dispense di “bioingegneria e informatica medica”...prodotto in serie e a basso costo. il...
TRANSCRIPT

Università degli Studi di Perugia Corso di Laurea in Medicina e Chirurgia
Docente: Pier Giorgio Fabietti
Dispense di
“Bioingegneria e Informatica Medica”
II a Parte
Anno Accademico 2009-2010

1
TIPOLOGIE DI ELABORATORI
Il primo elaboratore elettronico digitale, chiamato ENIAC, fu presentato nel
1946 all’Università della Pennsylvania, conteneva 18.000 valvole termoioniche,
pesava trenta tonnellate e occupava una superficie di 160 metri quadrati. I primi
computer furono commercializzati una sessantina di anni fa. Le loro unità centrali
di elaborazione (CPU, Central Processing Unit), progettate su commissione e
costruite manualmente, erano enormi e molto costose. Poiché queste macchine si
surriscaldavano molto facilmente, venivano tenute in ambienti con aria
condizionata e dovevano essere raffreddate ad acqua come i motori delle auto.
Erano talmente costose e complicate che venivano usate soltanto dalle grandi
imprese e vi avevano accesso solo persone molto qualificate. Gli altri impiegati le
utilizzavano soltanto per inserirvi dei dati da elaborare (dati di ingresso o input) e
per ritirare i lunghi elaborati stampati che costituivano il risultato della loro
elaborazione (dati in uscita o output). Nel 1969 M.E. Holf, ingegnere di una
piccola azienda, la Intel, riuscì a ridurre le dimensioni delle imponenti CPU a
quelle di un chip della grandezza di un francobollo che, al contrario delle prime,
costruite in esemplari unici, era estremamente facile da riprodurre. Si trattava del
primo microprocessore che, nonostante non fosse di uso generale come quelli
odierni, ha il merito di aver dato il via ad una vera e propria rivoluzione
tecnologica che ha cambiato la vita di milioni di persone. Oggi i microprocessori
vengono prodotti meccanicamente con l’efficienza di una catena di montaggio:
costano poco, sono piccoli, affidabili e soprattutto potenti. Ormai si trovano non
solo all’interno degli elaboratori dove ce ne può essere più di uno, ma anche in
posti assolutamente impensabili. Tutti i microprocessori sono dotati di un orologio
incorporato che ne determina la velocità di funzionamento.
Il computer è il centro nevralgico di quasi tutti i moderni sistemi
informativi. Gli elaboratori più potenti, utilizzati nei centri di calcolo delle grandi
aziende, dei ministeri e delle università, sono i supercomputer, i mainframe e i
minicomputer.

2
Supercomputer
I supercomputer sono i più potenti elaboratori disponibili. Hanno numerose
applicazioni tecniche e scientifiche, come l’elaborazione delle previsioni del
tempo, la progettazione di automobili e la creazione di effetti speciali
cinematografici di assoluto realismo. Alla fine degli anni ‘90 Intel ha creato il
primo supercomputer in grado di eseguire più di un trilione di operazioni al
secondo, una prestazione tre volte superiore a quella dell’elaboratore più veloce
costruito in precedenza. Mentre altri computer in genere hanno un unico
processore che effettua un calcolo per volta, questo supercomputer è dotato di più
di 7.000 processori capaci di eseguire altrettante operazioni contemporaneamente,
in base ad una procedura di elaborazione parallela. In un secondo può effettuare
un numero di operazioni pari a quelle che 265 milioni di persone riuscirebbero ad
eseguire in 125 anni utilizzando una calcolatrice manuale. La visualizzazione
grafica dei dati numerici esige spesso una notevole potenza di prestazione che può
essere fornita solo da un supercomputer. Attualmente uno dei supercomputer più
veloci al mondo si chiama Blue Mountain e viene impiegato nei Laboratori di Los
Alamos (Nuovo Messico). Recentemente Intel ha annunciato la costruzione di una
rete di calcolatori (costituita da più di 3300 processori non dislocati nello stesso
luogo, ma collegati da connessioni ad alta velocità) che avrà la potenza di calcolo
di un supercomputer e sarà, quindi, in grado di svolgere 13,6 trilioni di operazioni
in virgola mobile (flop) al secondo (13,6 Teraflops).
Mainframe e server
I mainframe (ora noti come server) in genere sono utilizzati nelle grandi
aziende per svolgere funzioni centralizzate come la gestione della contabilità e il
controllo dei magazzini. Di norma occupano un’intera stanza e sono gestiti da
personale altamente qualificato.

3
Fig. 1 – Mainframe
I supercomputer, i mainframe e i server sono in grado di elaborare i dati
immessi da centinaia e persino migliaia di utenti contemporaneamente, sia che
questi si trovino in uno stesso edificio oppure che siano sparsi in tutto il mondo.
Questo è possibile grazie alla costruzioni di reti di computer alle quali si può
accedere secondo varie modalità.
Minicomputer
I minicomputer (ora chiamati anch’essi server) sono meno potenti dei
mainframe e possono essere di diverse dimensioni, grandi quanto un frigorifero o
sufficientemente piccoli da stare su una scrivania. Sono spesso utilizzati dalle
grandi aziende e dai centri di calcolo delle piccole organizzazioni pubbliche e
private o da divisioni di grandi organizzazioni.
Personal Computer
I personal computer (PC) possono lavorare autonomamente od elaborare
dati ricevuti da altri computer ai quali sono connessi, eseguendo calcoli, creando
elenchi ordinati o rappresentando i dati in forma grafica.

4
Fig. 2 – Personal Computer
Terminali
I terminali, pur essendo simili ai personal computer, offrono delle
prestazioni molto più limitate. Sono dotati soltanto di uno schermo, una tastiera e
dei componenti elettronici necessari per comunicare con il computer a cui sono
connessi e servono esclusivamente ad inviare e ricevere informazioni. Non
essendo in grado di elaborare dati, vengono chiamati terminali stupidi. Esistono
tuttavia dei terminali, detti terminali intelligenti, con una limitata capacità di
elaborazione.
Gli ultimi nati sono i network computer e i network PC. Si tratta di un
incrocio tra i PC veri e propri e i terminali: funzionano come terminali in quanto
ricevono dati e programmi da computer più potenti e come PC sono in grado di
elaborare autonomamente i dati ricevuti.

5
PERSONAL COMPUTER
In genere i supercomputer e i mainframe sono costruiti su commissione ed
essendo molto costosi ne vengono venduti solo pochi esemplari. La diffusione del
calcolatore anche nelle nostre case è dovuta all’invenzione del microprocessore,
prodotto in serie e a basso costo. Il successo di questi computer ha portato a
numerose innovazioni e allo sviluppo di una grande varietà di modelli.
Desktop e workstation
Il personal più diffuso è il desktop, progettato per essere posizionato
permanentemente su una scrivania. Le workstation sono invece dei computer ad
alto rendimento e piccole dimensioni, utilizzate prevalentemente da scienziati,
ingegneri e grafici.
Fig. 3 – Workstation
Notebook
I notebook sono leggeri e maneggevoli, tanto che possono entrare
facilmente in una ventiquattrore; in viaggio funzionano grazie a batterie
ricaricabili, mentre in casa e in ufficio possono essere inseriti in una unità
fondamentale chiamata docking station, che consente di aumentarne il rendimento
fino a raggiungere la potenza dei sistemi desktop più grandi.

6
Fig. 4 – Notebook
I più piccoli
In alcuni casi i notebook sono troppo grandi e per questo motivo sono stati
creati dei computer ancora più piccoli: alcuni, chiamati Organizer, sono usati
soltanto per memorizzare promemoria, date e numeri telefonici; altri, invece, sono
più potenti.
Computer palmari sono i più piccoli in assoluto. Avendo tastiere piuttosto
piccole, non sono molto maneggevoli da usare per scrivere testi o inserire grandi
quantità di dati, ma risultano di grande utilità per molte altre applicazioni: i
commercianti li utilizzano per registrare i loro clienti, altri per eseguire calcoli,
memorizzare appuntamenti e annotare indirizzi e numeri telefonici.
Fig. 5 – Computer Palmare

7
PDA (Personal Digital Assistant) sono tra i modelli più piccoli, privi di
tastiera per essere ancora più maneggevoli: Possono essere dei semplici organizer,
con rubrica telefonica, calcolatrice e calendario, oppure delle unità più potenti in
grado di inviare e ricevere e-mail e persino di navigare in internet.
Fig. 6 – PDA (Personal Digital Assistant)
STRUTTURA DI UN MINICALCOLATORE
I sistemi informativi comprendono un’ampia varietà di dispositivi, tra cui
calcolatori, fax, stampanti, collegamenti di rete e persino trasmettitori satellitari.
Non è necessario comprendere in dettaglio come funzionano questi dispositivi, ma
conoscere i principi che regolano i sistemi digitali è importante anche per chi
vuole semplicemente leggere riviste specializzate di informatica o comprare
apparecchiature per la casa e per l’ufficio. Tra i numerosi dispositivi che fanno
parte delle tecnologie informatiche, il più importante è senza dubbio il computer.
Anche se non riparerete mai il computer da soli, qualche volta vi capiterà di
dover aggiungere dei componenti. Si potrebbe trattare di un’operazione semplice
come collegare una stampante o una operazione complicata (non molto a dire la
verità) come aprire il computer per inserirvi una scheda.
In questi casi può essere utile conoscere i principali componenti presenti
all’interno di un computer (Fig. 7).

8
CLOCK
D. M. A.
R A M
0101110001001
Memoria Programmi
Puntatore a 32 bit
ALU = Unità Logica Aritmetica
PerifericaI
INTERFACCIA
0101010111001
Memoria Dati
000000000001
A. L. U.
0101010111001
0101010111001
Registri Ausiliari
Registro Accumulatore
PerifericaI/O
PerifericaO
R.O.M .
CPU = Central Processing Unit
Struttura del Computer
C. P. U.
Bioingegneriaa.a. 2009/2010
Fig. 7 – Struttura di un minicomputer
La scheda madre
All’interno del computer troviamo la scheda madre, che contiene quasi tutti
i circuiti a cui sono collegati il microprocessore, la memoria, l’alimentatore ed
altri dispositivi ancora.
In un calcolatore si possono distinguere tre parti principali (fig.8):
- L’unità centrale di elaborazione (CPU) che controlla le operazioni del
sistema ed effettua le operazioni aritmetiche e logiche.
- La memoria, ove sono contenuti dati e programmi.
- Il sistema di ingresso/uscita (I/O).

9
Fig. 8 – Scheda madre di un PC prodotto nel 1999
CPU – (Unità Aritmetica, Logica e di Controllo)
L’ unità centrale di elaborazione (CPU) è formata dall’Unità Aritmetica-
Logica (ALU) e dall’Unità di Controllo. La prima effettua le operazioni
aritmetiche (addizione, sottrazione, moltiplicazione, divisione) e logiche
(confronto). Legge i dati dalla memoria centrale, li manipola e restituisce i
risultati alla memoria stessa, utilizzando appositi registri accumulatori. Mentre
l’ Unità di Controllo dell’elaboratore provvede alla decodifica ed alla esecuzione
delle istruzioni. L’unità di Controllo è costituita, tra l’altro, da:
- Un registro delle istruzioni, che contiene ogni istruzione mentre viene
decodificata ed eseguita;

10
- Un registro dell’indirizzo delle istruzioni, che contiene l’indirizzo
dell’istruzione che deve essere successivamente eseguita;
- Un decodificatore, che interpreta le istruzioni ed attiva i circuiti che le
debbono eseguire.
Fig. 9 – CPU su scheda inserita in uno slot di una scheda madre
Memoria Centrale o RAM (Random Access Memory)
La memoria centrale di un elaboratore elettronico può contenere una grande
quantità di dati binari e trasmetterli alle altre parti dell’elaboratore ogni qualvolta
esse ne facciano richiesta. La memoria centrale oggi costituita da chip, negli anni
50 era formata da nuclei di ferrite. Ogni nucleo poteva essere permanentemente
magnetizzato in un verso o nell’altro da un’apposita corrente. Alla
magnetizzazione in un senso veniva attribuito il valore 1, a quella in senso
opposto il valore 0. Pertanto ogni nucleo conteneva un bit.(°)
La dimensione della memoria centrale varia notevolmente da elaboratore ad
elaboratore e ne costituisce un fattore che determina, e spesso limita, le tecniche
di programmazione, i linguaggi da usare, il tipo di lavori che l’elaboratore può
svolgere. A titolo di orientamento, si può affermare che la memoria centrale varia
da alcuni milioni a qualche miliardo di caratteri o byte.(°°)
Altro elemento importante per la caratterizzazione delle prestazioni della
memoria centrale è il suo “tempo di accesso”, cioè il tempo intercorrente fra

11
l’istante in cui avviene la richiesta di un dato e l’istante in cui il dato stesso è letto
o registrato. Anche il tempo di accesso può variare notevolmente (da qualche
microsecondo a decimi di nanosecondo). E’ infine utile ricordare che l’insieme
delle istruzioni costituenti il programma in fase di elaborazione, è interamente
contenuto nella memoria centrale.
L’esistenza del programma memorizzato è infatti una delle caratteristiche
salienti degli elaboratori elettronici, che li differenzia nettamente dalle altre
apparecchiature per l’elaborazione dei dati.
Fig. 10 – Scheda RAM (Random Access Memory)
(°) Bit : Abbreviazione di binary digit, ossia cifra binaria. Una delle due cifre (0 e 1) usate nel sistema binario di numerazione. Il termine è esteso nell’uso alle varie forme di materializzazione di una cifra binaria, quali il nucleo magnetico, un’aureola magnetizzata su un supporto magnetico, un impulso in un circuito.
(°°) Byte: Parola di 8 bit. Essa può contenere un carattere alfanumerico o una rappresentazione numerica compresa fra 0-255.
(1 byte = 8 bit)
(1 K.byte = 1 Kilo-bytes = 1.024 bytes = 8.192 bits)
(1 M.byte = 1 Mega-bytes = 1.048.576 bytes)
(1 G.byte = 1 Giga-bytes = 1.073.741.824 bytes)

12
Sistema di Ingresso/Uscita (I/O)
Normalmente il trasferimento dei dati dalla periferica alla memoria (o
viceversa) avviene in tre passi successivi:
- Dalla periferica alla sua interfaccia.
- Dall’interfaccia all’unità centrale, attraverso un insieme di
collegamenti chiamato I/O BUS (Input/Output BUS).
- Dall’unità centrale (CPU) alla memoria.
Una seconda via per il trasferimento dei dati (DMA: Direct Memory
Access) evita di passare per l’unità centrale ed è usata per le periferiche
particolarmente veloci quali dischi, nastri magnetici e convertitori Analogici-
Digitali ad elevata frequenza di campionamento. Ogni periferica è collegata con
un cavo direttamente ad una cartolina di interfaccia all’interno del calcolatore.
Tale cartolina viene poi inserita in uno degli slots di I/O a ciascuno dei quali è
assegnato un prefissato indirizzo detto Select-code. Il calcolatore può allora
comunicare con una specifica periferica sulla base del suo Select-code. Quando
una periferica è pronta per essere servita (ci si riferisce al trasferimento dati I/O)
la sua interfaccia invia un segnale, detto “interrupt”, all’unità di controllo che
interrompe l’esecuzione del programma corrente (od il servizio ad una periferica
con priorità più bassa) per soddisfare la richiesta di questa periferica.
Le periferiche sono classificate in :
- Periferiche di Input : dispositivi utilizzati per trasmettere informazioni
all’Unità Centrale (es.: Tastiera, mouse, etc.) .
- Periferiche di Input/Output (I/O) : dispositivi utilizzati per trasmettere
informazioni all’Unità Centrale e ricevere informazioni dall’Unità
Centrale (es.: Hard-disk, modem, etc.) .
- Periferiche di Output : dispositivi utilizzati per ricevere informazioni
dall’Unità Centrale (es.: Display, stampanti, etc.) .

13
DISPOSITIVI DI INPUT
Tastiera alfanumerica
La tastiera alfanumerica è il più comune dispositivo di input. Essa trasforma
la pressione di un tasto nel corrispondente codice binario ASCII. Esistono diverse
versioni della tastiera per le diverse nazionalità o per particolari set di caratteri
grafici (vedi fig. 11).
Fig. 11 - Tastiera italiana e tastiera con caratteri dell’alfabeto greco
Mouse
Il mouse è un dispositivo di input grafico che viene spostato su un piano e
provoca lo spostamento di un puntatore sullo schermo del computer. Può essere di
tipo meccanico (con una pallina che gira a contatto con un piano) o di tipo ottico
(che è ancora più preciso sebbene richieda una superficie particolare).
Il mouse è ormai divenuto uno standard di mercato e questo dipende dalle
sue favorevoli caratteristiche ergonomiche. Rispetto alla penna ottica o allo
schermo sensibile al tatto non richiede di lavorare tenendo le mani sollevate, cosa
che a lungo andare stanca. Rispetto al joystick o alla trackball è molto più preciso.

14
Fig. 12 - Mouse
Joystick
Il joystick è una levetta che serve a indirizzare un puntatore sullo schermo.
Utilizzato di preferenza per giochi elettronici non è molto adatto per il disegno in
quanto poco preciso, ciononostante viene adottato da parecchi sistemi in
medicina, come gli ecografi, i TC, le gammacamere computerizzate, etc. .
Fig. 13 - Joystik
Trackball
La trackball è una sfera che viene fatta rotolare su un supporto e aziona un
puntatore sullo schermo. Anch’essa deriva da giochi elettronici, ma è possibile
trovarne in apparecchiature cha lavorano su immagini come TC, ecografi, etc. .

15
Fig. 14 - Trackball
Tavoletta grafica
La tavoletta grafica o digitizer utilizza una stilo a forma di penna che consente
di trasferire al computer i disegni prodotti direttamente sulla tavoletta.
Fig. 15 – Tavoletta grafica
Penna ottica
La penna ottica è il lettore più economico fra i lettori di codici a barre; per
effettuare la lettura la penna va messa a contatto con il codice. Questi codici sono
formati da barre e spazi di diverso spessore e convertiti dai lettori in dati numerici
in modo che le informazioni rilevate possano essere elaborate da un computer. I
lettori di codici a barre sono precisi, veloci ed economici. Queste caratteristiche ne
hanno permesso la diffusione nelle farmacie, nei supermercati ed in molte attività
commerciali.
Sempre più frequente è il loro utilizzo in sanità, come ad esempio nei

16
Laboratori di analisi, nei magazzini farmaceutici ed economali, nelle attività di
accettazione ospedaliera e in alcune fasi di di erogazione di prestazioni sanitarie.
Fig. 16 – Penna Ottica
Penna luminosa
La penna luminosa è un dispositivo che interagisce direttamente con lo
schermo in quanto dotato di una piccola fotocellula che intercetta il pennello
elettronico del monitor e consente al computer di individuarne la posizione. Non
avendo una precisione elevata, la penna luminosa viene utilizzata soprattutto
come dispositivo di puntamento per scegliere aree dell’immagine.
Scanner
Lo scanner è un dispositivo che consente di immettere nel computer un
disegno, una fotografia o una pagina di testo. Una testina scandisce l’immagine
linea per linea e una parte elettronica produce un’immagine nel formato digitale
comprensibile per il computer. Gli scanner possono essere forniti di particolari
programmi OCR (da Optical Chracter Recognition) per il riconoscimento dei
caratteri in una pagina di testo.
Questi strumenti consentono il trasferimento nella memoria del computer di
un enorme patrimonio di testi stampati che altrimenti richiederebbero un lavoro di
battitura molto lungo e costoso.

17
Fig. 17 – Scanner
Telecamera
Una telecamera applicata al computer ha più o meno lo stesso tipo di
applicazioni dello scanner. La differenza sta in una maggiore velocità di
acquisizione offrendo la possibilità di registrare immagini in movimento. Per
contro la precisione è molto inferiore e sono anche frequenti distorsioni
dell’immagine. Le telecamere digitali si possono collegare ad un elaboratore per
visualizzare filmati o registrarli su Hard-disk, CD o DVD.
Fig. 18 – Videocamera, Webcam, Fotocamera
Input vocali
Il microfono è un dispositivo che collegato ad un PC dotato di una scheda
audio, permette di registrare suoni nel computer. Il microfono viene spesso
impiegato per videoconferenze su Internet o reti locali, dove, grazie a specifici
programmi, gli utenti possono dialogare fra loro. E’ inoltre uno strumento molto
utile per i disabili in quanto consente l’utilizzo di speciali software di

18
riconoscimento vocale che permettono di dettare testi al computer e governare
quasi tutte le funzioni del mouse.
riconoscimento vocale
Quando chiamate la compagnia dei telefoni per una informazione, a volte vi
risponde un computer che vi invita a dire il nome dell’utente che dovete chiamare
e vi fornisce il corrispondente numero telefonico. Questo sistema funziona
indipendentemente dall’interlocutore. Di solito invece, i sistemi vocali sono
programmati per riconoscere la voce di un singolo utente. In questo caso è
necessario innanzitutto “allenare” l’elaboratore a riconoscere la vostra pronuncia.
Le parole contenute nel vocabolario del programma (fino a 120.000) vengono
visualizzate sullo schermo una alla volta e devono essere pronunciate ad alta voce
nel microfono. La vostra pronuncia viene quindi digitalizzata, analizzata e messa
in memoria come matrice vocale.
In seguito, quando parlate al computer, le vostre espressioni vocali vengono
immediatamente associate alle matrici presenti in memoria. Quando il computer
trova la matrice corrispondente a una parola, questa viene visualizzata o il
comando corrispondente eseguito. Per analizzare il vostro modo di parlare
vengono utilizzati sia un modello acustico che un modello linguistico. Con il
primo, la vostra pronuncia viene comparata a migliaia di campioni vocali presi da
altre persone, finchè non si ottiene il miglior corrispondente acustico di una
parola, accompagnato da una breve lista di alternative. Con il secondo, invece,
sulla base di analisi statistiche, si determina quale termine è più probabile che
occorra in un determinato contesto nei casi di omofonia (ad esempio “anno” e
“hanno”).
Schede Perforate (non più utilizzate)
La scheda è un rettangolo di cartoncino di circa cm 19x8, divisa in 12 righe
ed 80 colonne. Su ogni colonna viene perforato un carattere secondo un codice
(Hollerith) a 12 bit, un bit per riga. Una perforazione corrisponde al bit 1;
l’assenza di perforazione, al bit O.
Le schede vengono perforate con una macchina perforatrice, che ha una

19
tastiera simile a quella delle macchine da scrivere. Premendo un tasto si perfora
un carattere sulla scheda che, contemporaneamente, avanza di una colonna. La
perforatrice traduce quindi le informazioni in un codice binario e le perfora su
scheda.
Fig. 19 - Scheda a 80 colonne e a 12 righe non ancora perforata e con
prestampato il tracciato del record e le posizioni riservate ai campi
La traslazione dell’informazione dalla scheda alla memoria centrale con
traduzione del codice, da quello di Hollerith a quello usato in memoria, viene
effettuata dal “lettore di schede”. Un’altra unità, “il perforatore di schede”,
trasferisce l’informazione dalla memoria alla scheda (spesso le due unità fanno
parte di un’unica apparecchiatura).
Nastro Perforato (non più utilizzato)
E’ una striscia di carta larga mm 20,5 avvolta su una bobina e lunga fino a m 150
è divisa idealmente in strisce longitudinali, chiamate piste o canali. Ogni carattere
viene rappresentato perforando il nastro trasversalmente in corrispondenza delle
piste, secondo un codice dipendente dal numero delle piste stesse (fig. 20).
Fig. 20 – Nastro perforato

20
DISPOSITIVI DI INPUT/OUTPUT
Memorie di Massa
Fondamentali nel processo di elaborazione ed archiviazione dati sono i
dispositivi di memoria di massa disponibili in due diversi tipi: memorie statiche e
dinamiche. Le memorie statiche non richiedono alcun movimento meccanico per
l’accesso al dato e tipicamente impiegano semiconduttori o nuclei magnetici. Le
memorie statiche sono montate su cartoline simili a quelle della memoria
principale oppure su box separati che contengono anche i circuiti di controllo, di
alimentazione e l’interfaccia. Le memorie dinamiche sono invece memorie che
impiegano un supporto magnetico od ottico, quali ad esempio nastri o dischi, nelle
quali la lettura e la scrittura dei dati dipende da un movimento meccanico.
Unità a Nastro Magnetico
La registrazione su nastro magnetico e la lettura da nastro magnetico
rappresentano operazioni concettualmente molto semplici. Il processo è
rappresentato in fig. 21. Se una corrente elettrica fluisce attraverso la bobina, essa
genera un campo magnetico nel circuito magnetico costituito dalla testina e dal
nastro magnetico compreso fra le sue estremità. In questo modo è possibile
magnetizzare in modo permanente un punto del nastro.
Inversamente, se il punto magnetizzato si muove sotto la testina, nella
bobina si crea una corrente indotta per effetto della variazione di flusso magnetico
concatenato con la bobina stessa. In questo modo è possibile registrare dati su un
nastro magnetico in modo binario: un punto magnetizzato positivamente
corrisponde a "1" logico, un punto magnetizzato negativamente a “0” logico. Di
norma le testine di lettura e scrittura sono costituite da una serie di magneti posti
su di una linea perpendicolare alla direzione di spostamento del nastro magnetico.
Un nastro magnetico può essere magnetizzato in modo analogico oltre che digitale
come si è appena visto. In questo modo la corrente che fluisce nella bobina varia

21
nel tempo in modo continuo anziché impulsivo.
Fig. 21 – Nastro Magnetico
I vantaggi del nastro magnetico sono:
1. elevata velocità di trasferimento dei dati;
2. capacità d’immagazzinare un gran numero di caratteri (in media qualche
decina di miliardi di caratteri.
3. possibilità di uso ripetuto dello stesso nastro per contenere dati diversi;
4. economicità, in relazione alla capacità.
Gli svantaggi sono:
1. per raggiungere un dato sul nastro magnetico occorre esaminare tutti quelli
che fisicamente lo precedono (accesso sequenziale);
2. la presenza di polvere sulla testina di lettura-scrittura o sul nastro stesso
può causare errori;
3. i nastri debbono essere immagazzinati in ambienti accuratamente
controllati.

22
Dischi Magnetici
La memoria a dischi magnetici è costituita da un insieme di dischi uguali
disposti parallelamente, imperniati sullo stesso asse, distanziati fra loro di circa un
centimetro. Le facce dei dischi sono ricoperte di materiale magnetico e suddivise
in piste concentriche (qualche centinaio per ogni faccia di disco). I bit costituenti
il carattere vengono memorizzati in serie su una pista; ogni pista può contenere
migliaia di caratteri. La capacità di una memoria a disco varia da 50 a 500.000
milioni (500 giga) di caratteri. La lettura e la scrittura avvengono per mezzo di
apposite testine, una per ogni faccia di disco, disposte a pettine, in grado di
raggiungere qualunque pista con un solo movimento. Le testine sono installate
sulle “unità a disco magnetico” che trasferiscono le informazioni dal disco
all’unità centrale e viceversa.
Fig. 22 - Dischi magnetici
Il tempo di accesso varia da qualche millisecondo a 10 millisecondi; la
velocità di trasferimento dei dati da 10.000 a 100.000.000 caratteri/sec.
Vantaggi:
1. si possono raggiungere i dati localizzando in maniera semplice la pista su
cui si trovano (accesso diretto);
2. si possono memorizzare grandi quantità di dati;
lettura /scrittura

23
3. i dischi possono essere montati o smontati dall’unità in pochi secondi.
L’unico vero svantaggio da rilevare in passato era l’elevato costo per dischi
di grandi capacità.
Fig. 23 – Dischi Magnetici (Hard-disk)
Dischetti magnetici o Floppy Disk - (non più utilizzati)
Anni fa si è molto diffuso l’impiego di unità a dischi flessibili (“Floppy
Disk”) dato il loro costo contenuto, la loro maneggevolezza, la relativa semplicità
di interfacciamento ed impiego.
In questo tipo di realizzazione il disco è contenuto in un involucro di
materiale plastico che si inserisce nel “drive” dell’unità a floppy disk (fig. 24).
Sono utilizzati per memorizzare informazioni su un supporto magnetico esterno al

24
computer e spostare i dati da un PC ad un altro.
I Floppy variano per formato e densità; il formato standard è quello di 3
pollici e mezzo a doppia faccia e ad alta densità (DS/HD) con una capacità di 1,44
Mega-Bytes. Sui primi PC le dimensioni del floppy disk erano di 5 pollici e un
quarto o di 8 pollici su alcuni minicomputer, i dati potevano essere memorizzati in
semplice o in doppia densità in una faccia o nelle due facce.
Fig. 24 – Dischetto Magnetico da 3 pollici e mezzo (Floppy-disk)
Prima di essere pronti per memorizzare informazioni i dischetti devono
essere formattati, cioè predisposti dal computer per le operazioni di lettura e
scrittura dei dati
Essendo supporti magnetici, i floppy devono essere tenuti lontani da campi
magnetici, esposti a temperature elevate e protetti dalla polvere.
Il loro utilizzo, per limiti di capacità di memoria, è oggi ridotto per la
disponibilità di altre memorie a costi contenuti e notevolmente più performanti
(CD-R; DVD-RW; USB2-FlashPen, etc.)
Cartucce a Nastro Magnetico
Normalmente questi dispositivi vengono utilizzati con minicomputer e
mainframe per operazioni di salvataggio dati (backup). Le cartucce a nastro sono
delle cassette di plastica con all’interno un nastro magnetico di lunghezza
variabile (da 90 a 170 mt) e altezza da 4 o 8 mm. I lettori di queste cartucce si
chiamano tape-streamer. Essi sono gestiti da software proprietari che ad esempio
permettono di fare il backup dei dati ad un’ora prestabilita.

25
Compact Disk
I CD-ROM (Compact Disk – Read Only Memory), simili ai CD utilizzati
per le incisioni musicali, sono supporti ottici per la memorizzazione dei dati. I
CD-ROM, dopo essere stati registrati una prima volta, possono essere utilizzati
soltanto per la lettura delle in formazioni memorizzate. I CD sono costituiti di un
substrato di policarbonato, una pellicola riflettente, e una pellicola protettiva. Tra
il substrato e la pellicola, c’è una pellicola di registrazione composta da un
polimero colorante organico. Differentemente dai CD regolari, una spirale
preincisa è usata per guidare il laser, questo semplifica la progettazione hardware
e assicura la compatibilità dei dischi.
I CD sono di due tipi:
- CD-R
- CD-RW
Fig. 25 – CD-ROM (Compact Disk – Read Only Memory)
I CD-R sono CD-Registrabili e sono WORM (Write Once, Read Multiple,
cioè scrivi una volta, leggi più volte) e funzionano come i CD standard. Il
vantaggio di un CD-R rispetto ad altri media è che può essere letto da un lettore
CD standard. Lo svantaggio è che non può essere riutilizzato.
I CD-RW o CD Riscrivibili possono essere cancellati e riutilizzati tra 1.000
e 100.000 volte, ma tali dischi non funzionano in tutti i lettori.
I CD sono letti da lettori di CD e letti e scritti dai masterizzatori. Entrambi
questi dispositivi usano al posto della testina un raggio laser di determinata

26
frequenza (770-830 nm in lettura e 780 nm in scrittura). Un masterizzatore, in
scrittura, crea una serie di buchi nel colorante organico chiamati “pits”. Gli spazi
tra i pits sono chiamati “lands”. La sequenza di questi codifica l’informazione. La
spirale compie 22.188 rotazioni intorno al CD con circa 600 giri per millimetro.
Se srotolassimo la spirale, sarebbe lunga 5 km circa.
Il CD viene letto e scritto dall’interno verso l’esterno. E il tempo necessario
per scrivere un CD dipende da quanti dati si vuole incidere, e quanto è veloce il
masterizzatore. Per incidere 650 MB di dati s’impiega circa 74 minuti a 1x; 37
minuti a 2x e 19 minuti a 4x, bisogna aggiungere inoltre qualche minuto per
“finalizzare” il disco. Si ricorda che 1x equivale a 150KB/sec, 2x sono
300KB/sec, e così via. La durata dei CD varia da 75 ai 100 anni. Dimensioni e
Capacità:
Dimensioni (cm) Capacità (MB)
CD da 80 mm di diametro 185 ↔↔↔↔ 210 MB
CD da 120 mm di diametro 650, 700, 800, 870, 878 MB
Fig. 26 – Un masterizzatore interno
DVD (Digital Versatile Disk)
I DVD (Digital Versatile Disk) dal punto di vista concettuale sono dei CD
con una capacità molto più ampia. Il processo di scrittura è analogo a quello dei

27
tradizionali CD-R, dove uno degli strati più interni subisce una trasformazione
permanente delle proprie capacità di trasmettere la luce ad opera del raggio
emesso dal laser.
Necessitano di lettori e masterizzatori DVD per essere letti e scritti. e si dividono
in:
- DVD±R
- DVD±RW
- DVD-RAM
Dimensioni e Capacità:
Dimensioni (cm) Capacità (Byte)
DVD da 80 mm di diametro 1,4 GB
DVD (±R; RW; RAM) da 120 mm di diametro da 4,7 a 17 GB
Schermi sensibili al tatto (Touch Screen)
Invece di utilizzare la penna, si usa il proprio dito, la posizione rispetto allo
schermo viene rilevata da fasci di luce infrarossa che vengono interrotti dalla
presenza del dito. Evidentemente è un sistema solo di puntamento e non di
disegno.

28
DIPOSITIVI DI OUTPUT
Monitor
Il monitor, (chiamato anche “video” o “display”) è la periferica di output per
eccellenza, quella che permette di visualizzare le informazioni grafiche e testuali e
vedere il risultato dell’interazione con il computer.
D’aspetto è molto simile a un televisore: uno schermo di differenti misure
nel quale si formano le immagini, e alcuni dispositivi di controllo. Rispetto al
televisore però può vantare una qualità delle immagini nettamente superiore,
soprattutto per quanto riguarda la definizione dei dettagli.
Sul mercato sono presenti diverse tipologie di monitor. In passato i più
popolari erano quelli a tubo catodico (detti video CRT, Cathod Ray Tube – Figura
27); ma negli ultimi anni si sono diffusi gli schermi a cristalli liquidi (detti LCD,
acronimo di Liquid Cristal Display), già utilizzati nei computer portatili (Figura
28), e quelli al plasma.
I monitor a tubo catodico si basano sulla stessa tecnica dei televisori: lo
schermo di vetro rappresenta la parte finale del tubo catodico, una sorta di
ampolla di vetro sottovuoto che si estende per tutta la lunghezza del monitor. Lo
schermo è ricoperto da uno strato di fosfori che, colpiti da fasci di elettroni
prodotti dal cannone elettronico all’interno del tubo catodico, diventano
fosforescenti ed emettono luce.
Fig. 27 – Monitor a Raggi Catodici

29
I monitor a colori hanno tre cannoni che colpiscono rispettivamente i fosfori
blu, rossi e verdi che si trovano sullo schermo, in modo da produrre pixel di
colore corrispondente che, sovrapponendosi, possono formare una grande varietà
di tonalità cromatiche, la cui risoluzione dipende, come detto, dalla scheda video
impiegata.
L’architettura del monitor CRT non consente di visualizzare l’intera
immagine contemporaneamente su tutta la superficie dello schermo. L’immagine
è tracciata progressivamente e ripetutamente partendo dall’alto verso il basso e
seguendo una direzione da destra a sinistra. L’intera schermata viene quindi
ridisegnata continuamente. In termini tecnici la frequenza con cui viene
ridisegnata l’immagine si chiama frequenza di refresh e può arrivare fino a 120
Hz, vale a dire 120 volte in un secondo: in questo modo il computer è in grado di
tenere costantemente aggiornata l’immagine a video. Maggiore è la frequenza di
refresh, più l’immagine è nitida e stabile. Per lavorare senza stancare la vista è
consigliabile una frequenza di 75-80 Hz.
La frequenza di refresh non è assoluta, ma dipende dalla soluzione adottata.
Per esempio un video che raggiunge i 120 Hz alla risoluzione di 640 X 480 pixel
ha un refresh di 90 Hz alla risoluzione di 800 X 600, ma scende a 72 Hz con
risoluzione 1024 X 768 e raggiunge il minimo di 60 Hz con risoluzione 1280 X
1024. Alcuni monitor supportano frequenze di refresh “interfacciate”. In questi
modelli la visualizzazione delle immagini avviene in due passate: la prima per le
righe pari e la seconda per le righe dispari.
Lo schermo dei video CRT può avere varie dimensioni che, come per i
televisori, si misurano in base alla lunghezza in pollici della loro diagonale:
esistono monitor da 14, 15, 17, 19, 20, 21 pollici.
Il monitor attualmente più utilizzato nei PC da casa ha uno schermo da 15”
(pollici). I monitor più grandi (e più costosi) di solito sono di qualità superiore e
sono dedicati al mondo professionale della grafica e dell’editoria elettronica.

30
Fig. 28 – Monitor LCD
I monitor possono adottare varie risoluzioni, in relazione alle loro
caratteristiche e alle prestazioni della scheda video del PC. Per un monitor da 15”,
la risoluzione ideale è di 800 X 600 pixel, per uno da 17”, di 1024 X 768 pixel.
Con un video da 21” è possibile impostare anche una risoluzione di 1280 X 1024
pixel. Con i monitor LCD si utilizzano risoluzioni superiori rispetto a monitor
CRT di pari dimensione. Per esempio, un 15” LCD si utilizza, a livello di
risoluzione, come un 17” CRT, un 18” LCD come un 21” CRT etc.
Fig. 29 – Monitor Tuoch-Screen
Un cenno infine ai monitor tridimensionali che richiedono l’adozione di
occhiali polarizzatori in modo che lo schermo possa apparire alternativamente
all’occhio sinistro e all’occhio destro. In questa modo, differentemente dai primi
tentativi basati sa occhiali con lenti colorate, possono essere conservati tutti i
normali colori. Al momento attuale cominciano a comparire sul mercato le prime
realizzazioni.

31
Sistemi di stampa
I sistemi di stampa permettono di ottenere una documentazione permanente
delle elaborazioni col computer. Infatti i vari tipi di stampa sono anche indicati
come hard copy per contrapposizione all’output su video che dura solamente fin
quando la macchina è accesa.
Le stampanti più comuni collegabili con un minicalcolatore sono Laser e
Getto d’inchiostro, mentre oggi sono meno utilizzate quelle termiche o ad
impatto seriali o parallele.
Stampanti termiche
Di solito sono molto veloci e a basso costo. I caratteri sono formati da una
configurazione di punti prodotti da una testina formata da una matrice di punte
calde che al contatto sensibilizzano la carta termica; presentano l’inconveniente di
perdere lo stampato con il trascorrere del tempo o con l’esposizione della carta a
fonti di calore; sono sconsigliabile per archivi.
Stampati ad impatto
La stampanti ad impatto, così denominate perché la stampa avviene
utilizzando una matrice di aghi che colpendo un nastro ad inchiostro, compongono
i caratteri.
Le stampanti a matrice di punti hanno una testina composta da un insieme
di aghi (tipicamente 9, 18 a 24 aghi) che, spinti in avanti da un solenoide,
colpiscono il nastro e compongono il carattere. Il sistema è semplice ed
abbastanza economico e permette di stampare più tipi di caratteri e anche grafici,
ma la qualità non è elevata poiché risulta sempre più o meno evidente la matrice
di punti di cui è formato il carattere.
- Stampanti ad impatto seriali: questo tipo di stampanti formano un riga di
stampa con l’impressione successiva di un carattere per volta da sinistra a
destra (monodirezionali), da sinistra a destra e da destra a sinistra

32
(bidirezionali, più veloci).
- Stampati ad impatto parallele: questo tipo di stampanti imprimono i risultati
in uscita dal computer a una riga intera per volta.
Fig. 30 – Stampante ad Aghi (Stampante ad impatto seriale)
Stampanti laser
Le stampati laser utilizzano una tecnologia che presenta diversi punti in
comune con le macchine fotocopiatrici. Mentre in queste ultime l’immagine è
raccolta da un obiettivo che sensibilizza la superficie di un tamburo carico
elettrostaticamente il quale poi raccoglie il toner e lo trasferisce alla carta, nelle
stampati laser questa operazione è svolta da un sottilissimo pennello di luce. La
risoluzione è molto elevata, da 300 a 600 punti pollice (quella di una stampante a
matrice è di 70 punti pollice circa), è possibile utilizzare caratteri diversi e
stampare grafici, inoltre le copie successive di una singola pagina sono ottenute
molto velocemente e alla stessa qualità dell’originale come avviene nelle comuni
fotocopiatrici.
Infine, oltre agli altri vantaggi, la stampante laser è molto silenziosa, e
questo non è un particolare trascurabile per l’ergonomia dell’ambiente di lavoro.
L’unico handicap rimane il prezzo elevato, anche se la produzione in grande
serie sta portando a un notevole calo dei prezzi.

33
Fig. 31 – Stampante Laser
Stampanti su film
Comprendono i sistemi di stampa su diapositiva 35 mm e su lastre
radiografiche. In genere viene utilizzato un piccolo monitor e un sistema di lenti
che convoglia l’immagine sul film. Le immagini a colori possono essere realizzate
per esposizione successiva attraverso filtri colorati. Recentemente sono apparse
sul mercato stampanti su film che utilizzano la tecnologia laser con conseguente
altissima risoluzione.
Stampanti a getto d’inchiostro
Una schiera di centinaia di microscopici ugelli spruzzano minuscole gocce o
bolle di inchiostro a base di acqua sulla carta durante lo spostamento del carrello.
Il movimento dell'inchiostro è ottenuto per mezzo di due distinte tecnologie:
- pompe piezoelettriche che comprimono il liquido in una minuscola
camera,
- resistenze elettriche che scaldano bruscamente il fluido facendolo
schizzare dall'ugello.
Entrambi veri prodigi di fluidodinamica sono realizzate con tecnologie di
fotoincisione simili a quelle per la produzione di massa dei circuiti integrati, che
consentono costi per quantità molto contenuti. La risoluzione e la qualità di

34
stampa di queste testine raggiunge livelli paragonabili alla fotografia tradizionale,
ma solamente utilizzando carta la cui superficie sia stata opportunamente trattata
per ricevere l'inchiostro.
Il problema più grave di questa tecnica è l'essiccamento dell'inchiostro nelle
testine, che è frequente causa di malfunzionamenti. Un altro svantaggio è dato
dall'elevato costo per copia stampata se confrontato con le altre tecnologie.
Fig. 32 – Stampante a Getto di Inchiostro
Stampanti Braille
Queste macchine non impiegano inchiostri ma imprimono nella carta i
simboli caratteristici dell'alfabeto Braille per non vedenti. Dispongono di una serie
di punzoni mossi da elettromagneti che perforano o imbutiscono la carta.
Uscita audio
Le uscite audio dal computer sono fondamentalmente di due tipi: suoni e
voce. La generazione di suoni, al di là di particolari applicazioni in ambito
musicale (computer music), è importante come canale integrativo per richiamare
l’attenzione su determinati eventi, un esempio è il classico beep. Nell’ambito delle
applicazioni mediche si può ricordare l’uscita audio degli ecotomografi Doppler e

35
Cardiotocografi. In questo caso l’uscita audio può sostituire l’immagine grafica
dello spettro Doppler, consentendo all’utilizzatore di concentrarsi sull’immagine
della regione analizzata. La generazione della voce o sintesi vocale trova già
innumerevoli applicazioni, specie nel campo della telefonia. Già adesso esistono
sistemi capaci di leggere un testo scritto controllando non solo la pronuncia delle
singole parole, ma anche l’intonazione e la cadenza del discorso.
Fig. 33 – Scheda Audio
Attuatori meccanici
Il risultato dell’elaborazione del computer può essere l’attivazione e il
controllo di un motore elettrico. Una tipica applicazione è il controllo delle
macchine utensili come ad esempio un tornio, per realizzare un oggetto secondo
un modello elaborato interattivamente sullo schermo.

36
TRASDUTTORI
Il trasduttore trasforma una grandezza fisica in un’altra di diversa natura,
normalmente elettrica per i vantaggi che questa rappresentazione offre. I
trasduttori possono essere resistivi, fotoelettrici, elettrochimici, piezoelettrici, etc.
Un trasduttore di pressione ad es. genera una variazione di tensione in modo
proporzionale alle variazioni di pressione.
SEGNALI DIGITALI E ANALOGICI
I segnali analogici sono paragonabili a un’onda e trasmettono un ampio
spettro di informazioni. Il nostro è un mondo analogico. Il corpo umano è
programmato per percepire e interpretare onde luminose analogiche: noi non
percepiamo soltanto i punti massimi e minimi di queste onde, ma anche quelli
intermedi. Quando parliamo, il messaggio viene trasportato da onde analogiche, e
lo stesso accade quando ascoltiamo la musica. Ogni parte dell’onda trasporta
informazioni.
Le onde analogiche sono molto sensibili alle interferenze. Questo ci appare
evidente quando cerchiamo di seguire una conversazione in una stanza rumorosa,
o quando proviamo a sintonizzarci su una stazione radiofonica che ha un segnale
debole.
A differenza dei segnali analogici, i segnali digitali possono assumere solo
due stati, acceso e spento. Per un dispositivo è semplice distinguere questi due
stati, per cui le interferenze, ovvero le informazioni vaganti estranee al messaggio
principale, non influiscono sui sistemi digitali quanto quelli analogici
37
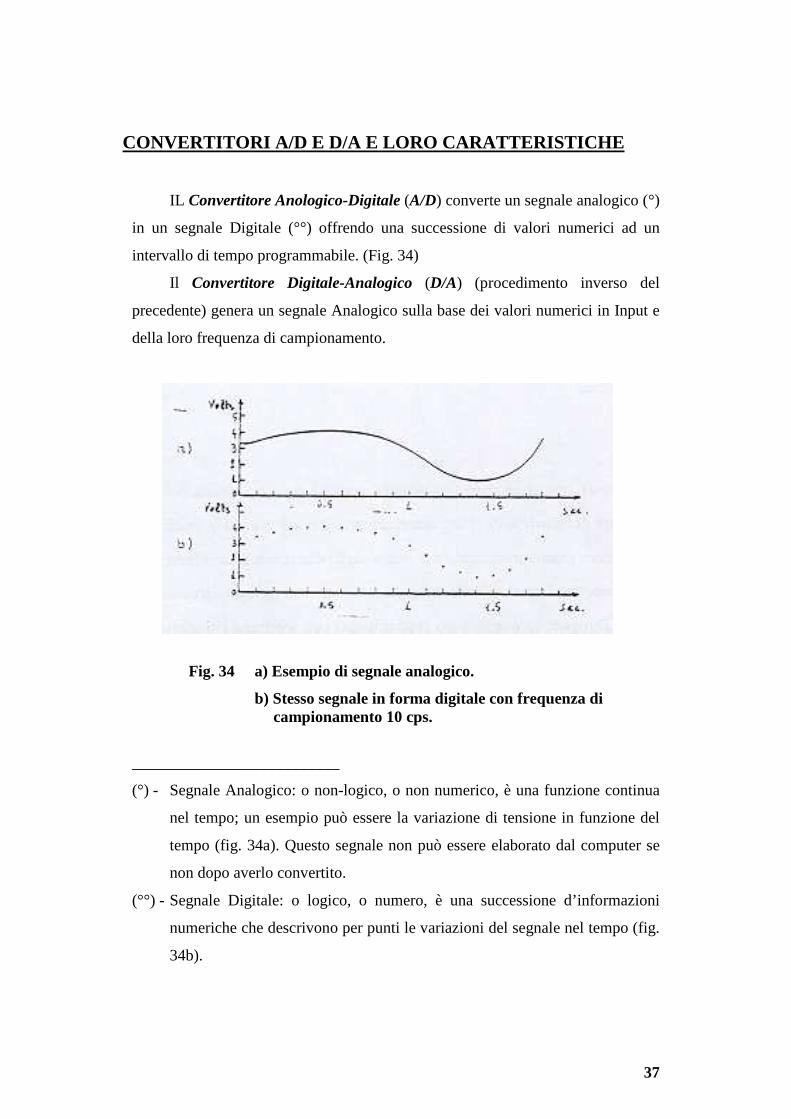
CONVERTITORI A/D E D/A E LORO CARATTERISTICHE
IL Convertitore Anologico-Digitale (A/D) converte un segnale analogico (°)
in un segnale Digitale (°°) offrendo una successione di valori numerici ad un
intervallo di tempo programmabile. (Fig. 34)
Il Convertitore Digitale-Analogico (D/A) (procedimento inverso del
precedente) genera un segnale Analogico sulla base dei valori numerici in Input e
della loro frequenza di campionamento.
Fig. 34 a) Esempio di segnale analogico.
b) Stesso segnale in forma digitale con frequenza di campionamento 10 cps.
__________________________
(°) - Segnale Analogico: o non-logico, o non numerico, è una funzione continua
nel tempo; un esempio può essere la variazione di tensione in funzione del
tempo (fig. 34a). Questo segnale non può essere elaborato dal computer se
non dopo averlo convertito.
(°°) - Segnale Digitale: o logico, o numero, è una successione d’informazioni
numeriche che descrivono per punti le variazioni del segnale nel tempo (fig.
34b).

38
Nonostante il largo impiego di convertitori A/D e D/A nel controllo dei
processi, non esiste una standardizzazione ed inoltre si riscontra spesso diversità
di nomenclatura. E’ quindi difficile per l’utente fare un confronto fra i vari
dispositivi in commercio e spesso si limita a prendere in considerazione i
convertitori forniti dal costruttore del calcolatore di processo.
I parametri da prendere in considerazione sono i seguenti:
� Risoluzione, cioè la minima variazione di ampiezza del segnale analogico
che il convertitore A/D può rilevare; è un parametro legato al numero di bit
della parola (b) e può essere calcolato con l’espressione Vt / 2b dove Vt è il
valore di fondo scala della tensione di ingresso; valori tipici per b sono: 8,
10, 12.
� Linearità, precisione con cui l’uscita risulta direttamente proporzionale
all’ingresso.
� Tempo di conversione, valori tipici sono 10 ÷ 100 µsec.
� Campo di tensione analogica in ingresso, valori tipici sono 0 ÷ 5 e 0 ÷10
Volts.
� Numero degli ingressi, nella maggior parte dei casi i convertitori A/D sono
“multiplexati” per cui possono avere anche un numero di ingressi molto
grande. Valori tipici sono 1÷32. In questo caso il tempo di conversione
deve essere aumentato del tempo di commutazione del multiplexer. Per i
convertitori D/A valgono parametri analoghi.

39
RAPPRESENTAZIONE DEI NUMERI
L’uomo è abituato a pensare i numeri in base 10 (rappresentazione
decimale). Viceversa un computer considera i numeri come stringhe di bit (dove
ogni bit può avere il valore 0 o 1), ed esegue la maggior parte delle sue operazioni
trattando i numeri in base 2 (rappresentazione binaria).
Questo paragrafo traccia una panoramica dei concetti di base della
rappresentazione dei numeri in base 2 (Sistema Binario).
- BINARIO 0 1- DECIMALE 0 1 2 3 4 5 6 7 8 9- ESADECIMALE 0 1 2 3 4 5 6 7 8 9 A B C D E F
SISTEMI DI NUMERAZIONE
0 0 0 0 01 0 0 0 12 0 0 1 03 0 0 1 14 0 1 0 05 0 1 0 16 0 1 1 07 0 1 1 18 1 0 0 09 1 0 0 1
1 0 1 0 1 01 1 1 0 1 11 2 1 1 0 01 3 1 1 0 11 4 1 1 1 01 5 1 1 1 1
DECIMALE BINARIO
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 35 – Sistemi di Numerazione
Le cifre binarie
Digitale deriva dall’inglese “digit”, cifra. Quando compiliamo un assegno,
contiamo il resto, componiamo un numero telefonico, consultiamo l’indice di un
libro e via dicendo, utilizziamo il sistema di numerazione decimale, chiamato
così perché impiega dieci cifre diverse, da 0 a 9, che possono essere combinate tra

40
loro per formare numeri diversi (ad esempio, con le cifre 1 e 9 possiamo ottenere
19, 91, 1919 ecc.)
I computer e gli altri strumenti digitali, invece, rappresentano tutti i numeri
con il sistema di numerazione binario, costituito da due sole cifre, 0 e 1.
Dato che il sistema binario utilizza soltanto le cifre 0 e 1, le informazioni
rappresentate in questo sistema possono essere elaborate secondo vari criteri e con
vari strumenti. Ad esempio, le combinazioni di zero e uno possono essere
rappresentate dalle condizioni acceso/spento, alto/basso, luce/buio, nord/sud,
su/giù, etc. . Tutte queste tecniche sono impiegate nei computer per memorizzare,
elaborare e visualizzare dati.
Come abbiamo visto le cifre 0 e 1 possono essere rappresentate,
memorizzate e visualizzate in diversi modi; tuttavia, perché abbiano un senso è
necessario stabilire un codice preciso. I segnali digitali non sono stati certo i primi
a essere usati per trasmettere informazioni: fin dai tempi più remoti l’uomo si è
servito di tamburi, segnali di fumo, bandiere, ecc.
Un esempio di codice digitale
Naturalmente la trasmissione di un messaggio più complesso richiedeva ben
più di due semplici lanterne. Ad esempio come sarebbe stato possibile avvertire i
volontari nel caso di un inaspettato cambiamento di direzione delle truppe inglesi?
Una soluzione fu trovata da Samuel Morse, che agli inizi dell’ottocento inventò il
telegrafo.
Per mezzo del telegrafo, battendo su un tasto, vengono inviati lungo un cavo
impulsi elettrici che, una volta giunti a destinazione mettono in azione un
dispositivo chiamato ricevitore acustico il quale scatta ogni volta che arriva un
impulso. Anche questo è un processo digitale, perché il ricevitore può essere
utilizzato o meno. Per trasmettere un messaggio, comunque, è necessario un
codice: Morse se ne sviluppò uno basato su scatti intervallati da pause lunghe o
corte, che una volta stampati apparivano come luci o punti. Ad esempio il ben
noto SOS è formati da tre punti tre linee e tre punti.

41
Rappresentazione Decimale
Prima di parlare della rappresentazione binaria, esaminiamo brevemente la
struttura della rappresentazione decimale. La rappresentazione decimale usa le
cifre 0,1,2, … 9. Ad esempio, prendiamo in considerazione il numero:
205
Vediamo che le sue cifre hanno un valore associato alla potenza del 10.
Infatti questo numero può essere pensato come:
2x102 + 0x101 + 5x100 = 205
10 2 10 1 10 0 � peso
2 0 5 � cifre del numero
2 x 10 2 0 x 10 1 5 x 10 0 =
2 x 100 + 0 x 10 + 5 x 1 = 2 0 5
Es.: Sistema decimale con 3 cifre
Base N = 10 3 = 1.000 0 – 999
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
SISTEMI DI NUMERAZIONE
Fig. 36 – Sistema di Numerazione Decimale
Rappresentazione Binaria
Il numero 205 in base 2 è:
11001101
si noti che in base 2, le cifre ammesse sono soltanto “1” e “0”. Quindi la

42
predetta rappresentazione binaria significa:
1x27+1x26+0x25+0x24+1x23+1x22+0x21+1x20
cioè:
128 + 64 + 8 + 4 + 1 = 205
Il concetto di valore di posizione esiste anche nella rappresentazione binaria.
L’unica differenza è che vengono prese in considerazione le potenze del 2 anziché
quelle del 10.
2 7 2 6 2 5 2 4 2 3 2 2 2 1 2 0 � peso
1 1 0 0 1 1 0 1 � cifre del numero
1 x 2 7 1 x 2 6 0 x 2 5 0 x 2 4 1 x 2 3 1 x 2 2 0 x 2 1 1 x 2 0 =
1 x 128 + 1 x 64 + 0 x 32 + 0 x 16 + 1 x 8 + 1 x 4 + 0 x 2 + 1 x 1 = 2 0 5
Es.: Sistema binario con 8 cifre
Base N = 2 8 = 256 0 – 255
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
SISTEMI DI NUMERAZIONE
Fig. 37 – Sistema di Numerazione Binario
Bit e Byte
L’unità minima del linguaggio digitale è il bit, termine che deriva dalla
contrazione dell’espressione inglese binary digit, cifra binaria. Un bit, proprio
come una lampadina, può assumere soltanto due stati: acceso (corrispondente a 1)
o spento (corrispondente a 0). Per trasmettere una maggiore quantità di dati, si

43
ricorre ad una unità più grande, il byte, che è costituito da otto bit e rappresenta
l’unità fondamentale del linguaggio dei computer. Poiché ognuno degli otto bit ha
due stati possibili, un byte può rappresentare fino a 28= 256 possibili
combinazioni.
Le stringhe di bit vengono solitamente suddivise in gruppi di 8 bit. Un
gruppo di 8 bit considerato come una singola unità di informazione, viene
denominato “byte”.
I bit di un byte sono numerati da 0 (il primo a destra, cioè il meno
significativo) a 7 (il primo a sinistra, cioè il più significativo).
In base a questa convenzione, il numero del bit e la potenza del 2 che
rappresenta sono identici. La seguente tabella fa vedere il numero di posizione di
un bit nell’ambito del byte e il suo valore corrispondente.
Bit = 0 1Byte = 8 Bits
0 1A = 000001
0 11 = 000110
0 0B = 100001
0 0V = 110101
01 1 01 11 Byte 0 0=
2V AMOR 1AI
11 Bytes = 88 BitsBioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
SISTEMI DI NUMERAZIONE
Fig. 38 – bit e Byte e alcune sequenze di caratteri ASCII

44
Dati Alfanumerici
Le stringhe (sequenze di caratteri ASCII) sono utilizzate per memorizzare
informazioni non numeriche, come nomi, indirizzi, codici, ecc. Per esempio la
costante:
“VIA ROMA 12”
è una costante stringa di 11 caratteri. Ogni carattere della stringa (compreso lo
spazio) è memorizzato in un byte e corrisponde a un codice della tabella ASCII. Il
BASIC memorizza la suddetta costante stringa come segue:
Dati Alfanumerici : sequenza di caratteri
esempio di variabile alfanumerica :
DATIAlfanumerici
Numerici
2V AMOR 1AI
0 0V = 110101
11 Bytes = 88 Bits
X$ =
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
SISTEMI DI NUMERAZIONE
Fig. 39 – Esempio di Variabile Alfanumerica
Dati Numerici
Il programmatore può far si che il BASIC memorizzi i numeri come:
- numeri interi (massima velocità di elaborazione, ma limitato campo di
definizione);

45
- numeri in semplice precisione (di uso generale);
- numeri in doppia precisione (massima precisione ma elaborazione più lenta).
0 0X# = 100001
Dati Numerici : Sequenza di cifre binarie
esempio di variabile numerica :
0 0….. 100001
Una variabileNumerica occupa
in semplice precisione : 4 bytes = 32 bits
in doppia precisione : 8 bytes = 64 bits
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
SISTEMI DI NUMERAZIONE
Fig. 40 – Esempio di Variabile Numerica Dal linguaggio umano al linguaggio dei computer e viceversa
Mentre gli elaboratori utilizzano il linguaggio binario, l’uomo comunica
mediante le lingue e si serve del sistema decimale. Di conseguenza, affinché ci
possa essere comunicazione, il computer deve convertire le informazioni che gli
forniamo nel linguaggio binario che è in grado di interpretare, e poi deve
riconvertire i risultati dell’elaborazione in un linguaggio a noi comprensibile.
Quando si digita un carattere o un numero sulla tastiera, l’elaboratore ricerca in
una tabella il numero binario che lo rappresenta e durante l’elaborazione si serve
di quel numero. Al termine dell’elaborazione avviene il processo inverso: il
computer ricerca nella tabella il carattere o il simbolo corrispondente al numero
binario e lo visualizza per l’utente. Le tabelle a cui fa ricorso l’elaboratore sono
chiamate codici.

46
Il codice ASCII è costituito esattamente da 256 caratteri (di cui alcuni sono
comandi) perché gli otto bit contenuti in un byte possono dare soltanto valori
compresi tra 0 e 255. Le varie combinazioni fra questi 8 bit possono dare un
numero binario compreso tra 00000000 e 11111111 o un numero decimale
compreso tra 0 e 255. Ognuno di questi 256 numeri decimali può rappresentare un
carattere, un numero o un comando.
I codici in uso
Il numero binario assegnato a un determinato carattere varia a seconda del
codice utilizzato. In informatica si usano vari sistemi di codifica, tra cui ASCII,
EBCDIC e UNICODE.
• Il codice ASCII, che sta per American Standard Code For Information
Interchange (codice americano standard per l’interscambio di
informazioni), è stato sviluppato dall’ANSI, l’American National Standard
Institute, ed è il codice più diffuso tra i personal computer. Nella tabella in
basso è riportata la codifica di una serie di caratteri nel codice ASCII. La
colonna a sinistra indica le decine e quella in alto le unità. Il simbolo “@”
ad esempio, è il numero 64, mentre “«” è il 174 .
• EBCDIC, acronimo di Extended Binary Coded Decimal Interchange Code
(codice di interscambio esteso BCD) è il codice più usato nei mainframe e
nei server più potenti.
• ASCII e EBCDIC funzionano perfettamente bene per l’inglese, ma per
scrivere i caratteri di altre lingue, come ad esempio il francese, il cinese, o
anche il fenicio e l’antico ebraico, è necessario un codice più esteso. Una
risposta a tale problema è rappresentata dallo standard UNICODE, che con
gli attuali 49194 caratteri è in grado di coprire le principali scritte del
mondo. I programmi che utilizzano UNICODE, come Windows NT, sono
in grado di elaborare e visualizzare sia le lingue moderne che quelle
antiche.

47
CODICE ASCII
La tabella seguente rappresenta in carattere decimale, esadecimale i codici
ASCII..
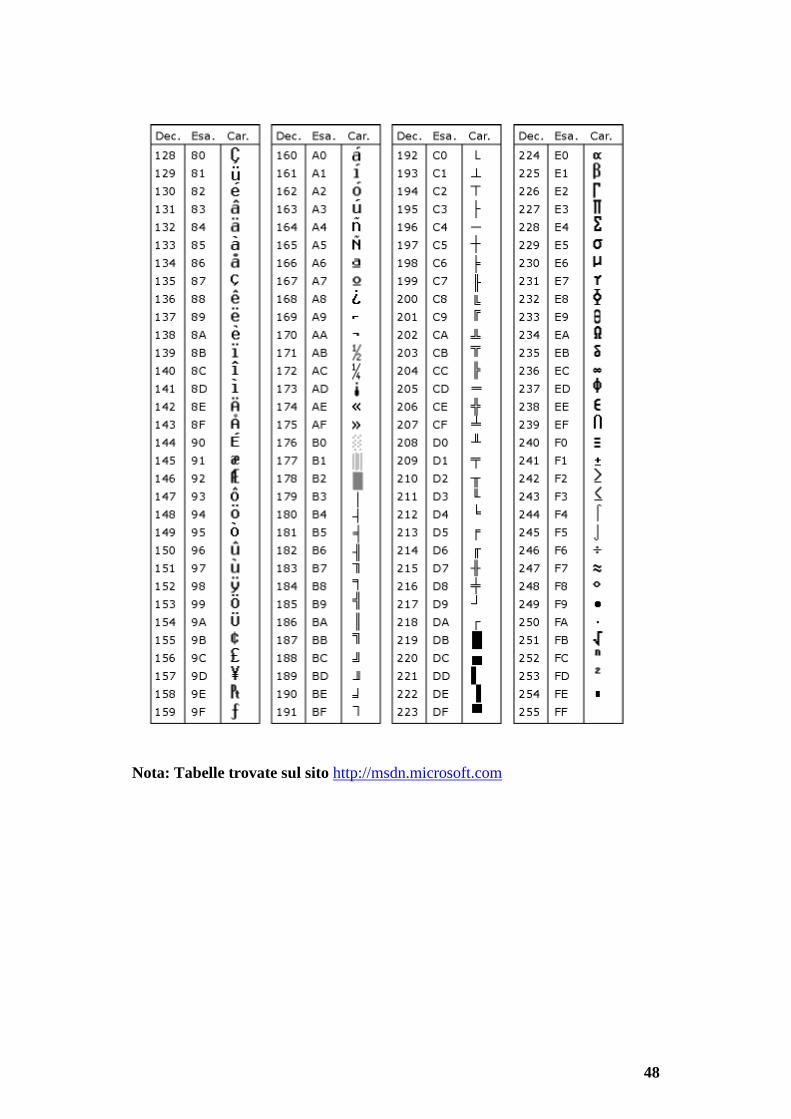
48
Nota: Tabelle trovate sul sito http://msdn.microsoft.com

49
SOFTWARE
Il Sistema Operativo
Dopo aver esaminato il computer come hardware trattiamo quella parte del
software che è detta di base, vale a dire che è fondamentale per il funzionamento
del calcolatore. Se noi accendessimo ora il nostro elaboratore, non accadrebbe
assolutamente nulla perché essendo capace solo di eseguire programmi, in assenza
di questi diviene un oggetto inutile.
Quando il calcolatore viene venduto, insieme ad esso possono essere
compresi anche una serie di programmi che formano il Sistema Operativo. Senza
il Sistema Operativo il computer sarebbe solo un insieme di fili e circuiti
elettronici non in grado di operare da soli. Il sistema operativo può essere
considerato solo come un insieme di programmi di supporto o come un
programma che interpreta ed esegue i comandi di controllo. In verità il Sistema
Operativo è un insieme di funzioni che servono ad aumentare l’efficienza del
calcolatore.
Mono-utente / Mono-processo
(es.: DOS ; Windows 3.1)
SISTEMI OPERATIVI
Mono-utente / Multi-processo
(es.: OS2 - Windows 95/98/NT/2000/XP/Vista)
Multi-utente / Multi-processo
(es.: Unix, Linux)
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 41 – Classificazione di alcuni Sistemi Operativi
I S.O. sono formati da molti programmi e solo pochi di questi sono visibili

50
all’utente. Questi sono i comandi che servono per scrivere, cancellare o
modificare altri programmi, per stampare dei dati o per produrre delle liste dei
nomi dei programmi o degli archivi esistenti su un disco o su un nastro. Ma questa
è solo la punta dell’iceberg, oltre ai comandi vi sono decine di programmi grandi
e piccoli da cui dipende il funzionamento del calcolatore.
L’MS-DOS
Descriviamo qui, brevemente, il sistema operativo MS-DOS (Microsoft
Disk Operating System) nato per i personal computer IBM nel 1981.
L’MS-DOS è un sistema operativo per microcomputer nato, come già detto,
nell’agosto del 1981 per il PC IBM. Questo S.O. è stato continuamente aggiornato
e migliorato rispetto all’originale versione 1.0 (questo metodo di numerazione è
classico del software: la prima cifra indica la versione, cioè la creazione o il
completo rifacimento di un sistema; le cifre successive indicano le patch, cioè le
riparazioni o le modifiche apportate al sistema originario). Si dice che l’MS-DOS
sia nato come copia semplificata dello Unix che vedremo in seguito. Forse questo
è vero, come è vero che molti dei comandi e l’impostazione generale sono simili,
ma è anche vero che per molte particolarità i due sistemi sono profondamente
diversi. Non dobbiamo dimenticare che il DOS raccoglie anche l’eredità lasciata
dal CPM-86, il sistema operativo dei microcomputer precedenti al personal
computer IBM e basati sul microprocessore Z80 della Zilog. L’importanza di
questo piccolo sistema operativo è chiara se si considerano le oltre 10 mila
applicazioni commercializzate e gli oltre 30 milioni di personal computer che lo
hanno utilizzato.
L’ MS-DOS (più semplicemente chiamato DOS) è un sistema mono-utente
e mono-processo realizzato dalla Microsoft per la gestione dei personal computer.
Considerando i computer di destinazione, l’MS-DOS è di dimensioni
contenute e non offre certamente tutte quelle particolarità e quelle facilitazioni dei
sistemi operativi più complessi. Come si è detto è monoutente, cioè prevede e
gestisce un solo utilizzatore; logico, visto che lavora su macchine nate come

51
personali e, di conseguenza, monoutenti. Non è quindi possibile (salvo artifici
prodotti dai programmi applicativi) eseguire più operazioni contemporaneamente
(dette concorrenti) fatta eccezione della stampa di file che viene gestita in
background, cioè sullo sfondo: mentre l’utente continua a lavorare, la CPU
utilizza le frazioni di secondo libere per gestire l’invio di caratteri alla stampante.
Fino alla versione 3.30 (o 3.31, per quella tradotta in italiano) l’interfaccia del
DOS è stata molto semplice. Questa viene gestita dal programma
COMMAND.COM che legge i caratteri da tastiera e ne consente una limitata
correzione e comprende i comandi elementari eseguendoli. Se una sequenza di
caratteri non è un comando gestito internamente da COMMAND.COM, questo
cerca un programma eseguibile con lo stesso nome; trovatolo, lo carica in
memoria e passa ad esso il controllo, in caso contrario emette un messaggio
d’errore. Le versioni di DOS successive alla 4.0 possiedono un’interfaccia grafica
che consente di vedere sempre i file disponibili e di lanciare i comandi di sistema
in modo molto più agevole.
Il DOS definisce un environment (ambiente), cioè uno spazio di memoria
che contiene delle variabili e delle definizioni necessarie al sistema. Le variabili
definiscono alcune stringhe che DOS usa nel suo lavoro; ad esempio PATH
determina in quali directory (oggi chiamate cartelle nel S.O. Windows) debbano
essere cercati i file eseguibili, mentre PROMPT identifica quale debba essere il
prompt cioè la sequenza di caratteri con la quale il sistema operativo avverte che è
pronto a ricevere degli input.
Ma più l’MS-DOS cresce di capacità, più cresce lo spazio di memoria che
occupa permanentemente. In contrapposizione a ciò, fino alla versione 4.0 il DOS
era ancora limitato alla gestione di 640 K di RAM nonostante la maggior parte dei
PC potessero raggiungere i 16 Mbyte. Per scavalcare questo limite tre costruttori
(Lotus, Intel e Microsoft) hanno definito lo standard LIM (dalle iniziali delle tre
aziende) che definisce le modalità software e hardware attraverso le quali è
possibile usufruire di tutti i 16 Mbyte di memoria centrale.
Il File System di questo sistema operativo è molto semplice. Esso prevede
una struttura organizzata ad albero alla cui base vi è la root directory identificata

52
dal simbolo “\“. Come già accennato nelle note generali sui Files System, la root
directory è un file come un altro e segue le stesse regole di assegnazione di nomi.
Un file DOS ha un nome composto da uno sino a otto caratteri sia numerici che
alfabetici e di interpunzione (punto escluso) indipendentemente dal tipo del
carattere iniziale. Seguono tre caratteri che definiscono l’estensione che è
facoltativa e quasi completamente arbitraria. Abbiamo detto quasi perché il
sistema operativo richiede solamente tre tipi di estensioni: i file. COM ed EXE
sono file compilati ed eseguibili e i BAT sono file di tipo batch (cioè file ASCII di
comandi e direttive DOS). Ciò non toglie che la maggior parte dei programmi non
di sistema imponga delle proprie regole per quanto concerne le estensioni.
Le directory seguono le stesse convenzioni di assegnazione dei nomi. Per
separare il nome di una directory da una subdirectory si usa, anche in questo caso
il simbolo ’\”.
Fig. 42 - Un'immagine... storica: il prompt del DOS
OS/2
L’Operating Sysrem/2 (o OS/2), è l’evoluzione del DOS che la Microsoft
ha progettato per i microcomputer PS/2 della IBM alla fine degli anni ‘80. La
prima release di OS/2 è del 1988.
Con questo Sistema Operativo la Microsoft ha inteso superare quei limiti del
DOS 3.0 che non rendevano possibile il pieno utilizzo dei già allora potenti PC.

53
Come già detto il DOS non consentiva di superare i 640K di memoria, mentre
erano numerosi i programmi che utilizzavano diversi Mega di RAM. Oltre a ciò
va aggiunto che gli utenti dei personal computer si erano abituati a programmi
applicativi molto evoluti basati su interfacce grafiche (GUI) altamente sofisticate
e mal vedevano il vecchio DOS che lavorava esclusivamente in modalità testo.
Già con il DOS 4.0 si era introdotto il DOS-Shell che “portava un po’ di colore”,
ma la concorrenza di altri sistemi basati sulle interfacce grafiche era sempre
pressante. Sotto DOS si sviluppò, nel 1985, Microsoft Windows, un sistema che
portava grafica di alta qualità e multitasking (virtuale) al DOS, ma i limiti di
progettazione del semplice sistema operativo non potevano essere superati.
OS/2 nasce come sistema operativo multitasking per macchine veloci e
dotate di RAM da 3 MB a 64 MB e con dischi di grande capacità. Nella sua
progettazione la Microsoft ha tenuto presente la rapida evoluzione delle
tecnologie e ha incluso un file system detto High Performance File System
(HPFS) non più basato sulla FAT, ma con una struttura molto più simile a quella
di Unix. L’HPFS è predisposto per poter utilizzare dischi ottici WORM e
riscrivibili, ma conserva la capacità di leggere i floppy scritti con il DOS.
Con questo sistema operativo viene utilizzata la GUI chiamata Presentation
Manager (PM) che, nella release 2.0, è divenuta praticamente identica a Windows
3.0. La struttura di questa interfaccia grafica è basata su finestre che possono
essere spostate, modificate nella forma e nei colori, chiuse o minimizzate,
sostituendo ad esse un’icona che ne rappresenta graficamente la funzione. Le
finestre sono gestite dai processi, cioè dai singoli programmi concorrenti, che
svolgono tutto il loro dialogo con l’utente attraverso di esse. Il Dynamic Data
Exchange (DDE) è un metodo che consente a programmi concorrenti di
scambiarsi dinamicamente i dati così due o più applicazioni possono parlare fra di
loro o condividere i dati su cui lavorare. I1 mouse è lo strumento essenziale per
poter utilizzare proficuamente e gradevolmente questa interfaccia grafica evoluta;
lavorare senza di esso non è possibile. Rispetto ai vecchi monitor a colori dei
primi PC l’OS/2 utilizza solo monitor EGA (Enhanced Graphics Adapter,
640x350 a 16 colori) in su, fino alle alte risoluzioni e ai 256 colori, e oltre.

54
Microsoft Windows Microsoft Windows è ormai da diversi anni di gran lunga il più diffuso
sistema operativo per personal computer. Dal 1985 ad oggi, Windows ha
conosciuto diverse versioni, Windows 1.0 (1985), Windows 2.0 (1987), Windows
3.0 (1990), Windows 3.1 (1992); fino ad arrivare nel 1993 ad una versione
professionale chiamata Windows NT (New Tecnology) mono-utente e multi-
processo, e giungere alle più recenti: Windows 95/98 / 2000 / NT / XP/ VISTA .
Fig. 43 - Un computer palmare con Windows CE
Windows, pur essendo abbastanza facile e intuitivo da utilizzare, è
indubbiamente un sistema operativo complesso, che permette di svolgere
moltissimi compiti e moltissime operazioni diverse. Riassumerne in poche parole
le caratteristiche essenziali è dunque un’impresa abbastanza difficile. Vogliamo
provare a cimentarci nell’impresa, cercando di individuarne dieci ‘tratti distintivi’
(molti dei quali sono del resto comuni alla maggior parte dei sistemi operativi
grafici)? Ebbene, facendo riferimento alla versione di Windows 2000, possiamo
forse dire che le dieci caratteristiche di base di Windows, dal punto di vista
dell’utente, sono: (1) uno spazio bidimensionale, o tavolo da lavoro (desktop),
all’interno del quale possono trovare posto (2) le piccole rappresentazioni
grafiche, o icone, che rappresentano dati e programmi. All’interno di questo
spazio si muove anche il (3) puntatore del mouse, utilizzato sia (con un singolo
click) per selezionare le icone degli oggetti – dati e programmi – con i quali
lavorare, sia (doppio click) per aprirli. Il puntatore del mouse è utilizzato anche
per trascinare e appoggiare (drag and drop) gli oggetti con i quali si lavora:
icone, finestre, ecc.; in questo caso, occorre posizionare il puntatore del mouse
sull’oggetto da trascinare, premere il tasto sinistro del mouse, e tenerlo premuto

55
spostando il mouse: l’oggetto trascinato seguirà i movimenti del puntatore, fino a
quando il tasto sinistro non viene rilasciato.
Fig. 44 - Il desktop di Windows 2000, con icone e menu a cascata; al menu principale si accede dal pulsante Start, in basso a sinistra
I programmi vengono eseguiti all’interno di (4) finestre che possono essere
sovrapposte, ridimensionate, spostate, o accantonate temporaneamente sulla (5)
barra delle applicazioni. La chiusura di una finestra corrisponde di norma alla
chiusura del relativo programma. Dell’interfaccia utente fanno parte integrante (6)
menu e (7) pulsanti (attivati attraverso un singolo click del mouse). Un pulsante
posto sulla barra delle applicazioni, detto (8) pulsante di avvio (Start), permette
l’accesso a un menu attraverso cui raggiungere tutti i principali programmi
installati nel computer, e tutte le componenti principali del sistema operativo. Fra
di esse, occorre ricordare innanzitutto la (9) finestra esplora risorse, che permette
la gestione dei file e l’accesso a tutte le risorse del computer, in sede locale (dischi
rigidi e altre memorie di massa, stampanti, etc. ) e remota (rete locale e rete
Internet). Sempre attraverso il menu Start, o attraverso il tasto F1, è sempre
disponibile (10) un sistema d’aiuto (Help) contestuale, che sostituisce ormai i
manuali del sistema operativo.
UNIX
Lo Unix è un sistema operativo che ha avuto molto successo a partire dalla

56
metà degli anni ottanta, ma pochi sanno che è nato quasi per caso ed è diventato di
dominio pubblico solo per l’entusiasmo degli utenti.
Ironia della sorte vuole che Unix sia stato ideato come sistema monoutente
in contrapposizione al sistema Multix, multiutente, mentre è oggi il sistema
multiutente forse più diffuso. La nascita avviene fra il 1969 ed il 1971 nei
laboratori della AT&T (American Telephone and Telegraph) ed è motivata
dall’esigenza di avere a disposizione un sistema operativo, flessibile e facilmente
modificabile, per il computer Digital PDP-7.
UNIX è un sistema operativo multi-processo e multi-utente caratterizzato da
una semplicità, flessibilità e potenza difficilmente raggiunte dai sistemi operativi
precedenti. Uno dei suoi punti di forza è la disponibilità su un gran numero di
macchine differenti grazie al fatto di essere costruito in maniera modulare. La
parte centrale, il kernel, è l’unica parte scritta in assembler e strettamente
dipendente dalla macchina. Questo nucleo gestisce i processi, la memoria, gli
interrupt, le chiamate a funzioni di sistema, l’I/O (Input/Output) verso le
periferiche. Tutto il resto del sistema (quello che l’utente vede) è scritto in C ed è
uguale per tutte le macchine.
UNIX nasce come sistema operativo modulare e flessibile rivolto soprattutto
all’utilizzazione da parte di programmatori professionisti (in effetti, imparare a
muoversi in un ambiente UNIX può essere tutt’altro che facile per i non
specialisti). Pur essendo un sistema operativo a caratteri, le sue capacità di
multitasking e multiutenza, la sua concezione modulare e l’utilizzazione diretta di
un linguaggio di programmazione particolarmente potente, il C, lo rendono tuttora
assai diffuso, anche se in genere a livello di workstation.
Negli ultimi anni, tuttavia, ha raggiunto una notevole diffusione una
versione ‘popolare’ di UNIX denominata Linux, realizzata per iniziativa del
programmatore Linus Torvalds, distribuita gratuitamente e capace di girare su
molte piattaforme diverse (inclusi i normali PC IBM compatibili). Molte
implementazioni di UNIX, compreso Linux, possono costituire la base sulla quale
far girare un sistema operativo grafico evoluto denominato X Windows.

57
I LINGUAGGI DELL’INFORMATICA
Dal linguaggio macchina ai linguaggi ad alto livello.
Accade nell’universo degli esseri umani e, naturalmente, non poteva
avvenire diversamente nel mondo dei personal computer; le macchine
programmabili, create dall’uomo, occupano una torre di Babele nella quale le
differenze tra i vari linguaggi sono tanto sentite almeno quanto nella società
umana. Così come per i linguaggi umani, esistono linguaggi con maggiore
importanza e diffusione, utili per intendersi un po’ dovunque (Inglese, Francese,
etc. ), nella Babele dei computer troviamo alcuni linguaggi protagonisti della
situazione: senza dubbio il più popolare è il BASIC. Ma le analogie non
terminano qui. Nella società umana molti idiomi presentano dialetti o varianti, più
o meno distanti dalla radice originale. Una realtà riconoscibile anche tra i
linguaggi dell’informatica, dove i dialetti e le versioni del BASIC sono numerose
quasi quanto i modelli di computer.
Qualunque discorso relativo ai linguaggi dell’informatica deve partire dal
personaggio centrale: il computer. Sappiamo che si tratta di una macchina la cui
principale caratteristica è quella di accettare una programmazione che gli consenta
di realizzare una notevole varietà di lavori: tanti quanti l’utente sarà in grado di
programmarne.
Data la sua struttura, un insieme di circuiti elettronici in tecnologia digitale,
il computer è in grado di comprendere un linguaggio costituito dai due elementi
minimi dell’informazione: 0, assenza di segnale elettrico, e 1, presenza di segnale
elettrico (in realtà lo zero non è sempre una totale assenza di segnale, ma un
livello basso rispetto all’uno).
A partire da questo alfabeto minimo (0 e 1), si possono costruire parole
(01101110) e, naturalmente, frasi (0011001111100011...) con le quali stabilire
una comunicazione ricca di contenuti.
Riassumendo: il computer, per sua natura, è in grado di dialogare in un
linguaggio che denomineremo linguaggio macchina, costruito a partire dagli

58
elementi minimi dell’informazione: 0 e 1. Questi elementi. i BIT (contrazione
della denominazione inglese BInary digiT: cifra binaria), coincidono con quelli
del sistema di numerazione binaria.
Livelli dei Linguaggi dell’Informatica
Abbiamo già parlato della capacità dei computer di scambiare dati con
l’utente. Per il momento abbiamo visto come sia possibile stabilire una
comunicazione con i suoi circuiti elettronici attraverso il suo linguaggio interno: il
linguaggio macchina. Qualche semplice riflessione su questo mezzo di colloquio
porta subito a conclusioni non troppo favorevoli verso il linguaggio macchina.
Prima di tutto non vi sono dubbi sul fatto che questo sia un linguaggio difficile da
apprendere per l’utente; non solo per la complessità inerente alla struttura del
linguaggio, ma forse di più per il fatto che la sua connessione intima con la
macchina rende necessaria una conoscenza approfondita del suo funzionamento
interno. Inoltre, bisogna ricordare che il computer è una macchina ignorante, che
deve essere istruita con tutti i più piccoli dettagli, un compito arduo se deve essere
portato a termine usando solo sequenze di zero ed uno.
Infine il computer non è altro che uno strumento creato per facilitare il
lavoro dell’uomo, quindi perché l’uomo dovrebbe adattarsi al linguaggio dalla
macchina, se esiste la possibilità di usare linguaggi molto più vicini a quello
umano? Il problema sta soltanto nel creare i traduttori adatti, che convertano le
descrizioni formulate con un linguaggio evoluto in frasi equivalenti del linguaggio
macchina.
Da questa idea nacquero i nuovi linguaggi dell’informatica, più evoluti e più
somiglianti al linguaggio dell’uomo.
Lo sviluppo dai linguaggi fu parallelo all’evoluzione dei computer. Poco a
poco nacquero linguaggi sempre più lontani dalla struttura della macchina e, più
tardi, comparvero i cosiddetti linguaggi ad alto livello, nei quali la sintassi, la
semantica e la pragmatica iniziavano ad assomigliare a quelle dei linguaggi
umani.

59
Attualmente la piramide dei linguaggi dell’informatica è costituita da tre
livelli:
• Linguaggi di alto livello :FortranBasicCobolPascal
CHTMLJava
Compilati - Interpretati
LINGUAGGI DI PROGRAMMAZIONE
• Linguaggi macchina
• Linguaggi Assemby o assemblatori
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 45 – Alcuni linguaggi di programmazione
Linguaggi Macchina
Occupano lo strato inferiore, meno evoluto, dei linguaggi dell’informatica.
Data la stretta connessione con la macchina è ovvio che il linguaggio cambierà a
seconda della macchina considerata.
Bisogna ricordare che il cervello o unità centrale di elaborazione è il
microprocessore; di conseguenza il linguaggio macchina adatto ad un computer
dipenderà dal microprocessore in esso contenuto. In effetti ogni microprocessore
(6502, Z80, 8088, 68000, etc. ) ha un proprio linguaggio macchina.
Linguaggio Assembly o assemblatori
La strato intermedio è occupato dai linguaggi assembly. Il repertorio di

60
elementi che contribuiscono alla composizione di un programma consiste, in
questo caso, in un insieme di simboli che offrono una maggiore comodità d’uso
rispetto alle sequenze di zero ed uno.
Il collegamento con il linguaggio macchina è molto stretto, al punto che
ogni famiglia di microprocessori possiede un proprio linguaggio assembly ed ogni
suo simbolo è in diretta corrispondenza con un simbolo del suo linguaggio
macchina.
Il compito di realizzare e correggere un programma diventa ora più facile
data la comodità di poter impiegare gruppi di lettere per definire le operazioni.
Non ci sono dubbi sul fatto che per incrementare un numero di una unità sia
meglio utilizzare INC A piuttosto che 0011100; ne consegue che la possibilità di
fare errori si riduce notevolmente.
Linguaggi di alto livello
Questi sono linguaggi evoluti che mantengono un notevole parallelismo con
i convenzionali linguaggi parlati. In questo terzo livello la differenza tra i vari
linguaggi non è causata dal microprocessore. I linguaggi d’alto livello più diffusi
(BASIC, PASCAL, FORTRAN, COBOL, LOGO, HTML, JAVA, etc.)
dispongono di diversi traduttori per poter essere convertiti nel linguaggio
macchina di quasi qualunque microprocessore.
I vantaggi sono evidenti: la scrittura di un programma risulta comprensibile
per l’utente e di conseguenza sarà più comoda la sua redazione e la ricerca degli
errori di sintassi. Inoltre il tempo di programmazione si riduce e, cosa molto
importante, si può pensare di far funzionare lo stesso programma su macchine
diverse.
Il BASIC è, senza dubbio, il linguaggio ad alto livello attualmente più
popolare. Un linguaggio di programmazione polivalente che ha generato numerosi
dialetti: a partire dalle versioni rivolte ai principianti fino alle versioni più
sofisticate orientate alla programmazione professionale. Ma non è da qui che parte

61
la storia dei linguaggi dell’informatica. Sono molti i linguaggi che hanno visto la
luce prima e dopo il BASIC: a partire dallo SHORT CODE che fu creato nel 1949
dal Dottor Mendy per la Univac, lo SPEED CODING nato nel 1953 per i
computer IBM, il LOGO (1976), un linguaggio progettato espressamente per
l’insegnamento assistito dal computer, fino ai più recenti, come il “C”, Java, etc. .
I primi linguaggi vennero sviluppati con una particolare attenzione alle
applicazioni matematiche e scientifiche: è il caso del MATHEMATIC, del GAL o
del più noto FORTRAN. Più tardi comparvero i linguaggi rivolti alla
programmazione di attività gestionali, dei quali il più noto è senz’altro il COBOL.
I linguaggi polivalenti o universali comparvero sulla scia del JOVIAL, il
primo linguaggio non specializzato, che vide la luce nel 1959. Ad esso seguirono
ALGOL, PL/1, APL, BASIC, PASCAL, FORTH, ADA, LOGO e molti altri
ancora.
La popolarità dei personal computer ha trascinato con sé alcuni linguaggi di
alto livello, ma ha anche relegato nell’ambito dei mini e dei grandi computer
alcuni classici linguaggi dell’informatica.

62
I PRINCIPALI LINGUAGGI AD ALTO LIVELLO
Linguaggio FORTRAN
(FORmula TRANslation Conversione di formule) Il nome mette in evidenza
il carattere matematico di questo linguaggio, uno dei più antichi tra i linguaggi
attualmente in uso. J. Backus lo sviluppò nel 1956 su un sistema IBM 704. In
passato molto usato, nei settori più disparati.
Linguaggio BASIC
(Beginners All Purpose Symbolic Instruction Code, Codice di istruzioni
simboliche di uso generale per principianti). E’, senza dubbio, il più popolare dei
linguaggi attuali e con un notevole distacco dai restanti linguaggi dell’informatica.
Nacque tra il 1964 e il 1965 presso il Dartmouth College come strumento per
l’insegnamento. Col tempo si sono diffusi diversi dialetti e versioni, al punto che
solitamente ogni fabbricate di computer sviluppa una propria versione di BASIC.
E’ molto difficile trovare un personal computer che non incorpori un interprete
per il BASIC, anche nella versione base. In seguito l’americana Microsoft ha
sviluppato dapprima il famoso MSX-BASIC, poi il Quik Basic ed infine il Visual
Basic, divenendo uno standard affermato.
Linguaggio COBOL
(COmmon Businnes Oriented Language - Linguaggio orientato alla
gestione). Il linguaggio specializzato nei compiti di gestione che ha avuto,
indubbiamente, la maggiore risonanza. Il Dipartimento della difesa degli Stati
Uniti promosse il suo sviluppo nel 1960. Ha avuto una grande diffusione tra i mini
e i grandi computer, ma nel campo dei microcomputer ha subito la concorrenza
del BASIC.

63
Linguaggio PASCAL
(In onore del celebre matematico francese Blaise PASCAL). E’ il
linguaggio strutturato per eccellenza, con una importante presenza nel mondo dei
microcomputer. Fu sviluppato da N.Wirth nel 1969 presso il politecnico di
Zurigo, basandosi sui fondamenti dell’ALGOL. Il PASCAL è un linguaggio che
permette di creare programmi chiari e comprensibili per merito delle sue
caratteristiche di linguaggio strutturato; ad esempio impone di definire
esplicitamente prima del programma, ogni dato in gioco. La versione più
popolare, di questo linguaggio, è quella creata appositamente per i microcomputer
dall’Università Californiana di San Diego: il PASCAL UCSD
Linguaggio C
Uno dei più recenti linguaggi di programmazione ad alto livello. Entro
questa categoria, il C è uno dei linguaggi maggiormente polivalenti e più vicini
alla realtà della macchina. Fu sviluppato originariamente dai Bell Laboratories per
lavorare sul sistema operativo UNIX. La popolarità di questo linguaggio cresce
giorno per giorno, per questo viene considerato unanimemente come uno dei
principali linguaggi di riferimento. La sua struttura semantica e sintattica è stata
edificata a partire da concetti avanzati come strutturazione, gerarchizzazione di
blocchi e controllo di flussi di dati.
Linguaggio LOGO
La prima versione del LOGO fu creata nel 1976 da Seymour Papert, presso
il Massachusetts Institute of Technology ed era ispirata al LISP. LOGO è un
linguaggio ideato per l’insegnamento assistito dal computer. La sua popolarità
deriva in gran parte dalla cosiddetta Turtle Graphics. cioè una serie di comandi
dedicati alla grafica, che fanno uso di un simpatico personaggio (la Tartaruga) per
facilitarne l’apprendimento. Pur essendo decisamente orientato al settore
educativo, non è trascurabile la sua utilità nel campo dell’intelligenza artificiale.

64
Il linguaggio HTML
Le pagine Web non devono essere soltanto belle e accattivanti ma anche
funzionali. Questa funzionalità è determinata da come sono organizzati la
formattazione e il collegamento ad altre pagine, effettuati inserendo nel
documento delle istruzioni nascoste dette tag (marcatori), che fanno parte di uno
speciale linguaggio di formattazione, HTML (Hypertex Markup Language), a sua
volta basato sul linguaggio SGML (Standard Generalized Markup Language), del
quale è un sottoinsieme. Il successo ottenuto da questi linguaggi di formattazione
è dovuto al fatto che non sono legati a uno specifico programma. Tanto per fare
un esempio, mentre un documento formattato in Word non può essere letto da un
altro programma o in un altro sistema se prima non è stato convertito, i tag sono
costituiti da testo e quindi possono essere letti da tutti i programmi. Questo perché
una pagina web, come è ovvio, aspira a raggiungere un pubblico il più vasto
possibile.
Quando formattate una pagina Web, potete inserire un tag
<H1><CENTER> per specificare che la sezione che segue è un titolo in posizione
centrata, oppure un tag leggermente diverso, </CENTER></H1>, per segnalare la
fine di quel tipo di formato. I documenti in formato HTML e i loro marcatori
possono essere visualizzati da qualsiasi programma di editing, e anche nei
browser di norma è presente un comando sorgente che consente di vedere il
codice HTML del documento visualizzato. Un altro linguaggio basato sull’SGML
è l’XML (eXtensile Markup Language); questo linguaggio permette la creazione
di tag personalizzati al fine di consentire lo scambio di informazioni e documenti,
formattati secondo questi tag, tra programmi applicativi diversi.
Linguaggio Java
Java è un linguaggio procedurale nuovo ma già molto diffuso, concepito per
sviluppare applicazioni distribuite in rete. I programmi Java, chiamati applet,
risiedono in genere su un server. Dal server possono essere trasferiti sul proprio

65
computer, dove vengono interpretati da un traduttore detto macchina virtuale Java.
Questo tipo di programma può dunque essere eseguito indifferentemente su ogni
computer, posto che questo sia dotato dell’apposito interprete.
PROGRAMMAZIONE
I calcolatori per uso generale sono in grado di eseguire diverse funzioni
come la lettura dei dati, le operazioni aritmetiche su di essi, il loro trasferimento,
il loro confronto, etc. ma essi non possono da soli, associare tali funzioni nelle
combinazioni necessarie a compiere un determinato lavoro e a risolvere un
determinato problema. Questo lavoro è affidato al programma. Un programma,
per definizione, consiste in un piano sistematico appositamente concepito per
giungere alla soluzione automatica di un problema specifico da parte di un
calcolatore. Nel caso di un problema specifico da sottoporre per la soluzione ad un
calcolatore per uso generale, un programmatore deve prima analizzare il problema
per stabilire in che modo utilizzare il calcolatore per ottenere lo scopo. Presa una
decisione al proposito, si traccia un piano sistematico, detto programma. Un
programma consiste in un elenco sequenziale di istruzioni particolareggiate, che
guida il calcolatore un passo dopo l’altro nella soluzione del problema.
Le fasi principali del lavoro di programmazione sono:
1. capire il problema e definirne la soluzione;
2. determinare la metodologia di risoluzione del problema. Il metodo più
usato è la realizzazione di diagrammi a blocchi o flow-chart;
3. stesura delle istruzioni di programma. La scelta del linguaggio è legata al
tipo di problema che si deve affrontare (Basic, Visual Basic, C, etc. per
problemi scientifici, o Cobol per applicazioni gestionali) e al tipo di
linguaggio che il computer a disposizione può interpretare;
4. memorizzazione del programma;
5. correzione del programma ed esecuzione.
La comprensione del problema (fase 1) è di fondamentale importanza. Nella

66
maggior parte dei casi il programmatore lavorerà in base a delle specifiche
dettagliate preparate per ciascun programma dall’analista. Queste specifiche
comprendono la descrizione dettagliata di tutti i dati in entrata, della elaborazione
da svolgere e dei risultati in uscita dal programma. Il programmatore deve
anzitutto sincerarsi che tutte le possibili situazioni siano state specificamente
previste e che ogni situazione non specificamente considerata possa comunque
essere adeguatamente trattata. Dopo essersi assicurato della adeguata definizione
del problema il programmatore deve quindi pensare alla strategia da adottare per
la redazione del programma.
In relazione alla complessità del problema, alla capacità di memoria
dell’elaboratore ed al tipo di linguaggio da usare il programma può essere scritto o
essere diviso in “routine” o “segmenti”, ognuna dedicata ad una certa sezione
logica del problema.
Sorvolando le fasi 2-3-4, di stesura del diagramma a blocchi, codifica del
programma e memorizzazione dello stesso, che saranno rese esplicite con un
esempio, ci soffermiamo sugli errori del programma.
E’ raro che un programma funzioni correttamente fin dalla prima volta che
lo si metta in esecuzione; questi errori possono essere di due tipi: errori di
“sintassi”, ossia dovuti ad un cattivo uso del linguaggio o codifica del programma,
o errori di “logica” derivanti da una errata interpretazione del problema.
I programmi vengono provati con dei dati di prova, cioè con dei campioni di
quegli stessi dati che il programma troverà normalmente in ingresso e i risultati
così ottenuti vengono confrontati con quelli ottenuti dall’elaborazione manuale
degli stessi. Quando i risultati ottenuti dal programma concordano con quelli
calcolati manualmente, e il programmatore o l’analista è sicuro che sono state
simulate tutte le possibili situazioni in cui è prevedibile che il programma si
imbatta nel suo normale operare allora si può dire che il programma funziona
correttamente. Peraltro anche un programma così collaudato non è utilizzabile se
non è corredato da una documentazione completa e rientra fra i doveri del
programmatore, oltre a prepararla, assicurarsi che essa venga costantemente
aggiornata e messa a disposizione di ogni utilizzatore del programma.

67
Esempio di programmazione:
FASE 1
Si supponga quale semplice esempio di voler stampare la radice quadrata di
tutti i numeri forniti dall’operatore tramite tastiera.
E’ necessario quindi, nel caso in cui l’operatore introduca valori negativi,
stampare un messaggio e continuare l’esecuzione.
FASE 2
Il metodo comunemente usato per giungere alla stesura di una metodologia di
risoluzione di un problema tramite calcolatore è nota come diagramma a blocchi.
Utilizzando i pochi simboli di base riportati alla fine di questo esempio il
problema definito alla fase 1 può essere illustrato dal seguente schema di flusso:
Impostare un numeroImpostare un numero
FASE 2
Rappresentare un messaggiodi errore sul monitor
Rappresentare un messaggiodi errore sul monitorNumero < 0Numero < 0
STARTSTART
Calcolare la radice quadratadel numero
Calcolare la radice quadratadel numero
Stampare la radicequadrata del numeroStampare la radice
quadrata del numero
SINO
PROGRAMMAZIONE
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 46 – Diagramma a Blocchi

68
FASE 3
Seguendo il diagramma a blocchi risulta facile scrivere le corrispondenti
istruzioni di programma utilizzando il Linguaggio BASIC :
10 CLS20 INPUT “Imposta un numero”; X30 IF X<0 GOTO 7040 Y = SQR(X)50 PRINT “Radice quadrata =”; Y60 GOTO 2070 PRINT “Impossibile calcolare la radice quadrata ”80 GOTO 20
PROGRAMMAZIONE
FASE 3
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 47 – Esempio di Programma in BASIC

69
PROGRAMMA : (Basic prime versioni)
10 CLS - Questa istruzione cancella il monitor.
20 INPUT “IMPOSTA UN NUMERO”;X - Con questa istruzione compare sul display il messaggio: IMPOSTA UN NUMERO, ferma l’esecuzione del programma e attende che l’operatore fornisca da tastiera un numero (ad es.: 4 da associare alla variabile X.
30 IF X <0 THEN 70 - Se la variabile X è minore di 0 salta le istruzioni 40-50-60 ed esegue l’istruzione N° 70; altrimenti esegue la successiva (per X=4 esegue la N° 40).
40 Y=SQR(X) - Associa alla variabile Y il valore della radice quadrata della variabile X (nel nostro es. associa ad Y il valore 2).
50 PRINT “RADICE QUADRATA=”;Y - Questa istruzione fa visualizzare il contenuto fra virgolette ed il valore associato alla variabile Y (es.: RADICE QUADRATA = 2)
60 GOTO 20 - Istruzione di salto; ritorna
all’istruzione n° 20.
70 PRINT “VALORE NEGATIVO ” - Visualizza su monitor: VALORE NEGATIVO; (nel nostro esempio non viene eseguita).
80 GOTO 20 - Invia all’esecuzione dell’istruzione n°
20.
90 END - Istruzione di fine programma.

70
FASE 4
Questa fase consiste nell’introdurre in macchina il programma linea per
linea. La linea deve essere impostata sul display e alla fine di ciascuna di esse
deve essere premuto il tasto di memorizzazione.
FASE 5
Dopo aver memorizzato il programma premendo il tasto “LIST” il
calcolatore fornirà una lista del programma; premendo il tasto “RUN” si comanda
l’esecuzione.
Per correggere od inserire istruzioni basta scrivere il numero di linea
corrispondente, la nuova istruzione e premere il tasto di memorizzazione.
SIMBOLI DI USO COMUNE NEI DIAGRAMMI A BLOCCHI

71
VARIABILI
Risulta spesso comodo associare ad una lettera un valore numerico ed
utilizzare la lettera all’interno di una espressione aritmetica. Nel corso di un
programma la lettera può assumere valori numerici diversi, da qui la
denominazione di variabile attribuita ad una lettera utilizzata nel modo illustrato.
Una lettera intesa come variabile può essere ad esempio utilizzata come
locazione di una memoria destinata a contenere una sommatoria di dati in corso di
aggiornamento. Una variabile può inoltre essere utilizzata per memorizzare una
costante che ricorre con frequenza nel calcolo.
Il calcolatore può gestire due tipi di variabili.
- variabili semplici;
- insiemi di variabili (Vettori, Matrici).
Variabili semplici: ciascuna delle 26 lettere maiuscole dell’alfabeto inglese
da A a Z (e in alcuni linguaggi combinazioni di esse) può essere utilizzata come
variabile.
Vettori e matrici: come per le variabili semplici le lettere alfabetiche (e in
alcuni linguaggi combinazioni di esse) rappresentano i nomi di vettori o matrici;
tali nomi sono seguiti da parentesi (quadrate o tonde) che racchiudono gli indici
dei vettori o delle matrici.
I vettori o le matrici devono essere necessariamente dichiarati con una istruzione
di dimensionamento. In questo modo si riserva della memoria per il vettore o
matrice e contemporaneamente vengono azzerati tutti gli elementi.
Es.:
DIM A(4) : Riserva una parte di memoria per 4 elementi del vettore A.
DIM B(4,5) : Riserva una parte di memoria per 20 elementi della matrice B (4
Righe, 5 Colonne).

72
LE RETI LOCALI (LAN)
Anche se per utilizzare le reti non è necessario sapere come funzionano,
conoscerne le caratteristiche può essere utile quando dovete installare il vostro
sistema, scegliere un servizio, utilizzare un’applicazione come la posta elettronica
e via dicendo. Gli elaboratori e gli altri dispositivi hardware che formano una rete
locale possono essere collegati tra loro in vari modi che determinano
l’ architettura o la topologia della rete.
Per architettura non si intende il modo in cui sono disposti i suoi
componenti fisici, ma la modalità di trasmissione dei dati all’interno della rete.
I componenti fondamentali di un’architettura
Gli elementi fondamentali che compongono una rete sono i nodi, i pannelli
di connessione e le dorsali.
Un nodo è un qualsiasi dispositivo hardware del sistema in grado di
comunicare con gli altri dispositivi che fanno parte della rete; può quindi essere
un computer, una stampante, un fax, un modem, una unità per CD-ROM etc.; in
ogni caso il nodo deve essere dotato di una scheda di rete.
I nodi sono collegati tra loro da un pannello di connessione (in inglese hub),
chiamato anche concentratore, che ha la funzione di semplificare la connessione
fisica tra i vari nodi e di instradare i segnali che vengono inviati da un nodo
all’altro.
Una dorsale è un cavo ad alta capacità al quale possono essere connessi più
nodi o concentratori e che ha la funzione di trasportare grandi quantità di dati.
I server
In una rete locale un server è un elaboratore che può essere condiviso dagli
altri computer collegati in rete. In molti casi è il computer più potente del sistema
perché tutti gli elaboratori, detti client, dipendono dal server sia per i programmi e

73
i dati che per le connessioni agli altri computer e dispositivi. I tipi di server più
comuni includono:
Il server gestore di dati (in inglese file server), sul quale si trovano i file e
alcuni programmi applicativi; questo elaboratore gestisce grandi quantità di dati
archiviati in varie memorie di massa, come dischi fissi, CD-Rom, unità a nastro e
altri dispositivi di memorizzazione;
Il server di stampa che memorizza sul disco fisso i dati da stampare finchè
la stampante non è pronta per riceverli;
Il server di comunicazione, che può essere un router (cioè un elaboratore
che instrada i dati tra i vari elaboratori, analogamente a una centrale telefonica per
le telefonate), un fax o un modem attraverso il quale i dati vengono trasmessi tra
un nodo e l’altro o all’esterno della rete, verso altre reti (ad esempio Internet).
L’architettura ad anello
In un’architettura ad anello i nodi della rete sono organizzati secondo una
configurazione a cerchio. Quando un computer invia un segnale, questo passa al
nodo successivo; se il messaggio non è indirizzato a quel nodo, viene ritrasmesso
al nodo seguente e così via finchè non raggiunge il nodo a cui è destinato. In
questa topologia, i computer sono collegati direttamente tra loro: le comunicazioni
passano infatti attraverso un pannello di connessione, all’interno del quale risiede
l’anello.
L’architettura a stella
Nell’architettura a stella i nodi sono collegati a un computer centrale detto
host. Quando un computer della rete invia un segnale, l’host lo instrada verso il
nodo a cui è indirizzato. Le comunicazioni tra i nodi della rete, quindi, non sono
dirette ma passano tutte attraverso l’elaboratore centrale.

74
L’architettura a bus
L’ architettura a bus o lineare, collega tutti i nodi a una linea di trasmissione
principale, secondo una organizzazione che ricorda quella dei componenti di un
elaboratore. Il segnale emesso da un computer viene inviato lungo la linea di
comunicazione ed esaminato da tutti gli altri nodi della rete: solo il nodo
destinatario preleverà il messaggio, mentre gli altri nodi, pur ricevendo il
messaggio, lo ignoreranno. Di norma, i nodi sono collegati tramite dei fili alla
dorsale della rete, che è costituita da un cavo di lunghezza standard con dei
terminatori alle estremità che impediscono la riflessione del segnale.
Le reti paritetiche (peer-to-peer)
La creazione e la gestione di una rete comportano numerose difficoltà e costi
piuttosto elevati. Per evitare questi inconvenienti si può realizzare una rete
paritetica, il cui controllo non è affidato al centro di calcolo aziendale di norma
competente ma è demandato agli utenti. In questa topologia tutti i computer
operano allo stesso livello per cui, diversamente da quanto accade nell’architettura
client/server, i dati non devono passare attraverso un elaboratore centrale. Mentre
lavorate a un foglio elettronico, ad esempio, il vostro computer può gestire le
richieste di stampa provenienti dagli altri elaboratori e inviarle alla vostra
stampante laser.
Le LAN senza fili
Nelle reti locali senza fili, come avviene per la radio e la televisione via
etere, i computer comunicano tramite segnali radio trasmessi da e verso una
stazione centrale collegata alla rete. Questo tipo di trasmissione consente di
spostare un computer portatile all’interno di un edificio, ad esempio, per fare una
presentazione, ed elimina il problema di installare i cavi di collegamento nei
vecchi edifici.
75
SWITCH
LAN
ROUTER
SERVERS
BI 1999
SISTEMA INFORMATIVO OSPEDALIERO
SERVER
HUB
FAST ETHERNET
A
T
METHERNET
HUB
SWITCH
ETHERNET
FAST ETHERNET
SWITCH
HUB
HUB
1°LIVELLO
3°LIVELLO
2°LIVELLO
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 48 – Esempio di LAN
Le reti locali in genere sono distribuite su un’area circoscritta, come ad
esempio un complesso aziendale o un istituto universitario. Per allargare i servizi
di rete a una città, a un paese, o al mondo intero, è necessario collegare le reti
locali tra loro per formare reti di più ampia portata.

76
LE RETI METROPOLITANE (MAN) e GEOGRAFICHE (WAN)
LAN (Local Area Network)LAN (Local Area Network)
WAN (Wide Area Network)WAN (Wide Area Network)
MAN (Metropolitan Area Network)MAN (Metropolitan Area Network)RetiReti
Reti di Comunicazione
Metri - Km
Decine di Km
Decine - Migliaia di Km
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 49 – Classificazione delle Reti di Comunicazione
A seconda dell’area che copre, una rete allargata può essere definita
metropolitana o geografica.
Le reti metropolitane (MAN, Metropolitan Area Network) sono circoscritte
all’area di una città, come ad esempio le reti dei telefoni cellulari.
Le reti geografiche (WAN, Wide Area Network) sono distribuite su aree
molto vaste; alcune parti della rete possono essere connesse tramite cavi, altre
tramite microonde e trasmissioni satellitari. Tipiche reti geografiche sono quelle
telefoniche, ma probabilmente la rete più ampia in assoluto è Internet, che collega
non solo le reti locali ma anche altre reti geografiche.

77
Le reti pubbliche
Molte reti geografiche, create di norma per un uso aziendale, sono private,
vale a dire che vi possono accedere soltanto i dipendenti dell’azienda, i clienti e i
venditori autorizzati. Altre invece sono pubbliche, ossia aperte a chiunque paghi
la tariffa prevista per la connessione. Visti gli elevati costi che l’installazione di
una rete geografica privata comporta, sono ben poche le organizzazioni che ne
possiedono una integralmente. Nella gran parte dei casi infatti, le reti di questo
tipo si appoggiano alle reti pubbliche delle compagnie telefoniche o di altri
operatori commerciali che forniscono servizi legati alle telecomunicazioni.
In alcuni casi, le aziende noleggiano alcune linee, in modo da assicurarsi una
costante capacità di trasmissione (cioè larghezza di banda) e il diritto di generare
una certa quantità di traffico senza subire ritardi. Ciò non esclude che altri clienti
dell’operatore che fornisce servizi possano utilizzare contemporaneamente quelle
stesse linee fisiche.
Le intranet
Molte compagnie utilizzano le tecnologie di Internet per realizzare una
propria intranet, cioè una rete limitata alle dimensioni dell’azienda e accessibile
soltanto ai dipendenti e ad altri utenti autorizzati. Una intranet non serve solo per
far circolare i documenti all’interno della compagnia, ma anche per permettere
agli utenti di condividere programmi, basi di dati e dispositivi hardware. Queste
reti utilizzano lo stesso linguaggio (cioè gli stessi protocolli di comunicazione), gli
stessi programmi e i dispositivi di Internet, ma sono di norma inaccessibili agli
utenti della Rete, perché protette da speciali barriere difensive denominate
firewall.
I firewall
Il pannello metallico che separa l’abitacolo dell’auto dal motore è chiamato
firewall (tagliafuoco) perché ha la funzione di impedire che un eventuale incendio
al motore invada la cabina passeggeri. Lo stesso concetto è stato ripreso nel
campo delle reti informatiche per impedire agli utenti di Internet non autorizzati di
accedere ai file e ai programmi di una rete locale. Quando un computer collegato

78
a Internet è connesso anche a una intranet, viene dotato di un sistema firewall che
rende la rete locale inaccessibile dall’esterno. I fruitori della rete locale hanno
libero accesso alle risorse di Internet ma non possono fornire né servizi di Internet
né di intranet agli utenti esterni al firewall. Se un’azienda intende fornire dei
servizi interattivi deve installare un server gestore di dati al di fuori del firewall.
In questo modo i servizi di posta elettronica e di informazione, le mailing list, etc.
diventano servizi store-and-forward a cui gli utenti esterni possono accedere senza
oltrepassare la barriera del firewall.
Internet
Internet oggi collega tra di loro centinaia di milioni di computer e di utenti.
Si prevede che nel volgere di pochi anni la maggior parte della popolazione
terrestre avrà la possibilità di accedere ed utilizzare Internet. La nascita di Internet
infatti risale ai primi anni ottanta mentre la sua applicazione più popolare - il
World Wide Web - vede la luce soltanto agli inizi degli anni novanta.
Ma qual è la catena di eventi che ha portato alla genesi di questa idea
rivelatasi poi così rivoluzionaria? Quali personaggi hanno contribuito a far sì che
dal computer di casa nostra fosse possibile raggiungere informazioni poste in ogni
parte del mondo con un semplice click del mouse?
Come nel caso della conquista della luna, anche la nascita di Internet trova il
terreno adatto in cui svilupparsi nella sfida tecnologico-militare tra sovietici e
americani che risale agli anni della guerra fredda, un periodo di tensione
internazionale che nasce alla fine della seconda guerra mondiale - con la
spartizione del mondo in due blocchi contrapposti - e termina soltanto nel 1989
con la caduta del muro di Berlino. Durante il 1957 i sovietici mettono in orbita il
primo satellite artificiale della storia, lo Sputnik.
Fig. 50 – Lo sputnik, il primo satellite artificiale

79
Questo evento, al di là della sua enorme importanza tecnica, genera una sorta
di choc tecnologico nel mondo occidentale che fino ad allora aveva basato le sue
certezze sulla supremazia tecnologico militare americana. Infatti un’ ovvia
ricaduta bellica di questo lancio era rappresentata dal fatto che una atomica
sovietica poteva disporre di un vettore in grado di farle raggiungere facilmente un
obiettivo posto in qualsiasi parte del mondo.
L’agenzia ARPA
Le risposte dell’amministrazione USA al lancio dello Sputnik da parte dei
sovietici non si fanno attendere e nel 1958, con lo scopo di coordinare i
finanziamenti per la ricerca tecnologica con ricadute belliche, approva la
costituzione dell’ARPA - Advanced Research Projects Agency – con sede a
Washington, nell’edificio del Pentagono.
Gli interessi dell’agenzia ARPA ben presto si rivolgono alla telematica,
mentre alla neonata NASA, come ben sappiamo, viene affidata la guida della
ricerca aereospaziale.
Lo scopo dell’ARPA, e di conseguenza anche delle principali industrie legate
alla difesa, si concentra su una delle questioni principali che preoccupano in
quegli anni gli Stati Uniti: come impedire che un possibile attacco atomico
interrompa del tutto le comunicazioni nel paese gettando l’America nell’anarchia.
Semplificando, possiamo vedere il problema in questi termini: se una grossa
centrale telefonica viene distrutta tutte le comunicazioni via telefono che la
attraversano sono interrotte. Di conseguenza è sufficiente interrompere i nodi
principali di una rete telefonica per isolare l’intera rete e impedire lo scambio di
informazioni nel paese.
La trasmissione dei dati a pacchetti
Già all’inizio degli anni sessanta, un ingegnere di nome Paul Baran,
dipendente di una industria bellica - la Rand Corporation - trova una interessante
soluzione teorica al problema di come creare una rete di comunicazioni che non
fosse così fragile. L’idea è quella di costruire molti collegamenti alternativi tra

80
due qualsiasi punti in comunicazione. In questo modo, anche se molti di questi
collegamenti vengono improvvisamente a mancare, è sempre possibile trovare una
via di comunicazione percorribile.
Oltre all'idea di una rete decentrata e ridondante, Baran ha un'altra intuizione
geniale: piuttosto che inviare tutto il messaggio su un unico percorso, perché non
dividere questo messaggio in tante piccole parti e fare seguire ad ognuna di queste
la sua strada verso la destinazione? In questo modo, se un percorso si interrompe
mentre trasmettiamo un messaggio, solo un pezzetto – o un pacchetto come si
direbbe oggi - andrà perso, mentre le altre parti del messaggio sceglieranno strade
alternative per giungere a destinazione e potranno quindi essere recuperate e
ricomposte. Considerate che l’idea di dividere un messaggio in tanti pacchetti di
dati indipendenti, chiamata attualmente packet switching, è tuttora alla base dei
protocolli per l’invio di messaggi in rete.
Il progetto Arpanet
La prima realizzazione pratica di un sistema di comunicazione tra computer
basato sulla trasmissione di pacchetti di dati prenderà corpo solo nel 1966, quando
un ingegnere dell’agenzia ARPA, Bob Taylor, propone al suo direttore un
progetto che riguarda la costruzione di una rete di comunicazione tra i computer.
Ovviamente su questo progetto si riversano molte delle idee originariamente
concepite da Paul Baran.
Le specifiche tecniche del progetto sono affidate ad un brillante informatico
di nome Larry Roberts che guiderà per primo la realizzazione del progetto
chiamato Arpanet. Un progetto che, nel volgere di pochi anni, porterà alla nascita
di Internet.
Il 1969 viene spesso ricordato come l’anno dello sbarco sulla luna. Ma nello
stesso anno accade un altro avvenimento molto importante per Internet: nel 1969
infatti vede la luce il primo nucleo di Arpanet che collega tra loro quattro
università americane.

81
Fig. 51 – Il primo nucleo di Arpanet
Negli anni successivi questo embrione si espande fino a collegare una
quarantina di nodi. Ma l'applicazione che forse ha la maggiore influenza
nell'evoluzione successiva della rete nasce per caso, nel marzo del 1972. Un
ingegnere chiamato Ray Tomlinson, per scambiare opinioni con i suoi colleghi
delle altre università installa su Arpanet un semplice sistema di messaggistica su
computer. E’ appena nata la posta elettronica e per la prima volta compare il
famoso simbolo a chiocciola, divenuto in seguito sinonimo di Internet.
La nuova applicazione riscuote un enorme successo tra i ricercatori e
l’attuale direttore scientifico del progetto ARPA, Bob Kahn, spinto da questo
entusiasmo, organizza nello stesso 1972 la prima dimostrazione pubblica.
Da Arpanet a Internet
La dimostrazione pubblica di Arpanet alla International Conference on
Computer Communications del 1972 sulle potenzialità della connessione in rete di
quattro computer ebbe un successo oltre ogni aspettativa. Negli anni successivi
infatti questo primo embrione di Arpanet si espande sempre di più sul territorio
americano e contemporaneamente iniziano a svilupparsi numerose altre reti di
computer indipendenti e più economiche che collegano tra loro università e centri
amministrativi.
La nuova idea che nasce verso la metà degli anni settanta quindi è quella di
creare un sorta di super rete che colleghi tra loro tutte le reti di computer esistenti,
in poche parole Internet. Ma per ottenere questo risultato non basta connettere
fisicamente queste reti di computer tra loro, occorre innanzitutto definire un
linguaggio comune che consenta a tutti i computer di capirsi. Ed è con questo

82
obbiettivo che Cherf e Kahn elaborano le specifiche di un nuovo protocollo per
comunicare su Internet, e lo battezzano Transmission Control Protocol o TCP.
I risultati di questo lavoro vengono pubblicati nel 1974 e l’anno successivo il
nuovo protocollo viene diviso in due parti: il TCP, che gestisce i pacchetti di dati,
e l’IP, che ne regola la trasmissione. E in questa forma questo protocollo
sopravvive ancora oggi e rappresenta il linguaggio universale su cui poggia il
funzionamento di Internet.
Solo nel 1982 però l’uso di questo fondamentale protocollo, il TCP-IP, viene
imposto a tutti i nodi di Arpanet, e la sua diffusione nel mondo si espande a
macchia d’olio. In gran parte dei paesi occidentali, infatti, la possibilità di
connettere reti locali di computer in un'unica Internet mondiale stimola la nascita
di molte nuove reti locali di computer che, grazie al TCP-IP, sono in grado di
comunicare con tutte le altre reti di computer già esistenti e connesse ad Internet.
A questo punto le nuove reti di comunicazione hanno ormai soppiantato la
vecchia Arpanet che ha esaurito la sua funzione propulsiva.
Il protocollo TCP-IP
Internet è una sorta di meta-rete costituita da molte reti telematiche connesse
tra loro. Non ha importanza quale sia la tecnologia che le unisce: cavi, fibre
ottiche, ponti radio, satelliti, o altro. Non è neanche rilevante di che tipo siano i
computer connessi: dal piccolo personal computer al grosso elaboratore, o
mainframe. Punto di forza di Internet, e motivo del suo velocissimo espandersi, è
la sua capacità di “parlare” un linguaggio universale, adatto alla quasi totalità
degli elaboratori esistenti.
Per definire questo linguaggio bisogna considerare che i computer, come
noto, possono usare sistemi operativi, codici di caratteri, strutture di dati spesso
incompatibili tra loro. Per permettere la comunicazione tra l'uno e l'altro è
necessario quindi definire un insieme di regole condivise da tutti i computer.
Questa funzione, nell'ambito della telematica, viene svolta dai protocolli.
Un protocollo di comunicazione definisce le regole comuni che un computer
deve conoscere per elaborare e inviare i bit attraverso un determinato mezzo di

83
trasmissione fisica verso un altro computer. Un protocollo dunque deve
specificare in che modo va codificato il segnale, in che modo far viaggiare i dati
da un nodo all'altro, in che modo assicurarsi che la trasmissione sia andata a buon
fine, e così via.
Nel caso di Internet, l'insieme di protocolli che permettono il funzionamento
di questo complesso sistema di comunicazione telematico, viene comunemente
indicato con la sigla TCP/IP, che è un acronimo per Transmission Control
Protocol/Internet Protocol.
Gli indirizzi su Internet
Per fare in modo che la comunicazione tra due computer su Internet vada a
buon fine, oltre ad un protocollo comune è necessario che ogni singolo computer
abbia un indirizzo univoco, che lo identifichi senza alcuna ambiguità, e che
indichi la via per raggiungerlo tra i milioni di suoi simili presenti sulla rete.
A questo fine ogni computer presente su Internet è dotato di un indirizzo
costituito da una sequenza di quattro numeri, da 0 a 255, separati da un punto
come ad esempio
141.250.60.18
Per capire la logica con cui è composto questo indirizzo pensate a quando
scriviamo un indirizzo su una lettera:
Perugia, Via Verdi, n.60, Paolo Rossi
In questo indirizzo ci sono quattro informazioni: la città, la via, il numero
civico e un nome. Ognuno di questi campi corrisponde ad una comunità sempre
più ristretta fino ad individuare una singola persona con il suo nome e cognome.
Per comporre un indirizzo in Internet invece che di comunità di uomini si
parla di comunità di computer, ovvero di reti e sotto-reti, fino ad arrivare alla fine
dell’indirizzo il singolo computer chiamato host.

84
Fig. 52 – Il Router o Gateway
Ognuna di queste sotto-reti, che usualmente vengono chiamate domini,
dispone di un gateway o router, che si incarica di spedire e di ricevere i pacchetti
di dati che provengono dal suo dominio.
Per indirizzare un pacchetto di dati quindi il computer usa un IP Address,
composto da quattro campi numerici:
141 . 250 . 60 . 18
Perugia - Via Verdi - n.60 - Paolo Rossi
Nel caso del nostro esempio, 141 indica l’indirizzo del dominio-città di
Internet. Il secondo numero, il 250, indica il dominio-strada, mentre il 60 indica il
dominio-n.civico e il 18 rappresenta il nome e cognome del singolo computer.
Fortunatamente Internet usa un sistema chiamato DNS - ovvero Domain Name
Service - per trasformare l’indirizzo numerico usato dai computer in qualcosa di
più comprensibile ad un uomo.
Attraverso il DNS ogni host di Internet può essere dotato di un nome
(domain name). È evidente che per un utente utilizzare dei nomi simbolici è molto
più semplice e intuitivo che maneggiare delle inespressive sequenze di numeri. Ad
esempio, all’host 141.250.60.18 corrisponde il seguente nome:
orione.med.unipg.it.

85
Ricordate quindi che dietro ad ogni indirizzo che vedete su Internet e nel
Web si nasconde un IP address numerico come quello che abbiamo visto.
Computer clienti e computer fornitori
Nei collegamenti Internet c’è un computer cliente ( client ) che chiede delle
informazioni e un computer fornitore ( server ) che li mette a disposizione.E’
proprio su questo principio, chiamato architettura client-server, che si basano
tutte le applicazioni usate su Internet.
Fig. 53 – Client e Server
Il World Wide Web
Il WWW, la più nota applicazione usata su Internet, nasce al CERN, il più
grande centro di ricerca europeo sulla fisica delle particelle elementari, dove
lavorano fisici di tutto il modo che usano quotidianamente la Rete per tenersi in
contatto e scambiarsi opinioni.
E proprio per migliorare questo tipo di comunicazioni un ricercatore di nome
Berners-Lee, nel 1990, propone ai suoi superiori un nuovo modo di utilizzare
Internet che chiama World Wide Web. Al di là del nome, la cosa più interessante
che si può notare nel progetto di Barners-Lee è che in questa proposta sono già
presenti tutte le idee guida che ancora oggi caratterizzano il Web. La prima regola
del Web è che i suoi documenti devono essere scritti in un particolare formato
chiamato ipertesto. In parole povere questo significa che tra le parole del testo
potranno essere inseriti dei riferimenti – link in inglese – ad altri documenti
presenti nel Web. Quando l’utente seleziona uno di questi riferimenti, il

86
documento corrispondente viene richiesto sul Web e visualizzato sul computer
dell’utente.
Questa proprietà delle pagine ipertestuali, pur essendo concettualmente
semplice, ha comportato una vera e propria rivoluzione nel modo di intendere una
rete di calcolatori. Prima dell’ipertesto, infatti, tutto quello che poteva fare
l’utilizzatore di Internet era ricevere o inviare un documento su un altro computer
collegato in rete. Dopo l’ipertesto, tutti i documenti presenti nel Web sono legati
tra di loro da un immensa ragnatela di collegamenti, gli ormai famosi link.
L’utente, seguendo questi link, è in grado di spostarsi istantaneamente da un
documento all’altro attraverso Internet.
Fig. 54 – Collegamenti ipertestuali tra pagine Web
Ricapitolando, quando si fa un click su una di queste parole chiave il browser
automaticamente preleva dal Web la pagina indicata dal riferimento e ce la
mostra, e come avete visto curiosando nel Web, usando la multimedialità, una
pagina può contenere non solo testo scritto ma anche immagini, suoni, filmati e
animazioni. La seconda idea che sorregge il Web è quella di definire un apposito
programma, il browser, che consenta di visualizzare gli ipertesti contenuti nel
World Wide Web.
Questo programma rappresenta qualcosa di completamente nuovo rispetto a
tutto quello che fino ad allora si era visto su un computer. Il browser infatti
rappresenta una sorta di finestra aperta sul mondo del Web e quindi deve essere in
grado di visualizzare non solo testi scritti ma anche immagini, filmati e perfino
suoni. Deve essere un programma multimediale nel senso più ampio del termine e
inoltre deve poter funzionare su qualsiasi tipo di calcolatore utilizzabile in
Internet.

87
I primi esempi di browser che vengono rilasciati gratuitamente dal CERN
sono dei primi anni novanta. La grande svolta avviene nel 1993 quando Marc
Andressen e Eric Brina dell’Università dell’Illinois sviluppano e distribuiscono
gratuitamente Mosaic, il primo browser con un interfaccia grafica, che consente di
visualizzare il contenuto di una pagina Web in modo molto simile a quello attuale.
Questo programma semplice e intuitivo avvicina finalmente alla rete molti nuovi
utenti incuriositi dalle possibilità aperte dal ciberspazio. Da quel momento inizia
l’esplosione del World Wide Web così come lo conosciamo oggi.
Collegarsi a Internet
La connessione tra un computer e Internet generalmente non avviene in
modo diretto. Per collegarsi alla rete infatti il nostro computer si mette in
collegamento, tramite il telefono, con un altro computer, quello del provider. Il
provider, o fornitore di connettività, è un po’ la nostra porta di accesso alla rete:
dispone infatti di un computer sempre acceso e sempre collegato a Internet,
attraverso veloci linee dedicate.
Fig. 55 – Collegamento ad Internet tramite provider
Quando il nostro computer ‘telefona’ al computer del provider, ne diventa un
po’ un’appendice, e sfrutta le sue linee per ricevere informazioni da tutto il resto
della rete.

88
Fino a poco tempo fa l’unico modo possibile per connettersi ad un provider e
navigare in rete era quello di utilizzare un modem, un piccolo dispositivo che
collega fra loro computer e linea telefonica.
Da qualche tempo, però, la situazione è diventata un po’ più complicata
SISTEMA INFORMATIVO OSPEDALIEROSISTEMA INFORMATIVO OSPEDALIERO
ROUTER
ROUTER
ROUTER
MAN / WAN
BI 1999
P.O. POLICLINICO P.O. SILVESTRINI
Via COTANI
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 56 – Esempio di collegamento utilizzando linee telefoniche
perché, anche limitandosi a considerare solo il collegamento telefonico, i possibili
modi di connettersi in rete sono diventati ben tre, ognuno con i suoi vantaggi e
svantaggi in termini di prestazioni e di costo. A complicare ulteriormente la
questione c’è il fatto che ognuna delle tre modalità di connessione richiede un suo
dispositivo particolare per essere utilizzata.
Ma vediamo quali sono e come si chiamano questi tre tipi di modalità per la
connessione:
• Modem (collegamento analogico, linea commutata).
• ISDN (collegamento digitale)
• ADSL (collegamento digitale)

89
Modem
Per chi ha iniziato da poco a navigare nel Web il modo più semplice per
connettersi ad Internet rimane tuttora quello di usare un modem. Questo
dispositivo si collega direttamente alla presa del telefono, esattamente come una
segreteria telefonica. Esistono due tipologie di modem, quelli esterni al computer
e quelli interni. I computer portatili sono oggi già forniti di un modem interno
pronto ad essere collegato ad una linea telefonica. Un modem esterno ha solo il
vantaggio di poter essere utilizzato su più computer collegandolo alla loro porta
seriale RS232.
Parlando di costi, se il provider che utilizziamo si trova nel nostro distretto
telefonico, usare il modem per connettersi ad Internet costa esattamente come
telefonare ad un vicino di casa. Quindi il costo della connessione dipenderà dalla
sua durata e dalle tariffe della compagnia telefonica che abbiamo scelto di
utilizzare. I limiti del modem invece sono essenzialmente due:
• scarsa velocità di trasferimento dei dati con il provider (causa principale
dei lunghi tempi d’attesa per ricevere le pagine Web);
• quando ci si connette ad Internet usando un modem, si isola la linea
telefonica, se si dispone di una linea telefonica tradizionale.
ISDN e ADSL
Sia la rete ISDN, acronimo di Integrated Services Digital Network, che
quella ADSL, acronimo di Asymmetric Digital Subscriber Line, permettono la
trasmissione di dati in forma digitale e garantiscono quindi una velocità molto
maggiore di quella del modem analogico.
Trasmissione in forma digitale significa che il segnale usato dal computer
non viene modulato secondo una determinata onda sonora, come nel caso del
modem, ma codificato e inviato lungo la linea come una lunga sequenza di zero e
uno. Le tre caratteristiche principali di ISDN sono:

90
• elevata velocità di trasmissione, pari a 64 Kbit al secondo per canale (ossia
1 Mb ogni 2 minuti o 70 pagine di documenti solo testo via fax al minuto);
in termini pratici i tempi di attesa si riducono di un fattore 5 rispetto al
modem;
• si può usare la linea telefonica mentre si è connessi ad Internet;
• costi di utilizzo accessibili.
La tecnologia ADSL è l’ultima arrivata e rappresenta una grande novità nel
mondo delle connessioni ad Internet per i seguenti motivi:
• si è sempre connessi alla Rete; non serve chiamare il provider ad ogni
connessione e non si pagano le singole telefonate ma una spesa forfettaria
mensile;
• potenzialmente ha una enorme velocità di connessione, fino a 640 Kbit al
secondo ovvero fino a 10 volte più veloce di ISDN;
• si può usare la linea telefonica mentre si è connessi ad Internet.
Queste nuove connessioni veloci sono ormai accessibili alla massa degli
utenti della Rete e questo ha comportato la vera rivoluzione sulle capacità
multimediali del Web.

91
SISTEMA INFORMATIVO OSPEDALIERO
Un Sistema Informativo Ospedaliero (SIO) o Hospital Information System
(HIS) ha lo scopo di gestire in modo unitario, le sempre più numerose
informazioni prodotte dai vari settori assistenziali, amministrativi e gestionali di
un ospedale.
In realtà solo pochi sistemi riescono ad assolvere compiutamente questa
funzione; di solito gli aspetti più curati sono quelli amministrativi, mentre
raramente l’HIS si fa carico della gestione integrata di procedure diagnostiche,
terapeutiche e riabilitative.
In pratica, la maggior parte dei sistemi ad oggi installati, sono
prevalentemente orientati a finalità amministrativo-finanziarie e rivestono scarsa
utilità sul piano sanitario.
I contenuti informativi gestiti da un HIS possono essere raggruppati in tre
principali classi di dati rispettivamente riferiti a:
1. pazienti (anagrafica, storia amministrativa e clinica, etc.),
2. attività (giorni di ricovero, esami diagnostici etc.)
3. risorse (personale, attrezzature etc.).
Questi insiemi di dati, vengono utilizzati a livello:
1. operativo, per assistere il personale sanitario ed amministrativo nello
svolgimento dell’attività quotidiana;
2. gestionale, per pianificare l’organizzazione delle attività e analizzare il
lavoro svolto;
3. di coordinamento e supervisione, per ottenere informazioni globali.
L'integrazione delle informazioni tra sistemi informativi ospedalieri di tipo
gestionale, apparati elettromedicali e strumenti di diagnostica è una delle strade
fondamentali da percorrere per fornire una migliore assistenza sanitaria ai pazienti
e a tutti gli utenti dei servizi ospedalieri. Nel mondo della sanità l'integrazione tra
sistemi è un problema, per le dimensioni e per le specificità di questo settore,
molto complesso e articolato, e la strada per raggiungere pienamente questo

92
obiettivo è ancora lunga. Attualmente negli ospedali esistono numerosi sistemi
informativi distinti, che gestiscono i dati anagrafici e clinici del paziente e le
immagini diagnostiche. Tra questi sistemi, i principali sono rappresentati dal
software di gestione del CUP (centro unico prenotazioni), dalla gestione degenze
(ADT), dai sistemi di cassa, cui si aggiungono sistemi dipartimentali, quali PACS
e RIS (ovvero Sistema di Archiviazione e Comunicazione delle Immagini
Radiologiche e Sistema Informativo Radiologico), e sistemi di supporto della
piattaforma amministrativa per la gestione di contabilità, approvvigionamenti,
magazzino, farmacia, manutenzione, e le altre attività ‘gestionali' di un ospedale.
Questi sistemi necessitano di condividere informazioni, ma, pur utilizzando
protocolli standard di comunicazione, spesso non sono in grado di scambiarsi dati,
perché gli standard possono presentare conflitti interpretativi e libera scelta di
opzioni.
Nel 1997, per superare questi problemi, la Direzione Bioingegneria operò una
dettagliata analisi del modello organizzativo e informativo dell’Azienda
Ospedaliera di Perugia e sulla base di questa analisi progettò un nuovo modello di
Sistema Informativo Ospedaliero.
Sistema Informativo Ospedaliero
ANAGRAFE DEGLI ASSISTITI
CARTELLE CLINICHE
AMMINISTRAZIONE
AMBULATORIODAY HOSPITAL
LAB. ANALISI
PACSRISREPARTI
ACCETTAZIONE
CUP
PRONTO SOCCORSO
SISTEMA INFORMATIVOOSPEDALIERO
SIS SISTEMA INFORMATIVO SANITARIO
SIO (HIS)
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 57 – SIO integrato dove il fulcro è l’Anagrafe degli assistiti
Il fulcro del modello d’informatizzazione è basato su due punti essenziali:

93
� anagrafe degli Assistiti quale punto di integrazione fra i vari sottosistemi
del Sistema Informativo Ospedaliero e contestualmente quale nodo di
congiunzione con il Sistema Informativo Sanitario Regionale (Figura 57);
� identificazione del paziente al momento del suo ingresso in ospedale.
Il nuovo modello rappresentato schematicamente in Figura 58 prevede la
produzione di un codice durante la procedura di accettazione ospedaliera del
paziente. Tale codice lo accompagnerà per tutto il suo percorso diagnostico-
terapeutico sia questo ricovero, day-hospital o ambulatorio. Ciò è reso possibile se
si prevede l’accettazione del paziente (ADT) direttamente da Reparto per la
degenza programmata, o dal Pronto Soccorso per le urgenze. Questo codice
univoco ci permette di automatizzare compiutamente il Laboratorio di Analisi ed i
vari settori diagnostici, di velocizzare il processo diagnostico e di evitare inutili
duplicazioni di archivi. Un ulteriore obiettivo è di mettere in condizione i Reparti
di collegarsi direttamente al Laboratorio di Analisi, alle Radiologie, alla Farmacia,
al Magazzino ed ai Servizi vari (Dietetico, manutenzioni, etc.) per richiedere
prestazioni, servizi e ricevere in tempo reale referti, immagini ed informazioni
utili alla loro gestione. Questo modello informativo offre la possibilità di
raccogliere contemporaneamente informazioni, in modo codificato ed
informatizzato, utili al Controllo di Gestione, alla Contabilità e alla Direzione
Sanitaria.
In particolare il progetto aveva l’obiettivo di stabilire riferimenti generali,
criteri e standard di base ormai ben consolidati, con la finalità di costruire un
sistema Informativo Ospedaliero aperto, modulare e scalabile con gradualità ed
inoltre superare il concetto di HIS, RIS, PACS, rete per l’emergenza, ADT, etc.
come sistemi separati e di vedere il Sistema Informativo Sanitario come un
sistema integrato e distribuito.

94
Sistema Informativo Ospedaliero - (HIS)
ADT
ADT
PRONTO SOCCORSO
REPARTO DIMISSIONE
Prenot. Ambulat. o Day Hospital
PAZIENTE
R
I
S
LAB
FUNZIONALI
CARTELLA
MAGAZZINO
FARMACIA
FATTURAZ.
ANALISI
ESAMI
CLINICA
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 58 – Possibili percorsi dei dati del paziente e delle attività assistenziali connesse
Oggi, nell’Azienda Ospedaliera di Perugia, molte procedure sono operative e
fra loro integrate, come ad esempio l’ADT da reparto, il Pronto Soccorso, il 118,
il Sistema RIS-PACS (che descriveremo successivamente), la trasmissione e
refertazione remota dei tracciati ECG, l’informatizzazione automatizzata dei
Laboratori di Analisi, non ultimo l’informatizzazione delle Sale Operatorie che
permetteranno non solo agli specialisti di settore di operare in diretta con
l’esterno, trasmettendo/ricevendo suoni ed immagini, ma anche di svolgere in
diretta dalla sala operatoria lezioni volte a studenti e specializzandi raccolti nelle
sale di videoconferenza già predisposte.
Attualmente, per realizzare un'efficace integrazione fra i vari sistemi, è
necessario definire e utilizzare standard di comunicazione; quelli maggiormente
coinvolti nei SIO sono: DICOM3 per l'imaging, ASTM nell'area dei laboratori e
HL7 per le informazioni sanitarie (Anagrafiche, anamnestiche, etc.).

95
HL7HL7
DICOM 3.0 DICOM 3.0
Lo StandardOSI
Lo StandardOSI
SESSIONE
COLLEGAMENTO
RETE
PRESENTAZIONE
TRASPORTO
Gli Standard
FISICO
APPLICAZIONE
Health Level Seven
Digital Imaging andCommunication in Medicine
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 59 – I più diffusi Standard di Comunicazione nei Sistemi Informativi Ospedalieri
Piano di sicurezza e riservatezza
Nella progettazione dei Sistemi Informativi Ospedalieri particolare
attenzione deve essere riservata al problema della sicurezza.
E’ indispensabile garantire l’inviolabilità delle risorse del SIO, e quindi delle
informazioni messe a disposizione degli operatori sanitari attraverso la rete e le
tecnologie informatiche, in particolare:
• la segretezza (la necessità di mantenere segreti alcuni dati);
• l’integrità (i dati non devono essere modificati da soggetti esterni o non
autorizzati);
• la disponibilità (stabilire l’utenza che può accedere alle informazioni).

96
Attacchi a dati estremamente riservati, come possono essere quelli relativi a
referti medici e informazioni private sulla salute del singolo cittadino, devono
comunque essere evitati.
La difesa dell’inviolabilità deve essere garantita attraverso strumenti di
protezione quali:
• host security (rafforzare la sicurezza di ogni macchina in rete utilizzando
gli strumenti hardware e software disponibili);
• Network security (pianificare la struttura della rete in modo da poter
controllare con maggior efficienza sia l’accesso alle proprie macchine che
ai servizi che esse offrono).
Pur raggiungendo un elevato grado di sicurezza garantendo quelli che sono i
servizi tipici di rete come e-mail, ftp, telnet e server web non è possibile
comunque realizzare un sistema di protezione assoluto e quindi, per quelle reti che
necessitano di tecniche di protezione per proteggere dati estremamente riservati,
diventa indispensabile che la gestione e pianificazione sia svolta da strutture in
grado di monitorizzare gli accessi e neutralizzare tempestivamente i tentativi di
violazione.

97
INTRODUZIONE AI SISTEMI INFORMATICI IN RADIOLOGIA
I sistemi informativi, in genere, hanno la funzione di coordinare la raccolta,
la gestione, la presentazione e lo scambio di informazioni.
In un’organizzazione come un ospedale o più specificamente, un reparto di
radiologia, un sistema informatico ha il compito di ottimizzare il flusso delle
informazioni con il fine di aumentare l’efficacia e l’efficienza assistenziale.
Un sistema informatico è la componente automatizzata del sistema
informativo. Nell’accezione normale, si tende a sfumare le distinzioni tra sistema
informativo e sistema informatico, perché non sembra possibile che l’uno possa
esistere senza l’altro.
D’altra parte, un sistema informatico risulta del tutto inutile se non esiste
prima una corretta e precisa opera di raccolta dei dati; in molti casi la mancanza o
l’inesattezza delle informazioni è dovuta a inefficienze organizzative e non a
quelle del sistema informatico.
All’interno dell’ospedale, la radiologia è probabilmente il reparto dove si fa
maggior uso delle tecnologie avanzate; fra queste, l’informatica occupa un posto
di primo piano.
Focalizziamo ora l’attenzione sui principali compiti di un sistema
informativo in radiologia:
� acquisizione in formato digitale, delle immagini fornite dalle diverse
apparecchiature diagnostiche e dei dati ad esse associati;
� elaborazione ed archiviazione di informazioni relative ai diversi momenti
della storia clinica del paziente;
� condivisione in rete di tutte le informazioni di utilità clinica ed
amministrativa.
Per fare in modo che l’intero sistema digitale radiologico funzioni, HIS, RIS
e PACS, devono essere correlati in modo da unire testi, anagrafica ed immagini di

98
uno stesso paziente, ed è per questo che i sistemi vengono gestiti da server
dedicati, che associano i file che altrimenti non dialogherebbero tra loro.
R I S(Radiology Information System)
R I S(Radiology Information System)
P A C S(Picture Archiving Communication System)
P A C S(Picture Archiving Communication System)
H I SH I S
Magazzino
Prenotazione
Gestione Servizio
Diagnostica per Immagini
Statistiche
Refertazione
Gestione e Archiviazionedelle Immagini
Fig. 60 – Le principali funzioni svolte dal RIS e PACS
Sistema Informativo di Radiologia
Il RIS ha la finalità di contribuire alla raccolta, alla gestione e alla
presentazione delle informazioni prodotte nel reparto di radiologia.
Richiesta d’esame: l’arrivo in radiologia della richiesta d’esame, attiva i processi
del RIS, con la raccolta di una serie di informazioni amministrative e di interesse
clinico. Tra le informazioni di carattere amministrativo rientrano l’anagrafica del
paziente, il tipo di esame, l’operatore, la sala e la presenza di eventuali vincoli
temporali all’effettuazione dell’esame (urgente o di routine). La seconda classe di
dati raccolti in questa fase, è rappresentata dalle informazioni di interesse clinico,
che riguardano essenzialmente la ragione per la quale l’esame viene richiesto.
Tutti i dati sono forniti direttamente dal paziente o acquisiti da altri sistemi
informativi.

99
Gestione dell’agenda radiologica: l’aggiornamento dell’agenda avviene sulla
base delle risorse disponibili: sale, personale, apparecchi. Il RIS ricerca,
all’interno dell’archivio, l’eventuale presenza di dati precedenti riguardanti il
paziente in questione, utili per rilevare l’incompatibilità tra esami o segnalare
l’avvenuta esecuzione della prestazione richiesta. A seguito di tali operazioni
viene fissato un appuntamento e prodotto un foglio informativo, che sarà
consegnato al paziente o inviato al reparto, contenente la preparazione necessaria
per poter svolgere gli esami richiesti.
Le principali attività svolte da un reparto di Radiologia, dove il RIS ha un
ruolo fondamentale nella gestione del paziente a fini diagnostici, sono
sinteticamente descritte in Figura 61.
Pianificazione Layout ePianificazione Layout eAccettazioneAccettazione
Fase di EsecuzioneFase di Esecuzionedelldell ’’EsameEsame
Fase CulturaleFase Culturale
Archiviazione eArchiviazione eDistribuzioneDistribuzione
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 61 – Le principali attività svolte dal Reparto di Radiologia
utilizzando il RIS
La Figura 62 descrive in modo dettagliato tutte le fasi del processo
diagnostico, dalla prenotazione dell’esame alla distribuzione delle immagini con
relativo referto medico.

100
PrenotazionePrenotazioneComplessaComplessa
PrenotazionePrenotazioneC.U.PC.U.P
PianificazionePianificazioneDegentiDegenti
PreaccettazionePreaccettazione
Vidimazione ListeVidimazione Liste
AccettazioneAccettazione
Produzione DocumentaleProduzione Documentale
Esecuzione EsameEsecuzione Esame
Completamento EsameCompletamento Esame
RefertazioneRefertazione
Archiviazione e DistribuzioneArchiviazione e Distribuzione
Pianificazione del lavoro ePianificazione del lavoro elayout operativo delle sezioni diagnostichelayout operativo delle sezioni diagnostiche
IdentifIdentif . personale. personale
PACSPACS
PACSPACS
PACSPACS
PACSPACS
PACSPACS
FirmaFirma
GestGest . Magazzino. Magazzino
GestGest . Farmacia. Farmacia
WL di IntegrazioneWL di Integrazione
ProtezionisticaProtezionistica
StatisticaStatistica
PrePre--fetchfetch
Creazione WLCreazione WL
AcquisAcquis . Immagini. Immagini
PACSPACS Aggiorna WLAggiorna WL
VisualVisual . Immagini. Immagini
PACSPACS Aggiorna StatusAggiorna Status
LANLAN ––WANWAN --WEBWEB
Dati Dati AnagrAnagr . . ClinciClinci
Completa DatiCompleta Dati
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 62 – Le attività svolte dal Reparto di Radiologia
Accettazione: l’arrivo del paziente che si presenta per sottoporsi all’esame
diagnostico, fornisce un’ulteriore occasione per rivedere e/o integrare i dati
raccolti fino a quel momento. Una volta che l’esame è definitivamente
autorizzato, il RIS provvede all’accettazione del paziente (da distinguere da
quella allo sportello, che ha significato puramente amministrativo). Se le
apparecchiature diagnostiche digitali sono collegate con un RIS per mezzo di un
protocollo dedicato, definito dallo standard DICOM con il termine di “worklist
management”, l’immissione dei dati del paziente avviene automaticamente, senza
l’intervento dell’operatore.

101
Pianificazione Layout e accettazionePianificazione Layout e accettazione
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 63 – Documentazione prodotta durante l’accettazione del paziente
Esecuzione dell’esame: questa fase coincide con la produzione delle immagini
diagnostiche e le indicazioni associate.
Negli ultimi tempi si è affermata la tendenza a considerare i dati relativi alla
tecnica di acquisizione delle immagini, come parte integrante dell’intero esame.
Ulteriori informazioni riguardanti la tecnica d’esame, sono quelle di tipo
procedurale, come la posizione del paziente o l’eventuale uso e modalità di
somministrazione del mezzo di contrasto.
Se le immagini sono in formato DICOM, tali dati possono essere forniti al
RIS in modo diretto, senza l’utilizzo aggiuntivo di file, evitando la
frammentazione dello studio. Infatti lo standard prevede che in uno spazio
predefinito del file d’immagine (header), vi siano riportate informazioni di tipo
alfanumerico, che oltre all’anagrafica del paziente, includono anche indicazioni di
tipo tecnico e procedurale.

102
Fase di Esecuzione dellFase di Esecuzione dell’’EsameEsame
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 64 – Fase di esecuzione
Refertazione: dopo l’effettuazione dell’esame, la fase dell’interpretazione delle
immagini e della produzione del referto, viene assistita dal RIS con le seguenti
modalità:
1. compilazione di una lista che consenta di stabilire la priorità di
refertazione;
2. visualizzazione degli esami precedentemente eseguiti dal paziente;
3. visualizzazione dei referti degli esami precedenti archiviati in forma
elettronica.
Il referto di solito presenta una struttura di questo genere:
1. descrizione dell’esame effettuato;
2. codice dell’esame;
3. descrizione dei segni radiologici rilevati sull’immagine;
4. ipotesi diagnostica e diagnosi differenziale;
5. codifica diagnostica.

103
Anche nella parte più strettamente clinica (in figura 61 chiamata culturale), il
RIS può offrire un contributo nella compilazione del referto, grazie alla possibilità
di richiamare testi prememorizzati in funzione del tipo di patologia.
Per refertare l’esame, il medico Radiologo utilizza un sistema di refertazione
vocale. E’ sufficiente parlare su un microfono collegato al computer per trasferire
automaticamente, attraverso un software in grado di interpretare le parole del
radiologo, la refertazione vocale in un file di testo.
Fase CulturaleFase Culturale
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 65 – Fase di refertazione
Il medico Radiologo per firmare il referto utilizza la firma elettronica, che
tecnicamente avviene tramite una smart card personale, che inserita nell’apposito
lettore, firma elettronicamente il documento.
Archiviazione: per quanto riguarda l’archiviazione, il RIS provvede alla
conservazione dell’informazione testuale raccolta e generata nel corso del
processo diagnostico. Per l’archiviazione delle immagini, il sistema informatico
utilizzato è il PACS.

104
Fig. 66 – Lettore di smart-card utilizzato per la firma elettronica
Archiviazione e DistribuzioneArchiviazione e Distribuzione
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig.
67 – Fase di distribuzione
Generalmente il RIS mantiene per almeno un anno tutti i referti su memorie
“in linea”. La progressiva riduzione del costo delle memorie digitali, sta
determinando un progressivo abbandono dell’archiviazione fuori linea, con il
mantenimento di tutto l’archivio dei referti in linea.

105
Sistemi di Archiviazione e Comunicazione delle Immagini (PACS)
I PACS sono sistemi per l’archiviazione e la trasmissione di immagini. Le
immagini già in formato digitale vengono direttamente acquisite dalle diverse
modalità di imaging diagnostico, quali radiografie digitali, tomografia assiale
computerizzata, risonanza magnetica, angiografia digitale, medicina nucleare,
videoendoscopia, tomografia ad emissione di positroni, mammografia digitale,
etc. o immagini non digitali dopo essere state digitalizzate da apposite interfacce
(DICA, Direct Image Capture).
ImmaginiDigitali
ImmaginiDigitali
Tomografia Computerizzata (CT)
Tecnologie per l’Acquisizione delle Immagini
Risonanza Magnetica (NMR)
Angiografia Digitale (DA)
Ultrsuoni (US)
Medicina Nucleare (NM)
Videoendoscopia (VE)
Radiografia Digitale (DR)
Risoluzione spaziale: Matrici >= 512 x 512
Profondità: >= 8 bit/pixel
BioingegneriaBioingegneriaBioingegneriaBioingegneriaa.a.a.a.a.a.a.a. 2009/20102009/20102009/20102009/2010
Fig. 68 – Le principali tecnologie che producono immagini direttamente
digitali
A prescindere dalle dimensioni, un sistema PACS è costituito da più
sottosistemi che svolgono le seguenti funzioni:
1. acquisizione delle immagini, che include i sistemi di radiologia digitale come
RM, TAC, i digitalizzatori di pellicole e le interfacce verso le apparecchiature
standard di imaging tradizionali con uscita analogica;

106
2. visualizzazione ed elaborazione delle immagini, questa funzione permette di
visualizzare le immagini sulle varie workstations, sia quelle acquisite in tempo
reale nelle varie modalità, che quelle tratte dall’archivio centrale e di
migliorare la qualità dell’immagine e favorire l’analisi diagnostica;
3. stampa delle immagini, questa funzione permette l’invio delle immagini a
stampanti laser per la copia su pellicola;
4. gestione ed archiviazione, che richiede un DMS (Database Management
System - sistema di gestione di basi di dati) per gestire l’archivio delle
immagini e dei dati ad esse correlati. Il server PACS dapprima archivia le
immagini su una memoria temporanea e successivamente, a refertazione
conclusa, le trasferisce in maniera definitiva sul Juke box centrale;
5. comunicazione di rete, che connette tutti i componenti e permette il
trasferimento di dati e di immagini ai vari reparti e ospedali collegati e, dove
necessario, la comparazione di immagini provenienti da diverse diagnostiche.
Fig. 69 – Jukebox di Archiviazione
Teleradiologia
La teleradiologia rappresenta lo sviluppo tecnologico più recente in ambito
sanitario. Con questa modalità informatica si possono trasmettere immagini
radiologiche, da un sito ad un altro, utilizzando una rete metropolitana (MAN) o

107
geografica (WAN) a differenza di quella utilizzata all’interno del reparto o di un
ospedale (LAN).
Nello specifico, la teleradiologia ha lo scopo di permettere la diagnosi a
distanza (telediagnosi) di esami eseguiti in altra sede.
In altre parole il sistema, ad esempio, permette ad un medico neuroradiologo
che sta svolgendo il suo lavoro nell’ospedale di Perugia di ricevere immagini di
esami neuroradiologici di un paziente traumatizzato inviategli da un collega di
Città di Castello che richiede una consulenza specialistica neuradiologica. In
tempo reale il neuroradiologo analizza le immagini, richiede eventuali nuove
proiezioni, compila il referto e lo trasmette via rete al collega di Città di Castello.
Una volta constatata l’affidabilità delle immagini (ovvero che quelle in
ricezione siano qualitativamente le stesse di quelle in trasmissione) e verificata la
velocità di trasmissione, si può affermare con certezza, che la teleradiologia
garantisce una maggior efficienza diagnostica ed una maggiore efficacia
terapeutica, soprattutto per gli utenti che afferiscono a strutture sanitarie minori.
Vantaggi di una Radiologia Digitale
I benefici di una Radiologia Digitale rispetto ad una radiologia tradizionale
sono evidenti e rappresentano la miglior soluzione in termini di efficacia ed
efficienza assistenziale.
Infatti, un’accettazione più rapida grazie al RIS, la stampa di un esame solo
se necessario, la semplice e rapida archiviazione, la possibilità di trasmettere
immediatamente le immagini ed i relativi referti ai vari reparti od ospedali
collegati, la refertazione vocale effettuata direttamente dal medico radiologo,
riducono i tempi ed ottimizzano le attività di diagnosi con una evidente ricaduta
sul piano assistenziale.
Vengono quasi totalmente eliminati gli errori di impostazione del carico della
dose di radiazioni, grazie alla possibilità di elaborare in post-processing le
radiografie eseguite, evitando di esporre nuovamente il paziente alle radiazioni
ionizzanti.

108
L'INTELLIGENZA ARTIFICIALE
L'intelligenza artificiale è uno dei numerosi campi di dibattito teorico tra
scienziati e filosofi. Per intelligenza artificiale, spesso abbreviata in AI
(dall'inglese Artificial Intelligence), si intende generalmente la possibilità di far
svolgere ad un calcolatore alcune funzioni e alcuni ragionamenti tipici della mente
umana. Nel suo aspetto puramente informatico, comprende la teoria e la pratica
dello sviluppo di algoritmi che rendano le macchine (tipicamente i calcolatori)
capaci di mostrare un'abilità e/o attività intelligente anche se in domini molto
specifici.
L'espressione "Intelligenza Artificiale" è stata coniata dal matematico
americano John McCarthy in seguito ad uno storico seminario interdisciplinare
svoltosi nel New Hempshire nel 1956. Secondo le parole di Marvin Minsky, uno
tra i "pionieri" della I.A., lo scopo di questa nuova disciplina sarebbe stato quello
di "far fare alle macchine delle cose che richiederebbero l'intelligenza se fossero
fatte dagli uomini".
Tali attività e capacità comprendono:
� l'apprendimento automatico (machine learning), utile in contesti quale il
gioco degli scacchi
� la rappresentazione della conoscenza e il ragionamento automatico in
maniera simile a quanto fatto dalla mente umana
� la pianificazione (planning)
� la cooperazione tra agenti intelligenti, sia software sia hardware (robot)
� l'elaborazione del linguaggio naturale (Natural Language Processing)
� la simulazione della visione e dell'interpretazione di immagini, come nel
caso dell'OCR (Optical Chracter Recognition)
La domanda al centro del dibattito sull'intelligenza artificiale è
fondamentalmente una sola: "I computer possono pensare?".
Le risposte sono varie e discordi, ma perché abbiano un senso bisogna prima
determinare cosa significhi pensare. Ironicamente, nonostante tutti siano d'accordo

109
che gli esseri umani sono intelligenti, nessuno è ancora riuscito a dare una
definizione di intelligenza soddisfacente; proprio a causa di ciò, esistono due
principali branche in cui è suddiviso lo studio dell'AI:
� la prima, detta intelligenza artificiale forte, sostenuta dai funzionalisti,
ritiene che un computer correttamente programmato possa essere veramente
dotato di una intelligenza pura, non distinguibile in nessun senso importante
dall'intelligenza umana. L'idea alla base di questa teoria è il concetto che
risale al filosofo empirista inglese Thomas Hobbes, il quale sosteneva che
ragionare non è nient'altro che calcolare: la mente umana sarebbe dunque il
prodotto di un complesso insieme di calcoli eseguiti dal cervello;
� la seconda, detta intelligenza artificiale debole, sostiene che un computer
non sarà mai in grado di essere equivalente a una mente umana, ma potrà
solo arrivare a simulare alcuni processi cognitivi umani senza riuscire a
riprodurli nella loro totale complessità.
Rimanendo nel campo della programmazione "classica", basata su linguaggi
simbolici e lineari, in cui la grande velocità di calcolo dei processori moderni
supplisce alla carenza di parallelismo, sicuramente assume una posizione
dominante l'AI debole, in quanto si può facilmente constatare come un computer
elabori una serie di simboli che non comprende e si limiti ad eseguire i suoi
compiti meccanicamente.
Bisogna tuttavia riconoscere che, con la diffusione sempre maggiore di reti
neurali, algoritmi genetici e sistemi per il calcolo parallelo la situazione si sta
evolvendo a favore dei sostenitori del connessionismo.
A detta di alcuni esperti del settore, però, è improbabile il raggiungimento,
da parte di un computer, di una capacità di pensiero classificabile come
"intelligenza", in quanto la macchina stessa è "isolata" dal mondo, o, al massimo,
collegata con esso tramite una rete informatica, in grado di trasmettergli solo
informazioni provenienti da altri computer. La vera "intelligenza artificiale",
perciò, potrebbe essere raggiungibile solo da robot (non necessariamente di forma
umanoide) in grado di muoversi (su ruote, gambe, cingoli o quant'altro) ed

110
interagire con l'ambiente che li circonda grazie a sensori ed a bracci meccanici.
Spesso, difatti, anche nell'uomo, l'applicazione dell'intelligenza deriva da qualche
esigenza corporea, perciò è improbabile riuscire a svilupparne un'imitazione senza
un corpo.
Inoltre, finora, nel tentativo di creare AI, si è spesso compiuto un errore che
ha portato i computer all'incapacità di applicare il buonsenso e alla tendenza a
"cacciarsi nei pasticci". L'errore consiste nel non considerare a sufficienza il fatto
che il mondo reale è complesso e quindi una sua rappresentazione lo sarà
altrettanto. Non solo sarà complessa, ma sarà anche incompleta, perché non potrà
mai includere tutti i casi che il robot potrà incontrare. Perciò, o immettiamo nel
cervello artificiale una quantità enorme di informazioni corredate da altrettante
regole per correlarle (il che originerà, probabilmente, un vicolo cieco logico alla
prima difficoltà incontrata), oppure lo mettiamo in condizione di imparare. La
chiave dell'AI, sembra proprio essere questa: l'imitazione della sua analoga
naturale, tenendo ben presente l'importanza dei processi evolutivi nello sviluppo
delle caratteristiche morfologiche e comportamentali di un individuo e nella
formazione di ciò che viene definito "senso comune".
Vincenzo Tagliasco, ricercatore al Laboratorio integrato di robotica avanzata
presso la facoltà di Ingegneria dell'Università di Genova, ci fa notare che
nell'evoluzione delle macchine intelligenti si è cercato di saltare intere generazioni
di macchine più modeste, ma in grado di fornire preziosi stimoli per capire come
gli organismi biologici interagiscono con l'ambiente attraverso la percezione, la
locomozione, la manipolazione. Ora, per fortuna, c'è chi segue un approccio più
coerente: prima di insegnare a un robot a giocare a scacchi, è necessario
insegnargli a muoversi, a vedere, a sentire. Insomma, anche nel robot intelligente
occorre creare una "infanzia", che gli consenta di mettere a punto autonomi
processi di apprendimento e di adattamento all'ambiente in cui si troverà ad agire.
È necessario quindi riprodurre due evoluzioni parallele: una che da costrutti più
semplici porti alla produzione di macchine sempre più complesse e sofisticate,
un'altra, tutta interna alla vita del singolo automa, che lo faccia crescere
intellettualmente, dandogli modo di apprendere, da solo o sotto la supervisione

111
umana, le nozioni necessarie al suo compito ed alla formazione di un'autonomia
decisionale.
Questo modo di procedere e' sintetizzato in una discplina di recente sviluppo
come branca dell'IA. Stiamo parlando di Artificial Life - A.I., la cui prima
proposta si deve a Chris Langton. Comprendendo in tale disciplina la robotica
avanzata si può anche introdurre lo studio della robotica evolutiva.
L'intelligenza artificiale, continuando lungo le attuali direttrici di sviluppo,
diverrà sicuramente un'intelligenza "diversa" da quella umana, ma, probabilmente,
comparabile a livello di risultati in quei campi dove è necessario applicare
capacità di scelta basate su casi precedenti, nozioni generali e "ragionamento".
È invece molto difficile immaginare un computer in grado di filosofeggiare
ed esprimere concetti e dubbi riguardo l'origine o il senso della vita.

112
I SISTEMI ESPERTI
Il termine sistema esperto identifica una categoria di programmi informatici
che, dopo essere stati opportunamente istruiti, sono in grado di dedurre nuove
informazioni da un insieme di informazioni di partenza.
Un sistema esperto si fonda sulla competenza umana registrata nella
cosiddetta base di conoscenza (ad esempio sotto forma di regole), aggiornabile in
base all'esperienza. Come avviene per l'esperto umano, il sistema esperto può
operare su dati qualitativi e incompleti. Può infatti utilizzare forme di
ragionamento approssimato, attraverso tecniche probabilistiche o facendo ricorso
alla cosiddetta "fuzzy logic", reso spesso come logica sfumata, un tipo di logica a
più valori.
Ciò che rende diversi i sistemi esperti da altri algoritmi di intelligenza
artificiale è che un sistema esperto è sempre in grado di spiegare logicamente le
sue decisioni, mentre ciò non è vero per esempio nelle reti neurali.
I sistemi esperti si dividono in due categorie principali:
Sistemi esperti basati su regole
I sistemi esperti basati su regole ricevono in ingresso un insieme di
informazioni con le relative deduzioni e estraggono delle regole che, dato un
nuovo insieme di dati, dovrebbero permettere ai sistemi di estrarre le relative
deduzioni. Per esempio, l'insieme di dati di partenza potrebbe essere costituito dai
dati anagrafici di alcuni conducenti e le relative macchine di appartenenza. Le
deduzioni fornite sarebbero il grado di pericolosità come conducenti. Dato questo
insieme il sistema esperto sarebbe in grado di estrarre delle regole che classificano
gli utenti a seconda della loro pericolosità presunta.
Sistemi esperti basati su alberi
Un sistema esperto basato su alberi, dato un insieme di dati ed alcune
deduzioni, creerebbe un albero che classificherebbe i vari dati. Nuovi dati
verrebbero analizzati dall'albero e il nodo di arrivo rappresenterebbe la deduzione.

113
È da notare che un sistema esperto non è "intelligente" nel senso comune
della parola, ossia in modo creativo. Le deduzioni di un sistema esperto non
possono uscire dall'insieme di nozioni immesse inizialmente e dalle loro
conseguenze. Ciò che li rende utili è che, come i calcolatori elettronici, possono
maneggiare una gran quantità di dati molto velocemente e tenere quindi conto di
una miriade di regole e dettagli che un esperto umano può ignorare, tralasciare o
dimenticare. La forma di rappresentazione basata su regole di produzione è ideale
per un’area d’interesse in cui vi sia un’importante conoscenza empirica che debba
ancora essere codificata in una struttura formale e di principi. Questo è
sicuramente il caso del campo della diagnosi e del trattamento di infezioni di cui
si occupa Mycin.
Oltre alla possibilità d’integrare tipi diversi di conoscenza, si può elaborare
una miscela «povera» di fatti mediante l’aggiunta di un componente numerico, il
quale esprime il grado di relazione che si crede esista tra loro (fattore di certezza).
L’architettura del sistema di produzione e il sistema di considerazione
probabilistica si sono dimostrati di notevole successo per quanto riguarda il loro
utilizzo nella risoluzione di problemi diagnostici all’interno di aree d’interesse in
cui predomini la conoscenza empirica.
Vi sono tuttavia dei punti deboli.
In primo luogo, ad esclusione dell’albero di contesto, ogni struttura causale
all’interno della conoscenza codificata nelle regole di produzione non viene
esplicitamente rappresentata, e così non è né visibile all’utente né direttamente
disponibile per l’elaborazione.
Un secondo problema è che, mentre il semplice processo di ragionamento è
progettato per essere comprensibile ad un utente, non è finalizzato a modellare i
processi realmente adottati dagli esperti umani.
Il risultato è che approcci di questo tipo sono efficacissimi per delle diagnosi
all’interno di aree d’interesse ristrette e ben definite dove l’utente abbia già
un’idea ragionevole della soluzione. Sono meno efficaci nei casi in cui le
soluzioni siano molto complesse o l’utente stia lavorando con una relativa
ignoranza delle soluzioni possibili.