adaptive summarisation of surveillance video sequences
TRANSCRIPT

Adaptive Summarisation of Surveillance Video Sequences
Jian Li1, Stavri G Nikolov2, Christopher P Benton1, Nicholas E Scott-Samuel11Department of Experimental Psychology, 12A, Priory Road, BS8 1TU2Department of Electrical and Electronic Engineering, MVB, BS8 1UB
University of Bristol, UK
AbstractWe describe our studies on summarising surveillance videosusing optical flow information. The proposed method incor-porates motion analysis into a video skimming scheme inwhich the playback speed is determined by the detectabil-ity of interesting motion behaviours according to prior in-formation. A psycho-visual experiment was conducted tocompare human performance and viewing strategy for sum-marised videos using standard video skimming techniquesand a proposed motion-based adaptive summarisation tech-nique.
1 IntroductionVisual surveillance systems can generally be used for twomain tasks: performing real-time online event detection,crime prevention and scene analysis; and performing off-line analysis and the retrieval of interesting events fromarchived surveillance footage. For the second task, a controlroom operator has to go through an entire video. Becauseinteresting events, such as suspicious targets and criminalbehaviour, occur infrequently, an operator may spend mostof the time viewing frames without any useful information.Psychologically, going through a long uneventful surveil-lance video may impair operator performance.
In this paper, we present our current work on adaptivesummarisation of surveillance videos, aiming to use shortertime to browse an archived surveillance video without re-ducing accuracy of event detection.
1.1 Video Summarisation Techniques
Video summarisation techniques usually aim to generate asummary of a video using key frames or video skims. Keyframe extraction techniques select one or several still im-ages from a video which could largely represent the con-tent. For example, Gong and Liu [3] adopted Singular ValueDecomposition (SVD) to remove redundant information sothat an optimal or nonredundant summarisation could beobtained. Alternatively, Wolf [10] utilised motion energy in
terms of optical flow information to identify stillness. In thiswork, it was assumed that either the camera will stop mov-ing or the gesture will be held when important informationis to be illustrated. In these situations, the motion energyreaches a local minimum and the corresponding frames canbe used as the key frames of the shot. Porter [9] incorpo-rated tracking techniques into the summarisation scheme todistinguish motions caused by gradual translation and mo-tions caused by camera or object movement so that the keyframes selected were the ones which were largely due tochanges of visual content.
Another technique to summarise videos is called videoskimming. Rather than using key frames to represent thewhole video, video skimming aims to generate a short im-age sequence in which the temporal information can alsobe illustrated. In this technique, the simplest method is todrop video frames at a constant rate. However, without con-sidering any visual content, the dropping procedure coulderase informative content from the original video. To alle-viate this problem, adaptive skimming schemes have beenproposed. Ma and Zhang [6] assumed that the human vi-sual system will concentrate on those local regions withhigh motion intensities and frames containing such infor-mation were retained in the summarised video. Peker andDivakaran [8] computed visual complexity using motion in-formation and used this to determine which frames to retain.
Psychology researchers have studied the influence ofvideo summarisation on human perception. Ding and Mar-chionini [2] examined the effects of different display speedsof key frames on the tasks of target identification and videocomprehension. They concluded that identification accu-racy decreases as the display speed increases, and once thespeed is higher than a certain level the identification taskbecomes impossible. Compared to identification, the videocomprehension task was less influenced by higher speedsof display and the top speed limit for comprehension washigher than that for identification.
1.2 MethodsSummarising surveillance videos aims to generate a con-cise representation of unsafe or threatening behaviours so
1978-1-4244-1696-7/07/$25.00 ©2007 IEEE.

that control room operators or security officers are able toreview and analyse these events precisely and efficiently.Our method combines motion detection with video skim-ming using constant frame dropping. We detect interest-ing events by analysing optical flow based motion vectorsand matching these with prior information. If no interestingevents are detected, we use constant frame dropping. Oth-erwise, frames with interesting events are retained in thesummarised video.
Applying a constant frame rate to the summarised videoresults in adaptive playback speeds based on the detectabil-ity of interesting events. Besides a basic way of evaluatingperformance by measuring missing frames and false alarms,we conducted a psycho-visual experiment to examine hu-man perception and performance on summarised videos us-ing the adaptive and constant playback speeds. During ourexperiment, we recorded gaze fixations to try to analyseand understand strategies used for viewing the summarisedvideos.
2 Adaptive Video SkimmingThe standard video skimming technique generates a sum-marised video by constantly dropping a number of frames,for example N − 1 frames in every N frames, from a nor-mal speed video. With the same frame rate, the summarisedvideo is then displayed at N times the normal speed, de-noted as Nx. Without considering visual content, the useof a large value of N results in significantly reducing thetime to browse a video, but at the expense of limiting timeto detect and analyse interesting events (which may be veryshort in duration). This problem motivates the generation ofan adaptive summarisation scheme.
Our adaptive summarisation technique combines a mo-tion detection procedure with a standard video skimmingscheme, whose general structure is shown in Figure 1 (a).With two successive video frames G(t) and G(t + 1), op-tical flow based motion information is estimated. Motionprocessing and analysis are then applied in a pixelwise man-ner to extract features which can be compared with priorinformation of interesting events defined in advance. Theform of interesting events varies for different tasks. Hereby ’interesting events’, we mean motions with certain ve-locity and orientation which happen in pre-defined regionsof interest (ROIs). Once an interesting event is detected, thecorresponding frame is then regarded as an important frameand is retained in the summarised video. Constant framedropping is applied to those frames that do not contain in-teresting events. When using the same frame rate as the nor-mal speed video, those successive frames are displayed at anormal speed while others are displayed at a speed of Nx.An explicit representation of adaptively switching playbackspeeds has been shown in Figure 1 (b).
G(t) & G(t+1)
Optical Flow Estimation
Motion Pre-processing &
Analysis
Motions in ROIDetected?
Write Frame to Summarised Video
PriorInformation
Yes
n=N?
n=n+1
No
No
Yes
n=1
t=t+1t=t+1
(a) The General Structure.
High
Normal
(b) Adaptive Playback Speed.
Figure 1: The Adaptive Summarisation Scheme.
It can be seen that the adaptive scheme has two advan-tages: firstly, slow display of frames with interesting eventsgives operators more time to analyse the events; secondly,the remaining frames without interesting events connectslow displayed segments so that the temporal coherence andcontinuity are retained.
2.1 Optical Flow Estimation
Optical flow estimation plays an important role in our adap-tive scheme. Optical flow measures displacements of pixelswithin the same pattern between successive video frames[5, 1]. Here we use the framework proposed by Li et al[4] in which a least squares (LS) or a modified total leastsquares (TLS) regression scheme is associated with an ex-tended optical flow constraint (EOFC) [7]. Here the noiselevel of the input video frames determines which regressionmethod should be adopted. Initially, moving patterns aresegmented from backgrounds. In our work, we use a tem-poral differentiation technique in which a pixel whose ab-solute temporal derivative is higher than a given thresholdis regarded as moving. The LS regression scheme is thenapplied to those moving pixels only.
2.2 Motion Processing and Analysis
The pre-processing aims to generate meaningful featuresfrom pixelwise estimates of the optical flow vectors. Theform of motion features to be extracted is determined by the
2

form of interesting events. For the task of detecting targetsmoving in a certain direction, we segment a video frameinto blocks with equal size. Each block is associated with adominant motion vector which is computed as the mean ofthe estimated optical flow vectors within this block. Subse-quently, the orientation of a dominant motion vector can becomputed as an angle in the interval (−180◦, 180◦].
2.3 Video Summarisation ResultsWe examined the performance of the adaptive summarisa-tion scheme by generating an example summarised videowhich slows down the playback speed when targets movingrightwards in Region B of the traffic scene shown in Figure2 have been detected.
Figure 2: The Region of Interest.
A clip which consists of 9600 frames was extracted froma longer video recorded by a static camera at a frame rate of25 frames per second (fps). Frame size was 720x576 pixels.In this task, interesting events were defined as the anglesof the dominant vectors falling in the interval [−20◦, 20◦].If the angles of more than one local dominant motion vec-tors fall in the angular interval, interesting events were con-sidered as being detected and the corresponding frame wasretained in the summarised video. For those frames with-out interesting events, a constant frame dropping (N = 16)was performed. Figure 3 shows an explicit illustration of
−1000 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000−5
−4
−3
−2
−1
0
1
2
3
4
5
Figure 3: Detection of Interesting Events.
event detection from the input video with normal playbackspeed. Here frames with and without interesting events arecoloured as red (dark) and green (bright), respectively. Thesummarised video contains all frames coloured as red andsome frames extracted from those coloured as green usingconstant frame dropping.
The initial evaluation of the performance of the sum-marised video is based on four criteria: ratio of length (R-L), false positive (F-P, type I error), false negative from
target missing (F-N TM, type II error) and false negativefrom frame missing (F-N FM, type II error). The ratioof length represents the ratio of lengths between the sum-marised video and the raw video. The false positive (F-P)corresponds to the number of frames mistakenly retainedin the summarised video which do not contain interestingevents. This is equivalent to the number of false alarms.The false negative from target missing (F-N TM) refers tothe number of missed targets with interesting events. Thefalse negative from frame missing (F-N FM) refers to thenumber of missed frames containing interesting events.
Table 1 shows the performance of the adaptive summari-sation technique. It can be seen that the summarised videohas a high compression rate with low false positive (or falsealarms). The zero F-N TM indicates that all targets movingfrom left to right in the ROI are retained in the summarisedvideo, i.e. for each interesting event there is at least oneframe with the target present in it that has been retainedin the summarised video. 113 frames containing the targetswith interesting events were missed using the adaptive sum-maristion scheme. This is largely due to the problem thatsome motions of the targets cannot be reliably detected.
Table 1: Detection Accuracy and Compression Ratio.Raw Summ. R-L F-P F-N F-N
Video Video TM FM9600 2942 30.65% 46 0 113
3 Human Visual Perception and Per-formance Experiments
In the previous section, we presented the performance ofthe adaptive summarisation technique in terms of data andinformation retainment. Below, we examine human perfor-mance using the summarised videos.
3.1 DesignThe experiment we conducted had three goals: firstly, togain a better understanding of the relationship betweenplayback speeds and human performance regarding a giventask; secondly, to evaluate human performance on the sum-marised videos using constant frame dropping scheme andthe adaptive scheme; and finally, to differentiate psycholog-ical strategies used for viewing videos of different playbackspeeds with the assistance of eye tracking techniques.
In the experiment, the task was to report the total numberof people moving rightwards in region B in Figure 2. Dur-ing the experiment, eye movements were recorded with aneye tracker. When preparing the videos, we recorded three
3

1-hour long videos of the same scene (see Figure 2 for ex-ample). Each video had a frame rate of 25 fps and a framesize of 720x576 pixels. Seven equal-length clips were thenmanually selected from the videos, each of which consistedof 9600 frames. The visual information in these clips wasvery similar but not identical. The number of targets foreach clip (C1-C7) is shown in Table 2.
Table 2: Correct Number of TargetsC1 C2 C3 C4 C5 C6 C7
Number 34 37 30 36 32 41 53
Each clip was used to generate seven summarised videosin which six summarised videos with speed of 1x, 2x, 4x,8x, 16x, 32x were generated using constant frame drop-ping and one summarised video was generated using theadaptive scheme. The lengths of videos with constant play-back speeds are shown in Table 3. The seven adaptive sum-marised videos have different lengths because of variationof the visual content. The average length is 2’07” witha standard deviation of 20”. The length is approximatelyequivalent to the summarised video at 3x speed using con-stant frame dropping.
Table 3: Lengths of Summarised Videos (Constant Speeds).Speed 1x 2x 4x 8x 16x 32x
Frames 9600 4800 2400 1200 600 300Duration 6’24” 3’12” 1’36” 48” 24” 12”
There were therefore 49 summarised videos in thedatabase. During the experiment, each participant wasshown seven summarised videos which were randomly se-lected from the database according to the following rules: 1)visual information is different among videos; 2) each partic-ipant will view seven clips that all have different speeds, i.e.there are no two clips that have the same speed.
3.2 Participants16 participants took part in the experiment (8 males). Agesranged from 19 to 56 years (mean=28.4, s.d.=10.36). Par-ticipants had normal or corrected-to-normal vision.
3.3 Experimental SettingsVideo stimuli were shown using the ClearView 2.6.8 soft-ware package, on a 3.2 GHz Intel Pentium D processor PCwith 2 GB RAM. A 22” flat screen CRT monitor running at85 Hz was used to display the stimuli. The screen resolu-tion was set to 800x600 pixels. Participants were requiredto use a chin-rest positioned 68cm from the monitor screen.A TobiiTM x50 remote eye tracker was used to collect eye
movement data. This is a table-mounted eye tracker thatsamples eye positions at 50 Hz with an approximate accu-racy of 0.5◦.
3.4 Procedure
Seven videos were displayed one by one with a short breakbetween each. After showing one video, participants wereasked to report the total number of targets they detectedfrom the video. Participants were also asked after the ex-periment to provide general comments about the setup andthe experiment.
3.5 Data Analysis
The accuracy of each playback speed can be evaluated bycalculating the difference between the number of detectedtargets and the number of existing targets. The latter wasdetermined manually by visually inspecting the videos andit is shown in Table 2. For a certain playback speed, the av-erage and the standard error for all participants were com-puted. The standard error (SE) is defined as:
SE = σ/√
P , (1)
where σ is the standard deviation of the errors and P is thetotal number of participants (P=16).
The eye tracker records gaze locations for both eyes at 50Hz. Each point is associated with a validity ranging from’0’ to ’4’, in which ’0’ means the highest certainty aboutthe correspondence between a gaze point and a particulareye and ’3’ means the lowest uncertainty. ’4’ means no eyeis detected. A fixation position is then obtained by aver-aging the gaze points from two eyes. Here we define theType I (raw) fixations as these recordings with validity ’0’for both eyes. The Type II fixation data is generated usingthe ClearView software package by grouping all the Type Ifixations which last for more than 100 milliseconds withina radius of 30 pixels.
With the Type I fixations, we characterised the degree ofconcentration at a certain playback speed by computing theratio between the number of fixations within the ROI andthe number of all fixations for all participants. To comparethe strategies used for viewing videos with different play-back speeds, we generated a Fixation-Duration Map (FDMap) using the Type II fixations. Each Type II fixationis associated with a duration. For a given playback speed,we scanned the fixations for all participants and summedthe durations at the same fixations. The durations werethen normalised by dividing a factor representing the length(duration) of the video for this playback speed. These nor-malised FD Maps show how participants manage their eyemovements.
4
3.6 ResultsThe mean errors and the mean absolute errors are shown inFigure 4. It can be seen that when the playback speed isless or equal to 8x, the accuracy is high and the individualdifferences are small. When the playback speed increases to16x or 32x, the mean of the absolute errors increases as doesthe standard error, indicating large individual differences.
From Figure 4, it can be seen that the adoption of themotion-based summarised videos guarantees accuracy. Themean errors and mean absolute errors by using the proposedvideos are −0.63 ± 0.27 and 0.75 ± 0.25, each of whichis the smallest among all playback speeds. When takingthe compression rate into consideration, the lengths of theadaptive summarised videos are equivalent to the lengths ofthe video at the speed 3x using constant frame dropping.
1x 2x 4x 8x 16x 32x Adaptive−15
−10
−5
0
5
10
15
20
Playback Speed
Err
or
ErrorAbsolute Error
Figure 4: Human Performance Accuracy.
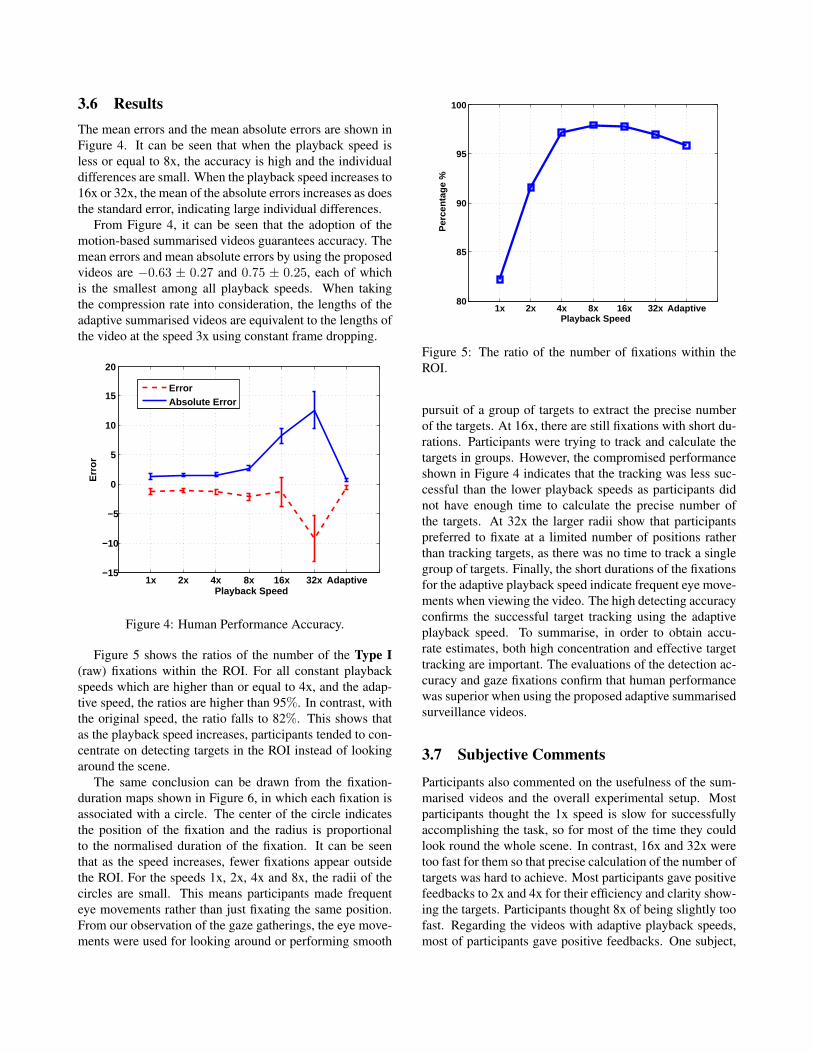
Figure 5 shows the ratios of the number of the Type I(raw) fixations within the ROI. For all constant playbackspeeds which are higher than or equal to 4x, and the adap-tive speed, the ratios are higher than 95%. In contrast, withthe original speed, the ratio falls to 82%. This shows thatas the playback speed increases, participants tended to con-centrate on detecting targets in the ROI instead of lookingaround the scene.
The same conclusion can be drawn from the fixation-duration maps shown in Figure 6, in which each fixation isassociated with a circle. The center of the circle indicatesthe position of the fixation and the radius is proportionalto the normalised duration of the fixation. It can be seenthat as the speed increases, fewer fixations appear outsidethe ROI. For the speeds 1x, 2x, 4x and 8x, the radii of thecircles are small. This means participants made frequenteye movements rather than just fixating the same position.From our observation of the gaze gatherings, the eye move-ments were used for looking around or performing smooth
1x 2x 4x 8x 16x 32x Adaptive80
85
90
95
100
Playback Speed
Per
cen
tag
e %
Figure 5: The ratio of the number of fixations within theROI.
pursuit of a group of targets to extract the precise numberof the targets. At 16x, there are still fixations with short du-rations. Participants were trying to track and calculate thetargets in groups. However, the compromised performanceshown in Figure 4 indicates that the tracking was less suc-cessful than the lower playback speeds as participants didnot have enough time to calculate the precise number ofthe targets. At 32x the larger radii show that participantspreferred to fixate at a limited number of positions ratherthan tracking targets, as there was no time to track a singlegroup of targets. Finally, the short durations of the fixationsfor the adaptive playback speed indicate frequent eye move-ments when viewing the video. The high detecting accuracyconfirms the successful target tracking using the adaptiveplayback speed. To summarise, in order to obtain accu-rate estimates, both high concentration and effective targettracking are important. The evaluations of the detection ac-curacy and gaze fixations confirm that human performancewas superior when using the proposed adaptive summarisedsurveillance videos.
3.7 Subjective Comments
Participants also commented on the usefulness of the sum-marised videos and the overall experimental setup. Mostparticipants thought the 1x speed is slow for successfullyaccomplishing the task, so for most of the time they couldlook round the whole scene. In contrast, 16x and 32x weretoo fast for them so that precise calculation of the number oftargets was hard to achieve. Most participants gave positivefeedbacks to 2x and 4x for their efficiency and clarity show-ing the targets. Participants thought 8x of being slightly toofast. Regarding the videos with adaptive playback speeds,most of participants gave positive feedbacks. One subject,
5

a surveillance officer, reported that adaptively changing theplayback speed helped him concentrate on the region whereinteresting events could happen. When the speed sloweddown, he assumed that something would happen and thenquickly moved his eyes to the left part of the ROI.
Figure 6: The Fixation-Duration Maps. Top row: 1x, 2x;Second row: 4x, 8x; Third row: 16x, 32x; Bottom row:Adaptive.
4 ConclusionsThe current paper presents our work on summarisingsurveillance videos using adaptive playback speed and ex-amining human performance when identifying interestingevents using summarised videos with constant and adap-tive playback speeds. The technical results showed that thesummarised videos with adaptive playback speeds ensureboth accuracy and efficiency for detecting targets. The sameconclusion was also obtained from an experiment requiring
participants to count visual targets. Gaze-fixation and eye-movement analysis implies that the superior performancewas largely due to the fact that the adaptive summarisedvideos allows more attention to be focused on the ROI andmore time to perform successful target tracking.
AcknowledgmentsThis work has been funded by the UK MOD Data and In-formation Fusion Defence Technology Centre (DIF DTC).
References[1] T. Brox, A. Bruhn, N. Papenberg, and J. Weickert. High ac-
curacy optical flow estimation based on a theory for warping.In European Conference on Computer Vision (ECCV2004),pages 25–36, 2004.
[2] W. Ding and G. Marchionini. A study on video browsingstrategies. Technical Report CLIS-TR-97-06, University ofMaryland, College Park, 1997.
[3] Y. Gong and X. Liu. Video summarization using singu-lar value decomposition. In Computer Vision and PatternRecognition, 2000. Proceedings. IEEE Conference on, vol-ume 2, pages 174–180 vol.2, 2000.
[4] J. Li, S. G. Nikolov, N. E. Scott-Samuel, and C. P. Benton.Reliable real-time optical flow estimation for surveillanceapplications. In IET The Crime and Security Conference:Imaging for Crime Detection and Prevention (ICDP), Lon-don, 2006.
[5] B. D. Lucas and T. Kanade. An iterative image registrationtechnique with an application to stereo vision. Proc 1th IntlJoint Conf on Artificial Intelligence (IJCAI), pages 674–679,1981.
[6] Y. F. Ma and H. J. Zhang. A model of motion attention forvideo skimming. In International Conference on Image Pro-cessing, volume I, pages 129–132, 2002.
[7] J. M. Odobez and P. Bouthemy. Robust multiresolution esti-mation of parametric motion models. Journal of Visual Com-munication and Image Representation, 6(4):348–365, 1995.
[8] K. A. Peker and A. Divakaran. An extended framework foradaptive playback-based video summarization. TechnicalReport TR2003-115, Mitsubishi Electric Research Labora-tories, 2003.
[9] S. V. Porter. Video Segmentation and Indexing using MotionEstimation. Phd thesis, University of Bristol, 2004.
[10] W. Wolf. Key frame selection by motion analysis. In ICASSP96, volume 2, pages 1228–1231, 1996.
6