decision tree learning
TRANSCRIPT

Decision Tree Learning
Md. Ariful HoqueRoll: MSC 140202Khulna University

Introduction. Decision Tree Terms. Example. Constructing A decision Tree. Calculation Of Entropy. Information Gain. Gini Impurity. Termination Criteria. Mathlab Example. Implementations. Advantage Limitation Conclusion
Outline

Decision tree learning is the construction of a decision tree from class-
labeled training tuples.
A decision tree is model of decisions and their possible consequences.
It Includes chance event outcomes, resource costs, and utility.
Its follow top down approach.
Decision trees classify instances by sorting them down the tree from the
root to some leaf node, which provides the classification of the instance
Introduction

Decision Tree Terms
Root Node
Condition Check
Leaf Node(Decision Point)
Leaf Node(Decision Point)
Condition Check
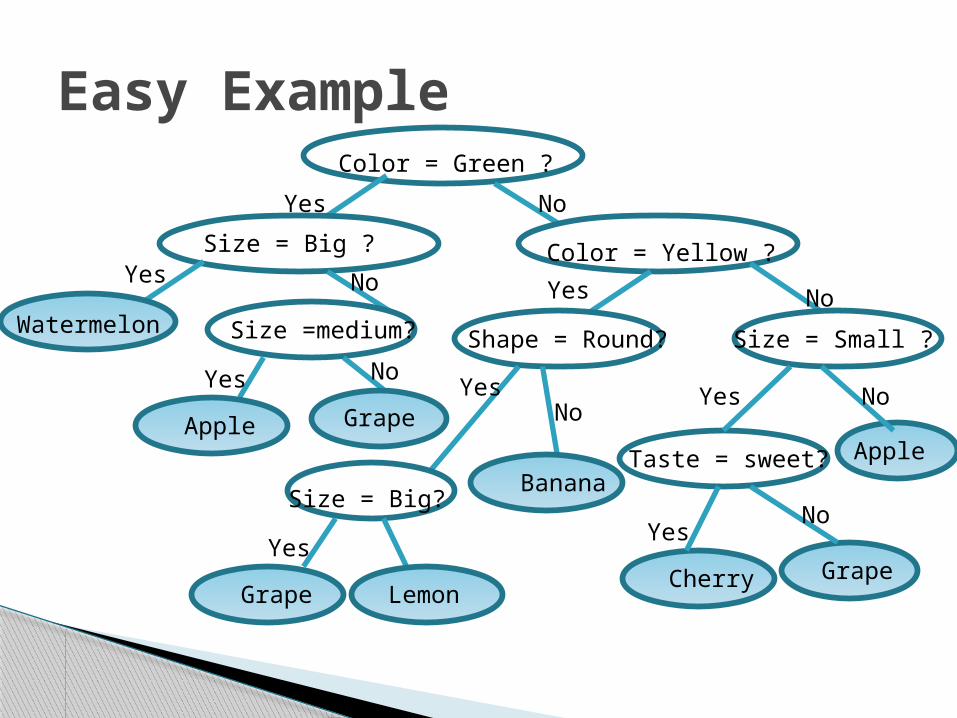
Easy Example
Yes
Color = Green ?
Size = Big ? Color = Yellow ?
Size =medium?Watermelon
Apple Grape
Shape = Round? Size = Small ?
Taste = sweet? Apple
Yes No
Yes No
Cherry Grape
Size = Big?
Grape Lemon
Banana
Yes
YesYes
YesYes
No
No
NoNo
No

There are many specific decision-tree algorithms- ID3 C4.5 CART CHAID MARS
Algorithms

Which attribute to choose?
◦ Information Gain
ENTROPY
Where to stop?
◦ Termination criteria
Constructing A decision Tree

Different algorithms use different metrics for measuring best. These generally measure the homogeneity of the target variable within
the subsets. Some examples are given in the next slides.
Metrics

◦ Entropy is a measure of uncertainty in the data
Entropy(S) = ∑(i=1 to l)-|Si|/|S| * log2(|Si|/|S|)
S = set of examples
Si = subset of S with value vi under the target attribute
l = size of the range of the target attribute
Calculation Entropy

Used by the ID3, C4.5 and C5.0 tree-generation algorithms. Information gain is based on the concept of entropy from information
theory.
Here , fi = fraction of items
m = Items
Information gain

Gini impurity Used by the CART (classification and regression tree). It measure incorrectly labeled of randomly chosen element. Gini impurity can be computed by summing the probability of each item
being chosen times the probability of a mistake in categorizing that item. It reaches its minimum (zero) when all cases in the node fall into a single
target category.
To compute Gini impurity for a set of items, suppose-
Let f be the fraction of items labeled with value i in the set.

All the records at the node belong to one class
A significant majority fraction of records belong to a single class
The segment contains only one or very small number of records
The improvement is not substantial enough to warrant making the split.
Termination Criteria

Create a classification decision tree for Fisher's iris data: load fisheriris; t = classregtree(meas,species,... 'names',{'SL' 'SW' 'PL' 'PW'}) view(t)
Mathlab Example

t =
Decision tree for classification if PL<2.45 then node 2 elseif PL>=2.45 then node 3 else setosa class = setosa if PW<1.75 then node 4 elseif PW>=1.75 then node 5 else versicolor if PL<4.95 then node 6 elseif PL>=4.95 then node 7 else versicolor class = virginica if PW<1.65 then node 8 elseif PW>=1.65 then node 9 else versicolor class = virginica class = versicolor class = virginica
Continue…

Continue…

In data mining software. Several examples include Salford Systems CART, IBM SPSS , KNIME,
Microsoft SQL Server, and scikit-learn.
Implementations

Decision-tree learners can create over-complex trees. There are concepts that are hard to learn because decision trees do not
express them easily, such as XOR, parity or multiplexer problems. When there are more records and very less number of attributes/features.
Limitations

Simple to understand and interpret. Requires little data preparation. Able to handle both numerical and categorical data. Performs well with large datasets.
Advantages

Decision tree learning is one of the predictive modeling approaches used in statistics, data mining and machine learning.
In our example section we saw a classification tree. Where the target variable can take a finite set of values. In Mathlab example section we saw regression trees. Where the target variable can take continuous values (typically real
numbers).
Conclusion

1. Decision tree learning[Online]. Available:http://en.wikipedia.org/wiki/Decision_tree_learning
2. Classregtree[Online]. Available:http://www.mathworks.com/help/stats/classregtree.html
3. Richard O.Duda, Peter E. Hart, David G. Stok. Pattern Classification. Second Edition
4. Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
References

Thanks