análise de corpora comparáveis em artigos científicos farmacêuticos_completo
TRANSCRIPT

São Paulo, 2013
UNIVERSIDADE SÃO JUDAS TADEU Centro de Pesquisa
Programa Voluntário de Iniciação Científica
Núbia Carolina de Oliveira Pinto
Análise de Corpora Comparáveis em Artigos
Científicos Farmacêuticos

São Paulo, 2013
UNIVERSIDADE SÃO JUDAS TADEU Centro de Pesquisa
Programa Voluntário de Iniciação Científica
Núbia Carolina de Oliveira Pinto
Relatório Final de pesquisa apresentado
ao Programa Voluntário de Iniciação Científica
do Centro de Pesquisa da Universidade São Judas Tadeu.
Orientadora: Profª. Ms. Nívia Maria Rodrigues Fernandes Marcello

AGRADECIMENTOS
Agradeço em primeiro lugar a Deus que iluminou o meu caminho durante esta jornada.
Aos meus pais e meu irmão que, com muito carinho e apoio, não mediram esforços para
que eu chegasse até essa etapa de minha vida.
À Profª Nívia, que me inspirou a fazer este projeto, e me ensinou o quão maravilhoso pode
ser a vida acadêmica.
A todos os professores da USJT, que foram tão importantes na minha vida acadêmica que
me ensinaram coisas tão valiosas para vida. Profª Verinha, que me mostrou que o português
vai muito além da gramática. Profª Beatriz que me apresentou as maravilhas da análise do
discurso. Professor Everaldo, sempre muito carinhoso e atencioso e ensinando literatura como
ninguém. Profª Lílian que me deu dicas ótimas e sempre me apoiou a nunca desistir do inglês.
Profª Josefa que gentilmente colaborou com a realização deste trabalho. Profª Rosalind que
não só dava dicas de inglês, dava dicas para a vida e que gentilmente me apresentou ao
Professor Adauri Brezolin que deu dicas maravilhosas para a conclusão deste trabalho. Profª
Érica que se desdobrou em mil para ensinar (maravilhosamente) literatura.
Aos amigos e colegas, pelo incentivo e pelo apoio constantes, principalmente da Camila e
Juliana, que aguentaram minhas reclamações ao longo de quatro anos.
A todos os autores de outros projetos que me serviram de inspiração, principalmente os
trabalhos dos pesquisadores Antônio Paulo Berber Sardinha, Ana Julia Perrotti-Garcia e Stella
Tagnin.
E a todos que me deram forças e contribuíram direta ou indiretamente a concluir mais essa
etapa da vida.

“O sucesso nasce do querer, da determinação e persistência em se chegar a um objetivo.
Mesmo não atingindo o alvo, quem busca e vence obstáculos, no mínimo fará coisas
admiráveis.”
José de Alencar

RESUMO
O aumento na produção científica brasileira fez com que tradutores brasileiros pensassem
a respeito da qualidade do inglês em artigos redigidos por brasileiros, ou seja, não nativos do
inglês. Essa qualidade pode afetar propagação dessas pesquisas, visto que o inglês é tido
como “idioma científico internacional” (MUGNAINI, JANNNUZI & QUONIAM, 2004 apud
PERROTTI-GARCIA, 2009). Em função disto a criação de corpora comparáveis para
pesquisa terminológica sob a luz da Linguística de Corpus tem sido a melhor opção dos
tradutores para elaboração e análise de sintagmas técnico-científicos, visto que os dicionários
técnicos não estão suprindo estas lacunas. O objetivo deste estudo foi a compilação e a
criação de um Corpus comparável no par linguístico inglês-português, tendo como área
específica a área farmacêutica e como subárea a utilização dos psicotrópicos. O afunilamento
desta pesquisa visa garantir a qualidade dos equivalentes tradutórios que posteriormente serão
avaliados. O estudo de caráter experimental foi dividido em coleta de artigos, processamento
computacional e análise de dados. A coleta consiste em compilar dois corpora um com
artigos científicos farmacêuticos em inglês e outro em português, obtidos através de bases de
dados confiáveis. Os textos dos corpora serão processados via programa WordSmith Tools
(Scott,1996) que nos permitirá a obtenção de dados como exemplos de uso, recorrência de
termos, reconhecimento de equivalentes, utilizando suas principais ferramentas como o
Wordlist, o Keyworde o Concord. A parte principal é a análise de dados onde encontraremos
os resultados gerados pelo computador. Nessa análise identificaremos padrões-léxico
gramaticais em ambos os corpora e faremos comparações, como o título da pesquisa sugere
(Análise de Corpora comparáveis em Artigos Científicos Farmacêuticos), a fim de
estabelecer possíveis equivalentes tradutórios. Os resultados obtidos mostraram que
Linguística de Corpus é uma alternativa eficaz para tradutores técnicos que não dominem

áreas específicas. Encontramos treze equivalentes tradutórios aplicados posteriormente em
versões de artigos científicos brasileiros para o inglês, comprovando sua utilidade.
Palavras-Chave: Linguística de Corpus; Corpora Comparáveis; Pesquisa Terminológica;
Artigos Farmacêuticos.

ABSTRACT
The increase in the Brazilian scientific production made Brazilian translators think about
the quality of English in articles written by Brazilians, i.e., not native English speakers. This
quality can affect the spread of such research, since English is considered as “international
scientific language” (MUGNAINI, JANNNUZI & QUONIAM, 2004 apud Perrotti - Garcia,
2009). Consequently, the creation of comparable corpora for terminology research in the light
of Corpus Linguistics has been the best choice for translators to process and analyze
scientific-technical phrases, since technical dictionaries are not filling this gap. The aim of
this study was the compilation and creation of a Comparable Corpus in the language pair
English- Portuguese, in the specific field of pharmacy and subfield as the use of psychotropic
medicine. The delimitation of the research problem area is to ensure the quality of
translational equivalents which will later be evaluated. This is an experimental study and it
was divided into: collection of articles, computer processing and data analysis. The collection
consists of compiling two corpora, one with scientific pharmaceutical articles in English and
another in Portuguese, obtained from reliable databases. The texts of the corpora were
processed via WordSmith Tools software (Scott, 1996) allowing us to obtain data such as
usage examples, recurrent terms, recognition of equivalents, using the main tools of the
program like Wordlist, Keyword and Concord. The analysis of data provides the results
generated by the computer. This analysis will identify lexical-grammatical patterns in both
corpora and make comparisons in order to establish possible translational equivalents. The
results showed that Corpus Linguistics is an effective alternative to technical translators who
are not familiar with specific fields. We found thirteen translational equivalents later applied
in translations of Brazilian scientific articles into English, thus proving its usefulness.

Keywords: Corpus Linguistics; Comparable Corpora, Terminology Research, Pharmaceutical
Articles.

Sumário
1. Introdução ........................................................................................................................... 12
1.1 Apresentação do tema e justificativa ............................................................................. 13
1.2 Objetivos ............................................................................................................................. 14
1.2.1. Objetivo Geral ................................................................................................................ 14
1.2.2. Objetivos Específicos ..................................................................................................... 15
1.3. Organização do Trabalho................................................................................................... 15
2. Fundamentação Teórica..................................................................................................... 16
2. 1 A Linguística de Corpus .................................................................................................... 16
2. 2 Corpus e Computação ....................................................................................................... 17
2. 3 Linguística de Corpus e a Tradução .................................................................................. 20
2. 4 Terminologia Básica .......................................................................................................... 20
3. Metodologia ......................................................................................................................... 24
3.1 Tipologia dos corpora ........................................................................................................ 24
3.2 Coleta de textos .................................................................................................................. 25
3.3Regras de inclusão e exclusão ............................................................................................. 27
3.4 Processamento no WordSmith Tools ................................................................................. 28
3.4.1 O WordSmith Tools ........................................................................................................ 30
3.4.2 Ferramentas ..................................................................................................................... 31
3.4.2.1 WordList ....................................................................................................................... 32
3.4.2.2 Keyword ....................................................................................................................... 32
3.4.2.3Concord ......................................................................................................................... 33
3.5 Processamento para análise ................................................................................................ 35
4. Resultados ........................................................................................................................... 40
4. 2 Sintagmas .......................................................................................................................... 41
1. Psicose maníaco-depressiva ................................................................................................. 41

2. Transtorno afetivo bipolar ................................................................................................. 42
3. Transtorno Bipolar ................................................................................................................ 43
4. Interações medicamentosas .................................................................................................. 44
5. Pacientes Ambulatoriais .................................................................................................... 44
6. Efeito colateral ..................................................................................................................... 45
7. Antidepressivos tricíclicos (ADT) ........................................................................................ 45
8. Ensaios clínicos ................................................................................................................. 45
9. Depressores do apetite .......................................................................................................... 45
10. Atenção primária à saúde ................................................................................................... 45
11. Inibidores seletivos da recapitação da serotonina (ISRS) .................................................. 46
12. Antagonistas da dopamina ............................................................................................. 46
13. Uso indevido de drogas ...................................................................................................... 47
4.3 Discussão ............................................................................................................................ 48
5. Considerações Finais .......................................................................................................... 54
6. Bibliografia .......................................................................................................................... 56
7. Anexos .................................................................................................................................. 58
7.1 Anexo 1: Amostra de artigo científico farmacêutico original usado na versão para
comprovação dos corpora. ........................................................................................................ 58
7.1 Anexo 2: Amostra de artigo científico farmacêutico original usado na versão para
comprovação dos corpora. ........................................................................................................ 59
7.1 Anexo 3: Amostra de artigo científico farmacêutico original usado na versão para
comprovação dos corpora. ........................................................................................................ 60
Anexo 4: Versão da amostra 1. ................................................................................................. 61
Anexo 5: Versão da amostra 2. ................................................................................................. 62
Anexo 6: Versão da amostra 3. ................................................................................................. 63

Índice de Figuras
Figura 1: Pastas com os artigos do Corpus-ENG. .................................................................... 28
Figura 2: Artigos da MedLine, base de dados do Corpus-ENG ............................................... 28
Figura 3: Base de dados MedLine ............................................................................................ 29
Figura 4: Base de dados Science Direct - filtros, títulos e resumos ......................................... 29
Figura 5: WordSmith Tools Help, manual que acompanha o programa de computador. ........ 31
Figura 6: Ferramenta WordList ................................................................................................ 32
Figura 7: Lista de palavras geradas pelo KeyWord .................................................................. 33
Figura 8: Artigos do Corpus-ENG selecionados. ..................................................................... 34
Figura 9: Linhas de concordância geradas para a palavra "misuse" ......................................... 34
Figura 10: Clusters para o nódulo "misuse" ............................................................................. 35
Figura 11: Lista de palavras mais recorrentes no Corpus-ENG ............................................... 36
Figura 12: Interface do KeyWord ............................................................................................. 37
Figura 13: Lista de palavras geradas pela ferramenta .............................................................. 38
Figura 14: Clusters gerados para a palavra "psychosis" ........................................................... 42
Figura 15: Clusters gerados para a palavra "bipolar" ............................................................... 43
Figura 16: Apenas duas linhas de concordância geradas para o sintagma "affective illness" .. 43
Figura 17: Lista de patterns para a palavra "drug" ................................................................... 44
Figura 18: Clusters gerados para a palavra 'indevido" ............................................................. 47
Figura 19: Lista de patterns para o termo "misuse' no Corpus-ENG. ...................................... 51
Figura 20: Lista de patterns para o termo "interactions" no Corpus-ENG ............................... 52
Figura 21: Lista de patterns para a sigla TCAS ........................................................................ 53
Índice de Tabelas
Tabela 1: Dados técnicos do Corpus-ENG ............................................................................... 40
Tabela 2: Dados técnicos do Corpus-BRA ............................................................................... 40
Tabela 3: Classificação do tamanho do Corpus........................................................................ 41
Tabela 4: Lista de equivalentes tradutórios .............................................................................. 48

12
1. Introdução
Em razão à crescente necessidade de divulgação internacional de pesquisas
acadêmicas, a publicação de artigos científicos redigidos por brasileiros em outras línguas
aumentou de forma expressiva. O número de publicação ainda continua inexpressivo se
comparado ao outras nações, principalmente em países onde o inglês é a língua materna, por
isso a maioria dos artigos científicos de países onde o inglês não é a língua oficial ou materna
necessitam de uma tradução para o inglês.
Segundo MUGNAINI, JANNUZZI & QUONIAM, 2004, apud Perrotti-Garcia,
2009, “o idioma de publicação está ligado à divulgabilidade dos artigos publicados, uma vez
que o inglês é considerado “idioma científico internacional”. Será por meio da qualidade
desse texto que o prestígio de determinada revista científica será estabelecido. Mas será que o
inglês escrito nesses artigos estãoem qualidade suficiente para competir com artigos
elaborados por falantes nativos do inglês? Esta pergunta é feita por profissionais da tradução
que trabalham vertendo esses artigos para outras línguas, e também pelos próprios
pesquisadores que desejam o sucesso internacional de seu trabalho. Qualquer oração, período,
sintagma ou até uma palavra, que cause estranheza ao leitor deve ser evitada.
O que geralmente acontece não é necessariamente um erro de tradução, mas sim falhas na
composição da estrutura sintática, estrutura lexical, ou até o uso errôneo de expressões
idiomáticas. Isso pode dificultar a compreensão do leitor nativo do inglês, e diminuindo a
aceitação por parte do mesmo. Existem dicionários técnicos que ajudam o tradutor a evitar
esse tipo de erro, mas infelizmente eles não são suficientes, pois as expressões estão sempre
em constante mudança e os dicionários técnicos muitas vezes não conseguem acompanhá-las.
(TEIXEIRA, 2008)

13
Para isso uma forma de pesquisa terminológica está sendo utilizada por muitos tradutores e
profissionais de áreas relacionadas, essa pesquisa tenta identificar equivalentes tradutórios
mais aceitáveis possíveis, reduzindo a possibilidade de erros de tradução e,
consequentemente, aumentando as chances de reconhecimento internacional do pesquisador
brasileiro. Esses tradutores e profissionais utilizam a Linguística de Corpus.
A Linguística de Corpus é um campo que cria e identifica os corpora (palavra latina plural
de corpus) que, por sua vez, significa conjunto de textos e transcrições de fala compiladas e
que servem para fazer análise de termos. (BERBER, 2009). O uso de um corpus para validar
resultados de uma pesquisa já vem sendo usado mesmo antes da invenção do computador
(FOMM, 2005), mas com o desenvolvimento da tecnologia a análise passou a ser feita por
eles, facilitando a vida do pesquisador, assim o linguista utiliza programas de computadores
para organizar os arquivos e analisá-los.
É com base nos problemas apresentados e com o auxílio da Linguística de Corpus que
iremos realizar nosso trabalho.
1.1 Apresentação do tema e justificativa
Segundo dados do Ministério da Saúde1, o mercado farmacêutico movimenta anualmente
R$ 28 bilhões e a tendência é de expansão. Entre as seis maiores empresas farmacêuticas do
mundo, quatro são brasileiras e apresentam crescimento acelerado na produção de genéricos.
Com um mercado tão grande, a área farmacêutica se torna atrativa não só para os
profissionais da saúde como também os da tradução. Os escritórios de tradução espalhados
pelo país se veem obrigados a contratar farmacêuticos proficientes no inglês para dar conta de
traduções dessa área e a carência de materiais específicos que auxiliem o tradutor também
1 Fonte: http://www.brasil.gov.br/sobre/ciencia-e-tecnologia/tecnologia-em-saude/industria-
farmaceutica/print

14
influenciam na decisão de escolher entre o tradutor e o farmacêutico o que pode alterar o
resultado final comprometendo até mesmo o prestígio do Brasil em relação ao mercado
mundial farmacêutico.
Tendo em vista essa falta de materiais confiáveis que possam auxiliar o tradutor, a
customização de corpora específicos se torna uma saída eficaz e eficiente. Trabalhando com a
língua em uso a Linguística de Corpus possibilita a visualização do contexto e a obtenção de
equivalentes tradutórios adequados.
Sendo assim, esta pesquisa tem a necessidade de comprovar o uso da Línguística de
Corpus como saída eficaz para o tradutor e contribuir para a comunidade farmacêutica com
fontes confiáveis de pesquisa terminológica, além de dar continuidade ao trabalho feito por
Pâmela de Moura Falarara no Centro de Pesquisa da USJT sobre corpora comparáveis na área
de medicina com o título: “Implementação de um Corpus Bilíngue Comparável em uma
Universidade Particular de São Paulo” durante o período de 2010/2011. No trabalho da
pesquisadora, ela teve como objetivo coletar textos da área de cardiologia para compilar um
corpus bilíngue comparável do par linguístico inglês-português.
1.2 Objetivos
1.2.1. Objetivo Geral
Este estudo possui como objetivo geral compilar um corpus farmacêutico experimental,
coletando artigos que versem sobre o assunto de uso de psicotrópicos no par linguístico
inglês-português e aplicar os preceitos da Linguística de corpus comprovando sua eficácia.
Após o término, o projeto será disponibilizado aos alunos de farmácia e tradução buscando-se
criar uma linha de pesquisa ainda mal explorada na Universidade onde o trabalho é
desenvolvido.

15
1.2.2. Objetivos Específicos
A pesquisa tem como objetivo específico utilizar o corpus compilado como fonte pesquisa
para a criação experimental e análise de equivalentes tradutórios da área de uso de
psicotrópicos, podendo suprir lacunas que os glossários comuns e técnicos ainda não
definidas.
A partir dos objetivos explanados esta pesquisa tentará responder as seguintes questões:
I. A partir dos corpora compilados foi possível identificar equivalentes tradutórios?
II. A metodologia da Linguística de Corpus se mostrou eficaz?
III. A análise de padrões-léxico gramaticais é eficiente em se tratando de auxílio ao
tradutor?
1.3. Organização do Trabalho
Seguindo as etapas de introdução e meta da pesquisa este projeto seguirá as seguintes
fases:
Explanará o embasamento teórico que auxiliará ao leitor a entender a importância do
desenvolvimento da pesquisa;
Explicará a metodologia utilizada pela pesquisadora e as ferramentas essenciais para
se chegar aos objetivos pretendidos;
Mostrará quais foram os resultados atingidos e como se chegou até eles.
E finalizará concluindo e discutindo pontos significativos dos resultados alcançados.

16
2. Fundamentação Teórica
A função desta parte da pesquisa é apresentar o embasamento teórico a respeito da
Linguística de Corpus (doravante LC), qual sua importância para este estudo e seu histórico,
portanto estará organizada seguinte forma:
1. A Linguística de Corpus
2. O Corpus e Computação
3. A Linguística de Corpus e a Tradução
4. A Terminologia Básica
2. 1 A Linguística de Corpus
A palavra corpus, advinda do latim, significa um conjunto de textos e transcrições de fala
armazenadas e que servem para análises e investigações linguísticas. A LC é a área que se
dedica à produção e análise dos corpora (plural de corpus) e respectivamente seu estudo,
(BERBER, 2009). Hoje a LC está diretamente relacionada ao uso do computador, mas nem
sempre foi assim.
Estudos apontam que a LC já existia bem antes da invenção do computador. A própria
história da linguística é antiga. A linguística só passou a se aceita como ciência após os
estudos de Ferdinand de Saussure (1857-1913) no século XIX, que ficou conhecido como pai
da linguística, (Saussure, 2002). Ele deu uma nova visão ao mundo e aos estudos da língua
apresentando novos pontos de vista como, por exemplo, Língua X Fala e Significante X
Significado.
Nesse mesmo século estudos com corpora manuais já eram feitos, (NAVARRO, 2011).
Um desses estudos analisava as falas das crianças por meio de um diário registrado pelos pais.

17
Outra pesquisa mostra a criação de um corpus com cerca de 11 milhões de palavras que
serviu para investigar a ortografia alemã.
Mas esse cenário perde força com o surgimento da obra Syntactic Structures, de Noam
Chomsky escrito em 1957. Nesta obra Chomsky afirma que o linguista se baseia numa visão
introspectiva, observações artificiais e na intuição do próprio linguista para chegar a
conclusões que não podem ser tidas com verdadeiras. Chomsky tinha uma visão mais
racionalista e em união com outras críticas pragmáticas e a alta probabilidade de erro que os
corpora poderiam apresentar fez com que eles parassem de ser usados. Sua grande quantidade
de palavras e a impossibilidade de armazenamento do cérebro humano tornou a análise de
corporainválida. (NAVARRO, 2011).
A análise de Chomsky era clara, pois o ser humano não teria capacidade suficiente para
analisar um corpus de, por exemplo, 11 milhões de palavras, isso tornaria os resultados
suscetíveis ao erro.
2. 2 Corpus e Computação
A LC possui dados inacessíveis ao nosso cérebro, sem o auxílio de alguma máquina a LC
moderna não poderia existir, (PERROTTI-GARCIA, 2009). Portanto a partir da invenção do
computador uma verdadeira revolução aconteceria dentro da linguística.
Com o uso do computador as análises se tornaram mais precisas e até maiores como afirma
FROMM, Guilherme. Linguística Computacional: uma intersecção de áreas, 2006, p.
135/140. “Corpora criados a partir de uma base totalmente eletrônica podem ter centenas de
milhões de palavras em seu corpo. Teoricamente, quanto mais palavras, ou seja, quanto maior
for o corpus de estudo (em qualquer área), mais precisos serão os resultados.”

18
E com a invenção da internet logo em seguida, as informações sobre o estudo da LC
passaram a ser trocadas entre os pesquisadores e hoje existem diversos sites que tratam do
assunto, aqui estão alguns deles:
WebCorp: usado para seleção de textosonline.
http://www.webcorp.org.uk
WordSmithTools: site onde podemos comprar ou fazer um download da versão demo do
programa de computador utilizado para a compilação e análise dos textos.
http://www.lexically.net
British National Corpus: O British National Corpus é uma coleção com 100 milhões de
palavras retiradas de amostras de língua escrita e falada de uma enorme variedade de fontes e
organizado para representar um amplo leque do inglês britânico do último século, ambos
falados e escritos.2
http://www.natcorp.ox.ac.uk
Linguateca: Site que disponibiliza outros endereços virtuais a respeito de corpora.
http://www.linguateca.pt/corpora_info.html
Lácio-Web: Lácio-Web (LW) é um projeto de 30 meses de duração financiado pelo CNPq,
iniciado em janeiro de 2002, com parceria entre NILC (Núcleo Interinstitucional de
Lingüística Computacional), localizado no ICMC-USP, IME (Instituto de Matemática e
Estatística) e FFLCH (Faculdade de Filosofia, Letras e Ciências Humanas). O objetivo deste
2Traducão minha: The British National Corpus (BNC) is a 100 million word collection of samples of written and
spoken language from a wide range of sources, designed to represent a wide cross-section of British English from the later part of the 20th century, both spoken and written.

19
projeto é divulgar e disponibilizar livremente na Web: a) vários corpora do português
brasileiro escrito contemporâneo, representando bancos de textos adequadamente compilados,
catalogados e codificados em um padrão que possibilite fácil intercâmbio, navegação e
análise; e b) ferramentas lingüístico-computacionais, tais como contadores de freqüência,
concordanciadores e etiquetadores morfossintáticos. O público-alvo do LW é heterogêneo: de
um lado linguistas, cientistas da computação, lexicógrafos, e etc. e, de outro, não especialistas
em geral.
http://www.nilc.icmc.usp.br/lacioweb/
GELC: Grupo de Estudos de Linguística de Corpus.
http://corpuslg.org/gelc/gelc.php
COMET: O COMET – Corpus Multilíngue para Ensino e Tradução, em construção junto ao
CITRAT (Centro Interdepartamental de Tradução e Terminologia) da Faculdade de Filosofia,
Letras e Ciências Humanas da Universidade de São Paulo, é um corpus eletrônico que tem
por objetivo servir de suporte a pesquisas linguísticas, principalmente nas áreas de tradução,
terminologia e ensino de línguas. O COMET é composto por três subcorpora:
- Corpus Técnico-Científico: CorTec
- Corpus Multilíngüe de Aprendizes: CoMAprend
- Corpus de Tradução: CorTrad
http://www.fflch.usp.br/dlm/comet/
Portanto, podemos afirmar que com o advento do computador e da internet o estudo da LC
não só foi retomado, mas ampliado, disponibilizando ao pesquisador maior precisão no
planejamento, na construção e na análise.

20
2. 3 Linguística de Corpus e a Tradução
Segundo Rodrigues (1998), apud, Tagnin (2007), o tradutor sempre enfrentou muita
dificuldade para encontrar um termo que, como ele mesmo diz “funcione” no texto de
chegada da mesma forma que “funciona” no texto de partida. Esse termo é conhecido por
tradutores como equivalente tradutório, ou seja, algum termo que tenha o mesmo sentido que
a palavra no texto de origem, mas que não seja necessariamente uma tradução ao pé dá letra.
A LC vem sendo utilizada de duas formas para auxiliar os tradutores a encontrar
equivalentes satisfatórios ao texto. Podemos aplicar a LC à tradução por meio de corpora
paralelos, ou seja, um corpus constituído de textos originais e suas traduções, e corpora
comparáveis que será utilizado neste trabalho, que é constituído por textos originais e
similares versando sobre o mesmo assunto.
É relevante dizer que existem dicionários e glossários específicos que auxiliam os
tradutores, mas eles nem sempre são convenientes, por não serem periodicamente atualizados
ou por haver falta de exemplos de uso (TAGNIN, 2007). Assim, o corpus surge para corrigir
essa falta de atualização dos glossários e dicionários, pois podem ser facilmente
modernizados.
2. 4 Terminologia Básica
Para finalizar a Fundamentação Teórica iremos esclarecer os termos relacionados à LC que
utilizaremos nesse trabalho. Parte dessa terminologia terá como fonte o Glossário de LC,
elaborado pela Dra. Stella E. O. Tagnin, professora da USP e que coordena o projeto
COMET.

21
Alinhamento: processo semiautomático (pois necessita de uma revisão manual) no qual
o texto original e suas traduções são postas alinhadas, podendo ser feito por parágrafo ou
a cada oração.
Clusters: Segundo Partington (2006) apud, Perrotti-garcia (2009), “os clusters são
sequências de palavras (de dois a oito itens), que evidenciam maneiras típicas de dizer
coisas e, portanto, típicas de determinado autor/falante”. Em uma análise com corpora
comparáveis pode ser útil para a identificação de termos de áreas que os autores desejam
melhorar seu desempenho na escrita.
Corpus:Conjunto de textos compilados e que servem para análise linguística. Existem 5
tipos de corpus.
Comparável:Corpus montado a partir de textos originais e suas traduções
versando sobre mesmo assunto, mesma época, mesmas delimitações ele pode
ser monolíngue ou bilíngue ou até multilíngue. Será este tipo de corpus
utilizado nesse estudo.
Customizado: São os corpora compilados para uso específico. É muito
utilizado por tradutores de textos técnicos que necessitam de fontes confiáveis
para tradução.
Estudo: É o corpus que usa a pesquisa a ser desenvolvida como base.
Paralelo: Este tipo de corpus é constituído de textos originais e suas traduções.
Referência: Corpus que é utilizado para servir de comparação com o corpus
de estudo, na maioria das vezes é maior que o corpus estudado.
Equivalente Tradutório: É como chamamos o termo que se encaixará da melhor forma
no texto de chegada ou como disse Rodrigues 1998, apud, Tagnin, 2007, que melhor
“funcione” nesse texto. O objetivo do tradutor é propiciar melhor entendimento do leitor
e maior fluência no texto.

22
Linhas de concordância: As linhas de concordância são geradas pela ferramenta Concord,
a partir dela produziremos os colocados que nos possibilitará a análise léxico-gramatical e a
comprovação da existência e eficiência de um equivalente tradutório.
Colocados: É como chamamos as palavras que aparecem próximas ao nódulo
é a partir dele que identificaremos um padrão que ajudará na construção de um
equivalente adequado.
Cotexto: É como chamamos as palavras que aparecem à direita ou à esquerda
do nódulo dentro da linha de concordância. Através do programa WST
podemos estabelecer quantas palavras aparecerão nesse cotexto.
Nódulo: É a palavra que se busca utilizando a ferramenta Concord. É a partir
dela que os colocados se formarão.
Tokens: O tokens é uma ferramenta do WordList que faz parte do programa WST, ele
informa quantas palavras há no corpus, inclusive as repetidas.
Types: O types é bem parecido com o tokens, entretanto ele elimina as palavras
repetidas, portanto na frase, “I am part of the power which forever wills evil and
forever Works good.” (Goethe). A palavra forever seria eliminada e teríamos 13 types
e 14 tokens.
WordsmithTools: O programa é um conjunto de programas integrados destinado à
análise linguística. Ele faz análises baseado nas ocorrências que aparecem nos corpora.
Foi criado em 1996, por Mike Scott da Universidade de Liverpool, Reino Unido. Está
atualmente na sua sexta versão e todas estão disponíveis no site
http://www.lexically.net/wordsmith/index.html. Suas ferramentas principais são:
Concord:Produz as linhas de concordância se baseando em uma palavra
específica (nódulo).
Keywords: Produz as palavras-chave de todos os textos que compõe o corpus.

23
Wordlist:Produz listas de palavras com todas as palavras do arquivo
mostrando o percentual e suas frequências e faz comparações das listas
compostas.
E seus principais utilitários são:
File Manager: ajuda no gerenciamento de arquivos
Splitter: auxilia na divisão de um arquivo em arquivos menores
Text Converter:faz várias funções no pré-processamento dos textos, como a
alteração de palavras, renomeação de muitos arquivos, mudanças de
diretórios...
Viewer&Aligner: oferece modos de visualizar os textos e alinha-os em um só.

24
3. Metodologia
Nesta parte da pesquisa definiremos o processo de análise para coleta de resultados e
enfatizaremos o uso do software WordSmith Tools, que foi fundamental para a realização
desse projeto.
3.1 Tipologia dos corpora
A razão em desenvolver uma pesquisa no campo da LC se deve ao fato de que há uma
lacuna no que se diz respeito a fontes confiáveis de padrões léxico-gramaticais. A delimitação
em artigos técnico-científicos foi escolhida visto que a tradução de textos técnicos
proporciona amplo mercado de trabalho é uma das áreas que possuem mais procura de
tradutores no mercado profissional, o que se possibilitaria o uso empírico dos resultados aqui
encontrados.
A delimitação farmacêutica foi em função de que a pesquisadora possui experiências
profissionais nessa área, e porque foi encontrado apenas um trabalho que analisava abstracts
de alunos da área de Ciências Farmacêuticas, mostrando a lacuna que há na área de
identificação de equivalentes tradutórios farmacêuticos. (Corpora no ensino do inglês
acadêmico: padrões léxico-gramaticais em abstracts de pós-graduandos brasileiros, Carmen
Dayrell, USP, Viana, Vander, 2010).
Para aprofundarmos e obtermos resultados mais precisos dentro da área de farmácia
decidimos coletar artigos farmacêuticos sobre psicotrópicos, em função da experiência
profissional da pesquisadora com traduções nessa área e da falta de material de tradução.
Os corpora podem ser divididos em subáreas (PERROTTI-GARCIA, 2009) e para essa
pesquisa o tipo de corpora escolhido foram os comparáveis. Os corpora comparáveis
compartilham de características semelhantes como: público-alvo, gênero textual e ano de
publicação aumentando a qualidade dos resultados obtidos e também por mostrar a língua em
uso através de uma observação autêntica. (VIANA, 2009).

25
Os corpora aqui utilizados possuem as seguintes características segundo os critérios citados
por Berber Sardinha (2004).
Modo: textos no modo escrito.
Tempo: O corpus trabalha com a linguística aplicada, com a língua em uso e por isso
buscamos artigos atuais. Os textos pertencem ao período de 2009 até 2012.
Conteúdo: Os artigos utilizados são do gênero técnico-científico especializado e
monolíngue, um em português e outro em inglês.
Autoria: Todos os artigos foram escritos por falantes nativos do idioma, tanto os de
português, quantos os de língua inglesa.
Finalidade: A partir da análise dos corpora pretende-se extrair resultados, ou seja, uma
quantidade significativa de equivalentes tradutórios.
3.2 Coleta de textos
Os artigos utilizados foram coletados em diversas bases de dados, houve uma tentativa de
utilizar apenas duas bases de dados, uma para cada língua, mas ao longo da coleta dos textos a
pesquisadora teve dificuldades em encontrar arquivos sobre o tema escolhido, principalmente
nas bases de dados brasileiras. Foram utilizadas quatro bases de dados para o corpus de língua
portuguesa (doravante, Corpus-BRA) sendo que em cada uma delas o Google Scholar foi
usado para redirecionara pesquisa para outras bases de dados. Para o corpus de língua inglesa
(doravante, Corpus–ENG) foram utilizadas cinco bases de dados mostrando uma quantidade
muito superior à brasileira em se tratando de produção científica farmacêutica. Portanto as
bases de dados utilizadas foram:
Corpus-BRA:
Lilacs: Uma das maiores bases de dados da América Latina. Disponibiliza artigos científicos
das mais diversas áreas de forma gratuita há mais de 27 anos.

26
Fonte: http://lilacs.bvsalud.org/
Dedalus: Base de dados da Universidade de São Paulo que disponibiliza artigos e teses dos
alunos da mesma universidade.
Fonte: http://dedalus.usp.br/F?RN=229574007
SciELO: A Scientific Electronic Library Online - SciELO é uma biblioteca eletrônica que
abrange uma coleção selecionada de periódicos científicos brasileiros. A SciELO é o
resultado de um projeto de pesquisa da FAPESP - Fundação de Amparo à Pesquisa do Estado
de São Paulo, em parceria com a BIREME - Centro Latino-Americano e do Caribe de
Informação em Ciências da Saúde.
Fonte: http://www.scielo.br/scielo.php?script=sci_home&lng=pt&nrm=iso
Google Scholar (Google acadêmico): Site vinculado ao site de buscas Google, seleciona
bases de dados e artigos relacionados à pesquisa inserida no Google redirecionando para
outras bases de dados.
Fonte: http://scholar.google.com.br/
Corpus – ENG
DOAJ (Directory of Open Acess Journal):Site americano de artigos e revistas científicas
que disponibiliza seu conteúdogratuitamente.
Fonte: http://www.doaj.org/doaj?uiLanguage=en
MedLine:É a mais abrangente fonte de periódicos da área da saúde em texto completo do
mundo, provendo artigos na íntegra de aproximadamente 1.200 periódicos indexados. Esse
site não disponibiliza os artigos gratuitamente, mas a universidade onde esta sendo
desenvolvida esta pesquisa possui convênio com esta base de dados possibilitando o acesso
aos artigos.

27
Fonte: http://web.ebscohost.com/ehost/search/basic?sid=32a1711c-a5f9-46a7-b54b-
658817898c33%40sessionmgr14&vid=2&hid=25
PubMed:Base de dados americana com artigos vinculados a diversas revistas eletrônicas. O
site disponibiliza artigos gratuitos e pagos, mas por não haver convênio com essa base de
dados, os artigos coletados foram somente os gratuitos.
Fonte: http://www.ncbi.nlm.nih.gov/pubmed
ScienceDirect: A Base de Dados Science Direct da Editora Elsevier é disponibilizada pelo
Portal Periódicos da CAPES para a Universidade São Judas.Atualmente encontra-se
disponível 9.6 milhões de artigos com texto completos.
Fonte: http://www.sciencedirect.com/
Scopus: Base de dados vinculada a Editora Elsevier, também disponibiliza arquivos da área
de saúde de forma paga.
Fonte: http://www.scopus.com/home.url
3.3Regras de inclusão e exclusão
De forma a manter a consonância dos resultados, regras para a coleta e análise dos artigos
foram estabelecidas. São elas:
Todos os textos de ambas as línguas devem ser artigos científicos;
Todos os textos devem respeitar o prazo de 5 anos a fim de manter a atualidade dos
dados.
Os artigos deveriam estar completos, abstracts não seriam aceitos.
Todos devem ter como tema psicotrópicos, podendo ser uma pesquisa sobre vários
medicamentos, ou apenas um.
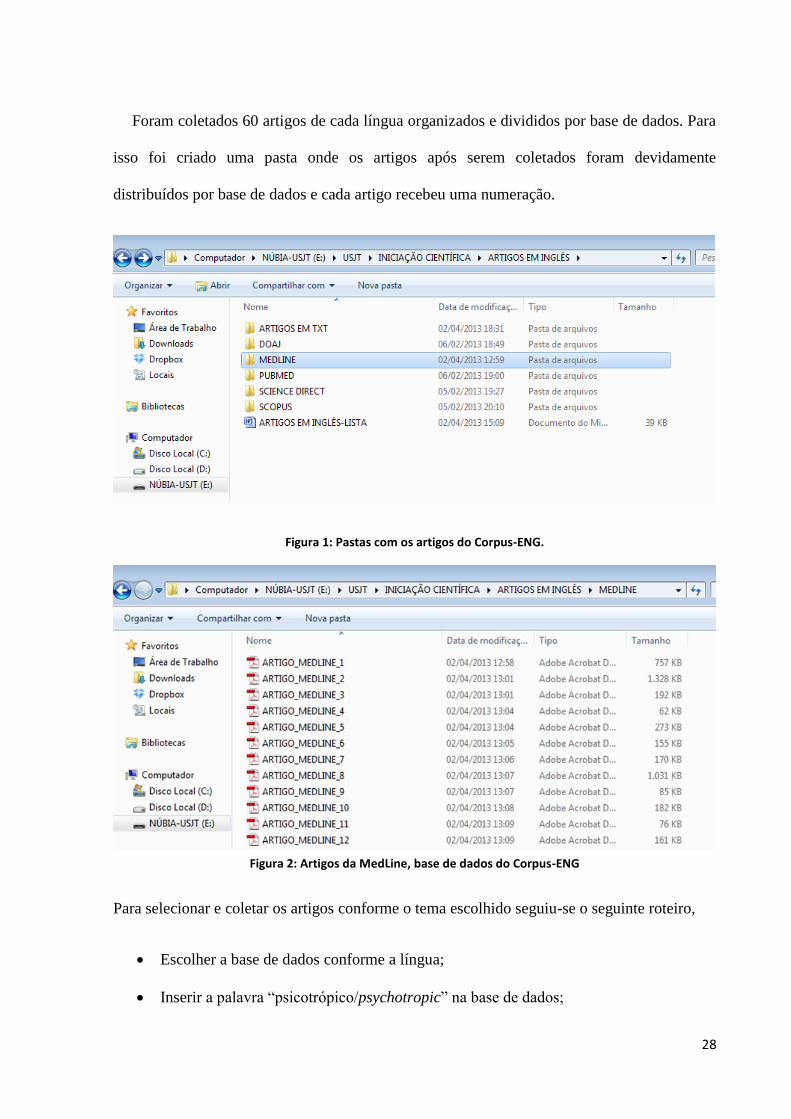
28
Foram coletados 60 artigos de cada língua organizados e divididos por base de dados. Para
isso foi criado uma pasta onde os artigos após serem coletados foram devidamente
distribuídos por base de dados e cada artigo recebeu uma numeração.
Figura 1: Pastas com os artigos do Corpus-ENG.
Para selecionar e coletar os artigos conforme o tema escolhido seguiu-se o seguinte roteiro,
Escolher a base de dados conforme a língua;
Inserir a palavra “psicotrópico/psychotropic” na base de dados;
Figura 2: Artigos da MedLine, base de dados do Corpus-ENG
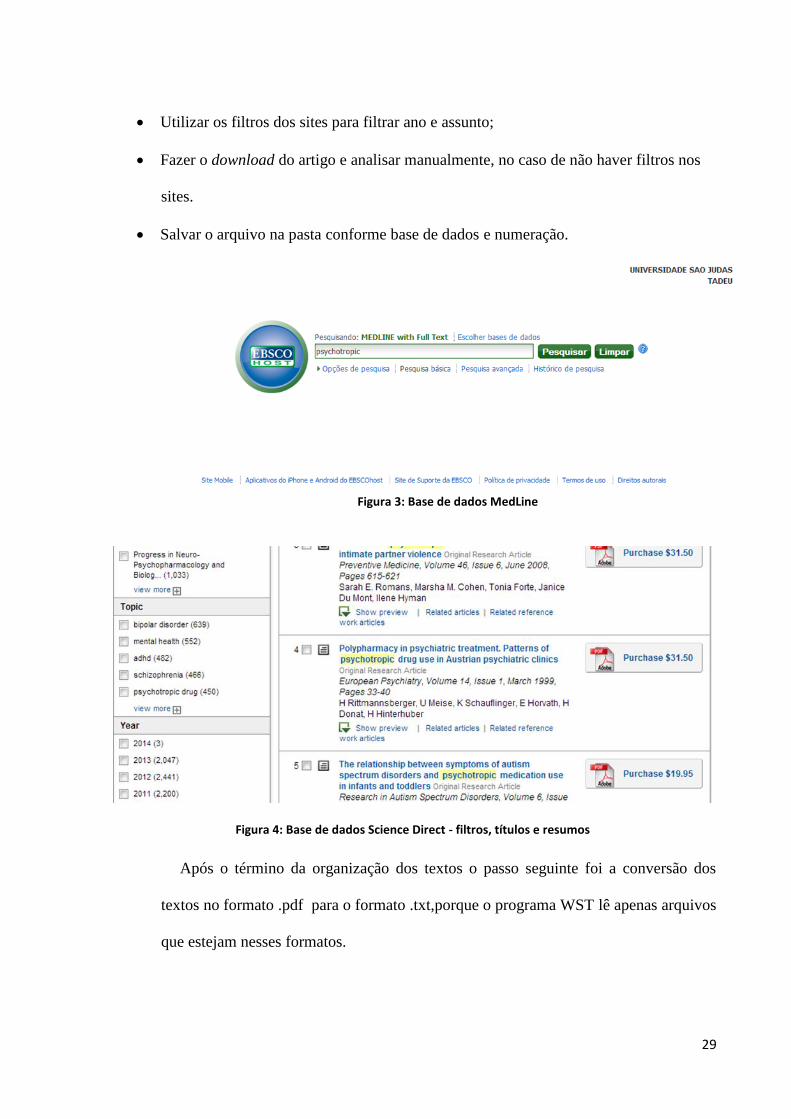
29
Utilizar os filtros dos sites para filtrar ano e assunto;
Fazer o download do artigo e analisar manualmente, no caso de não haver filtros nos
sites.
Salvar o arquivo na pasta conforme base de dados e numeração.
3.4 Processamento no WordSmith Tools
Após o término da organização dos textos o passo seguinte foi a conversão dos
textos no formato .pdf para o formato .txt,porque o programa WST lê apenas arquivos
que estejam nesses formatos.
Figura 3: Base de dados MedLine
Figura 4: Base de dados Science Direct - filtros, títulos e resumos

30
Para a conversão dos arquivos foi utilizado o seguinte site
(http://convertonlinefree.com/PDFToTXTEN.aspx) que faz a conversão
gratuitamente.
Os arquivos em .txt receberam a mesma nomeação e numeração que o arquivo em
pdf exemplificado na figura 2, a partir daí passaram a ser
“Artigo_BasedeDados_Número.txt”.
3.4.1 O WordSmith Tools
Biber (1988apud, SARDINHA, 1999) afirma que os computadores são os mais
confiáveis e eficientes para fazer tarefas tediosas como contar palavras, identificar
ocorrências e classificá-las. Também, o uso de computadores nas pesquisas linguísticas
veemcrescendo consideravelmente e para acompanhar esse desenvolvimento tecnológico
esta pesquisa também utilizou esse recurso.
Atualmente o programa computacional que melhor cumpre essa tarefa é o WordSmith
Tools.
Tagnin (2002) define o programa da seguinte forma:
“Wordsmith Tools, ferramenta que fornece, a partir de textos
pré-selecionados, concordâncias para a palavra de busca, clusters
(agrupamentos frequentes), listas das palavras mais
frequentes num texto, bem como palavras-chave de um texto.”
O programa foi desenvolvido por Mike Scott em parceria com Universidade de
Oxford e distribuído por Oxford University Press. Ribeiro (2000) definiu o programa
em três princípios básicos:
I. Ocorrência: O pesquisador só considera aquilo que está presente no Corpus.

31
II. Recorrência: Deverá ter no mínimo duas ocorrências de determinado termo,
isso determina a importância do tamanho do Corpus, quanto maior, mais fácil
encontrar termos raros.
III. Coocorrência: Os termos devem aparecem posicionados e relacionados com
outros termos, é assim que identificamos sua melhor colocação, e seu real
significado.
Sua interface é bem simples e vem acompanhada de ummanual. A obtenção do WST pode
ser feita no site pelo http://www.lexically.net/wordsmith/, há várias versões sendo a mais
recente delas até o termino desta pesquisa a versão de número 6, versões DEMO também
podem ser encontradas neste site. A versão utilizada neste trabalho foi a de número 3, a
licença foi cedida gratuitamente por Mike Scott quando a pesquisadora contatou o
desenvolvedor.
Figura 5: WordSmith Tools Help, manual que acompanha o programa de computador.
3.4.2 Ferramentas
O programa WST possui três ferramentais principais que serão aqui elucidadas:
32
3.4.2.1 WordList
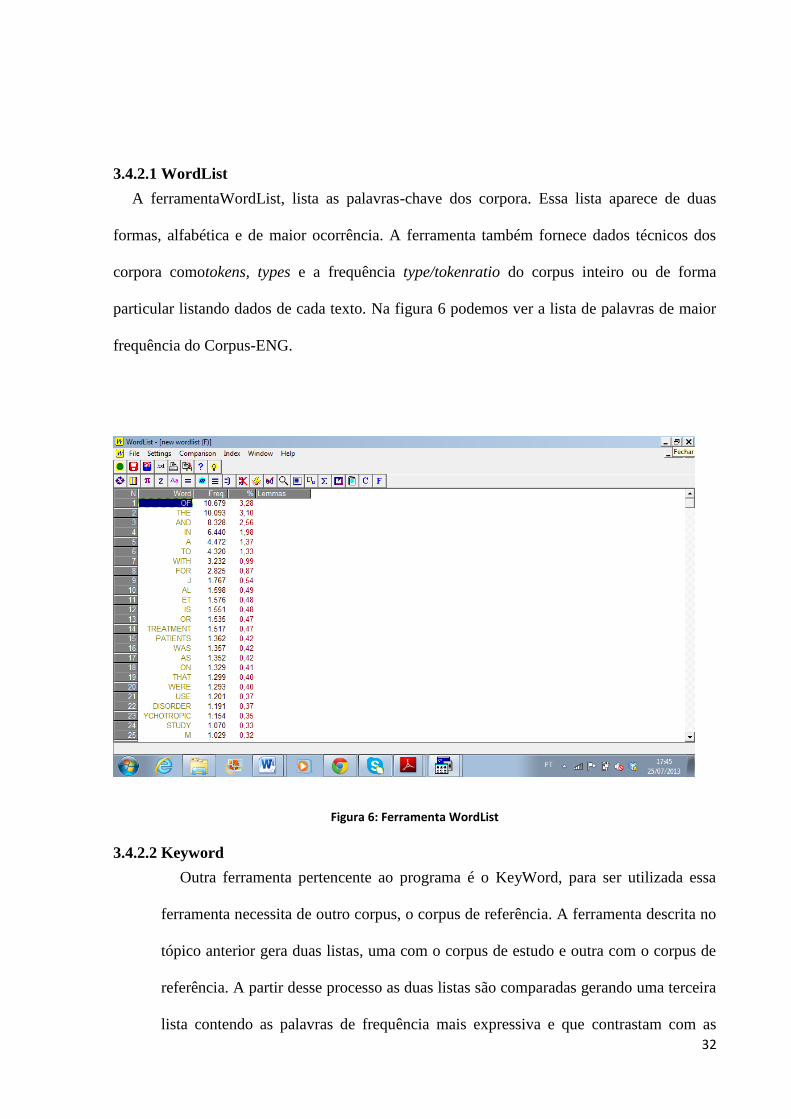
A ferramentaWordList, lista as palavras-chave dos corpora. Essa lista aparece de duas
formas, alfabética e de maior ocorrência. A ferramenta também fornece dados técnicos dos
corpora comotokens, types e a frequência type/tokenratio do corpus inteiro ou de forma
particular listando dados de cada texto. Na figura 6 podemos ver a lista de palavras de maior
frequência do Corpus-ENG.
Figura 6: Ferramenta WordList
3.4.2.2 Keyword
Outra ferramenta pertencente ao programa é o KeyWord, para ser utilizada essa
ferramenta necessita de outro corpus, o corpus de referência. A ferramenta descrita no
tópico anterior gera duas listas, uma com o corpus de estudo e outra com o corpus de
referência. A partir desse processo as duas listas são comparadas gerando uma terceira
lista contendo as palavras de frequência mais expressiva e que contrastam com as
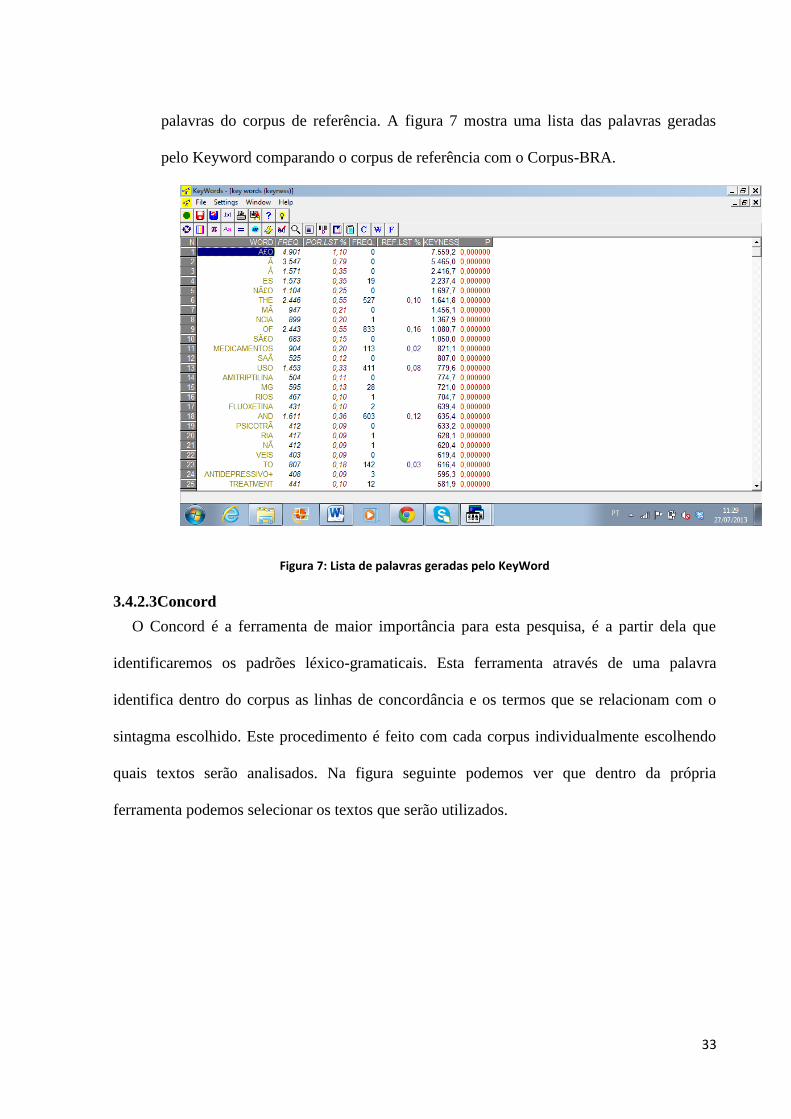
33
palavras do corpus de referência. A figura 7 mostra uma lista das palavras geradas
pelo Keyword comparando o corpus de referência com o Corpus-BRA.
Figura 7: Lista de palavras geradas pelo KeyWord
3.4.2.3Concord
O Concord é a ferramenta de maior importância para esta pesquisa, é a partir dela que
identificaremos os padrões léxico-gramaticais. Esta ferramenta através de uma palavra
identifica dentro do corpus as linhas de concordância e os termos que se relacionam com o
sintagma escolhido. Este procedimento é feito com cada corpus individualmente escolhendo
quais textos serão analisados. Na figura seguinte podemos ver que dentro da própria
ferramenta podemos selecionar os textos que serão utilizados.
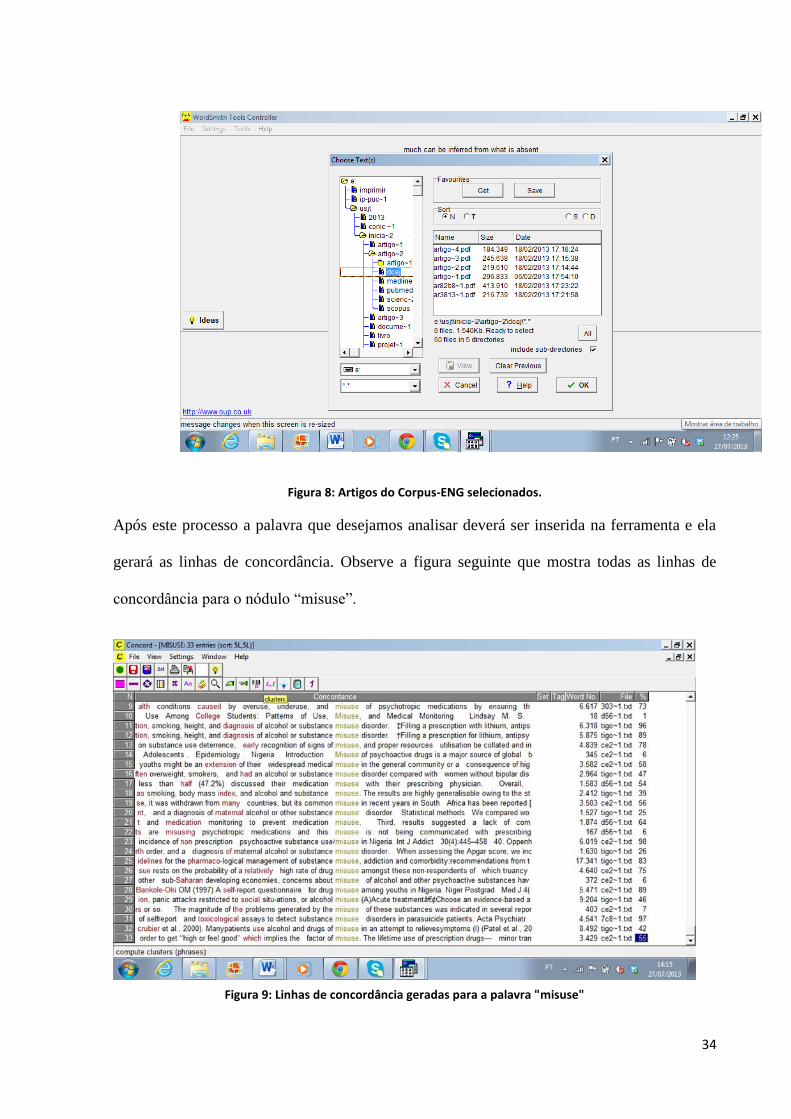
34
Figura 8: Artigos do Corpus-ENG selecionados.
Após este processo a palavra que desejamos analisar deverá ser inserida na ferramenta e ela
gerará as linhas de concordância. Observe a figura seguinte que mostra todas as linhas de
concordância para o nódulo “misuse”.
Figura 9: Linhas de concordância geradas para a palavra "misuse"

35
Através do botão “clusters” podemos identificar quais são os cotextos que se relacionam com
os nódulos
3.5 Processamento para análise
A última parte da metodologia consiste em descrever o processo para obtenção dos
resultados, que possuem como objetivo suprir as lacunas discutidas anteriormente.
O uso do programa WordSmith Tools foi crucial para a obtenção dos equivalentes
tradutórios.
A pesquisa iniciou-se com a coletados textos nas bases de dados que, após selecionados,
passaram por critérios de eliminação, foram organizados e divididos em dois corpora, Corpus-
BRA e Corpus-ENG.
Posteriormente, seguiu-se para o processamento no WST sendo que a primeira etapa
consistiu em elaborar duas listas de palavras, uma para cada corpus utilizando a ferramenta
WordList. Aqui podemos averiguar quais são as palavras mais recorrentes dentro do corpus.
A figura a seguir exemplifica o processo descrito.
Figura 10: Clusters para o nódulo "misuse"
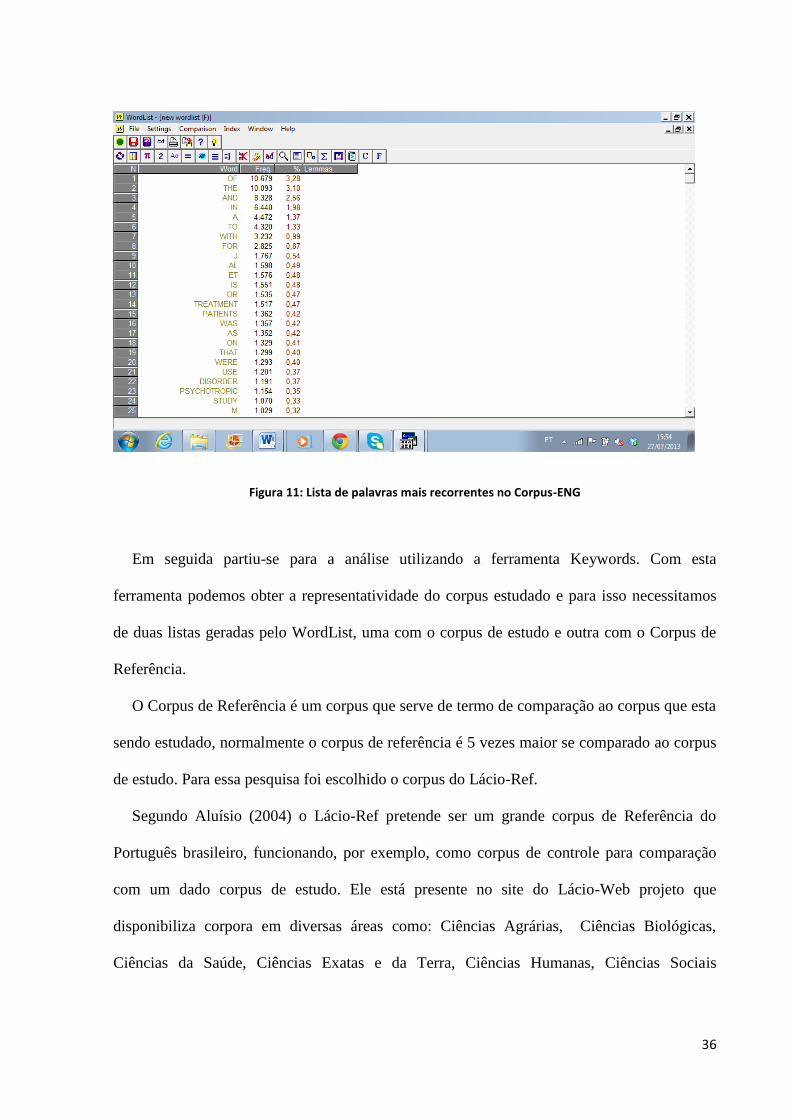
36
Figura 11: Lista de palavras mais recorrentes no Corpus-ENG
Em seguida partiu-se para a análise utilizando a ferramenta Keywords. Com esta
ferramenta podemos obter a representatividade do corpus estudado e para isso necessitamos
de duas listas geradas pelo WordList, uma com o corpus de estudo e outra com o Corpus de
Referência.
O Corpus de Referência é um corpus que serve de termo de comparação ao corpus que esta
sendo estudado, normalmente o corpus de referência é 5 vezes maior se comparado ao corpus
de estudo. Para essa pesquisa foi escolhido o corpus do Lácio-Ref.
Segundo Aluísio (2004) o Lácio-Ref pretende ser um grande corpus de Referência do
Português brasileiro, funcionando, por exemplo, como corpus de controle para comparação
com um dado corpus de estudo. Ele está presente no site do Lácio-Web projeto que
disponibiliza corpora em diversas áreas como: Ciências Agrárias, Ciências Biológicas,
Ciências da Saúde, Ciências Exatas e da Terra, Ciências Humanas, Ciências Sociais
37
Aplicadas, Generalidades e Religião e Pensamento. Para contrapor com o corpus de estudo
foi escolhido o corpus das Ciências da Saúde.
Após a coleta do Corpus de Referência, sua lista de palavras chave foi gerada pelo
WordList, para só então contrastarmos as listas de palavras chave do corpus-BRA com o
Corpus de Referência utilizando o programa KeyWords.
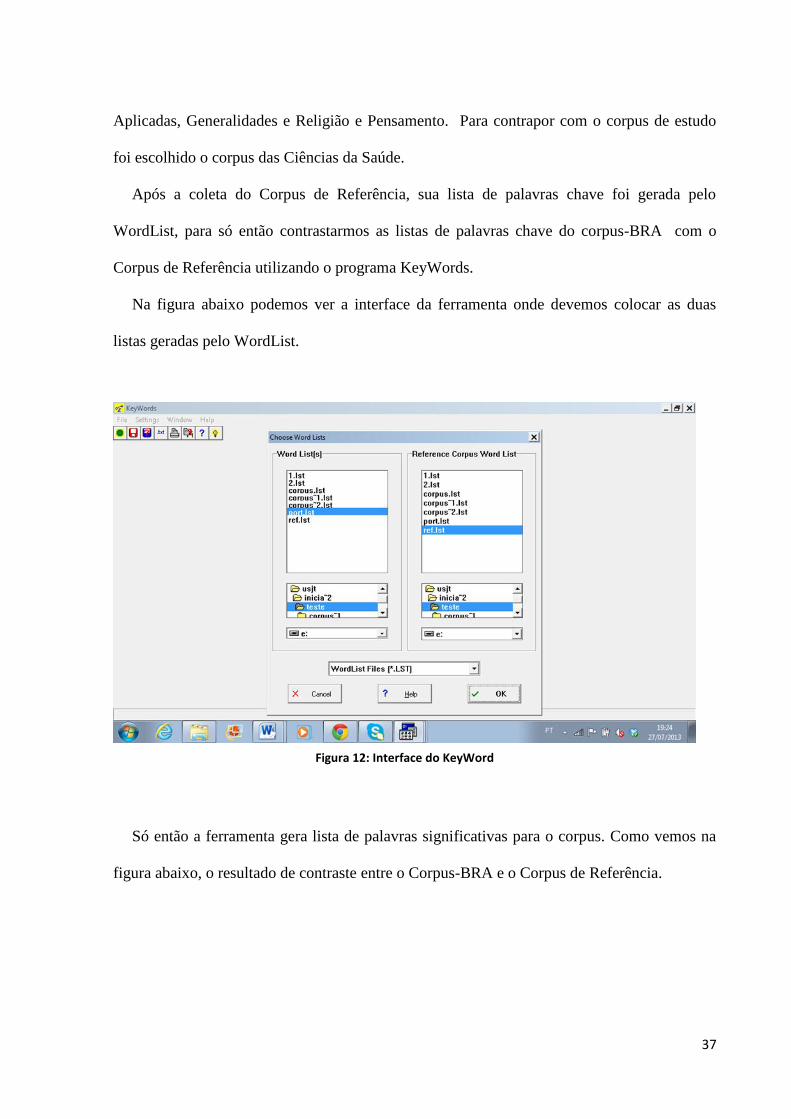
Na figura abaixo podemos ver a interface da ferramenta onde devemos colocar as duas
listas geradas pelo WordList.
Só então a ferramenta gera lista de palavras significativas para o corpus. Como vemos na
figura abaixo, o resultado de contraste entre o Corpus-BRA e o Corpus de Referência.
Figura 12: Interface do KeyWord

38
À vista disso a ferramenta Concord passa a ser o próximo passo. Nesta ferramenta cada
corpus é estudado de maneira singular. O Concord como o nome sugere, faz listas de
concordâncias com os nódulos e identificamos os colocados mais recorrentes.
Por fim, para legitimar a eficiência do Corpus, um artigo científico versando sobre o
mesmo assunto dos corpora compilados foi escolhido para que sua versão fosse feita e os
equivalentes tradutórios obtidos fossem utilizados, assim quando um sintagma técnico
científico correspondente ao assunto corpus compilado fosse encontrado as seguintes etapas
foram seguidas:
A tradução foi feita de forma tradicional, com auxílio de dicionários físicos e on-line , além
da assistência de tradutores automáticos;
Foram geradas duas listas de concordâncias uma para o termo técnico do Corpus-BRA e outra
para o corpus-ENG que foi obtido conforme o tópico anterior.
As listas geradas foram contrastadas para se confirmar o mesmo contexto, se o contexto fosse
o mesmo a análise se encerraria por aqui.
Figura 13: Lista de palavras geradas pela ferramenta

39
Em caso negativo, uma segunda análise deveria ser feita a partir dos colocados encontrados,
até que se chegasse a um equivalente que correspondesse ao contexto da língua de origem.

40
4. Resultados
Neste capítulo apresentaremos os resultados obtidos com as análises dos sintagmas
inseridos no WordSmith Tools. Os corpora foram subdivididos em dois Corpora: O Corpus-
BRA (referentes aos artigos em língua portuguesa) e o Corpus-ENG (referente os artigos em
língua inglesa). Dados técnicos dos corpora:
CORPUS-ENG
Tokens 325.706
Types 22.935
Type/Token Ratio 7,04%
Tabela 1: Dados técnicos do Corpus-ENG
CORPUS-BRA
Tokens 446.754
Types 29.405
Type/Token Ratio 6,58%
Tabela 2: Dados técnicos do Corpus-BRA
Portanto, como descrito no tópico Terminologia Básica o Tokens é a quantidade de
palavras que há no corpus, inclusive as repetidas e o Types elimina as palavras repetidas. O
Type/Token Ratio indica a quantidade de variação das palavras dentro do corpus.
Segundo Sardinha (1999), o tamanho do Corpus influencia na veracidade dos dados que
serão obtidos, portanto este corpus pode ser classificado como Médio conforme a tabela
abaixo:

41
Tamanho em Palavras Classificação
Menos de 80 mil Pequeno
80 a 250 mil Pequeno-médio
250 mil a 1 milhão Médio
1 milhão a 10 milhões Médio Grande
10 milhões ou mais Grande
Tabela 3: Classificação do tamanho do Corpus
4. 2 Sintagmas
Após a análise utilizando da metodologia descrita no capítulo anterior, obteve-se treze
equivalentes tradutórios. Aqui os processos para obtenção do equivalente será descrito:
1. Psicose maníaco-depressiva
Quando o termo ‘psicose’ é inserido na ferramenta Concord são geradas 16 linhas de
concordância sendo que em 9 delas aparecem o cluster ‘psicose maníaco-depressiva’. O
mesmo acontece quando o termo ‘maníaco’ é colocado na ferramenta Concord e 13 linhas de
concordância são geradas sendo o sintagma ‘psicose maníaco depressiva’ aparece 7 vezes.
Mas quando o termo ‘Depressive’ é colocado é inserido na ferramenta Concord no Corpus-
ENG são geradas 200 linhas de concordância e o cluster que mais aparece é ‘major
Depressive Disorder’ e só encontramos um equivalente próximo de ‘psicose maníaco-
depressiva’ na 20ª linha com apenas 4% de frequência ‘ Manic-Depressive Illness’. O termo
“psychosis” não apresentou nenhuma relação com “Manic Depressive Disorder”.

42
Figura 14: Clusters gerados para a palavra "psychosis"
2. Transtorno afetivo bipolar
Quando o sintagma ‘bipolar’ é inserido na ferramenta Concord dentro do Corpus-BRA
aparecem 204 linhas de concordância sendo que o cluster que mais aparece é ‘transtorno
afetivo bipolar’ com 40% de frequência. O mesmo acontece com o sintagma ‘afetivo’.
Quando o sintagma ‘transtorno afetivo bipolar’ é inserido no tradutor automático (Google
Translator) ele oferece apenas ‘bipolar disorder’ e omite o afetivo. Quando o termo ‘bipolar’ é
inserido no Corpus–ENG há 972 linhas de concordância sendo o cluster que mais aparece é
‘with bipolar disorder’ com 129% de frequência.
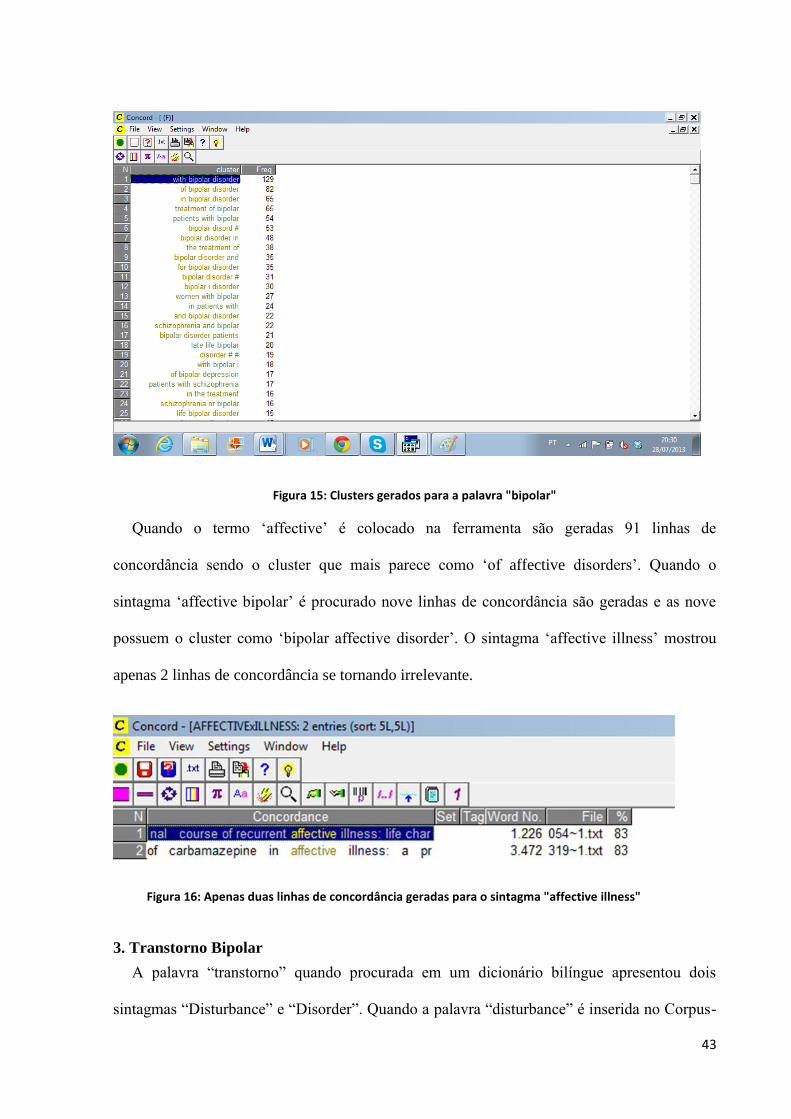
43
Figura 15: Clusters gerados para a palavra "bipolar"
Quando o termo ‘affective’ é colocado na ferramenta são geradas 91 linhas de
concordância sendo o cluster que mais parece como ‘of affective disorders’. Quando o
sintagma ‘affective bipolar’ é procurado nove linhas de concordância são geradas e as nove
possuem o cluster como ‘bipolar affective disorder’. O sintagma ‘affective illness’ mostrou
apenas 2 linhas de concordância se tornando irrelevante.
3. Transtorno Bipolar
A palavra “transtorno” quando procurada em um dicionário bilíngue apresentou dois
sintagmas “Disturbance” e “Disorder”. Quando a palavra “disturbance” é inserida no Corpus-
Figura 16: Apenas duas linhas de concordância geradas para o sintagma "affective illness"

44
ENG gerou 70 linhas de concordância sendo que seu cluster de maior frequência (10%) foi
‘sleep disturbance’ que possivelmente seria traduzido por ‘distúrbio do sono’, mas a palavra
não apresenta qualquer relação com a palavra bipolar. Já a palavra ‘disorder’quando inserida
na ferramenta Concord apresenta 1191 linhas de concordância sendo o seu cluster de maior
frequência (120%) ‘with bipolar disorder’.
4. Interações medicamentosas
A palavra ‘medicamentosas’ quando inserida na ferramenta Concord do Corpus-BRA, 49
linhas de concordância são geradas sendo que 15% delas pertencem ao cluster ‘interações
medicamentosas’. A expressão ‘drug-drug interactions’ gerou 57 linhas de concordância.
Somente a palavra “interaction” quando buscada na ferramenta Concord teve como terceiro
Pattern a palavra “drug”.
Figura 17: Lista de patterns para a palavra "drug"
5. Pacientes Ambulatoriais
Quando inserido na ferramenta Concord 4 linhas de concordância foram geradas, todas
relacionadas à palavra paciente. Quando a palavra foi inserida no tradutor automático (Google

45
Translator) o termo encontrado foi ‘outpatient’, o mesmo foi encontrado em um dicionário
bilíngue. No corpus-ENG foram geradas 22 linhas para a palavra ‘outpatients’.
6. Efeito colateral
Para o sintagma ‘efeito colateral’ 6 linhas foram geradas com a palavra colateral e todas
acompanhadas da palavra ‘efeito’. No Corpus-ENG o termo ‘side’ gerou 221 entradas sendo
seu cluster de maior frequência ‘side effects’.
7. Antidepressivos tricíclicos (ADT)
Para este sintagma foram geradas 31 linhas de concordância para a palavra ‘tricíclicos’
sendo que o cluster que mais apareceu foi seu acompanhante ‘antidepressivos’, em alguns
casos acompanhados da sigla. No Corpus-ENG foram geradas 43 linhas de concordância para
a palavra “tricyclic” sendo seu cluster de maior frequência “tricyclic antidepressive (tcas)”.
8. Ensaios clínicos
A palavra ‘ensaios’ quando inserida no Corpus-BRA teve 45 linhas de concordância sendo
o cluster de maior frequência “ensaios clínicos”. O tradutor automático e os dicionários
oferecem a tradução ‘clinical trials’ que aparece em 34 entradas do Concord.
9. Depressores do apetite
A palavra “depressores” quando inserida no Corpus-BRA gerou 11 linhas de concordância
sendo que 3 delas relacionadas a “apetite”. A palavra “apetite” gerou 64 linhas de
concordância sendo que 3% eram relacionadas a “depressores”. A palavra “appetite” gerou 16
linhas de concordância no Corpus-ENG sendo que seu único cluster foi “loss of appetite”. E
nenhuma linha foi gerada para a palavra “depressor”. A palavra “loss” gerou 84 linhas de
concordância sendo que 6% eram relacionadas à “appetite”.
10. Atenção primária à saúde
A palavra “atenção” gerou 176 linhas de concordância quando inserida no Corpus-BRA e
seu cluster de maior frequência foi “na atenção primária”. Quando a palavra “primary” é

46
inserida no Corpus-ENG 174 linhas de concordância são geradas, sendo o cluster de maior
frequência é “primary care physicians”. O mesmo acontece quando a palavra “care” é inserida
no Corcord, 363 linhas são geradas sendo que o cluster de maior frequência é “primary care
physicians” com 37% de frequência.
11. Inibidores seletivos da recapitação da serotonina (ISRS)
A palavra “serotonina” apresentou 113 entradas no Corpus-BRA, sendo seu cluster de
maior frequência com 18% foi “inibidores seletivos da”, os outros clusters presentes são
variações do mesmo sintagma como “recaptura da serotonina” e “receptação de serotonina”.
Quando a palavra serotonina é inserida no Corpus-ENG 125 linhas de concordância são
geradas, sendo o cluster de maior frequência com 29% é “serotonin reuptake inhibitors”. Os
outros clusters também são variações do sintagma principal.
12. Antagonistas da dopamina
A palavra “antagonista” quando inserida no Corpus-BRA apresentou 37 linhas de
concordância, sendo o cluster de maior frequência foi “antagonista de receptores” com 17%.
A palavra “dopamina” apresentou 38 linhas de concordância, sendo o cluster de maior
frequência com “receptores de dopamina” com 4 %. A palavra “dopamine” registrou 82
entradas no Corpus-ENG, os clusters apresentaram variações, mas todos registraram a mesma
frequência de 3% foram eles: “dopamine fiber density”, “dopamine reuptake inhibitor”
“dopamine reuptake inhibitors”, “dopamine transporter gene”, “dopamine transporter mrna”,
“dopamine reuptake and”,noradrenaline and dopamine” “noradrenaline-dopamine reuptake” e
“the dopamine transporter”. A palavra “antagonist” gerou 25 linhas de concordância, sendo o
cluster de maior frequência com 5% é “receptor neutral antagionist”.Uma consulta ao Google
revelou 215 mil resultados para o sintagma “dopamineantagonist”, este sintagma não foi
encontrado de forma conjunta no Corpus-ENG.

47
13. Uso indevido de drogas
A palavra “indevido” registrou 47 entradas no Corpus-BRA, sendo o cluster de maior
frequência “uso indevido de” com 18%.
Figura 18: Clusters gerados para a palavra 'indevido"
A própria expressão “uso indevido de drogas” também apresentou 6 entradas no corpus.
Equivalentes como “consumo indevido” também foram encontrados. A palavra “misuse’
apresentou 33 entradas no Corpus-ENG sendo o cluster de maior frequência “substance
misuse disorder” com 5%. A expressão “drug misuse” mostrou apenas 2 entradas. Já a
expressão “substance misuse” apresentou 11 entradas.
Assim, com base neste Corpus podemos obter os seguintes equivalentes tradutórios:

48
Sintagma Equivalente tradutório
1. Psicose maníaco-depressiva Manic Depressive Disorder
2. Transtorno afetivo bipolar Bipolar Affective Disorder
3. Transtorno Bipolar Bipolar Disorder
4. Interações medicamentosas Drug Interactions
5. Pacientes Ambulatoriais Outpatients
6. Efeito colateral Side Effects
7. Antidepressivos tricíclicos (ADT) Tricyclic Antidepressive (TCAs)
8. Ensaios clínicos Clinical Trials
9. Depressores do apetite Loss of Appetite
10. Atenção primária à saúde Primary Care Physicians
11. Inibidores Seletivos da Recapitação da
Serotonina (ISRS)
Selective Serotonin Reuptake
Inhibitor(SSRI)
12. Antagonistas da Dopamina Dopamine Antagonist
13. Uso indevido de drogas Substance Misuse
Tabela 4: Lista de equivalentes tradutórios
4.3 Discussão
Segundo Cordioliet et al(2000) a depressão é uma doença eu acomete em cerca de 15% da
população adulta. Este fator faz com que inúmeras pesquisas relacionadas às doenças, aos
tratamentos e aos medicamentos apareçam, e os dicionários, principalmente os físicos, muitas
vezes não conseguem acompanhar. Para a área farmacêutica não há dicionários
especializados, os tradutores recorrem muitas vezes aos dicionários da área médica, o que
nem sempre supre os dilemas da profissão. O que se aproxima de um dicionário bilíngue e
que pode auxiliar os tradutores são os livros: Dicionário Farmacêutico Andrei, que escrito em

49
francês e traduzido para o português por uma farmacêutica, e o DEF (Dicionário de
Especialidades Farmacêuticas), que contém as bulas de todos os medicamentos
regulamentados no país. Infelizmente ambos estão somente na língua portuguesa e não há
nenhum dicionário bilíngue, por isso a opção de customizar corpora é uma solução para
encontrar equivalentes tradutórios confiáveis.
Para atestar a efetividade dos resultados encontrados, versões para a língua inglesa de
artigos científicos farmacêuticos foram realizadas. Foram utilizados três artigos científicos
que eram compatíveis em ano e assunto com os artigos utilizados nos corpora.
O sintagma Transtorno Afetivo Bipolar quando inserido no tradutor automático obtêm a
tradução como Bipolar Disorder e o mesmo aconteceu com as doenças Transtorno Bipolar do
Humor (não investigado neste trabalho) e Transtorno Bipolar, sendo o último a única tradução
correta. Em outras vezes, o tradutor automático oferece Illness para transtorno o que
geralmente acontece quando o sintagma está inserido no texto. Isso dificulta as traduções, pois
a máquina nem sempre consegue escolher a melhor forma de utilizar a palavra.
Quando dentro de um contexto o tradutor automático ofereceu para psicose maníaco-
depressiva manic depressive-illness, mas quando retiramos o texto e deixamos apenas o
sintagma livre o tradutor muda e oferece apenas manic depressive. Outros dicionários online
oferecem apenas manic depressive psychosis, ou seja, a tradução literal.
Como já explanado anteriormente o termo Disorder geralmente é utilizado para denominar
doenças relacionadas a perturbações da mente e o termo Illness está ligado ao físico a doenças
como esquizofrenia, ou seja, existe uma relação semântica entre as palavras, como as palavras
doença que automaticamente ligamos a alguma condição física e a palavra transtorno na qual
fazemos ligação com mente e não o corpo. Mas alguns dicionários médicos oferecem opções
alternativas e isso vai depender da escolha do tradutor, qual é o melhor sintagma, pois o

50
sintagma Bipolar Disorder é bem abrangente, e a doença pode ter variações, ou seja, depende
muito do contexto. O que ajudaria os tradutores a resolver esses empecilhos seria uma
padronização destes sintagmas. Infelizmente, isso exige um estudo mais aprofundado, o que
seria inviável, pois fugiria do escopo da pesquisa que é fazer um levantamento experimental
de equivalentes tradutórios.
O primeiro termo do segundo artigo mostrou-se ser mais simples, pois, os equivalentes
tradutórios obtidos através dos corpora foram os mesmos obtidos pelos dicionários comuns,
neste caso são respectivamente Efeitos Colaterais e Side Effects. Isso acontece devido à
internacionalização do termo, isto é, uma padronização do sintagma facilitando a vida do
tradutor que encontra facilmente a melhor tradução para o sintagma.
Já o segundo termo, Uso indevido de Drogas, obteve como tradução no tradutor
automático Misuse of Drugs. A palavra drug possui um valor semântico ligado a algo ilícito,
mesmo que os medicamentos que comumente tomamos sejam drogas. O Dicionário Houaiss
da Língua Portuguesa oferece como definição da palavra droga:
Droga: s.f.1. qualquer substância ou ingrediente
usado em farmácia, tinturaria, laboratórios químicos, etc.
Mas por obter esse tipo de conotação ao longo do tempo, traduzir por droga, simplesmente
por Drugs, seguiria essa significação de algo ilícito, portanto o uso de Substance Misuse se
torna algo mais generalizado, podendo se referir ao mesmo tempo tanto às drogas lícitas
quanto às ilícitas. O próprio corpus elaborado demostrou isso. Outro fator que objeta esse tipo
de tradução é a questão da construção do sintagma. O corpus não apresentou o colocado of
para a palavra misuse.
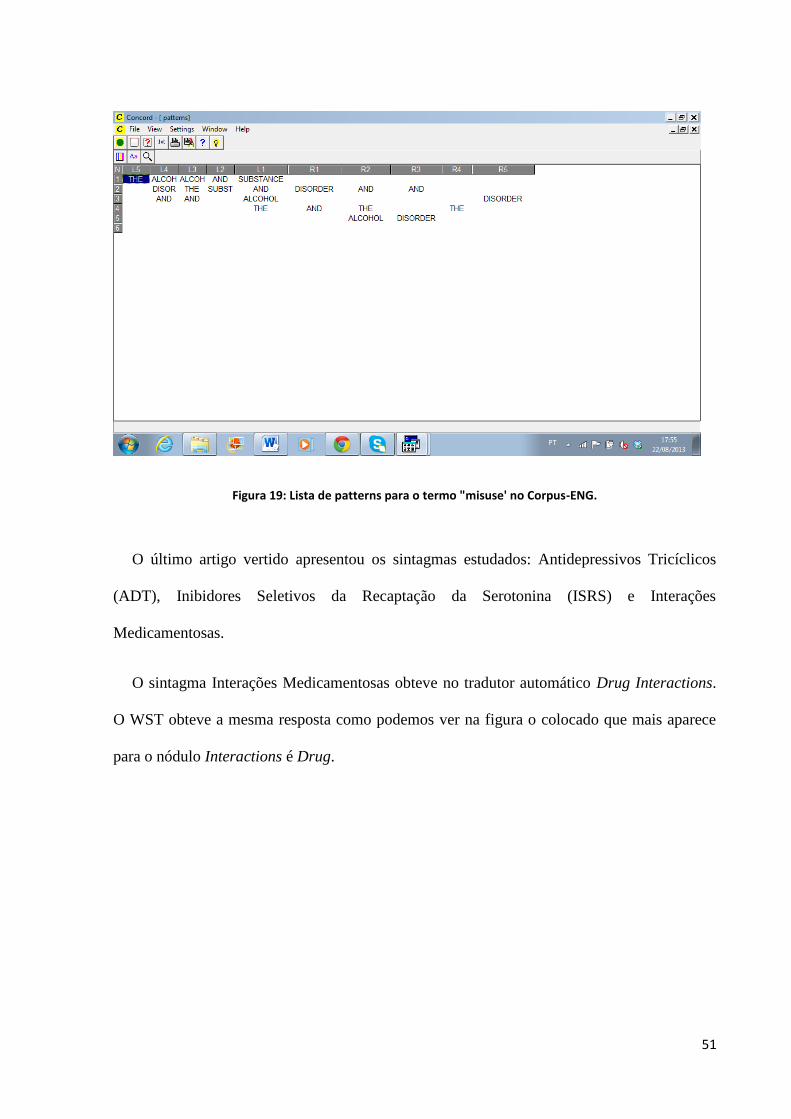
51
Figura 19: Lista de patterns para o termo "misuse' no Corpus-ENG.
O último artigo vertido apresentou os sintagmas estudados: Antidepressivos Tricíclicos
(ADT), Inibidores Seletivos da Recaptação da Serotonina (ISRS) e Interações
Medicamentosas.
O sintagma Interações Medicamentosas obteve no tradutor automático Drug Interactions.
O WST obteve a mesma resposta como podemos ver na figura o colocado que mais aparece
para o nódulo Interactions é Drug.

52
O mesmo se seguiu para os sintagmas Antidepressivos Tricíclicos que geralmente vêm
acompanhados de sua sigla (no português, ATD) e o mesmo acontece na língua inglesa, o
sintagma Tricyclic Antidepressants (no inglês, TCA) também pede sua sigla ao lado.
Figura 20: Lista de patterns para o termo "interactions" no Corpus-ENG
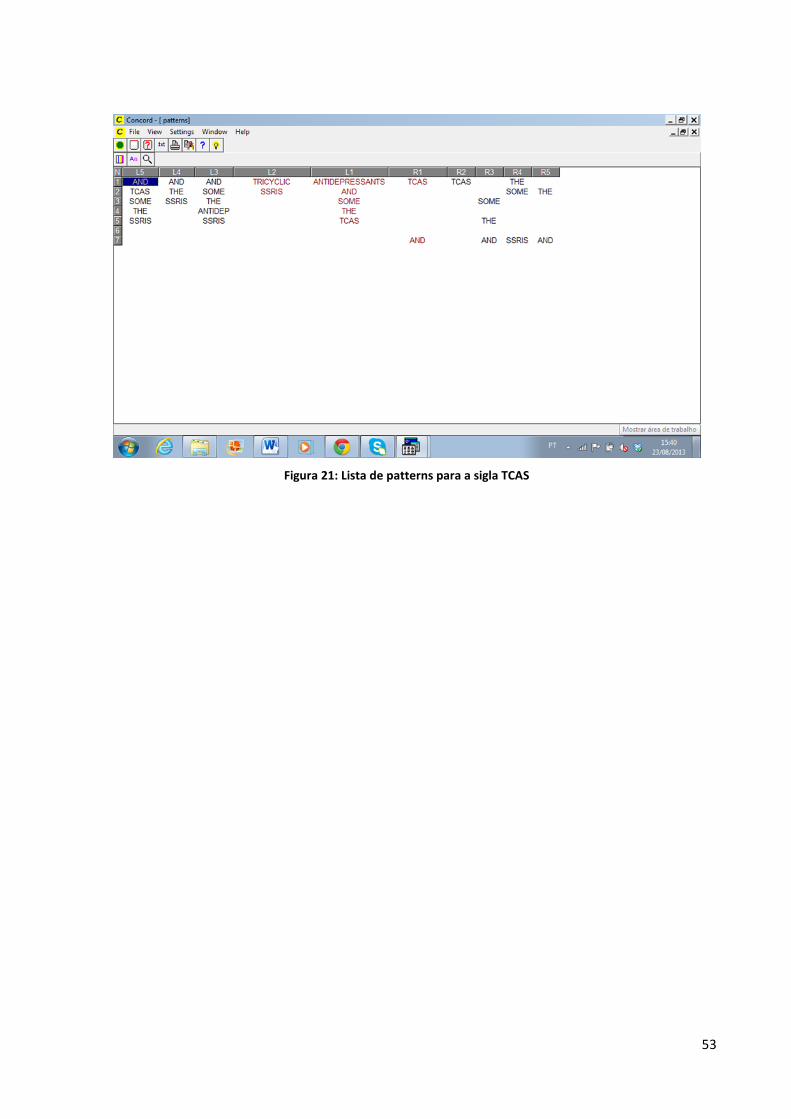
53
Figura 21: Lista de patterns para a sigla TCAS

54
5. Considerações Finais
O objetivo principal desta pesquisa consistia em elaborar um Corpus experimental para
identificação de equivalentes tradutórios versando sobre a utilização de psicotrópicos a fim de
auxiliar o tradutor técnico-científico. Após os resultados obtidos podemos concluir
respondendo as seguintes questões:
I. A partir dos corpora compilados foi possível identificar equivalentes tradutórios?
Apesar de que a pesquisa teve um caráter totalmente experimental o reconhecimento de
equivalentes tradutórios foi satisfatório. É importante deixar claro que os corpora aqui
compilados mostraram ser de tamanho médio (de 250 mil a 1milhão de palavras), ou seja, os
resultados aqui obtidos não são a resposta final, mas são saídas alternativas de tradução, cabe
ao tradutor ou não optar em usá-la.
II. A metodologia da Linguística de Corpus se mostrou eficaz?
A Linguística de Corpus é a mais flexível e atualizada fonte de soluções tradutórias, pois
apenas a partir dela podemos trabalhar com a língua em uso, com os termos mais usuais, visto
que os dicionários trabalham com termos isolados, o que muitas vezes não preenchem as
dúvidas dos tradutores técnicos.
III. A análise de padrões-léxico gramaticais é eficiente em se tratando de auxílio ao
tradutor?
Ao realizar as versões foi possível perceber que sem a consulta aos corpora a tradução
seria insatisfatória, pois além de não haver nenhum dicionário específico da área
farmacêutica, muito menos algum tipo de glossário especializado em uso de psicotrópicos, os

55
tradutores automáticos oferecem traduções errôneas como, por exemplo, o caso de Psicose
maníaco-depressiva, Transtorno afetivo bipolar e Transtorno Bipolar que obtiveram a mesma
tradução, Bipolar Disease, mesmo se tratando de doenças diferentes com características
diferentes. A pesquisadora pode ainda notar que mesmo em português ainda há uma falta de
padronização dos sintagmas, pois por ser bem abrangente o termo Transtorno Bipolar, é usado
de forma ampla e genérica, mesmo quando se trata de uma doença específica, como a Psicose
maníaco-depressiva por exemplo.
Podemos concluir que a customização de corpora é atualmente a melhor maneira de lidar
com sintagmas técnicos científicos, podendo assim obter uma tradução, melhorando o
trabalho do tradutor e aumentando o prestígio internacional, neste caso dos farmacêuticos que
conduzem pesquisas acadêmicas em sua área.
Lamentavelmente devido à limitação de tempo, a pesquisadora não aprofundará nem o
tamanho dos corpora, nem a quantidade de sintagmas estudados. Entretanto, há necessidade
de um aperfeiçoamento da pesquisa, podendo ser acrescentadas mais traduções farmacêuticas
ainda tão carentes de estudo.
A pesquisadora espera que este trabalho possa auxiliar futuras traduções técnicas
farmacêuticas e que desperte nos tradutores a importância da Linguística de Corpus e como
ela pode auxiliar a busca do termo exato.

56
6. Bibliografia
BERBER SARDINHA, T. Pesquisa em Lingüística de Corpus com WordSmith Tools.
Campinas: Mercado de Letras, 2009.
___________________, Linguística de Corpus, Ed. Manole, 2004.
___________________, T. Usando WordSmith Tools na investigação da linguagem.
DIRECT Papers, São Paulo, v. 40, 1999.
BOUCHERLE, André. JOSSERAND, Loiusette. Dicionário Farmacêutico Andrei. Editora
Andrei. 1995.
Dicionário de Especialidades Farmacêuticas, 2009/10. Ed. de Publicações Científicas LTDA.
FALARARA, Pâmela. Implementação de um Corpus Bilíngue Comparável em uma
Universidade Particular de São Paulo, São Paulo, 2011.
FROMM, G. Proposta para um modelo de glossário de informática para tradutores.
Dissertação de Mestrado. São Paulo: FFLCH/USP, 2002.
HALLIDAY, M.A.K., As ciências linguísticas e o ensino de línguas. Ed. Vozes, 1974.
LOPES, L. M. B; GRIGOLETO, A. R. L. Uso consciente de psicotrópicos: responsabilidade
dos profissionais da saúde. Brazilian Journal of Health v. 2, n. 1, p. 1-14, Janeiro/Abril 2011.
MAILLOT, Jean. A Tradução Científica e Técnica. Ed. McGraw-Hill do Brasil. 1975.
MATUDA, Sabrina. A fraseologia do futebol: um estudo bilíngue português-inglês
direcionado pelo corpus. Dissertação (Mestrado). São Paulo. Faculdade de Filosofia, Letras e
Ciências Humanas, Universidade de São Paulo, 2011.
NAVARRO, Sandra. Glossário bilíngue de colocações da hotelaria: um modelo à luz da
Linguística de Corpus.Dissertação (Mestrado). São Paulo. Faculdade de Filosofia, Letras e
Ciências Humanas, Universidade de São Paulo, 2011.
PERROTTI-GARCIA, A.J. Artigos Médicos em Inglês, Publicados em Periódicos do Brasil e
do Exterior: uma análise a partir de corpora comparáveis. Dissertação(Mestrado)São Paulo,
2009.
SILVA, Nayume M. Uso Racional de Antidepressivo na Rede Publica no Município De Bom
Jesus RS. Criciúma. 2012.
Soluções em Comunicação & Linguagem. Linguística de Corpus – ferramentas
computacionais e pesquisa online. Disponível em:
http://teacherwillians.g1real.com.br/?p=404Ultimo acesso em: 28/08/13

57
Step-by-Step Guide to Wordsmith.Disponível
em:http://www.lexically.net/wordsmith/step_by_step_English6/index.html Último acesso em:
28/08/13.
TAGNIN, STELLA, 2004, Universidade de São Paulo, CIATI. A linguística de corpus e o
tradutor: uma relação de futuro. Disponível em:
http://www.fflch.usp.br/dlm/comet/artigos/CIATI%202004%20Stella.pdf Último acesso em:
28/08/13.
_______________, Universidade de São Paulo. A Identificação de equivalentes tradutórios
em corpora comparáveis. 2007. Disponível em: http://www.fflch.usp.br/dlm/comet/ Último
acesso em: 28/08/13
________________, Corpora: o que são e para quê servem. Corpora para Terminologia.
Abril, 2004. Disponível em: http://www.fflch.usp.br/dlm/comet/Novo/Lexicografia.pdf
Último acesso em: 28/08/13
TEIXEIRA, Elisa Duarte. 2008. São Paulo. Como usar o Wordsmith Tools (Scott, 1999),
versão 3.Disponível
em:http://www.fflch.usp.br/dlm/comet/artigos/apostilaWSTools.pdfÚltimo acesso em:
31/08/2013
XAVIER, Mariane Da Silva; MACHADO, Cynthia Helena Ferreira; GONÇALVES, Mariam
De Oliveira; TERRA, Marlene Gomes. Oficina Terapêutica Do Conto: Um Espaço Para
Desenvolver Cuidado Multiprofissional Em Saúde Mental. 2011. Disponível em:
http://seer.unipampa.edu.br/index.php/siepe/article/view/2673 Último acesso em: 31/08/2013.

58
7. Anexos
7.1 Anexo 1: Amostra de artigo científico farmacêutico original usado na versão para
comprovação dos corpora.
Resumo 3
O transtorno afetivo bipolar (TAB) era denominado até pouco tempo de psicose maníaco-
depressiva. Esse nome foi abandonado, pois esse transtorno não apresenta necessariamente
sintomas psicóticos, na maioria das vezes os sintomas não aparecem. Dessa forma o
transtorno deixou de ser considerado uma perturbação psicótica para ser considerado uma
perturbação afetiva. Assim um sujeito que tenha uma fase depressiva, receba o diagnóstico de
depressão e dez anos depois apresentar um episódio maníaco tem na verdade TAB (MAROT,
2004). Assim, o TAB é uma doença grave, incurável afetando cerca de 1,5% dos homens e
mulheres em todo o mundo (MAROT,2004). Este estudo tem por objetivo descrever a
importância da realização de oficinas terapêuticas com pacientes que receberam diagnóstico
médico de TAB. Este estudo é um relato de experiência vivido por uma acadêmica de
enfermagem da UFSM na Unidade Psiquiátrica Paulo Guedes. Nesta, ocorre, uma vez por
semana, a “oficina terapêutica do conto” (OTC) que é realizada com os pacientes e
coordenada por uma Residente Multiprofissional. As oficinas são atividades de encontro de
vidas entre pessoas com transtorno mental, promovendo a cidadania, a livre expressão e a
convivência através da inclusão pela arte (VALLADARES et al,2003). Durante a realização
da “OTC” percebeu-se manifestações dos sintomas do TAB em um dos pacientes internados
como: delírio de grandeza, místico e com atitude sedutora, pois, encontrava-se na fase
maníaca da doença. Um episódio maníaco é definido por um período distinto de pelo menos
uma semana durante o qual existe um humor, anormal e expansivo, auto-estima elevada, sono
3Título: Oficina Terapêutica Do Conto: Um Espaço Para Desenvolver Cuidado Multiprofissional Em Saúde
Mental Autores: Mariane Da Silva XAVIER, Cynthia Helena Ferreira MACHADO,Mariam De Oliveira GONÇALVES, Marlene Gomes TERRA.

59
prejudicado, pressão para falar e fuga de idéias (MONTEIRO, 2007). Com essa vivência
percebeu-se o valor da oficina terapêutica, pois durante a mesma os pacientes tiveram a
oportunidade de manifestarem os seus sentimentos. Após a realização da oficina percebeu-se
que os pacientes ficaram menos ansiosos. O impacto da experiência da doença sobre a
personalidade do indivíduo acometido é muito grande, levando a modificações e perdas no
modo de vida, mesmo quando os sintomas de humor propriamente ditos não sejam mais
aparentes (CALIL, 2004). Entende-se oficina como uma forma de atividade socioterápica e
crítico-reflexiva que é válida devendo ser mantida e adotada nas unidades de internação
psiquiátricas. Faz-se necessário que o paciente reconheça os sintomas do TAB e os efeitos das
medicações. Cabe a equipe multiprofissional subsidiar ampla informação ao paciente a
respeito das características e necessidades de sua doença e das possibilidades de tratamento
com vistas a uma adesão e autonomia dos sujeitos. Assim a oficina permite, a partir de uma
reflexão crítica sobre si e do conhecimento sobre a sua doença, trabalhar na perspectiva de
saúde e autoconhecimento, na busca por uma efetiva reinserção psicossocial bem como,
permite que o paciente teça laços de confiança com a equipe, conheça melhor a sua patologia
inserindo-se no tratamento.
7.1 Anexo 2: Amostra de artigo científico farmacêutico original usado na versão para
comprovação dos corpora.
Trecho da Introdução4
Entre os medicamentos selecionados, há uma incidência significativa de efeitos adversos
como em sedativos, em que há: seis ocorrências de tontura nos oito antidepressivos
analisados; seis ocorrências de sonolência e de vômito em oito antiparkinsonianos; cinco
efeitos de vômito nos seis tipos de medicamentos antidemenciais analisados; cinco
4 Título: Uso consciente de psicotrópicos: responsabilidade dos profissionais da saúde.
Autores:Letícia Martins Borelli LOPES, Andréia Regina Lopes GRIGOLETO.

60
ocorrências de cefaleia nos nove ansiolíticos analisados e nos oito antiparkinsonianos; cinco
ocorrências de tontura, em nove tipos de ansiolítico e em oito antiparkinsonianos e também de
diarreia nestes medicamentos; quatro ocorrências de sonolência nos oito antipsicóticos
analisados assim como nos cinco anticonvulsivantes; quatro ocorrências de diarreia em seis
antidemencias analisados e em oito antidepressivos; nestes há também quatro ocorrências de
visão turva, vômito e cefaleia. Além disso, pode-se observar que, em alguns tipos de drogas,
há incidência de muitos dos sintomas selecionados como no caso dos antiparkinsonianos, nos
quais há ocorrências de todos eles e em grande número o que se torna significativo; também
relevante é as dos sedativos ansiolíticos. Além desses efeitos colaterais, foram detectados
muitos outros com menor ocorrência em cada tipo de medicamento, mas não menos
prejudiciais. Assim sendo, um profissional da saúde precisa ter o conhecimento necessário
para orientar de forma satisfatória o paciente evitando tanto o uso abusivo quanto o uso
indevido de medicamentos.
7.1 Anexo 3: Amostra de artigo científico farmacêutico original usado na versão para
comprovação dos corpora.
3. FUNDAMENTAÇÃO TEÓRICA5
3.1 ANTIDEPRESSIVO
O primeiro grupo de fármacos para o tratamento da depressão surgiu na década de 1960,
designado como tricíclicos (ADT), tendo a imipramina e a amitriptilina como os protótipos
desta geração. O segundo grupo é representado pelos inibidores da monoaminoxidase
(IMAO), com aparecimento também nos anos 1960, sendo a iproniazida o primeiro fármaco.
Em 1987, a agência reguladora de medicamentos e alimentos, Food and Drug Administration
5 Título: Uso Racional de Antidepressivo na Rede Publica no Município de Bom Jesus RS.
Autor: Nayume Magaldi da SILVA.

61
(FDA), dos Estados Unidos, aprovou o primeiro fármaco (fluoxetina) do grupo dos inibidores
seletivos da Recaptação da serotonina (ISRS), Com o advento de novos antidepressivos, o
médico depara-se com a necessidade de consultas frequentes à literatura científica, tendo
como conseqüência a memorização de um grande volume de informações, entre elas as
interações medicamentosas (Rocha e Hara, 2006). As interações medicamentosas tendem a
desencadear tanto antagonismo como sinergismo dos fármacos, podendo levar ao
agravamento dos já presentes efeitos colaterais dos antidepressivos.
Anexo 4: Versão da amostra 1.
Bipolar Affective Disorder (BAD) was until recently called Manic-Depressive Disorder.
This name was abandoned because the “Disorder” does not shows necessarily psychotic
symptoms, most often symptoms do not appear. Thus, disorder is no longer considered a
psychotic disturbance to be considered an affective disturbance.
So a person who has been through a depressive phase is diagnosed with depression. Ten
years after a manic episode, this person has BAD (MAROT, 2004). Thus, BAD is a serious
disease, incurable affecting about 1.5% of men and women worldwide (MAROT, 2004).
This study aims to describe the importance of therapeutic workshops with patients who
received a diagnosis of BAD. This study is a report of an experience lived by a Nursing
undergraduate student of the Federal university of Santa Maria (UFSM) at the Paulo Guedes
Psychiatric Unit.
The Workshop occurs once a week, "Short Story Therapeutic Workshop" (TTW) which is
carried by patients and coordinated by a multiprofessional resident. The workshops are
meetings of people with mental disorders, promoting citizenship, free expression and
coexistence through the inclusion of art (VALLADARES et al, 2003).

62
While performing "TTW" the author realized symptoms of BAD in one of inpatients as
grandeur, mystical and with seductive attitude delusions because he was in the manic phase of
the disease.
A manic episode is defined by a distinct period of at least one week during which there is
a, unusual and expansive mood, high self-esteem, sleep disorders, pressure to speak and flight
of ideas (MONTEIRO, 2007). With this experience it was realized the value of therapeutic
workshop, because the same patients had the opportunity of expressing their feelings.
After the workshop it was realized that patients were less anxious. The impact of disease
experience on the personality of the individual affected is very high, causing loss and changes
in lifestyle, even when mood symptoms are no longer apparent (CALIL, 2004).
Workshop is understood as a form of social therapy and critical-reflective theraphy which
is valid and should be maintained and adopted in psychiatric inpatient units. It is necessary
that the patient recognizes the symptoms of BAD and the effects of medicines.
The multidisciplinary team is responsible to provide patient information about the
characteristics and needs of their disease and treatment options aiming and personal autonomy
and adherence to treatment.
Anexo 5: Versão da amostra 2.
Among the selected drugs, there is a significant incidence of adverse effects as in sedative,
in which there are: six cases of dizziness in the eight antidepressants analyzed, six cases of
drowsiness and vomiting in eight antiparkinsonian, five vomiting effects of the six types of
antidementia drugs analyzed;
Five occurrences of headache in the nine analyzed and anxiolytics in the eight
antiparkinsonian, five cases of dizziness, nine types of anxiolytic and eight antiparkinsonian

63
and also these diarrhea medicines, four cases of drowsiness in the eight analyzed
antipsychotics as well as in the five anticonvulsants, four occurrences of diarrhea in six
antidemencias analyzed in six and eight antidepressants;
In these there are also four cases of blurred vision, vomiting and headache. Furthermore, it
can be seen that in some types of drugs, there are many incidences of symptoms selected as in
the case of antiparkinsonian, there are instances in which all of them in large numbers and
which becomes significant, it is also relevant to the sedative anxiolytics.
In addition to these side effects, many others were detected with lower occurrence in every
kind of medicine but no less harmful. Thus, a health professional must have the knowledge
necessary to guide the patient satisfactorily avoiding both substance overuse and the misuse.
Anexo 6: Versão da amostra 3.
3. THEORETICAL BACKGROUND
3.1 ANTIDEPRESSANTS
The first group of drugs for the treatment of depression emerged in the 1960s, known as
tricyclic antidepressants (TCAs), and imipramine and amitriptyline were the prototypes of this
generation.
The second group is represented by Monoamine Oxidase Inhibitors (MAOIs), also
appearing in the 1960s, and iproniazid was the first drug released. In 1987, the American
regulatory agency for medicine and food, Food and Drug Administration (FDA), of the
United States approved the first drug (fluoxetine) group of Selective Inhibitors of Serotonin
Reuptake Inhibitors (SSRIs)

64
With the advent of new antidepressants, a physician has to consult scientific literature
frequently, and as a consequence the memorization of a large load of information, including
drug-drug interactions (Rocha and Hara, 2006).
Drug interactions tend to unleash both antagonism and synergism of the drugs, which may
worsen antidepressants side effects already present.