cpsc 810: machine learning design a learning system
TRANSCRIPT

CpSc 810: Machine Learning
Design a learning system

2
Copy Right Notice
Most slides in this presentation are adopted from slides of text book and various sources. The Copyright belong to the original authors. Thanks!

3
Well posed learning problems
General: given task T, performance measure P, design an algorithm which improves on T as measured by P with experience E
Checkers playing: T= play checkers, P = percentage of games won against opponent,E = playing practice against itself
Handwritten digit classification: T = map image to {0,...,9}, P = percent of correctly classified images, E = digits from the US postal office

4
Not very interesting learning problems
Task: learn to sort a given set of numbers... we can solve this exactly in short time without experience just knowing the definition of sorted lists
Task: learn the speed of a ball falling from the leaning tower of Pisa
... we know a (sufficiently precise and efficiently computable) physical model
ML: for tasks which cannot efficiently be modeled exactly, but experience is available

5
ill-posed learning problems
Task: make something reasonable with my e-mail
... no objective given, simply delete e-mail?
Task: learn to draw a curve through given points
... we will not be happy with every curve
Task: learn an arbitrary binary series... we cannot learn random series
ML: for tasks which are learnable, i.e. structure is available (inductive bias), well-defined target

6
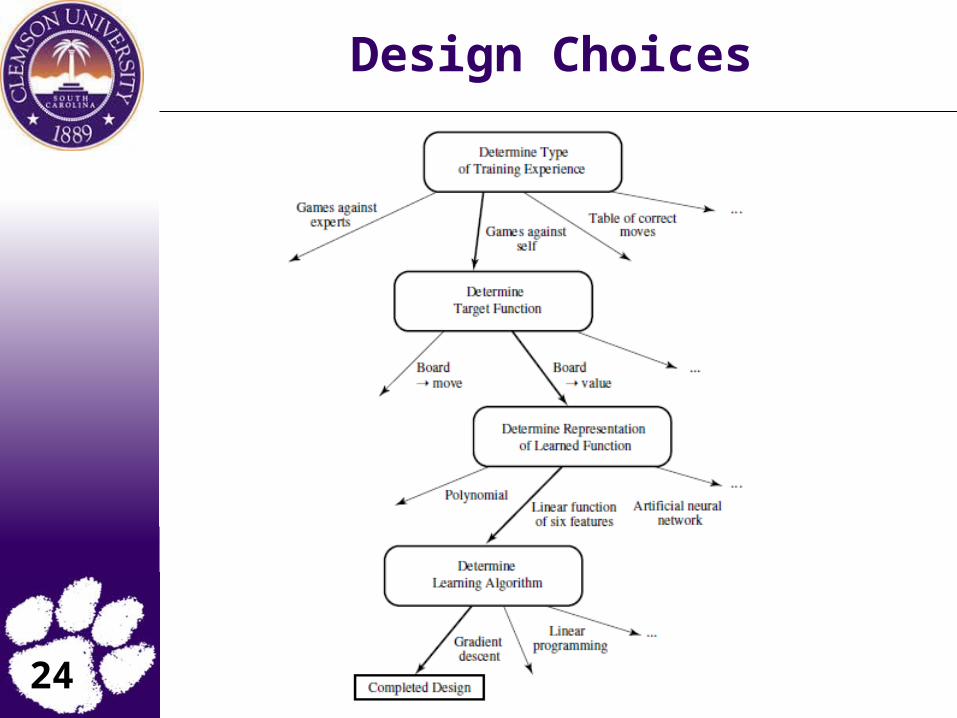
Design a learning system
Choose the training experience
Choose the target function
Choose a representation
Choose the parameter fitting algorithm
Evaluate the entire system... try to win the world-championship

7
Design a learning system
Choose training experience different learning paradigms: reinforcement
learning, supervised learning, unsupervised learning
different availability of data: online/offline examples

8
Design a learning system
Choose the target function make it as easy as possibly integrate all prior information learn only the aspects which you have to learn

9
Design a learning system
Choose a representation of the target function
representation of the input data:
integrate all relevant features make it easy
but not more than necessary curse of dimensionality
representation of the function:
different types of functions: classification, regression, density estimation, novelty detection, visualization, ...
different models: symbolic (logical rules, decision tree, prolog program, ...), subsymbolic (neural network, statistical estimator, ...), parameterized, lazy model, ...

10
Design a learning system
Estimate the parameters optimize some error/objective on the given data
linear/quadratic optimization
gradient descent
greedy algorithm, heuristics
discrete optimization methods such as genetic algorithms
statistical methods such as EM
mimic biological learning algorithms
Hebbian learning
imitation learning

11
Design a learning system
Evaluation does the system behave well in practicegeneralization to data not used for trainingmake sure the underlying regularity and not only the given (finite set of) data is learned

12
Learning to Play Checkers
T= play checkers,
P = percentage of games won against opponent
What is experience?
What exactly should be learned?
How shall it be represented?
What specific algorithm to learn it

13
Learning to Play Checkers: Choosing the Training Experience
Direct versus Indirect Experience Indirect Experience gives rise to the credit assignment problem and is thus more difficult
Teacher versus Learner Controlled Experience the teacher might provide training examples;
the learner might suggest interesting examples and ask the teacher for their outcome;
or the learner can be completely on its own with no access to correct outcomes
How Representative is the Experience? Is the training experience representative of the task the system will actually have to solve?
It is best if it is, but such a situation cannot systematically be achieved
Our task: train checker to play games against itself.

14
Learning to Play Checkers: Choosing the Target Function
Given a set of legal moves, we want to learn how to choose the best move
since the best move is not necessarily known, this is an optimization problem
ChooseMove: B --> M is called a Target Function ChooseMove, however, is difficult to learn. An easier and related target function to learn is V: B --> R, which assigns a numerical score to each board. The better the board, the higher the score.
Operational versus Non-Operational Description of a Target Function
An operational description must be given
Task: discovering an operational description of the ideal target function V.
Function Approximation The actual function can often not be learned and must be approximated

15
Learning to Play Checkers: Choosing the Target Function
A possible definition for Target Function VIf b is a final board state that is won, then V(b)=100If b is a final board state that is lost, then V(b)=-100If b is a final board state that is drawn, then V(b)=0If b is not a final state in the game, then V(b)=V(b’), where b’ is the best final board state that can be achieved starting from b and playing optimally until the end of game
This function give correct values, but is not operational!
Why?

16
Choosing a Representation for the Target Function
Expressiveness versus Training set sizeThe more expressive the representation of the target function, the closer to the “truth” we can get. However, the more expressive the representation, the more training examples are necessary to choose among the large number of “representable” possibilities.

17
Choosing a Representation for the Target Function
A simple representation: for a given board, its state is represented by the board features.
Bp(b): number of black pieces on board b.Rp(b): number of red pieces on board b.Bk(b): number of black kings on board b.Rk(b): number of red kings on board b.Bt(b) number of red pieces threatened by black (i.e., which can be taken on black’s next turn)Rt(b): number of black pieces threatened by red

18
Choosing a Representation for the Target Function
The target function will be calculated as a linear combination of the board features:
Where w0 through w6 are numerical coefficients, or weights, to be obtained by learning algorithm.
Weights w1 through w6 will determine the relative importance of different board features.
)()()()()()()(ˆ 6543210 bRtwbBtwbRkwbBkwbRpwbBpwwbV

19
Obtain Training Examples
A training example will contain a specific board state b and the training value Vtrain(b) for b.
<< Bp=3, Rp=0, Bk=1, Rk=0, Bt=0, Rt=0>, +100>This is a board state b in which black has won the game (Rp=0).
How to assign training values to the intermediate board states
One simple approach:
Where Successor(b) denotes the next board state following b.
))((ˆ)( bSuccessorVbVtrain

20
Training the System
Defining a criterion for success What is the error that needs to be minimized?One common approach is the squared error
Choose an algorithm capable of finding weights of a linear function that minimize that error
the Least Mean Square (LMS) training rule.
2
)(,))(ˆ)(( bVbVE train
examplestrainingbVb train

21
LMS Weigh Tuning Rule
Do repeatedly
Select a training example <b, Vtrain(b)> at random
Use the current weights to calculated
Compute error(b)
For each weight wi, update it as
Where xi is the value of the feature i and c is some small constant, e.g. 0.1, to moderate the rate of learning.
)(ˆ bV
)(ˆ)()( bVbVberror train
)(berrorxcww iii

22
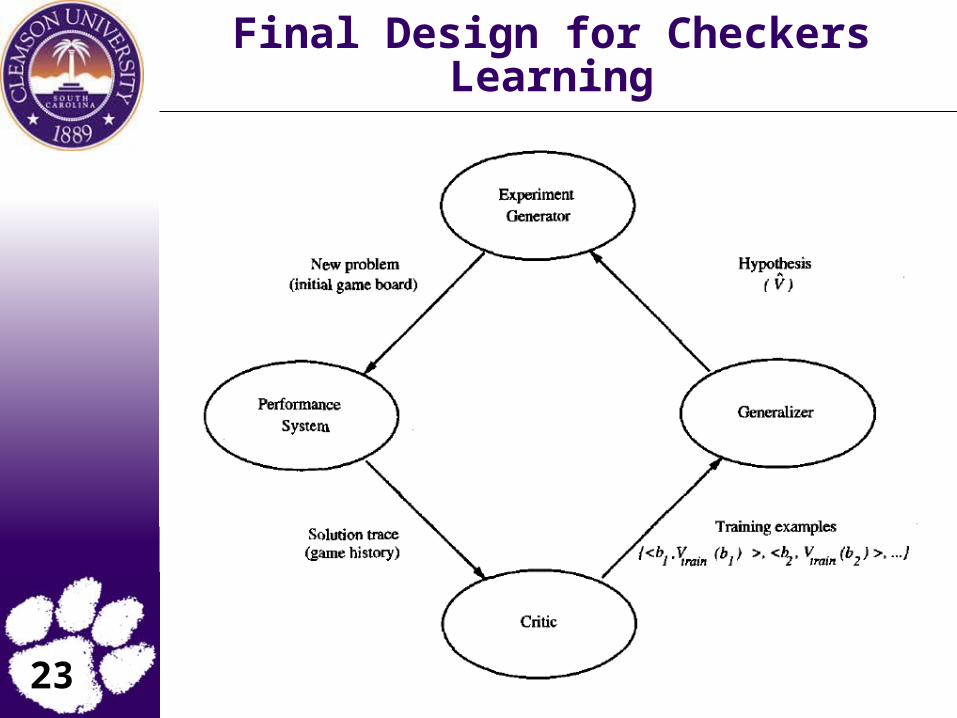
Final Design for Checkers Learning
The Performance System: Takes a new board as input and outputs a trace of the game it played against itself.
The Critic: Takes the trace of a game as input and outputs a set of training examples of the target function
The Generalizer: Takes training examples as input and outputs a hypothesis which estimates the target function. Good generalization to new cases is crucial.
The Experiment Generator: Takes the current hypothesis (currently learned function) as input and outputs a new problem (an initial board state) for the performance system to explore
23
Final Design for Checkers Learning
24
Design Choices

25
Issues in Machine Learning
What algorithms are available for learning? How well do they perform?
How much training data is sufficient to learn with high confidence?
When is it useful to use prior knowledge?
Are some training examples more useful than others?
What are best tasks for a system to learn?
What is the best way for a system to represent its knowledge?