detected in a 60bpm drums interpretation
Figure 12 Onsets detected in a 220bpm drums interpretation
With the onsets information the audio can be trimmed in the different events the
order is maintained with the name of the file so when comparing with the expected
events can be mapped easily The audios are passed to the extract_MusicalFeatures()
function that saves the musical features of each slice in a csv
43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

43 Music performance assessment 33
To predict which event is each slice the models already trained are loaded in this new
environment and the data is pre-processed using the same pipeline as when training
After that data is passed to the classifier method predict() which returns for each
row in the data the predicted event The described process is implemented in the first
part of Assessmentipynb6 the second part is intended to execute the visualization
functions described in the next section
43 Music performance assessment
Finally as already commented the assessment part has been focused on giving visual
feedback of the interpretation to the student As the drums classifier has taken so
much time the creation of a dataset with interpretations and its grades has not been
feasible A first approximation was to record different interpretations of the same
music sheet simulating different levels of skills but grading it and doing all the
process by ourselves was not easy apart from that we tended to play the fragments
good or bad it was difficult to simulate intermediate levels and be consistent with
the proposed ones
So the implemented solution generates an image that shows to the student if the
notes of the music sheet are correctly read and if the onsets are aligned with the
expected ones
431 Visualization
With the data gathered in the testing section feedback of the interpretation has
to be returned Having as a base implementation the solution of my companion
Eduard Vergeacutes7 and thanks to the help of Vsevolod Eremenko8 in the last cell of
the notebook Assessmentipynb the visualization is done
First the LilyPond file paths are defined Then for each of the submissions the
audio is loaded to generate the waveform plot
6httpsgithubcomMaciACtfg_DrumsAssessmentblobmasterAssessmentipynb7httpsgithubcomEduardVergesFranchU151202_VA_FinalProject8httpsgithubcomseffkaForMacia
34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

34 Chapter 4 Methodology
To do so the function save_bar_plot()9 is called passing the lists of detected and
expected onsets the waveform and the start and end of the waveform (this comes
from the lilypond filersquos macro) To properly plot the deviations in the code we are
assuming that the interpretation starts four beats after the beginning of the audio
In Figures 13 and 14 the result of save_bar_plot() for two different submissions is
shown The black lines in the bottom of the waveform are the detected onsets while
the cyan lines in the middle are the expected onsets when the difference between
the two values increase the area between them is colored with a traffic light code
(green good to red bad)
Figure 13 Onset deviation plot of a good tempo submission
Figure 14 Onset deviation plot of a bad tempo submission
Once the waveform is created it is embedded in a lambda function that is called from
the LillyPond render But before calling the LillyPond to render the assessment of
the notes has to be done In function assess_notes()10 the expected and predicted
events are passed with a comparison a list of booleans is created but with 0 in the
False and 1 in the True index then the resulting list is iterated and the 0 indices
are checked because most of the classification errors fail in one of the instruments
to be predicted (ie instead of hh+sd it is predicting sd) These cases are considered
partially correct as the system has to take into account its errors the indices in
which one of the instruments is correctly predicted and it is not a hi-hat (we are
9httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL112
10httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsdrumspyL88
43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

43 Music performance assessment 35
considering it more important to get right the snare and kick reading than a hi-hat
which is present in all the events) the value is turned to 075 (light green in the color
scale) In Figure 15 the different feedback options are shown green notes mean
correct light green means partially correct and red means incorrect
Figure 15 Example of coloured notes
With the waveform the notes assessed and the LilyPond template the function
score_image()11 can be called This function renders the LilyPond template jointly
with the waveform previously created this is done with the LilyPond macros
On one hand before each note on the staff the keyword color() size()
determines that the color and size of the note depends on an external variable (the
notes assessed) and in the other hand after the first note of the staff the keyword
eps(1150 16) indicates on which beat starts to display the waveform and
on which ends in this case from 0 to 16 in a 44 rhythm is 4 bars and the other
number is the scale of the waveform and allows to fit better the plot with the staff
432 Files used
The assessment process of an exercise needs several files first the annotations of the
expected events and their timesteps this is found in the txt file that has been already
mentioned in the 311 section then the LilyPond file this one is the template write
in LilyPond language that defines the resultant music sheet the macros to change
color and size and to add the waveform are defined when extracting the musical
features each submission creates its csv file to store the information and finally
we need of course the audio files with the submission recorded to be assessed
11httpsgithubcomMaciACtfg_DrumsAssessmentblob2aaf0dbdd1f026dfebfba65eaac9fcd24a8629afscriptsvisualizationpyL187
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
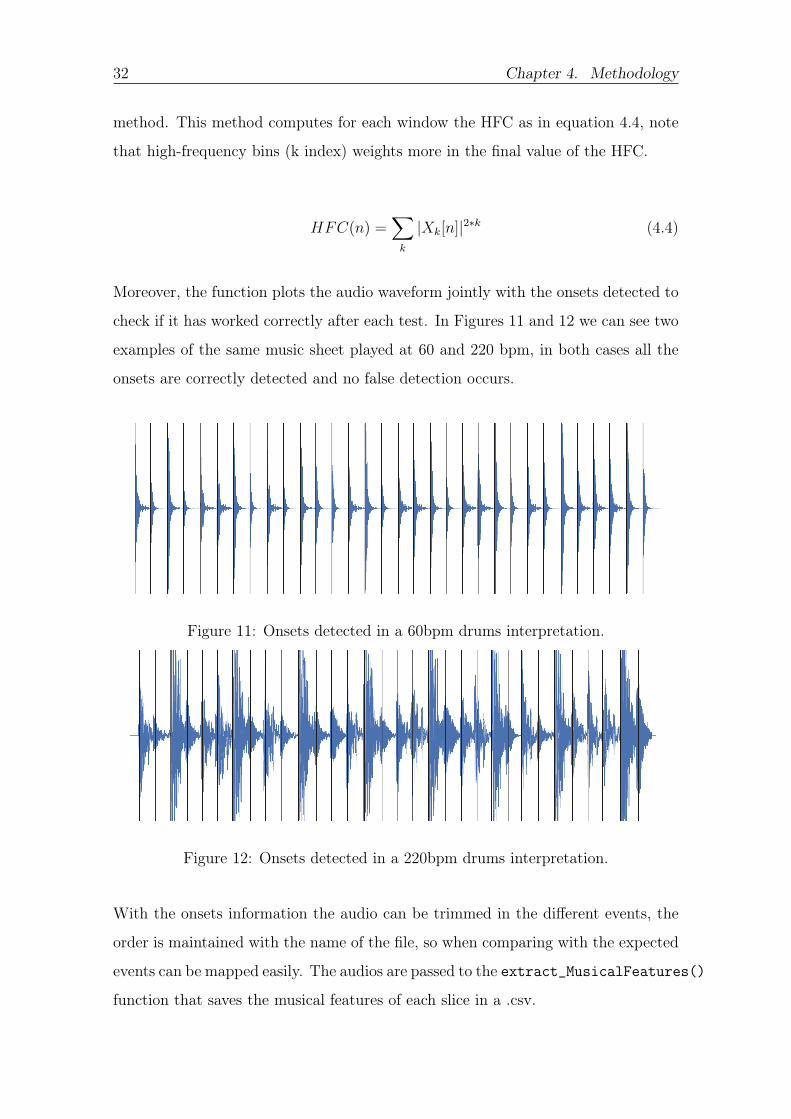
Chapter 5
Results
At this point the system has been developed and the classifier trained so we can do
an evaluation of the results to check if it works correctly and is useful to a student to
learn also to test which are the limits regarding the audio signal quality and tempo
The tests have been done with two different exercises recorded with a computer
microphone and played at a different tempo starting at 60 bpm and adding 40
bpm until 220 bpm The recordings with good tempo and good reading have been
processed adding 6dB until an accumulate of +30 dB
In this chapter and Appendix B all the resultant feedback visualizations are shown
The audio files can be listened in Freesound a pack1 has been created Some of
them will be commented on and referenced in further sections the rest are extra
results
As the High frequency content method works perfectly there are no limitations nor
errors in terms of onset detection all the tests have an f-measure of 1 detecting all
the expected events without detecting any false positive
1httpsfreesoundorgpeopleMaciaACpacks32350
36
51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

51 Tempo limitations 37
51 Tempo limitations
One of the limitations of the system is the tempo of the exercise the accuracy drops
when the tempo increases Having as a reference the Figures that show good reading
which all notes should be in green or light green (ie Figures 16 17 18 19 20
21 and 22) we can count how many are correct or partially correct to punctuate
each case a correct prediction weights 10 a partially correct weights 05 and an
incorrect 0 the total value is the mean of the weighted result of the predictions
Figure 16 Good reading and good tempo Ex 1 60 bpm
Figure 17 Good reading and good tempo Ex 1 100 bpm
Figure 18 Good reading and good tempo Ex 1 140 bpm
In Table 3 we can see that by increasing the tempo of exercise 1 the accuracy of the
classifier decreases it may be because increasing the tempo decreases the spacing
between events and consequently the duration of each event which leads to fewer
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
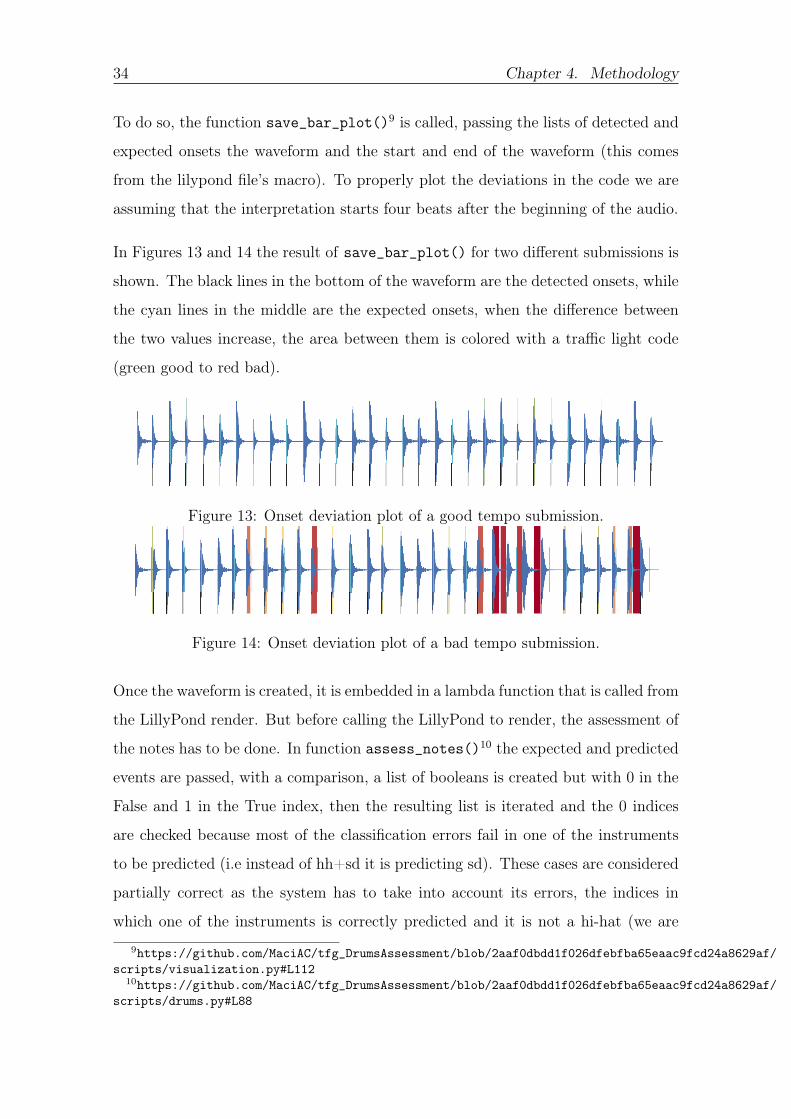
38 Chapter 5 Results
Figure 19 Good reading and good tempo Ex 1 180 bpm
Figure 20 Good reading and good tempo Ex 1 220 bpm
values to calculate the mean and standard deviation when extracting the timbre
characteristics As stated in the Law of Large numbers [25] the larger the sample
the closer the mean is to the total population mean In this case having fewer values
in the calculation creates more outliers in the distribution which tends to scatter
Tempo Correct Partially OK Incorrect Total60 25 7 0 089100 24 8 0 0875140 24 7 1 086180 15 9 8 061220 12 7 13 048
Table 3 Results of exercise 1 with different tempos
51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

51 Tempo limitations 39
Regarding the 128 exercise (Figures 21 and 22) we were not able to record faster
than 100 bpm But in 128 the quarter notes equivalent in tempo is 300 quarter
note per minute similarly to the 140 bpm on 44 which quarter note per minute
temporsquos is 280 The results on 128 (Table 4) are also better because there are more
rsquoonly hi hatrsquo events which are better predicted
Figure 21 Good reading and good tempo Ex 2 60 bpm
Figure 22 Good reading and good tempo Ex 2 100 bpm
40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

40 Chapter 5 Results
Tempo Correct Partially OK Incorrect Total60 39 8 1 089100 37 10 1 0875
Table 4 Results of exercise 2 with different tempos
52 Saturation limitations
Another limitation to the system is the saturation of the signal submitted Hearing
the submissions the hi-hat events are recorded with less amplitude than the snare
and kick events for this reason we think that the classifier starts to fail at +18dB
As can be seen in Tables 5 and 6 the same counting scheme as in the previous section
is done with Figure 23 and Figure 24 The hi-hat is the last waveform to saturate
and at this gain level the overall waveform is so clipped leading to a high-frequency
content that is predicted as a hi-hat in all the cases
Level Correct Partially OK Incorrect Total+0dB 25 7 0 089+6dB 23 9 0 086+12dB 23 9 0 086+18dB 24 7 1 086+24dB 18 5 9 064+30dB 13 5 14 048
Table 5 Results of exercise 1 at 60 bpm with different amplification levels
Level Correct Partially OK Incorrect Total+0dB 12 7 13 048+6dB 13 10 9 056+12dB 10 8 14 05+18dB 9 2 21 031+24dB 8 0 24 025+30dB 9 0 23 028
Table 6 Results of exercise 1 at 220 bpm with different amplification levels
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
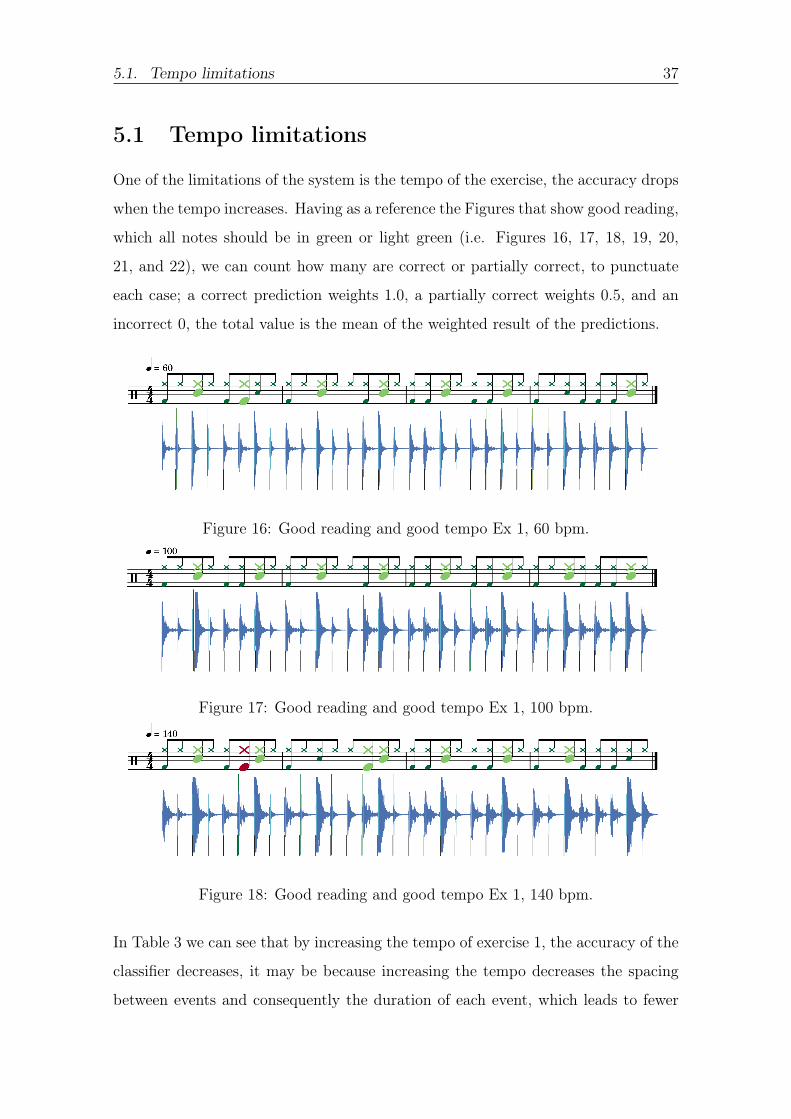
52 Saturation limitations 41
Figure 23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB ateach new staff
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
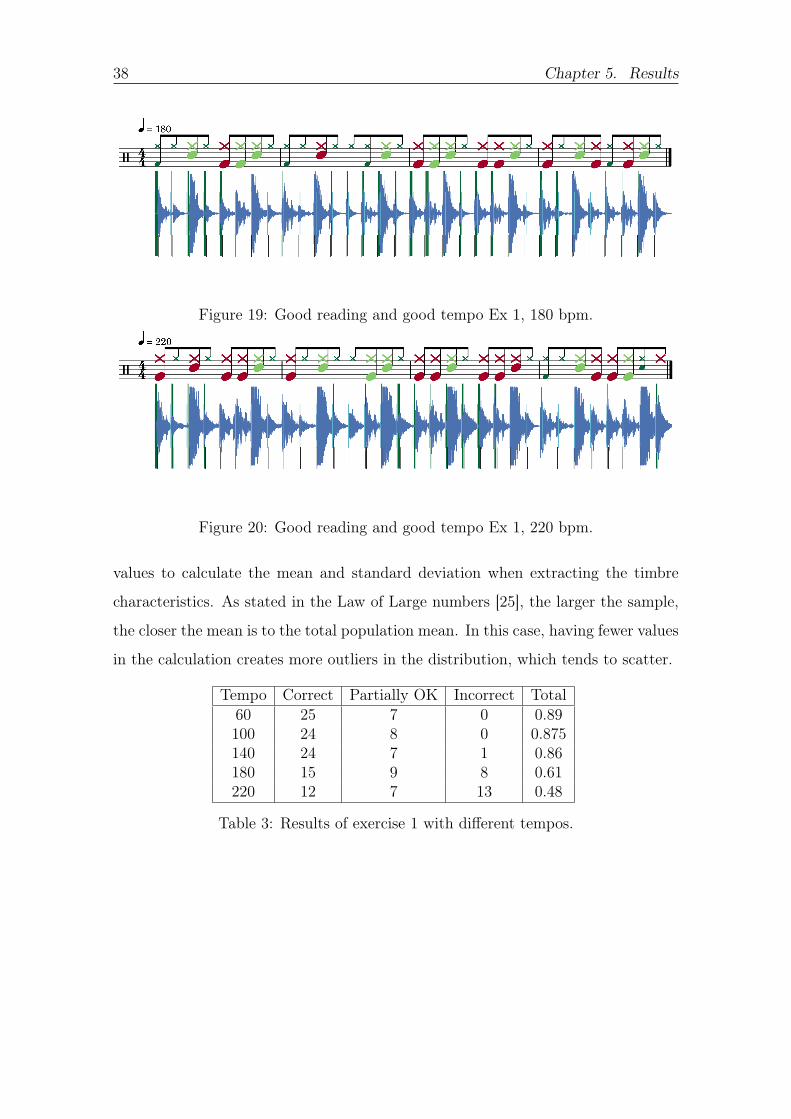
42 Chapter 5 Results
Figure 24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB ateach new staff
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
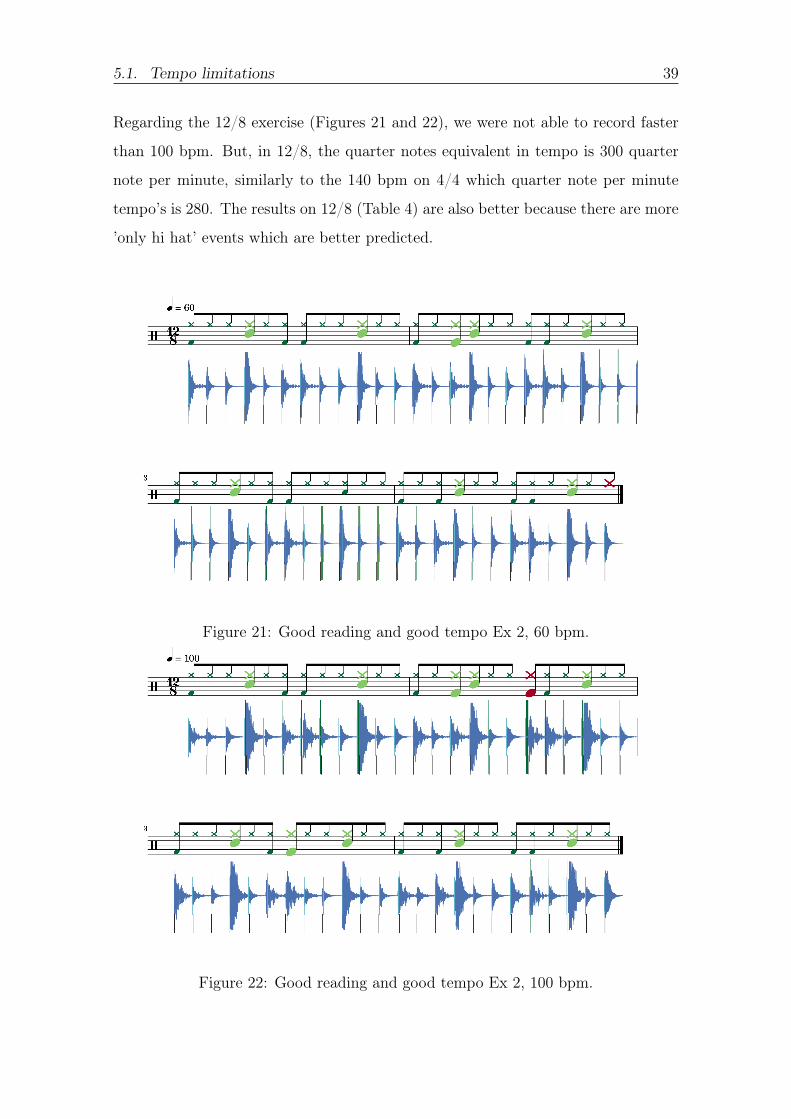
53 Evaluation of the assessment 43
53 Evaluation of the assessment
Until now the evaluation of results has been focused on the drums event classifier
accuracy but we think that is also important to evaluate if the system can assess
properly a studentrsquos submission
As shown in Figures 25 and 26 if the student does not play the first beat or some of
the beats are not read the system can map the rest of the events to the expected in
the correspondent onset time step This is due to a checking done in the assessment
which assumes that before starting the first beat there is a count-back of one bar
and the rest of the beats have to be after this interval
Figure 25 Bad reading and bad tempo Ex 1 100 bpm
Figure 26 Bad reading and bad tempo Ex 1 180 bpm
To evaluate the assessment we will proceed as in previous sections counting the
number of correct predictions but now in terms of assessment The analyzed results
will be the rsquoBad reading good temporsquo ones shown in Figures 27 28 and 29
44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

44 Chapter 5 Results
Figure 27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpmat each new staff
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
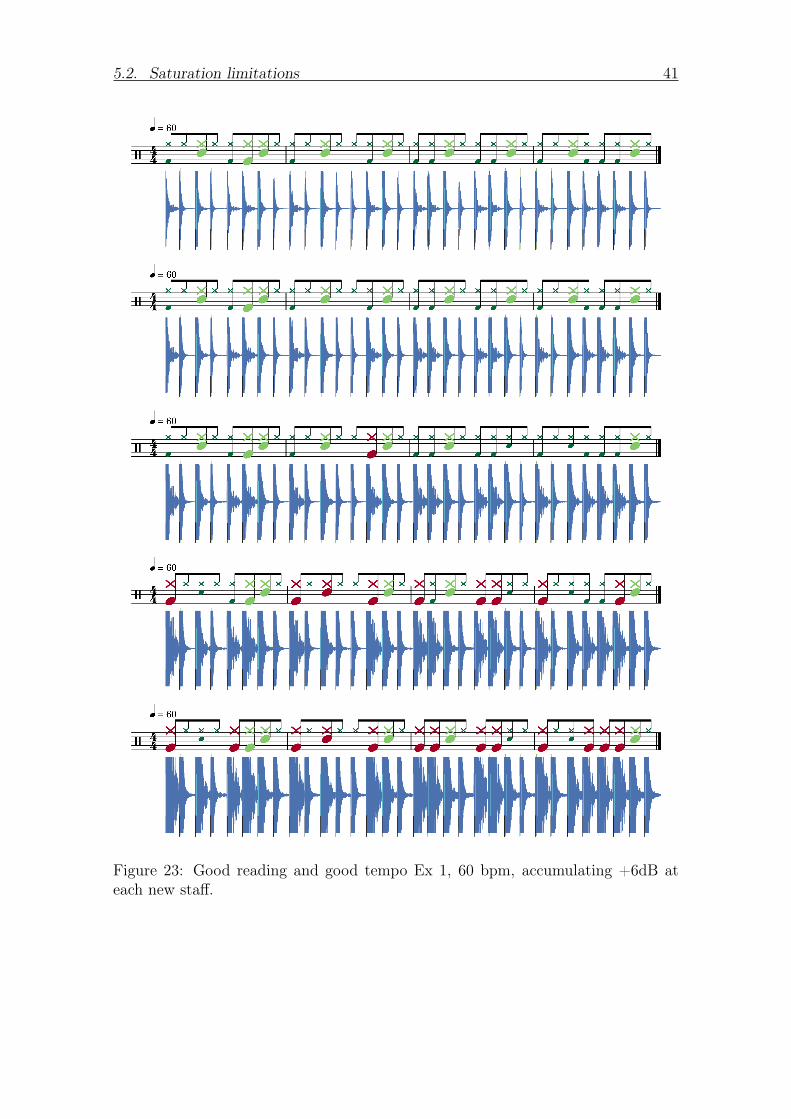
53 Evaluation of the assessment 45
Figure 28 Bad reading and good tempo Ex 2 60 bpm
Figure 29 Bad reading and good tempo Ex 2 100 bpm
On Tables 7 and 8 the counting is summarized and works as follows we count a
correct assessment if the note is green or light green and the event is the one in the
music score or if the note is red and the event is not the one in the music score
The rest of the cases will be counted as incorrect assessments The total value is
the number of correct assessments over the total number of events
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
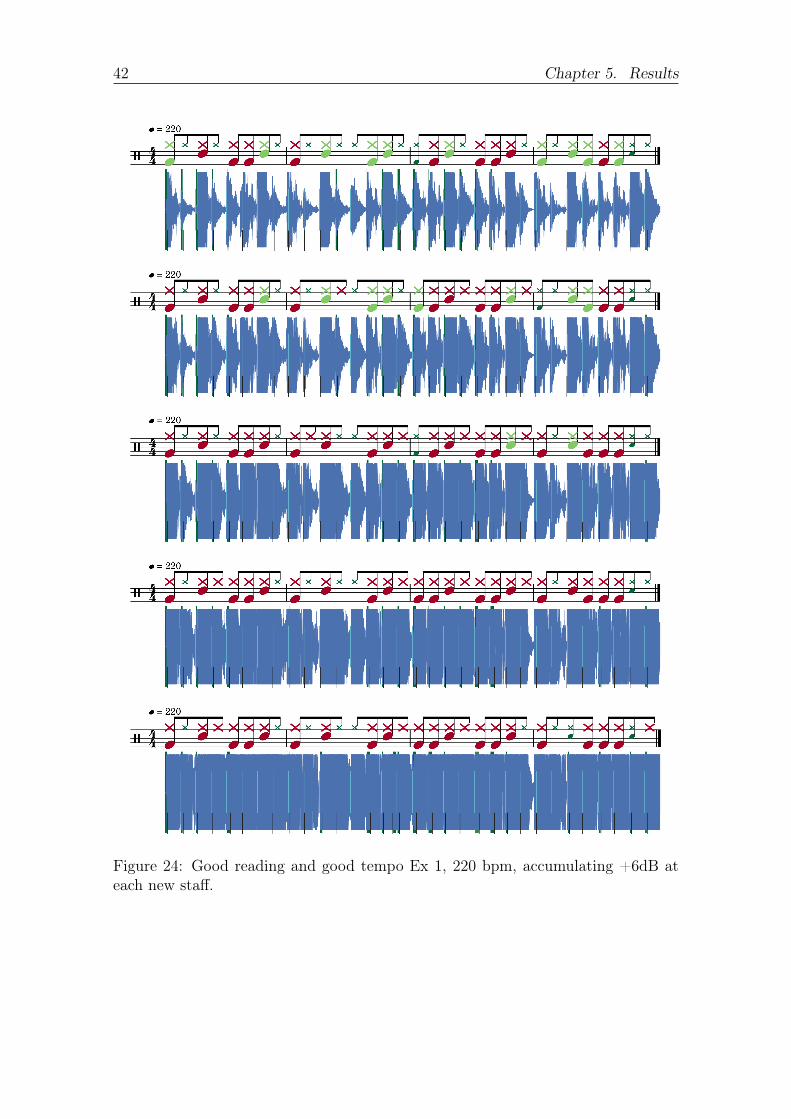
46 Chapter 5 Results
Tempo Correct assessment Incorrect assessment Total60 32 0 1100 32 0 1140 32 0 1180 25 7 078220 22 10 068
Table 7 Assessment result of a bad reading with different tempos 44 exercise
Tempo Correct assessment Incorrect assessment Total60 47 1 098100 45 3 09
Table 8 Assessment result of a bad reading with different tempos 128 exercise
We can see that for a controlled environment and low tempos the system performs
pretty well the assessment based on the predictions This can be helpful for a student
to know which parts of the music sheet are well ridden and which not Also the
tempo visualization can help the student to recognize if is slowing down or rushing
when reading the score as can be seen in Figure 30 the onsets detected (black lines
in the bottom part of the waveform) are mostly behind the correspondent expected
onset
Figure 30 Good reading and bad tempo Ex 1 100 bpm
Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Chapter 6
Discussion and conclusions
At this point all the work of the project has been done and the results have been
analyzed In this chapter a discussion is developed about which objectives have been
accomplished and which not Also a set of further improvements is given and a final
thought on my work and my apprenticeship The chapter ends with an analysis of
how reusable and reproducible is my work
61 Discussion of results
Having in mind all the concepts explained along with this document we can now list
them defining the completeness and our contributions
Firstly the creation of the 29k Samples Drums Dataset is now publicly available and
downloadable from Freesound and Zenodo Apart from being used in this project
this dataset might be useful to other researchers and students in their projects
The dataset indeed is useful in order to balance datasets of drums based on real
interpretations as the class distribution of these interpretations is very unbalanced
as explained with the IDMT and MDB drums datasets
Secondly a drums event classifier with a machine learning approach has been pro-
posed and trained with the aforementioned dataset One of the reasons for using
this approach to predict the events was that there was no literature focused on
47
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
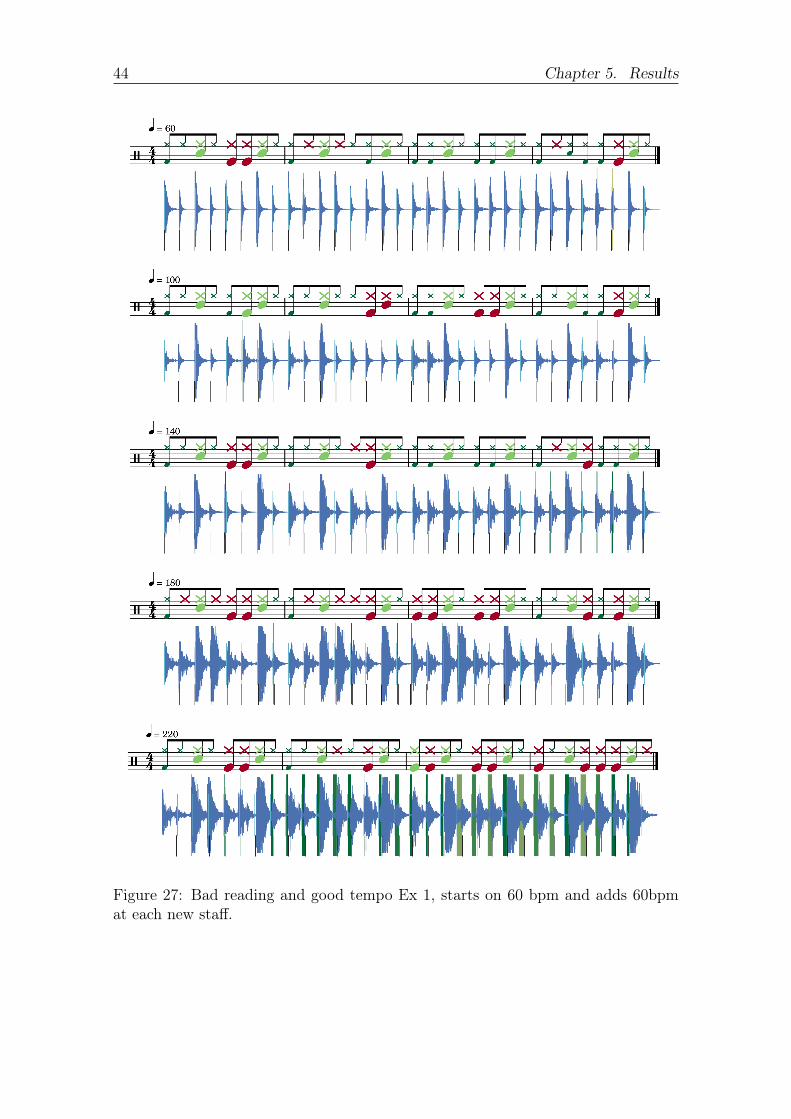
48 Chapter 6 Discussion and conclusions
classifying drums events in this manner As the results have shown more complex
methods based on the context might be used as the ones proposed in [16] and [17]
It is important to take into account that the task that the model is trained to do
is very hard for a human being able to differentiate drums events in an individual
drum sample without any context is almost impossible even for a trained ear as my
drums teacher or mine
Thirdly a review of the different music sheet technologies has been done as well as
the development of a MusicXML parser This part took around one month to be
developed and from my point of view it was a great way to understand how these
file formats work and how can be improved as they are majorly focused on the
visualization not the symbolic representation of events and timesteps
Finally two exercises in different time signatures have been proposed to demonstrate
the functionality of the system As well as tests of these exercises have been recorded
in a different environment than the 30k Samples Drums Dataset It would be fine
to get recordings in different spaces and with different drumsets and microphones
to test more exhaustively the system
62 Further work
In terms of the dataset created it could be larger It could be expanded with
different drumsets tuning differently each drumset using different sticks to hit the
instruments and even different people playing This could introduce more variance
in the drums sample dataset Moreover on June 9th 2021 a paper about a large
drums datasets with MIDI data was presented [26] in the ICASSP 20211 This new
dataset could be included in the training process as the authors state that having a
large-scale dataset improves the results of the existing models
Regarding the classification model it is clear that needs improvements to ensure the
overall system robustness It would be appropriate to introduce the aforementioned
methods in [16] [17] and [26] in the ADT part of the pipeline
1httpswww2021ieeeicassporg
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
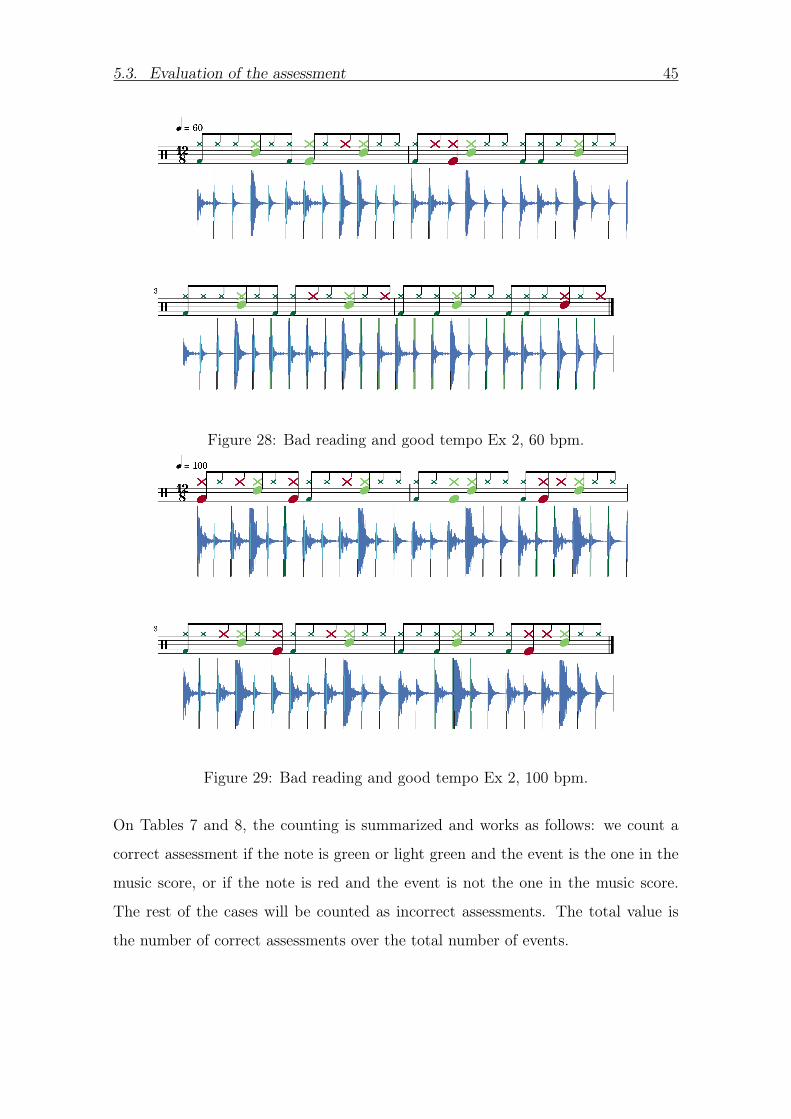
63 Work reproducibility 49
Also in terms of classes in the drumset there is a large path to cover in this way
There are no solutions that transcribe in a robust way a whole set including the toms
and different kinds of cymbals In this way we think that a proper approach would
be to work with professional musicians which helps researchers to better understand
the instrument and create datasets with different techniques
In respect of the assessment step apart from the feedback visualization of the tempo
deviations and the reading accuracy a regression model could be trained with drums
exercises assessed and give a mark to each student In this path introducing an
electronic drumset with MIDI output would make things a lot easier as the drums
classifier step would be omitted
About the implementation a good contribution would be to introduce the models
and algorithms to the Pysimmusic workflow and develop a demo web app like the
MusicCriticrsquos But better results and more robustness are needed to do this step
63 Work reproducibility
In computational sciences a work is reproducible if code and data are available and
other researchersstudents can execute them getting the same results
All the code has been developed in Python a widely known general-purpose pro-
gramming language It is available in my GitHub repository2 as well as the data
used to test the system and the classification models
The data created ie the studio recordings are available in a Zenodo repository3
and some samples in Freesound4 This is the 29kDrumsSamplesDataset as not all
the 40k samples used to train are of our property and we are not able to share them
under our full authorship despite this the other datasets used in this project are
available individually
2httpsgithubcomMaciACtfg_DrumsAssessment3httpszenodoorgrecord4923588YMRgNm4p7ow4httpsfreesoundorgpeopleMaciaACpacks32397
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
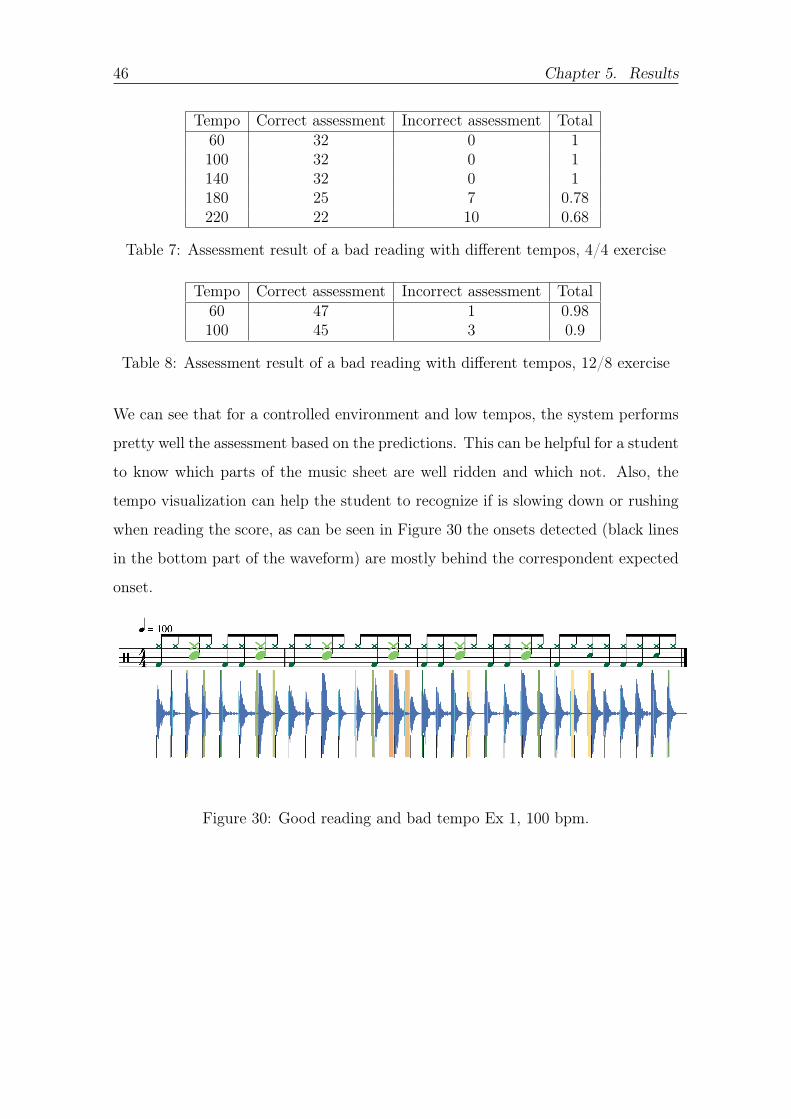
50 Chapter 6 Discussion and conclusions
64 Conclusions
This project has been developed over one year At this point with the work de-
scribed the goal of supporting drums learning has been accomplished Besides this
work rests in terms of robustness and reliability But a first approximation has been
presented as well as several paths of improvement proposed
Moreover some fields of engineering and computer science have been covered such
as signal processing music information retrieval and machine learning Not only
in terms of implementation but investigating for methods and gathering already
existing experiments and results
About my relationship with computers I have improved my fluency with git and
its web version GitHub Also at the beginning of the project I wanted to execute
everything on my local computer having to install and compile libraries that were
not able to install in macOS via the pip command (ie Essentia) which has been
a tough path to take and accomplish In a more advanced phase of the project
I realized that the LilyPond tools were not possible to install and use fluently in
my local machine so I have moved all the code to my Google Drive to execute the
notebook on a Collaboratory machine Developing code in this environment has
also its clues which I have had to learn In summary I have spent a bunch of time
looking for the ideal way to develop the project and the process indeed has been
fruitful in terms of knowledge gained
In my personal opinion developing this project has been a nice way to close my
Bachelorrsquos degree as I reviewed some of the concepts of more personal interest
And being able to relate the project with music and drums helped me to keep
my motivation and focus I am quite satisfied with the feedback visualization that
results of the system and I hope that more people get interested in this field of
research to get better tools in the future
List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

List of Figures
1 Datasets pre-processing 15
2 Sample drums score from music school drums grade 1 17
3 Microphone setup for drums recording 19
4 Number of samples before Train set recording 20
5 Number of samples after Train set recording 21
6 Proposed pipeline for a drums performance assessment system in-
spired by [2] 25
7 Confusion matrix after training with the dataset in Figure 4 28
8 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 1 29
9 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 30
10 Confusion matrix after training with the dataset in Figure 5 and
parameter C = 10 but only hh sd and kd classes 30
11 Onsets detected in a 60bpm drums interpretation 32
12 Onsets detected in a 220bpm drums interpretation 32
13 Onset deviation plot of a good tempo submission 34
14 Onset deviation plot of a bad tempo submission 34
15 Example of coloured notes 35
16 Good reading and good tempo Ex 1 60 bpm 37
17 Good reading and good tempo Ex 1 100 bpm 37
18 Good reading and good tempo Ex 1 140 bpm 37
19 Good reading and good tempo Ex 1 180 bpm 38
20 Good reading and good tempo Ex 1 220 bpm 38
51
52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

52 LIST OF FIGURES
21 Good reading and good tempo Ex 2 60 bpm 39
22 Good reading and good tempo Ex 2 100 bpm 39
23 Good reading and good tempo Ex 1 60 bpm accumulating +6dB at
each new staff 41
24 Good reading and good tempo Ex 1 220 bpm accumulating +6dB
at each new staff 42
25 Bad reading and bad tempo Ex 1 100 bpm 43
26 Bad reading and bad tempo Ex 1 180 bpm 43
27 Bad reading and good tempo Ex 1 starts on 60 bpm and adds 60bpm
at each new staff 44
28 Bad reading and good tempo Ex 2 60 bpm 45
29 Bad reading and good tempo Ex 2 100 bpm 45
30 Good reading and bad tempo Ex 1 100 bpm 46
31 Recording routine 1 57
32 Recording routine 2 58
33 Recording routine 3 58
34 Drumset configuration 1 58
35 Drumset configuration 2 59
36 Drumset configuration 3 59
37 Good reading and bad tempo Ex 1 60 bpm 60
38 Bad reading and bad tempo Ex 1 60 bpm 60
39 Good reading and bad tempo Ex 1 140 bpm 61
40 Bad reading and bad tempo Ex 1 140 bpm 61
41 Good reading and bad tempo Ex 1 180 bpm 61
42 Good reading and bad tempo Ex 1 220 bpm 62
43 Bad reading and bad tempo Ex 1 220 bpm 62
44 Good reading and bad tempo Ex 2 60 bpm 62
45 Bad reading and bad tempo Ex 2 60 bpm 63
46 Good reading and bad tempo Ex 2 100 bpm 63
47 Bad reading and bad tempo Ex 2 100 bpm 64
List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

List of Tables
1 Abbreviationsrsquo legend 4
2 Microphones used 19
3 Results of exercise 1 with different tempos 38
4 Results of exercise 2 with different tempos 40
5 Results of exercise 1 at 60 bpm with different amplification levels 40
6 Results of exercise 1 at 220 bpm with different amplification levels 40
7 Assessment result of a bad reading with different tempos 44 exercise 46
8 Assessment result of a bad reading with different tempos 128 exercise 46
53
Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Bibliography
[1] Wu C-W et al A review of automatic drum transcription IEEEACM Trans
Audio Speech and Lang Proc 26 (2018)
[2] Eremenko V Morsi A Narang J amp Serra X Performance assessment
technologies for the support of musical instrument learning e-repository UPF
(2020)
[3] MusicTechnologyGroup Pysimmusic httpsgithubcomMTGpysimmusic
[private] (2019)
[4] Kernan T J Drum set [drum kit trap set] Grove Encyclopedy of Music
(2013)
[5] Wachsmann K J Kartomi M von Hornbostel E M amp Sachs C Instru-
ments classification of Grove Encyclopedy of Music (2001)
[6] Mierswa I amp Morik K Automatic feature extraction for classifyng audio data
Mach Learn 58 (2005)
[7] Vos J amp Rasch R The perceptual onset of musical tones Perception Psy-
chophysics 29 (1981)
[8] Bello J P et al A tutorial on onset detection in music signals IEEE Trans-
actions on Speech and Audio Processing (2005)
[9] Essentia Algorithm reference Onsetdetection httpsessentiaupfedu
referencestreaming_OnsetDetectionhtml (2021)
54
BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

BIBLIOGRAPHY 55
[10] Herrera P Peeters G amp Dubnov S Automatic classification of musical
instrument sound Journal of New Music Research 32 (2010)
[11] Schedl M Goacutemez E amp Urbano J Music information retrieval Recent de-
velopments and applications Foundations and Trends in Information Retrieval
8 (2014)
[12] A van Dyk D amp Meng X-L The art of data augmentation Journal of Com-
putational and Graphical Statistics - J COMPUT GRAPH STAT 10 (2012)
[13] Nanni L Maguoloa G amp Paci M Data augmentation approaches for im-
proving animal audio classification CoRR (2020)
[14] Kol T Peddinti V Povey D amp Khudanpur S Audio augmentation for
speech recognition INTERSPEECH (2020)
[15] Adavanne S M Fayek H amp Tourbabin V Sound event classification and
detection with weakly labeled data DCASE 2019 (2019)
[16] Southall C Stables R amp Hockman J Automatic drum transcription for
polyphonicrecordings using soft attention mechanisms andconvolutional neural
networks ISMIR (2017)
[17] Lindsay-Smith H McDonald S amp Sandler M Drumkit transcription via
convolutive nmf 15th International Conference on Digital Audio Effects DAFx
2012 Proceedings (2012)
[18] Miron M EP Davies M amp Gouyon F An open-source drum transcription
system for pure data and max msp 2013 IEEE International Conference on
Acoustics Speech and Signal Processing (2012)
[19] Dittmar C amp Gaumlrtner D Real-time transcription and separation of drum
recordings based onnmf decomposition DAFx (2014)
[20] Southall C Wu C-W Lerch A amp Hockman J Mdb drums ndash an annotated
subset of medleydb forautomatic drum transcription ISMIR (2017)
56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

56 BIBLIOGRAPHY
[21] Gillet O amp Richard G Enst-drums an extensive audio-visual database for
drum signals processing ISMIR (2006)
[22] Marxer R amp Janer J Study of regularizations and constraints in nmf-based
drums monaural separation DAFx (2013)
[23] Bogdanov D et al Essentia An audio analysis library for musicinformation
retrieval Proceedings - 14th International Society for Music Information Re-
trieval Conference (2010)
[24] Goacutemez E Harte C Sandler M amp Abdallah S Symbolic representation of
musical chords A proposed syntax for text annotations ISMIR (2005)
[25] Upton G amp Cook I Laws of large numbers A dictionary of statistics (2008)
[26] Wei I-C Wu C-W amp Su L Improving automatic drum transcription using
large-scale audio-to-midi aligned data ICASSP 2021 - 2021 IEEE International
Conference on Acoustics Speech and Signal Processing (ICASSP) (2021)
Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Appendix A
Studio recording media
pound poundpound pound pound pound pound pound = 60
pound
poundpound poundpoundpound9 pound poundpound
poundpound poundpoundpound13pound poundpound
pound pound poundpound pound pound pound pound pound 17 pound pound pound pound poundpound pound
pound pound poundpound pound pound pound pound pound 21 pound pound pound pound poundpound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 31 Recording routine 1
57
58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

58 Appendix A Studio recording media
frac34frac34frac34frac34pound = 60 frac34frac34
frac34frac34 frac34frac345 frac34frac34
frac34frac34frac34frac34 frac34frac349
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 32 Recording routine 2
poundpoundpound poundpoundpound = 60 pound poundpound
pound pound poundpound pound pound pound poundpound pound pound pound pound poundpound5
pound
poundpoundpound poundpoundpound pound pound pound pound poundpoundpound poundpoundpoundpound pound poundpoundpound 9 pound poundpoundpound pound pound pound poundpound pound pound
Music engraving by LilyPond 2182mdashwwwlilypondorg
Figure 33 Recording routine 3
Figure 34 Drumset configuration 1
59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

59
Figure 35 Drumset configuration 2
Figure 36 Drumset configuration 3
Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

Appendix B
Extra results
Figure 37 Good reading and bad tempo Ex 1 60 bpm
Figure 38 Bad reading and bad tempo Ex 1 60 bpm
60
61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

61
Figure 39 Good reading and bad tempo Ex 1 140 bpm
Figure 40 Bad reading and bad tempo Ex 1 140 bpm
Figure 41 Good reading and bad tempo Ex 1 180 bpm
62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

62 Appendix B Extra results
Figure 42 Good reading and bad tempo Ex 1 220 bpm
Figure 43 Bad reading and bad tempo Ex 1 220 bpm
Figure 44 Good reading and bad tempo Ex 2 60 bpm
63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-

63
Figure 45 Bad reading and bad tempo Ex 2 60 bpm
Figure 46 Good reading and bad tempo Ex 2 100 bpm
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-
64 Appendix B Extra results
Figure 47 Bad reading and bad tempo Ex 2 100 bpm
- Introduction
-
- Motivation
- Existing solutions
- Identified challenges
-
- Guitar vs drums
- Dataset creation
- Signal quality
-
- Objectives
- Project overview
-
- State of the art
-
- Signal processing
-
- Feature extraction
- Data augmentation
-
- Sound event classification
-
- Drums event classification
-
- Digital sheet music
- Software tools
-
- Essentia
- Scikit-learn
- Lilypond
- Pysimmusic
- Music Critic
-
- Summary
-
- The 40kSamples Drums Dataset
-
- Existing datasets
-
- MDB Drums
- IDMT Drums
-
- Created datasets
-
- Music school
- Studio recordings
-
- Data augmentation
- Drums events trim
- Summary
-
- Methodology
-
- Problem definition
- Drums event classifier
-
- Feature extraction
- Training and validating
- Testing
-
- Music performance assessment
-
- Visualization
- Files used
-
- Results
-
- Tempo limitations
- Saturation limitations
- Evaluation of the assessment
-
- Discussion and conclusions
-
- Discussion of results
- Further work
- Work reproducibility
- Conclusions
-
- List of Figures
- List of Tables
- Bibliography
- Studio recording media
-
- Extra results
-