硕士研究生学位论文sewm.pku.edu.cn/tianwangliterature/masterthesis/%5bwangzk,2006%5d/... ·...
TRANSCRIPT

硕士研究生学位论文
题目:Maze 检索系统性能优化和资源评价
姓 名:王正克
学 号:10308160
院 系:信息科学技术学院
专 业:计算机系统结构
研究方向:计算机网络与分布式系统
导 师:李晓明教授,雷凯讲师
二〇〇六 年 五 月

版权声明
任何收存和保管本论文各种版本的单位和个人,未经本论文作者同意,不得
将本论文转借他人,亦不得随意复制、抄录、拍照或以任何方式传播。否则,引
起有碍作者著作权之问题,将可能承担法律责任。

北京大学硕士学位论文
- I -
摘 要
Maze 系统是基于 P2P 的内容交换系统,采用集中式架构管理用户和资源。本
文的研究范围为 Maze 检索系统以及 Maze 系统中资源的性质。
第一部分详细介绍了 Maze 检索系统的设计和实现,并针对 Maze 检索系统的
性能问题进行了研究,讨论检索效率的影响因素,并提出一些改进方法和途径。
这些方法包括改进整数压缩编码、基于 Peer 的多级缓冲技术等方法。 后对 Maze
系统的检索效率进行综合评测,并提出改进方案。
第二部分研究 Maze 系统中资源的性质。首先提出了根据文件指纹的搜索方
式,利用文件指纹聚合镜像文件,向用户提供所需文件的所有可下载源。然后提
出禁用指纹库和禁用词表结合的禁用文件识别方法,控制 Maze 网络中的禁用文
件的传播。 后,本文提出 ResourceRank 算法,利用下载关系构造一个投票模型,
评估资源的价值。ResourceRank 算法对资源进行全局评价,有助于选择性索引文
件资源和合理排序返回结果。
关键词: P2P,检索系统,倒排文件,缓冲机制,ResourceRank

Master's Thesis of Peking University
- II -
Retrieval Performance Optimization and Resource
Evaluation in Maze System Zhengke Wang( Computer Architecture)
Directed by Xiaoming Li, Kai Lei
Abstract Maze is a networks file exchange system based on P2P, it manages users and resources
through centralized architecture. In this thesis, we study the Maze retrieval system and
the attributes of the resources in Maze.
In the first part, we detailed introduce the design and realization of Maze retrieval
system. And we do the research on the performance of the Maze retrieval system,
discuss the factors of influencing the indexing efficiency. Some methods for
improvement are presented, which includes improving the integer compression code
and multistage cache technology based on the Peer. Then we evaluate the efficiency of
Maze retrieval system, and propose the scheme to improve.
In the second part, we study the attributes of the resources in Maze. We first
propose the search method based on the file figure. The file figure is used to cluster the
mirror image file, then the available sources can be provided to the user. What’s more,
we present a recognition method which makes user of both an invalid file figure
database and invalid words table to control the invalid file transfer in Maze.
At last, an algorithm called ResourceRank is proposed. We use the upload and
download relationship to construct a vote model to evaluate the resources.
ResourceRank makes the full evaluation to the resources in the system, and this will be
helpful to select files to be index and to arrange returned files reasonably.
Keywords: P2P,index system,inversed file,cache mechanism,ResourceRank

北京大学硕士学位论文
- III -
目 录
摘 要 .......................................................................................................................................I
Abstract ..................................................................................................................................... II
第一章 绪论 ..............................................................................................................................1
1.1 研究工作的背景和意义...............................................................................................1
1.2 本文研究工作的内容...................................................................................................3
1.3 本文的组织...................................................................................................................4
第二章 Maze 检索系统基本技术.............................................................................................5
2.1 引言 ..............................................................................................................................5
2.2 系统设计与结构...........................................................................................................6
2.2.1 目录服务模块...................................................................................................7
2.2.2 索引创建模块...................................................................................................7
2.2.3 检索服务模块...................................................................................................8
2.3 本章小结 ......................................................................................................................8
第三章 倒排文件技术和缓冲技术.........................................................................................10
3.1 引言 ............................................................................................................................10
3.2 倒排文件结构............................................................................................................. 11
3.3 整数压缩编码技术.....................................................................................................12
3.4 缓冲技术及评估.........................................................................................................14
3.4.1 倒排表缓冲.....................................................................................................14
3.4.2 中间对象缓冲.................................................................................................15
3.4.3 查询结果缓冲.................................................................................................17
3.5 本章小结 ....................................................................................................................18
第四章 检索效率的综合测评.................................................................................................19
4.1 引言 ............................................................................................................................19
4.2 仿真实验设计.............................................................................................................19
4.3 仿真实验结果.............................................................................................................20
4.4 改进前后的性能对比.................................................................................................21

北京大学硕士学位论文
- IV -
4.5 本章小结 ....................................................................................................................22
第五章 基于文件指纹的搜索和禁用文件控制.....................................................................23
5.1 引言 ............................................................................................................................23
5.2 文件指纹搜索方式.....................................................................................................23
5.3 禁用文件识别技术.....................................................................................................25
5.4 Maze 系统的禁用文件控制机制 ...............................................................................27
5.5 本章小结 ....................................................................................................................28
第六章 ResourceRank 算法 ....................................................................................................29
6.1 引言 ............................................................................................................................29
6.2 基于下载行为的投票模型.........................................................................................30
6.3 投票模型解释.............................................................................................................31
6.4 投票模型的数学表示.................................................................................................32
6.5 投票模型中的特殊 Peer 结构和改进........................................................................32
6.5.1 只上传 Peer ....................................................................................................32
6.5.2 只下载 Peer ....................................................................................................33
6.5.3 投票闭环群.....................................................................................................34
6.5.4 独立 Peer 群 ...................................................................................................35
6.5.5 模型的改进.....................................................................................................36
6.6 算法 ............................................................................................................................37
6.7 收敛性 ........................................................................................................................37
6.8 资源评价的应用.........................................................................................................38
6.9 查询结果排序.............................................................................................................39
6.10 本章小结.................................................................................................................41
第七章 总结与未来展望.........................................................................................................42
7.1 总结 ............................................................................................................................42
7.2 不足与展望.................................................................................................................43
参考文献 ....................................................................................................................................44
致 谢 ....................................................................................................................................46

北京大学硕士学位论文
- 1 -
第一章 绪论
1.1 研究工作的背景和意义
近年来,P2P 技术的蓬勃发展,改变了人们使用网络的方式。人们不再只是
浏览者,而是参与者,平等的交流认为 有价值的资源。如今,在文件交换方面
的应用,P2P 技术正是炙手可热。
自从 1999 年 Napster 诞生,它的用户量迅速增长,在短时间内激增到数千万
人。2000 年 Napster 和五大唱片商的对簿公堂,更使 P2P 技术成为人们的焦点。
而原告之一 BMG 公司与 Napster 达成和解协议,更证明了数字方式发布音乐是不
可阻挡的潮流,与其妄图阻止类似 Napster 的 P2P 共享软件的不断出现,不如将
其变成合法的在线音乐销售渠道。在 Napster 之后,基于 P2P 技术的内容共享软
件层出不穷,如 Gnutella、EDonkey、Emule、BT 等等。值得一提的是,2003 年
RedHat9.0 的发布,就是因为有 BT 这种 P2P 新技术,才让热于尝新的用户们第一
时间获得这样庞大的拷贝。如此快捷、自发而又有序的数据传播方式,在 P2P 技
术的兴起之前,可是不可思议的事。至此,基于 P2P 的内容共享,因其自由、平
等及高效等特性,成为人们不可缺少的数据传播方式。
基于 P2P 的内容共享系统,架构可分三种:集中式、混合式和纯分布式。因
其网络组织方式不同,其资源的定位算法也截然不同[Tsoumakos, et al., 2003]。
Napster 采取集中式的架构,中央服务器拥有所有 Peer 共享资源信息;由中央服
务器负责定位资源,回应 Peer 提交寻找资源的查询。混合式架构的 P2P 系统采取
不同的策略,如 Gnutella2 采用部分性能较好的 Peer 充当超级节点,由它们索引
相近的叶节点所共享的资源;由超级节点合作定位资源,回应 Peer 提交的寻找资
源的查询。而完全分布式架构的 P2P 共享系统有两种:一是完全无结构的,资源
定位算法有泛洪查找、宽度优先、和随机漫步等算法;若在每个节点保存一些关
于其他节点资源信息,则可采取以上算法的一些变种。二是结构化的纯分布式系

北京大学硕士学位论文
- 2 -
统采取 DHT 算法建立,所有的操作都基于 overlay 网,由它来处理资源分布和定
位。
本文的研究对象 Maze 系统采取集中式架构,有一系列的中央服务器负责用户
管理和资源管理。由用户服务器负责 Peer 注册、登陆管理;由心跳服务器负责用
户状态管理;由中央目录服务器接收 Peer 上传的 Peer 共享内容信息,以建立全
局的倒排索引;并有中央检索服务器接收和处理 Peer 的资源定位请求,并做禁用
资源控制和禁用用户管理。集中式架构的 Maze 系统具有检索高效、推荐 优和
系统可控的优点。
基于 P2P 的内容共享系统的检索系统建立于信息检索技术之上。信息检索技
术的研究,主要在于分析信息的结构和组织,研究其存放和检索,利用各种技术,
以有效提高其检索效率和效果。非结构化的文本一直是信息检索的研究重点,近
年来,大规模搜索引擎因其应用广泛、数据规模大、查询请求多且实时性要求高,
成为了信息检索技术研究的焦点。对搜索引擎的研究,在各个方面都获得了累累
硕果,从网页抓取、网页净化、镜像识别到检索效率和检索效果,都取得了极大
进展。其对 P2P 系统的检索系统研究有着极大的借鉴意义。
混合式和纯分布式的 P2P 系统的搜索方式是 P2P 方式的,它们的研究热点集
中在网络结构组织、资源存储、资源发现和查询请求转发等方面,与搜索引擎有
着极大的不同。本文研究兴趣不在于此,故不作深入阐述。
集中式架构的 P2P 系统,其检索系统有着和搜索引擎许多相似的研究点。它
们都需要收集分布在互联网的各个地方的资源信息,都需要对所收集资源进行预
处理,识别禁用资源和镜像资源,还需要对资源进行评价,以求返回给用户 贴
近用户需求的资源。它们也存在很多的不同点。首先研究对象不同,搜索引擎的
研究对象是网页,网页是半结构化文本,主要需要语言处理技术;而 P2P 系统的
研究对象是各式各样的文件,有文本、多媒体文件和各种软件等等,可利用信息
主要是文件名信息,若需更多的信息则得抓取额外描述信息,或采取多媒体处理
技术。再者资源所在站点性质不同,搜索引擎的资源所在网站是不知中央服务器
存在和只能被动提交资源信息;P2P 系统的组成 Peer 是可知中央服务器存在,且
具有计算能力,可自行处理部分数据。综上所述,集中式 P2P 系统的所需检索技
术可参考搜索引擎的检索技术,同时要针对自身特性研究新的检索技术。

北京大学硕士学位论文
- 3 -
本文主要分析 Maze 系统的检索技术。Maze 系统是一种基于 P2P 的、集中式
的内容共享系统,可从[maze]了解其基本概况。它的检索系统的设计实现参考学
习了天网搜索的检索技术,考虑文件资源和网页资源的差异,并充分利用 Peer 的
计算能力,采用针对 P2P 特性的技术,以打造高效的、可控的 Maze 系统。
1.2 本文研究工作的内容
本文的研究工作集中在 Maze 系统的检索系统性能的优化和资源评价,主要在
数据组织、检索效率、检索效果等方面进行研究。本文从用户行为、资源分布特
性等方面出发,研究 Maze 系统特性,提出以下技术:
基于 Peer 的多级缓冲技术。Maze 系统是由自主行为的 Peer 构成;Peer
的在线行为不可测,而 Peer 的在线与否决定了该 Peer 资源的可用性。本
文设计基于 Peer 的多级缓冲技术,充分利用 Peer 的在线属性,提高缓冲
效率。
文件指纹搜索技术。Maze 系统中有众多镜像文件,它们分布于不同的
Peer,各镜像命名差异较大。本文提出提取文件指纹,将分布于不同 Peer、
不同命名的镜像文件聚合在一块,提供根据文件指纹的搜索方式,查找用
户所需文件的所有可下载源。
禁用文件控制技术。P2P 系统具有众多禁用文件存在,识别它们并控制它
们的传播是 P2P 系统一项重要任务。本文提出通过人工提取禁用词,查
找含禁用词的文件,对这些文件进行人工查看和机器审查,进而提取确认
为禁用文件的指纹,组成禁用指纹库。Maze 系统利用禁用指纹库和禁用
词表,合作进行对禁用文件的控制。
ResourceRank 算法。ResourceRank 算法利用下载行为评估资源价值。它
通过挖掘 Maze 的下载日志,利用 Peer 与资源互相互动关系,建立投票模
型,刻画资源的热门度。利用资源评价,参与对返回结果排序。

北京大学硕士学位论文
- 4 -
1.3 本文的组织
本文第二章先围绕检索效率和检索效果,介绍 Maze 检索系统的结构设计,再
介绍 Maze 检索系统的组成模块和实现模块所需的基本技术。
第三章先介绍 Maze 系统的倒排索引文件结构设计,再介绍采用的索引压缩编
码,并对该编码方式进行效果实验;然后介绍 Maze 系统采用的对不同缓冲对象
各自采用的缓冲机制,并对缓冲的命中率进行分析。
第四章对 Maze 系统的检索效率进行综合测评。先对考察检索系统在不同负载
状况下的各个性能参数,对影响检索系统性能的主要因素进行分析。然后对运用
上述技术改进前后的性能进行对比。
第五章首先提出文件指纹搜索方式,阐述文件指纹搜索方式对于文件名搜索
方式的补充作用,以及其对深入搜索的意义。然后提出一种识别禁用文件方法,
就是结合禁用指纹库和禁用词表来发现禁用文件,并且叙述 Maze 系统中的禁用
文件控制机制。
第六章先提出基于下载行为的投票模型,从数学、算法和应用的方面对投票
模型进行详细解析。然后介绍结果排序所涉及的因素,并提出 Maze 中结果排序
算法。
第七章先总结 Maze 检索系统中的技术和 Maze 社区中资源性质的研究,然后
阐述现有检索系统不足和未来可发展的一些方向。

北京大学硕士学位论文
- 5 -
第二章 Maze 检索系统基本技术
2.1 引言
如前所述,P2P 系统有三种架构:集中式、混合性、完全分布式。对于资源
搜索来说,这三种架构各有利弊。
集中式架构的 P2P 系统,具有中央索引服务,可快速定位任意资源,具
有查询响应时间短的优点,而且可控性较好。但它需要所有用户向中央服
务器提交资源共享信息,并且中央服务器索引重建需要一定周期,因此它
有不能即时的体现 P2P 系统内共享信息的变化;另外集中式架构的 P2P
系统的扩展性相对较差,整个系统的瓶颈在于中央服务器的性能。
混合式和完全分布式的 P2P 系统,或采用超级节点的分层结构,或采用
DHT 算法定位资源,具有可扩展性好的优点。但它的资源定位能力较差;
虽热门文件定位迅速,但一般性文件定位至少需要 ln(n)的时间代价。
此外,它对 Peer 和资源的控制较差,对禁用文件和违规 Peer 不能及时进
行处理。
综合考虑上述优劣,Maze 系统采用集中式架构。Maze 系统在中央服务器上
接收用户共享内容列表,索引所有共享内容,并对禁用文件进行集中控制。在系
统设计时,Maze 系统充分考虑集中式架构的优点,追求尽可能快的给用户返回
好的资源信息,并且控制禁用文件的传播,打造高效的,健康的网上社区。另外,
考虑到集中式架构的缺点,设计时尽量缩短索引重建周期,尽可能快的体现社区
中资源的变化;并且尽可能的增强系统的可扩展性。
Maze 系统现有注册用户达 400 多万,索引约 1 亿个文件资源。每天活动用户
达 10 万余人,下载次数达 110 多万,每日查询次数达 17 万。本章以 Maze 系统
为基础,分析检索系统的基本技术和 P2P 系统的特有技术。
北京大学硕士学位论文
- 6 -
2.2 系统设计与结构
Maze 检索系统的设计考虑三个因素:检索效率,检索效果和系统可扩展性。
检索效率是用户可直接体验的因素,一般来说,对查询请求响应时间要求在秒级,
用户才没有等待的感觉。检索效果是另一个用户可直接体验的因素,主要表现在
返回结果列表中排列在前的结果与查询词是否相关度高,并且易于下载。检索效
率和检索效果是评价检索系统的成功与否的两个主要因素,它们存在竞争,为获
得较好的检索效果,需要在服务器做更多的计算,势必影响到检索效率。系统可
扩展性是指系统适应变化能力,是否能满足用户数量增长、文件资源增多后的查
询请求;这是集中式架构的较弱的环节,设计时要着重考虑。这三个要素对 Maze
检索系统整体及组成模块的设计都起了重大影响。Maze 系统的设计目标是,将查
询请求相应时间控制在秒级前提下,尽可能的提高返回结果的相关度,并且保证
系统具有一定的可扩展性。
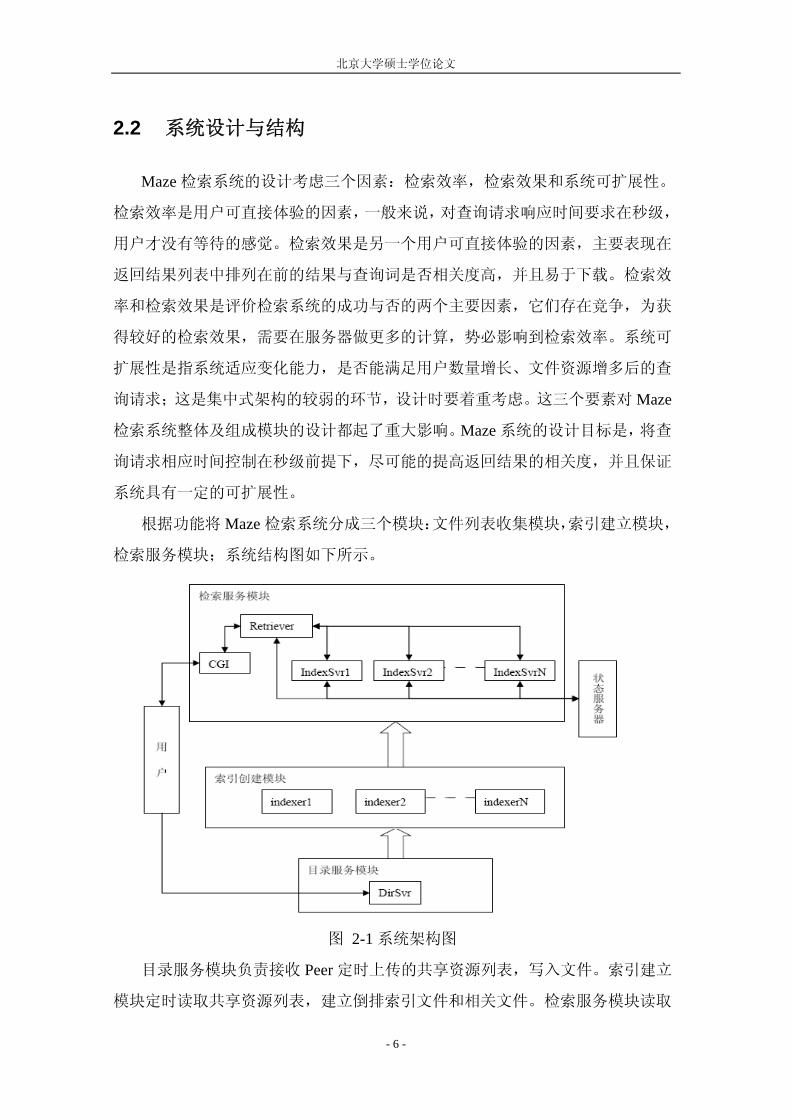
根据功能将 Maze 检索系统分成三个模块:文件列表收集模块,索引建立模块,
检索服务模块;系统结构图如下所示。
图 2-1 系统架构图
目录服务模块负责接收 Peer 定时上传的共享资源列表,写入文件。索引建立
模块定时读取共享资源列表,建立倒排索引文件和相关文件。检索服务模块读取

北京大学硕士学位论文
- 7 -
倒排索引文件和相关文件,定时从状态服务器接收用户在线状态列表,同时接收
和处理 Peer 提交的用户查询请求。下面详细描述各个模块功能,以及各个模块为
提高性能所采取的技术。
2.2.1 目录服务模块
目录服务模块负责接收 Peer 定时上传的资源列表。各个 Peer 每隔设定时间检
查自身共享内容,若未曾有过变化,向目录服务器提交时间更新消息,确认资源
的有效性;若自身共享内容发生变化,则发送新的资源列表。目录服务模块根据
收到的消息类型,或将接收到的资源列表写入文件,等待索引创建模块使用,或
更新该 Peer 资源列表的有效时间。
我们在设计资源信息结构时,充分利用了 Peer 的计算能力,将能在 Peer 独立
计算的所需资源属性都下放到 Peer 上计算,以减轻中央服务器的负载。比如文件
资源的指纹计算和禁用资源的部分过滤工作,都放在 Peer 上处理。
2.2.2 索引创建模块
索引创建模块负责资源的倒排索引的创建。对 Peer 上传的原始资源列表建立
倒排文件和其他资源相关文件,以供检索服务模块的使用。
倒排索引的设计,是检索服务的基础,对检索系统性能有着巨大影响。为提
高检索系统性能,本文关注以下内容:
索引结构设计。良好的索引结构设计可以提高解析效率和方便相关性评
价。在所有的与索引相关的结构体中,都考虑 Peer Id 属性,充分利用 Peer
的在线属性对资源可用性决定性的影响。
索引压缩技术。索引压缩的目的是以 CPU 计算时间换取空间, 终节约
磁盘访问时间,提高检索效率。这是大规模、多用户的检索系统提高性能
的重要手段。
禁用文件控制技术。利用禁用指纹库和禁用词表合作识别禁用文件,阻止
禁用文件的传播。另外根据用户共享的禁用文件情况,对用户进行审查,
记录违规用户的 ID,以便对违规用户进行惩罚, 终净化 Maze 社区。

北京大学硕士学位论文
- 8 -
2.2.3 检索服务模块
检索服务是用户直接参与的过程,也是用户体验 明显的过程。检索过程分
为以下几个步骤:
解析用户提交的查询请求;
查找与查询关键词相关的资源记录,考虑 Peer 在线属性,对非在线站点
资源进行过滤;
根据查询请求属性和资源属性过滤资源记录;
根据相关度和站点及文件评价对相关文件列表进行排序;
返回相关文件的描述信息
在检索过程中,影响效率的 大因素通常是对磁盘的访问;而影响效果的
大因素是返回结果的相关性评价和结果所在 Peer 的可下载性评价。在为提高查询
处理效率和检索效果, 终给用户良好的体验,我们采用了以下技术:
缓冲技术。利用数据访问的局部性,在内存保存使用可能性更高的数据,
以减少对磁盘的访问。使用缓冲技术,可以加快查询处理速度,减少用户
的等待时间,也有利于系统的可扩展性。
ResourceRank 技术。利用 Maze 社区中的 Peer 下载行为日志,建立基于
下载行为的投票模型,评价资源和 Peer。利用这些评价值对返回结果进
行重要性评价。
相关度的综合评价技术。综合查询词、资源评价和 Peer 评价等因素,计
算文件的相关度。根据相关度对返回资源进行排序,将相关度 高的一些
资源返回给用户。如此,可以减少无用的记录返回比例,提升用户的使用
感受。
2.3 本章小结
本章从 Maze 检索系统的设计和实现出发,探讨检索技术。首先介绍 Maze 检
索系统的设计目标,Maze 检索系统的设计是围绕效率、效果和可扩展性展开的。
接着介绍了 Maze 检索系统的架构,Maze 检索系统从功能可划分为三个模块:目

北京大学硕士学位论文
- 9 -
录服务、索引创建、检索服务。 后对 Maze 检索系统中各模块的功能进行描述,
并对其中采用的各种检索技术做了粗略介绍。这些技术包括索引压缩技术、缓冲
技术和相关度评价技术,它们是实现高效检索系统的保证。

北京大学硕士学位论文
- 10 -
第三章 倒排文件技术和缓冲技术
3.1 引言
倒排文件技术是一种检索系统常用的数据组织技术。它结构简单,检索效率
高,能迅速的定位所需资源的位置,是大规模、高效率的检索系统的基础。随着
网络的发展,网络应用的检索系统索引的数据量不断增大,对查询响应的实时性
要求也逐渐提高。如何有效的组织倒排文件、优化检索算法,一直是研究的热点。
近年来,CPU 的频率和内容容量大规模增长,而磁盘读写效率却相对增长较慢,
因此对磁盘上倒排表数据的访问常成为检索系统效率的瓶颈。于是有大量的研究
投入到对倒排表的压缩上[Scholer, et al., 2002],试图减少对空间的需求,充分的
利用 CPU 的计算能力,进而提高检索的整体效率。另外[Moffat and Zobel,1996]
提出在压缩的倒排表中插入同步点,使得可以跳过某些数据块,直接读取与用户
查询 相关的数据块,减少读盘和解压缩开销。[Witten, et al., 1999]对海量数据管
理方法进行讨论,全面的叙述了各种压缩技术和索引技术。
本章对倒排文件的设计需考虑下列因素
无二义性。只有一种明确的解析方式,这是倒排文件可正确使用的前提条
件。
倒排文件规模小。通过压缩倒排表,以增加 CPU 计算换取减少文件占用
空间,于是减少了磁盘访问开销,提高整体检索效率。
结构简单。简单的结构有助于快速的定位到 终相关资源的描述信息,减
少索引服务解析时间,提高检索效率。
综合上述思想,本章提出用 ByteCodeM 编码方式压缩倒排表,减少磁盘访问
开销;并且按 Peer 为基本单位组织倒排表,利用 Peer 的在线属性,只读取可用
的倒排表项。
另一方面,缓冲技术也是检索系统必不可少的技术。随着检索系统索引数据
量和访问量的增大,提高系统性能和扩展性至关重要。缓冲技术就是提高系统性

北京大学硕士学位论文
- 11 -
能和扩展性的重要手段,它在计算机的各个领域得到广泛应用。
缓冲技术的有效性建立于被缓冲对象的访问的局部性特征之上。在 web 搜索
引擎方面的缓冲技术已有很多的研究,如[Xie, et al., 2002], [Long, et al., 2005]等,
而 P2P 系统中的缓冲技术研究相对较少。虽然他们一是研究网页,二是研究文件,
但他们存在共性,因为使用者较多关心的都是热门资源。本文借鉴搜索引擎中对
缓冲技术的研究,考察 P2P 系统中各种数据使用,提出适用于 P2P 系统的缓冲技
术。
缓冲对象可分为三级:查询结果、中间对象、倒排表。本文根据 Maze 系统运
行产生的实际数据,对各种缓冲对象的局部性特征进行研究,实现对查询结果和
倒排表的缓冲机制,并设计基于 Peer 的中间对象缓冲方法。
本章第 2、3 节对倒排文件结构设计和压缩算法的应用进行阐述。第 4 节对各
种缓冲对象的局部性特征进行研究,第 5 节着重阐述基于 Peer 的中间对象缓冲方
法,顺带介绍对查询结果和倒排表的缓冲方法。
3.2 倒排文件结构
Peer 的在线属性是 Maze 检索系统的一个至关重要的属性,它贯穿整个检索系
统的设计。不同于 Web 检索系统,中央服务器不能实时的了解网站的服务状态;
而 Maze 系统有一个中央状态服务器,可以实时的了解 Peer 的在线信息,确定 Peer
是否提供服务。对于一个文件共享系统,资源所在 peer 的在线是该资源可用的前
提。资源所在 peer 若处于离线状态,那么这个资源就无法被其他 Peer 下载,也就
毫无使用价值。将无法下载的资源返回给用户,浪费了检索过程中的 CPU 和内存
资源,更影响用户对检索结果的评价。因此,对返回的用户查询结果,必须利用
Peer 在线信息进行过滤。
在检索服务设计时,要尽可能早的考虑在线属性的过滤。在检索早期进行根
据在线属性的过滤,能大量减少中间数据量和运算量,提高检索效率。因此 Maze
检索系统在倒排文件解压缩过程中,就根据在线属性进行过滤,对离线站点资源
不予以解压缩。
倒排文件分成两个部分,下面详细讲解各个部分的构成,及其作用:

北京大学硕士学位论文
- 12 -
倒排文件头:
{ <key> <offset in inverted-file> }
倒排文件头记录所有索引词对应的倒排表在倒排文件的起始偏移信
息。Key 为索引词序列号。Maze 检索系统不作切词,直接采用双字节作
为索引词,或为汉字,或为字母和数字组合。后一项属性是指该索引词对
应的倒排表在倒排文件的起始偏移。倒排文件头是对倒排文件访问的入
口。
倒排文件主体:
{ <site interval><site len> { <file interval> < offset in name > } }
倒排文件主体记录索引词对应的倒排表信息。倒排文件主体按关键词
顺序排列其对应的倒排表;在各关键词对应的倒排表内部,按站点顺序排
列各站点相关文件信息。对于每个资源,在倒排文件中可提取出三个属性:
站点序列号、站内文件序列号、索引词在资源名中的偏移量。站点序列号
信息,标识后续资源项的站点属性,方便考察该资源的在线属性。站点占
位长度标识该站点的资源在该索引词的倒排表占据的长度,据此属性可略
过对离线站点资源的解压缩。站内文件序列号和站点序列号一起表示一个
文件。 后一项属性是该索引词在文件名中的偏移,据此属性分析文件和
查询短语的相关度。
检索时,通过检索文件头定位所需索引词的对应倒排表在倒排文件的位置,
再读取所需倒排表,利用资源的站点序列号进行在线属性过滤,得到与查询相关
的文件列表。
3.3 整数压缩编码技术
我们采用整数压缩编码技术压缩倒排文件,存储和缓存压缩形态的倒排文件
或倒排表,只在使用时解压所需的倒排表。压缩倒排文件,增加了解压时 CPU 计
算时间的消耗,减少了内存和 IO 的消耗。对于大规模检索系统来说,IO 消耗通
常是系统的瓶颈,这样做在整体上提高了检索系统的功能。
对非定长整数编码通常有两种,分别是字节对齐整数编码和非字节对齐整数

北京大学硕士学位论文
- 13 -
编码。这两种编码各有利弊,字节对齐整数编码胜在解码效率高,;而非字节对齐
整数编码的压缩比率高。文献[彭波,2003]中,提到天网检索系统采用 ByteCode
压缩方式,并对 ByteCode 和 Golomb 做了性能测试实验,实验结果表明两者的压
缩比率分别为 0.3395 和 0.2635,解码时间的比例为 1:6。考虑字节对齐整数编码
的效率优势,在 Maze 检索系统中也采取字节对齐整数编码方式,采用文献[谢翰,
2005]中提出的 ByteCode 的变种――ByteCodeEx 编码。
ByteCodeEx 是一种字节对齐整数编码,它用可变长的位数表示压缩整数所在
字节数,并根据计算机的字节序(ByteOrder)采取不同的编码方式。举一例子说
明 ByteCodeEx 编码:以高位优先机器为例,考察已压缩整数 1011111111,起始
10 表示该压缩整数占 2 字节,有效位从第一个 0 后一位起,该整数的值为 255。
对于 ByteCodeEx 编码,m 个字节的压缩整数可表示整数的 大值为(2^(7*m))-1。
下面我们考察 Maze 中的倒排表的特点。索引词 Key 的对应倒排表的结构如
下
{ <site interval> <site length> {<file interval> < offset in name > } } 。
(设定 FI 代表<file interval>,OIN 代表<offset in name>)
OIN 项取值范围为 0-255,固定为一个字节。若对 FI 项单独处理,那么它至少占
一个字节,但因为其大部分值小于 16,因此浪费了较多空间。因此考虑将 FI 项
和 OIN 项通过合适编码,将其合并成一项数据,对合并数据进行 ByteCodeEx 编
码,定能提高压缩性能。我们设计如下的合并编码方法。将对 FI 项和 OIN 项合
并成<file stamp>:
0-3bit in FI 0-3bit in OIN 4-7bit in FI 4-7 bit OIN 8-24bit in FI
对 FI 项和 OIN 项合并编码后,索引词 Key 对应的倒排表结构变成了
{ <site interval> <site length> {<file stamp> } }
本文称对合并数据项的 ByteCodeEx 编码为 ByteCodeM 编码。用 ByteCodeEx
表示对各个数据项分开独立 ByteCodeEx 编码。考察 ByteCodeEx 编码和
ByteCodeM 编码的区别:
当 FI 取值在 0-16,OIN 取值在 0-8,占位分别为 2 字节和 1 字节,减少
一个字节
当 FI 取值在 128-255,OIN 取值为 0-64,占位分别为 3 个字节和 2 个字
北京大学硕士学位论文
- 14 -
节,减少了一个字节
其他情况下,编码后占位数相同
对 Maze 系统中的 800 多万个文件资源建立倒排索引,统计整数分布情形,进
行 ByteCodeEx 和 ByteCodeM 的比较实验。
表 3-1 压缩比率的比较
索引项取值 FI:0-16
OIN:0-8
FI:128-255
OIN:0-64
其他
出现次数 46,152,954 3,620,850 70,361,331
ByteCodeEx 字节数 2 3 不定
ByteCodeM 字节数 1 2 不定
实验数据表明,有 41%的索引项使用 ByteCodeM 可获得更好的压缩比率。对
整体数据, ByteCodeM 和 ByteCodeEx 的压缩比率比为 83:100,提高了 17%的压
缩比率。但在解压速率上,ByteCodeM 处于劣势,和 ByteCodeEx 在每 1M 个索
引项解压缩时间比例为 113:100。ByteCodeM 和 ByteCodeEx 各有优劣,对于不同
的数据规模,表现不同。
3.4 缓冲技术及评估
Maze 系统的缓冲分为三级:倒排表缓冲、中间对象缓冲和查询结果缓冲。各
级对象具有不同特性,采取不同的缓冲机制。倒排表是查询处理的基础,要保证
倒排表缓冲较高的命中率;中间对象有三种,着重考虑对资源描述属性文件的缓
冲机制,因为在线属性对资源的可用性有决定性的影响,所以以 Peer 为基本单位
对资源描述属性文件进行缓冲;查询结果占空间多,而内存有限,采取热门查询
词缓冲机制。下面详细介绍各级缓冲采用的缓冲机制。
3.4.1 倒排表缓冲
倒排文件是除热门词查询之外的所有查询的基础,被访问的频次很高。另外
索引词数目不多且单个索引词对应的倒排表占空间多,替换的代价比较高。因此
对倒排文件的缓冲,应尽可能的提供较多内存空间,保证倒排表缓冲的命中率比

北京大学硕士学位论文
- 15 -
较高。在 Maze 系统中,单机的索引数据量为 1893 万个文件,倒排文件大小为 540
多 M;系统提供 384M 大小的缓冲区,缓冲命中率达 95%。
3.4.2 中间对象缓冲
检索过程中,还需三种辅助数据:Peer 信息文件、资源过滤属性文件和资源描
述属性文件。下面介绍各个文件的数据组成和缓冲机制,其中对资源描述属性文
件进行重点介绍:
A. Peer 信息文件。
Peer 信息文件记录各个 Peer 的 ID、其资源在资源过滤属性文件中的起始
偏移和在资源描述文件中的起始偏移。Peer 信息文件在任何一次查询中都用
到,而且规模小,故而在内存常驻。
B. 资源过滤属性文件。
资源过滤属性文件记录资源的各种参与过滤的属性,另外记录该资源在资
源描述文件中的偏移。资源过滤属性文件也在任何一次查询中都用到,但对
于离线 Peer,它对应的资源过滤部分无用。由于这部分数据相对较小,Maze
系统采取上线就常驻内存的方法,而不考虑下线的影响。
C. 资源描述文件
资源描述文件记录资源的各种属性,包括名字、路径、种类、大小、和文
件指纹等所有属性,是 终返回给用户的结果组成部分。因每个资源描述记
录大约占 130 字节,资源描述文件总大小约为 2.6G 字节,不可能也没有必要
将所有资源描述记录常驻内存。为了提高系统的扩展性,本文利用访问的局
部性对资源描述文件进行缓冲。
对资源描述文件的缓冲,以 Peer 为基本单位组织缓冲数据。因为离线 Peer
对应的资源描述属性没有使用价值,而且各个 Peer 的资源描述记录被访问程
度不一,所以对不同的 Peer 采取不同大小的缓冲区,可充分利用 Peer 的访问
特性。而且,与以资源为基本单位相比,以 Peer 为基本单位组织缓冲数据,
加大访问控制的粒度,减少锁操作,降低额外开销。
缓冲对象的替换有两种层次。第一层次的替换是指 Peer 层次的替换,当

北京大学硕士学位论文
- 16 -
缓冲区满后,根据各个 Peer 被访问频率,调整 Peer 的可用缓冲区大小。第二
层次是在每个 Peer 内部进行替换,所用替换机制是 久未使用替换机制。
下面分析 Peer 短暂离线行为对缓冲效果的影响和解决方法。Peer 离线后,
它的资源将会毫无使用价值,缓冲机制应设计离线 Peer 的缓冲区的清除。但
若 Peer 只是短暂离线,而系统过早清除该 Peer 的缓冲区,那么系统需重新建
立该 Peer 的缓冲区,就极大的浪费了资源。因此需要设计一个恰当的离线 Peer
缓冲区清理机制。设计合理的对离线 Peer 的缓冲区清理机制,有助于提高缓
冲效果。
本文采取滞后清除的策略处理离线 Peer,具体的做法是:
将 Peer 的状态设为三种:在线,离线,预离线。预离线状态指,服
务器已收到该 Peer 的离线消息,但还未删除该 Peer 的资源描述的缓
冲区,也就是说该 Peer 不在线,但其资源描述的缓冲区不为空。离
线状态指,该 Peer 不在线并且其资源描述的缓冲区为空。
Peer 的行为使得 Peer 在三个状态之间转换,转换如图 3-1 所示:
图 3-1 Peer 状态转换图
Peer 下线时,使 Peer 进入预离线状态,短时间的保留离线 Peer 的缓
冲区。
滞后清除策略延迟对离线 Peer 的缓冲区的清除,减少短暂离线行为对缓
冲效果的影响。当然,滞后删除策略带来更多的内存消耗,但根据系统运行
日志来看,活动的资源描述信息并不多,所需的内存消耗总量不大。因此以
一些内存代价换取减少短暂离线行为的影响,提高查询处理效率是值得的。

北京大学硕士学位论文
- 17 -
分析 Maze 系统实际运行状态,发现资源描述文件的缓冲命中率不太高,
为 79%。P2P 系统的自由性是导致缓冲命中率不高的主要原因。在 P2P 系统
中,Peer 是自由个体,不是长期在线的稳定的服务器,而且它在线与否是不
可控制且难以预测。当 Peer 上线或下线时,资源描述的缓冲区会发生较大变
化,进而导致缓冲命中率不高。
为继续提高缓冲命中率,需要预测 Peer 中可能被访问的资源,在 Peer 上
线时,预先读取这部分资源信息。由于是集中读取这部分资源信息,相对于
根据后续需求分散读取来说,可以减少磁盘访问次数。但是,鉴于系统性能
的提升空间不多,而且资源被访问的可能性预测难度很高,因此本文不作访
问预测和缓冲区预读。
综上所述,针对以上三种中间对象的不同特性,设置不同的缓冲机制,减少
检索处理过程的磁盘访问次数。
3.4.3 查询结果缓冲
查询结果由与查询相关的文件描述属性组成,其由所有索引处理机器返回的
部分结果汇总整理而成。因此对查询结果的缓冲应置于索引服务模块的 后一个
环节。通过对 2006 年 4 月 2 日的查询日志分析,发现该日的独立查询约有 77480
个,而每个查询词未经过滤的查询相关文件平均为 300 个,而每个文件的描述属
性约占 130 字节,因此用单机对所有查询词进行缓冲,显然是不合适的。再考虑
查询结果缓冲的独立性以及重建一套处理机制的复杂性,因此只对热门查询词进
行缓冲。从日志可以发现,排名靠前 100 位的查询词占了所有查询查询的 11%。
我们采取如下的机制:
A. 热门词缓冲生成
每天分析查询日志,提取热门查询词表,查询词数量视系统规模和热
门度而定。然后提取所有热门查询词未经在线信息过滤的相关文件描述属
性列表。
B. 热门词缓冲使用
北京大学硕士学位论文
- 18 -
当系统收到查询请求时,先判断查询词是否落在热门查询词表。若是,
则提取热门词缓冲中内容,接着进行在线信息过滤, 后将过滤结果返回
给用户;若否,那么将请求转发给 IndexSvr,等待其处理结果, 后将结
果转发给用户。
本文设计实验测试查询结果缓冲的效果。效果测试实验从 2006 年 4 月 15
日的查询日志提取查询行为,构造虚拟请求,提交给检索系统处理;分析处
理日志可得下表。
表 3-2 热门查询词缓冲效果考察
热门词查询 其他查询 所有查询
查询次数 23040 186421 209461
平均处理时间(ms) 41 223 203
从表 3-2 可以看出,热门词查询的平均处理时间是其他查询的平均处理时
间的 18%,处理效率有了显著提高;且热门词的查询词数占所有查询的 11%,
减少了 IndexSvr 的负载,也是 IndexSvr 处理效率获得提高,进而提高整体查
询处理效率。
综上所述,Maze 系统结合三个层次的缓冲,根据缓冲对象的不同,设计不同
的缓冲机制,极大的减少了 IO 访问数量,缩短了查询处理时间。
3.5 本章小结
本章的研究重点在于提高检索系统效率,采用倒排表压缩技术和缓冲技术,
减少 IO 访问数量,提高查询处理效率。
首先介绍倒排表的结构设计,重点考虑 Peer 在线属性的影响;接着介绍
ByteCodeM 压缩编码,并将其和 ByteCodeEx 进行压缩比率和解压缩效率两方面
的性能比较。
后介绍 Maze 系统的缓冲机制,根据不同缓冲对象的具体情况,针对性设计
各对象的缓冲机制,并对各个对象的缓冲机制的效果进行考察。

北京大学硕士学位论文
- 19 -
第四章 检索效率的综合测评
4.1 引言
检索效率的综合评测的目的在于了解检索系统的查询处理性能,分析各个参
数对系统性能的影响,发现系统运行瓶颈,对系统性能的改进具有指导意义。此
外,比较系统改进前后的性能差异,可分析本文所采取的改进方法是否有效。
4.2 仿真实验设计
采用以下两个指标来评价系统的检索效率:平均查询响应时间和系统吞吐率。
平均查询响应时间指从收到查询请求到返回查询结果的平均所需时间,反应了检
索系统的处理效率。而系统吞吐率指系统每秒处理的查询数目,反应了检索系统
的查询处理能力。本实验主要考察在不同负载条件下,平均查询响应时间和系统
吞吐率的变化情况。
评测实验采用提交虚拟查询请求,对检索系统进行实际测量的方式。在实验
过程中,在同一局域网的其他机器上,建立多个虚拟客户端线程,向真实运行系
统,并发的提交虚拟查询请求,同时记录查询处理日志。本实验通过调整虚拟客
户端线程的数目,改变检索系统的负载,记录检索系统在不同负载下的表现,并分
析各个参数在其中的影响。
需要略加说明的是虚拟查询请求的构造。虚拟查询请求来源于 Maze 系统实
际运行的查询日志。为了更好的模拟实际情况,我们从查询日志中逐条提取查询
行为,并且保持各个查询行为在时间上的顺序。评测实验的环境:
CPU Pentium III 733M
Memory 1.0G DDR
Disk 希捷 SCSI
OS RedHat 9.0

北京大学硕士学位论文
- 20 -
评测数据:
资源数目 10,942,604
资源描述信息大小 1.5GByte
倒排文件大小 315M
文件指纹数据库大小 232M
查询请求数目 209461
独立查询词数目 79012
4.3 仿真实验结果
图 4-1 吞吐率随负载变化图
图 4-1 中的横坐标负载表示准备就绪的进程队列长度,纵坐标表示检索系统
每秒处理的请求个数。从图中可以看出,当负载比较小时,吞吐率也较低,此时
未能充分的发挥检索系统的能力。当负载慢慢升高,磁盘读写和 CPU 计算重叠,
系统吞吐率逐渐升高,当负载达到 6 时,吞吐率达到极值,这是检索系统 大的
处理能力。当仿真实验继续提高并发的虚拟客户端的线程数目,部分请求被丢弃;
而且限于检索服务模块的线程数目限制,负载不再上升。总结系统性能的表现,
吞吐率不太令人满意, 高只有每秒处理 15 个查询请求。分析 CPU 和内存使用
状况,CPU 的计算能力远未充分利用,故系统的主要瓶颈仍在磁盘访问。
北京大学硕士学位论文
- 21 -
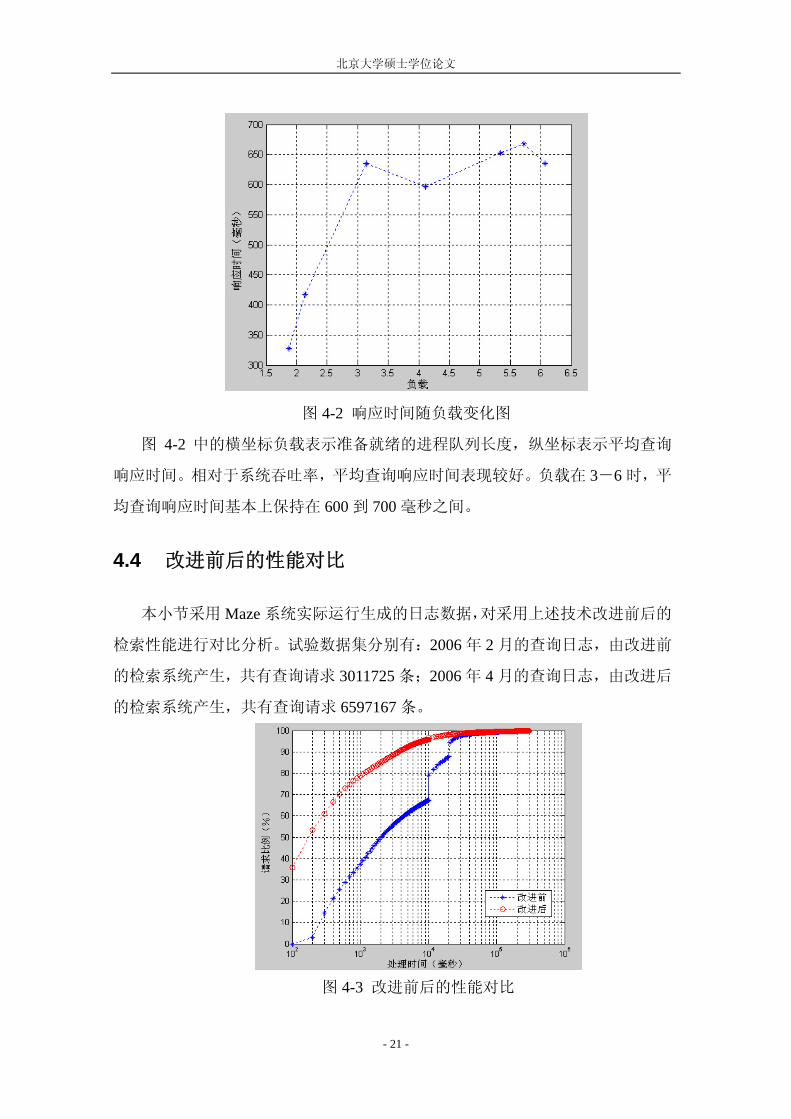
图 4-2 响应时间随负载变化图
图 4-2 中的横坐标负载表示准备就绪的进程队列长度,纵坐标表示平均查询
响应时间。相对于系统吞吐率,平均查询响应时间表现较好。负载在 3-6 时,平
均查询响应时间基本上保持在 600 到 700 毫秒之间。
4.4 改进前后的性能对比
本小节采用 Maze 系统实际运行生成的日志数据,对采用上述技术改进前后的
检索性能进行对比分析。试验数据集分别有:2006 年 2 月的查询日志,由改进前
的检索系统产生,共有查询请求 3011725 条;2006 年 4 月的查询日志,由改进后
的检索系统产生,共有查询请求 6597167 条。
图 4-3 改进前后的性能对比

北京大学硕士学位论文
- 22 -
我们比较平均查询处理时间,分析结果如图 4-3 所示。改进前的平均查询处
理时间为 8882 毫秒,而改进后的平均查询处理时间为 2973 毫秒,平均查询处理
时间缩短为原来的 1/3,检索性能有了明显的改进。
4.5 本章小结
本章首先介绍检索系统效率评估实验,发现系统的瓶颈依然在于磁盘访问。
当系统负载升高时,密集的磁盘访问提高查询的平均响应时间,限制了系统吞吐
率。虽然现代的内存已足够容纳 80%的索引相关数据,但对于剩余 20%数据的访
问,对系统性能有着决定性的影响。 后对 Maze 检索系统改进前后的运行性能
进行对比。

北京大学硕士学位论文
- 23 -
第五章 基于文件指纹的搜索和禁用文件控制
5.1 引言
在 P2P 网络中,热门文件的流传往往非常广泛。根据[Liu, et al., 2005],在
Maze 网络中,文件备份数呈重尾分布,其中热门类别影视类文件,平均备份数达
到了 8.92。因此有效的发现文件的备份所在位置,有利于充分利用 Maze 网络中
资源,均衡对 Peer 的负载要求,提高下载的可靠性和速度。
本文采用 MD5 哈希算法,针对文件内容计算文件指纹。通过文件指纹识别文
件的备份现象,并提出文件指纹搜索方式。
P2P 网络的 大亮点是每个 Peer 自由和平等的参与。因此也不可避免有违规
Peer 的存在,他们提供禁用资源的共享。发现并阻止的这些资源的传播,以及对
违规 Peer 进行惩罚,是 P2P 网络的研究重点之一,也是难点之一。集中式架构的
P2P 网络的 大优点就在于此,它能有效的控制禁用文件的传播,并对违规 Peer
施以惩罚,提高共享禁用资源的代价。
本文提出结合禁用指纹库和禁用词表,识别禁用文件。再从中央服务器发起
对 Maze 网络内禁用文件的控制。
5.2 文件指纹搜索方式
Maze 网络中有众多的文件资源,每个文件资源都可能有许多镜像,但部分镜
像的命名却完全没有联系;也有许多文件他们在内容上毫无相连,却有非常相似
的命名,混淆了人们对文件的使用。因此,根据文件名的搜索方式,不能发现目
标文件的所有镜像地址,不能充分利用网络中的文件资源。为了弥补根据文件名
的搜索方式的不足,本文提出根据文件指纹的搜索方式,对用户的目标文件做深
入搜索;下面称之为文件指纹搜索方式。
文件指纹搜索方式的流程如下:

北京大学硕士学位论文
- 24 -
1) 用户提交目标资源的文件指纹。
本文使用文件的部分内容的 MD5 值作为文件指纹。我们只使用文件
的部分内容,是基于下列考虑:在内容交换系统中,有大量的文件是影视
文件,文件都非常大,计算所有内容的 MD5 值代价非常高;此外,经应
用,只要合理选择参与计算的内容部分,镜像的误判率非常低,因此只选
取部分内容也足以表示文件内容差异。MD5 算法是一种广泛使用的哈希
算法,其碰撞率非常低,可以忽略不计,因此本文采用它来计算文件指纹。
2) 检索服务器查找所有具有所需文件指纹的资源,将所有在线的目标资源镜
像路径返回给用户。
本文生成以文件指纹为主键的数据库,将相同文件指纹文件聚合在一
块,可以迅速的返回所有具有所需文件指纹的文件信息。
3) 用户可尝试从所有可能下载位置多点下载资源。
通过文件指纹搜索方式,用户获得了所需资源的所有可下载源。利用
多点下载,充分利用了 Maze 网络中的资源,提高了下载效率,又平衡了
被下载方的负载。
文件指纹搜索方式可以发现目标资源所有的可下载源,主要用在两处:第一,
是对根据文件名的搜索方式的补充,对返回结果中用户感兴趣的资源进行深入搜
索;第二,在浏览过程中,发现感兴趣的资源更多的可下载源。尤其在第二种情
形,用户浏览好友或者邻居的共享资源列表,寻找感兴趣的资源;此时,对于目
标资源只有唯一的可下载源,由于网络原因,下载的成功率无法保证,而下载速
度也不能达到 优;文件指纹搜索方式正好适应了用户的需求,给出目标资源的
所有可能的下载源,提高下载成功率和下载速度。
文件指纹搜索方式是根据文件名的搜索方式的重要补充。分析 2006 年 3 月的
搜索日志,其中有 5.57%的搜索属于文件指纹搜索方式。

北京大学硕士学位论文
- 25 -
5.3 禁用文件识别技术
本文设计了一种禁用文件识别机制――结合禁用指纹库和禁用词表,合作识
别禁用文件。
禁用词表法是一种常用的禁用文件过滤方法,它通过审查文件文件名中是否
包含禁用词来判断文件是否为禁用文件。禁用词表法存在严重的不足,部分禁用
文件能够轻易逃过审查。因为违规用户可随意的改变文件名,改用一些诱惑性但
正常的词语来对禁用文件进行命名,这样既逃过了禁用词表法的审查,又保持了
文件的吸引力。
相对于文件名的易变,文件指纹相对稳定。虽然也可通过改变文件的内容,
来改变文件指纹。但这种改变代价相对较高,尤其对于多媒体文件。因此可收集
禁用文件的指纹,建立禁用指纹库。通过审查文件的指纹是否属于禁用指纹库来
判断文件是否为禁用文件。
禁用指纹库杜绝了禁用文件通过改名逃避审查的现象,但它只能识别已确认
的禁用文件,而不能识别新的禁用文件。而禁用词表法能够识别部分新的禁用文
件。因此本文提出结合禁用指纹库和禁用词表,合作识别禁用文件。
这个禁用文件识别机制的关键在于建立禁用指纹库和禁用词表。建立和更新
禁用指纹库和禁用词表的步骤为:
1)初步创建禁用词表;
2)用已有的禁用指纹库和禁用词表过滤每天的被下载文件。
3)考察文件名含有禁用词,但不具备禁用文件指纹的文件,再次审查它们
是否属于禁用文件,将确认为禁用文件的指纹添加到禁用指纹库;
4)考察文件名中不包含任何已有禁用词的禁用文件,审查其文件名中是否
有新的禁用词。
第 1 步只在初创禁用词表时做,而第 2-4 步是周期执行,通过人工参与和机
器学习,不断更新禁用指纹库和禁用词表。下面详细解释各个步骤:
1) 初步创建禁用词表。
这个步骤是人工收集能识别禁用文件的禁用词。这个步骤不要求禁用
词表规模很大,覆盖所有可能的禁用词,而是要求收集的禁用词有识别禁

北京大学硕士学位论文
- 26 -
用文件能力,误判率较低。
2) 用已有的禁用指纹库和禁用词表过滤每天的被下载文件。
这个步骤主要是根据已有过滤资源筛选禁用文件。其中,禁用文件有
三类:第一类文件名中含有禁用词,同时文件指纹属于禁用指纹库;第二
类是文件名中含有禁用词,但文件指纹不属于禁用指纹库;第三类是文件
指纹属于禁用指纹库,但文件名中没有已有的禁用词出现。对于第一类文
件,不作后续处理;对于第二类文件,在第 3 步中进行处理,据此更新禁
用指纹库;对于第三类文件,在第 4 步中处理,据此更新禁用词表。
3) 考察文件名含有禁用词,但不具备禁用文件指纹的文件,审查它们是否属
于禁用文件,将确认为禁用文件的指纹添加到禁用指纹库。
这个步骤更新禁用指纹库,将新的禁用文件指纹入库。这个步骤的关
键是审查禁用词表法判断的准确性。因为存在用户在正常文件的文件名中
加入禁用词以吸引下载,这种情况会造成对正常文件的误判。对过滤的准
确性的审查可以是人工审查或者机器审查。
人工审查是 正确的。管理员可下载具有该指纹的文件,通过观看文
件内容判断文件是否属于禁用文件。不过,这种审查方式,代价太高,需
要非常多的人工参与。只能偶尔对一些争议性高,影响重大的文件,进行
如此审查。
机器审查则是收集所有具有候选禁用指纹的文件的文件名,再对这些
文件进行禁用词表法过滤,当判断为禁用文件的比例超过设定阈值时才将
该指纹加入到禁用指纹库。这种审查方式方便,可作为日常更新所用的审
查方式。
4) 考察文件名不包含任何已有禁用词的禁用文件,看其文件名中是否有新的
禁用词。
这个步骤发现新的禁用词,更新禁用词表。首先对其文件名进行切词;
然后对所得每个词,计算其在禁用文件文件名库中出现频率,求得该词对
禁用文件的识别率;再对这些词,计算其在正常文件文件名库中出现频率,
求得该词的误判率。将综合识别能力高于设定阈值的词添加到禁用词表
中。

北京大学硕士学位论文
- 27 -
综上所述,设计过滤库更新算法,并列于下方:
5.4 Maze 系统的禁用文件控制机制
对于基于 P2P 的内容交换系统,因其自由的特性,禁用文件在资源中所占的
比例远高于社会其他传播渠道中的比例,因此对禁用文件的控制成为 P2P 网络重
要的课题。
Maze 系统的架构是集中式,可以采取中央发起的方式,对禁用文件进行控制。
Maze 系统的禁用文件控制机制,分为两个部分:

北京大学硕士学位论文
- 28 -
1) 禁用指纹库和禁用词表的更新。
这两项数据是禁用文件控制机制的基础,其更新方法如上所述。根据
Maze 系统的实际运行,而禁用指纹库则在不断的增加,每天约增加 62
项,禁用指纹库中已有 25842 项禁用文件指纹;禁用词表现在采用人工修
改方式更新。当然,其中仍存在误判率的问题,在 Maze 系统中,采取宁
枉勿纵的原则,尽可能的消除禁用文件的影响。
2) 对禁用文件的控制。
对禁用文件的控制分为两个部分,客户端和服务器端。
禁用词表较稳定,规模较少,且识别文件时的计算量较大,因此将禁
用词表加密后置于客户端。当用户共享资源时,用禁用词表对共享资源进
行审查,将禁用文件进行屏蔽,不予提供服务,且对该用户提出警告或惩
罚。
禁用指纹库在持续更新,而且库的规模较大,若将其放在客户端,同
步的代价较高,因此将禁用指纹库放在服务器端。服务器端用禁用指纹库,
审查 Peer 上传的共享资源列表,将禁用文件踢出服务范围,并对禁用 Peer
进行警告或惩罚。
Maze 系统的禁用文件控制机制,通过不断的更新禁用指纹库和禁用词表,能
识别新的禁用文件资源,从资源和 Peer 两个层面进行禁用文件的控制,减少了禁
用文件的传播,极大净化了 Maze 社区。
5.5 本章小结
首先,本章介绍了文件指纹搜索方式。文件指纹搜索方式是对具体目标文件
的深入搜索,发现目标文件的所有可下载源。本章对文件指纹搜索方式的需求背
景、原理和在 Maze 系统中的应用逐一做了介绍。
然后,本章介绍了禁用文件的控制机制。在 5.3 小节提出采取禁用指纹库和禁
用词表相结合的识别机制,以及它们的更新机制。在 5.4 小节,介绍了 Maze 系统
中的禁用文件控制机制,结合客户端和服务器端,从资源和 Peer 两个层面控制禁
用文件的传播,净化 Maze 社区。

北京大学硕士学位论文
- 29 -
第六章 ResourceRank 算法
6.1 引言
近年来,P2P 网络中用户信誉的评估一直是研究的热点。P2P 网络的开放性和
匿名性,大量不真实的文件迅速传播。对此,[Kamvar, et al., 2003]提出名为
EigenTrust 的信誉系统,通过下载 Peer 根据所下载文件对被下载 Peer 进行评分,
计算每个 Peer 的全局信任值,从而辨别恶意 Peer。[Li, et al., 2004] 也采取 Peer
根据交易情形对交易另一方进行评价反馈,同时结合交易方的反馈的可信任度等
综合评定 Peer 的信誉值。另外[Kung, et al., 2003]提出基于特征向量的信誉系统,
利用 Peer 之间的下载关系,计算 Peer 的服务分数和消耗分数,通过对服务分数
和消耗分数的比较,激励 Peer 共享资源。上述研究,都着眼于 Peer 的信誉,通
过分析 Peer 与 Peer 之间的交互行为或相互评价,进而获取各个 Peer 的全局信誉
值。在搜索引擎方面,[Page, et al., 1998]提出 PageRank 算法,通过网页间的链接
关系,对 web 中核心资源――网页进行全局的评价。
不同于前面所提到的论文的研究中心是 Peer,本章重点研究 P2P 系统中的文
件资源的价值。基于内容共享的 P2P 系统的核心资源是文件资源,只有文件资源
才直接满足 Peer 的需求。在 P2P 系统中,各文件资源受欢迎程度有着极大不同。
根据[liu , et al., 2005]所述,在 2004/12/1 到 2005/3/21 期间中,maze 网络中存在过
300 万个唯一文件资源,其中只有 1.7%曾经被人下载过;且各文件资源被下载次
数呈重尾分布。由此可见,对文件资源进行评价,区别对待不同文件资源,有利
于给用户提供更好的服务。
本文从文件资源和 Peer 之间的互动关系入手,提出基于下载行为的投票模型,
进行资源评价,称其为 ResourceRank 算法。投票模型用 Peer 的下载行为模拟投
票行为,用资源的得票数模拟资源的价值,用 Peer 被下载情况模拟 Peer 的投票
权。我们利用 ResourceRank 算法所得的资源评价,可以对返回资源结果进行合理
排序,以及选择性索引文件资源。

北京大学硕士学位论文
- 30 -
6.2 基于下载行为的投票模型
基于下载行为的投票模型的组成要素是 Peer、资源和下载行为。Peer 是投票
者,拥有投票权,即它可对资源进行投票;并且不同 Peer 可能拥有不同数量的投
票权。资源是候选物,它接受 Peer 的投票,将所得 Peer 投票,汇总成资源得票
数。下载行为模拟 Peer 对资源的投票行为。
投票模型的基本思想为:每个 Peer 拥有一定的投票权,它的每次下载就是给
所下载资源投票,若一个 Peer 下载了多个资源,则该 Peer 的投票权按下载次数
的比例分别投给这些资源;Peer 投票权则是由其上的资源被下载情况决定,与被
下载次数和被下载资源的价值都相关。
下面举一个例子,说明投票过程。
图 6-1 虚拟 P2P 网络及其下载行为矩阵
注:圆代表 Peer,矩形代表资源;从 Peer A 到资源 a 的虚
有向线表示 Peer A 下载了资源 a,从资源 a 到 Peer B 的实
有向线代表有 Peer 从 Peer B 上下载了资源 a。
在图 6-1 中的 P2P 网络中,有 A、B、C 三个 Peer,以及 a、b、c 三个资源,
在此中发生了四次下载:( A,B,a)、(A,C,b)、(B,A,c)、(C,B,c)。
(注:(A,B,a)表明 peer A 从 Peer B 下载资源 a )
设 Peer B 的投票权为 1,它有一次下载:(B,A,c)。我们来分析一下 Peer B
的下载引起的变化:
1) 考察资源 c 的得票数变化。Peer B 只下载了资源 c,那么 Peer B 对资
源的投票权全部投给资源 c,于是资源 c 的得票数增加 1。

北京大学硕士学位论文
- 31 -
2) 考察被下载 Peer A 的投票权变化。资源 c 的得票数增加了 1,但它增
加的部分并不是完全投给 A,因为 Peer B 也被下载资源 c,所以资源 c
增加的得票数平均分配给 Peer A 和 Peer B,于是 Peer A 的投票权增加了
0.5,Peer B 的投票权也增加了 0.5。
从上面分析可以看出,Peer B 的下载行为对所下载资源 c 的得票数有影响,
且对被下载 Peer A 的投票权有影响,同时还影响了未参与此次下载行为的 Peer B
的投票权。Peer B 投票权的变化是由于它所共享的资源 c 的得票数的增长所带来,
这合乎我们对 Peer 投票权的定义--不仅取决于下载次数,而且取决于其被下载
资源的价值。
6.3 投票模型解释
投票模型的设计目的是对资源价值进行评价。投票模型采用 Peer 的下载行为
模拟投票行为,对不同 Peer 根据被下载情况赋予不同的投票权,采用资源得票数
模拟资源的价值。
首先,下载行为是关于资源的 重要的行为。只有当 Peer 认为资源能够满足
它的需求时,下载行为才会发生。因此下载行为就是 Peer 对资源的认可,模拟投
票行为正是合适。
其次,区别对待 Peer,有助于体现 Peer 的影响力。我们用 Peer 的资源被下载
情况来决定 Peer 投票权,是基于假设:被下载资源总价值越高的 Peer,投票权应
该越大。其中 Peer 的被下载资源总价值取决于 Peer 的被下载次数和被下载资源
的价值。如果排除网络方面的因素,一个 Peer 被下载资源总价值越高,说明它在
资源内容方面更吸引人,因此该 Peer 越受信任,对整个 P2P 社区的影响就越大。
所以,在投票模型中,由 Peer 的被下载情况决定 Peer 投票权,更容易体现资源
潜在的影响力。
后,资源得票数体现了资源在网络中被使用的情况,资源得票数越高,说
明该资源被下载次数越多,或下载该资源的投票权越高,因此其潜在价值也就越
高。所以,在投票模型中,用资源得票数模拟资源价值。

北京大学硕士学位论文
- 32 -
6.4 投票模型的数学表示
我们定义向量 V 表示网络中 Peer 的投票权向量,定义向量 R 表示网络中资源
的票数向量。再定义矩阵 DM 表示下载矩阵,DM(i,j)表示 Peer j 下载资源 i
的次数;定义矩阵 UM 表示上传矩阵,UM(i,j)表示 Peer i 上传资源 j 的次数。
我们可用下载矩阵和 Peer 投票权向量计算资源得票数向量,
R k=DM ·V k (1)
用上传矩阵和资源得票数向量计算 Peer 投票权向量,
V k+1 = UM·R k (2)
合并(1),(2),我们直接用 Peer 投票权向量计算下一轮 Peer 投票权向量
V k+1 =UM·DM·V k (3)
设 Peer 投票权向量 V为公式(3)迭代计算的平衡值,资源得票数向量 R则为
R=DM·V (4)
6.5 投票模型中的特殊 Peer 结构和改进
在投票模型中,存在一些特殊的 Peer 结构,会对投票模型产生不良影响。下
面逐一讲述各种特殊的 Peer 结构,并阐述其引起的影响和改进方法。因为资源得
票数 R 可由 Peer 投票权 V 计算可得,所以下面对投票模型的讨论,只关注 Peer
投票权的变化,暂时忽略中间资源得票数。
6.5.1 只上传 Peer
在网络中存在一些只上传资源,而从未下载资源的 Peer,如图 6-2 中的 Peer C。
图 6-2 只上传 Peer

北京大学硕士学位论文
- 33 -
对于只上传的 Peer,它们的投票权从未投给任何资源,对于整个系统来说,
这些 Peer 的投票权会逐渐的流失,导致整体投票权减少。显然,若把这部分流失
的投票权一直累加在这些 Peer 上,那么所有投票权都会沉积于这些 Peer 上。因
此,对只上传 Peer 应当进行特殊处理,或者隔离只上传 Peer,或者将只上传 Peer
的投票权分散到其他 Peer。下面逐一说明。
第一种解决方法是,将只上传 Peer 隔离出来,先利用其他 Peer 计算资源价值,
后根据这些 Peer 的被下载情形计算投票权。因为只上传 Peer 没有对特定资源
的投票,所以先抛开它们,对资源价值计算并无影响。
但需要注意的是,以图 5-2 为例,隔离出 Peer C 以后,Peer B 对资源 b 投票
的有效性也需进一步的讨论。如果只有 Peer C 拥有资源 b,那么资源 b 也应被隔
离出系统;否则,因为投票会沉积在资源 b 上,同样会导致整体投票权的减少。
如果资源 b 也被隔离,而且 Peer B 只下载了资源 b,隔离资源 b 后,Peer B 成为
了新的“只上传”Peer,因此 Peer B 也应该被隔离出来。因此,隔离只上传 Peer,
在新的网络中有可能出现新的“只上传”Peer,需要多次反复隔离。
第二种解决方法是,将只上传 Peer 的投票权,以某种形式散布到整个网络。
有两种可选择的投票权分散方案。或者认为只上传 Peer 对所有的资源持相同看
法,将投票权平均投给所有资源;或者将只上传 Peer 的投票权,平均分给网络中
的所有 Peer,让它们代为执行投票权。认为后者较好,因为前者资源平等的假设
无法体现出资源之间的实际使用情况不一。
6.5.2 只下载 Peer
网络中还存在一些只下载资源、而从未上传资源的 Peer,如图 5-3 的 Peer A。
图 6-3 只下载 Peer

北京大学硕士学位论文
- 34 -
根据 Peer 投票权由 Peer 的被下载情况决定的假设,只下载 Peer 的投票权为
0,那么投给所下载资源的票数也为 0,也就是只下载 Peer 的投票无效。从只下
载 Peer 延伸出来,某些与只下载 Peer 有关联的 Peer 的投票权也为 0。如图 5-3
中所示,不仅 Peer A 因无上传,投票权为 0,而且还有 Peer B 和 Peer C 的投票
权也都为 0。综上所述,只下载 Peer 的影响,仅在于由于自身的投票权为 0,可
能使得网络中的许多下载行为失去投票价值,并不影响整体网络,故不对只下载
Peer 做特殊处理。
6.5.3 投票闭环群
我们将具有下列性质的 Peer 的群体称为投票闭环群:
A. 群内 Peer 只下载群内特有资源
B. Peer 之间的下载关系形成环
注:群内特有资源指的是只能从该群的 Peer 下载,不可能从群外 Peer 下载
的资源。
图 6-4 投票闭环群
图 5-4 中,Peer A、B、C 形成了一个投票闭环群。资源 a、b、c 是这些 Peer
特有的资源,且下载关系形成了环。显而易见,Peer A、B、C 的投票权只在这个
投票闭环群内流动。如果没有外界 Peer 对投票闭环群所拥有的资源进行投票,该
群的总投票权将保持不变。如果在这个投票闭环群之外,有 Peer 对该投票闭环群
所拥有的资源进行投票,那么这些 Peer 的投票权将向该投票闭环群流动,使得投
票权在投票闭环群内逐渐沉积, 终致使其他与该投票群有关联的 Peer 投票权均
为 0。因此,投票闭环群的存在将影响对资源价值的合理评估,需采取方案阻止
投票权在投票闭环群中的沉积。

北京大学硕士学位论文
- 35 -
可以引入补偿向量 E 减少投票闭环群的影响。向量 E 是参与补偿的向量,可
以保证 Peer 流向投票闭环群的投票权不断减少,直到无限趋近于 0。向量 E 对与
投票闭环群有关联的 Peer 进行补偿,使得这些 Peer 的投票权保持在一定水平,
防止了投票权在投票闭环群中的沉积。于是,投票权向量迭代公式变成:
V k+1=c*UM·DM·V k +c*E (5)
(参数 c保证向量||Vi|| =1)
6.5.4 独立 Peer 群
我们把具有以下性质的 Peer 的群,称为独立 Peer 群:
A. 群内的 Peer 只给该群特有资源投票
B. 群外的任何 Peer 都不给该群所拥有的资源投票
从以上性质可以推理出独立 Peer 群的一个性质:在原始的投票模型中,独立
Peer 群间互不影响,没有任何投票权流动。因为在原始的投票模型中,独立 Peer
群间互不投票,其投票权只在群内的 Peer 间流动,没有群间的投票权流动。而且,
如果独立 Peer 群内没有只上传 Peer,那么独立 Peer 群的总投票权保持恒定。
图 6-5 多个独立 Peer 群
独立 Peer 群的存在给原始投票模型提出了另一个问题:初值设定的影响。如
图 5-5 所示,网络中有两个独立 Peer 群,因为独立 Peer 群间没有投票权的流动,
所以这两个群的平衡时的总投票权只取决于投票权初值设定方式。这违背了投票
权初值设定和 终平衡结果不相关的 初设想。
所幸,在网络中出现独立 Peer 群的概率较小。独立 Peer 群的第一个性质,
群内 Peer 只下载群特有资源,则要求独立 Peer 群的规模要足够的大。试想构造
一个包含 Peer A 的独立 Peer 群。当 Peer A 下载一个资源,那么独立 Peer 群必

北京大学硕士学位论文
- 36 -
须包含所有拥有该资源的 Peer,该独立 Peer 群的扩张速度较快。而独立 Peer 群
的第二个性质,群外 Peer 不曾下载过群内拥有的资源,则要求独立 Peer 群的规
模要小。否则,独立 Peer 群较大,那么拥有很多的资源,群外 Peer 从不下载该
群内的资源概率就非常小。
虽然独立 Peer 群存在的概率较少,但我们还是来关注以下初始投票权的设定。
独立 Peer 群拥有 Peer 和资源构成,因此初始投票权的设定可有两种方式:
以 Peer 为中心。 初,认为所有 Peer 是平等的,拥有相同的投票权,初
始投票权向量 S 为全 1 向量。独立 Peer 群的初始投票权总值为该群的 Peer
数。
以资源为中心。 初,认为所有资源是平等的,具有相同的价值。那么初
始投票权向量 S 为:S= UM·1 (1 为全 1的向量,下面同此)。独立 Peer
群的初始投票权总值为该群的资源数。
6.5.5 模型的改进
由于投票闭环群的存在,我们需要将投票权向量 V 的迭代公式进行修改,其
中关键的是补偿向量 E 的设定。考察公式(5),当 c≥1 时,投票闭环群内的总
投票权保持递增,而与其相连的 Peer 和只上传 Peer 的投票权向其流入,依然存
在投票权沉积的问题,故公式(5)的 c必须小于 1。由此可见,补偿向量 E不仅
是对只上传 Peer 的补偿,将其投票权代投给模型中的所有 Peer,而且也将其他
Peer 的部分投票权,分散到模型中的所有 Peer。那么,补偿向量 E受如下限制。
||E ||1 >||V k ||1 - ||UM·DM·V k ||1 ≥0 (6)
因为||V k||=1,因此公式(5)可变为:
V k+1=Anew·V k (7)
Anew=c*( UM·DM + E× 1´ ) (8)
且 ||E ||1 > ||V k ||1 - ||UM·DM·V k ||1
通过补偿向量 E 解决了只上传 Peer 和投票闭环群对投票模型的影响。
至于独立 Peer 群的影响,没有好的办法避免它,因此只关注初始投票权 S 的
设定,采取上一小节所述的两种设定,并加以比较。对 2006 年 3 月 15 日至 3 月

北京大学硕士学位论文
- 37 -
21 日的下载日志进行分析,其中共有 50642 个 Peer 参与,共有 721777 次下载行
为,采用上一小节所述的两种不同设定,设其平衡状态下投票权向量各为 V p
和 V r,则有||V p-V r||2 约为 0.0003。可以看出 V p 和 V r 之间的差异非常的小,几
乎可以认为两者的投票权相同。由此可见,在 Maze 系统中独立 Peer 群出现概率
较小,影响极微。在后续研究中,初始投票权向量 S 设定为全 1 向量
6.6 算法
若不考虑规模的影响,ResourceRank 算法十分简单,只需迭代计算 Peer 投票
权 V i,求得平衡值 V,再由平衡值 V 求得资源评价 R。算法如下所示:
在迭代过程中,||V i ||1 将保持不变,恒为||S ||1,一般设为 1。并且由于补偿向
量 E 的存在,使得 V i 的变化不断减少, 终使其收敛到 V。
6.7 收敛性
ResourceRank 算法之所以能迅速收敛,得益于矩阵 Anew对应的有向图,是一
个近似的 expander 图。一个有向图被认为是 expander 图,必须具有性质:图中任
何一个节点集 S(该节点集规模不太大)的邻居节点集的规模不小于|S|*a;a是
图的扩大因子。一个图的扩大因子a较大,当且仅当该图对应矩阵的 大特征值
远大于第二大特征值。

北京大学硕士学位论文
- 38 -
下面简单的讲述一下随机漫步理论。随机漫步是一个随机过程。在图上随机
漫步,指在任何一个给定的时间,我们处于图中特定的一个节点,然后随机的选
择一条出去的边,决定下一时间访问的节点。如果在图上的随机漫步迅速收敛到
在图中节点的有限分布,那么说它是快速 mixing 的。随机漫步是快速 mixing 的,
当且仅当这个图是 expander 图或其对应的矩阵只有一个特征值。
而 ResourceRank 计算可以转化为求在 Anew对应的有向图上随机漫步的有限分
布。Peer 的投票权可以转化为,在 Anew对应的有向图上随机漫步足够长的时间,
停留在该 Peer 的概率。因为 Anew 对应的有向图是一个 expander 图,那么在图上
的随机漫步能迅速收敛于在节点上的有限分布,所以 ResourceRank 算法迅速收
敛。
图 6-6 ResourceRank 计算的收敛情况
对 2006 年 3 月 15 日至 3 月 21 日的下载日志进行分析,其中共有 50642 个
Peer 参与,共有 721777 次下载行为,取 E=0.4* 1 (1 为全 1 向量)。收敛情况如图
6-6 所示。
6.8 资源评价的应用
在 Maze 社区中有上亿的文件资源,但真正为用户所交换的文件资源却不过几
百万个而已。因此,有必要对 Maze 社区中的文件进行热门度的区别,对它们提

北京大学硕士学位论文
- 39 -
供不同的服务。ResourceRank 算法计算所得的资源评价主要用于查询结果排序。
结合资源评价和其他因素,如站点信息、镜像数目等等,一起对查询查询结果进
行排序,以期给用户提供 好的结果。
6.9 查询结果排序
本小节利用上文所述的 ResourceRank 算法,同时结合其他 Peer 或资源属性,
提出一个查询结果排序算法。
将查询结果进行排序,是非常有必要的。对于一些常用的查询词,一般有成
百上千的相关文件,而用户能够关注的通常只有 靠前的几十条文件信息。因此
对查询结果进行合理排序,优先显示 有价值的文件信息,将给用户带来更好的
使用体验。
用户评价一个查询结果,除了关注文件资源价值,还有文件的查询相关性,
还有非常重要的可下性。文件资源价值,在前文已做详细描述,主要是满足用户
需求的能力。查询的相关性则指文件资源内容和查询词的相关性,这点对查询结
果排序尤为重要,因为用户只关注想要的资源。还有就是可用性,在内容共享系
统,用户的 终目的是下载所要的资源,提交查询只是定位文件来源,更重要的
是根据返回的查询文件信息下载文件,因此返回文件信息中提供的文件能否下载,
也是结果排序的重要因素。下面,逐项讲述各因素。
首先,查询相关性是指查询结果文件内容和查询词的相关性。Maze 网络中具
有各式各样的文件,除去文本文件,其他文件唯有文件名属性能直接体现文件内
容。我们通过文件名和查询词的相关度,来表示内容和查询词的相关度。总而言
之,查询相关性取决于各个拷贝的文件名和查询词的相关。
其实,为了真正体现文件的内容,我们需要收集另外的文件信息,比如从网
上收集文件描述,深入表征文件内容;在详尽的文件内容描述前提下,查询相关
度才能比较准确的刻画;本文不作深入讨论。
其次,资源重要性则指查询结果文件价值。可由 ResourceRank 属性来衡量已
出现过的资源的价值,ResourceRank 属性高的资源具有更高价值。对于未出现过
的资源内容,根据他们所在的站点的 ResourceRank 属性进行资源重要性评价。总

北京大学硕士学位论文
- 40 -
而言之,资源重要性取决于资源的 ResourceRank 属性或该拷贝所在 Peer 的重要
性。
后,可用性指其来源的网络状态,这是内容共享系统中非常重要的一个性
质。对于返回的结果文件,通常有多个拷贝,因此返回结果文件的可用性决定于
拷贝的数目和各个拷贝所在 Peer 的可靠性。在中国,因为 IP 资源的缺乏,有非
常多的 Peer 是在内网中,他们之间的通信非常困难;此外,公网和教育网分离,
两者相对独立,它们之间的接口带宽严重不足,通讯能力也有所欠缺。因此每个
Peer 拥有两个网络属性:一是内/外网属性,取决于 Peer 是否拥有独立 IP;二是
心跳服务器序列号属性,是 Peer 所注册的心跳服务器序列号,可以认为在同一个
心跳服务器注册的 Peer,通常是属于相同类型的网络。此外每个 Peer 的投票权也
能够部分的体现 Peer 的可用性程度,因此将 Peer 投票权作为可用性的考虑参数。
总而言之,返回结果的可用性取决于拷贝的数目和各个拷贝所在 Peer 的三个网络
属性。
这三个方面的因素重要性各有不同。首先查询相关度应是 重要的参数,用
户只要她需要的文件;其次可用性因素权重较高,若无法下载,再好的文件也是
无用的; 后是资源的重要性。可将网络的可用性因素分成几个级别,在同等级
别的可用性因素上考虑资源的重要性。 后是文件重要性参数,将价值高的文件
排在前方。下图是对两个返回文件结果比较算法,返回 true 表示前者应排在前方。

北京大学硕士学位论文
- 41 -
6.10 本章小结
本章首先重点介绍资源和 Peer的评价机制,然后结合资源和 Peer的评价机制,
介绍 Maze 系统返回结果排序方法。
6.1-6.8 小节,介绍资源和 Peer 的评价机制。本文构造投票模型对资源和 Peer
进行评价,投票模型的主要思想是,根据 Peer 被下载状况确定 Peer 的投票权,
Peer 下载资源就是对该资源的投票。根据 Peer 的投票权来确定 Peer 的重要性,
根据资源的得票数确定资源的价值。在后续的小节中,对投票模型的问题和算法
等逐一进行介绍,并对 ResourceRank 算法的收敛性和资源评价的应用略作探讨。
6.9 小节介绍 Maze 系统结果排序方法。本文从相关度、文件价值和可下载性
三方面对返回结果进行评价,并介绍 Maze 系统中的结果排序算法。

北京大学硕士学位论文
- 42 -
第七章 总结与未来展望
7.1 总结
本文的研究重点是检索系统效率研究和文件资源性质研究。选择这两项课题
作为毕业论文的主题,是因为检索效率对集中架构的 P2P 系统尤为重要,而且研
究文件资源的性质有助于开展有特色的服务,因此在这两个方面的研究非常有意
义。
首先,本文在下列几个方面对检索效率进行改进:
1. 定义新的倒排文件格式,将 Peer 信息加入倒排文件中,支持更早对相关
结果进行 Peer 在线属性的过滤,减少中间数据规模。
2. 改进数据压缩编码,使倒排文件规模变小,从而减少倒排文件的内存空间,
也减少了检索时需要从磁盘读取的数据量。
3. 建立基于 Peer 的多级缓冲机制,提高了缓冲效果,减少了磁盘访问次数。
结合以上三个因素,使得新系统的性能比原有系统确实有所提高。
然后,本文根据 Maze 社区中的资源性质,提出:
1. 文件指纹搜索方式,是传统的文件名搜索方式的补充,可对具体的目标文
件进行深入搜索。
2. 禁用文件控制机制,结合禁用指纹库和禁用词表,识别禁用文件,从 Peer
和资源两个层面,控制禁用文件的传播。
3. ResourceRank 算法,建立基于下载行为的投票模型,对 Maze 社区中的资
源进行评价。
4. 返回结果排序算法,结合 Peer 属性、资源属性和查询词信息,综合评价
返回结果的重要性,给用户优先返回更有价值的资源信息。
以上技术和算法的提出, 终目的在于给用户提供高价值的、下载速率快的
资源,使用户获得更好的用户体验。但鉴于用户体验难以评估和时间限制,本文
没有进行效果评估实验,有所不足。在后续研究工作中,将探讨用户体验评价模

北京大学硕士学位论文
- 43 -
型,对以上技术和算法进行效果评价。
7.2 不足与展望
在研究的过程,有所收获的同时,也发现了系统的诸多不足:
1. 本文采用双字节为索引词,并没有对文件名进行切词。
如此处理的主要原因是考虑到文件名较短,且命名比较不规则。但研
究过程中发现,虽然文件命名不规则,但用户感兴趣的文件大部分为命名
比较有规则的文件。现采用如此简短的索引词,使其对应的倒排列表通常
比较长,致使检索处理时间较长。采用中英文切词技术,以词或短语作为
索引词,应能再次提高检索系统的性能。
2. 磁盘访问仍然是检索效率的瓶颈。
尤其在高负载的情况下,磁盘访问增多,限制了系统吞吐率的提高。
其中磁盘访问较多的过程是读取文件描述信息过程,因此再次优化文件描
述信息预读功能,应能减少磁盘访问次数。此外,异步 IO 能使多个 IO
被合并,有助于减少 IO 访问次数,使提高性能的一个方法,但异步 IO
实现比较复杂。
3. 检索效果评价缺乏。
本文没有进行检索效果评估,只能定性的描述各种技术和算法对检索
效果的影响。这是后续工作中非常重要的一部分。
4. 未能充分利用文件指纹,建立以文件指纹为主键的资源信息库
文件指纹将处于不同 Peer 的资源联系到一起,是资源唯一性的标识。
建立以文件指纹为主键的资源信息库,可以发现资源的更多的描述信息,
使其不仅仅依赖于文件名信息,此外还可融入禁用文件审查信息和资源评
价信息等等。而且,将资源信息库作为检索系统的核心,减少了资源同镜
像聚合代价,可以提高检索系统性能。
鉴于时间和能力限制,本文未能对上述不足进行深入研究,只能留待后续工
作的改进。
后,期待本文能对检索系统的性能研究和资源性质研究有所帮助。

北京大学硕士学位论文
- 44 -
参考文献
[Kamvar, et al., 2003] S. D. Kamvar, M. T. Schlosser, and H. Garcia-Molina , “The EigenTrust
Algorithm for Reputation Management in P2P networks”, In Proceedings of the Twelfth
International World Wide Web Conference,2003.
[Kung, et al., 2003] H. T. Kung and C. Wu. “Differentiated Admission for Peer-to-Peer Systems:
Incentivizing Peers to Contribute their Resource”, In Workshop on Economics of Peer-to-Peer
Systems, 2003.
[Li, et al., 2004] Li Xiong and Ling liu, “PeerTrust:Supporting Reputation-Based Trust for
Peer-to-Peer Electronic Communities”, IEEE Transactions on knowledge and data Engineering, vol.
16, NO.7, pp.843-857, 2004.
[liu , et al., 2005] Hanyu liu, Yu Peng, Mao Yang and Yafei Dai, “Characterization of P2P
File-Sharing System”,in the proceeding of International workshop AEPP’05,2005
[Long, et al., 2005] Long Xiaohui and Torsten Suel. “Three-level caching for efficient query
processing in large Web search engines”, In Proceedings of the 14th international Conference on
World Wide Web (Chiba, Japan, May 10 - 14, 2005). WWW '05. ACM Press, New York, NY,
257-266.
[maze] 北大 Maze 系统,http://maze.tianwang.com
[Moffat and Zobel,1996] A. Moffat and J.Zobel, “Self-indexing inverted files for fast text
retrieval”, Acm Transactions on Information Systems, vol. 14, pp.349-379, 1996.
[Page, et al., 1998] L.Page, S.Brin, R.Motwani, and T.Winograd. “The PageRank Citation Ranking:
Bring Order to the Web”, Technical report, Stanford Digital Library Technologies Project, 1998.
[Scholer, et al.,2002] F. Scholer, H. E. Williams, J. Yiannis, and J. Zobel, “Compression of inverted
indexes for fast query evaluation”, presented at proceedings of the Twenty-Fifth Annual
International ACM SIGIR Conference on Research and Development in Information Retrieval, Aug
11-15 2002,Tampere, Finland, 2002.
[Tsoumakos, et al., 2003] D.Tsoumakos and N. Roussopoulos, “A Comparison of Peerto -Peer

北京大学硕士学位论文
- 45 -
Search Method”, In WebDB, 2003.
[Witten, et al., 1999] I. Witten, A. Moffat and T. Bell. “Managing Gigabytes: Compressing and
Indexing Documents and Images”, Morgan Kaufmann Publishers, Los Altos, CA 94022, USA,
second edition, 1999.
[Xie, et al., 2002] Y. Xie and D. O’Hallaron. “Locality in search engine queries and its implications
for caching”, In IEEE Infocom 2002, pages 1238-1247, 2002.
[彭波, 2003] 彭波,“搜索引擎检索系统的效率优化与效果评估研究”,北京大学,博士论文。
[谢翰, 2005] 谢翰,“海量文档高速检索系统的设计与实现”,北京大学,硕士论文。

北京大学硕士学位论文
- 46 -
致 谢
回想三年的硕士研究生生涯,我的心中充满了感激之情。
首先,我要衷心感谢我的导师李晓明教授。在研究生的第一年,李老师在组
会上的发言,让我初步了解做学问的方法,更体会了做学问的乐趣,使我真正了
解了研究生的含义。衷心的感谢李老师在这三年中给我的教导和关心!李老师严
谨的工作作风和对事业的无比热情,也让我万分敬佩。
感谢教导和帮助过我的各位老师。感谢闫宏飞老师、王继民老师和彭波老师
在第一学年对我的引导和帮助。感谢韩华老师和谢正茂老师在初到深圳研究院对
我们的照顾和在课题研究中所作的指导。感谢雷凯老师和魏伟老师,在课题研究
和论文写作过程中,他们给予了大量的指导和帮助,帮我解决了许多的困扰和难
题。
感谢陪伴过我的各位同学。感谢天网组的各位同学,有已毕业的张志刚、陈
华、谢欣、谢翰和刘哓丽,还有未毕业的陈翀、龚笔宏、孟涛、黄连恩和朱家稷。
感谢在深圳研究院朝夕相伴的各位同学,有和我同时毕业的胡景贺、陈昴、杨长
喜、李永华、辜炜东、梁冰、王东海和林彦彦,有未毕业的李勤飞、郭桦楠、赵
阳和刘轶群,还有后来的各位同学。感谢各位同学,有了他们的相伴,我的生活
才变得灿烂多彩。
感谢北大网络实验室的其他老师和同学的热情帮助和支持。
后,感谢我的父母亲。父母亲的爱是支持我努力奋斗的 大力量。有他们
在背后的默默支持,我才能度过种种难关,创造美好生活。

北京大学硕士学位论文
- 47 -
北京大学学位论文原创性声明和使用授权说明
原创性声明
本人郑重声明: 所呈交的学位论文,是本人在导师的指导下,独立进行研究
工作所取得的成果。除文中已经注明引用的内容外,本论文不含任何其他个人或
集体已经发表或撰写过的作品或成果。对本文的研究做出重要贡献的个人和集体,
均已在文中以明确方式标明。本声明的法律结果由本人承担。
论文作者签名: 日期: 年 月 日
学位论文使用授权说明
本人完全了解北京大学关于收集、保存、使用学位论文的规定,即:
按照学校要求提交学位论文的印刷本和电子版本;
学校有权保存学位论文的印刷本和电子版,并提供目录检索与阅览服务;
学校可以采用影印、缩印、数字化或其它复制手段保存论文;
在不以赢利为目的的前提下,学校可以公布论文的部分或全部内容。 (保密论文在解密后遵守此规定)
论文作者签名: 导师签名:
日期: 年 月 日