dna, rna, protein structure prediction - aalto · on from generation to ... dependent...
TRANSCRIPT

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
1
DNA, RNA, Protein Structure Prediction
Laura Pombo
Laboratory of Computational Engineering
Helsinki University of Technology
23.11.2005

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
2
Table of Content
Table of Content ................................................................................................................. 2
1. Introduction..................................................................................................................... 2
1.1 Central Dogma.......................................................................................................... 3
2 RNA structure prediction................................................................................................. 4
3 DNA structure prediction................................................................................................. 9
4 Protein Structure Prediction........................................................................................... 10
5 Conclusions.................................................................................................................... 18
1. Introduction
In this work, I provide short introduction to bioinformatics and present and discuss in
more detail several software applications available through Internet and designed for the
DNA, RNA, or protein structure prediction.
Bioinformatics1 involves the integration of computers, software tools, and databases in an
effort to address biological questions. Bioinformatics approaches are often used for major
initiatives that generate large data sets.
Two important large-scale activities that use bioinformatics are genomics and
proteomics. Genomics refers to the analysis of genomes. A genome can be thought of as
the complete set of DNA sequences that codes for the hereditary material that is passed
on from generation to generation.
1 http://www.bioinformatics.ubc.ca/

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
3
These DNA sequences include all of the genes (the functional and physical unit of
heredity passed from parent to offspring) and transcripts (the RNA copies that are the
initial step in decoding the genetic information) included within the genome.
Thus, genomics refers to the sequencing and analysis of all of these genomic entities,
including genes and transcripts, in an organism. Proteomics, on the other hand, refers to
the analysis of the complete set of proteins or proteome. In addition to genomics and
proteomics, there are many more areas of biology where bioinformatics is being applied
(i.e., metabolomics, transcriptomics). Each of these important areas in bioinformatics
aims to understand complex biological systems. Many scientists today refer to the next
wave in bioinformatics as systems biology, an approach to tackle new and complex
biological questions. Systems biology involves the integration of genomics, proteomics,
and bioinformatics information to create a whole system view of a biological entity.
1.1 Central Dogma2
Portions of DNA Sequence Are Transcribed into RNA. The first step of a cell is to copy a
particular portion of its DNA nucleotide sequence ( =gene)
Similarities:
• DNA and RNA is a linear polymer made of four different types of nucleotide
subunits linked together by phosphodiester bonds
• DNA and RNA contains the bases adenine (A), guanine (G) and cytosine (C)
Differences:
• In RNA the nucleotides are ribonucleotides (=contain the sugar ribose)
• RNA contains uracil (U) instead of the thymine (T)
2 Molecular Biology of THE CELL (Bruce Alberts, et al.)

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
4
2 RNA structure prediction
There are different kinds of RNAs with different kinds of functions:
• mRNAs: (messenger RNAs), code for proteins
• rRNAs: (ribosomal RNAs), form the basic structure of the ribosome and catalyze
protein synthesis
• tRNAs: (transfer RNA), central to protein synthesis as adaptors between mRNA
and amino acids
• snRNAs: (small nuclear RNAs), function in a variety of nuclear processes,
including the splicing of pre-Mrna
• snoRNAs: (small nucleolar RNAs), used to process and chemically modify
rRNAs

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
5
• Other noncoding RNAs: function in diverse cellular processes, including telomere
synthesis, X-chromosome inactivation and the transport of proteins into te ER
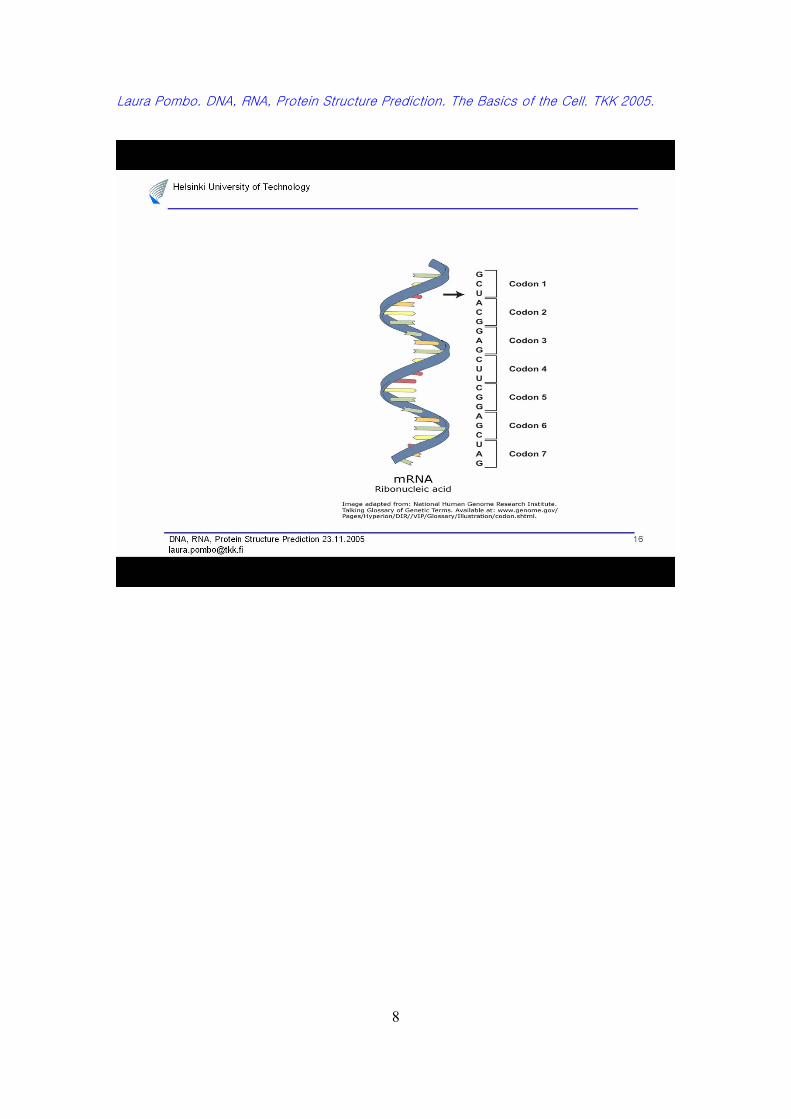
RNA is transcribed (or synthesized) in cells as single strands of (ribose) nucleic acids.
However, these sequences are not simply long strands of nucleotides. Rather, intra-strand
base pairing will produce structures.
In RNA, guanine and cytosine pair (GC) by forming a triple hydrogen bond, and adenine
and uracil pair (AU) by a double hydrogen bond; additionally, guanine and uracil can
form a single hydrogen bond base pair.

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
6
There are several software application for RNA structure prediction available in Internet.
Here, are the programmes that I studied and provided overview in the presentation.
Vienna RNA3 (PackageRNA Secondary Structure Prediction and Comparison)
including a few precompiled binaries for download. The Vienna RNA Package consists
of a C code library and several stand-alone programs for the prediction and comparison
of RNA secondary structures. RNA secondary structure prediction through energy
3 http://www.tbi.univie.ac.at/~ivo/RNA/

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
7
minimization is the most used function in the package. They provide three kinds of
dynamic programming algorithms for structure prediction: the minimum free energy
algorithm of which yields a single optimal structure, the partition function algorithm of
which calculates base pair probabilities in the thermodynamic ensemble, and the
suboptimal folding algorithm which generates all suboptimal structures within a given
energy range of the optimal energy.
RNAfold4 reads RNA sequences from stdin and calculates their minimum free energy
(mfe) structure, partition function (pf) and base pairing probability matrix. It returns the
mfe structure in bracket notation, its energy, the free energy of the thermodynamic
ensemble and the frequency of the mfe structure in the ensemble to stdout. It also
produces PostScript files with plots of the resulting secondary structure graph and a "dot
plot" of the base pairing matrix. The dot plot shows a matrix of squares with area
proportional to the pairing probability in the upper half, and one square for each pair in
the minimum free energy structure in the lower half.
ALIDOT program (Detecting Conserved RNA Structures)5 is designed to detect
conserved RNA secondary structures in small data sets of related RNA sequences. The
method, which is described in detail in [1,2], is a combination of structure prediction and
comparative sequence alignment.
4 http://www.tbi.univie.ac.at/~ivo/RNA/RNAfold.html 5 http://www.tbi.univie.ac.at/~ivo/RNA/ALIDOT/
Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
8

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
9
3 DNA structure prediction
Similarly, there are plenty of softwares for DNA structure prediction, which I have
looked at. I have included here as an example those that I found easy to start with and
accessible free via Internet.
MEME (Multiple EM for Motif Elicitation)6 is a tool for discovering motifs in a group
of related DNA or protein sequences. A motif is a sequence pattern that occurs repeatedly
in a group of related protein or DNA sequences. MEME represents motifs as position-
dependent letter-probability matrices which describe the probability of each possible
letter at each position in the pattern. Individual MEME motifs do not contain gaps.
6 http://www.psc.edu/general/software/packages/meme/

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
10
Patterns with variable-length gaps are split by MEME into two or more separate motifs.
MEME takes as input a group of DNA or protein sequences (the training set) and outputs
as many motifs as requested. MEME uses statistical modeling techniques to
automatically choose the best width, number of occurrences, and description for each
motif.
Other DNA structure prediction programs7 are for example: Cassandra8, GENEID which
does prediction of Exons and Gene Structure in Query Sequences (US), GRAIL,
GenHunt, Censor, Pythia, Entrez, Beauty, etc.
4 Protein Structure Prediction Protein: A large molecule composed of one or more chains of amino acids in a specific
order determined by the base sequence of nucleotides in the DNA coding for the protein.
Proteins are required for the structure, function, and regulation of the body's cells, tissues,
and organs. Each protein has unique functions. Proteins are essential components of
muscles, skin, bones and the body as a whole.
Protein is one of the three types of nutrients used as energy sources by the body, the other
two being carbohydrate and fat. Proteins and carbohydrates each provide 4 calories of
energy per gram, while fats produce 9 calories per gram.
The word "protein" was introduced into science by the great Swedish physician and
chemist Jöns Jacob Berzelius (1779-1848) who also determined the atomic and molecular
weights of thousands of substances, discovered several elements including selenium, first
isolated silicon and titanium, and created the present system of writing chemical symbols
and reactions.
7 http://restools.sdsc.edu/biotools/biotools16.html 8 http://www-hto.usc.edu/software/procrustes/cassandra/cass_frm.html

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
11
Protein structure prediction can be simplified in the following Figure9.
In the upper right of the figure, the prediction process can be seen to start with the
collection of experimental Data, for example on disulphide bonds, spectroscopic data, site
directed mutagenesis studies and knowledge of proteolytic cleavage sites.
Then, the next phase is protein sequence data processing in which the idea is to idenfity
the structure of the protein in general. Next, sequence database searching includes
comparisons with sequence databases to find homologues and building a profile from
some kind of multiple sequence alignment, incorporating multiple sequence information.
Futhermore, there are plenty of Secondary Structure Prediction methods such as PSI-pred
9 http://speedy.embl-heidelberg.de/gtsp/

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
12
(PSI-BLAST profiles used for prediction; David Jones, Warwick); JPRED Consensus
prediction (includes many of the methods given below; Cuff & Barton, EBI); DSC King
& Sternberg (this server); PREDATORFrischman & Argos (EMBL), etc. If no
homologue of known structure from which to make a 3D model exist it is necessary to
predict secondary structure. The protein structure analysis can move towards fold
recognition methods such as 3D-pssm (this server), TOPITS (EMBL), UCLA-DOE
Structre Prediction Server (UCLA), etc. Even with no homologue of known 3D structure
is found, it may be possible to find a suitable fold for the protein among known 3D
structures by way of fold recognition methods.
Prediction of protein 3D structures is not possible at present, and a general solution to the
protein folding problem is not likely to be found in the near future. However, it has long
been recognized that proteins often adopt similar folds despite no significant sequence or
functional similarity. There are numerous protein structure classifications now available
via the WWW: SCOP (MRC Cambridge), CATH (University College, London), FSSP
(EBI, Cambridge), 3 Dee (EBI, Cambridge), HOMSTRAD (Biochemistry, Cambridge)
and VAST (NCBI, USA).
Methods of protein fold recognition attempt to detect similarities between protein 3D
structure that are not accompanied by any significant sequence similarity. There are many
approaches, but the unifying theme is to try and find folds that are compatible with a
particular sequence.
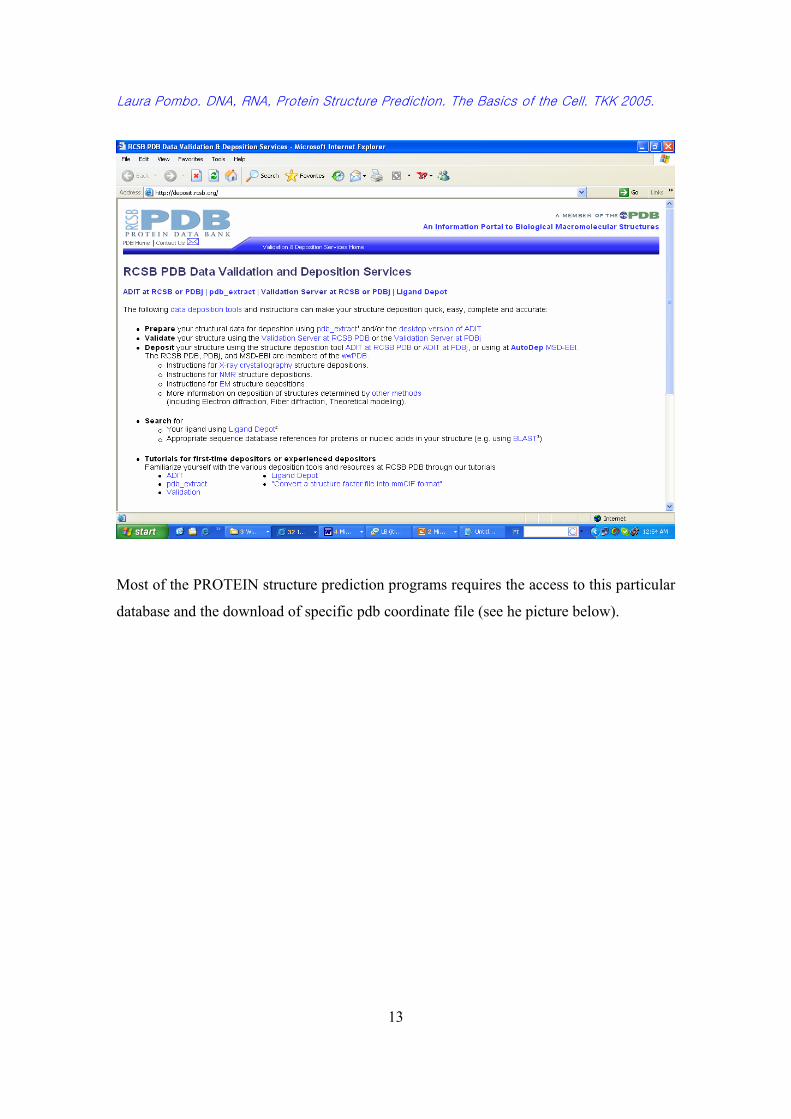
Such protein sequences are collected in data banks. The most prominent initiative of that
kind is PDB Protein Data Bank10 (See picture below).
10 http://deposit.rcsb.org/
Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
13
Most of the PROTEIN structure prediction programs requires the access to this particular
database and the download of specific pdb coordinate file (see he picture below).

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
14
Alignment of sequence to tertiary structure starts with the alignment from the fold
recognition method, and considering the alignment of secondary structures. Proteins
having similar three-dimensional structures with little or no sequence similarity can differ
substantial with respect to the finer details of their structures (i.e. loops, precise
orientation of side chains, orientation of secondary structures, etc.). Comparative or
Homology Modelling looks for homology to another protein of known three-dimensional
structure – model of a protein 3D structure can be obtained via homology modelling.
Indeed, there are different servers, portals and software applications available for
understanding and predicting protein structure:
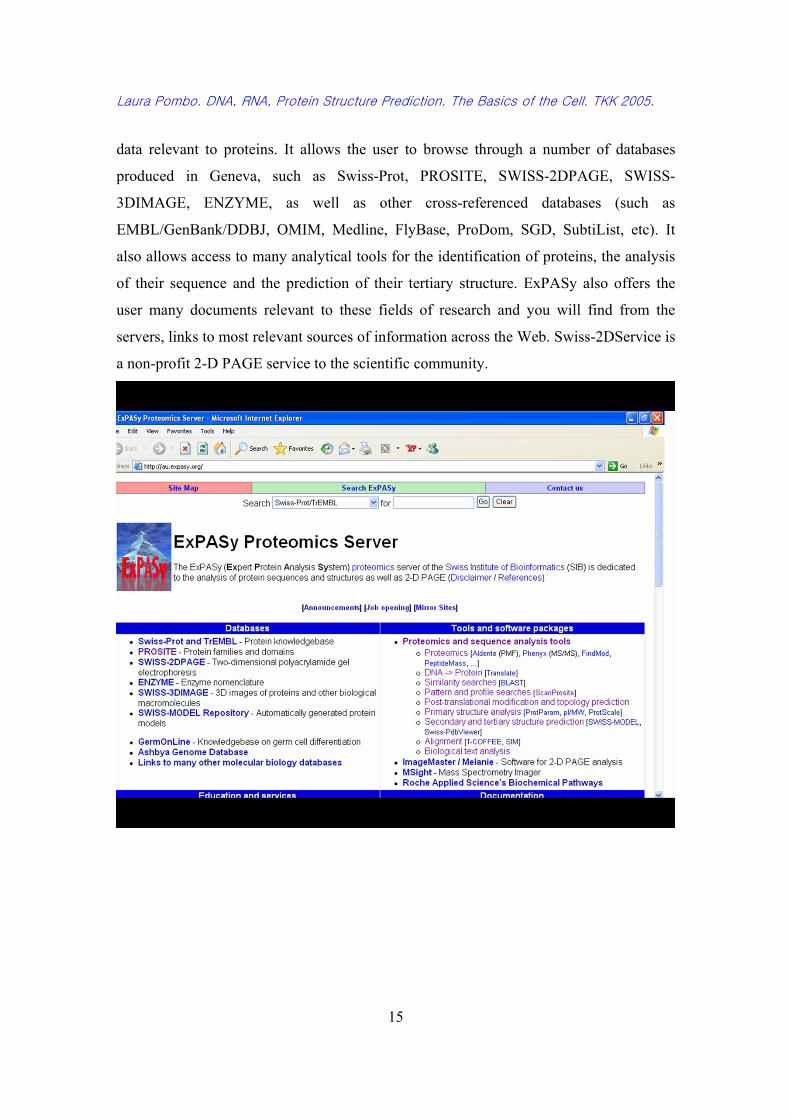
The ExPASy (Expert Protein Analysis System)11 proteomics server from the Swiss
Institute of Bioinformatics (SIB) is dedicated to molecular biology with an emphasis on
11 http://www.expasy.org/
Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
15
data relevant to proteins. It allows the user to browse through a number of databases
produced in Geneva, such as Swiss-Prot, PROSITE, SWISS-2DPAGE, SWISS-
3DIMAGE, ENZYME, as well as other cross-referenced databases (such as
EMBL/GenBank/DDBJ, OMIM, Medline, FlyBase, ProDom, SGD, SubtiList, etc). It
also allows access to many analytical tools for the identification of proteins, the analysis
of their sequence and the prediction of their tertiary structure. ExPASy also offers the
user many documents relevant to these fields of research and you will find from the
servers, links to most relevant sources of information across the Web. Swiss-2DService is
a non-profit 2-D PAGE service to the scientific community.

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
16
PROSITE12 is a database of protein families and domains. It consists of biologically
significant sites, patterns and profiles that help to reliably identify to which known
protein family (if any) a new sequence belongs.
It is based on the observation that, while there is a huge number of different proteins,
most of them can be grouped, on the basis of similarities in their sequences, into a limited
number of families.
Proteins or protein domains belonging to a particular family generally share functional
attributes and are derived from a common ancestor. It is apparent, when studying protein
sequence families, that some regions have been better conserved than others during
evolution. These regions are generally important for the function of a protein and/or for
the maintenance of its three- dimensional structure. By analyzing the constant and
variable properties of such groups of similar sequences, it is possible to derive a signature
for a protein family or domain, which distinguishes its members from all other unrelated
proteins.
PROSITE currently contains patterns and profiles specific for more than a thousand
protein families or domains. Each of these signatures comes with documentation
providing background information on the structure and function of these proteins.
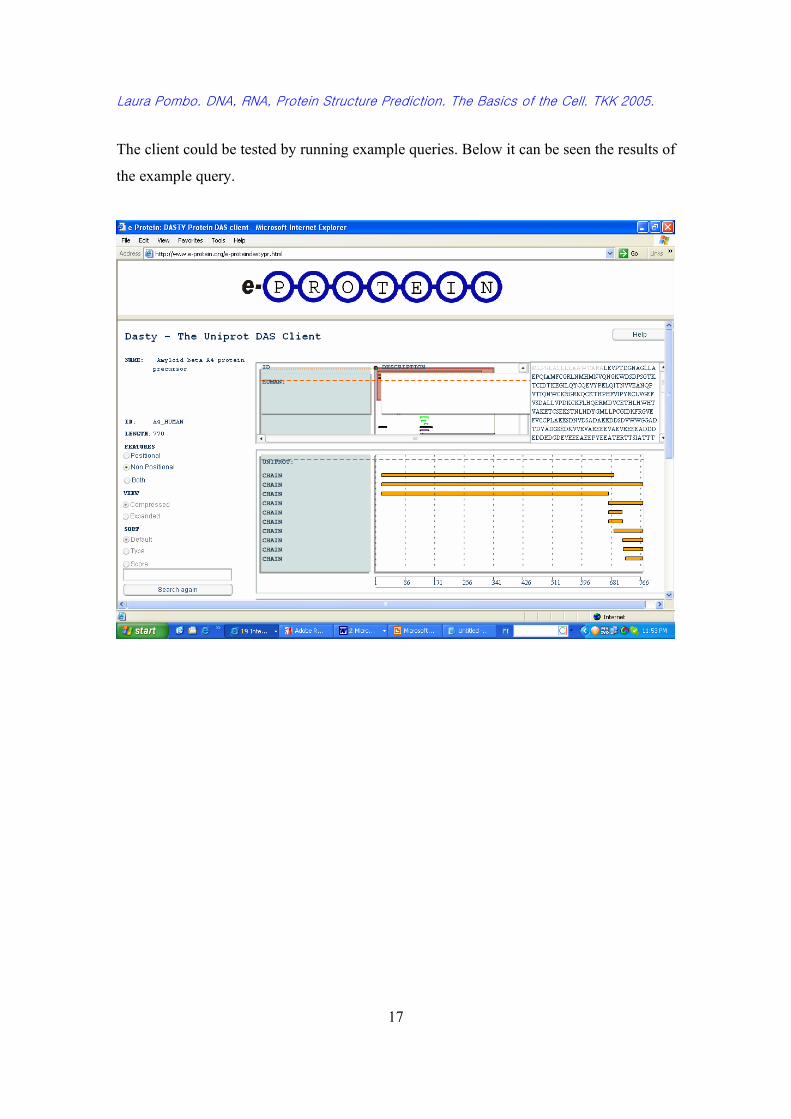
e-PROTEIN project provides a structure-based annotation of the proteins in the major
genomes linking resources at 3 sites by GRID technology. Part of the project, it has been
developed DAS (Distributed Annotation System)13 provides a means of collating
sequence annotation data from multiple sources and displaying the information to a user
in a single view. The team at the EBI have developed a new Flash-based Protein DAS
client for displaying protein annotations. Protein DAS Client queries protein DAS
Servers and visualizes protein sequence features.
12 http://au.expasy.org/prosite/ 13 http://www.e-protein.org/e-proteindastypr.html
Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
17
The client could be tested by running example queries. Below it can be seen the results of
the example query.

Laura Pombo. DNA, RNA, Protein Structure Prediction. The Basics of the Cell. TKK 2005.
18
5 Conclusions
There are many programs which can give us a proper idea how is the structure prediction
of DNA and RNA. But in the case of PROTEIN structure prediction, we face the
challenge of understanding tertiary structures especially, because proteins having similar
three-dimensional structures with little or no sequence similarity can still differ
substantial with respect to the finer details of their structures (i.e. loops, precise
orientation of side chains, orientation of secondary structures, etc.).