cmsc 828g: introduction to statistical relational learning (srl) & link analysis (la) january...
Post on 21-Dec-2015
218 views
TRANSCRIPT

CMSC 828G: Introduction to Statistical Relational Learning (SRL)
& Link Analysis (LA)
January 28, 2005

Today’s Outline
• Brief Introduction to SRL• Student Introductions• Course Mechanics• Slightly Longer Introduction to SRL• SRL focus problem• Exercise: Create your own SRL focus
problem• Discussion of SRL focus problems• Survey• Resources

Statistical Relational Learning
• Traditional machine learning and data mining approaches assume:– A random sample of homogeneous objects from
single relation
• Real world data sets:– Multi-relational, heterogeneous and semi-
structured
• SRL– newly emerging research area at the intersection
of research in graphical models, social network and link analysis, hypertext and web mining, graph mining, relational learning and inductive logic programming

SRL Approaches
• Combine logical/combinatorial structures with statistical/probabilistic models
• Families of Approaches– Entity-relation Models + Graphical Models
(BNs/Markov Models)– First-Order Logic + Graphical Models– Functional Programming + Stochastic
Execution

Sample Domains
• web data (web)• bibliographic data (cite)• epidimiological data (epi)• communication data (comm)• customer networks (cust)• collaborative filtering problems (cf)• trust networks (trust)• biological data (bio)

Recent SRL Activities• Dagstuhl Workshop on Probabilistic, Logical and Relational
Learning - Towards a Synthesis (1/30/05-2/04/05)http://www.dagstuhl.de/05051/
• ICML 2004 workshop on Statistical Relational Learning and its Connections to Other Fieldshttp://www.cs.umd.edu/projects/srl2004/
• IJCAI 2003 workshop on Statistical Relational Learninghttp://kdl.cs.umass.edu/srl2003/
• AAAI 2000 workshop on Statistical Relational Learninghttp://robotics.stanford.edu/srl
• Several related workshops:– KDD MRDM workshops
• http://www-ai.ijs.si/SasoDzeroski/MRDM2004/• http://www-ai.ijs.si/SasoDzeroski/MRDM2003/• http://www-ai.ijs.si/SasoDzeroski/MRDM2002/
• Benjamin Taskar and I are working on an edited SRL collection, and ideally we will have access to draft chapters from this collection.

Other SRL Related Courses• Tom Dietterich’s course at OSU
http://web.engr.oregonstate.edu/~tgd/classes/539/
• David Page, Mark Craven and Jude Shavlik at UWischttp://www.biostat.wisc.edu/~page/838.html
• Pedro Domingo’s course at UWash
• Eric Mjolsness course at UCI on Probabilistic Knowledge Representationhttp://computableplant. ics.uci.edu/emj/classes/280_04/Syllabus%20ICS%20280%20v2.doc
• Stuart Russell’s course at Berkeley on Knowledge Representation and Reasoninghttp://www.cs.berkeley.edu/~russell/classes/cs289/f04/
• Joydeep Ghosh course at UT Austin on Advanced Topics in Data Mininghttp://www.lans.ece.utexas.edu/course/382v/05sp/
• Michael Littman course at Rutgers on Learned Representations in AI,http://www.cs.rutgers.edu/~mlittman/courses/lightai03/
• David Jensen and Andrew McCallums course at UMass on Computational Social Network Analysishttp://kdl.cs.umass.edu/courses/csna/

Goals of this Course
• ***NEW*** area• Understand Foundations
– Tutorials on Graphical Models, Logic, ILP, etc.
• Understand existing work– Wade through and make sense of Alphabet Soup of
approaches (PRMs, BLPs, SLPs, MLPs, RMNs, LBNs, etc.)
• Understand interesting theoretical issues– Collective classification, Open World assumptions, etc.
• Study interesting and practical applications of SRL
• Do a significant (publishable) project in this area.

Course Mechanics
• Course meets 10:00-12:45. – We will have 15 minute break, typically
11:15-11:30– Class will consists of:
• Tutorials• Exercises• Readings and Discussion
• Course URL– http://www.cs.umd.edu/class/spring2005/
cmsc828g/
• Course Wiki– … stay tuned….

Course Expectations• SRL Focus problem (15%)
– Each student will develop an SRL focus problem (10%) due Feb. 11• Describe a domain• Describe useful inference and learning tasks• (Ideally) Collect data
– Each student will ‘solve’ SRL focus problem using at least two different SRL techniques (5%)
• Lead at least one class discussion (5%)– Each student will sign up to lead the discussion of one (or more depending on
class size) class discussion topic.• Class Participation (15%)
– Each week each student must turn in a short discussion of the readings by noon Thursday before class. The discussion leader should review the others responses, and use them to structure the class discussion.
• Class Project (50%)– Each student is expected to do a research project for the course.
• Feb. 18, Project Proposals Due• Mar. 18, Project Progress Report #1 due• Apr. 22, Project Progress Report #2 due• May 6, Project Presentations• May 12, Project Write-up Due
• Class Exercises (10%)– Throughout the course, there will be small class exercises
• Reviewer (5%)– Each student is expected to do 2 one-page reviews of submitted SRL Book
Chapters (Students reviewers will be acknowledged in text)

Introductions
• Name• Where you are originally from• Research Interest/Advisor if you have
one

SRL Intro Part II
An Example: Probabilistic Relational Models

Bayesian Networks: Problem
• Bayesian nets use propositional representation• Real world has objects, related to each other
Intelligence Difficulty
Grade
Intell_Jane Diffic_CS101
Grade_Jane_CS101
Intell_George Diffic_Geo101
Grade_George_Geo101
Intell_George Diffic_CS101
Grade_George_CS101A C
These “instances” are not independent

Probabilistic Relational Models
• Combine advantages of relational logic & BNs: – Natural domain modeling: objects, properties,
relations– Generalization over a variety of situations– Compact, natural probability models
• Integrate uncertainty with relational model:– Properties of domain entities can depend on
properties of related entities– Uncertainty over relational structure of domain

St. Nordaf University
Tea
ches
Tea
ches
In-course
In-course
Registered
In-course
Prof. SmithProf. Jones
George
Jane
Welcome to
CS101
Welcome to
Geo101
Teaching-abilityTeaching-ability
Difficulty
Difficulty Registered
RegisteredGrade
Grade
Grade
Satisfac
Satisfac
Satisfac
Intelligence
Intelligence

Relational Schema
• Specifies types of objects in domain, attributes of each type of object & types of relations between objects
Teach
Student
Intelligence
Registration
Grade
Satisfaction
Course
Difficulty
Professor
Teaching-Ability
In
Take
ClassesClasses
RelationsRelationsAttributesAttributes

Representing the Distribution
• Very large probability space for a given context – All possible assignments of all attributes of all
objects
• Infinitely many potential contexts– Each associated with a very different set of worlds
Need to represent infinite set of complex distributions
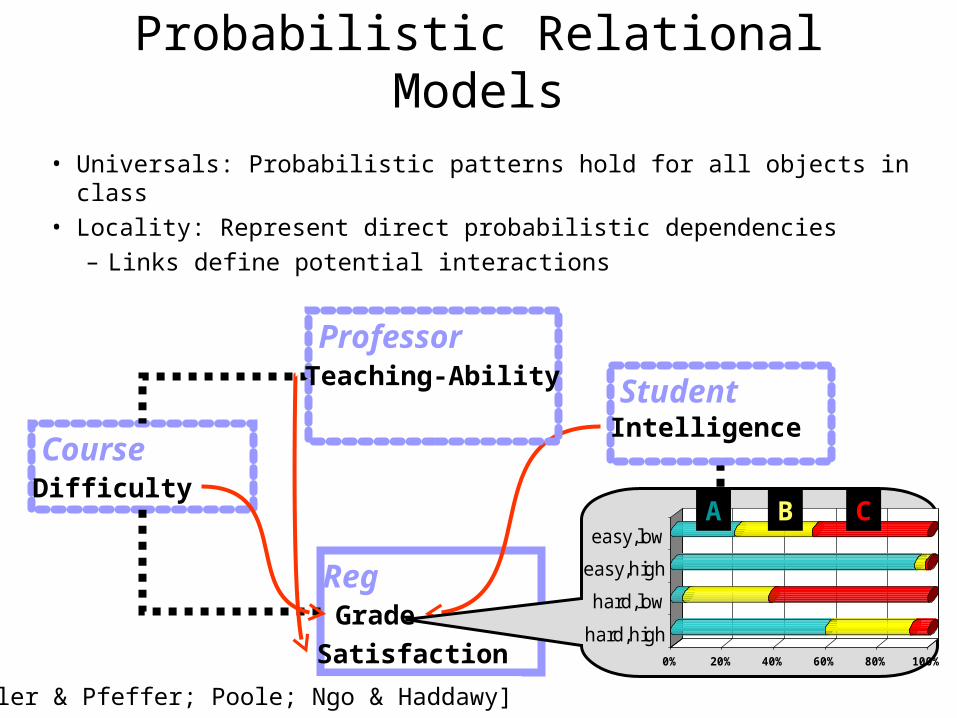
Probabilistic Relational Models
• Universals: Probabilistic patterns hold for all objects in class• Locality: Represent direct probabilistic dependencies
– Links define potential interactions
StudentIntelligence
RegGrade
Satisfaction
CourseDifficulty
ProfessorTeaching-Ability
[Koller & Pfeffer; Poole; Ngo & Haddawy]
0% 20% 40% 60% 80% 100%
hard,high
hard,low
easy,high
easy,lowA B C
Prof. SmithProf. Jones
Welcome to
CS101
Welcome to
Geo101
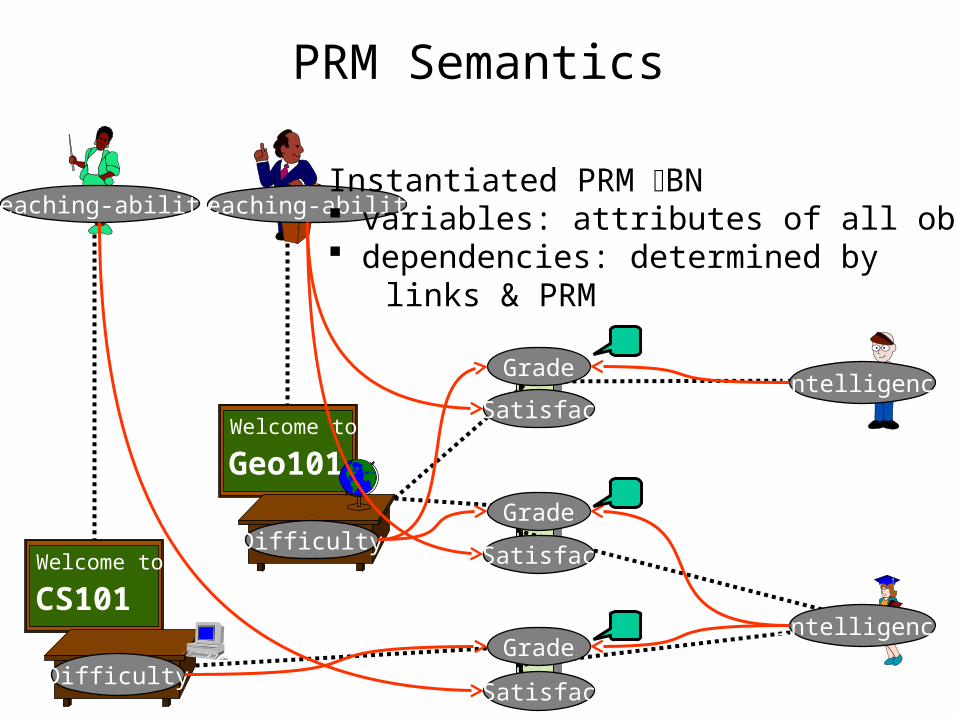
PRM Semantics
Teaching-abilityTeaching-ability
Difficulty
Difficulty
Grade
Grade
Grade
Satisfac
Satisfac
Satisfac
Intelligence
Intelligence
Instantiated PRM BN variables: attributes of all objects dependencies: determined by links & PRM
George
Jane
Welcome to
CS101
low / high
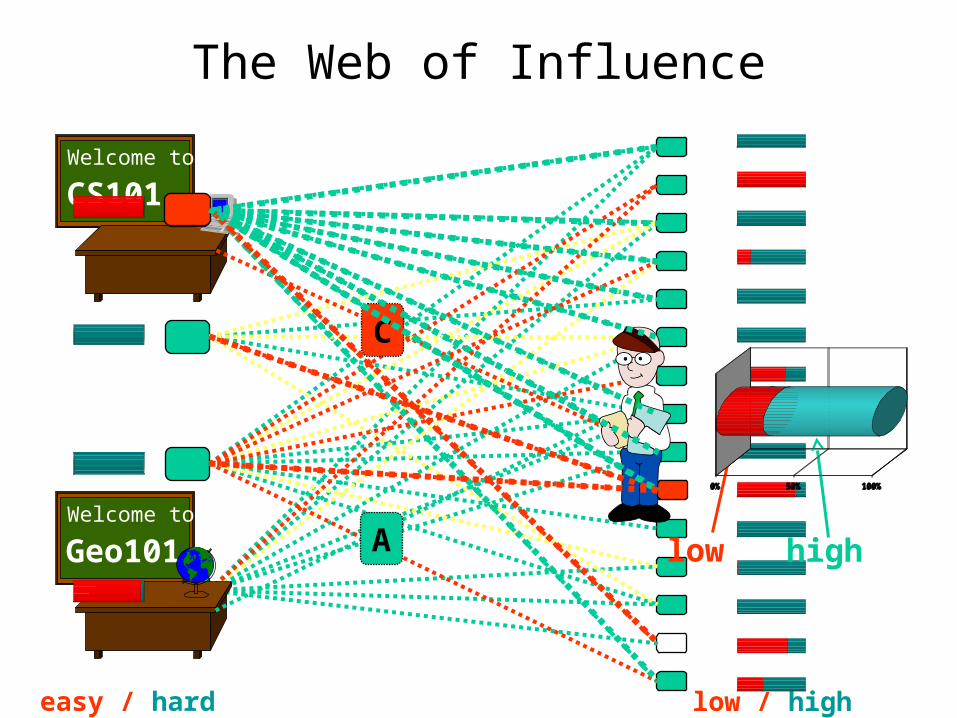
The Web of Influence
0% 50% 100%0% 50% 100%
Welcome to
Geo101 A
C
low high
0% 50% 100%
easy / hard

Reasoning with a PRM
• Generic approach:– Instantiate PRM to produce ground BN– Use standard BN inference
• In most cases, resulting BN is too densely connected to allow exact inference
• Use approximate inference: belief propagation
• Improvement: Use domain structure — objects & relations — to guide computation– Kikuchi approximation where clusters = objects

Data Model Objects
LearnerLearnerLearnerLearner
Database
Course Student
Reg
Expert knowledge
Probabilistic Model
Data for NewSituation
Prob.Prob.InferencInferenc
ee
Prob.Prob.InferencInferenc
ee
What are the objects in the new situation?How are they related to each other?
[Friedman, Getoor, Koller & Pfeffer;

PRM Summary
• PRMs inherit key advantages of probabilistic graphical models:– Coherent probabilistic semantics– Exploit structure of local interactions
• Relational models inherently more expressive
• “Web of influence”: use multiple sources of information to reach conclusions
• Exploit both relational information and power of probabilistic reasoning

SRL & Link Mining
General Issues

Linked Data
• Heterogeneous, multi-relational data represented as a graph or network– Nodes are objects
• May have different kinds of objects• Objects have attributes• Objects may have labels or classes
– Edges are links• May have different kinds of links• Links may have attributes• Links may be directed, are not required to be
binary

Link Mining Tasks
• Link-based Object Classification• Object Type Prediction• Link Type Prediction• Predicting Link Existence• Link Cardinality Estimation• Object Consolidation• Group Detection • Subgraph Discovery• Metadata Mining

Link-based Object Classification
• Predicting the category of an object based on its attributes and its links and attributes of linked objects
• web: Predict the category of a web page, based on words that occur on the page, links between pages, anchor text, html tags, etc.
• cite: Predict the topic of a paper, based on word occurrence, citations, co-citations
• epi: Predict disease type based on characteristics of the patients infected by the disease

Object Class Prediction
• Predicting the type of an object based on its attributes and its links and attributes of linked objects
• comm: Predict whether a communication contact is by email, phone call or mail.
• cite: Predict the venue type of a publication (conference, journal, workshop)

Link Type Classification
• Predicting type or purpose of link based on properties of the participating objects
• web: predict advertising link or navigational link; predict an advisor-advisee relationship
• epi: predicting whether contact is familial, co-worker or acquaintance

Predicting Link Existence
• Predicting whether a link exists between two objects
• web: predict whether there will be a link between two pages
• cite: predicting whether a paper will cite another paper• epi: predicting who a patient’s contacts are

Link Cardinality Estimation I
• Predicting the number of links to an object
• web: predict the authoratativeness of a page based on the number of in-links; identifying hubs based on the number of out-links
• cite: predicting the impact of a paper based on the number of citations
• epi: predicting the number of people that will be infected based on the infectiousness of a disease.

Link Cardinality Estimation II
• Predicting the number of objects reached along a path from an object
• Important for estimating the number of objects that will be returned by a query
• web: predicting number of pages retrieved by crawling a site
• cite: predicting the number of citations of a particular author in a specific journal

Entity Resolution
• Predicting when two objects are the same, based on their attributes and their links
• aka: record linkage, duplicate elimination, identity uncertainty
• web: predict when two sites are mirrors of each other.• cite: predicting when two citations are referring to the
same paper. • epi: predicting when two disease strains are the same• bio: learning when two names refer to the same protein

Group Detection
• Predicting when a set of entities belong to the same group based on clustering both object attribute values and link structure
• web – identifying communities • cite – identifying research communities

Subgraph Identification
• Find characteristic subgraphs• Focus of graph-based data mining (Cook
& Holder, Inokuchi, Washio & Motoda, Kuramochi & Karypis, Yan & Han)
• bio – protein structure discovery• comm – legitimate vs. illegitimate groups• chem – chemical substructure discovery

Metadata Mining
• Schema mapping, schema discovery, schema reformulation
• cite – matching between two bibliographic sources
• web - discovering schema from unstructured or semi-structured data
• bio – mapping between two medical ontologies

Link Mining Tasks
• Link-based Object Classification• Object Type Prediction• Link Type Prediction• Predicting Link Existence• Link Cardinality Estimation• Object Consolidation• Group Detection • Subgraph Discovery• Metadata Mining

SRL General Issues Summary
• SRL Tasks– Link-based Object
Classification– Object Type Prediction– Link Type Prediction– Predicting Link
Existence
• SRL Challenges– Logical vs. Statistical
dependencies– Feature construction– Instances vs. Classes– Collective
Classification
– Link Cardinality Estimation
– Object Consolidation– Group Detection – Subgraph Discovery– Metadata Mining
– Collective Consolidation– Effective Use of Labeled &
Unlabeled Data– Link Prediction– Closed vs. Open World

SRL Focus Problem #1
Citation Analysis

Domain• The first focus problem domain is bibliographic citation
analysis. A large number of SRL researchers have worked with this domain. Some advantages of this domain are: – the availability of data (thanks largely to Andrew McCallum,
William Cohen, Steve Lawrence and others) – the ease of understanding the domain and – our obvious inherent interest in the domain as academics,
. – the potential high payoff, high visability of SRL apporaches if
they can solve this problem.• Within this domain, some of the objects are:
– papers, authors, affiliations and venues and so on, • Some of the links or relationships are:
– citations, authorship and co-authorship and so on.
• An interesting aspect of the problem is that one must deal with indentity uncertainty: objects can be referenced in many ways, and an important task is entity resolution: figuring out the underlying object domains and mappings between references and objects.

SRL Tasks in FP #1• topic prediction: collective classification of the topics of papers • author attribution: predicting the author of a paper. An issue is
whether we assume a closed or open world for the authors. Plagiarism detection.
• author-topic identification: discovering the topic areas for authors. This can be used for example to assign reviewers for papers.
• entity resolution: collective clustering of the reference to objects to determine the set of authors, papers and venues.
• topic evolution: tracking change in topics over time. • group detection: finding collaboration networks. –• citation counting/ranking: predicting number of citations or
ranking based on predicted number of citations. • hidden object invention: Analogous to hidden variable
introduction, the introduction of a hidden object, such as an advisor, that relates two author instances.
• predicate invention: from co-author information, affiliation information and perhaps information such as position and room location, invent advisor predicate.

Data for FP #1
• Many people have constructed data sets by crawling bibliography servers such as CiteSeer, ACM, DBLP and, soon one would imagine, GoogleScholar.
• Steve Lawrence several years ago made available a large collection of the citeseer data, this is available by contacting him.
• Several versions of the Cora data set are available here: http://www.cs.umass.edu/~mccallum/code-data.html
• The recent 2003 KDD Cup challenge has data available from high energy physics, http://www.cs.cornell.edu/projects/kddcup/

Your Turn
• Come up with an SRL focus problem:– Define the schema, objects, links, etc.– Describe some SRL tasks in this domain– Think about where you could get the data

Survey

Next Time
• Graphical Models Review• Led by Indrajit Bhattacharya• Readings available for pickup and in
library. (Due to draft nature, they are not available on the web)