big data beers - introducing snowplow
TRANSCRIPT

Introducing SnowplowBig Data Beers, Berlin
Huge thanks to Zalando for hosting!

Snowplow is an open-source web and event analytics platform, first version released in early 2012
• Co-founders Alex Dean and Yali Sassoon met at OpenX, the open-source ad technology business in 2008
• After leaving OpenX, Alex and Yali set up Keplar, a niche digital product and analytics consultancy
• We released Snowplow as a skunkworksprototype at start of 2012:
github.com/snowplow/snowplow
• We started working full time on Snowplow in summer 2013

At Keplar, we grew frustrated by significant limitations in traditional web analytics programs
• Sample-based (e.g. Google Analytics)
• Limited set of events e.g. page views, goals, transactions
• Limited set of ways of describing events (custom dim 1, custom dim 2…)
Data collection Data processing Data access
• Data is processed ‘once’
• No validation
• No opportunity to reprocess e.g. following update to business rules
• Data is aggregated prematurely
• Only particular combinations of metrics / dimensions can be pivoted together (Google Analytics)
• Only particular type of analysis are possible on different types of dimension (e.g. sProps, eVars, conversion goals in SiteCatalyst
• Data is either aggregated (e.g. Google Analytics), or available as a complete log file for a fee (e.g. Adobe SiteCatalyst)
• As a result, data is siloed: hard to join with other data sets
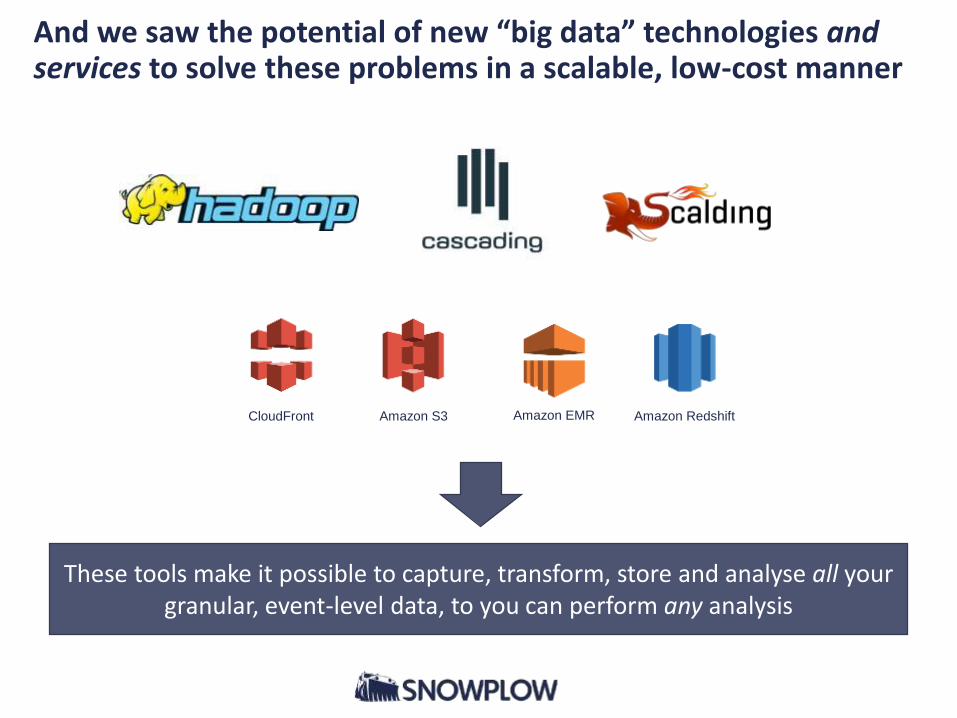
And we saw the potential of new “big data” technologies and services to solve these problems in a scalable, low-cost manner
These tools make it possible to capture, transform, store and analyse all your granular, event-level data, to you can perform any analysis
Amazon EMRAmazon S3CloudFront Amazon Redshift
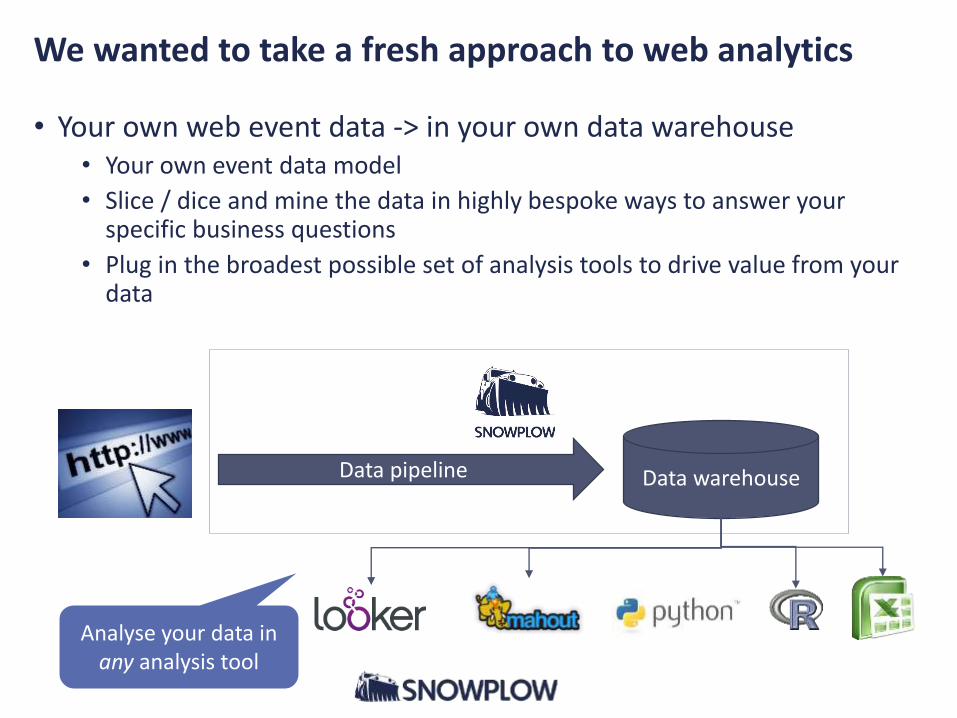
We wanted to take a fresh approach to web analytics
• Your own web event data -> in your own data warehouse• Your own event data model
• Slice / dice and mine the data in highly bespoke ways to answer your specific business questions
• Plug in the broadest possible set of analysis tools to drive value from your data
Data warehouseData pipeline
Analyse your data in any analysis tool
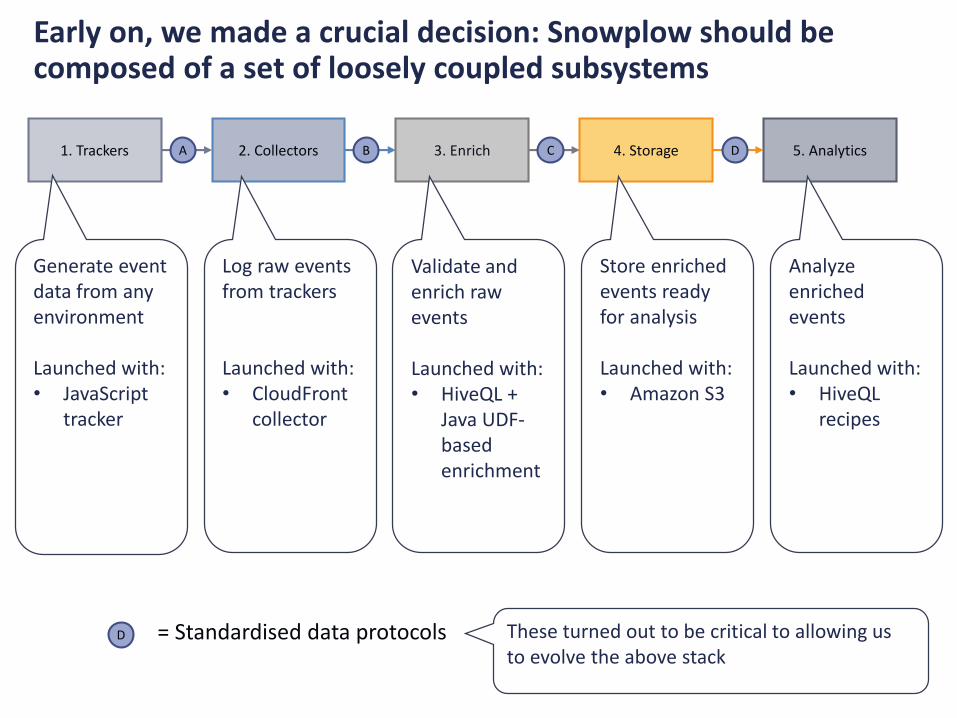
Early on, we made a crucial decision: Snowplow should be composed of a set of loosely coupled subsystems
1. Trackers 2. Collectors 3. Enrich 4. Storage 5. AnalyticsA B C D
D = Standardised data protocols
Generate event data from any environment
Launched with:• JavaScript
tracker
Log raw events from trackers
Launched with:• CloudFront
collector
Validate and enrich raw events
Launched with:• HiveQL +
Java UDF-based enrichment
Store enriched events ready for analysis
Launched with:• Amazon S3
Analyzeenriched events
Launched with:• HiveQL
recipes
These turned out to be critical to allowing us to evolve the above stack
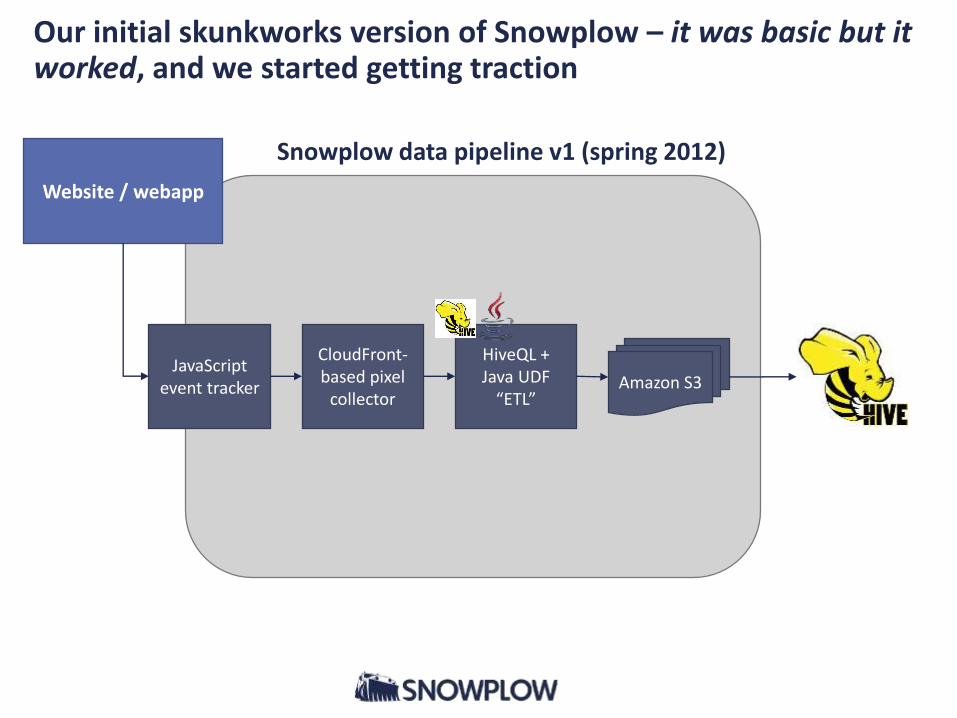
Our initial skunkworks version of Snowplow – it was basic but it worked, and we started getting traction
Website / webapp
Snowplow data pipeline v1 (spring 2012)
CloudFront-based pixel
collector
HiveQL + Java UDF
“ETL” Amazon S3
JavaScript event tracker
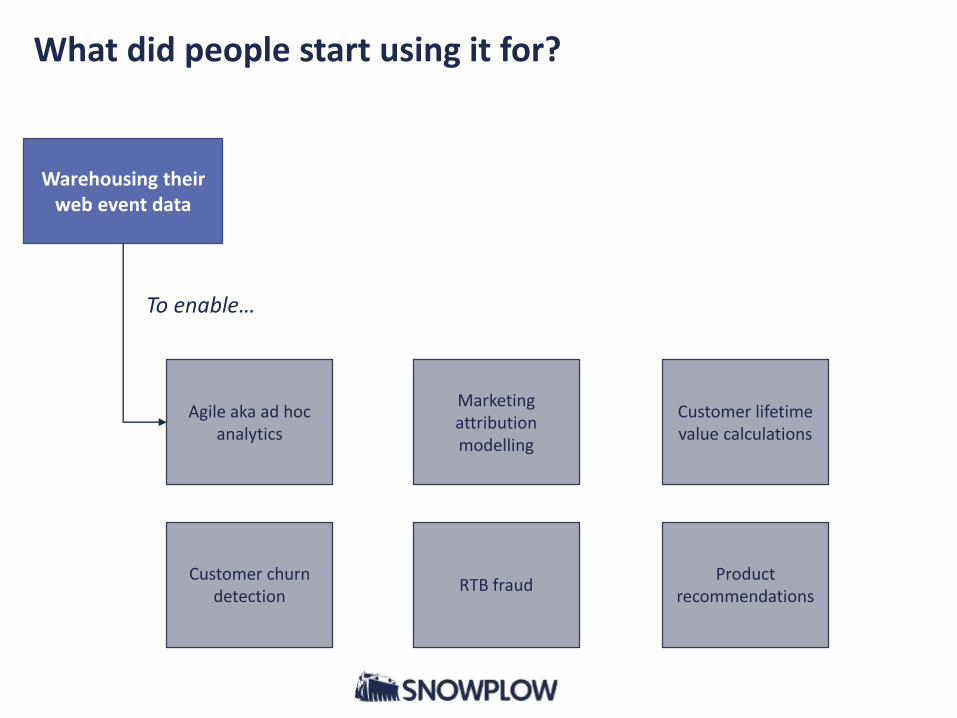
What did people start using it for?
Warehousing their web event data
Agile aka ad hoc analytics
To enable…
Marketing attribution modelling
Customer lifetime value calculations
Customer churn detection
RTB fraudProduct
recommendations

Current Snowplow design and architecture
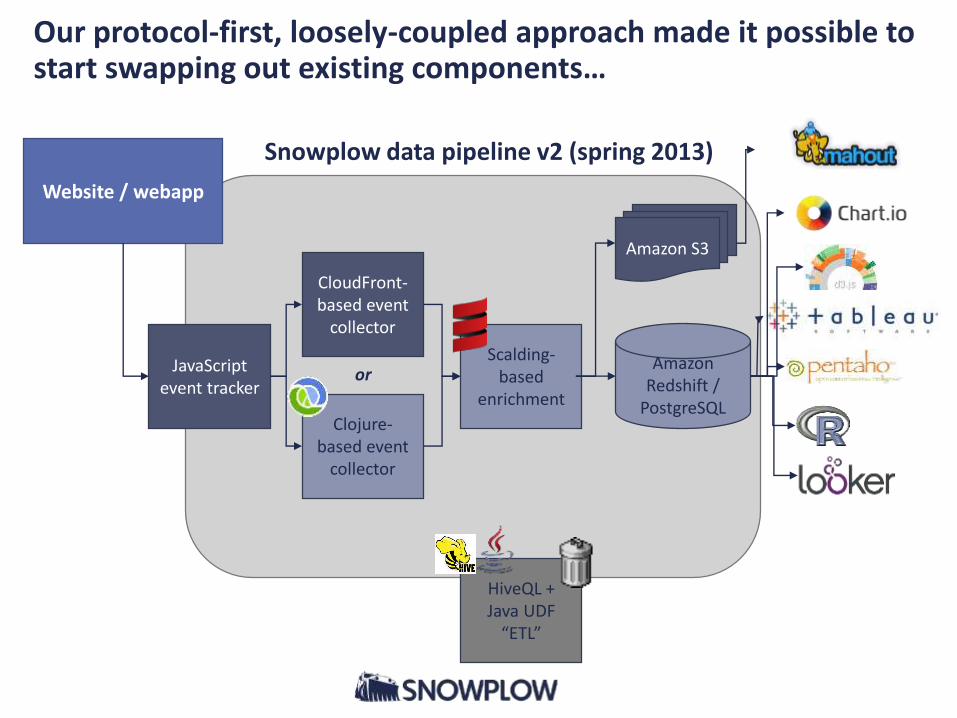
Our protocol-first, loosely-coupled approach made it possible to start swapping out existing components…
Website / webapp
Snowplow data pipeline v2 (spring 2013)
CloudFront-based event
collector
Scalding-based
enrichment
JavaScript event tracker
HiveQL + Java UDF
“ETL”
Amazon Redshift /
PostgreSQL
Amazon S3
or
Clojure-based event
collector
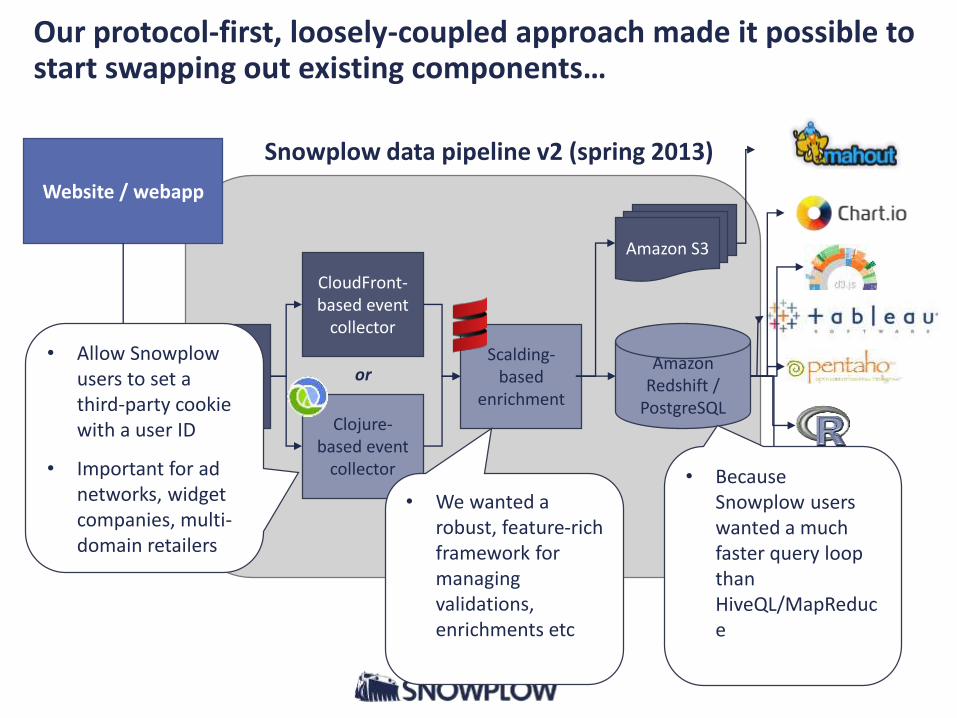
Our protocol-first, loosely-coupled approach made it possible to start swapping out existing components…
Website / webapp
Snowplow data pipeline v2 (spring 2013)
CloudFront-based event
collector
Scalding-based
enrichment
JavaScript event tracker
HiveQL + Java UDF
“ETL”
Amazon Redshift /
PostgreSQL
Amazon S3
or
Clojure-based event
collector
• Allow Snowplow users to set a third-party cookie with a user ID
• Important for ad networks, widget companies, multi-domain retailers
• Because Snowplow users wanted a much faster query loop than HiveQL/MapReduce
• We wanted a robust, feature-rich framework for managing validations, enrichments etc

So far we have open-sourced a number of different trackers –with more planned
Production ready:• JavaScript• No-JavaScript (image beacon)• Python• Lua• Arduino
Beta:• Ruby• iOS• Android• Node.js
In development:• .NET• PHP
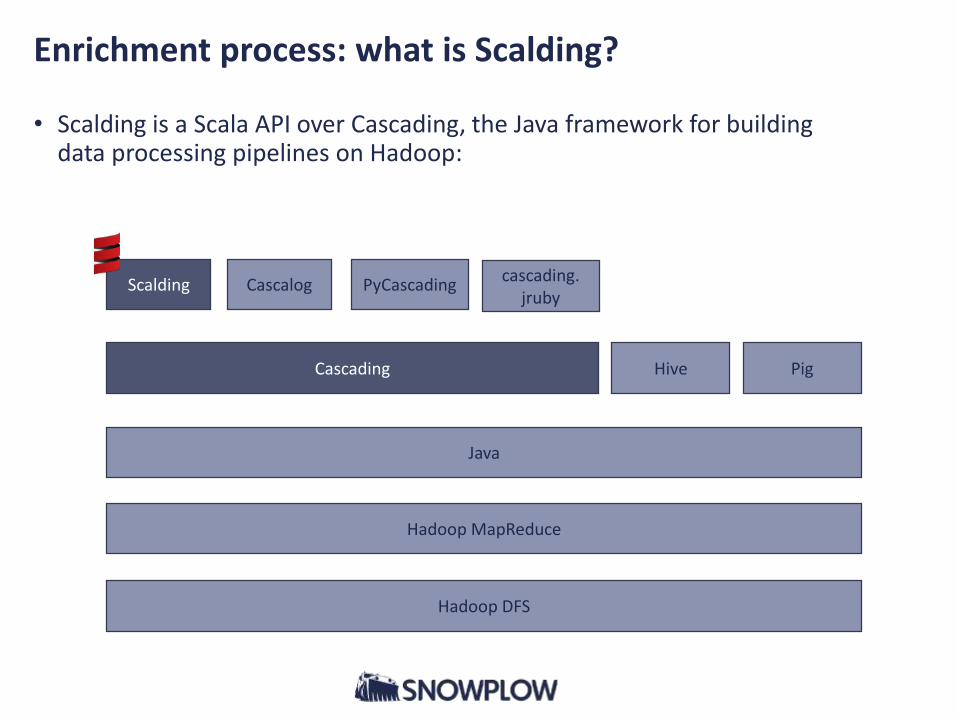
Enrichment process: what is Scalding?
• Scalding is a Scala API over Cascading, the Java framework for building data processing pipelines on Hadoop:
Hadoop DFS
Hadoop MapReduce
Cascading Hive Pig
Java
Scalding Cascalog PyCascadingcascading.
jruby
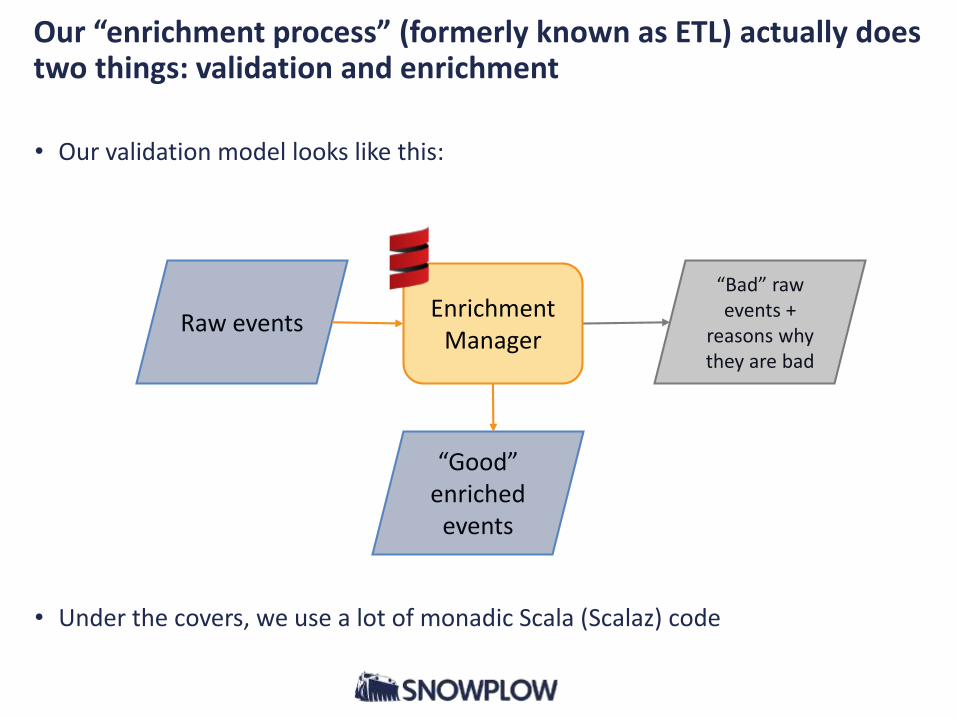
Our “enrichment process” (formerly known as ETL) actually does two things: validation and enrichment
• Our validation model looks like this:
• Under the covers, we use a lot of monadic Scala (Scalaz) code
Raw events
“Bad” raw events +
reasons why they are bad
“Good” enriched
events
Enrichment Manager

Adding the enrichments that web analysts expect = very important to Snowplow uptake
• Web analysts are used to a very specific set of enrichments from Google Analytics, Site Catalyst etc
• These enrichments have evolved over the past 15-20 years and are very domain specific:
• Page querystring -> marketing campaign information (utm_ fields)
• Referer data -> search engine name, country, keywords
• IP address -> geographical location
• Useragent -> browser, OS, computer information

Ongoing evolution of Snowplow

There are three big aspects to Snowplow’s 2014 roadmap
1. Make Snowplow work for non-web (e.g. mobile, IoT) environments as well as the web – RELEASED
2. Make Snowplow work with users’ JSON events as well as with our pre-defined events (aka page views, ecommerce transactions etc) – RELEASED
3. Move Snowplow away from an S3-based data pipeline to a unified log (Kinesis/Kafka)-based data pipeline – ONGOING
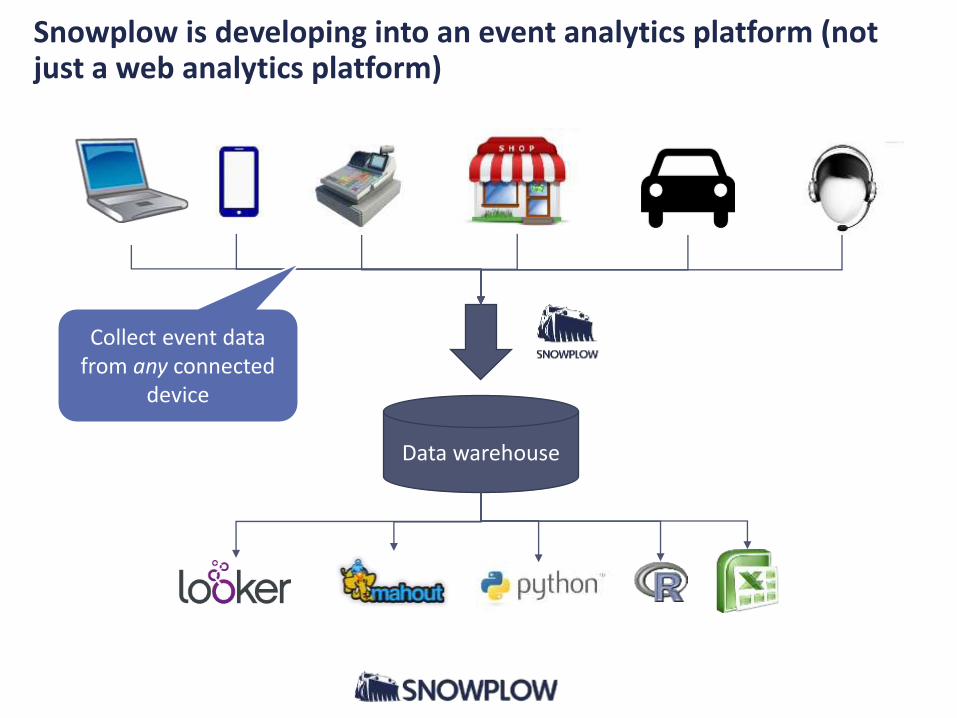
Snowplow is developing into an event analytics platform (not just a web analytics platform)
Data warehouse
Collect event data from any connected
device

Web analysts work with a small number of event types – outside of web, the number of possible event types is… infinite
Web events
All events
• Page view • Order • Add to basket• Page activity
• Game saved • Machine broke• Car started
• Spellcheck run • Screenshot taken• Fridge empty
• App crashed • Disk full• SMS sent
• Screen viewed • Tweet drafted• Player died
• Taxi arrived • Phonecall ended• Cluster started
• Till opened • Product returned ∞

As we get further away from the web, we needed to start supporting user’s own JSON events
• Specifically, events represented as JSONs with arbitrary name: value pairs(arbitrary to Snowplow, not to the company using Snowplow!)

Supporting a fixed set of web events and JSON events is a difficult problem
• Almost everybody in event analytics falls on one or other side of this divide:
Fixed set of web events (page views etc)+ custom variables
Send anything JSONs
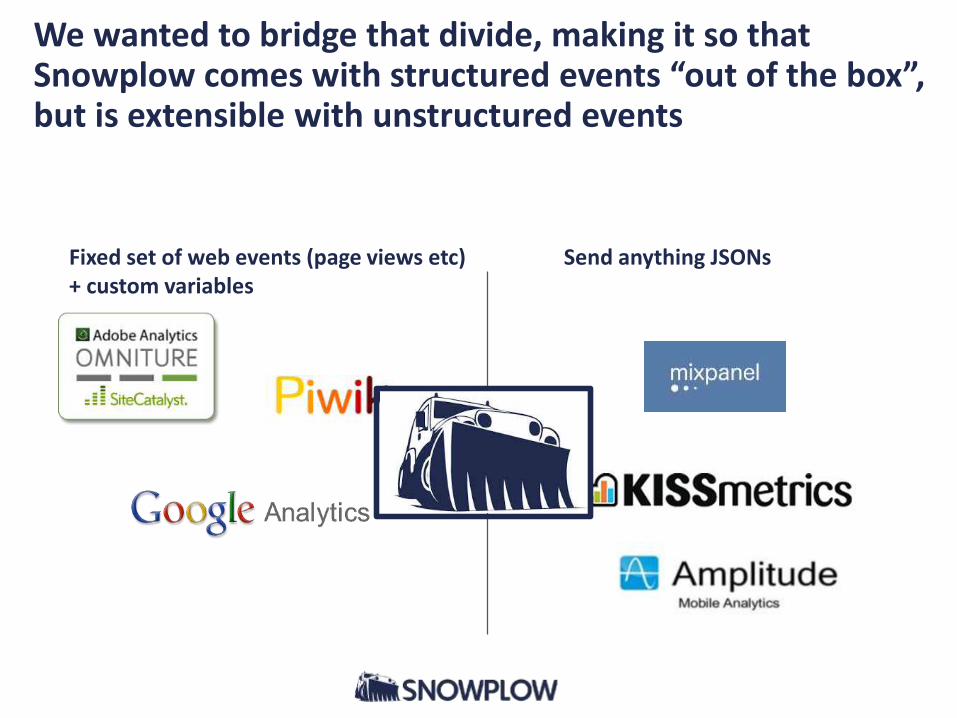
We wanted to bridge that divide, making it so that Snowplow comes with structured events “out of the box”, but is extensible with unstructured events
Fixed set of web events (page views etc)+ custom variables
Send anything JSONs

Issues with the event name:• Separate from the event
properties• Not versioned• Not unique – HBO video played
versus Brightcove video played
Lots of unanswered questions about the properties:• Is length required, and is it always a
number?• Is id required, and is it always a string?• What other optional properties are allowed
for a video play?
Other issues:• What if the developer
accidentally starts sending “len” instead of “length”? The data will end up split across two separate fields
• Why does the analyst need to keep an implicit schema in their head to analyze video played events?
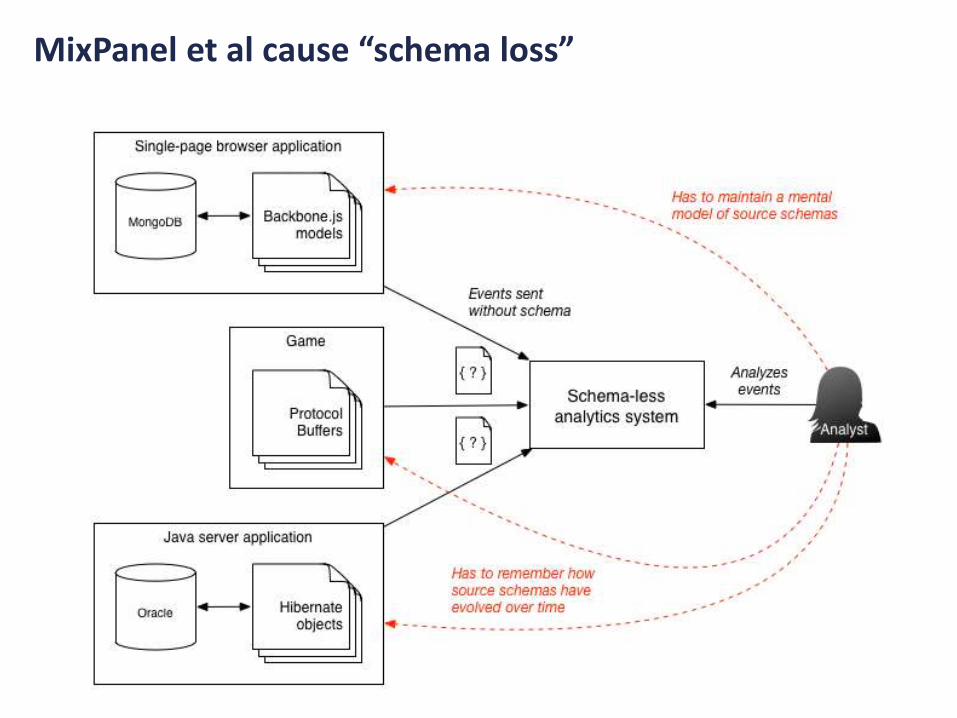
MixPanel et al cause “schema loss”

We decided to use JSON Schema, with additional metadata about what the schema represents

From a tracker, you send in a JSON which is self-describing, with a schema header and data body
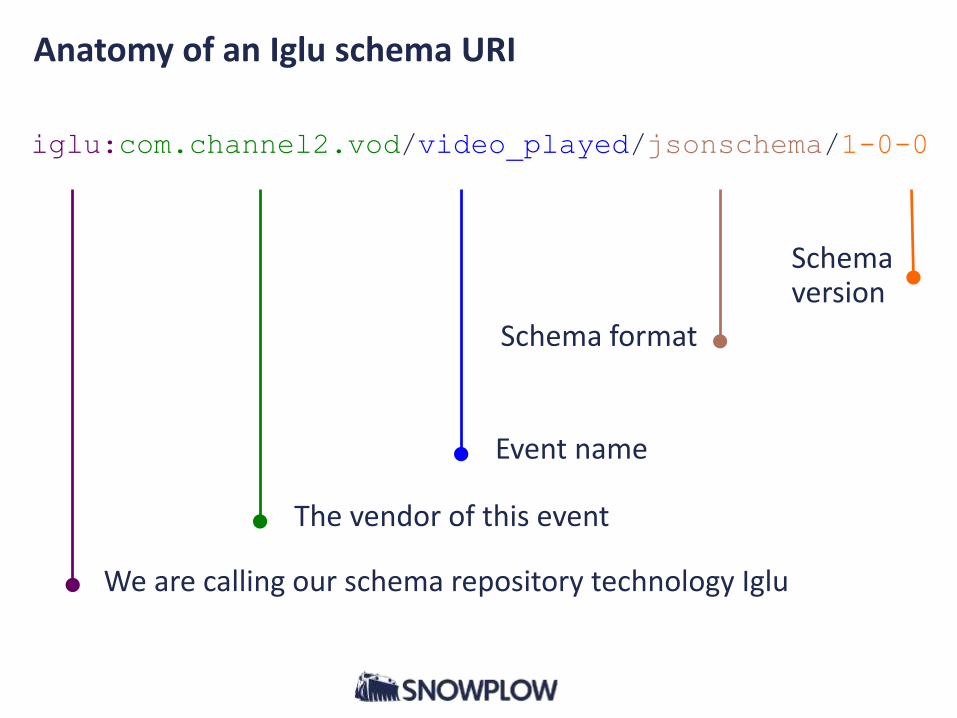
iglu:com.channel2.vod/video_played/jsonschema/1-0-0
We are calling our schema repository technology Iglu
The vendor of this event
Event name
Schema format
Schema version
Anatomy of an Iglu schema URI
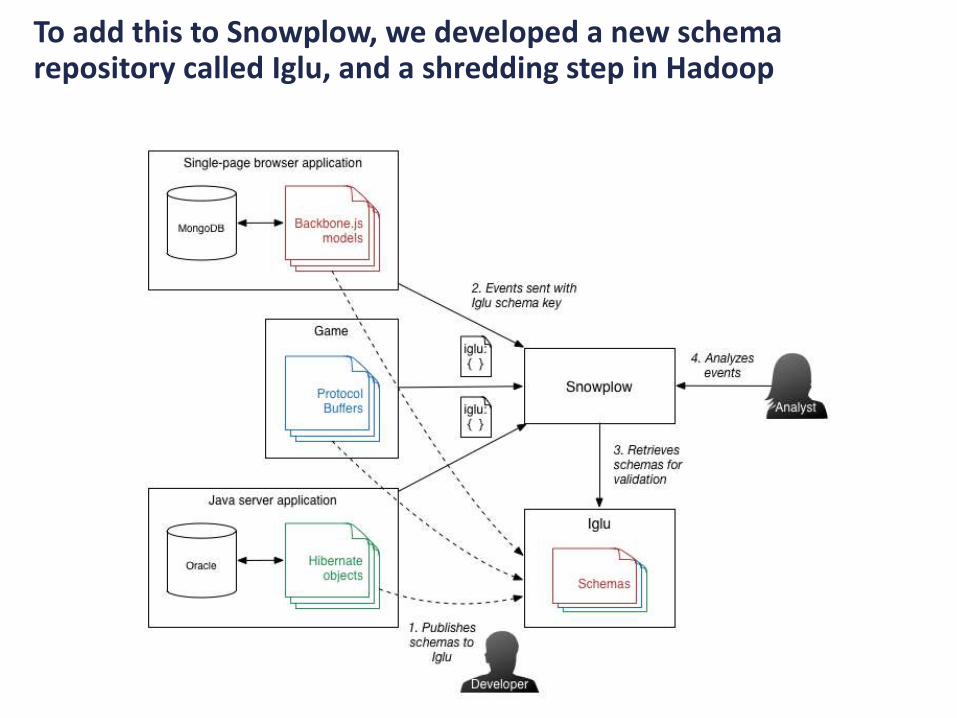
To add this to Snowplow, we developed a new schema repository called Iglu, and a shredding step in Hadoop
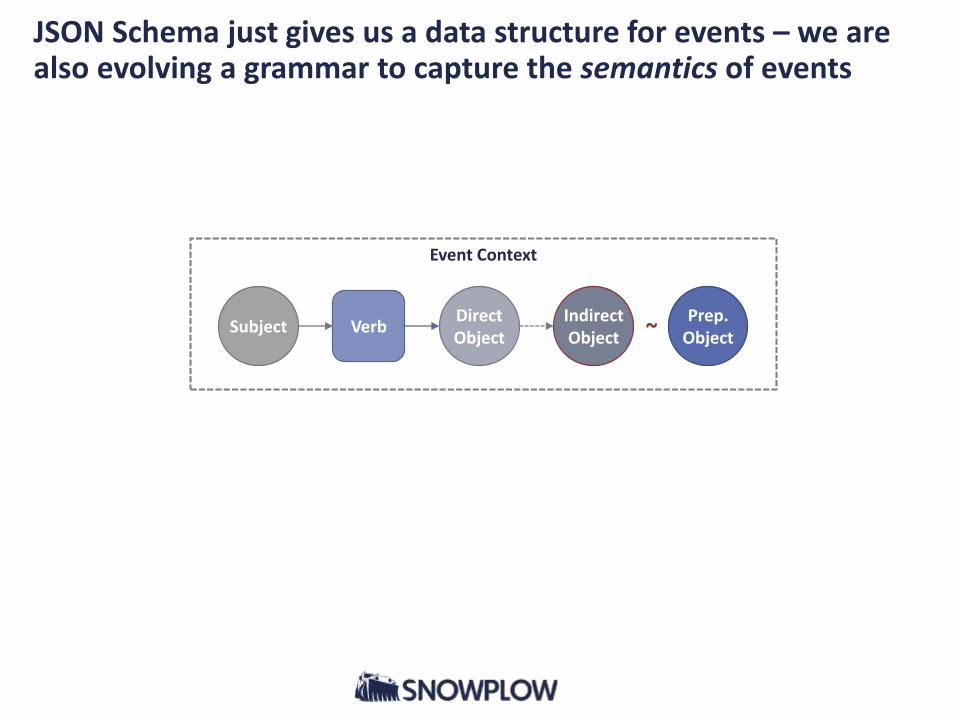
JSON Schema just gives us a data structure for events – we are also evolving a grammar to capture the semantics of events
SubjectDirectObject
IndirectObject
Verb
Event Context
Prep.Object~

In parallel, we plan to evolve Snowplow from an event analytics platform into a “digital nervous system” for data driven companies
• The event data fed into Snowplow is written into a “Unified Log”
• This becomes the “single source of truth”, upstream from the datawarehouse
• The same source of truth is used for real-time data processing as analytics e.g.• Product recommendations
• Ad targeting
• Real-time website personalisation
• Systems monitoring
Snowplow will drive data-driven processes as well as off-line analytics
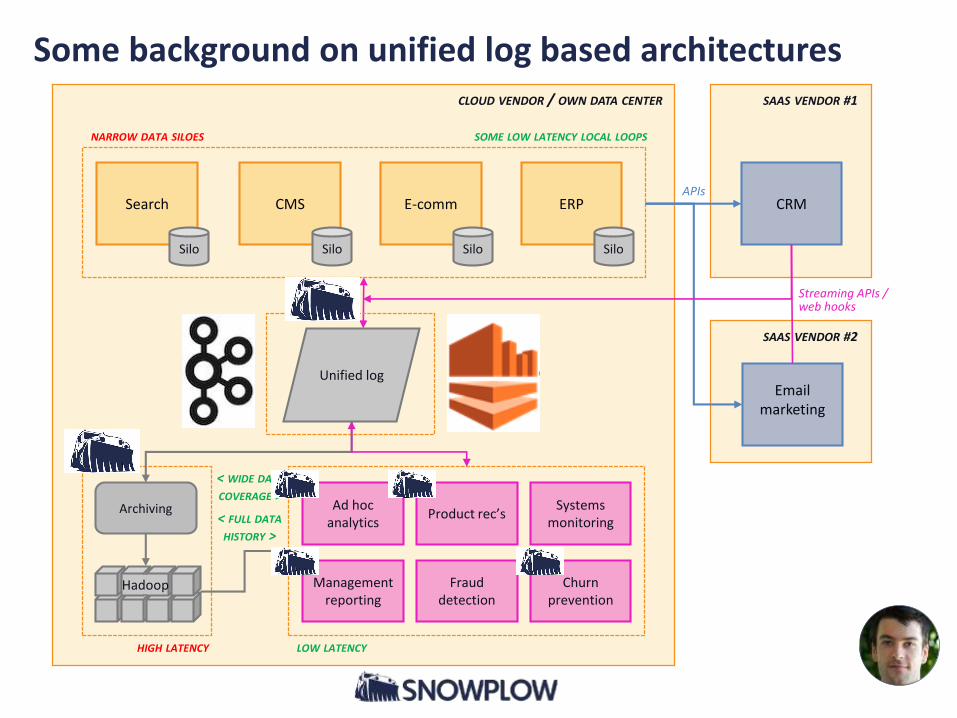
CLOUD VENDOR / OWN DATA CENTER
Search
Silo
SOME LOW LATENCY LOCAL LOOPS
E-comm
Silo
CRM
SAAS VENDOR #2
Email marketing
ERP
Silo
CMS
Silo
SAAS VENDOR #1
NARROW DATA SILOES
Streaming APIs / web hooks
Unified log
Archiving
Hadoop
< WIDE DATA
COVERAGE >
< FULL DATA
HISTORY >
Systems monitoring
Eventstream
HIGH LATENCY LOW LATENCY
Product rec’sAd hoc
analytics
Management reporting
Fraud detection
Churn prevention
APIs
Some background on unified log based architectures
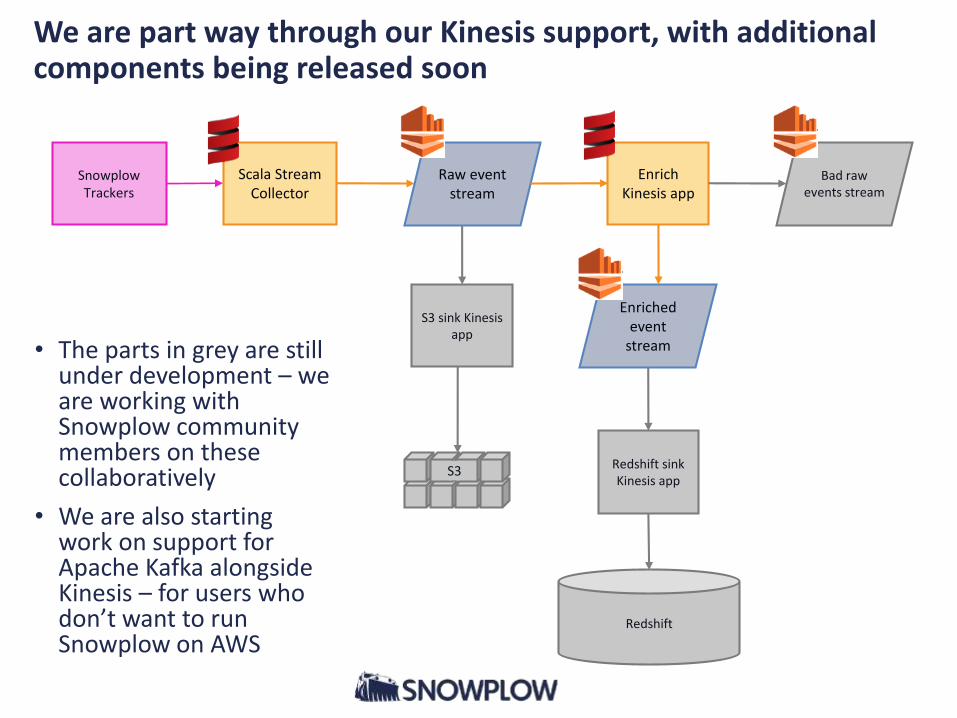
We are part way through our Kinesis support, with additional components being released soon
Scala Stream Collector
Raw event stream
Enrich Kinesis app
Bad raw events stream
Enriched event
stream
S3
Redshift
S3 sink Kinesis app
Redshift sink Kinesis app
SnowplowTrackers
• The parts in grey are still under development – we are working with Snowplow community members on these collaboratively
• We are also starting work on support for Apache Kafka alongside Kinesis – for users who don’t want to run Snowplow on AWS
Questions?
http://snowplowanalytics.com
https://github.com/snowplow/snowplow
@snowplowdata
I am in Berlin tomorrow – to meet up or chat, @alexcrdean on Twitter or [email protected]
ulogprugcf (43% off Unified Log Processing eBook)