data science for the enterprises (spark, kafka, mesos and cassandra) - andy petrella, kensu
TRANSCRIPT

KensuData Science for the Enterprise

Kensu Created in 2015
Mission: Lifting Data Science to the
Enterprise level
Product: ADALOG
Team Andy Petrella
Math, Spark Notebook
Xavier Tordoir Physics, Genomics
2 -> 11 scientists in 2016 Plenty of positions more in 2017

Data Science Team minded
Platform dedicated to data science team
Using production data
Including tooling
prototyping (local)
project (distributed)
Test Accept Prod
Data ScienceSpark
MesosHDFS Cassandra
KafkaSpark-Notebook JupyterCloudianMarathon Chronos
Git Artifactory
Enterprise
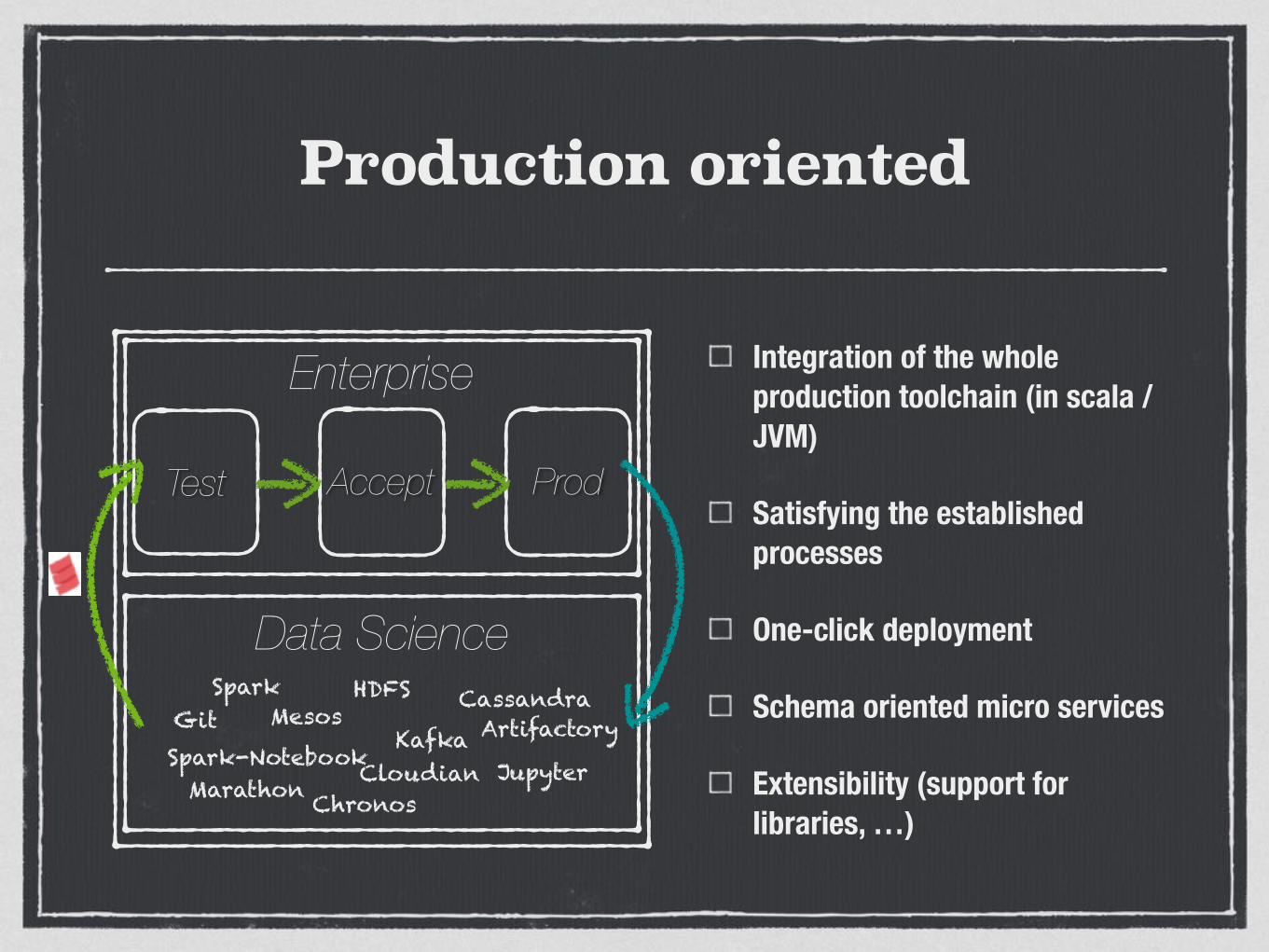
Production oriented
Integration of the whole production toolchain (in scala / JVM)
Satisfying the established processes
One-click deployment
Schema oriented micro services
Extensibility (support for libraries, …)
Test Accept Prod
Data ScienceSpark
MesosHDFS Cassandra
KafkaSpark-Notebook JupyterCloudianMarathon Chronos
Git Artifactory
Enterprise
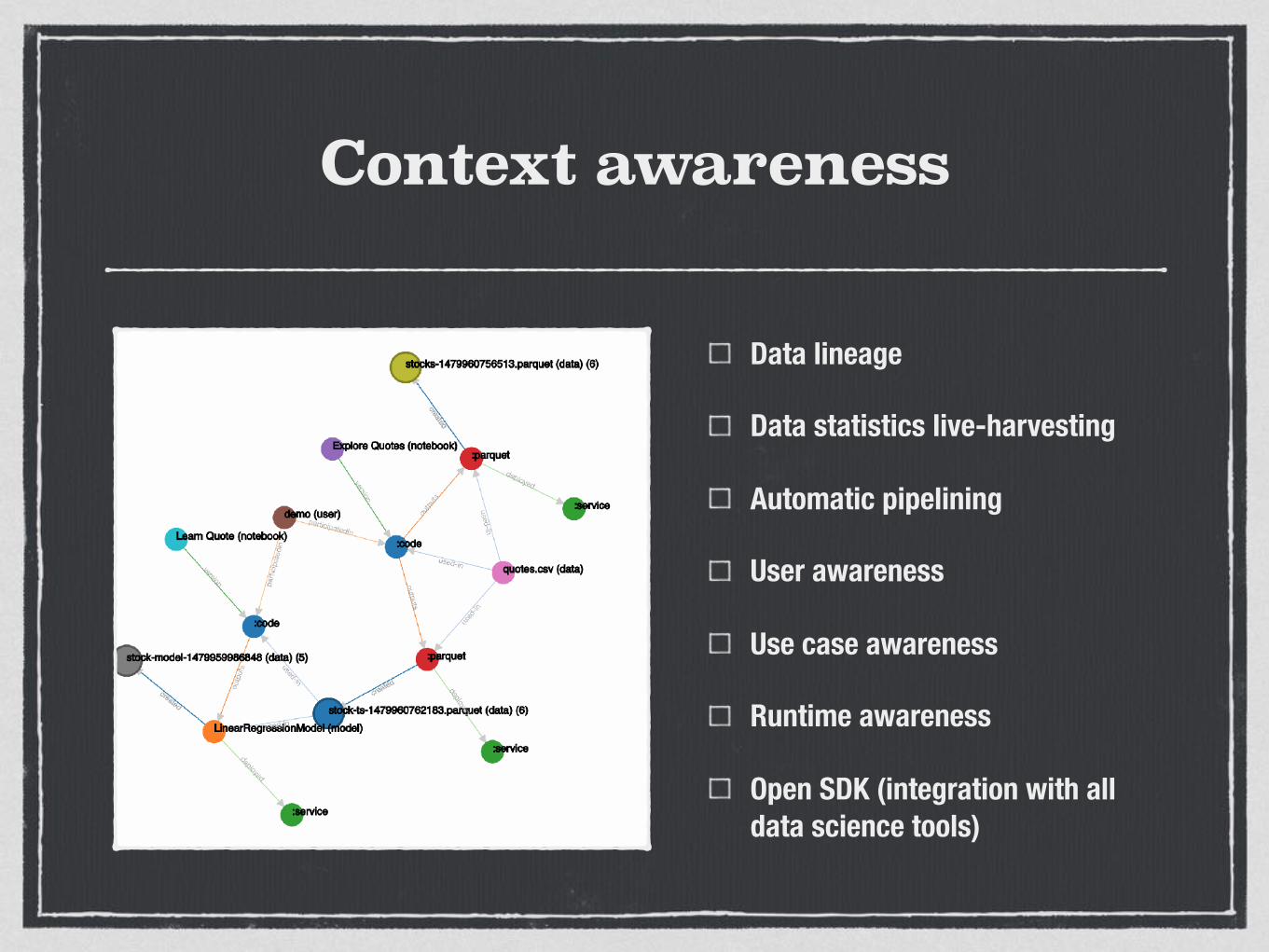
Context awareness
Data lineage
Data statistics live-harvesting
Automatic pipelining
User awareness
Use case awareness
Runtime awareness
Open SDK (integration with all data science tools)

Efficiency catalyser
Data recommendation
Model recommendation
User recommendation
Quality monitoring
Root cause analysis
Risk analysis
and more…

DEMO! (probably long ^^)
(there are/will be some pizza…)

Stay tune (@kensuio) Demo accesses on the way
Specially for O’Reilly trainees


KensuData Science for the Enterprise
Q/A