apsipa2017: trajectory smoothing for vocoder-free speech synthesis
TRANSCRIPT

12/15/2017©Shinnosuke Takamichi,
The University of Tokyo
Modulation spectrum-based
speech parameter trajectory smoothing
for DNN-based speech synthesis using FFT spectra
Shinnosuke Takamichi (Univ. of Tokyo, Japan)
APSIPA ASC 2017

/16
Statistical parametric speech synthesis: vocoder-based and vocoder-free
Statistical parametric speech synthesis (SPSS)
– Text-to-speech using HMMs, DNNs, etc.
History of SPSS and feature parameterization
– HMM-based SPSS with STRAIGHT [Kawahara+’99] (2005~)
– DNN-based SPSS with STRAIGHT/WORLD [Morise+‘16] (2013~)
– DNN-based SPSS generating raw speech features (2016~)
• WaveNet [Oord+’16], Tacotron [Wang’+17] etc.
Research target
– Speech data preprocessing for high-quality vocoder-free SPSS
2
w/ vocoders
w/o vocoders

/16
Speech data preprocessing
Speech parameter trajectory smoothing [Takamichi+’15]
– Based on modulation spectra of vocoder features [Takamichi+’16].
– Remove components that are difficult to be modeled with statistical
models and negligible for speech perception.
– Improve accuracy of acoustic model training.
Proposed: trajectory smoothing for SPSS using FFT spectra
– Find FFT spectra components that are unnecessary to be modeled.
– Remove the components to accurate training.
Result
– Improve the training accuracy compared with unprocessed ones.
3

/16
Statistical parametric speech synthesis using FFT spectra
4
[Takaki+’17]
Context feats. Speech feats.
t=1
t=2
t=T
Phoneme
(binary)
Accent
(binary)
Position context
(numerical) Prosody context
(e.g., F0)
etc.
a i
u …
1 2 3 …
0
1
0
1 0
Log spectrum
Neural networks
(acoustic models)
Text

/16
Problems
5
Lo
g s
pect
rum
at
freq
uen
cy f
Time t
Phoneme /a/ /r/ /i/
Predict
The detailed structures are difficult to predict,
but do we need to model them?
…
…

SPEECH PARAMETER
TRAJECTORY SMOOTHING
6

/16
Modulation spectrum-based trajectory smoothing
Modulation spectrum (MS)
– (Log) power spectrum of a temporal sequence of speech parameters
Effect of MS on speech perception
– Higher modulation freq. components are difficult to be modeled
with statistical models and negligible for speech perception.
MS-based trajectory smoothing
– Low-pass filtering to the speech parameter sequence
– Acoustic model training using the filtered parameters
7
[Takamichi+’15]
FFT log ⋅ 2 MS

/16
Examples of MSs of vocoder parameters
8
[Takamichi+’15]
Modulation frequency [Hz]
Mo
du
lati
on
sp
ect
rum
Unnecessary
→ remove in advance of DNN training.

/16
Research target revisits
Speech synthesis using STFT spectra
– Features: FFT spectra, not vocoder parameters
Trajectory smoothing for STFT spectra
– Which MS components can we ignore?
– Does the trajectory smoothing work to improve training accuracy?
9

EXPERIMENTAL EVALUATION
10
/16
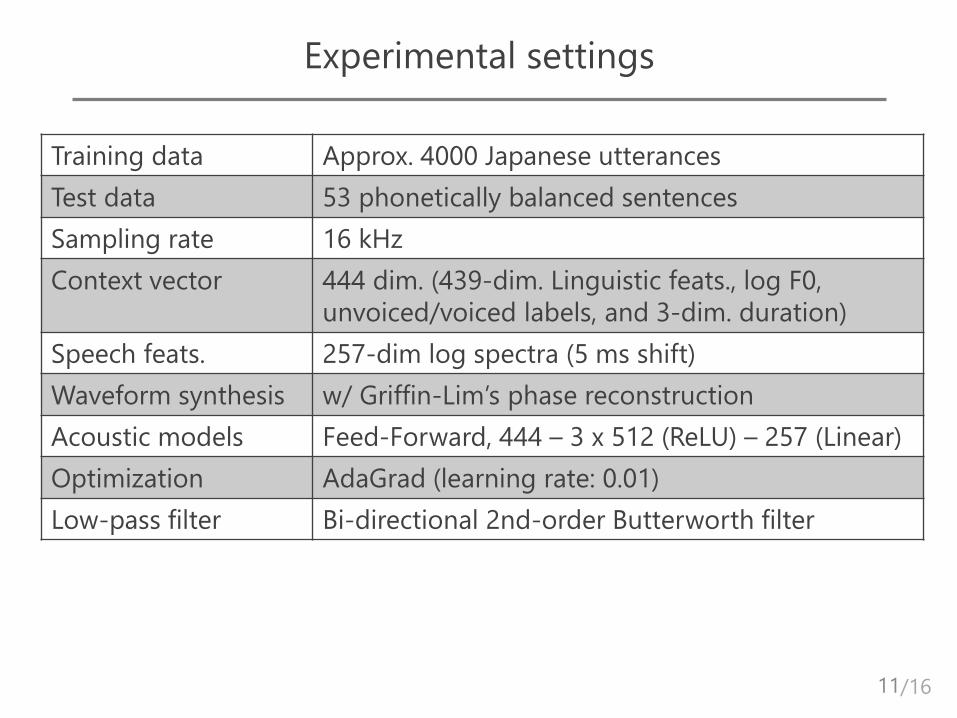
Experimental settings
11
Training data Approx. 4000 Japanese utterances
Test data 53 phonetically balanced sentences
Sampling rate 16 kHz
Context vector 444 dim. (439-dim. Linguistic feats., log F0,
unvoiced/voiced labels, and 3-dim. duration)
Speech feats. 257-dim log spectra (5 ms shift)
Waveform synthesis w/ Griffin-Lim’s phase reconstruction
Acoustic models Feed-Forward, 444 – 3 x 512 (ReLU) – 257 (Linear)
Optimization AdaGrad (learning rate: 0.01)
Low-pass filter Bi-directional 2nd-order Butterworth filter
/16
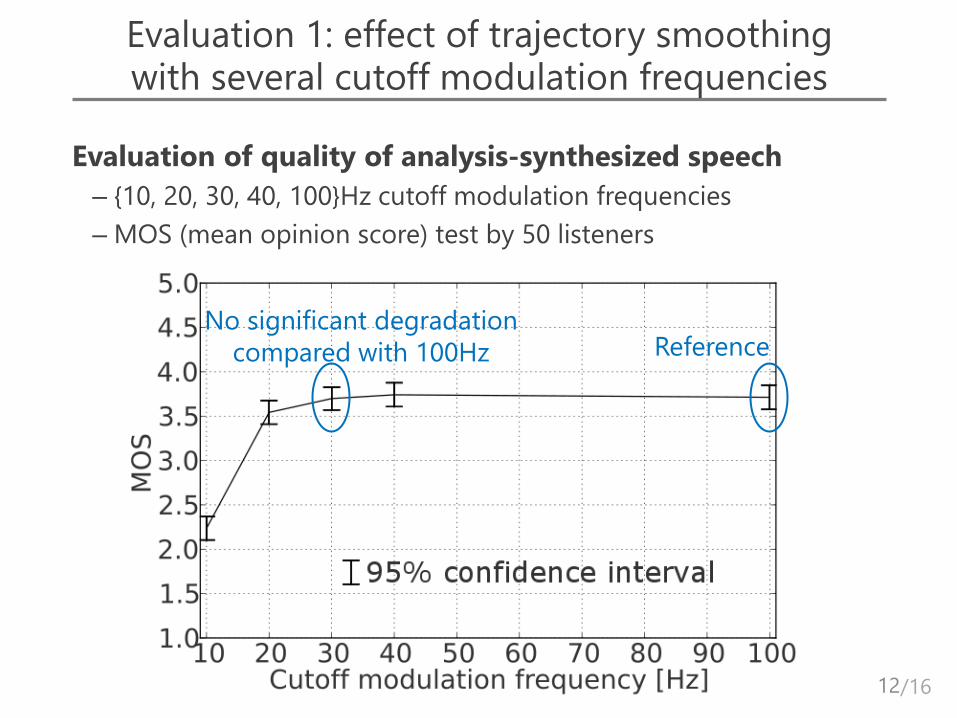
Evaluation 1: effect of trajectory smoothing with several cutoff modulation frequencies
Evaluation of quality of analysis-synthesized speech
– {10, 20, 30, 40, 100}Hz cutoff modulation frequencies
– MOS (mean opinion score) test by 50 listeners
12
Reference No significant degradation
compared with 100Hz

/16
Results of the trajectory smoothing with 30 Hz cutoff modulation frequency
13
/16
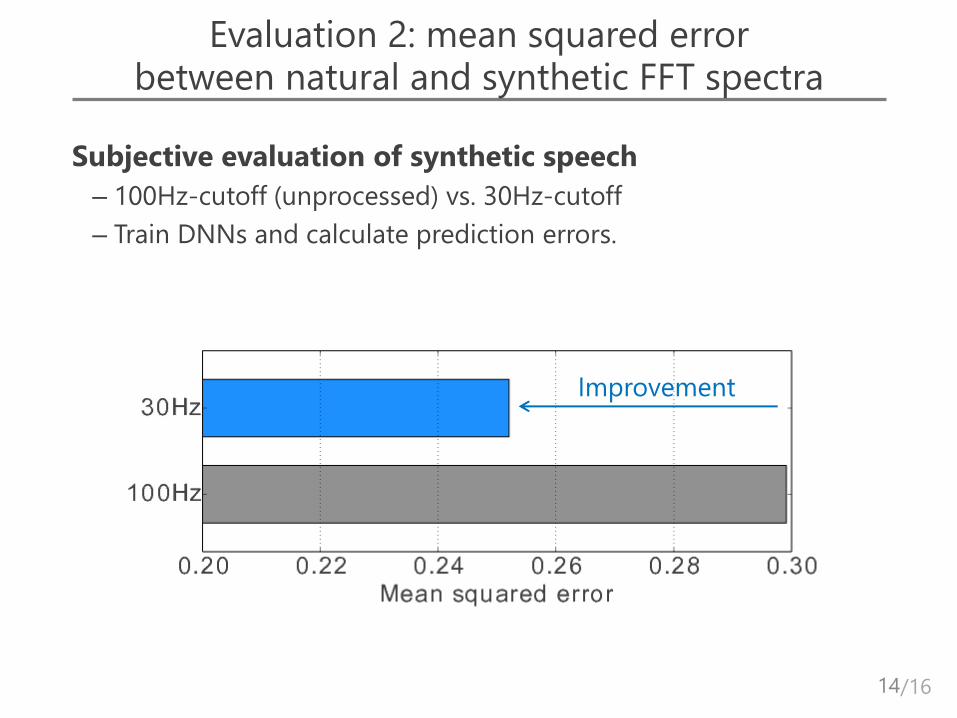
Evaluation 2: mean squared error between natural and synthetic FFT spectra
Subjective evaluation of synthetic speech
– 100Hz-cutoff (unprocessed) vs. 30Hz-cutoff
– Train DNNs and calculate prediction errors.
14
Improvement

/16
Evaluation 3: subjective evaluation for synthetic speech quality
Objective evaluation of synthetic speech
– 100Hz-cutoff (unprocessed) vs. 30Hz-cutoff
– Preference AB test by 20 listeners
15
No significant
difference

/16
Conclusion
Purpose
– Speech data preprocessing for high-quality speech synthesis using
FFT spectra
Proposed
– Modulation spectrum-based trajectory smoothing for FFT spectra
Results
– Low-pass filtering with the 30Hz-cutoff modulation frequency.
– Improvement of mean squared error betw. natural/generated spectra
Future work
– Evaluation using complicated DNN structures (e.g., WaveNet)
16