course planning and evaluation - autenticação · course planning and evaluation by: pedro tomás...
TRANSCRIPT

COURSE PLANNING AND
EVALUATIONBy: Pedro Tomás
ADVANCED COMPUTER ARCHITECTURES
ARQUITECTURAS AVANÇADAS DE COMPUTADORES (AAC)

Advanced Computer Architectures, 2014
OUTLINE
Introduction to computer architectures
Course planning
Student evaluation method
2
Advanced Computer Architectures, 2014
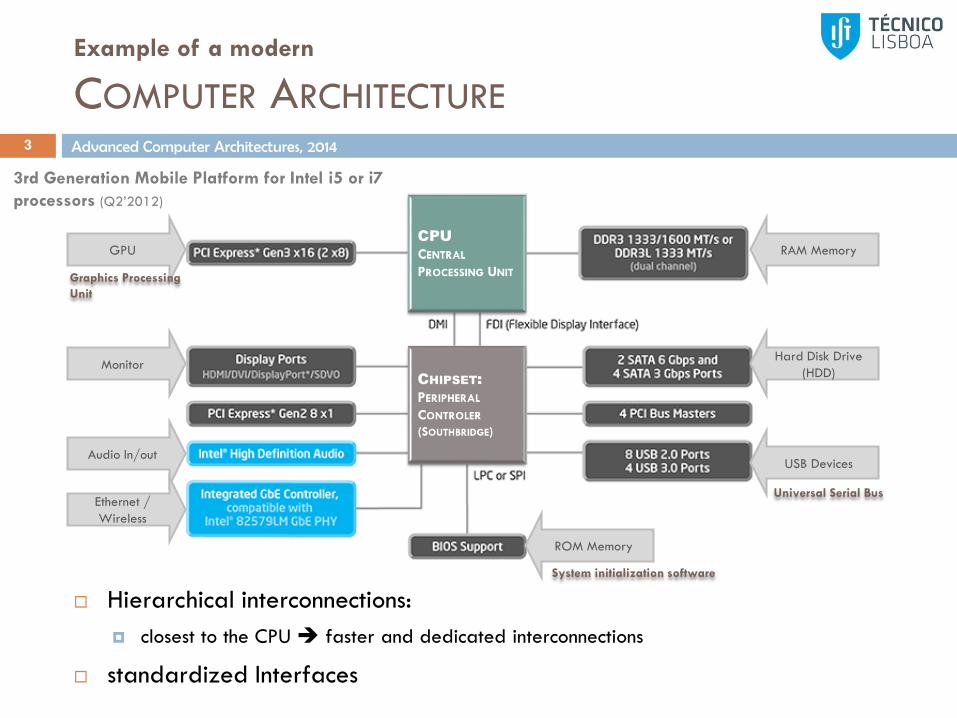
Example of a modern
COMPUTER ARCHITECTURE
3
Hierarchical interconnections:
closest to the CPU faster and dedicated interconnections
standardized Interfaces
Universal Serial Bus
Hard Disk Drive
(HDD)
USB Devices
Monitor
Audio In/out
Ethernet /
Wireless
GPU
Graphics Processing
Unit
RAM Memory
ROM Memory
System initialization software
3rd Generation Mobile Platform for Intel i5 or i7
processors (Q2’2012)
3

Advanced Computer Architectures, 2014
INTERCONNECTION HIERARCHY
4
Note: actual architecture
depends on the processor
model
Hierarchical interconnections:
closest to the CPU faster and dedicated interconnections
standardized Interfaces
Core#0
Core#0
L1-I
L1-DL2
L3:Last Level Cache (LLC)
PCIe Controller
Input/Output Controller Hub(Southbridge)
Graphics Core
Co
he
ren
ce R
ing
Inte
rco
nn
ect
Core#0
Core#1
L1-I
L1-DL2
Core#0
Core#2
L1-I
L1-DL2
Core#0
Core#3
L1-I
L1-DL2
4-core processor
Power and Clock Control
UnCore
Universal Serial Bus (USB) Controller
SATA Controller
PCI Controller
Audio Input/Output Controller
PCI Express Controller
Display Controller
Wireless/Ethernet Controller
Solid State Drive (SSD)or
Hard Disk Drive (HDD)
Additional GPUor
FPGA
GPUGraphics
Processing Unit
DDR3RAM Memory
CPUAdditional general purpose processor
(GPP)
CPU Chip
VGA/HDMI Display Interface
Quickpath Interconnect (QPI)
I/O Interface
DDR3 Memory Controller
Advanced Computer Architectures, 2014
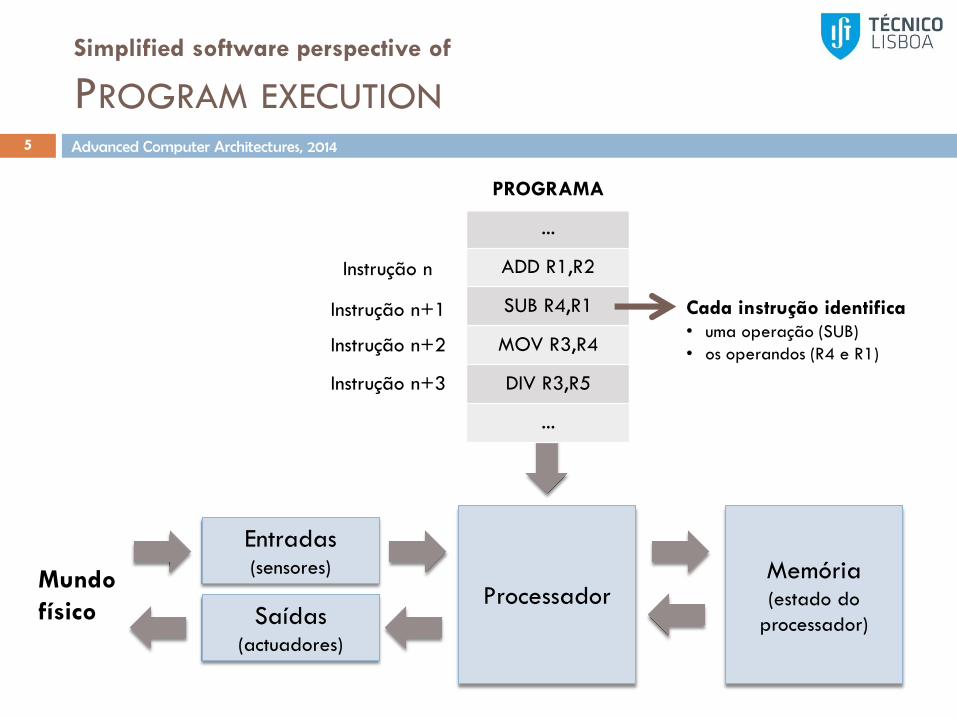
Simplified software perspective of
PROGRAM EXECUTION5
ProcessadorMemória(estado do
processador)
Entradas(sensores)
Saídas(actuadores)
Mundo
físico
PROGRAMA
...
ADD R1,R2
SUB R4,R1
MOV R3,R4
DIV R3,R5
...
Instrução n
Instrução n+1
Instrução n+2
Instrução n+3
Cada instrução identifica• uma operação (SUB)
• os operandos (R4 e R1)

Advanced Computer Architectures, 2014
Simplified hardware perspective of
PROGRAM EXECUTION6
Processador
STEP 1:The program counter is used to address the main memory and read (fetch) the instruction to execute
Memória(estado do
processador)
Program Counter (PC)
Instruction
Advanced Computer Architectures, 2014
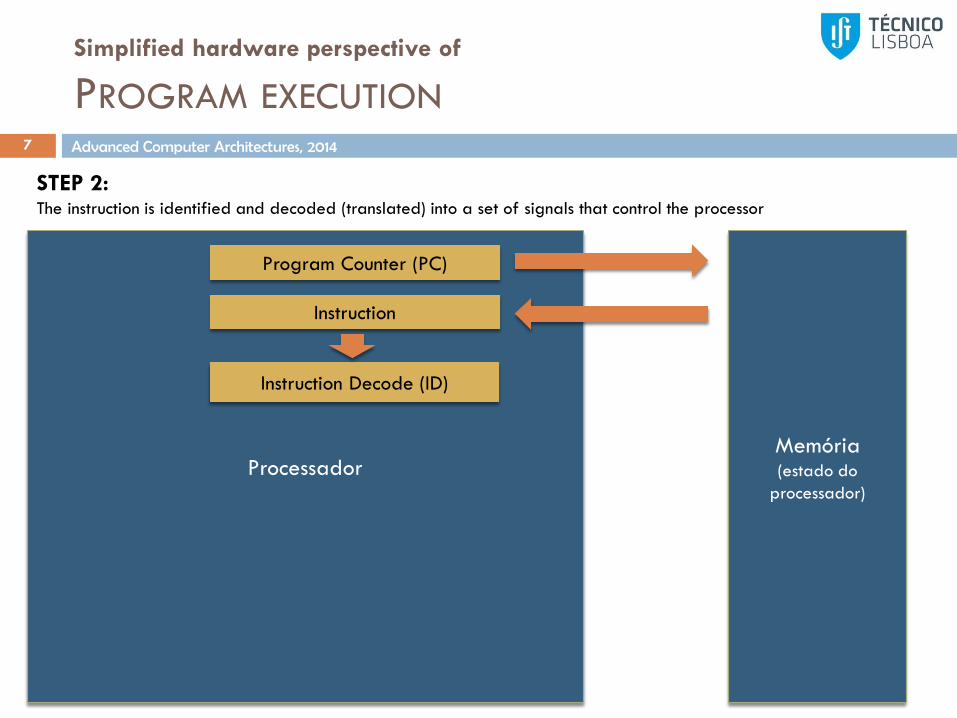
Simplified hardware perspective of
PROGRAM EXECUTION7
Processador
STEP 2:The instruction is identified and decoded (translated) into a set of signals that control the processor
Memória(estado do
processador)
Program Counter (PC)
Instruction
Instruction Decode (ID)

Advanced Computer Architectures, 2014
Simplified hardware perspective of
PROGRAM EXECUTION8
Processador
STEP 3:The instruction operands are fetch from either the registers or the memory
Memória(estado do
processador)
Program Counter (PC)
Instruction
Instruction Decode (ID)
Operand Fetch (OF)
R0
R1
R2
R3
R4
R5
R6
R7
R8
...

Advanced Computer Architectures, 2014
Simplified hardware perspective of
PROGRAM EXECUTION9
Processador
STEP 4:The instruction is executed in the Arithmetic and Logic Unit (ALU)
Memória(estado do
processador)
Program Counter (PC)
Instruction
Instruction Decode (ID)
Operand Fetch (OF)
R0
R1
R2
R3
R4
R5
R6
R7
R8
...
Execution (EX)

Advanced Computer Architectures, 2014
Simplified hardware perspective of
PROGRAM EXECUTION10
Processador
STEP 5:The results of the instruction (if any exist) are stored in either the registers or the memory
Memória(estado do
processador)
Program Counter (PC)
Instruction
Instruction Decode (ID)
Operand Fetch (OF)
R0
R1
R2
R3
R4
R5
R6
R7
R8
...
Execution (EX)
Write Back (WB)

Advanced Computer Architectures, 2014
Simplified hardware perspective of
PROGRAM EXECUTION11
Processador
STEP 6:Change the PC (typically by incrementing it) so that it points to the next instruction
Memória(estado do
processador)
Program Counter (PC)
Instruction
Instruction Decode (ID)
Operand Fetch (OF)
R0
R1
R2
R3
R4
R5
R6
R7
R8
...
Execution (EX)
Write Back (WB)
Increment PC

Advanced Computer Architectures, 2014
Usually addressed in
Computer Engineeringcourses
Hardware/Software view of a
COMPUTING ARCHITECTURE
Coordination between different abstraction levels
Convergence between technology and programming
Requires the project, analysis and evaluation of a processing system
Usually addressed in
Computer Sciencecourses
PR
OG
RA
MS
CIR
CU
ITS
12

Advanced Computer Architectures, 2014
COURSE TOPICS
13
Each instruction takes one
clock cycle to execute
The division of the processor in stages
allows increased clock frequency.
While each instructions now takes
multiple clock cycles to execute, the
instruction throughput is higher
The drawback is that multiple data and
control dependencies are generated.
These dependencies must be resolved
for correct operation
Static and dynamic techniques
allow to solve or mitigate these
dependencies
1. Data forwarding Processor
2. Static scheduling Compiler
3. Dynamic scheduling Processor
4. Branch prediction Processor
DpCtrl
3. solving data & control dependencies
Ctrl Dp Dp
DpCtrl
2. pipeline processor
Ctrl Dp DpDatapathControl
1. single cycle processor

Advanced Computer Architectures, 2014
COURSE TOPICS
14
Processors addressed in this course:
MIPS (main focus)
Latest generations of:
Intel x86 and x86_64 processors
ARM processors
Other dedicated processors, e.g., GPUs
To increase performance, modern
processors can simultaneously issue
(and execute) multiple instructions
at the same time
These processors are usually named
superscalar.
DpCtrl
4. multiple instruction issue
Ctrl Dp DpInstruction #0
Instruction #1
DpCtrl
3. solving data & control dependencies
Ctrl Dp Dp

Advanced Computer Architectures, 2014
COURSE TOPICS
15
Instruction Set Architectures (ISAs) addressed in this course:
RISC – Reduced Instruction Set Computer (e.g., MIPS and ARM)
CISC – Complex Instruction Set Computer (e.g., Intel Processors)
VLIW – Very Long Instruction Word (e.g., Digital Signal Processors)
Stream and Graphics Processors (e.g., GPUs)
Processors addressed in this course:
MIPS (main focus)
Latest generations of:
Intel x86 and x86_64 processors
ARM processors
Other dedicated processors, e.g., GPUs

Advanced Computer Architectures, 2014
COURSE TOPICS
16
Beyond the processing cores:
DpCtrl
5. accessing data
Ctrl Dp DpInstruction #0
Instruction #1
Memory
Inst
ruct
ion
s
Dat
a
Each processing core requires
access to the memory to fetch
instructions and read/write data.
Processor performance has been increasing faster than
memory performance.
Memory access is a bottleneck in overall performance.
Advanced Computer Architectures, 2014
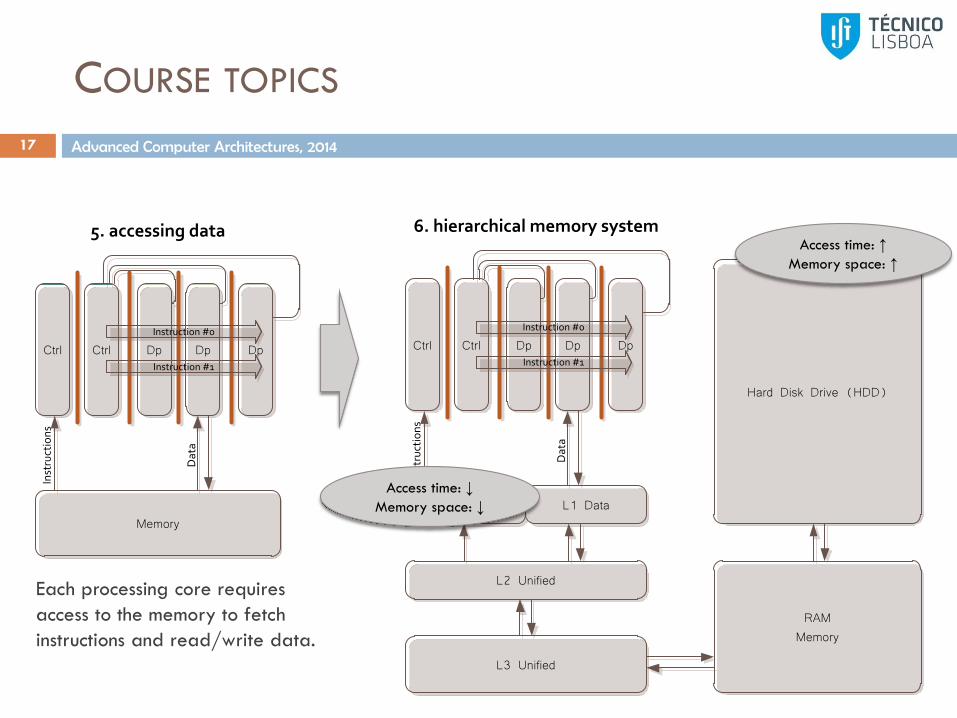
COURSE TOPICS
17
DpCtrl
5. accessing data
Ctrl Dp DpInstruction #0
Instruction #1
Memory
Inst
ruct
ion
s
Dat
a
Each processing core requires
access to the memory to fetch
instructions and read/write data.
DpCtrl
6. hierarchical memory system
Ctrl Dp DpInstruction #0
Instruction #1
L1 Instructions
Inst
ruct
ion
s
Dat
a
L1 Data
L2 Unified
L3 Unified
RAMMemory
Hard Disk Drive (HDD)
Access time: ↓
Memory space: ↓
Access time: ↑
Memory space: ↑

Advanced Computer Architectures, 2014
COURSE TOPICS
18
DpCtrl
7. virtual memory(support for multitasking)
Ctrl Dp DpInstruction #0
Instruction #1
Inst
ruct
ion
s
Dat
a
VirtualMemorySpace for
PROCESS A
VirtualMemorySpace for
PROCESS B
VirtualMemorySpace for
PROCESS C
To guarantee multitasking, one has to virtualize the memory
space for each process
The virtual memory decreases system performance
Caching of virtual memory addresses allows to significantly
reduce the performance penalty of virtual memory systems.

Advanced Computer Architectures, 2014
COURSE TOPICS
19
Can we still improve performance? Yes
Exploring fine-grained parallelism:
Vector processors
ISA extensions: MMX, SSE, SSE2, SSE3, AVX
Exploring coarse-grained parallelism
Multicore systems
Exploring thread-level parallelism
Stream and Graphics processors

Advanced Computer Architectures, 2014
COURSE ORGANIZATION:
THEORETICAL CLASSES20
RISC Processors
Pipelining
Identification of data and control dependencies
Solving data and control dependencies
Data forwarding paths in the processor
Compiler based techniques
VLIW processors
Dynamic Techniques: Scoreboard and Tomasulo
Branch Prediction
Superscalar and CISC processors
Midterm test 1 – April 15

Advanced Computer Architectures, 2014
COURSE ORGANIZATION:
THEORETICAL CLASSES21
Memory Hierarchy
Cache Memories
Virtual Memory
Cache + Virtual Memory
Parallel Architectures
Vector architectures
Single Instruction Multiple Data (SIMD) instructions
Multicore Systems
Graphics Processing UnitsMidterm test 2 – June 8
1st Exam date – June 8
2nd Exam date – June 27

Advanced Computer Architectures, 2014
COURSE ORGANIZATION:
LABORATORY22
1. Multi-cycle processor
2. Pipeline processor
3. Parallelism using one of the following choices:
a) Vector instructions (SIMD: Single Instruction Multiple Data)
b) Multicore processing (MIMD: Multiple Instruction Multiple Data)
c) General Purpose Processing on Graphics Processing Units (GPGPU)(not yet guaranteed)
Groups of 3 students, exceptionally 2.
Xilinx ISE (any version)
VHDL/Verilog, C/C++
Project 1 – March 14-18
Project 2 – April 28-May 1
Project 3 – May 23-27

Advanced Computer Architectures, 2014
COURSE ORGANIZATION:
EVALUATION23
Student grading is performed as follows:
Theoretical component (T)
𝑇 = max( 𝑚𝑖𝑑 𝑡𝑒𝑟𝑚 𝑡𝑒𝑠𝑡 𝑎𝑣𝑒𝑟𝑎𝑔𝑒 ; 𝑒𝑥𝑎𝑚 )
Practical component (P)
𝑃𝑎𝑣𝑔 = average( 𝑃𝑟𝑜𝑗𝑒𝑐𝑡 1 ; 𝑃𝑟𝑜𝑗𝑒𝑐𝑡 2 ; 𝑃𝑟𝑜𝑗𝑒𝑐𝑡 3 )
Grade subject to oral discussion at the end of the semester
Final Grade (F)
Grading is subject to completion of all project assignments (P1, P2 and P3); failure to deliver
any of the assignments results in a grade of N/A (not evaluated)
Minimum grade for either the theoretical (T) and the practical (P) components is 9.5
IF T≥9.5 and P≥9.5 then the final grade is computed as:
𝐹 = 0.5 × 𝑇 + 0.5 × 𝑃𝑎𝑣𝑔

Advanced Computer Architectures, 2014
COURSE ORGANIZATION:
BIBLIOGRAPHY24
RECOMMENDED:
Computer Architecture: A Quantitative Approach
5th edition, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
ALTERNATIVE/ADDITIONAL:
Computer Architecture: A Quantitative Approach
4th edition, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2006
Computer Organization and Design: the Hardware/Software Interface
4th edition, David A. Patterson and L. Hennessy, Morgan Kaufmann, 2008