annotation and alignment of the drosophila genomes centro de ciencas genomicas, may 29, 2006
TRANSCRIPT

Annotation and Alignment of the Drosophila Genomes
Centro de Ciencas Genomicas, May 29, 2006.


Genes or Regulation?
• “10,516 putative orthologs have been identified as a core gene set conserved over 25–55 million years (Myr) since the pseudoobscura/melanogaster divergence”
• “Cis-regulatory sequences are more conserved than random and nearby sequences between the species—but the difference is slight, suggesting that the evolution of cis-regulatory elements is flexible”
Richards et al., Comparative genome sequencing of Drosophila pseudoobscura: Chromosomal, gene, and cis-element evolution, Genome Res., Jan 2005.

Sequencing & Assembly Status Sequencing Center~3-fold WGS of w501 strain & 1-foldcoverage of 6 other strains complete(2 assemblies currently available; deepercoverage of w501 strain expected Fall ‘05)
Washington Univ.(WUGSC)
~3-fold WGS complete (assembly to bereleased by Sept 1)
Broad Institute
Release 4.2: 118.4 Mb with 23 gapsremaining (Release 5 in Fall 2005)
Celera/BDGP
~6-fold WGS complete (assembly inGenBank)(additional coverage - automated sequenceimprovement expected Fall ‘05)
Washington Univ(WUGSC).
~12-fold WGS complete & assembled Agencourt
~8-fold WGS complete & assembled Agencourt~9-fold WGS complete & assembled Baylor College of
Medicine (BCM)~4-fold WGS complete & assembled Broad Institute
~6-fold WGS (BAC paired ends currentlybeing sequenced; assembly to be released bySept 15)
Venter Institute(JCVI)
~8-fold WGS complete & assembled Agencourt~9-fold WGS complete & assembled Agencourt~8-fold WGS complete (assembly to bereleased by Sept 15)
Agencourt
http://rana.lbl.gov/drosophila/wiki/

BP England, U Heberlein, R Tjian. Purified Drosophila transcription factor, Adh distal factor-1 (Adf-1), binds to sites in several Drosophila promoters and activates transcription, J Biol Chem 1990.

S. Chatterji and L. Pachter, GeneMapper: Reference based annotation with GeneMapper, in press.
http://bio.math.berkeley.edu/genemapper/

Genes or Regulatory Elements?
• “10,516 10,867 putative orthologs have been identified as a core gene set conserved over 25–55 million years (Myr) since the pseudoobscura/melanogaster divergence”
• “Cis-regulatory sequences are more conserved than random and nearby sequences between the species—but the difference is slight, suggesting that the evolution of cis-regulatory elements is flexible”
Richards et al., Comparative genome sequencing of Drosophila pseudoobscura: Chromosomal, gene, and cis-element evolution, Genome Res., Jan 2005.

DroAna_20041206_ GTCGCTCAACCAGCATTTGCAAAAGTCGCAGAACTTGCGCTCATTGGATTTCCAGTACTCDroMel_4_ GTCGCTCAGCCAGCATTTGCAGAAGTCGCAGAACTTGCGCTCGTTTGATTTCCAGTACTCDroMoj_20041206_ GTCGCTTAACCAGCATTTACAGAAATCGCAATACTTGCGTTCATTGGATTTCCAGTACTCDroPse_1_ GTCGCTCAGCCAGCACTTGCAGAAGTCGCAGTACTTGCGCTCGTTTGATTTCCAGAATTCDroSim_20040829_ GTCGCTCAGCCAGCATTTGCAGAAGTCGCAGAACTTGCGCTCGTTTGATTTCCAGTACTCDroVir_20041029_ GTCGCTCAACCAGCATTTGCAGAAGTCGCAATACTTGCGTTCATTCGACTTCCAGTACTCDroYak_1_ GTCGCTCAGCCAGCATTTGCAGAAGTCGCAGAACTTCCGCTCGTTTGACTTCCAGTACTC ****** * ****** ** ** ** ***** **** ** ** ** ** ****** * **
Alignment of coding sequence
DroAna_20041206_ CTGAAGGAAT-------TCTATATT---------AAAGAAGATTTCTCATCATTGGTTGDroMel_4_ CTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGA---------GTTTDroMoj_20041206_ CTGGAATAGTTAATTTCATTGTAACACATAAACGTTTTAAATTCTATTGAAA-------DroPse_1_ CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG----DroSim_20040829_ CTGCGGGATTAGGAGTCATTAGAGT---------GCGGAAAAGCGG---------GTT-DroVir_20041029_ CTGCAGCAGTTAAATA-ATTGTAATAAACAATTCTCT--AATTTGGTCCAAA-------DroYak_1_ CTGCGGGATTAGCGGTCATTGGTGT---------GAAGAATAGATC---------CTTT *** * * * DroAna_20041206_ AATC-----ACTTACDroMel_4_ ATTCTATGGACTCACDroMoj_20041206_ ----TATTTACTCACDroPse_1_ ------TGTACTTACDroSim_20040829_ ATTCTATGGACTCACDroVir_20041029_ ----TATTTACTCACDroYak_1_ ATTTCATAAACTCAC
*** **
Alignment of non-coding sequence

DroAna_20041206_ GTCGCTCAACCAGCATTTGCAAAAGTCGCAGAACTTGCGCTCATTGGATTTCCAGTACTCDroMel_4_ GTCGCTCAGCCAGCATTTGCAGAAGTCGCAGAACTTGCGCTCGTTTGATTTCCAGTACTCDroMoj_20041206_ GTCGCTTAACCAGCATTTACAGAAATCGCAATACTTGCGTTCATTGGATTTCCAGTACTCDroPse_1_ GTCGCTCAGCCAGCACTTGCAGAAGTCGCAGTACTTGCGCTCGTTTGATTTCCAGAATTCDroSim_20040829_ GTCGCTCAGCCAGCATTTGCAGAAGTCGCAGAACTTGCGCTCGTTTGATTTCCAGTACTCDroVir_20041029_ GTCGCTCAACCAGCATTTGCAGAAGTCGCAATACTTGCGTTCATTCGACTTCCAGTACTCDroYak_1_ GTCGCTCAGCCAGCATTTGCAGAAGTCGCAGAACTTCCGCTCGTTTGACTTCCAGTACTC ****** * ****** ** ** ** ***** **** ** ** ** ** ****** * **
Alignment of coding sequence
Alignment of non-coding sequencedroAna1.2448876 CTGAAGGAATTCTA--TATTAAAG-------------------------------dm2.chr2L CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGT-TTATTCdroMoj1.contig_2959 CTGGAATAGTTAATTTCATTGTAA---------CACATAAA--CGTTTTAAATTCdp3.chr4_group3 CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCGdroSim1.chr2L CTGCGGGATTAGGAGTCATTAGAG---------TGCGGAAAAGCGGG--TTATTCdroVir1.scaffold_6 CTGCAGCAGTTAA-ATAATTGTAA---------TAAACAA----TTCTCTAATTTdroYak1.chr2L CTGCGGGATTAGCGGTCATTGGTG---------TGAAGAATAGATCCT-TTATTT *** * * * *
droAna1.2448876 AAGATTTCTCATCATTGGTTGAATC---------------------ACTTAC dm2.chr2L -----------------------------------------TATGGACTCACdroMoj1.contig_2959 -------------------------AAATATTT--------TATTGACTCACdp3.chr4_group3 -----------------------------------------TGT--ACTTACdroSim1.chr2L -----------------------------------------TATGGACTCACdroVir1.scaffold_6 ---------------------------------AAATATTTGGTCCACTCACdroYak1.chr2L -----------------------------------------CATAAACTCAC *** **

Example of a conserved microRNA target
UUCCCUAG--------CAAGUACCUCA------------------UUCCCUAG--------CAAGUACCUCA------------------UUCCCUAG--------CAAGUACCUCA------------------UUCCUUAGACUCUUAGCAAGUACCUCA------------------UUCCUUAGACUCUUAGAAAGUACCUCAAAAACGAAAUGCGAACACGACUCU----UUUUAGCAAGUACCUCAAAAUAUUUAAUUAAA-AC ACUCUU----UUUUAGCAAGUACCUCAAGAAUUACAAUUAAAUAU
Grun et al. microRNA target predictions across seven Drosophila species and comparison to mammalian targets, PloS Computational Biology, June 2005Lall et al. A genome wide map of conserved microRNA targets in C. Elegans, Current Biology, February 2006
AUGGAGU.
...
. . .. let-7

Per site analysis Group 1 mean per site % identity 51.3% 51.3% 47.8%
Group 2 mean per site % identity 47.8% 42.9% 42.9%
Difference of means (group 1 – group 2) 3.6% 8.4% 4.9%
Difference of means resampling p-value 0.05 0.003 1E-5
Distribution comparison KS p-value 0.026 0.0016 2E-6
Per base analysis Group 1 mean per base % identity 47.8% 47.8% 46.3%
Group 2 mean per base % identity 46.3% 42.4% 42.4%
Difference of means (group 1 – group 2) 1.5% 5.4% 3.9%
Richards et al., Comparative genome sequencing of Drosophila pseudoobscura: Chromosomal, gene, and cis-element evolution, Genome Res., Jan 2005.

dm2.chr2L CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGT-TTATTCdp3.chr4_group3 CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG
dm2.chr2L TATGGACTCACdp3.chr4_group3 TGT--ACTTAC
How is an alignment made from two sequences?
>dm2.chr2L CTGCGGGATTAGGGGTCATTAGAGTGCCGAAAAGCGAGTTTATTCTATGGACTCAC>dp3.chr4_group3CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCGTGTACTTAC
?
Given two sequences of lengths n,m:
n=50
m=62
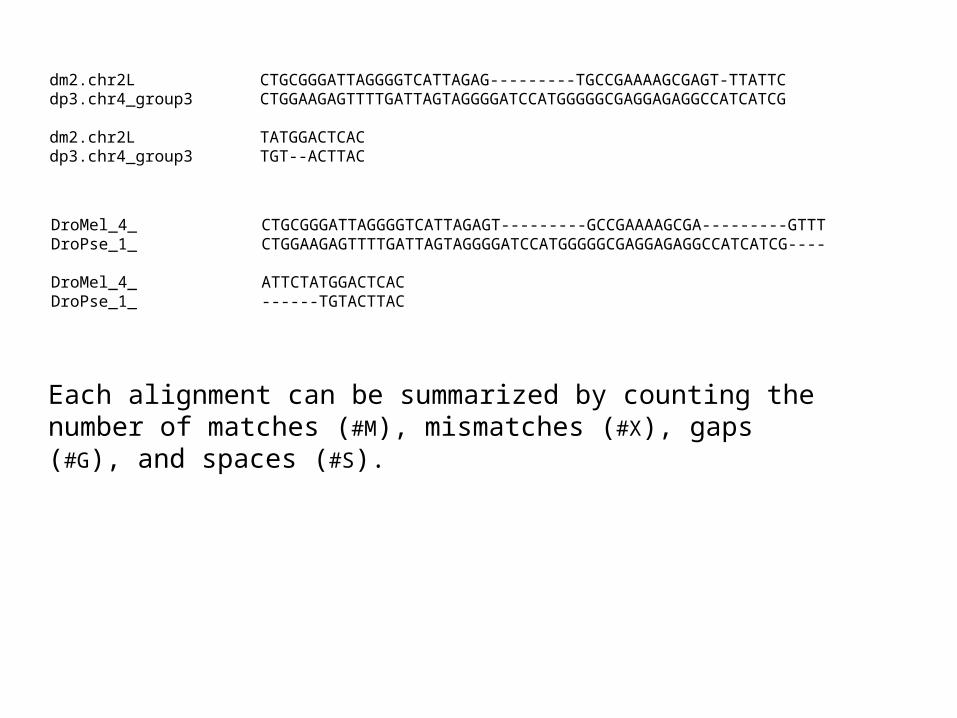
dm2.chr2L CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGT-TTATTCdp3.chr4_group3 CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG
dm2.chr2L TATGGACTCACdp3.chr4_group3 TGT--ACTTAC
DroMel_4_ CTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGA---------GTTTDroPse_1_ CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG---- DroMel_4_ ATTCTATGGACTCACDroPse_1_ ------TGTACTTAC
Each alignment can be summarized by counting the number of matches (#M), mismatches (#X), gaps (#G), and spaces (#S).

dm2.chr2L CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGT-TTATTCdp3.chr4_group3 CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG
dm2.chr2L TATGGACTCACdp3.chr4_group3 TGT--ACTTAC
DroMel_4_ CTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGA---------GTTTDroPse_1_ CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG---- DroMel_4_ ATTCTATGGACTCACDroPse_1_ ------TGTACTTAC
Each alignment can be summarized by counting the number of matches (#M), mismatches (#X), gaps (#G), and spaces (#S).
#M=31, #X=22, #G=3, #S=12
#M=27, #X=18, #G=3, #S=28
2(#M+#X)+#S=112 so #X,#G and #S suffice to specify a summary.

The summary of an alignment is a point in 3 dimensional space. For example, the two alignments just shown correspond to the points:
(22,3,12) (18,3,28)

The summary of an alignment is a point in 3 dimensional space. For example, the two alignments just shown correspond to the points:
(22,3,12) (18,3,28)
In the example of our two sequences there are 379522884096444556699773447791552717765633different alignments.

The summary of an alignment is a point in 3 dimensional space. For example, the two alignments just shown correspond to the points:
(22,3,12) (18,3,28)
In the example of our two sequences there are 379522884096444556699773447791552717765633different alignments, but only53890 different summaries. So we don’t need to plot that many points.

The summary of an alignment is a point in 3 dimensional space. For example, the two alignments just shown correspond to the points:
(22,3,12) (18,3,28)
In the example of our two sequences there are 379522884096444556699773447791552717765633different alignments, but only53890 different summaries. So we don’t need to plot that many points.
But 53890 is still quite a large number. Fortunately, there are only 69 vertices on the convex hull of the 53890 points.
These are the interesting ones, and we can even draw them…

>melCTGCGGGATTAGGGGTCATTAGAGTGCCGAAAAGCGAGTTTATTCTATGGAC>pseCTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCGTGTAC
For the sequences:
49 #x=24, #S=10, #G=2
There are eight alignments that have this summary.
the alignment polytope is:

mel CTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATC-GTGTAC
mel CTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG-TGTAC
mel CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATC-GTGTAC
mel CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG-TGTAC
mel CTGCGGGATTAGGGGTCATTAGA---------GTGCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATC-GTGTAC
mel CTGCGGGATTAGGGGTCATTAGA---------GTGCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG-TGTAC
mel CTGCGGGATTAGGGGTCATTAG---------AGTGCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATC-GTGTAC
mel CTGCGGGATTAGGGGTCATTAG---------AGTGCCGAAAAGCGAGTTTATTCTATGGACpse CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG-TGTAC

mel CTGCGGGATTAGGGGTCATTAGAGT===------===GCCGAAAAGCGAGTTTATTCTA=TGGACpse CTGGAAGAGTTTTGATTAGTAG===GGGATCCATGGGGGCGAGGAGAGGCCATCATC==GTGTAC
Consensus at a vertex

The vertices of the polytope have special significance.
Given parameters for a model, e.g. the default parameters for MULTIZ:
M = 100, X = -100, S = -30, G = -400
the summary is the result of maximizing the linear form
-200*(#X)-400*(#G)-80*(#S)
over the polytope.
Thus, the vertices of the polytope correspond to optimal alignments.
49 #x=24, #S=10, #G=2

What is usually done, is that a single set of parameters is specified (M = 100, X = -100, S = -30, G = -400 is a standard default) and then the optimal vertex is identified using dynamic programming. An alignment optimal for the vertex is then selected. The running time of the algorithm is O(nm) [Needleman-Wunsch, 1970, Smith-Waterman, 1981] and it requires O(n+m) space [Hirschberg 1975] .
Standard scoring schemes are:
Parameters Model
M,X,S Jukes-Cantor with linear gap penalty
M,X,S,G Jukes-Cantor with affine gap penalty M,XTS,XTV,S,G Kimura-2 parameter with affine gap
penalty
Needleman-Wunsch Alignment

Building Drosophila whole genome multiple alignments
• MAVID• http://hanuman.math.berkeley.edu/kbrowser
• MULTIZ• http://genome.ucsc.edu/ (currently no D. erecta)
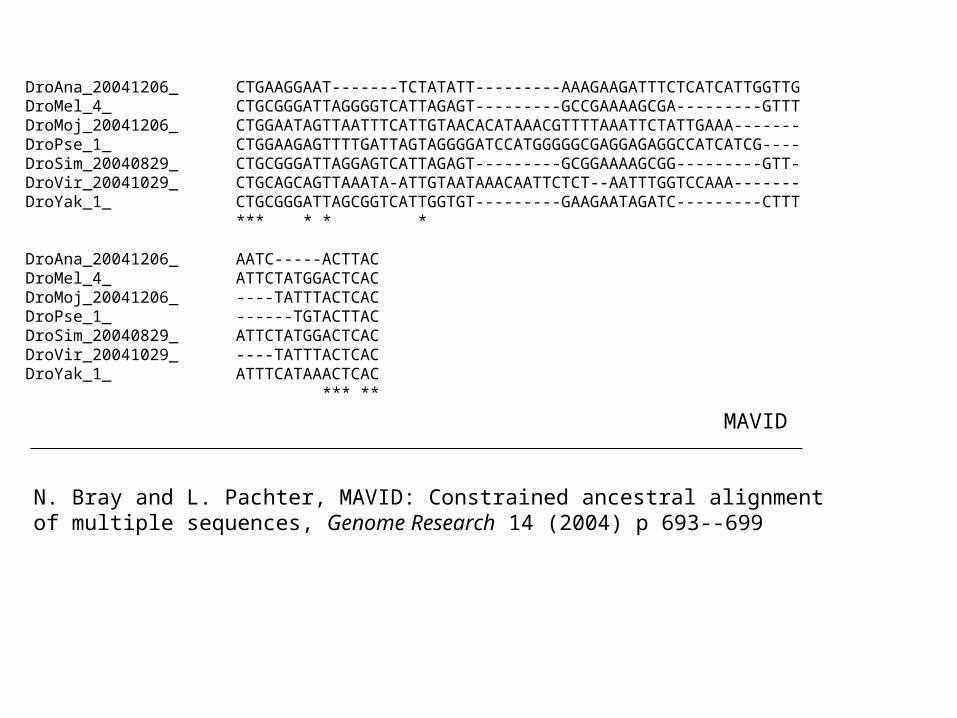
DroAna_20041206_ CTGAAGGAAT-------TCTATATT---------AAAGAAGATTTCTCATCATTGGTTGDroMel_4_ CTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGA---------GTTTDroMoj_20041206_ CTGGAATAGTTAATTTCATTGTAACACATAAACGTTTTAAATTCTATTGAAA-------DroPse_1_ CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG----DroSim_20040829_ CTGCGGGATTAGGAGTCATTAGAGT---------GCGGAAAAGCGG---------GTT-DroVir_20041029_ CTGCAGCAGTTAAATA-ATTGTAATAAACAATTCTCT--AATTTGGTCCAAA-------DroYak_1_ CTGCGGGATTAGCGGTCATTGGTGT---------GAAGAATAGATC---------CTTT *** * * * DroAna_20041206_ AATC-----ACTTACDroMel_4_ ATTCTATGGACTCACDroMoj_20041206_ ----TATTTACTCACDroPse_1_ ------TGTACTTACDroSim_20040829_ ATTCTATGGACTCACDroVir_20041029_ ----TATTTACTCACDroYak_1_ ATTTCATAAACTCAC
*** **
N. Bray and L. Pachter, MAVID: Constrained ancestral alignment of multiple sequences, Genome Research 14 (2004) p 693--699
MAVID

Needleman-Wunsch

droAna1.2448876 CTGAAGGAATTCTA--TATTAAAG-------------------------------dm2.chr2L CTGCGGGATTAGGGGTCATTAGAG---------TGCCGAAAAGCGAGT-TTATTCdroMoj1.contig_2959 CTGGAATAGTTAATTTCATTGTAA---------CACATAAA--CGTTTTAAATTCdp3.chr4_group3 CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCGdroSim1.chr2L CTGCGGGATTAGGAGTCATTAGAG---------TGCGGAAAAGCGGG--TTATTCdroVir1.scaffold_6 CTGCAGCAGTTAA-ATAATTGTAA---------TAAACAA----TTCTCTAATTTdroYak1.chr2L CTGCGGGATTAGCGGTCATTGGTG---------TGAAGAATAGATCCT-TTATTT *** * * * *
droAna1.2448876 AAGATTTCTCATCATTGGTTGAATC---------------------ACTTAC dm2.chr2L -----------------------------------------TATGGACTCACdroMoj1.contig_2959 -------------------------AAATATTT--------TATTGACTCACdp3.chr4_group3 -----------------------------------------TGT--ACTTACdroSim1.chr2L -----------------------------------------TATGGACTCACdroVir1.scaffold_6 ---------------------------------AAATATTTGGTCCACTCACdroYak1.chr2L -----------------------------------------CATAAACTCAC *** **
Blanchette et al., Aligning multiple sequences with the threaded blockset aligner, Genome Research 14 (2004) p 708--715
MULTIZ

One (possibly wrong) alignment is not enough: the history of parametric
inference• 1992: Waterman, M., Eggert, M. & Lander, E. • Parametric sequence comparisons, Proc. Natl. Acad. Sci. USA 89, 6090-6093
• 1994: Gusfield, D., Balasubramanian, K. & Naor, D. • Parametric optimization of sequence alignment, Algorithmica 12, 312-326.
• 2003: Wang, L., Zhao, J. • Parametric alignment of ordered trees, Bioinformatics, 19 2237-2245.
• 2004: Fernández-Baca, D., Seppäläinen, T. & Slutzki, G. • Parametric Multiple Sequence Alignment and Phylogeny Construction, Journal of Discrete Algorithms, 2 271-287.
XPARAL by Kristian Stevens and Dan Gusfield

Whole Genome Parametric AlignmentColin Dewey, Peter Huggins, Lior Pachter, Bernd Sturmfels and
Kevin Woods
Mathematics and Computer Science
• Parametric alignment in higher dimensions.• Faster new algorithms.• Deeper understanding of alignment polytopes.
Biology
• Whole genome parametric alignment.• Biological implications of alignment parameters.• Alignment with biology rather than for biology.

Whole Genome Parametric AlignmentColin Dewey, Peter Huggins, Lior Pachter, Bernd Sturmfels and
Kevin Woods
Mathematics and Computer Science
• Parametric alignment in higher dimensions.• Faster new algorithms.• Deeper understanding of alignment polytopes.
Biology
• Whole genome parametric alignment.• Biological implications of alignment parameters.•
CTGAAGGAAT-------TCTATATT---------AAAGAAGATTTCTCATCATTGGTTGCTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGA---------GTTTCTGGAATAGTTAATTTCATTGTAACACATAAACGTTTTAAATTCTATTGAAA-------CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG----CTGCGGGATTAGGAGTCATTAGAGT---------GCGGAAAAGCGG---------GTT-CTGCAGCAGTTAAATA-ATTGTAATAAACAATTCTCT--AATTTGGTCCAAA-------CTGCGGGATTAGCGGTCATTGGTGT---------GAAGAATAGATC---------CTTT
analysis

Whole Genome Parametric AlignmentColin Dewey, Peter Huggins, Lior Pachter, Bernd Sturmfels and
Kevin Woods
Mathematics and Computer Science
• Parametric alignment in higher dimensions.• Faster new algorithms.• Deeper understanding of alignment polytopes.
Biology
• Whole genome parametric alignment.• Biological implications of alignment parameters.•
CTGAAGGAAT-------TCTATATT---------AAAGAAGATTTCTCATCATTGGTTGCTGCGGGATTAGGGGTCATTAGAGT---------GCCGAAAAGCGA---------GTTTCTGGAATAGTTAATTTCATTGTAACACATAAACGTTTTAAATTCTATTGAAA-------CTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCG----CTGCGGGATTAGGAGTCATTAGAGT---------GCGGAAAAGCGG---------GTT-CTGCAGCAGTTAAATA-ATTGTAATAAACAATTCTCT--AATTTGGTCCAAA-------CTGCGGGATTAGCGGTCATTGGTGT---------GAAGAATAGATC---------CTTT
analysis

computational geometry

A Whole Genome Parametric Alignment ofD. Melanogaster and D. Pseudoobscura
• Divided the genomes into 1,116,792 constrained and 877,982 unconstrained segment pairs.
• 2d, 3d, 4d, and 5d alignment polytopes were constructed for each of the 877,802 unconstrained segment pairs.
• Computed the Minkowski sum of the 877,802 2d polytopes.
+ =

A Whole Genome Parametric Alignment ofD. Melanogaster and D. Pseudoobscura
• Divided the genomes into 1,116,792 constrained and 877,982 unconstrained segment pairs.This is an orthology map of the two genomes.
• 2d, 3d, 4d, and 5d alignment polytopes were constructed for each of the 877,802 unconstrained segment pairs.For each segment pair, obtain all possible optimal summaries for all parameters in a Needleman--Wunsch scoring scheme.
• Computed the Minkowski sum of the 877,802 2d polytopes.There are only 838 optimal alignments of the two Drosophila genomes if the same match, mismatch and gap parameters are used for all the segment pair alignments.






>melCTGCGGGATTAGGGGTCATTAGAGTGCCGAAAAGCGAGTTTATTCTATGGAC>pseCTGGAAGAGTTTTGATTAGTAGGGGATCCATGGGGGCGAGGAGAGGCCATCATCGTGTAC
How do we build the polytope for ?

Alignment polytopes are small
Theorem: The number of vertices of an alignment polytope for two sequences of length n and m is O((n+m)d(d-1)/(d+1)) where d is the number of free parameters in the scoring scheme.
Examples: Parameters Model Vertices M,X,S Jukes-Cantor with linear gap penaltyO(n+m)2/3
M,X,S,G Jukes-Cantor with affine gap penaltyO(n+m)3/2
M,XTS,XTV,S,G K2P with affine gap penalty O(n+m)12/5
L. Pachter and B. Sturmfels, Parametric inference for biological sequence analysis, Proceedings of the National Academy of Sciences, Volume 101, Number 46 (2004), p 16138--16143.L. Pachter and B. Sturmfels, Tropical geometry of statistical models, Proceedings of the National Academy of Sciences, Volume 101, Number 46 (2004), p 16132--16137.L. Pachter and B. Sturmfels (eds.), Algebraic Statistics for Computational Biology, Cambridge University Press.

BP England, U Heberlein, R Tjian. Purified Drosophila transcription factor, Adh distal factor-1 (Adf-1), binds to sites in several Drosophila promoters and activates transcription, J Biol Chem 1990.
Back to Adf1

Drosophila DNase I Footprint Database (v2.0)
Home Search Browse by Target Browse by Factor
Target GeneChromosom
e ArmStart Stop
Transcription Factor
Pubmed ID (PMID)
Footprint ID (FPID)
Footprint Alignment
ems (CG2988) 3R 9723806 9723816Abd
-B (CG11648)9491376 003205
Abd-B->ems:003205
ems (CG2988) 3R 9723843 9723853Abd
-B (CG11648)9491376 003206
Abd-B->ems:003206
ems (CG2988) 3R 9723998 9724008Abd
-B (CG11648)9491376 003208
Abd-B->ems:003208
ems (CG2988) 3R 9724091 9724102Abd
-B (CG11648)9491376 003209
Abd-B->ems:003209
ems (CG2988) 3R 9724526 9724536Abd
-B (CG11648)9491376 003211
Abd-B->ems:003211
ems (CG2988) 3R 9724557 9724567Abd
-B (CG11648)9491376 003213
Abd-B->ems:003213
ems (CG2988) 3R 9724614 9724624Abd
-B (CG11648)9491376 003214
Abd-B->ems:003214
dpp (CG9885) 2L 2454657 2454685 Adf1 (CG15845) 7791801 003665 Adf1->dpp:003665
Adh (CG3481) 2L 14615472 14615509 Adf1 (CG15845) 2105454 005046 Adf1->Adh:005046
Ddc (CG10697) 2L 19116303 19116321 Adf1 (CG15845) 2318884 005464 Adf1->Ddc:005464
Antp (CG1028) 3R 2825018 2825059 Adf1 (CG15845) 2318884 006446 Adf1->Antp:006446
Adh (CG3481) 2L 14616171 14616209 Adf1 (CG15845) 2105454 005059 Adf1->Adh:005059
Antp (CG1028) 3R 2825117 2825144 Adf1 (CG15845) 2318884 006447 Adf1->Antp:006447
Antp (CG1028) 3R 2825151 2825174 Adf1 (CG15845) 2318884 006448 Adf1->Antp:006448

Back to Adf1
mel TGTGCGTCAGCGTCGGCCGCAACAGCG pse TGT-----------------GACTGCG *** ** ***
BLASTZ alignment

Back to Adf1
mel TGTGCGTCAGCGTCGGCCGCAACAGCG pse TGT-----------------GACTGCG *** ** ***
mel TGTG----CGTCAGC--G----TCGGCC---GC-AACAG-CG Pse TGTGACTGCG-CTGCCTGGTCCTCGGCCACAGCCAAC-GTCG **** ** * ** * ****** ** *** * **

Back to Adf1
mel TGTGCGTCAGCGTCGGCCGCAACAGCG pse TGT-----------------GACTGCG *** ** ***
mel TGTG----CGTCAGC--G----TCGGCC---GC-AACAG-CG pse TGTGACTGCG-CTGCCTGGTCCTCGGCCACAGCCAAC-GTCG **** ** * ** * ****** ** *** * **
mel TGTGCGTCAGC------GTCGGCCGCAACAGCG pse TGTGACTGCGCTGCCTGGTCCTCGGCCACAGC- **** * ** *** * ** *****

Drosophila DNase I Footprint Database (v2.0)
Home Search Browse by Target Browse by Factor
Target GeneChromosom
e ArmStart Stop
Transcription Factor
Pubmed ID (PMID)
Footprint ID (FPID)
Footprint Alignment
ems (CG2988) 3R 9723806 9723816Abd-B
(CG11648)9491376 003205
Abd-B->ems:003205
ems (CG2988) 3R 9723843 9723853Abd-B
(CG11648)9491376 003206
Abd-B->ems:003206
ems (CG2988) 3R 9723998 9724008Abd-B
(CG11648)9491376 003208
Abd-B->ems:003208
ems (CG2988) 3R 9724091 9724102Abd
-B (CG11648)9491376 003209
Abd-B->ems:003209
ems (CG2988) 3R 9724526 9724536Abd
-B (CG11648)9491376 003211
Abd-B->ems:003211
ems (CG2988) 3R 9724557 9724567Abd
-B (CG11648)9491376 003213
Abd-B->ems:003213
ems (CG2988) 3R 9724614 9724624Abd
-B (CG11648)9491376 003214
Abd-B->ems:003214
dpp (CG9885) 2L 2454657 2454685 Adf1 (CG15845) 7791801 003665 Adf1->dpp:003665
Adh (CG3481) 2L 14615472 14615509 Adf1 (CG15845) 2105454 005046 Adf1->Adh:005046
Ddc (CG10697) 2L 19116303 19116321 Adf1 (CG15845) 2318884 005464 Adf1->Ddc:005464
Antp (CG1028) 3R 2825018 2825059 Adf1 (CG15845) 2318884 006446 Adf1->Antp:006446
Adh (CG3481) 2L 14616171 14616209 Adf1 (CG15845) 2105454 005059 Adf1->Adh:005059
Antp (CG1028) 3R 2825117 2825144 Adf1 (CG15845) 2318884 006447 Adf1->Antp:006447
Antp (CG1028) 3R 2825151 2825174 Adf1 (CG15845) 2318884 006448 Adf1->Antp:006448

Per site analysis Group 1 mean per site % identity 51.3% 51.3% 47.8%
Group 2 mean per site % identity 47.8% 42.9% 42.9%
Difference of means (group 1 – group 2) 3.6% 8.4% 4.9%
Difference of means resampling p-value 0.05 0.003 1E-5
Distribution comparison KS p-value 0.026 0.0016 2E-6
Per base analysis Group 1 mean per base % identity 47.8% 47.8% 46.3%
Group 2 mean per base % identity 46.3% 42.4% 42.4%
Difference of means (group 1 – group 2) 1.5% 5.4% 3.9%

Per site analysis Group 1 mean per site % identity 51.3% 51.3% 47.8%
Group 2 mean per site % identity 47.8% 42.9% 42.9%
Difference of means (group 1 – group 2) 3.6% 8.4% 4.9%
Difference of means resampling p-value 0.05 0.003 1E-5
Distribution comparison KS p-value 0.026 0.0016 2E-6
Per base analysis Group 1 mean per base % identity 47.8% 47.8% 46.3%
Group 2 mean per base % identity 46.3% 42.4% 42.4%
Difference of means (group 1 – group 2) 1.5% 5.4% 3.9%
80.4%

Per site analysis Group 1 mean per site % identity 51.3% 51.3% 47.8%
Group 2 mean per site % identity 47.8% 42.9% 42.9%
Difference of means (group 1 – group 2) 3.6% 8.4% 4.9%
Difference of means resampling p-value 0.05 0.003 1E-5
Distribution comparison KS p-value 0.026 0.0016 2E-6
Per base analysis Group 1 mean per base % identity 47.8% 47.8% 46.3%
Group 2 mean per base % identity 46.3% 42.4% 42.4%
Difference of means (group 1 – group 2) 1.5% 5.4% 3.9%
85.1%

Per site analysis Group 1 mean per site % identity 51.3% 51.3% 47.8%
Group 2 mean per site % identity 47.8% 42.9% 42.9%
Difference of means (group 1 – group 2) 3.6% 8.4% 4.9%
Difference of means resampling p-value 0.05 0.003 1E-5
Distribution comparison KS p-value 0.026 0.0016 2E-6
Per base analysis Group 1 mean per base % identity 47.8% 47.8% 46.3%
Group 2 mean per base % identity 46.3% 42.4% 42.4%
Difference of means (group 1 – group 2) 1.5% 5.4% 3.9%
86.5%

Per site analysis Group 1 mean per site % identity 51.3% 51.3% 47.8%
Group 2 mean per site % identity 47.8% 42.9% 42.9%
Difference of means (group 1 – group 2) 3.6% 8.4% 4.9%
Difference of means resampling p-value 0.05 0.003 1E-5
Distribution comparison KS p-value 0.026 0.0016 2E-6
Per base analysis Group 1 mean per base % identity 47.8% 47.8% 46.3%
Group 2 mean per base % identity 46.3% 42.4% 42.4%
Difference of means (group 1 – group 2) 1.5% 5.4% 3.9%
79.1%

Applications• Conservation of cis-regulatory elements
• Phylogenetics: branch length estimation
This is the expected number of mutations per site in an alignment with summary (x,s).
Jukes-Cantor correction:

Applications• Conservation of cis-regulatory elements
• Phylogenetics: branch length estimation

Algebraic Statistics -- A language for unifying and developing many of the algorithms for biological
sequence analysis --
• The few inference functions theorem
• Polytope propagation
• Phylogenetic tree reconstruction
• Evolutionary models
• Maximum likelihood estimation
• Mutagenic tree models