boosting named entity extraction through crowdsourcing
TRANSCRIPT

Vrije Universiteit Amsterdam
Boosting Named Entity Extraction through Crowdsourcing
what goes wrong with IE tools?what can we learn from the crowd?
Oana Inel
5th December 2016
1

Vrije Universiteit Amsterdam
● work best on limited (predefined) entity types (e.g., people, places, organizations, and to some extend time)
● are all trained on different data○ perform well only on particular type of data/entities
● their performance is highly dependent on ○ the type of input text○ the choice of gold standards
■ gold standards are not perfect■ large amount of training & evaluation data is needed
● similar performance, but different entities coverage ○ different confidence scores○ different way (non-transparent) of computing it
Named Entity Recognition: Observations
2

Vrije Universiteit Amsterdam
Problem:- difficult to understand the reliability of the different NER tools- difficult to choose “the best one” for your case
Solution:- Combined use, e.g. NERD- However, it also has problems
- On the spot reliability on other NER- Limited number of types identified
- An alternative to NERD
IE Tools Issues
3

Vrije Universiteit Amsterdam
1. Choose multiple SOTA NER tools
2. Combine (aggregate) their output
3. Identify cases where the NER tools underperform
4. Correct and improve NER tools output through crowdsourcing improved ground truth
Combining Machines & Crowd for NER
4

Vrije Universiteit Amsterdam
Usecase
5
5 NER tools● NERD-ML● TextRazor● SemiTags● THD● DBpediaSpotlight
Comparative analysis on:- their individual performance (output)- their combined performance (output)
Using two existing gold standard datasets:- Open Knowledge Extraction (OKE) Challenge 2015 & 2016
Vrije Universiteit Amsterdam
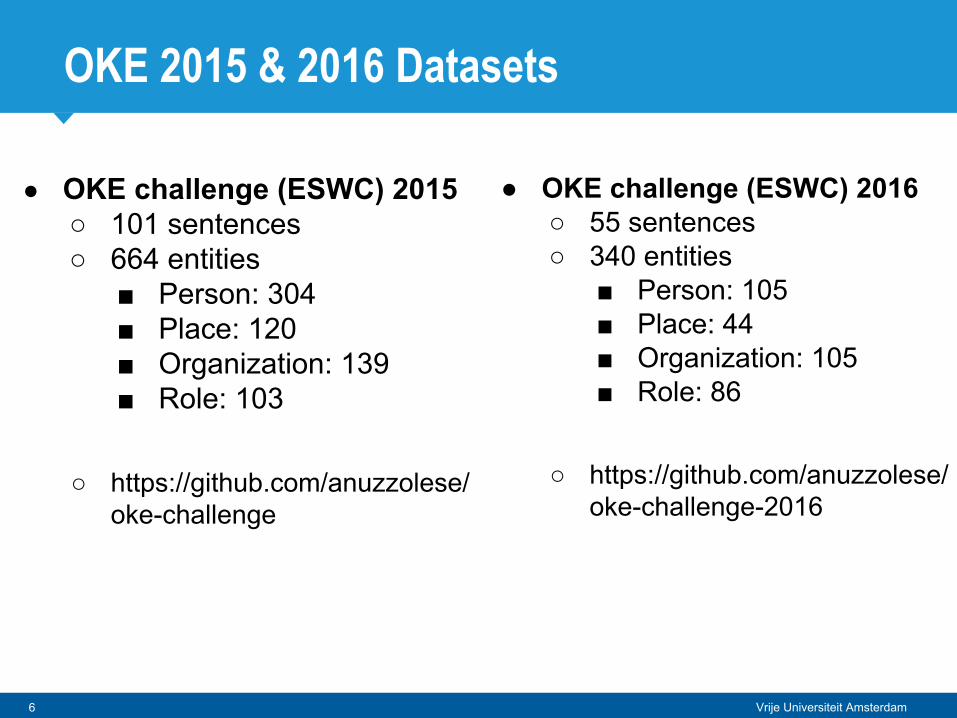
● OKE challenge (ESWC) 2015○ 101 sentences○ 664 entities
■ Person: 304■ Place: 120■ Organization: 139■ Role: 103
○ https://github.com/anuzzolese/oke-challenge
OKE 2015 & 2016 Datasets
6
● OKE challenge (ESWC) 2016○ 55 sentences○ 340 entities
■ Person: 105■ Place: 44■ Organization: 105■ Role: 86
○ https://github.com/anuzzolese/oke-challenge-2016

Vrije Universiteit Amsterdam
NER Performance: entity surface
7
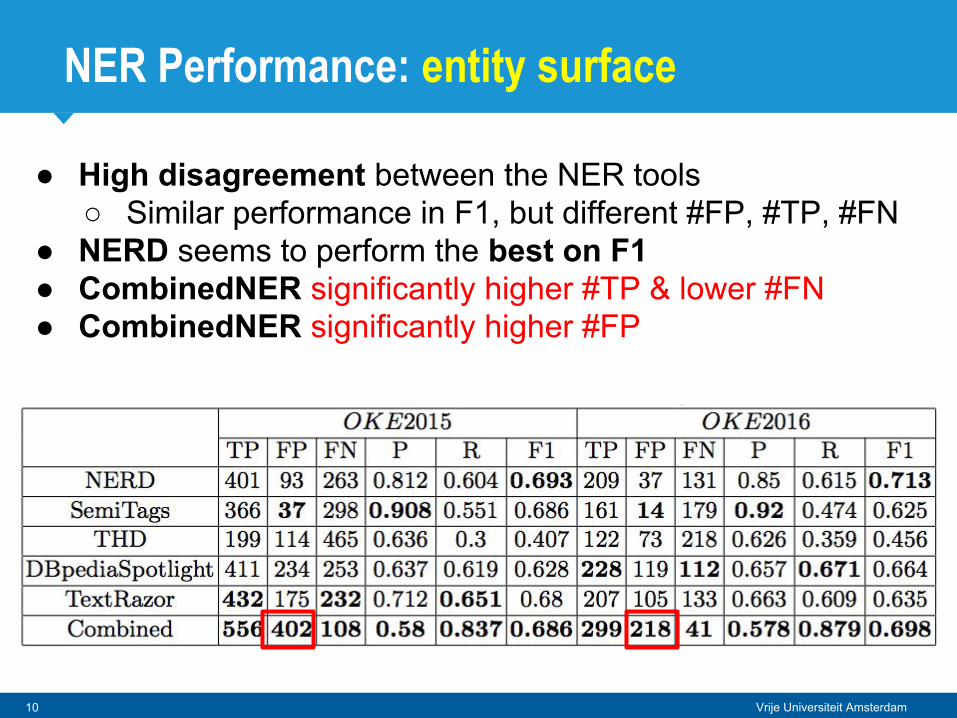
● High disagreement between the NER tools○ Similar performance in F1, but different #FP, #TP, #FN
● Low recall, many entities missed

Vrije Universiteit Amsterdam
NER Performance: entity surface
8
● High disagreement between the NER tools ○ Similar performance in F1, but different #FP, #TP, #FN
● NERD seems to perform the best on F1

Vrije Universiteit Amsterdam
NER Performance: entity surface
9
● High disagreement between the NER tools ○ Similar performance in F1, but different #FP, #TP, #FN
● NERD seems to perform the best on F1● CombinedNER significantly higher #TP & lower #FN
Vrije Universiteit Amsterdam
NER Performance: entity surface
10
● High disagreement between the NER tools ○ Similar performance in F1, but different #FP, #TP, #FN
● NERD seems to perform the best on F1● CombinedNER significantly higher #TP & lower #FN● CombinedNER significantly higher #FP

Vrije Universiteit Amsterdam
CombinedNER vs. SOTA NER
11
The more the merrier?Is performance correlated to the number of NER tools that
extracted a given named entity?
● Performance comparison:○ Applied CrowdTruth metrics on CombinedNER○ Likelihood of an entity to be contained in the gold
standard based on how many NER tools extracted it
Sentence-entity score = ratio of NER that extracted the entity

Vrije Universiteit Amsterdam
CombinedNER vs. SOTA NER
12
CombinedNER outperforms the-state-of-the-art NER tools at a sentence-entity score >= 0.4, which is also better than
considering the majority vote approach
Vrije Universiteit Amsterdam
Where do NER tools fail and why?
13

Vrije Universiteit Amsterdam
NER Performance: entity surface & type
14
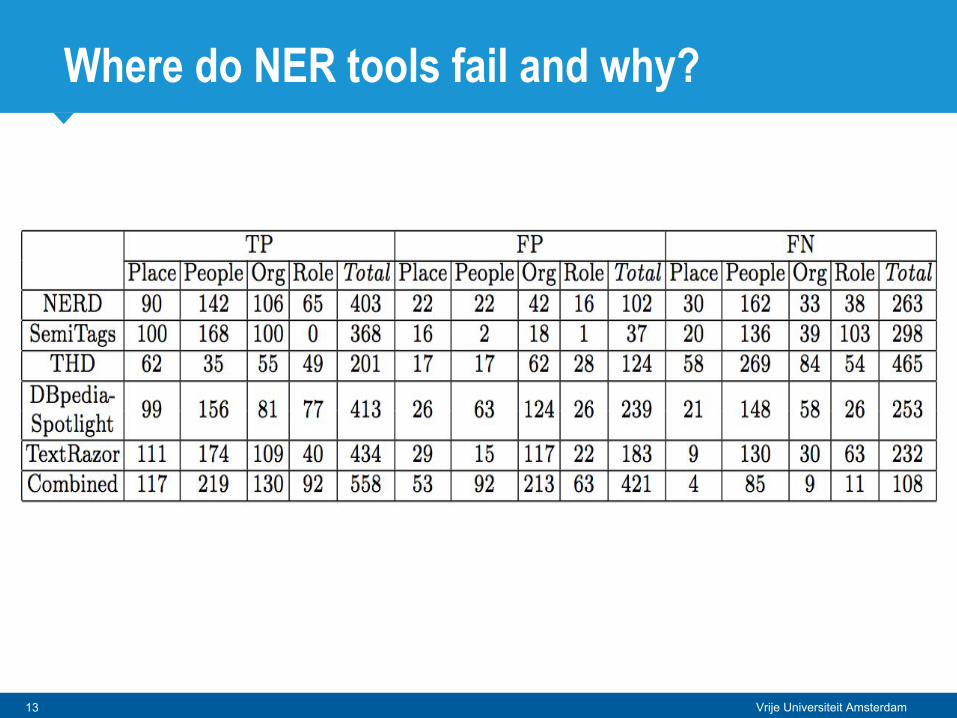
● many instances of “people” were missed

Vrije Universiteit Amsterdam
Deeper look in Ground Truth: People
15
● Personal pronouns (co-references) and possessive pronouns are considered named entities of type “person”○ 83/85 cases (in OKE2015)○ 26/27 cases (in OKE2016)
Giulio Natta was born in Imperia, Italy. [He] earned [his] degree in chemical engineering from the Politecnico di Milano university in Milan in 1924.
● There are also errors in the ground truth○ 1 case in OKE2015
[One of the them] was an eminent scholar at Berkeley.

Vrije Universiteit Amsterdam
NER Performance: entity surface & type
16
● many instances of “people” were missed● only few “places” were missed in 2015, and none in 2016

Vrije Universiteit Amsterdam
Deeper look in Ground Truth: Places
17
● There are concatenation of multiple entities of type place, e.g: City, Country
● 4/4 cases in OKE2015
Such a man did post-doctoral work at the Salk Institute in San Diego in the laboratory of Renato Dulbecco, then worked at the Basel Institute for
Immunology in [Basel, Switzerland].
but, the offsets given in the GT, do not match with the actual string
● Inconsistencies across datasets○ In 2016, such entities were actually classified as two entities of
type place

Vrije Universiteit Amsterdam
NER Performance: entity surface & type
18
● many instances of “people” were missed● only few “places” were missed in 2015, and none in 2016● many FP for entities of type “organization”

Vrije Universiteit Amsterdam
Deeper look in Ground Truth: Organization
19
● Many entities of type “organization” are a combination of “organization” + “place” ○ NER tools tend to extract each entity granularity○ GT does not allow for overlapping entities or multiple
perspectives■ 105/213 cases in OKE2015■ 62/157 cases in OKE2016
Such a man did post-doctoral work at the Salk Institute in San Diego in the laboratory of Renato Dulbecco, then worked at the [[[Basel]
[Institute]] for Immunology] in Basel, Switzerland.

Vrije Universiteit Amsterdam
NER Performance: entity surface & type
20
● many instances of “people” were missed● only few “places” were missed in 2015, and none in 2016● many FP for entities of type “organization”● several FP for entities of type “people” and “role”

Vrije Universiteit Amsterdam
Deeper look in Ground Truth: People & Role
21
● Multiple span variations for the same entity type “person”○ 73/92 cases in OKE2015○ 9/13 cases in OKE2016
The woman was awarded the Nobel Prize in Physics in 1963, which she shared with [[J.] [[Hans] D.] [Jensen]] and Eugene Wigner.
● Inconsistencies & ambiguous combinations of type “role” and “person” ○ Bishop Petronius → person○ But, Queen Elizabeth II was not typed “person”
■ Queen → role■ Elizabeth II → person
● Many combinations of “person” and “role”, especially when the “person” is an ethnic group (e.g., French author, Canadian citizen)○ 9/92 cases in OKE2015○ 2/13 cases in OKE2016

Vrije Universiteit Amsterdam
Crowdsourcing for better Ground Truth
22
● Crowd-driven Ground Truth
Case 1: Crowd reduces the number of #FP ● For each entity that has multiple variations (span
alternative) we create an entity cluster
Case 2: Crowd reduces the number of #FN● For each entity that was not extracted, we create a cluster
with partial overlaps but also every other combination of words contained in the overlap
● Goal: ○ identify all the valid expressions and their types ○ decrease the number of FP and the number of FN

Vrije Universiteit Amsterdam
Crowdsourcing task - template
23

Vrije Universiteit Amsterdam
Results : CombinedNER vs. CombinedNER+Crowd
24
CombinedNER+Crowd outperforms CombinedNER for each crowd-entity score
crowd-entity score - likelihood of an entity to be a valid entity in the dataset (based on CrowdTruth)

Vrije Universiteit Amsterdam
Conclusions
● difficult to find one NER tool that performs well
● combining the output of several NER tools results in disagreement
But,● using crowdsourcing to correct and improve their out results in a better
outcome● furthermore, the crowd can help us in identifying problems of the GT
25