cs152 / kubiatowicz lec13.1 3/17/03©ucb spring 2003 cs152 computer architecture and engineering...
Post on 20-Dec-2015
227 views
TRANSCRIPT

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.1
CS152Computer Architecture and Engineering
Lecture 13
Introduction to Pipelining:Datapath and Control
March 17, 2003
John Kubiatowicz (www.cs.berkeley.edu/~kubitron)
lecture slides: http://inst.eecs.berkeley.edu/~cs152/

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.2
Recap: Sequential Laundry
° Sequential laundry takes 6 hours for 4 loads° If they learned pipelining, how long would laundry take?
A
B
C
D
30 40 20 30 40 20 30 40 20 30 40 20
6 PM 7 8 9 10 11 Midnight
Task
Order
Time

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.3
Recap: Pipelining Lessons
° Pipelining doesn’t help latency of single task, it helps throughput of entire workload
° Pipeline rate limited by slowest pipeline stage
° Multiple tasks operating simultaneously using different resources
° Potential speedup = Number pipe stages
° Unbalanced lengths of pipe stages reduces speedup
° Time to “fill” pipeline and time to “drain” it reduces speedup
° Stall for Dependences
A
B
C
D
6 PM 7 8 9
Task
Order
Time
30 40 40 40 40 20

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.4
Recap: Ideal Pipelining
IF DCD EX MEM WB
IF DCD EX MEM WB
IF DCD EX MEM WB
IF DCD EX MEM WB
IF DCD EX MEM WB
Maximum Speedup Number of stages
Speedup Time for unpipelined operation
Time for longest stage
Example: 40ns data path, 5 stages, Longest stage is 10 ns, Speedup 4
Assume instructionsare completely independent!

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.5
° The Five Classic Components of a Computer
° Today’s Topics: • Recap last lecture/finish datapath
• Pipelined Control/ Do it yourself Pipelined Control
• Administrivia
• Hazards/Forwarding
• Exceptions
• Review MIPS R3000 pipeline
The Big Picture: Where are We Now?
Control
Datapath
Memory
Processor
Input
Output

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.6
Recap: Can pipelining get us into trouble?° Yes: Pipeline Hazards
• structural hazards: attempt to use the same resource two different ways at the same time
- E.g., combined washer/dryer would be a structural hazard or folder busy doing something else (watching TV)
• data hazards: attempt to use item before it is ready
- E.g., one sock of pair in dryer and one in washer; can’t fold until get sock from washer through dryer
- instruction depends on result of prior instruction still in the pipeline
• control hazards: attempt to make a decision before condition is evaulated
- E.g., washing football uniforms and need to get proper detergent level; need to see after dryer before next load in
- branch instructions
° Can always resolve hazards by waiting• pipeline control must detect the hazard
• take action (or delay action) to resolve hazards
3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.7
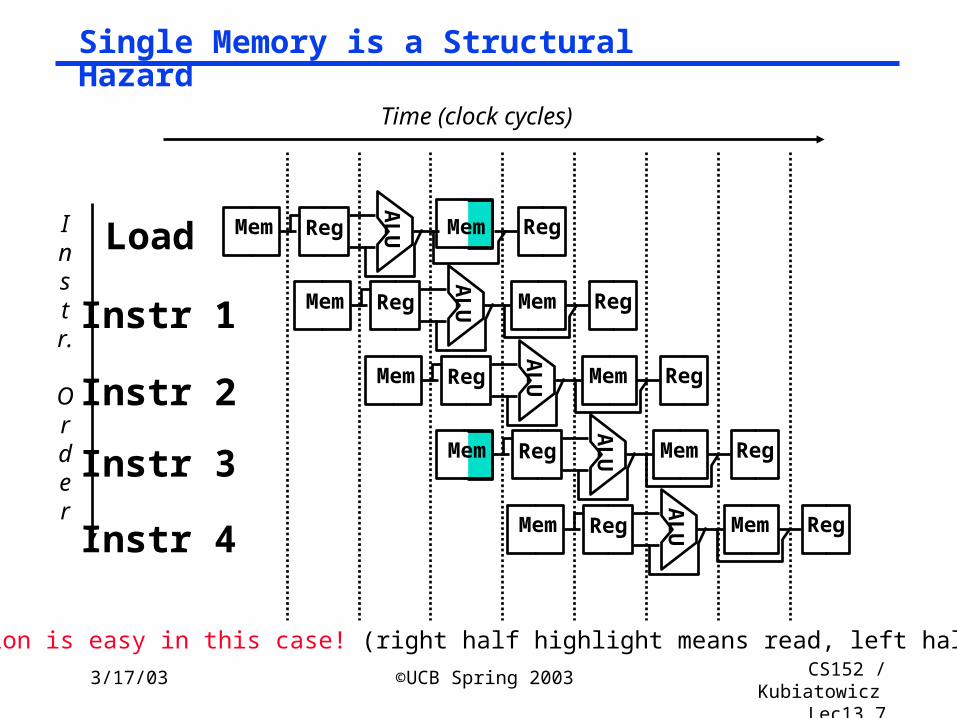
Mem
Single Memory is a Structural Hazard
Instr.
Order
Time (clock cycles)
Load
Instr 1
Instr 2
Instr 3
Instr 4A
LUMem Reg Mem Reg
AL
UMem Reg Mem Reg
AL
UMem Reg Mem RegA
LUReg Mem Reg
AL
UMem Reg Mem Reg
Detection is easy in this case! (right half highlight means read, left half write)

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.8
Structural Hazards limit performance
° Example: if 1.3 memory accesses per instruction and only one memory access per cycle then
• average CPI 1.3
• otherwise resource is more than 100% utilized

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.9
° Stall: wait until decision is clear° Impact: 2 lost cycles (i.e. 3 clock cycles per branch
instruction) => slow° Move decision to end of decode
• save 1 cycle per branch
Control Hazard Solution #1: Stall
Instr.
Order
Time (clock cycles)
Add
Beq
Load
AL
UMem Reg Mem Reg
AL
UMem Reg Mem RegA
LUReg Mem RegMem
Lostpotential

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.10
° Predict: guess one direction then back up if wrong° Impact: 0 lost cycles per branch instruction if right,
1 if wrong (right 50% of time)• Need to “Squash” and restart following instruction if wrong• Produce CPI on branch of (1 *.5 + 2 * .5) = 1.5• Total CPI might then be: 1.5 * .2 + 1 * .8 = 1.1 (20% branch)
° More dynamic scheme: history of 1 branch ( 90%)
Control Hazard Solution #2: Predict
Instr.
Order
Time (clock cycles)
Add
Beq
Load
AL
UMem Reg Mem Reg
AL
UMem Reg Mem Reg
Mem
AL
UReg Mem Reg

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.11
° Delayed Branch: Redefine branch behavior (takes place after next instruction)
° Impact: 0 clock cycles per branch instruction if can find instruction to put in “slot” ( 50% of time)
° As launch more instruction per clock cycle, less useful
Control Hazard Solution #3: Delayed Branch
Instr.
Order
Time (clock cycles)
Add
Beq
Misc
AL
UMem Reg Mem Reg
AL
UMem Reg Mem Reg
Mem
AL
UReg Mem Reg
Load Mem
AL
UReg Mem Reg

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.12
Data Hazard on r1: Read after write hazard (RAW)
add r1,r2,r3
sub r4,r1,r3
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.13
• Dependencies backwards in time are hazards
Instr.
Order
Time (clock cycles)
add r1,r2,r3
sub r4,r1,r3
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11
IF
ID/RF
EX MEM WBAL
UIm Reg Dm Reg
AL
UIm Reg Dm RegA
LUIm Reg Dm Reg
Im
AL
UReg Dm Reg
AL
UIm Reg Dm Reg
Data Hazard on r1: Read after write hazard (RAW)

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.14
• “Forward” result from one stage to another
• “or” OK if define read/write properly
Data Hazard Solution: Forwarding
Instr.
Order
Time (clock cycles)
add r1,r2,r3
sub r4,r1,r3
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11
IF
ID/RF
EX MEM WBAL
UIm Reg Dm Reg
AL
UIm Reg Dm RegA
LUIm Reg Dm Reg
Im
AL
UReg Dm Reg
AL
UIm Reg Dm Reg

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.15
Reg
• Dependencies backwards in time are hazards
• Can’t solve with forwarding: • Must delay/stall instruction dependent on loads
Forwarding (or Bypassing): What about Loads?
Time (clock cycles)
lw r1,0(r2)
sub r4,r1,r3
IF
ID/RF
EX MEM WBAL
UIm Reg Dm
AL
UIm Reg Dm Reg

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.16
Reg
• Dependencies backwards in time are hazards
• Can’t solve with forwarding: • Must delay/stall instruction dependent on loads
Forwarding (or Bypassing): What about Loads
Time (clock cycles)
lw r1,0(r2)
sub r4,r1,r3
IF
ID/RF
EX MEM WBAL
UIm Reg Dm
AL
UIm Reg Dm RegStall

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.17
Recap: Data Hazards
I-Fet ch DCD MemOpFetch OpFetch Exec Store
IFetch DCD ° ° °StructuralHazard
I-Fet ch DCD OpFetch Jump
IFetch DCD ° ° °
Control Hazard
IF DCD EX Mem WB
IF DCD OF Ex Mem
RAW (read after write) Data Hazard
WAW Data Hazard (write after write)
IF DCD OF Ex RS WAR Data Hazard (write after read)
IF DCD EX Mem WB
IF DCD EX Mem WB

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.18
Designing a Pipelined Processor
° Go back and examine your datapath and control diagram
° associated resources with states
° ensure that flows do not conflict, or figure out how to resolve conflicts
° assert control in appropriate stage

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.19
Control and Datapath: Split state diag into 5 pieces
IR <- Mem[PC]; PC <– PC+4;
A <- R[rs]; B<– R[rt]
S <– A + B;
R[rd] <– S;
S <– A + SX;
M <– Mem[S]
R[rd] <– M;
S <– A or ZX;
R[rt] <– S;
S <– A + SX;
Mem[S] <- B
If CondPC < PC+SX;
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
Equ
al
PC
Nex
t P
C
IR
Inst
. M
em
D
M

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.20
Pipelined Processor (almost) for slides
° What happens if we start a new instruction every cycle?
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
S
M
Reg
File
Equ
al
PC
Nex
t P
C
IR
Inst
. M
em
Valid
IRex
Dcd
Ctr
l
IRm
em
Ex
Ctr
l
IRw
b
Mem
Ctr
l
WB
Ctr
l
D

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.21
Pipelined Datapath (as in book); hard to read

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.22
Administrivia
° Midterm Results:• Avg: 70, StdDev= 9.5, Max=88, Low = 50
° Lab 4: How are you doing?• Control: Behavioral Verilog. Probably using CASE statement
• Data: Schematics on top of your components
• High-level simulation!
50 55 60 65 70 75 80 85 900
1
2
3
4
5Miderm 1 distribution
score
3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
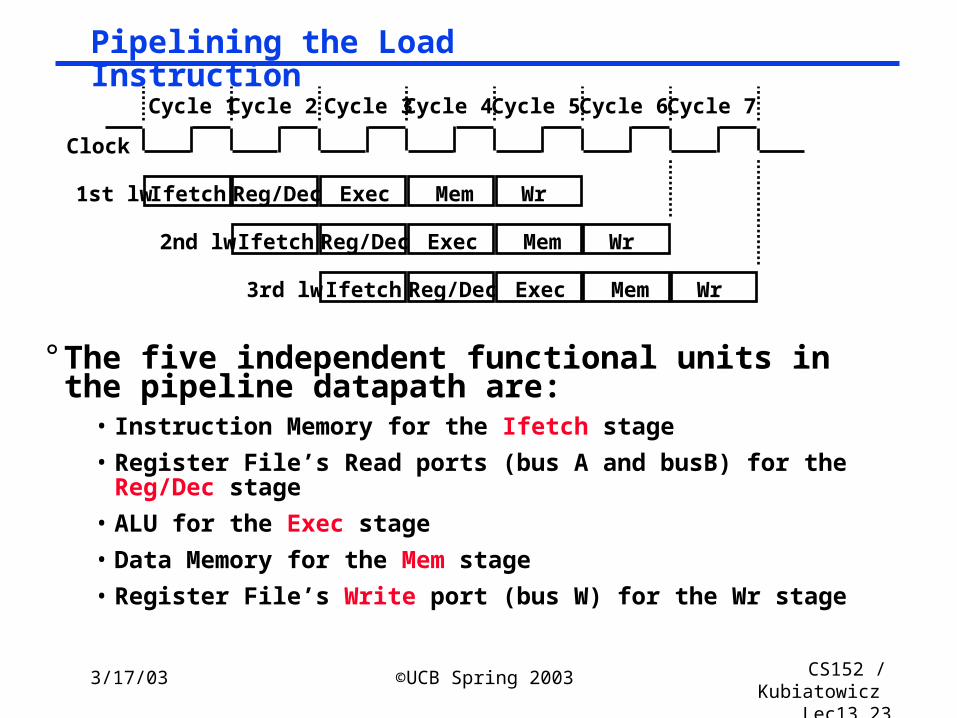
Lec13.23
Pipelining the Load Instruction
° The five independent functional units in the pipeline datapath are:
• Instruction Memory for the Ifetch stage
• Register File’s Read ports (bus A and busB) for the Reg/Dec stage
• ALU for the Exec stage
• Data Memory for the Mem stage
• Register File’s Write port (bus W) for the Wr stage
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7
Ifetch Reg/Dec Exec Mem Wr1st lw
Ifetch Reg/Dec Exec Mem Wr2nd lw
Ifetch Reg/Dec Exec Mem Wr3rd lw

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.24
The Four Stages of R-type
° Ifetch: Instruction Fetch• Fetch the instruction from the Instruction Memory
° Reg/Dec: Registers Fetch and Instruction Decode
° Exec: • ALU operates on the two register operands
• Update PC
° Wr: Write the ALU output back to the register file
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec WrR-type

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.25
Pipelining the R-type and Load Instruction
° We have pipeline conflict or structural hazard:• Two instructions try to write to the register file at the same time!
• Only one write port
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec Mem WrLoad
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec WrR-type
Ops! We have a problem!

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.26
Important Observation
° Each functional unit can only be used once per instruction
° Each functional unit must be used at the same stage for all instructions:
• Load uses Register File’s Write Port during its 5th stage
• R-type uses Register File’s Write Port during its 4th stage
Ifetch Reg/Dec Exec Mem WrLoad
1 2 3 4 5
Ifetch Reg/Dec Exec WrR-type
1 2 3 4
° 2 ways to solve this pipeline hazard.

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.27
Solution 1: Insert “Bubble” into the Pipeline
° Insert a “bubble” into the pipeline to prevent 2 writes at the same cycle
• The control logic can be complex.
• Lose instruction fetch and issue opportunity.
° No instruction is started in Cycle 6!
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec
Ifetch Reg/Dec Exec Mem WrLoad
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec WrR-type Pipeline
Bubble
Ifetch Reg/Dec Exec Wr

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.28
Solution 2: Delay R-type’s Write by One Cycle
° Delay R-type’s register write by one cycle:• Now R-type instructions also use Reg File’s write port at Stage 5
• Mem stage is a NOOP stage: nothing is being done.
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Ifetch Reg/Dec Mem WrR-type
Ifetch Reg/Dec Mem WrR-type
Ifetch Reg/Dec Exec Mem WrLoad
Ifetch Reg/Dec Mem WrR-type
Ifetch Reg/Dec Mem WrR-type
Ifetch Reg/Dec Exec WrR-type Mem
Exec
Exec
Exec
Exec
1 2 3 4 5

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.29
Modified Control & Datapath
IR <- Mem[PC]; PC <– PC+4;
A <- R[rs]; B<– R[rt]
S <– A + B;
R[rd] <– M;
S <– A + SX;
M <– Mem[S]
R[rd] <– M;
S <– A or ZX;
R[rt] <– M;
S <– A + SX;
Mem[S] <- B
if Cond PC < PC+SX;
M <– S
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
Equ
al
PC
Nex
t P
C
IR
Inst
. M
em
D
M
M <– S

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.30
The Four Stages of Store
° Ifetch: Instruction Fetch• Fetch the instruction from the Instruction Memory
° Reg/Dec: Registers Fetch and Instruction Decode
° Exec: Calculate the memory address
° Mem: Write the data into the Data Memory
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec MemStore Wr

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.31
The Three Stages of Beq
° Ifetch: Instruction Fetch• Fetch the instruction from the Instruction Memory
° Reg/Dec: • Registers Fetch and Instruction Decode
° Exec: • compares the two register operand,
• select correct branch target address
• latch into PC
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec MemBeq Wr

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.32
Control Diagram
IR <- Mem[PC]; PC < PC+4;
A <- R[rs]; B<– R[rt]
S <– A + B;
R[rd] <– S;
S <– A + SX;
M <– Mem[S]
R[rd] <– M;
S <– A or ZX;
R[rt] <– S;
S <– A + SX;
Mem[S] <- B
If Cond PC < PC+SX;
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
Equ
al
PC
Nex
t P
C
IR
Inst
. M
em
D
M <– S M <– S
M

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.33
Recall: Single cycle control!
DataOut
Clk
5
Rw Ra Rb
32 32-bitRegisters
Rd
AL
U
Clk
Data In
DataAddress
IdealData
Memory
Instruction
InstructionAddress
IdealInstruction
Memory
Clk
PC
5Rs
5Rt
32
323232
A
B
Nex
t A
dd
ress
Control
Datapath
Control Signals Conditions

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.34
Data Stationary Control
° The Main Control generates the control signals during Reg/Dec
• Control signals for Exec (ExtOp, ALUSrc, ...) are used 1 cycle later
• Control signals for Mem (MemWr Branch) are used 2 cycles later
• Control signals for Wr (MemtoReg MemWr) are used 3 cycles later
IF/ID
Register
ID/E
x Register
Ex/M
em R
egister
Mem
/Wr R
egister
Reg/Dec Exec Mem
ExtOp
ALUOp
RegDst
ALUSrc
Branch
MemWr
MemtoReg
RegWr
MainControl
ExtOp
ALUOp
RegDst
ALUSrc
MemtoReg
RegWr
MemtoReg
RegWr
MemtoReg
RegWr
Branch
MemWr
Branch
MemWr
Wr

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.35
Datapath + Data Stationary Control
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
PC
Nex
t P
C
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
rs rt
oprsrt
fun
im
exmewbrwv
mewbrwv
wbrwv

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.36
Let’s Try it Out
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
these addresses are octal

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.37
Start: Fetch 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
rs rt im
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
IF
PC
Nex
t P
C
10
=
n n n n

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.38
Fetch 14, Decode 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
2 rt im
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1, r
2(35
)
ID
IF
PC
Nex
t P
C
14
=
n n n

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.39
Fetch 20, Decode 14, Exec 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r2
B
SReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
2 rt 35
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
add
I r2,
r2,
3
ID
IF
EX
PC
Nex
t P
C
20
=
n n

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.40
Fetch 24, Decode 20, Exec 14, Mem 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r2
B
r2+
35
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
4 5 3
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
sub
r3,
r4,
r5
add
I r2,
r2,
3
ID
IF
EX
M
PC
Nex
t P
C
24
=
n

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.41
Fetch 30, Dcd 24, Ex 20, Mem 14, WB 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r4
r5
r2+
3
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M[r
2+35
]6 7
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
beq
r6,
r7
100
add
I r2
sub
r3
ID
IF
EX
M WB
PC
Nex
t P
C
30
=
Note Delayed Branch: always execute ori after beq

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.42
Fetch 100, Dcd 30, Ex 24, Mem 20, WB 14
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r6
r7
r2+
3
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=
M[r
2+35
]
9 xx
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
beq
add
I r2
sub
r3
r4-r
5
100
ori
r8,
r9
17
ID
IF
EX
M WB
PC
Nex
t P
C
100
=

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.43
Fetch 104, Dcd 100, Ex 30, Mem 24, WB 20
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15ID
EX
M WB
PC
Nex
t P
C
___
=
Fill it in yourself!
?

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.44
Fetch 110, Dcd 104, Ex 100, Mem 30, WB 24
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15EX
M WB
PC
Nex
t P
C
___
=
Fill it in yourself!
? ?
?
?
?

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.45
Fetch 114, Dcd 110, Ex 104, Mem 100, WB 30
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15M
WB
PC
Nex
t P
C
___
=
Fill it in yourself!
? ?
?
?
?
?

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.46
Pipelined Processor
° Separate control at each stage
° Stalls propagate backwards to freeze previous stages
° Bubbles in pipeline introduced by placing “Noops” into local stage, stall previous stages.
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
S
M
Reg
File
Equ
al
PC
Nex
t P
C
IR
Inst
. M
em
Valid
IRex
Dcd
Ctr
l
IRm
em
Ex
Ctr
l
IRw
b
Mem
Ctr
l
WB
Ctr
l
D
Stalls
Bubbles

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.47
Recap: Data Hazards
° Avoid some “by design”• eliminate WAR by always fetching operands early (DCD) in pipe
• eleminate WAW by doing all WBs in order (last stage, static)
° Detect and resolve remaining ones• stall or forward (if possible)
IF DCD EX Mem WB
IF DCD OF Ex Mem
RAW Data Hazard
WAW Data Hazard
IF DCD OF Ex RS WAR Data Hazard
IF DCD EX Mem WB
IF DCD EX Mem WB

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.48
Hazard Detection
° Suppose instruction i is about to be issued and a predecessor instruction j is in the instruction pipeline.
° A RAW hazard exists on register if Rregs( i ) Wregs( j )• Keep a record of pending writes (for inst's in the pipe) and compare
with operand regs of current instruction.
• When instruction issues, reserve its result register.
• When on operation completes, remove its write reservation.
° A WAW hazard exists on register if Wregs( i ) Wregs( j )
° A WAR hazard exists on register if Wregs( i ) Rregs( j )
Window on execution:Only pending instructions cancause exceptionsInst J
Inst INew Inst
InstructionMovement:

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.49
Record of Pending Writes In Pipeline Registers
° Current operand registers
° Pending writes
° hazard <=((rs == rwex) & regWex) OR
((rs == rwmem) & regWme) OR
((rs == rwwb) & regWwb) OR
((rt == rwex) & regWex) OR
((rt == rwmem) & regWme) OR
((rt == rwwb) & regWwb)
npc
I mem
Regs
B
alu
S
D mem
m
IAU
PC
Regs
A im op rwn
op rwn
op rwn
op rw rs rt

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.50
Resolve RAW by “forwarding” (or bypassing)
° Detect nearest valid write op operand register and forward into op latches, bypassing remainder of the pipe
• Increase muxes to add paths from pipeline registers
• Data Forwarding = Data Bypassing
npc
I mem
Regs
B
alu
S
D mem
m
IAU
PC
Regs
A im op rwn
op rwn
op rwn
op rw rs rtForward
mux

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.51
What about memory operations?
A B
op Rd Ra Rb
op Rd Ra Rb
Rd
to regfile
R
Rd
º If instructions are initiated in order and operations always occur in the same stage, there can be no hazards between memory operations!
º What does delaying WB on arithmetic operations cost? – cycles ? – hardware ?
º What about data dependence on loads? R1 <- R4 + R5 R2 <- Mem[ R2 + I ] R3 <- R2 + R1 “Delayed Loads”
º Can recognize this in decode stage and introduce bubble while stalling fetch stage (hint for lab 5!)
º Tricky situation: R1 <- Mem[ R2 + I ] Mem[R3+34] <- R1 Handle with bypass in memory stage!
D
Mem
T

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.52
Compiler Avoiding Load Stalls:
% loads stalling pipeline
0% 20% 40% 60% 80%
tex
spice
gcc
25%
14%
31%
65%
42%
54%
scheduled unscheduled

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.53
What about Interrupts, Traps, Faults?
° External Interrupts:• Allow pipeline to drain, Fill with NOPs
• Load PC with interrupt address
° Faults (within instruction, restartable)• Force trap instruction into IF
• disable writes till trap hits WB
• must save multiple PCs or PC + state
° Recall: Precise Exceptions State of the machine is preserved as if program executed up to the offending instruction
• All previous instructions completed
• Offending instruction and all following instructions act as if they have not even started
• Same system code will work on different implementations

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.54
Exception/Interrupts: Implementation questions
5 instructions, executing in 5 different pipeline stages!
° Who caused the interrupt?Stage Problem interrupts occurring
IF Page fault on instruction fetch; misaligned memory access; memory-protection violation
ID Undefined or illegal opcode
EX Arithmetic exception
MEM Page fault on data fetch; misaligned memory access; memory-protection violation; memory
error
° How do we stop the pipeline? How do we restart it?
° Do we interrupt immediately or wait?
° How do we sort all of this out to maintain preciseness?

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.55
Exception Handling
npc
I mem
Regs
B
alu
S
D mem
m
IAU
PClw $2,20($5)
Regs
A im op rwn
detect bad instruction address
detect bad instruction
detect overflow
detect bad data address
Allow exception to take effect
Excp
Excp
Excp
Excp

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.56
Another look at the exception problem
° Use pipeline to sort this out!• Pass exception status along with instruction.
• Keep track of PCs for every instruction in pipeline.
• Don’t act on exception until it reache WB stage
° Handle interrupts through “faulting noop” in IF stage° When instruction reaches end of MEM stage:
• Save PC EPC, Interrupt vector addr PC
• Turn all instructions in earlier stages into noops!
Pro
gram
Flo
w
Time
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
Data TLB
Bad Inst
Inst TLB fault
Overflow
3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
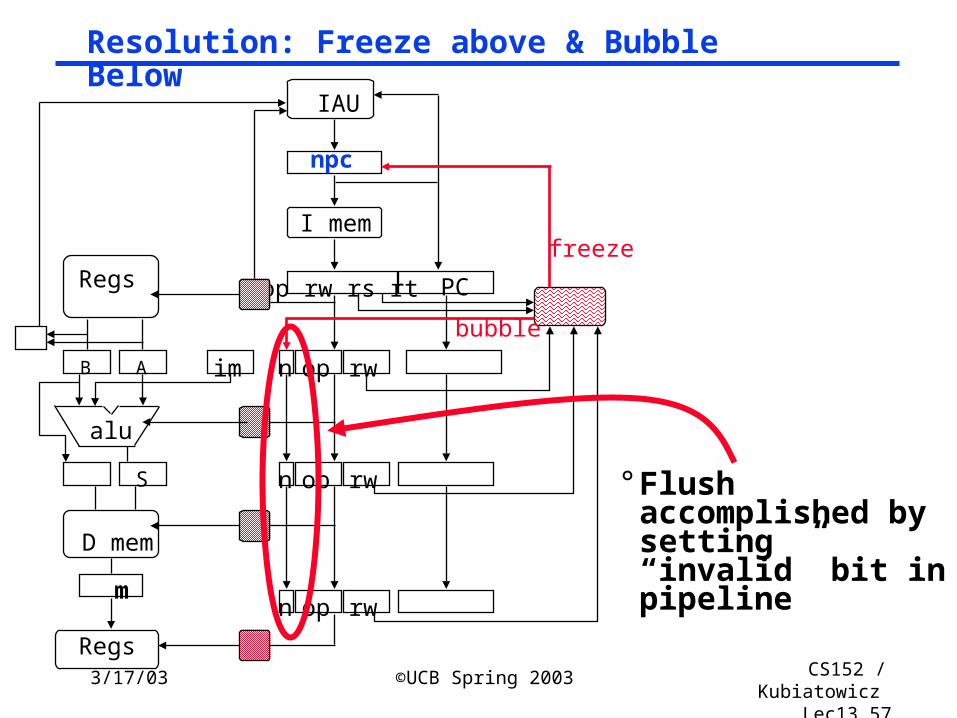
Lec13.57
Resolution: Freeze above & Bubble Below
° Flush accomplished by setting “invalid” bit in pipeline
npc
I mem
Regs
B
alu
S
D mem
m
IAU
PC
Regs
A im op rwn
op rwn
op rwn
op rw rs rt
bubble
freeze

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.58
FYI: MIPS R3000 clocking discipline
° 2-phase non-overlapping clocks
° Pipeline stage is two (level sensitive) latches
phi1
phi2
phi1 phi1phi2Edge-triggered

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.59
MIPS R3000 Instruction Pipeline
Inst Fetch DecodeReg. Read
ALU / E.A Memory Write Reg
TLB I-Cache RF Operation WB
E.A. TLB D-Cache
TLB
I-cache
RF
ALUALU
TLB
D-Cache
WB
Resource Usage
Write in phase 1, read in phase 2 => eliminates bypass from WB
3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
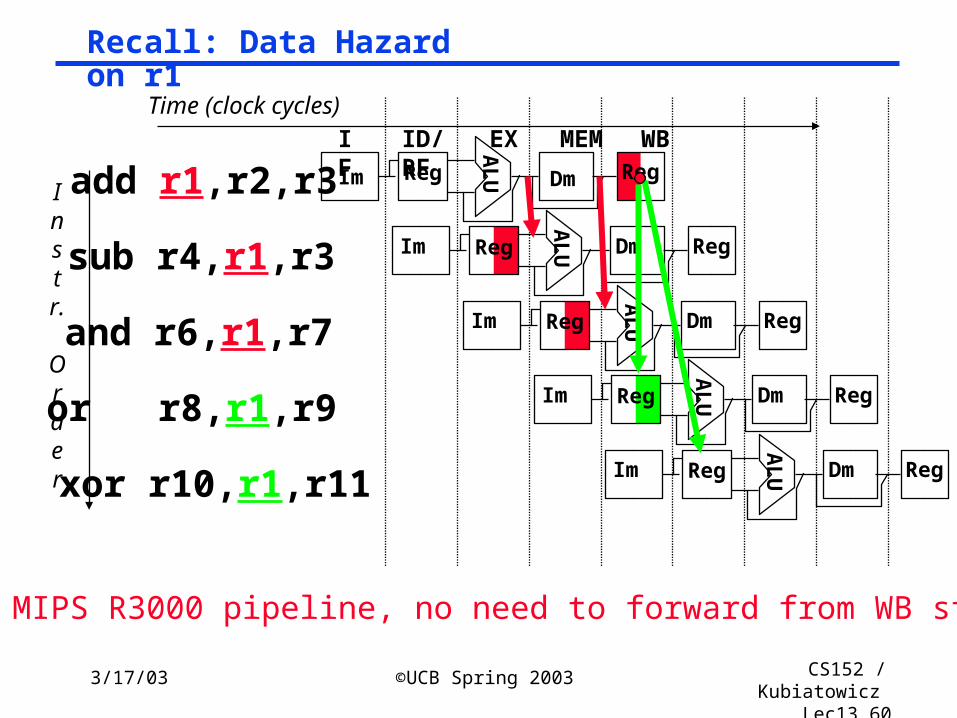
Lec13.60
Recall: Data Hazard on r1
Instr.
Order
Time (clock cycles)
add r1,r2,r3
sub r4,r1,r3
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11
IF
ID/RF
EX MEM WBAL
UIm Reg Dm Reg
AL
UIm Reg Dm Reg
AL
UIm Reg Dm Reg
Im
AL
UReg Dm Reg
AL
UIm Reg Dm Reg
With MIPS R3000 pipeline, no need to forward from WB stage

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.61
MIPS R3000 Multicycle Operations
Ex: Multiply, Divide, Cache Miss
Use control word of local stage to step through multicycle operation
Stall all stages above multicycle operation in the pipeline
Drain (bubble) stages below it
Alternatively, launch multiply/divide to autonomous unit, only stall pipe if attempt to get result before ready - This means stall mflo/mfhi in
decode stage if multiply/divide still executing
- Extra credit in Lab 5 does this
A B
op Rd Ra Rb
mul Rd Ra Rb
Rd
to regfile
R
T Rd

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.62
Is CPI = 1 for our pipeline?
° Remember that CPI is an “Average # cycles/inst
° CPI here is 1, since the average throughput is 1 instruction every cycle.
° What if there are stalls or multi-cycle execution?
° Usually CPI > 1. How close can we get to 1??
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB

3/17/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec13.63
Summary° What makes it easy
• all instructions are the same length
• just a few instruction formats
• memory operands appear only in loads and stores
° Hazards limit performance• Structural: need more HW resources
• Data: need forwarding, compiler scheduling
• Control: early evaluation & PC, delayed branch, prediction
° Data hazards must be handled carefully:• RAW data hazards handled by forwarding
• WAW and WAR hazards don’t exist in 5-stage pipeline
° MIPS I instruction set architecture made pipeline visible (delayed branch, delayed load)
° Exceptions in 5-stage pipeline recorded when theyoccur, but acted on only at WB (end of MEM) stage
• Must flush all previous instructions