agglomerative clustering of a search engine query log doug beeferman lycos research group lycos,...
Post on 21-Dec-2015
217 views
TRANSCRIPT

Agglomerative Clustering of a Search Engine Query Log
Doug BeefermanLycos Research GroupLycos, Inc.Waltham, MA USA
Adam BergerSchool of Computer ScienceCarnegie Mellon University
Pittsburgh, PA USA
Sixth ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
Monday, August 21, 2000

Talk overview
MotivationApproachAlgorithmic detailsSample application: Related
searchesExperimental resultsOther Applications

Motivation
Group together similar Internet entities Search queries {“rare books”, “magazines”, “bookstores”}
URLs {http://www.amazon.com, http://www.bn.com}
Users {Doug Beeferman, Adam Berger}
Applications Recommendation systems Automatic taxonomies Automatic communities

Approach
Exploit search result “click log” data, which bridges all three.
“DB searched for books and then went to bn.com” (DB, books,
bn.com)
DB
Lycos
booksSearch:
Search Results
1. www.bn.com2. www.amazon.com3. www.salon.com
bn.com
1 2 3

Approach
Accumulate click log over time:
Time User Query string Selected URL 1 <DB> <“books”> <http://www.bn.com> 2 <AB> <“magazines”> <http://www.amazon.com> 3 <DB> <“biographies”> <http://www.bn.com> 4 <AB> <“books”> <http://www.amazon.com>
DB searched for “books” and then went to bn.com AB searched for “magazines” and then went to amazon.com DB searched for “biographies” and then went to bn.com AB searched for “books” and then went to amazon.com

Approach
“Factor” data into bipartite graphs
DB
AB
books
magazines
biographies
books
magazines
biographies
bn.com
amazon.com

Approach
Choose two of the three entities, say queries and URLs.
Apply agglomerative clustering algorithm to the nodes in its bipartite graph: Merge the two “most similar” nodes in the left-hand-side Merge the two “most similar” nodes in the right-hand-side Repeat until some termination condition applies. At termination queries are clustered on the left-hand-side,
and URLs are clustered on the right-hand-side.

Distance metric
otherwise ,0
0)()(if ,)()(
)()(, 21
21
21
21
qNqNqNqN
qNqNqqD
Similarity of two vertices in graph defined as the number of neighbors in common, normalized by the total number of unique neighbors:

Approach
Agglomerative clustering in action 0 1 2 … n
C
A
B
D
E
F
G
H
3
1
2
4
5
6
7

Approach
Agglomerative clustering in action 0 1 2 … n
C, F
A
B
D
E
G
H
3
1
2
4
5
6
7

Approach
Agglomerative clustering in action 0 1 2 … n
C, F
A
B
D
E
G
H
3, 5
1
2
4
6
7

Approach
Agglomerative clustering in action 0 1 2 … n
C, F
A, D, E, H
B
G
2, 6, 3, 5
1
4
7

Algorithm
1. Score all pairs of query nodes according to distance metric D.
2. Merge the two query nodes q1 and q2 for which the distance D(q1, q2) is minimal.
3. Score all pairs of URL nodes according to distance metric D.
4. Merge the two URL nodes u1 and u2 for which the distance D(u1, u2) is minimal.
5. Unless a termination condition applies, go to step 1.

Algorithm: complexity
Naïve implementation requires a distance metric computation per pair of nodes, or (|Q|2 + |U|2) time per iteration.
But only a the neighbors of the affected nodes change during a merge, so the per-iteration cost is proportional to the maximum degree of any node.

Application: Related searches
Lycos.com “related searches” feature:
Baseline algorithm based on past audience overlap of individual query pairs
Data-intensive; poor coverage of rare queries
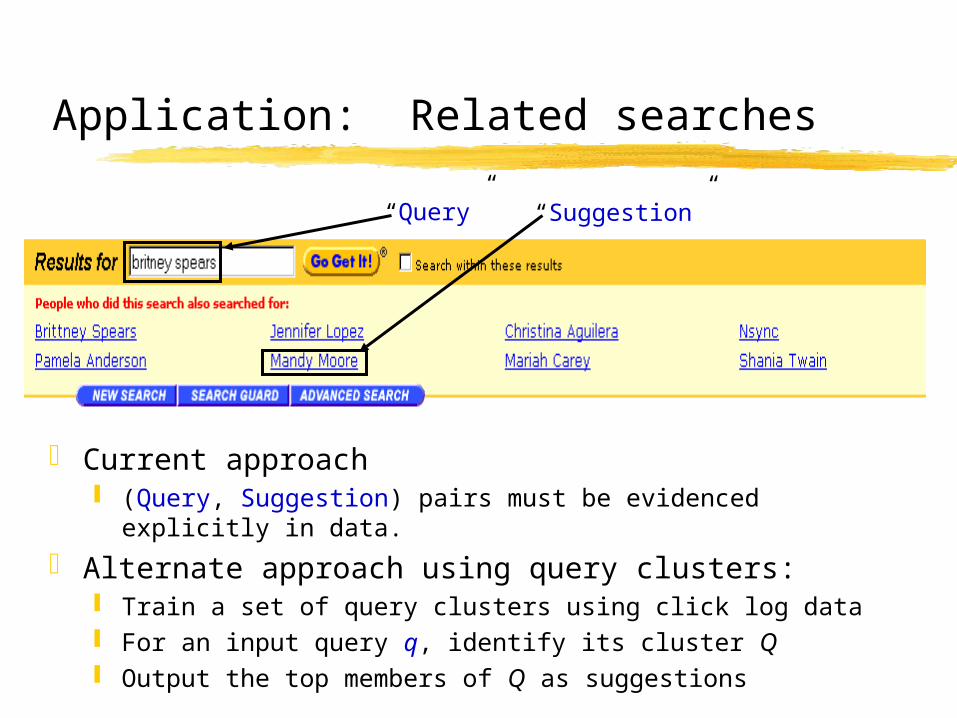
Application: Related searches
Current approach (Query, Suggestion) pairs must be evidenced explicitly in
data.
Alternate approach using query clusters: Train a set of query clusters using click log data For an input query q, identify its cluster Q Output the top members of Q as suggestions
“Query” “Suggestion”

Application: Related searches
Click log data:
About 500,000 click records from a portion of a day on Lycos.com
Pornographic queries filtered out Queries canonicalized:
• downcased• Whitespace collapsed
No URL canonicalization 243,000 unique queries and 362,000 unique URLs remained Ran agglomerative clustering algorithm for 100,000
iterations

Examples of query clusters
lyricsguitar tabstabssong lyrics irs
irs.govinternal revenue service forms
American airlinesaadvantageaa.com
movieshollywoodhbobad movies
casinoslas vegasonline casinoslas vegas strip
disneyvacationsdisney world tickets
fitnessmusclefitness magazines

1. Baseline 2. Full-replacement: Draw all suggestions for an
input query from its cluster 3. Hybrid: Replace only “weak” suggestions
Impact of experiments measured by “clickthrough rate” of the related searches feature:
Related Searches: Experiments
q
q
q
q
)(simpression
)(clicks

1. Baseline : 1.16% 2. Full-replacement: 1.03% 3. Hybrid: 1.31%
Related Searches: Results
q
q
q
q
)(simpression
)(clicks
Experiment Clickthrough rate

Related Searches: Conclusions
Full-replacement strategy (preferring cluster-derived suggestions) is inferior to baseline
Hybrid strategy is superior to both, overcoming data sparseness problems inherent in baseline query pair model.

Other applications
Cluster URLs with respect to queries Cluster URLs with respect to users Cluster users with respect to URLs, queries
All these treat documents as mere URLs. Such “content-ignorance” has its advantages: Faster: Less data manipulation Handles Web pages that lack text Handles Web pages that are restricted access Handles Web pages that are dynamic