cs 252 graduate computer architecture lecture 14: embedded computing krste asanovic electrical...
Post on 19-Dec-2015
220 views
TRANSCRIPT

CS 252 Graduate Computer Architecture
Lecture 14: Embedded Computing
Krste AsanovicElectrical Engineering and Computer Sciences
University of California, Berkeley
http://www.eecs.berkeley.edu/~krstehttp://inst.eecs.berkeley.edu/~cs252

11/1/2007 2
Recap: Multithreaded ProcessorsTi
me
(pro
cess
or
cycle
)Superscalar Fine-Grained Coarse-Grained Multiprocessing
SimultaneousMultithreading
Thread 1
Thread 2Thread 3Thread 4
Thread 5Idle slot

11/1/2007 3
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
Embedded Computing
QuickTime™ and aTIFF (Uncompressed) decompressorare needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.QuickTime™ and a
TIFF (Uncompressed) decompressorare needed to see this picture.
Robots
Automobiles
Set-top boxes
Games
Smart phones
Media Players
Sensor Nets
Routers
Cameras
Aircraft
Printers

11/1/2007 4
What is an Embedded Computer? A computer not used to run general-purpose
programs, but instead used as a component of a larger system. Usually, user does not change the computer program (except for manufacturer upgrades).
Example applications: Toasters Cellphone Digital camera (some have several processors) Games machines Set-top boxes (DVD players, personal video recorders, ...) Televisions Dishwashers Car (some have dozens of processors) Internet router (some have hundreds to thousands of processors) Cellphone basestation .... many more

11/1/2007 5
Early Embedded Computing Examples
• Intel 4004, 1971– developed for Busicom 141-PF
printing calculator
– Intel engineers decided that building a programmable computer would be simpler and more flexible than hard-wired digital logic
• MIT Whirlwind, 1946-51– Initially developed for real-time flight
simulator
– IBM later manufactured versions for SAGE air defence network, last used in 1983

11/1/2007 6
Reducing Cost of Transistors Drives Spread of Embedded Computing
• When individuals could afford a single transistor, the “killer application” was the transistor radio
• When individuals could afford thousands of transistors, the killer app was the personal computer
• Now individuals can soon afford thousands of processors, what will be the killer apps?
In 2007:
• human population growth per day >200,000
• cellphones sold per day >2,000,000

11/1/2007 7
What is different about embedded computers?
• Embedded processors usually optimized to perform one fixed task with software from system manufacturer
• General-purpose processors designed to run flexible, extensible software systems with code from third-party suppliers
– applications not known at design time
• Note, many products contain both embedded and general-purpose processors
– e.g., smartphone has embedded processors for radio baseband signal processing, and general-purpose processors to run third-party software applications

11/1/2007 8
Lesser emphasis on software portability in embedded applications• Embedded systems
– can usually recompile/rewrite source code for different ISA, and/or use assembler code for new application-specific instructions
– processor pipeline microarchitecture and memory capacity and hierarchy known to programmer/compiler
– mix of tasks known to writer of each task, usually static: uses custom run-time system
– each task usually “trusts” others, can run in same address space
• General-purpose systems– must have standard binary interface for third-party software
– compiler doesn’t know about this particular microarchitecture or memory capacity or hierarchy (compiled for general model)
– unknown mix of tasks, tasks dynamically added and deleted from mix: uses general-purpose operating system
– tasks written by various third-parties, mutually distrustful, need separate address spaces or protection domains

11/1/2007 9
Embedded application requirements & constraints
Real-time performance hard real-time: if deadline missed, system has failed (car brakes!) soft real-time: missing deadline degrades performance (skipping frames
on DVD playback)
Real-world I/O with multiple concurrent events sensor and actuators require continuous I/O (can’t batch process) non-deterministic concurrent interactions with outside world
Cost includes cost of supporting structures, particularly memory static code size very important (cost of ROM/RAM) often ship millions of copies (worth engineer time to optimize cost down)
Power expensive package and cooling affects cost, system size, weight, noise,
temperature

11/1/2007 10
What is Performance?
Latency (or response time, or execution time)– time to complete one task
Bandwidth (or throughput)– tasks completed per unit time

11/1/2007 11
Performance Measurement
Average rate: A > B > C
Worst-case rate: A < B < C
Processing Rate (Inputs/Second)
Inputs
ABC
Which is best for desktop performance? _______
Which is best for hard real-time task? _______
Average ratesWorst case rates

11/1/2007 12
Processors for real-time software
• Simpler pipelines and memory hierarchies make it easier (possible?) to determine the worst-case execution time (WCET) of a piece of code
– Would like to guarantee task completed by deadline
• Out-of-order execution, caches, prefetching, branch prediction, make it difficult to determine worst-case run time
– Have to pad WCET estimates for unlikely but possible cases, resulting in over-provisioning of processor (wastes resources)

11/1/2007 13
Power Measurement
Energy measured in Joules Power is rate of energy consumption
measured in Watts (Joules/second) Instantaneous power is Volts * Amps
Battery Capacity Measured in Joules 720 Joules/gram for Lithium-Ion batteries 1 instruction on Intel XScale processor takes ~1nJ
~1 billion executed instructions weigh ~1mg
V
I

11/1/2007 14
Power versus Energy
System A has higher peak power, but lower total energy System B has lower peak power, but higher total energy
Power
Time
Peak A
Peak B
Integrate power
curve to get energy

11/1/2007 15
Power Impacts on Computer System
• Energy consumed per task determines battery life– Second order effect is that higher current draws decrease effective battery
energy capacity (higher power also lowers battery life)
• Current draw causes IR drops in power supply voltage– Requires more power/ground pins to reduce resistance R
– Requires thick&wide on-chip metal wires or dedicated metal layers
• Switching current (dI/dt) causes inductive power supply voltage bounce LdI/dt– Requires more pins/shorter pins to reduce inductance L
– Requires on-chip/on-package decoupling capacitance to help bypass pins during switching transients
• Power dissipated as heat, higher temps reduce speed and reliability– Requires more expensive packaging and cooling systems
– Fan noise
– Laptop/handheld case temperature

11/1/2007 16
Power Dissipation in CMOS
Primary Components: Capacitor Charging (~85% of active power)
Energy is 1/2 CV2 per transition
Short-Circuit Current (~10% of active power) When both p and n transistors turn on during signal transition
Subthreshold Leakage (dominates when inactive) Transistors don’t turn off completely, getting worse with technology scaling For Intel Pentium-4/Prescott, around 60% of power is leakage Optimal setting for lowest total power is when leakage around 30-40%
Gate Leakage (becoming significant) Current leaks through gate of transistor
Diode Leakage (negligible) Parasitic source and drain diodes leak to substrate
CL
Diode Leakage Current
Subthreshold Leakage Current
Short-Circuit Current
CapacitorCharging Current
Gate Leakage Current

11/1/2007 17
Reducing Switching Power
Power activity * 1/2 CV2 * frequency
Reduce activity Reduce switched capacitance C Reduce supply voltage V Reduce frequency

11/1/2007 18
Reducing Activity
Clock Gating– don’t clock flip-flop if not needed
– avoids transitioning downstream logic
– Pentium-4 has hundreds of gated clocks
Global Clock
Gated Local Clock
Enable
D Q
Latch (transparent on clock low)
Bus Encodings– choose encodings that minimize transitions on average
(e.g., Gray code for address bus)
– compression schemes (move fewer bits)
Remove Glitches– balance logic paths to avoid glitches during settling
– use monotonic logic (domino)

11/1/2007 19
Reducing Switched Capacitance
Reduce switched capacitance C– Different logic styles (logic, pass transistor, dynamic)
– Careful transistor sizing
– Tighter layout
– Segmented structures
A B C
Bus
Shared bus driven by A or B when sending
values to C
Insert switch to isolate bus segment when B
sending to C
A B C

11/1/2007 20
Reducing Frequency
• Doesn’t save energy, just reduces rate at which it is consumed– Some saving in battery life from reduction in rate of discharge

11/1/2007 21
Reducing Supply Voltage
Quadratic savings in energy per transition – BIG effect
• Circuit speed is reduced
• Must lower clock frequency to maintain correctness

11/1/2007 22
Voltage Scaling for Reduced Energy
• Reducing supply voltage by 0.5 improves energy per transition to 0.25 of original
• Performance is reduced – need to use slower clock
• Can regain performance with parallel architecture
• Alternatively, can trade surplus performance for lower energy by reducing supply voltage until “just enough” performance
Dynamic Voltage Scaling

11/1/2007 23
“Just Enough” Performance
Save energy by reducing frequency and voltage to minimum necessary (usually done in O.S.)
t=0 t=deadlineTime
Fre
qu
ency
Run slower and just meet deadline
Run fast then stop

11/1/2007 24
Voltage Scaling on Transmeta Crusoe TM5400
Frequency
(MHz)
Relative Performance
(%)
Voltage
(V)
Relative Energy
(%)
Relative Power
(%)
700 100.0 1.65 100.0 100.0
600 85.7 1.60 94.0 80.6
500 71.4 1.50 82.6 59.0
400 57.1 1.40 72.0 41.4
300 42.9 1.25 57.4 24.6
200 28.6 1.10 44.4 12.7
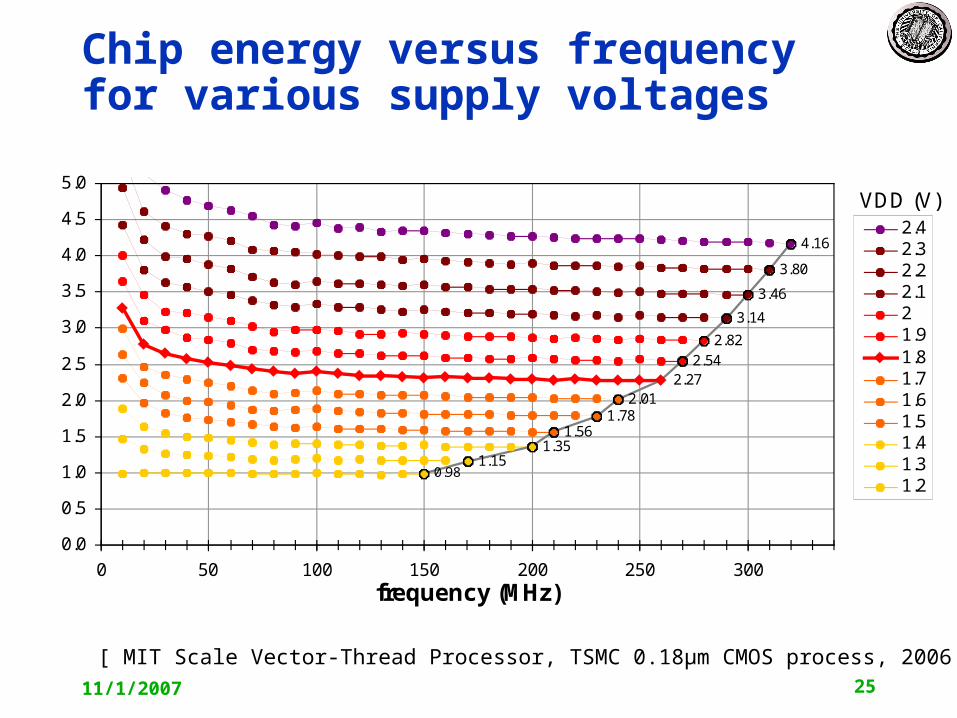
11/1/2007 25
4.16
3.80
3.46
3.14
2.822.54
2.272.01
1.781.56
1.351.15
0.98
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
0 50 100 150 200 250 300frequency (MHz)
energy per cycle (nJ)
2.42.32.22.121.91.81.71.61.51.41.31.2
VDD (V)
Chip energy versus frequency for various supply voltages
[ MIT Scale Vector-Thread Processor, TSMC 0.18µm CMOS process, 2006 ]

11/1/2007 26
4.16
3.80
3.46
3.14
2.822.54
2.272.01
1.781.56
1.351.15
0.98
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
0 50 100 150 200 250 300frequency (MHz)
energy per cycle (nJ)
2.42.32.22.121.91.81.71.61.51.41.31.2
VDD (V)
Chip energy versus frequency for various supply voltages
2x Reduction in Supply Voltage
4x Reduction in Energy
[ MIT Scale Vector-Thread Processor, TSMC 0.18µm CMOS process, 2006 ]

11/1/2007 27
Parallel Architectures Reduce Energy at Constant Throughput
• 8-bit adder/comparator– 40MHz at 5V, area = 530 k2
– Base power, Pref
• Two parallel interleaved adder/compare units– 20MHz at 2.9V, area = 1,800 k2 (3.4x)
– Power = 0.36 Pref
• One pipelined adder/compare unit– 40MHz at 2.9V, area = 690 k2 (1.3x)
– Power = 0.39 Pref
• Pipelined and parallel– 20MHz at 2.0V, area = 1,961 k2 (3.7x)
– Power = 0.2 Pref
Chandrakasan et. al. “Low-Power CMOS Digital Design”,IEEE JSSC 27(4), April 1992

11/1/2007 28
CS252 Administrivia
• Next project meetings Nov 12, 13, 15– Should have “interesting” results by then
– Only three weeks left after this to finish project
• Second midterm Tuesday Nov 20 in class– Focus on multiprocessor/multithreading issues
– We’ll assume you’ll have worked through practice questions

11/1/2007 29
Embedded memory hierarchies
• Scratchpad RAMs often used instead, or as well as, caches– RAM has predictable access latency, simplifies execution time analysis for
real-time applications
– RAM has lower energy/access (no tag access or comparison/multiplexing logic)
– RAM is cheaper than same size cache (no tags or cache logic)
• Typically no memory protection or translation– Code uses physical addresses
• Often embedded processors will not have direct access to off-chip memory (only on-chip RAM)
• Often no disk or secondary storage (but printers, iPods, digital cameras, sometimes have hard drives)
– No swapping or demand-paged virtual memory
– Often, flash EEPROM storage of application code, copied to system RAM/DRAM at boot

11/1/2007 30
Reconfigurable lockable caches
• Many embedded systems allow cache lines to be locked in cache to provide RAM-like predictable access
• Lock by set– E.g., in an 8KB direct-mapped cache with 32B lines (213/25=28=256
sets), lock half the sets, leaving a 4KB cache with 128 sets– Have to flush entire cache before changing locking by set
• Lock by way– E.g., in a 2-way cache, lock one way so it is never evicted– Can quickly change amount of cache that is locked (doesn’t
change cache index function)
• Can be used in both instruction and data caches– Lock instructions for interrupt handlers– Lock data used by handlers

11/1/2007 31
Code Size Cost of memory big factor in cost of many embedded
systems RISC core about same size as 16KB of SRAM
Intel Xscale (2001)
16.8mm2 in 180nm
Techniques to reduce code size: Variable length and complex
instructions Compressed Instructions
Compressed in memory then uncompressed in cache
compressed in cache
32KB 32KB

11/1/2007 32
Embedded Processor Architectures
• Wide variety of embedded architectures, but mostly based on combinations of techniques originally pioneered in supercomputers
– VLIW instruction issue
– SIMD/vector instructions
– Multithreading
• VLIW more popular here than in general-purpose computing
– Binary code compatibility not as important, recompile for new configuration OK
– Memory latencies are more predictable in embedded system hence more amenable to static scheduling
– Lower cost and power compared to out-of-order ILP core.

11/1/2007 33
System-on-a-Chip Environment
• Often, a single chip will contain multiple embedded cores with multiple private or shared memory banks, and multiple hardware accelerators for application-specific tasks
– Multiple dedicated memory banks provide high bandwidth, predictable access latency
– Hardware accelerators can be ~100x higher performance and/or lower power than software for certain tasks
• Off-chip I/O ports have autonomous data movement engines to move data in and out of on-chip memory banks
• Complex on-chip interconnect to connect cores, RAMs, accelerators, and I/O ports together

11/1/2007 34
Block Diagram of Cellphone SoC(TI OMAP 2420)

11/1/2007 35
“Classic” DSP Processors
X Mem Y Mem
Acc. AAcc. B
Multiply
ALU
Addr X
Addr Y
AReg 1AReg 0
AReg 7
Off-chip memory
AccA += (AR1++)*(AR2++)
Single 32-bit DSP instruction:
Equivalent to one multiply, three adds, and two loads in RISC ISA!

11/1/2007 36
TI C6x VLIW DSP
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
VLIW fetch of up to 8 operations/instruction
Dual symmetric ALU/Register clusters
(each 4-issue)

11/1/2007 37
TI C6x regfile/ALU datapath clusters
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
16b x 16b multiplies
32b arithmetic, 32b/40b shifts
32b/40b arithmetic
32b arithmetic, address generation

11/1/2007 38
Intel IXP Network Processors
RISC
Control
Processor
DRAM0
DRAM1
DRAM2
SRAM0
SRAM1
SRAM2
SRAM3
Network 10Gb/s
Buffer RAM
Buffer RAM
Buffer RAM
Buffer RAM
Buffer RAM
Buffer RAM
Buffer RAM
Register File
ALU
Scratchpad Data RAM
Microcode RAM
PC0PC1
PC7Eight threads
per microengine
MicroEngine 15
Register File
ALU
Scratchpad Data RAM
Microcode RAM
PC0PC1
PC7Eight threads
per microengine
MicroEngine 1
Register File
ALU
Scratchpad Data RAM
Microcode RAM
PC0PC1
PC7Eight threads
per microengine
MicroEngine 0
16 Multithreaded microengines

11/1/2007 39
Programming Embedded Computers
• Embedded applications usually involve many concurrent processes and handle multiple concurrent I/O streams
• Microcontrollers, DSPs, network processors, media processors usually have complex, non-orthogonal instruction sets with specialized instructions and special memory structures
– poor compiled code quality (% peak with compiled code)
– high static code efficiency
– high MIPS/$ and MIPS/W
– usually assembly-coded in critical routines
• Worth one engineer year in code development to save $1 on system that will ship 1,000,000 units
• Assembly coding easier than ASIC chip design
• But much room for improvement…

11/1/2007 40
Discussion: Memory consistency models• Discussion: Memory consistency models
– Tutorial on consistency models + Mark Hill’s position paper
– Conflict between simpler memory models and simpler/faster hardware