differentiated graph computation and partitioning on skewed graphs rong chen, jiaxin shi, yanzhe...
TRANSCRIPT

Differentiated Graph Computation and Partitioning on Skewed Graphs
Rong Chen, JiaXin Shi, Yanzhe Chen, and Haibo Chen
Institute of Parallel and Distributed SystemsShanghai Jiao Tong University
http://ipads.se.sjtu.edu.cn/projects/powerlyra.html
2014
PowerLyra
J
R Y
HB
H

Big Data Everywhere100 Hrs of
Video every minute
1.11 Billion Users
6 Billion Photos400 Million
Tweets/day
How do we understand and use Big Data?

Big Data Big Learning100 Hrs of
Video every minute
1.11 Billion Users
6 Billion Photos400 Million
Tweets/day
NLP
Big Learning: machine learning and data mining on
Big Data

It’s all about the graphs …

Example Algorithms
PageRank (Centrality Measures)
α is the random reset probabilityL[j] is the number of links on page j
𝑹 [𝟏 ]=0.15+0.85(𝑹 [𝟑 ]+ 13𝑹 [𝟒 ]+ 1
2𝑹[𝟓])
2 4
3 1 5
iterate until convergence
example:
http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
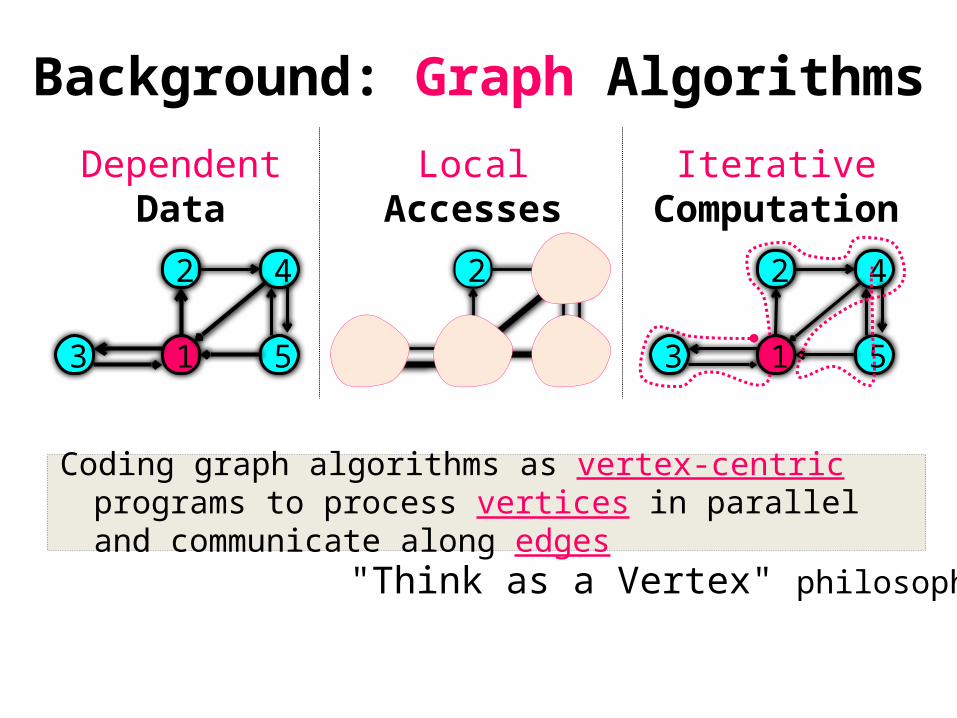
Background: Graph Algorithms
IterativeComputation
DependentData
LocalAccesses
2 4
3 1 5
2 4
3 1 5
2 4
3 1 5
Coding graph algorithms as vertex-centric programs to process vertices in parallel and communicate along edges
"Think as a Vertex" philosophy

Think as a Vertex
1. aggregate value of neighbors2. update itself value3. activate neighbors
compute(v): double sum = 0 double value, last = v.get () foreach (n in v.in_nbrs) sum += n.value / n.nedges; value = 0.15 + 0.85 * sum;
v.set (value);
activate (v.out_nbrs);
Example: PageRank
1
2
3
AlgorithmImpl. compute() for vertex

Graph in Real World
Hallmark Property : Skewed power-law degree distributions
“most vertices have relatively few neighbors while a few have many neighbors”
cou
nt
degree
Low Degree Vertex
High Degree Vertex
Twitter Following Graph:1% of the vertices are adjacent to nearly half of the edges
star-like motif
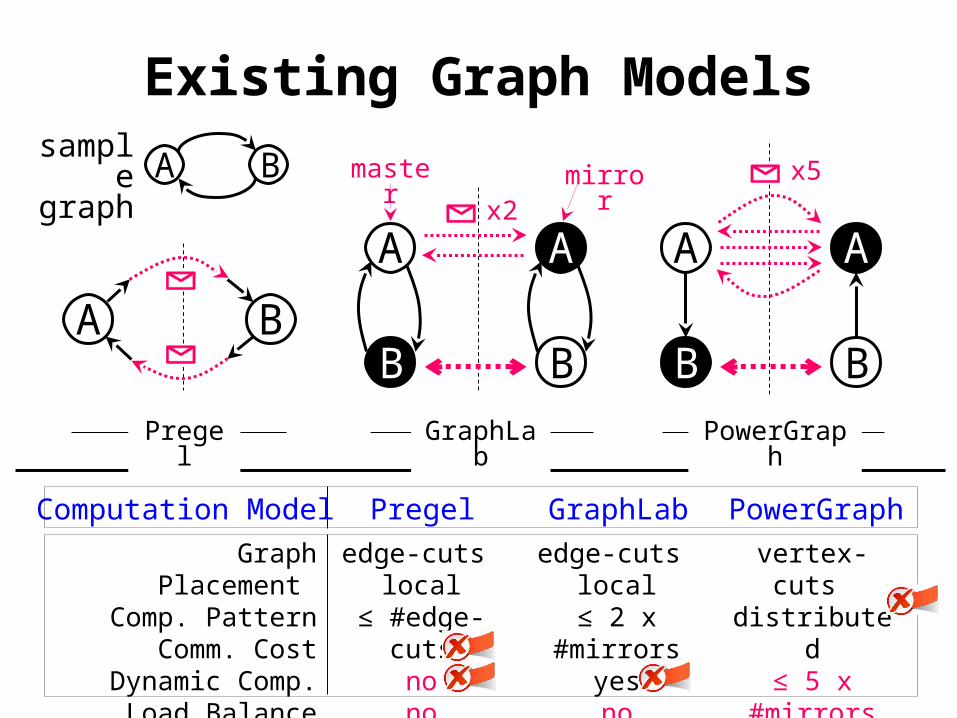
Existing Graph Modelssampl
e graph
Graph Placement Comp. Pattern
Comm. CostDynamic Comp.
Load Balance
edge-cuts local
≤ #edge-cutsnono
edge-cuts local≤ 2 x
#mirrorsyesno
vertex-cuts distributed
≤ 5 x #mirrors
yesyes
Computation Model Pregel GraphLab PowerGraph
A B
A B
Pregel GraphLab
PowerGraph
A
B
A
B
x5
A
B
A
B
x2mirrormaste
r
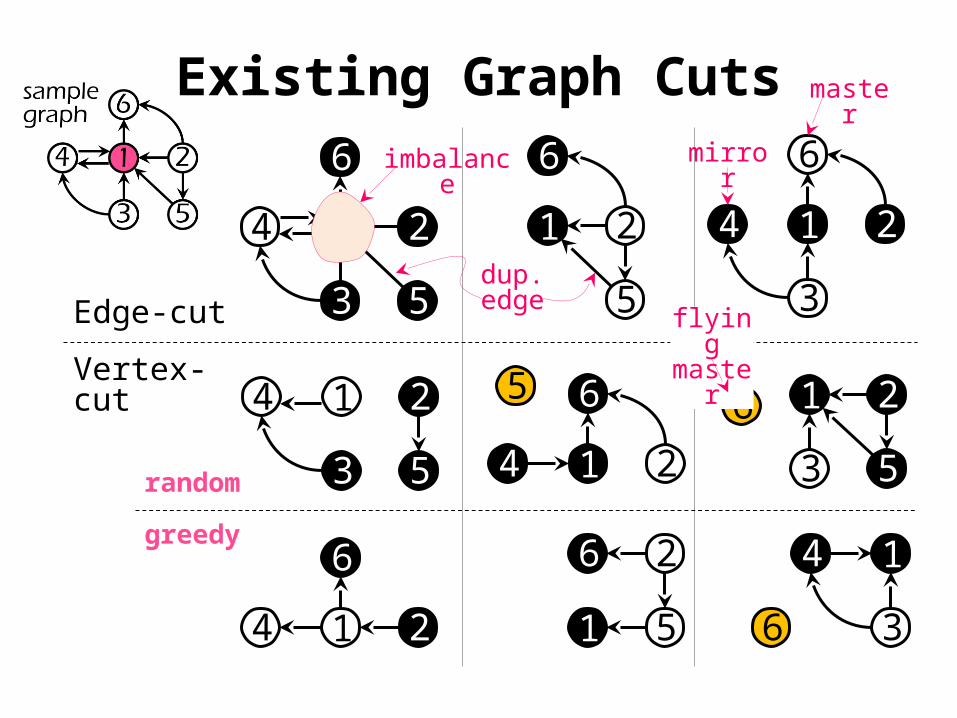
Existing Graph Cuts
14 2
3
6
5
1 2
6
5
14 2
3
6
14 2
3 5 14 2
65 1 2
3
6
5
14 2
6
1
26
5
14
36
Edge-cut
Vertex-cut
master
mirror
dup.edge
flying maste
r
randomgreedy
imbalance

partition λ ingress runtimeRandom 16.0 263 94.2
Coordinated 5.5 391 33.7
Oblivious 12.8 289 75.3
Grid 8.9 138 43.6
Issues of Graph Partitioning
Edge-cut: Imbalance & replicated edges
Vertex-cut: do not exploit locality□ Random: high replication factor*□ Greedy: long ingress time, unfair to low-degree
vertex□ Constrained: imbalance, poor placement of low-
vertex
∗𝑟𝑒𝑝𝑙𝑖𝑐𝑎𝑡𝑖𝑜𝑛 𝑓𝑎𝑐𝑡𝑜𝑟:𝜆=
¿𝑟𝑒𝑝𝑙𝑖𝑐𝑎𝑡𝑖𝑜𝑛𝑠¿ 𝑣𝑒𝑟𝑡𝑖𝑐𝑒𝑠
Twitter Follower Graph 48 machines, |V|=42M |E|=1.47B

Principle of PowerLyra
Differentiated Graph Computation and Partitioning
The vitally important challenges associated to
the performance of distributed computation system
1. How to make resource locally accessible?2. How to evenly parallelize workloads?
Conflict
High-degree vertex Parallelism
Low-degree vertex LocalityOne
Size fit
All

Computation Model
High-degree vertex□ Goal: exploit parallelism□ Follow GAS model [PowerGraph OSDI’12]
“Gather Apply Scatter”compute (v) double sum = 0 double value, last = v.get () foreach (n in v.in_nbrs) sum += n.value / n.nedges; value = 0.15 + 0.85 * sum;
v.set (value);
activate (v.out_nbrs);
gather (n): return n.value / n.nedges;
scatter (v) activate (v.out_nbrs);
apply (v, acc): value = 0.15 + 0.85 * acc; v.set (value);
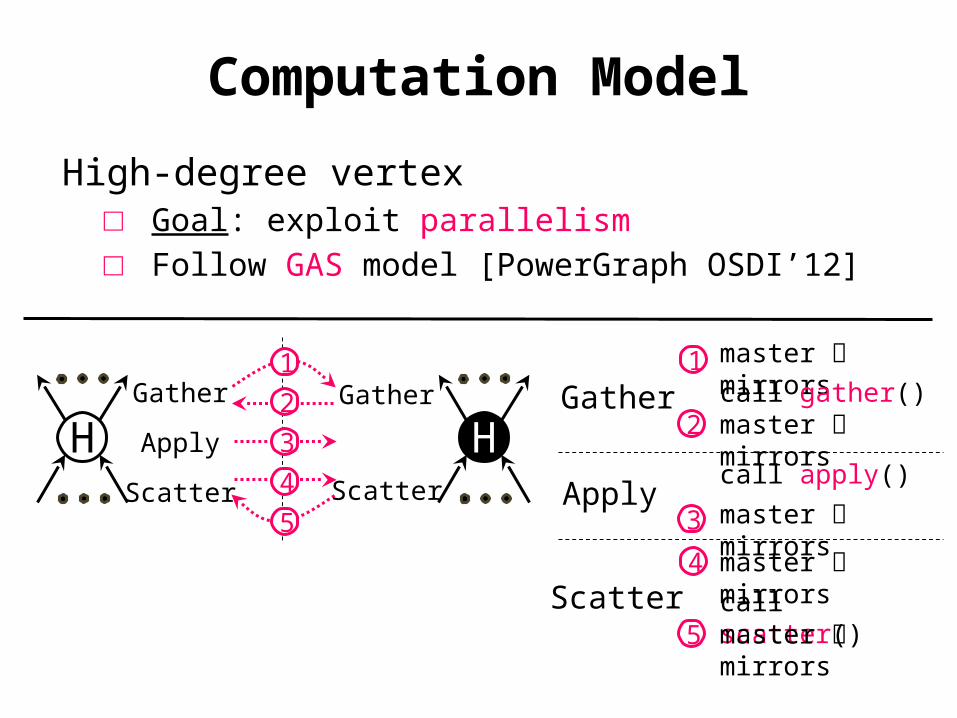
Computation Model
High-degree vertex□ Goal: exploit parallelism□ Follow GAS model [PowerGraph OSDI’12]
H HGather
master mirrorscall gather()master mirrors
1
2
Scattermaster mirrorscall scatter()master mirrors
4
5
Applycall apply()
master mirrors
3
1
2
3
4
5
Gather
Scatter
Apply
Gather
Scatter

Computation Model
Low-degree vertex□ Goal: exploit locality□ One direction locality (avoid replicated
edges)□ Local gather + distributed scatter□ Comm. Cost : ≤ 1 x #mirrors
L L
Gather call gather()
Scatter call scatter()
Applycall apply()
master mirrors
11
Gather
Scatter
Apply
Scatter
Observation: most algorithms only gather or scatter in one
direction(e.g., PageRank: G/IN and
S/OUT)
All of in-edges
e.g., PageRank: Gather/IN & Scatter/OUT
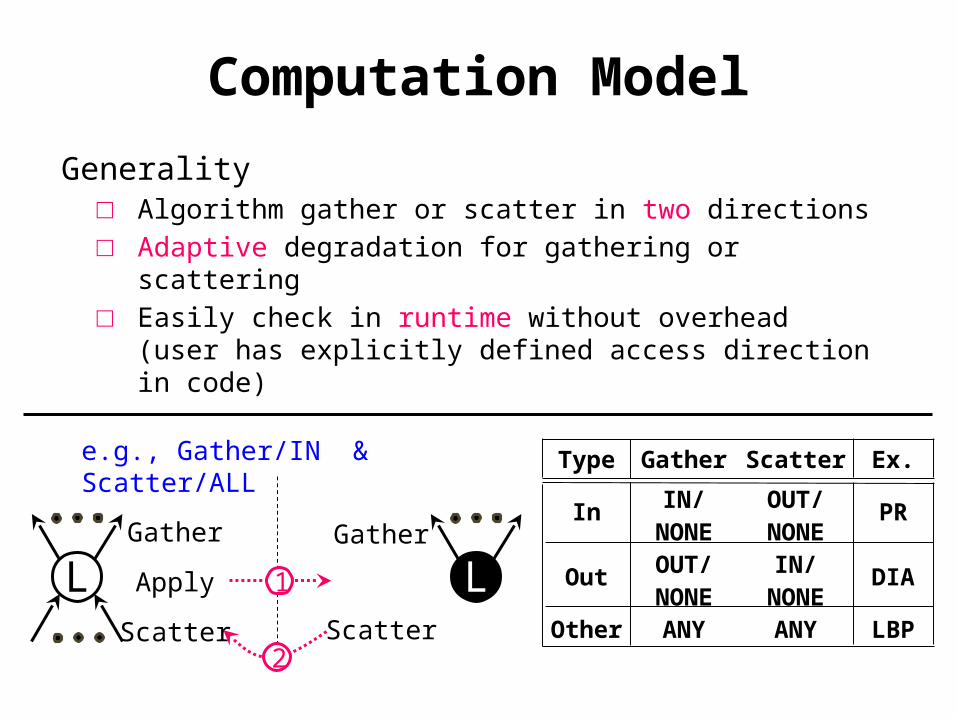
Computation Model
Generality□ Algorithm gather or scatter in two directions□ Adaptive degradation for gathering or scattering□ Easily check in runtime without overhead
(user has explicitly defined access direction in code)
L L1
Gather
Scatter
Apply
Gather
Scatter
e.g., Gather/IN & Scatter/ALL Type Gather Scatter Ex.
InIN/NONE
OUT/NONE PR
OutOUT/ NONE
IN/NONE DIA
Other ANY ANY LBP
2

1. Lower replication factor2. One direction locality3. Efficiency
(ingress/runtime)4. Balance (#edge)5. Fewer flying master
partition λ ingress runtime
Random 11.7 35.5 14.71
Coordinated 4.8 32.0 6.85
Oblivious 8.3 36.4 11.70
Grid 8.4 21.4 7.30
Low-cut 3.9 15.0 2.26
Synthetic Regular Graph*48 machines, |V|=10M |E|=93M
Graph Partitioning
Low-degree vertex□ Place one direction edges (e.g., in-edges) of a
vertex to its hash-based machine
□ Simple, but Best !
*https://github.com/graphlab-code/graphlab/blob/master/src/graphlab/graph/distributed_graph.hpp

Graph Partitioning
High-degree vertex□ Distribute edges (e.g., in-edges) according to
another endpoint vertex (e.g., source)□ The upper bound of replications imported by
placing all edges belonged to high-degree vertex is #machines
low-masterlow-mirror
high-masterhigh-mirror
Existing Vertex-cut
Low-degree mirror
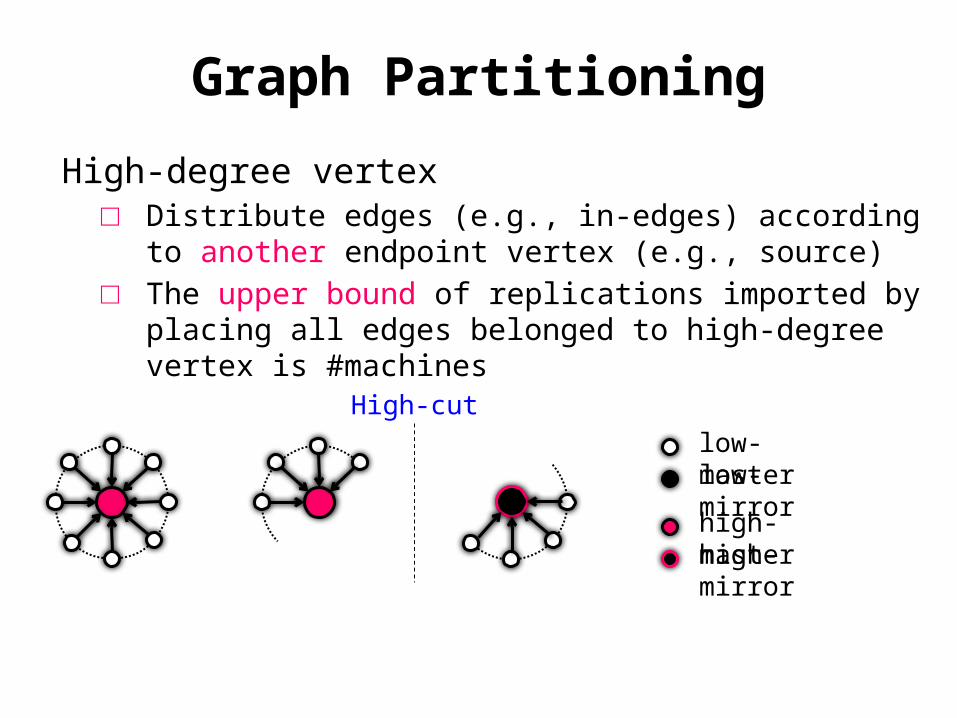
Graph Partitioning
High-degree vertex□ Distribute edges (e.g., in-edges) according to
another endpoint vertex (e.g., source)□ The upper bound of replications imported by
placing all edges belonged to high-degree vertex is #machines
low-masterlow-mirror
high-masterhigh-mirror
High-cut
Graph Partitioning
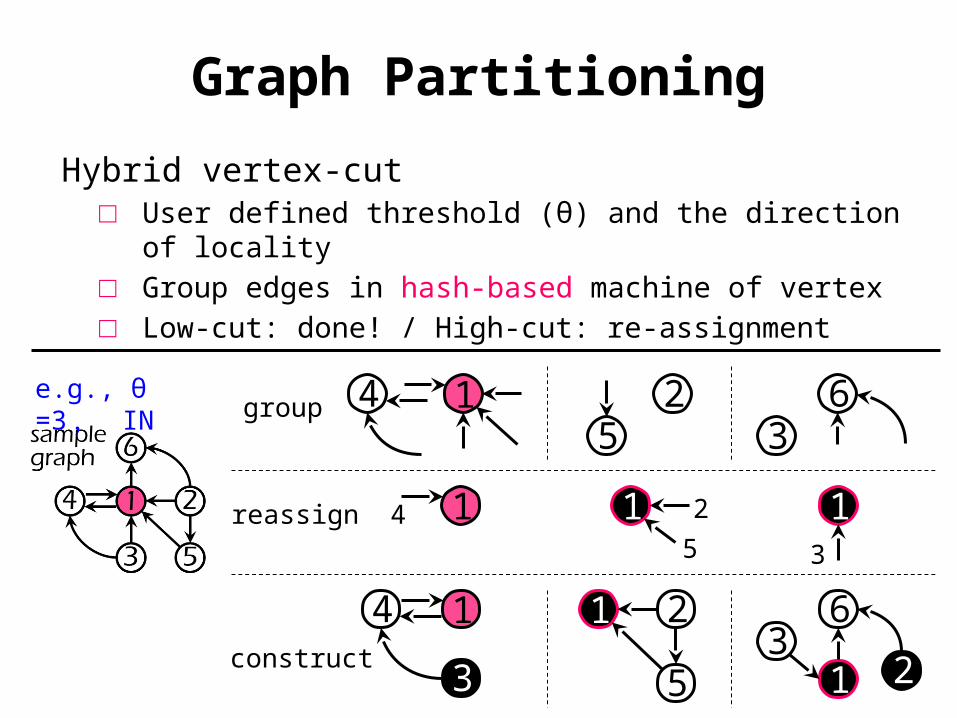
Hybrid vertex-cut□ User defined threshold (θ) and the direction of
locality□ Group edges in hash-based machine of vertex□ Low-cut: done! / High-cut: re-assignment
14 25 3
6
14 15
2 13
14
3
1 2
5 1 23
6
group
reassign
construct
e.g., θ =3 , IN

Heuristic for Hybrid-cut
Inspired by heuristic for edge-cut□ choose best master location of vertex
according to neighboring has located□ Consider one direction neighbors is enough□ Only apply to low-degree vertices□ Parallel ingress: periodically synchronize
private mapping-table (global vertex-id machine)
Optimization
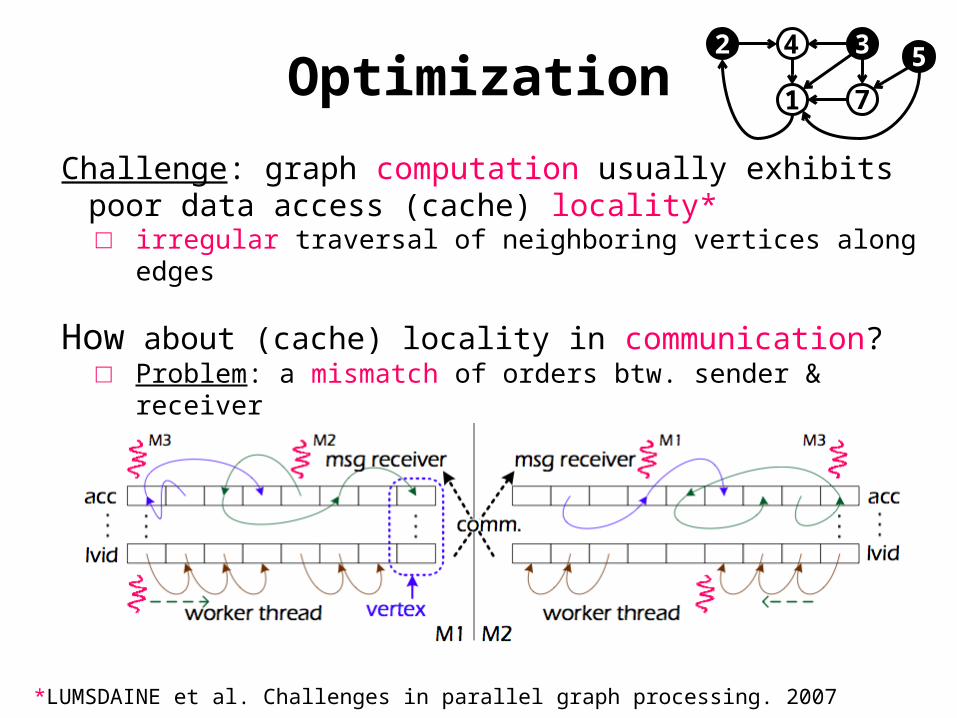
Challenge: graph computation usually exhibits poor data access (cache) locality*□ irregular traversal of neighboring vertices along
edges
How about (cache) locality in communication?□ Problem: a mismatch of orders btw. sender &
receiver
*LUMSDAINE et al. Challenges in parallel graph processing. 2007
4
1 7
2 53
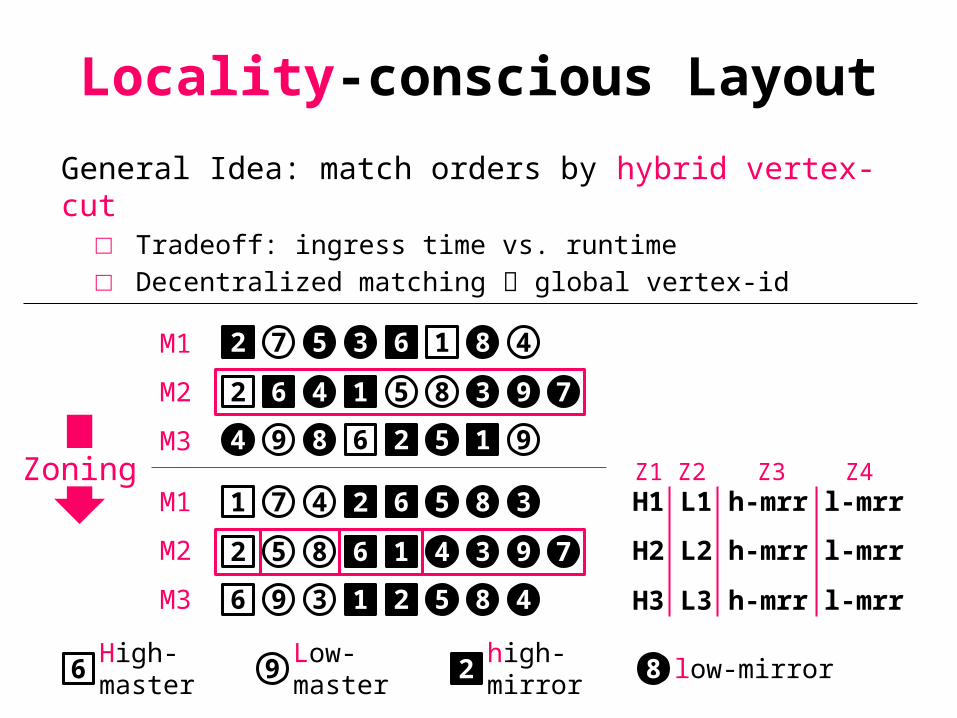
Locality-conscious Layout
General Idea: match orders by hybrid vertex-cut□ Tradeoff: ingress time vs. runtime□ Decentralized matching global vertex-id
9 86 2Low-master
high-mirrorHigh-master
low-mirror
4
35 4
5
72 6 1 8
2 6 1 8 3 9 7
4 9 8 6 2 5 1 9Zoning
M1
M2
M3
M1
M2
M3
H2 L2 h-mrr l-mrr
H3 L3 h-mrr l-mrr
H1 L1 h-mrr l-mrrZ1 Z2 Z3 Z4
8
15
52
8
4 371 6 8
2 6 4 3 9 7
9 3 1 2 5 46

Locality-conscious Layout
General Idea: match orders by hybrid vertex-cut□ Tradeoff: ingress time vs. runtime□ Decentralized algorithm global vertex-id
9 86 2Low-master
high-mirrorHigh-master
low-mirror
Grouping
M1
M2
M3
M1
M2
M3 8
15
52
8
4 371 6 8
2 6 4 3 9 7
9 3 1 2 5 46
8
65
82
8
4 371 6 5
2 1 4 7 9 3
9 3 1 2 4 56
H2 L2 h1 h3 l1 l3
H3 L3 h1 h2 l1 l2
H1 L1 h2 h3 l2 l3
H2 L2 h-mrr l-mrr
H3 L3 h-mrr l-mrr
H1 L1 h-mrr l-mrrZ1 Z2 Z3 Z4
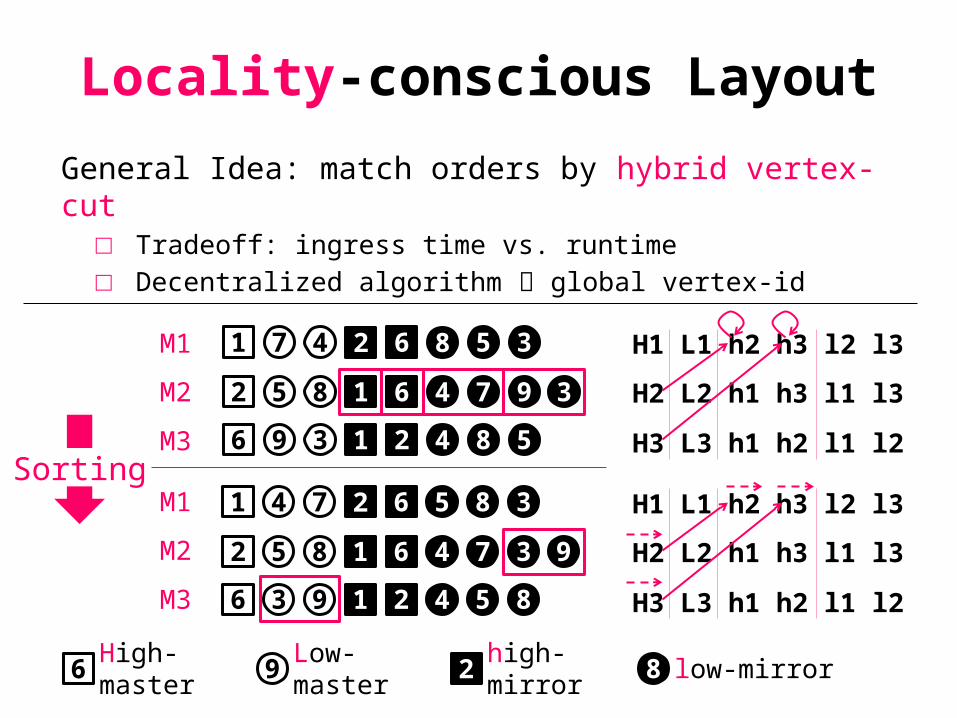
Locality-conscious Layout
General Idea: match orders by hybrid vertex-cut□ Tradeoff: ingress time vs. runtime□ Decentralized algorithm global vertex-id
9 86 2Low-master
high-mirrorHigh-master
low-mirror
Sorting
M1
M2
M3
M1
M2
M3 5
65
52
8
7 341 6 8
2 1 4 7 3 9
3 9 1 2 4 86
8
65
82
8
4 371 6 5
2 1 4 7 9 3
9 3 1 2 4 56
H2 L2 h1 h3 l1 l3
H3 L3 h1 h2 l1 l2
H1 L1 h2 h3 l2 l3
H2 L2 h1 h3 l1 l3
H3 L3 h1 h2 l1 l2
H1 L1 h2 h3 l2 l3
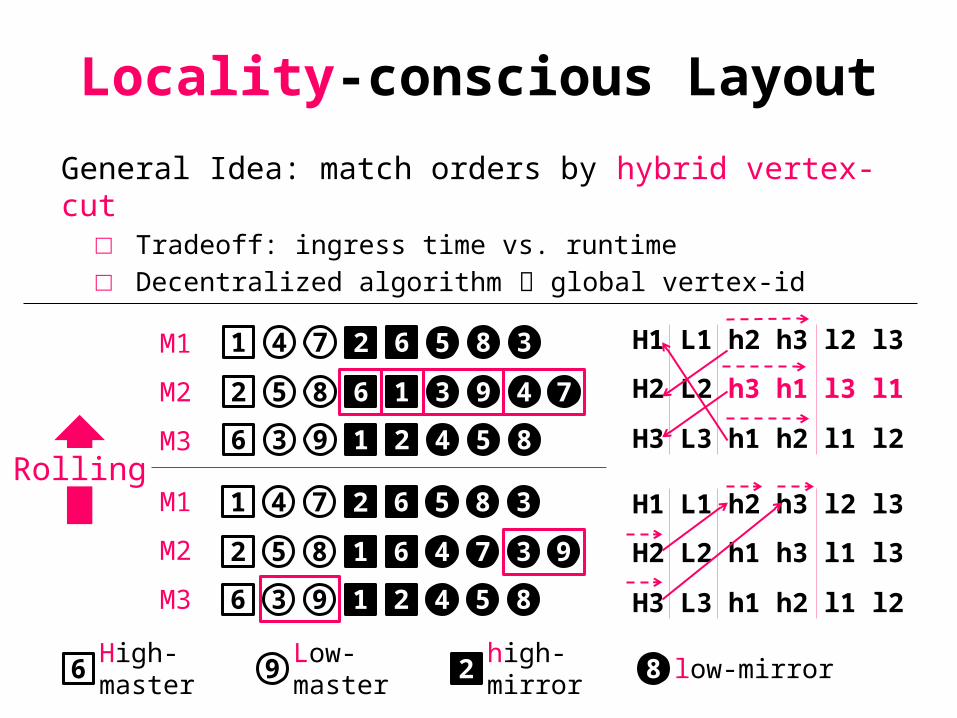
Locality-conscious Layout
General Idea: match orders by hybrid vertex-cut□ Tradeoff: ingress time vs. runtime□ Decentralized algorithm global vertex-id
9 86 2Low-master
high-mirrorHigh-master
low-mirror
Rolling
M1
M2
M3
M1
M2
M3 5
65
52
8
7 341 6 8
2 1 4 7 3 9
3 9 1 2 4 86
5
15
52
8
7 341 6 8
2 6 3 9 4 7
3 9 1 2 4 86
H2 L2 h3 h1 l3 l1
H3 L3 h1 h2 l1 l2
H1 L1 h2 h3 l2 l3
H2 L2 h1 h3 l1 l3
H3 L3 h1 h2 l1 l2
H1 L1 h2 h3 l2 l3

Evaluation
Experiment Setup□ 48-node EC2-like cluster (4-core 12G RAM 1GigE
NIC)□ Graph Algorithms
− PageRank− Approximate Diameter− Connected Components
□ Data Set: − 5 real-world graphs− 5 synthetic power-law graphs*
*Varying α and fixed 10 million vertices (smaller α produces denser graphs)
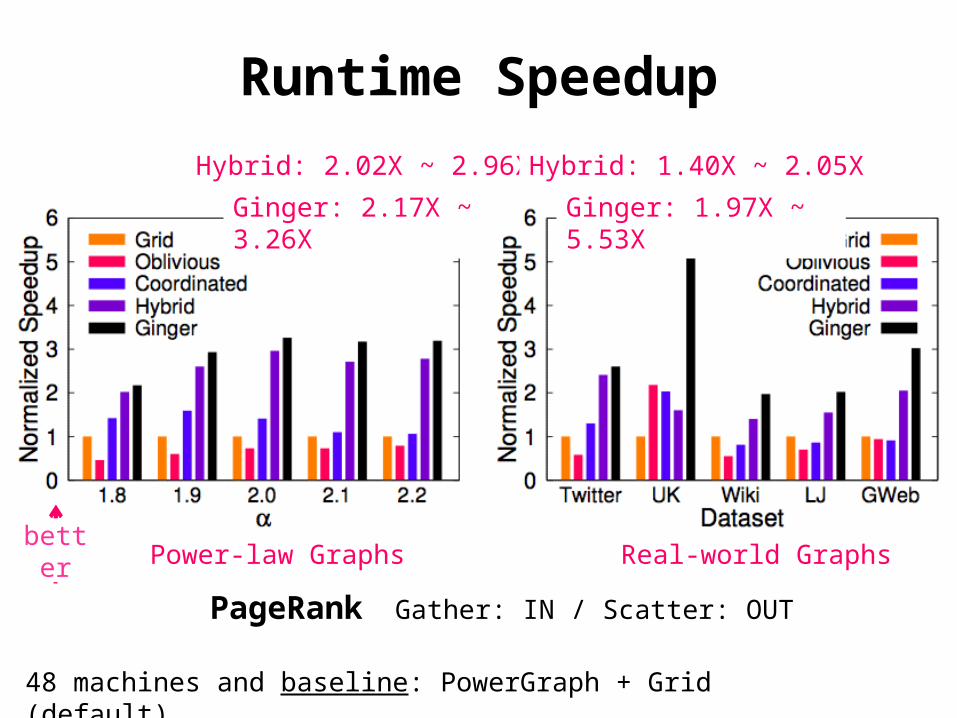
Runtime Speedup
48 machines and baseline: PowerGraph + Grid (default)
Real-world GraphsPower-law Graphs
Hybrid: 2.02X ~ 2.96X
Ginger: 2.17X ~ 3.26X
Hybrid: 1.40X ~ 2.05X
Ginger: 1.97X ~ 5.53X
PageRank Gather: IN / Scatter: OUT
better
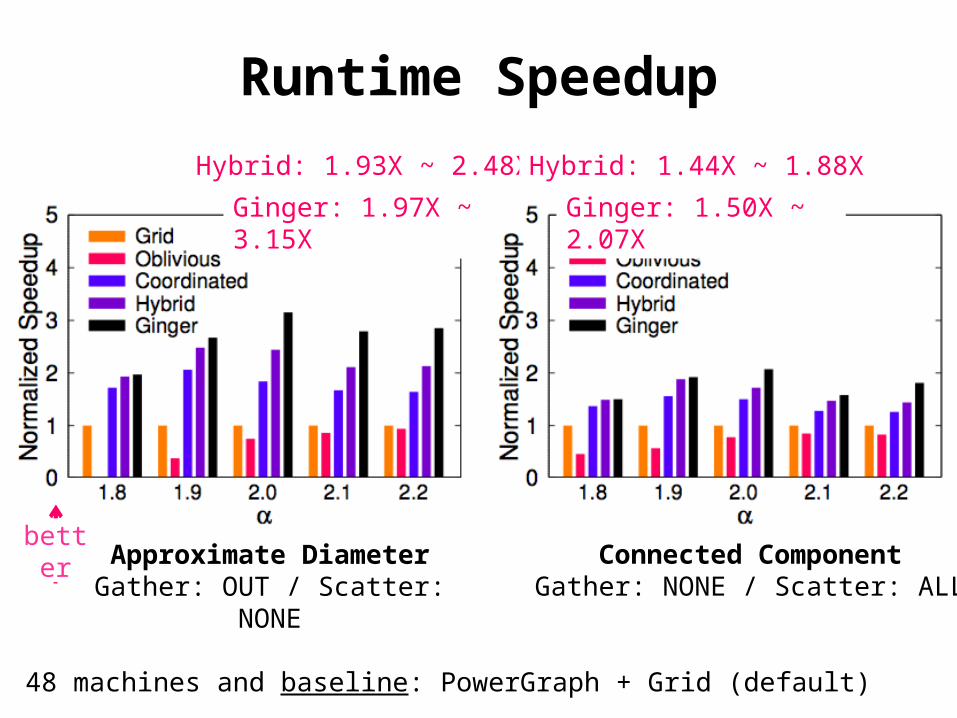
Runtime Speedup
48 machines and baseline: PowerGraph + Grid (default)
Connected ComponentGather: NONE / Scatter: ALL
Approximate DiameterGather: OUT / Scatter:
NONE
Hybrid: 1.93X ~ 2.48X
Ginger: 1.97X ~ 3.15X
Hybrid: 1.44X ~ 1.88X
Ginger: 1.50X ~ 2.07X
better
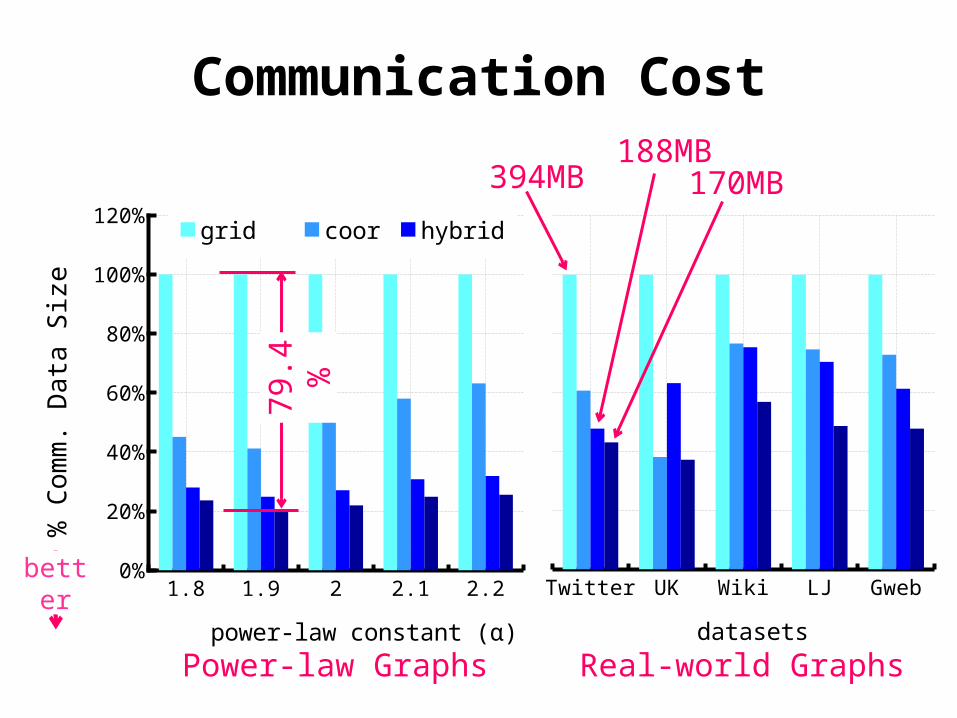
Communication Cost
1.8 1.9 2 2.1 2.20%
20%
40%
60%
80%
100%
120%grid coor hybrid ginger
power-law constant (α)
% C
om
m.
Da
ta S
ize
Twit-ter
UK Wiki LJ Gweb
datasets
Power-law Graphs Real-world Graphs
394MB 170MB188MB
79.4
%
better
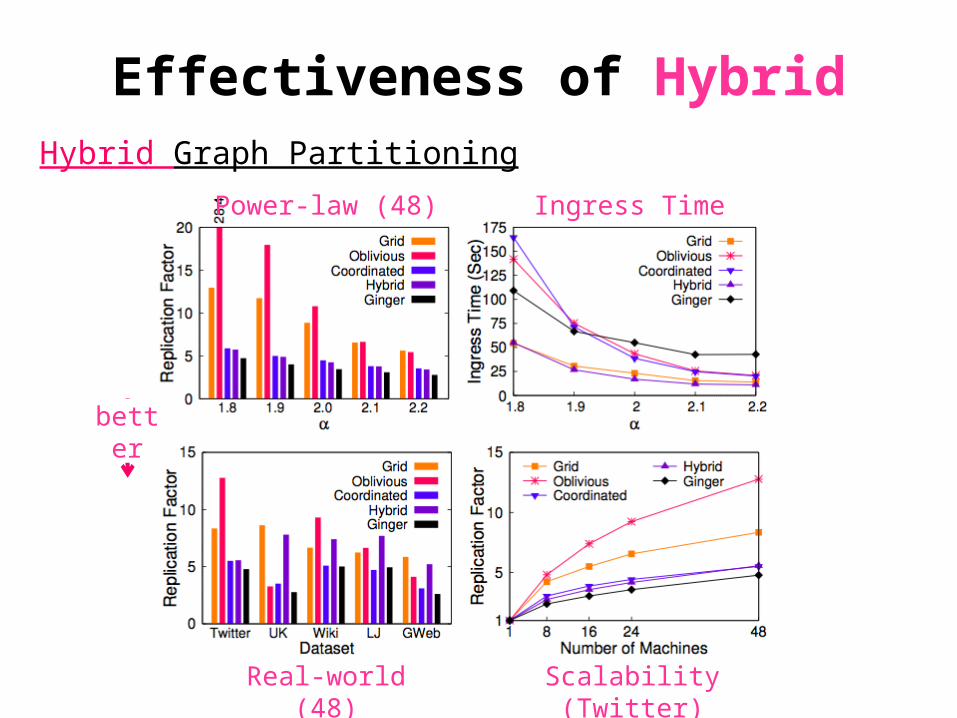
Effectiveness of Hybrid
Power-law (48)
Real-world (48)
Ingress Time
Scalability (Twitter)
Hybrid Graph Partitioning
better

Effectiveness of HybridHybrid Graph Computation
1.8 1.9 2 2.1 2.20
10
20
30
40
50
60
power-law constant (α)
On
e I
tera
tio
n C
om
ms
(MB
)
1.8 1.9 2 2.1 2.20
2
4
6
8
10
12PG+HybridPG+GingerPL+Hybrid
power-law constant (α)
Exe
cuti
on
Tim
e (
Se
c)
better
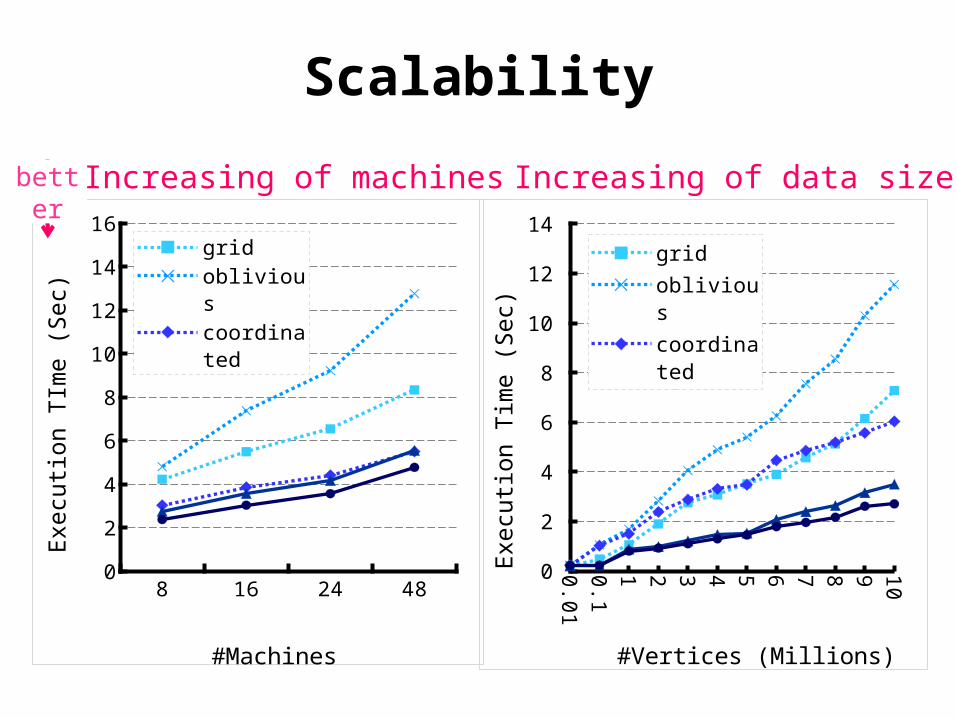
Scalability
Increasing of machines Increasing of data size
0.01
0.1
1 2 3 4 5 6 7 8 9 100
2
4
6
8
10
12
14 gridobliviouscoor-di-natedhybridginger
#Vertices (Millions)
Execu
tion T
ime (
Sec)
8 16 24 480
2
4
6
8
10
12
14
16gridobliviouscoor-di-natedhybridginger
#Machines
Execu
tion T
Ime (
Sec)
better

Conclusion
PowerLyra□ a new hybrid graph analytics engine that
embraces the best of both worlds of existing frameworks
□ an efficient hybrid graph partitioning algorithm that adopts different heuristics for different vertices.
□ outperforms PowerGraph with default partition by up to 5.53X and 3.26X for real-world and synthetic graphs accordingly
http://ipads.se.sjtu.edu.cn/projects/powerlyra.html

Questions
Thanks
PowerLyra
http://ipads.se.sjtu.edu.cn
Institute of Parallel And Distributed Systems
http://ipads.se.sjtu.edu.cn/projects/powerlyra.html