amia tb-review-13
TRANSCRIPT

Translational Bioinformatics 2013: The Year in Review
Russ B. Altman, MD, PhDStanford University
1

Disclosures• Founder & Consultant, Personalis Inc (genome
sequencing for clinical applications).
• Consultant current or recently: 23andme, NextBio, Novartis.
• Funding support: NIH, NSF, Microsoft, Oracle, Lightspeed Ventures, PARSA Foundation.
• I am a fan of informatics, genomics, medicine & clinical pharmacology.
2

Goals
• Provide an overview of the scientific trends and publications in translational bioinformatics
• Create a “snapshot” of what seems to be important in March, 2013 for the amusement of future generations.
• Marvel at the progress made and the opportunities ahead.
3

Process
1. Follow literature through the year
2. Solicit nominations from colleagues
3. Search key journals and key topics on PubMed
4. Stress out a bit.
5. Select papers to highlight in ~2-3 slides
4

Caveats• Translational bioinformatics = informatics
methods that link biological entities (genes, proteins, small molecules) to clinical entities (diseases, symptoms, drugs)--or vice versa.
• Considered last ~14 months (to this week)
• Focused on human biology and clinical implications: molecules, clinical data, informatics.
• NOTE: Amazing biological papers with straightforward informatics generally not included.
• NOTE: Amazing informatics papers which don’t link clinical to molecular generally not included.
5

Final list
• 350 Quarter finalists, 242 Semi finalists, 98 finalists
• 27 Presented here (briefly) + 10 “shout outs”
• Apologies to those I misjudged. Mistakes are mine.
• This talk and bibliography will be made available on the conference website and my blog on rbaltman.wordpress.com
• TOPICS: Omics medicine, cool methods, cancer, drugs, delivery.
6

Thanks!
• Darrell Abernethy
• Andrea Califano
• Josh Denny
• Joel Dudley
• Mark Gerstein
• George Hripcsak
• Konrad Karczewski
• Isaac Kohane
• Lang Li
• Yong Li
• Tianyun Liu
• Yves Lussier
• Dan Masys
• Hua Fan-Minogue
• Alex Morgan
• Sandy Napel
• Lucila Ohno-Machado
• Raul Rabadan
• Dan Roden
• Nigam Shah
• David States
• Nick Tatonetti
• Jessie Tenenbaum
7

Omics Medicine
8

“The predictive capacity of personal genome sequencing.” (Roberts et al, Science TM)
• Goal: Estimate the “maximum capacity” of genome to identify clinical risk for disease.
• Method: Estimate clinical risk based on identical twin disease co-occurrence statistics.
• Result: For 23/24 most individuals negative, but for 19 diseases still significant risk. 90% of individuals alerted to at least one increased risk.
• Conclusion: Limited value of genomics to individuals.
9

Min/Max % of population test positive
Min/Max RR of disease after testing negative
10

“Comparison of family history and SNPs for predicting risk of complex disease.” (Do et al, PLOS Genetics)
• Goal: Understand relative value of family history versus common SNPs.
• Method: Compare risk assessment using FHx and SNPs.
• Result: Family history most useful for common disease and roughly equivalent to SNPs. SNPs more useful for rare disease (<4%).
• Conclusion: Genetics may be doing better than commonly assumed in terms of clinical utility.
11
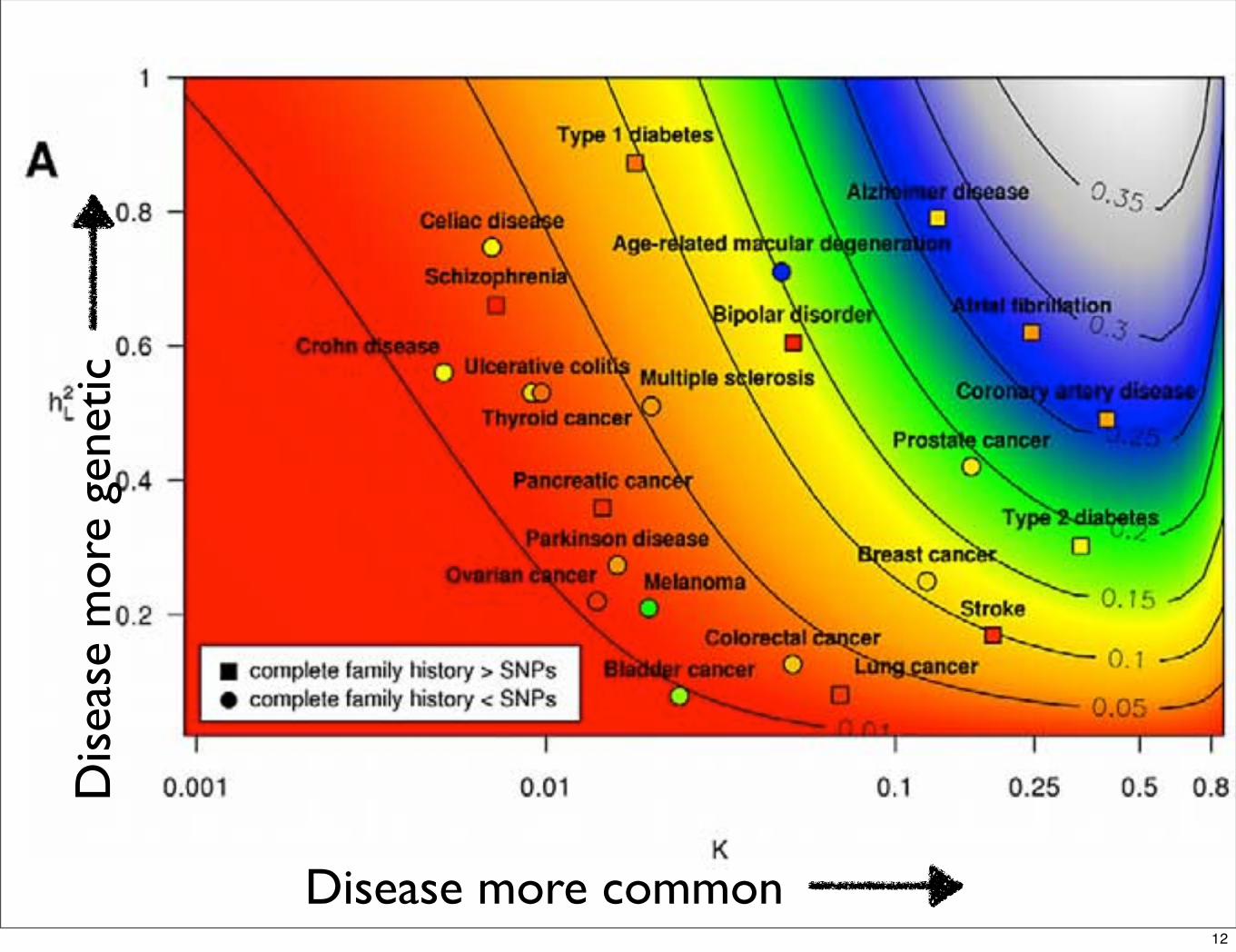
Disease more common
Dis
ease
mor
e ge
netic
12

“Diverse types of genetic variation converge on functional gene networks involved in schizophrenia.” (Gilman et al, Nature Neuro)
• Goal: Define the underlying molecular mechanisms of schizophrenia.
• Method: Integrated analysis of disease-related genetic data (CNVs, SNVs, GWAS associations).
• Result: Several cohesive networks identified. Genes expressed in brain, especially prenatally. Pathways related, but mutations different from those seen in autism.
• Conclusion: Schizophrenia may begin to yield...
13

14

“Tracking a hospital outbreak of carbapenem-resistant Klebsiella pneumoniae with whole-genome sequencing.” (Snitkin et al, Science TM)
• Goal: Use whole-genome sequencing to track epidemiology of deadly resistant bacteria.
• Method: Integrate genomics & epidemiology to reconstruct outbreak dynamics.
• Result: Index patient transmitted to 3 others & was discharged 3 weeks before next case!
• Conclusion: Genomics is powerful tool for outbreak monitoring and reconstruction.
15

16

16

“Plasma HDL cholesterol and risk of myocardial infarction: a mendelian randomisation study.” (Voight et al, Lancet)
• Goal: Assess whether HDL is causal for reducing risk of MI or simply biomarker.
• Method: Find genetic variants that raise HDL, and see if they also reduce risk of MI. (Control: LDL)
• Result: LDL is causal. HDL...not so much.
• Conclusion: Genetics provides a window for not only discovering biomarkers but validating them as causal or not.
17

18

Goal: Explain why genetic associations seem to leave so much heritability unexplained.
“The mystery of missing heritability: Genetic interactions create phantom heritability.” (Zuk et al, PNAS)
“Estimating genetic effects and quantifying missing heritability explained by identified rare-variant associations.” (Liu & Leal, Amer J Hum Gen)
Shout outs
19

Other shout outs...“Identification of risk loci with shared effects on five major psychiatric disorders: a
genome-wide analysis.” Cross-Disorder Group of the Psychiatric Genomics Consortium, Lancet
“An integrated map of genetic variation from 1,092 human genomes” The 1000 Genomes Project Consortium, Nature
“An integrated encyclopedia of DNA elements in the human genome.” ENCODE Project Consortium, Nature
“Architecture of the human regulatory network derived from ENCODE data.” Gerstein et al, Nature
“Personal omics profiling reveals dynamic molecular and medical phenotypes..”Chen et al, Cell
“Systematic localization of common disease-associated variation in regulatory DNA.”
Maurano et al, Science
20

21

22

Cool methods
23

“Bayesian ontology querying for accurate and noise-tolerant semantic searches.” (Bauer et al, Bioinformatics)
• Goal: Support semantic search over disease phenotypes tolerant to noise in data & input
• Method: Combine ontological analysis and Bayesian networks to infer diseases from input phenotypes
• Result: Improved search performance (ROC)
• Conclusion: Bayesian reasoning on ontologies can smooth them and make inference more tolerant to noise in input and in annotations.
24

25

“Ultrafast genome-wide scan for SNP-SNP interactions in common complex disease.” (Prabhu & Peer, Genome Research)
• Goal: Sampling approach to detecting epistasis: SNP-SNP interactions, can’t test ~1012
• Method: Randomization technique (10-100x faster) focusing on small groups of cases (with guarantees of coverage!)
• Result: On bipolar GWAS data set, find significant interacting SNPs (including calcium channel interactions)
• Conclusion: There is hope for finding SNPs that work together to create phenotypes.
26

27

CACNA2D4 + others
28

“Utility of gene-specific algorithms for predicting pathogenicity of uncertain gene variants.” (Crockett et al, JAMIA)
• Goal: Assess the value of generic vs. specific predictors of impact of genetic variations.
• Method: Naive Bayes classifier built for 20 genes and compared to generic tools (SIFT etc...)
• Result: Gene-specific often outperform generic tools.
• Conclusion: Detailed biology matters, and it is probably overly optimistic to expect variants to be triaged with general purpose tool.
29

30

“Complex-disease networks of trait-associated single-nucleotide polymorphisms (SNPs) unveiled by information theory.” (Li et al, JAMIA)
• Goal: GWAS “hits” may reveal complex disease modularity and suggest drug repositioning.
• Method: Compute phenotype similarity based on GWAS hits, GO annotations.
• Result: 177 disease traits connected, similarity correlates with shortest protein interaction distance.
• Conclusion: GWAS hits are not only individually useful, but in aggregate for “GWAS repurposing.”
31

32

33

34

“A vector space model approach to identify genetically related diseases.” (Sarkar, JAMIA)
• Goal: Combine information from literature and genome resources to link diseases based on similarity.
• Method: Vector space model on OMIM, Genbank, Medline. Apply to Alzheimer’s & Prader-Willi.
• Result: A constellation of associated diseases which suggest underlying common pathways.
• Conclusion: There is a continuing hunger to re-conceptualize our taxonomy of disease.
35

36

37

“A whole-cell computational model predicts phenotype from genotype” (Karr et al, Cell)
• Goal: Build the first whole-cell model of a living cell.
• Method: 27 interacting subsystem simulations using several simulation techniques.
• Result: Remarkably able to recapitulate several experimental measures, and predicts others.
• Conclusion: Comprehensive whole-cell models of bacterial are here, and eucaryotes are the next big challenge.
38

39

40

Model recapitulates literature.
41

Cancer
42

“An integrated approach to identify causal network modules of complex diseases with application to colorectal cancer.” (Wen et al, JAMIA)
• Goal: Find causal expression modules for complex diseases (vs. consequential)
• Method: Use linear programming to define modules, apply to transcriptional control of colorectal cancer.
• Result: DNA methylation of TFs may be causal.
• Conclusion: Regulation of expression is an emerging method for understanding disease etiology.
43
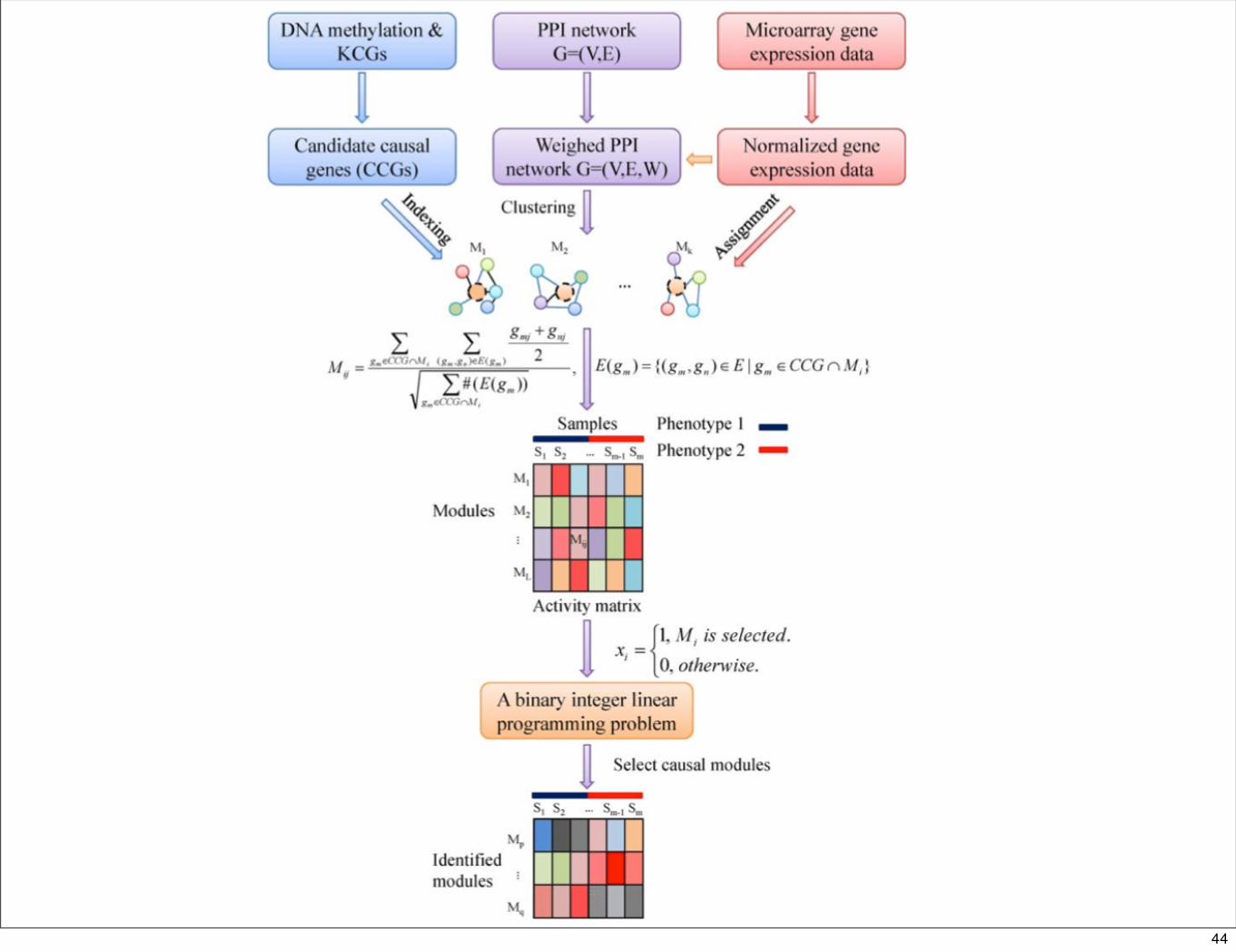
44

Rows = modules, Cols = (N)ormal, Colon Cancer
45

“Systematic identification of genomic markers of drug sensitivity in cancer cells.” (Garnett et al, Nature)
• Goal: Find cancer genes that are biomarkers for drug sensitivity.
• Method: Screen cancer lines with 130 drugs, associate drug sensitivity with genetic changes.
• Result: Unexpected sensitivities, e.g. EWS translocation to poly(ADP-ribose) polymerase (PARP) inhibitors.
• Conclusion: Genetic profiles may supplement histology in determining best treatments.
46

Circle = drug-gene (biomarker) association, size = # of lines screened
47

Top associations black: expressionred: mutationblue: copy #green: tissue
Significant genes for predicting sensitivity and resistance to dasatinib
48

“Whole-genome analysis informs breast cancer response to aromatase inhibition.” (Ellis et al, Nature)
• Goal: Correlate clinical response to aromatase inhibitors with genomic features of breast cancer.
• Method: Sequence tumor/normal and assess mutations, map to pathways.
• Result: 18 genes identified, MAP3K1=low grade, TP53 = high grade. GATA3 = aromatase response. Distinct phenotypes associated with distinct somatic mutation patterns.
• Conclusion: Individualized cancer therapy will become the norm.
49

50

51

52

“Quantitative image analysis of cellular heterogeneity in breast tumors complements genomic profiling.” (Yuan et al, Science TM)
• Goal: Integrate histology and genomics to improve prognosis of breast cancer.
• Method: Create predictor of survival in ER-neg breast cancer integrating imaging and expression.
• Result: Combined predictor outperforms individual data sources.
• Conclusion: Traditional pathology needs to integrate genomic measurements into diagnosis and prognosis measures.
53

54

55

“Conflicting biomedical assumptions for mathematical modeling: the case of cancer metastasis.” (Divoli et al, PLOS Comp Bio)
• Goal: Understand differences in expert models of key biomedical process: cancer metastasis
• Method: 28 experts queried in structured way for views of biology of metastasis (MD, PhD, MD/PhD). Markov modeling.
• Result: Biggest disagreement: when cancer enters/leaves bloodstream!
• Conclusion: Expert opinion for modeling exercises is divergent/incompatible. Modelers beware.
56

57

58

28 experts, 32 opinions!
1 expert = no comment
59

Drugs
60

“Systematic identification of pharmacogenomics information from clinical trials.” (Li & Lu, J Biomed Inf)
• Goal: Evaluate clinicaltrials.gov as source for drug-gene-disease relationships.
• Method: NLP approach for identifying d-g-dz in CT.gov.
• Result: 74% accuracy by human review. Several associations not in PharmGKB.
• Conclusion: Clinicaltrials.gov can serve as a preview of biomedical knowledge before publication.
61

62

63

“Use of genome-wide association studies for drug repositioning” (Sanseau et al, Letter to Nature Biotech)
• Goal: Use the GWAS investment to understand drug opportunities.
• Method: Find GWAS gene hits and compare associated trait with drug indication.
• Result: When trait matches indication, confidence. When trait doesn’t match indication, repurpose.
• Conclusion: GWAS results give a rich insight into molecular underpinnings of disease, with multiple uses.
64

65

66

“Analysis of functional and pathway association of differential co-expressed genes: a case study in drug addiction.” (Li et al, J Biomed Inf)
• Goal: Seek genetic pathways common to addiction disorders.
• Method: Co-expression meta-analysis to expression data for: alcohol, cocaine, heroin.
• Result: Common pathways: electron transport, synaptic transmission, cell migration, insulin, energy, dopamine, NGF signalling, locomotor behavior.
• Conclusion: There is a trend in neuropsychiatry towards a shared/spectrum view of disease.
67

68

69

“Automatic filtering and substantiation of drug safety signals.” (Bauer-Mehren et al, PLOS Comp Bio)
• Result: Able to assign risk of QT prolongation based on molecular networks for several psych drugs.
“Literature based drug interaction prediction with clinical assessment using electronic medical records: novel myopathy associated drug interactions.” (Duke et al, PLOS Comp Bio)
• Result: Novel predictions for myopathy with strong evidence.
Shout outs...
70

Delivery
71

“A clinician-driven automated system for integration of pharmacogenetic interpretations into an electronic medical record.” (Hicks et al, Clin Pharm & Ther)
“Incorporating personalized gene sequence variants, molecular genetics knowledge, and health knowledge into an EHR prototype based on the Continuity of Care Record standard.” (Jing et al, J. Biomed. Inf.)
“Operational implementation of prospective genotyping for personalized medicine: the design of the Vanderbilt PREDICT project.” (Pulley et al, Clin. Pharm & Ther)
72

73

74

75

“Identifying personal genomes by surname inference.” (Gymrek et al, Science)
• Goal: Develop methods to reidentify study subjects.
• Method: Take advantage of coinheritance of Y-chromosome & surname, combine with other public data sources.
• Result: Demonstrated ability to identify specific individuals who participate in public sequencing projects.
• Conclusion: 15 year old in U.K. did something similar in 2005. We need social mechanisms to disallow this.
76

77

“A novel, privacy-preserving cryptographic approach for sharing sequencing data.” (Cassa et al, JAMIA)
• Goal: Securely transmit genome sequence data.
• Method: Use subset of sequence as a shared secret key to entire sequence.
• Result: Robust to sequencing errors, population structure, sibling disambiguation.
• Conclusion: Can protect sensitive parts of genome by using less sensitive subset as a key.
78

79

“Disclosing pathogenic genetic variants to research participants: quantifying an emerging ethical responsibility.” (Cassa et al, Genome Research)
• Goal: Quantify the amount of clinically significant genomic variants that may need to be disclosed.
• Method: Apply recent recommendations to extrapolated estimates of clinically significant variation.
• Result: 4000-18000 variants qualify for disclosure. Will grow by 37% in next 4 years. 2000/person.
• Conclusion: The incidentalome is here, and it could overwhelm genomic medicine implementations.
80

81

82

“An Altered Treatment Plan Based on Direct to Consumer (DTC) Genetic Testing: Personalized Medicine from the Patient/Pin-cushion Perspective” (Tenenbaum et al, J Pers Med)
• Goal: Can DTC information be used to predict and prevent disease?
• Method: 23andme DTC data used for pregnant woman to predict high risk of clotting.
• Result: Anticoagulants offered to patient. No clots. Emergency C-section for unrelated reasons.
• Conclusion: Cs who get DTC genetic data expect their providers to use it.
83

84

“Pharmacogenomics in the pocket of every patient? A prototype based on quick response codes.” (Samwald & Adlassnig, JAMIA)
• Goal: Give consumers control of access to their genotype for pharmacogenomics.
• Method: Create “Medicine safety” barcode (QR).
• Result: Can encode genotypes, and provide local access to interpretation on web. No large scale infrastructure required.
• Conclusion: Consumers can use existing technology to control access to their genetic measurements.
85

86

2012 Crystal ball... Cloud computing will contribute to major biomedical discovery.
Informatics applications to stem cell science will increase
Immune genomics will emerge as powerful data
Flow cytometry informatics will grow
Molecular & expression data will combine for drug repurposing
Exome sequencing will persist longer than expected
Progress in interpreting non-coding DNA variations
87

2012 Crystal ball... Cloud computing will contribute to major biomedical discovery.
Informatics applications to stem cell science will increase
Immune genomics will emerge as powerful data
Flow cytometry informatics will grow
Molecular & expression data will combine for drug repurposing
Exome sequencing will persist longer than expected
Progress in interpreting non-coding DNA variations
88

2013 Crystal ball... Increased focus on methods to untangle regulatory control of clinical phenotypes
Rare variant GWAS with exomes & genomes
Microbiome integrated with immunology & metabolomics, and disease risk.
Emphasis on non European-descent populations for discovery of disease associations
Mobile computing resources for genomics
Crowd-based discovery in translational bioinformatics
89
