improving free energy functions for rna folding rna secondary structure prediction
Post on 20-Dec-2015
218 views
TRANSCRIPT

Improving Free Energy Functions for RNA Folding
RNA Secondary Structure Prediction

Why RNA is Important
• Machinery of protein construction
• Catalytic role in cells– May be possible to destroy specific sequences of
RNA (to interrupt protein production)– RNase P (Cech/Altman c.1981)

RNA Structural Levels
Primary
AAUCG...CUUCUUCCA
Secondary Tertiary
Secondary: http://anx12.bio.uci.edu/~hudel/bs99a/lecture21/lecture2_2.htmlTertiary: http://www.leeds.ac.uk/bmb/courses/teachers/trnballs.html

Abstracting the problem
U
C
C
A G
G
A
C
Zuker (1981) Nucleic Acids Research 9(1) 133-149

Why it is hard
n
nn
E
enOkn
n
8.1]ψ[
)(1
ψ
mer- for RNA sequencessecondary ofnumber ψ
n
5.12/3n
n
Hofacker et al. (1994) Monat. Chem. 125 167-188
• Large search space (hard to enumerate)

Why it is hard
• Secondary structure does not exist.– Unlike proteins– Putative structures (prone to revision)
• Quality of Energy Functions– Discussed later

Current Algorithms
• Single-Strand– Minimum Free Energy (Zuker et. al. 1981)
– Partition Functions (McCaskill 1990)
• Comparative Sequence Analysis– Max. Weighted Matching (Nussinov et. al. 1978)
– Stochastic CFG (Sakikibara et. al. 1994)
– Phylogenetic Trees (Gulko et. al. 1995)
– Statistical Significance (Noller & Woese, early 80’s)
See proposal for references

MFE / Tinoco Hypothesis
The free energy of a secondary structure equals
the sum of the free energies of the loops and stacked pairs
Tinoco et al. (1971) Nature 230 362-367.
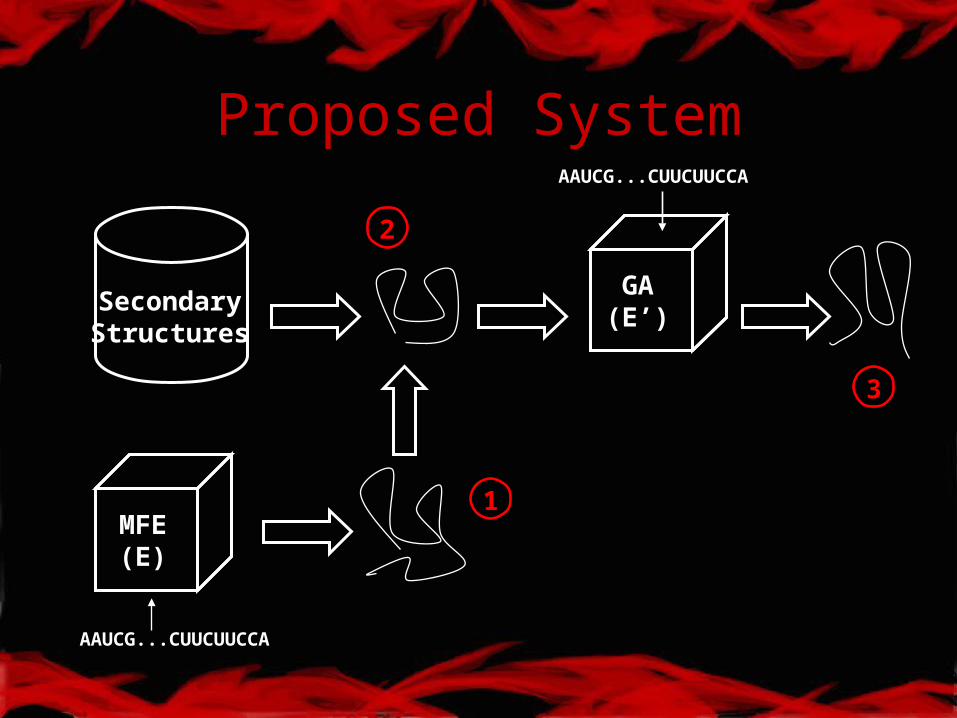
Proposed System
SecondaryStructures
MFE(E)
GA(E’)
AAUCG...CUUCUUCCA
AAUCG...CUUCUUCCA
1
2
3

Step I - Calc MFE Structure
• Given a sequence apply the MFE algorithm– Generates secondary structure S

Step II - Structural Similarity
• Given a database of experimentally verified RNA structures– Let Q be the database structure most
similar to S
– Based on RNase P Database (Brown 1999)

Step III - Construct E’
• Create a new energy function:
step)next (see generation
]1,0( where
SES,1
SE'
n
QSimilarityn

Discussion on E’
• E’ has global information• Global information precludes the use of
dynamic programming (MFE, Partition)
• Leaves (stochastic) combinatorial optimization Gradient Descent (no E/S)Genetic Algorithms / Simulated Annealing

Step IV - Genetic Algorithm
• RNA Structural Prediction by GA– Input: sequence – Output: structure that maximizes E’ for – Steady State Genetic Algorithm– Pseudoknots forbidden (conflicts)– Fitness = -E’
– Effect of Similarity(Q, S) diminishes with each generation (pseudo-SA).

Genetic Algorithm - Repn.
• Stem-loop representation (Chen et. Al. 2000)
– Window method (EMBOSS Palindrome)
23 52
(23 52 3 3.2)
startend
length
weight

Genetic Algorithm - Operators
• Mutation– Add stem from stem pool to a child
• Crossover
P1
P2
C1
C2
Fit stems of P2 into C1 or C2 randomly.
Placement must be conflict free.

Preliminary Results
• E’ does not lead to drastic speed up
• Genetic algorithm is very slow– If initial population generated randomly
from stem pool.– Use suboptimal folding for initial
population.

Preliminary Results Explained
• The real structure is usually very similar the Tinoco optimal structure.
• View E’ as a way of choosing among the suboptimal structures.

Future Work
• More testing on the entire RNase P Database (> 400 structures)
• Tune E’
• Accuracy comparison to MFE and Partition Function Algorithms
• Parallelize genetic algorithm

END