adaptive routing for dynamic applications in massively parallel architectures
TRANSCRIPT

Adaptive Routing for Dynamic Applications in Massively Parallel Architectures Maurelio Boari, Antonio Corradi, and Cesare Stefanelli
Let i zi a Leon a rd i Universita di Bologna
Universita di Modena
@Routers in a dynamic environment must efficiently deliver messages without knowledge of an application 's process allocation. Hot-Spot Avoiding routing and virtual Path routing, two complementary strategies, achieve this for different communication patterns.
daptive routing protocols exploit alternative paths between communicating nodes to more efficiently use nmvork band- width and provide resilience to failures. The latter property is particularly important for large-scale architectures, because A expanding the system size increases the probability of
encountering a faulty network component. In static environments, where the number of application processes and
their allocation do not change during execution, adaptive routing algo- rithms can take advantage of knowing the allocation of the communicat- ing processes. Because the algorithm has complete knowledge of the net- work topology and the precise allocation of the destination process, at any step messages flow closer to the destination node.'
However, in dynamic environments the allocation of the application processes might change frequently: tasks can be either created or termi- nated dynamically. Moreover, trying to achieve load balancing can induce process migration.2 If the routing algorithm takes into account knowl- edge of process allocation, this information must be frequently updated so that each process can maintain knowledge of the allocation of other processes in the system. This updating causes high traffic, and does not guarantee the router a consistent view of the system.
The only way to avoid these problems is to use routing policies that can deliver messages without requiring knowledge of process allocation. Unfortunately, these policies can misroute messages; the message in an intermediate node can move farther from the destination. Moreover, mes- sages can become trapped in loops (this is called li~elock).~
1063-6552/95/$4.00 0 1995 IEEE 61 Spring 1995

Tbe routingproblem Routing is normally part of runtime sup- port. From the user’s point of view, the entire system should be dedicated to application execution; any component of support occupies resources and competes with the execution. In this view, support is an intrusive agent, whose resource use must be limited and reduced in time. Routing is acceptable only if it uses a small percentage of the application time; otherwise the routing overhead is intol- erable.
Dynamic routing has special require- ments, which we’ll now sketch.
While there are several communica- tion modes for a message to occupy the system resources in the path toward a des- tination, packet-switching is preferable, because it establishes no direct connec- tion between any source and destination.’
The routing system must be indepen- dent of the architecture and the network topology. Such a system can deal with fault conditions that change any predefined configuration, and lets the application pro- gram’s needs determine the topology.
Two other basic requirements for
routing are scalability and dynamicity, which may sometimes conflict. T o sup- port scalability, the router must be inde- pendent of the system size. To support dynamicity, the router must work in sys- tems whose resource use can only be known during execution; h s implies the adoption of adaptive routing strategies.
Adaptivity provides several advantages. First, the system load can be distributed over all the system resources, either exe- cution nodes or links, to balance the load. Second, the systeq can react better when the application changes. This is compul- sory when application behavior cannot be foreseen. Third, adaptive routing can follow any runtime reconfiguration of the topology. However, adaptation has a cost: The more dynamic the application, the more intrusive it is to adapt routing promptly.
Adaptivity can be achieved in many different ways. In some adaptive routing strategies, any node is aware of any other one process allocation (for example, the distance-vector and link-state strategies’). However, as soon as the allocation changes,
distribution of the change clashes with scalability. When a change must be prop- agated to other nodes, the larger the sys- tem, the more intrusive the propagation. Global propagation of allocation is expensive because of the time it takes to distribute information to every node in the system; in addition, a situation is like- ly to be obsolete as soon as it is assessed. By limiting the propagation to a local neighborhood, local policies achieve scal- ability, but they renounce global coordi- nation.
Because of the disadvantages of allo- cation propagation in a dynamic system, the only solution is a routing policy with no knowledge of the entity allocation. Algorithms that do not depend on process allocation can intrinsically adapt to the dynamics of applications; no prop- agation is needed. In these strategies, a message that goes from the source to the destination via several intermediate nodes cannot know whether it progresses toward its destination, and misrouting is a normal possibility.
A well-known example of such a policy
The key decision of these routing strategies is how to choose the link to forward the message at any inter- mediate node. A generally accepted criterion considers system resource use. T o achieve this goal, we must obtain some knowledge of the system state. Several pro- posed algorithms assume a global knowledge of system resource use4; others are more local and are based either on local knowledgeS or on knowledge of a limited neighborhood.
We’ve developed an adaptive routing system for a com- pletely dynamic environment. Our system proposes two different strategies, depending on the application’s com- munication patterns. In the first solution, the Hot-Spot Avoiding (HSA) algorithm, each message separately finds the route toward the destination. Even messages exchanged between the same couple of processes follow different, possibly nonminimal, paths. The HSA algo- rithm uses neighborhood information to choose the node to which the message is forwarded. It limits the number of hops in the source-destination path by reducing the occurrence of loops in it.
The second algorithm, Virtual Path (VJ?), is tailored to long-lasting entities that cooperate intensively by exchanging messages. It achieves efficiency by finding a path at the beginning and following that path for several
messages. For performance’s sake, this algorithm par- tially renounces the HSA algorithm’s adaptiveness.
Both algorithms provide synchronous and asynchro- nous communications between any couple of applica- tion processes. Both algorithms are also independent of topology and process allocation, and they use local knowledge of system resource use. This transparency is useful in application areas where process allocation changes very often because of migration and a high rate of process generation and termination. Such dynamicity can occur in parallel object-oriented environments6 and in the implementation of support for parallel logic pro- gramming.
Our system uses packet-switching communication and adopts a method of deadlock prevention that sat- isfies all the assumptions our routing policies are based on (see the sidebar). This method does not limit the choice of path-connecting nodes, nor does it use any form of global knowledge (that is, adaptivity is pre- served and no allocation/configuration is assumed). Furthermore, this method is independent of both topology and network size. (This article considers architectures where routing is supported by software and neglects cases where separate processors are ded- icated to it.)
___
62 IEEE Parallel & Distributed Technology

is the hot-potato strategy. It is indepen- dent of topology and entity allocation, and is adaptive. These advantages are not without cost: a message can be misrout- ed and follow a path where any hop ignores previous ones. A message can be trapped into loops and be locked there, instead of reaching the destination. This livelock situation can become the major problem of this class of routing algo- rithms. An adaptive routing algorithm should be able to not only actuate its pol- icy, but also avoid an excess of loop occurrence. In other words, the message- forward decision depends on the path already followed.
The last requirement is to avoid deud- lock. In a packet-switching communica- tion mechanism, the lack of buffers to store messages in intermediate nodes can cause deadlock. When a node exhausts its buffers, it enters a saturation phase. Dead- lock occurs when two or more saturated nodes await each other, circularly inca- pable of delivering messages. Prevention and recovery techniques have been intro- duced to solve this problem’-’; their draw- back is the high overhead, which conflicts with the need to limit the intrusion.
OTHER ROUTING SYSTEMS Some routing systems meet particular aspects of these requirements, but no sys- tem has met all the requirements. Among the packet-switching routing systems, Tiny implements an adaptive strategy based on local tables containing the min- imal paths between any two processors in the network? The cost of updating the routing tables clashes with dynamic envi- ronments where process allocation is he- quently modified.
The Multiple Rings is a two-phase adaptive routing system.’ Even though this algorithm does not consider dynam- icity, its second phase-introduced for livelock prevention-can deliver mes- sages to processes of unknown allocation.
The Chaos router, targeted for n-hypercube topologies, can misroute messages to adapt to the current load condition: In the case of dynamicity, this algorithm can fail to deliver messages.
The above routing systems are not tai- lored to fully answer all the requirements imposed by dynamic systems, particularly allocation transparency. The routing sys- tem presented in this article considers all those requirements.
Our deadlock-prevention strategy is similar to another that permits delivery of messages when buffers of inter- mediate nodes become saturated with messages7 O u r strategy requires each node t o reserve a limited buffer- ing capacity. These special buffers let any two saturat- ed neighbor nodes exchange messages, which will ulti- mately reach their destinations. I n saturation, message throughput lowers but can increase as soon as the situ- ation becomes less congested.
T h e most important feature of the prevention strat- egy is low intrusion. T h i s technique has n o cost during normal execution and activates only during saturation, thus introducing negligible overhead. In other words, it executes only when the system can n o longer guaran- tee any acceptable response time.
The Hot-Spot Avoiding strategy HSA rout ing is an evolution of the hot-potato algo- rithm.* Hot-potato is an isolated algorithm; that is, it is purely local and makes decisions independently of any other node situation. In each node, it directs messages toward the output link with the shortest output queue. So, any node tends to balance the lengths of the output message queues.
References
1. A.S. Tanenbaum, Computer Networks, Prentice-Hall, Englewood Cliffs, N.J., 1988.
2. W.J. Dally and C. Seitz, “Deadlock-Free Message Routing in Multiprocessor Interconnection Networks,” IEEE Trans. Computers, Vol. 36, No. 5, May 1987, pp. 547-553.
3 . P. Merlin and P. Schweitzer, “Deadlock Avoidance in Store-and-Forward Net- works I: Store-and-Forward Deadlock,” IEEE Trans. Communications, Vol. 28, No. 3 , Mar. 1980, pp. 345-354.
4. L. Clarke and G. Wilson, “Tiny: An Effi- cient Routing Harness for the Inmos Transputer,” Concurrenry: Practice and Experience, Vol. 3, No. 3, June 1991, pp. 22 1-245.
5. M. Cannataro et al., “Design, Imple- mentation, and Evaluation of a Dead- lock-Free Routing Algorithm for Con- current Computers,” Conruwency: Practue andExperiace, Vol. 4, No. 2 , Apr. 1992,
6. S. Felperin et al., “Routing Techniques for Massively Parallel Communication,” IEEE Proceedings, Vol. 79, No. 4, Apr.
pp. 143-161.
1991, pp. 488-502.
T h e HSA policy enlarges the scope of interest to the neighborhood. A node decides its routing mategy based on its knowledge of the computational load of its neigh- bor nodes. Th i s avoids overloads: a node with low per- formance caused by a high execution load is used pro- gressively less by its neighbors.
To implement this strategy, HSA routing not only examines the lengths of the local output message queues, but also measures the computational load of the neigh- bor nodes. Th i s reduces message delivery time.
T h e output queuc lengths are locally available. T h e router could explicitly ask all its neighbors for their load; however, any explicit exchange of information induces intrusion and overhead. Wheneve r t h e architecture provides low-level synchronous message-passing, two neighbor routers can implicitly obtain the information about each other’s load. T h e sender router can extract information about its partner from the local response time of each communication, thus avoiding an explicit message exchange. Th i s happens, for instance, for such Transputer-based architectures as the Meiko CS-1 used in ou r implementation. T h e HSA algorithm uses the implicit approach; a neighbor’s load is locally esti- mated o n the basis of the response times of previous communications.
Spring 1995 63

I Link
Input output manager
I
I /----
Drocesses
Figure 1. Routing implementation scheme. In a node, each link is handled by two communication managers: innut and outnut Merzaoez are buffered onlv in the ourpur queue. I ne memory Tor Dunering messages IS
not statically reserved but is dynamically allocated.
Receiver - Exit path
Figure 2. A spiral path.
FINDING THE FASTEST LZNK We’ll now describe how the HSA algorithm determines the link capable of fastest message delivery. While a gen- eral structure for message routing can provide two queues, one for input and one for output, we assume an organization with only one output queue for each com- munication link; the input is not buffered because low- level communications are synchronous. No memory is statically reserved for buffering (except that for avoid- ing deadlock); memory is dynamically allocated from the heap by need (see Figure 1).
The waiting time Tq, of a message for each link i can be expressed as
k=l
where i = 1, ..., n; n is the number of links of the node; Lq, is the number of messages in the output queue of link i; and Trr,k is the time for the transmission of the kth message over i.
Each Tr,,k is unknown; the router approximates its value by assuming
TYt,k = Tp, (2) where k = 1, ..., Lq,, and Tp,is the time to transmit the previous message over link i. Any communication over the link updates the Tp, value used for the estimation. From Equations 1 and 2, it follows that
Tq, Lq, * Tp, (3) The router evaluates the waiting time Tqz for every
link i in the node and chooses the l inkj whose Tq, is minimal:
(4) The information used by the routing policy is com-
pletely local; this limits overhead. In fact, in the mes- sage service time
T, = T, + TqJ
Tql = min {Tqt : i = 1, ..., n}
the computation load T, is almost constant and is lim- ited to the time requested to evaluate Equation 4, and Tql is the predominant factor and depends on the sys- tem situation.
AVOIDING LIVELOCK The absence of knowledge of where processes are allo- cated and how they can be reached makes livelock impossible to solve completely. Even knowledge of the interconnection topology could not guarantee the absence of livelock in case of migration. In fact, given a specific topology, a message could be forced to visit every node in the system, after exceeding a chosen threshold (that is, after visiting a certain number of node^).^ This technique guarantees the delivery of mes- sages in a number of hops up to the number of nodes only when the receiver process is not allowed to migrate in the meantime.
Process-allocation independence often forces HSA routing to misroute messages; misrouting can occur at each hop. Because there is no upper bound to the num- ber of nodes traversed by a message, we consider a mes- sage to be in livelock when this number is greater than
64 IEEE Parallel 81 Distributed Technology

a predefined threshold, related to the number of nodes in the network. The threshold Tb is defined in terms of the number of hops instead of delivery time, to rule out any dependence on network traffic.
T o limit livelock, the HSA algorithm provides each message with a header that keeps track of the traversed nodes. A header length of L records the last L traversed nodes. The HSA algorithm uses this information to pre- vent a message from passing through the same node more than once. The algorithm forwards messages to one of the neighbor nodes not yet traversed by applying the policy we discussed earlier.
With a header of length L, the router can avoid loops of up to L dimensions in the network. The header length L must be tuned, depending on network size (we’ll dis- cuss this later). Some message loops cannot be avoided; when all neighbor nodes have already been traversed (see Figure 2), the router chooses the least recently tra- versed node. This policy can, for instance, let a message escape a spiral path.
EXPERIMENTAL RESULTS We implemented the HSArouter on a Meiko CS- 1 with 100 T800 nodes and a configurable interconnection net- work. Each node has 4 Mbytes of RAM. The network can be configured for any topology as long as there are no more than four links per node. We performed tests on mesh topologies, the typical transputer intercon- nection, but our router does not use any network topol- ogy information.
The testbed application used to evaluate the HSA router presents three kinds of application processes that exchange messages of variable length (100-500 bytes) asynchronously (see Figure 3):
Asendtheamreprocess sends test messages on the net- work to a reply process, and waits for a reply mes- sage. This process measures the round-trip time, that is, the time from the sending of the test message to the receipt of the corresponding reply message. The reply process receives the test message and sends back the reply message. Trafic processes generate messages representing the communication load of applications. We have ana- lyzed the system under different traffic patterns and volumes.
All our tests allocate the send&measure process and the reply process to nodes at the maximal distance in the network (the worst possible case), and allocate one traf- fic process to every other node.
-.cl
TP = Traffic process
Figure 3. The testbed application processes in a 4x4 transputer mesh.
All measurements are local to the node where the send&measure process resides, and refer to the sending of a test message and the receipt of a corresponding reply. These two messages aim to produce time consis- tency by measuring time intervals at the same node.
There are two significant parameters for messages routed by the HSA router: average number of hops and average delivery time. Our first set of tests considers the number of hops per message (for these tests, a test mes- sage and its reply message constitute one message). Fig- ure 4 reports the number of hops obtained by varying the header length associated with each message, for meshes of different sizes. (The minimum number of hops possible for a test message and its reply in a gen- eral nxn mesh is 4*(n - l).) The minimum average num- ber of hops is obtained with a header length compara- ble to the network size, and is considerably lower than the number of hops obtained with a hot potato routing algorithm (represented in Figure 4 by the header length of zero).
Figure 5 shows the distribution of the number of hops in more detail for the HSA router with different header sizes and the hot-potato policy, for a 4x4 mesh. The solution with the fewest hops is the one that records the last 15 nodes, which allows 95% of the messages to be delivered in fewer than 50 hops. The recording of tra- versed nodes not only influences the average number of hops per message, but also decreases the number of mes- sages in livelock. Aviable choice for the livelock thresh- old Th is an order of magnitude greater than the num- ber of nodes in the network. With a hot-potato routing algorithm, a number of messages incur livelock, while with the HSA algorithm, a proper header length (about 15) ensures that no message is undelivered; that is, no livelock occurs.
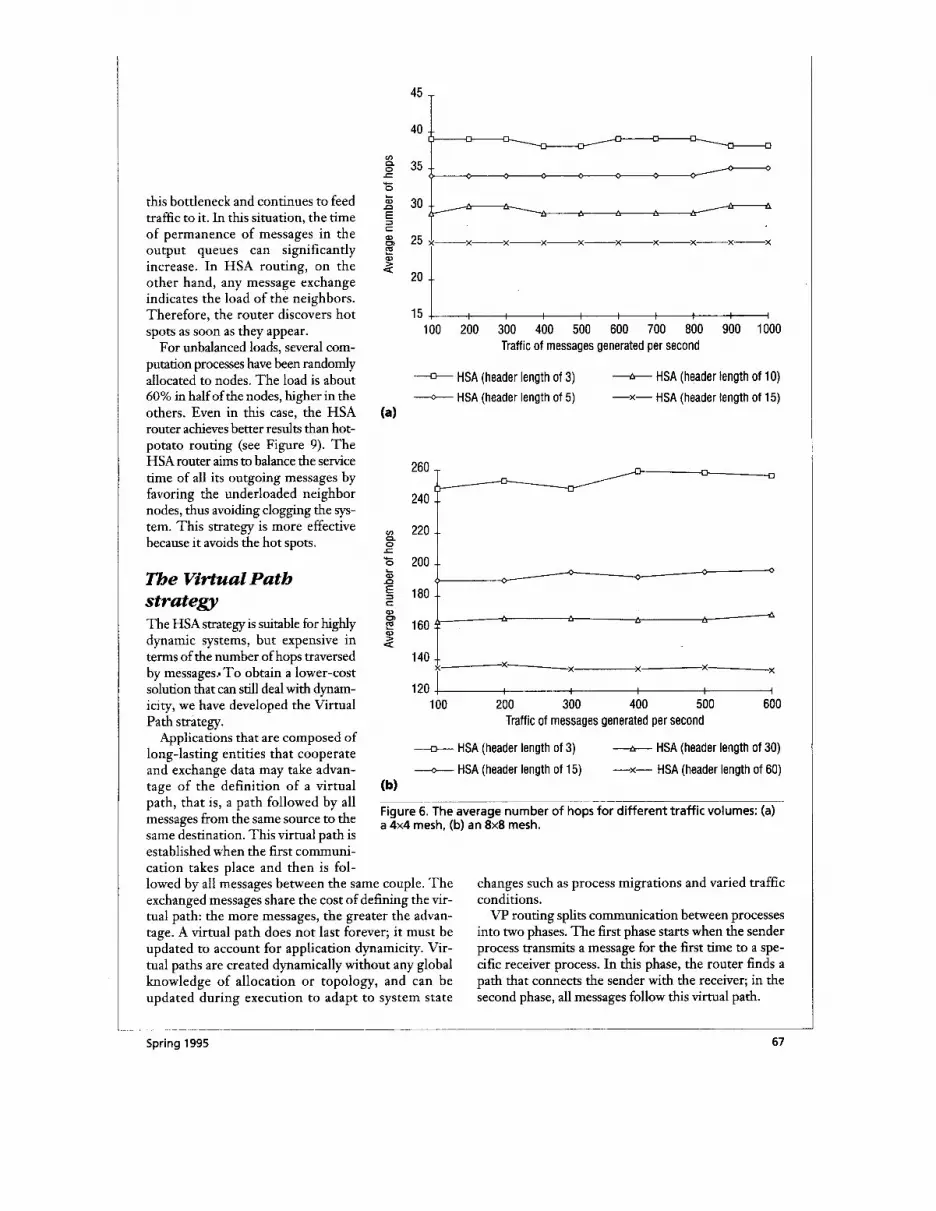
Although the reduced number of traversed nodes produced by using a specified header length depends on network size, that number is independent of the net- work traffic volume. Figure 6 shows that the average number of nodes traversed with a predefined header length does not vary significantly when the traffic vol-
Spring 1995 65

g 160
140 E & 120
5 100
5
n
c is 80
2 60
40
L
W
f 20 >
h -0- 4x4 mesh - 6x6 mesh
I
0 5 10 15 20 25 30 35 40 Number of nodes recorded in the header
a o c (a)
600 m a E 500 L
400
f 300
200
EJ 100
v ) n 0
0
W L
5 c m
T
A - 8x8 mesh - 10x1 0 mesh
I
0 10 20 30 40 50 60 70 80 90 100 Number of nodes recorded in the header (b)
Figure 4. Average number of hops for headers of different length in meshes of different size: (a) a 4x4 and a 6x6 mesh, (b) an 8x8 and a 10x10 mesh. The minimum number of hops is circled.
._ _ _ _ ~ _ _ _ _ _ _ _ _ _ _ _ _ ~ _ _ .--
800
700
g 600 P g 500
- 400
300 E
2! 0
z' 200
100
- Hot-potato - HSA (header length af 5) - HSA (header length gf 15)
I (I' , I
0 0 18 30 42 54 66 78 90 102 114 126 138 150>160
Number of hops
Figure 5. Distribution of messages per number of hops (5000 messages in a 4x4 mesh).
(for example, hot-spot trafficlo) over all network nodes. In this case, per- formance is not affected by traffic paf- tern, but only by traffic volume. So, in the following, we will consider only uniform traffic patterns.
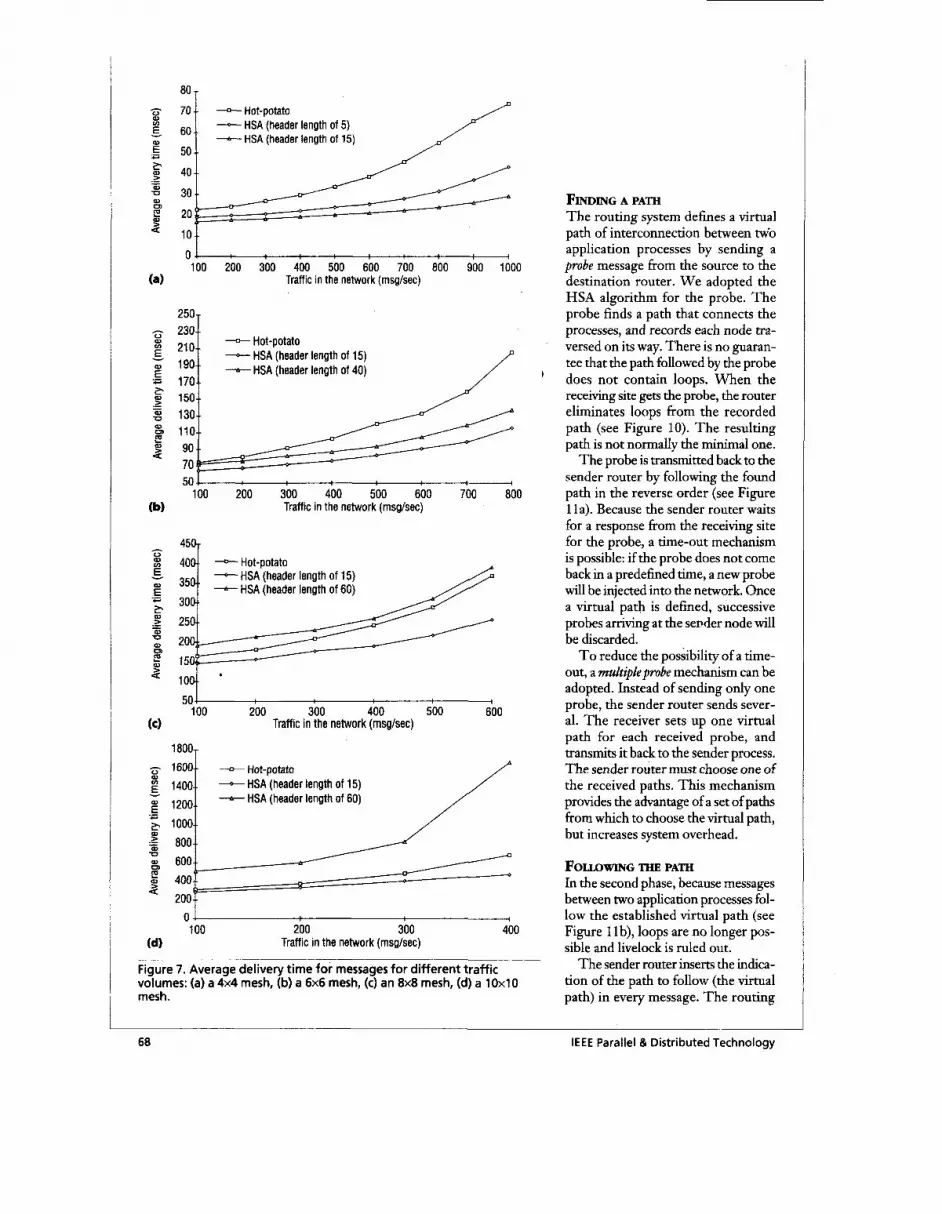
Generally, while the average num- ber of hops can always be reduced by using a header length comparable with the number of nodes, this header length does not reduce the average delivery time for messages when the number of nodes increases (see Figure 7 ) . The higher the number of nodes, the greater the effort to examine the longer header a t each intermediate node. So, messages take more time to traverse nodes.
The choice of header length depends on a trade-off between the number of traversed nodes and the increased overhead in each node to deal with the headers. In our Trans- puter-based architecture, all tests show that the header length for the best time performance is lower than the total number of nodes. Figure 7 iden- tifies a length of about 15 nodes as the best trade-off. Average delivery time increases with traffic volume, until sat- uration is reached.
T o complete our analysis of the HSA algorithm, we'll now show how the system's computational load affects average message delivery time. We load every node in our testbed application with some compute- bound processes. The number of these processes and their distribution rep- resent balanced or unbalanced loads.
For balanced loads, each node has compute-bound processes that engage the processor for about 60% of the time. In this case, HSA rout- ing achieves better performance than hot-potato routing (see Figure 8).
ume changes. This is because any change in volume affects the lengths of all queues in the same way; on the average this does not change routing decisions.
The HSA router tends to spread nonuniform traffic
The hot-potato policy chooses the link only on the basis of local queue lengths. One of the neighbors can be overloaded and become very slow in routing mes- sages. The hot-potato does not promptly recognize
~
66 IEEE Parallel & Distributed Technology
45 T
this bottleneck and continues to feed traffic to it. In this situation, the time of permanence of messages in the output queues can significantly increase. In HSA routing, on the other hand, any message exchange indicates the load of the neighbors. Therefore, the router discovers hot spots as soon as they appear.
For unbalanced loads, several com- putation processes have been randomly allocated to nodes. The load is about 60% in half of the nodes, higher in the others. Even in this case, the HSA router achieves better results than hot- potato routing (see Figure 9). The HSA router aims to balance the service time of all its outgoing messages by favoring the underloaded neighbor nodes, thus avoiding clogging the sys- tem. This strategy is more effective because it avoids the hot spots.
me Virtual Patb strategy The HSA strategy is suitable for highly dynamic systems, but expensive in terms of the number of hops traversed by messages.* T o obtain a lower-cost solution that can still deal with dynam- icity, we have developed the Virtual Path strategy.
Applications that are composed of long-lasting entities that cooperate and exchange data may take advan- tage of the definition of a virtual path, that is, a path followed by all messages from the same source to the same destination. This virtual path is established when the first communi- cation takes place and then is fol-
15 100 200 300 400 500 600 700 800 900 1000
Traffic of messages generated per second
---a- HSA (header length of 3) - HSA (header length of 5)
+ HSA (header length of 10)
-x- HSA (header length of 15) (a)
n 0
120 1 i
100 200 300 400 500 600 Traffic of messages generated per second
-+-- HSA (header length of 3)
-0- HSA (header length of 15)
-+- HSA (header length of 30)
-x- HSA (header length of 60) (b)
Figure 6. The average number of hops for dif ferent traffic volumes: (a) a 4x4 mesh, (b) an 8x8 mesh.
lowed by all messages between the same couple. The exchanged messages share the cost of defining the vir- tual path: the more messages, the greater the advan- tage. A virtual path does not last forever; it must be updated to account for application dynamicity. Vir- tual paths are created dynamically without any global knowledge of allocation or topology, and can be updated during execution to adapt to system state
changes such as process migrations and varied traffic conditions. VP routing splits communication between processes
into two phases. The first phase starts when the sender process transmits a message for the first time to a spe- cific receiver process. In this phase, the router finds a path that connects the sender with the receiver; in the second phase, all messages follow this virtual path.
Spring 1995 67
- Hot-potato - HSA (header length of 5) - HSA (header length of 15) 50
101 0 1 100 200 300 400 500 600 700 800 900 1000
Traffic in the network (msg/sec) (a)
250T - Hot-potato -0- HSA (header length of 15) - HSA (header length of 40)
- E + 170
150 2 130 s 110
a 70
f 90
50 4 :--.+-------.I
100 200 300 400 500 600 700 800 Traffic in the network (msgkec) (b)
- HSA (header length of 60)
100 200 300 400 500 600 Traffic in the network (msgkec)
1800- 1600- -c- Hot-potato 1400.. 1200 1000--
- HSA (header length of 15) - HSA (header length of 60)
O J I
100 200 300 400 Traffic in the network (msgkec)
Figure 7. Average delivery time for messages for different traffic volumes: (a) a 4x4 mesh, (b) a 6x6 mesh, (c) an 8x8 mesh, (d) a 10x10 mesh.
FINDING A PATH The routing system defines a virtual path of interconnection between two application processes by sending a probe message from the source to the destination router. We adopted the HSA algorithm for the probe. The probe finds a path that connects the processes, and records each node tra- versed on its way. There is no guaran- tee that the path followed by the probe does not contain loops. When the receiving site gets the probe, the router eliminates loops from the recorded path (see Figure 10). The resulting path is not normally the minimal one.
The probe is transmitted back to the sender router by following the found path in the reverse order (see Figure 1 la). Because the sender router waits for a response from the receiving site for the probe, a time-out mechanism is possible: if the probe does not come back in a predefined time, a new probe will be injected into the network Once a virtual path is defined, successive probes arriving at the semier node will be discarded.
To reduce the possibility of a time- out, a multipleprobe mechanism can be adopted. Instead of sending only one probe, the sender router sends sever- al. The receiver sets up one virtual path for each received probe, and transmits it back to the sender process. The sender router must choose one of the received paths. This mechanism provides the advantage of a set of paths from which to choose the virtual path, but increases system overhead.
FOLLOWING THE PATH In the second phase, because messages between two application processes fol- low the established virtual path (see Figure 1 1 b), loops are no longer pos- sible and livelock is ruled out.
The sender router inserts the indica- tion of the path to follow (the virtual path) in every message. The routing
68 IEEE Parallel & Distributed Technology

algorithm is static and has no compu- tation overhead. There is no routing policy to compute (see Figure 12); in any intermediate node, the router only identifies the output link of the virtual path carried by the message. The addi- tional overhead caused by the limited increased size of messages is negligi- ble, particularly compared with the cost of communication setup.
Nevertheless, the VP algorithm is still adaptive, because it can react to system evolution. It takes into account the following exceptional conditions:
Fault. When there is a hardware failure (a node failure or a faulty link) or a software failure (for instance, a request to an object no longer in the system). Migration. When a receiver process can no longer be found because it has moved to another node during execution. Path congestion. When a virtual path becomes congested, and message delivery time increases.
Generally, the router reacts to these conditions by finding a new virtual path. The routing system’s behavior depends on the degree of synchronic- ity of the communication between application processes.
For synchronous communication, the router can follow a time-driven approach, where the router finds new virtual paths a t a predefined, fixed time interval, or an event-driven approach,
140
-ct-- Hot-potato - HSA (header length of 15) 120 I
2o f o ! I
100 200 300 400 500 600 Traffic in the network
Figure 8. Comparison of hot-potato andHSA routers for balanced loads in a 4x4 mesh.
500 -,- -----ct- Hot-potato
450
400
350
300
250
200
150
100
/ t --A-- HSA (header length of 15) - --A-- HSA (header length of 15)
I
50 t o ! I
100 200 300 400 Traffic in the network (msg/sec)
Figure 9. Comparison of hot-potato and HSA routers for unbalanced loads (60%-100%) in a 4x4 mesh.
where an event imposes changes of the virtual path. In the second approach, a time-out event can detect any of the above-mentioned exceptional conditions. The time- out triggers a new first phase, and all successive mes- sages follow the new virtual path.
For example, let’s consider a client-server model. The client process waits for an acknowledgment to each sent message within a time-out interval. If the time-out expires, the client process assumes that one of the excep- tional situations has occurred, and the router at the client site sends a new probe to establish a new virtual path to the server process.
With asynchronous communication between applica- tion processes, the event-driven approach is not possi- ble. Only a time-driven approach is feasible. Based on the application’s dynamicity, new virtual paths are designed at predetermined time intervals.
Migration can also be dealt with in different ways. In client migration, the client process modifies all the virtual paths it uses by resending new probes. Sewer migration is more complex because the server does not know which processes need its services, and there is no way of noti- fying them of its migration. Two possible solutions stand out. In the static solution, the server process leaves afor-
Spring 1995 69

Sender
Sender process
Router
4 r- ...................... -~~~
L. ..... ... . ... ...... .~..O ..... ~. ..o .......... 6
0 0 0
0 0 0 0 ;
Receiver process
Router
0 @ .......... 0 ......... 0 ......... 0
I
o o o o o d Receiver Probe Path
Messages sent
Virtual path
Figure IO. The definition of a virtual path in a 6x6 mesh.
Sender node
Sender process
message
Router
Receiver node
Router
I (2) Probe (HSA routed) ~
(3) Returning probe (a) (with a virtual path)
Figure 11. The two phases of the VP algorithm: (a) finding a path, (b) following a path.
MSG
Link L: -
MSGI ILink L1 i A
Bypass I
Figure 12. The message MSG is directly put into the L2 output queue, bypassing the local routing strategy.
ward in the node from which it moved. Messages reaching that node are directly forwarded to the current loca- tion of the server process (see Figure 13a). In the dynamic solution, the serv- er does not leave any forward. Mes- sages arriving a t the node where the server previously resided must look for the new location, in the same way as probe messages do (see Figure 13b).
For synchronous communication, a third solution is possible. The client process can be forced to look for a new virtual path when it tries to communi- cate with the migrated server and is notified of the migration by a message sent by the router of the node where the server resided before migration. This avoids either an excess of forwards or the dynamic solution's search overhead.
We have simplified the migration discussion by assuming that a process is only either a client or a server. This, of course, is not the real case: a process can be a client of some processes and a server for others.
~ ? ~ " N T A L RESULTS Our tests compared the VP algorithm to the HSA algorithm. The aim is not to show which performs better, but to show that an application's behavior can indicate which algorithm to use.
While the HSA algorithm is fully adaptive and reacts promptly to changes in highly dynamic applications, the VP algorithm is more efficient for a range of applica- tions with a slower rate of dynamicity. We used the same testbed application as for the HSA router.
Our first tests varied the number of probes sent. Send- ing multiple probes lets us choose the path with the smallest number of hops, from among several virtual paths. The choice of the number of probes to send is a trade-off between the cost of the multiple-probe solu- tion and the number of messages that use the virtual path. The more messages using the same virtual path, the more probes we can advantageously send. There is no need to wait for a response to all sent probes; we can choose the virtual path from a subset of them. Figure 14 shows the average delivery time for different numbers of messages exchanged between the processes: only one probe sent
70 IEEE Parallel & Distributed Technology
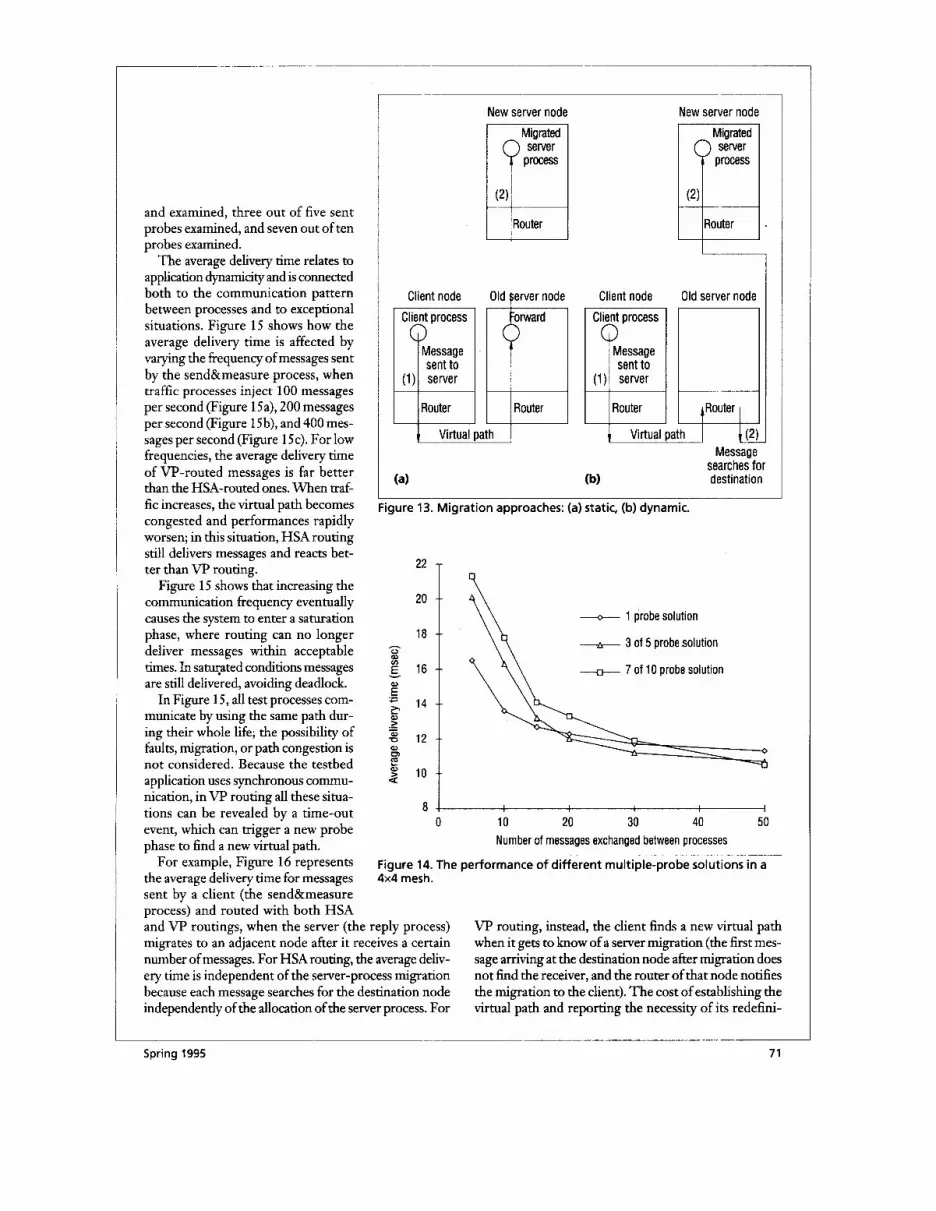
and examined, three out of five sent probes examined, and seven out of ten probes examined.
The average delivery time relates to application dynamicity and is connected both to the communication pattern between processes and to exceptional situations. Figure 15 shows how the average delivery time is affected by varying the frequency of messages sent by the send&measure process, when traffic processes inject 100 messages per second (Figure 1 Sa), 200 messages per second (Figure 15b), and 400 mes- sages per second (Figure 15c). For low frequencies, the average delivery time of VP-routed messages is far better than the HSA-routed ones. When maf- fic increases, the virtual path becomes congested and performances rapidly worsen; in this situation, HSA routing still delivers messages and reacts bet- ter than VP routing.
Figure 15 shows that increasing the communication frequency eventually causes the system to enter a saturation phase, where routing can no longer deliver messages within acceptable times. In satupted conditions messages are still delivered, avoiding deadlock.
In Figure 15, all test processes com- municate by using the same path dur- ing their whole life; the possibility of faults, migration, or path congestion is not considered. Because the testbed application uses synchronous commu- nication, in VP routing all these situa- tions can be revealed by a time-out event, which can trigger a new probe phase to find a new virtual path.
For example, Figure 16 represents the average delivery time for messages sent by a client (the send&measure process) and routed with both HSA
22
20
18 h
0 w
16 Y
.- E 14
8 12
E
.- E - aa 0)
g 10
Client node
-
--
--
--
--
--
--
Client process 0
Message sent to
Router
New server node New server node Migrated
server process
/Router
Old berver node orward i Router
1 Virtual path I
Client node Client process
sent to
Router
Migrated
process
H Router .
Old server node
B Router
4 Virtual path /o Message
searches for (a) (b) destination
Figure 13. Migration approaches: (a) static, (b) dynamic.
--o- I probe solution
-A- 3 of 5 probesolution
-z- 7 of 10 probe solution
8 4 I 0 10 20 30 40 50
Number of messages exchanged between processes
Figure 14. The performance of different multiple-probe solutions in a 4x4 mesh.
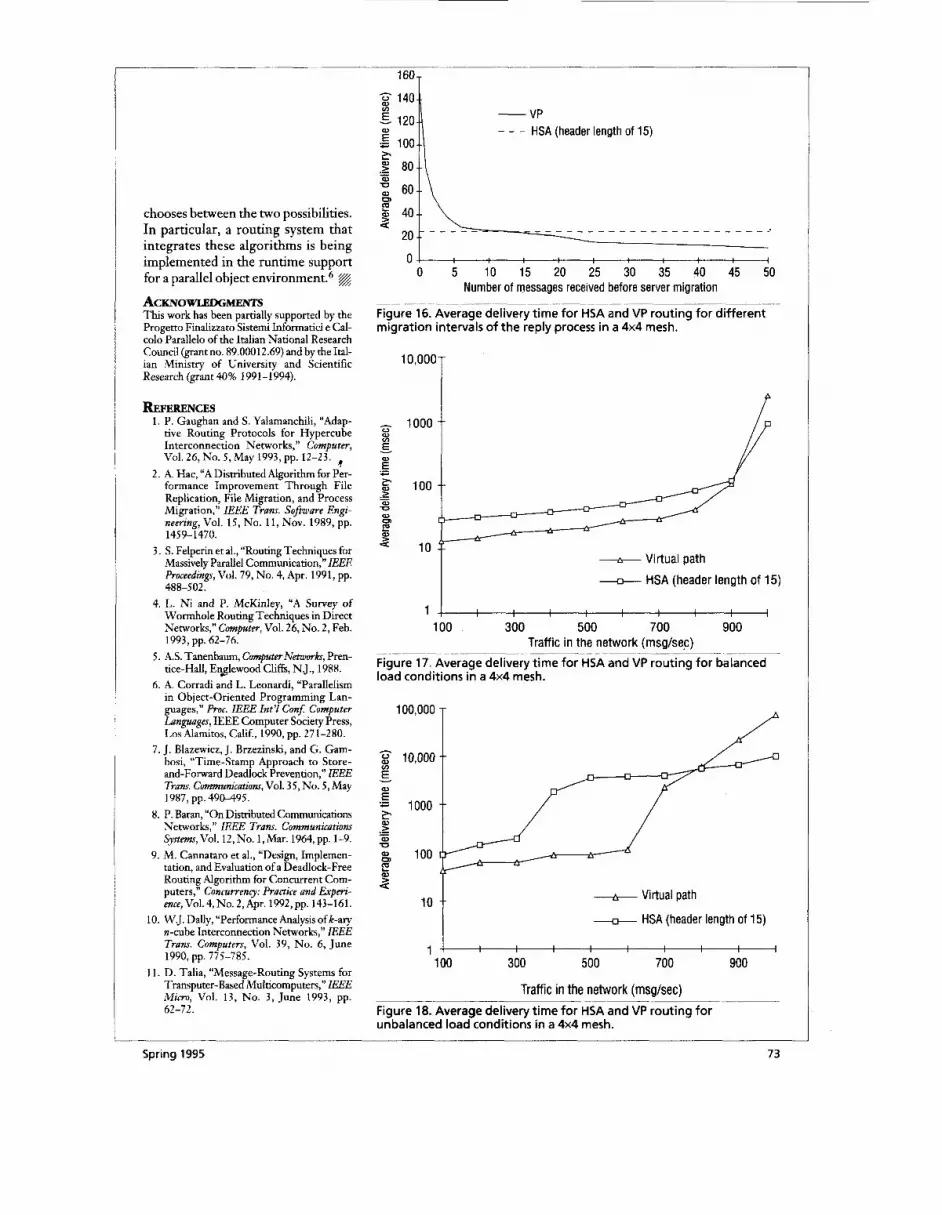
Hnd VP routings, when the server (the reply process) migrates to an adjacent node after it receives a certain number of messages. For HSArouting, the average deliv- ery time is independent of the server-process migration because each message searches for the destination node independently of the allocation of the server process. For
VP routing, instead, the client finds a new virtual path when it gets to know of a server migration (the first mes- sage arriving at the destination node after migration does not find the receiver, and the router of that node notifies the migration to the client). The cost of establishing the virtual path and reporting the necessity of its redefini-
Spring 1995 71

4500
4000
3500
E 3000
.- E 2500
h
0 a,
w
- F 2000
p 1000 2
.- - 0)
W 1500
500
0
1 -E- HSA (header length of 15)
/
(a) 50 100 150 200 250 300 350 400
3000
2500
0 0)
g 2000 v
.- E c
a, m e 3
1500
Communication frequency (msg per second)
P I
I
I
0 4 Y d I
(bl 50 100 150 200 250 300 Communication frequency (msg per second)
14,000
12,000
8 10,000 E E 8000
- w
.- c
$ 6000
4000
2000
0
.- - W U
E
(C) 50 100 150 200 250 300 Communication frequency (msg per second)
~ _ _ _ _ ~
Figure 15. Average delivery time for HSA and VP routing, for different communication frequencies on an 8x8 mesh: (a) the traffic volume is 100 messages per second; (b) the traffic volume is 200 messages per second; (c) the traffic volume is 400 messages per second.
$on, affects the average delivery time of the messages that use it. W routing compares well with HSA routing as soon as a small number of messages follow the same virtual path.
The last set of tests deals with the system's computational load. T o com- pare HSA and VP routing for balanced and unbalanced loads, several com- pute-bound processes are allocated to nodes, as we described earlier.
Figures 17 and 18 report balanced and unbalanced conditions. In both cases, W routing generally performs better than HSA routing, but HSA routing handles high-traffic condi- tions better because it exploits all avail- able paths connecting nodes.
lthough HSA and VP routing are based on somewhat expensive assumptions, when A implemented for Trans-
puter-based architectures they com- pare well with the Multiple Rings and Tiny routing systems'(see the sidebar). The Multiple Rings routing has a mean internode latency from 450-1 200 microseconds, depending on the traffic volume, and the Tiny routing has a latency of about 500 microseconds, for light loads.' ' HSA and VP routing present similar latency (450-900 microseconds), even though HSA routing can require a non- minimal number of hops.
Our two algorithms answer differ- ent and complementary requirements. The HSA algorithm is suitable for very dynamic situations, where no knowledge can be reasonably main- tained about process allocation. The VP algorithm is less dynamic, but more suitable to situations where process allocation lasts for the exchange of a set of messages. The two algorithms can be combined into a sin- gle routing system that efficiently
72 IEEE Parallel 81 Distributed Technology
- VP - _ _ HSA (header length of 15)
1
chooses between the two possibilities. In particular, a routing system that integrates these algorithms is being implemented in the runtime support for a parallel object environment.6 a ACKNOWLEDGMENTS This work has been partially supported by the Progetto Finalizzato Sistemi Informatici e Cal- col0 Parallel0 of the Italian National Research Council (grant no. 89.00012.69) and by the Ital- ian Ministry of University and Scientific Research (grant 40% 1991-1994).
-o--- HSA (header length of 15)
I I
REFERENCES 1. P. Gaughan and S. Yalamanchili, “Adap-
tive Routing Protocols for Hypercube Interconnection Networks,” Computer, Vol. 26, No. 5,May 1993, pp. 12-23. a
2. A. Hac, “A Distributed Algorithm for Per- formance Improvement Through File Replication, File Migration, and Process Migration,” IEEE Trans. Sofcware Engi- neering, Vol. 1 S, No. 11, Nov. 1989, pp.
3. S. Felperin et al., “RoutingTechniques for Massivelv Parallel Communication.” ZEEE
1459-1470.
ProceediLgs, Vol. 79, No. 4, Apr. 1991, pp. 488-502.
4. L. Ni and P. McKinley, “A Survey of Wormhole Routing Techniques in Direct Networks,” Computer, Vol. 26, No. 2, Feb.
5 . AS. Tanenbaum, CwnpzrrevNerwwh, Pren- tice-Hall, En3lewood Cliffs, NJ., 1988.
6. A. Corradi and L. Leonardi, ”Parallelism in Object-Oriented Programming Lan- guages,” Proc. IEEE Znt’l Conf: Computer Languages, IEEE Computer Society Press, Los Alamitos, Calif., 1990, pp. 27 1-280.
7. J. Blazewicz, J. Brzezinski, and G. Gam- bosi, “Time-Stamp Approach to Store- and-Forward Deadlock Prevention,” IEEE Trm. Cmunacations, Vol. 3 5 , No. 5, May 1987, pp. 49M95.
8. P. Baran, “On Distributed Communications Networks,” IEEE Trans. Communications System, Vol. 12, No. 1, Mar. 1964, pp. 1-9.
9. M. Cannataro et al., “Design, Implemen- tation, and Evaluation of a Deadlock-Free Routing Algorithm for Concurrent Com- puters,” Concurrency: Practice and Experi- ence,Vol. 4, No. 2, Apr. 1992,pp. 143-161.
10. W.J. Dally, “Performance Analysis of k-ary n-cube Interconnection Network$,’’ ZEEE Trans. Computers, Vol. 39, No. 6, June 1990, pp. 775-785.
11. D. Talia, “Message-Routing Systems for Transputer-Based Mulacomputers,” ZEEE M i m , Vol. 1 3 , No. 3, June 1993, pp.
1993, pp. 62-76.
62-72.
I
0 5 10 15 20 25 30 35 40 45 50 Number of messages received before server migration
~- -. ~ ~~ -. ______ Figure 16. Average delivery time for HSA and VP routing for different migration intervals of the reply process in a 4x4 mesh.
OTOOOT
1000
100
10 - Virtual path - 1
Figure 17. Average delivery time for HSA and VP routing for balanced load conditions in a 4x4 mesh.
T 100,000
3 10,000 E E 6
& 100
P
v
‘E 1000 3.
a U .- -
e W
10 --A- Virtual path
-G- HSA (header length of 15)
i 100 300 500 700 900
Traffic in the network (msg/sec) Figure 18. Average delivery time for HSA and VP routing for unbalanced load conditions in a 4x4 mesh.
Spring 1995 73

Maurelio Boari is a professor in the Deparment of Electronics and Computer Science at the University of Bologna, Italy. His scientific interests include parallel and distributed systems, programming envi- ronments, and operating systems. He is a member of the IEEE, ACM, and AICA. He can be reached at the Dept. of Electronics, Computer Science, and Systems, DEIS, 2 viale Risorgimento, 40136 Bologna, Italy; Internet: boariadeis3 3 .cineca.it.
Antonio Corradi is an associate professor of computer science at the University of Bologna, in Bologna, Italy, where he teaches basic and advanced engineering courses. His scientific interests are disuibuted systems, object-based systems, object-oriented programming, mas- sively parallel systems and architectures, and programming environ- ments for parallelism. He received his Masters in electrical engmeer- ing from Come11 University in 198 1, and his laurea degree in electronic engineering from the University of Bologna in 1980. He is a member of the IEEE, ACM, and AKA. He can be reached at the Dept. ofElec- tronics, Computer Science, and Systems, DEIS, 2 viale Risorgimen- to, 40136 Bologna, Italy; Internet: [email protected].
Letizia Leonardi is an associate professor of computer science at the University ofModena,h Modena, Italy, where she teaches basic and advanced engineering courses. Her scientific interests include obje‘ct- oriented programming environments, and distributed and massively parallel architectures. She received her PhD in computer science from the University ofBologna in 1988, and her laurea degree in electronic engineering from the University of Bologna in 1982. She is a mem- ber of AICA. She can be reached at the Dept. of Electronics, Com- putet Science, and Systems, DEIS, 2 viale Risorgimento, 40136 Bologna, Italy; Internet: letiziaadeis3 3 .cineca.it.
Cesare Stefanelli is a doctoral candidate in computer science at the University of Bologna in Bologna, Italy. His research interests include distributed and massively parallel systems, and programming envi- ronments for parallelism. He received his laurea degree in electronic engineering from the University of Bologna in 1992. He can be reached at the Dept. ofElectronics, Computer Science, and Systems, DEIS, 2 viale Risorgimento, 40136 Bologna, Italy; Internet: cesareadeis3 3 .cineca.it.
Programming Languages for I Parallel Processing
edited by David B. Skillicorn and Domenico Talia
Discusses programming languages for parallel processing architectures and describes the implementation of various paradigms to support different models of parallelism. The text provides an overview of the most important languages designed in the last decade and introduces issues and concepts related to the development of parallel software. The book covers those languages currently used to develop parallel applications in many areas, from numerical to symbolic computing.
Contents: Preface Introduction Shared-Memory Paradigms Distributed-Memory Paradigms Parallel Object-Oriented Programming Parallel Functional Programming Parallel Logic Programming More Innovative Approaches to Parallel Programming
4 16 pages. November 1994. Softcover. ISBN 0-8186-06502-5. Cutolog # BP006502 -Members $34.00 / List $ 4 5 . 0 0
C ~ ~ P U T E R SOCIETY
Ins t cuc tion-level Par ollel Processors edited H.C. Tarng and Stamatis Vassiliadis
Details the innovations and advances that produced Intel’s Pentium and IBM/Motorola/Apple’s PowerPC and the powerful, versatile processors that are yet to come. The book explores the potential, design, and implementation of instruction-level parallelism in modern processors. Its first chapter includes two frequently referenced papers that detail pioneering processo;s with multiple-function units that provided the basis for the development of ILP processors. Other chapters illustrate solutions to the true data dependency problem and the control dependency problem, examine code scheduling, and detail machine organizations resulting from the compaction of instructions into VLIW.
Contents: Dependencies Among Instructions and their Resolution Branch Handling Superscalar Machine Organizations Memory Accesses, Interrupt Handling, and Multithread Processing Measurements of Instruction Level Parallelism
480poges. December 1994. Softcover. ISBN 0-8186-65270. Cotdog# BP06527- Members $36.00 /L ist$48.00