budapest spark meetup - basics of spark coding
TRANSCRIPT

Apache SparkMate Gulyas

CTO & Co-FounderGULYÁS MÁTÉ
@gulyasm

Getting Started

Spark CoreSpark SQLSpark StreamingMLlibGraphXCluster Managers
UNIFIED STACK
Spark CoreSpark SQLSpark StreamingMLlibGraphXCluster Managers

RDD API
Dataframe API
Dataset API
UNIFIED STACK
Spark Core
RDD API
Dataframe API
Dataset API

❏ Scala❏ Java❏ Python❏ R
WHICH LANGUAGE TO SPARK ON?

SPARK INSTALL

DRIVERSPARKCONTEXT

DRIVER PROGRAMYour main function. This is what you write.
Launches parallel operations on the cluster. The driver access Spark through SparkContext.
You access the computing cluster via SparkContext
Via SparkContext you can create RDDs.

❏ INTERACTIVE
❏ STANDALONE
A “SPARK SOFTWARE”

Resilient Distributed Dataset (RDD)
THE MAIN ATTRACTION

RDD

❏ TRANSFORMATION
❏ ACTION
OPERATIONS ON RDD

CREATES ANOTHER RDDTRANSFORMATION

CALCULATE VALUE AND RETURN IT TO THE DRIVER PROGRAM
ACTION
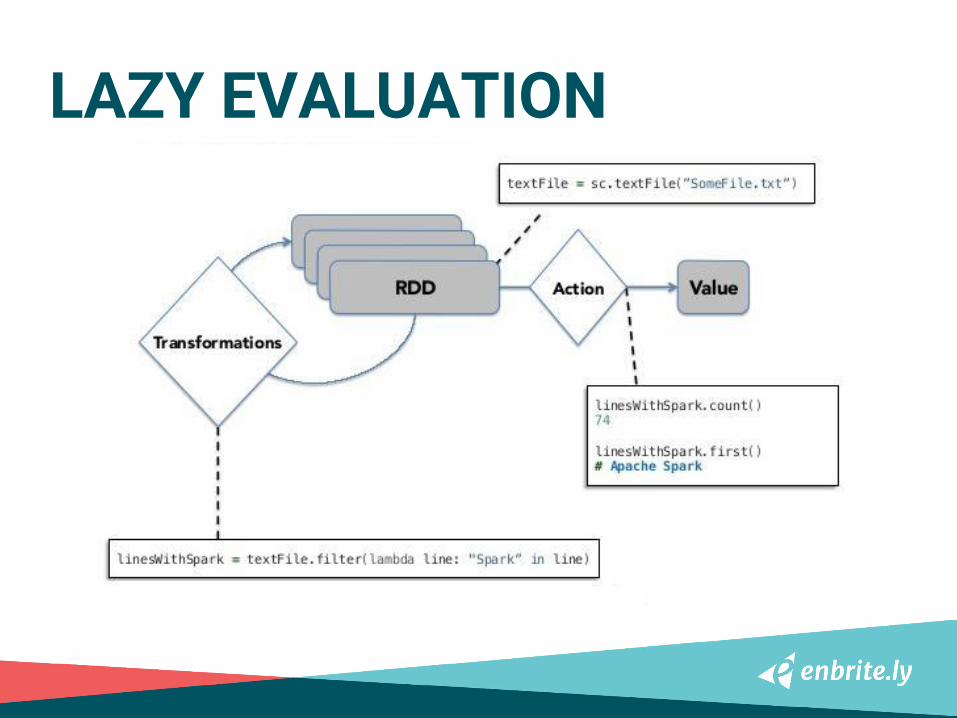
LAZY EVALUATION

INTERACTIVE

❏ The code: github.com/gulyasm/bigdata
❏ Databricks site: spark.apache.org
❏ User mailing list
❏ Spark books
MATERIALS


TRANSFORMATIONSACTIONSLAZY EVALUATION

LIFECYCLE OF A SPARK PROGRAM
1. READ DATA FROM EXTERNAL SOURCE
2. CREATE LAZY EVALUATED
TRANSFORMATIONS
3. CACHE ANY INTERMEDIATE RDD TO REUSE
4. KICK IT OFF BY CALLING SOME ACTION

PARTITIONS

RDD INTERNALS
RDD INTERFACE
➔ set of PARTITIONS
➔ list of DEPENDENCIES on PARENT RDDs
➔ functions to COMPUTE a partition given parents
➔ preferred LOCATIONS (optional)
➔ PARTITIONER for K/V pairs (optional)

MULTIPLE RDDs /** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
/** Implemented by subclasses to return the set of partitions in this RDD. */ protected def getPartitions: Array[Partition]
/** Implemented by subclasses to return how this RDD depends on parent RDDs. */ protected def getDependencies: Seq[Dependency[_]] = deps
/** Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations (split: Partition): Seq[String] = Nil
/** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None

INTERNALS

THE IMPORTANT PART
❏ HOW EXECUTION WORKS
❏ TERMINOLOGY
❏ WHAT SHOULD WE CARE ABOUT

PIPELINING
❏ Parallel to CPU pipelining❏ More steps at a time❏ Recap: computation kicks of when an
action is called due to lazy evaluation

PIPELINING
text = sc.textFile("twit1.txt")words = nonempty.flatMap(lambda x: x.split(" "))fwords = words.filter(lambda x: len(x) > 0)ones = fwords.map(lambda x: (x, 1))result = ones.reduceByKey(lambda l,r: r+l)result.collect()

PIPELINING
text = sc.textFile( )words = nonempty.flatMap( )fwords = words.filter( )ones = fwords.map( )result = ones.reduceByKey( )result.collect()

PIPELINING
sc.textFile( ) .flatMap( ) .filter( ) .map( ) .reduceByKey( )

PIPELINING
sc.textFile().flatMap().filter().map().reduceByKey()

RDD RDD RDD RDD RDD
textFile() flatMap() filter() map() reduceByKey()
text resultwords fwords ones
PIPELINING

PIPELINING
def runJob[T, U]( rdd: RDD[T],partitions: Seq[Int], func: (Iterator[T]) => U)
) : Array[U]

RDD RDD RDD RDD RDD
textFile() flatMap() filter() map() reduceByKey()
text resultwords fwords ones
collect()
PIPELINING

JOB
❏ Basically an action
❏ An action creates a job
❏ A whole computation with all dependencies
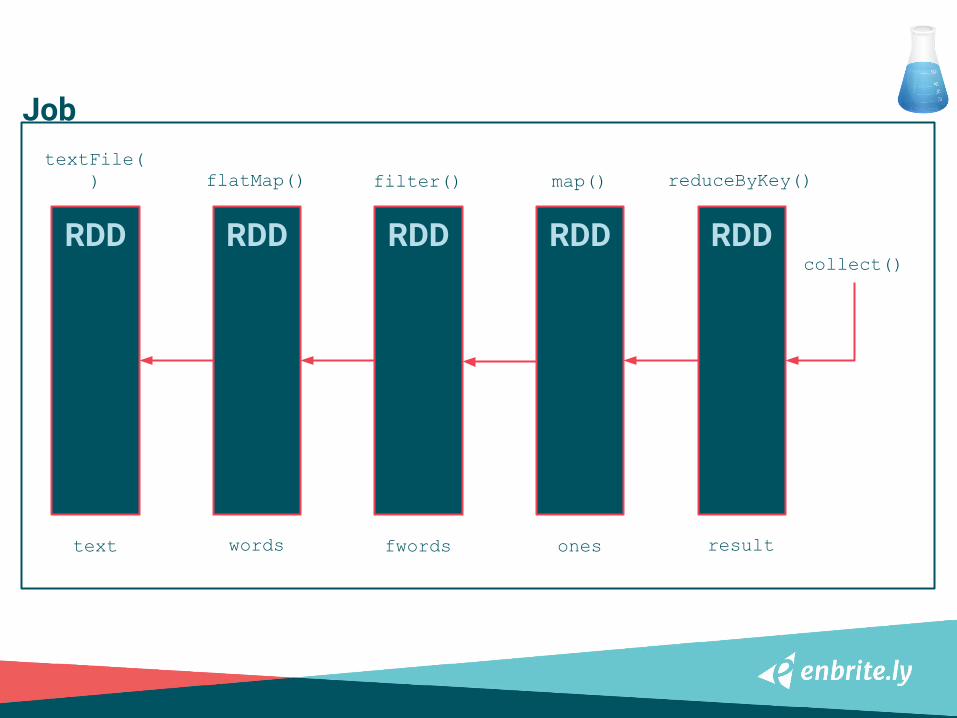
RDD RDD RDD RDD RDD
textFile() flatMap() filter() map() reduceByKey()
text resultwords fwords ones
collect()
Job

STAGE
❏ Unit of execution❏ Named after the last transformation
(the one runJob was called on)
❏ Transformations pipelined together into stages
❏ Stage boundary usually means shuffling

RDD RDD RDD RDD RDD
textFile() flatMap() filter() map() reduceByKey()
text resultwords fwords ones
collect()
JobStage 1 Stage 2

STAGE
❏ Unit of execution❏ Named after the last transformation
(the one runJob was called on)
❏ Transformations pipelined together into stages
❏ Stage boundary usually means shuffling
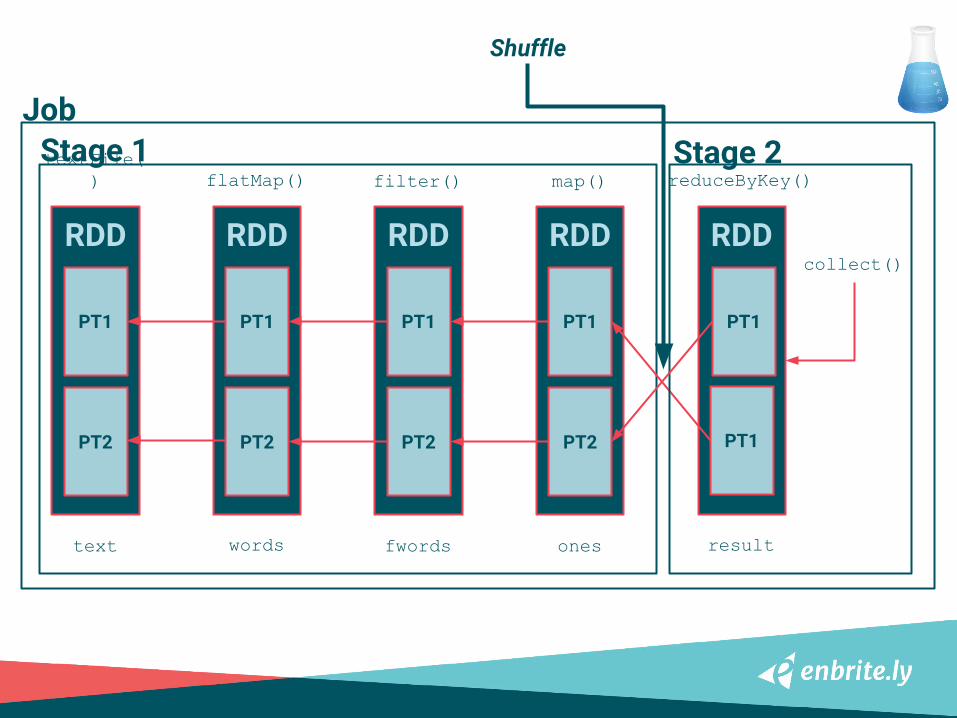
RDD RDD RDD RDD RDD
textFile() flatMap() filter() map() reduceByKey()
text resultwords fwords ones
collect()
JobStage 1 Stage 2
PT1
PT2
PT1
PT2
PT1
PT2
PT1
PT2
PT1
PT1
Shuffle

Repartitioning
text = sc.textFile("twit1.txt")words = nonempty.flatMap(lambda x: x.split(" "))fwords = words.filter(lambda x: len(x) > 1)ones = fwords.map(lambda x: (x, 1))rp = ones.repartition(6)result = rp.reduceByKey(lambda l,r: r+l)result.collect()

TaskSet
THE PROCESSRDD Objects DAG Scheduler Task Scheduler Executor
RDD
RDD RDD
RDD
RDD
sc.textFile.map()
.groupBy()
.filter()
Build DAG of operators
T
T
T
T
T
T
T
T
T
S
S
SS
- Split DAG into stages of tasks- Each stage when ready = ALL dependent task are finished
DAG Task
Task Scheduler
- Launches tasks- Retry failed tasks
ExecutorBlock manager
Task threads
Task threads
Task threads
- Store and serve blocks- Executes tasks
