bug localization with machine learning techniques wujie zheng [email protected]
TRANSCRIPT


Background of Bug Localization Software is far from bug-free Debugging is a methodical process of finding
and correcting the bugs in a program Manual debugging is laborious and expensive It is possible to automatic or semi-automatic this
process Bug localization is to find a set or a ranking of
source code locations that are likely buggy through automatic analysis

Techniques of Bug Localization Program Slicing Experimental Methods Machine Learning Methods

Program Slicing
Debugging with Program Slicing Start from the inputs or the variables that cause the failure (but not root
cause), find all statements that may cause the failure Program Dependence Graph (PDG)
Control dependence Data dependence
Static Slice vs. Dynamic Slice Static slice: all statements that may affect the value of a variable at a
program point for any arbitrary execution of the program Dynamic slice: all statements that actually affect the value of a variable at a
program point for a particular execution of the program Forward Slice vs. Backward Slice
Forward slice: the statements that are affected by the value of variable v at statement s
Backward slice: the statements that affect the value of variable v at statement s
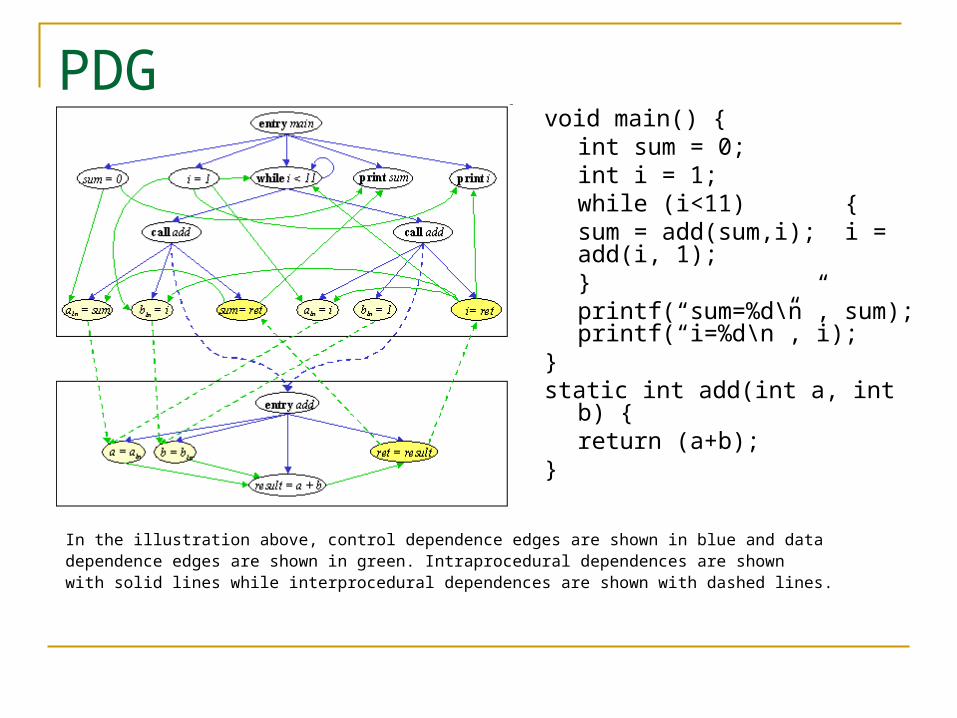
PDG void main() {
int sum = 0; int i = 1; while (i<11) {
sum = add(sum,i); i = add(i, 1);
} printf(“sum=%d\n”, sum); printf(“i=%d\n”, i);
} static int add(int a, int b) {
return (a+b); }
In the illustration above, control dependence edges are shown in blue and datadependence edges are shown in green. Intraprocedural dependences are shown with solid lines while interprocedural dependences are shown with dashed lines.

Experimental Methods
Delta Debugging Generalize and simplify some failing test case to a
minimal test case that still produces the failure Separate the test case into two sub tests, choose
the sub test that fails, and repeat the process. When both sub tests pass, perform another divide-and-test again
Essentially a binary search algorithm
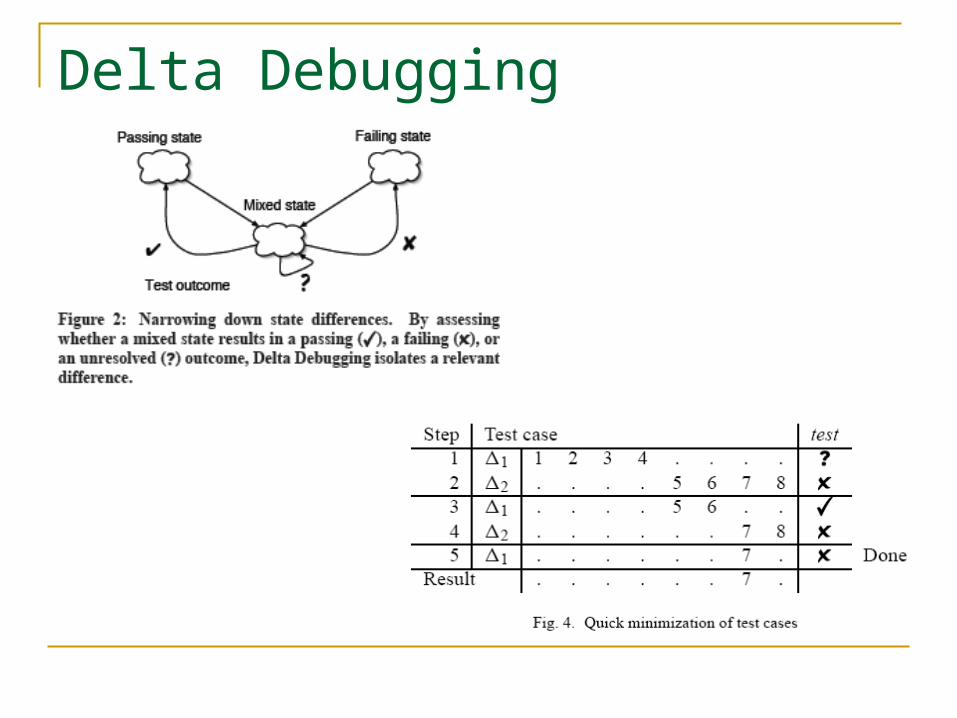
Delta Debugging

Machine Learning Methods
Problem Setting A set of failing and passing test cases are
observed (test cases as the samples) The statements are instrumented and some
traces are collected (statements as the features) Find a set or a ranking of the statements that are
likely buggy

Machine Learning Methods
Direct correlation analysis Tarantula LIBLIT05
Build a classification model of the test cases (feature selection) Logistic regression Decision tree
Build a behavior model of the statements from passing test cases, and then check violations in failing test cases Dynamic invariants SOBER PPDG

Tarantula
Visualization:

Logistic regression The logistic function
Maximize the likelihood of the training set
The regularization term
The input features are normalized first The larger the resulting coefficient is, the
more suspicious the statement is

Dynamic invariants
Given a set of test cases, mine the implicit rules over the variables
The templates Invariants over any variable: x=a … Invariants over two numeric variables: y=ax+b … Invariants over three numeric variables: y=ax+by+c … …

SOBER
SOBER [Liu05]
the probability density function of the evaluation bias of P on passing runs and failing runs respectively
The bug relevance score of P is then defined as the difference between them

Probabilistic Program Dependence Graph (PPDG) Conditional Independence
The state of a statement is independent of the previous statements conditioned on its immediate parents
Dependence Network Allow cycles, suitable for loops in programs
Usage in debugging The distributions of conditional probabilities are learned
from the passing runs The lower the conditional probability of a state has, the
more suspicious the statement it belongs to is

Our Work
Belongs to the group of “Build a classification model of the test cases (feature selection)” Association Rule Mining
The procedure Mine all the strong (high frequency and high confidence)
association rules X=>fail Select the rule X’=> with highest confidence (the best
classification model of this kind) Output the statement set X’ as the results
Problems: It is hard to justify that such rule (only conjunction phrase) based
model is suitable The resulting rule may contain lots of statements. Further ranking
scheme is still needed High computational overhead

Our Work
Belongs to the group of “Build a classification model of the test cases (feature selection)” Feature Subset Selection
The procedure Iteratively evaluates a candidate subset of features, then modifies
the subset and evaluates if the new subset is an improvement over the old.
Greedy forward selection Evaluation of the subsets requires a scoring metric that grades a
subset of features. F-measure (i.e., harmonic average of precision and recall,
1/(1/precision+1/recall)) Problems
Too simple, just a traditional method

How to improve the work?
Adopt the association rule mining method to mine the behavior models Association rule mining is better for mining
frequent patterns than building classification models
Difficulties: Usage pattern may dominate, while failure statements
related pattern may be not frequent If we consider relative frequent pattern for every
statements, there may be too many results to be mined and used effectively
Consider program dependence graph may help

How to improve the work?
Consider the debugging problem of specific bugs such as data race Data race is an important kinds of bugs, and it is
difficult to debug Sequential pattern mining? Combine dynamic analysis with machine learning
Existing dynamic analysis methods can provide valuable features, e.g., the potential data race in a certain execution (many false positives)

How to improve the work?
…

Other topics of automated debugging Failure classification
NLP Failure trace clustering NLP + Failure trace clustering
Failure replaying Record the failures in user sites compactly and
reproduce it in developer sites Debugging with replaying
Traverse to any point of an execution without restarting the program
Query the trace database

Thank you!