data mining in forschung und lehre in deutschland · data mining in forschung und lehre in...
TRANSCRIPT

Ludwig-Maximilians-Universität München Schriften zur Empirischen Forschung und Quantitativen Unternehmensplanung
Ludwig-Maximilians-Universität München Institut für Unternehmensentwicklung und Organisation Seminar für Empirische Forschung und Unternehmensplanung Prof. Dr. Manfred Schwaiger Kaulbachstr. 45 / I D-80539 München Tel.: (089) 2180 5640 Fax: (089) 2180 5651 e-mail: [email protected] http://www.efoplan.de
Data Mining in Forschung und Lehre
in Deutschland
Dr. Matthias Meyer, Max Lüling
Heft 15 / 2003

Data Mining in Forschung und Lehre
in Deutschland
Dr. Matthias Meyer
Ludwig-Maximilians-Universität München
Seminar für Empirische Forschung und Unternehmensplanung
Kaulbachstraße 45 / I
80539 München
E-Mail: [email protected]
Max Lüling
Gustav-Heinemann-Ring 50
81739 München
E-Mail: [email protected]

Inhaltsübersicht
1 Einleitung........................................................................................... 1
1.1 Zielsetzung und Struktur des Arbeitsberichts .................................... 1
1.2 Relevante Grundlagen des Data Mining ............................................ 2
1.2.1 Begriffe .............................................................................................. 2
1.2.2 Methoden ........................................................................................... 3
1.2.3 Softwaretools ..................................................................................... 4
2 Angaben zur Durchführung der Erhebung......................................... 7
3 Ergebnisse .......................................................................................... 7
3.1 Zusammensetzung der Stichprobe ..................................................... 7
3.2 Data Mining in Forschung und Lehre ................................................ 8
3.2.1 Data Mining in der Forschung ........................................................... 8
3.2.2 Data Mining in der Lehre................................................................. 11
3.2.3 Kombinierte Betrachtungen ............................................................. 14
3.3 Data Mining in der Unternehmenspraxis ......................................... 16
3.3.1 Praxisorientierung der Befragten ..................................................... 16
3.3.2 Bedeutung des Data Mining in der Unternehmenspraxis ................ 16
3.4 Nutzen und Bedeutung des Web Mining und des Text Mining....... 19
4 Fazit und Ausblick ........................................................................... 20
Literatur ....................................................................................................... 23
Anhang I: Adressen der Softwareanbieter ............................................... 26
Anhang II: Ankündigungsschreiben bzw. -E-Mail ................................... 27
Anhang III: Interviewleitfaden................................................................... 28
Anhang IV: Liste der angefragten Lehrstühle ............................................ 36

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 1
1 Einleitung
1.1 Zielsetzung und Struktur des Arbeitsberichts
Die enorme Zunahme verfügbarer Daten und Informationen (siehe zur Unterscheidung der Begriffe z. B. [FiSV01, 68; VoGu01, 24]) in den letzten Jahrzehnten ist vor allem das Er-gebnis einer Verbesserung elektronischer Speichermedien [StHa02, 57f.], immer höher entwickelter Datenbankmanagementsysteme [StHa02, 545ff.] und eines Ausbaus der au-tomatisierten Datenerfassung. Dies hat zur Entstehung riesiger Datenbanken in vielen Be-reichen geführt, wie z. B. im Handel durch den Einsatz von Scannerkassen, in der Biologie durch die Automatisierung der Gensequenzierung oder in der Geologie durch Satelliten-aufnahmen der Erdbewegungen. Da nicht alle erfassten Daten einen Nutzen generieren, gilt es die potenziell nützlichen Daten aus der Gesamtheit der Daten herauszufiltern. War dies früher manuell möglich, so ist dies auf Grund der Größe der Datenbanken meist nicht mehr zu bewältigen [EsSa00, 1]. Daher werden zunehmend unter dem Begriff Data Mining (siehe Kapitel 1.2) zusammengefasste Methoden eingesetzt, von denen man sich eine effi-ziente Datenverarbeitung und vereinfachte Analysemöglichkeiten verspricht, d. h. es soll einem breiten Kreis von Anwendern die Möglichkeit gegeben werden, in akzeptablen Re-chenzeiten zu (individuell) neuen Erkenntnissen zu gelangen.
Der einschlägigen Literatur zufolge ist das Data Mining sowohl für die Forschung als auch für die Unternehmenspraxis von Interesse [Deck03, 49; Haus03, 17; Küpp99, 17]. Aller-dings gibt es bis dato nur wenige empirische Untersuchungen, die derartige Aussagen um-fassend überprüfen. Existierende Studien konzentrieren sich auf die Data Mining-Nutzung und -Erfahrungen in der Unternehmenspraxis (z. B. [MeGr97; HiMW02a-c]), auf Erfolgs-faktoren des Data Mining-Einsatzes [Hilb02] und auf Einsatzgebiete des Data Mining [Küpp99, 123ff.]. [HiMW02a-c] und [Hilb02] haben Unternehmensbefragungen durchge-führt. [Küpp99] stützt sich dagegen auf Angaben von Softwareherstellern, auf Expertenge-spräche während Messen und Konferenzen sowie auf Recherchen im Internet.
Im Gegensatz zu diesen Untersuchungen wurden für die hier behandelte Erhebung aus-schließlich Wissenschaftler aus dem Data Mining-Bereich (siehe Anhang) nach Einschät-zungen und Meinungen in Bezug auf das Data Mining befragt. Eine vergleichbare Heran-gehensweise wurde bislang in keiner Untersuchung in diesem Bereich gewählt. Bei der Untersuchung standen die folgenden Fragestellungen im Mittelpunkt:
- Welche gegenwärtige und künftige Bedeutung hat das Data Mining in Forschung und Lehre aus Sicht der ausgewählten bzw. befragten Lehrstühle?
- Wie schätzen die Lehrstühle die gegenwärtige und die künftige Bedeutung des Data Mining in der Unternehmenspraxis ein?
- Wie beurteilen die befragten Lehrstühle die aktuelle und künftige Bedeutung des Web Mining und des Text Mining?
Grund für die dritte Fragestellung war, dass es sich mit dem Web Mining und dem Text Mining um relativ neuartige Spezialisierungen bzw. Erweiterungen des Data Mining han-delt, deren Anwendungs- und Nutzenpotenziale intensiv untersucht und diskutiert werden.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 2
Kapitel 1.2 enthält ausgewählte Grundlagen des Data Mining. Zunächst werden in Kapi-tel 1.2.1 relevante Begriffe des Data Mining behandelt, die Kapitel 1.2.2 und 1.2.3 geben eine grobe Übersicht über Data Mining-Methoden und -Softwaretools. In Kapitel 2 wird die Durchführung der Befragung beschrieben. Die dabei erzielten Ergebnisse sind Gegens-tand von Kapitel 3. In Kapitel 3.1 wird auf die Zusammensetzung der Stichprobe einge-gangen, während die Kapitel 3.2, 3.3. und 3.4 Detailergebnisse zu den eingangs genannten Fragestellungen umfassen. Zum Abschluss der Arbeit befinden sich in Kapitel 4 einige zusammenfassende Bemerkungen und Schlussfolgerungen. Der Anhang enthält eine Liste der Internet-Adressen der vorgestellten Softwarelösungen, das Anschreiben, den Interview-leitfaden und eine Liste der in Betracht gezogenen Lehrstühle.
1.2 Relevante Grundlagen des Data Mining
1.2.1 Begriffe
Um bei Befragungen valide Aussagen zu erhalten, bedarf es einheitlicher Auffassungen zentraler Begriffe. Insbesondere für den Begriff des Data Mining gibt es unterschiedliche Abgrenzungen und Auslegungen. Für die Durchführung der Interviews wurden folgende Definitionen zugrunde gelegt (für eine ausführliche Behandlung der Grundlagen des Data Mining siehe z. B. [HaTF01; BeLi00; BeHa99; BeST00; WiFr00; Hand02]):
- Unter Knowledge Discovery in Databases (KDD) wird in Anlehnung an [FPSU96] der nichttriviale Prozess der Identifikation gültiger, neuartiger, potenziell nützlicher und letztlich verständlicher Muster in (großen) Datenbeständen verstanden.
- Data Mining lässt sich als ein Schritt im KDD-Prozess betrachten, in dem Data Mi-ning-Methoden zur Musterentdeckung eingesetzt werden. Vielfach wird Data Mining ebenfalls als ein Prozess beschrieben, der sich im Wesentlichen mit dem des KDD deckt. Zahlreiche Autoren verwenden die Begriffe KDD und Data Mining synonym (siehe dazu [AdZa96, 5; CHSV97, 12; BeST00, 116; Säub00, 9]). Um Missverständ-nisse und Abgrenzungsprobleme zu vermeiden, wurde für die Befragung eine weite Begriffsauslegung gewählt, d. h. die Begriffe wurden ebenfalls synonym verwendet.
- Unter Web Mining wird allgemein die Anwendung von Data Mining-Methoden auf im Web erfasste Daten verstanden [BeWe99, 426]. Dabei wird in der Regel zwischen Web Content Mining, Web Structure Mining und Web Usage Mining unterschieden, wobei zahlreiche Autoren sich auf das Web Usage Mining konzentrieren. Oftmals werden die Begriffe Web Mining und Web Usage Mining synonym verwendet (z. B. [Deck03, 67; SäHu03]), sodass auch hier von einer engen Begriffsauslegung abgesehen wurde.
- Beim Text Mining handelt es sich um eine vergleichsweise junge Forschungsrichtung [MeBe00, 165]. Hierunter fasst man Ansätze zur Analyse von in Texten enthaltenen In-formationen zusammen [DöGS01, 466]. Eine zentrale Rolle spielt dabei die sog. Fea-ture Extraction, d. h. die Zerlegung von Texten in Worte, die Reduktion der Worte auf Stammformen, die Normalisierung mit Hilfe linguistisch motivierter Heuristiken etc. [DöGS01, 469f.; MeBe00, 166]. Im Anschluss an die Extraktion von Informationsele-menten können dann Data Mining-Methoden zur Anwendung kommen, um beispiels-weise Texte zu gruppieren oder zu klassifizieren. Im Gegensatz zum Web Mining ist

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 3
das Text Mining noch nicht so weit entwickelt und bekannt (siehe auch die Ergebnisse in Kapitel 3.4).
1.2.2 Methoden
Das Gebiet des Data Mining kann als sehr breit gefächert bezeichnet werden. Entsprechend umfangreich ist das Spektrum der Methoden, die dem Data Mining zugerechnet werden können. [Küst01, 95f.] unterscheidet allein sechs Disziplinen, aus denen die Methoden stammen:
- Traditionelle Statistik und Datenanalyse, insbesondere die Regressions-, Faktoren-, Cluster-, Diskriminanz- und Zeitreihenanalyse einschließlich der Prognostik und der robusten Statistik.
- Künstliche Intelligenz, insbesondere das maschinelle Lernen, künstliche neuronale Net-ze, evolutionäre Algorithmen, intelligente Agentensysteme und probabilistische Exper-tensysteme (bayesianische Netze).
- Traditionelle Mustererkennung (Pattern Recognition).
- Datenbanktheorie und -praxis, insbesondere Assoziationsnetze und On-Line Analytical Processing (OLAP).
- Computerlinguistik und Information Retrieval, insbesondere Text Mining und fallba-siertes Schließen.
- Computergraphik, insbesondere Visualisierungsmethoden.
Data Mining-Methoden stellen demzufolge nicht zwingend Neuentwicklungen dar, son-dern sind in der Regel konsequente Weiterentwicklungen bekannter Ansätze, die auf um-fangreiche Datensätze aus bestehenden Datenbanken angewendet werden [Küst01, 124]. Auf Grund der großen und sich ständig verändernden Anzahl an Methoden bietet es sich an, die Methoden anhand der jeweiligen Zielsetzung zu gruppieren. Zentrale Bedeutung haben dabei die folgenden Gruppen:
- Assoziations- und Sequenzanalyse: Mit Hilfe von Assoziationsanalysen lassen sich sog. Assoziationsregeln generieren, anhand derer sich Zusammenhänge zwischen Objekten erkennen und beschreiben lassen. Mit Hilfe spezieller Maße – in den meisten Fällen werden der Support-, der Confidence- und der Lift-Wert verwendet – lässt sich beurtei-len, inwieweit die gefundenen Zusammenhänge als auffällig angesehen werden können (siehe ergänzend [Boll96; HeHi01; Adam01]). Ein typisches Anwendungsgebiet sind Warenkorbanalysen. Sofern Objekte bzw. Objektkombinationen mit Zeitstempeln ver-sehen sind, lassen sich Sequenzanalysen durchführen, d. h. es werden zeitbezogene bzw. zeitraumbezogene Zusammenhänge aufgedeckt (siehe zur Vertiefung z. B. [Zaki01; SrAg96; PHMZ00; Adam01]). Ein typischer Anwendungsfall ist die Untersu-chung von Nutzungsdaten aus dem Internet.
- Gruppierung bzw. Clustering: Hierunter versteht man Verfahren zur Zusammenfassung ähnlicher Objekte zu Gruppen. Ziel ist es, dass sich die Objekte innerhalb der Gruppen möglichst ähnlich sind und sich zwischen den Gruppen möglichst stark unterscheiden. Für die Bestimmung der Ähnlichkeiten gibt es eine Vielzahl von Maßen und Metriken,

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 4
die je nach verfolgtem Analyseziel und je nach Datencharakteristik zum Einsatz kom-men. Ähnlich vielfältig ist die Menge vorhandener Clusterverfahren (siehe zur Vertie-fung z. B. [BEPW00; Bach02]). Die mit Hilfe von Clusteranalysen ermittelten Gruppen können entweder zur Datenbeschreibung eingesetzt werden oder dienen als Basis für weitere, gruppenspezifische Auswertungen.
- Klassifikation: Ziel der Klassifikation ist es, Modelle bzw. Funktionen zu finden, mit deren Hilfe Datenobjekte vorher identifizierten Klassen zugeordnet werden können. Die Ableitung eines Modells basiert in der Regel auf einer Menge von Objekten, für die die jeweilige Klassenzuordnung bekannt ist (siehe zur Vertiefung z. B. [BoAr01; HaTF01]). Mit Hilfe des zu ermittelnden Modells sollen Objekte klassifiziert werden, für die keine Klassenzuordnung bekannt ist. Die Modelle können mit Hilfe von Dis-kriminanzanalysen (siehe z. B. [BoAr01]), Entscheidungsbäumen (siehe z. B. [BFOS84; HaTF01]) oder neuronalen Netzen (siehe z. B. [PoSi01]) ermittelt werden.
- Regression: Mit Hilfe der Regressionsanalyse sollen funktionale Abhängigkeiten zwi-schen den Variablen eines Datensatzes bestimmt werden. Die derart ermittelten Model-le dienen der Schätzung bzw. der Vorhersage von Variablenwerten. Zur Repräsentation der Abhängigkeiten gibt es neben linearen auch nicht-lineare (z. B. quadratische, logis-tische oder Poisson) Regressionsansätze (siehe zur Vertiefung [ChHP00; AlSk99; Kraf99]).
Neben den hier genannten Gruppen von Methoden gibt es weitere Ansätze aus den Berei-chen Zeitreihenanalyse, Visualisierung und bzw. Evolutionäre Algorithmen (einen Über-blick gibt beispielsweise [Küst01]).
Als typische Data Mining-Methoden werden in der Literatur üblicherweise Verfahren der Regressions-, der Cluster- und der Diskriminanzanalyse sowie Entscheidungsbaumverfah-ren bzw. maschinelles Lernen, künstliche neuronale Netze und Assoziationsanalyseverfah-ren genannt (siehe zu den Grundlagen der Methoden beispielsweise [BEPW00; BeLi97; HaKa01]). Dies bestätigen auch die Ergebnisse der vorliegenden Befragung – jede dieser Methoden wird von mindestens fünf der befragten Lehrstühle in der Forschung und/oder in der Lehre eingesetzt (siehe auch Kapitel 3.2.3).
1.2.3 Softwaretools
Parallel zur Neu- und Weiterentwicklung von Data Mining-Methoden wurden von mehre-ren Anbietern entsprechende Software-Produkte entwickelt. Grundsätzlich lässt sich dabei unterscheiden zwischen von Grund auf neu entwickelten bzw. eigenständigen Data Mi-ning-Produkten (z. B. IBM Intelligent Miner, SPSS Clementine, SPSS AnswerTree, Prud-sys Discoverer, WEKA) und Produkten, in die Data Mining-Methoden integriert wurden oder die um neue Schnittstellen und Benutzeroberflächen ergänzt wurden (z. B. SAS En-terprise Miner, Insightful Miner). Bei einer weiteren Gruppe von Produkten handelt es sich um klassische Statistik-Pakete, die für Data Mining-Aufgaben eingesetzt werden (z. B. SPSS, S-PLUS). Auf die genannten Produkte wird im Folgenden jeweils kurz eingegan-gen. Die Angaben basieren zum Teil auf einer Internet-Recherche. Die entsprechenden Internet-Adressen befinden sich im Anhang.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 5
Vollständig neu entwickelte Produkte
- Mit dem IBM Intelligent Miner for Data handelt es sich um eine ursprünglich auf DB2 aufsetzende Lösung für komplexe Analysen großer Datenmengen, die für eine Vielzahl an Plattformen verfügbar ist (u. a. Windows NT/2000, AIX, OS/400, OS/390). Folgen-de Methoden stehen u. a. zur Verfügung: Neuronale Netze, Clustering-Verfahren, As-soziations-/Sequenzanalyse, Radial Basis-Funktionen, Entscheidungsbäume. Endbe-nutzerschnittstellen und programmierbare Schnittstellen ermöglichen die Anpassung des Mining-Prozesses an verschiedene Benutzergruppen. Darüber hinaus bietet IBM Anwendungslösungen an, die auf dem Intelligent Miner aufbauen und vorgefertigte Spezialisierungen beinhalten.
- SPSS Clementine ist eine Data Mining-Plattform, die den gesamten Analyseprozess durch eine grafische Programmieroberfläche unterstützt. Das Tool läuft auf zahlreichen Plattformen (u. a. Windows NT/2000, Windows XP, Sun Solaris, HP UX, AIX HP 9000, AS400). Neben umfangreichen Datenimport- und Aufbereitungsprozeduren stehen Neuronale Netze, Entscheidungsbäume, Regressionsanalyse, Faktorenanalyse, Assoziations-/Sequenzanalyse und Clustering-Verfahren zur Verfügung. Für die Ver-arbeitung großer Datenmengen gibt es eine Client/Server-Version.
- SPSS AnswerTree ist ein relativ verbreitetes Tool zur Erstellung von Entscheidungs-bäumen. Es stehen insgesamt vier Algorithmen zur Verfügung. Das Tool bietet ver-schiedene Datenimport-Möglichkeiten und Schnittstellen an und steht auch als Client/Server-Version zur Verfügung.
- Der Prudsys Discoverer bietet in erster Linie einen universellen Ansatz zur Erzeugung von linearen und nichtlinearen Entscheidungsbäumen (siehe dazu [ItST01]) sowie ein Sparse Grids-Klassifikationsverfahren vor allem für große Datenmengen. Das Tool un-terstützt verschiedene Datenbankformate und läuft ausschließlich auf Windows-Systemen. Mit dem Discoverer können sowohl automatisch als auch interaktiv Data Mining-Modelle erstellt werden. Weitere Verfahren, wie z. B. Clustering-Verfahren, Zeitreihenanalyse und Assoziations-/Sequenzanalyse, sind in weiteren Prudsys-Produkten enthalten.
- Die Java-basierte Entwicklungsumgebung WEKA (The Waikato Environment for Knowledge Analysis) stellt als open source-Software eine Besonderheit unter den Software-Produkten dar (siehe auch [WiFr00]). Sie bestand unrsprünglich aus einer Ansammlung von Algorithmen aus dem Bereich des maschinellen Lernens für die Lö-sung von Data Mining-Problemen. WEKA beinhaltet Tools zur Datenaufbereitung, Klassifikation, Regression, Clustering, Assoziationsanalyse und Visualisierung. Die Algorithmen können entweder direkt auf einen Datensatz angewendet werden oder ü-ber Java Code aufgerufen werden. Zudem können eigene Ansätze des maschinellen Lernens implementiert werden. In jedem Fall benötigt WEKA eine Java Runtime-Umgebung.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 6
Um Data Mining-Funktionalitäten erweiterte Produkte
- Der SAS Enterprise Miner ist eine Data Mining-Lösung, die auf verschiedenen Modu-len des sog. SAS-Systems basiert. Die Definition von Data Mining-Prozessen wird durch eine grafische Benutzeroberfläche unterstützt, wobei die Struktur an die sog. SEMMA-Methodologie angelehnt ist. Zusammen mit SAS Data Warehouse-Lösungen und OLAP-Techniken entsteht eine Lösung, die das gesamte Spektrum des Knowledge Discovery abdeckt. Als Methoden stehen u. a. Neuronale Netze, Entscheidungsbäume, Regressionsanalyse, Memory Based Reasoning, Clustering-Verfahren, Assoziati-ons-/Sequenzanalyse und Zeitreihenanalyse zur Verfügung. Darüber hinaus kann auf zahlreiche weitere statistische Verfahren, wie z. B. Verfahren der deskriptiven Statistik, multivariate Verfahren und Visualisierungsmöglichkeiten zurückgegriffen werden. Das Programmpaket ist individuell anpassbar bzw. programmierbar, läuft unter verschiede-nen Betriebssystemen und kann sowohl auf PCs, auf Großrechnern und in Client-Server-Umgebungen genutzt werden.
- Der Insightful Miner ist ebenfalls eine prozessorientierte Data Mining-Lösung, die auf dem Statistikpaket S-PLUS basiert und um weitere Funktionalitäten ergänzt wurde. Der Insightful Miner ist für Windows- und Unix-Systeme verfügbar (u. a. Win-dows NT/2000/XP, Sun Solaris) und bietet zahlreiche Datenbank-Schnittstellen sowie Import-Möglichkeiten für verschiedene Dateiformate. Das Programm ermöglicht die Erstellung neuer Anwendungen und die Anpassung an individuelle Bedürfnisse. Als Methoden stehen u. a. Neuronale Netze, Entscheidungsbäume, Regressionsanalyse, Clustering-Verfahren, Assoziations-/Sequenzanalyse und Zeitreihenanalyse zur Verfü-gung. Darüber hinaus kann weitere in S-PLUS verfügbare Verfahren zurückgegriffen werden.
Statistik-Pakete
- SPSS ist eine weit verbreitete Statistik-Software, die aus verschiedenen Modulen be-steht und als Einzelplatzversion unter verschiedenen Windows-Systemen lauffähig ist. Ähnlich wie SAS umfasst SPSS eine Fülle statistischer Analysemethoden. Neben Ver-fahren der Regressions-, Cluster- und Diskriminanzanalyse steht eine Vielzahl weiterer statistischer Methoden zur Verfügung, wie z. B. Verfahren der deskriptiven Statistik, multivariate Verfahren und Visualisierungsmöglichkeiten. Als Client Server-Version läuft die Software unter Windows und Unix (z. B. Sun Solaris, Linux). Zusätzlich gibt es Programmiermöglichkeiten, um Analyseschritte (teilweise) zu automatisieren. Dar-über hinaus bietet SPSS vorgefertigte Spezialisierungen bzw. Branchenlösungen an.
- S-PLUS ist ein Statistik-Paket, das unter Windows- und Unix-Systemen genutzt wer-den kann. Schnittstellen zu zahlreichen, verbreiteten Datenbanken- und Dateiformaten sind vorhanden. Ähnlich wie SAS und SPSS stellt S-PLUS neben Verfahren der Regressions-, Cluster- und Diskriminanzanalyse eine Vielzahl statistischer Methoden zur Verfügung, wie z. B. Verfahren der deskriptiven Statistik, multivariate Verfahren und Visualisierungsmöglichkeiten. Bereits existierende Methoden können modifiziert werden, neue Methoden können in einer speziellen Programmiersprache implementiert werden.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 7
2 Angaben zur Durchführung der Erhebung
Als Auskunftspersonen wurden ausschließlich Wissenschaftler aus der Betriebswirtschafts-lehre, der Wirtschaftsinformatik, der Informatik und der Statistik in Betracht gezogen, da nach Einschätzung der Autoren in diesen Fachrichtungen ein erheblicher Anteil der Ent-wicklung und Anwendung von Data Mining-Methoden stattfindet. Forscher anderer Fach-richtungen, wie z. B. Medizin, Biologie (Genomforschung) und Astronomie, wurden nicht befragt, da die Data Mining-Fragestellungen dieser Bereiche zum Teil innerhalb der Statis-tik und der allgemeinen Informatik bzw. in Spezialgebieten (z. B. Bio- und Medizin-Informatik) behandelt werden. Zudem wurde unterstellt, dass die auf die Unternehmens-praxis bezogenen Fragen bereits von Vertretern der hier betrachteten Fachrichtungen be-antwortet werden können.
Für die Befragung von Wissenschaftlern sprach, dass sich diese generell mit dem Einsatz und Nutzen von Data Mining-Methoden beschäftigen und sich eher mit der Bedeutung des Data Mining als Disziplin auseinandersetzen, als es von Vertretern aus der Unternehmens-praxis zu erwarten wäre. Nachteilig ist möglicherweise, dass sich die Ergebnisse nur auf relativ wenige Auskunftspersonen stützen, die zudem nicht die Bedeutung für die Unter-nehmenspraxis abschätzen können. Den Ergebnissen in Kapitel 3.3 kann jedoch entnom-men werden, dass die befragten Personen überwiegend Praxiserfahrungen vorweisen kön-nen.
Als Erhebungsform wurde die Durchführung telefonischer Interviews mit schriftlicher An-kündigung bzw. Terminvereinbarung gewählt (siehe Anhang). Dadurch konnte die Ant-wortbereitschaft positiv beeinflusst werden. Zudem konnten während der Interviews ein-zelne Fragen erläutert und somit Missverständnisse ausgeräumt werden. In zwei Fällen wurde aus Termingründen der Interviewleitfaden (siehe Anhang) als Fragebogen versendet und von den Auskunftspersonen schriftlich beantwortet. Die Befragung wurde ab Mitte November 2002 bis Mitte Januar 2003 durchgeführt.
3 Ergebnisse
3.1 Zusammensetzung der Stichprobe
Insgesamt wurden 51 Lehrstühle aus den Bereichen Betriebswirtschaft, Wirtschaftsinfor-matik, Informatik und Statistik ausgewählt (siehe Anhang). Ausschlaggebend für die Aus-wahl war die Forschungs- und Lehrtätigkeit im Bereich Data Mining, d. h. ein Lehrstuhl gelangte genau dann in die Auswahl, wenn zwischen dem WS 2000/01 und dem WS 2002/03 Lehrveranstaltungen (Vorlesungen, Übungen, Seminare) mit Bezug zum Data Mining stattgefunden haben bzw. von Mitarbeitern des Lehrstuhls einschlägige Publikatio-nen erschienen sind. Von den ausgewählten Lehrstühlen nahmen 22 an der Befragung teil, wobei entweder der Lehrstuhlinhaber oder ein benannter Mitarbeiter die Antworten gege-ben hat. Dies entspricht einem Rücklauf von 43%. Die Verteilung auf die einzelnen Berei-che kann Tabelle 1 entnommen werden (aus Anonymitätsgründen wurden die Lehrstühle in Gruppen zusammengefasst). Für die Überprüfung, ob die Häufigkeiten von den erwarte-ten Häufigkeiten abweichen (H1-Hypothese) oder nicht (H0-Hypothese), wurde ein Chi-

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 8
Quadrat-Anpassungstest durchgeführt. Da in drei der fünf Gruppen die erwartete Häufig-keit weniger als fünf beträgt und damit eine wesentliche Voraussetzung der asymptoti-schen Standardmethode nicht erfüllt ist, wurde die in dem SPSS-Zusatzmodul „Exact Tests“ implementierte Variante verwendet. Dabei ergab sich ein Chi-Quadrat-Wert von 0,425 und eine exakte Signifikanz von 0,983, sodass die H0-Hypothese nicht abgelehnt werden kann. Daher wird davon ausgegangen, dass die Stichprobe für die zugrunde gelegte Grundgesamtheit repräsentativ ist.
Tabelle 1: Stichprobenzusammensetzung
Lehrstuhlbezeichnung N Erwartete Häufigkeit Stichprobenhäufigkeit Statistik 10 4,314 5
Betriebswirtschaft 4 1,725 2 Wirtschaftsinformatik 9 3,882 4
Datenbanken 12 5,177 4
Info
rmat
ik
Künstliche Intelligenz, Neuroin-formatik, Natürlichsprachliche
Systeme etc. 16 6,902 7
Gesamt 51 22 22
Im Weiteren werden die Ergebnisse der Befragung vorgestellt und diskutiert. Es handelt sich in erster Linie um deskriptive Auswertungen zur Beschreibung des Meinungsbilds zum Data Mining und des Status quo. Da nur eine relativ kleine Stichprobe vorliegt, wurde von der Anwendung komplexerer Auswertungsmethoden abgesehen.
3.2 Data Mining in Forschung und Lehre
3.2.1 Data Mining in der Forschung
Um die Bedeutung des Data Mining aus Sicht der Befragten zu erfahren, sollten diese die Relevanz für die Forschung insgesamt und für die eigene Forschung bewerten (Bild 1). Er-wartungsgemäß stellte sich heraus, dass 12 von 22 Befragten die Bedeutung des Data Mi-ning in der eigenen Forschung als eher oder als sehr bedeutend betrachten und weitere fünf Befragte zumindest eine mittlere Bedeutung angeben. In Bezug auf die gesamte For-schungslandschaft liegt der Schwerpunkt der Einschätzungen bei einer mittleren Bedeu-tung. Dies lässt auf eine Spezialisierung der befragten Lehrstühle in Richtung Data Mining schließen.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 9
Bedeutung der Data Mining-Forschung
0
2
4
6
8
10
Sehr
gerin
g
Eher
gering Mitte
l
Eher
bede
utend
Sehr
bede
utend
fehlen
d
insgesamt
am Lehrstuhl
Bild 1: Bedeutung der Data Mining-Forschung
Neben der aktuellen Bedeutung sollten die Befragten auch die künftige Bedeutung des Da-ta Mining in der Forschung (und der Lehre) einschätzen (siehe Tabelle 2). Nahezu einhel-lig sind die Befragten der Meinung, dass die Bedeutung leicht zunehmen wird. Als Gründe für die leichte Zunahme wurden weiterhin steigende Datenmengen, Verbesserungen der Methoden und die Orientierung des Forschungs- und Lehrangebots an der (steigenden) Nachfrage aus der Unternehmenspraxis angegeben. Gegen ein starkes Wachstum wurde angeführt, dass die Bedeutung bereits als hoch anzusehen sei und daher nicht mehr stark wachsen könne. Entsprechend könne davon ausgegangen werden, dass im Bereich des Da-ta Mining keine neuen Stellen an den Lehr- und Forschungseinrichtungen geschaffen wer-den, da das Hochschulangebot schon weitgehend ausreiche, um den Bedarf in der Lehre zu decken.
Tabelle 2: Künftige Bedeutung des Data Mining in Forschung und Lehre
„[...] Die Bedeutung des Data Mining an den Lehr- und For-schungseinrichtungen wird ...“
Häufigkeit Prozent
Stark zurückgehen 0 0,0
Leicht abnehmen 2 9,1
Gleich bleiben 2 9,1
Leicht zunehmen 16 72,7
Stark wachsen 1 4,5
Fehlend 1 4,5
22 100,0

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 10
Um die Bedeutung des Data Mining für die eigene Forschungsarbeit durch zusätzliche In-dikatoren zu erfassen, sollten die Befragten angeben, wie viele Diplomarbeiten bzw. Dis-sertationen im Bereich des Data Mining betreut wurden (Tabelle 3) und ob bzw. in wel-chem Ausmaß publiziert wird (Tabelle 4).
Tabelle 3: Anzahl Diplomarbeiten und Dissertationen in den letzten zwei Jahren
N Minimum Maximum Mittelwert Median Modus
Anzahl Diplomarbeiten 20 0 20 6 4 5
Anzahl Dissertationen 20 0 7 1,8 1 1
Im Schnitt ergeben sich pro Lehrstuhl in etwa drei Diplomarbeiten und eine Dissertation pro Jahr (Anm.: Die Angaben bezogen sich auf einen Zeitraum von zwei Jahren). Auf Grund der erheblichen Spannweite bei den Angaben, die sich vermutlich auf die unter-schiedliche Auslegung des Begriffes Data Mining zurückführen lässt, bietet sich die Be-trachtung des Medians und des Modus an. Diesen beiden, gegen Extremwerte deutlich un-empfindlicheren Maßzahlen zufolge wurden an den befragten Lehrstühlen in einem Zeit-raum von zwei Jahren im Bereich des Data Mining ca. vier bis fünf Diplomarbeiten und eine Dissertation betreut. Dies ist aus Sicht der Autoren ein durchaus plausibles Bild.
Tabelle 4: Publikationsaktivitäten im Bereich des Data Mining
„Werden an Ihrem Lehrstuhl Publikationen zu diesem Thema [Data Mining] erstellt?“
Häufigkeit Prozent
Gar nicht 1 4,5
Selten 6 27,3
Regelmäßig 7 31,8
Häufig 6 27,3
Durchgehend 1 4,5
Fehlend 1 4,5
22 100,0
Die Forschungsaktivitäten lassen sich zusätzlich an der Anzahl der Publikationen in die-sem Bereich ablesen (siehe Tabelle 4). Bei der entsprechenden Frageformulierung wurde bewusst nicht danach gefragt, auf welchen Zeitraum sich die Angaben beziehen, um Zu-ordnungsprobleme zu vermeiden. Trotz der dadurch verursachten Unschärfe lässt sich fest-stellen, dass der Großteil der befragten Lehrstühle regelmäßig oder häufig zu diesem The-ma publiziert. Dieses Ergebnis deckt sich mit der Feststellung von Säuberlich, dass die Veröffentlichungsaktivitäten im Bereich des Data Mining stark zunehmen bzw. zugenom-men haben [Säub00, 51]. Somit verwundert es nicht, dass lediglich ein Lehrstuhl nicht zu diesem Thema publiziert hat.
Um einen Eindruck zu erhalten, inwieweit im Rahmen der Forschungsarbeit Software-Tools eingesetzt werden, sollten die Befragten entsprechende Angaben zum Software-Einsatz machen. Dabei stellte sich heraus, dass bei 20 Lehrstühlen ein oder mehrere Tools

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 11
verwendet werden. Ein Lehrstuhl setzt keine Software ein, da keine adäquate Software für die Textanalyse existiert. An einem weiteren Lehrstuhl wird keine aktive Forschung im Bereich des Data Mining betrieben und somit keine Software für diesen Zweck eingesetzt.
Offensichtlich beschränken sich die befragten Lehrstühle nicht ausschließlich auf die Be-handlung theoretischer Aspekte des Data Mining, sondern wenden mit Hilfe geeigneter Tools Data Mining-Methoden an (siehe zum Softwareeinsatz und zu präferierten Methoden Kapitel 3.2.3). Zum Einsatz kommen dabei neben Standardapplikationen (siehe Kapi-tel 3.2.3) auffällig oft auch Eigenentwicklungen, wobei diese vor allem im Bereich der Informatik verbreitet sind. Dort setzen sieben von elf Lehrstühlen Eigenentwicklungen ein, während es nur zwei von elf Lehrstühlen in den anderen Disziplinen sind. Auf Nachfrage wurde dies damit begründet, dass vorhandene Software-Produkte entweder methodische Defizite aufweisen oder nicht erschwinglich sind.
3.2.2 Data Mining in der Lehre
Ähnlich wie zu der Bedeutung des Data Mining in der (eigenen) Forschung sollten die Be-fragten einschätzen, welche Rolle das Data Mining in der Lehre einnimmt (siehe Tabel-le 5). Dabei stellte sich heraus, dass weniger als ein Fünftel der Befragten die Bedeutung als gering oder sehr gering und die Hälfte als eher oder sehr bedeutend beurteilt. Erwar-tungsgemäß hat das Data Mining für die befragten Lehrstühle eine tendenziell höhere Be-deutung.
Tabelle 5: Bedeutung des Data Mining in der Lehre
„Welchen Stellenwert räumen Sie der Data Mining Lehre an Ihrem Lehrstuhl ein?“
Häufigkeit Prozent
Sehr gering 1 4,5
Eher gering 3 13,6
Mittel 7 31,8
Eher bedeutend 8 36,4
Sehr bedeutend 3 13,6
22 100,0
Um die Bedeutung des Data Mining in der Lehre mit Hilfe zusätzlicher Fragestellungen ermessen zu können, wurden entsprechende (offene) Fragen zum zeitlichen Umfang Data Mining-bezogener Lehrveranstaltungen und zur Lehrerfahrung (Anzahl der Jahre seit erstmaligem Angebot einer einschlägigen Lehrveranstaltung) gestellt (Tabelle 6). Dabei stellte sich heraus, dass an den Lehrstühlen im Mittel vor 5,09 Jahren die erste Lehrveran-staltung mit Bezug zum Data Mining angeboten wurde.
Bezüglich der Summe der Semesterwochenstunden, die die Lehrstühle im Bereich des Da-ta Mining anbieten, ergibt sich ein Mittelwert von 5,00 bzw. ein Median von 4,00 Stunden (Tabelle 6). Auf Grund der Verzerrung des Mittelwerts durch Extremwerte wird für die vorliegenden Daten der Median präferiert. Der Wert von 4 Semesterwochenstunden kor-respondiert mit den Angaben zum Lehrveranstaltungsangebot. Wie Bild 2 entnommen

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 12
werden kann, handelt es sich bei den Lehrveranstaltungen in erster Linie um Vorlesungen zum Data Mining mit dazugehöriger Übung. In wenigen Fällen beschränkt sich das Ange-bot auf Vorlesungen ohne Übung (inkl. Schwerpunktübungen mit Vorlesungscharakter) bzw. in einem Fall um eine Übung ohne Vorlesung. Einige Lehrstühle bieten zusätzlich oder alternativ Veranstaltungen zur explorativen Datenanalyse und zur multivariaten Sta-tistik an, die jedoch einen Bezug zum Data Mining aufweisen. Unter Sonstiges wurden in erster Linie Seminarveranstaltungen zum Data Mining zusammengefasst. Derartige Veran-staltungen boten 9 der 22 Lehrstühle an.
Tabelle 6: Lehrerfahrungen und Lehrumfang
Anz. gültige Werte Minimum Maximum Mittelwert Median Modus
Lehrerfahrung in Jahren 22 1 12 5,09 5,00 5 Semesterwochenstunden 22 1 18 5,00 4,00 4
0
2
4
6
8
1012
14
16
18
20
22
nur VL nur Übung VL+Übung Veranstaltungmit Data
Mining-Bezug
Sonstiges
Bild 2: Lehrveranstaltungstypen im Bereich Data Mining
Die Lehrveranstaltungen werden überwiegend entweder jedes (11 Lehrstühle) oder zumin-dest jedes zweite Semester (9 Lehrstühle) angeboten (Fragestellung „In welchem Semes-terrhythmus werden diese Veranstaltungen angeboten?“).
Tabelle 7: Adressatenkreise von Lehrveranstaltungen zum Data Mining
„Sind diese Veranstaltungen an Ihrem Lehrstuhl für alle Studenten Ihrer Fakultät be-legbar oder handelt es sich um Spezialveranstaltungen?“
Häufigkeit Prozent
Schwerpunktintern 3 13,6
Fakultätsintern 6 27,3
Fakultätsübergreifend 13 59,1
22 100,0

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 13
Nur selten werden die Data Mining-Veranstaltungen als Spezialveranstaltungen einem begrenzten Kreis von Studierenden zugänglich gemacht. Mehr als vier Fünftel der befrag-ten Lehrstühle bieten die Lehrveranstaltungen entweder innerhalb der eigenen Fakultät oder sogar fakultätsübergreifend an. Dies weist darauf hin, dass das Data Mining als für einen breiten Hörerkreis relevant betrachtet wird.
Ähnlich wie im Bereich der Forschung sollten die Befragten angeben, welche Data Mi-ning-Methoden und welche Software-Tools im Rahmen der Lehre behandelt bzw. einge-setzt werden. Die Ergebnisse werden ausführlich in Kapitel 3.2.3 behandelt. Hervorzuhe-ben ist, dass von den 22 befragten Lehrstühlen insgesamt 90 Methoden genannt wurden (Mehrfachnennungen möglich). Dies entspricht vier bis fünf unterrichteten Methoden je Lehrstuhl. Typische Methoden eines BWL-Lehrstuhls sind beispielsweise die Assoziati-onsanalyse, Entscheidungsbäume, die Clusteranalyse und neuronale Netze.
Bezüglich der eingesetzten Software-Produkte konnte festgestellt werden, dass in der Leh-re die Rolle kommerzieller Produkte deutlich größer ist als in der Forschung (siehe zu den weiteren Ergebnissen Kapitel 3.2.3).
Der Einsatz von Software-Produkten in der Lehre setzt die Verwendung geeigneter Bei-spiele bzw. Datensätze voraus. Daher sollten die Befragten angeben, welcher Art die für Lehrzwecke verwendeten Daten sind (siehe Tabelle 8). Während zwei Lehrstühle keinerlei Beispiele benutzen, da keine Software eingesetzt wird, kommen bei 20 Lehrstühlen mehr oder weniger große Datensätze bzw. Zahlenbeispiele zum Einsatz. Bei mehr als der Hälfte der Lehrstühle werden Datensätze mit mehreren Tausend Beobachtungen bearbeitet. Sechs Lehrstühle setzen Datensätze mit immerhin bis zu tausend Beobachtungen ein und zwei Lehrstühle beschränken sich auf die Verwendung von Zahlenbeispielen. Als Gründe für die Verwendung von Zahlenbeispielen bzw. die Beschränkung auf kleine Datensätze wur-den in vier Fällen zeitliche Restriktionen und in zwei Fällen ein erwarteter geringer Nutzen angeführt. In zwei Fällen befand sich die Verwendung von konkreten, größeren Datensät-zen in der Planung.
Tabelle 8: Verwendung von Datensätzen in der Lehre
„In welchem Umfang wird bei Ihnen eine Bearbeitung kon-kreter Datensätze im Unter-richt durchgeführt?“
Häufigkeit Prozent
Keine Beispiele 2 9,1
Zahlenbeispiele 2 9,1
Kleine Datensätze 6 27,3
Große Datensätze 12 54,5
22 100,0

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 14
3.2.3 Kombinierte Betrachtungen
Im Folgenden wird genauer auf den Einsatz von Methoden und Software-Produkten einge-gangen, wobei eine kombinierte Betrachtung von Forschung und Lehre erfolgt.
Bei den Methoden gibt es sowohl in der Forschung als auch in der Lehre eindeutige Favo-riten (Bild 3). Offensichtlich kommt Clusteranalyseverfahren, Ansätzen der Assoziations-analyse, Entscheidungsbäumen und Neuronalen Netzen eine zentrale Bedeutung zu. Inte-ressanterweise hat die Diskriminanzanalyse bei acht Lehrstühlen einen festen Platz in der Lehre, spielt aber keine Rolle im Rahmen der Forschung.
In Bezug auf die Rolle der Data Mining-Methoden in der Forschung wurde bei der Befra-gung nicht hinterfragt, welchen Anteil dabei die (Weiter-)Entwicklung von Methoden und welchen Anteil die Anwendung bzw. der Vergleich von Methoden ausmacht. Für weitere Untersuchungen ergibt sich daraus beispielsweise die Frage, bei welchen Methoden große (Weiter-)Entwicklungspotenziale gesehen werden.
0
2
4
6
8
10
12
14
16
18
20
22
Cluster
analy
se
Asso
ziation
sana
lyse
Entsc
heidu
ngsb
äume
Neuron
ale N
etze
Regres
sion
Regelb
asier
te Ve
rfahre
n
Diskrim
inanz
analy
se
Baye
s-Netz
e/-Ve
rfahre
n
Evol./
Genet.
Algorit
hmen
Neuo-F
uzzy-
Method
en
Visua
lisierun
gsmeth
.
Sons
tiges
Forschung
Lehre
Bild 3: Data Mining-Methoden in Forschung und Lehre
Wie Bild 4 entnommen werden kann, ergibt sich bezüglich des Software-Einsatzes im Ge-gensatz zum Methodeneinsatz ein etwas ausgeglicheneres Bild. Während in der Forschung auffällig häufig eigene Software-Entwicklungen zum Einsatz kommen, dominieren in Leh-re und Forschung der SAS Enterprise Miner, der IBM Intelligent Miner, S-PLUS und SPSS Clementine. Bemerkenswert ist zudem der relativ häufige Einsatz der Open Source-Software WEKA für Forschungszwecke.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 15
0
2
4
6
8
10
Cart
Clemen
tine
Enter
prise
Mine
r
Intelli
gent
Miner
Matlab R
S Plus
Weka
Eigen
e Softw
are
keine
Softw
are
Forschung
Lehre
Bild 4: Software-Einsatz in Forschung und Lehre
Vier Lehrstühle setzen in der Lehre keine Software ein. Als Gründe gaben zwei Lehrstühle in einer zusätzlichen offenen Frage an, dass der Einsatz geplant sei. Ein Lehrstuhl hält die Nutzung für zu zeitaufwändig, und ein weiterer gab als Gründe hohen Zeitaufwand und hohe Kosten an. Ein Lehrstuhl nutzt keine Software in der Forschung und gab als Grund an, dass es keine passende Software für spezielle Textanwendungen gäbe.
Dass die meisten Lehrstühle im Rahmen der Lehre Software-Produkte einsetzen, deutet auf eine überwiegend anwendungsorientierte Ausbildung hin. Dies bestätigen auch die Anga-ben zu der Frage, ob im Rahmen der Lehre größere Datensätze bearbeitet werden (siehe Kapitel 3.2.2).
Aus der Vielzahl der existierenden Methoden im Data Mining bzw. in der Datenanalyse wird in Zukunft einigen eine zunehmende oder abnehmende Rolle zukommen. Auf die entsprechende Frage, welche Methoden in Zukunft an Bedeutung gewinnen oder verlieren werden, wurde allen voran Neuronalen Netzen (fünf Mal), außerdem der Assoziationsana-lyse und den Entscheidungsbäumen (je drei Mal) sowie Visualisierungsmethoden (zwei mal) eine steigende Bedeutung bescheinigt. Als Gründe wurden unter anderem Verände-rungen hinsichtlich Datenqualität und Rechnerleistung sowie Neu- und Weiterentwicklun-gen von Methoden genannt. Eine abnehmende Bedeutung wurde lediglich bei der Diskri-minanzanalyse gesehen. Begründet wurde dies unter anderem damit, dass die „klassische“ Diskriminanzanalyse durch neuere und bezüglich der Anwendung und Interpretation einfa-chere Verfahren ersetzt werden wird.
Im Rahmen einer offenen Frage wurden die Befragungsteilnehmer gebeten, interessante bzw. künftige Anwendungsgebiete des Data Mining zu nennen. Eine Übersicht über die Antworten enthält Tabelle 9. Neben den auch in der Literatur häufig genannten Anwen-dungen fiel bei den Antworten auf, dass mehrfach die Auswertung von Bilddaten genannt wurde.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 16
Tabelle 9: Anwendungsgebiete des Data Mining
Fachrichtung Anwendungsgebiet Übergreifende Anwendungen
Astronomie Satellitenaufnahmen
Biologie Biotechnologie, Proteinanalyse, Genomanalyse/DNA
Wirtschafts-wissenschaften
Scannerdatenanalyse, Frühwarnsysteme, Prognostik, Marketingana-lysen, Kundenbewertung, Qualitätssicherung, Finanzdatenanalyse, E-Commerce
Medizin Diagnostik, Auswertung medizinischer Bilder
Chemie Analyse chemischer Reaktionsdaten
Informatik Softwareentwicklung, Bild-/Personenerkennung, Webdatenanalyse
Dokumentenre-cherche, Aus-wertung von Experimenten, Visualisierung
3.3 Data Mining in der Unternehmenspraxis
Zur Beantwortung der eingangs gestellten Frage zur Rolle des Data Mining in der Unter-nehmenspraxis sollten die Auskunftspersonen Angaben zu eigenen Praxiserfahrungen ma-chen, die Praxisrelevanz des Data Mining beurteilen und zu einigen Aussagen Stellung nehmen.
3.3.1 Praxisorientierung der Befragten
Zunächst wurden die Interviewteilnehmer gefragt, ob und wie häufig sie mit Unternehmen zusammenarbeiten (Tabelle 10). Da zu vermuten war, dass die Personen die Frage nach der konkreten Anzahl durchgeführter Projekte nur recht ungenau oder überhaupt nicht beant-worten, wurde eine unscharfe Formulierung gewählt. Auch wenn dadurch die genaue An-zahl durchgeführter Praxisprojekte offen bleibt, wird deutlich, dass die befragten Personen nahezu durchweg über Praxiserfahrungen verfügen. Daher kann davon ausgegangen wer-den, dass die Wissenschaftler in der Lage sind, die Rolle des Data Mining in der Unterneh-menspraxis zu beurteilen.
Tabelle 10: Projekte in Zusammenarbeit mit der Praxis
Bearbeiten Sie Pro-jekte in Zusammen-arbeit mit der Praxis?
Anzahl
sehr selten 3
gelegentlich 5
regelmäßig 10
häufig 2
ständig 1
keine Angabe 1

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 17
3.3.2 Bedeutung des Data Mining in der Unternehmenspraxis
Die Befragten bescheinigen dem Data Mining überwiegend eine mittlere Bedeutung in der Unternehmenspraxis (Tabelle 11). Mögliche Ursachen für diese Einschätzung sind die mangelnde Verfügbarkeit geeigneter, strukturierter Daten, die falsche Einschätzung der Anforderungen und Potenziale des Data Mining und Enttäuschungen über erzielte Resulta-te (siehe dazu auch die Begründungen zur Einschätzung der künftigen Bedeutung des Data Mining in Kapitel 4). Zudem ist davon auszugehen, dass das Data Mining nur für spezielle Aufgabenstellungen und -bereiche der Unternehmenspraxis besonders geeignet ist. Auch dies dürfte ein Grund für die geschätzte mittlere Bedeutung in der Unternehmenspraxis sein. Die vorliegende Befragung beantwortet jedoch nicht abschließend, für welche Praxis-anwendungen das Data Mining als besonders bedeutend angesehen wird. Diesbezüglich müsste eine gezielte Befragung durchgeführt werden bzw. kann auf die eingangs erwähn-ten Untersuchungen von [Hilb02; HiMW02a-c; Küpp99] zurückgegriffen werden.
Tabelle 11: Rolle des Data Mining in der Praxis
Die Rolle des Data Mining in der Praxis ist...
Anzahl
kaum wahrnehmbar 0
eher untergeordnet 4
mittel 14
bedeutend 4
sehr bedeutend 0
0
2
4
6
8
10
Absolutnicht
Eigentlichtnicht
Teils, teils ImGroßen
undGanzen ja
Absolut ja
ist nur eine Modeerscheinung
es wird mehr versprochen alsgehalten werden kann
kann mehr als Praktikerdenken
Bild 5: Aussagen zur Rolle des Data Mining in der Unternehmenspraxis
Zusätzlich sollten die Auskunftspersonen angeben, inwieweit sie ausgewählten Aussagen zur Praxistauglichkeit des Data Mining zustimmen (Bild 5). Auffällig ist, dass immerhin

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 18
acht Personen sowohl der Aussage, dass beim Data Mining mehr versprochen wird als gehalten werden kann, als auch der Aussage, dass Data Mining mehr kann als Praktiker denken, zustimmen (gekennzeichneter Bereich in Tabelle 12). Die Zustimmung zu beiden Aussagen stellt jedoch keinen Widerspruch dar, sondern legt eher die Vermutung nahe, dass zumindest aus Sicht dieser Personen bislang über das Data Mining ein falsches Bild vermittelt wurde. Diese Vermutung wird dadurch relativiert, dass sich die Wissenschaftler überwiegend nicht der Aussage anschlossen, dass es sich mit dem Data Mining um eine Modeerscheinung handelt (Bild 5). Dies deckt sich mit der überwiegend getroffenen Ein-schätzung, dass die Bedeutung des Data Mining entweder zunehmen oder zumindest gleich bleiben wird (Bild 6).
Tabelle 12: Ausgewählte Aussagen zur Rolle des Data Mining in der Unternehmenspraxis
Data Mining kann mehr als die meisten Praktiker denken.
Absolut nicht
Eigentlich nicht
Teils, teils Im Großen und Gan-zen ja
Absolut ja
Gesamt
Absolut nicht 1 1
Eigentlich nicht 1 1
Teils, teils 2 2 2 6
Im Großen und Ganzen ja 2 2 3 2 9
Es wird oft mehr ver-sprochen als gehalten werden kann.
Absolut ja 2 1 2 5
Gesamt 0 4 5 6 7 22
Die Bedeutung des Data Mining in der Praxis wird ...
0
2
4
6
8
10
Starkzurückgehen
Leicht abnehmen Gleich bleiben Leicht zunehmen Stark wachsen
Bild 6: Künftige Bedeutung des Data Mining in der Unternehmenspraxis

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 19
3.4 Nutzen und Bedeutung des Web Mining und des Text Mining
Sowohl in der Forschung als auch in der Unternehmenspraxis wird gegenwärtig der Nutzen des Web Mining und des Text Mining untersucht und diskutiert. Daher wurden die Wis-senschaftler zu ihrer Meinung zur aktuellen und zur künftigen Bedeutung dieser Speziali-sierungen bzw. Erweiterungen des Data Mining befragt.
Auffällig ist, dass sieben Personen die Frage, ob sie sich bereits einmal mit dem Text Mi-ning beschäftigt haben, verneinten (siehe Bild 7). Mit dem Web Mining haben sich dage-gen zwei Personen noch nicht beschäftigt.
Bei der Beurteilung des Nutzens des Web Mining fällt auf, dass immerhin acht Personen dem Web Mining eindeutig einen Nutzen bescheinigen, weitere sechs Personen sehen nur teilweise einen Nutzen. Demgegenüber schätzen sechs Personen den Nutzen als gering bis sehr gering ein. Bei der Beurteilung des Text Mining scheint – unabhängig von der großen Anzahl an Personen, die kein Urteil abgeben konnten – Unsicherheit zu herrschen, da zwar sieben Personen teilweise einen Nutzen darin sehen, sich aber jeweils vier Personen für einen eher geringen Nutzen bzw. für einen eher positiven Nutzen aussprechen (Bild 7).
0
2
4
6
8
10
Sehr geringerNutzen
Eher geringerNutzen
Teilweise vonNutzen
Durchausvon Nutzen
Von großemNutzen
noch nichtdamit
beschäftigt
Web MiningText Mining
Bild 7: Nutzen des Web Mining und des Text Mining
In Bezug auf die Bewertung der künftigen Bedeutung des Web Mining und des Text Mi-ning ist festzustellen, dass immerhin elf Befragte einen Nutzenzuwachs für das Web Mi-ning sehen, während sieben Personen eine gleich bleibende Bedeutung erwarten (Bild 8). Beim Text Mining sprechen sich ebenfalls die meisten Befragten für eine zunehmende bzw. gleich bleibende Bedeutung aus.
Vermutlich ist aus Sicht der Befragten die Forschung und Entwicklung beim Web Mining im Gegensatz zum Text Mining weiter fortgeschritten, sodass sich die Mehrheit eine Mei-nung zur aktuellen und künftigen Bedeutung des Web Mining gebildet hat, während ein

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 20
großer Teil noch keine Meinung zum Text Mining äußern konnte. Nach Einschätzung der Befragten wird die Bedeutung des Web Mining und des Text Mining in Zukunft deutlich bzw. leicht zunehmen. Dies legt die Vermutung nahe, dass die Befragten zurzeit noch nicht endgültig vom Nutzen des Web Mining und des Text Mining überzeugt sind, aber von der Weiterentwicklung der Methoden und von erfolgreichen Anwendungen ausgehen, sodass der Nutzen bzw. die Bedeutung wachsen wird.
0
2
4
6
8
10
Stark z
urückg
ehen
Leich
t abn
ehmen
Gleich b
leiben
Leich
t zune
hmen
Stark
wachs
en
noch
nicht
damit b
esch
äftigt feh
lend
Bedeutungdes WebMining wird ...
Bedeutungdes TextMining wird ...
Bild 8: Künftige Bedeutung des Web Mining und des Text Mining
4 Fazit und Ausblick
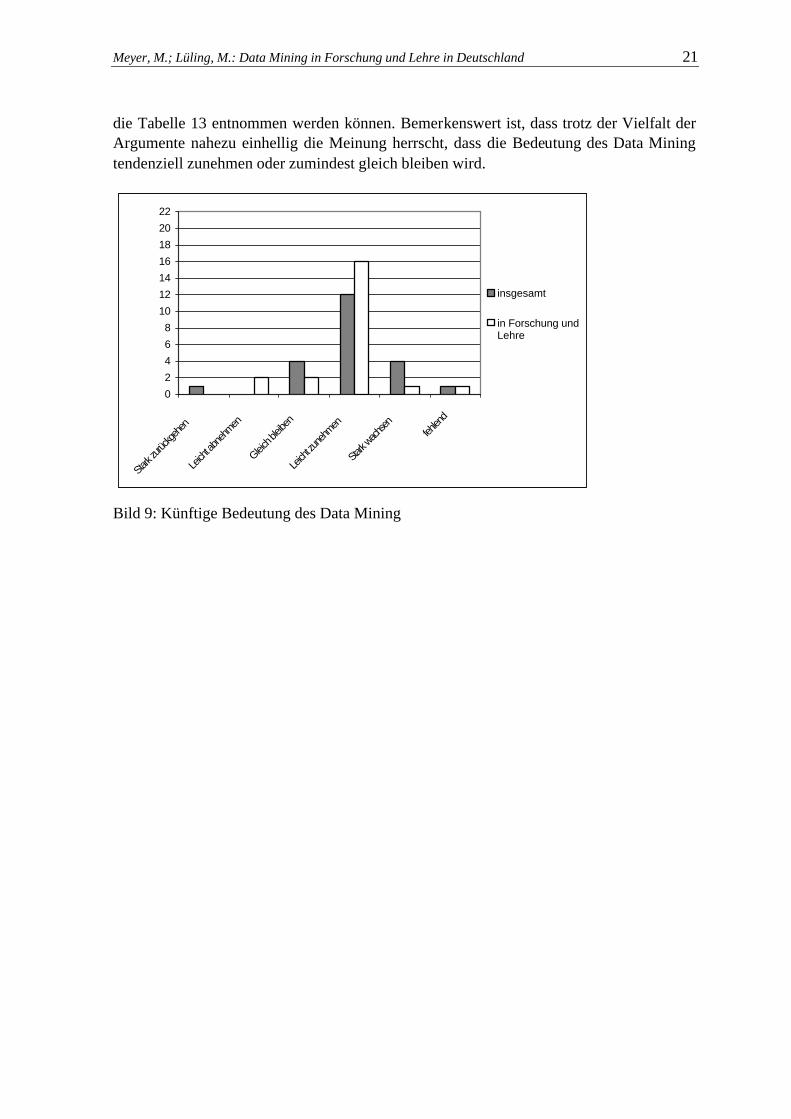
Die vorgestellten Ergebnisse zeigen, dass sich das Data Mining in Forschung und Lehre sowie in der Unternehmenspraxis etabliert (hat). In Anbetracht zahlreicher Forschungspro-jekte, Publikationen und Softwaretools, die in den 90er Jahren im Bereich des Data Mining zu verzeichnen waren, entstand zunächst der Eindruck einer „Anfangseuphorie“. Einschlä-gigen Publikationen (z. B. [BeLi00]) zufolge eröffneten sich völlig neue Möglichkeiten, um beispielsweise aus Kunden- und Zugriffsdaten im Web Einsichten in Verhaltensweisen und Wirkungszusammenhänge zu erhalten. Allerdings lassen sich auch mit Hilfe von Data Mining-Ansätzen nicht ohne Weiteres automatisch vollkommen neue Erkenntnisse gewin-nen [Deck03, 76ff.], sodass sich mittlerweile eine Zurückhaltung bei den Versprechungen und Erwartungen beobachten lässt. Dies bestätigen die vorliegenden Befragungsergebnis-se, insbesondere die Einschätzungen zum Web Mining und zum Text Mining. Auch die Aussagen der befragten Lehrstühle in Bezug auf die künftige Bedeutung des Data Mining insgesamt und in Bezug auf Forschung und Lehre sind eher zurückhaltend (siehe Bild 9). In einer offenen Frage wurden zusätzlich die Gründe für die jeweiligen Urteile abgefragt,
Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 21
die Tabelle 13 entnommen werden können. Bemerkenswert ist, dass trotz der Vielfalt der Argumente nahezu einhellig die Meinung herrscht, dass die Bedeutung des Data Mining tendenziell zunehmen oder zumindest gleich bleiben wird.
0
2
4
6
8
10
12
14
16
18
20
22
Stark
zurüc
kgeh
en
Leich
t abne
hmen
Gleich b
leiben
Leich
t zune
hmen
Stark
wachsen feh
lend
insgesamt
in Forschung undLehre
Bild 9: Künftige Bedeutung des Data Mining

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 22
Tabelle 13: Begründungen für die Einschätzung der künftigen Bedeutung des Data Mining
Die Bedeutung des Data Mining insgesamt wird ...
Begründung
stark zurückgehen Es fehlt ein gemeinsames Verständnis, was Data Mining eigentlich ist, deshalb bleibt Data Mining ein typischer Hype-Begriff.
gleich bleiben Wer es einsetzt, wird die Grenzen erkennen, wer noch nicht, wird sich viel versprechen. Die Wirkung hält sich die Waage.
gleich bleiben Data Mining kehrt wieder zurück zur Statistik.
gleich bleiben Die Euphorie sinkt, Arbeit an Etablierung in Softwaretools und Realisierung.
gleich bleiben Nichts wirklich neues, Verfahren sind mathematisch lange bekannt.
leicht zunehmen Hängt von der Anwendungsentwicklung ab, im Kontext wichtig.
leicht zunehmen Datenmengen steigen.
leicht zunehmen Versprechungen können durch verfügbare Produkte nicht gehalten werden, automatische Analyse nicht machbar, mehr Handarbeit, als die meisten Anwender glauben.
leicht zunehmen noch kein Flächendeckender Einsatz, Daten nicht in guter Form, mit zunehmender Eignung steigt Bedeutung sprunghaft an.
leicht zunehmen Menge der erfassten Daten steigt immer weiter an.
leicht zunehmen Expertenwissen nötig, Datenmengen, -wissen steigt.
leicht zunehmen Datenmengen steigen, Handhabung der Software wird besser.
leicht zunehmen Datenverarbeitungsentwicklung, leistungsfähige Algorithmen, gute Interpretierbarkeit.
leicht zunehmen Bedeutung kommt in Wellen, Konkretisierung in Spezialgebieten, Verfahrensforschung.
leicht zunehmen Optimierungszwang für Unternehmen aus der Kostensituation.
stark wachsen In vielen Anwendungsgebieten, insbesondere in der Wirtschaft, hat man das Potenzial noch nicht erkannt.
stark wachsen Entwicklung des Internets (Suchmaschinen), der Fernerkundung (z. B. Kontrollen durch Satelliten), Automatisierung in der Medizin, Prognosen in der Wirtschaft.
stark wachsen Datenmengen steigen, daher Bedarf nach effizienten Analyseinstrumenten größer.
stark wachsen Bessere Definition sorgt für Gesamtansicht, bessere Datenerfassung, Ausbau der Thematik.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 23
Literatur
[Adam01] Adamo, J.-M.: Data Mining for Association Rules and Sequential Patterns. Berlin 2001.
[AdZa96] Adriaans, P.; Zantinge, D.: Data Mining. Harlow 1996.
[AlSk99] Albers, S.; Skiera, B.: Regressionsanalyse. In : Hermann, A.; Homburg, C. (Hrsg.): Marktforschung: Methoden – Anwendungen – Praxisbeispiele. Wiesbaden 1999, S. 203-236.
[Bach02] Bacher, J.: Clusteranalyse: anwendungsorientierte Einführung. 2. Aufl. , Mün-chen 2002.
[BEPW00] Backhaus, K.; Erichson, B.; Plinke, W.; Weiber, R.: Multivariate Analyseme-thoden – Eine anwendungsorientierte Einführung. 9. Auflage, Berlin 2000.
[BeWe99] Bensberg, F.; Weiß, T.: Web Log Mining als Marktforschungsinstrument für das World Wide Web. In: Wirtschaftsinformatik 41 (1999) 5, S. 426-432.
[BeLi97] Berry, M. J. A.; Linoff, G.: Data Mining Techniques – For Marketing, Sales, and Customer Support. New York et al. 1997.
[BeLi00] Berry, M. J. A.; Linoff, G. S.: Mastering Data Mining. New York et al. 2000.
[BeST00] Berson, A.; Smith, S.; Thearling, K.: Building Data Mining Applications for CRM. New York et al. 2000.
[BeHa99] Berthold, M.; Hand, D. J. (eds.): Intelligent Data Analysis – An Introduction. Berlin et al. 1999.
[Boll96] Bollinger, T.: Assoziationsregeln – Analyse eines Data Mining Verfahrens. In: Zeitschrift Informatik Spektrum, 19 (1996), S. 257-261.
[BoAr01] Bonne, T.; Arminger, G.: Diskriminanzanalyse. In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K. D. (Hrsg.): Handbuch Data Mining im Marketing. Wiesba-den 2001, S. 193-239.
[BFOS84] Breiman, L.; Friedman, J. H.; Olshen, R. A.; Stone, C. J.: Classification and Regression Trees. Belmont, CA, 1984.
[CHSV97] Cabena, P.; Hadjnian, P.; Stadler, R.; Verhees, J.: Discovering Data Mining – From Concept to Implementation. Upper Saddle River 1997.
[ChHP00] Chatterjee, S.; Hadi, A. S.; Price, B.: Regression Analysis by Example. 3rd Edition, New York 2000.
[Deck03] Decker, R.: Data Mining und Datenexploration in der Betriebswirtschaft. In: Schwaiger, M.; Harhoff, D. (Hrsg.): Empirie und Betriebswirtschaft. Stuttgart 2003, S. 47-82.
[DöGS01] Dörre, J.; Gerstl, P.; Seiffert, R.: Text Mining. In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K. D. (Hrsg.): Handbuch Data Mining im Marketing. Wiesba-den 2001, S. 465-488.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 24
[EsSa00] Ester, M.; Sander, J.: Knowledge Discovery in Databases – Techniken und An-wendungen. Berlin et al. 2000.
[FiSV01] Fink, A.; Schneidereit, G.; Voß, S.: Grundlagen der Wirtschaftsinformatik. Hei-delberg 2001.
[FPSU96] Fayyad, U. M.; Piatetsky-Shapiro, G.; Smyth, P.; Uthurusamy, R. (eds.): Ad-vances in Knowledge Discovery and Data Mining. Menlo Park 1996.
[HaKa01] Han, J.; Kamber, M.: Data Mining – Concepts and Techniques. San Francisco et al. 2001.
[Hand02] Hand, D. J.: Modern Data Analysis: A Clash of Paradigms. In: Gaul, W.; Ritter, G. (eds.): Classification, Automation, and New Media. Berlin et al. 2002, S. 75-85.
[HaTF01] Hastie, T.; Tibshirani, R.; Friedman, J.: The elements of statistical learning: data mining, inference, and prediction. New York et al. 2001.
[Haus03] Hauschildt, J.: Zum Stellenwert der empirischen betriebswirtschaftlichen For-schung. In: Schwaiger, M.; Harhoff, D. (Hrsg.): Empirie und Betriebswirtschaft. Stutt-gart 2003, S. 3-24.
[HeHi01] Hettich, S.; Hippner, H.: Assoziationsanalyse. In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.): Handbuch Data Mining im Marketing. Wiesba-den 2001, S. 427-463.
[Hilb02] Hilbert, A.: Data Mining Projekte im unternehmerischen Umfeld: Eine empiri-sche Untersuchung deutscher Unternehmen. Arbeitspapiere zur mathematischen Wirt-schaftsforschung, Heft 183/2002, Universität Augsburg.
[HiMW02a] Hippner, H.; Merzenich, M.; Wilde, K. D.: Data Mining im Marketing: An-wendungspraxis in deutschen Unternehmen. In: Hippner, H.; Merzenich, M.; Wilde, K. D. (Hrsg.): Markstudie Data Mining. Düsseldorf 2002, S. 127-143.
[HiMW02b] Hippner, H.; Merzenich, M.; Wilde, K. D.: Web Mining in der Praxis. in: Hippner, H.; Merzenich, M.; Wilde, K. D. (Hrsg.): Markstudie Web Mining. Düssel-dorf 2002, S. 81-93.
[HiMW02c] Hippner, H.; Merzenich, M.; Wilde, K. D.: Web Mining in der Praxis – eine empirische Untersuchung. In: Hippner, H.; Merzenich, M.; Wilde, K. D. (Hrsg.): Handbuch Web Mining im Marketing. Wiesbaden 2002, S. 311-336.
[ItST01] Ittner, A.; Sieber, H.; Trautzsch, S.: Nichtlineare Entscheidungsbäume zur Optimierung von Direktmailingaktionen. In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.): Handbuch Data Mining im Marketing. Wiesbaden 2001, S. 707-723.
[Kraf99] Krafft, M.: Logistische Regression. In: Hermann, A.; Homburg, C. (Hrsg.): Marktforschung: Methoden – Anwendungen – Praxisbeispiele. Wiesbaden 1999, S. 237-264.
[Küpp99] Küppers, B.: Data Mining in der Praxis. Frankfurt u. a. 1999.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 25
[Küst01] Küsters, U.: Data Mining Methoden: Einordnung und Überblick. In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.): Handbuch Data Mining im Marketing. Wiesbaden 2001, S. 95-130.
[MeBe00] Meier, M.; Beckh, M.: Text Mining. In: Wirtschaftsinformatik 42 (2000) 2, S. 165-167.
[MeGr97] Meta Group: Data Mining: Trends, Technology, and Implementation Impera-tives. Meta Group Study 1997, http://www.hpcwire.com/dsstar/97/1104/100028.html, Abruf am: 24.07.2003.
[PHMZ00] Pei, J.; Han, J.; Mortazavi-Asl, B.; Zhu, H.: Mining Access Patterns Efficiently from Web Logs. In: Proc. Pacific-Asia Conference on Knowledge Discovery and Data Mining 2000.
[PoSi01] Poddig, T.; Sidorovitch, I.: Künstliche Neuronale Netze: Überblick, Einsatzmöglichkeiten und Anwendungsprobleme. In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K. D. (Hrsg.): Handbuch Data Mining im Marketing. Wiesbaden 2001, S. 363-402.
[Säub00] Säuberlich, F.: KDD und Data Mining als Hilfsmittel zur Entscheidungsunter-stützung. Frankfurt u. a. 2000.
[SäHu03] Säuberlich, F.; Huber, K.-P.: A Framework for Web Usage Mining Anonymous Logfile Data. In: Schwaiger, M.; Opitz, O. (eds.): Exploratory Data Analysis in Em-pirical Research. Berlin et al. 2003, S. 309-318.
[SrAg96] Srikant, R.; Agrawal, R.: Mining Sequential Patterns: Generalizations and Performance Improvements. In: Proc. of the Fifth Internationall Conference on Extending Database Technology (EDBT), Avignon, France 1996.
[StHa02] Stahlknecht, P.; Hasenkamp, U.: Einführung in die Wirtschaftsinformatik. Ber-lin 2000.
[VoGu01] Voß, S.; Gutenschwager, K.: Informationsmanagement. Berlin et al. 2001.
[WiFr00] Witten, I. H.; Frank, E.: Data Mining – Practical Machine Learning Tools and Techniques with Java Implementations. San Francisco 2000.
[Zaki01] Zaki, M. J.: SPADE: An Efficient Algorithm for Mining Frequent Sequences. In: Machine Learning, 42 (2001) 1/2, S. 31-60.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 26
Anhang I: Adressen der Softwareanbieter
(letzer Abruf am 26.08.2003)
- IBM Intelligent Miner http://www-5.ibm.com/de/entwicklung/produkte/im4d.html
- SAS Enterprise Miner http://www.sas.com/technologies/analytics/datamining/miner/
- SPSS http://www.spss.com/de/module/base.htm
- SPSS Clementine http://www.spss.com/de/module/clement.htm
- SPSS Answer Tree http://www.spss.com/de/module/answer.htm
- S-Plus http://www.s-plus.com/products/splus/default.asp
- S-Plus Insightful Miner http://www.s-plus.com/products/iminer/default.asp
- Prudsys Discoverer http://www.prudsys.de/Produkte/Softwarepakete/Discoverer/
- WEKA http://www.cs.waikato.ac.nz/~ml/weka/

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 27
Anhang II: Ankündigungsschreiben bzw. -E-Mail
Sehr geehrte/-r /Frau/Herr Professor ..................,
ich schreibe zurzeit an meiner Diplomarbeit zum Thema „Data Mining in Forschung und Lehre im deutschsprachigen Raum1“ am Lehrstuhl für empirische Forschung und quantitative Unter-nehmensplanung (Professor Manfred Schwaiger) an der LMU München unter der Betreuung von Dr. Matthias Meyer. In diesem Zusammenhang möchte ich mit ausgewiesenen Experten dieses Themengebietes ein Telefoninterview durchführen. Mit Hilfe dieser Studie sollen Aus-sagen zur zukünftigen Bedeutung des Data Mining gewonnen werden.
Hierbei bitte ich Sie um Ihre Unterstützung bei der Durchführung dieses Projektes. Die Fragen, die gestellt werden sollen, beziehen sich zum einen auf die Gestaltung der Lehre, zum anderen auf die gegenwärtige Forschung, sowie auf Ihre ganz persönliche Meinung nach der zukünfti-gen Entwicklung des Data Mining. Selbstverständlich wird Ihre Anonymität gewahrt. Das Te-lefoninterview wird ca. 20 Minuten in Anspruch nehmen.
Für Ihre Unterstützung wäre ich sehr dankbar. Ich werde versuchen, Sie in den nächsten Tagen telefonisch zu erreichen. Sollten Sie selbst verhindert sein oder aus anderen Gründen an der Be-fragung nicht teilnehmen können, wäre ich Ihnen dankbar, wenn Sie mir einen geeigneten An-sprechpartner nennen könnten. Terminwünsche oder inhaltliche Fragen nehme ich jederzeit gerne entgegen ([email protected]). Bei Interesse lasse ich Ihnen die Ergebnisse der Studie gerne zukommen.
Mit freundlichen Grüßen
Max Lüling
1 Anmerkung: Das Thema wurde im Laufe der Arbeit in „Data Mining in Forschung und Lehre in Deutsch-land“ geändert.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 28
Anhang III: Interviewleitfaden
Teil 1: Lehre
Zunächst möchte ich Ihnen einige Fragen zur Lehre im Bereich Data Mining an Ihrem
Lehrstuhl stellen.
1. Wurde an Ihrem Lehrstuhl in jüngerer Vergangenheit wenigstens eine Lehr-veranstaltung mit Data Mining bezogenem Inhalt angeboten?
ÿ ja ÿ nein
Falls ja => 2., falls nein => Ende Teil 1, weiter mit Teil 2A
2. Wann wurde an Ihrem Lehrstuhl die erste Data Mining bezogene Lehrveran-staltung angeboten?
.................................................................................................................................
3. Welcher Art sind die Data Mining bezogenen Veranstaltungen Ihres Lehr-stuhls? ÿ Data Mining-Vorlesung ÿ Data Mining verwandte Vorlesung
ÿ Übungsveranstaltung ÿ sonstige, nämlich ..........................................
4. Welche Methoden behandeln Sie in der Lehre schwerpunktmäßig? ÿ Entscheidungsbäume ÿ Assoziationsanalyse ÿ Regression
ÿ Clusteranalyse ÿ neuronale Netze ÿ Diskriminanzanalyse
ÿ Regelbasierte Verfahren ÿ ................................ ÿ ...................................
5. Welchen Stellenwert räumen Sie der Data Mining-Lehre an Ihrem Lehrstuhl ein? ÿ sehr gering ÿ eher gering ÿ mittel ÿ eher bedeutend ÿ sehr bedeutend
6. Wie viele Semesterwochenstunden umfassen alle Data Mining bezogenen Ver-anstaltungen Ihres Lehrstuhls zusammen?
.................................................................................................................................
7. In welchem Semesterrhythmus werden diese Veranstaltungen angeboten? ÿ jedes Semester ÿ alle zwei Semester ÿ alle drei Semester ÿ sonstiges, nämlich ...........................................................................................

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 29
8. Sind diese Veranstaltungen an Ihrem Lehrstuhl für alle Studenten Ihrer Fa-kultät belegbar oder handelt es sich um Spezialveranstaltungen? ÿ für Studenten aller Fakultäten ÿ nur für Fakultätsangehörige
ÿ nur für Fakultätsangehörige innerhalb eines bestimmten Schwerpunktes
ÿ ............................................
9. Wird bei Ihnen im Unterricht mit Software gearbeitet? ÿ ja ÿ nein
Falls ja => 10., falls nein => 11.
10. Welche Software verwenden Sie in der Lehre? ÿ Clementine (SPSS) ÿ Enterprise Miner (SAS) ÿ Darwin (Th.Mach.)
ÿ Intelligent Miner (IBM) ÿ S Plus ÿ Cart
ÿ Insightful Miner ÿ Dicoverer (PrudSys) ÿ ................................
Weiter mit 12.
11. Warum verwenden Sie keine Software im Unterricht? ÿ zu geringer Leistungsumfang ÿ zu hohe Kosten ÿ zu zeitaufwendig
ÿ sonstiges, nämlich ............................................................................................
12. In welchem Umfang wird bei Ihnen eine Bearbeitung konkreter Datensätze im Unterricht durchgeführt? ÿ gar nicht ÿ Zahlenbeispiele zum Verständnis
ÿ kleinere Datensätze als Beispiel
ÿ Datensätze mehrerer Tausend Daten zur Bearbeitung
Falls Letzteres => Ende Teil 1 und weiter mit Teil 2A, sonst => 13.
13. Warum führen Sie keine Bearbeitung größerer Datensätze im Unterricht durch? .................................................................................................................................

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 30
Teil 2: Forschung
Im zweiten Teil will ich Ihnen einige Fragen in Bezug auf die Forschung im Bereich Data
Mining, im besonderen an Ihrem Lehrstuhl, sowie über Ihre ganz persönliche Meinung
über eine mögliche zukünftige Rolle des Data Mining stellen.
A: Aktuell
Zuerst werde ich Sie über die momentane Rolle der Arbeit im Forschungsgebiet Data Mi-
ning, insbesondere an Ihrem Lehrstuhl, fragen.
1. Beschäftigt sich Ihr Lehrstuhl auch über die Lehre hinaus mit dem Themen-komplex Data Mining?
ÿ ja ÿ nein
Falls ja => 2., falls nein => Ende Teil 2A, weiter mit 2B
2. Wurden zu diesem Thema in den letzten zwei Jahren Diplomarbeiten oder so-gar Dissertationen an Ihrem Lehrstuhl durchgeführt?
ÿ ja ÿ nein
Falls ja => 3., falls nein => 4.
3. Wie viele Diplomarbeiten und wie viele Dissertationen wurden in den letzten zwei Jahren an Ihrem Lehrstuhl durchgeführt? .... Diplomarbeiten .... Dissertationen
4. Werden an Ihrem Lehrstuhl Publikationen zu diesem Thema erstellt? ÿ Gar nicht ÿ selten ÿ regelmäßig ÿ häufig ÿ durchgehend
5. Wie beurteilen Sie die Bedeutung der Data Mining-Forschung an Ihrem Lehr-stuhl? ÿ sehr gering ÿ eher gering ÿ mittel ÿ eher bedeutend ÿ sehr bedeutend
6. Wie beurteilen Sie die Bedeutung der Data Mining-Forschung in der gesamten Forschungslandschaft? ÿ sehr gering ÿ eher gering ÿ mittel ÿ eher bedeutend ÿ sehr bedeutend
7. Verwenden Sie Software in Ihrer Forschungsarbeit im Data Mining? ÿ ja ÿ nein
Falls ja => 8., falls nein => 9.

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 31
8. Welche Software verwenden Sie? ÿ Clementine (SPSS) ÿ Enterprise Miner (SAS) ÿ Darwin
ÿ Intelligent Miner (IBM) ÿ S Plus ÿ Cart
ÿ Insightful Miner ÿ Dicoverer (PrudSys) ÿ ................................ Weiter mit 10.
9. Warum verwenden Sie keine Software in der Data Mining-Forschung?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................
10. Welchen Methoden des Data Mining sprechen Sie eine besonders wichtige Rol-le in der Forschung Ihres Lehrstuhl zu? ÿ Entscheidungsbäume ÿ Assoziationsanalyse ÿ Regression
ÿ Clusteranalyse ÿ neuronale Netze ÿ Diskriminanzanalyse
ÿ Regelbasierte Verfahren ÿ ................................. ÿ .................................
11. Welche Anwendungsbereiche spielen Ihrer Meinung nach in der Forschung eine besonders wichtige Rolle?
.................................................................................................................................
.................................................................................................................................
12. Bearbeiten Sie Projekte in Zusammenarbeit mit der Praxis? ÿ sehr selten ÿ gelegentlich ÿ regelmäßig ÿ häufig ÿ ständig

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 32
Teil 2: Forschung
B: Zukünftig
Dann würde ich gerne Ihre ganz persönliche Meinung über eine mögliche zukünftige Rolle
des Data Mining erfragen.
1. Einerseits wird dem Data Mining in der Literatur vielfach ein Bedeutungszu-wachs für die Zukunft prognostiziert, andererseits wird gesagt, Data Mining wäre in seinen Möglichkeiten schon jetzt überschätzt. Wie ist Ihre Meinung dazu?
Die Bedeutung des Data Mining wird insgesamt...
ÿ stark zurückgehen ÿ leicht abnehmen ÿ in etwa gleich bleiben
ÿ leicht zunehmen ÿ stark wachsen
2. Aus welchem Grund sind Sie dieser Auffassung?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................
3. Zwar wird bereits an vielen Universitäten im Themenkomplex Data Mining gelehrt und geforscht, dennoch stellen diese zahlenmäßig bei weitem den ge-ringeren Teil aller Universitäten. Was denken Sie über die zukünftige Entwicklung der Bedeutung des Data Mi-ning an den Lehr- und Forschungseinrichtungen?
Die Bedeutung des Data Mining an den Lehr und Forschungseinrichtungen wird...
ÿ stark zurückgehen ÿ leicht abnehmen ÿ in etwa gleich bleiben
ÿ leicht zunehmen ÿ stark wachsen
4. Aus welchem Grund sind Sie dieser Auffassung?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 33
5. Können Sie sich Methoden des Data Mining vorstellen, denen in Zukunft eine bedeutend größere oder geringere Aufmerksamkeit zukommen wird?
ÿ ja ÿ nein
Falls ja => 6., falls nein => 7.
6. Welche Methoden werden Ihrer Meinung nach in Zukunft an Bedeutung ge-winnen oder verlieren und aus welchem Grund?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................
7. Können Sie sich Anwendungsbereiche (beispielsweise Medizin, Biologie, Wirt-schaftswissenschaften, Astronomie) vorstellen, in denen Data Mining in Zu-kunft eine bedeutend größere Rolle zukommt?
ÿ ja ÿ nein
Falls ja => 8., falls nein => Ende Teil 2 und weiter mit Teil 3
8. Welche Anwendungsbereiche könnten Sie sich vorstellen und aus welchem Grund?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................
9. Denken Sie dabei an bestimmte Fachgebiete (beispielsweise Marketing als Fachgebiet innerhalb der Wirtschaftswissenschaften, oder Pharmazie als Fachgebiet innerhalb der Medizin)?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 34
Teil 3: Data Mining in der Praxis, Web Mining und Text Mining
Im dritten und letzten Teil möchte ich Ihre Meinung über Web Mining und Text Mining
einholen, da diese Themen in der jüngeren Literatur besonders oft erwähnt werden. Außer-
dem würde ich gerne Ihre Meinung über die Rolle des Data Mining in der Praxis erfahren.
1. Haben Sie sich schon einmal mit Web Mining beschäftigt?
ÿ ja ÿ nein
Falls ja => 2., falls nein => 5.
2. Wie schätzen Sie den momentanen Nutzen des Web Mining ein? ÿ sehr geringer Nutzen ÿ eher geringer Nutzen ÿ teilweise von Nutzen
ÿ durchaus von Nutzen ÿ von großem Nutzen
3. Wie ist Ihre Meinung über die zukünftige Rolle des Web Mining? Die Bedeutung des Web Mining [in der Praxis] wird...
ÿ stark zurückgehen ÿ leicht abnehmen ÿ in etwa gleich bleiben
ÿ leicht zunehmen ÿ stark wachsen
4. Aus welchem Grund sind Sie dieser Auffassung?
.................................................................................................................................
.................................................................................................................................
.................................................................................................................................
Durch Text Mining werden die, typischerweise unstrukturierten, Daten eines Textes analy-
siert, um nützliche Informationen zu extrahieren.
5. Haben Sie sich schon einmal mit Text Mining beschäftigt? ÿ ja ÿ nein
Falls ja => 6., falls nein => 9.
6. Wie schätzen Sie den momentanen Nutzen des Text Mining ein? ÿ sehr geringer Nutzen ÿ eher geringer Nutzen ÿ teilweise von Nutzen
ÿ durchaus von Nutzen ÿ von großem Nutzen

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 35
7. Wie ist Ihre Meinung über die zukünftige Rolle des Text Mining? Die Bedeutung des Text Mining [in der Praxis] wird...
ÿ stark zurückgehen ÿ leicht abnehmen ÿ in etwa gleich bleiben
ÿ leicht zunehmen ÿ stark wachsen
8. Aus welchem Grund sind Sie dieser Auffassung? ..................................................................................................................................................................................................................................................................................................................................................................................................................
Zum Abschluss ist noch Ihre persönliche Meinung zum Data Mining in der Praxis gefragt.
9. Wie beurteilen Sie die momentane Rolle des Data Mining in der Praxis? Die Rolle des Data Mining in der Praxis ist...
ÿ kaum wahrnehmbar ÿ eher untergeordnet
ÿ keine unwichtige, aber auch keine wichtige
ÿ eine bedeutende ÿ eine sehr bedeutende
10. Über Data Mining in der Praxis gibt es sehr verschiedene Meinungen. Bitte äußern Sie Ihre Zustimmung oder Ablehnung zu den folgenden.
+ -
Data Mining in der Praxis ist nur eine Modeerscheinung. ÿÿÿÿÿ
Mit Data Mining wird oft mehr versprochen, als gehalten werden kann. ÿÿÿÿÿ
Data Mining kann mehr, als die meisten Praktiker denken. ÿÿÿÿÿ
stimme voll zu / stimme im Großen und Ganzen zu / teils, teils / stimme eigentlich nicht zu / stimme absolut nicht zu
11. Was denken Sie über die zukünftige Rolle des Data Mining in der Praxis? Die Bedeutung des Data Mining in der Praxis wird...
ÿ stark zurückgehen ÿ leicht abnehmen ÿ in etwa gleich bleiben
ÿ leicht zunehmen ÿ stark wachsen
Ende des Interviews

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 36
Anhang IV: Liste der angefragten Lehrstühle
Prof. Dr. Hans-Jürgen Appelrath, Informationssysteme, Universität Oldenburg Prof. Dr. Michael Bastian, Wirtschaftsinformatik und Operations Research, RWTH Aachen Prof. Dr. Ralph Bergmann, Daten und Wissensmanagement, Universität Hildesheim Prof. Dr. Wilfried Brauer, Theoretische Informatik u. Grundlagen der Künstlichen Intelligenz, TU München
Prof. Dr. Alejandro Buchmann, Datenbanken und verteilte Systeme, TU Darmstadt Prof. Dr. Joachim Buhmann, Mustererkennung und Bildverarbeitung, Universität Bonn Prof. Dr. Peter Chamoni, Wirtschaftsinformatik und Operation Research, Universität Duisburg Prof. Dr. Reinhold Decker, Betriebswirtschaftslehre und Marketing, Universität Bielefeld
Prof. Dr. Horst Degen, Statistik und Ökonometrie, Universität Düsseldorf Prof. Dr. Werner Dilger, Künstliche Intelligenz, TU Chemnitz Prof. Dr. Bernd Erichson, Marketing, Universität Magdeburg Prof. Dr. Roland Gabriel, Wirtschaftsinformatik, Universität Bochum
Prof. Dr. Wolfgang Gaul, Marketing, Marktforschung und Unternehmensplanung, TU Karlsruhe Prof. Dr. Ulrich Güntzer, Datenbanken und Informationssysteme, Universität Tübingen Prof. Dr. Wolfgang Härdle, Statistik und Ökonometrie, HU Berlin Prof. Dr. Matthias Jarke, Informationssysteme, RWTH Aachen
Prof. Dr. Daniel A. Keim, Datenbanken und Visualisierung, Universität Konstanz Prof. Dr. Ulrich Kockelkorn, Statistik und Wirtschaftsmathematik, TU Berlin Prof. Dr. Rudolph Kruse, Neuronale Netze und Fuzzy Systeme, Universität Magdeburg Prof. Dr. Ulrich Küsters, Statistik und quantitative Methoden der Wirtschaftswissenschaften, KU Eichstätt
Prof. Dr. Egbert Lehmann, Abteilung für Intelligente Systeme, Universität Stuttgart Prof. Dr. Hans-Joachim Lenz, Produktion, Wirtschaftsinformatik und Operations Research, FU Berlin Prof. Dr. Peter Lockemann, Systeme der Informationsverwaltung, TU Karlsruhe Prof. Dr. Wolfgang Menzel, Natürlichsprachige Systeme, Universität Hamburg
Prof. Dr. Katharina Morik, Künstliche Intelligenz, Universität Dortmund Prof. Dr. Werner Neubauer, Statistik und Mathematik, Universität Frankfurt Prof. Dr. Otto Opitz, Statistik und mathematische Wirtschaftstheorie, Universität Augsburg Prof. Dr. Günther Palm, Neuroinformatik, Universität Ulm
Prof. Dr. Frank Puppe, Künstliche Intelligenz und angewandte Informatik, Universität Würzburg Prof. Dr. Svetlozar Rachev, Ökonometrie und Statistik, TU Karlsruhe Prof. Dr. Luc de Raedt, Maschinelles Lernen und Natürlichsprachliche Systeme, Universität Freiburg Prof. Dr. Rolf-Dieter Reiss, Statistik und Data Mining, Universität Siegen
Prof. Dr. Ulrich Rendtel, Statistik und Mathematik, Universität Frankfurt Prof. Dr. Michael M. Richter, Künstliche Intelligenz: Wissensbasierte Systeme, Universität Kaiserslautern Prof. Dr. Helge Ritter, Neuroinformatik, Universität Bielefeld Prof. Dr. Johannes Ruhland, Wirtschaftsinformatik, Universität Jena
Prof. Dr. Torsten Schaub, Wissensverarbeitung und Informationssysteme, Universität Potsdam Prof. Dr. Manfred Schwaiger, Empirische Forschung und Unternehmensplanung, Universität München Prof. Dr. Myra Spiliopoulou, Wirtschaftsinformatik des E-Business, Handelshochschule Leipzig Prof. Dr. Rudi Studer, Wissensmanagement, TU Karlsruhe
Prof. Dr. Bernhard Thalheim, Datenbank- und Informationssysteme, BTU Cottbus Prof. Dr. Rainer Thome, Wirtschaftsinformatik, Universität Würzburg Prof. Dr. Alfred Ultsch, Neuroinformatik und Künstliche Intelligenz, Universität Marburg Prof. Dr. Antony Unwin, Rechnerorientierte Statistik und Datenanalyse, Universität Augsburg

Meyer, M.; Lüling, M.: Data Mining in Forschung und Lehre in Deutschland 37
Prof. Dr. Bernd Walter, Datenbanken und Informationssysteme, Universität Trier Prof. Dr. Gerhard Weikum, Database and Information Systems, Universität Saarbrücken
Prof. Dr. Klaus D. Wilde, Wirtschaftsinformatik, KU Eichstätt Prof. Dr. Manfred Wolff, Wirtschaftsinformatik, Universität Wuppertal Prof. Dr. Stefan Wrobel, Wissensentdeckung und maschinelles Lernen, Universität Bonn Prof. Dr. Fritz Wysotzki, Methoden der künstlichen Intelligenz, TU Berlin
Prof. Dr. Roberto Zicari, Datenbanken und Informationssysteme, Universität Frankfurt

Schriften zur Empirischen Forschung und Quantitativen Unternehmensplanung Heft 1/1999 Rennhak, Carsten H.: Die Wirkungsweise vergleichender Werbung unter
besonderer Berücksichtigung der rechtlichen Rahmenbedingungen in Deutschland
Heft 2/2000 Rennhak, Carsten H. / Kapfelsberger, Sonja: Eine empirische Studie zur Einschätzung vergleichender Werbung durch Werbeagenturen und werbetreibende Unternehmen in Deutschland
Heft 3/2001 Schwaiger, Manfred: Messung der Wirkung von Sponsoringaktivitäten im Kulturbereich – Zwischenbericht über ein Projekt im Auftrag des AKS / Arbeitskreis Kultursponsoring
Heft 4/2001 Zinnbauer, Markus / Bakay, Zoltàn: Preisdiskriminierung mittels internetbasierter Auktionen
Heft 5/2001 Meyer, Matthias, / Weingärtner, Stefan / Jahke, Thilo / Lieven, Oliver: Web Mining und Personalisierung in Echtzeit
Heft 6/2002 Meyer, Matthias / Müller, Verena / Heinold, Peter: Internes Marketing im Rahmen der Einführung von Wissensmanagement
Heft 7/2002 Meyer, Matthias / Brand, Florin: Kundenbewertung mit Methoden des Data Mining (Arbeitstitel)
Heft 8/2002 Schwaiger, Manfred: Die Wirkung des Kultursponsoring auf die Mitarbeiter-motivation – 2. Zwischenbericht über ein Projekt im Auftrag des AKS / Arbeitskreis Kultursponsoring
Heft 9/2002 Schwaiger, Manfred: Die Zufriedenheit mit dem Studium der Betriebswirtschaftslehre an der Ludwig-Maximilians- Universität München – eine empirische Untersuchung
Heft 10/2002 Eberl, Markus / Zinnbauer, Markus / Heim, Martina: Entwicklung eines Scoring-Tools zur Messung des Umsetzungsgrades von CRM-Aktivitäten – Design des Messinstrumentes und Ergebnisse der Erstmessung am Beispiel des deutschen Automobilmarktes –
Heft 11/2002 Festge, Fabian / Schwaiger, Manfred: Direktinvestitionen der deutschen Bau- und Baustoffmaschinenindustrie in China – eine Bestandsaufnahme
Heft 12/2002 Zinnbauer, Markus / Eberl, Markus: Bewertung von CRM-Aktivitäten aus Kundensicht
Heft 13/2002 Zinnbauer, Markus / Thiem, Alexander: e-Paper: Kundenanforderungen an das Zeitungsmedium von morgen – eine empirische Studie
Heft 14/2003 Bakay, Zoltàn / Zinnbauer, Markus: Der Einfluss von E-Commerce auf den Markenwert
Heft 15/2003 Meyer, Matthias / Lüling, Max: Data Mining in Forschung und Lehre in Deutschland
Heft 16/2003 Steiner-Kogrina, Anastasia / Schwaiger, Manfred: Eine empirische Untersuchung der Wirkung des Kultursponsorings auf die Bindung von Bankkunden

ISSN 1438-6925